
Abstract
Amidst the climate of crisis surrounding the rise in opioid-related overdose in the USA, early in 2019, Google and Deloitte launched ‘Opioid360’. Here came a platform combining browser histories, credit, insurance, social media, and traditional survey data to sell the service of risk calculation in population health. Opioid360's approach to automating risk calculation not only promised to identify persons ‘at risk’ of opioid dependence, but also paved the way for broader applications anticipating common chronic diseases and coordinating logistical operations involved in pandemic response. Beginning with this experimental platform, this paper develops an analysis of the Big Data mode of risk calculation - an epistemological and political shift that involves technology companies, investors, insurers, governments, and public health institutions. The analysis focuses on the re-emergence of ‘social determinants of health’ (SDOH) in the rhetoric accompanying novel analytic platforms that estimate, calculate, and compute individual health risks. While the treatment of SDOH has always been a site of political contestation within the discipline of public health, powerful interests are crystallising around the concept and instrumentalising it in platforms that sell algorithmic prediction. Silicon Valley's breed of asset-oriented technoscience appears not only to be amplifying the behaviouralist elements of public health. Among the stakes of the Big Data mode is the paradoxical retreat from changing social conditions that contribute to the prevalence of health and illness in populations; and instead, the promotion of an apparatus for pricing and exchanging individual risk or excluding from services those who bear risk most acutely.
Keywords
This article is a part of special theme on Digital Phenotyping. To see a full list of all articles in this special theme, please click here: https://journals.sagepub.com/page/bds/collections/digitalphenotyping
Introduction
The public health professors explained that they had come here to prepare their students for the future. Around us, the glamourous digital health technology conference in Las Vegas was drawing to a close. Hundreds of exhibitors’ stalls buzzed and flickered. Introductions were interrupted as two figures in white leotards strode towards us. The music changed abruptly as the two figures pulled themselves into the air by long, shiny silks and proceeded to flip and twirl over our heads. “It's all advertising” one professor said, waving towards the stalls. Dismayed by the lack of evidence for many of the interventions they had witnessed, the other professor responded that she was “really fed up with the tone of discovery” in digital health technologies. Among the discoveries they noted was the concept of social determinants of health, “it's like they discovered it yesterday”. [fieldnotes, 18 December 2019]
In recent years, the claim that around 80 percent of contemporary health issues are attributable to social factors 1 has become a mantra at digital health technology conferences. In the global context of rising chronic disease prevalence, technology companies are positioning themselves to address epidemiology's longstanding challenges in identifying, measuring, scaling, and economising social risk factors. The market for health data analytics is booming. In 2020, by some estimates, digital health technologies attracted $10 billion in venture investment, a quantity that would double by the third quarter of 2021 (Hawks et al., 2021). In the first quarter of that year, data analytics was the second largest area of investment in digital health technologies, tailing telemedicine, but greater than clinical decision support tools, wearables, and digital apps (Landi, 2020). Among health data analytics platforms is a strong ambition to streamline tracking, monitoring, and analysis of so-called ‘social determinants of health’ (herein SDOH 2 ). In the US healthcare sector, where this study focuses, recent advocacy for improvements in standardised social risk measurement has not only come from industry-sponsored forums, but also from several major professional associations and public health institutions 3 . This is happening almost 20 years after the World Health Organization (WHO) launched its policy agenda to address SDOH. Within the historic articulations of SDOH are divergent approaches to identifying, managing, and intervening in the social, economic, and political conditions that shape the health of populations.
One might follow the sceptical public health voices in the opening conversation, as they question the evidence upon which many commercial predictive platforms are based. Indeed, much recent scholarship has set about looking under the hood of algorithmic prediction to unmask the ways that Big Data and automated decision making can perpetuate bias and discrimination (Benjamin, 2019; Noble, 2018; Obermeyer et al., 2019; O'Neil, 2017). Obermeyer et al. (2019), for example, examined an algorithm routinely used in a major US health system to identify patients at high-risk of complex health conditions. They showed how the widespread practice of using claims data as a proxy for the presence of health issues was leading to a gross underestimation of the actual prevalence of disease and disease risk among Black Americans. This was not because the algorithm itself was programmed to discriminate, but because the data it used transmits legacies of racist segregation, neglect, and the systemic undervaluing of Black lives (Benjamin, 2019). Within public health scholarship, attention is also turning to a range of methodological considerations arising with ‘big data’. To date, these have canvassed the limitations of observational data (Barrett et al., 2013; Breen et al., 2019; Fuller et al., 2017; Jones et al., 2019;), representativeness and selection bias (Breen et al., 2019); the challenges of validating (Barrett et al., 2013) and weighting different primary and secondary data (Salerno et al., 2017). Noting the importance of these critical accounts of the technical limits of algorithmic observation, this paper introduces a complimentary discussion on how the politics of estimating, calculating, and computing disease risk in populations are being shaped.
The insight that technological and economic knowledge have historically moved in tandem (Kuhn, 1962; Mirowski and Nik-Khah, 2017; Winner, 1986) invites us to consider how Silicon Valley's particular breed of asset-oriented technoscience 4 could be shaping contemporary rationales of population management. A critique of the political economy of health data analytics might ask: what do these technologies do with measurements of risk? What objectives, rationales, and interests are being animated or advanced in these technologies? Critical attention to the technical processes of risk calculation can only partially answer these questions. Approaches that probe the conceptual terrains, discursive practices, and infrastructural alignments that are baked into risk technologies are called for.
In this paper, I explore how commercial analytics tools that promise to predict population health risks are taking up the rhetorical figure of SDOH. Interventions in preventative healthcare and social services are manifestations of the contentious politics of risk. Responses to risk variously push and pull between ambitions to socialise or individualise risks (Bouk, 2015; Cooper, 2020; Ewald, 1991; Zelizer, 1979), economise risk via financial instruments (Feher, 2018; Langley, 2008), identify new service markets; or promote ‘risking together’ through cooperatives or other local initiatives (Bryan and Rafferty, 2018). The current re-deployment of SDOH in population health risk calculation may direct, nudge, or coerce action along a mix of these trajectories, or perhaps open new ones. This paper sets out to investigate by taking four analytic steps.
A ‘predictive’ platform marketed to public health actors by Google and Deloitte will serve as the point of entry. Opioid360 combined browser histories, credit, insurance, social media, and traditional survey data to calculate disease and other health-related risks. In the second section, I examine Google's move into healthcare through recruitment of key figures, involvement in public-private institutions, and interventions in expertise and standards related to SDOH measurement. The lively and contested debates about SDOH over the past two decades are the focus of the third section, which contextualises the present re-deployment of SDOH in population health risk calculation software. The final section considers key contemporary policy iterations of SDOH, which reveal links between SDOH in calculations of individual risk and the financialisation of preventative interventions. The analysis allows readers to see how population health risk prediction platforms, through the rhetorical figure of SDOH, are offering a technical ‘solution’ to prevention that advances pricing and exchanging individual risk, while always-already holding the potential to exclude those whose risks exceed the prescribed boundaries.
This research draws on ethnographic fieldwork at over a dozen digital health industry events in the USA and Australia, including six major conferences, several symposiums, and corporate training activities held between 2018 and 2020. Over that period, I also conducted eighteen in-depth interviews with attendees of these conferences. These people worked in technology companies, public health departments and research institutions, venture capital funds, insurance companies, and often a mix of the above. The research also included an extensive engagement with extant grey literature, including articles published by key digital health industry news outlets. I analysed the financial, marketing, and promotional materials of a range of emerging producers of risk calculation platforms for population health, as well as social media posts and conference presentations of key representatives.
This paper contributes to an analysis of a mode of risk calculation in population health that has emerged with Big Data (Table 1). I present here just one approach to theorising this mode, understood to be a significant epistemological, political, and economic shift that involves a range of actors. The experimental data analytics platforms, emerging infrastructural alliances, and population management strategies of governments and industry, themes of this paper, are compelled by contingencies. Futures are bound to transpire in ways unpredicted by technology corporations, multinational consultants, and investors 5 . Alongside this paper's attention to commercial interests in health risk calculation, locally situated struggles, contexts, and resistances will be fundamental to the emergence of the Big Data mode. The modest scope of this paper hopes to sit alongside investigations into these other powerful and potentially emancipatory forces.
Two modes of risk calculation.

Opioid360: anticipating addiction
In conditions of crisis experimentation flourishes. Such were the circumstances in which the first digital platforms for predicting opioid addiction risk were developed in the United States. With characteristic fanfare, in October 2017, Donald Trump declared the rising rate of drug-related overdose in the USA to be a public health emergency. Before the pandemic, between 2014 and 2018, life expectancy in the United States had declined for the first time in one hundred years (Woolf and Schoomaker, 2019). Opioid-related premature death was commonly held to have been the driver of these shocking statistics (Woolf and Schoomaker, 2019). Characterised as a crisis ‘unlike anything we have ever seen’, the stage was set for path-breaking interventions (Deloitte, 2020). In March 2019, the multinational professional services company, Deloitte, announced its partnership with Google, the global data behemoth, and DataStax, then an infant database management company also based in Silicon Valley. Together they launched Opioid360, an exemplary case of a machine learning platform aiming to assess social, lifestyle, and behavioural risks associated with drug dependence. As with many proprietary platforms operating in health, subscription to the platform offered access to a combination of novel and routine data + algorithm. Its competitive edge was framed around claims that it could capture a complete picture of the social contexts in which disease risk gestates, as well as being able to produce instant and actionable calculations of those risks at both individual and population levels.
Opioid360 was marketed to health and human services at several information technology, investment, and health informatics conferences. Several pilots were announced including within state medicare offices. The platform was presented to the data science ‘community’ as a morale boosting, feel-good story. To healthcare services, it was offered as a tool that would support over-worked clinicians to see invisible signs of potential addiction, and to act swiftly on these signs. To public health units and local government departments, it could act as a research interface generating ‘real-time’ findings about the social contexts in which people “grow, live, work, and age” (WHO, 2007). While Opioid360 targeted addiction risk, the platform was promoted as a model with international possibilities for other health and social applications, such as diabetes or obesity. During the COVID-19 pandemic, further opportunities for expansion of the platform's applications were sought, a point that I will return to shortly. To begin, I offer an analysis of Opioid360's promotion, which converged around promises of providing a total vision of social practices and contexts, uncovering hidden truths, and making measurements of SDOH actionable.
Promises of total vision
The most emphasised aspect of Opioid360's promotions was the breadth of data that the platform could access. The platform integrated 23–30 datasets containing over 5000 datapoints. An assemblage of three major data clusters was set up to be the platform's competitive edge. These were 1) Google Analytics data drawn from web-search histories, 2) lifestyles or social determinants of health data (names used interchangeably in Opioid360's promotions) which originated in purchased and proprietary records of insurance claims, consumer transactions, and social media posts, and 3) public datasets including population health and demographic surveys (see Figure 1). Extending digital phenotyping imaginaries, Opioid360's presentation appealed to the notion that comprehensive personal data can offer to behavioural science the precision that genomics has offered to the identification of rare diseases (Potier, 2020).

Opioid360 presentation slide, 2019. Source: Youtube.
The volume of this data was made relatable to health and medical audiences with comparisons between established methods of clinical and public health risk identification. The sheer volume and breadth of data were used by presenters as the basis of comparisons to trials regulated by the US Federal Drug Agency. One representative compared clinical trial samples with the breadth of data captured by the platform. Clinical trials, he said, are “lucky to get a sample of 1,000s of patients, most FDA trials have 5000 to 8000 patients”, whereas Opioid360 captured data from “millions of patients” (Google, 2019). Another representative immediately completed the thought, noting that, in terms of statistical significance, “you could intuitively, [from your] gut, understand, that the sample size is going to be very impactful” (Google, 2019). In comparison with clinical trials, which must be precise in their sampling strategy, Opioid360's promotions suggested that representativeness and validity had been resolved by the immense size and scope of the datapoints to be processed.
Not only was the data applied in Opioid360 presented as being superior in volume and variety, but it was also presented as data that health services and public health institutions could simply not obtain. In a gesture to the public health audience, proprietary commercial data acquired for the platform was marketed as ‘SDOH data’. These data were presented as enriching and surpassing traditional limits (e.g. census and population health surveys) and also getting beyond the siloed and myopic lens of health services (e.g. medical data). Proxies for SDOH were individual purchasing behaviour, consumer engagement with advertising, insurance claims, sentiment, and expression in online forums, credit histories, and online social networks. How (if at all) these datapoints, mediated entirely through purchasing behaviors and social media engagement, could align with meaningful action to address SDOH was not a prominent concern.
Uncovering hidden truths
Using just traditional data, two people's profiles might look like they have the same risk of addiction, but ‘at the touch of a button’ Opioid360 would find out the hidden truth. This was the big reveal moment in Opioid360 demonstrations. The colourful dashboard compared the silhouettes of ‘John’ and ‘Bill’ using status-quo data sources. This generated the same score (see Figure 2), which would lead physicians to prescribe both men with the same pain relief. However, when the two risk profiles were generated using Opioid360's digital traces of millions of people matched with these hypothetical men, the outcome would be different. Bill scored 45%, which put him in a high-risk bracket, whereas John scored just 3% (see Figure 3). Presenters of Opioid360 proposed that the social factors that shape disease trajectories are not necessarily exposed in the clinic and they can be hidden from surveys and other health research, resulting in missed opportunities for intervention.
“Everybody lies”, the title of ex-Google data scientist Seth Stephens-Davidowitz's book (2017), reflects the basic assumption that Big Data can make things visible that we did not even realise about ourselves. Opioid360 promised to resolve the problematic of accurately capturing ‘true’ social practices and, in this case, to uncover propensity to drug addiction. The risk score itself defied explanation. Was John's score 3% because he was married, employed and owned a dog? Despite flagging reductive factors, presenters struggled to coherently explain the complex ingredients making up these scores. The explanatory power of Opioid360's risk score was of lesser importance than the actions that scores would apparently prompt. SDOH – once a reference to structural factors – here stood in for personal social and economic factors that might evade explanation as well as medical medical oversight. Deloitte and Google's decision to target their foray into predictive population health analytics platforms with a focus on drug addiction is unlikely to have been an accident. By targeting a social phenomenon that is often criminalised and associated with deviance or stigma, Opioid360 introduced the paternalistic desire to probe practices that people may seek to hide (even from ourselves), habitually perform, or chose to represent in other ways.

Opioid360 dashboard displaying risk assessment with public health data only. Source: Author's photo.
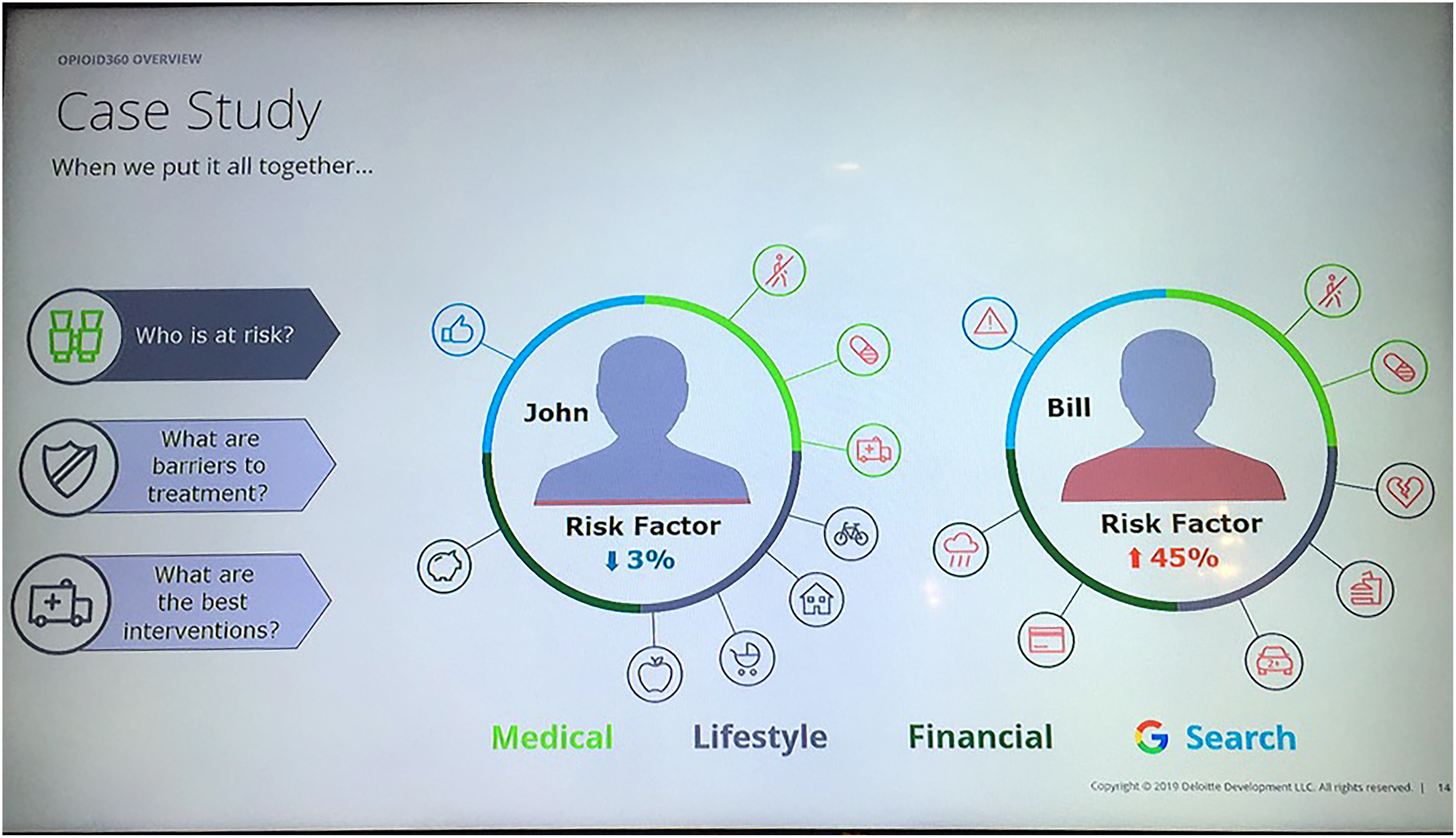
Opioid360 dashboard displaying risk assessment involving Google Analytics and a range of commercial datasets. Source: Author's photo.
The promise of making ‘social determinants’ actionable
Among the persuasions of algorithmic risk calculation via corporate platforms is their promise to produce actionable information. The concept of ‘SDOH’ has been criticised for being too abstract or too hard to change in the short-term (Arons et al., 2019). The makers of Opioid360 offered to solve this problem. As Louise Amoore explains, algorithms offer to “bind together a unity of incompatible, fraught elements as though difficulties and differences could be resolved” (2020, 22). In Opioid360's algorithms, a range of seemingly disparate datapoints related to individual social and economic circumstances was drawn on to calculate risk scores. For a clinician or public health team, acting on these risk scores would likely mean imposing a cutoff point or bracket within which a predetermined response would be triggered. The score might not dictate action, but could illuminate or guide intervention through locating people in fluid and instantaneous comparisons with one another.
The urgency of preventative action to curb overdose rates was leveraged in Opioid360 to promote real-time data acquisition and analysis. Opioid360's instantaneous output, generated by any user of the platform, further appealed to this notion of actionability. ‘Just in time’ production of prediction implies faster intervention 6 . Presenters suggested that annual, bi-annual, or less regular traditional population surveys (though also used by Opioid360) are simply too slow to produce relevant calculations of addiction risk. Deloitte representatives described, “we shoot that data over to Google and ask, what else [do] you know about this neighbourhood?” (Google, 2019). One implication of this statement is that because the Big Data mode of risk calculation is always in motion, it can also immediately interpret signals and identify the things (or people) that warrant action.
Aside from enlisting major data monopolists in population health risk calculation, Opioid360 also offered to transform users into data analysts by allowing them to generate queries, risk scores, plots, and maps over the platform's dashboards. Users could shift between individual and sub-population profiles. They could select groups in the population by characteristics such as single mothers, age brackets, or area of residence. In presentations to potential adopters of the platform, Deloitte presenters called this process of selection ‘building’ population profiles, conjuring a sense of control and decision on part of the user. The platform, however, did not reveal in which areas’ data was sparse, or the density of proxy measures being employed as the basis of inference. The trade-off for the promise of rapid, decisive indications of individual and population-level health risk was that the underlying data providing the platform's competitive advantage, along with its algorithmic design, remained enclosed by the platform's makers.
Bigger ambitions: Opioid360 returns as HealthPrism
During 2020, updates about Opioid360 went quiet and the platform seemed to have disappeared from the conference circuit 7 . In December, Deloitte announced an ambitious new population health intelligence platform called HealthPrism (Deloitte, 2021). HealthPrism absorbed Opioid360 and lessons from its pilots. As with many health data analytics platforms, HealthPrism attempted to capture the pandemic moment with a pilot that identified underserved areas for COVID-19 testing and mask distribution (Deloitte, 2021).
From its beginning, Deloitte's presenters had explained how Opioid360 could also excel at detecting fraud and identifying the risk of obesity, diabetes, or other common health issues. Remarkably, a part of the HealthPrism pitch is a singular, unified ‘social determinants of health dataset’ with over 20 pre-programmed chronic disease queries. The profitability of predictive platforms, Sun-ha Hong observes, “hinges on the expectation that any given algorithm, any process of datafication, might potentially be exported as a standard procedure for an indefinite range of activities” (2020, 25). From Opioid360 to HealthPrism, the ambition to act as a knowledge generating system for public health agencies has become clearer8.
Opioid360 offered to guide clinical decision-making with individual-level prediction, as well as to amass digital phenotypes as evidence for future government policies and other interventions. With HealthPrism, completely gone are Opioid360's earlier narratives of anxious, overworked doctors encountering devious patients on the precipice of addiction. Opioid360 foresaw its primary clients as state governments, the US Department of Health and Human Services, and law enforcement (DataStax, 2019). HealthPrism now unambiguously aims to become a part of public health operations by highlighting high-risk groups for intervention at state, county, and local levels.
The corporate model for ‘smart solutions’ has a tendency towards technology lock-in (Geiger and Gross, 2017; Sadowski and Bendor, 2018). Processes of refining algorithmic prediction in moments of crisis and philanthropic zeal have been seen to hurtle towards lucrative technology lock-ins with healthcare systems, as well as policing, military operations, and other domains of public policy 9 . But before the contracts are signed, a common language, supportive networks, infrastructures, and institutional investments contribute to making technology uptake possible. Expectations play a powerful role as mobilisers of infrastructure, resource coordination, approaches to managing uncertainty (Brown and Michael, 2003), and bridges across discipline or epistemological boundaries (Borup et al., 2006). In the next section, I consider how technology company interests feature in the discursive strategies and infrastructural alignments that mark the re-emergence of SDOH in the Big Data mode of population health risk calculation.
Silicon Valley discovers ‘social determinants of health’
As Opioid360 premiered on the health tech and Silicon Valley conference circuit, Google appointed its first Chief Health Officer. Karen DeSalvo came from a background in medicine, government, and public health. Her career had involved engineering Louisiana's healthcare system in the wake of Hurricane Katrina before becoming the Obama Administration's National Coordinator for Health Information Technology. In a medical doctor with years of experience in public health, Google had found a powerful interlocutor with the American public health sector 10 .
Interviewed at a major US digital health technology industry conference in 2018, DeSalvo's words illustrated how a constellation of Silicon Valley tech companies, health insurers, and policy-makers conceive of possible alternative sources of data that could reveal insights into social practices and relationships. I’m increasingly of a mind that there's probably a pretty good footprint of somebody's health in claims data and in other data sources about them, self-generated or contextual, like where they live and retail [data]. We’re learning that pretty sophisticated analytics can paint a picture of somebody's health trajectory absent the EHR [electronic health record] data (Rock Health, 2018).
Prior to joining Google, in 2017, DeSalvo founded the industry sponsored National Alliance to Impact the Social Determinants of Health (NASDOH). NASDOH is an expression of the strategic alignment of Silicon Valley companies with public health actors to promote approaches to social measure and public health risk calculation. As a public-private partnership involving university affiliated researchers, public health department officials or ex-officials, and health insurance companies, this association sets itself up as a legitimate player in developing scientific approaches for studying SDOH. NASDOH styles itself as a stage for the new generation of health analytics companies. Among these are companies that either focus on capturing and integrating measures of social, economic, and environmental factors for automated decision making in clinical and planning activities; or companies that coordinate various social service providers over a single interface.
Pointing to previous debates within the discipline of public health, one of the start-ups promoted by NASDOH states that attention to SDOH has now progressed “from altruism to a business case” (Socially Determined, 2019). This promotes the position that earlier SDOH measurement strategies have been vague and non-specific, well-intentioned, but ineffective. An instructive example, Socially Determined's vision statement reads: At Socially Determined we believe that the social determinants of health (SDOH) can be measured and that a new science must be created in order to glean insight into actionable interventions which impact outcomes… We envision a future where SDOH risks are identified and quantified, potential interventions are scored and prioritised, and there exists an analytics-curated marketplace for community interventions. (2019)
Given data access and ownership issues, as well as the technical expertise to process the types of so-called SDOH data, the Big Data mode signals a challenge to public health institutional authority. DeSalvo has signalled the value of health data and the tussle between powerful interests over controlling it, where Big Data analytics could “shift the power structure so that the health system doesn’t feel it owns and controls the story” (Rock Health, 2018). Leaning into notions of democracy, transparency, and open data to justify the entry of major data monopolist corporations such as Google, cynically glazes over the important issues of disparities in data access, algorithm, and other design patents.
Pressure on public health actors to adopt automated risk calculation platforms also arises from resource constraints. Proponents of SDOH risk calculation platforms consciously reflect upon this. For example, in the American Journal of Public Health, Wang and DeSalvo (2018) suggested that the use of ready-made analytics tools and data packages is a way to address funding limitations for public health and the discipline's current shortfalls in data analytics expertise.
Writing about Silicon Valley, Geiger and Gross (2017) argue that the construction of shared meaning is necessary to stabilise emerging markets. This insight extends to the nascent health data analytics sector. As seen here in Google's activities, for the adoption of the Big Data mode of risk calculation in population health to succeed a conceptual architecture is being generated. Constructing this architecture involves engaging with critiques of present challenges to public health 11 . As demonstrated in Opioid360's promotion, technology companies interface with public health through comparisons to gold-standard evidence-making methods and to the challenges of measuring SDOH. This has been facilitated by recruiting key public health and medical experts, advocating through industry and research associations, and pitching platform-based prediction as a solution to some of the thorniest challenges faced by healthcare systems. In each of these strategies, SDOH appears as a rhetorical figure through which to form alliances and gain legitimacy. Debates about social variables of interest and their parameters have long had to grapple with the costs of social reproduction and the political economy of prevention. An understanding of competing rationales in public health is also needed to understand how Silicon Valley's deployment of SDOH appears to be amplifying particular perspectives, and what the stakes of these may be.
Social determinants of health, a contested concept
Before a range of data analytics start-ups and dominant global tech corporations recognised the utility of SDOH for articulating their brands of social risk calculation, the term had a different infancy in the millennial macroeconomics of the WHO (Lee and Goodman, 2002). From the late 90s, after years of conservative rule, on both sides of the Atlantic major anglophone powers had swung to Democrat and New Labor governments. Under the former Norwegian Prime Minister Gro Harlem Brundtland's direction, and the economist, Jeffrey Sachs’ role as Chair, the grip of microeconomic policy rationales within the WHO loosened (Irwin and Scali, 2007). The key thing about the WHO agenda during this period was its efforts to foster ‘upstream’ or structural reforms. The WHO asserted that the health of populations, particularly in the Global South, was a necessary basis for economic development and should be invested in by governments through progressive taxation and public healthcare systems (Irwin and Scali, 2007). This was the institutional context that surrounded the launch of the WHO's SDOH agenda in 2005.
At that time, the WHO's Committee on the Social Determinants of Health (CSDH) conceptualised ‘social determinants’ in terms of a social gradient involving degrees of social exclusion, life-course trajectories, levels of stress, access to employment and income, social support, food and transport – and the compounding effects of all of these (Wilkinson and Marmot, 1998). The research from which the term was coined suggested that social determinants could be measured in individuals and households, as well as in systems (e.g. the quality of health systems) and contexts (e.g. political participation) (Wilkinson and Marmot, 1998). While the WHO's Committee called for more attention to addressing structural factors, it remained ambiguous about if and how the measurement of individual behaviours could advance agendas for structural change.
This ambiguity speaks to a longstanding debate in public health institutions about how best to improve collective health. To oversimplify for the purpose of illustration, one pole of the debate focuses on programmes that aim to encourage and incentivise individuals to modify their behaviours and lifestyles. Another pushes for redistribution of social wealth through public services and infrastructure. Today's proponents of these divergent approaches are interested in using Big Data for risk calculation, however commercial health risk calculation platforms (such as Opioid36) so far appear to focus on calculations of individual risk with the primary objective to reduce spending on an individual's care. Where they produce regional or other group risk calculations (usually for policy or planning purposes), they presume an approach that aggregates individual scores, rather than an approach that bases calculations on social, environmental, or other systemic measures. Whether this approach, passing as an interest in addressing SDOH, can present meaningful change to the social contexts in which people “live, work, play, and age” (WHO, 2007) remains to be seen. In addition to this are important trends in contemporary US health policy. The next section reads these with attention to their role in shaping (and be shaped by) the emergence of the Big Data mode of population health risk calculation.
How ‘social determinants of health’ became a market opportunity
While the literature examining the technical processes involved in the Big Data mode of risk calculation is growing, the market for social risk prediction has received relatively less attention. Approached from this angle, the development of social risk calculation platforms in population health is demonstrative of an ambition to measure, monetise, and financialise health and social risk. The development of algorithmic prediction goes hand in hand with calculating and acting on risk as a key strategy for profit. How risk is perceived may generate mitigation or aversion strategies, and it can also compel management and optimisation. These ambitions are carried forward in the way health and social risks are rendered through technoscientization processes (Clarke et al., 2003). Technoscientization processes signal more than the design of algorithms and the biases in the data that they process. As we have seen in the trajectory of Opioid360, conceptual, discursive, and infrastructural architectures are formed between technology companies, public health departments, government officials, investors, and insurance markets.
Investment is attracted to health risk platforms not only because of developments in computing or with the aim of answering the many questions that genomics has left unanswered (Reardon, 2017; Engelmann, 2020), but also because in the aftermath of the 2008 Global Financial Crisis there has been an increased attention to pricing risk. Specifically, in healthcare, a major catalyst for the rising attention to pricing risk was the Affordable Care Act, passed by Obama in 2009. This remarkable policy shift incentivised the development of preventative interventions as part of a strategy to reduce overall healthcare spending (Chait and Glied, 2018; Coughlin et al., 2019). The reforms bundled payments and penalties to hospitals depending on whether patients returned to their care within 30 days of being discharged (Kaufman, 2016). Incentivised to reduce the costs associated with factors such as re-admissions or non-compliance with medical regimes, population health management activities have turned increasingly to monitoring the social and environmental contexts in which people live. Commercial opportunities for a particular breed of data analytics have subsequently grown (CB Insights, 2020; Suennen and Augenstein, 2020).
A data analytics for SDOH is forecast to “create a market for interventions” (Socially Determined, 2019). It is noteworthy that risk scores appear with purpose in many of the associated data analytics platforms (including Opioid360 and HealthPrism). Contributing factors and lived experiences of health risks might differ qualitatively, but representation via a score allows the automatic bundling of people into distinct tranches of risk. As seen in Opioid360, risk scores are levers of action. Scoring enables the diverse contexts of people to be objectified, stratified, grouped, and managed. Risk calculated for a group can, in theory, be traded with another provider, or investors in a particular program can interpret the likelihood of an intervention delivering a certain outcome. As scores produce commensurability, they also facilitate exchange. Therefore, health risk scores are not only useful for the immediate classification of patients or the planning of public health programmes, but they are also of use to investors looking to leverage or hedge their exposure to risk.
As a communication device for SDOH, risk scores become part of pricing metrics for certain interventions, or they can facilitate a cut-off point – that is, to ‘redline’ groups who are deemed to be too risky. In this vision, groups are triaged to services according to their level of risk, high-risk groups are subject to ‘preventive’ targeting and groups whose exposure to risk is deemed catastrophic are designated uninsurable. The directly disciplinary, exclusionary, and punitive potential of scoring individual risk has certainly been seen before 12 . However, the appearance of SDOH within its justification is a novel development. There are already concerning indications of how action on SDOH is being reworked in programs that link health, housing, and employment data. Two examples will serve to illustrate this.
The first Healthcare Hotspotting program was launched in New Jersey by one of the NASDOH's member agencies, the Camden Coalition of Health Care Providers. Since 2007, this program has linked geospatial data with hospital and insurance claims data to identify the top 1% of healthcare resource users by their locations of residence (Krupar and Ehlers, 2017). The program targeted social workers and social support services to these people, with the aim of averting hospital admissions. Several other US counties have since rolled out similar interventions (Frishman et al., 2016). Finkelstein et al.'s (2020) large, randomised, control trial found no significant difference in hospitalisation rates between people who were enrolled in the Camden program and those who were not. In considering this finding, perhaps one should pose the more fundamental question of whether hospital admissions can and should be avoided by people who have very high healthcare needs. Furthermore, Krupar and Ehlers (2017) point out that targeting so-called super utilizers of healthcare with limited services (such as transport vouchers or social workers) promotes the idea that healthcare needs emanate from individual choices, habits, and behaviours. They argue that the perpetuation of conditions that generate social inequality and deprivation are not addressed in this iteration of social and health data linkage for targeting purposes.
A second indication of how ‘SDOH’ is being reworked came with the Centre for Medicare and Medicaid Services (CMS) announcement in early 2018. The CMS declared that it would allow states to implement work requirements for conditional access to public healthcare programs (Garrett et al., 2018). This announcement was justified in terms of SDOH, specifically, that employment is related to the likelihood of better health. The states of Kentucky, Arkansas, and Indiana were the first of several states to take up the new exclusion criteria, removing public health care access for tens of thousands of people in the condition of unemployment (Garrett et al., 2018) 13 . In this case, a crude measurement of one kind of SDOH is being used to designate a population as uninsurable. In a context where peoples’ access to living conditions conducive to health and longevity is increasingly turbulent 14 , these iterations of SDOH are concerning.
Paradox in the rhetoric
Algorithmic risk calculation using commercial platforms is being sold to public health as a more efficient, accurate, and actionable way of understanding and acting on the complex social factors that shape the health of populations. Considerable rhetorical work is accompanying these developments and reanimating previous debates in public health. While SDOH emerged as part of an agenda to address how systems can enhance or undermine the health of populations, it is now appearing in tools that measure individual-level risk to guide individual-level intervention. An apparatus for financialising preventative interventions depends on more precise calculations of risk. This means that not only does Silicon Valley's breed of asset-oriented technoscience appear to be amplifying the behaviouralist elements of public health; it is also accompanying a drive to price and exchange social and health risk, and to exclude from services those who bear risk most acutely. It would be a cruel paradox indeed if the rhetorical use of SDOH in population health risk calculation accompanied a retreat from addressing the social factors that contribute in major part to the prevalence of health and illness in populations.
Footnotes
Acknowledgments
Many thanks to Niamh Stephenson, Michael Richardson, Alison Ritter, BD&S editor Matthew Zook and two anonymous reviewers for their insightful and constructive comments on earlier drafts of this manuscript. I wish also to acknowledge participants in the EASST-4S 2020 panels Digital Phenotyping: Unpacking Intelligent Machines For Deep Medicine And A New Public Health, in particular, Ger Wackers and Lukas Engelmann for their initiative and supportive engagement with this work. Thanks to all interview participants for their time and observations.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This research was partially supported by the Australian Government through the Australian Research Council's Discovery Projects funding scheme (project DP200100062).