
Abstract
In this paper, we introduce the causal forests method (Athey et al., 2019) and illustrate how to apply it in social sciences to addressing treatment effect heterogeneity. Compared with existing parametric methods such as the multiplicative interaction model and traditional semi-/non-parametric estimation, causal forests are more flexible for complex data generating processes. Specifically, causal forests allow for nonparametric estimation and inference on heterogeneous treatment effects in the presence of many moderators. To reveal its usefulness, we revisit existing studies in political science and economics. We uncover new information hidden by original estimation strategies while producing findings that are consistent with conventional methods. Through these replication efforts, we provide a step-by-step practice guide for applying causal forests in evaluating treatment effect heterogeneity.
Keywords
Introduction
In this paper, we provide a brief and non-technical introduction to causal forests (CF) as well as its possible applications in social sciences. CF are a data-driven machine learning algorithm to estimate heterogeneous treatment effects (Athey and Wager, 2019). The most important feature of causal forests is that they are extremely flexible: CF are fully nonparametric and can deal with many moderating variables. Specifically, CF generate heterogeneous treatment effect estimates without imposing a functional form relationship among model primitives. 1 Moreover, for each treatment effect estimate, CF provide an asymptotically valid confidence interval on which we can draw inference.
We illustrate how CF can be applied to social science research by replicating the results of publications in political science and economics using CF. In particular, social scientists are interested in (1) whether there exists treatment effect heterogeneity, and if so, the main drivers (moderators) of such heterogeneity; (2) how the heterogeneous treatment effects vary along with moderators. In both examples we cover in the main text, CF successfully identify moderating variable(s) that are hidden by using alternative estimation strategies. In other words, CF are particularly powerful in the exploration of potential moderating variables. We also document the possibly nonlinear moderating effects with confidence intervals, adding new insights to this research. Through these replication efforts, we provide a step-by-step practice guide for applying CF in evaluating treatment effect heterogeneity. More replication results are provided in the appendix.
Heterogeneous treatment effect estimation using causal forests
Same as other treatment effect estimators, CF are used to quantify the difference between the potential outcomes at different status of treatment (Neyman, 1923; Rubin, 1974).
2
Formally, CF estimate the Conditional Average Treatment Effect (CATE) defined as

Here, we provide a non-technical introduction to CF. For the technical details, please refer to the appendix. At a high level, CF share the same insights with some classical nonparametric methods such as kernel and k-nearest neighbors estimation. Given a point X = x, classical methods seek the observations close to x to estimate τ(x). For example, k-nearest neighbors take the k closest observations to x using Euclidean distance, and kernel methods weight the observations using kernel functions. In contrast, CF determine the closeness with respect to decision trees and forests. Specifically, for an evaluation point x, the weight given to each observation measures the frequency of that observation falling into the same “leaf” with point x in the forest; an observation staying in the same leaf with x in more trees is a more similar individual to x, and therefore receives higher weights. Athey et al. (2019) establish the consistency and root-n asymptotic normality for the CF estimator
Parametric models (e.g., Brambor et al. (2006)) are a common practice in treatment effect estimation, which are easy to implement and interpret but may risk encountering model misspecification. Traditional semi-/non-parametric methods (e.g., Hainmueller et al. (2019)) alleviate the restrictions in functional form, but the slow convergence rate hinders their usage in the presence of many moderators (Li and Racine, 2007). Recent years have witnessed the rapid growth of applying machine learning algorithms to estimating heterogeneous treatment effects, whereas few of them possess a valid inference theory. In contrast, CF demand no restrictions on the functional form of the regression, and its convergence rate does not decay as the dimension of X grows. Therefore, CF nonparametrically estimate the heterogeneous treatment effects and admit inference which is practically feasible with many moderators. There is also a large literature about estimating average treatment effects (e.g., Imai and Ratkovic (2014)), which portrays the treatment effects from an integrated level, while CF provide the information of heterogeneity from a micro level.
CF have attracted growing attention from social scientists. In economics, Davis and Heller (2017a, 2017b) apply CF to estimate the effects of summer youth employment programs. In marketing, Guo et al. (2021) use CF to explore the effect of information disclosure on physician payments. We will show that CF can be applied to causal inference in political science as well. 4
Exploring treatment effect heterogeneity using CF
To illustrate possible applications of CF in social sciences, we replicate the results of two publications in leading political science and economics journals using CF. We choose these two cases as they help illustrate how CF can be applied to addressing discrete and continuous moderators, respectively. Our replication results show that while the conventional methods fail to fully uncover treatment effect heterogeneity, CF are better suited for testing the existence of heterogeneity, exploring potential moderators, and capturing complex interactions between treatment and moderator(s). Hence, CF can offer interesting theoretical insights hidden by traditional estimation strategies in a data-driven manner. Moreover, the results generated by CF are reasonable compared with conventional methods. Hence, CF is more of an improvement than a rejection of them. 5
Replication case I: Oreopoulos (2011)
To illustrate the usefulness of CF, we replicate the experiment by Oreopoulos (2011) using CF. In this application, the covariates are all discrete. We will provide an example of continuous moderators below in replication case II.
In his experiment, Oreopoulos (2011) investigates why immigrants struggle in the labor market. The author randomly generates 13 thousand resumes sent to Canadian firms for job applications. To study the effect of being an immigrant, he varies the name listed in the resumes. The author also randomizes the applicants’ nine other characteristics, such as gender and education. The outcome variable is a binary measure, which takes the value of 1 if the applicant receives a callback from the Canadian firm and 0 otherwise. The original OLS results suggest that applicants with an English sounding name are more likely to receive a callback than those with a foreign sounding name (See Table 5, Panal A, in Oreopoulos (2011)), indicating that substantial discrimination against immigrants exists. To simplify analysis, we create a binary treatment variable from the Oreopoulos (2011) data, English sounding name, which is coded as 1 if the applicant has an English sounding name and 0 if she or he has a foreign sounding name.
Step 1: Estimating individual and average treatment effects
We then proceed to replicate the results using CF. First of all, CF estimate the CATE, that is, the treatment effect of having an English sounding name, for each individual. The distribution of the treatment effects is presented in Figure 1. The red vertical line in Figure 1 denotes the Average Treatment Effect (ATE) estimated using the Augmented Inverse Propensity Weighting (AIPW) estimator. This AIPW estimate is calculated from the estimated CATEs (Robins et al. 1994, 1995).
6
Moreover, CF provides standard errors for each estimated treatment effect. In this sample, among the n = 10, 184 estimated CATEs, 3222 are significant at 95% level. All but three are positive. Histogram of individual treatment effects.
Step 2: Assessing treatment effect heterogeneity
Best linear prediction test.

***p < 0.001; **p < 0.01; *p < 0.05.
Step 3: Finding important moderators
After demonstrating the existence of treatment effect heterogeneity, it is natural to ask: what are the drivers of such heterogeneity? In this subsection, we look for potential moderators of treatment effects in a data-driven manner.
Variable importance.

Step 4: Evaluating treatment effect heterogeneity in important moderators
In the previous subsection, we find that the applicant’s gender and quality of undergraduate education are potentially two important moderators for the effect of English sounding names. If the treatment effect is truly moderated by these two covariates, using linear regressions without interaction terms will suffer from omitted variable bias and model misspecification. Subsequently, we would like to quantify whether and how the treatment effect varies along these covariates.
ATE and CATE for woman and man.

***p < 0.001; **p < 0.01; *p < 0.05.
ATE and CATE for BA degree quality.
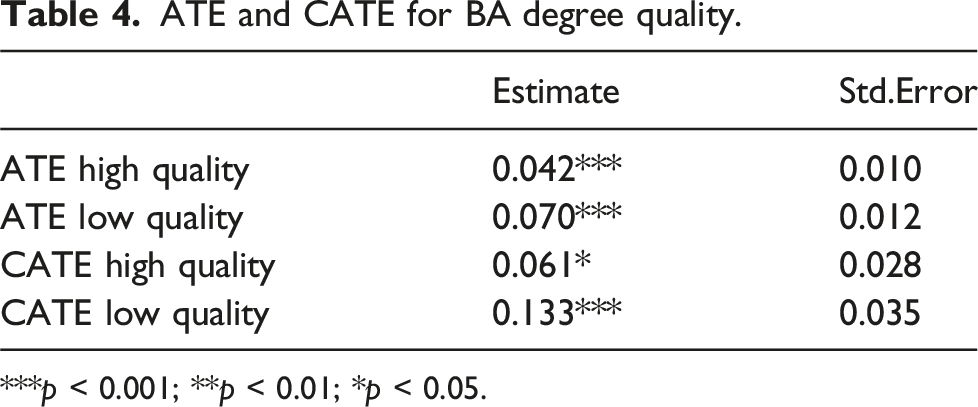
***p < 0.001; **p < 0.01; *p < 0.05.
We find that woman applicants tend to receive a larger treatment effects compared to males. According to the ATE estimates, on average there is a 4-percentage-point difference in the effect of English sounding name between a man and a woman. Moreover, having an English sounding name tends to impose larger treatment effects for applicants without a bachelor’s degree from a top 200 university. Based on the difference in the ATE estimates, the effect of having an English sounding name for job applicants with lower BA degree quality is 2.8 percentage points higher than those with a better BA degree. Such moderating effects of gender and education are not revealed in Oreopoulos (2011).
Comparing OLS estimation results with and without interaction terms.
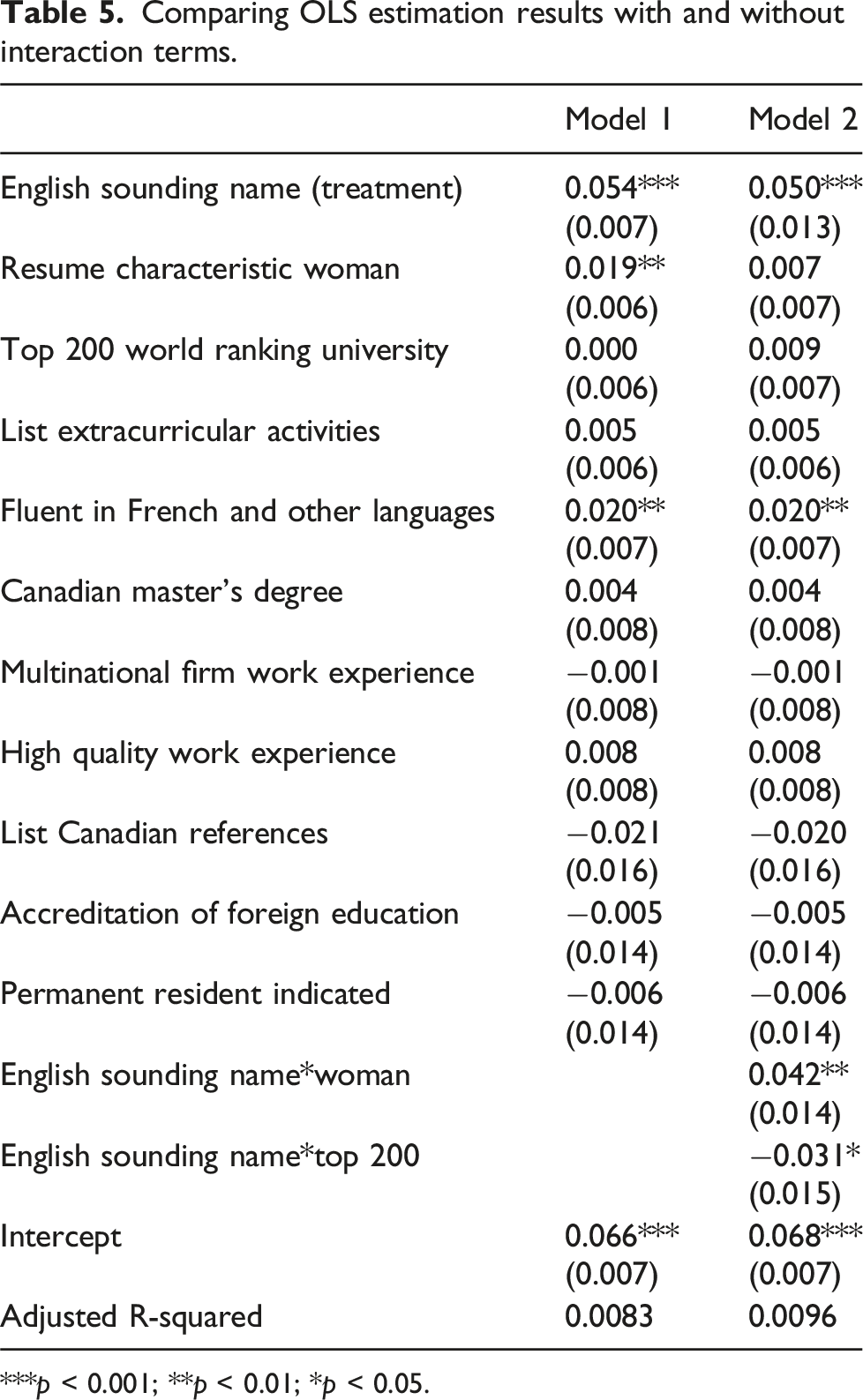
***p < 0.001; **p < 0.01; *p < 0.05.
In this exercise, we use CF to replicate the work by Oreopoulos (2011) who estimates a constant treatment effect using linear regression models. Oreopoulos (2011) claims that an English sounding name positively contributes to the likelihood of receiving a callback, while our CF results provide a more nuanced understanding on discrimination against immigrants. Through this replication effort, we provide a four-step guideline on how to use CF to identify important moderators hidden from using linear regression models. These procedures can be applied when researchers are exploring the possibility of treatment effect heterogeneity in a data-driven manner.
Replication case II: Huddy, Mason, and Aarøe (2015)
CF are useful as well when the potential moderators are continuous, when there could be multiple moderators, and when these moderators may interact with each other in determining treatment effects. Indeed, a major advantage of CF over traditional semi-/non-parametric approaches is that they can effectively handle more than one moderating variables. To illustrate these points, we replicate the study of Huddy et al. (2015) and compare our CF analysis with linear interactive models used in Huddy et al. (2015). 11
In Huddy, Mason and Aarøe (2015), the authors examine whether party identity in America is instrumental or expressive in nature using experiments. In their study, the treatment variable is threat of electoral loss, which takes the value of 1 if the subjects read a fictitious blog entry claiming that their party would lose in the upcoming election. Huddy et al. (2015) examine how this treatment variable affects the level of anger, a form of action-oriented political emotions. Specifically, they evaluate the degree to which political anger is driven instrumentally by threats to ideology and issue positions (thus is felt most intensely by the strongest ideologues) and the degree to which anger is expressive in nature (thus the threat of electoral loss is experienced most intensely by those with the strongest partisan identity). Operationally, they create two continuous moderators, partisan identity and ideological issue intensity, to measure the expressive and instrumental facets of partisanship, respectively, and interact them with the treatment variable of electoral loss.
Huddy et al. (2015) estimate linear interactive modes and find that the interaction term between electoral threat and partisan identity is positive and statistically significant at 99% level, while the interaction term between the threat variable and ideological issue intensity is statistically indistinguishable from 0 at any conventional levels (see Column 2, Table 5 in Huddy et al. (2015)). Their results find support for the expressive model: threatened with electoral loss, strongly identified partisans feel angrier than weaker partisans, while subjects who hold a strong and ideologically consistent position on issues are not more aroused emotionally than others by electoral threats.
To apply CF, we repeat the four steps in the aforementioned guideline and the full analysis is presented in the appendix. Here we expand the discussion on the last step to display the ability of CF to trace the nonlinear moderating effect with a continuous moderator, and the complex interactions among moderators.
Step 4′: Evaluating moderating effect along a single and multiple variables
We first use CF to explore the variation of treatment effect along a single continuous moderator. Figure 2 shows the estimated treatment effect as a function of partisan identity with confidence interval at 95% level, holding all other covariates at their median level.
12
Note that this corresponds to the marginal effect figure in the multiplicative interaction model, though we give a nonlinear trend of marginal effect of treatment with respect to the moderator. We see that the effect of electoral threat on anger is indeed moderated by the partisan identity, and strongly identified partisans feel angrier than weaker partisans when threatened with electoral loss. This finding is consistent with the results of multiplicative interaction models used in Huddy et al. (2015). Treatment effect along partisan identity.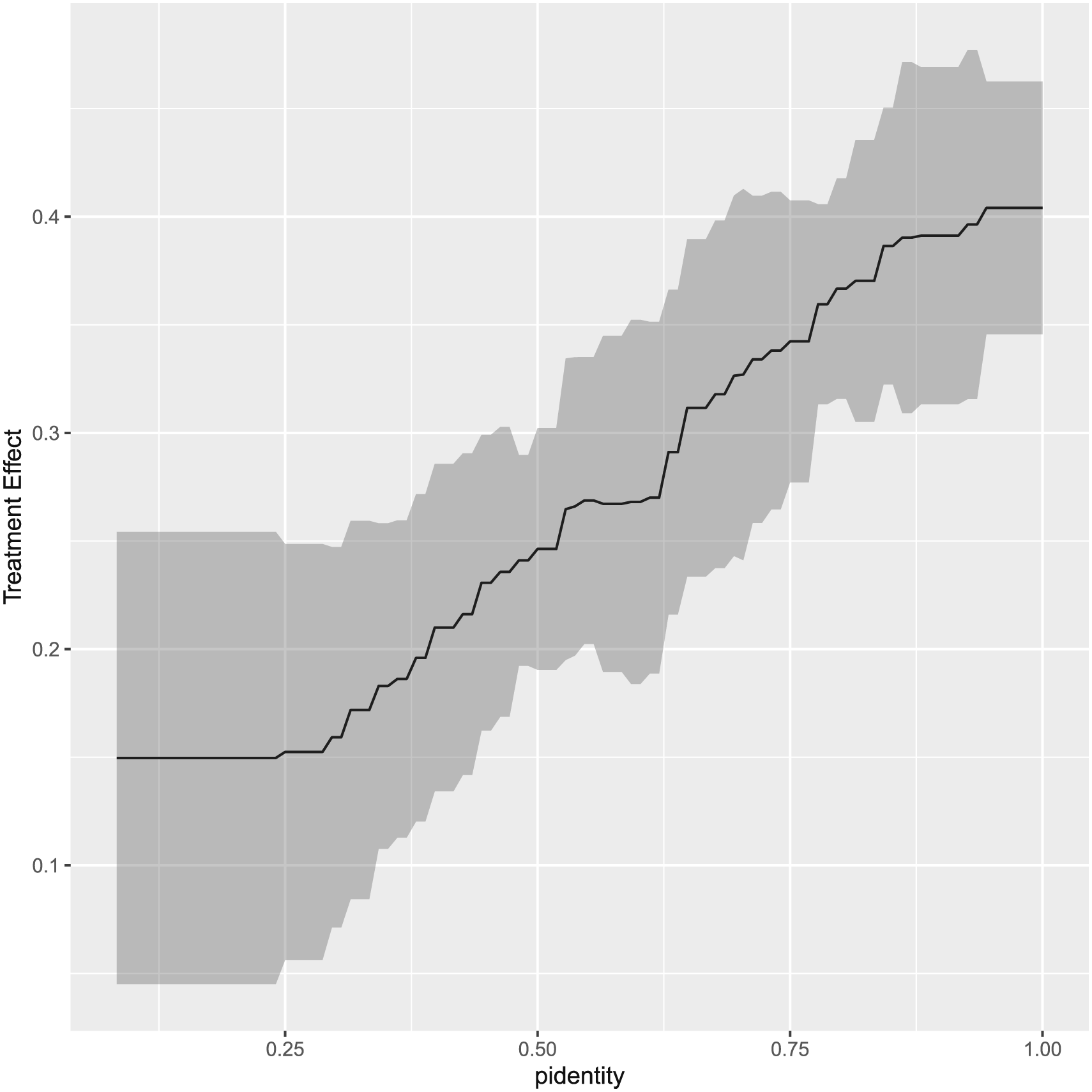
When a practitioner is interested in exploring whether treatment effects are moderated by many moderators (and their possible interactions), CF offers a practically effective approach for analysis. One intuitive way to evaluate moderating effect along multiple variables is to consider the CATE function for all the two-way combinations of moderators, and plot them using heat-maps (see Figure 3). Treatment effect with two moderating variables.
The upper three heat-maps show that the CATE is increasing in the strength of partisan identity while the other covariates—education, age, and political knowledge—do not alter this trend substantially. They largely confirm the estimation results based on multiplicative interaction models used in Huddy et al. (2015). However, when we include the interaction of ideological issue intensity and another covariates as moderators, CF reveal interesting patterns hidden by using interaction models. First, less educated people are more angry about the threat of electoral loss, regardless of their ideological issue intensity. Second, people above 50 with low ideological issue intensity seem to be most impacted by the threat treatment. Third, the CATE is decreasing in ideological issue intensity but increasing in the level of political knowledge, which is measured by the percentage of questions about American politics that are correctly answered by the subject. Thus, the effects of electoral threat are stronger among subjects who are less concerned about ideological issues and are more knowledgeable about American politics. In other words, people who know a lot about politics but care little about substantive social and economic issues tend to respond more emotionally if their party loses. This is an intuitive but interesting finding hidden from using conventional methods. In sum, compared to other estimation strategies, CF can better capture treatment heterogeneity caused by complex interactions among the treatment variable and multiple moderators.
Conclusion
In this paper, we use a machine learning method, the causal forests, to estimate and evaluate treatment effect heterogeneity. Using the CF algorithm, we can obtain heterogeneous treatment effect estimates and their confidence intervals that allow for statistical inference. Compared to existing methods that are designed to estimate heterogeneous treatment effects and evaluate conditional theories, CF is more flexible in the sense that it requires no assumption on model specification and can handle multiple moderators. Therefore, we believe that CF is particularly useful for researchers to identify important moderators and to explore possible complex interactions among them in a data-driven manner.
To provide some guidance for practitioners who intend to conduct analyses using CF, we summarize our procedure of evaluating heterogeneous treatment effects with CF estimates: (1) obtain the CATEs with their confidence intervals and plot their distribution; (2) test for heterogeneity formally; (3) if the null of no heterogeneity is rejected, proceed to find the source of heterogeneity, that is, the important moderators for the treatment effects; (4) evaluate the heterogeneous treatment effects on these moderators. Using CF, one could draw policy evaluation based on which subset of subjects will receive high or low treatment effects and design an optimal treatment policy accordingly.
Supplemental Material
Supplemental Material - Estimating and evaluating treatment effect heterogeneity: A causal forests approach
Supplemental Material for Estimating and evaluating treatment effect heterogeneity: A causal forests approach by Li Zheng and Weiwen Yin in Research & Politics
Footnotes
Acknowledgments
We are grateful to Xun Pang, Ye Wang, Han Zhang, Youlang Zhang, the two anonymous reviewers, and participants at the Asian Polmeth VIII & ASQPS IX for their helpful comments and discussions. We also want to thank the Research & Politics editors for their support. The two authors contributed equally to this work.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Correction (June 2025):
Supplemental Material
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.