
Abstract
This study investigates how the presence of people in a built environment influences visual attention and navigational performance. Using immersive virtual reality and eye-tracking, participants navigated an airport terminal featuring either dynamic human avatars (social setting) or no avatars (non-social setting). Fixation durations on signage and human figures were measured to assess attentional allocation, and navigation performance was evaluated through task duration, error count, and spatial knowledge tasks. Participants in the social setting fixated significantly less on signage and more on humans, indicating attentional competition. Human and signage fixation durations were strongly negatively correlated. While overall navigation performance did not differ between conditions, attention to signage significantly predicted lower error counts. Mediation analysis showed that human presence indirectly increased navigation errors by reducing attention to signage. Spatial learning, measured by pointing accuracy and landmark placement, was less clearly affected, though social presence was associated with better landmark placement accuracy. The results highlight how social stimuli capture attention and reduce the processing of task-relevant cues like signage. The findings underscore the perceptual demands of navigating socially complex environments and suggest that maintaining visual attractiveness of signage is critical in crowded public settings.
Keywords
How to Cite this Article
Orlu Özen, G., Imamoğlu, Ç., Surer, E., & Altay, B. (2026). Visual attention allocation between social and navigational cues during wayfinding: An eye-tracking study in virtual reality. i-Perception, 17(1), 1–27. https://doi.org/10.1177/20416695251414080
Introduction
Navigating public spaces is challenging due to their complexity. Individuals must manage both environmental and social external distractions that compete for attention and influence decisions. Visual attention plays a central role in filtering these competing cues and enabling successful navigation. Prior research on wayfinding and spatial knowledge has examined spatial layout (Doğu & Erkip, 2000; Passini, 1996), spatial complexity (Hölscher et al., 2006), legibility (Li & Klippel, 2016), geometry (Wiener et al., 2012), signage (He & Hegarty, 2020; Rodrigues et al., 2019; Su et al., 2022), landmarks (Hund & Minarik, 2006; Karimpur & Hamburger, 2016; Lin et al., 2012), color and lighting (Hidayetoglu et al., 2012; Süzer et al., 2018), and digital navigation tools (Tünger & Imamoğlu, 2022). Many studies also addressed the influence of individual factors such as gender (Lin et al., 2012; Munion et al., 2019; Yang & Merrill, 2017), personality (Meneghetti et al., 2020), spatial ability (Kuliga et al., 2019; Zomer et al., 2019), schemas (Farzanfar et al., 2023), and environmental familiarity (Doğu & Erkip, 2000; Muffato & Meneghetti, 2020) on wayfinding and spatial knowledge acquisition. Among these, signage and spatial layout are considered most influential (Passini, 1996). People use both social and non-social cues (Lawton, 1996) and often rely on multiple stimuli for spatial knowledge acquisition (Wolbers & Hegarty, 2010).
While most research on wayfinding and spatial knowledge has emphasized non-social factors (e.g., signage, landmarks, and layout), the influence of social elements (i.e., other people) remains a gap. This gap is especially relevant in large-scale transit environments, where individuals must process dynamic visual scenes under time pressure, elevating cognitive and perceptual load (Lavie, 2005; Sweller, 1988). Although previous studies emphasize the value of visual cues (Montello & Sas, 2006; Vilar et al., 2014; Werkhoven et al., 2014; Wiener et al., 2012), how individuals balance attention between social and non-social information remains unclear. Neglecting social elements limits our understanding of how combined perceptual inputs shape both wayfinding and spatial learning.
The present study aims to address this gap by investigating how visual attention is distributed between social (humans) and non-social (signage) elements during navigation in complex public spaces. Human figures are visually attractive and may divert attention from task-relevant cues like signage, yet their impact on attentional allocation remains underexplored.
Wayfinding and Spatial Knowledge Acquisition
Wayfinding behavior involves both locomotion and spatial decision-making (Montello, 2015). While locomotion refers to physical movement, wayfinding requires the selection and linking of paths from a spatial network in response to environmental input (Golledge, 2020). During navigation, individuals acquire spatial knowledge, beginning with egocentric cues and gradually forming allocentric representations, commonly referred to as cognitive maps (Golledge, 2020; Haq & Zimring, 2003; Ishikawa & Montello, 2006).
Cognitive maps (Lynch, 1960) consist of constructs that help individuals in wayfinding (Montello & Sas, 2006) and navigate environments effectively (Ishikawa & Montello, 2006; Wolbers & Hegarty, 2010). Cognitive maps form through repeated exposure to environmental cues and involve both egocentric and allocentric processing (Spiers & Maguire, 2008). Wayfinding often relies on environmental cues like landmarks and signage (Passini, 1996).
Earlier, Siegel and White (1975) suggested that survey knowledge develops in stages from local landmarks to route learning to a global map. Montello (2005) later proposed that some individuals acquire these forms simultaneously, rather than in stages. Regardless of how it is developed, individual differences such as spatial ability and prior familiarity impact how spatial information is encoded and retrieved (Dalirnaghadeh & Yılmazer, 2022).
Effective wayfinding and spatial knowledge acquisition both rely on the perception of relevant environmental features. In complex environments such as airport terminals and malls, clear visual cues reduce attentional demands and support memory encoding (Kuliga et al., 2019).
Attention in Wayfinding and Its Effect on Spatial Learning
Attention during wayfinding supports perception of the environment (Carrasco, 2018) and the acquisition of spatial knowledge (Yamamoto & Philbeck, 2013). Selective attention theory suggests that individuals filter environmental stimuli, focusing on certain information while ignoring others (Carrasco, 2018; Lavie, 2005). Ignoring irrelevant cues may help or reduce learning depending on task demands and context (Staal, 2004). Inattention to signage can impair spatial learning, as signage plays a critical role in complex environments (Rodrigues et al., 2019; Su et al., 2022). Social stimuli in the environment can increase perceptual load by adding competing visual information, which limits the attentional resources available for task-relevant cues (Lavie, 2005). Unlike cognitive load, which reflects demands on memory and reasoning (Sweller, 1988), perceptual load arises from the number and complexity of visual elements present in the scene, making it a more relevant factor in understanding how human presence interferes with navigation. Competing stimuli, such as humans and signage, can increase perceptual load and lead to divided attention.
Attention during wayfinding can be overt, directing visual focus, or covert, peripheral observation without fixation (Engbert & Kliegl, 2003). Overt attention can be measured using eye tracking (Kiefer et al., 2017; Orquin & Holmqvist, 2018). Gaze patterns provide insight into how individuals prioritize environmental information. Individuals with better spatial acquisition often fixate more on visually relevant landmarks and decision points (Çöltekin et al., 2020; Kapaj et al., 2024; Wiener et al., 2009). Visually attractive features, which stand out or hold greater importance (Davies & Peebles, 2010), guide attention during indoor wayfinding (Dong et al., 2020). Inattention to landmarks is related to reduced spatial knowledge (Kiefer et al., 2017). This selective focus helps cognitive map formation and supports survey knowledge acquisition (Foo et al., 2005). Kapaj et al. (2024) also found that attention to landmarks improves distance estimation and recognition, suggesting a role in strengthening spatial memory.
A recent gaze behavior study by Keller and Sutton (2021) has employed dynamic (continuous) eye-tracking for a navigation task in virtual environment. They found that participants with accurate and inaccurate cognitive maps spent similar time fixating on landmarks, suggesting navigation differences derived not from attention, but from memory processing after attention has been allocated. This indicates that spatial knowledge acquisition may depend more on how information is encoded after attention has occurred.
Eye-tracking studies in environmental assessment and spatial cognition use fixations to examine perceptual-cognitive processes (Jacob & Karn, 2003). A fixation, typically lasting 200‒400 ms, indicates where visual processing occurs (Salvucci & Goldberg, 2000). Fixation duration and frequency reflect gaze behavior and preferred areas in a scene (Birmingham et al., 2008; Glaholt et al., 2009). These metrics show whether people are searching for objects or memorizing the space (Castelhano et al., 2009; Henderson et al., 1999).
Recent studies suggest that social cues, such as the presence of other humans, can also influence navigation and spatial behavior (Krukar & Dalton, 2020), highlighting that navigation is shaped not only by environmental features like layout and signage, but also by social presence. This emerging area highlights the potential impact of both social and environmental factors in guiding attention during wayfinding. However, research on how attention allocation to social versus non-social cues affects wayfinding and spatial knowledge acquisition remains underexplored.
Virtual Applications in Navigational Attention
Virtual reality (VR) provides a controlled, immersive environment for studying spatial behavior and attentional processes (Moussaid et al., 2016; Schrom-feiertag et al., 2017). Compared to real-world studies, VR enables precise manipulation of environmental and social variables, such as crowd presence or signage visibility, that would be difficult to isolate otherwise (Memikoğlu & Demirkan, 2020; Tang et al., 2009). This makes it an ideal platform for investigating how visual attention is allocated during wayfinding.
Previous research has shown that wayfinding behaviors and cognitive processes in VR closely mirror those observed in real-world settings (Dong et al., 2022; Kim et al., 2013; Marín-Morales et al., 2019; Ruddle & Lessels, 2009). VR simulations also enable the integration of dynamic social stimuli (animated avatars), allowing researchers to examine attentional responses to human presence under ecologically valid conditions (Kinateder & Warren, 2016; Li et al., 2019). Although VR effectively assesses navigation and offers controlled conditions (Waller & Greenauer, 2007), it may not fully reflect real-world attentional dynamics unless it incorporates moving elements like pedestrians, which naturally attract attention (Keller & Sutton, 2021). When combined with eye-tracking, VR becomes a powerful tool to assess how gaze behavior is distributed across navigational and social cues in real time (Kiefer et al., 2017).
Influence of Social Elements on Cognitive Outcomes
In large-scale public spaces (e.g., airports and hospitals), others often play a critical role in wayfinding behavior. Social wayfinding research shows that, especially in unfamiliar environments, people tend to follow paths with visible individuals, even when signage indicates a shorter route, indicating a reliance on both social and visual cues (Dalton et al., 2019). Unlike static signage, social cues are dynamic and can either guide or distract attention. Wayfinding choices may shift due to (1) a tendency to follow others (Barker, 2019; Silva et al., 2015; Vaez et al., 2020) or (2) efforts to avoid them as distractions (Li et al., 2019; Yang et al., 2018; Yi et al., 2015). In high-density settings, the behavior of following others is well-documented. Helbing et al. (2000) and Moussaid et al. (2016) found that people often follow crowds over signage in crowded or emergency conditions.
Social cues not only serve as implicit navigational aids but can also highlight areas of interest (AOIs). In unfamiliar environments, observing others’ movements can help locate destinations, especially when signage is unclear or hard to spot. Silva et al. (2015) found that people in virtual environments preferred following avatars over using other wayfinding strategies, suggesting that social cues can override signage. The dynamic nature of social elements matters. Yang et al. (2018) showed that moving people attracted more attention and influenced choices more than stationary groups, diverting focus from static signage. In a VR study, Kinateder and Warren (2016) found that under time pressure, individuals preferred following crowds over signage, highlighting the dominance of social cues in high-stress contexts. Bode et al. (2014) showed that route choices reflect both signs and crowds unless the two conflict. Introducing “social wayfinding,” Dalton et al. (2019) proposed that people use others as cues alongside, or even instead of, signage when navigating unfamiliar environments.
The influence of social elements in navigation appears to be context-dependent. While people may balance social and non-social cues in routine settings, some cases may increase reliance on social cues, emphasizing the need for strategies that address both. Although prior studies explored social influences on navigation, the impact of increased attention to social elements on spatial knowledge acquisition remains underexplored. This raises intriguing questions about how humans in the environment shape visual attention and, in turn, affect navigation outcomes.
The Present Study
We aimed to answer the five research questions in the present study:
RQ1. How does human presence in the environment affect visual attention to navigational signage? RQ2. Does human presence influence navigational outcomes (wayfinding performance and spatial knowledge acquisition)? RQ3. In environments with both signage and human cues, how does attention to each source relate to navigational outcomes (wayfinding performance and spatial knowledge acquisition)? RQ4. Does attention to signage mediate the relationship between human presence and wayfinding performance? RQ5. Does attention to signage mediate the relationship between human presence and spatial knowledge acquisition? Our five assumptions based on our research questions and conceptual framework are presented below.
A1. Attention allocated to humans would be higher than the attention to signage cues, as they are naturally more attractive, and this may divert attention from critical signage during navigation. A2. Wayfinding performance would be higher, and spatial knowledge acquisition would be lower in an environment with human presence compared to one without, as other people may help guide navigational direction to a correct destination, but also divert attention from necessary environmental constructs that help shape survey knowledge. A3. Wayfinding performance would be better for people who attend to humans more than signage, and spatial knowledge acquisition would be less for people who attend to humans more than signage; as following other humans may help reach the same destination, but they may also cause distractions that will later impair their spatial memory performance. A4. Visual attention to signage cues would emerge as a significant mediator between human presence in the environment and wayfinding performance measured by:
Distance traveled Task duration Error count A5. Visual attention to signage cues would emerge as a significant mediator between human presence in the environment and spatial knowledge acquisition, measured by:
Pointing accuracy Landmark locating accuracy
To explore this, we developed a virtual airport environment with two conditions: one with dynamic avatars simulating other travelers (social setting [SS]) and one without avatars (non-social setting [NSS]). Eye-tracking was used to record fixation durations to signage and humans while participants navigated through either one of the settings from a first-person view to complete a wayfinding task. Navigation outcomes (task duration, distance, and error count) and spatial knowledge measures (pointing accuracy and landmark placement) were analyzed to assess whether attention shifts explain behavioral differences.
Method
Experiment Design
The experiment included one independent variable (human presence: social vs. non-social) and two dependent variables reflecting separate dependent measures: wayfinding performance and spatial knowledge acquisition. Wayfinding performance was assessed through task duration, distance traveled, and number of navigation errors, while spatial knowledge acquisition was assessed through pointing accuracy and landmark locating accuracy. Attention (fixation proportions on signage and humans) was examined as a mediating variable between human presence and these dependent outcomes. The study employed a between-subjects experimental design. Participants were assigned to one of the two experimental settings through quota-assignment:
SS with the presence of human avatars simulating other travelers; 42 participants (21 men, 20 women, and one non-binary). NSS with the absence of human avatars; 40 participants (22 men and 18 women).
Previous findings implied that human wayfinding performance is influenced by individual factors such as gender, sense of direction, age differences, and familiarity (Haghani & Sarvi, 2017; Kato & Takeuchi, 2003; Kuliga et al., 2015; McCullough & Collins, 2018; Munion et al., 2019; Palmiero & Piccardi, 2017; Zomer et al., 2019).
Participants
Eighty-two participants (Mage = 25.3, SD = 3.2, range = 18–44; 43 males, 38 females, and one non-binary) from three universities in Ankara, Türkiye took part in the study. Inclusion criteria were being 18–45 years of age, having normal or corrected-to-normal vision, and no self-reported cognitive impairments. Two participants with high familiarity with the airport (rated ≥4 on a 5-point scale) and one who withdrew due to motion sickness were excluded. To ensure equivalence between conditions, independent samples t-tests were conducted to compare participant characteristics across the social (n = 42) and non-social (n = 40) settings. The two groups did not differ significantly in gender, t(80) = −0.94, p = .351; age, t(80) = 0.56, p = .577; education level, t(80) = 0.87, p = .385; familiarity with airports, t(80) = −0.15, p = .882; familiarity with Istanbul Airport (IGA), t(80) = −1.51, p = .135; and familiarity with the international transfer terminal, t(80) = −0.57, p = .571. Similarly, there was no significant difference in Santa Barbara Sense of Direction (SBSOD) scores between groups, t(80) = 1.29, p = .202. Power analysis using G*Power (Faul et al., 2009) confirmed that the final sample exceeded the required size for medium to large effects. For between-group comparisons with a medium effect size (d = 0.56), α = .05, and power (1 − β) = .80, the calculation indicated a required sample size of 32 participants per group, totaling 64 participants. Post-hoc analysis of the obtained effect size (d = 0.56), α = .05, and total sample size of 82 participants, the achieved statistical power for t-tests was greater than 0.80. With a large effect size (r = −.636), α = .05, and sample size of 42, the achieved power for the correlation analyses was greater than .99. Mann–Whitney U tests, with a moderate effect size (r = .345), α = .05, and n = 42, achieved a power greater than 0.73. All participants gave informed consent, and the study was approved by the Bilkent University Ethics Committee.
Apparatus
The experiment took place in the VR environment viewed through an HTC Vive Pro-Eye headset (2160 × 1200 px, 90 Hz) with integrated Tobii Pro eye-tracking (120 Hz). The Vive's handheld controller was used for self-navigation. Physical rotation was tracked 360° using sensors on the headset and two base stations placed across from each other in the experiment room. The HTC Vive Pro Eye has been shown to offer some of the lowest eye-tracking latencies among commercial head-mounted displays, making it suitable for real-time gaze-contingent applications (Stein et al., 2021).
Stimuli
The virtual environment was modeled after Istanbul Airport (IGA), closely replicating the international terminal's layout. Its predominantly linear configuration reflects typical passenger flow in arrival halls. The number of gates and terminal length were reduced to control the experiment duration. Task-competitive colors, lighting, and textures were eliminated to control their possible effects. Modeled using existing plans from the airport and rendered with Unity VR Game Engine, the environment was transformed into a self-navigable setting featuring animated human avatars for the wayfinding experiment.
Key features of the environment included: (1) avatars, representing humans, simulating traveler behavior to create realistic social dynamics; (2) visual navigational signage, based on the real environment; and (3) visual landmarks, based on the real environment. The landmarks included Gates A, B, and C, restrooms, ATMs, elevators, escalators, ramps, an information desk, passport control kiosks, domestic transfer kiosks, and international transfer kiosks. In our virtual airport, signage was directional and contextually relevant (Calori et al., 2015), displaying arrows and text (like “Passport Control,” “Baggage Claim,” and “Gates”) positioned at major decision points. Thus, signs were potentially helpful for navigation (Vilar et al., 2014), but not strictly necessary to complete the task, as the route may also be inferred from the spatial layout. This design choice allowed us to examine how participants distributed attention between social and non-social cues under conditions of moderate task ambiguity.
Screenshots taken from the virtual environment at key decision points and landmarks are represented in Figure 1.

Visual representation of the virtual environment and navigation data. (a) View of the elevators and escalators from the lower floor, (b) view of the elevators and escalators from the upper floor, and (c) view from the starting point on the upper floor (Gate A4) facing towards the elevators (source: created by the first author).
The SS included all three; the NSS lacked avatars but retained signage and landmarks (Figure 2). Avatars were adjusted to match the environment's visual tone (e.g., attractiveness, contrast, and texture). The avatars were intentionally designed as neutral, silhouette-like figures to achieve a high level of experimental control and minimize extraneous effects. They lacked individualized features such as clothing and facial expressions, ensuring that fixations on these figures reflected social attention rather than attraction to visually attractive features (Birmingham et al., 2008; Foulsham et al., 2011). This approach follows prior work emphasizing the balance between ecological validity and stimulus control in virtual social environments (Krukar & Dalton, 2020; Pan & Hamilton, 2018).

Screenshots of the virtual reality setting in the social condition (top) and non-social condition (bottom) (source: created by the first author).
Passenger flow and avatar behavior mirrored the real airport's dynamics. Data were informed by the Directorate General of the State Airports Authority (2022) and reference video footage captured by the first author. The video helped estimate how many people typically appear at key decision points and how they move relative to navigation targets. Unity's navigation and pathfinding modules were utilized to simulate pedestrian movement within the airport's arrival and transfer floors. The simulated crowd behavior was controlled to reproduce realistic flow patterns, using video recordings of the actual airport as reference. Virtual passengers were spawned at selected arrival gates to represent the disembarkation of aircraft. Upon spawning, each passenger was assigned a destination among the domestic transfer area, international transfer area, or passport control zone based on the video recordings. On the upper (arrival) floor, passengers in the reference video were observed walking from gates toward elevators, escalators, or ramps leading downstairs; the avatars in the VR environment replicated these circulation patterns. On the lower (transfer) floor, avatars were placed in both static (e.g., seated, waiting, and queuing) and dynamic roles (e.g., walking toward passport control, transfer gates, restrooms, or information desk), reflecting naturalistic airport activity. Movement dynamics were calibrated for realistic conditions: avatars walked at 2.8 m/s, reflecting average walking speeds recorded on-site.
Because participants were free to navigate the environment at their own pace, the number of visible avatars and signage elements varied naturally across individuals and over time. Avatars were continuously animated, and their movements were not synchronized with participants’ positions, resulting in dynamic and participant-specific visual exposure. Consequently, the exact number of humans and signs visible at any given moment could not be standardized across participants. This design choice was intentional, reflecting real-world variability in visual experience and prioritizing ecological validity over fixed stimulus presentation.
Tasks
Wayfinding Task: Participants completed the wayfinding task in the VR using a self-exploration, search-based approach. They followed a scenario prompt requiring stops in a specific order, simulating a real-life arrival process. The scenario required: exiting the gate, locating amenities (e.g., restrooms and ATMs), seeking assistance, passing passport control, and collecting baggage. This sequence was based on typical airport procedures to preserve ecological validity. The route design was informed by an on-site analysis and video documentation of actual passenger flow. The selected airport had a linear structure (Figure 3). Although the linearity may reduce navigational variability, it reflects real-world arrival terminals, where deviations typically occur only to meet specific needs (e.g., service points). This design ensured a balance between ecological validity and experimental control.

Top-down schematic view of the airport terminal representing the target stops from the task and important landmarks (source: created by the first author).
Upon reaching each stop, a screen text instructed participants on the next destination. The task concluded at the final point (Figure 3). All participants in both settings received the same prompt. The total route length was approximately 520 m and took about 282 s (4 min, 42 s) to complete without errors or delays.
Landmark Locating Task: Spatial orientation was assessed through a landmark locating task, which involved positioning seven listed landmark points that the participants came across during navigation (A4 gate, ATMs, information desk, elevators, ramp, passport control, baggage claim) on a sketch map of the task environment on A4 paper as accurately as possible (Muffato et al., 2017). The completed sketch maps were scanned and uploaded to the software (Gardony et al., 2016) for analysis.
Pointing Task: In this task, participants were asked to mentally access spatial relationships between three points and estimate their relative directions (Hegarty & Waller, 2004; Shelton & McNamara, 2004). Participants received an A4 sheet with four questions, on which they were asked to point in the direction of particular landmarks from memory, following Ishikawa & Montello (2006). Each question featured a circle with a central landmark. Participants were instructed to imagine standing at the center landmark, facing a second one marked at 0°, and then estimate the direction of a third by drawing a line from the center toward the circle's edge, as represented in the sample below (Figure 4).
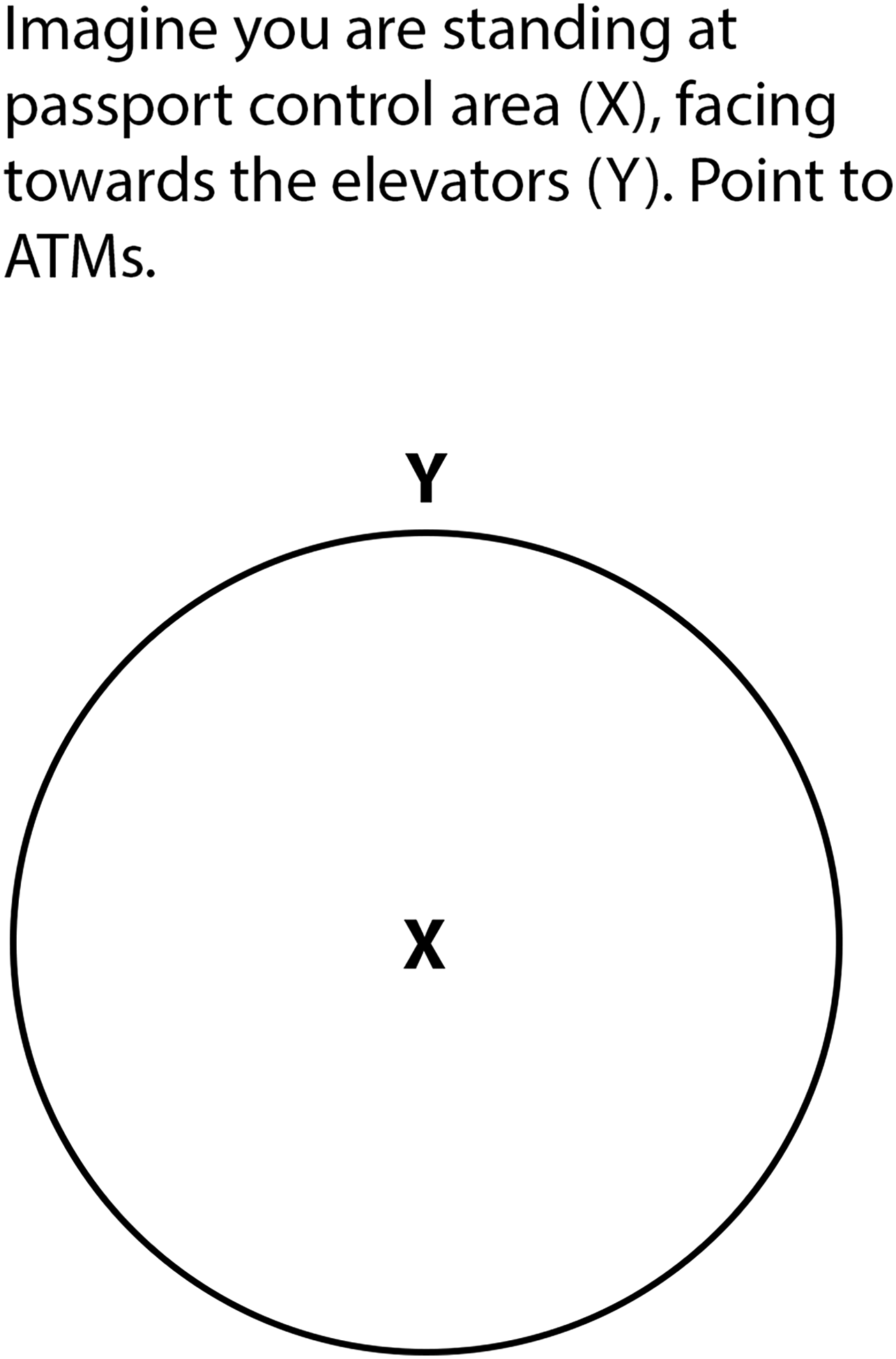
One of the four questions taken from the pointing task.
Procedure
Participants were tested individually in a laboratory setting. The experiment followed a three-phase procedure.
In Phase 1, participants completed consent forms, and demographic questionnaires were used to record age range, gender distribution, familiarity with the environment, and sense of direction. The sense of direction was assessed using the SBSOD questionnaire (Hegarty et al., 2002), having 15 items with a 7-point Likert scale (1 = strongly agree to 7 = strongly disagree).
In Phase 2, participants were guided into a standing position, familiarized with the hand controller, and wore the VR apparatus. Eye-tracking calibrations were conducted. Participants were instructed to rotate 360° and navigate using the hand controller. A short trial session in a separate virtual area helped participants become acquainted with navigation. Once they were ready, the wayfinding task began.
The participants self-navigated in the VR from a first-person view at 3 m/s using a wireless single-hand controller. Rotation in the virtual environment was controlled by the physical body rotation in the real world. The search-based task simulating a real-life arrival process required a fixed sequence of stops (e.g., gate exit, amenities, passport control, and baggage claim) based on an on-site analysis of the terminal procedures and video documentation of actual passenger flow. The environment's linear layout reflected actual arrival terminals and balanced ecological validity with experimental control. At each stop, on-screen instructions guided participants to the next destination. The route covered approximately 520 m and took about 4.7 min to complete without delays. Unity scripting recorded timestamps, travel distance, and gaze data, with all metrics time-stamped and screen activity recorded for later error analysis. In Phase 3, they completed two spatial knowledge tasks at a desk.
Data Analysis
Visual Attention: For visual attention analysis, eye-tracking data were collected using Tobii XR SDK with Unity's built-in eye-tracking and Tobii Gaze-2-Object-Mapping. Eye fixations were classified into three AOIs: humans, signage, and other. Gaze-2-Object-Mapping data were filtered to identify fixations on humans and signage with start and end timestamps. Fixations shorter than 150 ms were excluded, as they reflect low-level visuomotor activity (Schleicher et al., 2008) and lack cognitive relevance. Fixation proportions (

Longer proportions reflected greater attention (Dong et al., 2022; Wiener et al., 2012).
Additionally, normalized signage fixation proportions (

The normalization process excludes fixation duration on human figures from the total task duration to account for the absence of humans in the NSS. Normalized measures were used only as supplementary analyses. Non-normalized fixation proportions were reported as the main results, as they more directly capture attentional allocation without introducing additional transformation.
Wayfinding Performance: Navigation metrics included task duration (s), travel distance (m), and number of navigation errors (wrong turns). They were processed using a Python script based on the Gaze Analytics Pipeline (Kiefer et al., 2017). A shorter travel distance and task duration, and a lower error count demonstrated a better wayfinding performance (Dalirnaghadeh & Yılmazer, 2022; Montello & Sas, 2006).
Spatial Knowledge: Two post-navigation tasks were used:
Pointing Task: Participants estimated directions between landmarks, measured as the absolute angular deviation (in degrees) between the participant's estimate and the correct direction (Credé et al., 2019). Lower angular error indicated higher accuracy and stronger survey knowledge (Hegarty et al., 2002). Landmark Locating Task: Participants placed seven landmarks on a blank map. Sketch accuracy was analyzed using the Gardony Map Drawing Analyzer and the square root of the canonical organization (SQRT-CO) index (Gardony et al., 2016). Sketch maps were analyzed via a bidimensional regression method (Friedman & Kohler, 2003) comparing the landmarks that participants drew to the true Cartesian coordinates. The SQRT-CO, ranging from 0 to 1, served as a global accuracy index (Gardony et al., 2016; Muffato & Meneghetti, 2020). A higher score indicated a better landmark locating accuracy.
Results
Data were analyzed using SPSS 26.0 (IBM, USA). The Shapiro‒Wilk test assessed normality for each variable by group. Wayfinding performance and landmark accuracy scores were non-normally distributed (p < .05), while fixation proportions were normally distributed (p > .05). Skewness and kurtosis analyses supported these results. Though statistical tests showed normality for pointing accuracy, histogram and Q–Q plot inspections revealed skewness, consistent with prior findings on angular error (Credé et al., 2019; Hegarty et al., 2002). Therefore, non-parametric tests were used for pointing accuracy.
Attention Allocation to Humans and Signage
Our first assumption was that humans would attract more visual attention than signage in an environment. To test this assumption, signage fixation proportions were examined within the SS (n = 42). As expected, participants allocated a greater visual attention to human figures (M = 0.35, SD = 0.07) than to signage (M = 0.16, SD = 0.05).
To address RQ1, signage fixation proportions were compared between the SS and NSS. An independent-sample t-revealed a significant difference between settings, t(80) = 9.971, p < .001, d = 2.20, with the social group (M = 0.163, SD = 0.052) showing significantly lower attention to signage compared to the non-social group (M = 0.283, SD = 0.056), as expected (Figure 5).

Signage fixation proportion between settings.
For completeness, we additionally compared normalized signage fixation proportions between settings to account for the absence of humans in the NSS. This analysis also revealed a significant difference between settings, t(80) = −2.54, p = .013, d = 0.56, with the social condition showing lower normalized attention to signage than the non-social condition. These results supported the primary findings from non-normalized calculations.
Furthermore, a correlation analysis within the SS (n = 42) revealed that human fixation and signage fixation proportions were strongly negatively correlated (r = −.636, p < .001), suggesting that increased attention to humans was associated with reduced attention to signage. This means that participants with longer focusing durations on humans had less time focusing on signage, as expected.
Attention and Wayfinding Performance
We examined participants’ wayfinding performance metrics to assess whether navigating with human presence in the environment would influence their performance, to address our second assumption. Task duration was measured as completion time from start to finish. The total navigation task completion time across groups ranged from 281 to 1344 s (M = 455, SD = 173). An independent sample Mann–Whitney U test was conducted to compare results for all wayfinding performance metrics between groups. The results revealed that participants’ task completion time, travel distance, and count of errors did not show significant differences between SS and NSS (p > .05). Descriptive statistics showed participants in the non-social condition (n = 40) made slightly more wrong turns (M = 2.08, SD = 1.87), travelled farther (M = 707.23 m, SD = 275.64), and took longer to complete the task (M = 479.32 s, SD = 188.58) than those in the social condition (n = 42) (M = 1.83, SD = 1.32; M = 683.43 m, SD = 196.95; M = 432.58 s, SD = 156.40, respectively). These results suggest that the presence of human figures did not substantially affect overall wayfinding performance.
We then conducted correlational analyses within the SS (n = 42) to address our third assumption concerning the relationship between visual attention allocation and wayfinding performance. These exploratory analyses revealed that attention to signage was not significantly related to travel distance and task duration outcomes. However, a significant positive correlation emerged between fixation to humans and error count (r = .345, p = .025, n = 42), suggesting that attention to dynamic social elements could interfere with effective navigation (Table 1).
Correlations between fixation proportions and wayfinding performance metrics (n = 42, α<.05).

*p < .05.
A regression analysis was conducted using PROCESS Model 4 (Hayes, 2022) to examine whether attention to signage mediates the relationship between human presence in the environment and wayfinding performance, specifically error count (shown in Figure 6). As shown in Table 2, the direct effect of human presence on fixation to signage was significant (B = −0.035, SE = 0.014, t = −2.52, p = .014, R2 = .075), suggesting that human presence in the environment significantly reduced attention to signage. In the full model for wayfinding errors, attention to signage was a significant negative predictor (B = −7.044, SE = 3.099, t = −2.27, p = .02), while the direct effect of human presence on errors was not significant, B = −0.487, p = .236, R2 = .079, F(2, 79) = 2.60, p = .08.
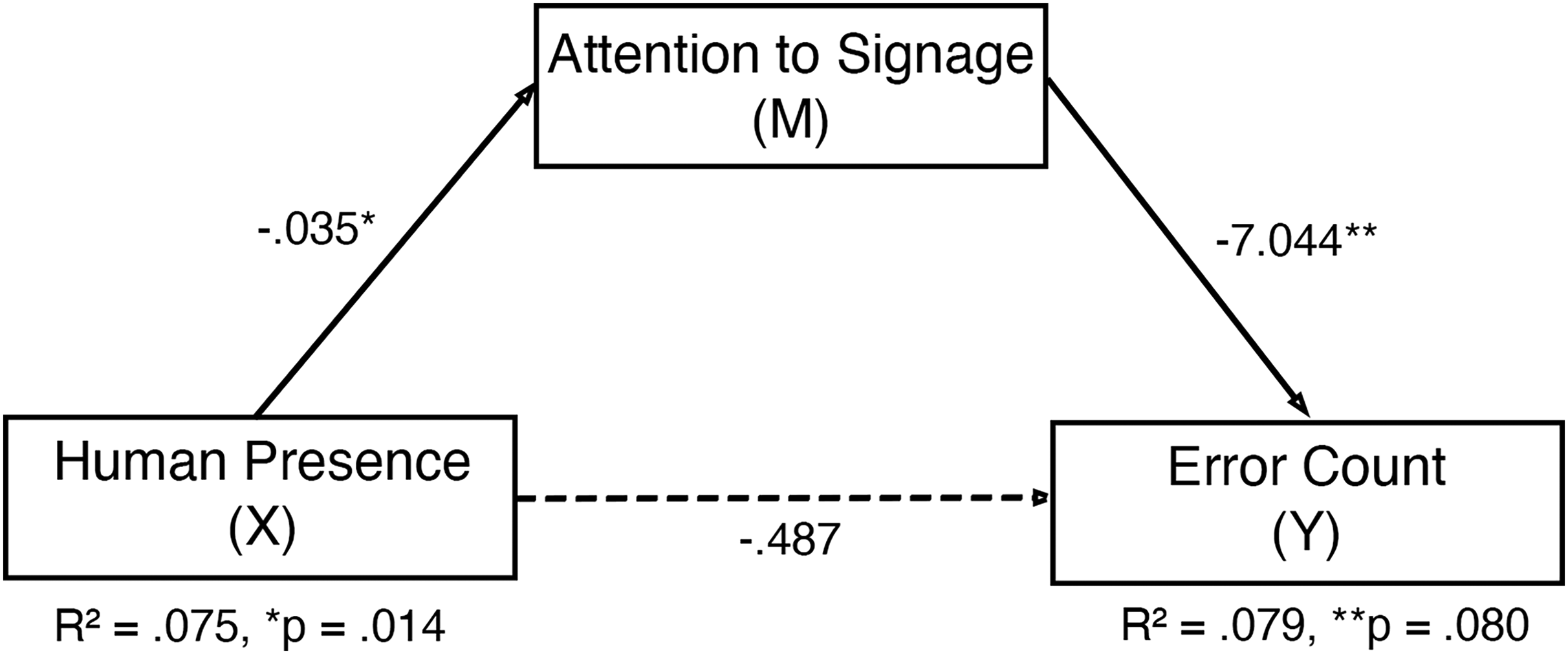
Statistical diagram of the mediation model of attention to signage between human presence and error count.
Model coefficients for the mediation of attention to signage, human presence, and error count.

Note. Indirect effects are based on bootstrapped 95% confidence intervals (Boot CI). Full mediation is defined as a statistically significant indirect effect and a non-significant total effect.
*p < .05, **p < .001, ***p < .10 (trend level).
A bootstrap analysis using 5,000 bootstrap samples confirmed a significant indirect effect of human presence on error count via fixation to signage (indirect B = 0.245, 95% CI [0.03, 0.57]). These results indicate full mediation, suggesting the effect of human presence in the environment on wayfinding errors was fully mediated by visual attention to signage. In contrast, a mediation was not observed for distance traveled and task duration (p > .67), although attention to signage was still significantly influenced by human presence. Hence, our fourth assumption was partially supported through the mediation of attention to signage between human presence and wayfinding errors, but not on other wayfinding metrics. Exploratory regression models including SBSOD scores as an additional predictor revealed no significant effect of sense of direction on error count (p = .41), suggesting that individual differences in self-reported spatial ability did not meaningfully influence the observed effects of attention.
Attention and Spatial Knowledge Acquisition
Pointing Accuracy
A Mann–Whitney U test was conducted to compare the performance of SS and NSS on the pointing task. When we examined pointing accuracy as the mean angular deviation averaged across the four questions of the pointing task, we found no statistically significant difference between settings. We also compared the scores of each of the four pointing task questions separately between settings and found no significant difference in pointing accuracy between the social (n = 42) and non-social (n = 40) conditions, U = 800.00, Z = −0.37, p = .711, r₍rb₎ = −.04. The mean rank for the social condition (42.45) was slightly higher than that of the non-social condition (40.50), but this difference represented a negligible effect size. While this suggests that human presence may not have interfered with survey knowledge acquisition in this context, further studies are needed to determine whether this pattern holds in more complex or realistic settings.
No significant relationships were found between pointing accuracy and attention to signage or humans within the SS, suggesting that within the parameters of this task, visual attention patterns were not significantly related to pointing accuracy.
Regression analysis was applied to investigate the mediating effect of attention given to signage between human presence and pointing accuracy. None of the pointing accuracy (total or task-based scores) showed a significant mediation, as the indirect effects were not significant and confidence intervals contained zero (p > .15), as opposed to our fifth assumption (b).
Landmark Locating
The SQRT-CO, ranging from 0 to 1, was used as a measurement of landmark locating accuracy. A Mann–Whitney U test was conducted to assess performance differences between SS and NSS. Results revealed a significant difference, U(619) = −2.052, p = .04, between the SS (Mdn = 0.83, IQR = 0.24) and the NSS (Mdn = 0.76, IQR = 0.21), suggesting that the presence of humans has positively influenced landmark locating accuracy (Figure 7).

Landmark locating scores between settings.
To examine whether attention to signage mediated the effect of human presence on landmark placement accuracy (Figure 8), as proposed in our fifth assumption (b), we conducted a regression analysis using PROCESS Model 4 (Hayes, 2022). As shown in Table 3, the direct effect of human presence on attention to signage was significant (B = −0.035, SE = 0.014, t = −2.52, p = .014, R2 = .075), indicating reduced attention to signage in the presence of humans. In the full model, attention to signage significantly predicted landmark placement accuracy (B = −0.606, SE = 0.298, t = −2.03, p = .045), while the direct effect of human presence on accuracy was not significant, B = 0.041, p = 0.33, R2 = .066, F(2, 79) = 3.00, p = .055.

Statistical diagram of the mediation model of attention to signage between human presence and landmark locating accuracy.
Model coefficients for the mediation of attention to signage, human presence, and landmark locating accuracy.

Note. Indirect effects are based on bootstrapped 95% confidence intervals (Boot CI). Full mediation is defined as a statistically significant indirect effect and a non-significant total effect.
*p < .05, **p < .001, ***p < .10 (trend level).
The bootstrapped (5,000 bootstrap samples) indirect effect was positive but did not reach statistical significance at the 95% confidence level (B = 0.021, 95% CI [−0.0002, 0.0502]), suggesting a trend-level mediation. Although the indirect effect did not reach statistical significance at the 95% confidence level in bootstrapped estimates, the observed pattern suggests a potential mediating role of visual attention in spatial knowledge acquisition.
Discussion
This study examined the impact of the presence of others in a public space on visual attention during navigation. Eye-tracking results revealed that participants in the social condition spent significantly less time fixating on signage and more on human figures. This shift in gaze behavior suggests attentional competition between task-relevant cues (signage) and socially relevant distractors (humans), which are known to attract spontaneous visual attention (Bindemann et al., 2005; Kuhn et al., 2009).
The reduction in signage fixations was associated with increased wayfinding errors, indicating that decreased attention to navigational cues impairs performance. These findings align with theories of limited attentional capacity, where highly attractive social stimuli can draw gaze away from functional information (Pessoa, 2009; Tatler et al., 2011). In visually complex environments, such competition may disrupt encoding of spatial layout or impair recognition of directional cues. This indirect relationship warrants further consideration in light of how participants may have integrated multiple sources of spatial information during navigation. While signage was designed to be directional and contextually relevant, the relationship between attention to signage and navigation performance was not straightforward. This pattern suggests that attending to signage alone may not fully predict wayfinding success, as participants could also rely on other cues such as spatial layout geometry, memory, or incidental learning (Dalton, 2003; Hölscher et al., 2011; Montello, 2005). The findings therefore suggest that competition from social stimuli, rather than an absence of useful signage, likely reduced attention to signs, which in turn partially mediated the relationship between social presence and navigational errors (Krukar & Dalton, 2020).
Interestingly, despite impaired wayfinding, participants in the social condition did not perform worse on all spatial learning measures. While pointing accuracy remained unaffected, landmark placement scores were higher. This divergence may reflect different underlying cognitive processes: landmark memory might be supported by incidental encoding triggered by human presence, while directional accuracy relies more directly on structured navigational attention (Ishikawa & Montello, 2006). In other words, the dissociation suggests a trade-off between task-focused attention and incidental learning. While social stimuli may divert attention away from task-relevant cues such as signage, thereby impairing goal-directed navigation, they can simultaneously promote more environmental engagement and incidental encoding of contextual information, including landmarks. This interpretation aligns with prior findings indicating that socially rich environments heighten arousal and depth of processing, even when task performance is reduced (Birmingham et al., 2008; Tatler et al., 2011).
It is also important to note that our study focused on attentional effects of social presence rather than crowd dynamics. The avatars acted as controlled, non-guiding representations of human presence, allowing us to isolate attentional competition between social and navigational elements.
Visual Attention and Perceptual Competition
Participants in the social condition fixated significantly more on human figures than on signage, aligning with evidence from social attention research showing that human figures strongly attract gaze even when they are task-irrelevant. They are also consistent with selective attention theories emphasizing the importance of social stimuli (Fysh et al., 2024). Competing cues, such as humans and signage, increase perceptual demand, forcing participants to divide their attention. Consistent with studies showing that moving elements capture visual attention more effectively than static ones (Itti & Koch, 2001; Yang et al., 2018), the movement of humans likely contributed to the division of attention. However, they may also likely have interacted with the participant's ego motion in the VR environment (Warren & Rushton, 2009). However, participants still fixated more on human figures than on signage, suggesting that the social relevance and biological motion of humans may override motion-compensation effects during self-motion. Thus, the observed attention allocation likely reflected not only visual motion but also the social relevance of human figures within a dynamic, self-moving visual field.
The present study findings reveal a complementary pattern with recent real-world evidence using eye-tracking, where individuals reduced fixations on social stimuli under increased cognitive demands (De Lillo et al., 2021). Our findings revealed that when humans are present in a navigational context, they can take attention away from task-relevant information such as signage. Together, they describe the same attentional competition mechanism from opposite directions: social presence and navigational cues compete for limited attentional resources, and the balance between them depends on task demands and context.
Similarly, Bindemann et al. (2009) showed that attention to faces can be endogenously changed according to task requirements, suggesting that the tendency to fixate on human figures in our study may be modulated when participants prioritize navigational goals. Furthermore, Fysh et al. (2024) observed that when crowds in the background were present during a face-identification task in an airport environment, attentional competition and perceptual load increased, resulting in delayed responses. This recent evidence is also consistent with our observation that dynamic social stimuli can divert attention from task-relevant signage.
Wayfinding Performance and Gaze Behavior
Overall, wayfinding metrics did not differ significantly between conditions. This contrasts with prior studies where social cues either aided or hindered navigation (Dalton et al., 2019; Kinateder & Warren, 2016; Silva et al., 2015), depending on context. Environmental legibility may reduce the effects of distraction in linear layouts, so critical signage remains sufficient.
However, within the social condition, increased fixation on humans predicted higher error counts, indicating that attentional allocation, not presence alone, impairs navigational accuracy. Mediation analysis further confirmed that attention to signage explained the relationship between human presence and navigation errors. This aligns with the Load Theory (Lavie, 2005), explaining how social stimuli can distract from relevant environmental information and increase perceptual load. Attention to task-relevant stimuli is constrained when the visual field contains attractive distractors (Lavie, 2005), that may particularly be relevant for individuals with lower spatial ability (Ishikawa & Montello, 2006), and it highlights the need for designs that minimize perceptual competition at critical decision points in complex public environments where social distractions are frequent, and maintain signage visibility to support effective navigation.
From a practical standpoint, our findings highlight the importance of wayfinding systems that remain effective in socially dynamic environments where crowds cannot be controlled. Since social stimuli naturally attract attention, signage systems must compete successfully for perceptual priority. Enhancing attractiveness of signage through increased size, contrast, and strategic placement at key decision points can help maintain visibility despite the crowds (Rodrigues et al., 2019; Su et al., 2022). Additional visual cues such as directional arrows and color-coded floor lines may further support wayfinding by providing continuous, easily followed cues that reduce reliance on recurring overhead signage. Such systems could be extended to airports and other complex facilities. Implementing these design strategies may help balance the attentional demands resulting from crowded environments, supporting a more efficient and error-resilient wayfinding.
Spatial Acquisition and Social Context
While human presence did not affect pointing accuracy, landmark placement accuracy was interestingly higher in the social condition. This contrasts with earlier studies linking attention to environmental features with improved spatial learning (Çöltekin et al., 2020; Foo et al., 2005), implicating that contextual and task-related factors may moderate this relationship. Our results indicate increased environmental engagement or the use of people as incidental reference points. Although attention to signage did not significantly mediate this effect at the 95% confidence level, the trend observed suggests a potential pathway worth exploring further. The absence of a strong mediating effect of signage attention on this outcome suggests that spatial learning may rely on both attentional and memory-based processes. Wayfinding involves dynamic cognitive processes, including memory retrieval and decision-making (Spiers & Maguire, 2008). While attention was directed toward social or non-social cues, it may not have translated into spatial memory. These findings reveal the relationship between gaze behavior and spatial encoding, again highlighting the complexity of perceptual learning in dynamic settings.
Limitations and Future Directions
Prior work shows that gaze behavior and social presence can differ between virtual and real contexts (Blascovich et al., 2002; Oh et al., 2018; Pan & Hamilton, 2018). Our research design increased internal validity by minimizing visual variability, yet its ecological realism can be discussed based on the mentioned difference between real and virtual contexts. We ensured a controlled design to reflect attentional effects of social presence rather than visual salience. Future studies could test how increased avatar realism and social interactivity affect attentional allocation in more naturalistic settings. While the increased fixation on human figures likely reflects the importance of social cues, it is also possible that a small portion of this effect was influenced by perceptual or affective responses to avatar realism. As noted by de Borst & de Gelder (2015) the “uncanny valley” phenomenon can provoke momentary attentional engagement with artificial agents that appear almost but not entirely human. However, in the present study, this influence was likely minimal given that the avatars were neutral grey silhouettes without facial or textural detail, specifically designed to reduce perceptual salience and emotional expressiveness. It also strengthens internal validity by ensuring that fixations on avatars primarily reflect social attention rather than attraction to visually salient features (Birmingham et al., 2008; Foulsham et al., 2011). We include this consideration as a potential improvement point rather than a bias. Future research could systematically manipulate avatar realism and motion realism to further separate social and perceptual contributions to attentional allocation.
In our study, we used non-parametric tests to compare wayfinding performances between conditions due to non-normal data distributions for the three performance metrics: task duration, distance travelled, and navigational errors. However, we acknowledge that these are conceptually interrelated. While separate Mann–Whitney U tests provided a conservative approach suitable for two-group comparisons, future studies could apply non-parametric multivariate analysis of variance methods (He et al., 2017) to evaluate these correlated outcomes jointly and capture shared variance patterns across performance metrics.
Furthermore, although VR offered experimental control, limited peripheral vision, and a lack of multisensory input (e.g., ambient sound and motion cues) may have reduced the richness needed for spatial encoding (Marín-Morales et al., 2019). Future studies using mobile eye-tracking in physical environments could enhance ecological validity.
The linear layout of the airport may also have limited spatial variability; testing more complex geometries with multiple decision points could reveal stronger perceptual effects. Additionally, attention does not always translate into encoding (Keller & Sutton, 2021), suggesting the need to separate perceptual and memory processes. Further research should examine individual moderators (e.g., spatial anxiety and personality traits) and contextual variables (e.g., crowd dynamics and time pressure). Predictive models based on gaze data could inform adaptive systems (Sattar et al., 2020), while exploring different types of social stimuli may offer deeper insight into perceptual priorities during navigation.
Conclusion
This study demonstrates that visual attention is a key mediator in how people navigate socially complex environments. When other humans are present, attention is drawn toward socially relevant cues at the expense of task-relevant information such as signage. While overall wayfinding metrics remained stable across conditions, gaze behavior specifically reduced attention to signage, and it was linked to increased navigation errors. This suggests that it is not only social presence, but the perceptual competition between social and navigational elements, that affect performance.
These findings strengthen the idea of behavioral observation. They reveal the attentional mechanisms that shape human–environment interaction. By quantifying moment-to-moment shifts in attention, particularly in populated or visually dynamic settings, eye-tracking exposes the perceptual processes underlying navigation. From an architectural perspective, these results emphasize that human figures are not peripheral but integral parts of spatial environments. They actively shape how users perceive, prioritize, and act upon environmental information. Recognizing this interaction allows designers and researchers to move toward more perceptually informed theories of wayfinding, ones that account for social importance, attentional competition, and the dynamic nature of real environments.
Supplemental Material
Footnotes
Acknowledgements
The authors would like to extend their sincere gratitude to Yiğit Özen for his assistance in programming and to Besmir Kamberi for his help in modeling and animating the virtual environment. The authors also thank all participants for their involvement in the study. This work was completed as part of the first author's doctoral dissertation in the Department of Interior Architecture and Environmental Design at Bilkent University.
Ethical Statement
The Bilkent University Ethics Committee approved this study's protocol. All participants gave informed consent and were informed of their right to withdraw at any time. All data were anonymized to maintain confidentiality.
Author Contribution(s)
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: Open access publication fee for this article was supported by Bilkent University. This research did not receive any specific grant from funding agencies in the public, commercial, or not-for-profit sectors.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
The data that support the findings of this study are available from the corresponding author (Gökçe Orlu Özen) upon reasonable request.
Supplemental Material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.