
Abstract
The article examines the relationship between commercial search engines, using Google Search as an example, and various forms of ignorance related to climate change. It draws on concepts from the field of agnotology to explore how environmental ignorances, and specifically related to the climate crisis, are shaped at the intersection of the logics of Google Search, everyday life and civil society/politics. Ignorance refers to a multi-facetted understanding of the culturally contingent ways in which something may not be known. Two research questions are addressed: How are environmental ignorances, and in particular related to the climate crisis, shaped at the intersection of the logics of Google Search, everyday life and civil society/politics? In what ways can we conceptualise Google's role as configured into the creation of ignorances? The argument is made through four vignettes, each of which explores and illustrates how Google Search is configured into a different kind of socially produced ignorance: (1) Ignorance through information avoidance: climate anxiety; (2) Ignorance through selective choice: gaming search terms; (3) Ignorance by design: algorithmically embodied emissions; (4) Ignorance through query suggestions: directing people to data voids. The article shows that while Google Search and its underlying algorithmic and commercial logic pre-figure these ignorances, they are also co-created and co-maintained by content producers, users and other human and non-human actors, as Google Search has become integral of social practices and ideas about them. The conclusion draws attention to a new logic of ignorance that is emerging in conjunction with a new knowledge logic.
Keywords
This article is a part of special theme on The State of Google Critique and Intervention. To see a full list of all articles in this special theme, please click here: https://journals.sagepub.com/page/bds/collections/stateofgooglecritiqueandintervention
Introduction
Google Search, the world's most visited website, is not only woven into the informational texture of issues but also into the practices and routines that make up everyday life. With a set of algorithms that search, index, organise, filter, select and order data for the public, search engines inevitably determine what information is amplified and what is less visible or even hidden from sight. The same applies, of course, to many other products in the company's portfolio, above all Google Maps and YouTube, but also Google Translate, Google Drive or Gmail, all of which, incidentally, are increasingly integrated with each other. In this, Google and Google Search are no different from other actors in an information ecosystem, but its invisible yet ubiquitous curatorial role (Andersen, 2018) means that the platform must be understood as a key participant in the creation of meaning in society (cf. Airoldi, 2022). It should be clear, then, that Google Search, as part of the production of order and shape of knowledge in society, is also involved in the production of ignorance. As such, it continuously transforms knowledge constellations, which includes the selective and partial concealment of what is and can be known.
In this article, we position the climate crisis and the way Google Search is involved in creating, sustaining or otherwise shaping ignorances surrounding it as a paradigmatic case. We focus specifically on climate change, and to some extent related environmental problems, because it is a problem of existential scope unlike any other, and yet capacity to address the unfolding climate crisis is shaped and limited by, among others, the domains of ethics, knowledge, culture and risk, which all are society-specific (Adger et al., 2009). Against this backdrop, we explore several instances of how ignorances emerge at the intersection of Google Search and everyday life, social values and cultural imperatives (see also Greyson, 2019). With respect to climate change, there is broad scientific consensus about the core problem as well as the radical nature of the solutions required (Pathak et al., 2022). However, even though ‘the science’ may be clear on climate change, there is not just one single, ‘rational’ form of knowledge involved in understanding and confronting it (Adger et al., 2009). Similarly, there is not only one form of ignorance, nor can ignorance be reduced to the opposite of knowledge, which we will discuss in more detail shortly. As complex collective responsibilities are intertwined with various forms of knowledge about how to deal with the unfolding climate crisis, these responsibilities also become entangled with various forms of ignorance that have to do with denial, inaction, avoidance or averting responsibility, but also with necessary and even potentially liberating forms of ignorance.
The most discussed and visible forms of ignorance are those (potentially) created through incorrect information of which outright climate change denial is the most obvious expression. These manifestations of information disorder in contemporary society (Wardle and Derakshan, 2017) are important and much can and must be said about them and about the role of Google and similar platforms in their proliferation. However, there are other forms of ignorance that are more subtle and therefore more difficult to circumscribe, but just as important to understand. Importantly, a discussion of the relationship between Google and ignorance should not be reduced to questions of incorrect information, but should also pay attention to the many nuances of how ignorances can be viewed and how they operate, and Google's involvement in these.
Thus, this article explores the relationship between commercial search engines using the example of Google Search and various forms of ignorance by asking two questions, one empirical and one conceptual: How are environmental ignorances, and in particular related to the climate crisis, shaped at the intersection of the logics of Google Search, everyday life and civil society/politics? In what ways can we conceptualise Google's role as configured into the creation of ignorances?
Ignorance(s)
The field of ignorance studies, if it can be called that, has exploded in the last decade. Disciplines as diverse as history, philosophy, sociology, psychology or geography have joined the conversation and each contributes with valuable insights into the emergence and maintenance of ignorances across a broad spectrum of cultural domains and human activities from their respective perspectives (e.g., Gross and McGoey, 2015b; Verburgt and Burke, 2021). The study of ignorance as culturally produced requires a nuanced repertoire of interlinked and overlapping notions to adequately capture, in the words of Robert Proctor (2008: 3), ‘the conscious, unconscious, and structural production of ignorance, its diverse causes and conformations, whether brought about by neglect, forgetfulness, myopia, extinction, secrecy, or suppression’.
Moreover, to reiterate a point that others have already made (e.g., McGoey, 2016; Proctor, 2008; Smithson, 2015), ignorance cannot simply be understood as the opposite of knowledge or as something purely negative, undesirable and to be overcome. Rather, to quote Smithson (2015: 387), a shift away from such an understanding is necessary to recognise ‘that unknowns play a major productive and constitutive roles in human cognition, social interaction, culture, and politics. These roles are no less central than those played by knowledge, and are not simply opposites of the roles played by knowledge’. Indeed, as Gross and McGoey (2015a) and also Pinto (2015) remind us, so as not to encourage conspiratorial thinking or to gullibly advance normative assumptions, it is important to consider ignorance as a regular feature of science and society, not least of decision-making, but also of everyday life more broadly. This implies quite concretely, that ignorance cannot be overcome but only shifted and amended. The meaning of ignorance is thus as contextually varied as the meaning of knowledge.
Importantly, as Smithson (2015) points out, there are not only countless typologies of ignorance in different fields of research, but also just as many criteria on which they are based, since they are also closely linked to disciplinary conditions and empirical interests, theoretical assumptions and methodological possibilities. Smithson (2015) proposes a set of orienting strategies specifically to support the study of socially produced forms of ignorance. He distinguishes three broad categories: first, constructed unknowns, which can best be thought of as a consequence of what is or might be known in a knowledge community; second, unintended unknowns, which arise as corollaries to social or psychological processes; and third, ‘deliberately generated, maintained and/or imposed unknowns’, which can be the result of strategic manipulation, but also simply part of social interaction or legal agreements (Smithson, 2015: 386). These orienting strategies illustrate the multiplicity of the social production of ignorances, and also help to understand the different disciplinary contributions that can be made.
It is not our intention to add to the already existing typologies of ignorance. Instead, we revisit Proctor's (2008) theoretical framing and tactically add to it in order to apply it to the specific conditions of a culture where sociotechnical systems configure and co-constitute not only what is to be known, but also what is not (Greyson, 2019) and where search engines and specifically Google are invisibly embedded in almost all parts of everyday life and across society (Haider and Sundin, 2019; Halavais, 2018). In his seminal text establishing the field of agnotology (ignorance studies), Proctor (2008) suggests a preliminary taxonomy to distinguish four forms of ignorance: (a) Ignorance as a resource (native state) which refers to ignorance driving curiosity and knowledge development or learning; (b) Ignorance as a selective choice (lost realm) which suggests that there are always things that we could know but do not; (c) Ignorance as an active construct or a deliberately created, strategic ploy by actors with specific intentions; (d) and Finally the notion of ignorance as a virtue, which refers to not knowing as a form of resistance or moral prudence (see also Greyson, 2019). Each of these forms of ignorance constitutes in itself a multi-faceted assemblage of different expressions and manifestations of ignorance with many overlaps and connections. As a schematic division, considering ignorance in these terms, as intentional or unintentional, as strategic or as a resource, provides a basis for drawing out the sometimes very different implications and multiple meanings of the ways in which ignorance is generated in society. Specifically, it helps to examine how arrangements of ignorance are enmeshed across discourses, practices and organisations in different ways through Google Search.
Google Search, relevance and new knowledge/ignorance configurations
We conceptualise and refer to Google Search as a social agent that through negotiating relevance and visibility contributes to societal meaning-making (Airoldi, 2022) in relation to environmental issues. To understand how and where this social agent is part of practices and cultural imaginaries, we draw on the figure of the configuration. That is, following Lucy Suchman (2012: 48), ‘a device for studying technologies with particular attention to the imaginaries and materialities that they join together’ and that helps to ‘think with about the work of drawing the boundaries that reflexively delineate technological objects, and as a conceptual frame for recovering the heterogeneous relations that technologies fold together’. So when we refer to Google, on the one hand, we include design decisions for the underlying machine learning algorithms based on capitalist corporate values and the skills and understanding of developers (Mager, 2012; Passi and Sengers, 2020). On the other hand, we include an understanding of the search engine as ‘the point of interaction between Google, advertisers and internet users’ (Bilić, 2016) and the multitude of data collected not only for and in search engine results pages, but also data that continuously improves the functioning of algorithms in both general and targeted search engine results pages (Denton et al., 2021; Kotras, 2020).
A fundamental concept in information retrieval, and thus important for Google Search, is that of relevance. Simply put, relevance decisions determine not only which documents are retrieved in response to a search query, but also the order of results. And usually the result deemed most relevant is displayed first or at the top, depending on the presentation mode or medium. The various signals that contribute to how Google establishes relevance are not entirely stable and not all the details are publicly known. However, there is a good overall understanding of what considerations are involved. Some are basic and long-established principles of information retrieval, such as matching the term to the material being searched through, balancing recall and precision. Others are specific to Google Search and similar platforms, which are optimised for advertising and data extraction, retrieving from an ever-changing database of sources of very different quality and age (Lewandowski, 2023). In a search engine like Google, different types of relevance come together. What the system interprets as a relevant result in response to a particular search query may not be perceived as relevant by the person performing the search or by the company promoting a product, or it may conflict with societal relevance, interests and values. In other words, relevance is a fluid concept and a profoundly social one (Gillespie, 2014). The term ‘multi-sided relevance’ (Sundin et al., 2022) encapsulates this confluence of different, potentially contradictory forms of relevance that contribute to how information is ordered in Google Search and which inevitably occurs in differently biased ways that often tend to perpetuate oppressive social structures (Benjamin, 2019; Graham, 2022; Noble, 2018). Algorithmic systems, such as Google Search, are pervasive in society, as Gillespie (2014: 192) emphasises, ‘not just as codes with consequences, but as the latest, socially constructed and institutionally managed mechanism for assuring public acumen: a new knowledge logic” and, we argue, also a new ignorance logic.
While Google arguably has by far the biggest following and the largest enabling and supportive ecosystem of currently available search engines, the main arguments we advance in this paper can also be transferred to and directed at other search engines as long as they make algorithmic judgments of relevance. Parts of our argument, however, relate to the extreme ubiquity of Google Search in everyday life and the way it shapes and enables certain social practices and forms of knowledge. In this sense, it is specific to Google's search engine, at least in those parts of the world where it dominates.
In this article, we contribute to the study of the involvement of technologies, especially information technologies, in the cultural production of ignorances. Just as what counts as knowledge, what counts as ignorance is also often subject to disputes, which in themselves are necessary for the production and maintenance of ignorances. In these disputes, or even ‘what counts as an acceptable practice of not-knowing and what does not’ (Aradau and Blanke, 2021: 10), information technologies are mobilised in specific ways (e.g., Rose and Bartoli, 2020). Greyson (2019) points to the need for careful analysis of the involvement of what they call ‘technical system(s) for the creation, exchange, organisation and use of information’ in so-called agnotologic processes and practices. Greyson further emphasises that such careful analysis requires attention to issues such as the purpose of these processes and practices, the ethical defensibility of the way they work against particular individual or common interests, the evidence that can be generated and used to address particular instances of not-knowing, or the information that is lost through constant interconnectedness.
Material and methods: Environmental ignorances on Google as a paradigmatic case
This article is built around two research questions, which are mentioned in the introduction: One concerns the ways in which ignorances related to the climate crisis are shaped at the intersection of the logics of Google search, everyday life, and civil society/politics. The other question concerns how Google's role in creating ignorance can be conceptualised.
Rather than seeking to provide clear and definitive answers to these questions, we use them as guidelines and approach the concern they point to, and which is the focus of this paper, by considering environmental ignorances on Google as a paradigmatic case of ignorances co-created in search engine configurations. A paradigmatic case brings to light more general features of a particular phenomenon for which the case is considered to be of ‘metaphorical and prototypical value’ (Flyvbjerg, 2016: 232). A singular example is placed in a floating relationship to a phenomenon and in this way makes the phenomenon understandable (Pavlich, 2010). In the words of Pavlich (2010: 646), this means that a paradigmatic case ‘steps out of a class at the very moment that it reveals and defines it. /…/ The paradigmatic case simultaneously, if paradoxically, emerges from, and constitutes, the set to which it belongs’.
We elaborate on our paradigmatic case by telling four stories in the form of vignettes, each illustrating a different intersection of Google Search, ignorance and the climate crisis. Similar to how Grimmelmann (2008) develops what he calls the Google Dilemma through telling the stories of searches, our short vignettes serve as reflexive tools to help think about, and thus articulate, how the search engine is implicated in the creation of ignorances. We selected the four stories from our previous and ongoing research on Google Search, whereby each is meant to illustrate and think through one of the four types of ignorance discussed above – which in retrospect appear less distinguishable since we considered ignorances as co-constructed. Together, the stories function as the article's ‘empirical spine’ 1 : they do not provide a complete picture or definite answers, but instead provide a multi-faceted illustration of how deeply the social production of ignorances is intertwined with Google Search.
For further methodological context, we provide some background on each vignette's origin and status in relation to other research projects. Vignette One sets the scene for the argument presented in this article. It was created in response to media reports about the specific event that forms the starting point of the vignette. We traced the media coverage by first following the search queries suggested in Google Trends and then following the links on the first page of the SERP to the various articles and blogs. An inductive approach using ignorance as our sensitising concept (Bowen, 2006) allowed us to connect climate anxiety and Google Search as recounted in the vignette. Since we are interested in describing broader trends rather than collecting replicable data, we employed an approach that approximates ‘everyday’ experiences (Rogers, 2019) and used our own computers and browsers for these searches. Vignette Two stems from a research project on search and search engine use in everyday life, based on 21 focus groups with 127 participants and the situation described in the vignette occurred during one of these. More details on the focus groups and their subsequent analyses can be found in previous publications (Haider and Sundin, 2019; Sundin et al., 2017). Vignette Three originates in a research project on algorithmic harm that is developing the notion of algorithmically embodied emissions based on experiential evidence and iterative test searches, and by bringing together ideas from carbon accounting and algorithmic impact assessment. For more information on this approach, see previous publications (Haider et al., 2022). Vignette Four is based on preliminary results from ongoing research into the role of strategic query planting and data voids in Swedish climate change denialism, which uses data crawled from various blogs and forums as well as newspaper archives and aims to investigate appeals to googling and the construction of data voids as a discursive practice. Table 1 summarises the vignettes.
Overview of the vignettes.
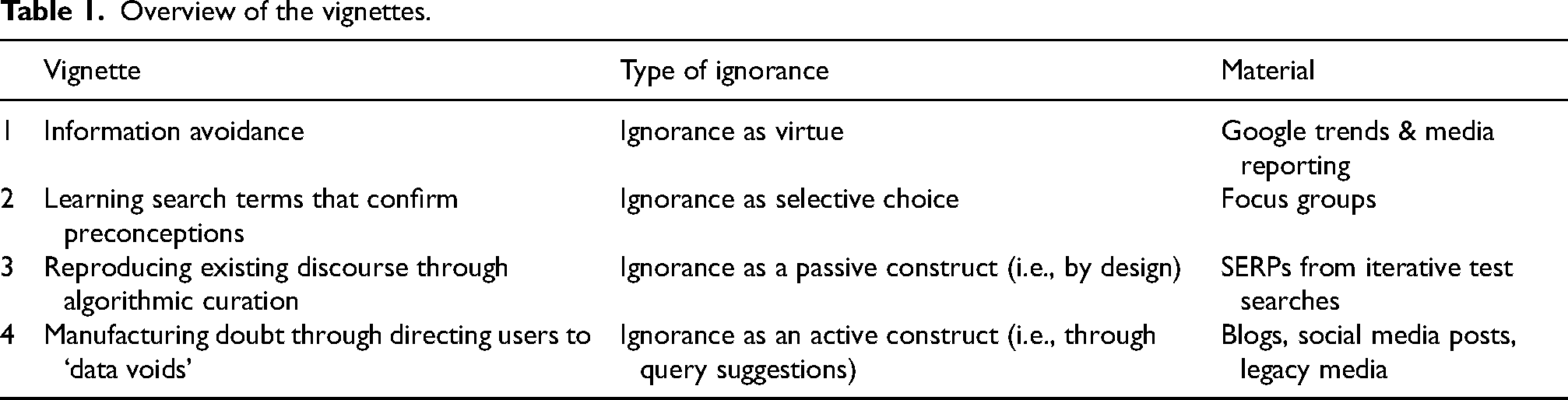
Even if this article only gives a momentary and selective impression of the multiplicities of ignorances that Google Search is involved in, it sheds light on the choices that different actors, including content producers, end-users, and developers, but also the various technical elements that make up the search engine software, the code, the data and the business decisions informing those, make regarding their engagement with search engines. Ultimately, this will get us closer to a more nuanced account of some of the instances of ignorance that Google co-creates or co-maintains. In order to do so, first, we need to look more closely at the concept of ignorance so as to find a more precise terminology for our analyses.
Four stories (vignettes) on Google and ignorance
In the following four sections, we discuss a series of ignorances that are co-produced in different ways by Google Search, its index, its use and its logic. These vignettes are independent yet interconnected, benign and taken out of the everyday life of the search engine, as they all relate to what Google Search makes (visible and) invisible in the complex relationships between different actors, interests and logics that the search engine configures. The first two stories focus on the person searching, case three centres on the responsibility of the search engine and case four highlights the strategic interplay of Google, content producers and other media, not least social media platforms.
Ignorance through information avoidance: Climate anxiety
Vignette One: In the autumn of 2021, the media noted that Google searches for ‘climate anxiety’ had skyrocketed (e.g., Yoder, 2021 ). There was a reported 565% increase in searches over the past year. This data is provided by Google's own Google Trends service, which shows the relative interest in a search term over time. But what kind of content is returned in response to such a search? A considerable number of links lead to pages that treat the phenomenon as a psychological disorder, to media reports, but also to scientific reports. Unsurprisingly, quite a number of sites give advice on how to curb climate anxiety if you're affected by it, but there are also personal testimonials. In several, Google is given a central role, firstly in how climate anxiety manifests itself – doom googling – and secondly as a means of containing the anxiety – googling to enable positive change. So instead of ‘endlessly Googling how f**ked [sic] we are’ ( Tasha's Little Corner, 2021 ), the advice is instead to avoid googling terms like climate change: ‘Doom, doom, doom. That's what you get if you Google “climate change” and for a good reason’ ( Aranake, 2021 ). Google Search is even suggested as a means to regain control in face of climate anxiety: ‘practical “what can I do?” searches could be a way to exercise some amount of control over an uncertain future (even if it feels tiny in comparison to the scope of the crisis)’ ( Yoder, 2021 ).
Information avoidance is intimately linked to information searching (Johnson, 2009). It is a well-known part of coping mechanisms and as such, it has been particularly researched in relation to serious illness (e.g., Case et al., 2005; Jensen et al., 2021). However, deliberate avoidance of information can also be a consciously employed strategy in many other situations (Narayan et al., 2011). Those can be as mundane as not spoiling an experience or social occasion but also due to taboos or religious beliefs (Johnson, 2009). What is interesting here, is the central position Google Search occupies in these negotiations of information avoidance, and especially how it is removed from a situation (Haider and Sundin, 2019).
It is the search engine and the way it is used that contributes to triggering or at least reinforcing people's climate anxiety. Cast in agnotologic terminology, the desire to search using Google can be understood as an attempt to leave what Proctor might call a native state of ignorance, whereby googling would presumably accumulate and enrich more knowledge in order to emerge from this state of ignorance. And this is what recommendations to google about possible actions follow through with. The complete opposite is happening with the guidance on climate anxiety, which suggests that googling certain terms should be avoided so as not to create a form of knowledge that is perceived as disabling. So when ignorance is intentionally created, as in this case, it is seen as facilitating action rather than hindering it. In fact, it seems to be preferable. This is related to Sarah McGrew and Sam Wineburg's concept of strategic ignoring, a key element of what they call civil online reasoning and which is closely related to media and information literacy (Wineburg and McGrew, 2019). The question of selection is indeed central to the way search, and search engines in particular, work, and this inevitably leads to certain patterns of knowledge and ignorance. The reflective capacity and underlying resources that enable people to look something up and judge it are central to information seeking and this, as Johnson (2009) emphasises, always involves decisions about what to not look up. Increasingly information technologies are configured into these decisions in different ways. In Google Search, as in other contemporary search engines, the task of selection is of course largely automated and it also takes place below the surface of the user interface, far removed from the social practices to which a particular search might belong. What becomes clear in this story is that it is not only the use of search engines that mobilises affective dimensions (Huvila, 2016), but also their non-use. Together, this creates new patterns of knowing and not knowing, but they are not patterns with sharp edges and clear contrasts. There is no doubt that Google plays a central role in how patterns of knowledge and ignorances around climate change emerge and fluctuate, including the affective dimensions of knowing and not knowing, but more importantly, Google is assigned this central position in the public imagination.
Ignorance as selective choice: Gaming search terms
Vignette Two: In a focus group conducted in 2016 in Sweden on the topic of online searching and the environment, a discussion arises between the six participants about how they find out about the environmental impact of different foods in relation to health concerns and when they feel the need to find out more or when they just ignore something. They talk about organic and industrial farming, about sprayed potatoes and vegetables imported from the Netherlands, about the benefits of oatmeal and about meat, milk and dairy products, to mention just some of the subjects that are touched upon. They agree on two things. First, Google Search is the place to turn to. Second, in order to turn to Google Search you need to be confronted with an issue that stands out, either because it seems just too strange or because it confirms something positive you already believe to be true. The discussion goes on for quite a while, meandering back and forth to consider the role of the media in providing them with prompts to google something, personal experiences and preferences, or the importance of values for how and with which terms you search. Someone talks about googling into different directions depending on what you want to achieve. After a while, one participant explains: ‘Then it's a question of what you want. For example, I am pretty convinced that milk is bad because I have read this since time immemorial, also because I stopped drinking milk quite early, sort of. And then I do not sit down and google “milk good for health”, I google “milk bad”’. And someone replies: ‘Yes, that's often how it works’. The conversation topic of milk here is probably not arbitrary: Earlier in 2016, a Swedish oat milk brand had asked the population in a large integrated marketing campaign to ‘google milk’, specifically also in relation to health and the environment, in order to motivate them to switch to more environment friendly alternatives to dairy.
Animal-based food is considered a major contributor to the climate impacts of diets (Aleksandrowicz et al., 2016), and Google is an important intermediary to confirm that one's convictions about consumption decisions are ‘correct’ and supported by ‘evidence’. For example, in relation to meat eating, people selectively engage with information that reaffirms their own view (Lueders et al., 2022), while they are generally not influenced by the provision of additional information (Bianchi et al., 2018). Together with the vignette, this suggests that Google can provide affirmation to justify presumably any consumption choice to oneself or within an argument.
Google is involved here in two different ignorance arrangements: First, something is ignored because it is not salient enough. A topic such as a credible statement or a consensus opinion fades into the background, which means there is nothing to find out, and that usually translates into ‘no need to google’. These remain unexplored and its potential complexity is ignored. Like many other things that do not happen, are not known or do not exist, this observation may seem trivial. And yet, Google Search is so much a part of the trivial, the mundane and the seemingly obvious (Andersen, 2018; Sundin et al., 2017) that its involvement in ignorance arrangements extends to these dimensions as well.
Second, the strategic use of search terms to achieve certain results always includes ideas about results on a topic that could be retrieved but are deliberately left unselected and ignored. Lueders et al. (2022) found that their study participants only read news articles with headlines that resonate with their individual views on meat consumption, even if they had access to other information as well. Here, similarly, Google Search is used in anticipation of the results that a specific query leads to. If search results would not confirm an individual's view on a specific food item and therefore not be useful, there is no reason to seek them out in the first place. In particular through choice of search terms, Google Search can be said to serve as a tool for confirmation bias (Tripodi, 2022) and is involved in literacy practices sustaining systemic ignorances (Bhatt and MacKenzie, 2019). Similarly, Proctor (2008: 7) suggests: ‘Part of the idea is that inquiry is always selective. We look here rather than there; … and the decision to focus on this is therefore invariably a choice to ignore that’. However, in this case we have more than the awareness of an expert who knows where to find a book and where not to. Instead, both the searcher and the algorithms select and make choices. Search in this specific way therefore consciously exploits the searcher's own position in the infrastructure, as they predict the prediction and pre-empt it (Haider and Sundin, 2022a; 2022b). That is, people know from experience what type of results they will get, and which will be hidden, when they submit certain terms to Google and they act accordingly by anticipating whether a likely result will work for or against them. This is a form of future-oriented algorithm awareness that is mobilised to intentionally create selective ignorance through tactical concealment of information.
Ignorance by design: Algorithmically embodied emissions
Vignette Three: Type the names of two major European cities into the Google search bar, press enter, and the likelihood of getting information about flights between them is very high, even when the distance between them is quite modest as it is for most places in Europe. Google's assumption that you are looking for travel options rather than, say, the cities’ historical connections, their main libraries or a comparison of housing prices is not unreasonable. And as users, we have become accustomed to it and probably even expect it. However, there is another assumption, namely that you want to fly, or more precisely that you are interested in cheap flights. Even that might be a relevant result for many who enter such a search. However, this makes other options, not least train travel, much less visible. A similar observation can be made when looking for typical, Western, middle-class household practices or goods. A search for ‘children's clothes’ returns a list of nearby as well as online shops, with the assumption that purchasing these is what the user looked for. What cannot be seen are, presumably equally or more valid for parents, online platforms where children's clothes are swapped, instructions for mending, or even a list of local second hand shops. Similarly, a search for ‘what can i eat for dinner today’ returns plenty of recipe lists that emphasise ‘quick’, ‘easy’, or ‘healthy’ ideas for food, as well as a few nearby eateries. None of the immediately visible search results suggests that there are other ways to think about food; for example that there is plenty of time to cook, or that cooking more sustainably, such as with local, meat-free, or waste-free ingredients is also a possibility.
Selecting from a large body of content and presenting some of it in a specific order necessarily implies that other possible content is not presented or moved further down the list. But this is far from trivial and needs to be considered in a much wider perspective than is often done and which tends to focus on harm to specific groups that are misrepresented or rendered invisible in different ways (see e.g., Graham, 2022; Noble, 2018). It is perfectly possible to find information on train travel for these places, to find information on swapping children's clothes, or meat-free dinner ideas, but it requires an effort in the form of additional search terms. Google seems to put ‘flight’, ‘buying’, and ‘quick’ into the query – but without any disclosure. This creates a double invisibility, because, firstly, the assumptions underlying the search are not displayed, and secondly, the existence of alternatives is left open, and as such, the search engine bears at least some responsibility towards the environmental impacts of the thereby facilitated choices, something we call algorithmically embodied emissions (Haider et al., 2022).
Google portrays itself as enabling ‘sustainable choices’ (Google, 2021), for example for short period it displayed greenhouse gas emissions alongside flight suggestions. However, the feature itself has since disappeared from the main page, and the system seems to have no temporally stable and scientifically based emissions calculator itself (Rowlatt, 2022). Furthermore, the low presence of comparisons to train (or even car) journeys in the list of emissions limits the pool of information on which this ‘sustainable choice’ can be based. Together with the aforementioned double invisibility of Google making implicit assumptions and hiding alternatives, the idea of a ‘sustainable choice’ rather represents ‘the least evil’.
There are many different ways in which (pro-environmental) behaviour change can be conceptualised, for example through interaction with information in the theory of planned behaviour, different choices in behavioural economics, or discourses as part of social practice theory (Keller et al., 2016). Regardless of which is assumed, Google acts as the invisible yet ubiquitous intermediator between people and information, choices, and discourses respectively (Haider et al., 2022). That Google understands itself as enabling ‘sustainable choices’ must be questioned based on the examples above, and both dimensions of the double invisibility contribute to this: Users are not made aware that the assumptions of the algorithms may have environmental implications. The ‘sustainable choice’ is not the default and may not even be visible. Google's extensive and frequently updated Search Quality Evaluator Guidelines, used to train and support its global team of human quality raters (see Bilić, 2016), does not mention climate change or other environmental concerns. They are also not among the so-called Your-Money-Your-Life (YMYL) topics, which these guidelines single out for particular attention since low-quality pages on topics with this designation are considered potentially harmful. Instead, presumably resting on the assumption that users see through the limitations of the search engine results and overcome these by amending the search term appropriately, the ‘sustainable choice’ necessarily involves further input to change the default settings in search of content challenging the prevalent ‘high-carbon visibility discourse’ (Berglez and Olausson, 2021)
Just as the widespread public and commercial discourse that its data is based upon, Google often defaults options that involve one of the heavier burdens on the environment. Proctor (2008), when suggesting ignorance as a resource to further investigation, assumes that there needs to be awareness of ignorance and the intention to overcome it. In this concrete example, this means that identifying the ‘sustainable choice’ requires prior knowledge or curiosity about the sustainability implications of any given search, and somehow find ways to adjust the search terms in order to find out more about it. Alternatively, the search results provide a reflection of what Google deems relevant based on a dominant societal discourse – which (still) tends to ignore or sideline sustainability aspects. As such, Google allows people to maintain ignorance about sustainability by not highlighting the relations to the search terms and results. The search engine results page suggests that the predominant meaning of food is to have something convenient or sometimes healthy – but not necessarily something good for the planet – , of clothes as something that needs to be bought first hand – and not as something to use, swap, share and mend – , and of places to be primarily related by travelling between them, typically, by plane. This way ‘high-carbon visibility discourses’, to use Berglez and Olausson's (2021) terminology, are reproduced in search engine results, and with it a passive ignorance about the multitudes of human contributions to environmental issues such as climate change. Therefore, although Google shows some consideration for the ‘sustainable choice’ as a gradient of emissions, by prioritising some semantic interpretations of search terms and not showing alternatives, ignorances related to the climate crisis and of the radical changes required are part of the search engine's basic design (Haider et al., 2022).
Ignorance through query suggestions: Directing people to data voids
Vignette Four: The Swedish Skeptics Association, whose name translates as ‘Science and Adult Education’, is a non-profit organisation with around 2800 paying members. It was founded in 1982 and aims to ‘promote popular education about the methods of science and its results’ and to reject pseudoscientific ideas. It publishes a journal and awards two prizes, which are regularly reported in the media. In other words, it is a respectable association run by volunteers. Its Facebook group is public and, with over 40,000 members, has considerably more members than the association itself. In one of the many contributions, a text by climate deniers was reproduced and is introduced as follows: ‘I myself am convinced that the climate is one of the greatest challenges of our time. I have seen these posts, which seem plausible to me, but as an amateur I cannot refute [these claims]. Can anyone help me?’ Some comments clearly label the copied post as climate denialist, which is not surprising. What is notable in the post, however, are two calls to do a Google search using specific search terms that are presented verbatim in quotation marks; loosely translated, the post suggests at the very beginning, to ‘Google “effect of carbon dioxide on the climate”’ and as a final statement that seems to sum up the post and give it a final legitimacy: ‘Go ahead and google “cheating in the climate debate.”’
The post that was reproduced here originated from one of the two major climate denialist blogs in Sweden (see Ernström, n.d.). When we follow the appeals to google these terms – variously using quotes and/or including the appeal itself and not only the search term – , we notice a vast proliferation of these two phrases. While some other content may use similar phrases, a majority of the prominent search results found when using quotes are signed by the same person, an author of the climate denialist blog. Appeals appear in letters to the editor in small, regional newspapers, as well as in opinion articles in a few major newspapers, including the Swedish national newspaper Aftonbladet. Throughout these letters and articles, the author continuously asks readers to ‘google’ these and other phrases. Many search engine results also link back to the original blog, where we can find a vast complexity of other phrases that are suggested to be googled.
Interacting with online search engines is a skill that people continuously refine and improve. It has become common knowledge that you can find confirmation for almost any claim online, if you only use the right search terms (Norocel and Lewandowski, 2023; Tripodi, 2018). And yet, it may be seen as rather unusual that this cultural skill is transferred other than by tacit learning. However, this is exactly what is done in this text. One may wonder whether the appeal to the reader to ‘google’ something is a natively digital one (cf. Rogers, 2013) or originates from the necessity that hyperlinks do not work in printed press and are prohibited in many online comment sections. Two aspects are particularly noteworthy about this means of signposting to ‘googling’ to spread (dis)information, which is discussed in the following paragraphs.
Firstly, appeals to ‘googling’ put the reader of these posts and articles in control. Especially in online spaces when a hyperlink may easily link to the intended content, the appeal to ‘google’ co-opts Google as a seemingly impartial information broker, with manifold implications. The search engine results page provides evidence that the made claim is not an insular opinion on the internet, i.e., that there exists much more content with the same claim. Suggesting a search term instead of a hyperlink makes it appear as if the reader has some control over the content and is therefore able to evaluate the trustworthiness of the sources instead of blindly following a link. Finally, as the reader is in control of their search, they essentially do their own independent, curiosity-driven research and are therefore more likely to remember it. These appeals then render the reader as someone who is encouraged to overcome their own ignorance and learn more about these (conspiratorial) topics.
Secondly, the suggested search terms are strategically placed and reproduced. They connect to secluded semantic spaces within the corpus of the search engine, so called data voids, in which this denialist content can exist relatively undisturbed. They ‘occur when obscure search queries have few results associated with them, making them ripe for exploitation by media manipulators with ideological, economic, or political agendas’ (Golebiewski and boyd, 2018: 2). The appeals to googling strategically planted keywords and queries throughout online and legacy media in order to create traffic to search terms for which there is little other indexed content considered ‘relevant’ – a method which according to our explorations also other groups with fringe or extremist views make use of. Here, the optimisation of their websites as well as the use of specific words and constructs goes hand in hand with the identification of meaningful queries to be spread. Mirroring Proctor's (2008) conceptualisation of ignorance as actively constructed and maintained, climate deniers create and maintain a semantic space within the search index as they exploit search engine affordances.
Concluding remarks
In this article, we have outlined some of the ignorances in which Google Search is involved in order to explore how these configurations can be understood as a new, algorithmic logic of ignorance. We have looked at the various ways in which users, queries, content producers, or algorithms co-create and co-maintain ignorances. With ignorances we refer not to the opposite of knowing, but to a multi-facetted understanding of the culturally contingent ways in which something may not be known. We have approached this through four conceptualisations of ignorance (Proctor, 2008) and the paradigmatic case of the climate crisis as seen through the lens of Google Search. By means of four vignettes (see Table 1) we have demonstrated how the search engine is implicated in creating and upholding a variety of ignorances: The first vignette showed how people think about how to avoid finding certain content on Google, whereby ignorance is embraced by the person searching as strategic ignorance or a virtue. The second vignette demonstrated how the (learnt) choice of search terms is important to confirm existing preconceptions; hereby ignorance is a selective choice that is upheld by the person searching. The third vignette investigated how the reproduction of existing discourse through search engines hides important assumptions about search results, whereby ignorance is rendered as a passive construct upheld by the search engine. Finally, the fourth vignette examined how actors can spread uncertainty and doubt through the systematic use of otherwise unused phrases and keywords via a seemingly impartial search engine, which makes ignorance an active construct maintained by content producers in order to spread specific worldviews.
While on the surface we can identify the main actors in each of these vignettes, the figure of configuration helps us to see how responsibility and agency are distributed and constantly renegotiated to foreground different forms of ignorance related to the climate crisis. Google Search works to connect various imaginaries and materialities of the different involved actors, so that their heterogeneous relations are folded together in ways that create these ignorances. In all four vignettes, as illustrated in Table 1 in the section Materials and methods above, these ignorances result from the interplay of developers, advertisers, content producers, end-users and all these actors’ decisions, but also of algorithms, data traces, user interfaces and further technical elements (Rieder, 2022). For content producers, advertisers, service providers and others, the popularity of Google Search makes this search engine the primary means of rendering content and themselves visible, increasingly in conjunction with Google Maps. This, of course, entails and shapes worldviews of the various actors involved: Ignorance (or its anticipation) plays a role in optimising for certain search terms but not others, as well as in attempts to modify people's search tactics by suggesting which terms should and should not be googled. End-users, in turn, are either actively involved themselves, for instance when they intentionally avoid or only use certain search terms, or they are exposed to content mediated by the search engine or produced by others with specific goals. Algorithms and data – in the form of content, connections and various digital traces – configure the relationships between these actors, but they are also shaped by these interactions as they continuously establish and refine calculated relevance, ignoring other information that is deemed less relevant or not at all relevant. The algorithms underlying Google Search, which essentially determine relevance, are born out of a data capitalist ideology (West, 2019) and embody a logic that assumes end users as consumers (Mager, 2012). The commodities Google Search sells and gets its revenue from are time, glances and clicks; conversely, people exchange these for convenient access to information and links, and without disturbance by concerns that they deem unrelated or prefer to remain ignorant of.
Intertwining the materialities of data with the materialities of everyday life in capitalist society, Google Search joins imaginaries of Google as a neutral provider of content with those of a multi-sided commercial platform casting all content producers as advertisers and all end users as consumers. This configuration of Google as simultaneously impartial and invested as well as both elusive and concrete, throws into relief how Google co-creates ignorances related to the climate crisis in specific ways, some of which the vignettes in this article have brought to the fore. Meaningful and nuanced engagement with the climate crisis is kept at bay by users (vignette one) or content producers (vignette four), or it is simply not deemed relevant in a specific context, both by confirmation-seeking users (vignette two) or algorithm design (vignette three). Like the results of any model, search results relate to their multiple inputs, and as such ignorances are defined by and defining of search engine users’ social realities and their engagement with this crisis. This becomes materially relevant through the pathways of not knowing, not wanting to know, not needing to know, or not being able to know – which are upheld through intents of users (vignette one and two) and content producers (vignette four), as well as the desired function of the algorithm (vignette three).
It is not uncommon for articles concerning algorithmic systems to end with a call for transparency and accountability. While this is clearly important, we suggest a more nuanced discussion: Google Search portrays itself and is often portrayed by others as a neutral information provider that, moreover, suggests itself to enable the ‘sustainable choice’. And just like the rest of us, it constantly makes decisions about relevance. What is problematic is not that Google Search makes these relevance judgements – it has to – , but that the ways in which the assumptions, contexts, and histories that underlie these judgements and their results melt into the background. This further consolidates the appearance of the search engine as an impartial information provider and gives way to a multitude of ignorances that are co-created and co-maintained by developers, end-users, content creators, business imperatives, the legal system, and a myriad of other human and non-human actors, through the configuration of Google Search.
It goes without saying that ignorance is inevitable and in many forms is necessary or even desirable. Yet, ignorance can be as powerful as knowledge in decision making, which requires both concepts to be understood in conjunction (Paul and Haddad, 2019). Accordingly, we conclude – in analogy to Gillespie's (2014) suggestion of a new knowledge logic – by inviting more discussions on a new logic of ignorance that is emerging alongside a logic of knowledge and for the search engine to be clearly included in such considerations. This means that search engines are tools that both enable and conceal specific insights, which here implies different kinds of ignorances related to the climate crisis and its interconnectedness to all areas of life. The current ignorance arrangements and their implications for the climate crisis and other current problems of humanity also pertain to other algorithmic platforms and their positions in capitalist society and everyday life, including map services or social media; the system-specific ignorances of these platforms presumably follow similar mechanisms but remain to be explored in detail. In addition, the implications of the new knowledge and ignorance logics ought to require any policy for ‘responsible AI’, such as the European Union's (EU) Artificial Intelligence Act, to also include societal harm and not just impact on individuals (Smuha, 2021). Acknowledging the significant risks posed by the climate crisis and recognising the mechanisms of ignorance logics, the plans of EU policymakers to exclude most public-facing AI from their regulatory proposal on the grounds of low-risk (Tähtinen, 2022) appear overly naive, or outright dangerous. By combining societal harm and risk frameworks under the umbrella of ignorance logics, we suggest expanding the concept of ‘relevance’ as employed by search engines and other algorithmic systems to more explicitly include societal interest as an important dimension, and to do so in a way that ensures accountability and offers ways for democratic participation.
To conclude, not unlike other information technologies and platforms, Google's main concern is contained in the highly contextual and fluid notion of relevance (Bilić, 2016; Gillespie, 2014). Relevance decisions are embedded in complex decision-making processes and machine learning algorithms, and they are certainly caught up in multiple conflicting motivations about how to establish relevance, whether in relation to a topic, to a particular person's need, a commercial agenda, a societal interest, or planetary well-being, to name just a few (Sundin et al., 2022). But relevance is not only highly contextual. Assigning relevance and making it visible and thus contestable demands an understanding of what falls outside its perimeters. Refining a repertoire of critique, therefore, requires sustained, transdisciplinary and cross-sectoral engagement with the relationship between ignorance and relevance and a nuanced understanding of how the social production of ignorance is configured at the intersection of algorithmic systems, corporate platforms, capitalist society and everyday life.
Footnotes
Acknowledgements
This work has been supported by Mistra, the Swedish Foundation for Strategic Environmental Research, through the research programme Mistra Environmental Communication. The authors wish to thank three anonymous reviewers and the participants at the workshop ‘The State of Google Critique and Intervention’, 11–12 April 2022 in Vienna for their valuable comments and the participants at Data & Society's ‘The Social Life of Algorithmic Harms Academic Workshop’, in March 2022 for their feedback on algorithmically embodied emissions. With mixed feelings, we acknowledge the existence of Google Search, Google Docs and Google Scholar, which all were essential in preparing this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship and/or publication of this article: This work was supported by the Stiftelsen för Miljöstrategisk Forskning (grant number MISTRA Environmental Communication).