
Abstract
The article develops a methodological and empirical approach for gauging the ways Big Data can be collected and distributed through mobile apps. This approach focuses on the infrastructural components that condition the disclosure of smartphone users’ data – namely the permissions that apps request and the third-party corporations they work with. We explore the surveillance ecology of mobile apps and thereby the privacy implications of everyday smartphone use through three analytical perspectives: The first focuses on the ‘appscapes’ of individual smartphone users and investigates the consequences of which and how many mobile apps users download on their phones; the second compares different types of apps in order to study the app ecology and the relationships between app and third-party service providers; and the third focuses on a particular app category and discusses the functional as well as the commercial incentives for permissions and third-party collaborations. Thereby, the article advances an interdisciplinary dialogue between critical data studies, political economy and app studies, and pushes an empirical and critical perspective on mobile communication, app ecologies and data economies.
Introduction
In a recent conference talk, executive vice-president of the EU-Commission, Margrethe Vestager (2019), encouraged the audience to ‘imagine your smartphone was your mother’. She continued, ‘the first thing you see each morning and before you go to sleep. It’s not that you’re doing anything she wouldn’t approve of – she raised you after all – it’s just that she would be there with you all the time’. Vestager’s analogy underlines that we would resist it if anyone were to monitor our every move to the extents that our smartphones do. It also focuses our attention to the underlying and comprehensive surveillance mechanisms of mobile apps that go largely unnoticed as users scroll down the endless pages of terms of service (ToS) agreements only to click accept upon request. The ubiquitous problem of ‘informed consent’ (Nissenbaum, 2011) creates a challenge for researchers and policy-makers alike, and calls for basic research into the various infrastructures and surveillance practices of mobile communication.
Despite smartphones being an integral part of everyday communication, we know relatively little about the data collection practices of different mobile apps (for exceptions see e.g. Atkinson et al., 2015; Binns et al., 2018). We address this research gap by developing a methodological and empirical approach for gauging the ways Big Data can be collected and distributed through mobile apps. More specifically, the article presents a study of the infrastructural components that condition the disclosure of smartphone users’ data – namely the permissions that apps request and the third-party corporations they communicate with. These components represent the two most significant gateways into understanding the ways apps collect and distribute user data. Based on a dataset consisting of 173 unique mobile apps that appear on the home screens of 10 Danish regular smartphone users, the article asks how we assess and map the intrusiveness of mobile apps. We offer three empirical explorations that look at permissions and third-party services from the analytical perspectives of: (1) individual app repertoires (what we in this article name appscapes); (2) categories of apps (i.e. finance, sports, weather); and (3) similar apps within a category. This approach enables us to explore the surveillance ecology of mobile apps as well as the privacy implications of everyday smartphone use, and calls for empirical and critical data studies that make otherwise invisible infrastructures visible.
The article is divided into four parts: in the first, we position ourselves as part of the field of critical data studies that focus on apps, and outline the theoretical foundation for our methodological approach and empirical explorations; the second part describes the methods and discusses methodological issues surrounding the study of apps and (big) data; the third part applies the approach and presents explorative, comparative, and descriptive analyses from the perspective of individual appscapes, app categories, and particular apps; and in the fourth, we discuss the findings and future research prospects, and argue that increased public awareness of the surveillance mechanisms of mobile apps can support policy-efforts to regulate the data economy.
State of the art and theoretical foundations
The article is placed at the intersection between distinct yet overlapping research fields that motivate an empirical and critical perspective on mobile communication, data and privacy. When exploring the intrusiveness of mobile apps, we build on and contribute to existing research on digital privacy, critical data studies, political economy of communication, as well as the emergent field of app studies.
Infrastructures for/against privacy
Privacy studies often revolve around philosophical and ethical issues, and investigate how comprehensive and ubiquitous datafication of people’s everyday lives challenges and transforms established, yet increasingly hazy, conceptualisations of privacy (e.g. Cheney-Lippold, 2017; Mai, 2016). Other studies have focused on regular people’s understandings and strategies towards protecting their personal data and have for instance identified a disconnect between people’s concerns and their actual behaviour (commonly referred to as the privacy paradox (Barth and de Jong, 2017)). Scholars have also concentrated on individuals’ experiences and imaginations of data and algorithms (Bucher, 2017). And human rights researchers (Jørgensen, 2019; MacKinnon, 2013) have raised alarm over violations by Big Data corporations working within a ‘governance gap’.
In this article, we address the questions raised by digital privacy research by empirically approaching the ways the extensive collection, processing, and distribution of data through internet-based services change the fundamental conditions for protecting and controlling one’s privacy. While acknowledging the influence of socio-cultural factors on how people (and apps) behave, we stress the importance of uncovering and understanding the underlying infrastructures that support the surveillance ecology of mobile apps. In doing this, the article follows the so-called ‘turn to infrastructure’ in digital media and communication research (Musiani et al., 2016), and uncovers the ways privacy (or lack thereof) is built into the architecture of digital infrastructures. Mobile communication is, in this perspective, conditioned by the technological configurations of smartphones and operating systems (OSs), but also by the different apps that run on them and their various terms and conditions.
In exploring app infrastructures, we inevitably have to look at how app-based activities are controlled, and by whom. If we are to comprehend the pervasive economic incentives to collect ever-increasing amounts of data, we need to understand the underlying business models, operations, and ownership structures of the mobile app ecology and the data economy. Critical data studies (Dalton et al., 2016) have pushed this agenda by looking beyond the hype surrounding Big Data (Boyd and Crawford, 2011) and discussing the implications of datafication in terms of social sorting (Kitchin and Lauriault, 2014), commodification of users (Couldry and Yu, 2018), and data (in)justices (Dencik et al., 2019). Computer scientists have worked on reverse engineering the web tracking mechanisms of the biggest data resellers in order to expose the depth and extent of datafication (Falahrastegar et al., 2016; Kalavri et al., 2016).
Building on knowledge in these fields, we follow the infrastructural connections that support the harvesting and transport of data as a digital currency, in much the same way as researchers ‘followed the money’ in past studies of commercial media (DeFleur, 1971). We study data as ‘bits of power’ (Mansell, 2017) that provide insights into the emerging institutionalisation of digital (and mobile) communication and enable us to understand and discuss the conditions and control mechanisms that frame mundane communication. As such, we built on and contribute to research within the field of political economy of communication (Hardy, 2014; Mosco, 2014), focusing on the commercial incentives, business models, and power struggles of large tech companies operating in a data economy where the commodification of human experience is key (Zuboff, 2019).
App ecologies
Common for most research mentioned in the previous section is a focus on the web as a particularly important component of the internet’s application layer. However, the increasing usage of mobile connections and smartphones renders the realm of mobile apps critically important for studying and discussing digital privacy, datafication and the political economy of communication. The emergent field of app studies addresses this research gap. Studies dedicated to apps in particular are few and far apart, although more and more are emerging across disciplines. Gerlitz et al. (2019) differentiate between three strands of research that are largely concerned with apps, namely studies on mobile media and communications, mobile app usage and stakeholders, and studies that adhere to the infrastructural turn (e.g. Dieter et al., 2019; Gerlitz et al., 2019). The latter often feature case studies of particular apps or app categories like policing apps (Wood, 2019), dating apps (Weltevrede and Jansen, 2019), or social media apps (Nieborg and Helmond, 2018), which provide valuable insight on the app or category in question.
A fourth strand of research, which is not included in the three mentioned above, consists of large-scale studies of app infrastructures, coming out of the computer science field. These studies focus mainly on third-party services, thereby charting the mobile tracker ecosystems. While some emphasise particular types of apps, like smart TV apps (Mohajeri Moghaddam et al., 2019), several studies map the broader ecosystem of different third-party services and their parent companies across large bodies of Android apps (Binns et al., 2018; Vallina-Rodriguez et al., 2016). Similarly, but with a focus on the permissions requested by apps, Pew Research Center (Atkinson et al., 2015) has analysed the relationship between categories of apps and permissions requested at that time by one million apps existing in the Google Play Store.
This article extends and builds on, but also diverges from the majority of previous app studies, by: (1) combining analyses of the permissions requested and the cooperating third-parties across a larger sample of disparate apps and categories; and (2) focusing on individual smartphone users’ suites of apps as situated in the greater app ecology in order to (3) analyse the implications of smartphone use in light of the power structures, business models and control mechanisms that make up the political economy of apps-based communication.
While some of the case studies on apps (Forbrukerrådet, 2020; Weltevrede and Jansen, 2019) have looked at both the permissions requested by the particular apps as well as the third-party connections the same apps make, there is, to the best of our knowledge, very limited research that combines the two, and the studies that do, focus on particular apps or categories of apps rather than the broader app ecology. This article, in other words, fills a gap in the existing studies, and the following empirical explorations will testify to the potentials in combining both aspects in future large-scale analyses. Whereas the permissions relay important information on the extents of access requested by the apps, they also represent the ‘last bastion’, insofar as users are able to exercise their agency through dismissing or granting (some of) the permissions. Third-party services, on the other hand, are not explicitly requested, but are significant for understanding the extents to which users’ data is shared with corporations that are fundamental to the (commercial) app ecology at large. Had we only looked at one or the other, we would miss out on the ways apps combine permissions and third-parties in order to get to know increasingly more about their users as well as the complex power structures and market formations of the data economy. Applying an ecological perspective encourages us to look beyond particular apps or categories of apps and directs attention to the ways in which the entire app ecology frames and conditions the use of smartphones. It enables analyses of individual smartphone users’ appscapes (the constellation of apps and their associated permissions and third-party services) as well as of the larger ‘app ecologies’ (the broader compilations of apps in for instance an app store such as Google Play Store).
Taken together, we stress that data practices of mobile apps are materially and infrastructurally rooted and that varying degrees of privacy are built into the architecture of the different apps; we emphasise the underlying business models, market structures, and governance dynamics as vital for grasping and explaining mobile data harvesting, processing, and distribution; and finally, we apply an analytical perspective that cuts across specific apps and types of apps and look into the broader app ecology while at the same time combining two empirical indicators (mobile permissions and third-party-services).
Methods
In comprising the datasets for the article, we began by creating maps charting the apps found on the smartphones of regular users sampled according to maximum variation principles. These individuals stem from an ethnographic fieldwork on the social uses of the internet in Denmark (Lai et al., 2019). The ethnography combined various methods, including walkthroughs (Light et al., 2018) of respondents’ phones (and other devices), which relay information on, among other aspects, the download and usage of various apps. The walkthroughs entailed the respondents giving ‘guided tours’ of their phones, where they would relay information on the kinds of apps they had acquired, the ways they used them, and so on. For this study, we focused on 10 respondents from the ethnography sample, and collected their individual repertoires of apps from screenshots taken by the respondents of their home screens. We find between 34 and 104 downloaded apps on the individual phones and a total of 173 unique apps – some are shared by all 10 respondents, and some are unique to just one of them. Taken together, the 173 apps create a sample of common and generally used apps as well as lesser known ones down the longtail of existing apps. None of them are paid apps, although a bulk of them offer in app purchases or require subscription upon download in order to access the app functions. There is to date no public database containing information on the most used apps (although App Annie Content (n.d.) offers information on the most downloaded apps at present, it does not relay information on which is most used). That is, the 173 apps constitute a valuable though not representative sample of apps downloaded and used by Danish smartphone users.
The permissions required by the 173 apps, as well as the different types of third-party services they communicate with, function as empirical indicators for gauging their intrusiveness. That is, we do not analyse particular data flows from one app (the first party) to one or several third-parties (see e.g. Weltevrede and Jansen, 2019 for the use of a package inspection tool like WireShark to decipher the exact transmission of data between a particular (dating) app and its third-party service), or make claims about what the apps, or the third-parties, actually do, but rather what they are able to do as a result of the accesses they obtain and the connections they establish.
The permissions provide insight into the types of data and metadata that are available to a given app, granted by the user upon installation. This information was acquired through scraping of the Google Play Store for all information (price, rating, category, developer, etc.) on each app as well as its required accesses (e.g. ‘location’, ‘phone’, ‘calendar’) and permissions (e.g. ‘precise location (GPS & network-based)’, ‘read call log’, ‘read calendar events and confidential information’) in February 2020. In effect, the data adheres to the standards of the Google Play Store at that time as well as the standing Android OS (the Android 10 release), which also means that the upcoming explorative analyses reflect this particular empirical constellation and cannot account for differences across, for instance, Android and iOS, different OS releases, or different app stores. The reality of the fieldwork respondents, whose app repertoires provided the basis for the dataset, is of course more complex than that: they owned devices running OSs from both Android and Apple, some of them had the latest software on their phones, and some of them had not updated for months. This type of data moves very fast, and analyses will, as a result, always reflect a particular point in time including particular OS releases, configurations of apps, and so on. Google Play Store is, to date, the standard for large scale app studies (see e.g. Binns et al., 2018) as it allows for researcher access to data whereas for instance Apple’s Appstore blocks this kind of interaction.
The third-party services associated with each of the 173 apps were harvested from the Exodus Privacy (n.d.) database, which extracts the third-parties from the source codes of the apps. More specifically, third-party services as pieces of software are often distributed by companies in ready-made toolkits, called software development kits (SDKs). These SDKs come with a multitude of different purposes, including running analytics, profiling users, serving ads, establishing location and so on, and some are more intrusive than others. Although the Exodus database is updated regularly, it has shortcomings, as apps may install new third-party services at any given time. The database is also incomplete insofar as it lacks reports for a number of apps, be it because they expired or are not available in Google Play Store. In result, by using this database, we are unable to account for the third-parties of 11 out of the 173 apps in the dataset. Exodus represents the most substantial database over app third-party services and is a valuable tool for studying mobile tracking independent of specific and microscopic protocol analyses.
The dataset
All permissions and third-parties that figure in the dataset are associated with one or several of the 173 apps. There are 115 unique permissions distributed across 15 overall types of access, and 107 unique third-party services, or SDKs, owned by 88 different companies.
Table 1 overviews a number of the most prominent permissions in the dataset and the specific accesses they require. For instance, the permission to ‘take pictures and video’ accesses the phone’s ‘camera’. The table also explains in more detail what the specific permissions allow the apps to do.
Commonly asked permissions by the 173 apps.

Permission marked with a * are listed as ‘dangerous’ in Google’s Android Developers Guide. Source: Android Permissions (n.d.).
Some of the 115 permissions are central to the functionings of the particular apps (that is, strictly whenever the apps are used) while other permissions are requested for commodification and data re-selling (as highlighted by for instance a recent case on flashlight apps requesting more than 70 permissions that have nothing to do with the specific functionality of a flashlight (Cimpanu, 2019)). However, importantly, permissions that are central to the functioning of an app can also provide data that is sold on to advertisers (think of for instance location data harvested in Google Maps (Gundersen, 2020)). That said, it is difficult to decide what potential harm to a smartphone user follows from any specific piece of data collected by an app. Let alone what potential harms follow from any specific constellations of data collected by an app. It is hard to imagine what kinds of damage can come from an app being able to ‘view Wi-Fi connections’ (simply what Wi-Fi-networks are available), while an app accessing ‘precise location (GPS and network-based)’ is more straightforwardly sensitive. Yet for both permissions, the data has potential (and at times critical) implications for privacy. In other words, it all depends. Rather than deciding what is and what is not sensitive data, we here consider any kind of data to be potentially harmful – in the hands of the wrong people, in case of hacking (e.g. Easyjet, 2020) or poor anonymisation practice (Gundersen, 2020), unencrypted connections (Weltevrede and Jansen, 2019), and so on.
Two of the most common permissions, present on four out of five apps in the dataset, are the ‘read the contents of your USB storage’ and ‘modify or delete the contents of your USB storage’ relating to accessing ‘storage’ and ‘pictures/media/files’ (see Table 1). They allow the apps to access data stored in the phone’s external storage (e.g. the SD card) and change or erase that data. The privacy implications of these permissions depend on a variety of factors, not least the kinds of data that the individual users have in their storages (e.g. photos of children, videos containing sexual content, etc.). Another example of a prominent permission is the ‘find accounts on the device’ accessing ‘contacts’, which is found on one-third of the apps in the dataset. By granting access, the app can access all user accounts on the phone, including the ones in other apps.
It is important to mention two ways in which users can counter (certain) permissions. First, particular permissions, for instance ‘read phone status and identity’ or ‘take pictures and videos’, are categorised as ‘dangerous’ in Google’s Android Developers guide (Google Developers, n.d.), meaning ‘a higher-risk permission that would give a requesting application access to private user data or control over the device that can negatively impact the user’. That is, access to user data which is considered private in the eyes of Google developers. These permissions require that the user explicitly approves them upon download – that is, for instance in a pop-up message the first time the app is opened. Second, as of 2017 for iOS (iOS11) and late 2019 for Android (Android 10), some permissions can be turned off in the smartphone settings after instalment of the particular app or they can be limited to only apply whenever the app is in use. All permissions are, however, upon download by default set to apply all the time. These countering mechanisms are dependent on the user making informed decisions based on privacy policies and ToS agreements that are both transparent and accessible, which is usually not the case (bursting with information, the Facebook ToS, for instance, is a staggering 14,000 words long). Moreover, unlike web-based tracking where users are requested to agree to the cookies of a given site they visit, there are no cookie notices or other types of consent forms that apply to mobile platforms, which effectively leaves the end-user with no way of blocking or controlling third-party tracking by apps (except for in mobile browsers; Binns et al., 2018: 2).
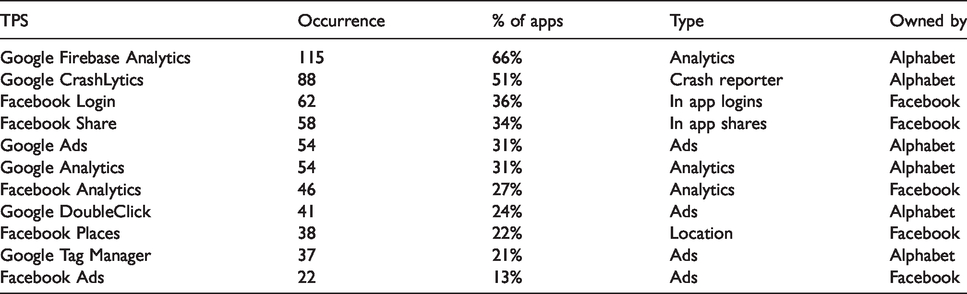
Table 2 lists the top 10 third-party services in the dataset as well as their functions and ownership. It shows that the most recurrent ones are owned by one of two companies, namely Alphabet (Google’s parent company) or Facebook. Found on half of the 173 apps, Google Firebase Analytics, which makes performance reports based on the user’s usage of the app, is the most common tracker. Also, Alphabet’s Google Ads and Google DoubleClick feature frequently. Similar to the distinction between permissions for functionality or commodification purposes, we can distinguish between trackers that serve performance monitoring purposes or advertising purposes only. However, it is important to mention that functionality and commodification are not mutually exclusive. Just like free-of-charge apps are not free in the sense that they do not charge anything, but only insofar as data rather than cash constitute the currency by which users pay for the services, free-of-charge performance monitoring tools like Google Analytics are not for free in a strict sense. That is, Google acquire data on market developments in real-time from the myriads of apps (and websites) that employ their services. Data which, in turn, grounds their other undertakings and thereby their bottom line. Furthermore, previous research in the realm of cookie-based tracking on websites shows how Google Analytics can, if embedded by a another third-party tracker, distribute data beyond the specific service using Google Analytics (Roesner et al., 2012). More research is needed for determining whether or not the same could be the case for app SDKs.
The most prominent third-party services in the dataset.
The next part of the article features three empirical explorations that traverse micro- and macroscopic levels, deriving inspiration from quali-quantitative approaches (Venturini and Latour, 2010).
Analysis
In order to exemplify how the intrusiveness of mobile apps can be mapped and assessed, we analyse the material through empirical explorations according to three analytical perspectives: First, we assess the apps, permissions, and third-party services of each respondent’s phone and explore how different appscapes have different implications in terms of data harvesting and privacy; we then look at the app ecology made up by the sample of apps installed on the respondents’ smartphones and explore the characteristics of different categories of apps as well as the broader market structures; and finally, we look at one particular category, ‘communication’, in order to investigate the differences between similar apps in light of their underlying business models.
Comparing appscapes
The following explorative analysis exemplifies the appscape perspective on the intrusiveness of mobile apps. Table 3 overviews the 10 respondents, the number of apps they have downloaded, and the accumulated number as well as the average number of permissions and third-party services associated with their individual apps. It illustrates how the number of apps vary significantly, but also how the degree of surveillance depends on the specific app repertoires of the respondents. While Marie (pseudonymous name, ed.) is placed at the top of the table with a total of 62 installed apps, the average number of permissions required for using these apps is the lowest among the 10 respondents (15.4 permissions per app) and the average number of third-parties is 5.7. At the other end of the scale, Ena has installed 11 apps, yet, in average, each of these requires 29 permissions and connects to six third-parties. In order to understand the relationship between the downloaded apps, and the degrees of data harvesting and third-party tracking, we chart the respondents’ individual appscapes.
Overview of respondent and their appscape data.

Figure 1 and 2 illustrate the apps and associated permissions of two of the respondents, Liam and Louise. The inner circle outlines the different categories of apps found on their phones, followed by the specific apps, and their accesses and permissions. These visualisations function as research tools rather than results in and of themselves, and aid us in comparing and understanding the privacy implications of individual app repertoires. For instance, in Figure 1 we get an impression of how the 350 permissions on Liam’s smartphone are distributed across his 16 apps. While the privacy app Adblock requires three permissions (‘view WI-FI connections’, ‘view network connections’, and ‘full network access’), Google’s search app requires no less than 72 permissions (e.g. ‘read your own contact card’, ‘precise location’, ‘read call log’, etc.). As illustrated in Figure 2, Louise’s 22 apps require 581 permissions in total among which Google Search reappear as the most pervasive, measured by the number of permissions, followed by Facebook (52 permissions), and Facebook Messenger (46) as well as the communication apps Signal and Viber (both 44). As we will discuss later in the article, the communication apps in general contain a large amount of permissions compared to other categories such as for instance ‘e-government’. Louise’s preference for communication apps (9 of her 22 apps support different types of communication (e.g. text messaging, e-mail, voice calls, etc.) thereby enhances the amount of permissions granted in comparison to for instance Liam (who only have two communication apps, Gmail and Viber, that require a total of 83 permissions).

Liam’s appscape – permissions.

Louise’s appscape – permissions.
While the visualisations of permissions show what types of data different apps have access to, Figures 3 and 4 illustrate the third-party services found in the different apps’ source codes and thereby the third-parties that can access data from the app. The figures, again, focus on Liam’s and Louise’s appscapes, and the inner circle represents the app categories, which links to the individual apps, that in turn link to the outer layer comprising the third-parties. Similar to the permissions, the prevalence of third-party services reflects the differences in Liam and Louise’s app repertoires: Liam’s apps connect to 31 unique third-party services that appear 69 times in total across his apps, while Louise’s apps connect to a total of 86 third-party services (30 unique). Also similar to the permissions, the communication category contains a significant number of third-parties (e.g. Messenger and Viber have 10 and 11 third-parties). For both Liam and Louise, however, the most heavily tracked are the news apps: Louise’s NYTimes app and Liam’s BlicMobile app communicate with respectively 15 and 16 third-party services.

Liam’s appscape – third-party services.

Louise’s appscape – third-party services.
By visualising individual appscapes and zooming in on the permissions and third-parties associated with the specific repertoires of apps, we can make sense of the possible privacy implications of smartphone use at an individual micro-level. The visualisations and calculations above allow us to discuss and compare how different app constellations enable different degrees of data harvesting and distribution of data to different third-parties. However, comparing individual appscapes is only one way of analysing a disperse sample of apps like the one in this study. Another is to compare app categories as broad containers of apps that serve similar purposes.
Comparing app categories
The explorative analysis of this section exemplifies the app ecology perspective. Google Play Store breaks apps into a number of different categories that developers then assign their apps to appear in. The 173 apps in this study appear in 29 different categories. The smallest category (‘Auto and vehicles’ and ‘Search’) comprise just one app, while there are 25 in the largest (‘Travel and Navigation’). The distribution of apps across categories, their average number of permissions and third-party services, and examples of particular apps found in each category are outlined in Table 4.
App categories.

The table shows that the app category requiring the highest number of permissions is ‘Search’ (which consists only of Google’s search app), followed by ‘Communication’ with an average of 34 permissions across nine apps. In the bottom, we find the ‘Auto & Vehicles’ category (containing only the Mazda app) that requires four permissions. ‘Video Players & Editors’ (also with one app, Imgur) has the highest number of third-party services (20), followed by ‘Social’, ‘Education’, and ‘Games’ with an average of 12 per app. The ‘E-government’ category (comprising E-boks, a dedicated state and public communication app) has the lowest, with just one third-party.
Figure 5 looks closer at the particular permissions that the different categories of apps require. The model outlines, from the left, the different app categories (‘Search’, ‘Social’, ‘Communication’, etc.), the different types of access, and the particular permissions as they relate to the different types of access and categories. The ‘Search’ category is, not surprisingly, placed at the top as it requires a total of 72 unique permissions among which 45 are categorised as ‘Other’. ‘Other’ is by far the largest type of access: it contains 83 unique permissions, and 466 permissions of the 173 apps belong to this group, just as 28 of the 29 app categories require permissions classified under ‘Other’ types of access. The second-largest access, ‘WI-FI-connections’, has seven unique permissions that appear 31 times in the sample. Two permissions appear across all 29 app categories: ‘modify or delete the contents of your USB storage’ and ‘read the content of your USB storage’. These are placed under the access categories of both ‘Pictures/media/files’ and ‘Storage’, and the permissions enable the apps to save, alter, and access data that is saved in the device’s storage.

App categories, required accesses and permissions.
There are distinct patterns in what permissions different categories of apps ask for. For instance, the categories ‘Communication’, ‘Search’, ‘Social’, and ‘Travel & Navigation’ cluster in two ways: The apps in these categories generally ask for a lot of permissions and also tend to ask for the same types of permissions that are less frequent across the remaining categories. These include access to the phone’s calendar and permission to ‘read calendar events plus confidential information’, ‘add or modify calendar events’ and ‘send email to guests without owners' knowledge’, as well as access to messages in order to read, edit, receive, and send SMS and MMS. A common denominator for the permissions that are particular for these four categories is the labelling of them as dangerous in Google’s Android Developers guide.
In Figure 6, we see similar patterns with regards to the third-parties that the different categories of apps connect to. From the left, the figure outlines the app categories and connects these with the different third-party services, which connect to the parent third-party companies. As described earlier, the most intrusive app categories measured in terms of the average number of third-parties are ‘Social’, ‘Education’ and ‘Games’. However, if we look at the number of unique third-party services within the different categories, the apps found in ‘Games’ and ‘Travel & Navigation’ rank highest as they both connect to 36 different ones, followed by ‘Photography’ with 35 unique third-parties. As mentioned in the introduction to the dataset, Alphabet and Facebook dominate the ecology of third-parties, and for instance own the 10 most common third-party services in the dataset.

App categories, third-party services and the companies that own the third-parties.
Figure 7 compares the average number of permissions (Y) and third-party services (X) for each app category. The colour and size of the coordinates illustrate the combination of the average number of permissions and third-parties. The ‘Search’ category stands out, as it, as mentioned, requires 72 permissions but only communicates with two third-party services. At the other end of the scale, the ‘Video players and editors’ category cooperates with a large number of third-parties but require relatively few permissions. ‘Social’ and ‘Communication’ are examples of categories that both request a lot of permissions and connect to many third-parties.

App categories plotted according to their average number of permissions and third-party trackers.
The results of this analysis raise important questions about the relationship between the (technological) functionality of the analysed apps, their business models, and user commodification. Are the permissions and third-party services identified in our study necessary for the apps to work or do they serve commodification purposes only (i.e. advertisement and data reselling)? If we are to understand why different apps collect different types of data and distribute it to different third-parties, we need to look closer at the particular apps as they serve different purposes and depend on access to data in different ways. Focusing on and comparing particular types of apps is also necessary if we are to understand the large differences within the app categories as they relate to the business models, economic conditions, and market positions of the various stakeholders in the data economy. In the following and last part of the analysis, we therefore focus on the ‘Communication’ category in order to discuss and explain the prevalence of permissions and third-parties across the specific communication apps.
Comparing apps
The last empirical exploration serves as an example of analyses at the level of individual apps. Table 5 overviews the nine apps in the ‘Communication’ category, their occurrence in the sample, the companies that own them, and their number of permissions and third-party services. We emphasise this particular category since it comprises an interesting combination of permissions and third-parties as well as a number of common apps that are less specific to the Danish context only. Furthermore, many of the communication apps (e.g. email, instant messaging, internet-based voice calls, cooperative work platforms, etc.) are increasingly essential to most people’s everyday lives – as underlined by the current Corona crisis. The apps all serve the same or similar purposes, namely to communicate personally or in networks (more dedicated social networking apps such as Facebook, Instagram, and YouTube are placed in the ‘Social’ category) making them fairly easy to compare. More specifically, the table shows that Facebook’s Messenger is the most common communication app in our sample, and, at the same time, the app that asks for the highest number of permissions, and cooperate with the most third-parties compared to the other apps in the category. Interestingly, Facebook also owns the second-most used and most intrusive app when measured in terms of permissions, namely Whatsapp.
Apps in the ‘communication’ category.

Figure 8 further explores the permissions required by the individual communication apps by outlining, from the left, the particular apps, the types of access they require, and the particular permissions. As mentioned in the section above, the most common access category is ‘Other’, comprising a wide variety of different permissions. Reflecting the general findings across categories, the most frequent permissions are ‘modify or delete’ or ‘read the contents of your USB storage’. The more specific permissions required by the apps in this particular category speak (to some extent) to the purpose of the apps: It seems reasonable (although strictly whenever the app is actually used) for an app like Viber to ask for permission to ‘record audio’ or ‘directly call phone numbers’; it makes sense that WhatsApp requires permission to send and receive text messages, and so on. However, it is less obvious why these apps require access to ‘read calendar events plus confidential information’ or use the smartphone’s GPS to determine the user’s ‘precise location’.

‘Communication’ apps, required accesses and permissions.
Figure 9 illustrates the third-party services that apps in the communication category connect to. From the left, we see the particular apps, the third-party services installed as SDK’s on the apps, and lastly the companies owning these services. When looking at this figure, the positions of Alphabet and Facebook are striking: Both companies supply some of the most used apps for communication (Messenger, Gmail, and WhatsApp), and at the same time dominate the third-party-market by owning some of the most frequent services, be it for performance monitoring (Google Analytics, Facebook Analytics, etc.) or advertisement (Google DoubleClick, Facebook Ads, etc.). Again, what these third-party companies actually track through the apps and what they use it for is another story. We discuss the implications of the third-party constellations shortly, but also make a call for future further research into the business models and incentives for collecting ever-increasing amounts of app data as well as for vertical integration strategies.

‘Communication’ apps, their third-party services and the companies owning the third-parties.
Returning to the perspective of the individual app users, their choices, and capabilities for navigating in the complex app ecology and data economy, the analysis above shows that, in terms of users’ privacy, there are significant differences between apps that on the surface look similar. However, as others have discussed before us (e.g. Mansell, 2017: 16; Nissenbaum, 2011), few users are equipped for making informed decisions regarding consent that rest on actually assessing the ToS and privacy policies they agree to. In the following, we discuss the approach and explorative findings of the study, as well as the future prospects for analysing and increasing awareness and transparency of the data practises of mobile apps.
Discussion
We started out asking how the intrusiveness of mobile apps can be approached empirically and answered this question by focusing on permissions and third-parties exemplified through three empirical explorations that build on and inform each other. In this section, we discuss the potentials and limitations of the approach as well as the analytical perspectives and assess the results of the analyses.
The first perspective, and the explorative analysis applying it, demonstrates that mobile apps, permissions, and third-parties make up a structuring environment for the wide, and ever-growing, range of activities that smartphones support. The mappings and visualisations of individual appscapes are useful for grasping the extensive and complex ways that smartphone users’ data is harvested and distributed. The appscapes make it possible for users, as well as researchers, to see how our lives, whether we are aware of it or not, are framed and conditioned by the datafication that is built into smartphone apps, and enabled by mobile permissions and third-party agreements. As mentioned in the methods section, the empirical approach focuses on the intrusiveness and possible privacy implications rather than the actual consequences of using particular apps, which limits our ability to determine what specific bits of data is sent where and to whom. However, as the business models of digital corporations such as Facebook and Alphabet rely heavily on data harvesting, tracking, profiling and targeted advertisement (Curran, 2018; Singer, 2018), the permissions and third-party services that enable these undertakings are, to say the least, important to consider.
When you grant an app permission to ‘read your text messages’ or accept terms and conditions informing you on the use of third-party services, you also contribute to the (re-)production of a complex ecology (and economy) where Big Data is shared across applications and different corporations, and value is generated in opaque ways. In lack of official top lists and statistics, the individual appscapes thereby also serve as gateways for exploring the greater app ecology and form the basis for the second perspective and empirical analysis. By mapping all apps in a given sample (in this case 173), the permissions they require, and the third-party services they communicate with, we are able to identify the most common permissions and the largest third-party-services, as well as to discuss differences and similarities across app categories (e.g. streaming and VOD apps, sports apps, etc.). By comparing the different categories in terms of both permissions and third-parties, we can visualise and explore how certain types of apps tend to require more permissions or collaborate with more third-parties (or both, as in the case of the communication category).
This approach also makes it possible to identify the dominating market actors across both apps and third-party services and to explore market structures and vertical alignment strategies. For instance, the finding that Alphabet’s apps are among the ones that require the highest numbers of permissions, but distribute data to the fewest number of third-parties is interesting. If we use only the number of permissions or the associated third-parties as strict indicators for measuring intrusiveness, we miss the complex dynamics and power structures that shape the app-ecology. By looking at both permissions and third-parties as well as the underlying ownership structures, we can interpret the results in a more nuanced way. Alphabet then appears not only as an essential app provider, but, and perhaps more importantly, as a dominating third-party service that connects to most other apps. Needless to say, the Google search app does not require any other services than Alphabet’s own. Add to that, the fact that Alphabet holds and controls the largest app store in the world (Google Play Store), and the most used OS for smartphones (Android). The analytical approach and empirical explorations presented in this article thereby contributes to existing studies of the political economy of communication by exploring an important arena where power battles are played out, market monopolies are built and sustained, and communication systems are commercialised (Manzerolle and Daubs, 2015).
The final perspective and the empirical exploration drew attention to the business models and ownership structures of similar apps within a category in order to compare their data practises. Such investigations are important, especially when discussing the degree of privacy, as apps that serve different purposes utilise data in different ways. When interpreting the patterns illustrated in for instance Figure 7, it is vital to discuss how the constellations of permissions and third-parties relate to the functionality of the apps on the one hand, and to the commodification of users on the other. When is a permission necessary for the functionality of an app (e.g. a voice call app surely needs access to your microphone and speakers, although this is only the case so long as the app is in use), when is the permission used for other purposes (e.g. the training of a voice recognition algorithm), and when does it support commercial purposes only (e.g. collection of data that can be passed on to advertisers)? How dependent is an app of various third-party services, what do these services do, how are they reimbursed, and how does a ‘free’ app as well as the cooperating companies make a living? One could argue that a certain degree of commodification is unavoidable as users have gotten used to free-of-charge apps. However, it could also be argued that the price for these services should be transparent and subject to more debate – they are indeed not cheap if we consider the large sums of data taken in return for the services. In the final section, we reflect on how the article contributes to this debate and outline the potential future analyses that can build on and develop the methodological approach and the analytical perspectives presented here.
Conclusion
The aim of this article was to explore the possible privacy implications of smartphone apps through empirically investigating mobile permissions and third-party services as key indicators of intrusiveness. Operationalising this, we developed and tested the methodological approach in three empirical explorative analyses that can be used to further understand and discuss the data practises of mobile apps:
Exploring and comparing different appscapes demonstrate the important and far-reaching consequences of which and how many mobile apps users download. For instance, our analysis shows that a preference for communication apps typically results in a high degree of intrusiveness when measured in terms of both the amount of permissions and third-parties. Such analyses can serve as starting points for studying individual smartphone users’ capabilities and strategies in terms of digital privacy. This, in turn, can increase public, and individual, awareness of the surveillance practises of mobile apps and can be used for developing tools for consumer empowerment. Exploring and comparing the amount of data that different types of apps collect and the number of businesses that can access information, allow for researchers to explore the conditions and dynamics of the greater app ecology. Comparing permissions and third-parties on the one hand, and the providers of apps and third-party services on the other, offer valuable insights into the complex power structures and business models of the (mobile) data economy. Our analysis, for instance, illustrates Alphabet’s and Facebook’s dominant positions as both app and third-party providers and thereby enables discussions of the consequences of their multi-sided business models. Studies building on this empirical approach can thereby be an inspiration for market analyses, monitoring and regulatory interventions. And finally, analyses and comparisons of similar apps within a particular category can qualify discussions of legitimate data practises by exploring which permissions and third-party services are vital to the technological functionality of an app and which serve commercial purposes only. In the analysis, we emphasise the communication category as particularly interesting due to the high variation in the numbers of both permissions and trackers, but also the potential harmfulness of the permissions requested. Further insights into the technological configurations as well as economic motives that drive data harvesting, processing, and distribution are necessary if researchers, policy-makers, and regulators are to challenge the power and knowledge-monopolies of the large tech companies.
The approach, the three analytical perspectives, and the application in the following explorative analyses have scholarly and societal potentials that should be pursued through in-depth as well as large-scale studies. In effect, we suggest three next steps for research on apps, critical data, and privacy: first, packet inspection of the apps analysed in this study would increase our knowledge on the implications of different permissions, by following the specific bits of data that are transported from the app to a given third-party. While some of the studies mentioned earlier have already done this on a limited number of apps (e.g. Forbrukerrådet, 2020; Weltevrede and Jansen, 2019), no large-scale studies combining the permissions and third-parties of different apps and categories of apps have been carried out so far. If we are to investigate what data the different apps actually harvest, how it is transported and stored, what it is used for, and by whom, we need publicly available tools that can be used across disciplines and institutions; Second, and relatedly, the results of our analyses leave us with a multitude of questions unanswered about the relationship between apps and third-parties, for instance: How can and do apps control what data third-parties can access – do they use encryption, restrictions on data reselling, and so on? Future studies should look into these relationships and dynamics not only for the sake of the app users but also in order to qualify debates and initiatives related to regulating the data economy; And third, future studies should use the method and empirical approach presented here to conduct large-scale analyses comprising for instance all apps in an app store or the long tail of most popular apps used within a given societal context. Larger data collections could be used for building a database containing information on app permissions and third-parties in a transparent and assessable way and thereby countering established strategies of corporate obfuscation (Brunton and Nissenbaum, 2015) and user resignation (Draper and Turow, 2019). Such a database will for instance enable users to compare different apps that serve similar purposes and choose the less intrusive one.
In conclusion, we believe that public debate, transparency and access to the data processing of mobile apps are necessary stepping stones for developing policies and regulatory tools that can target digital surveillance. Enhancing our knowledge, and ability to gain knowledge, on the app ecology and data economy, is a necessary first step away from the current scenario of user exploitation and alienation and towards a future of emancipation and empowerment. Returning to the article’s opening allegory, the problem is not whether you are doing something on your smartphone that your mother would not approve of. It is rather whether your smartphone is doing something that you (or your mother) would not approve of.
Footnotes
Acknowledgements
We thank the three anonymous reviewers whose comments and suggestions were very insightful and helpful.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This was included in the upload of the original article. The funder is The Carlsberg Foundation, grant ID: CF16-0001.