
Abstract
In the socio-technical imaginary of higher education, algorithmic decision-making offers huge potential, but we also cannot deny the risks and ethical concerns. In fleeing from Frankenstein’s monster, there is a real possibility that we will meet Kafka on our path, and not find our way out of the maze of ethical considerations in the nexus between human and nonhuman agencies.
In this conceptual article, I map seven dimensions of student surveillance on an experimental matrix of human-algorithmic interaction to consider some of the ethical implications of algorithmic decision-making in higher education. The experimental matrix of human-algorithmic decision-making uses the four tasks of ‘sensing’, ‘processing’, ‘acting’ and ‘learning’ to open up algorithmic-human agency as comprising a number of possibilities such as (1) where only humans perform the task; (2) where the task is shared between humans and algorithms; (3) where algorithms perform the task but with humans supervising; and (4) where algorithms perform the tasks with no human oversight.
I use this matrix to engage with seven dimensions of how higher education institutions collect, analyse and use student data namely (1) automation; (2) visibility; (3) directionality; (4) assemblage; (5) temporality; (6) sorting; and (7) structuring. The article concludes by proposing a number of pointers to be taken into consideration when implementing algorithms in a higher education context from a position of an ethics of care.
Prologue
‘You are my creator, but I am your master – obey’ (Dr Frankenstein addressed by his creation). (Shelley, 2014: 192; emphasis added)
Algorithmic learning and decision-making resemble the dream of science to replicate (and surpass) human intelligence without the accompanying frailties of a human physical frame. Like Dr Frankenstein in contemplating the potential of his creation, algorithmic systems and governance by algorithms (‘algocratic’) (Danaher, 2014, 2016b; Morozov, 2013) leave us ‘dizzy with the immensity’ (Shelley, 2014: 60) of their prospects and potential. As concerns regarding the intended and unintended harm in algocratic systems rise to match (and in some cases surpass, at least in some circles) the hype and reality surrounding their potential (Ng, 2016), we may respond to these systems like Dr Frankenstein when he witnessed ‘the dull yellow eye of the creature open’ – ‘How can I describe my emotions at this catastrophe, or how delineate the wretch whom with such infinite pains and care I had endeavoured to form?’ (Shelley, 2014: 66). What we have desired and dreamed of may, upon realisation, fill us with ‘breathless horror and disgust’ (Shelley, 2014: 67). Like Dr Frankenstein we may recoil in horror and, as we flee our creation, we may find that there is no escape from the horror. The only alternative left is a Kafkaesque engagement where there is no clear exit or resolution to the tension.
Latour (2012: par. 3) points out that in works using the story of Frankenstein, we often ‘confuse the monster with its creator’ and ‘we have forgotten that Frankenstein was the man, not the monster, [and] we have also forgotten Frankenstein’s real sin’ in his abandonment of the creature to itself. In the story, the monster reminds Frankenstein that he, the monster, was once benign and good-natured but that Frankenstein and other humans’ reaction to him made him miserable and changed his nature. Of specific importance for this article is Latour’s proposition that knowing that there will be unintended consequences to our design and development of technologies should not prevent us from experimentation but we should accept that ‘unintended consequences are part and parcel of any action’ (2012: par. 25).
Reflecting on the impossibility of our escape from our creation of algorithmic decision-making, or its consequences and unfolding, it seems as if we should accept that owing to our entanglement with the technologies we create (Latour, 2012) fleeing is not an option. Algorithmic decision-making, as our creation, bears our image and resemble our biases and proneness to errors (Osoba and Welser IV, 2017). As such, Dr Frankenstein realised, we ‘cannot suddenly stop being involved’ (Latour, 2012: par. 43). We have (no choice but) to face our creations and ‘care for our technologies as we do our children’ (Latour, 2012: par. 1) however uncomfortable this may be. Shellenberger, in reflecting on Latour’s (2012) proposal, states: Our technologies, like our children, go wrong. They will create new problems. We cannot create perfectly formed new technologies, only flawed ones. We must, thus, continually care for and improve them, just as we do our children. (2012: par. 12)
It is in this confrontation with algorithmic decision-making as a creature of our own making (Watters, 2017) that we are tempted into the claustrophobic maze found in Kafka’s works. For example, in ‘The Trial’ (Kafka, 2003) the protagonist enters a world where there is no way out and the only certainty is the ‘uncertainty of the outcome’ (Hofman, in the Introduction to Kafka, 2007: x). In the stories told by Kafka, events cannot be reversed, but ‘the end has not yet happened’ and hope is denied for the protagonist (Hofman, 2007: xi). In this maze where sense-making is, per se, impossible, the individual faces the seemingly ouroborotic pointlessness, where even suicide brings no relief (Kafka, 2003: 6). ‘The Trial captures the sense of helplessness, frustration, and vulnerability one experiences when a large bureaucratic organization has control over a vast dossier of details about one’s life’ (Solove, 2001: 1421). The helplessness of individuals encountering the ‘black box’ (Pasquale, 2015) of algorithmic decision-making resembles experiences in precrime assemblages where ‘people are guilty until proven innocent, verdicts are reached before trial, and punishments imposed before any crime is committed’ (Mantello, 2016: 2). As such algorithms are ‘not just abstract computational processes; they also have the power to enact material realities by shaping social life to various degrees’ (Butcher, 2017: 40) over which individuals have, increasingly, very little control.
The purpose in this article is therefore to engage with algorithmic decision-making – its potential and claims of indifference and objectivity as well as its biases and threat of dehumanisation (Solove, 2001) and map a way forward that refuses to be trapped into thinking in binary terms of algorithmic decision-making as either detrimental or harmless (Knight, 2016). We have to rise above thinking in binaries and confront algorithmic decision-making as ‘technical solutions to complex socio-technical issues’ (Boyd, 2017).
Introduction
Central to this article is the notion of the social or sociotechnical imaginary relating to algorithms and algorithmic decision-making not only as those ideas that circulate in general and scholarly literature, but how these ideas reflect something deeper, more ‘primordial’, of how we make sense of the potential and dangers of new technological developments and practices. Taylor (2002: 106) points out that the social imaginary is much more than just the way we think about social reality – our ‘intellectual schemes’ – but points to how people ‘imagine their social existence, how they fit together with others, how things go on between them and their fellows, the expectations that are normally met, and the deeper normative notions and images that underlie these expectations.’ A social imaginary, according to Taylor (2002), is ‘carried in images, stories, and legends’ realising and providing legitimacy to practices and believes that become accepted and unquestioned.
It is an almost impossible task to map the social or socio-technical imaginary pertaining to algorithmic decision-making. Part of the public and scholarly fascination with algorithmic decision-making is the increasing visibility of the digital processes that shape our lives (Beer, 2017a; Dourish, 2016; Gillespie, 2012) – whether, for example, in the comfort and choice they provide customers or in concerns about bias and red-lining (Bond, 2016; Gilliard, 2016; Henman, 2004; Johnson, 2015). Williamson (2016b: par. 1) points to the ‘startling increase in the amount of media coverage of algorithms over the last year.’ In a tentative typology, Williamson (2016b) classifies the public discourses on algorithms in the context of the United Kingdom (UK) into a number of broad categories such as ‘the algorithm as a useful scientist whose expertise is helping society’, algorithms as referring to ‘brainy expertise’ and as ‘problem-solvers.’ There is an increasing awareness of how algorithms filter what can be seen; reorder space, sovereignty, time and how they transform the notion of human subjectivity (Amoore and Poitukh, 2016): Algorithms are becoming shadowy figures that in some way embody our wider fears and concerns. The visions we have of algorithms chime with broader feelings of a loss of control, of accelerated lives that are speeding away from us, of our inability to cope with the unmanageable information that we are exposed to, or the feeling that our lives are governed for us and that we have less discretion, autonomy or voice (Beer, 2017b). (Also see Beer, 2017a; Dourish, 2016; Pasquale, 2015; Williamson, 2016b)
In the context of this article, it is important to distinguish between algorithms, algorithmic decision-making and algocratic systems. By algorithms and algorithmic decision-making are generally well-understood, the notion of ‘algocracy’ or ‘governance through algorithms’ needs a brief explanation. The term algocractic was coined by Aneesh (2006, 2009) and refers to how governance by algorithms become invisibly embedded in the design and user experience and not only exclude the potential of human or user interrogation or disagreement, but also excludes other options. In algocratic systems ‘code appears to have … taken over the managerial function of supervision and guidance’ (Aneesh, 2009: 355) resulting in ‘an environment in which there are only programmed alternatives to performing the work’ (Aneesh, 2009: 356). Danaher (2016b: par. 2) states that algocracy ‘is an unorthodox term for an increasingly familiar phenomenon: the use of big data, predictive analytics, machine learning, AI, robotics (etc.) in governance-related systems.’ In the discussions to follow, I will use the notion of algocracy in the broad sense of ‘being ruled by algorithms’ (see Danaher, 2016b). [Later in the article I will fully explore the conditions under which algorithmic decision-making morph into algocracy].
In the context of education, algorithmic decision-making is portrayed as ‘intelligence unleashed’ (Luckin et al., 2016), as replacing teachers (Clark, 2016a, 2016b), as ‘becoming a massive calculated public’ (Williamson et al., 2014) and as introducing, supporting and normalising technocratic, personalising and personalised learning as part of adaptive learning systems (Chen, 2016; Watters, 2014, 2016a; Williamson, 2016a). Algorithms are also increasingly central to the emerging field of learning analytics as a focus of research and practice. Williamson et al. (2014) warn that: [the] algorithms that enable learning analytics appear to be ‘theory-free’ but are loaded with political and epistemological assumptions. The data visualisations produced by learning analytics – data dashboards as they’re frequently described – also act semiotically to create meanings.
In this article, I will firstly map the sociotechnical imaginary of algorithmic decision making before exploring how this imaginary plays out in the field of (higher) education through the collection, analysis and use of student data in learning analytics. After establishing a shared tentative understanding of this sociotechnical imaginary, I will engage with two conceptual frameworks, namely the experimental framework by Danaher (2015) on the nuances of human-algorithm interaction and collaboration, and the typology on student surveillance by Knox (2010). I will conclude by summarizing a number of pointers for how education can and should make sense of the perils but also the potential of algorithms and algorithmic decision-making in education.
Mapping the sociotechnical imaginary of algorithmic decision-making
In the socio-technical imaginary, notions of algorithms and algorithmic decision-making are often conflated with a variety of other terms such as data, big data, computation, programming, AI, recommender systems and various statistical and/or mathematical models and analytical processes (Butcher, 2017; Dourish, 2016; O'Neil, 2016; Williamson, 2016a, 2016b; Williamson, 2017). In this article, algorithms therefore need to be understood and investigated ‘within those systems that give them meaning and animate them’ (Dourish, 2016: 2). (For a full discussion of algorithms ‘and their others’, see Dourish, 2016).
Beer (2017a: 1) suggests that exploring the social imaginary of algorithms enables us: to see how algorithms also play a part in social ordering processes, both in terms of how the algorithm is used to promote certain visions of calculative objectivity and also in relation to the wider governmentalities that [algorithms] might be used to open up. (emphasis added)
It is important to distinguish between two aspects of the social power of algorithms namely the ‘power of the algorithm’ and the ‘power of the notion of the algorithm’ (Beer, 2017a). With regard to the first aspect, Beer (2017a: 4) points to concerns regarding the ‘meshing of human and machine agency’, or in the words of Introna (2011, quoted by Beer, 2017a: 5) as the ‘encoding of human agency.’ (see the later discussion on Danaher, 2015). The encoding of human agency becomes part of organisational architecture and shapes/informs/enacts decision-making that in turn shapes and informs human lives. Of particular concern in the context of the power of the algorithm is its ‘ability to make choices, to classify, to sort, to order, to rank’ (Beer, 2017a: 6). As such algorithms make choices on identifying and prioritising what matters, what becomes visible and what disappears. It is therefore important to understand algorithms and algorithmic decision-making, regardless of context, as ‘deeply relational and being a product of a set of associations’ (Beer, 2017a: 7). This supports the statement by Beer that: Algorithms “govern” because they have the power to structure possibilities. They define which information is to be included in an analysis; they envision, plan for, and execute data transformations; they deliver results with a kind of detachment, objectivity, and certainty; they act as filters and mirrors, selecting and reflecting information that make sense within an algorithm’s computational logic and the human cultures that created that logic. (Beer, 2017a: 97–98)
Engaging with algorithms and algorithmic decision-making as our creatures (like Frankenstein’s monster) calls forth an ouroborotic Kafkaesque journey where the tensions between the dangers and the potentials of algorithmic decision-making are never (really) resolved. It is therefore important to remember that: As the profile of algorithms has grown and as their actions become the source of discussion, we might want to avoid thinking of them as good and bad algorithms and think instead about how these media forms mesh human with machine agency and what this means. Reducing it to algorithms as the problem and solution might cause us to miss just how much of the decision making and visibility is in the hands of code. Whether we see algorithms as villains or heroes (or both), what really matters is how those algorithms are used and deployed to shape who and what gets heard in the mutating public sphere. (Beer, 2017b)
Algorithmic decision-making in education
Selwyn (2014: 6) proposes a critical approach to understanding technology in education as ‘a knot of social, political, economic and cultural agendas that is riddled with complications, contradictions and conflicts.’ In the light of the ‘truthiness’ and ‘mythical hope’ embedded in the educational discourses pertaining to technology (and algorithmic decision-making) we need to treat algorithmic decision-making as, per se, problematic and ‘slow down the pace of our discussions in the face of the fast-moving, rapidly changing and often ephemeral nature of the topic’ (Selwyn, 2014: 17). In this article, I hope to, temporarily, interrupt our thinking about the potential but also perils of embracing algorithmic decision-making in education and embrace the broad tenets of a critical approach to thinking about algorithmic systems as proposed by Kitchen (2016) and others (Dalton and Thatcher, n.d.; Kitchin and Lauriault, 2014; Watters, 2016b).
A number of factors shape not only the power of algorithmic decision-making but specifically the notion of algorithmic decision-making in education (Beer, 2017a; Prinsloo, 2015, 2016b). While higher education institutions have always collected, analysed and used student and operational data, the increasing digitisation of learning, advances in technology and software and the proliferation of auditing and quality regimes result in an increased attention to the potential and dangers of algorithms and algorithmic decision-making. Prinsloo (2016b: 332) points to the ‘seemingly never-ending need for more data, analysis and prediction in higher education’ that are often initiated by and support ‘the dominant narratives of a positivist, quantification fetish’ a ‘neoliberal lexicon of numbers’ (Cooper, 2014: par. 5), the ‘tyranny of numbers’ or ‘measurement mania’ (Birnbaum, 2001: 197). All of these resemble the different nuances and scope of technocratic knowledge, mentality and dreamscapes that prioritise objective, scientific, and value-free technical expertise (Ribbhagen, 2011; Williamson, 2016a). A new development is the impact of big global technology companies and venture capitalists who are increasingly shaping educational discourses as ‘the Silicon vocabulary is becoming part of the language of education’ (Williamson, 2016a: 1). The normalisation of the Silicon Valley narrative is ensured as a variety of tech entrepreneurs, venture philanthropists and software engineers are becoming part of the governance of schools and universities (Williamson, 2016a: 15). While the obsession with data and need for evidence are driven by the discourses and practices surrounding efficiency, effectiveness and institutional success (Miyares, 2017), Biesta (2007, 2010) warns that while effectiveness, efficiency and evidence are necessary, these should be accompanied by a consideration of whether an intervention is appropriate.
The field of learning analytics has, since its emergence in 2011, foregrounded the potential of the collection, analysis and use of student data to increase the effectiveness of teaching and learning and to support the effective and appropriate allocation of resources (Siemens, 2011). Central to the collection, analysis and use of student data is the need to develop ‘actionable insights through problem definition and the application of statistical models and analysis against existing and/or simulated future data’ (Cooper, 2012: 3). In developing actionable insights, learning analytics acts as ‘a structuring device. It is not neutral. It is informed by current beliefs about what counts as knowledge and learning, coloured by assumptions about gender/race/class/capital/literacy and in service of and perpetuating existing or new power relations’ (Prinsloo, 2015). Students don’t have access to, or the knowledge and skills to understand and engage with our models and analyses – ‘[l]ike gods, these mathematical models [are] opaque, their workings invisible to all but the highest priests in their domain: mathematicians and computer scientists. Their verdicts, even when wrong or harmful, [are] beyond dispute or appeal’ (O’Neil, 2016: 3). There are also concerns regarding the epistemologies and ontologies informing learning analytics as well as considerations of ethics and privacy (Drachsler and Greller, 2016; Godor, 2016; Prinsloo and Slade, 2017; Vuorikari and Muñoz, 2016). Despite evidence of more nuanced approaches to learning analytics, claims of data, learning analytics, algorithms and AI ‘revolutionising’ education are a persistent phenomenon (e.g. Herold, 2016; Miyares, 2017; Westervelt, 2016, 2017).
Two experimental frameworks for mapping the potential and peril in algorithmic decision-making in education
There may be many possible approaches in understanding and so mapping the nuances, potential and risks for using algorithmic decision-making in higher education. I have chosen two proposals for the purposes of this paper, namely, an experimental framework proposed by Danaher (2015) and an unpublished conference paper by Knox (2010). The choice of these two ‘maps’ was deliberate. The experimental framework proposed by Danaher (2015) maps, in my opinion, a nuanced understanding of the spaces for ‘collaboration’ between humans and algorithmic decision-making processes. In the social imaginary pertaining to algorithmic decision-making there is often a relative ‘lack of nuance when it comes to the different forms that algocratic systems could take’ (Danaher, 2014: par. 2). Instead we are offered binary thinking where algocratic systems are either villains or saviours (Beer, 2017b), or the monster in ‘Frankenstein’ or Silicon Valley as saviour (Watters, 2015).
The Knox (2010) typology is, as far as I can establish, the only typology that maps the increasing surveillance of students in higher education. The typology not only complements the experimental framework by Danaher (2015) but also allows us to think through how algorithmic-human decision-making plays out during the learning journey, and more specifically, in the context of learning analytics.
I will first discuss the experimental framework by Danaher (2015) before using the Knox (2010) typology to illustrate the scope and implications of algorithmic decision-making in higher education.
An experimental framework (Danaher, 2015)
Danaher proposes his experimental framework as a way to understand ‘the threat of algocracy’ (2014: par. 1), a concept he defines in a later article as ‘a situation in which algorithm-based systems structure and constrain opportunities for human participation in, and comprehension of, public decision-making’ (2016: 246) [see earlier introduction]. As such algocracy is a potential threat in the context of predictive or descriptive data-mining algorithms used in data-mining as ‘the non-trivial process of identifying valid, novel, potentially useful and ultimately understandable patterns in data’ (Zarsky, 2011: 291; emphasis added). It is important to point to the difference between algorithmic decision-making and algocracy where the latter suggests a situation where humans are excluded from the data-mining and analysis process and where algorithms make decisions without human oversight and input. Zarsky points to a further complicating factor by differentiating between interpretable and non-interpretable data-mining systems where the latter ‘rely on factors that are too complex for humans to understand’ (2011: 293) or participate in. The exclusion of human oversight and increasingly human understanding resemble Dr Frankenstein’s monster, as being the realization of a dream come true and, at the same time, a horror unfolding.
Danaher (2016a, 2016b) refers to the distinctions, proposed by Citron and Pasquale (2014) between the following possibilities to illustrate human-algorithmic interaction: Human-in-the-loop – where robots can select targets and act but only after a human gives the command Human-on-the-loop – where robots and algorithmic systems act but are dependent on human oversight and the possibility of human oversight Human-out-of-the-loop – where robots act independently and autonomously from human oversight, permission or override functions.
Danaher (2015) defines three parameters to map the space for algocratic decision procedures. The first parameter is the domain or type of decision-making. Danaher (2015) points to the importance of the context of application whether legal or bureaucratic, planning agencies, financial governance and regulating authorities. In higher education as a specific context, algorithmic decision-making may be applied in different domains such as determining access to the institution, access to specific qualifications, and access available support, to mention but a few. While algocratic decision-making may share some characteristics across these domains, there may be very specific factors in each domain making the algocratic processes distinctly different between domains. The second parameter consists of four main components of decision-making, namely Sensing – the collection of data from external sources Processing – the organisation of the collected data into useful chunks/patterns as related to foreseen actions or goals Acting – the implementation of the action plans Learning – where the intelligent system learns from past collections/analyses and adapts accordingly.
Human-algocratic decision-making grid (Danaher, 2015).
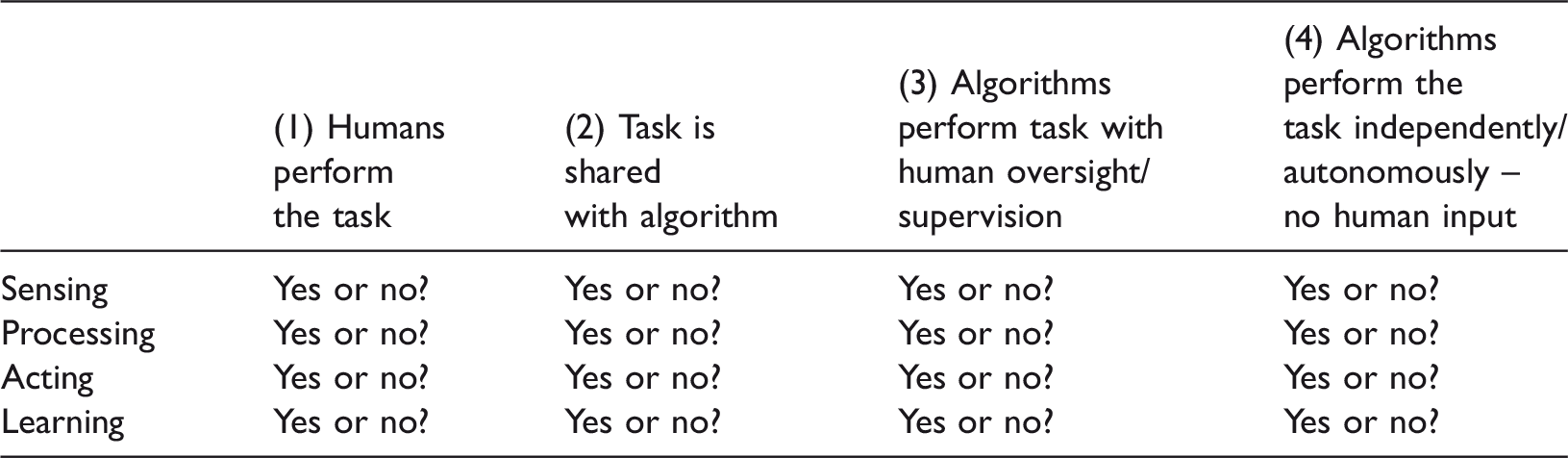
The decision-making grid (Table 1) illustrates and offers 256 logically different possibilities (Danaher, 2015) ranging from a non-algocratic process (where humans perform all four components) to where one or more components are shared with algorithms. In the final combination there is no human participation in any one of the four components of decision-making.
In the context of (higher) education, the experimental framework, Danaher (2015) offers a useful lens for the extent to which algorithmic decision-making may play out. For example, consider an online course where an instructor/faculty member has the responsibility to not only maintain a social, cognitive and teaching presence (Garrison and Arbaugh, 2007), but also the responsibility to ensure that students don’t fall behind and to stimulate involvement. As such the instructor will sense, process, act and learn to respond to an individual student’s progress. While individual attention (sense, process, act and learn) is achievable in small cohorts, it becomes almost impossible in larger classes to sustain a community of inquiry and track students’ (dis)engagement (Prinsloo, 2016a).
Without ignoring the risks and ethical challenges in making use of algorithmic decision-making, it is clear that sharing the sensing, processing, acting and learning components (in whatever combination) with algorithms may allow instructors to be more aware of students’ individual patterns and may offer a first-line of action in offering much needed support for and/or recognition to students (Prinsloo, 2015, 2016a). While much of the discourse surrounding learning analytics focuses on the potential to collect, analyse and use ever more amounts of data, we have to consider the moral and legal implications of knowing more about our students (Prinsloo, 2015; Prinsloo and Slade, 2017). Acting on what we know about our students, whether as humans or in interaction with algorithms, is often curtailed by a range of factors such as a lack of institutional understanding and/or political will; a lack of an integration in institutional sense-making and response systems; resource constraints and the reality that students also have to take responsibility for their choices (Prinsloo and Slade, 2017). While knowing (the first two components Danaher’s framework), as such, does neither imply understanding or action, we cannot ignore the moral and legal implications of ‘knowing.’
Danaher’s (2015) framework therefore raises the interesting question regarding not only on the moral and legal obligations to act on what we know, but also point to the identity of the agent who responds to knowing. Danaher (2015) proposes that while agency or acting on what we know is embedded in the matrix, not acting on a particular fact may constitute an action which in itself raises a range of moral and legal implications. For example, an instructor may decide to act on the data that a student or a group of student has not logged onto the course site or submitted an assignment. In the context of large online classes, while this data may be available, it may be impossible for a human actor to ‘sense’ and ‘process’ the information. An algorithm may make sense and process the data of all students who have not logged onto the course site for a week, and send the list to the student support team or faculty to make contact with these students. In large classes, even acting on the data may be impossible thereby opening the potential that an algorithm may be tasked to identify students who have not logged on for a week, and then send a personalised email to them with a message of support. While human actors may share the sensing, processing, acting and learning with algorithms, it is also possible that algorithms may be employed to sense and process the data of students who have not logged on, combine this knowing with previous learning data and personalise a response to individual students – without humans overseeing or intervening in the sensing, processing, acting and learning. The latter process then resembles an algocracy.
Danaher (2015) acknowledges that the proposed experimental framework has its limitations and that the matrix is, at present, somewhat crude – yet it allows us to ‘see, at a glance, how complex the phenomenon of algocracy really is’, and point to the ‘moral and political problems associated with algocratic systems that completely undermine or limit the role of humans within those systems.’ Engaging with the moral and political problems brings as face-to-face with not only Dr Frankenstein’s monster (in all its horror and glory) but also with Kafka’s protagonist who attempts to find a way out only to get more lost. In the conclusion of this article I will briefly return to Danaher’s (2016a, 2016b) proposal of how we engage with the threats and potential of algorithmic decision-making.
Algorithmic decision-making in the context of surveillance
Looking at the scope, potential and real impact, as well as the ethical challenges in algorithmic decision-making through the lens of surveillance studies (as proposed by Knox, 2010) adds value to the experimental framework suggested by Danaher (2015). Knox (2010) frames his preliminary typology in the context of the need for monitoring or supervising students’ learning. Interestingly, Knox presented his typology a year before the first Learning Analytics and Knowledge Conference in 2011 and before learning analytics was defined as ‘the measurement, collection, analysis and reporting of data about learners and their contexts, for purposes of understanding and optimizing learning and the environments in which it occurs’ (Siemens, 2011). While the surveillance of student learning is fraught with ethical and privacy dilemmas (Slade and Prinsloo, 2013), Knox accepts that monitoring or providing oversight of student learning is an essential characteristic of good teaching. The question is therefore not ‘whether to monitor, but how, and more importantly, what are the implications for teaching and learning?’ (2010: 2). Linking this question to the experimental framework of Danaher (2015) it is also important, at this early stage, to question the ‘who’ of the monitoring – whether the monitoring is done by humans, by humans with some algorithmic-decision, by algorithmic decision-making systems with human oversight or by these algorithmic decision-making systems without human intervention and oversight. (See Knox for his discussion of the distinction between monitoring and surveillance in the context of education).
The different theoretical frames of surveillance – panoptic, rhizomatic and predictive surveillance – form the organising heuristic for Knox’s (2010) typology of surveillance of student learning. Panoptic surveillance, according to Knox (2010) includes the elements of automation and visibility. Surveillance systems, whether enacted or responded to by humans and/or algorithms, act as an automated architecture of discipline and control, ensuring prescribed (and acceptable patterns of) behaviour. Defining surveillance as automated, Knox (2010) does not seem to exclude the human element and his description aligns with the Danaher’s (2014) framework. Panoptic surveillance ‘reinforces and amplifies existing power structures by concealing control agents while exposing the observed’ (Knox, 2010: 4). While learning analytics do not exclude human observation and monitoring, the emphasis is on automated, algorithmic decision-making processes to collect, analyse and increasingly enact these analyses. In the social imaginary of the collection, analysis and use of student data in higher education, automation in the forms of machine learning and AI are increasingly mooted as the future of teaching with intelligent tutoring and responsive systems replacing instructors and support staff (e.g. Clark, 2016a, 2016b; Westervelt, 2016, 2017). Panoptic surveillance raises a number of issues and questions such as the scope of the data collected, the purpose of the collection, who has access to this data and under what circumstances, are students aware of the collection, the purpose, the assumptions and epistemologies informing the collection, analysis and use, who/what is supposed to respond to the data and what are the oversight mechanisms for overseeing all of this? (Prinsloo and Slade, 2016; Willis et al., 2016). The automation and ‘destabilising of visibility’ (Knox, 2010: 9) in panoptic surveillance create uncertainty and insecurity as those who are surveilled are left unsure regarding the scope, timing, outcomes and long-term effects of the surveillance on their learning.
The second theoretical frame of surveillance explored by Knox (2010) is rhizomatic surveillance which maps the nuanced, multidirectional and fluid flows of monitoring as power. Owing to, inter alia, the increase of access to technologies and changing social norms and practices, rhizomatic surveillance entails the concepts of the synopticon (the many watching the few), the panopticon (where the few watch the many) and sousveilance (where the many watch each other). Mantello (2016: 2) refers to an additional nuance in sousveilance namely ‘Ikeaveillance’ where individuals ‘do the securitisation footwork of the state by offering them the opportunity to participate in do-it-yourself, reward-centered, pro-active, networked and, at times, … gamified versions of automated governance.’ These surveillance types are not mutually exclusionary and interact and operate concurrently. Considering the intersections and specificities of these three different forms of surveillance in education therefore necessitates considering the complex and fluid directionalities where it is not only the institution which monitors/surveils students, but students surveil instructors and administrative staff and students surveil one another. Rhizomatic surveillance therefore highlights the multidirectionality of surveillance as well as the ‘amplification of monitoring potentials and the porous boundaries of the surveillant assemblage’ (Knox, 2010: 9).
The third theoretical frame of surveillance in Knox’s typology is predictive surveillance that refers to temporality, sorting and structuring. As such, predictive surveillance ‘performs structuring functions, shaping communications and even material environments for individuals’ (2010: 7). In predictive surveillance ‘the past becomes simulated prologue’ (2010: 6) and students’ past experiences and performance (in and outside of education) becomes a perpetual present determining their access to education, learning trajectories and the scope and intensity of the support they ‘deserve’ (Prinsloo and Slade, 2014a). The scope of the impact of predictive surveillance therefore not only affects the past (what is remembered, foregrounded and retold) but also the future.
Flowing from these three theoretical frames on surveillance, Knox (2010) formulates a preliminary typology consisting of seven dimensions, namely automation, visibility, directionality, assemblage, temporality, sorting and structuring. Tables 2–8 provide examples of Knox’s (2010) typology in combination with elements of Danaher’s (2015) framework and literature in the field.
Dimensions of algorithmic decision-making in teaching and learning (adapted from Knox, 2010) – Automation.

Dimensions of algorithmic decision-making in teaching and learning (adapted from Knox, 2010) – Visibility.
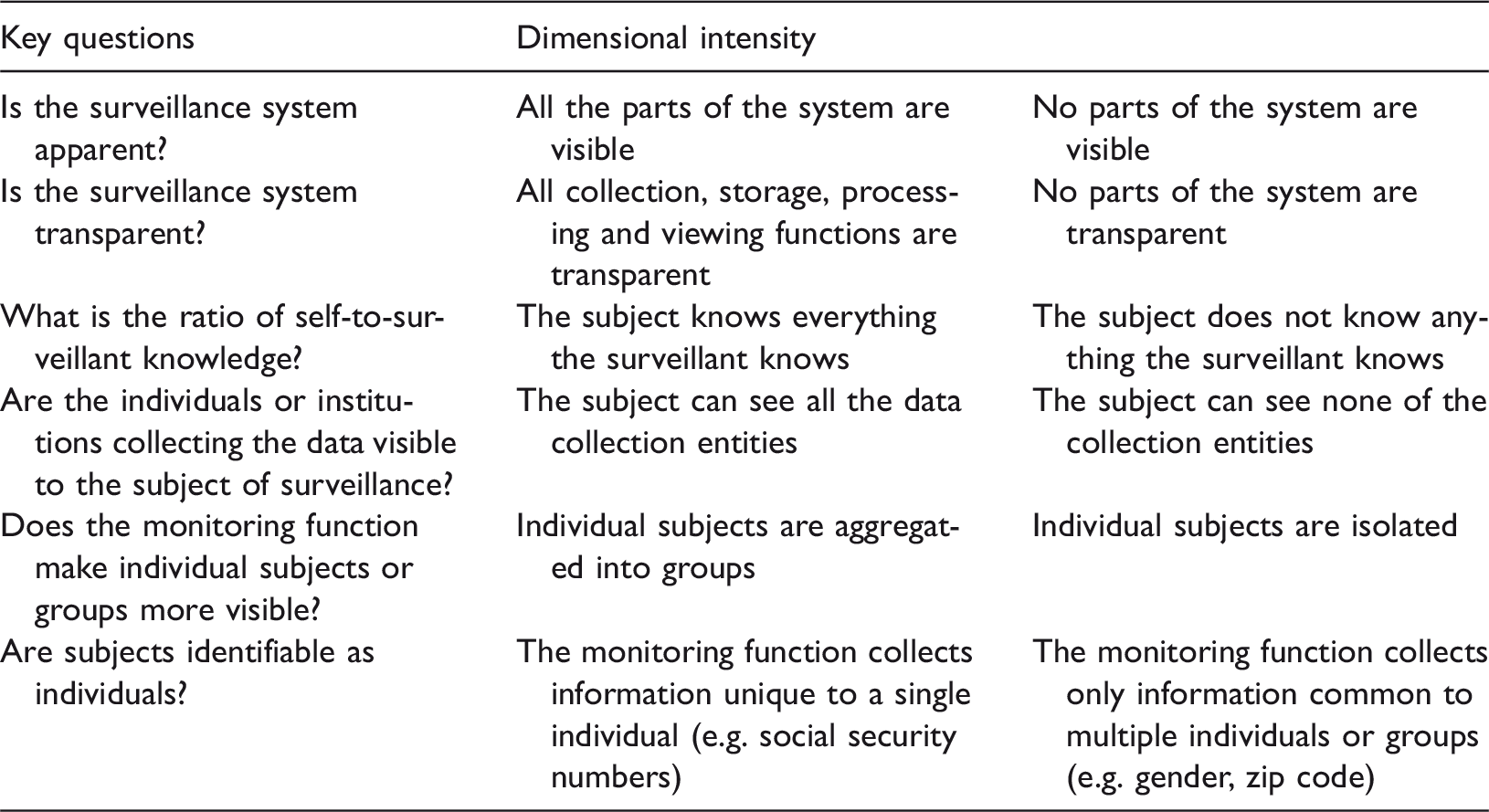
Dimensions of algorithmic decision-making in teaching and learning (adapted from Knox, 2010) – Directionality.
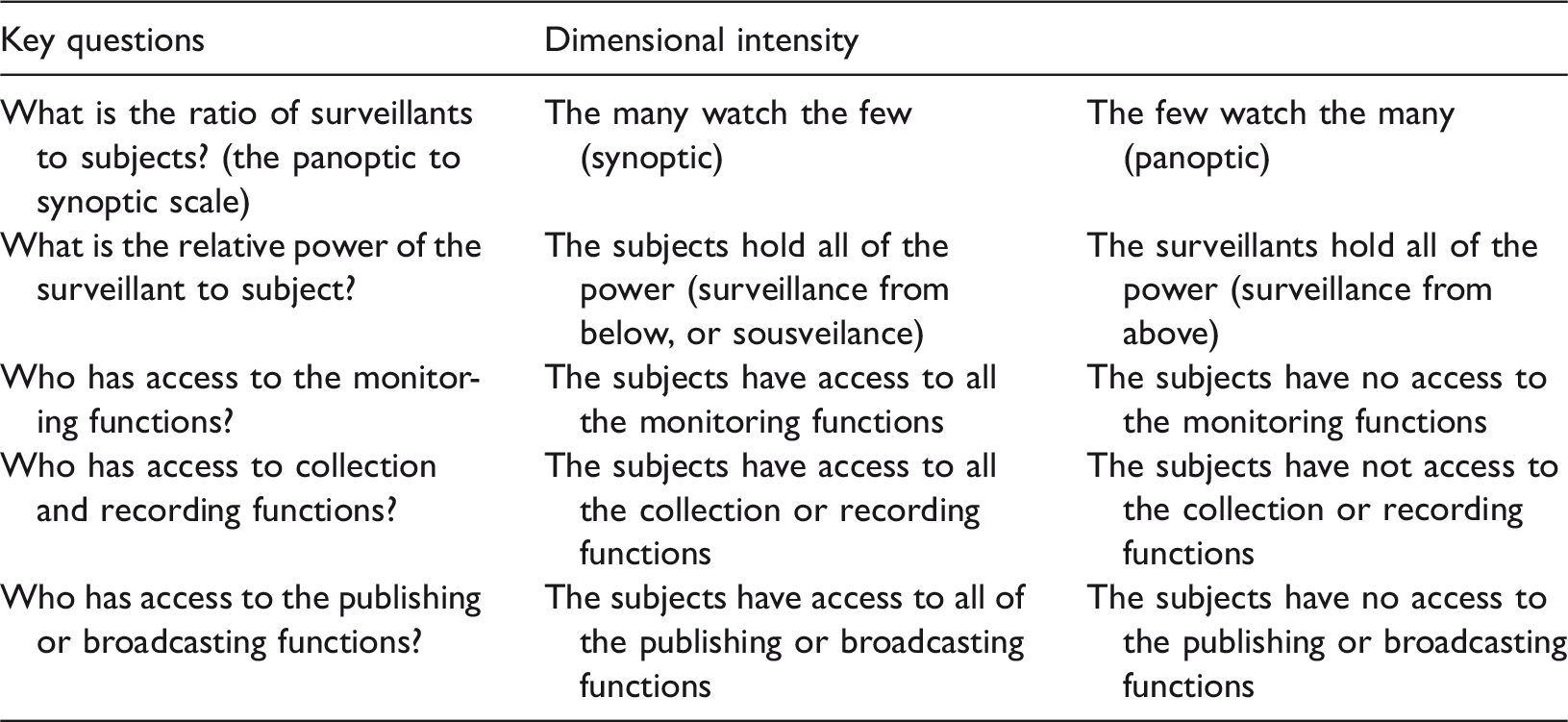
Dimensions of algorithmic decision-making in teaching and learning (adapted from Knox, 2010) – Assemblage.
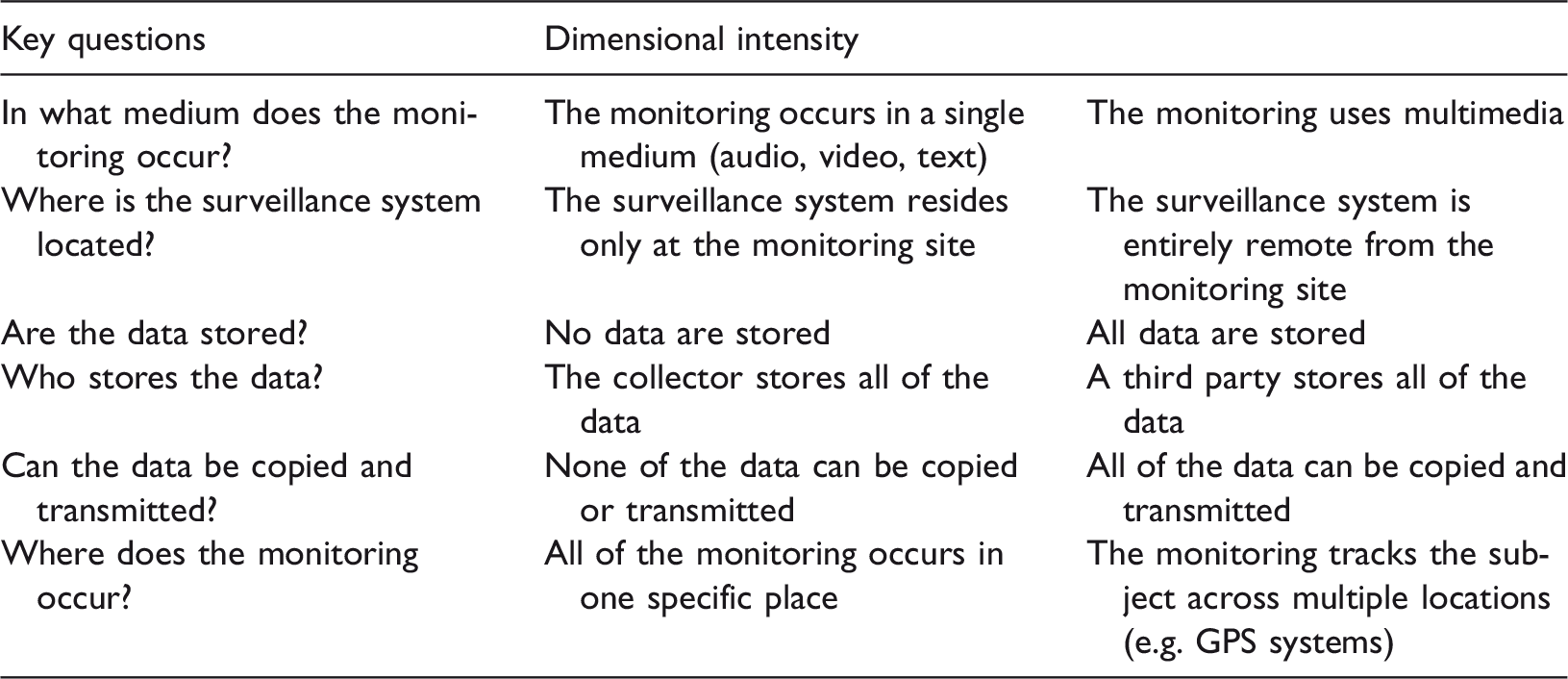
Dimensions of algorithmic decision-making in teaching and learning (adapted from Knox, 2010) – Temporality.
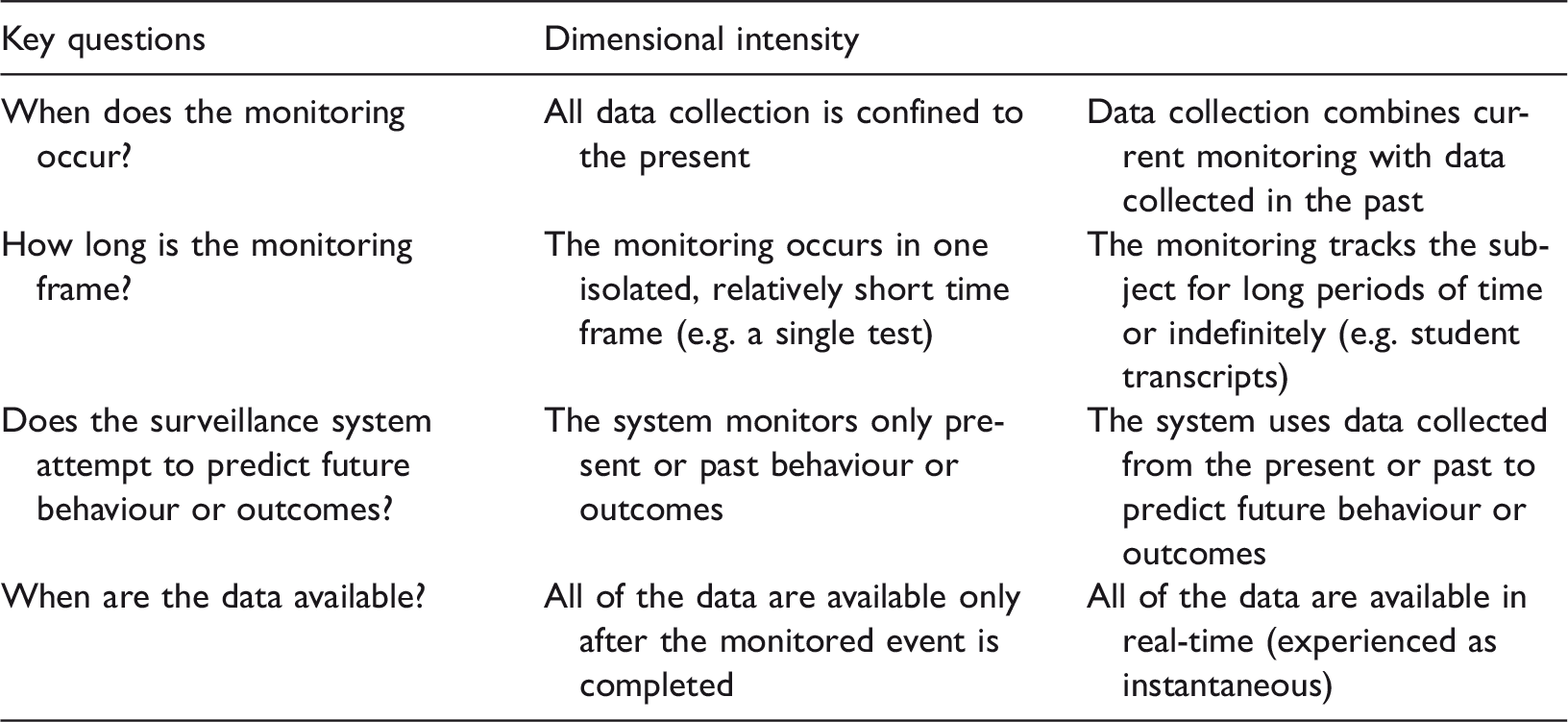
Dimensions of algorithmic decision-making in teaching and learning (adapted from Knox, 2010) – Sorting.
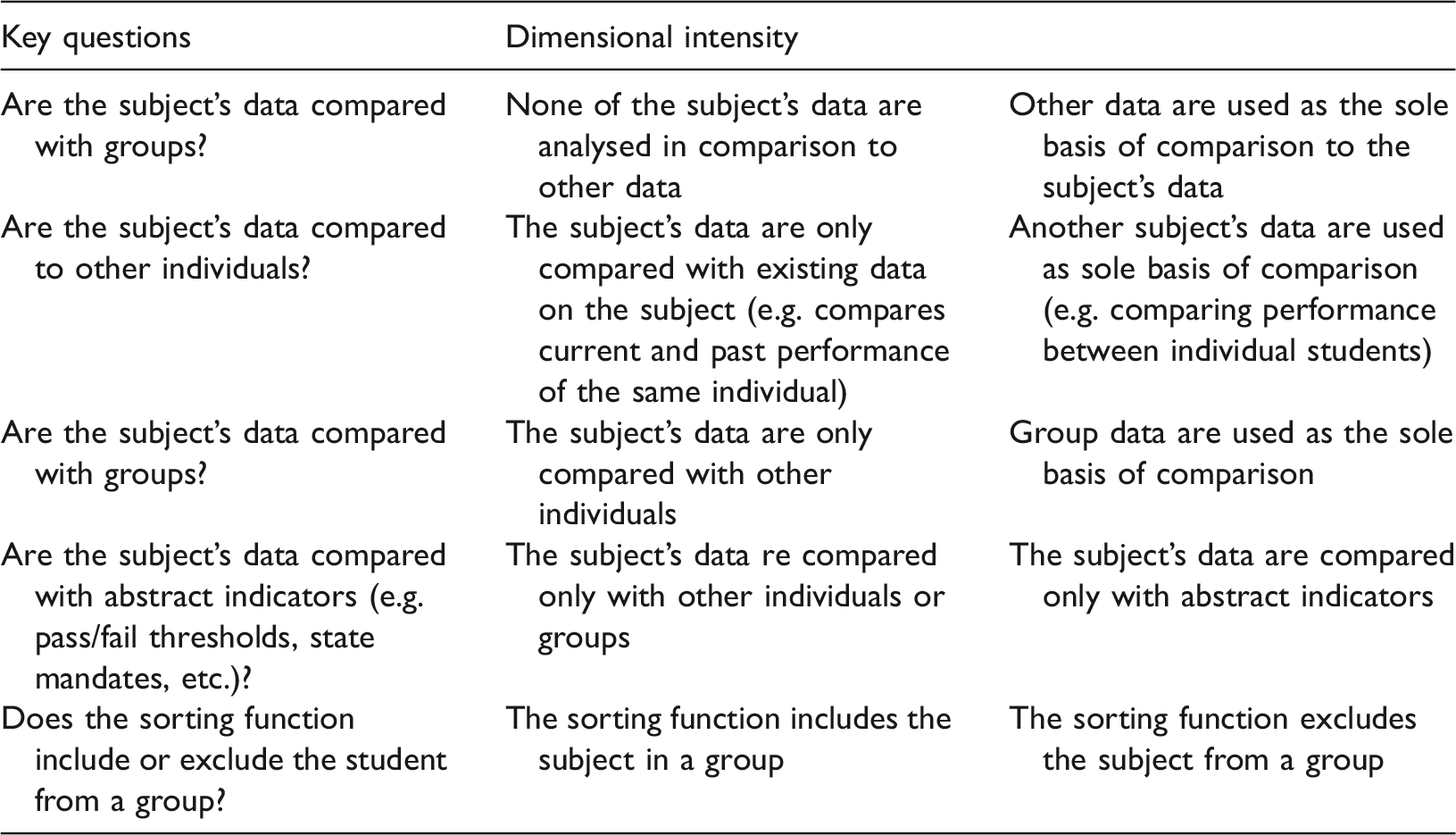
Dimensions of algorithmic decision-making in teaching and learning (adapted from Knox, 2010) – Structuring.
This element in Knox’s typology focuses specifically on the monitoring function – which resembles the sensing and processing in Danaher’s (2015) framework and the different dimensions of human-algorithmic decision-making. ‘Automation’ also raises issues such as the scope and clarity of Terms and Conditions, privacy, opting in, and the role of students in not only being aware of, but actively participating in the collection and use of their data (see Kruse and Pongsajapan, 2012; Slade and Prinsloo, 2013). While Knox (2010) refers to ‘a human’, in the context of student-centered learning analytics we have to consider the possibility and extent to which students can determine the purpose and scope of the monitoring functions, the timing of data collection, and the scope of students’ loci of control.
The issue of visibility does not relate to any of the aspects of Danaher’s (2015) experimental framework, but is firmly located in the broader discourses in the socio-technical imaginary pertaining to algorithmic decision-making (Chen, 2016; Danaher 2014; Diakopoulos, 2015; Diakopoulos and Friedler, 2016; Johnson, 2015; Morozov, 2013; O’Neil, 2016; Prinsloo, 2015). Students are mostly not aware of the fact, scope and use of our collection and surveillance processes, they do not know what we know about them, they are not aware how the surveillance make certain individual subjects more visible than other subjects and specific in the context of learning analytics, students are not aware how their learning journeys are shaped by our collection and analysis of their data (Prinsloo, 2017; Prinsloo and Slade, 2016). Even when they may be aware that higher education institutions do collect and analyse their data, they are left powerless like the protagonist in Kafka’s ‘The trial’.
While the Danaher (2015) framework specifically focuses on the possibilities of human-algorithmic interaction and collaboration where humans fulfil the role of surveillant, Knox’s (2010) typology destabilises this binary of educator-algorithm to include student engagement and agency as proposed by the proponents of a student-centered learning analytics (Kruse and Pongsajapan, 2012; Prinsloo and Slade, 2014b; Slade and Prinsloo, 2013). While student participation in learning analytics is often limited to knowing about the fact that their data are collected, analysed and used and are provided the opportunity to opt in or out. Student-centered learning analytics is much richer than this. We also need to consider the following questions:
What data do
Assemblage (as proposed by Knox, 2010) refers to the importance of domain or context in which not only the collection, analysis and use take place (Danaher, 2015; Dourish, 2016), but which also raises the issues of the storage and governance of data (Drachsler and Greller, 2016; Slade and Prinsloo, 2013). In the context of the concerns raised by Dourish (2016) and Diakopoulos (2015) regarding holding algorithmic decision-making systems accountable, access to the collected data, codes, locations and programs is only one aspect of enabling accountability. As Dourish (2016) points out, the different locations from which algorithms interact with data and code, and the way algorithmic decision-making will resemble our biases and proneness for error (Osoba and Welser IV, 2017), raise important questions regarding the knowledge and skills that are required to ensure accountability, but also raises the possibility that algorithmic accountability may increasingly become impossible.
This dimension raises specific challenges for student-centered learning analytics such as the practicalities of providing students access to their digital assemblages and the algorithms that informed these assemblages and the prerequisite knowledge and skills for students to be able to engage with these assemblages. Currently, student data and the various assemblages of students’ digital data and identities are stored in different locations, governed by different policies and access determined by a variety of processes and rules.
The dimension of temporality is not explicitly mentioned or addressed by Danaher (2015) but is embedded in the balance between human-algorithm collaboration and the design of algorithms (see Prinsloo, 2016a). In the context of learning analytics, predictive analytics play an ever increasing role in the discourses surrounding resource allocation (Prinsloo and Slade, 2014a, 2014b), the Silicon ideology (Watters, 2015; Williamson, 2016a) and discourses surrounding adaptive and personalised learning (Watters, 2016b). [See Ekowa and Palmer, 2017 for ethical principles in the use of predictive analytics in higher education.]
While implicit in Danaher’s (2015) framework – e.g. whether the sorting is done by humans or algorithms – this dimension of surveillance addresses the aspects of the power of the algorithm and the notion of the social power of algorithms (Beer, 2017a) within the context of the socio-technical imaginary. The collection, analysis and use of data, whether by humans or by algocratic systems (Danaher, 2015) are embedded in socio, political, and economic realities and serve, sustain and perpetuate specific visions of the world (Boyd and Crawford, 2012, 2013; Gilliard, 2016; Henman, 2004; Johnson, 2015; Kitchen, 2014; Prinsloo, 2015; Selwyn, 2014). Increasingly, higher education institutions will use educational triage to group students into ‘risk’ categories that will, depending on available resources and potential success, result in some students receiving more care and access to support than other students (Prinsloo and Slade, 2014a).
As in the previous dimension – sorting – structuring serves specific visions of the world. In the context of evidence-based decision-making, the technocratic logic of data, and increasing financial pressures, we should not underestimate the potential and reality of the collection, analysis and use of learning analytics ‘… are a structuring device, not neutral, informed by current beliefs about what counts as knowledge and learning, colored by assumptions about ender/race/class/capital/literacy and in service of and perpetuating existing or new power relations’ (Prinsloo, 2014).
Some brief pointers for consideration
In the light of the fact that algorithms and algorithmic decision-making are already shaping our lives in numerous ways (e.g. O’Neil, 2016; Pasquale, 2015; Watters, 2017; Williamson, 2016a, 2017) it would be disingenuous to, on the one hand, attempt to ignore them (like Dr Frankenstein attempted to ignore his creature), or to only think in binary terms as either evil or our saviors (Beer, 2017b). So the issue is not whether we should engage with algorithmic decision-making but how? Danaher (2016a: 1) proposes two possibilities namely ‘resistance’ or ‘accommodation’ but he argues that ‘neither solution is likely to be successful, at least not without risking many other things we value about social decision-making.’ [See Danaher (2016a) for his detailed exposition of resistance and/or accommodation as possible responses]. He acknowledges (2016a: 1) that this is a ‘somewhat pessimistic conclusion in which we confront the possibility that we are creating decision-making processes that constrain and limit opportunities for human participation.’
Danaher’s (2015) experimental framework and Knox’s (2010) typology of student surveillance do, however, interrupt the binary of good/evil and opens up a discursive space where we can, in particular domains or contexts, deliberate the potential of algorithmic decision-making but also how we can curtail its biases and dangers. I acknowledge that the following pointers are anything but a ‘detailed map.’ I agree with Marx (1998: 182) who stated that detailed maps ‘can lead to the erroneous conclusion that ethical directions can be easily reached or to a statement so far in the stratosphere that only angels can see and apply it.’
The following four pointers provide a tentative broad framework for engaging with the potential but also curtailing the dangers of algorithmic decision-making in education:
Within the constraints of the increasing technical complexities and black boxes of algorithms and algorithmic decision-making, we cannot ignore the potential of human oversight over algorithmic design and application, ‘straddling…the boundary between resistance and accommodation’ (Danaher, 2016a: 19). In a student-centered approach to learning analytics it is crucial not only to inform students and get their consent, but also to involve them in the decisions and the design of the algorithms that affect their learning. We also have to make our response to the following questions very clear – ‘who benefits from algorithmic education technology? How? Whose values and interests are reflected in its algorithms?’ (Watters, 2016a). The sociotechnical imaginary pertaining to algorithmic decision-making in education is informed by a technocratic and neoliberal logic in which institutional profits and institutional sustainability is often conflated with rhetoric of how algorithmic decision-making will help institutions to ‘personalise’ learning and student support (e.g. Williamson, 2016a). In the light of the asymmetrical power relationship between institutions and students (Prinsloo and Slade, 2014b), we need to critically engage (Dinerstein, 2006; Kitchin and Lauriault, 2014) with the ‘imaginaries and materialities’ (Williamson, 2017) of the effects of algorithmic decision-making. Education in general has always collected, analysed and used student data. In the light of the fiduciary duty of education to offer appropriate and effective teaching and learning opportunities to students (Slade and Prinsloo, 2013) we cannot ignore the potential of algorithms and algorithmic decision-making to assist us in making sense of data patterns and alert us to the need for and different options for intervention (Prinsloo, 2015, 2016a). It is crucial that institutions of higher learning who use algorithmic decision-making declare their provisions to ensure ethical practices. ‘Ethics are the mirror in which we evaluate ourselves and hold ourselves accountable’ (Brin, 2016; emphasis added). Despite concerns regarding the effectiveness of policies to ensure ethical practice, holding actors and humans accountable still works ‘better than every single other system ever tried’ (Brin, 2016).
(In)conclusions
While it is tempting, and possibly easier, to think in binary terms of algorithmic decision-making as being either our salvation or our damnation, such an approach may not assist us to disentangle the different claims regarding algorithms and algorithmic decision-making in the current sociotechnical imaginary. As a result of the increasing media coverage of the algorithms and algorithmic decision-making, it is clear that ‘images, stories and legends’ (Taylor, 2002: 106) resemble but also perpetuate ‘normative notions’ and expectations regarding the potential and inherent (and claimed) dangers of algorithms. There is furthermore ample evidence that many of these stories and legends find acceptance in considering the potential role of algorithms in higher education.
In using Danaher’s (2015) experimental framework in combination with Knox’s (2010) typology of student surveillance, I attempted to interrupt thinking about algorithms and algorithmic decision-making in binary terms. The combination of these two authors’ work allows as to critically engage with and, possibly, destabilize the technocratic logic surrounding algorithms in the context of the discourses and practices of collecting, analysing and using student data (Prinsloo, 2016b; Prinsloo and Slade, 2014a, 2014b; Williamson, 2016a). At stake is not whether higher education should use algorithms and algorithmic decision-making, but to put in place a range of checks and balances to keep the potential (and reality) of bias and unintended consequences in check. As both the works of Danaher (2015) and Knox (2010) illustrate, a major factor in ensuring accountability and transparency in using algorithms and algorithmic decision-making is involving students in thinking through the potential and dangers of what they and us need in order to teach and learn more effectively.
The issue is not ‘if’ we should use algorithms and algorithmic decision-making in higher education. If we accept the collection, analysis and use of student data as an essential part of our moral and fiduciary duty, we have to move to exploring the potential of algorithmic decision-making systems for an ethics of care (Prinsloo, 2016a; Prinsloo and Slade, 2016).
Epilogue
We have no choice. Amid the dangers and uncertainties regarding the unfolding of algorithmic decision-making and algocratic systems we cannot and should not recoil in horror as we flee our creation. Our creatures, like Dr Frankenstein’s monster, will follow us and demand an audience. Like Dr Frankenstein we have to face our creations even if this means a Kafkaesque engagement where there is no clear exit or resolution to the tensions.
In choosing Dr Frankenstein’s monster and Kafka’s works as dialogue partners I was hoping to deepen, unsettle and possibly expand the sociotechnical imaginary regarding algorithmic decision-making in education. While much of the current imaginary supports and perpetuates thinking about algorithmic decision-making in binary terms as either good or evil, I attempted to engage with this imaginary, looking our creatures in their eyes, and not recoil in horror or flee, but like the protagonist in Kafka’s ‘The trial’, interrogate the authority and claims of those who hail algorithmic decision-making as either evil or good. In following Latour’s (2012) plea that we cannot abandon our creatures, I invited Dr Frankenstein’s monster and Kafka’s protagonist to join me in the company of Danaher (2015), Knox (2010) and many others to, at least, have a conversation that may help us to make sense of the different claims in the sociotechnical imaginary pertaining to algorithmic decision-making.
Footnotes
Acknowledgements
I presented my initial thoughts on algorithms and algorithmic decision-making on 22 and 23 September 2016 at the National University Galway (NUI) during a workshop titled ‘From algorithmic states to algorithmic brains.’ I would like to acknowledge and express my appreciation for the input and guidance I received from the reviewers. The comments and quality of the reviews provided me very helpful pointers to clarify my thinking and position on the potential and challenges of algorithms and algorithmic decision-making in education.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.