
Abstract
The aggregated judgments of many usually outperform individual estimates of vaguely known facts. Communication among individuals may, however, undermine this wisdom-of-crowd effect because it makes judgments mutually dependent. Deliberative democratic theory, on the other hand, suggests that communication promotes correct decisions. We investigate this puzzle about the positive and negative consequences of consensus formation on the wisdom of crowds using experimental methods. Subjects in small deliberative committees had to communicate and thereafter judge vaguely known facts. We varied the agreement rules in groups and compared the groups’ change of performance from initial to final estimates. Interestingly, groups’ performance worsened on average when they had to reach a majority decision. Groups came on average closer to the truth if they had to decide unanimously or if they did not have any restrictions to reach agreement. The low performance under majority rule is robust against different knowledge questions, group sizes and communication types. The majority rule may be worst because it makes people too focused to reach a majority so that valuable minority opinions are disregarded or not even voiced. This implies that majoritarian democracy may be less suitable for truth-finding than less or more restrictive quorum rules.
Introduction
Understanding the interplay between collective decisions and collective intelligence is as important for small expert committees as it is for large democratic societies. The design of discussion rules and quorums critically shape the way groups find agreement and converge towards correct decisions. Advisory boards and expert committees are increasingly part of political decision making. Such committees make decisions on issues ranging from expected economic growth and tax estimates to estimates on the sea level in 2050 and 2100 (task of the “Intergovernmental Panel on Climate Change” (IPCC)). By definition of their task, committee members share the same preference of correctly assessing the state of the world. Disagreement is limited to different beliefs about this state. Because of the presupposition that a correct answer exists, the government and the public often expect experts to deliver consensual answers on which policy decisions and investments can be based.
Various aggregation methods of individual beliefs are used in such committees. For example, the preparation of the IPCC reports has recently been described as a “bazaar” of studies where actors “bargain” about the expected rise of the sea level (Bojanowski, 2011), and pooling of expert assessments has been used for truth-finding (Bamber and Aspinall, 2013). Such often chaotic political deliberation processes needs to be better informed by investigations about the interplay of collective decisions and collective intelligence, in particular the impact of quorum rules on truth-finding capacity. What works better: a majoritarian quorum, where strong approval is guaranteed but “esoteric” minority opinions can be disregarded? Or unanimity rule, where all minority opinions have to be taken seriously? Or should the deliberation process be unrestricted and allow for individual decisions from which political decision makers extract their guiding policy, for example by averaging? This paper sheds light on these research questions with findings from a controlled experiment.
Truth-finding versus settlement in deliberative committees
As early as 1907, Galton (1907b) demonstrated that aggregating the independent judgments of many individuals in an estimation competition approximates the true value with surprising accuracy. He argued that the median should be taken as method of aggregation (Galton, 1907a). The empirical finding has become a stylized fact and found its way into the popular science literature as the “wisdom-of-crowd phenomenon”, establishing the idea of collective intelligence (Surowiecki, 2004; Page, 2007). The median voter theorem (Downs, 1957) links the idea of median aggregation to majority rule which delivers the median voter’s opinion as its only stable outcome. From that perspective majoritarian democracy should produce the wisdom of the crowd.
In reality, expert committees do not simply aggregate or vote on their diverse beliefs. They typically decide after ample time of discussion, where they exchange arguments and knowledge to improve their capacity to make close to correct decisions. This exchange resembles the ideal of deliberative democracy (Thompson, 2008), according to which people debate, exchange and revise their beliefs in order to produce a rational consensus about the state of the world and appropriate collective action (Lehrer and Wagner, 1981; Mansbridge, 1983; Habermas, 1998).
In contrast to this ideal, a long tradition of social psychological research has highlighted a variety of pitfalls of group discussions and decisions, such as group polarization and groupthink (Kerr and Tindale, 2004). Political science also highlights the possibility of the rational polarization (Spector, 2000). These and other mechanisms of polarization (Dixit and Weibull, 2007; Pardos-Prado and Dinas, 2010; Wojcieszak, 2011) can shift behavior from proximity voting, which underlies the median voter theorem, to directional voting (Adams et al., 2005), where voters intentionally cast votes that are more extreme than their real positions. Even when communication and incentives are fully focused on truth-finding, communication undermines independence of judgments and thus the statistical foundation of the wisdom-of-crowd effect. Mild social influence about others’ estimates narrows the range of estimates to such an extent that the true value is often excluded (Lorenz et al., 2011). This can create an exaggerated perception of accuracy in groups. The unresolved question is to what extent these social influence effects spoil truth-finding in committees and how this is moderated by quorum rules.
A conceptual step towards understanding truth-finding in groups is to distinguish it from finding a consensual settlement. These two dynamics can be separated into the concepts of “informational influence” and “normative influence”. Kaplan and Miller (1987) showed experimentally that for an intellective issue (assessing the size of a damage) people exerted more informational influence by sharing facts and persuading each other. For a judgmental issue (assessing the size of an appropriate punishment), they exerted more normative influence through reference to conformity and decision norms. The difference was stronger under unanimity rule than under majority rule. As truth-finding is an intellective issue, this implies that groups may be more focused on truth-finding under unanimity rule than under majority rule.
Similarly De Dreu et al. (2008) distinguish between epistemic and social motivation in group decision making. Epistemic motivation is the willingness to expend effort and search information to develop accurate and well-informed opinions. Social motivation is the preference for fair outcomes in the group, where people can be egoistic (proself) or fair (prosocial). Velden et al. (2007) showed experimentally that proself motives trigger minority opinion holders to block decisions under unanimity rule. Under majority rule, however, minority members are often overruled by proself majority opinion holders. This may imply that unanimity quorums may preserve valuable minority opinions better compared with majority quorums if the minorities sufficiently insist on their opinion.
The question of optimal quorums has a long tradition in political science. Buchanan and Tullock’s (1967) seminal proposition that the costs of decision making rise and the costs externalized on outsiders fall with an increasing quorum speaks for intermediate quorums, but it has received mixed support from experimental tests (Vanberg and Miller, 2013; Dougherty et al., 2014). Our research question is different from this question because we focus on truth-finding, where subjects have common epistemic preferences instead of diverse egoistic preferences. Another related discussion addresses the relative merits of majority and unanimity in the dichotomous truth-finding problem of juries, guilt or innocent (Feddersen and Pesendorfer, 1998; Coughlan, 2000; Goeree and Yariv, 2011). In contrast to these lines of research, we frame the decision space as a continuum instead of a dichotomy (convict or acquit), and hence depart from these debates at a fundamental level.
Nevertheless, all of these results show that collective decisions and collective intelligence are interrelated phenomena. Whether consensus formation promotes or spoils truth-finding may be strongly related to the quorum. The unanimity rule gives minority opinions strong veto power if minorities insist on their opinion. Instead, a majority quorum makes it easier to reach agreement in the group. However, there is little empirical evidence yet which shows under which quorum rules groups reach more accurate decisions. We thus designed an experiment to compare the ability of groups to find the truth under different agreement rules.
Experimental design
We translated the problem of deliberative collective judgment into a controlled computer-based laboratory experiment, using z-tree (Fischbacher, 2007) and ORSEE (Greiner, 2004). A total of 141 subjects were recruited from the student subject pool of the Experimental Laboratory at the University of Oldenburg. There were five sessions with 24 participants each. Another session consisted of 21 participants due to attrition.
The task in the experiment was to estimate quantitative facts about the real world. All questions were about percentages which were typically not, or only vaguely, known by subjects. The full list of questions is shown in Table 1. Factual questions enable us to pose and incentivize group problems with unambiguous measures of performance based on an objective truth. Subjects were paid by the accuracy of their answers (for details see below).
List of questions (English translation, German original in the Online Appendix) and true values. In each session questions appeared in that order. Only one of the questions labeled a, b, c appeared in each experimental session.

From pretests and earlier experiments we knew that the substance of the question has a large impact on results. This regards formal properties as the theoretical range or the location of the truth in the range, as well as population properties as the felt difficulty, the diversity or a systematic bias. In real-world estimation problems of expert committees where the truth is unknown to everybody, difficulty, diversity, and bias cannot be fully controlled a priori. Nevertheless, there might be mechanisms at play which have a substantial effect on average over many questions. To detect such mechanisms, it is thus important to test many different questions. On the other hand, it is also important to fix questions to control for other treatment effects. We chose a mixed strategy in our experiment with some questions we use very often and some questions we use in different versions (labeled a, b, and c in Table 1).
In each experimental session, subjects completed nine periods, each with a new estimation task. Each subject gave consecutive answers to each of the nine questions in two different stages. The first stage was a “private opinion stage” and the second one a “deliberation stage”.
We varied the deliberation stage on three dimensions. Subjects had to deliberate about their estimates in differently large groups, in different communication modes and they had to reach a final decision under different agreement rules.
(i)
(ii)
Qualitative communication happened in an ordinary chat window in which subjects could write to all other group members.
Quantitative communication was restricted to the information about 10 consecutive numerical estimates of others. Each subject had to state 10 estimates electronically which were shown to all group members immediately after they were entered by means of a table with a column for each group member. A new estimate was only possible when all others in the group had entered the same number of estimates.
(iii)
In the individual treatment, there were no restrictions for collective agreement in final decisions. The majority treatment required an agreement of a majority of group members. The unanimity treatment required an agreement of all group members. Hence, for a valid group decision, more than half of the group members had to enter exactly the same value under the majority rule and all members under the unanimity rule. Payments were based on the final group decision. Groups who failed to reach a valid group decision did not receive any payments. Disagreeing group members were paid based on the group decision. Under the individual rule, subjects were individually paid out based on their final decision, regardless of the opinions of other group members. The deliberation phase was here merely to exchange information.
Payments were a function of the distance between the final decision and the correct value: 4 Euros were paid for a distance not larger than 1.5 percentage points, 2 Euros for a distance not larger than 3, 1 Euro for a distance not larger than 6 and 50 Eurocents for a distance not larger than 12 percentage points. Distances larger than 12 units yielded no earnings. Thus, the payment differences from moving one unit closer to the correct value are always greater compared with the payment differences for moving one unit further away from the correct value. This generates an incentive to become better even if one believes to be already moderately close to the correct value. The payment function communicates to subjects: “Your group (or yourself) performs well if you come really close to the truth. We are not satisfied with moderately close answers. If you are way off, we don’t care about the magnitude and don’t pay you anyway”. The payment function also defines our main measure of performance.
Subjects were allocated to treatments based on a balanced treatment plan shown in the Online Appendix. In total we obtained a data table consisting of 1269 observations, with each case collecting all entered data of a subject in one period. The dataset divides into 207 groups and each subject participated in nine of them. For questions Q2, Q4, Q6, Q8, and all question families (e.g. Q1a, Q1b, Q1c) we have groups with both communication modes, and group sizes and all three agreement rules. The experiment and the data is fully documented in the Online Appendix. Data and code producing figures and tables is available in a dataverse (Lorenz et al., 2015).
Results
Range reduction through communication
For a first impression of our data, we show the range of individual opinions before and after deliberation. Figure 1 shows histograms of opinions for the main questions Q2, Q4, Q6 and Q8. These questions were used under all agreement rules. (The histograms for the other questions are shown in the Online Appendix and yield similar results.) The first row shows the range of initial opinions. The rows below show opinions after deliberation under the individual, majority and unanimity rule. It is apparent that the range of estimates becomes smaller under all quorum rules even when they do not have to agree. Likewise, groups agree on different opinions, which is demonstrated by the variance of group decisions under the unanimity rule.
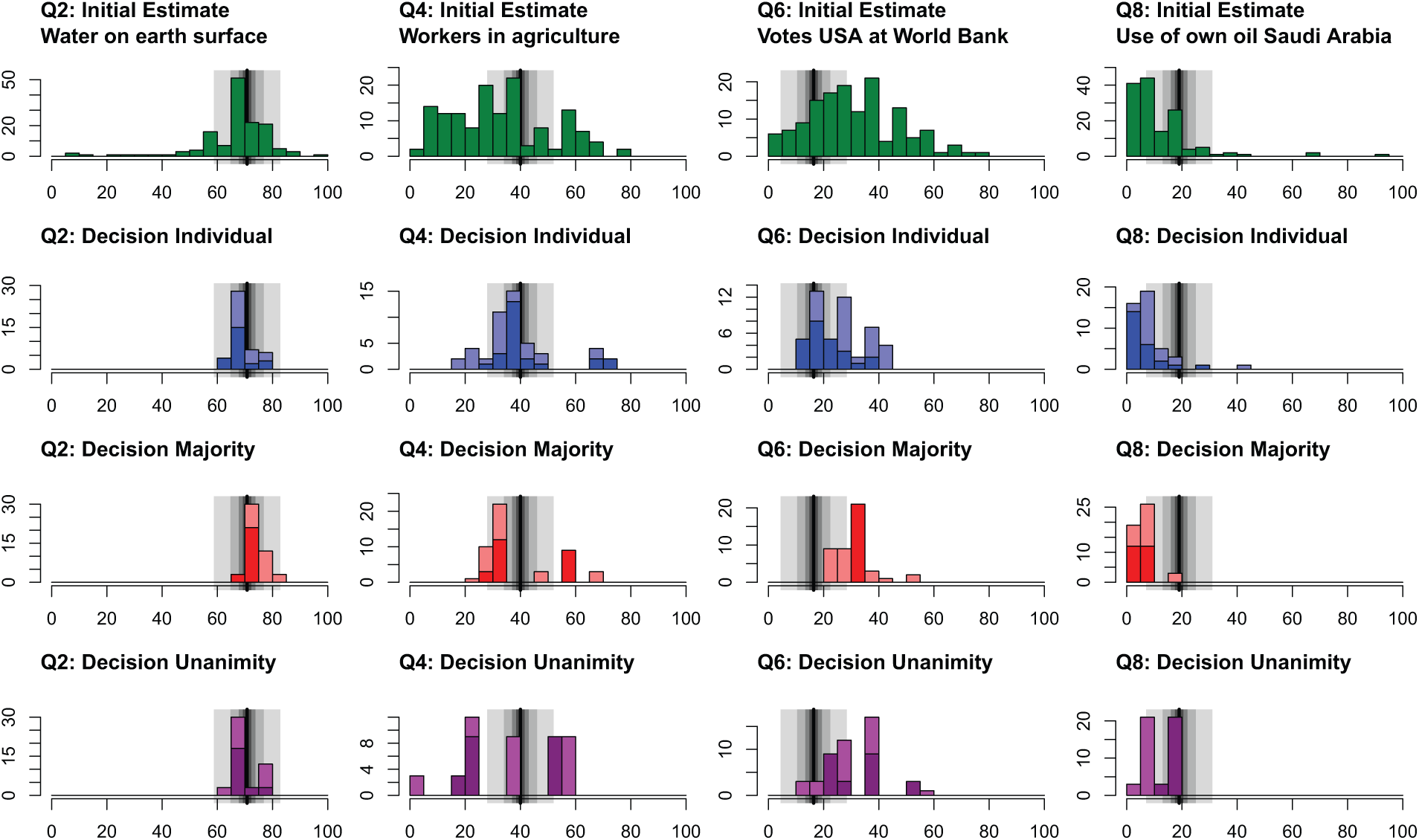
Histograms of individual initial estimates before communication and individual final decisions from which the collective decision was aggregated. Decisions are separated by agreement rules and stacked by the mode of communication. Fully colored bars represent decisions after qualitative chat communication. Shaded colored bars on top represent decisions after quantitative communication by numbers only. The black lines in the background denote the true value, the shaded gray areas the payment zones with decreasing payments for decreasing shades of gray. (Analog histograms for all missing questions are in the Online Appendix.)
Empirical inferiority of the majority quorum
To answer our central question under which agreement rule opinions converge closest to the truth, we aggregated a group dataset. This aggregated data set is used to compute the following results for group performance. For the final decisions, majority and unanimity groups aggregated their group decision themselves through the agreement rule. For groups where subjects were paid individually, we took the median of the final decisions as the group decision as Galton (1907a) proposed. Analogously, initial and intermediate estimates were aggregated by the median of all group members. The group decision was set missing if the group failed to agree. The individual certainty assessments for the initial estimate and the final decision were averaged to measure group certainty.
Group performance was measured in Euros by using the payment function from the experiment. In particular, we measure initial group performance and final group performance. Initial group performance is the potential payment of the group based on the initial estimates which were independent of the estimates of others. Deliberative group performance is the payment for the group decision. The effect of deliberation and agreement rule on group performance is measured by the change in group performance as the difference between initial and final group performance. This change measure levels out the differences in initial performance under different agreement rules. Using the (potential) payments instead of the raw distance to the truth is the natural measure of performance regarding the incentives in the experimental setup. The Online Appendix shows robustness tests with alternative measures for the dependent variable: final performance after decision neglecting initial performance, the change of the distance to the truth, and the level of the distance to the truth after decision. Results are qualitatively the same.
Figure 2A shows that the payoff of groups declined by about 0.3 Euros on average under the majority rule. In contrast, performance increased by about 0.4 Euros on average under the unanimity and the individual rule. The difference between majority and both other rules is statistically significant (p ≤ 0.01, see the Online Appendix). The average certainty of groups increased through deliberation. Interestingly, increase of certainty is strongest under the majority rule (Figure 2B). Looking at the absolute performance of collective decisions shows that groups under majority rule earned on average 0.7 Euros, while they earned 1.24 Euros under unanimity rules and 1.19 Euro under the individual rule. This corresponds to an average final group distance to the truth of 15.5 percentage points under majority rule compared to 9.8 and 10.4 under unanimity and individual rule.
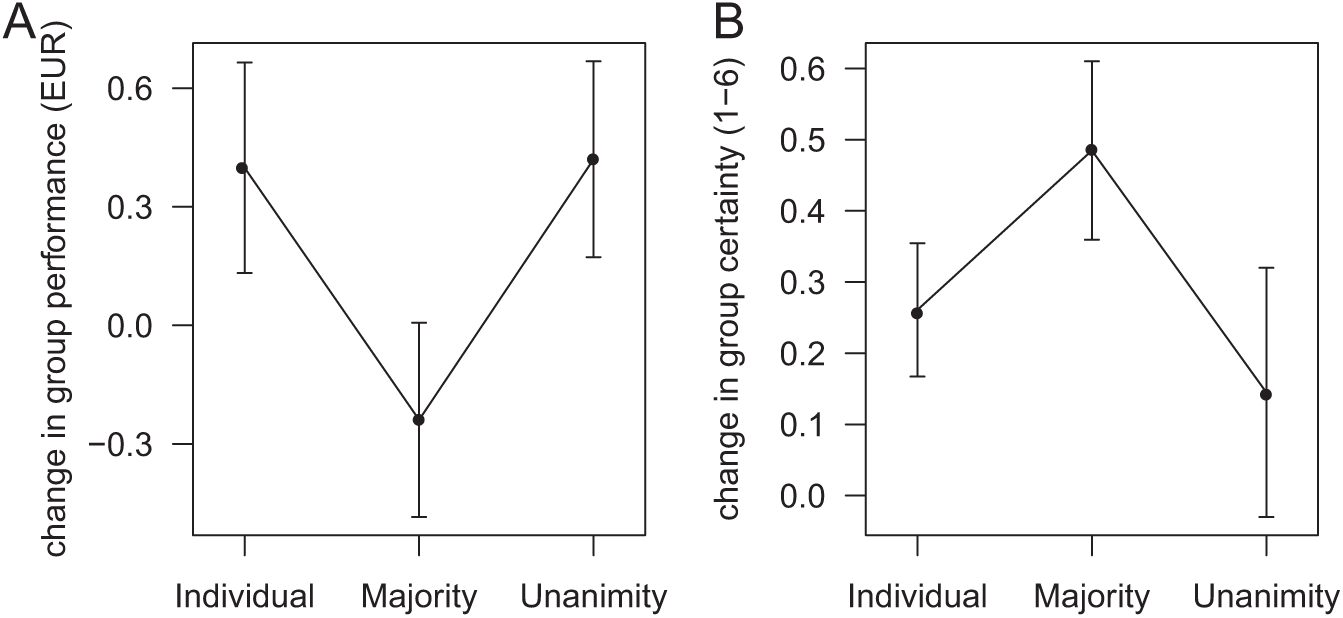
Group performance deteriorates under the majority rule and improves under individual and unanimity rules (A). Certainty increases most under the majority rule and less under individual and unanimity rule (B). Data comprises of 69 runs in each agreement rule. Error bars are adjusted 95% confidence intervals (see the Online Appendix).
Robustness over group size and mode of communication
A crucial question is whether the inferiority of the majority quorum is robust across other aspects of the situation. Figure 3 demonstrates the robustness of our findings against group size and mode of communication. Both do not substantially change the effect of the agreement rule. This is also substantiated with a full factorial model of agreement rule, group size and communication and all two-way interactions (see the Online Appendix). There are mild effects suggesting that subjects under the individual rule might benefit from larger groups while it does not seem to help under unanimity and majority rule. Subjects under majority or unanimity rule seem to benefit more from communication by chat than subjects under the individual rule.

In larger groups the effect is slightly stronger; especially in groups with individual decisions (A). Communication by chat leads to slightly larger improvements under majority and unanimity rule (B). The superiority of individual and unanimity rule over the majority rule prevails always. The gray line represents all groups as in Figure 2A for comparison. Error bars are adjusted 95% confidence intervals (see the Online Appendix).
Robustness over different questions
Another important robustness check is whether the inferiority of the majority quorum is similar across different questions. In order to test for question effects, we estimated a mixed maximum likelihood regression model treating the agreement rule as fixed effects and questions as random effects. Coefficients are shown in Table 2, documenting a significant and substantial difference in the change of group performance under majority rule compared to the other agreement rules. We compared the model with an analog fixed effects model for agreement rules and questions (see the Online Appendix). The Hausman test did not reject the null hypothesis that the two sets of coefficients are identical (p = 0.59). Given that question families 1, 3, 5, 7 and 9 have been phrased in slightly different ways in order to minimize session effects, we have also calculated coefficients for a model restricted to the data relating to questions 2, 4, 6, and 8, which did not vary across treatments. The coefficients are robust to this change (see the Online Appendix). There is considerable variation over different questions regarding magnitude and direction of the effect as further shown in the Online Appendix, but majority rule is almost always inferior compared with the other rules.
Mixed effects regression with agreement rule as treatment variables and questions as random effects.

Note: Reference category is majority rule. Random effects refer to questions. Significance: ***p < 0.01, **p < 0.05, *p < 0.1.
Truth-finding or deliberating a settlement?
What mechanism may drive our finding that the majority quorum is inferior? We believe that different quorum rules trigger different kinds of social motivations in group members.
In order to assess social motivation for agreement, we calculated the extent of consensus in the three different agreement rules by averaging the number of finally agreeing subjects in groups. Under majority rule these were 2.88 out of 3 in small groups and 8.17 out of 9 subject in large groups. This is much more than necessary for a successful majority decision. A total of 72.4% of all majority rule groups ended up in full unanimity. There was only one group which failed to reach a majority decision. This suggests that the majority rule triggers a strong motivation to reach an agreement and group members tend to follow the crowd more than necessary.
Under the unanimity rule, 5 out of 69 groups (7.2%) failed to reach a unanimous decision. In the individual treatment, there is much less consensus. Full agreement happened only in 7.2% of the groups and only in groups of three. These findings give an indication that majority rule triggers a bandwagon effect, where subjects converge too quickly on what seems to be a feasible group decision. Subjects under unanimity and individual rules seem to stay more focused in a truth-finding mode. Under the unanimity rule, group members with strong opinions can play out their veto power, because their expected payoff of decision failure and subjection to the majority rule both equal zero. Under the individual rule, where we aggregated the group decision by the median, the wisdom of crowd does a better job after deliberation. Both advantages are limited under the majority rule.
An additional argument for different motivations under different agreement rules is strategic reasoning. From a game-theoretic perspective, the motivation behind public opinion utterances can be twofold. First, one can inform others truthfully about one’s belief. Second, one can try to coordinate a collective decision as close as possible to one’s belief by strategic utterances of estimates, such as advancing more extreme estimates.
The mix of different motives behind public utterances may be inferred by the empirical trajectories. Figure 4 gives an illustration. It shows the average time trend of group performance under number communication from initial private over ten intermediate estimates to the final group decision. Average trends (top) are complemented by exemplary sessions for each agreement rule (bottom). The first row shows the average performance under individual, majority and unanimity rule. The two rows below exemplify the superiority of individual and unanimity rule over majority rule by single group trajectories.

Average performance of groups over time for the three agreement rules (top). Example trajectories with three (middle) and nine subjects for each rule (bottom). Average group performance is computed only for communication by numbers because for chat communication there are no structured intermediate estimates. The difference of the EUR values for “private” and “decision” correspond to the dashed line in Figure 3B. The exemplary trajectory for majority rule (middle) with three subjects shows four marked utterances and their possible underlying motivations.
The middle trajectory in Figure 4 serves as an illustration for possible strategic reasoning. The four marked utterances can be assigned to the possible motivations: (a) truthful information of others about one’s belief; (b) strategic utterance higher than one’s belief to pull others towards one’s belief; (c) strategic decision to approach one agent in order to form a winning coalition; (d) confirm that the majority’s opinion is accepted.
Seeing our groups within the motivation model of De Dreu et al. (2008) we can first assume that all subjects have an epistemic motivation due to our payment scheme. Social motivations are particularly important under majority and unanimity rule, where others have to be persuaded to reach payments. Under majority rule, however, subjects may find themselves in a minority position in which they cannot enforce others to consider their epistemic judgments and may thus quickly loose their epistemic motivation in favor of social motivation. This may silently lead the group to “satisfice” under a low level of epistemic motivation, because finding a settlement represses truth-finding.
Conclusion
In summary, the majority quorum is surprisingly inappropriate in aggregating the wisdom of the crowd. On average, majority rule leads deliberative groups to reach worse results in which they gain more confidence compared to groups deliberating under unanimity rule or without a requirement for agreement. The effect is robust over group size, mode of communication and different questions. There is variation within our results, and not every single group on every single issue performs worse in truth-finding when using majority rule. Still, we think that the substantial difference warrants a careful consideration of the interplay of majority decisions and collective intelligence. When expert committees are established, they should either decide unanimously or aggregate independent judgments instead of imposing a majority decision.
It is noteworthy that our experiment does not create any conflict of interests. It is often argued that experts have conflicting interests and therefore do not work towards finding the truth. We negated this problem with payments for finding the truth; even then, the majority rule proved to be an unfavorable institution for truth-finding. Hence, if we are concerned with truth-finding, then our results turn Buchanan and Tullock’s (1967, Ch. 6) argument about intermediate quorums for conflicts of interest between heterogeneous preferences on its head. The intermediate quorums is not best, but worst.
Of course, also the type of question and related systematic biases, diversity of background knowledge and the level of difficulty have a large impact on performance. In contrast to the rules of deliberation and the agreement rule, these variables are typically not under the control of the principal who is looking for an assessment of an expert committee. Our results show that there is a significant, robust and substantial effect that majority rule is inferior for truth-finding in deliberative committees.
Supplemental Material
WoCdeliberationRP_SOM_Revision_final_online_appendix – Supplemental material for Majoritarian democracy undermines truth-finding in deliberative committees
Supplemental material, WoCdeliberationRP_SOM_Revision_final_online_appendix for Majoritarian democracy undermines truth-finding in deliberative committees by Jan Lorenz, Heiko Rauhut and Bernhard Kittel in Research & Politics
Footnotes
Acknowledgements
We thank Robert Goldstone and Stefan Herzog for sharing batteries of questions with us. The paper benefited from discussions in the Study Group “Dynamics of Collective Decisions” (2011–2014) at the Hanse-Wissenschaftskolleg Institute for Advanced Study, Delmenhorst, Germany.The experimental design and work was done while Jan Lorenz and Bernhard Kittel were with the Carl von Ossietzky Universität Oldenburg, Germany.
Declaration of conflicting interest
The authors have no conflicts of interest to declare.
Funding
This work was supported by the Ministry of Science Culture in Lower Saxony. Jan Lorenz used a part of grant DFG LO2024/2-1 for the preparation of the manuscript.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.