
Abstract
This paper addresses how measurements of cognitive skill differ based on survey mode, from a face-to-face interview to a self-completed survey, using the Wordsum vocabulary test found in the General Social Survey. The Wordsum acts as a proxy for general cognitive skill, and it has been used to predict a variety of political variables. Therefore, knowing differences in cognitive skill by mode are important for political science research because of the proliferation of self-completed Internet surveys. I leverage a large-scale mode experiment that randomizes a general population sample into a face-to-face or self-completed interview. Results show that historically easy questions are more likely to yield correct answers in the face-to-face treatment, but modest-to-difficult test questions have a higher rate of correct answers in the self-completed treatment (marginal distributions). A cognitive skill scale using item response theory, however, does not differ by mode because the ordering of ideal points does not change from a face-to-face interview to a self-completed survey. When applying the scale to a well-established model of party identification, I show no difference by mode, suggesting that a transition from face-to-face interviews to self-completed surveys may not alter conclusion drawn from models that use the Wordsum test.
Introduction
The importance of mode research for political science
Since the 1940s, most of the data used in political science research on elections, public opinion, and voting behavior was gathered by the American National Election Study (ANES) or General Social Survey (GSS) through in-person, face-to-face surveys. In-person interviewing, however, is costly, and becoming more so over time. In 2012, the cost per interview was approximated at US$2,100.00 (inclusive of both interviews but exclusive of staffing costs) to produce the ANES (Segura et al., 2010). An attractive alternative to face-to-face interviewing is online, self-completed surveys because of the proliferation of Internet usage, the increase in computer literacy, and the lower cost per interview. While self-completed surveys are becoming more popular in political science, much of the survey methodology literature does not directly address the mode differences between face-to-face interviewing and self-completed surveys. Regardless of whether a researcher prefers face-to-face or self-completed surveys, federal budgeting realities might force political scientists to pursue more online, self-completed surveys.
In this paper, I address how measures of cognitive skill differ by survey mode. To isolate the effects of mode, I use data from a large-scale experiment in which we randomly assigned respondents into a face-to-face or self-completed survey with identical questions (n=505 per mode). 1 The survey treatment assignments occurred after respondents agreed to participate in the experiment, which eliminates any of the confounders related to sampling and selection bias associated with the mode of survey administration. Results show a difference by mode for the marginal distribution of individual knowledge questions, where more respondents are answering moderate to difficult questions correctly in the self-completed mode. But once the knowledge test as a whole is scaled together using a two-parameter item response theory (IRT) model, little difference in cognitive skill exists by mode because the cognitive skill ideal points are order preserving regardless of mode. I then use the cognitive skill ideal points in a model of party identification to show that conclusions from the Wordsum test do not differ in a face-to-face interview relative to a self-completed survey. These results demonstrate that the presence of an interviewer can affect the marginal distribution of knowledge questions; respondents will be less likely to answer difficult questions correctly with an interviewer. But when the cognitive skill test is aggregated together, which is how most political scientists use knowledge tests, no difference by mode exists. Therefore, my results present an initial piece of evidence that a transition from a face-to-face interview to a self-completed survey might not alter conclusions from knowledge models even if the marginal distributions of each knowledge question will be different.
Measuring cognitive skill
I measure cognitive skill through the Gallup–Thorndike Verbal Intelligence Test (Thorndike, 1942; commonly called a “Wordsum” test, which became a part of the GSS in 1972 (Davies et al., 2007). Wordsum questions present respondents with a single vocabulary word and five answer choices: the answer choices are individual words as well. Respondents are then asked to select the answer choice that comes closest to the meaning of the prompted word. 2 As opposed to longer intelligence tests, the GSS Wordsum test is brief, only ten questions: six “easy” words (characterized by a high level of correct responses in the GSS) and four “hard” words (low level of correct responses). A wide range of fields such as political science, statistics, education and psychology use the Wordsum test to measure various dimensions of intelligence; for a comprehensive and thorough review of the Wordsum test in the social sciences, see Malhotra et al., 2007) found at the National Opinion Research Center and Cor et al., 2012).
Early research using the Wordsum test as a general measure of cognitive skill shows that the test is highly correlated (from 0.75 and above) with a more extensive, in-depth intelligence test (Miner, 1957). This connection between general intelligence and vocabulary is replicated in more recent studies as well (Alwin, 2010; Zhu and Weiss, 2005), demonstrating that a short vocabulary test can be an effective proxy for general intelligence and cognitive skill. In political science, the Wordsum test is used as a measure of cognitive skill to predict voter turnout, political knowledge, preferences on economic issues, and general ideology (Caplan and Miller, 2010; Erikson et al., 2002; Rempel, 1997; Verba et al., 1985).
I selected four of the ten Wordsum items that were used in this randomized experiment: the four words are Broaden, Space, Cloistered and Allusion (asked in that order). The first two words are historically considered easy and the latter two are consider difficult because a majority of respondents answer the first two correctly and a majority answer the second two incorrectly (Cor et al.,2012; Malhotra et al., 2007). The four items used in this study were randomly selected within each level of difficulty so that I tested two easy and two hard questions. How closely related is my abbreviated four-item scale with the full ten-item scale? To make this comparison, I first ran an IRT model on all 10 items from the 2010 GSS, and then I ran the same IRT model using only the four items taken from the 2010 GSS. The Pearson correlation on the two scales is 0.79. Although the scales are not perfectly correlated, the abbreviated scale correlates very strongly with the full scale.
Knowledge differences by survey mode
Does survey mode change a respondent’s answer to a question? There are many reasons to expect response differences due to survey mode, whether it face-to-face, over the phone, or self-completed (Acree et al., 1999; Bishop et al., 1988; Chang and Krosnick, 2010; De Leeuw, 2002; Fowler et al., 1998; Gano-Phillips and Fincham, 1992; Kiesler and Sproull, 1986; Malhotra, 2009; Shulman and Boster, 2014; Sudman and Bradburn, 1974). In one other true mode investigation in which respondents (college sophomores) were assigned to a mode of interview, Chang and Krosnick (2010) found that lower cognitive skill respondents who completed the survey on a computer exhibit higher concurrent validity: “Oral presentation might pose the greatest challenges for respondents with limited cognitive skills, because of the added burden imposed by having to hold a question and response choices in working memory while searching long-term memory and generating a judgment” (Chang and Krosnick, 2010: 155). But in the Chang and Krosnick (2010) experiment, the researchers were not interested in how measurements of cognitive skill differ by mode, which is the focus of this study. Instead, they used SAT scores as a proxy for cognitive skill to show how intelligence can interact with survey mode (Chang and Krosnick, 2010). 3
With knowledge tests in the self-completed treatment, I expect a lower rate of correct answers among the easy questions due to satisficing in the self-completed treatment (Krosnick, 1991; Malhotra, 2009). Satisficing occurs when individuals are presented with a task, and instead of maximizing their ability to complete the task, individuals will only exert a minimum amount of effort (Krosnick, 1991; Simon, 1957). Satisficing leads individuals to be “less than thorough” when interpreting survey questions (Krosnick, 1991; Krosnick et al., 1996). Recent work shows that individuals can be less engaged with easy tasks in self-completed surveys, leading to a higher level of satisficing (Malhotra, 2009). As a result, I expect a higher level of satisficing in the self-completed treatment for the less-difficult Wordsum questions. But harder questions encourage more careful consideration in self-completed surveys, and so I do not expect satisficing to persist for the difficult Wordsum questions.
For more difficult questions, I expect a higher rate of correct answers in the self-completed treatment compared with the face-to-face treatment because of the presence of an interviewer. Tourangeau et al. (2000: 179) detail a mechanism from which the instability of responses arises in different survey settings. Which considerations a respondent retrieves and places weight on depends on the momentary accessibility of each consideration, and these considerations are influenced by many factors, some temporary (Tourangeau et al., 2000). I argue that the accessibility of such considerations can also be mode dependent. Tourangeau et al. consider this circumstance, arguing that judgments about considerations may also be affected by momentary changes to the environment, including the presence of an interviewer (Tourangeau et al., 2000: 180). Difficult questions asked by an interviewer, therefore, might reduce the level of correct answers because the interviewer inhibits the respondent from utilizing their retrieval and judgment abilities. When respondents sit down with an interviewer to complete a survey, they might feel added pressure to answer difficult questions correctly, which would not otherwise exist if respondents were alone behind a computer.
Data: randomized mode experiment with a block design
In order to isolate mode effects on measurements of cognitive skill, I leverage a large-scale randomized experiment conducted during the summer of 2011 that tested and evaluated self-completed surveys on a computer as a replacement to interviewer-assisted surveying. 4 The experiment took place at the CBS research facility within the MGM Grand Hotel in Las Vegas, Nevada, where CBS conducts daily focus groups on its programming. Face-to-face interviews were conducted by six professional interviewers in one of four simulated living rooms in the research facility. The self-completed computer surveys took place individually in small rooms, which resemble a small home office, and respondents could take as long as they needed. 5
The randomized experiment used a blocking design on 3 key indicators, age, race and gender, which creates 18 distinct blocks. Blocking ensures that both the face-to-face and the self-completed modes are balanced on demographics that might confound estimated treatment effects (Green and Gerber, 2012). After respondents agreed to participate, they were brought into a waiting room where age, race and gender were estimated by graduate students and entered into an algorithm using R that made the treatment assignment. 6 After the treatment assignment (face-to-face or self-completed; a respondent is then matched with the next agreeable participant with identical demographics, who is then assigned to the opposite mode treatment. This blocking technique created a sample that is balanced on treatment assignment, age, race, and gender for a total sample size of 1010.
Results
Marginal distributions by mode
Figure 1 displays the percentage point difference by mode, taking self-completed responses minus the face-to-face responses, where positive values show more correct answers in the self-completed treatment and negative values indicate more correct answers in the face-to-face treatment. Each difference is accompanied by a 95% confidence interval using blocked standard errors (Green and Gerber, 2012). 7 Figure 1 shows that the easier words (Space and Broaden) have a higher rate of correct answers in the face-to-face treatment, while the two more difficult questions (Allusion and Cloistered) show more correct answers in the self-completed treatment relative to face-to-face. These results suggest that an interviewer might be more beneficial to respondents who might have trouble with historically easy words, where 90% of the population can answer correctly, but the interviewer might be a hindrance for more challenging words such as Allusion and Cloistered.

Percentage point difference in correct answers by mode.
In addition, self-completed respondents are more likely to satisfice with easier questions. These results suggest that respondents give less thought to easy tasks with a self-completed survey, potentially because simply tasks “may cause respondents to become bored and not expend cognitive effort to carefully consider the item” (Malhotra, 2009: 182). On the other hand, difficult tasks using self-completed surveys do not encourage satisficing because they require more thought and effort to answer (Malhotra, 2009). My results support these conclusions: respondents might be less likely to answer easy questions correctly in the self-completed treatment relative to face-to-face. Moreover, my evidence shows that self-completed respondents did not feel the need to look up answers to factual questions on the Internet, which is a legitimate concern when testing knowledge levels online. 8
Scaling cognitive skill by mode
Typically, survey knowledge items are not used by scholars on a question-by-question basis, but instead as a collection of questions that constitute cognitive skill or knowledge more broadly defined. To that end, I jointly scale both modes together using a two-parameter IRT model, and then compare the ideal points for differences by mode. IRT models show the relationship between some latent trait (in this case, cognitive skill) and the response given to each question (Albert, 1992; De Ayala, 2009; Clinton et al., 2004; DeMars, 2010; Embretson and Prenovost 1999; Hambleton and Swaminathan, 1999; Jackman, 2009; Lord, 1980). 9
Figure 2 shows a density plot of the cognitive skill scale, separated by mode after the ideal points were estimated. 10 Visual inspection of both plots shows very little difference in the shape of each scale by mode. Face-to-face respondents tend to cluster just below average (zero; out-numbering self-completed respondents, but self-completed respondents out-number face-to-face respondents on the high and low ends of the scale. Ostensibly, the difference appears to be modest.

Jointly scaled cognitive skill compared by survey mode.
The current IRT literature does not provide a general test for comparing IRT scales, and as a result, I am employing a new method of comparing scales using the Markov chain iterations. I compared the mean ideal point estimates during each iteration of the chain for both modes of a jointly scaled IRT model. I can establish that the face-to-face and self-completed cognitive skill distributions do not differ from each other by comparing their mean estimates during each iteration (the posterior over the distributions). If both distributions are the same, we should observe substantial overlapping between the face-to-face and the self-completed ideal points during each iteration of the Markov chain. Figure 3 plots these mean differences as a density for each iteration with a vertical line at zero (indicating no difference in means). To calculate this difference, I subtracted the self-completed ideal point means for each respondent at each iteration in the chain from the face-to-face ideal point estimates:


Comparing scales by mode: difference of ideal point estimations during each iteration.
where
From this mean difference, I calculated the percentage of iterations that differ by mode, which can be found by summing the total number of mean differences that exceed 0, and then dividing the sum by the total number of iterations:
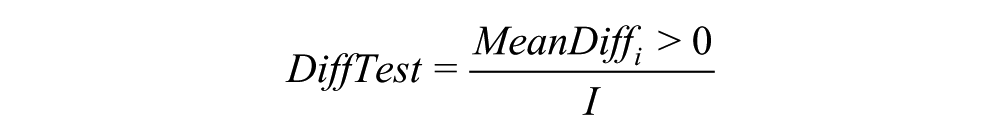
which creates a percentage of iterations that are different by mode. If both modes are different, then the mean difference should not exceed zero more than 5% of the time (mirroring a hypothesis test with a significance level of 1.96). As a point of comparison, I can use this difference test statistic to compare simulated distributions that we know are different to make sure my test works. Take two random normal distributions, for example, with sample sizes of 1000 each (simulating the Markov chain iterations; both with standard deviations of 1, but with differing means of 4 and 3 (simulating different posteriors over the distributions for the face-to-face mode and the self-completed mode). Using my DiffTest difference statistic to compare the simulated normal distributions, I find that 1% of the mean differences are greater than zero, suggesting that the simulated distributions are different at a 99% confidence level with a 2.575 Z-score.
Returning to the survey mode data, I find that only 52% of the face-to-face means exceed the self-completed means, which is far from a standard 95% confidence level. In other words, my difference test statistic suggests that the face-to-face mode and self-completed mode are only different at a 48% level; therefore, I can conclude that the Wordsum IRT scales are not different by mode. These results show that the cognitive skill scales are order preserving within mode even if there are marginal differences found in the previous section. The top quarter of cognitive skill respondents in the face-to-face interview, for example, will still be the top quarter of cognitive skill respondents in the self-completed survey. For further evidence, please see Table 2 in which I predict the ideal points with education levels, a measure of knowledge that is unaffected by mode, I show no mode difference. In addition, I find that a simple additive scale does not differ by mode using a t-test of means (p = 0.40), demonstrating that my results are consistent across scaling procedures.
Predicting cognitive skill with education by mode.
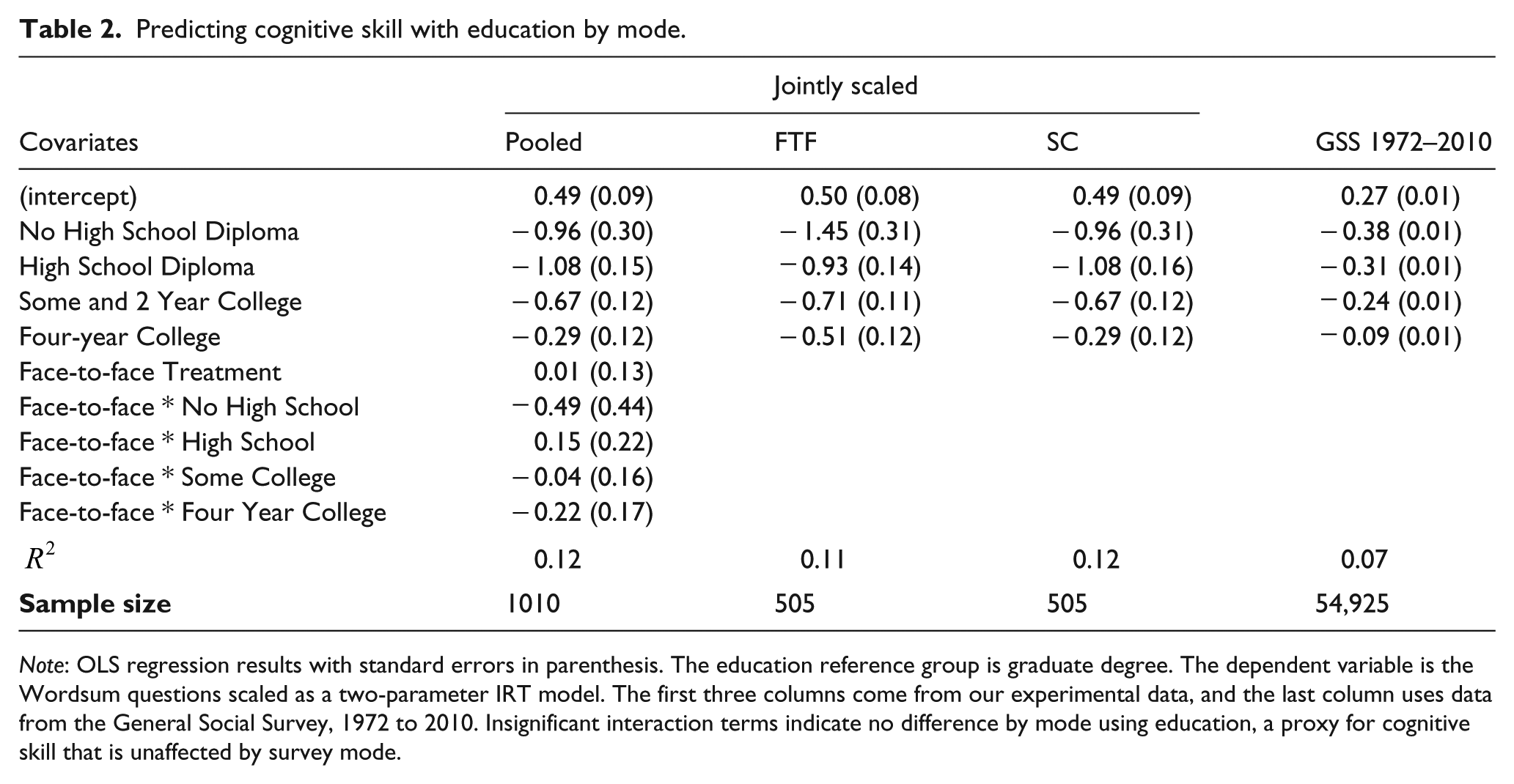
Note: OLS regression results with standard errors in parenthesis. The education reference group is graduate degree. The dependent variable is the Wordsum questions scaled as a two-parameter IRT model. The first three columns come from our experimental data, and the last column uses data from the General Social Survey, 1972 to 2010. Insignificant interaction terms indicate no difference by mode using education, a proxy for cognitive skill that is unaffected by survey mode.
Application in political science
This section applies the cognitive skill scale by mode to a political science question, showing that a well-established finding does not change based on survey mode. A robust finding in American politics is that an increasing level of knowledge (usually operationalized as a fact-based test) is strongly associated with political constraint (Converse, 1964; Zaller, 1992). That is, higher levels of knowledge are associated with reporting attitudes that are identical to a respondent’s preferred political party (Converse, 1964; Zaller, 1992). This type of knowledge effect, however, is uniquely ideological because high knowledge moderates are not any more likely to support a political party than low knowledge moderates. The effect of knowledge is borne out through ideology where high knowledge liberals (conservatives) are more likely to be strong Democrats (Republicans); and low knowledge liberals (conservatives) are more likely to be weak Democrats (Republicans) (Zaller, 1992).
This section shows that these well-established findings are confirmed regardless of survey mode. These findings represent an initial step toward showing that little difference exists in cognitive skill scales by survey mode. I model party identification using cognitive skill and ideology for both modes using an ordinary least squares (OLS) regression:
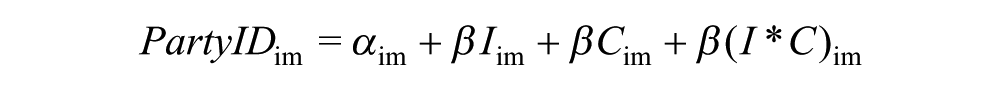
where PartyID is the party identification (seven-point) for respondent i in mode m, I is the ideology (three-point) for respondent i in mode m, C is the cognitive skill ideal point for respondent i in mode m, and
Predicting party ID with ideology and cognitive skill by mode.

Note: OLS regression coefficients with standard errors in parenthesis. The dependent variable is a seven-point party identification scale. Party identification non-response and “other” responses are coded as independent, and ideology non-response is set as the mean.
To help visualize the lack of difference by mode, Figure 4 plots these results. Each line in Figure 4 is the predicted level of party identification by cognitive skill for each type of ideology: conservatives, moderates and liberals. Although the plots are not identical, the general pattern shows no difference by mode. In addition to these results, similarities by mode for other political science models are found elsewhere too; for example, no difference by mode exists for models of retrospective voting and issue voting models (Fiorina, 1981; Gooch and Vavreck, 2015, manuscript A). But these results are only one knowledge scale from a single experiment, and more evidence using different conceptualization of cognitive skill is needed to generalize further.
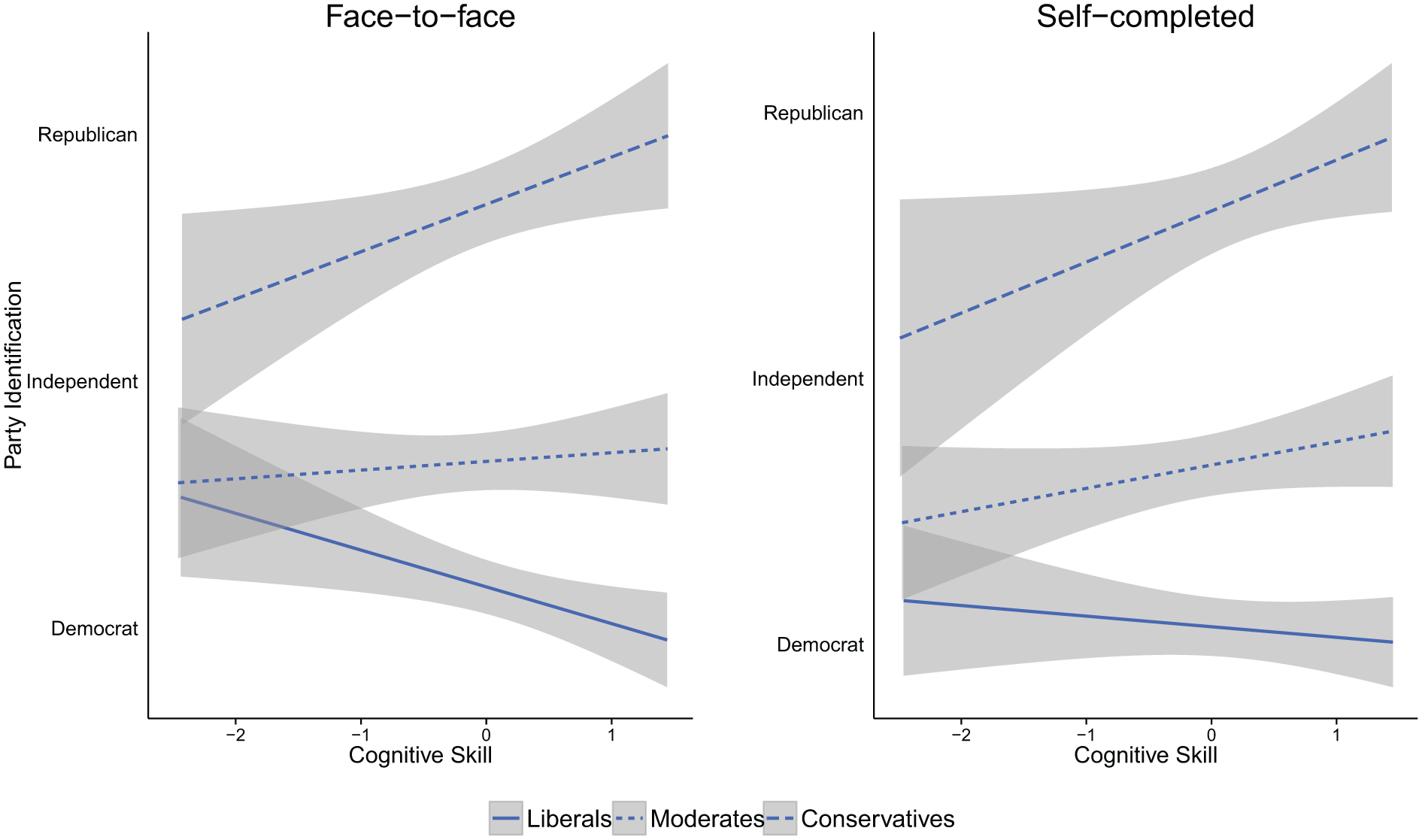
Face-to-face: predicting party ID with ideology and cognitive skill.
Conclusion and implications for survey methodology in political science
If budgeting realities force political scientists to pursue a less costly mode of interview, such as a self-completed survey online, specific differences and similarities should be expected. The marginal differences by mode on the Wordsum test are driven by the level of question difficulty. Easy questions are answered correctly more often in the face-to-face treatment, and modest to difficult questions are answered correctly more often in the self-completed treatment. 13 But when the Wordsum items are considered together as a test, which is how most researchers use knowledge items, no mode differences exist. In addition, my party identification model replication by mode is one piece of evidence that inference drawn from statistical models will not change with a transition from face-to-face interviews to self-completed surveys. Future research needs to explore other aspects of cognitive skill, and how measurements of it may differ by mode.
The lower rate of correct answers for the easy questions in the self-completed survey might be due to satisficing: individuals are less engaged with easy tasks in self-completed surveys (Malhotra, 2009). But difficult questions encourage more careful consideration in self-completed surveys, and so satisficing does not persist with difficult questions (Malhotra, 2009). Moreover, the higher rate of correct answers in the self-completed survey supports the findings in educational testing (Ben-Shakhar and Sinai, 1991; Casey et al., 1997; Cronbach, 1946; Shulman and Boster, 2014). And Tourangeau et al., (2000, 179) detail a mechanism from which the instability of responses arises in different survey settings. Which considerations a respondent retrieves and places weight on depends on the momentary accessibility of each consideration, and these considerations are influenced by many factors, some temporary (Tourangeau et al., 2000). The accessibility of such considerations, demonstrated in this experiment, can also be interviewer dependent (Tourangeau et al., 2000: 180). Difficult questions asked by an interviewer, therefore, might reduce the level of correct answers because the interviewer inhibits the respondent from utilizing their retrieval and judgment abilities. When respondents sit down with an interviewer to complete a survey, they might feel added pressure to answer factual questions correctly, which would not otherwise exist if respondents were alone behind a computer.
Footnotes
Appendix
Acknowledgements
I would like to thank Professor Lynn Vavreck for involving me in this project. I also thank the project’s manager, Brian Law, who kept things running on time and effectively at the MGM Grand, and the graduate students who helped administer the experiment in Las Vegas: they are Felipe Nunes, Sylvia Friedel, Gilda Rodriguez, Adria Tinnin and Chris Tausanovitch. I also greatly appreciate helpful comments on this paper from Chris Tausanovitch, Lynn Vavreck, Jim DeNardo, Michael Chwe and John Zaller. I also appreciate the help of Doug Rivers and Jeff Lewis, who wrote parts of the backend program responsible for the randomization and blocking. Finally, I thank John Aldrich, Larry Bartels, Alan Gerber, Gary Jacobson, Simon Jackman, Vince Hutchings, Gary Segura, John Zaller and Brian Humes, who helped to design this experiment in the summer of 2010.
Funding
This research is supported by a grant from the National Science Foundation (award number SES-1023940 to Lynn Vavreck).