
Abstract
Prior research finds that statistically significant results are overrepresented in scientific publications. If significant results are consistently favored in the review process, published results could systematically overstate the magnitude of their findings even under ideal conditions. In this paper, we measure the impact of this publication bias on political science using a new data set of published quantitative results. Although any measurement of publication bias depends on the prior distribution of empirical relationships, we determine that published estimates in political science are on average substantially larger than their true value under a variety of reasonable choices for this prior. We also find that many published estimates have a false positive probability substantially greater than the conventional α = 0.05 threshold for statistical significance if the prior probability of a null relationship exceeds 50%. Finally, although the proportion of published false positives would be reduced if significance tests used a smaller α, this change would not solve the problem of upward bias in the magnitude of published results.
Introduction
Many academic papers (and especially the first few articles on a topic) describe relationships that turn out to be illusory upon closer examination (Ioannidis, 2005). Additionally, the typical published estimate is probably of larger magnitude than the true relationship (Ioannidis, 2008). Recent large-scale attempts to replicate social scientific findings have discovered that many of these findings become substantially smaller and more uncertain than initially indicated (Boekel et al., 2015; Camerer et al., 2016; Hartshorne and Schachner, 2012; Ioannidis et al., 2014; Klein et al., 2014; Maniadis et al., 2014; Open Science Collaboration, 2015); the “replication crisis” has plagued fields in the hard sciences as well (e.g. Begley and Ellis, 2012; Prinz et al., 2011; Steward et al., 2012). Replicability problems are exacerbated by researcher behaviors like p-hacking (analyzing the same data in multiple ways but only reporting the most statistically significant findings). 1 But even if behaviors like this were eliminated, the problems would continue to exist because the publication process privileges statistically significant results (Brodeur et al., 2016; Coursol and Wagner, 1986; Gerber et al., 2001; Gerber and Malhotra, 2008a,b; Sterling et al., 1995), including by influencing authors’ decision to write up and publicize their findings (Franco et al., 2014). When null findings are not published, they cannot place anomalously large and statistically significant results into their proper context; such anomalous results can attract a great deal of scientific interest because of their novelty and counterintuitiveness. 2 These problems are often collectively referred to as publication bias (Scargle, 2000). Although the publication bias created by “misunderstanding or misuse of statistical inference is only one cause of the ‘reproducibility crisis’ … to our community, it is an important one” (Wasserstein and Lazar, 2016: 2). 3
While much of the previous work in this area focuses on establishing that publication bias is real and pervasive in disciplines that use statistical evidence (e.g. by using “caliper tests” of published p-values, as in Gerber and Malhotra (2008a) and Brodeur et al. (2016)), our paper seeks to determine how publication bias has affected the accumulated body of knowledge in political science. We measure the impact of publication bias on political science using a new data set of published quantitative results. Although any measurement of publication bias depends on the prior distribution of empirical relationships, we estimate that published results in political science are distorted to a substantively meaningful degree under a variety of reasonable choices for this prior.
We come to three conclusions. First, published estimates of relationships in political science are on average substantially larger than their true value. The exact degree of upward bias depends on the choice of prior, but at the high end we estimate that the true value of published relationships is on average 40% smaller than their published value. More optimistic priors yield a lower average bias, but still find that at least 14% of results are biased upward by 10% or more. Second, we find that many published results have a false positive probability substantially greater than the conventional α = 0.05 threshold for statistical significance if the prior probability of a null relationship exceeds 50%. These two findings are quantitatively and qualitatively similar to results uncovered by the large scale replication studies noted above, suggesting that publication bias can explain much of the “replication crisis” these studies have observed. 4 Finally, we find that both the upward bias in magnitude and the probability of being a false positive is smaller for results with p-values further from the threshold for significance. Our last finding suggests that requiring a more stringent statistical significance test (with a smaller α) for publication might be effective at combating publication bias (Johnson, 2013). Unfortunately, although the proportion of published false positives would be reduced by this strategy (Bayarri et al., 2016; Goodman, 2001), we find that such a reform would not solve the problem of upward bias in published results: published results near the new threshold of significance would still be (on average) substantially biased upward.
Measurement strategy
Trying to measure the degree of upward bias in an estimate

where
However, in a published work, β is unknown. We must therefore calculate

under some reasonable assumptions about our prior beliefs about β,
We estimate the degree of expected publication bias in the political science literature as a proportion of the published result,
a spike-and-slab distribution with a spike at
a spike-and-normal distribution with a spike at
The first distribution represents a 33% probability prior belief that a non-zero
We use our prior belief density
Data set
We estimate the effect of publication bias on the literature in political science using a new data set of quantitative work recently published in prominent, general interest journals. Our data set is composed of 314 quantitative articles published in the American Political Science Review (APSR: 139 articles in volumes 102–107, from 2008–2013) and the American Journal of Political Science (AJPS: 175 articles in volumes 54–57, from 2010–2013). 9 To simplify the analysis, we analyze only articles with continuous and unbounded dependent variables. Among the 173 articles with continuous and unbounded dependent variables, 10 6 articles have at least one missing value regarding their estimates or sample sizes, which are necessary for our analysis. Therefore, we remove these 6 articles from our analysis. Consequently, we are left with 167 quantitative articles published in the APSR (70 articles) and the AJPS (97 articles). Finally, 25 studies out of these 167 quantitative articles (or 15% of that number) report statistically insignificant results as their main relationship under a two-tailed test with α = 0.05, although 17 of the 25 studies are statistically significant if using a one-tailed test with α = 0.05. 11 We omit these studies from our analysis as their interpretation is unclear in the context of assessing publication bias when using an α = 0.05 two-tailed significance test, leaving 142 studies for analysis. The consequence of omitting statistically insignificant results is that our estimates are upper bounds on the degree of publication bias in the literature: the more likely it is that statistically insignificant results will be published, the smaller that publication bias will be.
A complete list of the rules we used to identify and code observations in our data set is provided in Appendix 2; we summarize the procedure here.
12
Each observation of the collected data set represents one article and contains the article’s main finding (viz., an estimated marginal effect,
Results
The result of applying this technique to the published (and statistically significant) marginal effects estimates in our data set reveals a substantial tendency toward upward bias in magnitude, as illustrated in Table 1. As the table shows, if we have a baseline expectation that only 10% of our hypotheses correctly predict a relationship a priori, then over 50% of published findings are expected to be at least 10% larger in magnitude than the true relationship. The typical published result in this scenario is on average at least 29% larger than the true relationship. Even if there are no relationships that are exactly zero under a normal prior density (with standard deviation equal to
Expected bias in a sample of published marginal effects from APSR and AJPS.

The table shows the estimated prevalence of upward bias in estimate magnitude in a sample of 167 articles from the American Political Science Review and the American Journal of Political Science; the sample size is 142 after 25 statistically insignificant results are excluded. We generate 100,000 draws
The implication of the analysis is that a substantial portion of published results overestimate the true size of the relationship being studied because statistical significance tests are used to screen results for publication. Biases that are large enough to be substantively meaningful are not uncommon; if our assumptions about
Not all publications are equally susceptible to bias, as seen in Figure 1. The figure shows that individual results vary greatly in terms of expected publication bias, regardless of the prior probability of a null effect
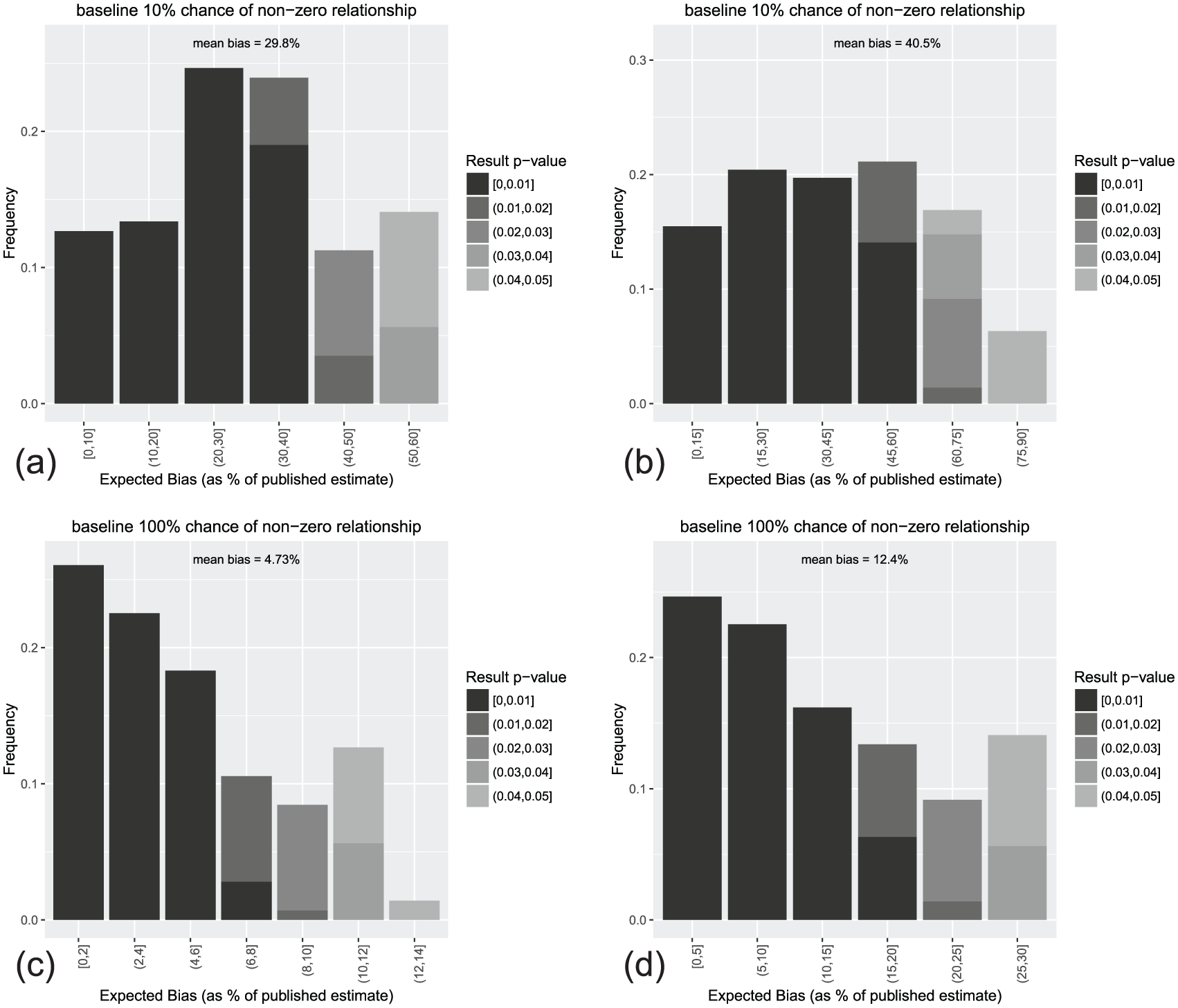
Histogram of expected bias calculations from APSR and AJPS. (a) Spike-and-slab prior,
Calculating susceptibility to false positives
Statistical significance testing is designed to lower the risk of concluding that a relationship exists when the evidence could be consistent with no relationship at all. However, it is well established (though perhaps not widely understood) that statistical significance testing is often insufficient to reduce the chance of a false positive to an acceptable level when the prior probability of studying a null relationship is very high (Bayarri et al., 2016; Goodman, 2001; Nuzzo, 2014; Siegfried, 2010). A key factor is the prior probability that the null hypothesis is true (i.e., the a priori expectation that the relationship being studied does not actually exist). That is:

We can use this formula to calculate this probability for the observations in our data set; this is similar to a calculation that Goodman (2001) and Bayarri et al. (2016) performed using Bayes’ factors and to a closely related formula offered by Maniadis et al. (2014). To establish a lower bound for
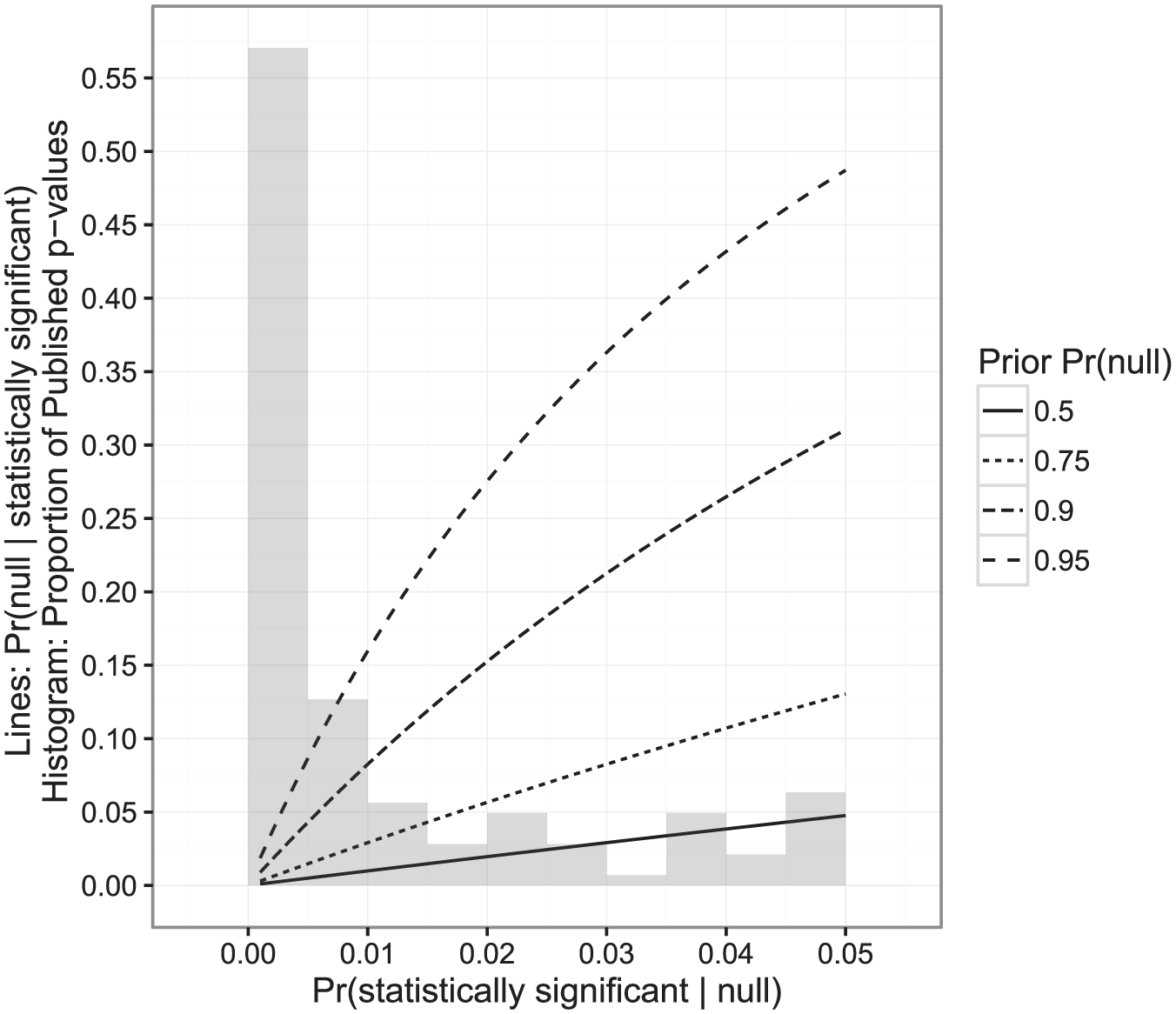
Expected lower bound false positive probability calculations. The figure shows the relationship between the probability that the null hypothesis is true given a statistically significant result
As the figure shows, not all published work has an equal expected probability of being a false positive. Results that are close to the boundary of statistical significance (with
Figure 2 indicates that our concern about the likelihood of a false positive should be geometrically related to our prior belief about
Conclusions and implications
The problem of publication bias has been studied for years and permeates all scientific disciplines that use statistical evidence (Rosenthal, 1979; Sterling et al., 1995). Interest in the problem has been reignited by effort to replicate results in multiple disciplines that have met with a surprisingly high rate of failure (Boekel et al., 2015; Camerer et al., 2016; Hartshorne and Schachner, 2012; Ioannidis et al., 2014; Klein et al., 2014; Maniadis et al., 2014; Open Science Collaboration, 2015). Prior work has established that statistically significant results are favored in political science (e.g. Gerber and Malhotra, 2008a), but to what extent does it distort substantive knowledge in the discipline? Are our findings contaminated by results that are biased upward in magnitude? Are false positive findings published too often in that literature? The answers depend on the unknown prior distribution of true relationships. But we find evidence for both problems in the published political science literature, and the problems are large enough to be qualitatively meaningful under a wide variety of different prior distributions. If these problems exist, they occur because statistically significant results are favored in the publication process: smaller values in an estimate’s sampling distribution are disproportionately ignored and null relationships are still likely to be published (Brodeur et al., 2016; Coursol and Wagner, 1986; Gerber et al., 2001; Gerber and Malhotra, 2008a,b; Sterling et al., 1995). We believe that our paper complements the findings of large-scale replication projects by placing them into a clearer theoretical context: under reasonable assumptions for the prior distribution of effects
Based on our evidence, results with smaller p-values are less affected by publication bias because they are further from the α = 0.05 threshold. These results are also at lesser risk of being a false positive (Bayarri et al., 2016; Goodman, 2001). However, using a decreased threshold for statistical significance (i.e. only publishing results that can pass a significance test with α lower than 0.05), as suggested by Johnson (2013), simply recreates the problem for results near the new threshold. Consider the simulations of Table 1 for the spike-and-slab prior when
The empirical “credibility revolution” in economics and political science has rightfully made us ask harder questions of the quality of our research designs on a paper-to-paper basis (Angrist and Pischke, 2010). But as long as statistically significant results are privileged in the publication process, even researchers who do everything right from a causal identification perspective could still produce a literature with results that are (on average) biased upward and overpopulated with false positives. Just as the credibility revolution has made us more skeptical of some research designs, we believe that our findings (and the larger universe of findings concerning replicability) demand increased skepticism of novel results. This is particularly true if the result is only marginally statistically significant, because marginally significant results are at increased risk of being false positives. Consequently, it may be prudent to place less importance on the novelty and originality of a scholar’s output in evaluating his or her contribution to the discipline— recognizing, of course, that these are still important and valuable qualities!— and more importance on work that checks the robustness of existing findings, including replication studies. We should also be careful about allowing the initial discovery of a new phenomenon to shape our research agenda before the phenomenon is thoroughly replicated. In the event that the discovery is a false positive, researchers seeking to apply the findings to other areas will necessarily be building their work on a null finding, thereby raising the overall prior probability of null hypotheses (viz.
Footnotes
Acknowledgements
We thank Ashley Leeds, Will H. Moore, Cliff Morgan, Ric Stoll, our anonymous reviewers, and participants in our sessions at the 2013 Annual Meeting of the American Political Science Association and the 2013 Annual Meeting of the Society for Political Methodology for their helpful comments and suggestions.
Correction (June 2025):
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.
Supplementary material
The replication files are available at: https://dataverse.harvard.edu/dataverse/researchandpolitics. The supplementary files are available at: ![]()
Notes
Carnegie Corporation of New York Grant
The open access article processing charge (APC) for this article was waived due to a grant awarded to Research & Politics from Carnegie Corporation of New York under its “Bridging the Gap” initiative. The statements made and views expressed are solely the responsibility of the authors.