
Abstract
Explosive loading in a confined internal environment is highly complex and is driven by nonlinear physical processes associated with reflection and coalescence of multiple shock fronts. Prediction of this loading is not currently feasible using simple tools, and instead specialist computational software or practical testing is required, which are impractical for situations with a wide range of input variables. There is a need to develop a tool which balances the accuracy of experiments or physics-based numerical schemes with the simplicity and low computational cost of an engineering-level predictive approach. Artificial neural networks (ANNs) are formed of a collection of neurons that process information via a series of connections. When fully trained, ANNs are capable of replicating and generalising multi-parameter, high-complexity problems and are able to generate new predictions for unseen problems (within the bounds of the training variables). This article presents the development and rigorous testing of an ANN to predict blast loading in a confined internal environment. The ANN was trained using validated numerical modelling data, and key parameters relating to formulation of the training data and network structure were critically analysed in order to maximise the predictive capability of the network. The developed network was generally able to predict specific impulses to within 10% of the numerical data: 90% of specific impulses in the unseen testing data, and between 81% and 87% of specific impulses for data from four additional unseen test models, were predicted to this accuracy. The network was highly capable of generalising in areas adjacent to reflecting surfaces and as those close to ambient outflow boundaries. It is shown that ANNs are highly suited to modelling blast loading in a confined internal environment, with significant improvements in accuracy achievable if a robust, well distributed training dataset is used with a network structure that is tailored to the problem being solved.
Keywords
Introduction
Background
Recent high-profile terrorist incidents, such as the Manchester Arena bombing (2017, 22 fatalities) and the Brussels Airport attacks (2016, 33 fatalities), involved the use of high explosives detonated in a crowded internal environment (Ben-Ezra et al., 2017; Kwon et al., 2017). Whilst the payload from vehicle-borne improvised explosive devices (VBIEDs) is considerably larger than those from person-borne explosives, the effects of a VBIED attack can be mitigated by enforcing a safe stand-off distance through the use of hardened security checkpoints and anti-vehicle barriers (Cormie et al., 2009). Whilst security checkpoints can also deter or prevent access to those intending to use person-borne explosives, they remain impractical for sites where large volumes of people require ready access, for example, airport pick up and drop off zones, train stations and concert halls.
Accurate prediction of the blast load arising from detonation of a high explosive remains a crucial step in assessing structural response (Rigby et al., 2019) and human injury (Pope, 2011). Detailed maps of the peak loading in an internal environment, and a comprehensive understanding of the factors affecting the magnitude of this loading, will allow for better provision of (active) mitigation systems, and will assist in planning interior layouts for enhanced (passive) blast protection strategies. Accordingly, a tool that can rapidly and accurately predict the complex loading in a crowded space is vital for risk-based engineering practice.
Existing semi-empirical approaches for predicting blast parameters, for example, the Kingery and Bulmash method (Kingery and Bulmash, 1984) and ConWep (Hyde, 1991), are known to be accurate only for far-field, geometrically simple scenarios (Rigby et al., 2014b).
When an explosion occurs in a complex environment, coalescence of multiple shock fronts that have reflected off or diffracted around obstacles is highly nonlinear (Larcher and Casadeia 2010) and hence simple superposition methods are unsuitable. Whilst methods for predicting confined loading exist in current design guidance, such approaches can only be used to calculate the average pressure acting on a single internal wall (assumed to be uniformly distributed and neglecting the walls parallel and opposite to the surface in question (US Department of Defence [US DOD], 2008), or the decay of quasi-static pressures, again averaged throughout the domain, for situations with high degrees of confinement and therefore low venting area (Anderson et al., 1983). Clearly, a more refined approach is required to consider situations which feature considerable interaction of blast waves, multiple reflections and development of increased specific impulses near the walls and the corners of the domain. Computational fluid dynamics (CFD) approaches offer the potential to develop a comprehensive and accurate description of an internal blast load, however it is impractical to use such approaches to inform risk-based engineering owing to the relatively high associated computational cost.
There is therefore the need to develop a predictive approach with the accuracy of a physics-based numerical scheme and the low computational cost of a semi-empirical method. Artificial neural networks (ANNs) are suitable as they have a proven ability to accurately predict complex nonlinear problems for various scenarios with simulations times comparable to basic solvers (see Figure 1). Applications of ANNs include estimating thermal performance of buildings (Flood et al. 2004), predicting blast-induced ground vibrations (Shahri and Asheghi, 2018) and quantification of blast loading on a building behind a blast wall (Remennikov and Rose, 2007) or along simple city streets (Remennikov and Mendis, 2006). Despite a clear applicability, the use of ANNs for internal explosions remains largely unexplored.
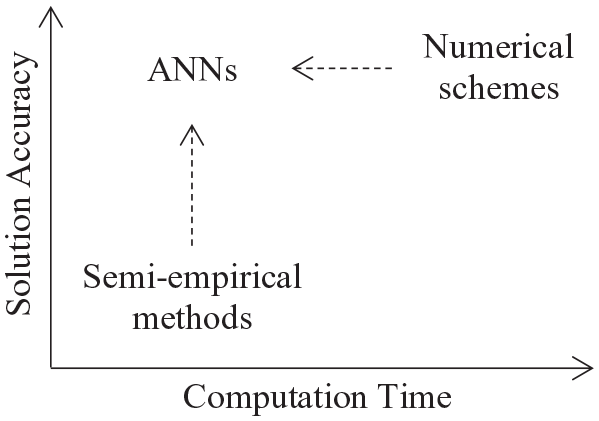
Desired performance of ANNs.
The first aim of this paper is to critically evaluate the design of an ANN trained to simulate a given internal blast scenario. This is achieved through consideration of how the training dataset is generated and formatted before being used in the development of the ANNs. Additionally, a range of network structures are developed using various neuron counts to identify an optimum network configuration. The second aim of the study is to demonstrate the applicability of ANNs for predicting blast loading in an internal environment. Predictions generated by the ANNs are directly compared to numerical data from 72 different explosive scenarios during the training process. This allows for a comprehensive evaluation of the network performance including an assessment of how the network’s accuracy is dependent on each of the input values. The best performing network configuration is then evaluated using unseen input data from four additional tests to show that the ANN approach is capable of simulating specific impulse with percentage errors that are comparable to alternative methods.
Artificial neural networks
The progression of experimental techniques and bespoke modelling methods enable the use of ANNs for solving complex non-linear problems, especially those where the functional relationship between the input variables and output parameters is unknown (Alizadeh et al., 2017). They have applications involving data mapping, regression, classification and image processing (Dogan et al., 2017; Lee et al., 2012). However, for this study, focus will be placed on feed-forward, backpropagation regression networks. Training will take place using a supervised learning regime that generates improvements to the ANNs predictive accuracy through comparisons between the model output and known targets.
ANNs are formed of many neurons that process information being translated via connections. An example of a typical network is shown in Figure 2, with a forward pass being from left to right. Each connection holds a numerical weight that defines how large the value being passed via a given connection is. At each neuron, the translated values from the incoming connections are summed with a predefined bias that provides the neuron with a baseline magnitude. Before this summation result is passed onto the next neuron, it is standardised by an activation function that helps to prevent the input variable’s magnitudes from skewing the results disproportionally. Hidden layers/neurons allow for the interdependencies of the input variables to be captured which enables predictions to be made for complex problems.
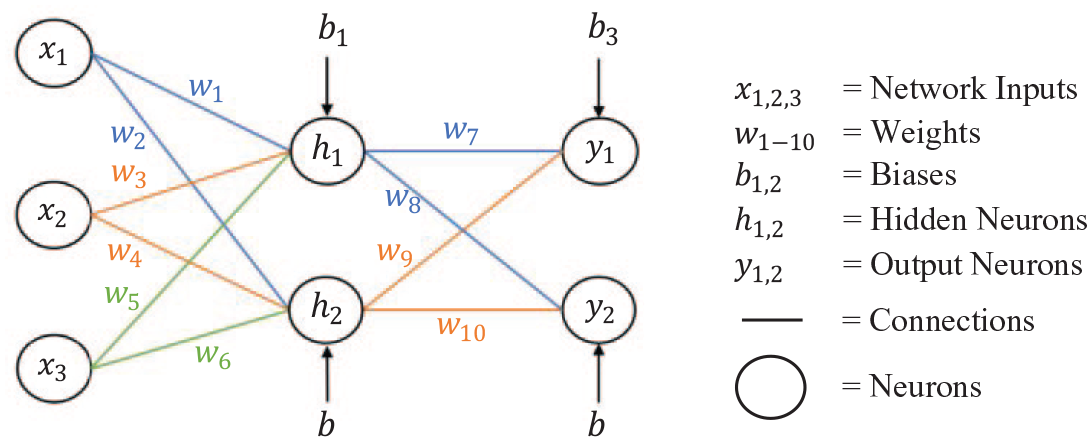
Example artificial neural network indicating the key components.
A summary of this calculation process for a given neuron is shown in Figure 3. It should also be noted that due to how the regression network will be required to predict continuous values, the activation function used on the output layer of neurons will be linear so that the predictions remain unbounded. This differs from the sigmoid or rectified linear unit (ReLU) functions that are commonly used at each of the hidden or input neurons.
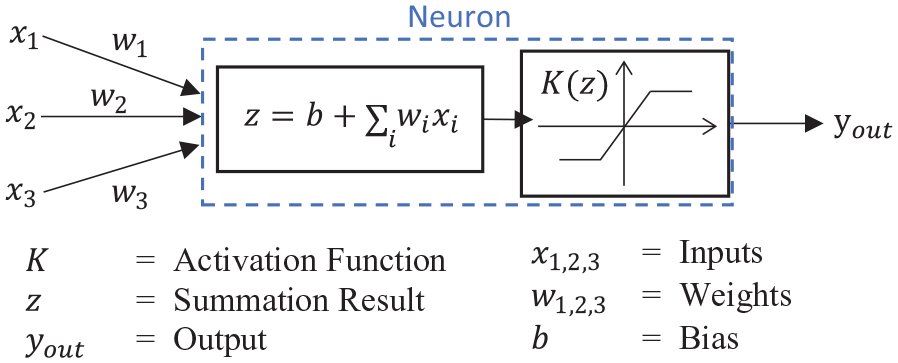
Example mathematical procedure for a single hidden neuron. Adapted from Remennikov and Rose (2007).
Initially, all weights and biases are given random values. The process of backpropagation is then used as part of the training process to reduce the output prediction errors using a gradient descent algorithm. By passing the output prediction errors from the forward pass back through the network, the weights and biases responsible for the inaccuracy are identified and optimised.
Once training is complete, testing of the network can take place using unseen input patterns. Rapid predictions can be formed by the network in this stage as the weights and biases are no longer being updated. The number of training patterns used, the complexity of the problem being modelled, and the network architecture will all influence the accuracy of a trained network because each of these factors control its ability to generalise from the training dataset (Remennikov and Rose, 2007).
Literature review
Field experiments provide the best chance at capturing the complex wave interaction processes associated with confined internal environments. However, they require specialist equipment and expertise that can often be very costly, and therefore simplifications are required. Experimental work by Anthistle et al. (2016), for example, utilised symmetry of the testing domain in order to model only a quarter of the environment. Here, it was found that good reproducibility was achieved between each test and therefore the use of symmetry constraints was considered acceptable.
Alternative approaches include modelling the entire domain at a scaled size. Fouchier et al. (2017) adopted this approach, using a range of wooden test structures at a 1:200 scale to analyse various street arrangements. It allowed for direct comparisons between each road/building layout to be conducted in a safer and more economical way. Hopkinson-Cranz scaling laws (Cranz, 1926; Hopkinson, 1915) were also shown to provide good agreement for the free-field and straight road arrangements meaning the results could be used for validation work in the future. It has been shown that numerical modelling of blast loading in an internal environment is highly complex, with the presence of multiple reflections requiring many equations and mathematical relationships to be solved in parallel (Larcher and Casadeia, 2010).
In situations where multiple field tests are not suitable, mathematical modelling presents a means of obtaining predictions for an unbounded range of scenarios, however experimental data is still required to rigorously validate these numerical approaches. A study by Xu et al. (2018) developed codes for 1D, 2D and 3D models based on finite difference schemes to analyse various test problems. The 3D code was then validated against experimental data for a confined chamber to prove that the model produced reliable overpressure-time histories. Generally, the accuracy of these methods is controlled by the coarseness of the element mesh forming the environment or the step size used in the calculation process. This is discussed further by Caçoilo et al. (2018), who studied the propagation of blast waves inside a survival blast chamber using an LS-DYNA numerical model. Through comparing the numerical results to a physical experiment, the authors reported specific impulse errors below 19% when using a mesh size of 3.25 mm. A finer mesh may improve on this further, however there is a trade-off between accuracy and computation time that will change based on the general arrangement of the simulations and intended use of the results. In this case, for the highly complex wave interaction processes that within the chamber, the paper shows how numerical methods are able to provide reasonable predictions for blast loading parameters without the need for experimental programmes beyond the validation stage.
The continuous development of numerical methods is driven by the increasing use of probabilistic approaches for modelling blast scenarios. These approaches allow for the uncertainties associated with explosions to be accounted for in risk analyses or cost-benefit assessments which ultimately makes them very useful for blast design and building appraisal (Netherton and Stewart, 2016). An example of this approach is detailed in a study by Alterman et al. (2019) where ProsAir was used to estimate blast loads, 1 m above the floor resulting from the detonation of an improvised explosive device (IED) in a typical ground floor foyer of a commercial or government building. A Monte-Carlo analysis framework was used to provide distributions of the model input parameters so that various conclusions could be made about the domain based on the likelihood of certain attacks taking place (Alterman et al., 2019). The need to simulate the same environment with a large number of varying input parameters does not lend itself to this sort of numerical approach as the computation times were reported to be between of 0.07 and 29.52 hrs for each model. A fast running deterministic model would therefore help to expedite the process of environment evaluation whilst also increasing the number of input parameters that could be considered.
Recent studies, for example, Gault et al. (2020), have been focussed on provide new methods for complex environment predictions using experimental records to form relationships between various blast parameters. The targeted benefit being that they can quickly produce reasonable outputs without a significant loss of accuracy. In this case, around 15% error is achieved for a tool that is flexible to allow the user to define a mesh and domain size in addition to a charge size and location.
Artificial neural networks (ANNs) present an alternative approach to providing rapid analyses without the need for relationships to be derived manually. The two broad categories for their use in blast engineering are for assessments of localised structural response to blast loads and for the prediction of key blast parameters. With the focus of this study being on the latter, papers by Remennikov and Rose (2007) and Remennikov and Mendis (2006) indicate that high predictive accuracy can be achieved both behind blast walls and along simple city streets. The former reports correlation coefficients in testing of 0.997 for overpressure, and 0.998 for specific impulse. Here the correlation coefficient is a numerical indication of the agreement between the output predictions and targets, with a value of 1 suggesting total agreement. This was achieved using two hidden layers in fully connected regression networks.
Similarly, Flood et al. (2009) details the results from two separate studies that both looked at predicting blast loading parameters behind walls. The first utilised a dataset of 1365 training patterns and 252 testing patterns that were gathered from numerical simulations, whereas the second used 195 for training and five for testing from scaled experiments. It was found that the testing phase correlation coefficient for peak overpressure decreased from 0.996 to 0.830 as the dataset size was reduced. It is also noted that the experimental dataset contained a larger variability in the spacing between each data point. The generalisation capability of the network was therefore restricted due to the lack of data that is well distributed throughout the value boundaries associated with each input variable (Flood et al., 2009).
A study by Bortolan Neto et al. (2020) noted a similar conclusion as a network was trained to predict the mechanical response of mild steel plates experiencing localised blasts. Through supplementing sparse experimental data with validated numerical modelling data, it was found that a robust training dataset could be formed which included a greater amount of training patterns. The inclusion of a core of experimental data also helped to provide confidence that the network was modelling blast scenarios that are physically accurate. This stage therefore acted as validation for the developed ANNs.
Overall, a review of literature shows that the ability of ANNs to generate rapid predictions with engineering-level accuracy could benefit probabilistic methods that require consideration of the variability of key blast parameters. However, the need for a robust dataset means that numerical or experimental methods (rather than simple analytical tools) will still be required in the development of ANNs. Clearly an increase in computational power will also expedite the data generation and training/validation processes, hence ANNs are expected to remain advantageous over pure CFD approaches.
Numerical modelling
Validation of APOLLO Blastsimulator
Introduction and mesh sensitivity
Numerical analyses were performed using APOLLO Blastsimulator (‘Apollo’ hereafter). Apollo is an explicit CFD software which specialises in the simulation of high-dynamic flow problems (Fraunhofer EMI, 2018). The conservation equations for transient flows of compressible, inviscid and non-heat conducting, inert or chemically reacting fluid mixtures are solved using a second-order finite-volume scheme with explicit time integration. Features such as dynamic mesh adaptation (DMA), 1D-to-3D mapping and 3D-to-3D staged mapping allow for efficient use of computational resources. DMA is controlled through the specification of a ‘zone length’,
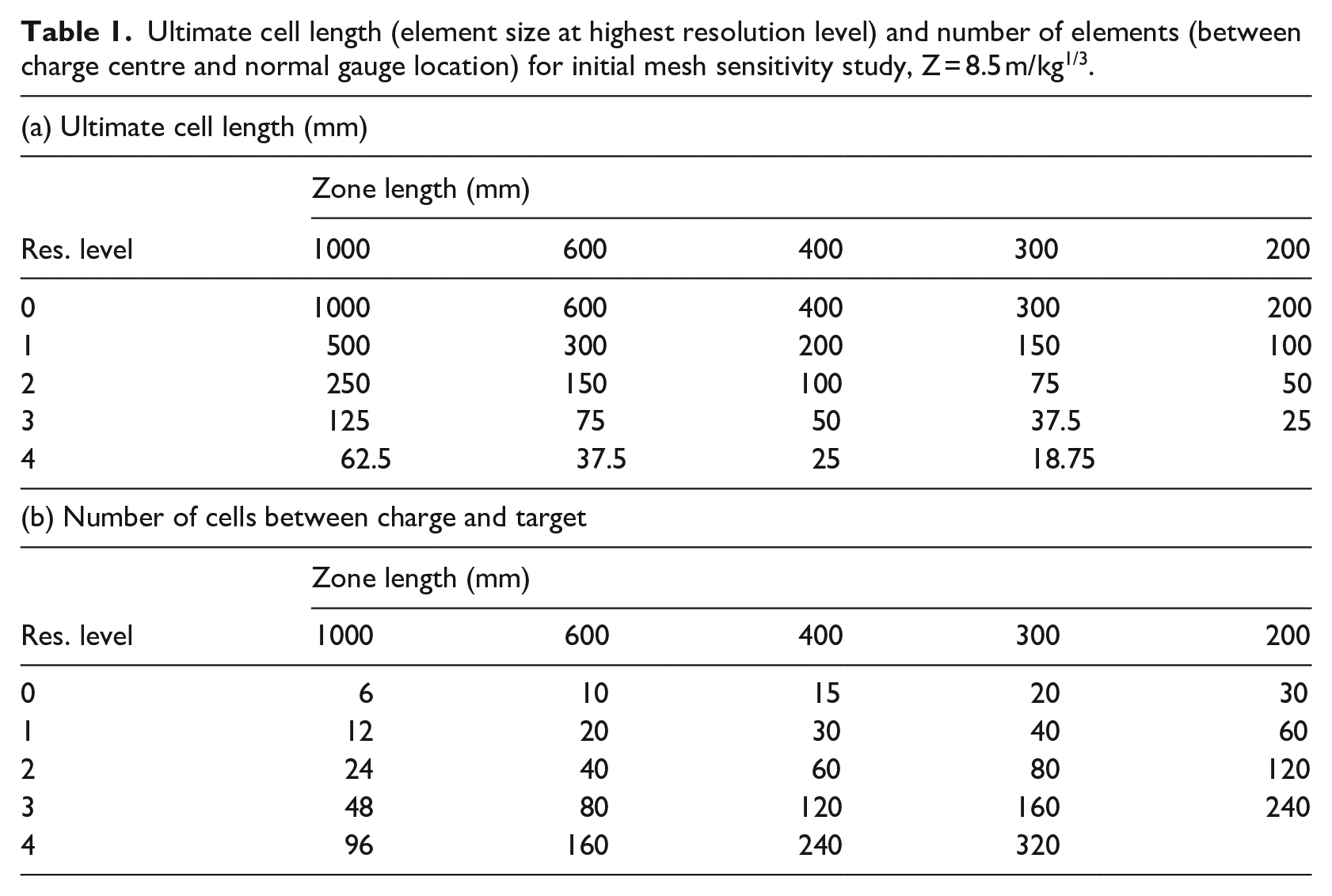
A mesh sensitivity study was completed in order to determine required element sizes to achieve convergence. A series of numerical simulations were completed for a 0.35 kg hemispheres of PE4 (modelled as a 0.7 kg sphere in Apollo), located at a stand-off distance,
The domain size was
Ultimate cell length (element size at highest resolution level) and number of elements (between charge centre and normal gauge location) for initial mesh sensitivity study, Z = 8.5 m/kg1/3.
Results from the mesh sensitivity analysis are shown in Figure 4, each sub-figure shows: peak overpressure; peak specific impulse and total analysis time (termed ‘wall time’), all plotted against the ratio of stand-off distance,
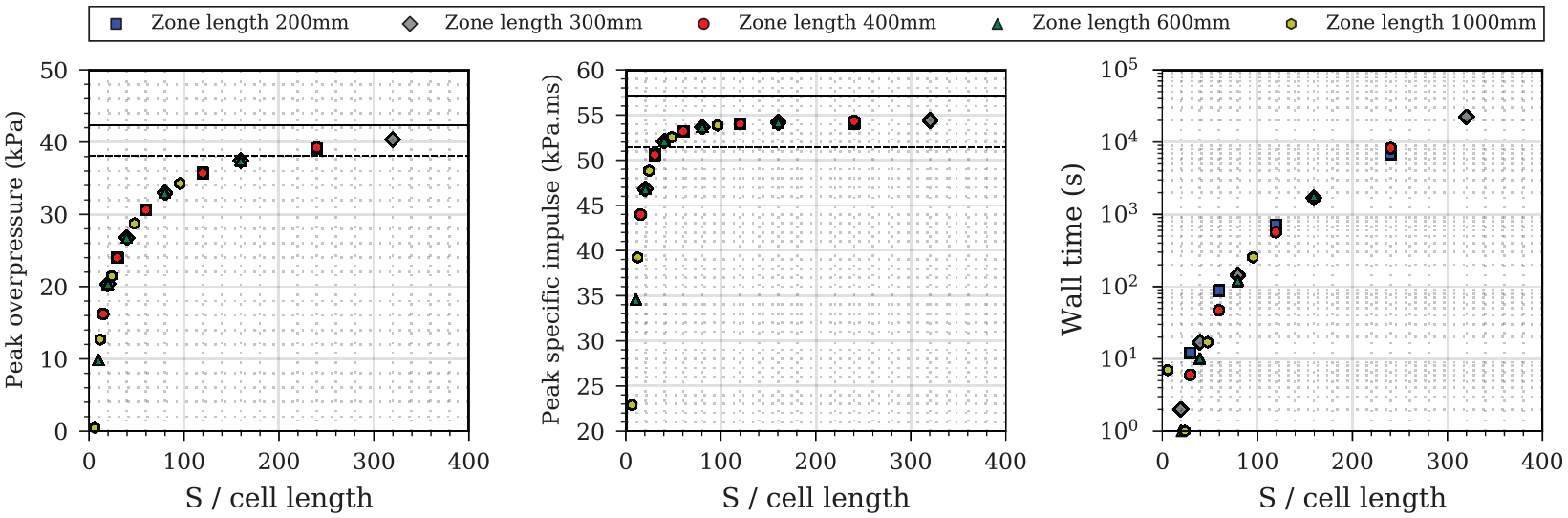
Mesh convergence study for 0.35 kg PE4 at 6 m stand-off from a rigid reflecting wall. Solid line indicates average experimental value (Rigby et al., 2015) and dashed line indicates 10% variation from the experimental value.
The study suggests that an ultimate cell length of
The benefits of the DMA module can be seen when wall time is considered: at
Experimental validation
Rigby et al. (2015) present a series of experimental trials where pressure gauges, embedded flush with the surface of a large, reinforced concrete bunker wall, were used to record reflected pressure histories from 0.18 to 0.35 kg PE4 hemispheres located 2 to 10 m from the bunker wall. The experimental set-up is shown in Figure 5. For this validation exercise, only data from the normally reflected gauge, ‘G1’, was used.
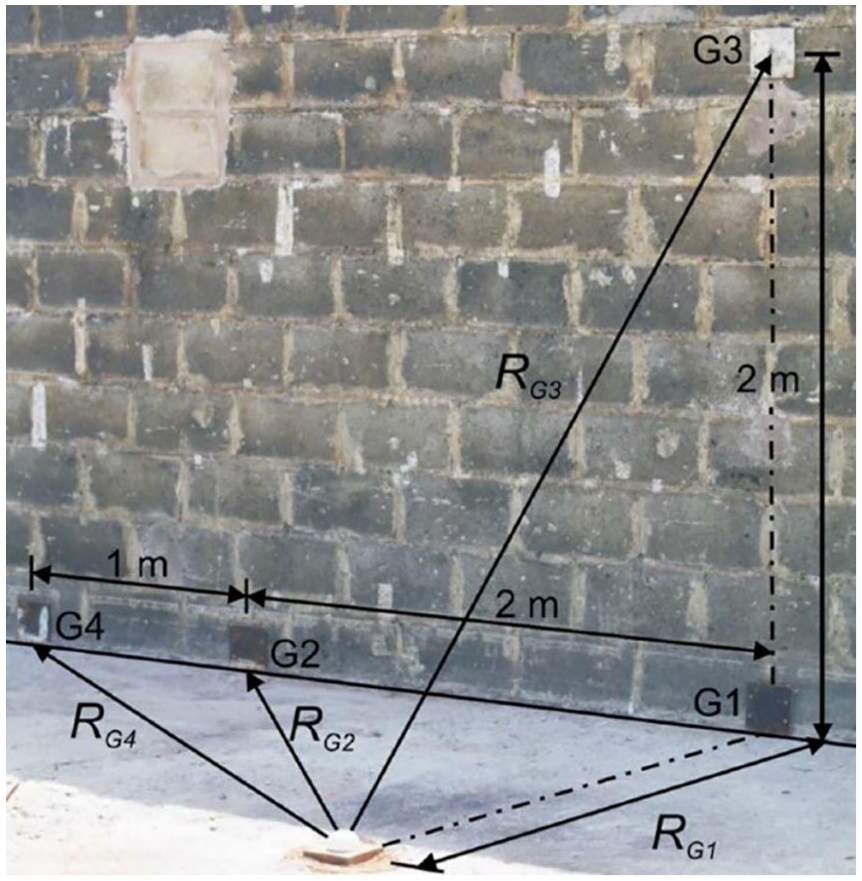
Pressure gauge location and general test arrangement of experimental data (Rigby et al., 2015).
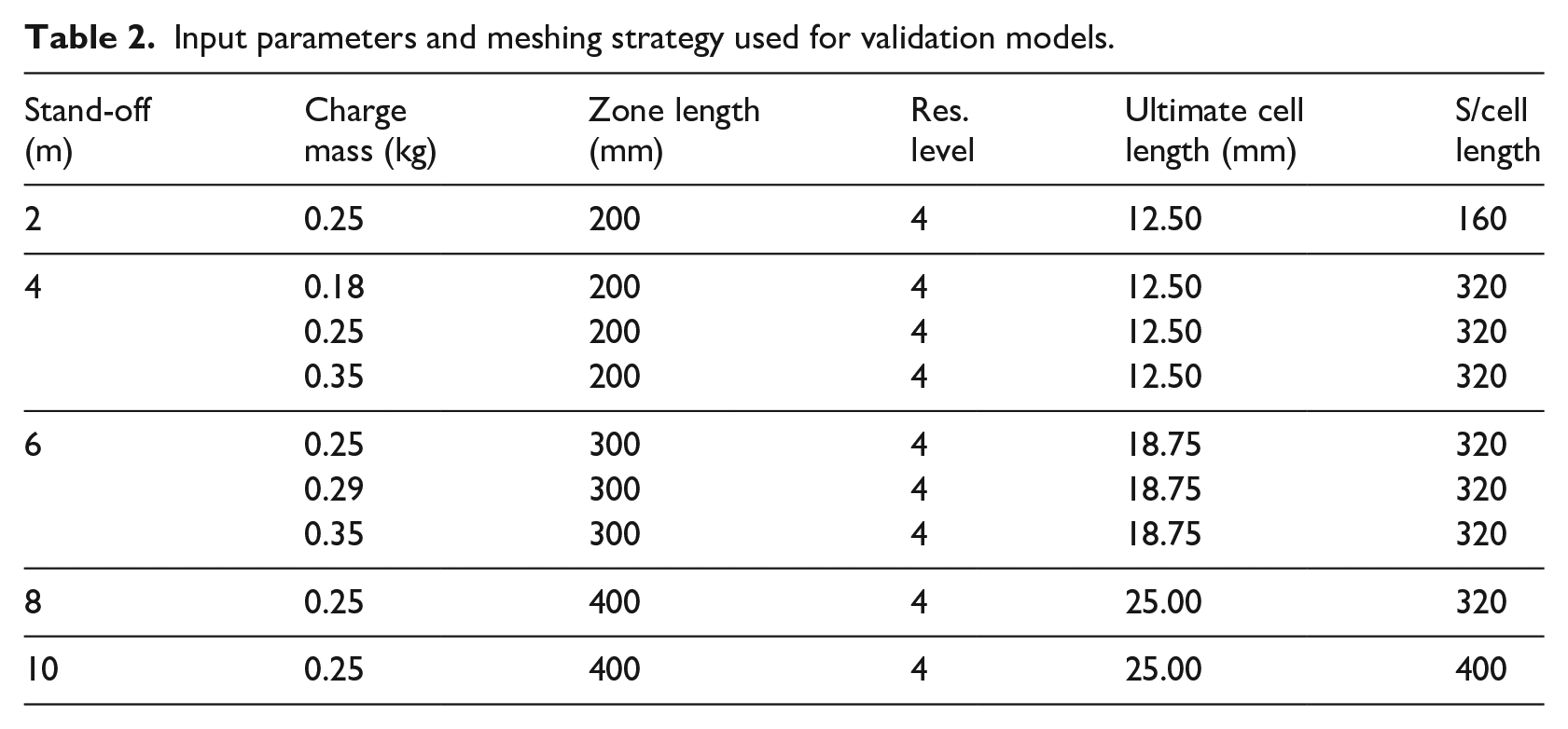
The experimental dataset consists of 19 tests at nine unique scaled distances, therefore nine numerical analyses were performed. In each, the domain size was a regular cube with side-length equal to the stand-off distance in each case. As in the mesh sensitivity study, eighth-symmetry was used, with symmetry planes located in the directions orthogonal and opposite to the reflecting wall, originating at the centre of the charge. Outflow boundaries were defined at the roof of the domain and the remaining side. A numerical pressure gauge was placed at the base of the wall directly opposite the charge centre. Further information for each of the validation models is presented in Table 2, including resolution level, ultimate cell length and resulting stand-off/cell length (
Input parameters and meshing strategy used for validation models.
Results from example numerical analyses are compared to experimental data in Figure 6. Here, results from the 4 m stand-off scenarios are presented: PE4 hemispheres of 0.18 (a), 0.25 (b) and 0.35 kg (c) corresponding to scaled distances of 7.08, 6.35 and 5.68 m/
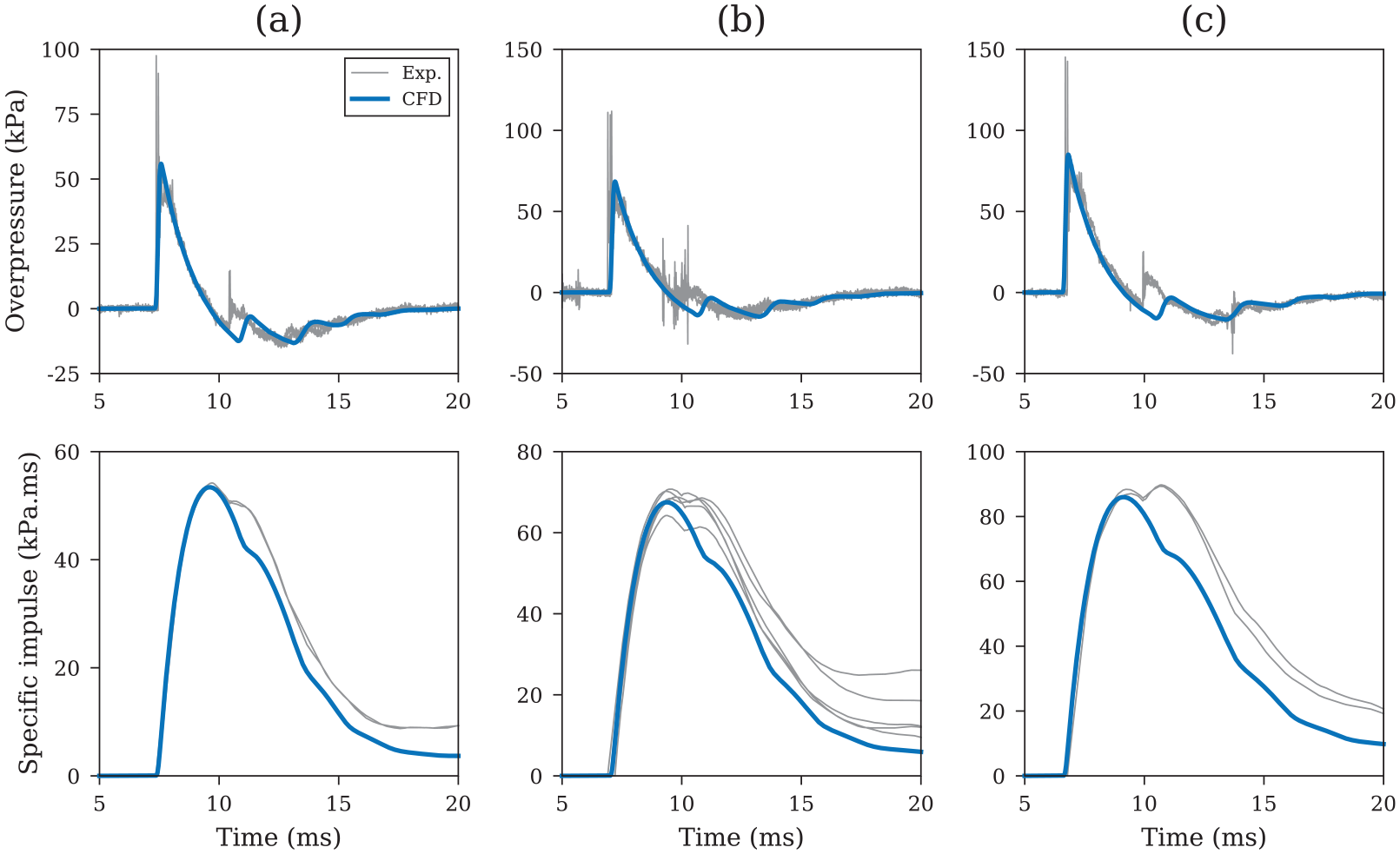
Experimental validation of numerical overpressure and specific impulse histories at 4 m stand-off for: (a) 0.18 kg, (b) 0.25 kg and (c) 0.35 kg PE4 hemispheres.
Additionally, a comparison of numerical and experimental scaled peak specific impulse values (divided by the cube-root of the charge mass) is presented in Figure 7. The numerically generated peak specific impulses can be seen to closely match the experimental data consistently across the entire range of scaled distance and therefore Apollo can be considered to provide accurate specific impulse values in this region of scaled distances, provided the mesh requirements outlined in Introduction and mesh sensitivity are satisfied.
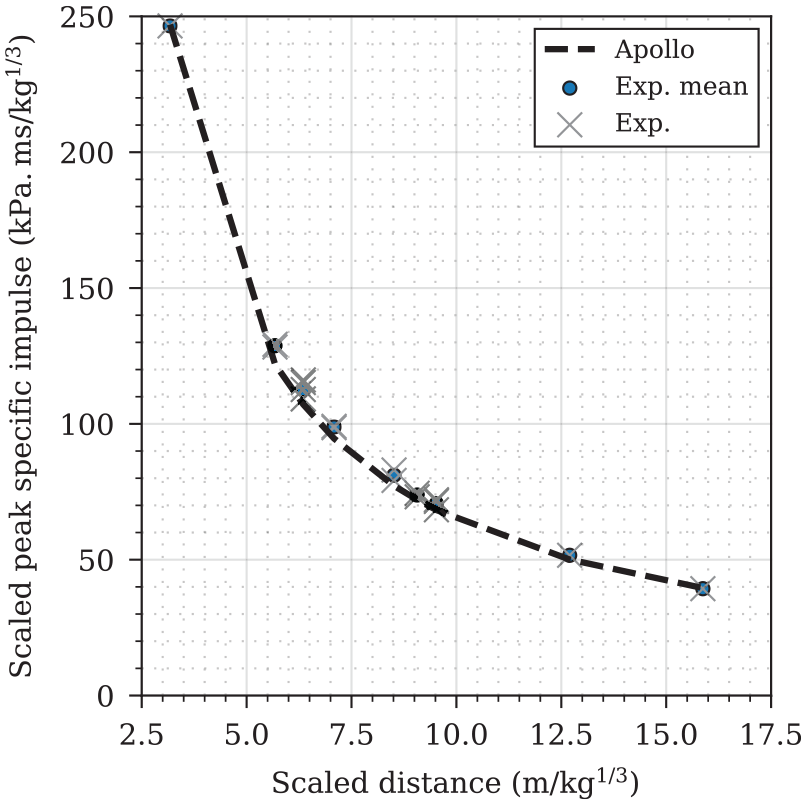
Validation of Apollo scaled peak specific impulse against experiments (Rigby et al., 2015).
Generation of dataset
Problem domain
A domain was selected in order to be representative of a typical internal environment whilst offering the capability to train and test an ANN over a wide range of input parameters and output targets. As such, preliminary testing led to a domain of
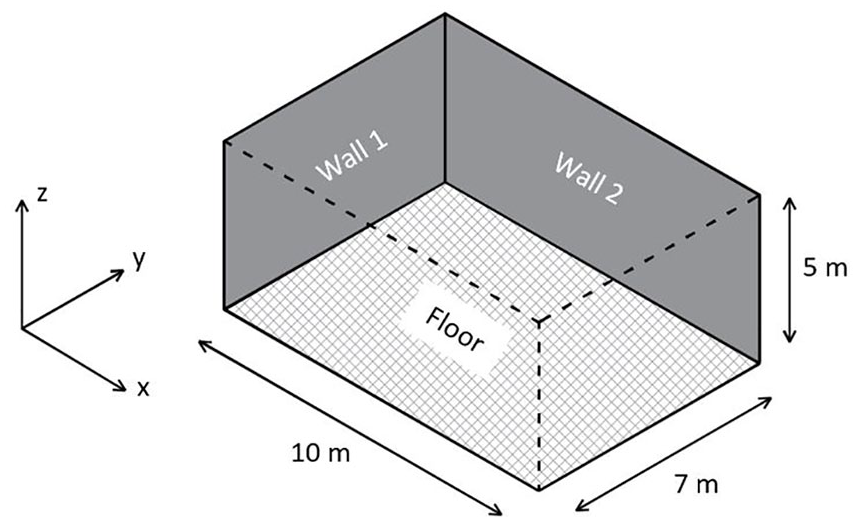
Simulation model boundaries and dimensions.
Whilst the ANN will be trained on a single domain and layout, the network will be tested on its ability to generalise by considering a range of charge masses and locations. Inclusion of additional parameters relating to the domain itself, for example, room size and wall/reflecting surface configuration, is outside the remit of this study. However, the network architecture is highly adaptable and new parameters can be incorporated into the network by specifying a number of additional input nodes, provided the network demonstrates an ability to generalise to the initial reduced problem set.
Data harvesting and simulation specifications
Williams (2015) reported that most hand-held improvised explosive devices are ~5 kg hence, in this study TNT explosive masses between 3 and 10 kg were used, as in Table 3, using Apollo’s in-built model for TNT. The range of charges were modelled in nine locations that form a grid around the centre of the domain, as shown in Figure 9, and were detonated from a height of 1 m above the floor. These charge locations correspond to a minimum normal scaled distance of 0.93 m/
Training variable constraints.

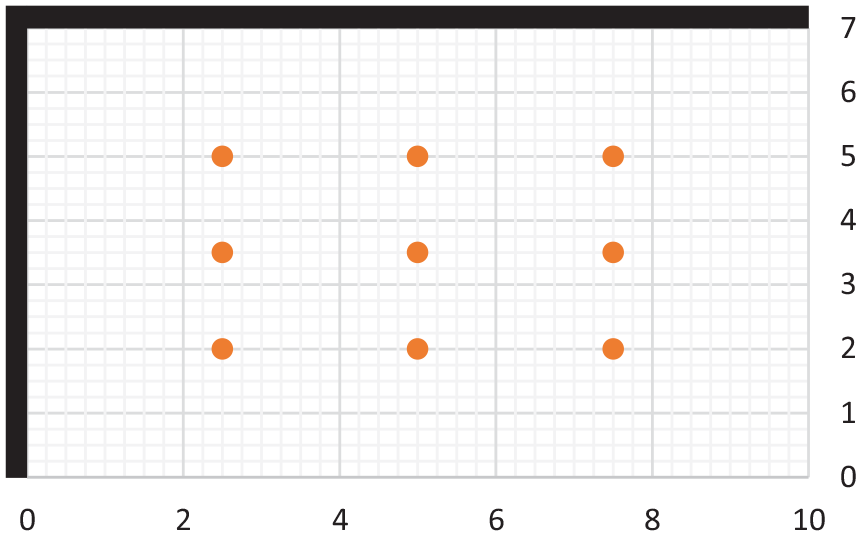
Charge locations within the chosen domain on plan. Black boundaries locate the rigid walls, clear boundaries represent ambient/outflow conditions [plan view].
To comply with the findings of Introduction and mesh sensitivity, the ultimate cell length for specific impulse convergence should be
The positions of the gauges included in the sampling mesh will be explored as part of the study as they will directly influence the performance of the trained ANNs. The height of the gauges was set to be 1 m above ground level, that is, in line with the centre of the charge. Sampling data at a fixed height above the ground is a common technique for reducing complexity of the data harvesting process for studies using numerical analyses or practical experiments (Alterman et al., 2019; Gajewski and Sielicki, 2020). Additionally, this decision does not significantly alter the architecture and predictive ability of the ANN but considerably reduces the time required for training and validation.
Once the data had been harvested and compiled, it was randomly reordered and sorted into two subsets: one for training and one for testing. For this study, the former will utilise 75% of the data, with the remaining 25% left for testing. This ratio is typical for neural network studies as training percentages can range from 70% to around 85% depending on the quantity of data (Dehghanbanadaki et al., 2019; Zaleski and Prozument, 2018).
Output check
Figure 10 shows the locations of three points within the chosen domain, with Figure 11 displaying the associated pressure-time and impulse-time histories for an 8 kg TNT charge located in the centre of the domain. Also shown are the ConWep (Hyde, 1991) semi-empirical predictions for positive phase incident overpressure and specific impulse for comparison. Note that the negative phase (Rigby et al., 2014a) has been omitted from the semi-empirical predictions as verifiable relations in the near-field are unavailable (Bogosian et al., 2002). The results differ significantly from the simple free-air case as expected. Gauge (a) shows the arrival of two clear pressure peaks, one from the primary shock wave, followed by a reflection from each of the rigid walls which arrive concurrently due to the position of the gauge. Gauge (b) shows a single, dominant pressure owing to its close proximity to the charge. Gauge (c) shows a simple free-air-type blast load with low-level, late-time pressure loading due to the partially-confined nature of the domain. In all cases, the pressure load initially appears similar to the ConWep incident pressure, with significant differences developing thereafter. This demonstration gives confidence that the physical processes are occurring and being modelled as expected, and that there is a clear, tractable dependency of the results on gauge location.
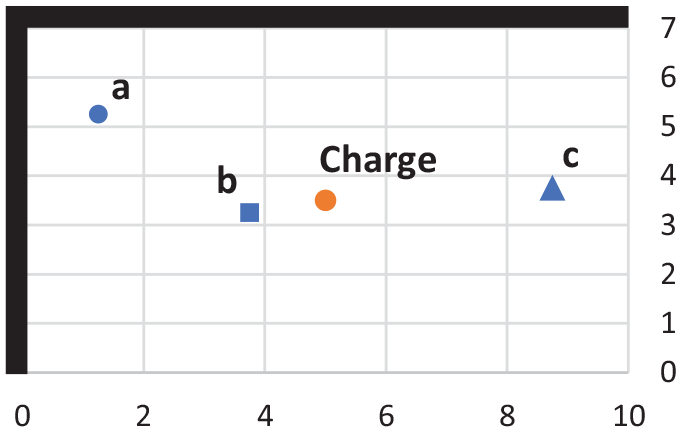
Charge positioning and labelled gauge locations of the model output check [plan view].
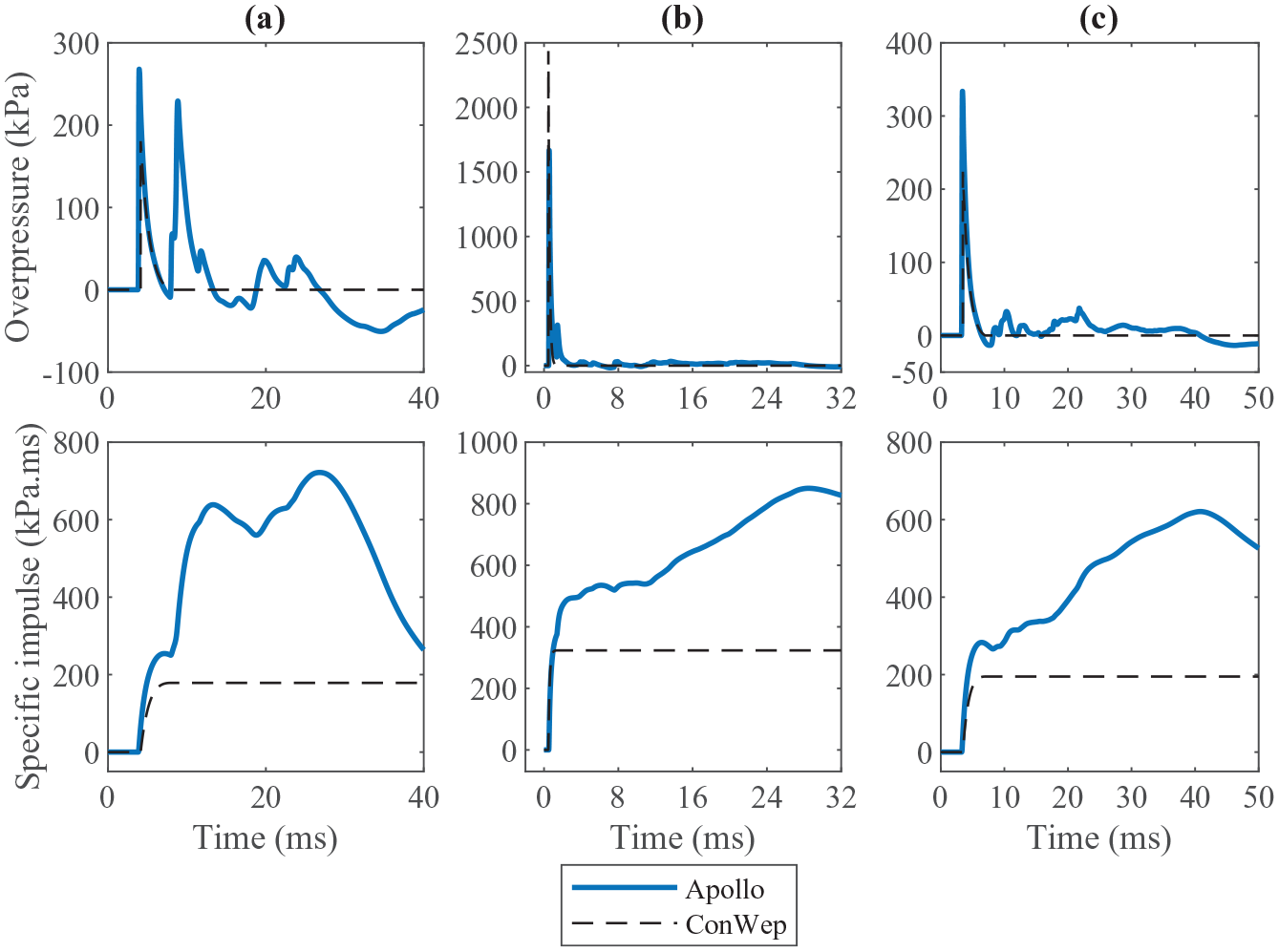
Apollo overpressure-time and specific impulse-time histories for three gauges shown in Figure 10 and ConWep (Hyde, 1991) incident wave overpressure-time and specific impulse-time histories at the corresponding stand-off distances.
Development of artificial neural network
Base network structure
The feed-forward, backpropagation, fully connected network developed by this study is shown in Figure 12. To limit the amount of structural trial and error, the number of hidden layers was fixed at two, with the number of neurons being varied during the development of the ANN. Two hidden layers were specified as Remennikov and Rose (2007) found this arrangement to perform better than when one, or three hidden layers are used. The location of the point of interest within the domain, and the size and positioning of the explosive charge form the input pattern and the peak specific impulse forms the solitary output.
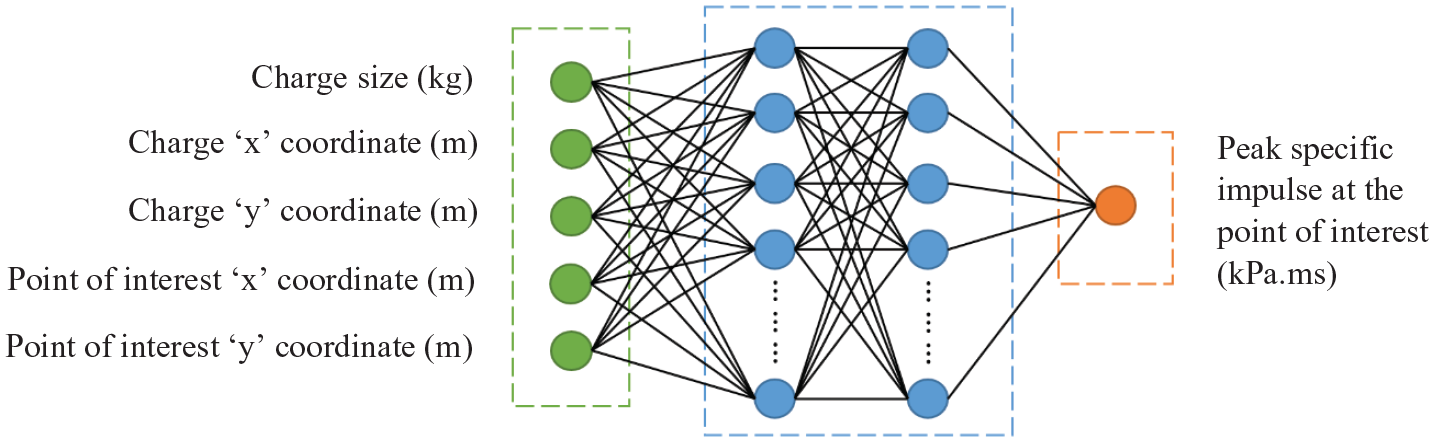
Base regression network structure.
Bewick et al. (2011) found that the use of non-scaled input parameters leads to improved correlations between targets and predictions. Additionally, the errors related to charge size may be obscured if scaled values are used. As a result, non-scaled inputs have been specified for all networks being developed in this paper. The used ANN code was written in Python using the Tensor Flow package for Machine Learning. Table 4 shows the network parameters that remained unchanged when training the ANNs.
Fixed network parameters.

The number of training steps used in this study dictates how many times the weights and biases are updated given the error obtained from a randomly selected batch of 100 input patterns. In addition to using L2 regularisation terms, dropout is utilised to prevent overfitting. A dropout rate of 0.1 determines the number of neurons that are excluded and not updated in a given step of the training process. This helps to prevent ‘brittle co-adaptations that work for the training data but do not generalise to unseen data’ (Srivastava et al., 2014). Once training is complete, the testing dataset will be simulated in a single batch so that the network is assessed with unseen data that does not impact the weights and biases.
The AdaGrad (Adaptive Sub-gradient Descent) algorithm has been chosen as it adapts the learning rate and therefore the magnitude of variable updates during training so that common features within the dataset have smaller impacts whilst the rare features have larger impacts (Hadgu et al., 2015). It can therefore produce well-trained ANNs for datasets featuring localised effects and wide variations in output values. Further information concerning this algorithm can be found in a paper by Duchi et al. (2011).
Dataset development
Performance evaluation
To explore multiple methods of forming the training dataset with limited computational expense, a preliminary development stage has been implemented. It involves the use of 27 of the 72 simulations corresponding to the 3, 6 and 10 kg tests for all 9 charge locations. Neural networks trained using the various datasets are given a fixed number of neurons per hidden layer (100) based on initial testing of the training process that found training times remain below 20 mins. Maintaining consistency with this parameter allows for effective performance comparisons to be made. Then, once the best performing dataset configuration is identified, the full range of charge sizes will be used to explore the impacts of changing the hidden neuron count before the network is evaluated at the conclusion of this paper. Performance evaluation will initially take place using two metrics. The first is the Youngs Correlation Coefficient, calculated using equation (1).

Where

Gauge spacing
The ability of a network to accurately model unseen situations is directly related to the quality and quantity of training data. The choice of a suitable resolution of gauge points is therefore key for the latter aspect, with each gauge providing a single data point that corresponds to the point of interest inputs of the network.
Figure 13 shows how gauges spaced at 1 m (a) provide 70 points per simulation, whereas a 0.5 m spacing (b) provides 280 points. For the 72 tests being simulated these correspond to either 5040 or 20,160 total input patterns for this domain. Sufficient gauge resolution is required to capture the spatial distribution of peak specific impulse across the entire domain, however, too fine a resolution will increase the prevalence of low magnitude impulse values and may limit the network’s ability to learn interdependencies between the two ‘point of interest’ input nodes and specific impulse. This would result in poorer predictions for higher-magnitude, spatially concentrated values of specific impulse, in particular in areas where shock fronts coalesce and superimpose, that is, along the two rigid walls of the domain and in the corner between them.
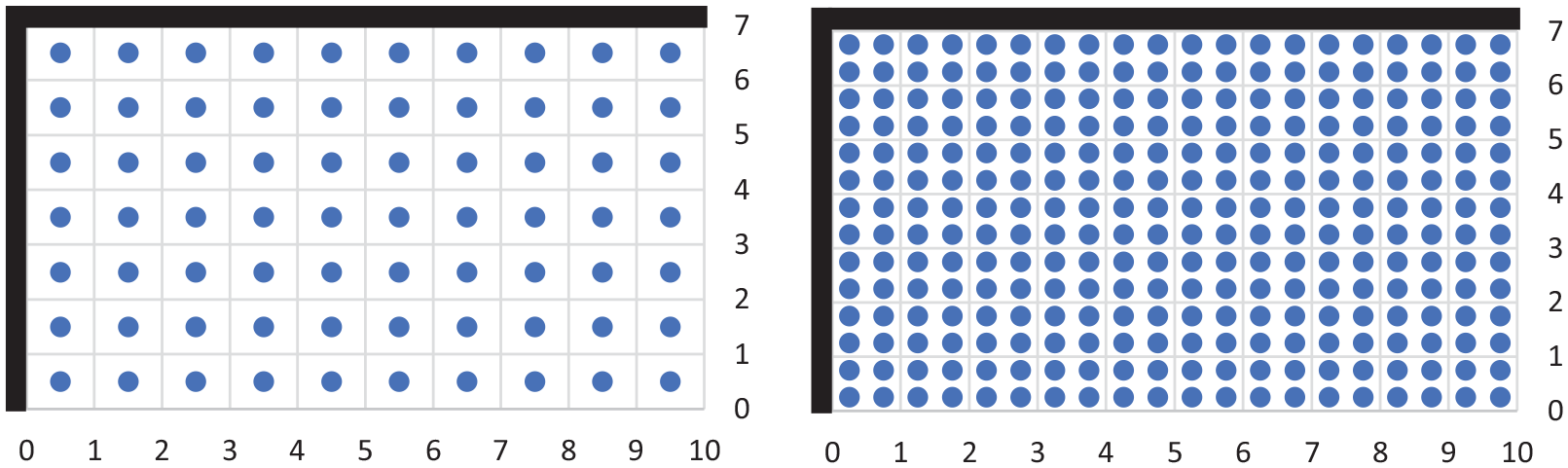
Gauge spacing options for the chosen domain [plan view].
Table 5 presents the achieved performance from networks trained using both dataset options. It is worth stating that despite the presented results being taken from the first network trained using the given conditions, the networks critiqued in this study have been trained multiple times to ensure that the reported performance statistics are not unique.
Network performance results achieved for ANNs using varied gauge spacing training datasets.
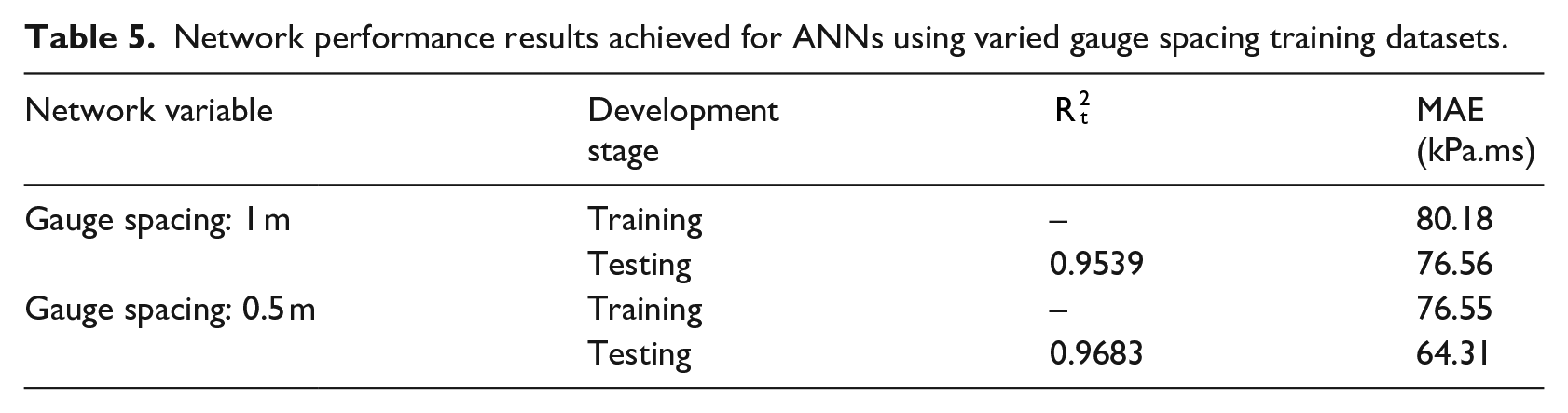
In this case, providing a greater number of data points with the finer mesh of gauges leads to an improved network performance in terms of MAE and correlation between targets and predictions. Overfitting is also avoided as in both instances, as the testing performance surpassed that which was achieved in training. All subsequent networks trained in this study therefore use data from gauges spaced 0.5 m apart with an origin at (0.25, 0.25).
Limited peak specific impulse
Figure 14 shows the distribution of testing predictions and targets for the network trained with 0.5 m gauge spacing with the solid black line representing a perfect prediction. This shows that larger specific impulse values appear to be predicted with considerably less accuracy. It is suggested that this is due to the reduced number of higher magnitude specific impulses included in the training dataset. The network weights and biases are updated less frequently for these predictions and, despite the AdaGrad descent algorithm being used to mitigate the implications of this, generalisation of the network for higher specific impulses appears unsatisfactory.
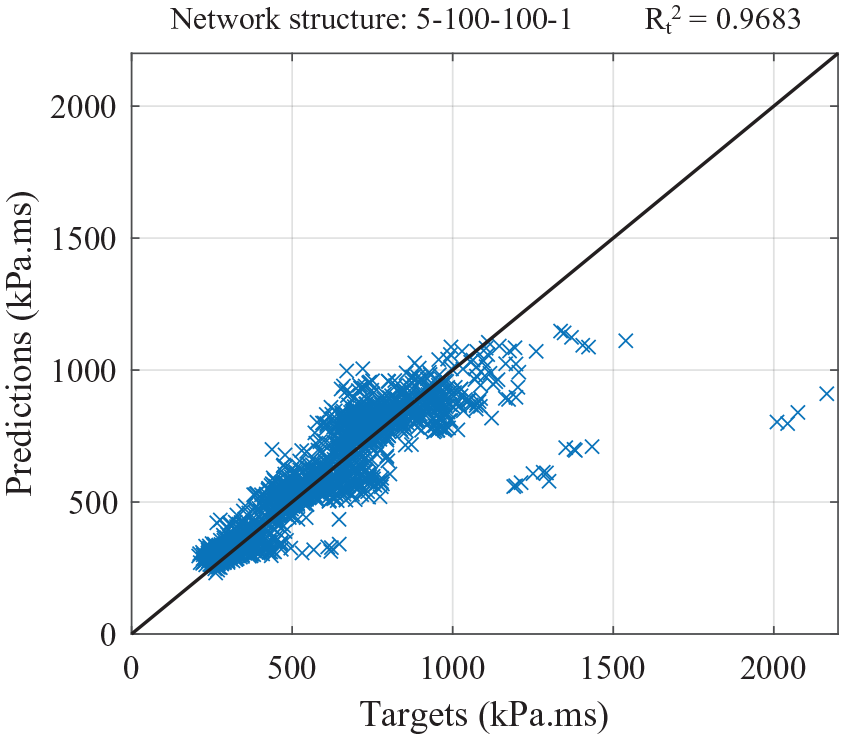
Testing targets and predictions from the ANN developed using 0.5 m gauge spacing in the training dataset.
The largest magnitudes of specific impulse, directly around the charge, will far exceed any human injury criteria. It is also not practical to design a protective structure to resist such loading. The focus of the paper is therefore placed on the points outside of the zone immediately surrounding the charge. Through removing the influence of high specific impulses on the trained network variables, better predictive accuracy may be observed for points close to the dataset mean. To test this theory an impulse limit has been applied to the training dataset, defined as the mean plus two standard deviations (
The distribution of targets and predicted points for the network which utilises the impulse limit is shown Figure 15. It can be seen that the larger target values are still predicted with reduced accuracy compared to the rest of the data. However, when viewed against the results in Figure 14, it becomes clear that removing 44 data points that from the testing dataset that exceeded the impulse limit (of 1890 points in total) results in significant improvement. Table 6 presents the performance metrics from the initial and limited impulse analyses. In limiting the maximum impulse, the correlation coefficient has increased from 0.9683 to 0.9817, and the MAE has decreased from 64.31 kPa.ms to 56.99 kPa.ms. This proves that setting an impulse limit results in general improvements in the ability of the ANN to predict the entire dataset, and also leads to increased generalisation.
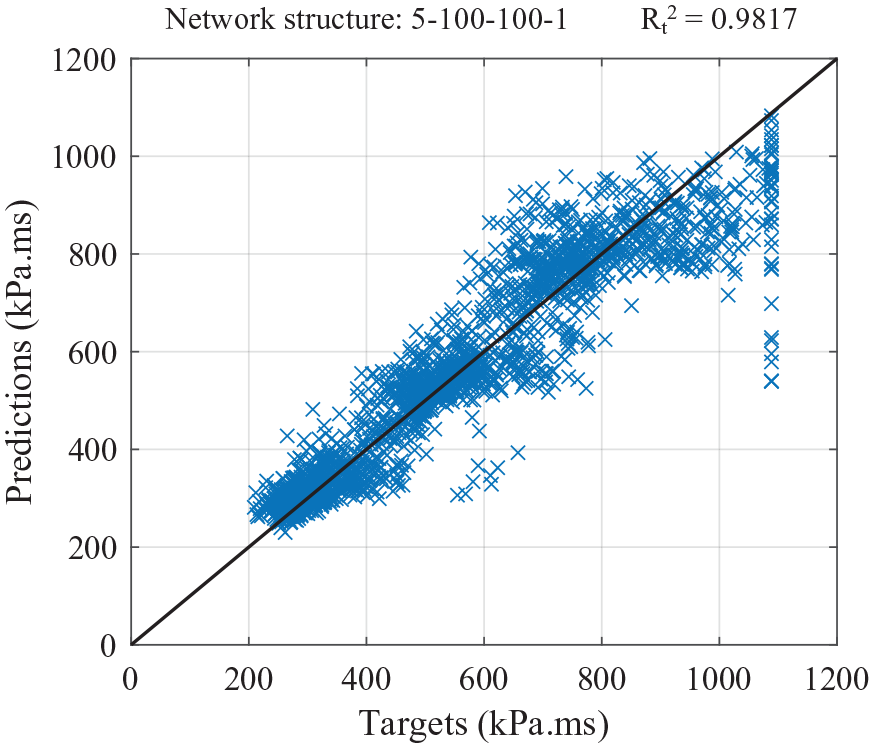
Testing targets and predictions from the ANN developed using a specific impulse limit.
Testing network performance results with and without a specific impulse limit.

Network performance assessment
Accuracy evaluation
Following the configuration of the training dataset, an exploration of the neuron count for both hidden layers was performed. A training dataset made up of 15,120 points from all 72 tests using gauge spacing of 0.5 m was used with the associated impulse limit (

Where
Using this method of accuracy evaluation, the following sections will assess the performance of the ANNs with a view to quantifying typical differences between predicted and numerical data.
Hidden neuron count experimentation
Figure 16 shows that increasing the neuron count for both hidden layers leads to a continual decrease in the average percent error achieved when using the trained network with unseen inputs from the testing dataset. The number of points being predicted within a 10% error envelope also continuously increases as more neurons are added, albeit with decreasing improvements as the number of neurons increases.
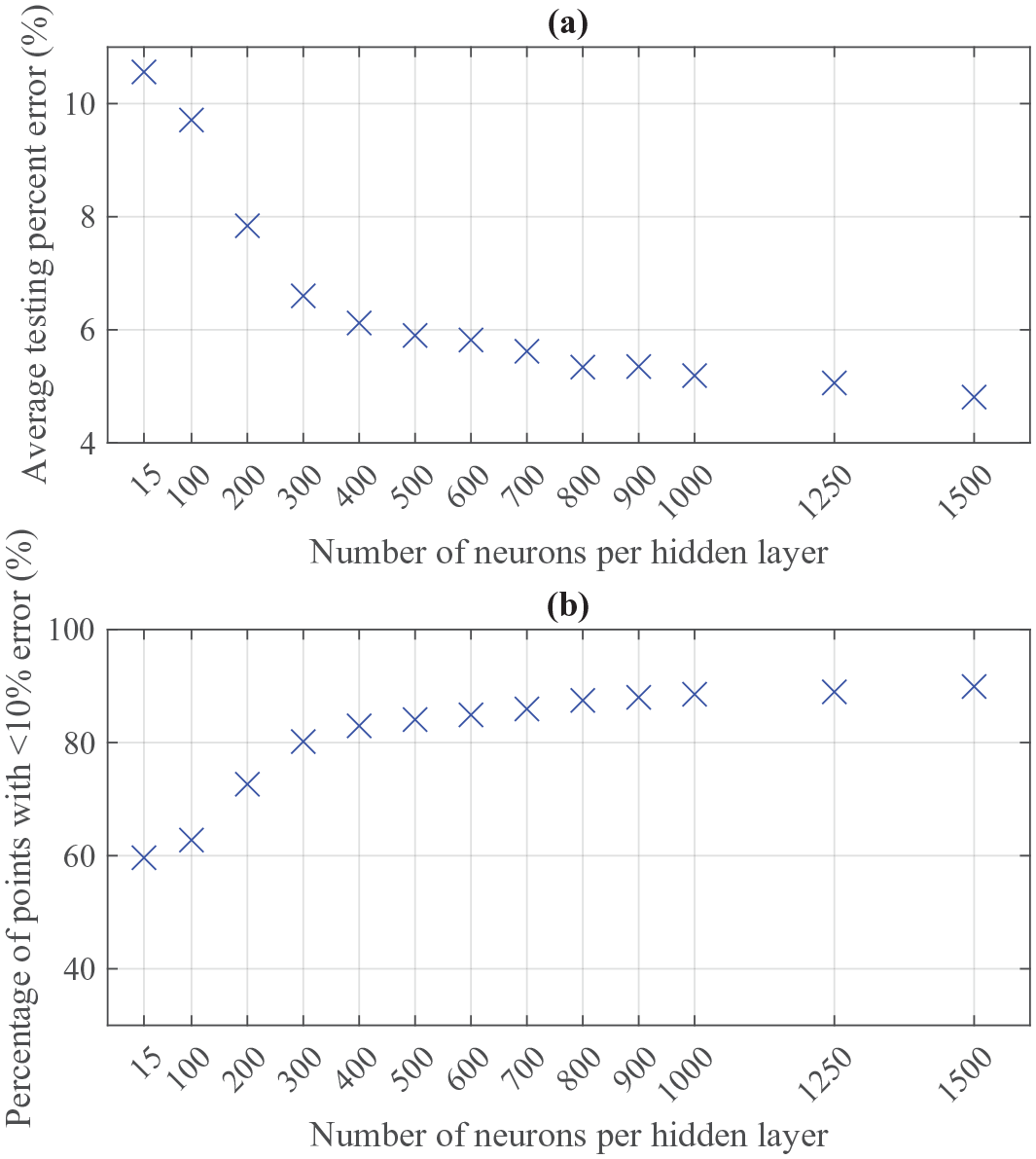
Error assessment of network predictions against unseen testing data: (a) mean percentage error, (b) percentage of points within a 10% error envelope.
Unlike many other studies using experimental data, here the training patterns comprise of incrementally stepped values in all variable space required for the network to operate. It is not common for a study to have such a detailed overview of the entire problem, and in many cases, it is commented by researchers that the reason for inconsistent performance is related to sparse datasets (Bewick et al., 2011). This may be why improvements in testing performance are seen in this manner for uncommonly large networks as the mean percentage error reaches 4.81% for a total of 3000 hidden neurons (MAE in testing was 29.9 kPa.ms for an average specific impulse of 591.5 kPa.ms).
Ultimately there is a diminishing return in performance improvement as the neuron count increases. The 1500/1500 structure required a training time of 190 mins to achieve the aforementioned accuracy level, whereas the 500/500 structure required 17 mins to achieve a mean percentage error of 5.90% and MAE of 36.3 kPa.ms. However, as the aim of this article is to demonstrate the effectiveness of ANNs for predicting blast loading in an internal environment, the most accurate network (1500/1500 neurons) is adopted for further study.
Figure 17 shows the training progress of the chosen network. It is clear that whilst rapid learning occurs to reduce the testing MAE from an initial value of
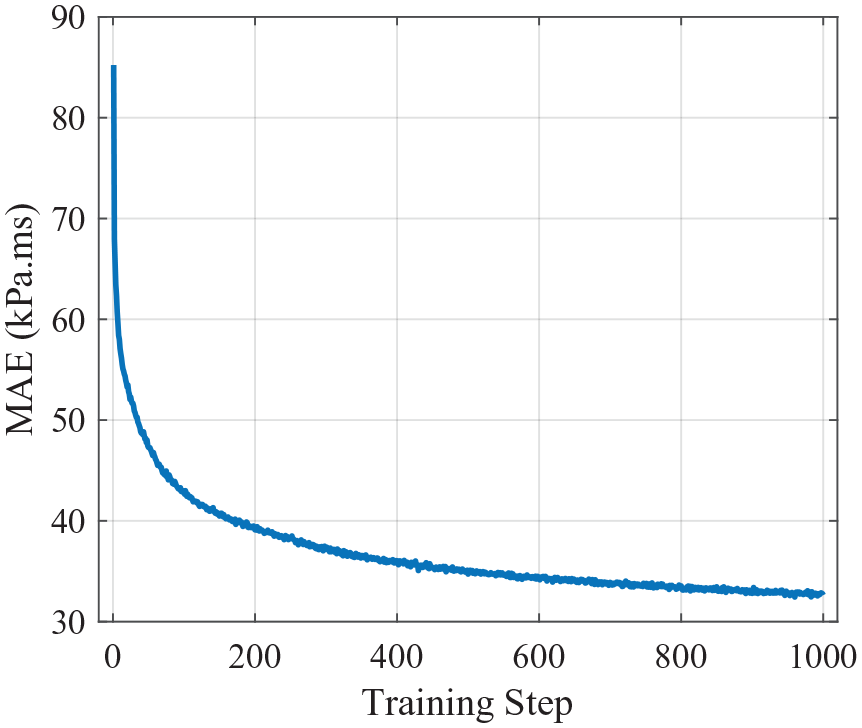
Training progress of the 5-1500-1500-1 structured network.
Impulse magnitude error variation
Figure 18 shows the 10% error envelope with the predictions and targets from testing for the 1500/1500 network. Details of how the error varies depending on specific impulse magnitude are given in Table 7. For specific impulses below 800 kPa.ms, over 90% of predictions are within 10% of the target value. For values
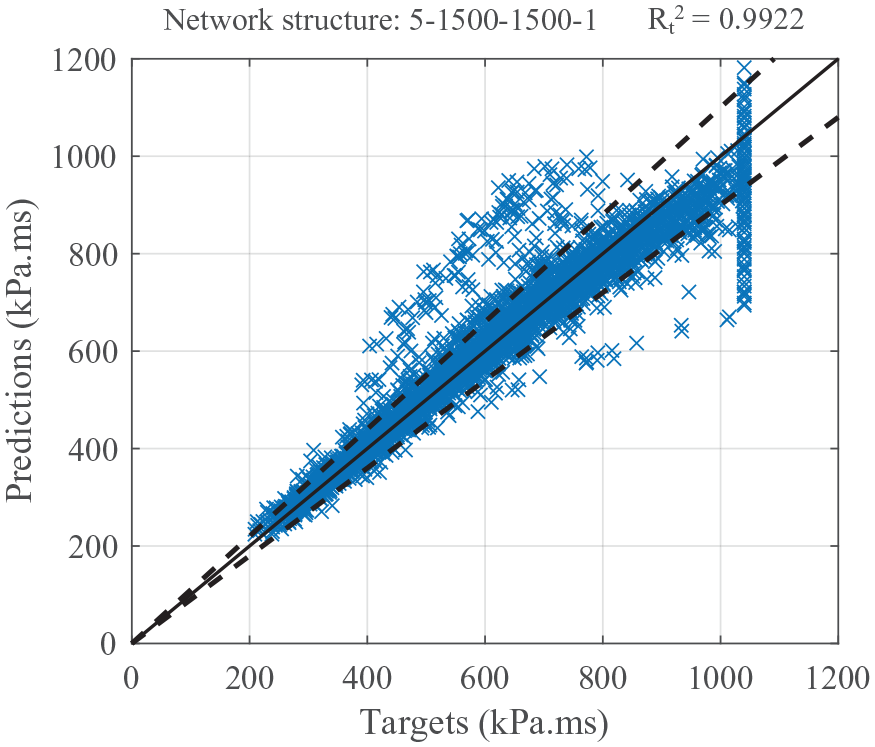
Testing targets and predictions from the ANN developed with 1500 neurons in each hidden layer. The solid black line represents a perfect match between predictions and targets whilst the dashed lines represent a
Variation of network predictive performance relative to the target specific impulse magnitude.
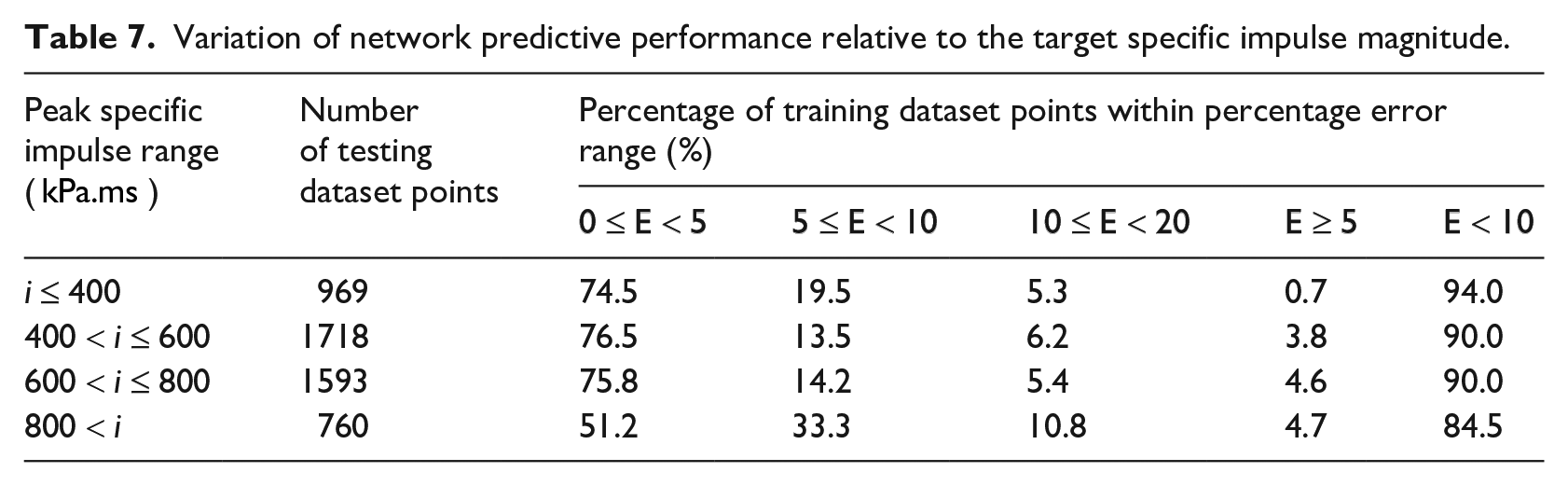
For specific impulse values less than 400 kPa.ms, 94% of predictions are within 10% of the target value. This is the highest accuracy of any specific impulse range, despite being occupied by the second lowest number of testing data points (with the range
Overall, the network predicted 89.9% of points in the testing dataset to within 10% of the target (numerical) impulse. This shows how the approach is largely successful even in this first assessment of its use for internal blast predictions.
Charge size error variation
The previous section leads into the need to assess if there is a variation in the predictive performance on the ANN based on the size of the explosive. Table 8 shows that for explosive masses less than 10 kg, performance is largely consistent, with only slight variations in accuracy for each range and charge mass. This shows that the network is able to generalise between the similar charge sizes well, particularly at the centre of the variable space (6 kg). However, for samples from the 10 kg tests, there is around a 5% reduction in the number of values being predicted with 10% error, despite there being a similar number of patterns used for each charge size in both training (
Variation of network predictive performance relative to the input charge size.
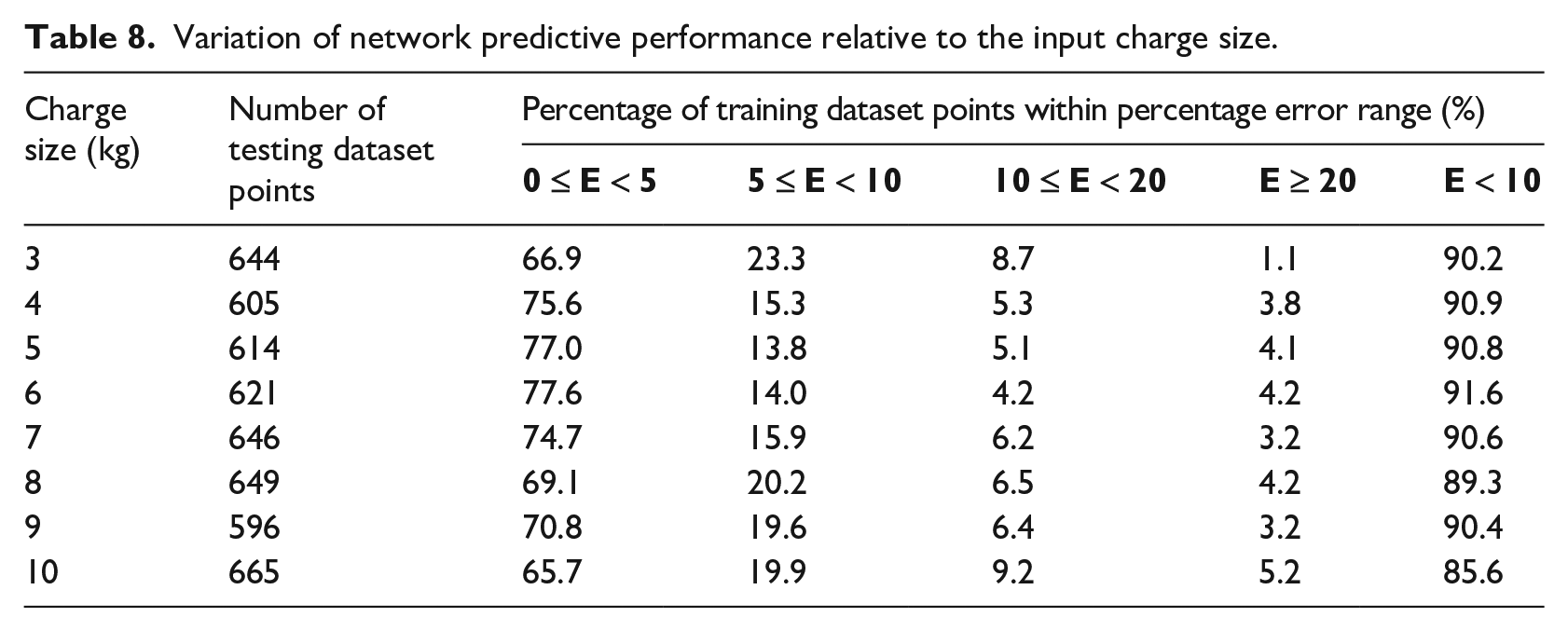
This performance reduction may be caused by an increased number of higher peak specific impulse readings within the domain, which was shown in the previous section to lead to less accurate predictions. If this study were to have included charge sizes
Charge location error variation
The 9 charge locations have also been analysed separately to identify any performance variations. These locations are shown in Figure 19, with the results from the analysis presented in Table 9.
Labelled charge locations 1–9 within the chosen domain [plan view].
Variation of network predictive performance relative to the charge location.
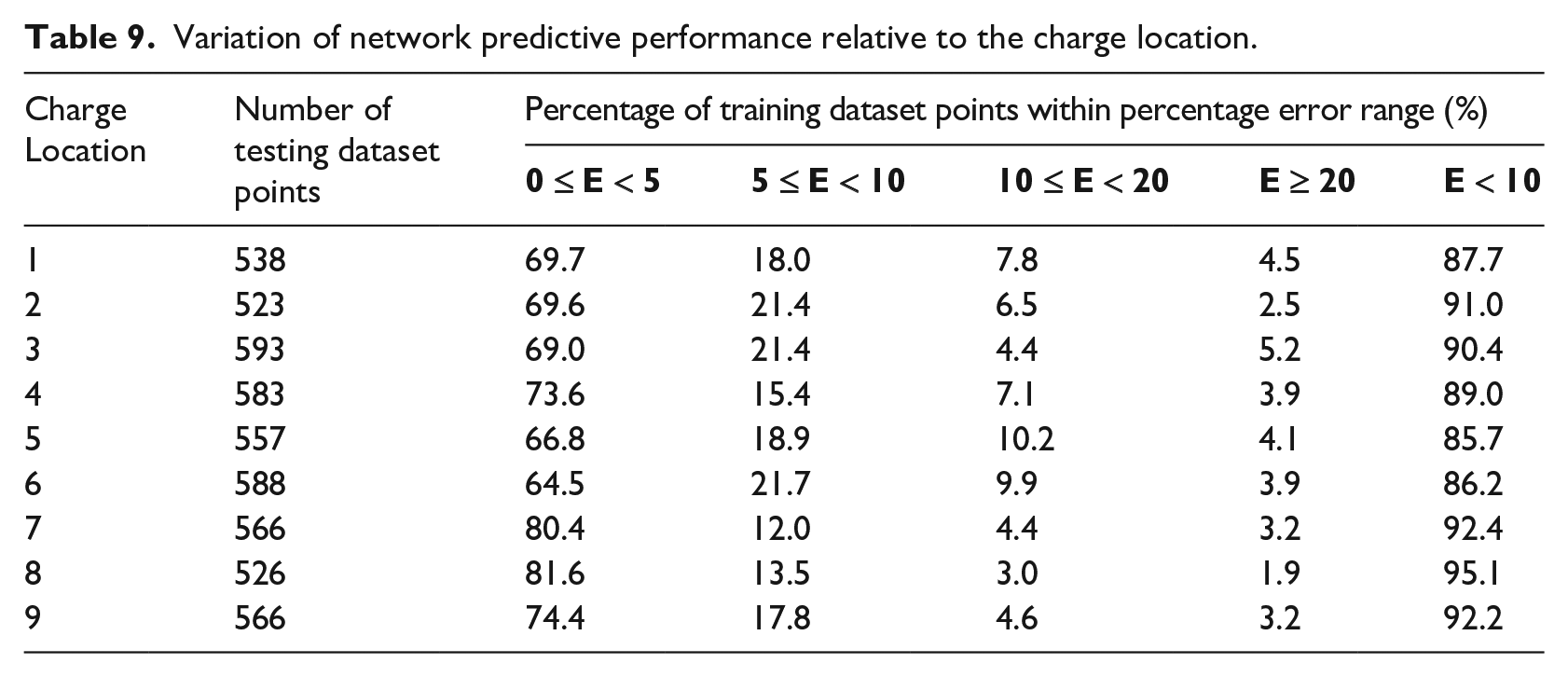
The network appears to display some dependency on charge position, with the performance for positions 7 to 9 exceeding all others. The reason for this is not immediately clear, however it may be due to the larger distance between the charge locations and the longer outflow boundary (see Figure 19), thus increasing the prevalence of lower magnitude impulse values for which the network is better able to generalise. This theory does not extent to charge locations 1 and 4, however, which are the charge locations most remote from the shorter outflow boundary. It is suggested that this is due to the influence of the longer reflecting wall along the top edge of the domain, which will likely have a more significant effect on the pressure fields further downstream.
As the charge in location 5 is in the centre of the domain, this leads to a more balanced distribution of points, with some experiencing additional reflections and confinement effects, and others exhibiting more simple free-air-type loading. This will lead to a larger range of specific impulses to train over, hence making generalisation more difficult. Despite this, the model is still able to predict 85.7% of the specific impulses to within 10% of the numerical data (Table 9).
Final network design
Based on the findings outlined in the previous sections, the final network design is as follows:
Inputs: charge size (kg TNT); charge
Output: peak specific impulse at the point of interest (kPa.ms)
Hidden layer structure: 1500/1500 (two layers)
Activation function: ReLU (linear at output)
The associated network restrictions are then as follows:
Usable charge size range: 3 to 10 kg of equivalent TNT
Predictable points of interest: no closer than 0.25 m to a boundary and at 1 m height
Charge origin (
Predictable impulse limit derived from the training dataset (given as
Predicting blast loading in an internal environment using the ANN
With the network demonstrating a high level of accuracy when considering training data that was obtained from the original 72 simulations, it is essential that the approach is also tested on its ability to predict unseen data from new analyses. This involves using the trained network to predict four additional sets of values from scenarios where the variables are new to the network, but still within the respective variable spaces. The variable constraints that were implemented during training and testing are shown in Table 10, with Table 11 indicating how these values have been altered in each of the new test cases studied in this section.
Training variable constraints.

Details of input variables used in additional unseen tests.
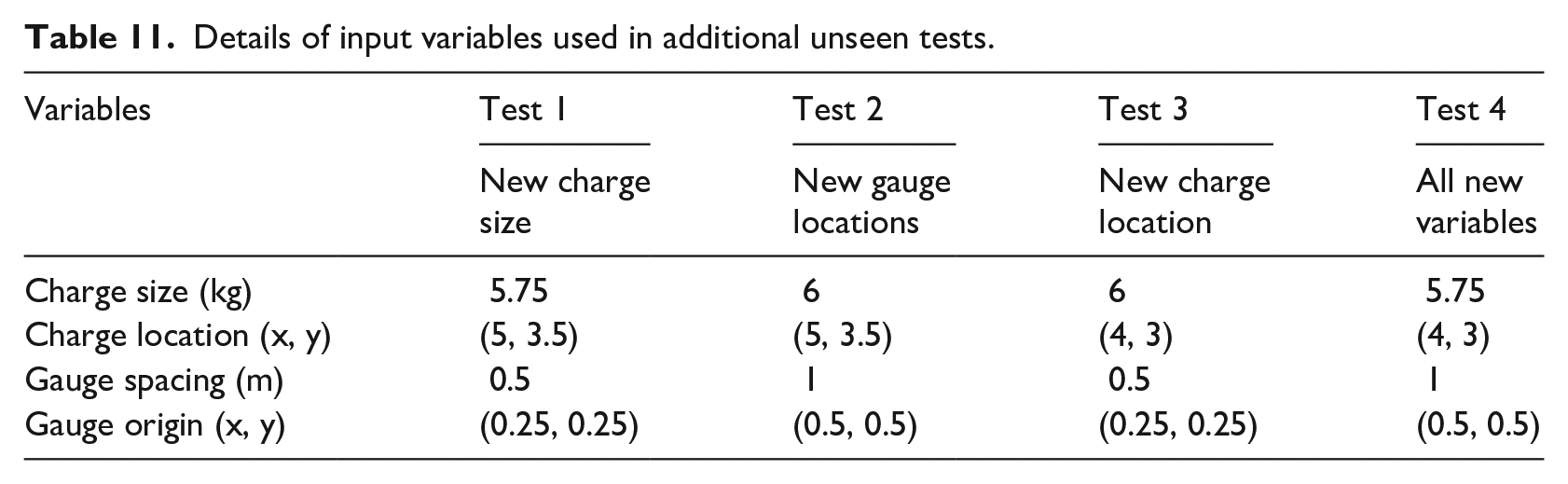
Each of the first three tests are intended to investigate how the network copes with one change from the training variables. The final test then combines each of these alterations to present an entirely new input pattern to the network. Through assessing each of these variables it will highlight how well the network can interpret new inputs by relating them to the training variables it has seen before.
Figure 20 displays the obtained distributions from Apollo and the trained ANN. As per the previous simulations, the new models were run with a zone length of 0.24 m and resolution level of 3. Note that the maximum value of the colourbar is limited to 1000 kPa.ms for ease of interpretation, despite the limiting specific impulse used in the analysis equalling 1040.2 kPa.ms. The numerical and predicted specific impulse distributions are presented alongside a visualisation of percentage error. The error assessments of each test are provided in Table 12.
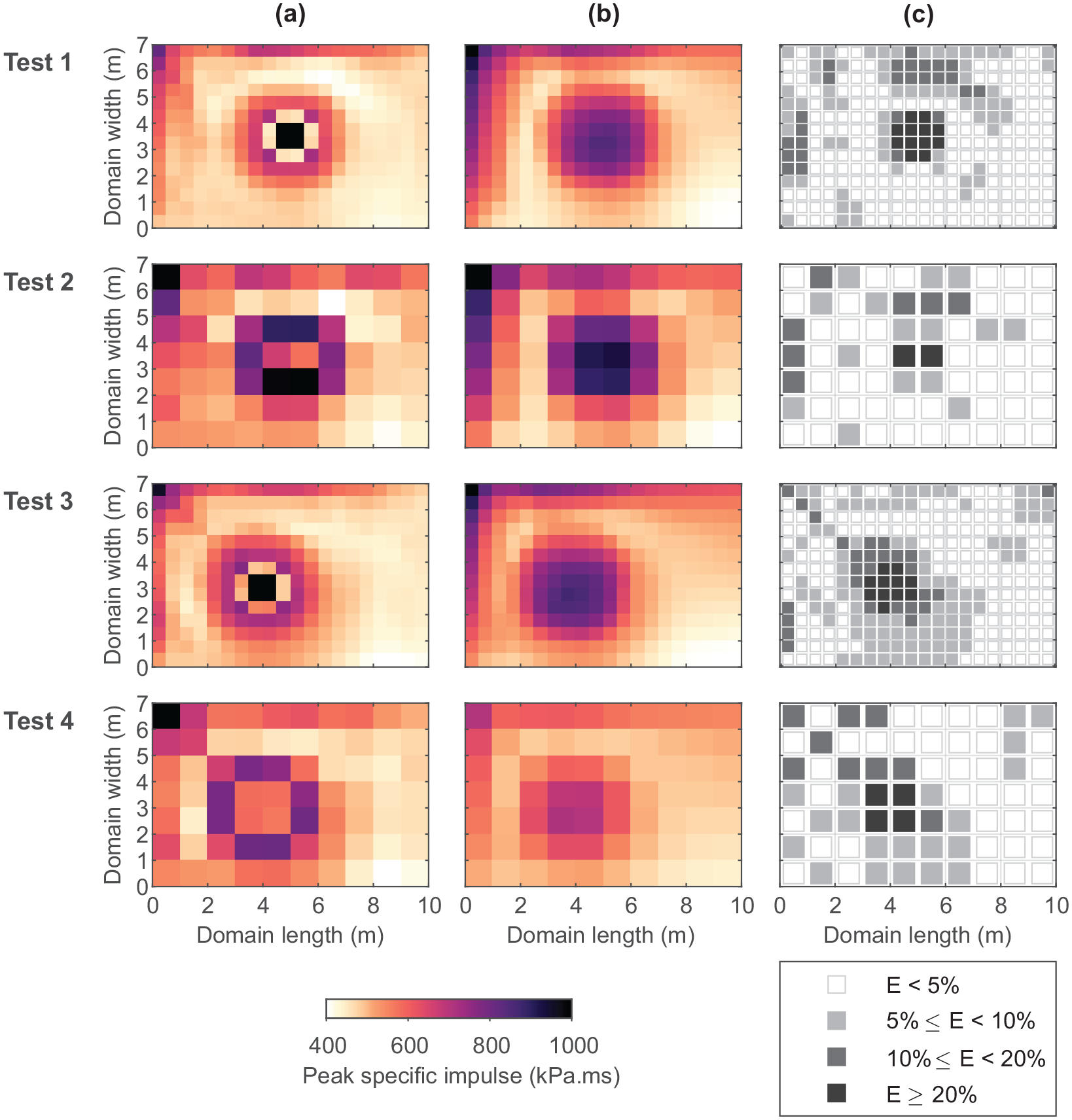
(a) Numerical specific impulse distributions, (b) ANN predicted specific impulse distributions, and (c) percentage error. Colourbar maximum is set to 1000 kPa.ms for ease of interpretation (limiting specific impulse is 1040.2 kPa.ms).
Additional test percentage error results.
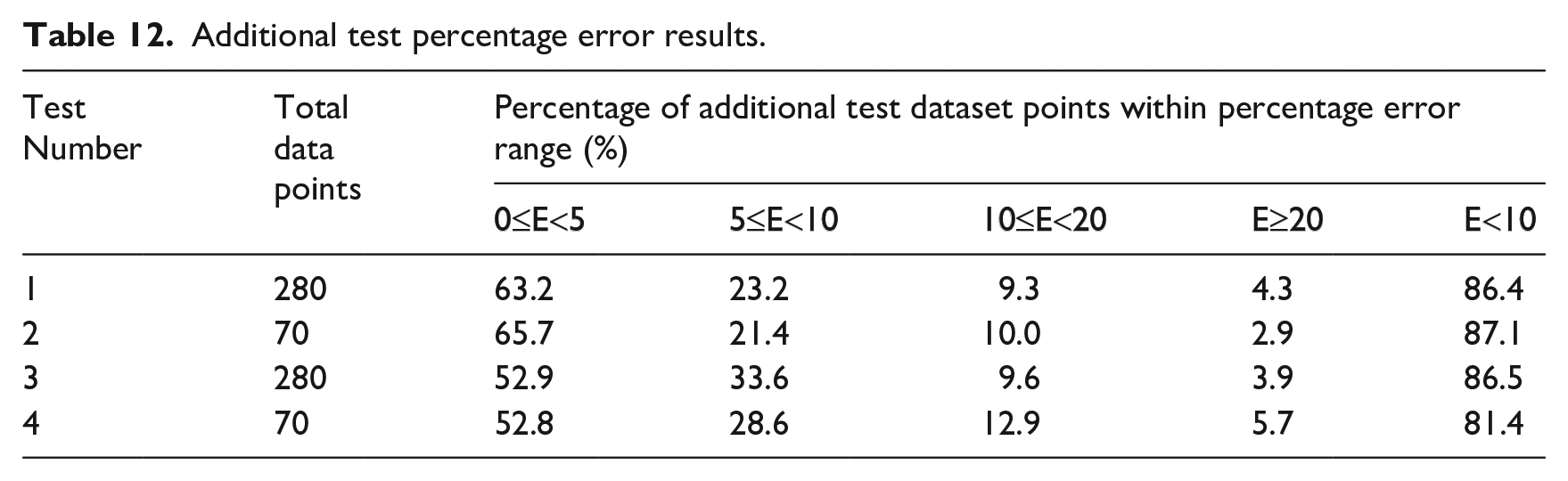
It can be seen that the ANNs are able to reproduce the modelling results to a high level of accuracy across the entire domain both qualitatively and quantitatively. It is shown in Table 12 that at least 81.4% of the predicted impulses were within 10% of the numerical values for all four test models. Generally, the ANN is able to provide highly accurate predictions in areas where specific impulse is dominated by high magnitude, nonlinear superposition of reflected shocks, that is, along each reflecting wall and, in particular, in the corner between the two walls. In these regions, the complex interaction processes present many challenges to existing modelling approaches. Here, typical errors are
The agreement is less satisfactory in regions immediately adjacent to the charge, with errors consistently above 20%, albeit only in a relatively focussed area of the domain. The true magnitudes of these errors are not known due to the use of the impulse limit as explained previously. However, as discussed in Limited peak specific impulse, this is deemed acceptable as the areas surrounding the charge will be subjected to excessive specific impulses for which designing protective structures or preventing human injury would be impractical.
In total, each ANN was able to generate the predicted specific impulse distributions within 4 mins. The rapid generation of results and high level of agreement attained, both with the testing dataset and the additional test models presented in this section, shows that ANNs can be a highly useful tool for generating blast loading predictions in confined internal environments. The general structure of the network permits the inclusion of more complex analysis cases through the use of additional input nodes, for example, those representing the presence of internal reflecting obstacles, and more complex confinement and venting around the edges of the domain. Further exploration of alternative regularisation techniques, or activation functions that do not include a linearisation effect, also present many ways for future work to achieve more robust predictive performance for highly nonlinear cases.
Summary and conclusion
This study presents an evaluation of artificial neural networks (ANNs) for predicting the complex blast loading in a confined internal environment. Design of the ANN was rigorously evaluated through considerations of parameters such as gauge spacing (for the training and testing dataset), limited peak specific impulse, and number of hidden neurons, set domain size considered to be ‘fully vented’ according to the terminology in UFC 3-340-02 (US DOD, 2008).
Apollo Blastsimulator was used to gather training and testing data for the ANN. Firstly, Apollo was validated against available experimental data (Rigby et al., 2015) and shown to be in good agreement for far-field blast predictions. A full dataset was then harvested from 72 separate models from eight different charge sizes, each located at nine different positions within a
It was found that both increasing the quantity of the available data and setting a limit on the maximum peak specific impulse (equal to the mean specific impulse plus two standard deviations) resulted in an improved performance of the network. Following this, the an optimised network structure was identified to include two hidden layers of 1500 neurons each, with five input neurons and a single output neuron. The network was able to predict the specific impulse for
The benefits of using ANNs to predict unseen data were clearly demonstrated with four new models. Here, the numerical analyses each took approximately 2 hrs, whereas the network was able to generate predictions within 4 mins. In each case, specific impulse was predicted to within 10% accuracy for between 81% to 87% of the gauge locations, with a high level of accuracy demonstrated along the rigid reflecting walls and in the corner between the two. Errors were found to be
The ANN method is highly flexible and can be readily adapted to incorporate a wider range of input parameters. Extension of this method to account for charge shape effects, to predict loading at a range of heights within the domain, and to model different domain sizes with differing degrees of confinement, can be achieved by adding relevant input nodes to describe the new parameters. Such changes will not require substantial adjustments to the remaining architecture of the ANN, nor will the process of generating and format training/validation data differ from the methods we present in this article, and therefore the findings presented herein can also be considered as valid for ANNs developed to predict blast load parameters in scenarios which differ to those presented herein.
Footnotes
Acknowledgements
The authors wish to thank Dr Andrew Liew at The University of Sheffield for providing the artificial neural network code that has been adapted for use in this study.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.