
Abstract
The “credibility revolution” has forced quantitative social scientists to confront the limits of our methods for creating general knowledge. As a result, many practitioners aim to generate valid but local knowledge and then synthesize and apply that knowledge to predict what will happen in a target context. Positivist social science has until recently been hamstrung with other, more immediate threats to validity and inference, but I argue that recent advances in statistical approaches to the problem of external validity reveal limits of the current paradigm. This article and the term “temporal validity” illustrate the intrinsic limits of agnostic (i.e., assumption-free) external validity when the target setting is in the future. These limits, I argue, suggest a re-orientation of social science methodology. We should acknowledge that no research design, no empirical knowledge, is perfectible; instead, we should explicitly aim to increase the amount and quality of knowledge we produce. I believe it is useful to characterize this perspective as part of “Meta-Science,” an emerging paradigm within the social sciences. “Temporal validity” and the implied “knowledge decay” thus represent a meta-scientific intervention aimed at increasing the usefulness of the knowledge we produce. Among other structural reforms, I argue that the binary reality of academic scholarship (a paper is published or not) reifies the perfectibility of empirical knowledge and is thus an impediment to recognizing the continuous nature of all forms of scientific validity.
The imperfectibility of social science
“We are directed in time, and our relation to the future is different from our relation to the past. All our questions are conditioned by this asymmetry, and all our answers to these questions are equally conditioned by it.”—Norbert Wiener, Cybernetics
Methodological progress has demonstrated that conducting internally valid empirical research—making true statements even about particular cases—is more difficult than once thought (Angrist and Pischke, 2010). The rise of randomized control trials (RCTs), regression-discontinuity designs, and natural experimental approaches has increased the credibility of social science research, but it has also increased the relevance of concerns about external validity. Compared to regressions that purport to describe global phenomena, this research generates an internally valid estimate of the causal effect of a given treatment, in a given time and place, and on a given subject population (Samii, 2016).
The goal of this research is to accumulate generalizable knowledge; in the words of Dehejia et al. (2021), “with a large number of internally valid studies across a variety of contexts, it is reasonable to hope that researchers are accumulating generalizable knowledge...The success of an empirical research program can be judged by the diversity of settings in which a treatment effect can be reliably predicted” (p. 217).
This view is prominent across the social sciences. Political scientist Phil Schrodt argues that “explanation in the absence of prediction is not scientifically superior to predictive analysis, it isn’t scientific at all!” (Schrodt, 2014). In Economics, 2019 Nobel Laureate Esther Duflo called for economists to “adopt the mindset of a plumber. Plumbers try to predict as well as possible what may work in the real world” (Duflo, 2017). Sociologist Duncan Watts also advocates for a more “solution-oriented social science” (Watts, 2017) and argues that prediction is a valuable tool for explanation (Hofman et al., 2021). And in Psychology, Tal Yarkoni has advocated for incorporating more prediction (Yarkoni and Westfall, 2017), which has in turn caused him to confront what he calls the “Generalizability Crisis” (Yarkoni, 2022).
My premise is thus that one of the primary goals of social science is prediction. There are other goals, of course, and social science is no stranger to methodological pluralism. See Ashworth et al. (2021) for a recent reflection on the state of the deductive paradigm, Mahoney (2021) for a discussion of the set-theoretic, qualitative paradigm, and Reiss (2007) for a general defense of pluralism in social science goals.
The “credibility revolution” taking place across the social sciences means that more attention must be paid to causal identification, and thus that researchers must devote more effort developing their identification strategy and less on novel theorizing. In a landmark outline of the paradigm he calls “causal empiricism,” Samii (2016) argues that this does not mean that “‘theory is being lost’ but rather that theory is being held constant as we go about the difficult business of trying to do credible causal inference,” and that “generalization and theory development are better left to synthesis studies.”
The rate of production of internally valid causal knowledge is increasing, even accelerating, in the presence of methodological innovations, exogenous information technological developments and economies of scale in research practices. This is a major step forward, but it highlights a blind spot in the way that social science methods have been adapted towards this goal. Academic research takes place as time advances. As internally valid studies accumulate, the world changes. If this approach to social science is to succeed, it is necessary that the rate of knowledge accumulation outpace the rate at which old knowledge decays due to the world changing.
Knowledge “decays” if was produced in a temporal context that is relevantly distinct from when it is to be applied. That is, actions based on the knowledge would have originally aided the actor in achieving their desired ends; as the knowledge decays, it becomes less helpful, irrelevant, or possibly even harmful.
The rate of knowledge decay is thus related to the rate of change of the world, what I will call r. I expand on this concept below, but consider r the change in the accuracy a machine learning algorithm gains from having access to that knowledge in making predictions in different temporal contexts. That is, if the predictor gains 2% accuracy from the knowledge in time T but gains only 1% accuracy in time T + 1, then r is 1.
This paper conceptualizes the problem of knowledge decay as a specific form of external validity: temporal validity. Although time-related scientific validity concerns date back at least to Hume, and although fields like time series econometrics and corpus linguistics have long centered change over time, I argue that the contemporary external validity literature that aims to accumulate, integrate, and apply causal social scientific knowledge has not yet come to terms with the fact that the paradigm under which they operate implies application in the future. Prediction that does not acknowledge the scientist’s temporal position—all of our knowledge comes from the past, all of the contexts to which we wish to apply that knowledge are in the future—is merely counterfactual history. 1
I use the term “temporal validity” not to claim any novel insight in either the philosophy of science or statistical methods, but simply to call attention to the inherent contradiction between existing methods for external validity, the inherited institutions of social science practice, and a paradigm aiming to make predictions.
All of the knowledge contained in published papers comes from the past, and all action is in the future: without confronting this reality, papers that perfectly explain the past are an exercise in what machine learning practitioners call “overfitting.” Despite the goal of reducing the prediction error of estimates of the effects of human behavior in the “test dataset” of the future, current methodological efforts focus too heavily on minimizing bias (i.e., maximizing internal validity) in the “training dataset” of the past.
Although not an explicit part of the research programme, I argue that the motivating spirit of the causal revolution—the agnostic perfectibility of internal validity through research design—shapes the orientation to the problem of external validity as well. As philosopher of social science Julian Reiss puts it, “External validity is normally juxtaposed with internal validity, and the former defined in terms of the latter” (Reiss, 2019).
More concretely: Egami and Hartman (2022) provide a rigorous framework for the conditions under which external validity is feasible. The structure of this argument extends the formalism of the Neyman–Rubin potential outcomes model at the heart of causal empiricism, consolidated in textbooks like Angrist and Pischke (2009). 2 The bulk of this impressive effort is devoted to defining the necessary assumptions and developing statistical machinery that would allow an internally valid inference to also be externally valid.
Making the necessary assumptions explicit reveals that they are generally implausible, at least when the researcher wishes to generalize results with the level of precision currently valorized in normal scientific practice. Egami and Hartman (2022) pragmatically suggest a radically lower bar for external validity, abandoning the standard “effect-generalization” for “sign-generalization”:
“Sign-generalization is also sometimes a practical compromise when effect-generalization is not feasible...when required data on target populations, treatments, outcomes, or contexts are not available.”
Given that the required data on contexts can never be fully available when the target is in the future, effect-generalization is never entirely “feasible.”
This conception of what I call “agnostic” external validity as a formal statistical procedure is the logical extension of the central emphasis of the causal empiricist paradigm: causal identification. RCTs are considered the gold standard research design because they are fully agnostic: they ensure unconfoundedness and positivity (internal validity) through research design, with zero modeling assumptions about the structure of the world (Aronow et al., 2021).
If r is positive, if the relationship between causally relevant variables changes over time—or if new values of those variables appear—then agnostic external validity is impossible if the target context is in the future. The problem of “temporal validity” is an insurmountable event horizon for agnostic social scientific knowledge. The unknowability of the future makes external validity imperfectible. 3
The severity of the problem in practice varies, with r, across different realms of inquiry; for most social science questions, there are more pressing sources of error. However, decades of methodological progress have reduced many of these error sources. It is only by standing on the shoulders of giants that the problem of temporal validity becomes more than a third-order concern.
If external validity is imperfectible and all we can aim to achieve is sign-generalization, social science methodology and practice should be radically restructured. The question of how to restructure it is a meta-scientific one, with elements both normative—what, exactly, are we trying to achieve?—and positive—how do we evaluate our achievement?
Although the motivation for the causal empiricist paradigm is pragmatic, I agree with Hofman et al. (2017) that this pragmatism requires more rigor in its application: we need to make many more predictions (about the future) and standardize the process by which these predictions are evaluated. Temporal validity requires taking time seriously, and this includes using the veil of the future as both the strictest and most realistic test of the success of our knowledge production endeavors.
We should not abandon the goal of improving political decision-making by increasing the diversity of settings in which we can predict outcomes. At present, however, too much of our methodological innovation and too great a percentage of researcher energy and graduate curriculum is spent reinforcing the internal validity of individual research projects.
To evaluate where this energy should be re-allocated requires the embrace of meta-science as a major branch of social science methodology. We are not trying to produce perfect academic papers; producing perfect academic papers is impossible. We are trying to produce knowledge. My normative position is that we should be trying to produce knowledge that helps align human action with human intention—that is, knowledge that enhances the likelihood that the actions that people choose to take will result in their desired outcome, a prediction.
From any paradigmatic position, I argue that the fundamentally binary nature of academic publication (published or unpublished; valid or not valid) and in-line citation (one unit of knowledge per citation, accumulating and not decaying) serve to reify the perfectibility of social science.
External validity in theory
“No man ever steps in the same river twice, for it’s not the same river and he’s not the same man.”—Heraclitus
Given that a single study is necessarily restricted in its scope, the premise of the causal empiricist paradigm is to aggregate findings from across many studies such that the union of their scope covers the entirety of the covariate and treatment component spaces. This knowledge aggregation is not trivial, however, and this subject has been the focus of much recent methodological attention (Athey and Imbens, 2016; Dehejia et al., 2021; Egami and Hartman, 2018; Gechter, 2015; Green and Kern, 2012; Hartman et al., 2015; Ho et al., 2007; Imai et al., 2013; Kern et al., 2016; Slough and Tyson, 2022a; Stuart et al., 2011; Taddy et al., 2016; Wager and Athey, 2017).
However, the majority of the developments cited above use agnostic methods. One approach is to use matching and reweighting to find the location where the treatment effect is known that is most similar to the target context in the treatment ∗ covariate space. A complementary approach uses machine learning to discover the covariate values with the largest effect heterogeneity, restricting the space in which matching or reweighting is necessary; this is related to the “Double Machine Learning” approach of Chernozhukov et al. (2017), recently advanced within political science by Ratkovic, 2023.
These statistical innovations reduce the costs of precise generalizability by identifying the portion of the covariate ∗ treatment component space for which we need internally valid estimates of treatment effects in order to transport those effects to the entire space.
The fundamental problem of generalizability to the future is not that the covariate ∗ treatment component space is large, but that it expands over time. Because all of our knowledge is from the past and all the contexts to which we hope to apply that knowledge are in the future, it is always possible that Hotz et al. (2005)’s “no macro-effects assumption”/“support condition” will fail to obtain.
Let t denote the time at which a study is conducted, where t < 0 denotes the past, t = 0 the present, and t > 0 the future. Let X denote the covariate space of the units of analysis. Because time is unidirectional
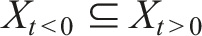
Time is infinitely divisible, and this process is not instantaneous. Let the rate of change (r) of a given phenomenon be the minimum time difference such that the covariate set expands:
4

For a concrete example, consider the case of the Arab Spring. Ignoring the simplistic argument that Twitter was a necessary and sufficient cause of the revolutions in the Middle East in the early 2010s, 5 it is undeniably the case that the spread of information technology changed the nature of the strategic problem facing regimes and protesters (Tufekci, 2017). In the past, government censorship caused a favorable media ecosystem. Once enough people had smartphones and internet access, this causal relationship failed to hold; the effect of government censorship on the success of a revolution became unclear.
In all of the “studies” conducted prior to the mid-2000s, the value of the covariate Smartphone was undefined. 6 After the exogenous spread of smartphones, however, Smartphone takes some non-zero value, violating the support condition. The rate of change r of the effect of government censorship was thus, around the time of the revolution in mobile phone technology, high.
Alternative formalization
An agnostic formulation of the problem might be somewhat different. What are the necessary assumptions of a research design which actually would enable agnostic externally valid inference?
Define time T as a member of the covariate space X. One crucial element of the potential outcomes framework is the exclusion restriction:


Egami and Hartman (2022) define M
i
as the vector of potential context-moderators, allowing them to define the contextual exclusion restriction as
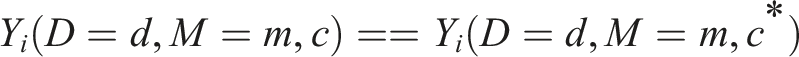
This means that the potential outcomes conditional on treatment and context are the same, provided that the context-moderators are the same across contexts. “This assumption is plausible when the measured context-moderators capture all the reasons why causal effects vary across contexts” (p. 13).
Reformulating this assumption to emphasize the time component:

This requires that we have measured at time t (the present) all of the moderators of potential outcomes at time t + r (the future). In other words: nothing matters in the future that does not matter today.
Returning to the case of the Arab Spring: what would an externally valid estimate of the effect of regime repression on the success of a revolution require, if the study was conducted in 2000 and the target context was the year 2011? It would require that the context-moderator Smartphone2011 have been measured in the year 2000. This is impossible.
The necessity of qualitative knowledge
The use of mathematical notation in the previous section is begging the question at issue. The agnostic approach has nothing to say about the process by which new variables are added to the dataset. The world is always changing, and we must decide how to measure novel phenomena. How does it happen that a social scientist elects to add the Smartphone column to the covariate matrix? The current paradigm pays very little attention to this question, and full attention to violations of the exclusion restriction in a given study. 7
The already-existing columns in that covariate matrix cannot answer this question. The necessary information is instead encoded in the variable names, which themselves represent prior work by a human mind to decide that the numbers in that column refer to a relevant social phenomenon. There is no agnostic statistical process for determining the relevance of future social phenomena based on the “training data” from the past; this is a qualitative task. Intuition and common sense imply that some of our knowledge must be transferable from existing covariates to the novel phenomenon—we might manipulate the covariates that are “most similar” to the novel covariate. This appeal to “similarity” or “relevance” is ultimately unavoidable. The philosopher of science Nancy Cartwright has repeatedly criticized RCTs on the grounds that generalizability ultimately requires some appeal to the target context being “similar enough” to known contexts (Cartwright, 2007a, 2007b; Deaton and Cartwright, 2018). 8
My critique is related: agnostic approaches cannot achieve temporal validity. Because time is unidirectional, the future will contain novel states of the world or novel treatment moderators that a given model cannot account for, regardless of how much data from the past it has access to. This was a common critique among philosophers of science, natural scientists, and qualitative or historical social scientists when the modern “naturalist” social sciences emerged in the postwar United States. 9 The goal of finding some “Unity of the Sciences” was doomed at the start: “[Behavioral scientists] consider that the main task of the immediate future is to extend to the fields of anthropology, of sociology, of economics, the methods of the natural sciences, in the hope of achieving a like measure of success in the social fields. From believing this necessary, they come to believe it possible. In this, I maintain, they show an excessive optimism, and a misunderstanding of the nature of all scientific achievement” (p. 162, Wiener (1948)).
Even the standard practice of social science is imperiled. Replication is generally considered a key component of this practice. But true replication—of all but the most tightly controlled lab or survey experiments—is impossible without some recourse to a non-rigorous “similarity” between contexts. This is a serious problem for “naturalist” paradigms of social science.
Indeed, this problem has become sufficiently self-evident that social scientific reformers in other disciplines have resorted to redefining the word “replication” in order to square the reality of social science with the naturalist tradition. Nosek and Errington (2020) argue that the “common understanding...of replication is intuitive, easy to apply, and incorrect.” Instead, they assert that “Replication is a study for which any outcome would be considered diagnostic evidence about a claim from prior research.” 10
This rhetorical move may lead to better scientific practice by sidestepping sometimes tedious debates about whether one experiment is “similar enough” to another to count as a replication, but it requires giving up on the agnostic approach to external validity entirely. This conception of replication represents a radical re-routing of the social scientific process through the intuitions and judgments of social scientists. Indeed, I argue that this brazen re-definition is evidence of a paradigm in distress (Kuhn, 2012).
External validity in practice
“There can be no demonstrative arguments to prove, that those instances, of which we have had no experience, resemble those, of which we have had experience.”—David Hume, A Treatise of Human Nature
Frequently replicated experiments on a given population are insufficient, even in the presence of large sample sizes and rich individual-level covariate information. Allcott (2015) demonstrates this limitation in a paper on “site selection bias” even with “large samples totaling 508,000 households, 10 replications spread throughout the country, and a useful set of individual-level covariates to adjust for differences between sample and target populations.” However, the “extrapolation bias” of the effect of the same intervention applied at other sites is an order of magnitude larger than the estimated standard error of the treatment effect. Similarly, Vivalt (2020) aggregates the results of impact evaluations of international development programs from 635 published papers. Development economics is “one of the first fields...with enough papers on comparable topics to do this analysis,” and the results are not promising: “results are much more heterogeneous than in other fields.” 11
Tolerably unbiased extrapolation has been shown to be empirically possible. Frequently replicated experiments that span both decades and the globe can be used to aggregate treatment effects and extrapolate them to novel contexts. Using the Angrist and Evans (1996) natural experiment (that the sex distribution of a household’s first two children acts as an as-if random assignment to have additional children), Dehejia et al. (2021) use 142 country-years of census data (with an aggregate sample size of 10 million) from the Integrated Public Use Microdata Series. In this case, knowledge appears to be accumulating: the addition of more country-years of data generally reduces the out-of-sample prediction error, and the use of a rich set of both micro- and country-level covariates reduces the out-of-sample prediction error to close to zero. 12 Bisbee et al. (2017) extends this approach to the case of instrumental variables.
Both of these cases require knowledge of the covariate values in the context being extrapolated to. Temporal validity reminds us that this is impossible, in practice. Rather than using the observed values of the relevant covariates (only possible because the “prediction” in these papers all takes place in the past), covariate-adjusted treatment effect prediction must first predict the value of the covariates. This additional source of variance is a problem, but not an insurmountable one; in the Dehejia et al. (2021) analysis, the most important covariates are macro-level variables like GDP per capita and total fertility rate, things that can be extrapolated at least a few years into the future with tolerable accuracy.
The more serious issue is that this approach cannot account for the creation of novel covariates or novel treatment moderators. Consider the recent COVID pandemic. This “pandemic” moderator does not exist in the dataset—that is, it was not measured as part of any of the natural experiments.
But preliminary evidence suggests that the pandemic shifted the causal system under study. A report from the UN Population Fund finds that, beginning several months after March 2020, developed and middle-income countries experienced a significant decline in birthrates (UNFPA, 2021). Perhaps the effect of this macro-shock on the treatment effect of interest would be captured by the huge change in the covariate for total fertility—in which case the error would be introduced when predicting that covariate, which the veil of the future prevents us from observing directly.
It is possible that the problem is still more serious. Frueh (2022) argues for “a shift in who gave birth” in the United States, that the decline in fertility was disproportionately concentrated among older age groups and those with greater education and resources. This would imply that the relationship between these covariates and the treatment effect is different when pandemic = 1. This novel mechanism is not a source of error that covariate adjustment can fix.
A final problem is that the pandemic affected the literal data generating process—not the social phenomenon of interest, but rather the relationship between that phenomenon and the data produced by Census agencies. The magnitude of the shock of the pandemic on Census practices was high; the downstream implications on our capacity to predict the the numbers they report are unknown, and unknowable within the virtual, statistical world of agnostic external validity.
The authors argue that the external validity natural experiment under study is a “possibility result” (p. 236). Fair enough. But the logic of “site selection bias” suggests that we should not expect external validity results—the ones we observe, because they were conducted in a plausible context—to be externally valid with respect to the target population of relevant external validity results.
Even in this best-case scenario, I argue that r is both positive and unpredictable.
Conclusion
Unfortunately, this manuscript does not propose a solution to the problem of induction. That would be the ideal way out of what I see as a contradiction: 1. External validity requires knowledge of the target 2. The target context for prediction is in the future 3. We cannot have knowledge of the future
In other words: the agnostic impulse of causal empiricism—which I see as a dialectical response to the previous quantitative social science paradigm that produced global but spurious causal claims—remains, even as the methodological frontier moves beyond “local” internal validity. The contradiction emerges because agnostic external validity requires knowledge (gnosis).
Given the imperfectibility of our knowledge, the members of the community of social scientists whose primary goal is to increase the accuracy of our predictions are forced to confront what I see as the fundamental question of meta-science: how should we allocate our scarce social science resources?
Just as with standard social science, this meta-scientific question should be approached with a combination of quantitative and qualitative methods and then synthesized in institutions of knowledge production.
For example, the concept of temporal validity might (when further elaborated) help align social scientific resources and methods with the scope of possibility. I have argued that the amount of bias in future predictions is related to the rate of change r. At any given time, r varies across different subject areas.
As meta-scientific inquiry into temporal validity is not yet mature, my priors about where r is likely to be high or low are extremely diffuse (other than for online behavior, my area of substantive expertise). My goal in this manuscript is to convince other social scientists to begin taking r seriously. We should begin developing qualitative tools to sharpen our intuitions about how r might vary across context and research question and quantitative tools for measuring r and then refining those intuitions.
For many of the subjects that have been studied with RCTs, r has been sufficiently low that its contribution to bias has been small relative to problems of experimental design and practical implementation, as well as the total variance of effect heterogeneity for a given treatment. That is, temporal validity is a less serious source of bias than, say, construct validity, in the context of development experiments.
However, more and more human behavior is taking place online, a context in which r is likely to be high. This makes certain methods a poor allocation of our scarce resources. Consider a hypothetical example. Assume that study XXXX (2014) and YYYY (2022) were both perfectly-executed RCTs in which a random sample of US Facebook users were paid to stop using Facebook for a month. We might then encounter the following sentences in a research article: “XXXX (2014) finds that Facebook desistance causes an increase in partisan affective polarization; however, YYYY (2022) finds the opposite, that Facebook desistance causes a decrease in partisan affective polarization. Future research is needed to adjudicate which of these is correct.”
The example is intended to be absurd: r is far too high this context, so that accumulating knowledge about the effect of “Facebook use” is meaningless. Another perspective on this problem is that “Facebook use” is a poorly-defined construct, that it bundles together too many disparate treatments and mechanisms. This is likely true, absent any efforts at construct validity (Esterling et al., 2021). But citizens and researchers alike think it is a meaningful construct, that it structures their understanding of the world. The related policy questions are certainly salient: “Is Facebook good or bad? Should I use Facebook?”
This is not an argument for nihilism on the question of Facebook, however. Just as there are contexts in which effect-generalizability is implausible, I contend that contexts in which r is sufficiently high are too expensive for rigorous causal knowledge. Given our community’s inelastic endowment of resources, I believe that employing this method will not generate sufficiently durable knowledge to justify the cost. But there are many other scientific questions that social scientists can hope to answer: “What is Facebook? How has it changed over time? Who uses Facebook? How do they use it?”
To be clear: none of this descriptive knowledge solves the fundamental problem of induction; temporal validity remains unapproachable. But I contend that this descriptive knowledge is cheaper, and that is thus a better investment of our scarce resources. If our goal is to help empower citizens and their representatives to make better predictions and thus decisions, I contend that we should re-allocate our resources towards these more cost-effective methods (Munger et al., 2021).
The answers to qualitative or descriptive questions like these can be used to make predictions about causal effects in the future, even in the absence of causal estimates from the past—but only if we embrace the need for humans in the loop. I argue that agnostic temporal validity is a dead end. Instead of attempting to excise human subjectivity, we should take it more seriously. By “human subjectivity” here I mean both our formal priors as researchers and our human biases about, for example, what research questions are most important. More of the energy of social scientists—more of the attention of methodologists, more of our rigor—should be allocated towards studying our own beliefs and in using those beliefs to make predictions about the future.
A necessary first step is to actually make predictions about the future. There has been considerable interest in the methods for rigorous prediction over the past decade, using experts who invest intensively in the task (Tetlock, 2009), moderate-intensity surveys of practitioners, as in the Social Science Prediction Platform (DellaVigna et al., 2019), or more decentralized prediction markets (Hahn and Smith, 2008). The recent COVID prediction project reported in Golden et al. (2023) is especially promising.
These approaches provide some rigor at the end of the chain of knowledge production and application. But the middle of this chain—the normal science we have inherited, with the goal of producing machine-readable knowledge that can be used for agnostic external validity—should be restructured as well. An anonymous reviewer asks “why Bayesian updating fails...why we can’t gradually update our priors based on past knowledge when a new study comes out, which is implicitly what are doing now?”
My personal prior is that this Bayesian updating is performing poorly. As good Bayesians, we need to confront our priors with evidence. However, we have only begun to allocate much rigor to this crucial link in the knowledge production chain; see, for example, the pioneering work by Little and Pepinsky (2021). In other words: how much time do social scientists spend reading studies as they come out? Is this the right amount of time? How much heterogeneity is there in the priors of scholars in a given subfield? How do they update in response to new information?
To conclude: why does our society invest resources and confidence in a rigorous social science premised on method? Part of our justification has to be that we provide something that intuitive, unrigorous methods for learning about the social world cannot. The scope, scale and complexity of the processes which we seek to understand render our evolved Bayesian information processing systems insufficient to the task. Social science is a specialized information processing system that aims to transcend these limitations. The problem is that social scientists remain human. The agnostic impulse aims to limit the role of human subjectivity in social science, but as I have argued, this system runs aground on the problem of temporal validity. The meta-scientific response is thus to apply the methods of social science to ourselves, to conduct rigorous research on the questions posed in the previous paragraph and to be able to provide evidence about how well we are doing as an epistemic community.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.