
Abstract
In the age of the digital generation, written public data is ubiquitous and acts as an outlet for today's society. Platforms like Facebook, Twitter, Google+ and LinkedIn have profoundly changed how we communicate and interact. They have enabled the establishment of and participation in digital communities as well as the representation, documentation and exploration of social behaviours, and had a disruptive effect on how we use the Internet. Such digital communications present scholars with a novel way to detect, observe, analyse and understand online communities over time. This article presents the formalization of a Social Observatory: a low latency method for the observation and measurement of social indicators within an online community. Our framework facilitates interdisciplinary research methodologies via tools for data acquisition and analysis in inductive and deductive settings. By focusing our Social Observatory on the public Facebook profiles of 187 federal German politicians we illustrate how we can analyse and measure sentiment, public opinion, and information discourse in advance of the federal elections. To this extent, we analysed 54,665 posts and 231,147 comments, creating a composite index of overall public sentiment and the underlying conceptual discussion themes. Our case study demonstrates the observation of communities at various resolutions: “zooming” in on specific subsets or communities as a whole. The results of the case study illustrate the ability to observe published sentiment and public dialogue as well as the difficulties associated with established methods within the field of sentiment analysis within short informal text.
Keywords
Introduction
With social media, political parties can bring their message to the public faster, positing on recent events before the interaction and interpretation of local or national media (Stieglitz and Dang-Xuan, 2012). Putting issues onto the public stage they can directly interact with voters, supporters or residents of their election districts, thereby acting locally as well as nationwide. While this conversation is well-addressed on the micro-blog platform Twitter (Böcking et al., 2014; Housley et al., 2014; Mckelvey, 2013; Pak and Paroubek, 2010; Tumasjan et al., 2010), under-addressed are the characteristics of online political sentiment on Facebook. We argue that a significant entrance barrier to Facebook studies is a lack of easily employed, valid measurement systems and tools suitable for non-technically fluent users. Text from Facebook can be spliced for context and content, compared, and measured for sentiment and conceptual domains as a means of community assessment. Sentiment-based artefacts using publicly available data promise unprecedented access to the expectation of issues arising ex-ante, and the totality of effect of incidents ex-post, therefore, enabling researchers and decision makers to analyse, develop, implement and tune policies.
To address this, we present a Social Observatory: an unobtrusive, low latency 1 multi-resolution framework for the observation, analysis and modelling of digital societies in action (see ‘Big Data challenges in the social sciences’ section). With a Social Observatory, we aim to realize an automated framework that facilitates, reviews, and assesses specific aspects of online communities via Facebook using qualitative and quantitative methods (see ‘Related work’ section). Our research contribution is a framework that empowers interdisciplinary researchers with the tools to facilitate the understanding of phenomena within Facebook, as well as the communities they represent (see Appendix 1).
To validate our objective, we present a prototype implementation and case study analysing public political dialogue of German federal politicians (see ‘Application of a Social Observatory: Political sentiment in Germany’ and ‘Zooming in and out of a social network’ sections). Our dataset comprises all politicians with a Facebook presence from the five German federal parties: 2 the Christian Democratic Union (CDU/CSU), the Social Democrats (SPD), the Free Democrats (FDP), the Green Party (Grüne), and The Left Party (Die Linke). Using this data set, we evaluate the following research questions: Is Facebook a valid research medium for assessing political discourse online? If so, what are the characteristics of discourse and engagement with and of German politicians on Facebook (see ‘Discussion’ and ‘Conclusion’ sections)?
Big Data challenges in the social sciences
Our vision of a Social Observatory is a low latency method for the observation and measurement of social indicators. It is a computer-mediated research method at the intersection of computer science and the social sciences. The term Social Observatory is used in its original context (Hackenberg, 1970; Lasswell, 1967); our framework is the archetypal formalization of interdisciplinary approaches in computational social science. The essence of a Social Observatory is characterised by Lasswell (1967: 49) as follows: The computer revolution has suddenly removed age-old limitations on the processing of information […] But the social sciences are data starved […] One reason for it is reluctance to commit funds to long-term projects; another […] is the hope for achieving quick success by ‘new theoretical breakthroughs’ […] It is as though we were astronomers who were supposed to draw celestial designs and to neglect our telescopes. The social sciences have been denied social observatories and told to get on with dreams.
In Figure 1, we illustrate a general architecture of a modern Social Observatory entailing three processes; namely 1) Data Acquisition; 2) Data Analysis; and 3) Interpretation. Please see the Online Appendix for a discussion of the technical implementation. While it is apparent that a Social Observatory captures multiple streams of data, currently few scientific papers or services report this ability in a way easily replicable. This is despite prevalent availability of Application Programming Interfaces (APIs), and an almost endless supply of papers and studies that focus on specific platforms (Atefeh and Khreich, 2013; Burnap et al., 2014; Pak and Paroubek, 2010; Russell, 2013; Schwartz et al., 2013; Tanasescu et al., 2013). Though this article concentrates on Facebook, the architecture could be extended to other platforms.
A general architecture for a Social Observatory.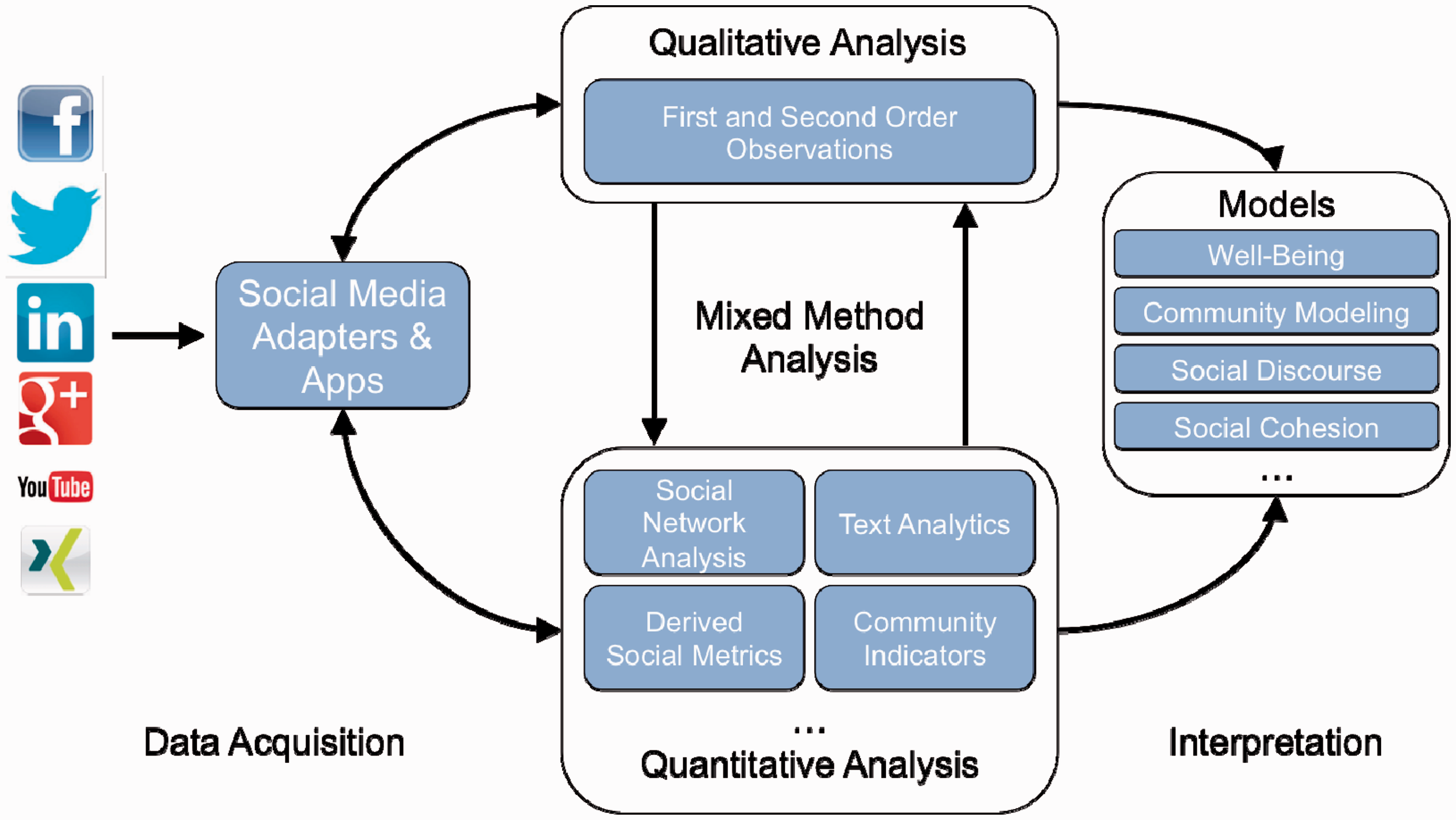
Data Acquisition is well supported by most social media platforms via REST or streaming APIs, which are underpinned by lightweight data interchange formats like JSON, and authentication with technologies such as OAuth. The challenges instead lie in data volume, velocity, and variety, access rights, and cross-platform differences in curating data. The Big Data aspects of social media data are well known and do not need to be repeated here. With respect to access rights for data, however, we first need to distinguish between public data (like a Tweet or Facebook page) and personal data (like a Facebook profile). The authorisation rights for these types are significantly different. Although it has been shown that gamified settings can enable access to personal data (Hall et al., 2013a, 2013b), we expect a Social Observatory to rely mainly on public data, as opposed to studies like Kramer et al. (2014) and Schwartz et al. (2013).
Lastly, the method of data curation is not without its ambivalence. For example Twitter data curation tends to be forward-facing; accessing future Tweets that fulfil a specific set of attributes starting at a given time point. Facebook is retrospective; given a Facebook entity (e.g. a person, or page) researchers access current and historical posts, profiles, likes etc. From the perspective of analysing social data, this subtle difference significantly alters the effort and planning needed to curate a data set and the implicit biases associated with the method (González-Bailón et al., 2014; Ruths and Pfeffer, 2014). The technical challenges also differ significantly from receiving a continuous stream of data (i.e. tweets) vs. Facebook's paginated results. The latter incites large numbers of API calls, which are not limitless.
(Mixed Method) Analysis as illustrated in Figure 1 is inherently iterative and interdisciplinary. Foreseeable is repeated interaction with social media adapters and apps. While approaches from computer science and computational social science are becoming more prevalent, the question of research methodology is often a poignant discussion point and challenge that cannot be overlooked; computer and social scientists leverage diverse and often non-overlapping research methodologies. Therefore, a Social Observatory needs to accommodate a vast array of (interdisciplinary) methodological approaches.
Irrespective of methodology, an important feature of a Social Observatory is the ability to view a community at a variety of resolutions; starting from an individual micro layer, and progressively zooming out via ego-centric networks, social groups, communities, and demographic (sub)groups, up to the macro layer: community. This ability is of significant importance for understanding a community as a whole.
Interpretation is domain specific in nature, and should be decided according to the proposed research questions. Our architecture supports inductive and deductive research.
Related work
A new approach in the area of information-driven decision support is found in computational social science (Cioffi-Revilla, 2014, 2010), where the interaction of technology, online communities and individuals' perceptions are investigated at a previously unmanaged scale (Burrows and Savage, 2014; Savage & Burrows, 2007; Taylor et al., 2014; Tinati et al., 2014). In an exhaustive survey, Wilson et al. (2012) constructed five supra-categories for Facebook-based research: descriptive analysis of users, motivations for using Facebook, identity presentation, the role of Facebook in social interactions, and privacy and information disclosure. In terms of a Social Observatory, all five categories could be addressed, whereas this paper concentrates on descriptive user analysis and social interactions in an unobtrusive manner. Recognizable is that the usage of Facebook's API by non-Facebook staff or partners to support unobtrusive studies is low.
Many of the commonly applied methods in community analysis like judging communal sentiment, assessing tie strength, or participation and/or exchange in given contexts are often done qualitatively. Human-centric approaches have a long history and are well applied in varied domains (Hsieh and Shannon, 2005; Kassarjian, 1977), but lack scalability. When dealing with the volume required by Big Data analyses, either crowdwork (e.g. Hall and Caton, 2014; Paolacci et al., 2010) or automated programs are generally required. Crowdwork for the analysis of items like status updates and tweets however poses ethical issues (Markham and Buchanan, 2012), and can run afoul of platforms' terms and conditions.
The (social) scientist needs the necessary systems, and tools to leverage computational approaches. Text analysis, as a mechanism for measuring social impact, is becoming increasingly validated as a proxy for social phenomena (Böcking et al., 2014; Chung and Pennebaker, 2014; Housley et al., 2014; Mckelvey, 2013). Twitter-based studies are common in the social media space and address a variety of social science-oriented research questions. It has, however, been established that sentiment and conversation styles differ across platforms (Davenport et al., 2014; Lin and Qiu, 2013), though the available tools do not match this research need. Facebook tools tend to rely either on crawling techniques, which cannot fully acquire paginated Facebook data and are disallowed in the terms and conditions, or data extraction via the Graph API but either focus on the logged-in user 4 or do not return data in full. 5
Several authors have addressed the creation of frameworks for supporting Twitter studies (Burnap et al., 2014; Housley et al., 2014; Stieglitz and Dang-Xuan, 2012; Pak and Paroubek, 2010). These lack the corresponding technical infrastructure that allows researchers to create new, build on, or replicate the studies. 6 The closest in reach to a Social Observatory are those where the infrastructure is both open-source and requires minimal knowledge of computational infrastructure in order to be accessed (Housley et al., 2014), or the tools are of a plug and play nature (Kivelä and Lyytinen, 2004; McCallum, 2002). 7
Key contribution differences are the observation viewpoint and elicitation of points of reference. Many studies observe the Twitter landscape at a macro level, whereas our interest is to facilitate micro, meso and macro observations. For example, Calvo and D'Mello (2010), Hampton et al. (2011) and O'Connor et al. (2010) demonstrated the predictive power of self-reported interests in social profiles and the observation of social practices. While the scientific value of such work is significant, their isolated investigations only give us insights into well-grounded research processes rather than assisting in the construction of a general approach. Similarly, Mitchell et al. (2013) investigate a macro-scale dataset of happiness, urbanization and obesity correlates, but do not create a generalizable model for wide-scale usage. Allen et al. (2014) and Jaho et al. (2011) investigated how content traversed social graphs, and explored opportunistic mechanisms for the dissemination of content via social structures. A focus of their work was mechanisms for community detection, and subsequent analysis of social structures for observing information paths through social networks. However, the emphasis is not on analysing the communities themselves.
Two mechanisms are widely used to support the automated recognition of written sentiment: corpus-based approaches and dictionary-based approaches (Turney and Pantel, 2010). The corpus-based approach is based on the co-occurrence of words, relying on the latent relation hypothesis, stating that words with similar meaning or sentiment co-occur more frequently (Turney and Pantel, 2010). Given a set of known and evaluated words, this methodology identifies words with similar orientation. This can be especially useful when searching for instances of sarcasm or irony, otherwise lost in the dictionary-based approach (Liu, 2010). Dictionary-based approaches use predefined word lists containing sentiment-loaded words. By scanning the considered text, sums of positive and negative affect can be derived, usually normalized regarding the length of the overall text. Kramer subtracts said sums to get a one-dimensional measure of sentiment (Kramer, 2010; Kramer et al., 2004), whereas Golder and Macy argue the independence of both dimensions by measuring them separately (Golder and Macy, 2012). The dictionary-based approach, however, is unable to find domain specific orientations and context oriented sentiment (Dodds et al., 2011; Thelwall et al., 2010).
Notable dictionary-based tools are Linguistic Inquiry and Word Count (LIWC) (Pennebaker et al., 2007; Tausczik and Pennebaker, 2010), Text Analysis and Word Count (TAWC) (built upon the LIWC 2007 dictionary), SentiWordNet (Baccianella et al., 2010) and OpinionFinder (Wilson et al., 2005). SentiWordNet sums up possible positive and negative sentiment and the third term of “neutrality” (Baccianella et al., 2010), OpinionFinder classifies subjectivity and objectivity within sentences (Wilson et al., 2005). To date, both lack linguistic localization, a feature making LIWC's 13 languages favourable.
Using short informal text as the foundation of sentiment measurement is challenging (Thelwall et al., 2010) due to length restrictions, the usage of abbreviations and emotional tokens, slang in various forms and styles and truncated sentences (Wang et al., 2014). Yet, the existence of items like emoticons can help to understand the intended sentiment. The use of positive and negative, or positive, negative, and neutral classifications of social media texts as opposed to more contextual sentiment is a common method (Burnap and Williams, 2014; Pak and Paroubek, 2010). A foundational paper from Go et al. (2009) looked at the classification of Twitter sentiment from the commercial perspective, identifying positive and negative tweets based on query terms of emoticons. Kouloumpis et al. (2011) found that intensifiers are most useful in the automated detection of sentiment in tweets. This study found that part-of-speech features are not necessarily useful in automated sentiment detection. A study by O'Connor et al. (2010) applied positive and negative sentiment scoring to the 2008 US presidential elections and found the method can be used to supplement consumer confidence polls.
Notable studies from Facebook Research also look at public sentiment. Kramer (2010) used status updates based in the United States to create a composite well-being index. This has since been criticised in Wang et al. (2014), who state that Facebook status messages are not appropriate for well-being assessment, but rather mood regulation. Another series of studies by Kramer (2012; Kramer et al., 2014) reviews emotional contagion on Facebook. These findings support that short informal text like Facebook status updates can be used to measure sentiment online.
LIWC originally was not intended to be used on short informal text, but to analyse text of expressive and therapeutic writing (Pennebaker et al., 2007; Wang et al., 2014). However, its expansive psychometric dictionary offers a unique opportunity to reveal the latent emotional context of text-based data. LIWC has been shown to possess excellent precision and recall abilities with high but not overfitting correlations in the analysis of latent sentiment (Mahmud, 2014; Salas-Zárate et al., 2014), but machine learning approaches often perform better for prediction tasks (Balahur and Hermida, 2012; Komisin and Guinn, 2012). LIWC returns the percentage of words across the categories of social processes, affective processes, cognitive processes, perceptual processes, biological processes, work and achievement, as well as punctuation and structural details (Pennebaker et al., 2007; Tausczik and Pennebaker, 2010). Per cent based information shows the latent context and relative worth of categories in speech. This facilitates measuring change, looking for group-based patterns, monitoring individual trends and identifying psycholinguistic profiles.
We note the study of Tumasjan et al. (2010), which concentrates on the application of LIWC to text gained from German politicians' Twitter handles in advance of the 2009 elections. Our analysis has several distinct differences. We used the German dictionary (Wolf et al., 2008), rather than translating text content to English for analysis to retain the original intention of the writer as closely as possible. Whereas Tumasjan and colleagues review selected LIWC categories, we consider all German dictionary categories and established psycholinguistic profiles. Finally, the aim of our study is a descriptive analysis of political messaging on Facebook. It is not a prediction task.
Application of a Social Observatory: Political sentiment in Germany
Still unknown and an open challenge for social researchers is the actual impact and relationship between politicians on Facebook and their followers. Does some relationship exist, and if so, what are the important parameters thereof? This study reviews 54,655 posts and 231,147 comments by 257,305 unique users at three granularity levels (all posts and comments per party; monthly posts and comments per party; individuals’ posts and comments per party) in the year preceding and one month after the 2013 federal elections. We establish macro trends, leading to discussions on the difference between politicians and constituents, then concentrate on discourse related to campaigning and individual discourse patterns. Each ‘zoom’ of the Social Observatory reveals telling yet sometimes-contradictory indicators.
On the 2013 German federal elections 8
Germany's multi-cameral Parliament tends to be composed of five different political parties. Centre of right and right parties are the former governing coalition of the CDU/CSU and the FDP, and centre of left and left are the Grüne, SPD, and Linke. The CDU/CSU is the largest party of both the 17th and 18th federal Parliament, and SPD is the largest of the opposition parties from the 17th and 18th Parliaments. The FDP did not obtain enough votes in total to maintain their representation and is not a member of the 18th Parliament. While the CDU/CSU came near to an absolute majority (which in and of itself signifies a largely stable political culture and election series), they did not have enough votes to form a government without a partner. Without the FDP in Parliament, the CDU/CSU was forced to find a new coalition partner. This was the SPD, which obtained the second highest amount of votes in the election.
Descriptive aspects of German Parliament members on Facebook
Descriptive attributes of dataset (numbers are rounded for representation purposes).

Facebook is used mainly as a medium for promoting individual (political) agendas. Interactions between politicians are relatively low: 3,883 occurrences (0.23%) across all profiles. Figure 2 visualises interactions between politicians and their audience, capturing 85,679 bi-directional edges considering only text-based interactions, 345,704 considering only likes and 385,936 when considering both. On average, politicians and individual audience members interacted 2.70 times via comments, with a maximum of 1,503; 4.30 and 998 respectively for likes, and 4.45 and 1554 considering both.
The extracted social interaction graph with all and weightiest edges.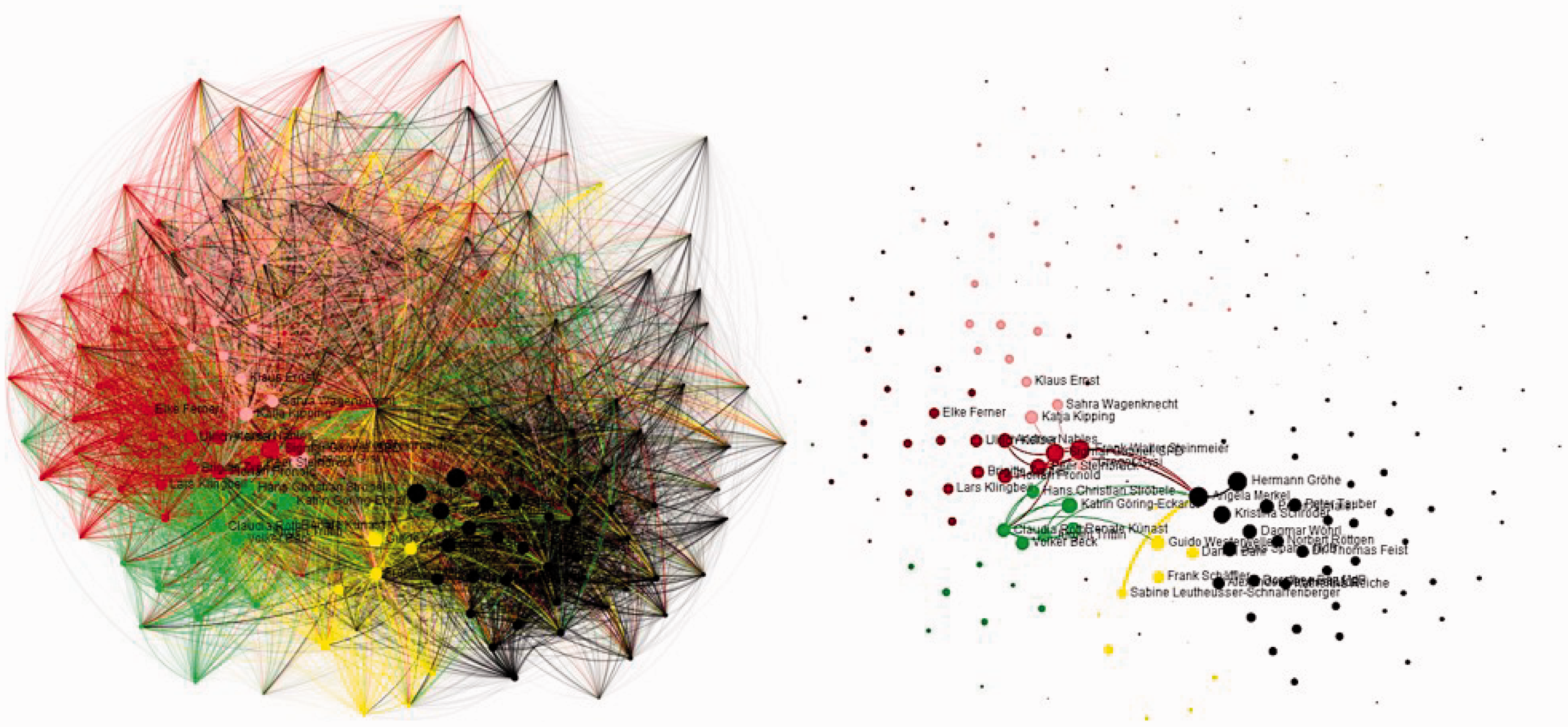
Politicians posted on average 292 times (just over a post a day). The average profile contains 29,301 words, from which 25% were six letters or more (a measure of linguistic complexity). The average post length was 40.8 words, differing from the findings of Kramer (2010), who found that the average length of a Facebook post is nine words. This finding and its discrepancy compared to Kramer's results likely has its origin in the language of this sample.
Timing of posts and comments as well as daily patterns suggests that politicians see their positions as jobs, while constituents act as if their elected officials should be constantly available. Figure 3 depicts the continuum of hourly posting behaviour, with politicians posting in the morning and at lunchtime, and constituents responding in the afternoon. Politicians also tend to post on working days, whereas constituent volume shows no significant difference between weekdays and weekends (Figure 4).
Distributions of hourly posting behaviours, posts and comments. Weekday and weekend post and comment activity (logarithmic scale).

Public conversation maps temporally and in interest-based ways to the realistic and real-time public events in Germany. The monthly distribution of posts and comments depicted in Figure 4 show an increase in activity leading to the elections with two exceptions: December 2012, also observed in 2009–2012, and July 2013 during Parliament's summer recess. December is also a “slow” period for comments. Posting activity significantly dropped in October 2013, directly after the elections. This drop is not reflected in the comments, nor is the recess drop in July. Comments show spikes in November 2012 and March 2013, corresponding to interest in the various public scandals of the former German President Christian Wulff (Figure 5).
11
Monthly post and comment activity.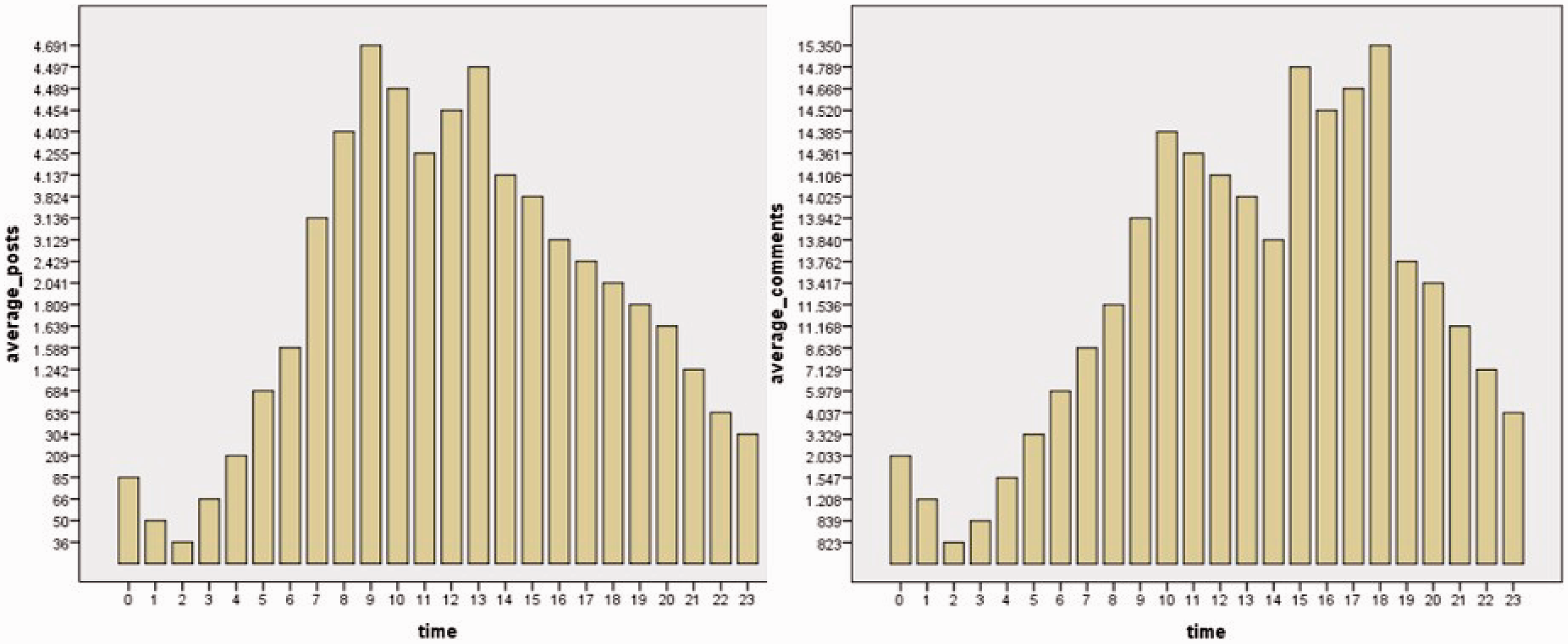
Negative emotions, anger and money discussions are positively related (rs(331) = .137, p < .0005; rs(331) = .184, p < .0005), reflecting on-going public sentiments at financial bailouts to neighbouring countries across the European Union. The most commonly repeated post was “STOPPT die Massentötung in Rumänien! STOPPT die Tatenlosigkeit aller Verantwortlichen in der EU! JETZT!” (Stop the mass murders in Romania! Stop the inaction of EU stakeholders! Now!), referring to wildly unpopular policy inaction over Romanian ‘fur farming’. 117 unique users repeated this single post 234 times.
Zooming in and out of a social network
Macro-level assessment
Nearest neighbours, politicians and constituents where k = 5.

As the space is small but not equal with an absolute range from 2.017 (Linke comments and SPD comments), to 10.523 (Grüne posts and SPD comments) (Table 2), high dimensionality does not unexpectedly compress the data. As there are no “popular” hubs, we can also reject that hubness is driving the results (Radovanovic et al., 2010).
Paired Sample t-Tests.
While some results are not unanticipated, other pairings are unusual. There is no significant difference between the posts or comments of the two centre-right parties CDU/CSU and FDP (t(63) −1.788, p < .05), or between the leftist parties SDP and Linke (t(63) = −.290, p < .05). Unexpectedly, no significant differences between the posts and comments of either the right-oriented parties CDU/CSU or FDP, and the socialist party Linke (t(63) = −.893, p < .05); (t(63) = −.867, p < .05) are found. Interestingly, the only non-significant difference of the Grüne was between that of the posts of the CDU (t(63) = .799, p < .05). All other pairings with the Grüne were significantly different. All post-comment combinations have significant differences, which is supported by the results of the nearest neighbour test.
These differences between relationships as found in the nearest neighbours and t-tests are interesting, as it suggests that politicians and their audiences on Facebook often concentrate on different points, giving importance to different topics across their general discussions. When considering only the posts, this finding supports the assumption that there is a diversity of political conversation amongst Facebook users. As the parties are platform based, this is a positive finding. The results defy the thesis of linguistic accommodation of Niederhoffer and Pennebaker (2002); a reason for the lack of coalescence here could be that conversation partners change too rapidly to adapt to one another. It is worth noting that the overall corpus follows the pattern of polite discussion put forth in Brown and Levinson (1987) and Pennebaker et al. (2003).
Meso-level assessment
There is a distinct propensity to discuss in present tense, which suggests that politicians on Facebook are not ‘campaigning’ in the traditional sense, but are rather discussing their daily activities. Considering the population, this is an unexpected finding. Whereas it may not be unusual for politicians and political discourse to focus on the present rather than the past, the absence of future references, especially in the face of national elections, is unanticipated (Figure 6). Manifestos have 3.19 times more references to the present than the past and 3.05 times more references to the present than the future, with the exception of the Grüne manifesto that has an inverse present–future relationship. Posts are slightly more balanced with present/past references having a 1.57 difference and present/future discrepancies at 2.73. Comments are the most present-focused, with audiences referring to the present 3.23 times more than the past and 4.46 times more than the future. The findings reported in Tausczik and Pennebaker (2010) of a political discourse study by Gunsch et al. (2000) state that this could also be related to positive campaigning rather than ‘dirty’ campaigning.
Social references in party manifestos, posts and comments.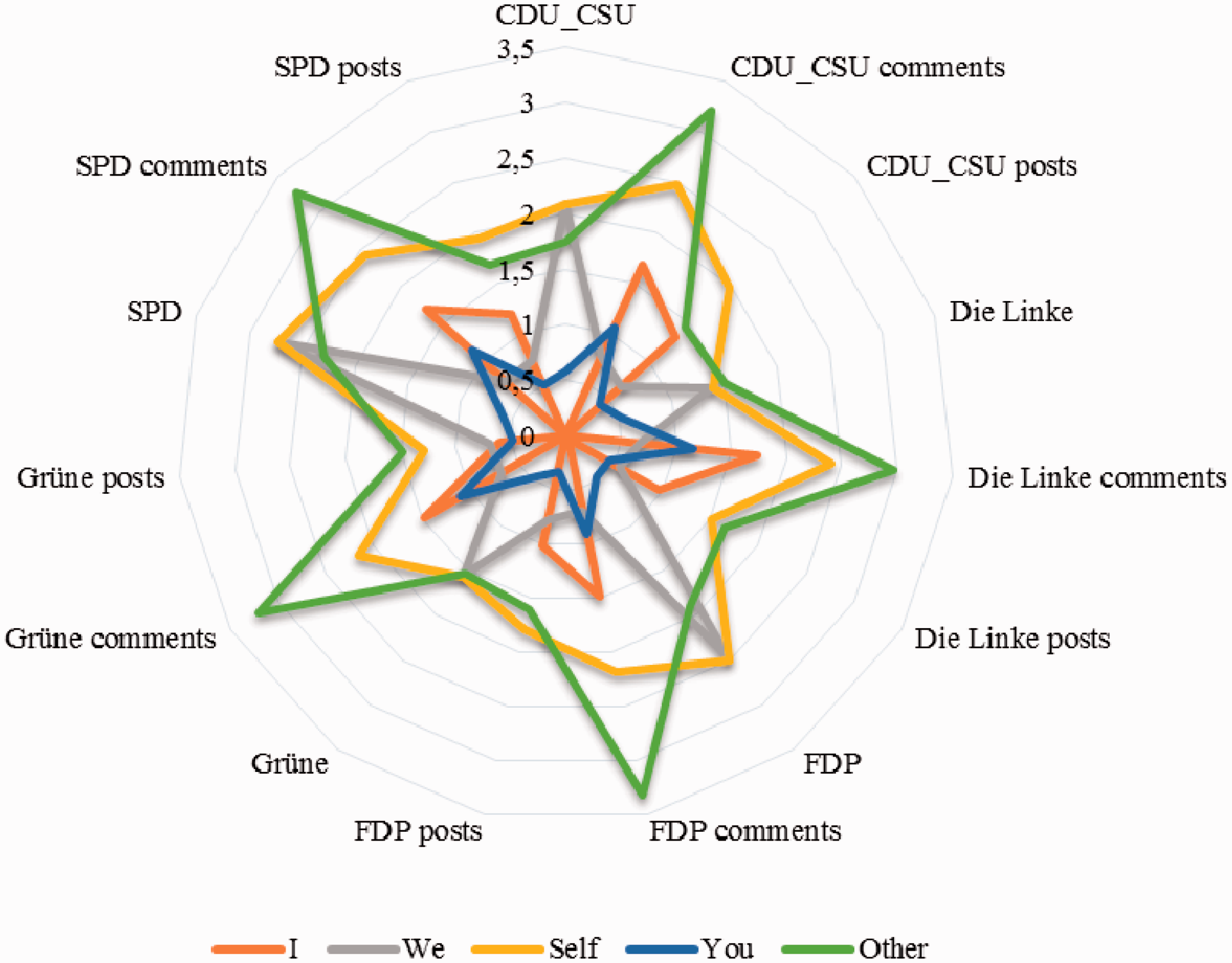
Reviewing this further, no significant correlation exists between positivity, negativity, use of first or third person, and tense and thereby does not replicate (Gunsch et al., 2000). The authors also state that first person references are related to positive campaigns and third person campaigns are related to negative campaigning. This is again a positive finding. Also rejected is that the social aspects reflect an “Us-Them” mentality, when taking the relative frequency of inclusivity and exclusivity into consideration (Figure 7). Especially manifestos and posts orient towards inclusive discourse. Comments, while having spikes of exclusionary sentiment, are also overarchingly inclusive.
Inclusive and exclusive references in manifestos, posts and comments.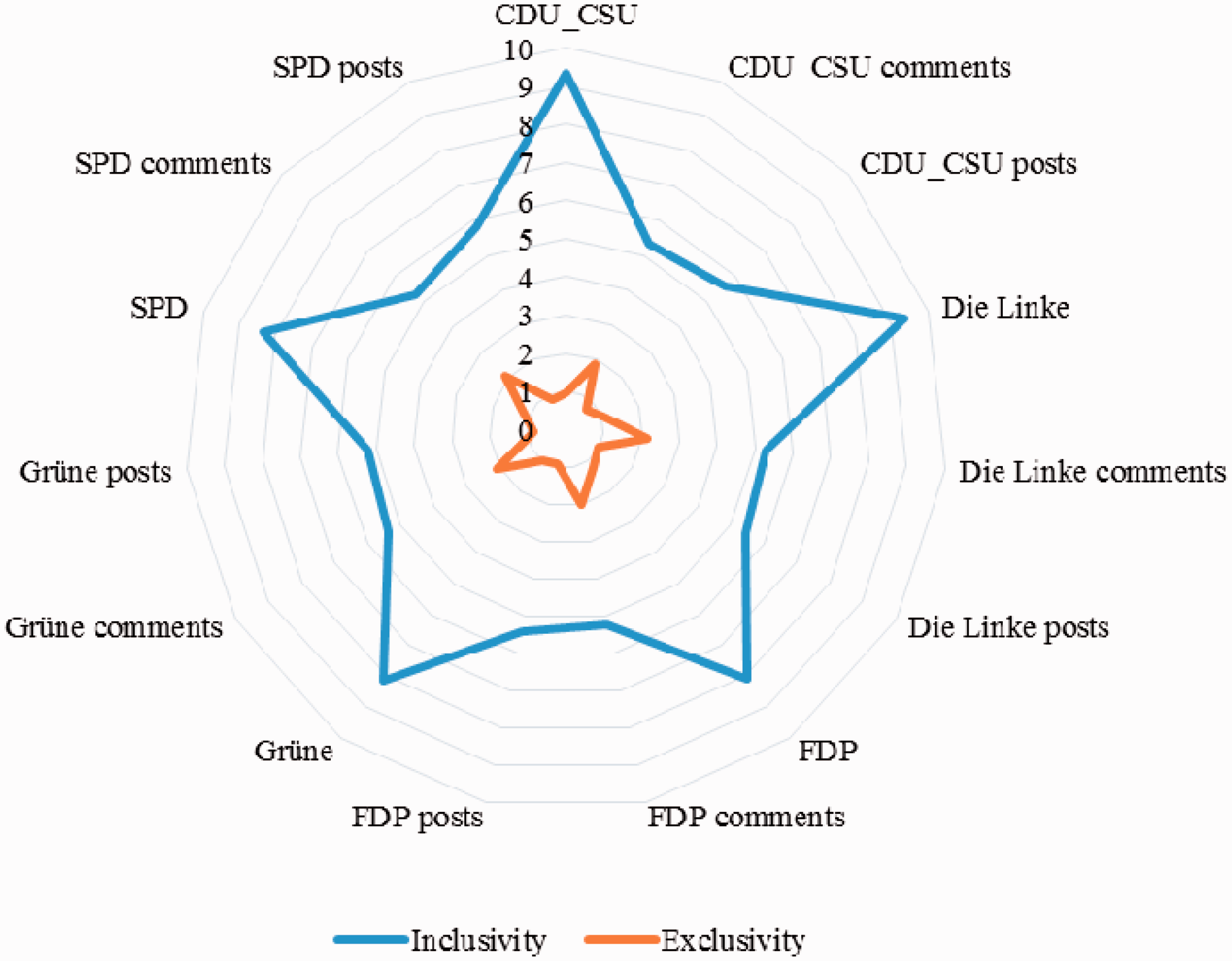
Political discourse does seem to be communal discourse as displayed by the manifestos and Facebook activity. Social references rank well above references to the self; first person plural and the second person “you” come before first person singular (Figure 8). There is no cause to believe that the politicians or constituents are using the “Royal We,” in which “we” is used to imply cohesion but indicates commands (Tausczik and Pennebaker, 2010).
Language tense patterns of party manifestos, posts and comments.
Micro-level sentiment
While warning scholars to proceed with caution, Pennebaker et al. (2003) identified sentiment analysis as an area of future research in their 2003 article. As expected, emotion words are relatively low, accounting for 1.5–4% of the party's corpus (Figure 9). Gathering all posts and analysing for monthly changes, we cumulated all posts and comments, resulting in the graph depicted in Figure 9. A bump in positive sentiment for both posts and comments is visible coinciding with the lead-up to the federal elections, along with a minor drop in negatively intoned posts. The rise in positive sentiment within the last month of 2012 is due to increased use of holiday wishes analogous to the finding of Dodds et al. (2011) and Kramer (2010).
Average sentiment per month, posts and comments.
As seen in Figure 10(a–d), the message that the parties would like to display is not necessarily being followed in day-to-day interactions of politicians and their constituencies. Overall, manifestos have nearly double the occurrence of positive emotion words as compared to posts and comments, and are more negatively intoned than posts in all cases. Positive sentiment within the posts and comments often concerns congratulations on birthdays, campaigning activities and self-promotion.
Sentiment by (a) manifesto, (b) politicians, (c) constituents and (d) overview of all (error bars at 95% confidence interval).
At this granularity level, there are almost no differences in the means of negative emotion usage, with posts tending to contain slightly less negative emotion words as compared to party manifestos and comments. The greater use of words bearing positive sentiment compared to words bearing negative sentiment is noticeable, especially in light of 60% more words within the LIWC dictionary being associated with negative sentiment (Pennebaker et al., 2007; Wolf et al., 2008). The highlights in negative sentiment typically detail posts about child abuse, angry discussion on night flight operations, as well as reflections on situations in the Middle East and Greece. While criticism of opposing parties is present, the low negativity levels suggest that ‘dirty’ campaigning on Facebook is kept to a minimum, supporting our previous finding and diverging from Gunsch et al. (2000) for this user sample.
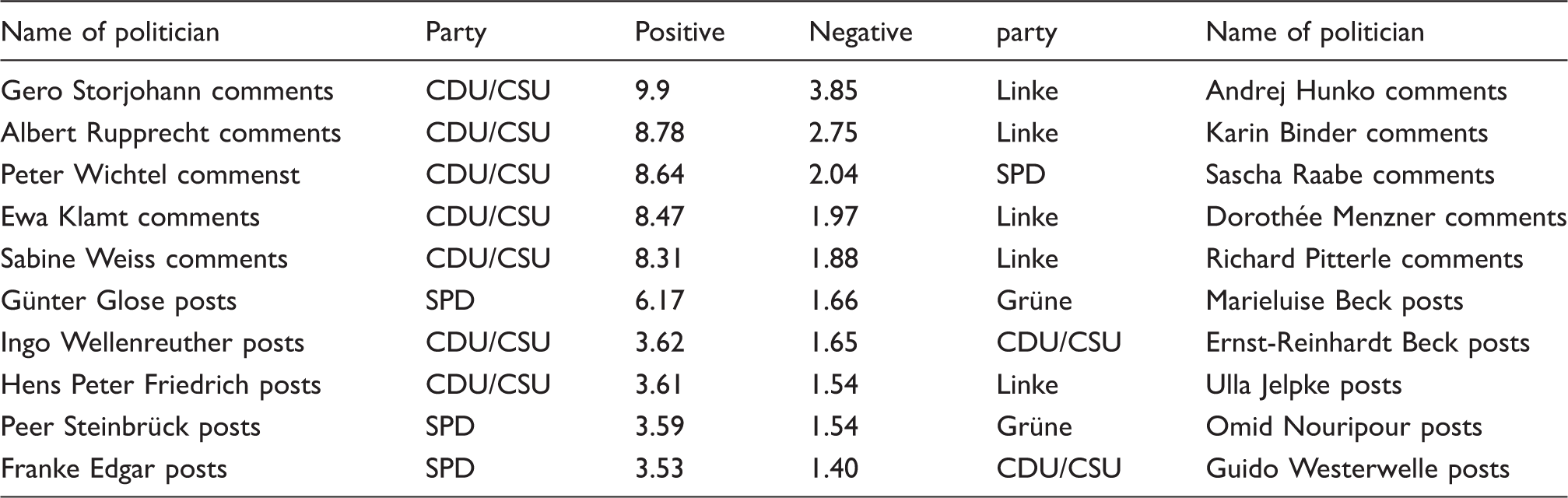
Most positive and negative posts and commentator groups by relative per cent.

A further look at social discourse between individual politicians to their constituents bears more interesting features. At the politician level, there are no significant differences in speech patterns based on gender, nor are there gender differences found in constituents' responses to politicians. There are no indications of the psycholinguistic indicators common to deception (more negative emotion, more motion words, fewer exclusion words, and less first-person singular) (Newman et al., 2003). Posts tend to be statements and comments tend to ask questions, which is indicative of an implicit hierarchy in politician discourse according to the finding that higher status people ask less questions (Tausczik and Pennebaker, 2010). Anecdotally, Chancellor Merkel's posts did not contain a single question mark for the 13 months of this analysis.
Discussion
German political discourse is a rich, dense network. A major characteristic of German political discourse is that it occupies a close space, though distinct patterns appear at the correct resolution. Political discourse on Facebook is polite yet hierarchical. Especially the two largest parties (CDU/CSU and SPD) tend to use online speech in similar ways, while the three smaller parties have attributes onto themselves. Where the Grüne can be characterised as the least similar and most future-oriented party, the Linke has the highest concentration of negative commentators. Distinct in its nondescriptness, the FDP showed no discrete patterns. This lack of platform-based engagement is quoted as a major reason why the FDP did not meet the minimum criteria of to be re-elected into the 18th Parliament in favour of its larger, less conservative partner CDU/CSU. 12 Having established that a signal was available in the data that the FDP was losing constituent engagement, the next question is if and how this information could have been utilised by campaign managers and policy workers as a prediction tool.
Facebook offers an open, deliberative and participatory civil society forum for exchange. This was illustrated in the lack of gendered discourse and gender-directed responses in the face of a growing body of literature stating that Internet anonymity can increase sexist remarks. 13
However, where politicians seek to be as inclusive as possible, constituents are careful to make distinctions in their viewpoints, thereby delimitating their own environments. Active campaigning is kept to a minimum, in favour of daily updates of how the politician is serving their community. One overarching fact of this study is that posts and comments are oftentimes intransitive, indicating that politicians and constituents are more often than not talking past one another.
Our analysis of political sentiment mining indicates that modern assessments of public opinion are largely improperly scaled. Individual sentiment scoring is an especially revealing method for community modelling. Positive and negative sentiment display interesting characteristics but show only limited potential as public opinion gauges, in agreement with Chung and Mustafaraj (2011), Jungherr et al. (2011) and Pennebaker et al. (2003). Much more revealing is the meso-analysis, as aggregating sentiment levels of users at the macro level leads to an averaging value without distinct significance, causing a blurred view. Accordingly, it is striking that when observing at different levels, i.e. all, a party, or an individual, we uncover subtleties otherwise lost in the aggregation method.
Our Facebook-based Social Observatory facilitates interdisciplinary mixed method research on aspects of online communities. It adds to the toolbox of social media researchers that is today predominantly occupied by Twitter applications. Using a point and click style interface (social science) researchers can avoid the technical challenges of extracting social media data. We have also provided basic analytical capabilities that we will extend as required by future use cases. Although we present a case study in political science, our Social Observatory can be leveraged for any case study requiring Facebook data. Here, we envisage case studies in areas such as business as well as competitive intelligence, marketing and campaign management, and community detection and monitoring. Using our approach, researchers can mitigate the research biases common to social media research (see González-Bailón et al., 2014; Ruths and Pfeffer, 2014) as we can extract complete timelines, not samples thereof. We do, however, note that just because Facebook data is made available in this manner, not all research facilitated by a Social Observatory is ethical. Researchers need to be aware of the ethical boundaries of Facebook-based studies as the recent Facebook contagion study (Kramer et al., 2014) painfully demonstrated. Anecdotally, most users are completely unaware that Facebook pages are publically accessible and consequently do not provide informed consent to studies conducted by third parties. Simply by clicking like on a page, they conceivably become an entity in a dataset that a Social Observatory can curate for a researcher to analyse.
Conclusion
The continuing integration of the offline and digital self creates new requirements for social researchers and stakeholders. Missing has been a generalisable, open-source tool for accessing and analysing these phenomena that is specific to Facebook. We have presented the vision and architecture of a Social Observatory: a low latency method for the observation and measurement of social indicators within an online community. To explore the usefulness and possibilities of a Social Observatory for policy and decision makers, we implemented a Facebook adapter that allowed us to focus the Observatory on 187 German federal politicians and 257,305 lay constituents, as proxies to public opinion. We were able to observe how users interacted, with whom and at what volume. In addition, by leveraging the LIWC text analysis toolkit, we were able to identify different facets of communication processes and observe significant differences in sentiment between the politicians and their followers.
The implications of this work are threefold; firstly, we offer a framework to automatically extract public data troves (even from Facebook profiles) for use in studies related to online communities. Secondly, that by providing a few generalizable tools quite complex interdisciplinary research processes can be undertaken. Finally, using only a small number of points of reference, i.e. the 187 politicians, our approach can discover and analyse the actions of an entire (sub)community. By employing similar techniques and extending the analysis stages, we would be able to undertake the same study on any online social community, shedding light on specific social dynamics, and identifying key or influential actors unobtrusively. This ability is of key strategic use for public figures that wish to assess, for example, their public standing, or the reactions to specific actions.
While we believe the results of our case study are encouraging, the methods are not without fault. Within our quality control of selected users we found posts with incorrectly labelled sentiment scores. A misinterpretation by the word/word stem approach is likely, as these methods are notoriously hard to apply to cases of irony and sarcasm (Tsur and Rappoport, 2010). We will also revisit our post filtering approach; we included only status updates without photos, videos or links. Some politician profiles heavily use media content and are consequently largely omitted from our analysis. Politicians have PR teams that may post on their behalf; as such, we will extend our feature extraction and filtering methods to enable differentiated author studies. We will also automate the text analytics functionality currently provided by LIWC, making it an invokable tool in the future iterations of the Social Observatory workflow.
Footnotes
Acknowledgements
We would like to thank and acknowledge the work of Lukas Brückner (for review purposes) in the preparation and implementation of the Facebook adapter used in this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.