
Abstract
Emotion recognition, and in particular acial emotion recognition (FER), is among the most controversial applications of machine learning, not least because of its ethical implications for human subjects. In this article, we address the controversial conjecture that machines can read emotions from our facial expressions by asking whether this task can be performed reliably. This means, rather than considering the potential harms or scientific soundness of facial emotion recognition systems, focusing on the reliability of the ground truths used to develop emotion recognition systems, assessing how well different human observers agree on the emotions they detect in subjects’ faces. Additionally, we discuss the extent to which sharing context can help observers agree on the emotions they perceive on subjects’ faces. Briefly, we demonstrate that when large and heterogeneous samples of observers are involved, the task of emotion detection from static images crumbles into inconsistency. We thus reveal that any endeavour to understand human behaviour from large sets of labelled patterns is over-ambitious, even if it were technically feasible. We conclude that we cannot speak of actual accuracy for facial emotion recognition systems for any practical purposes.
Introduction
Emotional artificial intelligence (AI) (McStay, 2020) is an expression that encompasses all computational systems that leverage ‘affective computing and AI techniques to sense, learn about and interact with human emotional life’. Within the emotional AI domain (but even more broadly, within the entire field of AI based on machine learning (ML) techniques), acial emotion recognition (FER), 1 which denotes applications that attempt to infer the emotions experienced by a person from their facial expression (Paiva-Silva et al., 2016; McStay, 2020; Barrett et al., 2019), is one of the most controversial (Ghotbi et al., 2021) and debated (Stark and Hoey, 2021) applications.
In fact, ‘turning the human face into another object for measurement and categorization by automated processes controlled by powerful companies and governments touches the right to human dignity’ 2 and ‘the ability to extract […physiological and psychological characteristics such as ethnic origin, emotion and wellbeing…] from an image and the fact that a photograph can be taken from some distance without the knowledge of the data subject demonstrates the level of data protection issues which can arise from such technologies’. 3 On the other hand, opinions diverge among the specialist literature. Some authors highlight the accurate performance of FER applications and their potential benefits in a variety of fields; for instance, customer satisfaction (Bouzakraoui et al., 2019), car driver safety (Zepf et al., 2020), or the diagnosis of behavioural disorders (Paiva-Silva et al., 2016; Jiang et al., 2019). Others have raised concerns regarding the potentially harmful uses in sectors such as human resource (HR) selection (Mantello et al., 2021; Bucher, 2022), airport safety controls (Jay, 2017), and mass surveillance settings (Mozur, 2020). In addition, the scientific basis of FER applications has been called into question, either by equating their assumptions with pseudo-scientific theories, such as phrenology or physiognomy (Stark and Hutson, Forthcoming), or by questioning the validity of the reference psychological theories (Barrett et al., 2019), which assume the universality of emotion expressions through facial expressions (Elfenbein and Ambady, 2002). Lastly, others have noted that the use of proxy data (such as still and posed images) to infer emotions should be supported by other contextual information (McStay and Urquhart, 2019), especially if the output of the FER systems is used to make sensitive decisions, so as to avoid misinterpretation of the broader context. According to Stark and Hoey (2021) ‘normative judgements can emerge from conceptual assumptions, themselves grounded in a particular interpretation of empirical data or the choice of what data is serving as a proxy for emotive expression’.
From a technical point of view, FER is a measurement procedure (Mari, 2003) in which the emotions conveyed in facial expressions are probabilistically gauged to detect the dominant one or a collection of prevalent emotions. As a result, FER can be related to the concepts of validity and reliability. A recognition system is valid if it recognizes what it is designed to recognize (i.e. basic emotions); it is reliable if the outcome of its recognition is consistent when applied to the same objects (i.e. a subject’s expression). However, when FER is achieved by means of a classification system based on ML techniques, its reliability cannot (and should not) be separated from the reliability of its ground truth, i.e. training and test datasets (Cabitza et al., 2019). In this scenario, reliability is defined as the extent to which the categorical data from which the system is expected to develop its statistical model are generated from ‘precise measurements’, i.e. human ‘recognitions’ exhibiting an acceptable agreement. This is because, by definition, no classification model can outperform the quality of the human reference (Cabitza et al., 2020b).
In this study, we will not contribute to the vast (and heated) debate still currently going on about the validity of automatic FER systems (Franzoni et al., 2019; Feldman Barrett, 2021; Stark and Hoey, 2021), that is, we do not address the classification task from the conceptual point of view (how to define emotions, if possible at all) nor merely from the technical point of view (how to recognize emotions, whatever they are). For the sake of argument, we assume that the main psychological emotion models make perfect sense and we do not address how robust recognition algorithms are, how well they perform in external settings, and, most importantly, how useful they can be, i.e. whether they provide the benefits that their promoters envision and advocate.
Instead, we focus on the reliability of their ground truth, which is not a secondary concern from a pragmatic standpoint (Cabitza et al., 2020a, 2020b). To that end, we conducted a survey of the major FER datasets concentrating on their reported reliability as well as a small user study by which we address three related research questions: Do existing FER ground truths have an adequate level of reliability? Are human observers in agreement regarding the emotions they sense in static facial expressions? Do they agree more when the context information is shared before interpreting the expressions?
The first question is addressed in the ‘Related work and motivations’ section and the answer is in Table 3. The other questions are addressed by means of a user study described in the ‘User study: Methods’ section and whose results are reported in the ‘Results’ section. Finally, in the ‘Discussion’ section, we discuss these findings and their immediate implications, while in the ‘Conclusion’ section we interpret them within the bigger picture of FER reliability and relate them to implications for the use of automated FER systems in sensitive domains and critical human decision making.
Related work and motivations
In recent years there has been a rapid increase in interest in (and debate around) FER technologies, which have been used or proposed for use in a variety of settings (Kołakowska et al., 2014), including: in usability engineering, to detect usability issues (Johanssen et al., 2019); in behavioural therapy, to assist individuals with autism spectrum disorder in expressing and detecting emotions (Jiang et al., 2019; White et al., 2018); in computer-assisted car driving, to detect potentially dangerous emotional states (e.g. drowsiness, anger) (Jabbar et al., 2018; Zepf et al., 2020); in security and surveillance, to potentially prevent malicious behaviour (Bullington, 2005; Mukhopadhyay and Sharma, 2020); in HR, for assisting HR personnel in the interview and recruitment process (Vardarlier and Zafer, 2020; Bucher, 2022).
Despite the promising (but yet uncertified) results in the aforementioned application domains, or possibly because of them, the development of FER technology has been accompanied by criticism, on both ethical-legal and scientific-technological grounds (Franzoni et al., 2019; Crawford, 2021).
In terms of ethical and legal issues, numerous researchers and experts have highlighted the potential risks associated with the development and adoption of FER systems, including threats to privacy (Jay, 2017) and other fundamental human rights (Authors, 2020). Particularly shocking in this regard is the case of the Muslim minority Uyghurs in the Xinjiang region of China, who are allegedly subjected to daily surveillance with emotion detection cameras (Wakefield, 2021). Other related concerns include issues with image gathering and curation processes (Birhane and Prabhu, 2021), as well as copyright violations (Harvey and LaPlace, 2021). As a consequence, several authors have suggested the use of guidelines to avoid potential risks and infringements (Chancellor et al., 2019).
On the other hand, the technological viability of FER has been questioned in a variety of ways, ranging from mild stances that question the inability of the current approaches to take into account the subjectivity and context-dependence of emotion expression (Han et al., 2017; Stark and Hoey, 2021; Washington et al., 2021), to more hard-line stances that strongly reject the scientific soundness of the underlying psychological models (Barrett et al., 2019; Stark and Hutson, Forthcoming) or even refute the definition of emotions as measurable entities (Barrett, 2006).
As stated in the introduction, we are not going to discuss the viability of FER systems in relation to any of the above aspects. Instead, we focus on the reliability of their ground truth, i.e. the extent to which different human observers agree on the emotions they recognize in the face of some subjects. To better grasp these concepts and their significance, it should be underlined that current FER systems are based on ML and are thus trained on large labelled datasets of images. Human raters annotate these initially unlabelled datasets with one or more labels based on a specific emotion model: either categorical models, which describe emotions in terms of basic categories, e.g. Ekman’s basic emotion model (Ekman, 1999); or dimensional models, which describe emotions in terms of continuous or ordinal feature vectors in a multi-dimensional space, e.g. the Valence-Arousal-Dominance (VAD) model (Mehrabian, 1996). The human raters tasked with annotating such datasets are typically given no information about the subjects involved, their social context, or the conditions under which such pictures were obtained (Barrett et al., 2019; Stark and Hoey, 2021). Because these datasets can contain tens of thousands of images, annotation is typically undertaken by multiple raters, each of whom may label multiple images (e.g., crowdsourcing settings). In this context, then reliability of the annotations refers to, and is operationalized as, the degree of agreement for the labels provided by the raters involved, i.e. what in the literature is usually called the inter-rater reliability (Hayes and Krippendorff, 2007).
Reliability and its measuring in FER
There are multiple measures for quantifying inter-rater reliability, including the simple percentage agreement
An important question thus regards what levels of reliability are ‘high enough’ for a set of annotations to be considered sufficiently reliable to support further research. We describe two methods to address this question.
The first method is analytical and is based on the selection of a desired level of accuracy of the FER system. Once this value has been set, the nomogram depicted in Figure 1 can be used to establish a lower-bound threshold for adequate reliability, by following the relationship between reliability, ground truth correctness and ML model accuracy demonstrated in Cabitza et al. (2020a). Thus, having fixed a minimum acceptable value of actual accuracy

The relationship between reliability, correctness of the ground truth, and the actual accuracy of an machine learning (ML) model trained on that ground truth (adapted from Cabitza et al. (2020a)). The figure can be used as a sort of nomogram, i.e. a visual computation device that allows to approximate a function’s computation by using only straight-line, equally graduated scales Given a minimum desirable level of accuracy (actual model accuracy) for an ML model and the corresponding theoretical model accuracy (i.e. the accuracy of the model as measured on a hypothetical 100% correct dataset), the diagram can be used to obtain the minimum acceptable reliability score for ground truth (cfr. the red dotted path). An example of use is shown in the figure with three dotted arrows and connected from right to left.
The second method builds on the body of knowledge that is available in the content analysis literature. Klaus Krippendorff was among the first researchers in the content analysis field to speculate how minimum acceptable coefficients should be chosen according to the importance of the conclusions to be drawn from annotated data and found the famous (and still wide spread) criteria proposed by Landis and Koch (1977) to be too broad and too overconfident. In 2004, Krippendorff (Krippendorff, 2004) suggested that when the costs of mistaken conclusions are high, as in biometric identification or other morally questionable AI applications such as FER, the minimum reliability value must also be set high. The recommendation of Krippendorff, followed and even reinforced by several other researchers (Carletta, 1996; Neuendorf, 2017), is that, lacking precise knowledge of the risks of drawing false conclusions from unreliable data, researchers should consider reliable data as those with reliability values higher than 0.8; should use data with values between 0.8 and 0.67 only to draw tentative conclusions; while data whose reliability measures are lower than 0.67 should be discarded.
Both methods provide similar reliability thresholds, in particular, the 0.7 threshold obtained by the analytic method is lower- and upper-bounded by the thresholds defined by Krippendorff. For this reason, in the following, we adopt these latter reliability reference values. It should be noted, however, that by the connection shown in 1, these two ground truth reliability thresholds can ultimately be translated into thresholds regarding the accuracy of a FER system, i.e. how many classification errors we are willing to accept in the face of a ground truth that has been built with a given level of agreement by the raters involved (assuming their representativeness and a uniform, natural, capacity for interpretation).
Nonetheless, despite its importance in quantifying the intrinsic complexity and subjectivity of any task, the reliability of the datasets commonly used to develop FER applications is often overlooked in the literature. There could be several explanations for this. For example, it has been widely noted that in ML research work on the model is seen as high-level and valuable, while data work, i.e. work on the underlying dataset, is typically devalued and considered to be mundane (Sambasivan and Veeraraghavan, 2022). Datasets can often be introduced in a few sentences, disregarding the source material, their creation, and provenance. Labour on the dataset (e.g. data cleaning) is often carried out by students, postdocs, or even crowdsourcing services, without any attention to the quality of the collected data (Paullada et al., 2021). In Table 3 we report the number of images, annotators per image, reliability scores (if reported), number of subjects (if reported), emotion classification model (either categorical models, which describe emotions in terms of basic categories, e.g., Ekman’s basic emotion model, or dimensional models, which describe emotions in terms of continuous or ordinal feature vectors in a multi-dimensional space, e.g., the VAD model), typology and source for some of the most commonly used benchmark datasets for FER applications. Table 3 includes information on a selection of the datasets mentioned in two recent, comprehensive surveys (Dalvi et al., 2021; Mellouk and Handouzi, 2020), including the datasets which were openly available online and which are picture-based (i.e. no physiological data), and published after 2010.
As highlighted in Table 3, only one third of the reviewed studies (i.e. 6 out of 16) reported reliability values. Furthermore, of the studies reporting the reliability of their ground truths, one study reported only the simple percentage agreement
User study: Methods
Building on previous observations, the aim of this article was to evaluate the reliability of FER ground truths. Our analysis in Table 3 highlights the scarce reporting on the reliability of FER ground truths. It should also be highlighted that commonly used emotion recognition datasets do not usually provide the original multi-rater labellings, making replication or meta-validation studies hardly feasible. For our study, we thus considered a relatively small, but realistic, dataset of genuine (vs. posed) facial expressions, which is described in what follows. In particular, we designed and performed two annotation experiments to address the following three hypotheses:
(H1) Can the reliability of our FER ground truth be considered sufficient (according to the previously mentioned criteria) to support reliable research and analysis? In this sense, we will refer to the previously defined thresholds defined by Krippendorff (2004): one threshold below which labels should be discarded (unacceptability threshold), set at 0.67, and one threshold above which labels are of adequate reliability (adequacy threshold), set at 0.8. (H2) Given that the raters involved in the annotation of FER ground truths are not usually provided with contextual information regarding the images to be annotated, does providing some sort of contextual information have any effect on the ground truth reliability? . (H3) Even more problematic than different raters who differ in their interpretations of given facial expressions is the same rater who cannot make up their mind about the same facial expressions after some (short) washout period, that is the lack of intra-rater reliability. We therefore also focus on whether the intra-rater reliability of our FER ground truth is high enough.
To address the hypotheses mentioned above, we involved a large number of raters (from now on, participants) in the annotation task of a FER dataset. The dataset encompassed 30 genuine, not posed, closeup pictures of facial expressions extracted by randomly selecting single frames from an online video depicting a conversation among participants in a class video meeting. The original video is freely available (upon registration) on Videvo,
4
and was released under a royalty-free, model released, free-use license. The pictures, each 300x300 pixel wide, depict five young subjects, four female students and one male student, at six different times, for a total of 30 pictures (see Figure 2).

Six pictures depicting three subjects whose related emotions had to be recognized by the sample of raters involved in the study. The top images were associated with the highest agreement scores (easiest facial expressions to interpret and emotions to detect); the bottom ones with the lowest scores (hardest emotions to detect).
First experiment: Inter-rater reliability
In the first experiment, we evaluated the inter-rater reliability of our FER ground truthing process. Participants in the first experiment were students enrolled in two master’s degree courses at the University of Milano-Bicocca (namely, ‘Interaction Design’ and ‘Digital Communication’), who had been invited to the experiment by direct e-mail after the rationale of the test had been explained in class. The experiment was conducted by means of an online questionnaire, implemented on the LimeSurvey platform,
5
through which the participants annotated the 30 pictures mentioned above. The participants were randomly assigned to two different groups:
Participants assigned to the first group (no-context group) were only shown the 30 pictures, one picture for each questionnaire page, randomly ordered. Participants assigned to the second group (context group), were first shown the high-definition (1138

Screenshot of an annotation page of the online questionnaire used during the experiment. The legend on the bottom runs (in Italian): ‘1: emotion absent; 5: emotion present and very intense. Any other value: emotion present but with proportional intensity.’
Participants were asked to annotate each image in the dataset according to Ekman’s basic emotion model (Ekman and Friesen, 1986; Ekman, 1999), which is one of the categorical models most commonly adopted in FER applications (e.g., (Mehendale, 2020; Brodny et al., 2016; Stark, 2018)) . According to this model, each facial expression can be associated with one or more basic emotions from among 7 basic types (Ekman and Friesen, 1986) conjectured to be universal across human cultures: namely, enjoyment, contempt, surprise, fear, sadness, disgust and anger . 6 In order to also take into account dimensional models, in our experimental setting raters were asked to indicate, for each image, a sort of arousal, 7 expressed in terms of the perceived pertinence of each basic emotion for the facial expression therein depicted, by means of a 5-value ordinal scale ranging from 1 (this emotion cannot be detected in the current expression) to 5 (this emotion is present and it’s very intensely expressed). 8 This scale thus produces both categorical annotations and dimensional (continuous) ones, as shown in the following paragraphs.
After collecting the annotations, we measured the reliability of the obtained multi-rater labels through Krippendorff’s


One of the pictures associated with the lowest reliability scores. For all basic emotions excluding ‘enjoyment’ the ratings spread the range of emotional intensity.
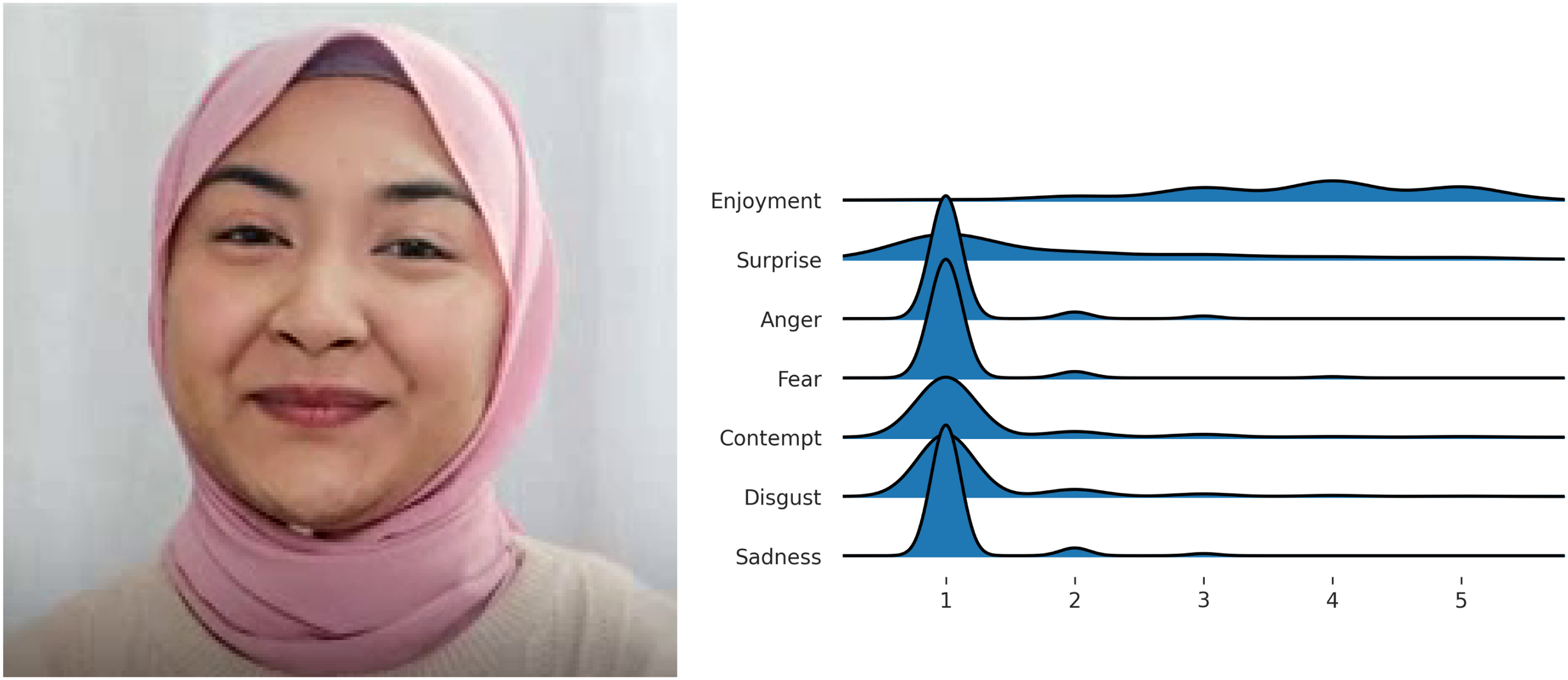
One of the pictures associated with the highest reliability scores. Note the peak on emotion intensity 1 (i.e.‘absent’) for all basic emotions except ‘enjoyment’.
We considered, in particular, three different representations of ratings, which include some of the most common label representation approaches in the FER literature (Ko, 2018; Washington et al., 2021):
Multi-label representation: each rater judgement is expressed in terms of the emotion(s) that they considered more intense, discarding the other less intense ones. For instance, for rater Distribution-based representation: each rater judgement is represented in percentage terms of a whole constituted by all the non-absent emotions, like, for rater Ordinal representation: each rater judgement is simply expressed as the list of reported emotional intensity values between 1 and 5. For the multi-label representation, the distance between two ratings is defined as the intersection-over-union distance, that is two ratings are considered more similar if they encompass the same emotions. For the distribution-based representation, the distance between two ratings is defined as the Euclidean distance between the respective probability distributions. For the ordinal representation, the distance between two ratings is simply defined, for each emotion
Clearly, the multi-label representation corresponds to a categorical emotion model, while the ordinal and distribution-based representations take into account features of both categorical and dimensional emotion models. These three different representations are reflected in a different definition of the
We, therefore, considered nine different values of reliability (one for each basic emotion, in addition to the multi-label and distribution-based ones). For each of these values we evaluated the two hypotheses
In both cases, we considered
Second experiment: Intra-rater reliability
In the second experiment, we evaluated the intra-rater reliability in emotion recognition ground truthing, in order to answer our third hypothesis
Participants in the second experiment were not the same students as those involved in the first one, however, they were from the same classes, and they were tasked with filling in a slightly modified version of the questionnaire shown to the context group. As in the context group cohort in the first experiment, all participants were first shown the video from which the pictures were extracted. The rationale for this was that we aimed to evaluate intra-rater reliability in the most conservative scenario, in which the raters had access to all relevant contextual information for the labelling task. However, unlike the first experiment,from the 30 pictures shown in the questionnaire, 5 were repeated (not consequently, and at a random number of pictures apart, to minimize the likelihood that participants might notice the repetition), so that only 25 expressions were shown and the pairs of pictures could be used to evaluate the intra-rater reliability.
As in the first experiment, intra-rater reliability was evaluated by means of Krippendorff’s

One of the pictures with the lowest intra-rater reliability scores. Note the large spread over the whole emotion intensity range, with a peak around intensity 1 (i.e. absent) for all basic emotions.
After computing the reliability values, we tested whether the intra-rater reliability was sufficiently high, by comparing the 9 reliability
Results
After closing the survey for the first experiment, we collected a total of 198 complete responses, from as many participants, for a total of 5940 expressions and 41,580 emotion ratings. The difference in rating distributions for the two groups is reported in Figure 7.

Differences in emotion ratings between the context and no-context groups. The reported values correspond to the frequency for context group, minus the frequency for the no-context group. Red cells, therefore, denote a higher frequency for the context group for the respective rating and emotion, while blue cells denote a higher frequency for the no-context group. Note the higher frequencies in the medium and high-intensity values for ‘enjoyment’, as well as for the low intensity (i.e. rating 1) for other emotions (except ‘surprise’), for the context group.
A total of 101 participants were assigned to the no-context group, while 97 participants were assigned to the context group. The reliability values, for each of the representation models and the two groups, are reported in Table 1.
Inter-rater reliability values and
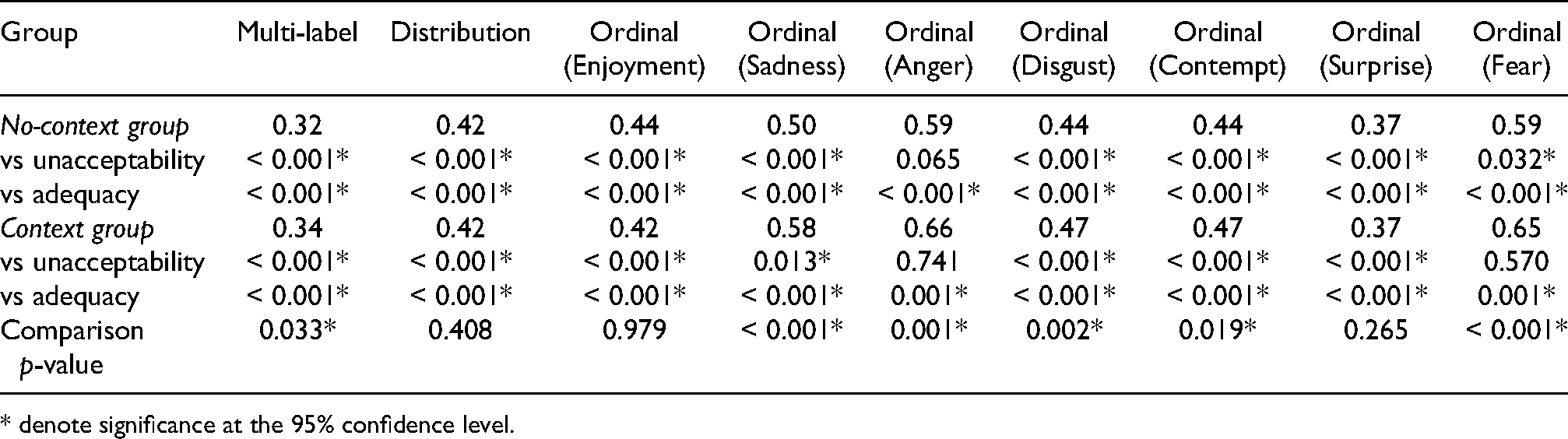
* denote significance at the 95% confidence level.
All reliability values were significantly lower than the adequacy threshold. In addition, all values except for the ordinal representation for ‘anger’ (for both groups) and ‘fear’ (for the context group) were significantly lower than the unacceptability threshold. The reliability values for the context group were higher than the corresponding values for the no-context group for all representation models except for the distribution-based model and the ordinal model for the enjoyment and surprise emotions. The distribution of emotion ratings (for ‘enjoyment’ and ‘disgust’) for the picture for which the difference in reliability scores between the two groups was highest is reported in Figure 8.
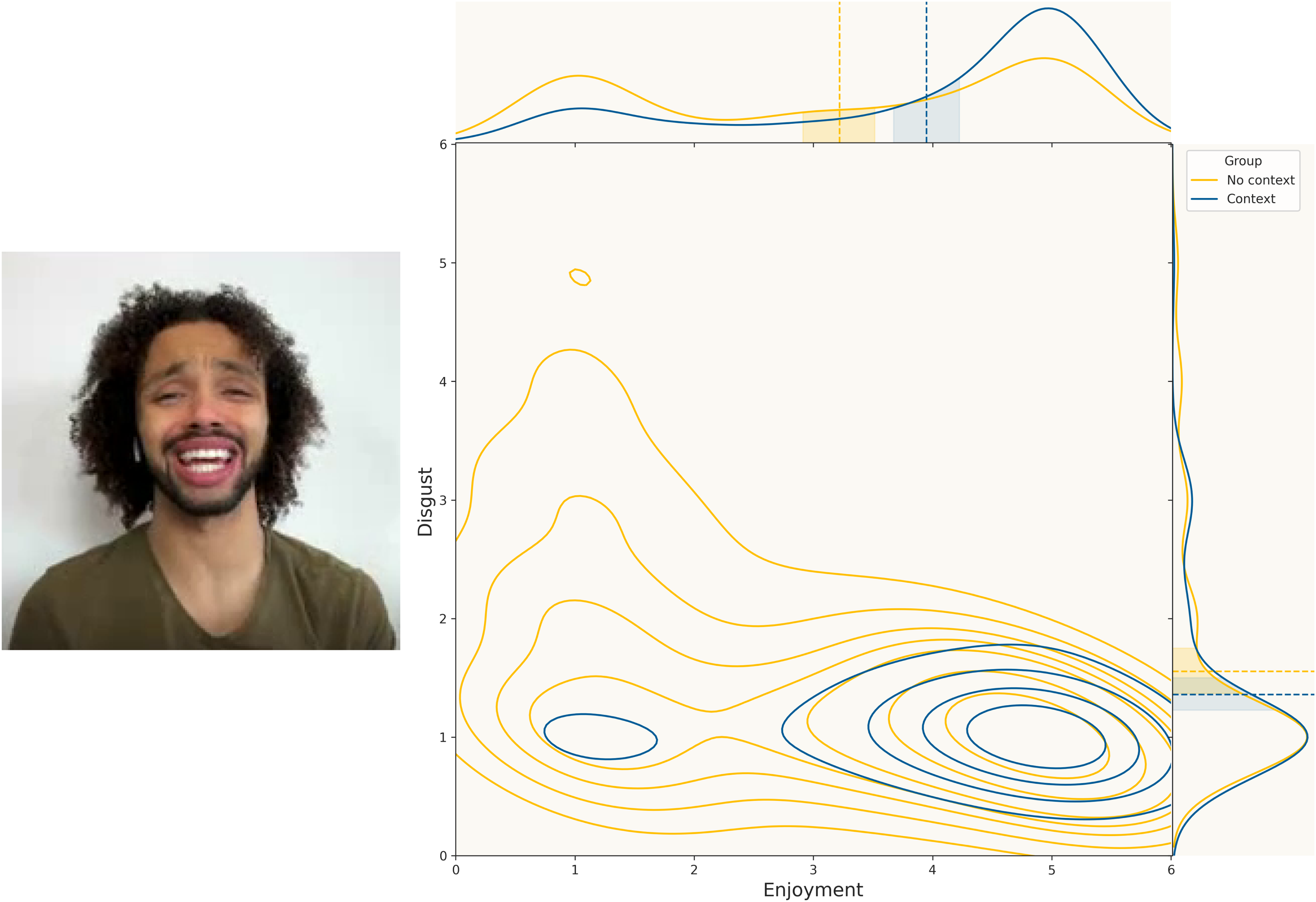
Distribution of emotion ratings (for ‘enjoyment’ and ‘disgust’) for the image for which the difference in reliability scores between the two groups was highest.
With regard to the second experiment, we collected a total of 51 complete responses, from as many participants for a total of 1530 expressions, and 10,710 emotion ratings. The reliability values are reported in Table 2.
Intra-rater reliability values and

* denote significance at the 95% confidence level.
The reliability values for the multi-label and distribution-based representations were significantly lower than the unacceptability threshold, while all other reliability values were not significantly different from the former threshold. In particular, the reliability values for the emotions of ‘sadness’, ‘anger’ and ‘fear’ were higher than the unacceptability threshold. By contrast, all reliability scores were lower than the adequacy threshold, and this difference was significant for all representation models except the ordinal one for the emotions of ‘enjoyment’, ‘anger’ and ‘fear’.
Discussion
As Table 3 shows, the FER community seems to suffer from a problem of ground truth reliability, i.e. a problem with the reliability of the data used to train their classification systems. In fact, all of the reliability scores are below the adequacy threshold, and two-thirds of the reported ones are even below the unacceptability threshold defined in the previous section. However, low ground truth reliability is a much smaller problem than ignoring it (as the ‘Reliability Score’ column in Table 3 is empty for 10 datasets out of 16), as this implies not taking countermeasures or, worse still, taking majority subjective opinions on facial expressions as real objective phenomena, to ground the delivery of multiple delicate services (such as profiling, diagnosis) on.
Summary and characteristics of the reviewed datasets.

In the emotion model column, VAD stands for valence-arousal-dominance, while VA stands for valence-arousal.
There may be several reasons for the low awareness and underestimation of this reliability problem, including the devaluation of data work in the ML community, or the methodological decision to adopt outdated criteria that overstate rater agreement and underestimate observer variability (Landis and Koch, 1977). In this study, we assumed that data collected by people who agreed about what expression or emotion they were observing less than two out of three times (or 7 out of 10), not including the number of times they did so by chance, cannot be trusted, especially in sensitive contexts or for applications with significant legal effects. The ongoing popularity of FER systems and similarly controversial applications of ML in the real-world often side-steps relevant discussions (Bender, 2022) about the validity, and even the semantics, of the underlying data because of the promise of knowing what customers ‘really feel’ (Munn, 2020). In stark contrast with this, we believe that these untrustworthy data cannot be used to develop systems that will end up being arbitrary, yet disguised as an objective evaluation (Basile et al., 2021). In our view, systems based on these data are not capable of producing useful identifications and recognitions of what emotions people actually feel. Our study, although limited with regard to the number of depicted subjects (6) and pictures (30) considered, thus contributes to the literature that converges to this conclusion. It also provides commercial stakeholders with further empirical evidence backing their decision to discontinue facial analysis screening, as recently done by HireVue, Inc. (Bucher, 2022).
In terms of our first hypothesis
Our second hypothesis,
In our study, we collected evidence that providing context, in the form of a short silent video depicting the situation where the facial expressions were produced, can yield significant differences, making the agreement among observers higher, and hence the reliability sounder, although still insufficient for reliable FER systems. Indeed, in 6 cases out of 9 (67%) the reliability observed in the context group was significantly higher than for the no-context group. Furthermore, even though the reliability values were small for both groups, two out of the three reliability values which were greater than the unacceptability threshold occurred for the context group.
Further details in regard to the results can be observed from Table 1, which reports the differences in the frequencies of emotions’ intensity values for the two groups. The participants in the context group were better able to identify the dominant emotions (that is, ‘enjoyment’ and ‘surprise’) in the original video, as this can be noticed by the negative rates in the low-intensity values as well as the positive rates in the medium (and high, for ‘enjoyment’) intensity values. Similarly, the participants in the context group were better able to exclude the less-pertinent emotions, as can be noticed by the positive rates in the low-intensity values for all other emotions. Thus, access to context information not only improved the reliability of the raters, but it also improved their ability to identify the emotions expressed. The same point is highlighted in Figure 8, which represents one of the pictures for which the difference in reliability between the two groups was larger. Indeed, we can easily note how the distribution of ratings from participants in the context group was much more concentrated on the average and high emotional intensity values for the emotion ‘enjoyment’, as well as on the low-intensity values for the emotion ‘disgust’. By contrast, the ratings expressed by the no-context group were much more uniformly distributed across the whole range of emotional intensity.
Finally, the answer to our third hypothesis (
Conclusion
Summarizing our findings, we note that our results are consistent with previously reported low-reliability values for FER ground truths (see Table 3). Although this fact was observed in previous studies (Stark and Hoey, 2021), we corroborated this claim by performing a reliability-focused literature survey and, mostly important, by making the point that the reported low-reliability score is excessively low for a viable use of that information. This means that excessively low reliability on FER data necessarily entails low accuracy of FER applications (Cabitza et al., 2020a), as shown in Figure 1 and discussed in the ‘Related work of motivations’ section.
We also confirmed that access to situational context improves emotion recognition by humans (in terms of reduced disagreement), and this kind of context is what it is usually missing in the reference data that are used to train automatic recognition systems (besides often lacking also the naturalness that cannot be represented in posed stills), not to speak of how AI systems could actually understand situational context even once this was supplied to them.
Our findings thus provide empirical support for the inherent subjectivity and ambiguity of FER tasks, which have been already discussed in psychological, neurological and anthropological studies (Abu-Lughod and Lutz, 1990; Barrett et al., 2019; LeDoux and Hofmann, 2018; Wearne et al., 2019), but seldom related to its potential impact on the development of FER technologies. As a consequence, our results challenge the technical reliability and soundness, as well as the very definition of accuracy (Cabitza et al., 2021), of FER systems based on ground truths obtained by aggregating annotations provided by multiple raters. Indeed, low-reliability values correspond to a low agreement between the annotating raters: therefore, any FER system trained on such aggregated ground truths (even highly accurate ones) would be able to identify only a part of the emotions associated with the facial expressions to be classified.
Lastly, our results regarding intra-rater reliability also question the consistency and reliability of the individual annotations: although the intra-rater reliability was higher than the inter-rater reliability (indeed, most values were higher than the unacceptability threshold), it still failed to meet the requirements of good reliability (i.e. being significantly greater than the adequacy threshold).
We believe these observations lend further support to recent calls for adopting alternative annotation practices, and related ML methods, such as perspectivist ground truthing (Basile et al., 2021), which take into account all available annotations (to avoid the problem of low inter-rater reliability), as well as additional information about the raters, such as their confidence or uncertainty (to address the problem of low intra-rater reliability). More in general, our results resonate with recent initiatives (Bender and Friedman, 2018; Gebru et al., 2021; Holland et al., 2018) aimed at raising awareness about the data production process (Gitelman, 2013), including the need to document in which (technical, social, economical and political) context the data were collected and how annotation was actually performed. As discussed in a recent survey (Paullada et al., 2021) and as we highlighted in the previous sections, the ‘data’ aspect has always been a critical aspect of ML development but it remains extensively mishandled in practice and ignored in theory. We believe that a shift in focus from model development to the issues and approaches mentioned above could allow researchers to develop FER systems that are more representative of the subjectivity of the task.
All that said, this is why we assert the somehow provocative (but grounded) claim that we cannot speak of accuracy for facial expression and emotion recognition technology: in fact, no reference can be reliably established against which to compute meaningful error rates. One could object that the present study regards only one particular FER dataset, which nevertheless was built by involving a large number of raters, much larger than in common facial expression datasets (see Table 3), and one particular set of emotion labels (the Ekman’s basic emotion model), but we feel that this interpretation of our study would be too narrow. Indeed, in Table 3 we show several reference datasets as examples of reliability scores which when reported, are low, and, through the nexus demonstrated in Cabitza et al. (2020a) and depicted in Figure 1, that low reliability entails low accuracy.
This means that, besides any ethical considerations (Stark and Hoey, 2021; Ghotbi et al., 2021), the irredeemable low reliability of emotion classification poses important challenges to the validation, and hence certification, of FER technologies or of the systems embedding FER capabilities. We believe these difficulties are especially relevant due to the growing interest in so-called appraisal-based FER systems McStay and Urquhart (2019), i.e. systems that rely not only on still images and basic emotion categories but also on multi-faceted contextual, physiological or personal information. While we showed that using additional contextual information (such as videos) could improve the reliability of the data underlying such applications, obtaining such information clearly poses even greater ethical and privacy risks for the individuals involved. Furthermore, in our experiments, we showed how even the emotion ratings produced with the aid of more informative contextual information were associated with reliability that could be deemed insufficient to enable practical applications.
For this reason, we share the appeal recently made by Ienca and Malgieri (2021) that the next regulations on Artificial Intelligence, and among these the European Artificial Intelligence Act, should explicitly include the AI systems that rely on mental information derived from emotion recognition systems in the high-risk list. Regulations should subject these systems to specific compliance duties and requirements to manage the risks involved, such as conformity certifications, risk management plans, and human oversight.
Footnotes
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.