
Abstract
This paper explores the political potential of digital failure as a refusal to work in service of today’s dataveillance society. Moving beyond criticisms of flawed digital systems, this paper traces the moments of digital failure that seek to break, rather than fix, existing systems. Instead, digital failure is characterized by pesky data that sneaks through the cracks of digital capitalism and dissipates into the unproductive; it supports run-away data prone to misidentifications by digital marketers, coders, and content moderators; and it celebrates data predisposed to “back-talk” with playful irreverence toward those that seek to bring order through normative categorization and moderation. I call these data entropic, fugitive, and queer and explore their mischievous practices through three case studies: the unaccountable data in identity resolution, public shaming of the ImageNet training data, and reading practices of sex worker and influencer, @Charlieshe. Together these case studies articulate the political potential of digital failure as a process of unbecoming the good data subject by pushing past the margins of legibility, knowability, and thinkability, to reveal what is made illegible, unknowable, and unthinkable to data’s seeing eye. As predictive analytics, automated decision-systems, and artificial intelligence take on increasingly central roles in public governance, digital failure reveals how data itself is a flawed concept prone to political abuse and social engineering to protect the interests of the powerful, while keeping those marginalized over-surveilled and underrepresented.
Keywords
Introduction
There has been growing attention to moments of “digital failure” pertaining to data inequities in machine learning and artificial intelligence from soap dispensers (Lazzaro, 2017) and facial recognition technologies (Buolamwini and Gebru, 2018) that fail to recognize darker skin tones, racially biased prison-sentencing algorithms (Angwin et al., 2016), to sexist job recruitment (Dastin, 2018) and credit assessment (Vigdor, 2019) algorithms. Solutions to the issue of flawed algorithms include diversifying input data to be more inclusive and increasing diversity in the field of AI research and development (Eubanks, 2017; Noble, 2018; West et al., 2019). Others have suggested that fixing existing systems may unwittingly legitimize “predatory inclusion” (Taylor, 2019), where more accurate targeting and recognition will actually improve racist technologies used to surveil Black and brown communities, rather than questioning the need for the system in the first place (Hassein, 2017). Legal scholar, Frank Pasquale (2019) has proposed a periodization schema for research on algorithmic accountability, where first-wave research focused on the need to diversify data inputs to achieve more accurate outputs, and the second-wave is concerned with structural forces, issues of governance, and power inequities endogenous to societies of control. In line with second wave concerns, this paper asks how can we build meaningful resistance to algorithmic governance when so many of these systems are invisible?
While the issue of flawed data and broken digital systems calls for urgent solutions at all scales from anti-oppression training data sets to critiquing structural dynamics that constitute data infrastructures, this paper advocates for a type of failure that seeks to break rather than fix existing systems. Here, I draw a distinction between flawed algorithmic systems and digital failure. Derived from old Norse flaga, a flaw was used to describe something “weak” and “feminine” and applied to materials such as a “slab of stone” (“Flaw, n.1,” n.d.). The etymological gendering of flaw is brought forward to today’s gendered and racialized flawed digital systems and flipped in my analysis to reveal its deeply patriarchal and white-washed logics encoded into algorithmic systems. Alternatively, failure is premised on deficiency and marks something left “to be wanting” (“Fail, v.,” n.d.), which Jesper Juul (2013) argues motivates humans to strive towards “escaping failure” even when it has us coming back to the games we fail at. As such, failure can also be hopeful and agentive.
Where flawed algorithmic systems point to the ways error and uncertainty are central to how these systems “work”, digital failure is seen as an agentive “failure to work” in service of today’s dataveillance society (Dijck, 2014) and mode of refusal to algorithmic governance (König, 2019) and platform logics (Srnicek and De Sutter, 2017). Digital failure is a process of unbecoming a “good” data subject to challenge data’s “God’s eye view” (Haraway, 1988) and push past the margins of legibility, knowability, and thinkability, to interrogate what is made illegible, unknowable, and unthinkable to data’s seeing eye. In this way, it falls into a similar tradition to Stuart Hall’s “low theory”, Eve Sedgwick’s “weak theory”, and Donna Haraway’s “partial and situated perspectives” all of which divest from positivism’s search for universal truths and relinquish the illusion of data’s objectivity. It undermines the legitimacy and value placed in data and instead questions: whose data? In service of what ends?
Moving from failure’s connotative proximity to the broken, toward Halberstam’s (2011) understanding of failure as defying neoliberalism’s tyranny of success, this paper explores the moments of digital failure when subjects defy normative categorization and “talk back” (Hooks, 1989) at the algorithm from the subjugated position. I argue that the data industries are bound by a certain failure, always one-step behind, trying to anticipate your identity and solve for it retrospectively at the same time. In this way, our “data doubles” (Fourcade and Healy, 2016), “algorithmic identities” (Cheney-Lippold, 2017), or digital “proxies” (Steyerl, 2014) never quite represent us, but are an assemblage of data crumbs, which come into being through our digitally captured actions. While some may see this as a flaw in the algorithm, this paper argues for the potential in digital failure as a way to unsettle histories of naming and categorization that have long been entangled in histories of sovereignty, colonialism, subjugation, and exploitation. It is from a place of failure where we can trouble the flaws, reveal their inconsistencies, and seek new strategies to undo their logics from within.
The digital failure this paper advocates is characterized by pesky data that sneaks through the cracks of digital capitalism and dissipates into the unproductive; it supports run-away data prone to misidentifications by digital marketers, coders, and content moderators; and it celebrates data predisposed to “back-talk” with playful irreverence for those that seek to bring order through normative categorization and moderation. I call these data entropic, fugitive, and queer and explore their mischievous practices through three case studies. First, I consider entropic data, the unaccountable and unusable data which digital marketers seek to resolve through probabilistic identity resolution. Next, I explore fugitive data through misidentifications in the image recognition training platform, ImageNet, which applied misgendering, racialization, and mischaracterizations to its digital subjects. Finally, I tease out queer data through the posts of sex worker and social media influencer, @Charlieshe, who talks back at the damaging effects of shadowbanning on marginalized communities through playful and erotic posts that speak directly to the content moderators and platform owners. Through these examples, I explore the ways digital failure offers pleasure and playfulness that toys with its panoptic watchers. By failing digital capitalism’s subjectification, this paper seeks an alternative reading of digital failure that aims to denaturalize these “algorithms of oppression” (Noble, 2018) to resist being “apprehended or made transparent” (McGlotten, 2016) by those that seek to categorize. As predictive analytics, automated decision-systems, and artificial intelligence take on increasingly central roles in public governance, digital failure reveals how data itself is a flawed concept prone to political abuse and social engineering to protect the interests of the powerful, while keeping those marginalized over-surveilled and underrepresented.
Digital failure: A “low theory” of unbecoming
Digital failure takes as its jumping off point the truism “data does not precede fact” but are cooked, constructed, and constitutive of material-semiotic assemblages (Dixon-Román, 2017; Gitelman and Jackson, 2013; Kitchin and Lauriault, 2014). Similar to events which are enunciated against the “continuity of time”, data is enunciated against the “seamlessness of phenomena” and is called into being “out of an otherwise undifferentiated blur” (Gitelman and Jackson, 2013: 3). Data must first be imagined before being called into existence. As such, data is not neutral, nor pre-existing, but shape and are shaped by contested socio-cultural politics from which they come (Dalton and Thatcher, 2014).
Gitelman and Jackson (2013) discuss the rhetorical shift from datum, as the singular, to data as a mass noun, where data has come to represent both the many and the one by taking on a polysemic relationship to the multiple and the singular. Similar to Galloway’s (2015) conception of the digital as “one becomes two”, data is the many becomes one; and the one represents the many. Galloway defines the digital as a way of thinking, just as Gitelman and Jackson define data as a way of thinking; as either particular or universal. Data is both unique, discrete, unitized, and data are constitutive, aggregative, and accumulative. As Gitelman and Jackson argue, data IS/ARE suspended between the singular and the plural. The slippage between plural and singular affords data special rhetorical powers to mold to situational meaning.
These rhetorical powers are encoded into the etymology of the word, datum, which derived from the Latin dare (to give), was used to reference something given in an argument or taken for granted (Rosenberg, 2013). While facts might be considered ontological (derived from Latin facere, or to do), evidence as epistemological (derived from the Latin word videre, or to see), data is rhetorical and intended to persuade (Rosenberg, 2013: 18). When a fact is proven false, it ceases to be fact, but false data exists, nonetheless. Digital failure, then, is suspicious of data’s ontoepistemological claims of “being and meaning” and instead sees data as emergent and part of a rhetorical and ideological struggle to fix and assign meaning (Laclau and Mouffe, 1985).
The project of digital failure calls into question who is identifying whom and for what purpose? Hortense Spillers (1987) takes up the question of who is granted the power to name in “American Grammar Book”, wherein Spillers complicates deceptively simple terms like “black woman” and “mother” which are “so loaded with mythical prepossession that there is no easy way for the agents buried beneath them to come clean” (1987: 65). Drawing to the surface the reductive violence of naming and categorizing, Spillers argues these discursive practices render a “hieroglyphics of the flesh” that become hidden in the “cultural seeing by skin color” (1987: 67). If these discursive practices are pressed into the flesh and bodies themselves can be read like a “script” (Jackson, 2006), then how do we “read” our digital identities that have been reduced into a series of zeros and ones?
Digital failure is a failure of sociotechnical subject formation in post-modernity. Denise Ferreira da Silva (2007) argues the great project of modernity produced the “transparent I” as a self-determined subject defined by conditions of interiority and temporality. The transparent, fully formed sovereign subject is what Sylvia Wynter (2015) might call Man 2, or homo oeconomicus, which she argues is not the human itself, but a genre of human characterized as “Western Man” or the universalist “human”. To displace the modernist “transparent I”, Ferreira da Silva offers homo modernus, the modern subject that emerges as an effect of “exteriority and spatiality” and attends to the ontoepistemological “mode of representing human difference as an effect of scientific signification” (Ferreira da Silva, 2007: 4). In line with Ferreira da Silva and Wynter’s critique of the modern, liberal and universal subject made through exterior processes of naming and categorization, digital failure centers an ontology of difference and unbecoming the data subject through entropic, fugitive and queer data. This is not to suggest these three forms of digital failure are the only mode of unbecoming the good data subject. Rather, these non-exhaustive and non-exclusive modes of digital failure simply offer a starting point to discuss the political potential of claiming failure from within and below, fueled not by revolt, but by a desire to “escape the conqueror’s hold” and data’s claims to universal truths (Gauchet 1997 quoted in Wynter, 2015).
The view from below aligns with what queer theorist, Eve Sedgwick (1997) calls “weak theory” informed by “reparative reading” practices that attend less to the dangers lurking behind systems of power, in favor of a risky positional shift toward a sustained “seeking of pleasure”. The reparative mode offers an important corollary to the paranoid mode, which Sedgwick argues is informed by cybernetic theorizing where the paranoid has become synonymous with critique itself in a closed feedback loop. Taking up this challenge, Jack Halberstam (2011) borrows “low theory” from Stuart Hall to advance an alternate mode of theorizing that aims to avoid the “hooks of hegemony” and “seductions of the gift shop” (a euphemism for capitalism he draws from SpongeBob Square Pants). Instead, low theory seeks “a grammar of possibility” in a theory that “flies below the surface”, is “assembled from eccentric texts”, and “refuses to confirm the hierarchies of knowing that maintain the high in high theory” (Halberstam, 2011: 16). While Halberstam (2011) calls for a grammar of possibility as a political project to find a space for “low theory” in the academy, I argue it can also be applied to the ways we talk about digital identity construction to find space for the unrecognized, displaced, and abject bodies.
Entropic data: The unaccountable in identity resolution
Philosopher of science, Isabelle Stengers (2010), explains “The Not So Profound Mystery of Entropy” as the degradation of energy that increases over time until all useable energy, capable of producing work, disappears. Similarly, Ramon Amaro (n.d.) argues entropy reveals a “system inclusive of contingency, instability [with] multivalent modes of perceptions, indeterminacies, and iterations of self-actualization.” Now critiqued as a technological fantasy (Hong, 2020), the turn to Big Data brought about a feverish desire to track, capture, compute, and analyze endless customer data points to gain “insights” about customer preferences and behaviors. The trick marketers face is putting all this data “to work” when so much of this data is rendered indescribable and unusable. This is what I call, entropic data, which drawing from its scientific counterpart, entropy, refers to the data which dissipates without return, rendering a possible “insight” lost, unaccountable, and indeterminate.
Given the vast quantity of data about preferences and behaviors, data brokers have begun to offer a service known as “identity resolution” to keep track of an individual’s complete digital profiles. Identity resolution aims to “solve for identity” (LiveRamp, n.d.) through a process of matching uniquely identifiable information from “offline sources” such as voting records, medical records, and proprietary customer lists, with “online identifiers” such as cookies, email addresses, and browser histories. Identity resolution results in two kinds of data matches: deterministic (derived from known first-party data) and probabilistic (a murkier, less resolute prediction of a user’s identity). While “deterministic” data fashions first-party data as a kind of objective “ground truth” and is ripe for critical inquiry, here I am most interested in the “probabilistic” customer identities, which treats identity as potential rather than something given, known, or taken for granted. Where deterministic matching represents the “known” and accounted for, the probabilistic represents the unknown, unable to be fully captured data: that is, the entropic data.
Pre-history of identity resolution
One of the key pillars of modern digital identities, the credit score, began in the late 19th-century with the development of the credit bureaus who established “the modern concept of financial identity” (Lauer, 2017). In the wonderful history of the credit industry, Josh Lauer (2017) shows how data about one’s personal identity became morphed into financial identity, where personal success became conflated with financial success. The early credit bureau began collecting detailed personal information on individuals involving complex rating systems and moral judgments on personal character as a way to assess someone’s creditworthiness. The “credit man” (as they were always men) would codify a person’s creditworthiness according to the “three Cs—character, capital, and capacity,” where character was considered the most reliable factor in assessing a person’s ability and wiliness to pay back debt (Lauer, 2017: 20). Creditor’s would conduct extensive interviews and look for clues in a person’s appearance such as “physical appearance and personality; marital status (or strife); the condition of one’s home; drinking habits; predilections for gambling or philandering; and one’s reputation,” cross-referencing these observations with neighbors or colleagues who would provide a character reference (Lauer, 2017: 20). Many of these referents are still used to draw digital profiles of people today.
Lauer (2017) makes an important intervention in our understanding of surveillance capitalism by highlighting the relationship between the credit bureaus and advertising. Lauer (2017) explains that at the same time industrial production was finding a science of control and time-management, the consumption industries were developing scientific models to segment markets. The credit industries soon realized they had amassed a “strange and intangible new commodity: personal information,” which would become extremely valuable to both marketers and government agencies (Lauer, 2017: 8). This relationship between credit reporting and advertising is often overlooked in critiques of the data industries and provides important historical context to the development of identity resolution. In particular, it helps us understand how Experian and Acxiom, the credit reporting giants, have become leaders in the field of identity resolution.
From credit reporting to identity resolution
According to Christine Frohlich (2018), Vice President of Product Management at Experian (credit agency and data aggregator), deterministic matching helps “identify the person behind the screen, giving the advertisers a high level of confidence that they know who the customer is,” while probabilistic matching uses statistical likelihood to “predict, with some level of confidence, who the individual is.” How data aggregators arrive at probabilistic matches depends on their own proprietary black-boxed algorithm and methodology and is generally useful for modeling “look-alike” audiences (Iyer, 2019) and marketers seeking “reach and scale” rather than accuracy (Frohlich, 2018). Acxiom explains probabilistic matching on their website as “‘fuzzy matching,’ which is commonly used to match data points based on how similar the data is. For example, if you were trying to determine whether Tanya Smith from Columbus, OH, is actually the same person as Tanya Jones from Phoenix, AZ” identity resolution would offer a probabilistic match (What Is Identity Resolution?, n.d.). As probabilistic matching can only identify an individual to a certain confidence interval, it reveals a certain ambivalence to one’s underlying identity. Importantly, there is a qualitative difference here between the credit man of past who made subjective judgments on one’s character and systemic coded inequities built into systems of automation and categorization as seen in the practices of identity resolution. But what exactly is identity resolution?
Identity resolution has emerged as a service to “tie all of your marketing data back to real people” by linking “first-, second-, or third-party digital and offline data silos” (LiveRamp, n.d.). IdentityLink, LiveRamp’s main product for identity resolution, is promoted as a service that: “connects people, data, and devices across the digital and physical world, powering the people-based marketing revolution and allowing consumers to safely connect with the brands and products they love” (Liveramp.com, n.d). According to a strategic report by Forrester, identity resolution is the new frontier for “customer-obsessed” marketers because it “spans every interaction” for more accurate cross-channel marketing (Stanhope et al., 2016).
To be a “customer-obsessed” marketer in the age of Big Data requires not only the ability to process large data sets, but also the ability draw meaningful insight from data. Boyd and Crawford (2012) argue, Big Data is less about data being big, than the “capacity to search, aggregate, and cross-reference” disparate and extensive data (p.663). Marketers call this “activating your data” (Acxiom, 2017) and in the age of multiple personal devices and endless data extraction, keeping track of data related to a single entity becomes a major challenge to those trying to anticipate or influence your next purchase.
Identity resolution has become such a valuable service that in 2018 legacy marketing firm, Acxiom, sold off their marketing arm and rebranded to LiveRamp, their “identity platform” business (Levine, 2018). In 2019, the company brought in over $380 million in revenue and was valued at a market cap of $3.53 billion (USD) in 2020. Experian, the other Big Data aggregator in the identity space, named “identity solutions” as a key area of growth in their 2019 Annual Report (Experian, 2019) and a 2018 company blog post stated: “Solving for identity is at the core of every marketing activity. The ability to accurately identify consumers is the most basic prerequisite for marketing analytics, orchestration and execution” (Portoff, 2018). The 2019 Experian Annual Report also outlines the growing importance of machine learning, artificial intelligence, and process automation “for businesses across all industries to operate more efficiently and secure productivity gains” (Experian, 2019: 17) where correctly identifying customers is tied to business productivity.
Wading past equivocal marketing jargon, early company patents provide important political-economic insight into the worlds of intellectual property as a tool to secure financial gains from future uses of a new technology (Shapiro, 2020) and are often based on the “dreaming of technoscientific order” (Hemmungs Wirtén, 2019). LiveRamp’s US Patent No. 8,620,642 B1 (2013), outlines a system that determines the likelihood that a unique identifier (UID) is associated with the same user. The patent authors explain that most UIDs “such as email addresses, website usernames, and even phone numbers are issued to a single human” (Hoffman et al., 2013). The correlation system then uses aggregated data to return a score representing the confidence that multiple different identifiers are related to the same person, see Figure 1.
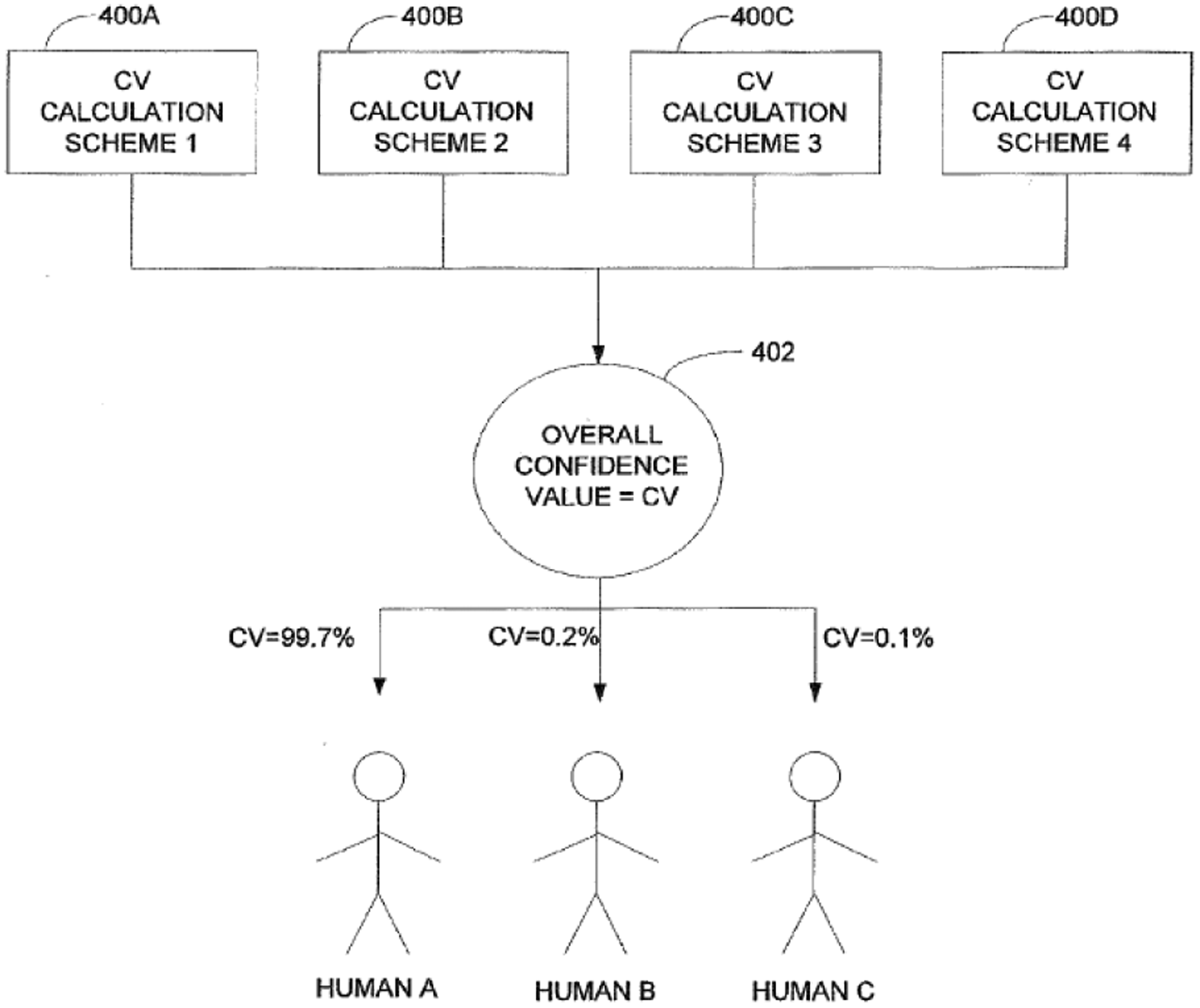
LiveRamp Patent Diagram (No. 8,620,642 B1, 2013).
According to semiotician Charles Sanders Peirce (1992), a diagram offers flexibility “because it suppresses a quantity of details, and so allows the mind more easily to think of the important features… in respect to the relations of their parts” rather than as accurate depictions of objects. However, diagrams can also be understood as technologies in and of themselves which can reveal mechanisms of power and the “essence of social technologies” (Shapiro, 2020). The comparison of Human A, B, and C in Figure 1 with the estimated confidence values of 99.7%, 0.2%, and 0.1% is predicated on an underlying ambivalence about a customer’s true identity and the quantification of Type 1 error (the chance of getting a false positive) into the confidence value, where the error rate represents 1 – C.V. Human A, B, and C are represented as identical diagrammatic figures whose value is reduced to the “confidence” they can be targeted accurately.
The patent goes on to explain how this type of correlation system could enable government and law enforcement to identify “illegal and forbidden activities and prevent wrongdoings and crimes.” Ever present in these accounts is the construction of the morally impaired Other, the “failing” citizen which must be logged and tracked, justifying the creep of surveillance technologies like identity resolution. The patent authors also explain how this system could be used to track sex offenders, who are currently not required to register their email address with the state. The patent explains how even if convicted sex offenders were mandated to report their email address, it is very easy to create a new one and identity resolution could be used to tie the new accounts back to one person. Identity resolution is presented as the “noble” solution to more effectively track, surveil, and potentially punish sex offenses. The implicit assumption here is that because sex offenders are considered a high risk to reoffend, they require more invasive and pervasive forms of social control, but some scholars argue this is unsupported by the empirical evidence on the effectiveness of such registries (Sample and Bray, 2003, 2006; Tewksbury et al., 2012). That aside, what’s important here is how the patent authors argue that the same technology that can be used to track and surveil sex offenders will be applied by marketers and creditors to track and surveil customers.
In another example, the patent authors outline how background checks do not usually investigate online activities or a person’s “Internet footprint history” (No. 8,620,642 B1, 2013). The correlation system then could be used to generate “trustworthiness or Social credit scores for different individuals based on these Internet activities” (No. 8,620,642 B1, 2013). The process is similar to credit scores, except the “user correlation system can identify multiple email addresses used by the same individual, [therefore] the trustworthiness or Social credit score more accurately represents the true reputation of the individual” (No. 8,620,642 B1, 2013). The trustworthiness or social credit score provides an economized moral judgement on someone’s character, with legacy data going back to the early credit bureaus that bring with it encoded racial, gendered, and subjective biases that have preceeded the development of digital data industries. The LiveRamp patent refashiones public-facing corporate messaging of “connecting people” as connecting data points about people.
A 2018 GDPR (the EU’s data protection laws) complaint lodged against Acxiom (now LiveRamp) by Privacy International illuminates the vast array of data that Acxiom collect and sell to their clients. This includes data gathered directly from a data subject such as household composition, grocery purchases, credit and loans, employment and income, newspaper readership, general insurance, and viewing behaviors; and indirect, or inferred, data such as, “marital status (probability of separation or widowed)”. Other inferred data includes: Hobbies and interests, including whether they are interested in bet horse racing, Current Affairs, Crosswords/Puzzles, Cycling, Do It Yourself, Eating Out, Fashion Clothing, Fine Arts Antiques, Football, Gardening, Grandchildren, Gold, Fine/Food, Cooking, Gym/Classes, Health Foods, Jogging/Physical Exercise, National Trust, Household Pets, Prize Draws/Competitions, Going to the Pub, Book Reading, Religious activities, Listening to music, Theatre/Cultural Events, Hiking/Walking, Wildlife/Countryside, Vitamins/Food Supplements … the probability of a non-smoker, level of interest in cultural pursuits, entertainment, animal/nature awareness and outdoor pursuits… what supermarkets you go to, also medical insurance, betting/gambling and alcohol at home. (Privacy International, 2018: 46)
The entropic data that goes unaccounted for is viewed as a problem to be solved by marketers; it is a failure of identification. The probabilistic confidence value in identity resolution strives to grasp at the seeping––entropic––data rendered unusable by untraceable, untaggable, and unnamable to wanting marketers. These data dissipate when someone gets a new IP address, a new email address, a new device, a new last name, a new mailing address, a new credit card, a new bank account, a new husband, wife, partner, or child, all of which pose threats to capturing a “holistic” view of a single consumer. In Glissant's (1997) terms, “to grasp” is to reach for something and bring it back to the self: it is a gesture of enclosure. Identity resolution represents a grasping for the “Transparent I”, the universal liberal subject constructed by Western white ontoepistemologies, not premised on identity, but on identification. Oscar Gandy (2000) argues there has been a context collapse between identity and identification in online transactions, where identity assumes individual agency related to the ability of the individual to shape their identity “beyond the gaze and influence of powerful others”. Identification, on the other hand, refers to the “exercise of power and authority” (Gandy, 2000). The grasping in identity resolution is a failure to grasp identity and a grasping for identification. The attempt to automate and re-solve identity reveals its cybernetic impulses where, as Tiffany Lethabo King so eloquently put it, the recursive feedback loop “justifies and legitimizes itself while hiding the ways humans are both produced by (written by) and produce these codes” (King, 2019). By defractively reading these industry texts through a queer theory and Black studies lens, they reveal their own flaws and recover the failed attempts to reconstruct data subjects as transparent, fully formed identities. Similarly, fugitive data shares a failure of identification though rather than waiting to be activated by advertisers, this data is agentive and actively evading capture.
Fugitive data: (mis)recognition in ImageNet roulette
Fugitive data is cunning, run-away data that slips through the roadblocks of digital captivity to evade its oppressor. Born of false positives and true negatives, fugitive data orients itself to the “undercommons of enlightenment where the work gets done, where the work gets subverted, where the revolution is still Black, still strong” (Harney and Moten, 2013: 26). Fugitivity not only escapes but “fugitivity is being separate from settling” in the logical, logistical, housed and the positioned (Halberstam in Harney and Moten, 2013). Fugitive data draws from C. Riley Snorton's (2017) account of how the “ungendering of blackness became a site of fugitive maneuvers,” wherein cross-gendering practices of fugitive actors in the antebellum period allowed slaves to traverse space undetected. In this way, fugitive data finds company in the misidentified, misrecognized, and miscategorized.
Fugitive data also draws on the concept of apophenia as theorized by Hito Steyerl (2016) as the (mis)recognition of patterns in data. Apophenia is the tendency to mistakenly perceive connections and meaning between unrelated things and as Steyerl (2016) argues “one has to assume that sometimes, analysts also use apophenia.” To explain this process, Steyerl offers “dirty data” which denotes the noise that interrupts the signal in data. Converse to fugitive data, dirty data does not have agency: it is identified as a problem to be fixed and is cleansed through data purification processes.
This case study of fugitivity follows the story of a neural network designed to recognize and categorize images, but through misrecognition, the data subjects ultimately get away. I draw from the circulation of images on Twitter that document the failure of image recognition program, ImageNet. According to the ImageNet website, it is one of the largest training data sets which arose out of a growing “need for more data” (ImageNet, n.d.). Over a 10-year period, ImageNet grew to over 14 million images that were organized into 20,000 categories and became the benchmark for machine learning in the field of object and facial recognition (Crawford and Paglen, 2019). Although it soon became apparent that many of the categories that were determined by precarious “ghost workers” (Gray and Suri, 2019) through platform labor markets such as Amazon Mechanical Turk, were laden with racialized, sexualized, and bigoted judgments. In an effort to reveal these biases, ImageNet Roulette, a collaborative art project between critical AI scholar, Kate Crawford and digital artist, Trevor Paglen, allowed people to upload photos to see how AI categorizes (or mis-categorizes) your own photo. ImageNet Roulette pulled from the ImageNet training data set to reveal the ways that human subjects are categorized by the image recognition algorithm. See Figure 2 for screenshots of how the AI categorized me.

Author screenshots of photos uploaded to ImageNet Roulette.
I am at once a beekeeper, astronaut, orphan, sick person, and a cog in the machine who is “subordinate” and “performs an important but routine function.” While most of these categories appear banal, if somewhat mildly offensive, there are implicit assumptions and value judgments being made based on the whiteness of my skin and how I measured against coded stereotypes. Some of the more overtly violent and damaging results were circulated online with headlines such as, “The viral selfie app ImageNet Roulette seemed fun – until it called me a racist slur” (Wong, 2019).
In such examples, white women were coined “hussy”, “slut”, “trollop”, “mantrap”, “dish”, while white men were categorized as “skinhead”, “klansmen” or more positively as “statesman” or “elder”. Black men were coded “first offender”, “wrongdoer”, and Black women as “Black woman” or “Black African” (see Figures 3 and 4). The categories reveal deep human biases and how histories of racialization and sexualization are replicated in supposedly neutral machine-learning tools.

ImageNet Roulette images circulated on Twitter (Monster, 2019).

ImageNet Roulette images circulated on Twitter (@galdemzine, 2019; @kareem_carr, 2019).
Given the wide-spread media attention and virality of this project, ImageNet agreed to scrub 1.5 million images in the “person” category. While the result was a victory for the ImageNet Roulette project, it also underscored how invisible biases encoded into data can be instantly erased at the platform’s will. One of the more fascinating aspects of the whole project was the intense affective response that it generated online, which flowed between disgust and outrage, to amusement and play. While many of the pictures circulated on Twitter were motivated by pointing out the violence of racism and misogyny, the practice of sharing the miscategorizations also created an affect of pleasure and solidarity in the re-circulation of these images as humans pointing back at the algorithmic failure. Here humans are using the moment of digital failure to delegitimize our reliance on these fallible systems. Although ImageNet was able to cleanse itself from its “dirty data” (Steyerl, 2016), it was unable to scrub the more systemic issue of racism and sexism.
To understand the linkages between fugitivity, failure, and ImageNet, let us interrogate the bounding box as a site of critical inquiry. The bounding box is used in object recognition to draw boundaries around the object of interest. It’s that thin blue, green, or yellow box that floats around the object and tries to capture and classify the image. Within computer science, it is a contentious little box that is often said to exclude too much of the external data and too much of the surrounding context to accurately identify its contents (Lempitsky et al., 2009). In science and technology terminology, the bounding box might be called a “boundary object”, described by Star and Griesemer (1989) as “plastic enough to adapt to local needs… yet robust enough to maintain a common identity across sites”. In ImageNet, the bounding box is placed around an object or person and given a label following the semantic structure provided by WordNet, a database of classifications developed at Princeton in the 1980s (Crawford and Paglen, 2019).
The bounding box represents captive data that help machines “see” the world like humans. In the ImageNet database, as with many other databases used for facial recognition, the images were scraped from the internet without user’s consent and the classification of these images was outsourced to precarious labor networks. In the same way that identity resolution tries to grasp at identification, the bounding box tries to grasp the human face and make sense of it. Through the ImageNet Roulette project, users were able to locate the flawed assumptions which wrongfully and offensively classified their own images. In his analysis of fugitive slaves performing cross-gendering practices, Snorton articulates how these were “performances for rather than of freedom” (2017: 58). Similarly, the images with offensive labels that were circulated through social media were shared out of unfreedom to classify and identify oneself: these were acts for rather than of freedom. Just as Snorton explores how fungibility of gender became a fugitive maneuver to fool bounty hunters and avoid capture, the ImageNet Roulette photos circulated online are stories of misidentification due to the ignorance of classification systems. It was only after these images with their offensive labels were captured and circulated that ImageNet agreed these classifications were an issue and to solve the problem, it rid itself of thousands of classifications.
This case study shows how the ImageNet training data set was forced to look back at itself through an art project which revealed its own flawed logics. The ImageNet Roulette project became an agitator in the cybernetic feedback loop and a mediator for people to speak back at the system imbued with racial and patriarchal logics. At the moment the training data were reformatted for wide-spread public trail in the ImageNet Roulette project, they became fugitive data. These images broke free of the recursive system, which trained new image recognition algorithms on how to correctly identify biased data and in doing so, provided a tale of fugitive data that escaped captivity.
Queer data: Sousveillance and “reading” the shadowban
First conceived as a way to flip panoptic power on its head by “watching from below” (Mann et al., 2002), the political potential of sousveillance has gained traction in our digitally connected and controlled worlds. Expanding the theoretical frame of sousveillance, Simone Browne, (2015) coined the term “dark sousveillance” to characterize the resistive practices used to challenge racialized surveillance. Colin Burke (2020) recently outlined the potential of “digital sousveillance” as a method of studying surveillance practices through computation methods like network analysis. Queer data further extends the literature on sousveillance, where the practice of “reading” is seen as a form of queer sousveillance.
Queer data embraces the queering effect that happens between data and data subjects, “where something queer happens to the signified – to history and bodies – and something queer happens to the signifier – to language and to representation” (Britzman, 1995). Britzman’s (1995) “Queer Pedagogy” offers a mode of interpretation and method of theorizing digital failure as the failure to work. According to Britzman (1995), “queer” signifies a social relation that troubles conceptual orders. Britzman offers three methods to enact a queer analytic, the first of which is committed to the study of limits, understood as “a problem of thinkability” that questions the limits of what is thinkable (Britzman, 1995: 216). This mode attempts to draw attention to the “unmarked criteria” within a field of study and what that field “cannot bear to know” (Britzman, 1995: 216). The second method advocates the study of ignorance or that which is unintelligible or illegible to state and corporate interests. The third method is a study of reading practices, which include reading for alterity, engaging in a dialogue with the self as the self reads, and practices of theorizing how one reads.
Here I extend the study of reading to include the practice more akin to E. Patrick Johnson's (1995) definition of “reading” as a way to set someone “straight” by putting them in their place and revealing a flaw in their character. Different from Britzman’s reading for alterity, Johnson’s “reading” is a performative act that speaks back and destabilizes power structures. Through the performative “reading” of the shadowban, queer data drops the fourth wall of critical distance and invites its audience to engage in the meaning making process of digital identity construction, which is at once mindful of its artifice and yet willing to suspend disbelief for a moment of creative pleasure. I explore queer data through the case study of, sex worker and micro-influencer, Charlieshe, who employs playfulness and comedy to talk directly to the content moderators of Instagram.
Charlieshe’s body exists outside the limits of platform acceptability, troubling the normative codes of content production on Instagram. In a picture seemingly taken from a bathroom, Charlieshe bends forward covering their chest with their hands and the caption reads: “Wednesday is right here  to remind ya my body exists beyond this platform. Naked is not sexual. Im just a sexy ass bitch
to remind ya my body exists beyond this platform. Naked is not sexual. Im just a sexy ass bitch  stop projecting” (Charlieshe, 2019b). Charlieshe offers playfulness and comedy as a way to talk about inequities in content moderation that categorize queer bodies as sexual and often lead to take-downs and practices of shadowbanning.
stop projecting” (Charlieshe, 2019b). Charlieshe offers playfulness and comedy as a way to talk about inequities in content moderation that categorize queer bodies as sexual and often lead to take-downs and practices of shadowbanning.
A shadowban is when content moderators block or partially block content in a way that is not apparent to the user or their followers (Myers West, 2018). It is a particularly damaging practice to those who rely on platforms for building their own personal brand and growing their network, though has become a hot-button topic among conservative circles who claim the “liberal” social media platforms are silencing conservative voices (Romano, 2018). The difference between conservative claims of victimization by practices of shadowbanning and those of sex workers and other marginalized voices, is the conservative groups represent the white-male dominant social group. The politicization of shadowbanning has become a rhetorical maneuver of deflection away from how these practices disproportionately harm minoritarian communities by focusing on how these practices might harm those with political power. In this way, shadowbanning is underpinned by an operative logic of opacity (Roberts, 2018) which relies on obfuscation, secrecy, and, I add here, deflection by groups with political power.
By centering a queer analytic, this paper refutes claims of victimization by the conservative right and instead focuses on moments of shadowbanning against minority groups who use “reading” as a way to highlight these inequities. For example, Charlieshe posted a song in response to the practice of shadowbanning dedicated to “Zucky baby”, a diminutive nickname for Facebook founder and owner of Instagram, Mark Zuckerberg (see Figure 5).

Instagram Posts, @Charlieshe (Charlieshe, 2019a).
The post was accompanied with the lyrics, which read:
*Shaddowbanned you hate me. You take away my visibility, you take away the possibilities of me to grow, you need control, my little Zuckybaby. Shaddowbanned, you hate these. You can’t take away these big ol’ titties, you gotta stop w your obsession, you gotta stop w your obsession, zucky soocky baby* #jinglealert
Charlieshe is “reading” Zuckerberg by calling out the secretive and uneven practices of shadowbanning that are applied on his platform when a body does not fit within the normative bounds of platform acceptability. Charlieshe also dedicates the jingle to other users who have been shadowbaned by “complacent fascists” who enact control over queer bodies and queer sexuality through content scrubbing practices that are hidden from users view.
In another post (see Figure 6), Charlieshe calls Zuckerberg “zaddy zuck”, cleverly pairing alliteration with a jab at the paternalistic, over-bearing fatherly like stance of content moderators to censor sexualized queer bodies.
Instagram Posts, @Charlieshe (@charlieshe, 2020).
Charileshe uses disidentification through humor as a way to re-frame and dislodge normative ideas about which bodies are rendered acceptable and therefore visible on the platform. Muñoz explains: [c]omedy does not exist independent of rage… [when] rage is sustained and it is pitched as a call to ACTIVISM, a bid to take space in the social that has been colonized by the logics of white normativity and heteronormativity (1999: xi-xii).
In some ways, the practice of shadowbanning is the ultimate fail for social media platforms whose marketing spin hinges on the technoutopian dream of connecting everyone on the planet. Instead, the posts of Charlieshe point to an alternative interpretation of Zuckerberg’s utopian vision, which rather than connecting every body on the planet, chooses only to connect some bodies. The bodies that exist beyond the comprehension of platform standards are suspended in a state of indeterminacy, unable to be assigned value to advertisers and designated by platform moderators as errant or null (absent of value) (Gaboury, 2018). The threat of shadowbanning highlights how certain populations will always be at risk of being marked as a failed subject.
Applying Britzman’s (1995) queer analytic to online shadowbanning practices offers a way to see how the shadowban is used as a tool for the politically powerful to govern which bodies are rendered visible and which bodies are censored from their platform. Charlieshe offers a way to “read” the shadowban by revealing a flaw in its character, thereby creating a space for the queer data subject to “talk back” (Hooks, 1989) at the platform standards and “observe the observer” (Burke, 2020) through queer sousveillance. It is these moments of refusal to comply and accept the ways content moderators sort and classify bodies that offer the kind of potential Halberstam advocates as a way to criticize the flaws of patriarchal capitalism.
Data pressure points and the threshold of algorithmic undoing
By thinking opacity, fugitivity, and back-talk through a lens of queer digital failure, this paper offers a novel way to think through some of the tensions between Black studies and queer theory. Specifically, where queer theories of refusal have been critiqued as necessitating a white positionality of safety in which to fail or refuse, Black studies offers modes of being and resisting aimed at destabilizing unequal power relations. In turn, queer theories of failure offer a performative mode of unsettling practices of identification and identity construction. Rather than seeing the two fields in opposition, this paper extends on the project outlined by E. Patrick Johnson and Mae G. Henderson (2005) in Black Queer Studies which sees the two liberatory and interrogatory practices as dialogic, dialectic, and committed to blurring methodological and disciplinary boundaries.
Together these liberatory practices offer navigational aids to locate the pressure points within algorithmic systems. These pressure points can be viewed as sites of stress, as cracks of potential, which, by applying pressure, we may begin to forge alternative possibilities. Like the bending of plastic too many times, which can create “stress cracking” due to the brittle failure of thermoplastic, the practices outlined in this paper views these failures as potentialities. Just as plastic will fracture under increased pressure and exposure to unfriendly chemicals, could we view these moments of digital failure as data pressure points? Similarly, if the internal cracks in thermoplastic exist at the threshold of collapse, could these points of digital failures exist at the threshold of algorithmic undoing?
Rather than viewing these failures as something to be fixed, the three case studies in this paper reveal moments of cybernetic rupture where preexisting biases and structural flaws make themselves known: where the failures reveal the flaws. The moments of data entropy, fugitivity, and queerness offer sites of reflection to identify how and why certain subjectivities are made unknowable or unproductive to algorithmic systems and how we might locate broader flawed assumptions that lead to these failures in the first place. Taken collectively, the three case studies articulate a crucial difference between a flawed system where racist, sexist, and discriminatory practices are built into the proper functioning system and digital failure as failing to be recognized in the system or to comply with its rules.
This analysis extends on existing critiques of the Quantified Self and how “datafication turns bodies into facts” (Hong, 2020) by seeking out the moments where data itself reveals failure as either a deficiency or something left wanting. Heeding Sun-ha Hong’s (2020) directive that critique of data-driven truth must “deliberately disrespect the rationality of technology”, digital failure hopes to dislodge data’s objective claims to truth. Turning to the logics of data, entropic and fugitive data might be understood in statistical terms as increasing the likelihood of Type II error, or the chance of a false negative, whereas queer data dismisses the smoothing practices of data normalization and pushes the boundaries of error classification. While all three types of data directly challenge the racialized and gendered practices of the “panoptic sort” (Gandy, 1993), it is queer data that articulates these practices in the face of its oppressor. Drawing strength from Black feminist theory, queer data moves “from silence to speech” (Hooks, 1989) in an act of defiance to forge a new path. As bell hooks so eloquently argued, “[i]t is that act of speech, of ‘talking back,’ that is no mere gesture of empty words, that is the expression of our movement from object to subject––the liberated voice” (1989: 29). To that point, I offer queer data as a way to speak back to our digitally captured selves, to become the liberated voice, and open up possibilities for non-normative creativity and play.
Conclusion
At a moment when it is crucial to critique the ills of surveillance capitalism, the omnipotence of platform power and consider forms of political, legal, and social intervention, this paper shifts the focus from what needs to be fixed, to the political potential of failing to work. This paper explores how moments of digital failure shed light on critical social cleavages and growing inequities of who has power over and within these systems. It is precisely in response to the continued violence of segregation of bodies into categories of moral and economic value that continues to uphold the hetero-white male as the unmarked data point on which all others are measured, from which the political call to digital failure is waged. This is the refusal and failure to work in service of today’s data society. In this mode, digital failure is seen as a resistive strategy to denaturalize surveillant systems imbued with histories of racial and gendered oppression, and instead seek solace in failure as a way to “talk back” and “read” the inequities built into these digital systems.
The mischievous practices of entropic, fugitive, and queer data explored in this paper are not cunning because they use data incorrectly, but instead they contest the mischievous uses of data that are presented as normal and taken for granted in the first place. Collectively, the case studies articulate the political potential of digital failure as a process of unbecoming the compliant, detectable, and ordered digital subject as a way to undermine modernist claims of ontological truths through data and to subvert the recursive paranoid readings that work to reproduce these systems of oppression. Instead, these entropic, fugitive, and queer data push past the margins of legibility, knowability, and thinkability, and reveal what is made illegible, unknowable, and unthinkable to data’s seeing eye. As more crucial public services are outsourced to flawed digital systems, the modes of digital failure explored herein, seek solidarity beyond individual actions and instead hope to build a collective movement of resistance against the uncritical embrace of algorithmic governance.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
References

 on Twitter
on Twitter on Instagram: “▪ ZUCKY BABY ▪. on Instagram
on Instagram: “▪ ZUCKY BABY ▪. on Instagram