
Abstract
Our aim in this paper is to improve the efficiency of a learning process by using learners’ traces to detect particular needs. The analysis of the semantic path of a learner or group of learners during the learning process can allow detecting those students who are in needs of help as well as identify the insufficiently mastered concepts. We examine the possibility of using a student’s browsing path during a learning session, based on his navigation traces, to update the learner model. We assume that the domain concepts examined outside the learning platform but that are related to the course concepts are problematic to the learner. Knowing about these concepts may allow the course’s author to adapt the course to the learner’s needs regarding these concepts, as well as allow the tutor to help and assist the learner on these problematic concepts. We rely on Web data mining methods to filter, organize, and analyze the student’s browsing path. More precisely, we use a domain ontology of the course and the similarities that exist between external documents (visited pages) and the domain concepts (the course keywords). This analysis process makes it possible to detect students’ learning difficulties and to adapt the course based on the learner’s model.
Keywords
Introduction
Online learning using existing environments allows learners to access numerous educational resources on the web. In this context, adaptive systems dedicated to online learning are becoming more specialized. One distinctive feature of such systems is the user model, a representation of the user’s information (Micarelli et al., 2007). According to several researchers, the key constraint involved in user modeling is to collect the appropriate information and to have a complete description of all aspects of the user’s behavior and environment (Akharraz et al., 2018).
Various approaches use the explicit entry of information provided by the user, which is long and complex to process. Hence, implicit user modeling, based on the analysis of his past and current interactions is important. So, we define the user profile as “a machine-exploitable description of the user model” (Li et al., 2008; Baishuang and Wei, 2009).
To build an adaptive learning system, it is necessary to understand the behavior of learners and evaluate their needs and gaps, while identifying interactions, knowledge, and learning conditions (Mustafa, 2018). Finding the knowledge contained in the course being taught (domain concepts) that is poorly or not mastered by a learner is a key element to adapting the learning content and process. This requires updating the learner’s profile, by specifying the domain knowledge that poses problem, and then based on this, the system can decide how to achieve the adaptation (Wu, 2002).
Here, we are interested in the learner’s interactions in the e-learning environment, especially those related to resources that are external to the environment. For this purpose, it is necessary to examine several aspects related to the interactions with external resources. For example, why did the learner visit some external content during the learning session? Is the external content related to the domain of study? If so, what is the degree of relationship and to which concepts of the learning domain is this content related?
Answering these questions can provide useful information on a learner’s progress−or lack of progress−as well as on the effectiveness of the content of a course. This is what we propose to exploit in this paper: enrich the learner’s model by identifying the poorly understood domain concepts using an implicit method of learner modelling based on the collection and interpretation of the learner’s interaction traces. In our study, we assume the learning environment is an e-learning platform within which the learner navigates from page to page by clicking on hyperlinks representing different learning units. The external environment that we consider is any content browsed on the Web outside the e-learning platform. We rely on the URL (Uniform Resource Locator) of the visited web pages to recover the learner’s navigation paths. This restriction is not arbitrary: the content of the visited resources on the Web is naturally available (can be visited or downloaded), as opposed to the local resources (located on the learner’s machine) that are less (or not) accessible. Figure 1 presents an outline of a learner’s path during a learning session, containing two different types of bubbles depending on the type of interaction: with the internal environment versus with the external one. A learner’s path during a learning session.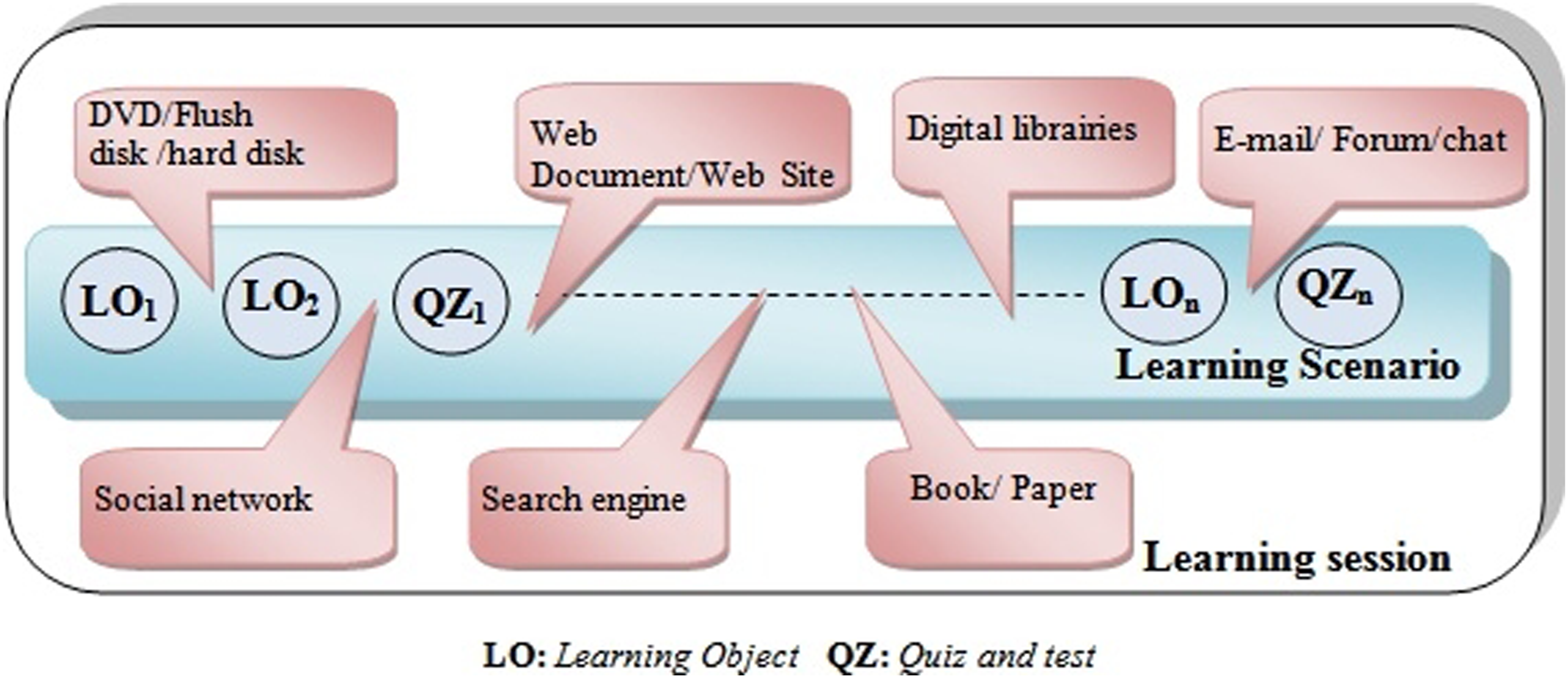
Our goal is to identify the correspondence that exists between the content visited in the learning (internal) environment and the one visited outside (external). Our objective is to identify the reasons, possibly related to the learning system, which made the learner visit external documents or communicate with his peers (or the tutor) about the course content. Identifying these course concepts that may cause problems can allow both the author to adapt the course—by restructuring or enriching its content— and the tutor to identify the learners that are encountering difficulties.
To reach this goal, we propose a method that makes it possible to detect, on one hand, concepts of the domain visited outside the internal environment, and, on the other hand, learners who explore these concepts in the external environment. We propose to enrich the learner’s model by identifying the poorly understood domain concepts using an implicit method of learner modeling based on the collection and interpretation of the learner’s interaction traces. To identify these poorly understood concepts, we use the course domain ontology to correlate information between the different educational content viewed by the learner—i.e., course content versus external content.
The rest of the paper is organized as follows. Firstly, we describe related work that discusses the role of ontology for adaptability of the learner modeling. Next, we propose an ontology model, which can be used for the domain model and the learner model. Then, we present our proposed approach based on the ontology and learning trace. Finally, we discuss experimental results and evaluation.
Related work
In the literature, we find several types of works, which convert learner raw data, coming from learning systems into useful information that could potentially have a greater impact on educational research and practice (Baker and Yacef, 2009). These works can be classified under different perspectives, depending on the expected objective of the study.
Some work on modeling learners using the trace analysis is done with the aim of personalizing and adapting learning. One of the most common forms of personalization in online learning environments is, adaptation of learning concepts to fit the “learning style” of the learner (Kumar and Ahuja, 2020; Truong, 2016; Yang et al.,2013). Other personalization strategies include adapting to the user’s “intelligence profile”, “media preferences”, “prior knowledge”, or “motivation level” (Tetzlaff et al., 2020).
Other works in the same context are done for the purpose of recommendations and tutoring (Tarus et al., 2017; Chanaa and El Faddouli, 2020), these works show the interest in the analysis of learner’s data to predict learners’ needs for recommendation and help even for the learner or/and tutor.
There are also works done to build and enrich the learner knowledge model based on Modeling learning, forgetting, and item difficulty. (Gan et al., 2020; Minn et al., 2018; Nagatani et al., 2019)
Further work is to identify learning difficulties, (Howard et al., 2010; Jeong et al., 2010; Vahdat et al. 2015; Ariouat et al., 2016). Other to assess learner engagement in learning. For example (Cocea and Weibelzahl, 2009; Sundar and Kumar, 2016; Aluja-Baneta et al., 2017) analyzed log-files in a web-based learning environment to construct behavioral indicators which measure the learners’ engagement in an online learning environment.
All these studies are based on analyzing the user’s interactions— i.e. traces, learning traces— to implicitly build the user model. These traces, available and recorded on servers, are then filtered and analyzed, for a learning purpose. These works also intend to update the user profile, more precisely, her/his Knowledge, Behavior, interests, preferences and intentions, to allow improved recommendation, adaptability, and personalization.
Our approach is along the same line. However, we propose to model the knowledge of the learner and enrich it for an eventual adaptation of his learning process. We assume that any learning concept or resources visited outside of the learning platform may indicates either a lack of learner’s understanding of this concept or a lack of information or structuring of the concept in the course content.
To facilitate the identification, search and semantic reuse of these resources on and from the Web, the taught domain concepts are modeled through a domain ontology specific to the delivered course. We present our domain ontology model below.
Our domain ontology model
A domain ontology (Siti et al., 2010) includes a set of terms, knowledge—including vocabulary, semantic relations—and several logic-inference rules for a particular domain.
As presented in the previous section, the use of ontology in learning environments aims to provide mechanisms to improve the search process and semantic discovery of learning resources. It also offers the possibility to organize and display information, such as relationships between concepts (Melis et al., 2009) (Vesin et al., 2013).
In our context we propose modeling the domain concepts being taught using a domain ontology specific to the course to facilitate detecting the domain concepts that the learner browses both inside a platform and outside. We consider that ontology O is composed of a set of concepts C and relations R between these concepts. A unique identifier is assigned for each concept; these concepts are labeled with one or several terms.
Methodology of research
In this research, our goal is twofold. First, we aim to identify the domain concepts that are referenced most often outside of the learning system. Second, we aim to identify the learners who viewed these documents to seek more knowledge about the related domain concepts. We consider a learning environment, such as an e-learning platform. In this context, we are interested in the learning traces, saved as a log file on the learner side. This approach allows us to trace all the learner’s interactions with—and outside of—the learning environment. We then identify and compare the external content with the content studied in the course, which is done using our domain ontology.
Figure 2 summarizes this approach, which is divided into five basic processes: (1) collecting the learner’s traces; (2) managing and processing of traces; (3) building a document corpus; (4) conceptual indexing; (5) managing and processing the results—the latter step leading to updating the learner’s profile (Layered Overlay Model). The architecture of the semantic analysis system learning traces to updating learner’s profile.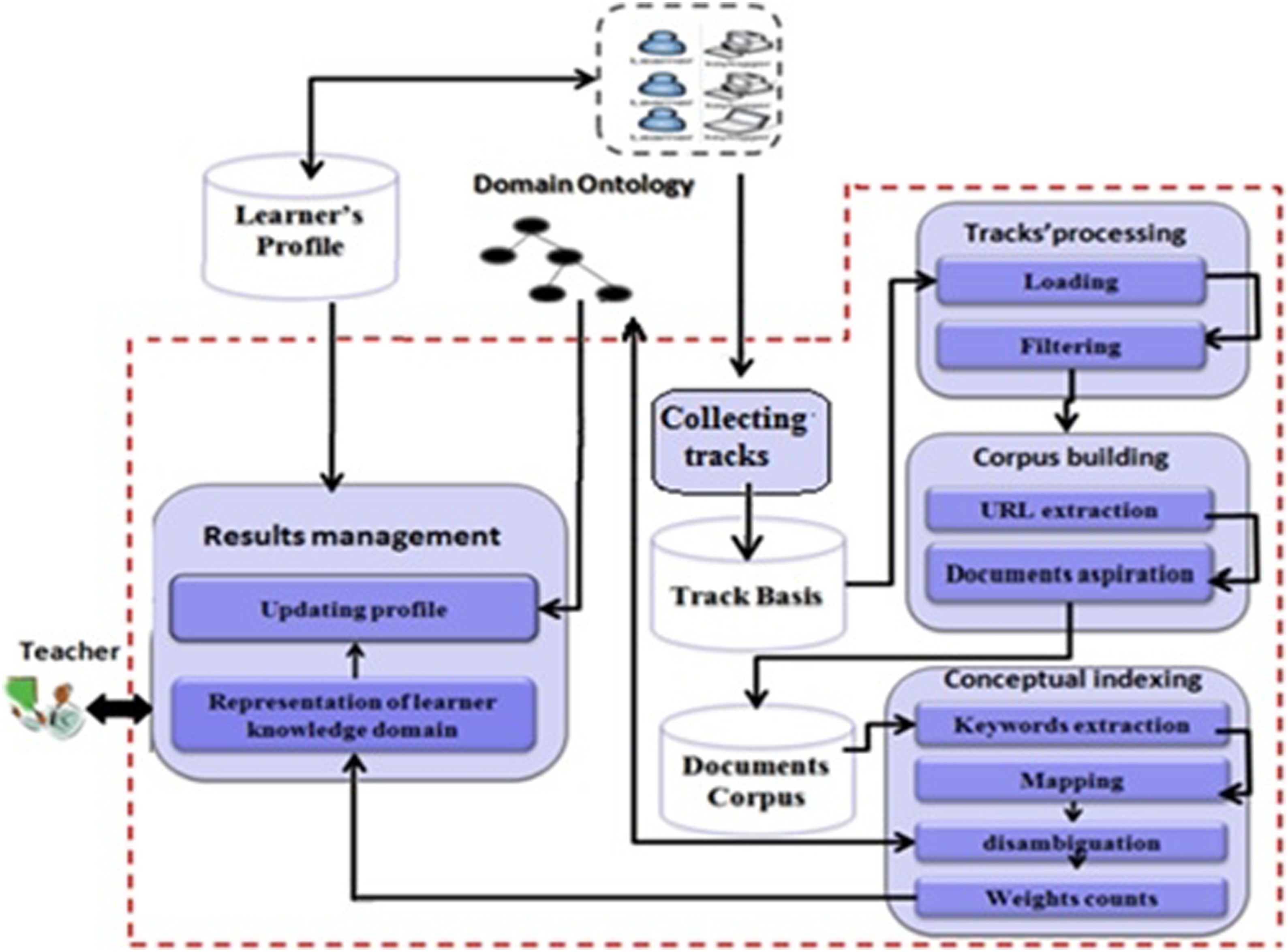
Collecting the learner’s traces
For a more complete representation of all learners’ activities, we opted for a collecting software approach. The goal is to trace all the learner’s interactions through an observation tool installed on his/her machine. For ethical reasons, the user must activate explicitly this observation tool. The generated logs are filtered, structured, and stored in an XML file that includes the following data: - Information about the learner: The learner’s Id in the e-learning environment and his IP address; - Session Id: The learning session’s Id, specific to the learner; - Browsed pages: The rank, URL, type, title, and browsing date of each visited page; - Actions on the visited pages: The type (printing, saving, etc.), date, and time of the event.
The data presented in the trace file concern only those pages visited on the web—files visited locally are not included. The following diagram (Figure 3) describes the proposed trace’s model. Trace’s model.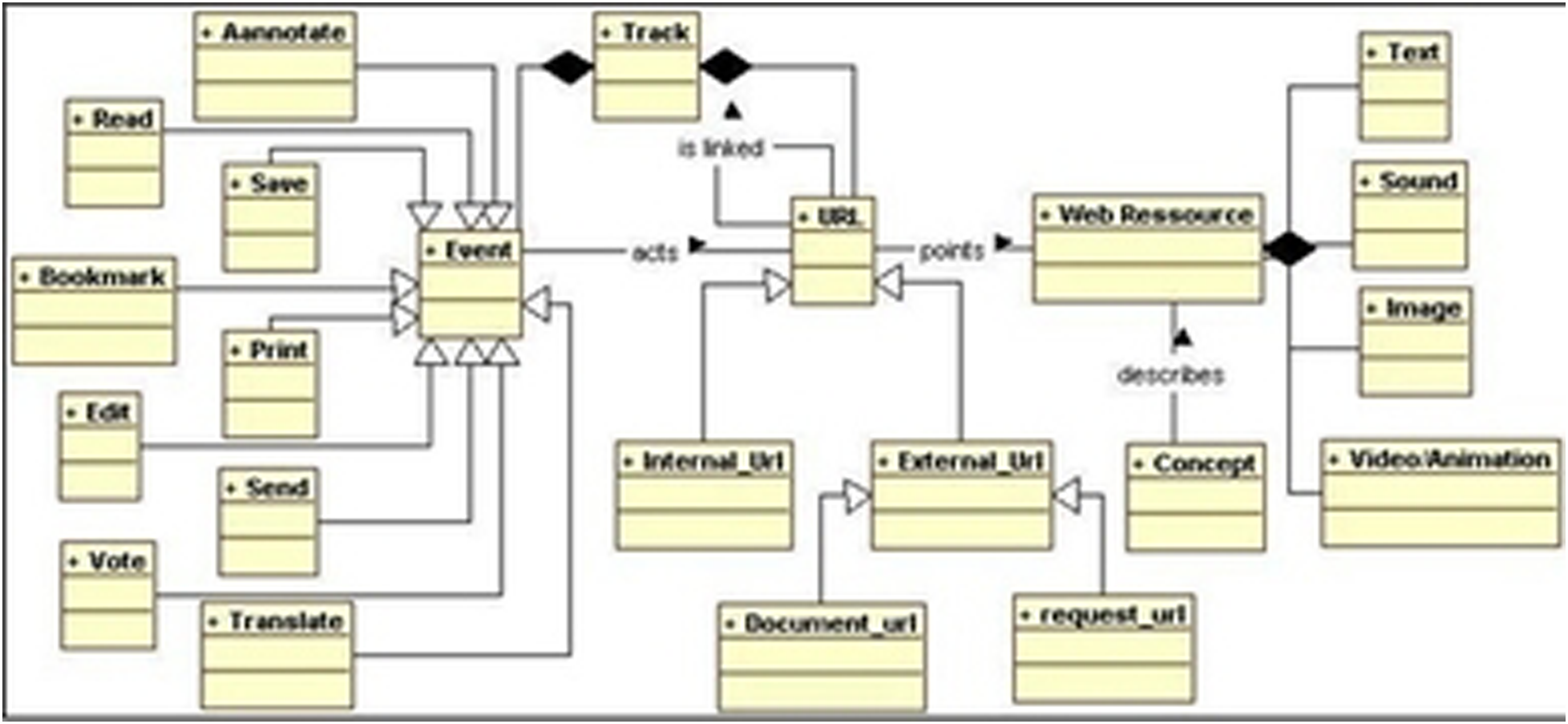
Managing and processing traces
After observing the learner’s interactions and saving these observations in the trace database, we use it to recover the URLs of documents and pages visited by the learner and to obtain their contents.
We first proceed to filter trace files taking into account the relevance of these URLs. The degree of relevance is considered as a discriminating factor for to the decision to download or not a document (Figure 2). Indeed, it is not because a learner viewed a Web resource (URL in the log file) that it is considered important. According to (Goecks et al., 2000; Claypool et al., 2001; Kim and Chan, 2005), some indicators can signal the page’s relevance for the learner. We use the following indicators: α1: Bookmarking of the page; α2: Annotating the page; α3: Downloading or saving the page; α4: Printing the page; α5: Editing (e.g. copy on the page); α6: Sending an Email; α7: Reading—interpreted by combining the visit duration with the user’s movements (a click, a mouse movement, or the use of the scroll bar) to ensure the page has been opened and read; α8: Translating (e.g. using a translation Web site);
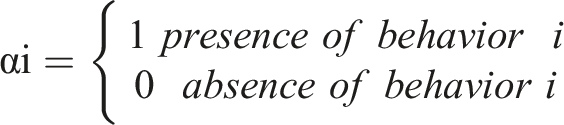
We consider a document to be relevant if any of the 8 indicators is checked, then the visited page or document is deemed relevant. The filtering result of the log file is another trace file, in the same format, but with a subset of the initial URLs.
Building the document corpus
To perform the indexation of concepts, we need the textual content of the browsed web pages. Here, a problem arises: reconstructing the Web pages that were visited by the learner during the browsing session. Our solution is to integrate a tool to reconstitute pages from URLs—i.e., we use a “page crawler”. This allows us to identify the content of the learner’s browsing path. We then save the content into a repository to produce a local corpus of the documents browsed on the web (Figure 2).
Conceptual indexing
The purpose of the conceptual indexing process is to identify and extract the concepts that represent the semantic content of the documents. In our case, we use a domain ontology of the studied course. Below, we present the process that implements the indexing from the extraction of the terms using the weighting of the concepts.
Keyword extraction
To identify the domain concepts that are browsed on the web as well as the learners who accessed them, we represent each page by its keywords. We assume the course concepts are already described by a domain ontology. However, the pages consulted outside the learning environment may not be indexed. If the browsed Web pages contain metadata, keywords are directly extracted from the pages. If not, we extract these keywords by a classical indexing approach, i.e. tokenization, removal of empty words, and lemmatization (Liu, 2009).
To represent the downloaded documents, we use a vectorial model. Each document is described by a vector of n dimensions, where each dimension corresponds to a different term (word). Each term has an associated weight calculated using the TF. IDF method. Thus, a document i is represented by a vector Di
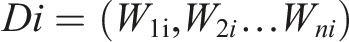
Once we have the keywords in each document of the trace file, we proceed with the other steps of the conceptual indexing (Figure 2). To perform this process, we need an external resource that offers at least an organization by concepts and structures (Baziz et al., 2007). In our case, we use a domain ontology formalized with SKOS 1 (Simple Knowledge Organization System) (Tuominen et al., 2009).
Mapping
The purpose of this step is to identify ontology concepts that correspond to document words. Concept identification is based on the overlap of the local context of the analyzed word with every corresponding domain ontology entry. The concept identification algorithm is given in Figure 4. The Mapping algorithm (Ait Adda et al., 2016).
In an ontology, a set of terms is used to label the concepts and links between concepts. The method that we propose to extract the concepts from the vectors of a document consists in assigning to each term (simple or compound) of the document’s vector a concept associated to an entry in the domain ontology. If this process cannot be done automatically—for instance when the concept can be associated with many entries in the ontology—, we consider the term to be ambiguous, and thus, a disambiguation step is necessary.
Term disambiguation
Consider an ambiguous term
In our case, we use Lin’s method (Lin, 1998) to measure the semantic similarity. This method considers the information shared by the two concepts and also what distinguishes them • P(c) is the probability of encountering an instance of the concept c. • mscs(Ci, Ck) is the common concept subsuming the two concepts.
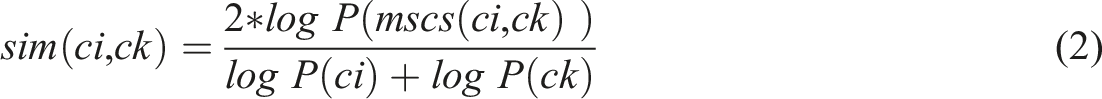
The candidate concept
Concept weighting
Once the concepts are extracted from the document, we have to assign a weight to each one indicating its importance in the document. The extracted concepts are weighted according to a method named cfc-idf (concept frequency-inversed document frequency) (Hogenboom et al., 2011). In this method, each extracted term necessarily represents a concept in the ontology. Therefore, the frequency of a concept C in a document is based on the cumulative frequency of the associated terms in the document (Dragoni et al., 2010). This frequency is computed as follows

The weight of each concept in a document D is then computed as follows

Managing and processing the results
Semantic representation of the learner’s visited concept
After conceptual indexing, each document is represented by a weighted concepts vector. Thus, all documents in the corpus C will be represented by an occurrence matrix of documents and concepts.
From the occurrence matrix, we identify the most visited concepts by summing the weights of the same row in the matrix. The result is a vector V
learner
containing the weights of the concepts in the corpus C.
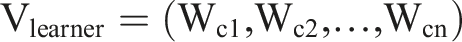
Concepts with a large weight—greater than a threshold
To detect all learners searching these concepts outside of the learning platform, we evaluate the degree of similarity between the concepts that constitute the corpus C, of each learner and those of the course (the domain ontology). To do this, we use a binary vectorial representation (Arguello, 2013).
We consider V C the vector of concepts in the corpus C and V O the vector of concepts of the domain ontology. The course vector V O (ontology) is initialized to a unit-vector (all concepts are present), while the concepts’ values of the vector V C will change according to the presence or absence of the concept in the corpus.
Among the measures of semantic similarity between vectorial representations of documents, we chose the Jaccard index (Ljubešić et al., 2008), which is based on the presence/absence of words.
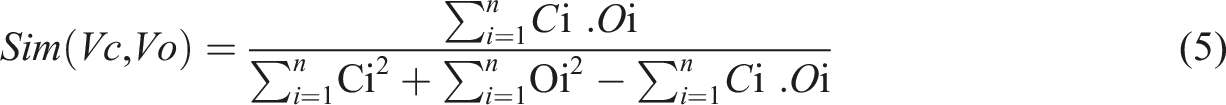
Here, Ci and Oi represent, respectively, the i th concept of vectors V C and V O , and n is the vectors’ size.
The similarity result is still a normalized value in the interval [0, 1]. Consequently, as long as the measure is large and close to 1, this means there are similarities between the content of the corpus and the course, thus a learner may be “in trouble” and might need help and support. A threshold
Having established the necessary measures and values for the evaluation of learners, the results of the performed observation must then be incorporated in the learner’s knowledge model.
The learner’s knowledge model
Learner’s knowledge models are cognitive models that provide relevant information for a learning system to adapt learning to the knowledge, competences, features, preferences, and objectives of apprenticeship of a learner in a particular domain (Murray and Pérez, 2015; Herder, 2016; Labib et al., 2017)
An often-used learner model is the Overlay model (Carr and Goldstein, 1977), it is a dynamic model which is based on an ontology structure (hierarchical representation of value). It represents the learner’s knowledge as a subset of the domain model, which reflects the expert-level knowledge of the subject. One of its extensions is the layered overlay model (Carmona and Conejo, 2004). A layered model stores several values to represent the state of the user’s knowledge for each concept.
In our case, we propose an overlay knowledge model with four layers (levels). The learner’s mastered level for a concept is represented as a quadruple of “concept-session-aspect-value”, in which “aspect” interprets the layer (the observation source) as shown in Figure 5. The learner knowledge model.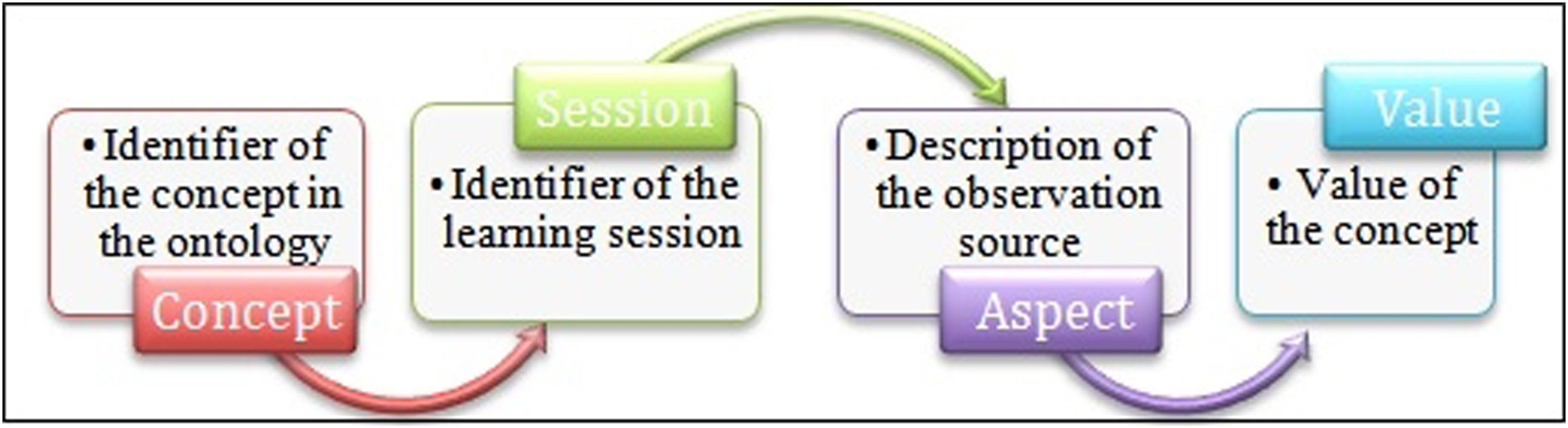
Accordingly, the learner model in the proposed system has an ontological representation since we use a domain ontology as an expert model. Figure 6 shows an algorithm for building the learner’s knowledge model relative to the concepts browsed on the Web. The algorithm for learner’s knowledge model acquisition.
After detailing the proposed approach and explaining the necessary steps in its implementation, we present, in the following section, some experimentation that we conducted to validate the proposed hypothesis.
Experiment and results
To validate our research hypothesis that it is possible to identify these concepts, we present some experimental results. In our case, we have conducted an observational study, by extracting the traces from the learners which are observed during their learning session, then we have analyzed and compared these observed data with the other experimental source’s data (test and evaluation questionnaire) to confirm the hypothesis.
We first present the methodology we adopted to conduct and analyze the experiments, then we discuss the results.
Research instruments
The research instruments used in this study included a Web-based course and questionnaires.
The web-based course
To conduct our experiment, we designed a hypermedia course on “PHP and Mysql”. This undergraduate course was in HTML format. We limited our experiment to such resources to focus on the learner’s navigation behavior from page to page in a web-based learning environment.
The course was created using the Opale
2
software and follows the SCORM standard (Sharable Content Object Reference Model
3
). The course contains 6 chapters, consisting of 81 web pages. The domain ontology mainly composed of 8 key concepts and 49 sub-concepts. The main concepts are: C1: Variables&Constants; C2: Operators; C3: Control Structures; C4: Functions; C5: Forms; C6: MySQL; C7: Files; C8: Sessions&Cookies. The course is implemented on the Moodle platform (Figure 7). A snapshot of the course.
In addition to the course, the platform provides several tools and services to learners, such as e-mail, forum, chat, keyword research, internal digital library. These tools can be used for different purposes, so that learners have the freedom to develop their own navigation strategies.
Questionnaires
To validate our hypothesis and compare our results, we used two questionnaires: - A test questionnaire: To evaluate the learners’ comprehension, we asked them to complete 20 multiple-choice questions. This test is based on the course content (course concepts), and each question includes at least two concepts scored with a weight, which will be compared later with the weights of the concepts regarding the visited Web pages and queries on the search engine. - An evaluation questionnaire: To understand the learners’ behaviors, we asked the participants to specify their motivation to go beyond the course to visit, search, or discuss with their classmates or teachers, or to view content external to the platform. We also asked the learners to identify the concepts that were problematic for them. The questionnaire contained 15 questions, closed as well as open ones. This behavioral questionnaire was elaborated thanks to interviews with experienced teachers and feedback of students. Figure 8 shows an extract of this questionnaire. Extract of an Evaluation questionnaire.

Participants
The experiment involved 182 undergraduate students (second year bachelor’s degree in computer science) at the Mouloud Mammeri University (Tizi-Ouzou, Algeria), which have responded favorably to do this experiment. These students are concerned by this course (experiment) as part of their university curriculum for the Web development module. Their participation in the online course is voluntary since the same course is offered in the classroom and they had not taken the course before, which leads us to use voluntary non-probabilistic sampling techniques, for the different outputs that they generate.
Procedure
The students worked on machines equipped with the collecting software, using a personal account on the Moodle platform, containing their preferences and knowledges. Observation of the students’ behavior started at their connection to the e-learning platform, after activation of the collecting tool.
We collected traces of the learners’ activities carried out on the Moodle platform (courses, chat, forum, and digital library), as well as the activities carried out on the web, whether on websites or in search engine. Thus, we considered five navigation contexts: course, communication (chat/forum), digital library, Web (including educational sites, blogs), and search engine (queries).
The experiment was conducted during 4 weeks in sessions of 90 min. During the first session, we presented the web-based material to all participants, and then online help was provided. So, Students will be expected to learn how to create a form and perform the necessary checks, save the forms data to the database and manage sessions and cookies. At the end of the experiment, the participants were asked to take a test and complete the evaluation questionnaire to characterize their reactions.
Data analysis
The log files were stored in XML format for processing: 182 log files were gathered (for 182 learners). After analyzing and processing traces using or approach (cf. Figure 2), we obtained 182 learner’s corpus C (cf.Sect.5.5.1). The analysis of these corpuses allowed us to update the proposed learner model with weight values for each concept of the Web context. Weight values were also computed for the assessment aspect using the test questionnaire. We then performed the following steps: 1. Analyze the learners’ navigation behaviors: To understand and explain the learners’ navigation behaviors according to the generated learners’ model, we computed, for each participant and for the 4 weeks of the experimentation, the following indicators, here N is the number of learners: - Average External Navigation Rate (AExNR); The External Navigation Rate for learner i is: - Average Number of Requests made (ANR): NR is the number of requests retrieved from the Url_Request trace file for the learner i, - Average Number of External Visited URLs (ANExU): NExUi is the different number of external visited Url for learner i, - Frequency to leave page: The number of times that a course’s page was left to visit an external content outside the platform. - Exploration indicator (EI):
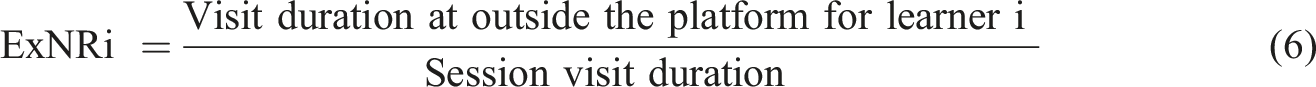



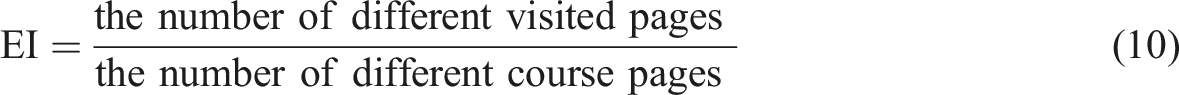
If the value of this indicator is close to 1, it means that almost pages of the course were visited, so we conclude a deep exploration, otherwise the exploration was superficial. - Visit duration rate (VDR): The visit duration at a context level ( - Deconcentration indicator 2. Create groups of learners: To facilitate the analysis and validate the hypothesis that our approach helps to detect learners in difficulty, we used the results of the test questionnaire given at the end of the experiment to create groups of learners (clusters). Among various clustering techniques, we chose the K-means algorithm because it is widely used to partition data into multiple clusters based on their similarities (Han et al., 2001). We used the Weka
4
system to apply this algorithm on our data. 3. Evaluate the results: the goal of this step is to identify the reasons that led learners to visit or search concepts outside the taught course. For this, we first analyzed the visit duration rate indicator for each cluster built in the previous step. We also analyzed the other indicators for each cluster while using the result of the evaluation questionnaire.
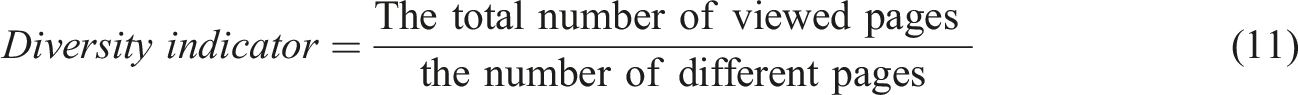

Based on these steps, we present, in the following sections, the results of the experiment.
Results
Analyzing the learners’ navigation behaviors
The graph in Figure 9 shows the average visit duration rate, for all learners and for the whole experiment, at the platform level and outside the platform (Web pages, Requests on search engine). Visit duration rate for each context.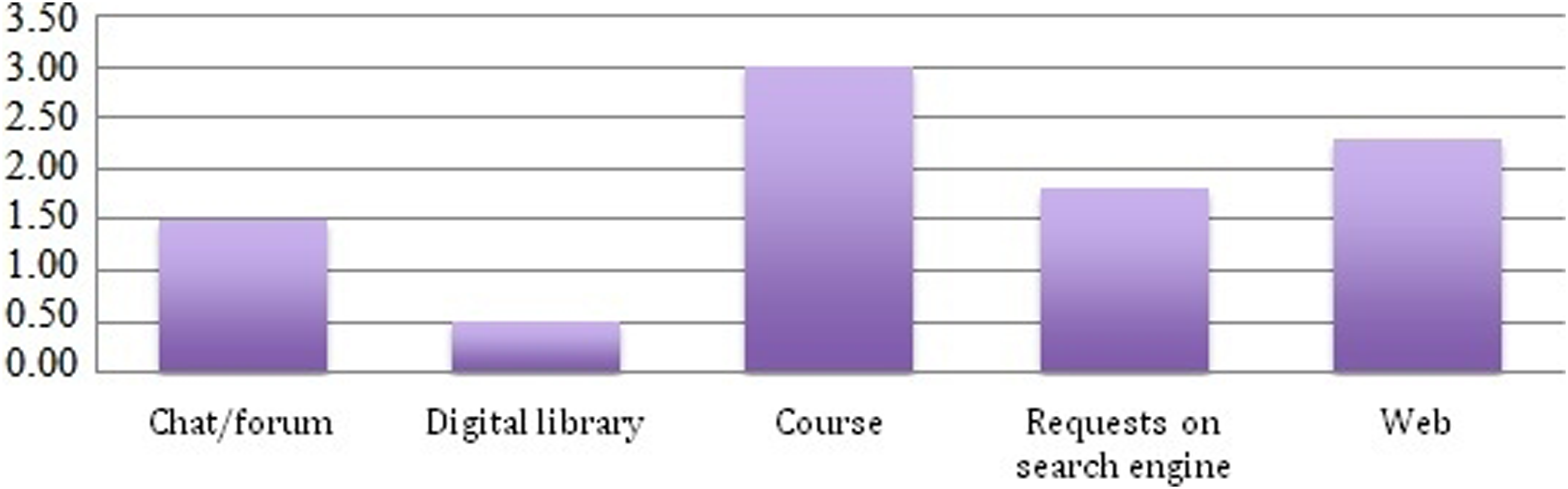
As we can see, the time spent on the course content is the most important one, which is natural since the purpose of the course is to acquire the course content. We also find that the communication tools (Chat/Forum) take a significant amount of time during the learning session. However, we notice that learners spend time on other activities outside the e-learning platform by visiting Web pages or doing searches. Thus, we can deduce that learners visit content outside the platform during their sessions and take a considerable time.
The graph in Figure 10 shows the visit duration rate indicator for the 5 contexts during the 4 weeks of the experiment: The visit duration rate during the 4 weeks of the experiment.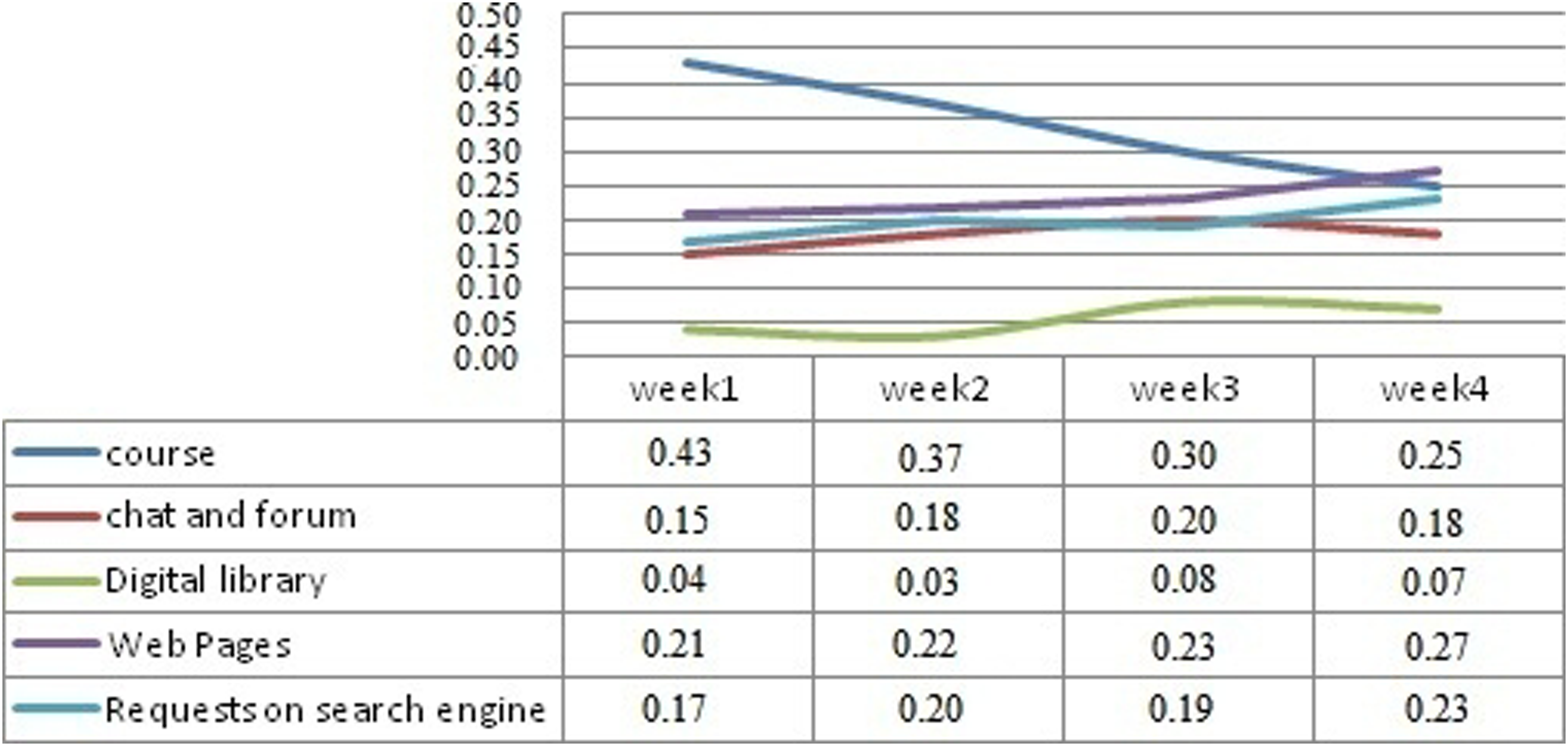
We notice that the course visit duration rate decreases from 1 week to another (from 0.43 to 0.25). As for the contexts related to the platform level, we observe a weak evolution for the communication context (0.15–0.2–0.18), and a very modest one for the digital library context (from 0.04 to 0.07). Otherwise, for the contexts outside the e-learning platform, we observe a significant evolution: Web (from 0.21 to 0.27) and search engine (from 0.17 to 0.23).
We also analyzed the evolution of the deconcentration indicator via the following graph, which summarizes the averages of this rate for all participants during the 4 weeks of the experiment.
As shown in Figure 11, during the 4 weeks, learners often leave the platform to visit other contexts. Using the evaluation questionnaire, we analyzed the motivation of participants to go outside the course. The diagram in Figure 12 summarizes the reasons gathered. Evolution of the deconcentration indicator during the 4 weeks of the experimentation. Statistics of learners’ reasons for visiting external contents.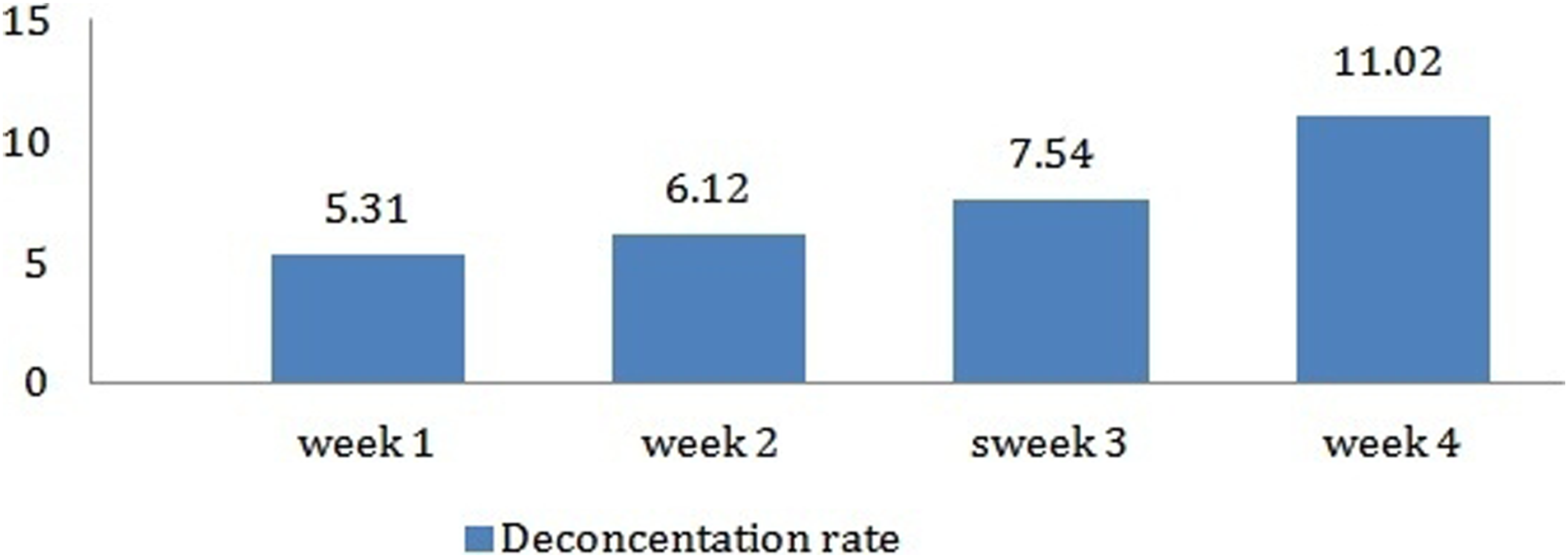
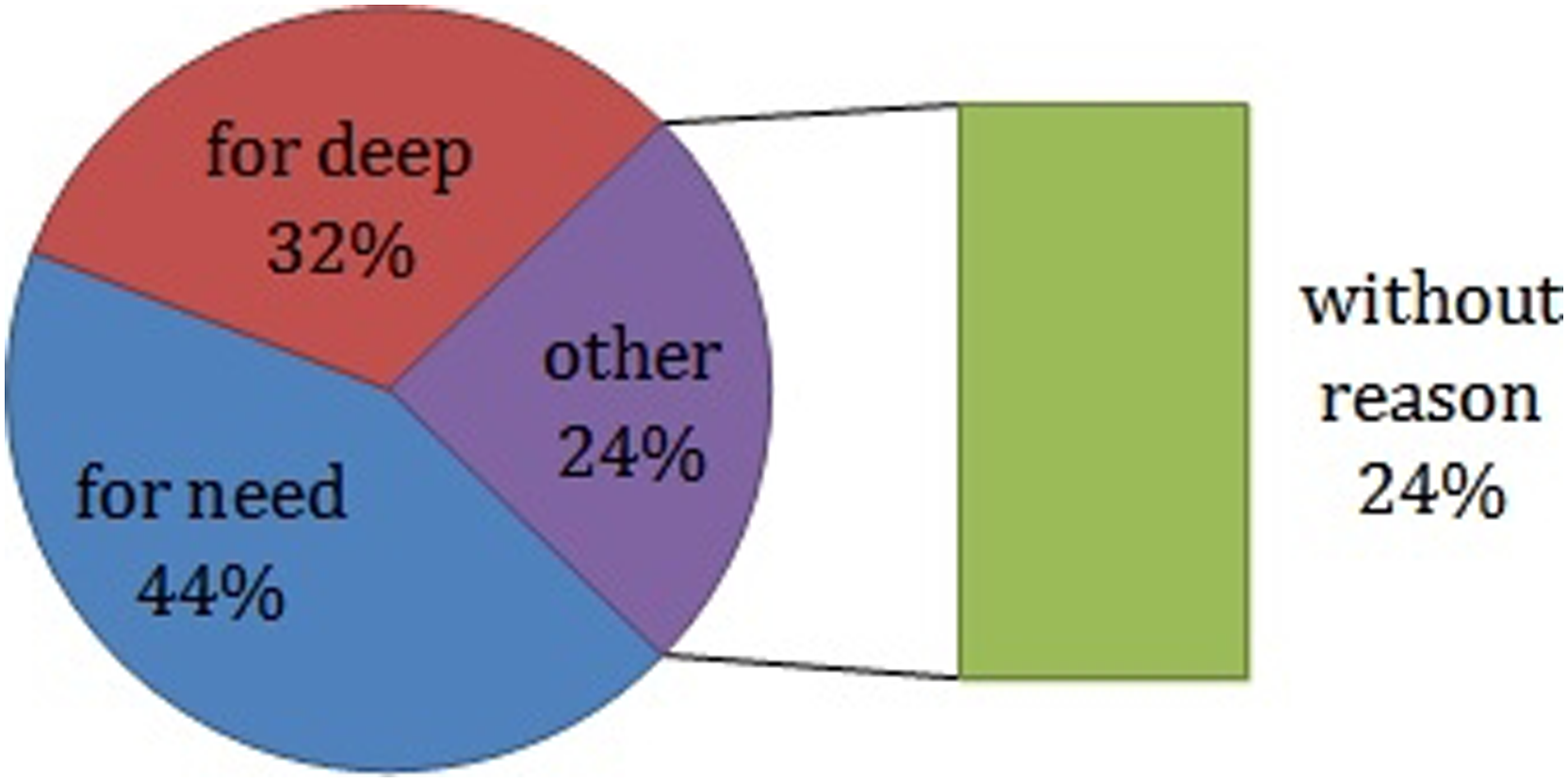
Thus, we found that 44% of participants conducted visits or made queries outside the platform because they did not understand the concepts presented in the course. 32% of other participants responded that their visits it is to deepen their learning. In other words, we can deduce that 76% of learners visited external environment for poorly understood or not mastered domain concepts, which support our assumption. The other remaining learners (24%) justified their external visit for no reason related to the course content (the contents visited are not related to the content of the course). So, the main reason for the learner to move from one concept to another is the need to learn.
To check if the visited content outside the platform related to the content of the course, we analyzed the similarity between these contents. But before doing this, we proceed in the following section to create groups of learners to identify those who are in trouble.
Creating groups of learners
Using the K-means clustering algorithm, we decide that we can group learners in three clusters as shown in Table 1, to have the three usual categories of homogenous learner groups (high-level, middle, and lower-level performance). The percentage of learners in each group is satisfactory since the number of members in each group is reasonably balanced. The mean and standard deviation (SD) of the results of the test questionnaire for each group are shown below. • Cluster 1 (N = 42): The 42 learners in this group responded well to the test. • Cluster 2 (N = 82): Learners in this group had average results. • Cluster 3 (N = 58): Learners in this group had poor results. test questionnaire results for each cluster.

After identifying the clusters according to the test results, we analyzed the weights of the visited concepts on the Web.
Weights of concepts
Table 2 below shows the average and standard deviation of the weights of the concepts on the visited Web pages as well as these regarding queries on the search engine
5
for each cluster identified in the previous section. These values are obtained by first computing the vector of weights of concepts of each cluster. • Weights of the concepts regarding the visited Web pages and queries on the search engine.
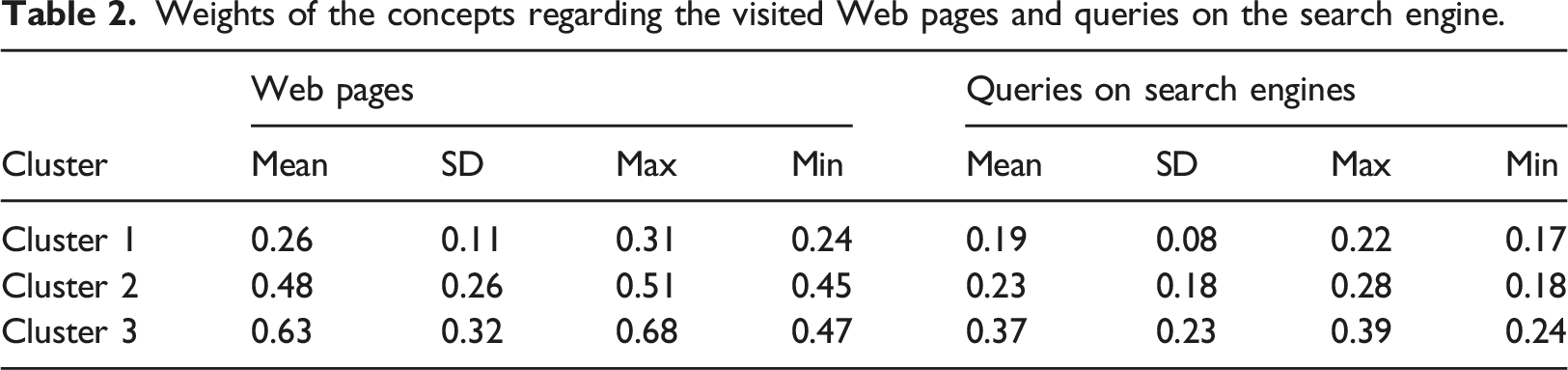
As for the weights of concepts regarding queries on the search engine, we found it minimal compared to the other two clusters. The learner with the best performance in the test questionnaire has a weight of 0.2. • •
Thresholds setting
To set the thresholds for the weights of concepts that identify the concepts that may be difficult for learners and/or those that may be improved by the course author, we rely primarily on the results obtained from the medium and weak learners (Clusters 2 and 3).
Thus, we choose to set the thresholds as the average of the minimum values of Cluster 2 and maximum values of Cluster 3. Therefore, thresholds are set at: • •
Results’ evaluation
To identify the reasons that pushed learners to acquire knowledge outside the platform, we first analyze the mean and the standard deviation of the following indicators regarding the learners’ behavior in the course: the page visit frequency, the diversity, the exploration, and the page reading duration for each cluster. The results are detailed in the following Table 3:
Indicators describing the learners’ navigation behaviors in the course for each cluster.
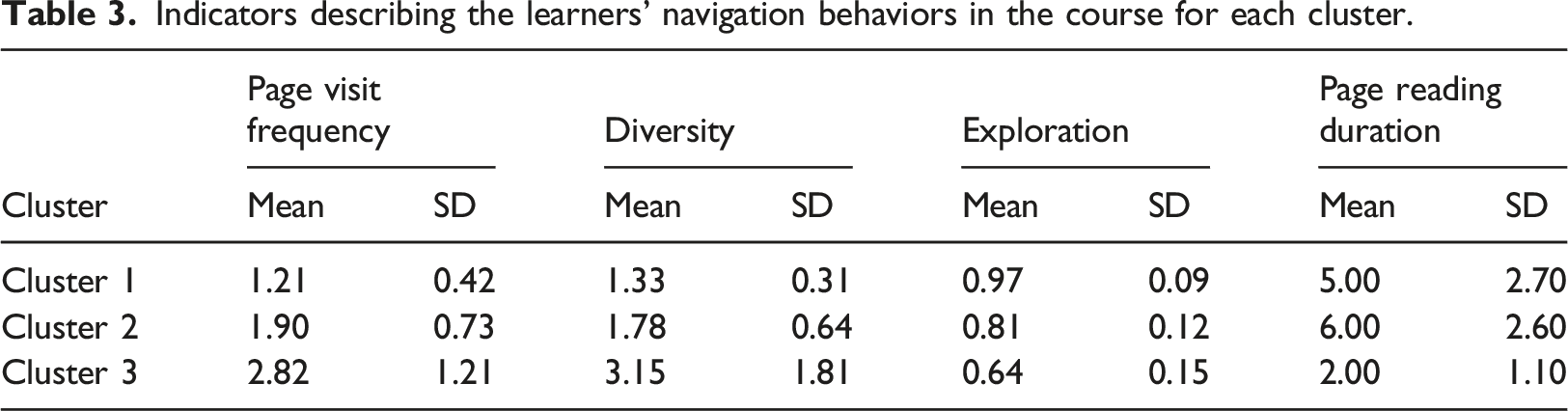
By contrast, in Clusters 1 and 2, the learners perform a deep reading, with a considerable time spent reading the educational content; furthermore, they revisit less the course’s pages.
Average of deconcentration indicator and visit duration rate for each cluster.
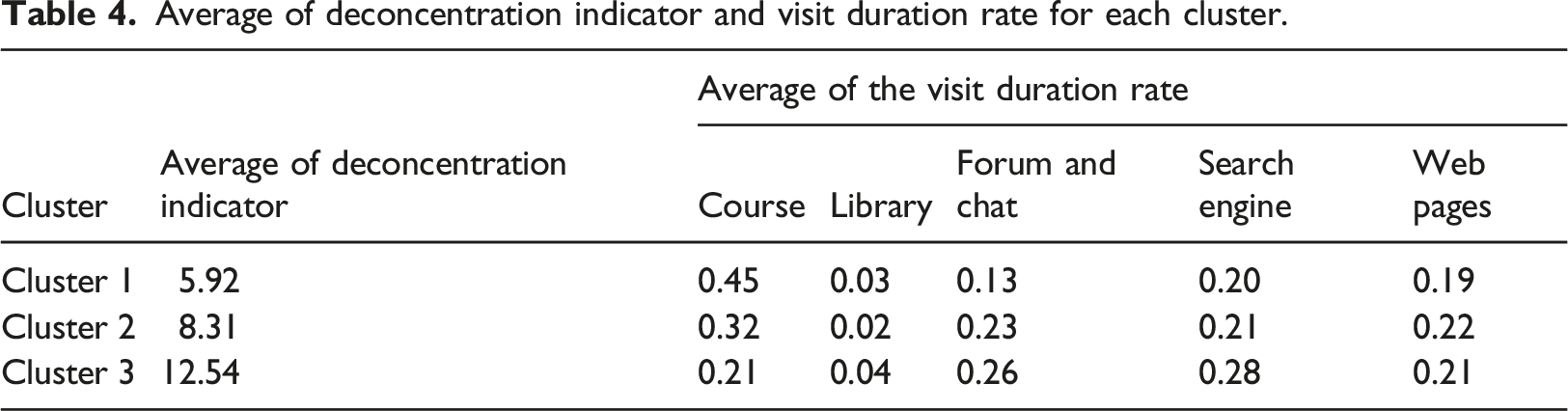
We note that learners who have poor performance in the test questionnaires (Cluster 3) have a propensity to leave the platform (average concentration of 12.54) and have the lower visit duration rate for their courses (21%) compared to the learners in other clusters. On the other hand, learners who have the best test results (Cluster 1) focus much more on their courses: the average of deconcentration indicator is 5.92 and the visit duration rate for the course is 45%.
Average visit similarity score for each cluster.
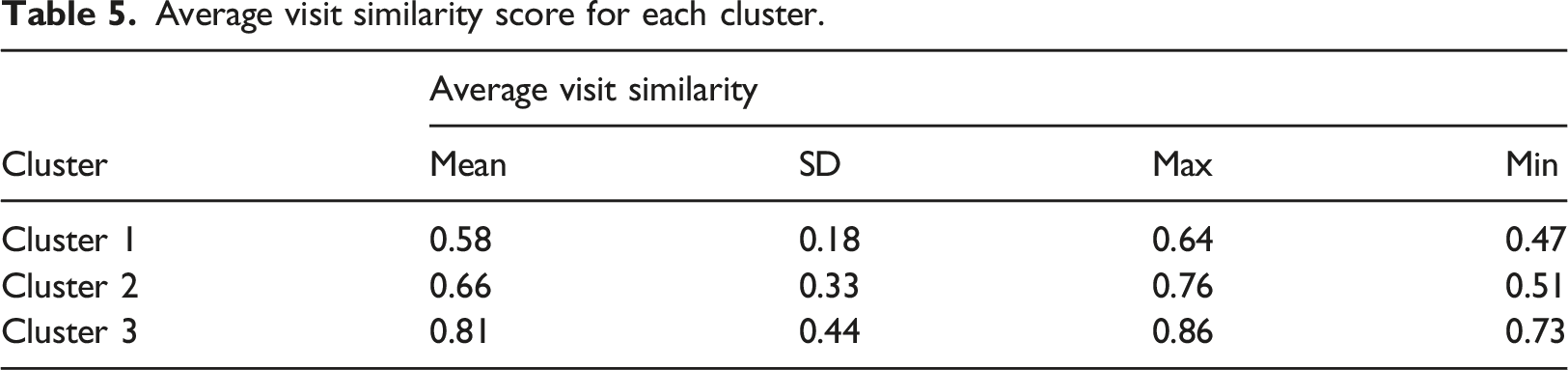
We note that the similarity score is high for the three clusters, which shows that learners visit external sites whose content is often related to the course content. We also note that Cluster 3 contains the highest similarity score, which may mean that they are really in difficulty or that they search other content better adapted to them to explain the course concepts.
To recognize the causes of learners’ tendency, we mainly use the analysis of the learners’ results in Cluster 3. However, we listed pages with frequency navigation greater than one (Figure 13) and, for these pages, we noted the frequency to leave these pages to visit Web pages (Figure 14); these frequencies are compared with those from the various clusters. Frequency navigation page greater than one. Frequency to leave page from course to outside platform.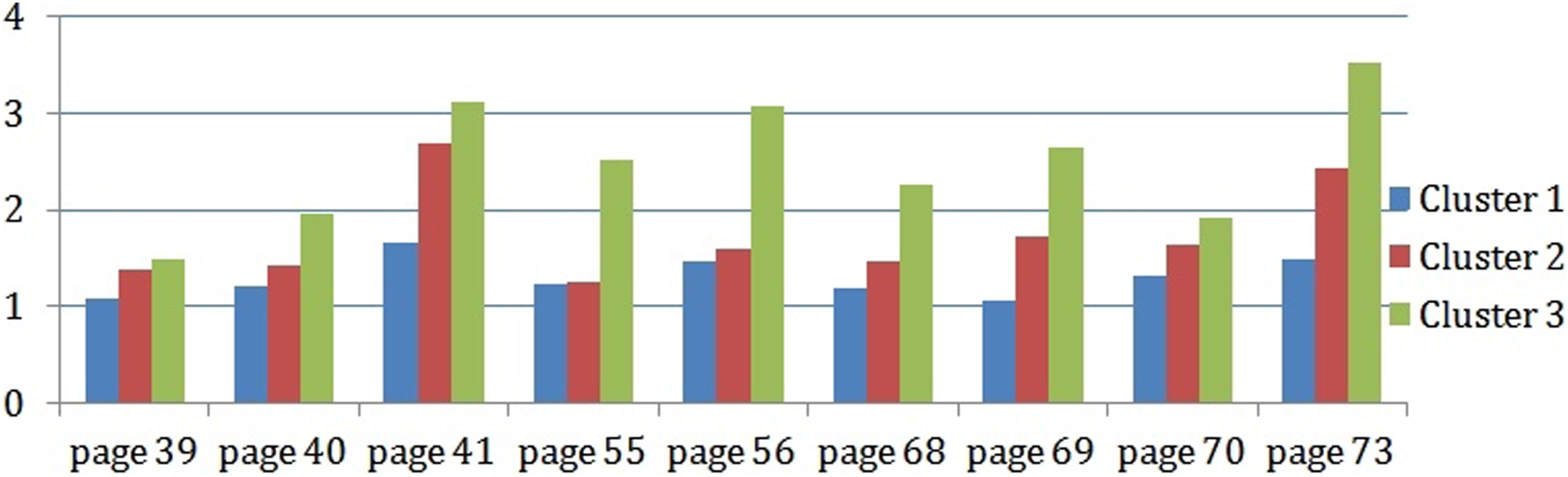
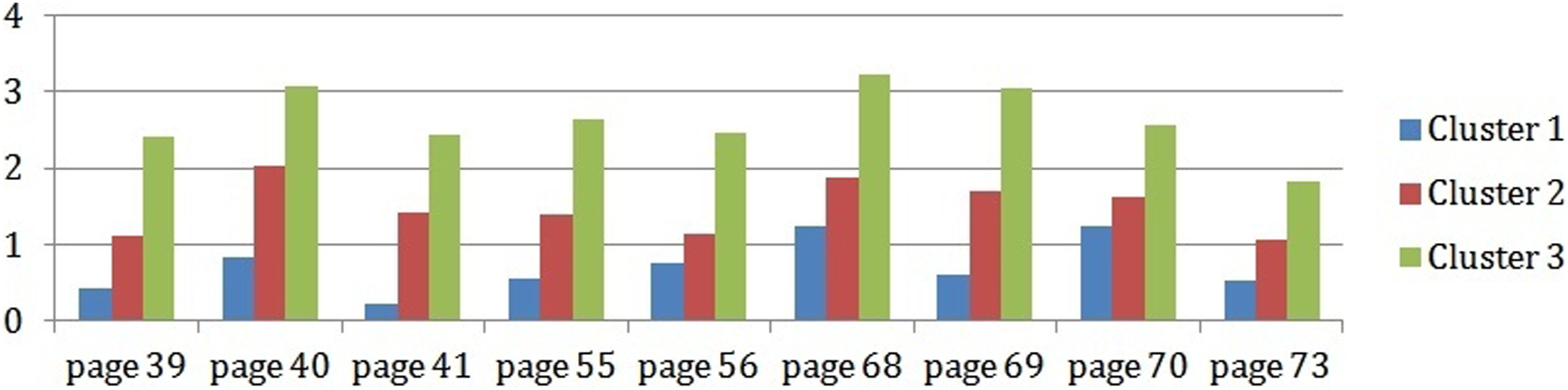
The pages presented in the Figure 14 focus specifically on concepts and sub-concepts of forms management (pages 39–41), Mysql (55–56), and session and cookies (68–69, 73). As we observe, these pages have been revisited more than once and are the pages inducing external navigation—and similarly for the other two clusters. This is due to the complexity of the concepts contained in these pages, as these concepts are new (not seen in other courses) and are strongly related.
Figure 15 summarizes the average score obtained in the test questionnaire by the learners for these three concepts and their sub-concepts for the different clusters. Average Mark in test questionnaire of the high weight of concepts visited in Web pages.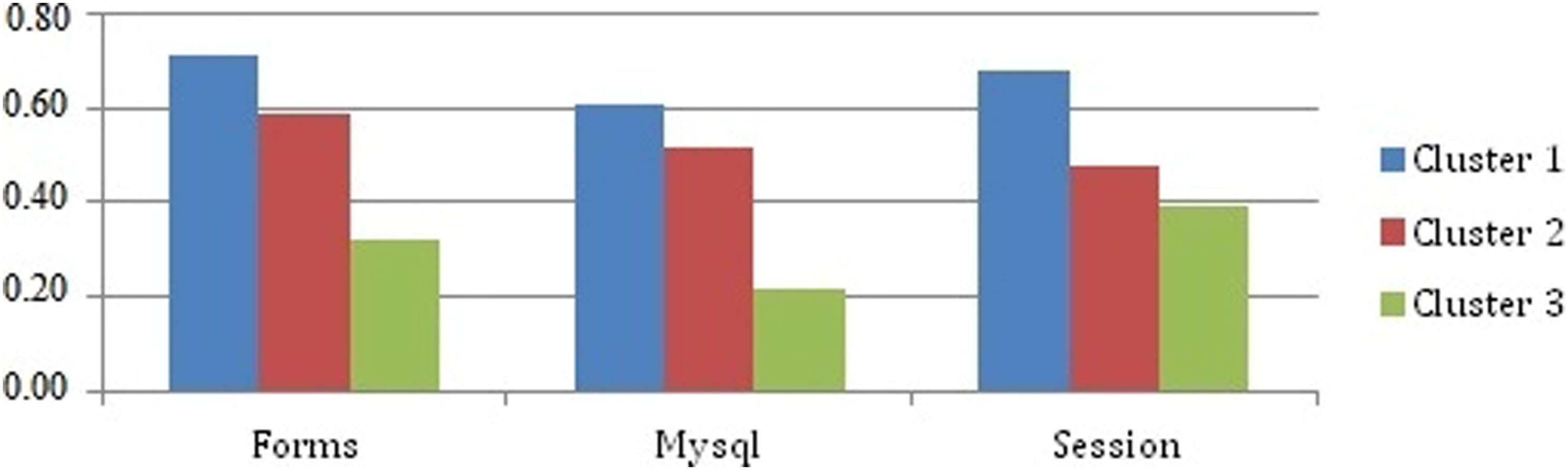
The mark obtained in the test questionnaire by the learners in Cluster 3 for the three previous concepts is the lowest ones (<0.4). This can clearly justify the high page visit frequency observed for these concepts (Figure 13).
The correlation between mark of concepts in test questionnaires and weights of concepts visited in Web Pages is negative (r = −0.354; p < .05), as the correlation with the weight of the concepts regarding queries on the search engine (r = −0.256; p < .05). Therefore, this sustains the interpretation that a learner who is in difficulty tends much more to visit and search for the concepts that are problematic for him.
Discussion and limitations
In summary, the students in Cluster 3 have lower learning performance than those from the other two clusters and have a lack concentration comparable to the students from the other two clusters. In general, the problematic concepts are often those contained in the pages revisited more than once and that have been left to visit external content which is similar to the course content. This behavior can be due to the poor definition or explanation of these concepts and/or to an overload of information on these pages.
The weight of concepts, visited on web pages and regarding queries in search engine, is one of the keys that allows us to identify poorly understood concepts by most learners (Concepts C5, C6, C8). This observation is corroborated by the page reading frequencies, deconcentration, and visit similarity indicators. Consequently, this experiment validated that our learner’s model helps detect the concepts poorly mastered by learners, which should help the tutor in his/her tracking task and the course’s author to improve the course material.
However, we fixed the threshold in this experiment manually according to the test questionnaire, further work needs to be done to automatically fix these thresholds and bring out these problematic concepts and learners in difficulty. Another limitation of the approach is the difficulty of getting real-time trace.
Conclusion
In this paper, we highlighted the ability to observe and exploit a learner’s interactions during learning sessions to improve and adapt the learner’s content path. This path, represented as an XML log file, is used as a resource for a semantic analysis approach that we presented. The resulting learner model is a layered overlay model proposed to inform about the link between the visited contents outside the learning environment and the course, using a domain ontology that represents the studied course. The weight of concepts modeled in the learner’s knowledge model are used to identify the domain concepts that cause problems to learners in order to help the course author review and enrich his/her course, and the tutor to support learners having difficulty with these concepts.
An experiment, carried out on a group of learners taking a PHP course, enabled us to validate the proposed approach and to calibrate some parameters to identify domain concepts that appear to be poorly understood. More specifically, this experiment allowed us to validate the hypothesis that learners often rely on external document to compensate for a lack of understanding or for insufficient knowledge acquired from the learning environment.
The proposed approach is used as a complement to other methods and tools used to detect learners in difficulties such as tests, tutoring etc. It is an approach used to enrich the learner model, only, this approach is not reliable.
Although these results are promising, further work needs to be done by additional experiments and tests, which we are currently conducting. We also envisage as perspective, to associate the learning preferences of the learners in their learning style, to be able to detect in advance the reason that pushes them to consult the concepts of the domain outside the platform. Moreover, it should be stressed that we have considered here only the web as an external environment, based on the URLs of the browsed web documents. One line of research we would like to investigate is to consider other contexts, such as communications and collaborations with other learners and Social Media.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.