
Abstract
This article studies whether countries’ speeches at the United Nations General Assembly (UNGA) matter for international aid allocation. I use a supervised machine learning algorithm called Wordscore and 7,533 different statements from 198 countries made in the period from 1975 to 2018 to measure countries’ preferences from text. Then, by employing panel regression analysis and the synthetic control method, I find considerable evidence that countries’ preferences derived from speeches affect aid allocation. Both the US and Russia provide more aid to countries that present speeches more in line with their current agenda and preferences.
Introduction
Since the Cold War, the US and Russia have competed for cultural and political influence, often using development aid to incentivize political alignment. This has been extensively studied using historical United Nations (UN) voting records. However, a richer, underutilized source of information exists in the speeches made by heads of state and high-level officials at the UN General Assembly (UNGA) each year. These speeches, spanning thousands of pages, are crucial for the UN’s internal debate and international politics. This article investigates whether UN speeches matter for international aid allocation, using panel data from 194 countries between 1975 and 2018. First, I use the Wordscore supervised machine learning algorithm (Baturo et al., 2017) to analyze UNGA speeches and measure countries’ preferences with a text-as-data approach. To scale the different documents, the algorithm looks at the feature-frequency matrix of the different speeches and uses the speeches of the US and Russia as reference points. The resulting countries’ preferences exhibit both cross-sectional and time variation, making it the perfect case for panel regression analysis. Second, to empirically analyze the relationship between speech alignment in the UNGA and the recipiency of US/Russia aid, I deploy Ordinary Least Squares (OLS) regressions with country-time fixed effects. Third, to investigate the reverse causality problem, I do a case study on 2010 dramatic Haiti earthquake, leveraging its plausible exogenous shock to deploy the synthetic control methods (SCM). The SCM allows me to estimate the impact of the earthquake on Haiti’s speech at the UNGA to attract US aid. Overall, I find that countries’ statements at the UNGA do matter for aid allocation. The US allocates more aid to countries whose speeches leaned more toward the US preference and less to those countries that, instead, pleased more Russia. The same phenomenon applies to Russia: Moscow grants more aid to countries whose speeches are closer to its own.
Literature review
Understanding why countries give international aid has long been studied in international relations and comparative politics. Besides altruistic reasons, research shows that aid is often used for selfish purposes, such as buying political influence, gaining economic benefits, promoting strategic interests, and rewarding countries that align politically (Becker 2023; De Mesquita and Smith, 2009; Hoeffler and Outram 2011; Kono and Montinola 2015; Schraeder et al., 1998).
Scholars have overwhelmingly relied on UNGA voting records to measure the relationship between international aid and the political alignment of recipient countries with the donor (Bailey et al., 2017). Many studies find that countries receiving aid tend to vote similarly to donors in the UN (Adhikari 2019; Alesina and Dollar 2000; Alesina and Weder 2002; Bernstein and Alpert 1971; Gates et al., 2004; Rai 1980; Wang 1999; Wittkopf 1973; Woo and Chung 2018).
On the other hand, other studies find that aid is ineffective in influencing the voting behavior of recipients (Kato 1969; Kegley et al. 1991; Morey and Lai 2003).
Lundborg (1998) focuses on the aid provision of the United States and the Soviet Union from 1948 to 1979. His analysis shows that recipients voted in line with the USA or USSR to stimulate aid provision from them. Alesina and Dollar (2000) argued that the US rewards recipients’ voting compliance by granting more aid while Alesina and Weder (2002) and Gates et al. (2004) find that the same aid reward behavior applies to other G7 countries. Woo and Chung (2018) account for the potential endogeneity of aid and provide evidence that US aid has indeed bought voting compliance in the UNGA from 1973 to 2002. Similarly, Alexander and Rooney (2019) exploits natural variation from the rotating structure of nonpermanent UN Security Council members and identifies a causal relationship consistent with the claim that the United States uses foreign aid to procure voting support for its positions on the UN Security Council.
Despite its wide use, UN voting records are an imperfect solution for constructing measures of government preferences and political alignment (Brazys and Panke 2017; Voeten 2013). Measures based on votes in the UNGA often fail to separate changes in the UN’s agenda from shifts in state preferences. At the same time, vote choice is frequently constrained by existing alliances, strategic voting, the topic of the issue to be voted, and external pressures.
To overcome the aforementioned drawbacks, Baturo et al. (2017) proposed an alternative measure of government preferences that do not rely on UNGA votes but on the speeches that the countries’ representatives give at the UN General Debate. At the UN General Debate, countries’ representatives are free to comment on any topics that they feel of relevance without any legally binding consequences. The fact that speeches at the UNGA are not confined to a predefined topic or agenda is beneficial for measuring countries’ preferences, as it does not limit the scope of discussion to topics chosen by agenda setters. Baturo et al. (2017) uses text analysis on these statements to introduce a new measure that captures hidden government preferences.
Speeches at the UNGA offer a valuable basis for developing a multidimensional measure of government preferences. Adhikari et al. (2022) note the significant media coverage of UNGA sessions, which leaders use for political positioning. Similarly, Kentikelenis and Voeten (2021) discuss how General Debate speeches attract domestic attention, often broadcasted back home by accompanying media teams. These speeches are used strategically by leaders to shape their public image, indicating their utility in analyzing governmental policies and preferences.
Words are vehicles of meaning and, with far more shades of significance than votes, are of crucial relevance in international relations. This article contributes to the existing literature on international aid by using quantitative text analysis techniques to uncover the relationship between speeches in the UN General Debate and aid provision.
Data and method
Text as data
Every year at the UN, member states deliver statements during the General Debate (GD) discussing major issues in world politics. High-level country representatives and heads of state fly from all over the world to gather in New York and express their political views at the UNGA. I collect the text data on countries’ statements at the UN General Debate from the United Nations General Debate Corpus (Jankin Mikhaylov et al., 2017). In total, I gather 7,533 different speeches of 198 countries from 1975 to 2018. On average, speeches are 4,154 words long and contain 1,130 unique words.
Figure 1 provides a snapshot of the raw text data, illustrating that each country’s speech is stored in a separate .txt document for each respective year. As an example, observing the initial responses from the US, UK, Russia, and Belarus to the 9/11 attacks, we note a universal condemnation of the terrorist acts. The rhetoric from the US and its allies subtly incorporated themes of autocracy, emphasizing the enforcement of United Nations authority through military means. In contrast, Russia and its allies leaned toward promoting international collaboration, suggesting a collective approach to addressing global security challenges. Excerpts of speeches 2002. Note: For each year, each country has a different .txt file containing the text of its raw speech.
Per standard text analysis pre-processing methodologies, all raw speeches were subjected to tokenization, stop word removal, stemming, and the refinement of the document-feature matrix. To illustrate the most frequently occurring words post-pre-processing, Figure 2 presents word clouds for the speeches from the United States and Russia in 1989 and 2002. Word clouds of USA and Russian speeches at the UNGA in 1989 and 2002: (a) USA (1989), (b) Russia (1989), (c) USA (2002), and (d) Russia (2002). Note: Word cloud plots do not include English stop words. Furthermore, all words are reduced to their primitive form. As an example: humanity, humanitarian, inhumane, humanize, etc., are reduced to human.
In 1989, a pivotal year marked by the fall of the Berlin Wall, both superpowers extensively discussed the notions of “nation” and “world,” albeit with differing ideological emphases. The United States highlighted concepts such as freedom, peace, and rights, reflecting its diplomatic and cultural priorities. In contrast, Russia focused on terms like nuclear, Soviet, and community, underscoring its geopolitical and social concerns during this transformative period in global politics.
By 2002, the speeches of both nations mirrored the international urgency following the 9/11 attacks. As anticipated from the raw text analysis, the lexical choices of the two countries diverged significantly. The United States concentrated on Iraq, weapons, and authoritarian regimes, whereas Russia adopted a more neutral tone, frequently using terms such as “international” and “terror.”
I use a scaling-supervised machine learning algorithm called Wordscore to convert text data into numerical information. Wordscore (Laver et al., 2003) is the most popular text scaling method to estimate policy positions on dimensions of interest in political science. It differs from other text scaling methods such as Wordfish (Slapin and Proksch 2008) as it requires some reference texts, already labeled, to use as training documents. In other words, the texts of reference, for which the position on the dimension of interest is known, are used by the algorithm as a guide to scale the other text documents. 1 One drawback of this approach is that it requires the researcher to provide some initial information to the algorithm. However, this allows for a clear definition of the measured dimension. In contrast, unsupervised methods like Wordfish make it difficult to determine the specific angle of the multidimensional space where the scaling occurs.
I use the US and Russian speeches at the General Debate as reference points. Each year, I rank the distance of each country’s statement from the US and Russian statements using the Wordscore algorithm. I interpret these Wordscore measures as the countries’ relative distance between the US and Russia on policy and ideology for that year. The US is assigned a score of −1 and Russia +1. Results are rescaled as proposed by Benoit and Laver (2008). In this way, all countries’ Wordscore is comprised between −1 and +1. A lower Wordscore indicates country preferences closer to the US and higher scores greater distance.
Despite the government preferences and policy positions of the US and Russia can vary through time, getting closer and farther apart from them, depending on the year, the analysis allows for time comparisons. Indeed, our analysis is centered on the countries’ preferences closeness to the two superpowers, whatever these preferences may be. For each year, the algorithm re-scales the UN members’ preferences based on the US and Russian statements of that session.
Figure 3 maps Wordscore estimates for the 1989 UN General Debate. As expected, the world is divided into two strong areas of influence with Eastern Europe much under the influence of Russia and Anglo-Saxon countries much closer to the US. The rest of the world, instead, resembles an open ground for clashes of political influences. To see how the Wordscore evolves over time, I plot the time trends of UN countries’ Wordscores. Figure 4 reveals that government preferences meaningfully vary both through time and cross-country. Wordscores map. Note: The scores are estimated in the quanteda package (version ’2.0.1′) and quanteda.textmodels package (version ’0.9.1′) in R (Benoit et al.). I follow standard preprocessing during the tokenization stage, remove English stopwords, and perform stemming. I also trim the document-feature matrix to have features that appear at least 10 times in five documents. The US is given a reference score (−1) and Russia (+1). Results are rescaled as proposed by Martin and Vanberg (2008), hence predicted scores are within the range (−1; +1). Wordscores plot. The graph plots the Wordscore of 194 countries over a period of 43 years. To allow for time comparisons, raw Wordscores are rescaled as proposed by Martin and Vanberg (2008). Hence, estimates shall be interpreted as relative distances of each country’s speeches from the US and Russia.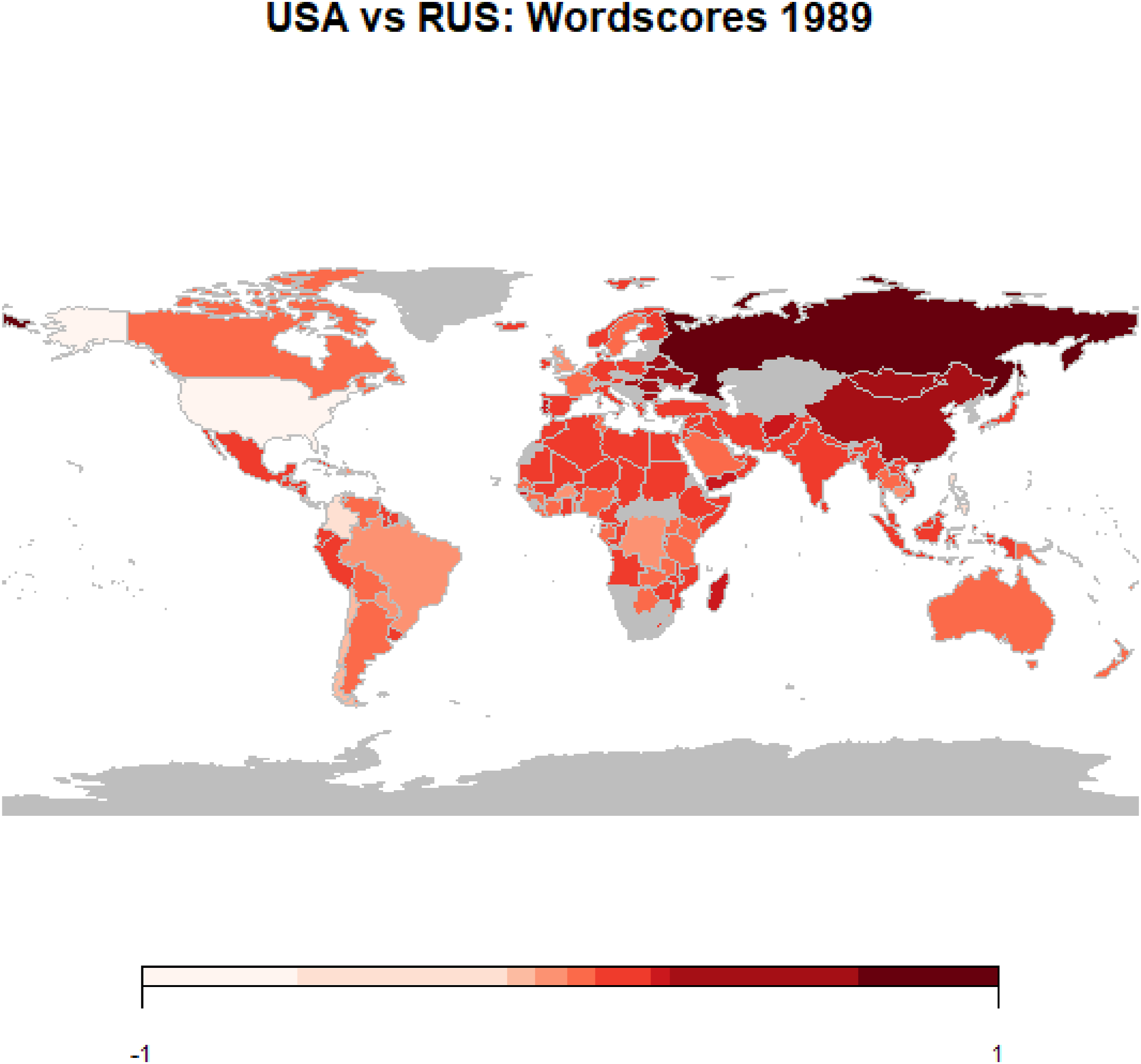

To further investigate the validity of Wordscore index, I examine its correlation with traditional metrics of political affiliation, specifically voting similarities at the United Nations General Assembly (UNGA) (see Figure B1 in Appendix). Voting similarities are quantified using Lijphart’s index of agreement, which measures the alignment between the voting patterns of states and those of the US or Russia, as developed by Bailey et al. (2017). As expected, the Wordscore is inversely correlated with voting alignment with the US and positively correlated with alignment with Russia. Nonetheless, substantial variability is evident between these two measures of governmental preferences. This variability supports the assertion made by Baturo et al. (2017) that UN General Debate speeches reveal a more nuanced dimension of governments’ preferences than UNGA voting patterns alone can capture. The Wordscore index and the voting similarities of each country with the US and Russia are correlated at 1% level of significance (see Table B1 in Appendix).
Bilateral aid
I collect aid data on the US and other DAC donors from the World Bank. Specifically, I use net bilateral aid flows (current US dollar) and convert them into real US dollars using the consumer price index (2010 = 100) of the World Bank.
Finding comprehensive and structured information on Soviet and Russian development aid is a challenging task. A complete account is yet to be produced and will probably be available only if Moscow authorizes an official release of documents. During the Soviet years, scholars have resorted to reports produced by the United States Central Intelligence Agency and the replication data in Dannehl (1995). With the end of the Soviet Union, Russia ceased its development programs altogether. Only in 2007, under the presidency of Vladimir Putin, Russia started to rebuild its aid ambitions, beginning to report its ODA statistics to the OECD aid community in 2011.
I collect aid data on Russia from Dannehl (1995) and Development OECD data. Such information is less comprehensive if compared to its US counterpart; nevertheless, it covers from 1975 to 1989 for the Soviet aid and from 2011 to 2018 for Putin’s modern Russia.
Other controls
Data on socio-economic variables such as GDP, PPP (constant 2017 international US dollar), total population, and trades are collected from the Development OECD Data. Data about the level of electoral democracy, liberal democracy, freedom of expression, and share of the population with suffrage are from the Democracy/Autocracy Dataset of Ulfelder (2012), while data on the militaristic political leaderships is from the Database of Political Institutions (Cruz et al., 2018). To reduce the sparsity of observations on Russia, I also collect GDP historical data from the Maddison Project and historical data from Dannehl (1995).
Methods of estimation
The research uses panel data for all available UN countries from 1975 to 2018. To test whether countries’ statements at the UN General Debate matter for the allocation of American and Russian aid, I estimate a set of regressions using ordinary least squares (OLS).


Since some of the data are not available for all countries or years, the number of observations depends on the choice of explanatory variables. For transparency, the results will be shown using both the baseline model and the extended model with all control variables included.
Due to the absence of a quasi-experimental design, I cannot assert causal relationships. However, I conducted extensive robustness tests to demonstrate a reliable positive association between government preferences from speeches and international aid allocation. These tests include baseline OLS regressions using varied Wordscore indexes and several placebo outcomes.
I also applied the synthetic control method (SCM) as introduced by Abadie and Gardeazabal (2003) to a case study of the 2010 Haiti earthquake. SCM constructs a synthetic control unit to approximate Haiti’s UNGA speech alignment with the US had the earthquake not occurred, thereby isolating the impact of the disaster on aid-seeking behavior. This method provides a counterfactual analysis, highlighting the immediate impact of an exogenous shock on UNGA speech alignment.
Results
UN speeches and aid recipiency
Relationship between international aid and Wordscore (1975–2018).
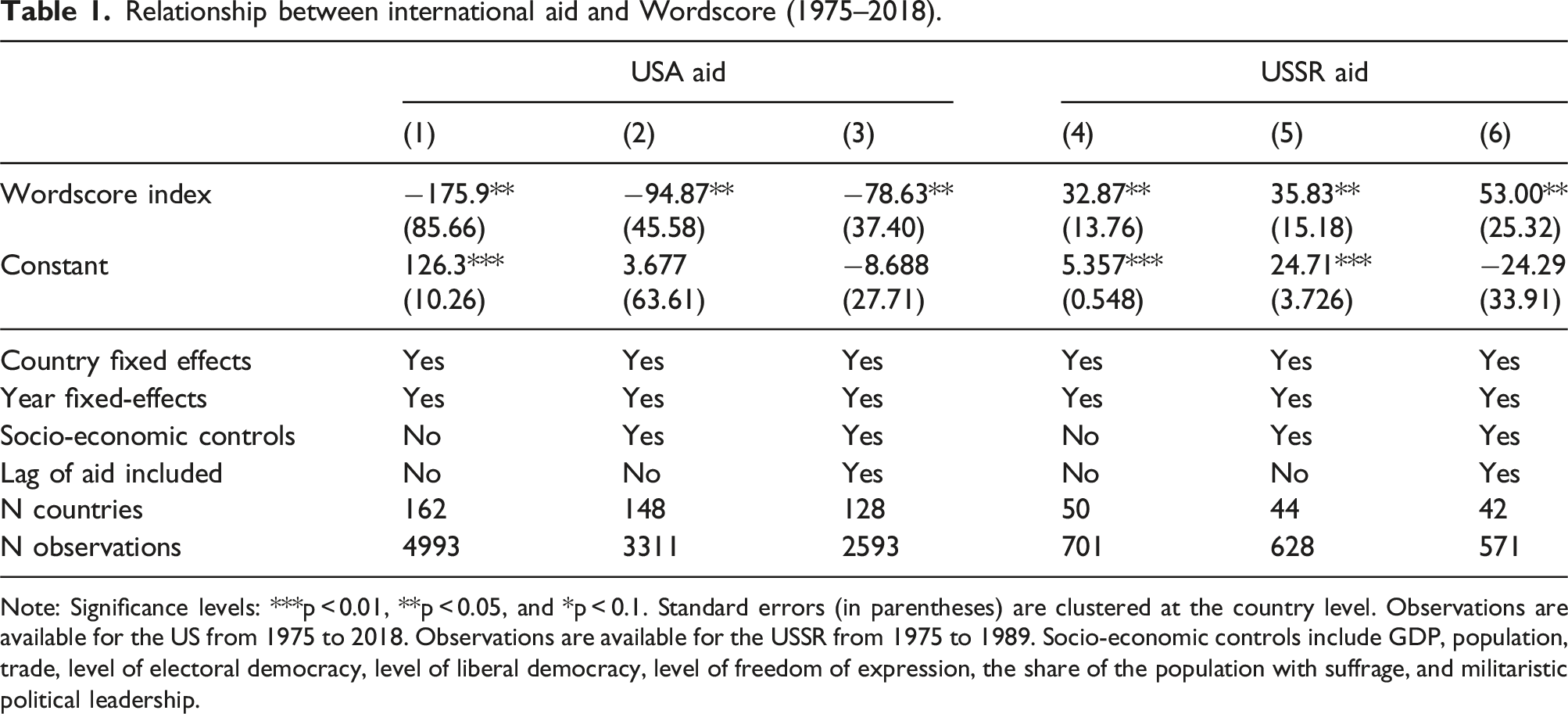
Note: Significance levels: ***p
Overall, an increase of 1 unit in the index corresponds to a decrease of around 100 million US dollars in aid from the US. On the other hand, the same 1 unit increase in the index coincides with an increase of around 50 million US dollars in aid from Russia. The coefficients are significant at 5% level in all specifications. It is reassuring to observe that the estimated result is not sensitive to the inclusion of control variables such as democracy and freedom (see columns 3 and 6), suggesting that the use of text as data approach is indeed capturing a more subtle and multidimensional representation of countries’ preferences.
Furthermore, I examine the relationship between the Wordscore index and aid recipiency and compare it to the more traditional voting similarity index and its association with aid recipiency (see Table B2 in Appendix). Consistent with the mentioned body of research, I find a positive correlation between voting similarity and aid recipiency. However, its statistical significance varies when controls such as country and year fixed effects are included, reflecting the tendency of voting patterns to align with blocs formed by countries’ political alliances. This observation aligns with Baturo et al. (2017) argument that deriving government preferences from UN General Debate speeches might mitigate some limitations associated with using votes in the UNGA. Notably, voting similarity accounts for approximately twice the total variation in aid allocation compared to Wordscore. Yet, the variation explained correlates more strongly with specific countries and temporal factors than Wordscore.
Relationship between international aid and Wordscore decomposed by geographical area (1975–2018).

Note: Significance levels: ***p
The dissolution of the USSR in 1991 marked the end of the Cold War and the bipolar world order, leading to a period of unipolarity with the United States as the sole superpower (Brooks and Wohlforth 2015; Huntington 1999). By 2002, US foreign policy had shifted focus from Russia to the Global War on Terror, following the 9/11 attacks.
Relationship between international aid and Wordscore by period.

Note: Significance levels: ***p
Robustness tests
To ensure the robustness of our results, various robustness tests were conducted.
First, I used placebo outcome variables, such as aid from other DAC donors, which presumably remain unaffected by speech alignment with the US or Russia. The results, presented in Appendix B (see Figure B2), show that none of the placebo estimates are statistically significant, indicating robustness in our methodological approach.
Second, I verified the sensitivity of our results to text analysis pre-processing choices. The main results were consistent even when using an index built with different trimming decisions (see Table B3 in Appendix).
Despite the extensive dataset and control variables, reverse causality remains a potential concern. To address this, I examined the directionality of the effect by inverting our regression equations, as detailed in Table B4 (in Appendix). The results support the conclusion that UN speeches influence aid allocation, not the other way around.
Finally, to rule out any effect of future speeches on current aid allocation, I included forward-lagged variables of the Wordscore index in our main regressions. The coefficients of these forward-lagged variables, plotted in Figure B3 (in Appendix), are statistically insignificant, reinforcing the absence of reverse causality.
For detailed results and further discussion, please refer to Appendix B.
Case study: The 2010 Haiti earthquake
To explore the found relationship between UN speeches and aid allocation from a more counterfactual standpoint, I focus on a case study, namely, the 2010 Haiti earthquake, by employing the synthetic control method (SCM) of Abadie et al. (2015, 2010).
In 2010, a magnitude 7.0 earthquake struck Haiti, killing 220,000 people, forcing 1.5 million individuals into homelessness, and bringing the entire country to its knees. Such catastrophic and exogenous event generated one of the largest disaster relief efforts in modern history launched by the international community (Kligerman et al., 2015).
The magnitude of this relief effort can be observed in Figure 5, which shows 2010 as the historical peak of US aid to Haiti. On the other hand, the Russian relief support has been more modest, constrained by the country’s financial constraints of the 2000s. Historical plot of US aid toward Haiti. Note: The line plot shows the trend of US bilateral aid to Haiti from 1975 to 2018. Main events represented by the vertical lines: the Hurricane Gordon (1994) and the Haiti earthquake (2010).
The SCM is particularly suitable for this case as I have only one treated country (Haiti) and many non-treated countries (all other UN countries). Hence, I can evaluate the impact of the 2010 Haiti earthquake on the Wordscore index. If the article’s argument stands, the 2010 Haiti earthquake should have had a negative effect on the Wordscore index (speeches closer to the USA) as a means to attract as much US aid as possible. Furthermore, since the treatment is temporary and not permanent, the effect should disappear a few years after the earthquake, being the urgent need to attract aid ceased.
Figure 6 presents the results of the SCM. The synthetic Haiti almost perfectly matches the real Haiti in the pre-treatment period, diverging then sharply in 2010. The negative effect of the Haiti earthquake on the Wordscore index disappeared around 2015, as things went back to normal. It is reassuring to observe that the treatment effect matches our expectations. The fact that the effect on the speeches does not last much longer after the earthquake makes it likely that the speech change was indeed to attract aid and not a consequence of it. Trends in Wordscore index: Haiti versus synthetic Haiti. Note: The graph plots the actual versus the synthetic Wordscore of Haiti. The 2010 Haiti earthquake is defined as the exogenous treatment. The Wordscore index lags are used as predictors. All countries for which the predictor is available in the entire pre-treatment period (149 countries) are employed for the synthetic control method donor pool.
As suggested by Abadie et al. (2015), I conducted in-time placebo and leave-one-out tests to assess the robustness of our SCM results. Both tests yielded reassuring outcomes.
For the in-time placebo test, the treatment date was reassigned 5 years before the actual event, showing no significant divergence (see Figure B4 in Appendix). The leave-one-out test, where each donor country was excluded one by one, indicated that no single country drove the results (see Figure B5 in Appendix).
Conclusions
The United Nations General Debate provides a platform for leaders to freely express their country’s views.
I use machine learning and text as data approach to build a quantitative measure of UN countries’ preferences based on their statements at the UN General Debate. Thanks to the supervised machine learning algorithm “Wordscore,” countries are scaled based on their speech similarities to the US and Russia for all years from 1975 to 2018. Panel analysis shows that UN statements have a relevant role in international aid allocation: the US and Russia give more aid to countries whose speeches align more closely with their current agenda and preferences.
The magnitude of the effect is economically relevant as a reduction of 1 unit in the index equates to an increase of 100 million US dollars in aid from the US. The same reduction of 1 unit in the index is linked with a drop of 50 million US dollars in aid from Russia. Results are robust to the inclusion of country-year fixed effects as well as control variables such as GDP, population, trade, democracy level, freedom level, and government type.
Looking at the effect decomposed by geographic area, the US rewards speech alignment especially in Africa, Asia, and Latin America, while Russia focuses on Asia. Furthermore, this effect is most pronounced during periods of heightened rivalry between the two superpowers.
A subsequent case study utilizing the synthetic control method (SCM) to analyze the dramatic 2010 Haiti earthquake also demonstrates that speech alignment at the UNGA can explain patterns of international aid allocation, particularly in response to countries’ needs arising from unforeseen events.
To the best of my knowledge, this is the first research that studies international aid allocation by employing a “Wordscore” index as a measure of countries’ preferences within a panel regression framework. This research contributes to the existing literature on international aid by finding empirical evidence on the relevance of UN members’ speeches (as a measurement of government preferences) for aid allocation decisions. Existing literature has shown that countries can signal political alignment through strategic voting and be rewarded. The presented work suggests that also speech alignment can explain aid recipiency.
Finally, this study lays the groundwork for an array of promising future research directions. The presented “Wordscore” index could be used to uncover the relationship between UNGA speeches and other outcome variables such as military alliances and trade agreements, broadening our understanding of the influence of diplomatic language. Additionally, the text-as-data and machine learning methods developed here can be used to analyze speech patterns between other major world players like the US, China, or the European Union. Future research could reveal how these government preferences derived from speeches affect trade dynamics, policy liberalization, and collaborative responses to terrorism and climate change.
Supplemental Material
Supplemental Material - Words that matter: A machine learning analysis of UN General Assembly speeches and their influence on aid allocation
Supplemental Material for Words that matter: A machine learning analysis of UN General Assembly speeches and their influence on aid allocation by Alessio Mitra in Research & Politics.
Footnotes
Acknowledgement
I wish to thank Manuel Bagues, Irma Clots Figueras, Bansi Malde, Anirban Mitra, Nicole Rae Baerg and Charles R. Dannehl for their useful suggestions and excellent research assistance. I also thank two anonymous reviewers for their constructive suggestions and feedback, which were very helpful in improving the manuscript. This article was not prepared for the European Commission; it reflects the views solely of the author. The research for this article was conducted at the University of Kent.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Correction (September 2024):
Acknowledgement section has been updated in the article.
Data availability statement
Data and replication code are available in the supplementary material.
Supplemental Material
Note
Appendix
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.