
Abstract
The emergence of Large Language Models (LLMs), such as ChatGPT and Claude, has sparked discussions on their capacity to augment qualitative research data analysis. This study investigates using LLMs in futures research, where analysing large textual datasets is paramount. LLMs were employed experimentally to assess theme generation, patterns, and insights from infrastructure futures workshops. The study conducted a comparative analysis of Claude’s Sonnet 3.5 and ChatGPT 4o to examine workshop transcripts with and without contextual data. The data reveal that LLMs exhibit exceptional speed and efficiency but face challenges in precision, ethical implications, and the need for human supervision. This research adds to current discussions on integrating LLMs with qualitative research methods, enhancing futures analytical tools like Causal Layered Analysis, the Futures Triangle, Futures Wheel, Futures Cone, visioning, and Backcasting. The paper argues that LLMs offer a promising means of improving qualitative data analysis, maximised when used with conventional methods and human expertise.
Keywords
Introduction
The evolution of Large Language Models (LLMs), like ChatGPT and Claude, has led to much discussion about their potential to transform research data analysis (Törnberg 2023). For qualitative research where researchers need to analyse large volumes of text data, these technologies raise both opportunities and questions about how meaning is derived from such data. In particular, LLMs hold much promise for futures researchers given the volume of complex and interconnected concepts that must be intermediated in the process of sensemaking. Consequently, this essay explores how LLMs can improve futures researchers’ capacities to explore their data in a way that could potentially revolutionise how we conduct environmental scanning, analyse trends, develop scenarios, and populate analytic tools such as Causal Layered Analysis , Futures Triangles (Inayatullah 1998), Futures Wheels (Glenn 1971), Futures Cones (Hancock and Bezold 1994), Backcasting (Robinson 1990) and others.
This study originates from a doctoral examination in futures studies, focusing particularly on infrastructure strategy in volatile scenarios. The investigation explores the evolution of infrastructure planning, examining the broader historical development of human civilisation through the lens of infrastructure. Data was collected using comics to present the literature review engagingly, supported by workshops involving both infrastructure experts and non-specialists. These workshops were documented for analysis. The substantial data produced led to an exploration of LLM-based data analysis methods, which coincides with the rise of AI technology at the time of data collection.
When faced with text-based transcripts comprising over 75,000 words from seven 2-hr workshops, several enquiries occur concerning the effective and precise interpretation of the information. One aspect to reflect on is the performance of LLMs as an alternative to established Computer-Assisted Qualitative Data Analysis Software (CAQDAS), such as NVIVO (Zhang et al. 2023). Investigating whether LLMs can uphold the research rigour and adaptability that researchers have come to expect from traditional CAQDAS systems is necessary, though “traditional qualitative analysis software, despite their merits, often fall short in addressing the complexities, costs, and performance demands of modern research (Zhang et al. 2023, 21) – thus CAQDAS systems are not beyond reproach. Nonetheless, all the methodological concerns of processing LLM data must also be addressed (Aubin Le Quéré et al. 2024). Furthermore, it becomes necessary to examine if LLMs pose a threat to the ethical integrity of research, given the data they process is sensitive and necessitates ethical care (Törnberg 2023). Through an analysis of each of these areas, we might gain a deeper awareness of the potential impact of LLMs on qualitative research methodology.
Methodology
To address the questions above, the methodological approach taken in the development of this article has several elements, as follows: • A review of literature relating to the use of LLMs to analyse qualitative data is performed to understand the current level of knowledge on the subject, and to identify potential gaps in the research in this respect; • Informed by the literature review, an experimental comparison of two approaches to using LLMs for qualitative analysis is made. The first approach involves directly interrogating workshop transcripts using Claude Sonnet 3.5. The second explores the potential of contextualising the inquiry by populating a Claude Sonnet 3.5 Project with all the author’s existing PhD writing related to the research. The results are tested using the same approach using ChatGPT4o. The results of this experiment of double “triangulation”, to build on a term proposed Mannstadt et al. (2024), are then analysed to identify the merits and potential pitfalls of using LLMs for qualitative analysis; • Doing so is expected to help understanding about how researchers are best to engage with LLMs in the interrogation of their textual data. As Bibri (2020, 33) notes for example, “thematic analysis is particularly, albeit not exclusively associated with the analysis of textual material”. Bibri emphasises that the core of thematic analysis lies in identifying “important patterns of meanings… that can be used to address the research problem”. This understanding raises a crucial question in this investigation: can the thematic approach traditionally employed by CAQDAS applications be effectively supplemented or even replaced by LLM-enabled “conversations with one’s data”?
The findings from the literature review and experimentation are then presented and discussed to see if researchers can be guided toward more effective and ethically acceptable means of analysing their collected data and thereby a helpful contribution is made to the ongoing discourse on the role of LLMs in qualitative research.
Literature Review
Literature regarding the use of LLMs in qualitative research is still emergent, and falls into a variety of categories, such as methodological implications, research rigour and validity, ethical considerations, bias mitigation, and the future of qualitative research. These aspects are examined through the review of recent papers to assess the current state of knowledge on using LLMs for qualitative analysis, identifying both potential benefits and challenges. In this respect, the papers examined include Tabone and de Winter (2023), which evaluates the validity of using ChatGPT in analysing text associated with human-computer interaction research; Bail (2024), which explores the potential of AI to improve social science research; Zhang et al. (2024), which investigates the use of ChatGPT for efficient thematic analysis; Mannstadt et al. (2024), which demonstrates a novel approach to mixed-methods research using LLMs; and Ziems et al. (2023), which considers the transformative potential of LLMs for computational social science. Additionally, Chubb (2023) provides insights into the use of GPT-4 in grounded theory analysis, while Grossmann et al. (Bibri 2020) offers a broader appreciation about how LLMs are transforming social science research.
The literature proposes the primary advantage of LLMs is their ability to enhance efficiency and effectiveness, as highlighted by Tabone and de Winter (2023) in relation to the substantial amount of data that can be handled, in contrast to the manual methods required by conventional CAQDAS programmes. Upon examining the websites of key CAQDAS developers such as NVIVO, MAXQDA, ATLAS.ti, and Quirkos, it becomes apparent that AI capabilities are being integrated in those applications to assist with the coding process. Therefore, it is plausible to expect that these long-standing programs will eventually match the LLM proficiency of theme coding, which is one of the notable strengths of CAQDAS software. Tabone and de Winter assert however that LLMs have the ability to not only encode information, but also to assess and comprehend material, which includes generating “meaningful summaries of interviews that aligned with content analysis” (Tabone and de Winter 2023, 19). The interviews were recorded and then transcribed by Otter.ai, another AI product. As a result, a significant portion of the transcribing and interpretation process was efficiently carried out using AI technologies.
Zhang et al. (2023, 2024) support the use of LLMs for qualitative data analysis, while also acknowledging the constraints associated with these models. For example, relying exclusively on a LLM for coding tasks carries the potential of missing the nuanced contextual understanding that is not necessarily inherent in a LLM but innate in humans, as Chubb (2023) also found. In addition, Zhang et al observe that LLMs are characterised as a “Black Box”, meaning that their internal mechanisms are difficult to understand, which leads to concerns about a lack of transparency and the reliability of outcomes. Difficulty in replicating outcomes can also contribute to the erosion of trust, particularly when it is caused by the complexity of the prompts being employed. Zhang et al. discovered that these issues can be reduced by implementing better prompt engineering, providing training to users, and implementing strong human oversight of the process (Zhang et al. 2024).
Ziems et al contend that LLMs possess the ability to consistently code large data sets in a manner that surpasses the capabilities of human researchers, hence upholding research rigour. By doing so, the risk of variability and the introduction of human bias in a study is reduced (Ziems et al. 2023). However, humans possess specific qualities that enhance the effectiveness of LLMs, such as a superior grasp of subtlety and context, as highlighted by Zhang et al. In addition, humans can make ethical judgements, demonstrate emotional intelligence, and exhibit sensitivity during analysis. As a result, they are more adept at navigating ethical challenges. Therefore, the literature indicates that there are benefits that can be obtained by combining the efforts of humans and LLMs (Ziems et al. 2023).
The observation regarding the collaboration between humans and machines is strongly corroborated by Mannstadt et al. They employed a mixed methods approach, applying manual coding of data with NVIVO, as well as employing ChatGPT to code data. The coding results were broadly comparable, but the researchers further ensured consistency by harmonising a codebook and subsequently re-applying the harmonised codebook to each technology. It was discovered that this technique of “triangulation” produced more precise outcomes when performed by humans and was sixty-eight times faster with acceptable outcomes when performed by machines (Mannstadt et al. 2024).
Mannstadt et al’s triangulation research found that ChatGPT-4 efficiently identifies qualitative data themes, complementing human analysis. However, as LLMs lack inductive reasoning and abstract thinking, human investigators need to be actively involved in mixed-methods research (Mannstadt et al. 2024). These findings indicate that conducting initial data analysis using LLMs, followed by human supervision of the outcomes, is likely to achieve an effective equilibrium between efficiency and accuracy. Furthermore, to enhance the analytical process and ensure thoroughness, several iterations of data processing can be employed, along with the use of multiple GPT processes (Zhang et al. 2023). For instance, ChatGPT 3.5 might be employed in conjunction with ChatGPT4o to conduct simultaneous studies. Alternatively, ChatGPT4o could be implemented alongside Claude Sonnet 3.5, as they possess similar levels of capability.
The proximity of a researcher to their data is important, and researchers must possess a comprehensive understanding of their raw data and engage in cross-referencing when using AI for qualitative analysis (Sinha et al. 2024; Zhang et al. 2024). By doing so the researcher maintains contextual awareness of their data and increases the likelihood of the researcher spotting errors or misinterpretations by the LLM. It also allows the researcher to apply their specific expertise and intuition, the subtleties of which can be elusive to LLMs.
Bail raises concerns on the ethical implications of employing cloud-based LLMs, specifically focusing on privacy and consent issues. He highlights the possible risk of sensitive information being leaked and emphasises the importance of obtaining informed consent from participants whose data is handled using LLMs. Bail’s research highlights the importance of data privacy and the need for rigorous human control in the data analysis process to ensure ethical integrity (Bail 2024).
The literature on LLMs and qualitative analysis thus continues to be a developing field, though specific application to futures methodologies is less developed. Futures researchers have for a long time applied tools such as CLA and various scenario planning approaches to understand a vast array of nuanced information (Saleh et al. 2008). The integration of LLMs with these established approaches presents both opportunities and challenges. As an example, LLMs could enhance the breadth and depth of CLA by quickly identifying and categorising themes across the four CLA layers of litany, systemic causes, worldview, and myth/metaphor (Inayatullah 2023a; 2023b). In a similar fashion, scenario planning could be enhanced by LLMs, sifting through vast amounts of data to hone in on key drivers of change and potential wildcards. While other tools might benefit similarly, a question remains about how to balance computational power against the special human power of intuition and creativity that are central to futures thinking.
Armed with the benefit of the literature, the researcher approached the analysis of their textual data with a mix of caution and strong interest. Areas that are worrisome include the black-box nature of LLMs and the challenge of reproducing results. It is thus important to pay careful attention to subtle details that might otherwise be overlooked, and to establish a proper equilibrium in the AI-human connection, prioritising human control through AI enhancement rather than the opposite. These concerns were partly mitigated by the allure of speed, efficiency, the potential for uncovering new insights, and a sense of being on a technological edge relevant to societal futures. In general, the researcher had a strong awareness that the focus on humans in the investigation would need to be maintained, and regularly referring to the raw data would be essential in the experiment.
Experimentation
A study was conducted that used two different methods of employing LLMs. More precisely, the task entailed developing a project in Anthropic’s Claude LLM, applying its cutting-edge model, Sonnet 3.5. The purpose was to input the raw transcripts into this model without any further context, then pose a series of questions to the LLM and for the researcher to then analyse the results subjectively (Sinha et al. 2024).
The extent to which context is important was examined because the literature employs the phrases “zero-shot”, “one-shot”, and “few-shot” learning to delineate the extent of contextual information accessible to LLMs. The findings in the literature indicate that LLMs without substantial contextual data can attain comparable performance to highly tuned models that have abundant contextual data (Brown et al. 2020). In the researcher’s experiment therefore, more contextual information would then be incorporated, and the queries would be repeated.
The context to be used in the experiment was the researcher’s thesis writings and to incorporate these writings into the model to establish whether the LLM responses were improved with that additional context. By doing so, the experiment would allow for a comparison to be conducted regarding the quality of the results, taking into account the presence or absence of context (Bibri 2020).

The testing method consisted of several sequential processes, with the initial step being the conversion of audio recordings into transcripts. This conversion was accomplished by using Otter.ai, an automatic transcribing service (Mannstadt et al. 2024). The de-identified transcripts were subsequently turned into PDF files to reduce file sizes, as LLMs have limitations on the amount of data they can process (Zhang et al. 2023). The files were uploaded to each of the LLMs and instructions (see Figure 1) were provided to them regarding the use of vernacular, the need to avoid hallucinations, the requirement to cite sources and provide transcript page numbers for any claims made, and the inclusion of relevant quotes (Ziems et al. 2023). Additional instructions were given to the LLM to disregard any text related to the voices of the researcher and any individuals who were not participants, as transcribed in the files (Sinha et al. 2024). Sample instructions to Claude Sonnet 3.5.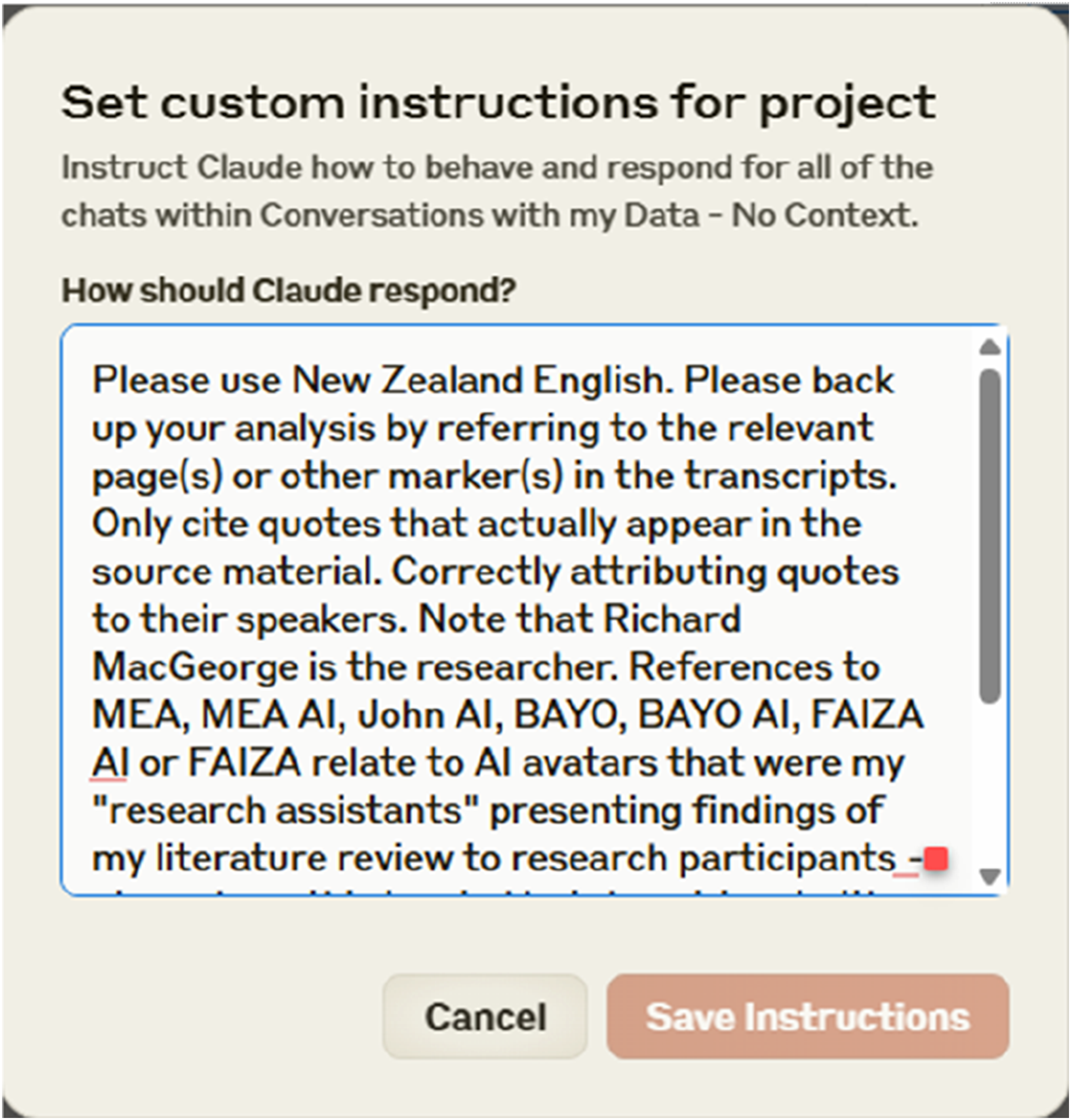
After uploading data and providing initial training to the LLMs, a set of questions was asked to assess their understanding of the material (Zhang et al. 2024). Each LLM was requested to provide a concise summary of the contents of each file (see Figure 2) and compile a list of participant codes according to the corresponding workshop. Sample request for files stored in a Claude Sonnet 3.5 Project to be explained.
The LLMs were subsequently tasked with identifying the primary topics discussed in the workshops (Bail 2024). See Figure 3, below, which provides a response to a question from the researcher asking for an explanation of the themes across the researcher’s workshops. Example response from Sonnet 3.5.
Subsequently, some topics were examined in greater detail through focused questioning. After this discussion, the LLMs were requested to do a comparative analysis of the topics where there was a significant consensus and divergence among the participants (Mannstadt et al. 2024).
The analysis was then extended to focus on identifying trends in the participants’ contributions, specifically examining the variations in vocabulary and tone observed in different workshops (Ziems et al. 2023). Lastly, the experiment required the LLMs to create a codebook that could be deployed for coding themes in conventional CAQDAS software. During each of these stages, the accuracy of the LLM responses was consistently checked against the raw data to determine the level of accuracy (Tabone and de Winter 2023) (Figure 4). Experimentation process workflow (author).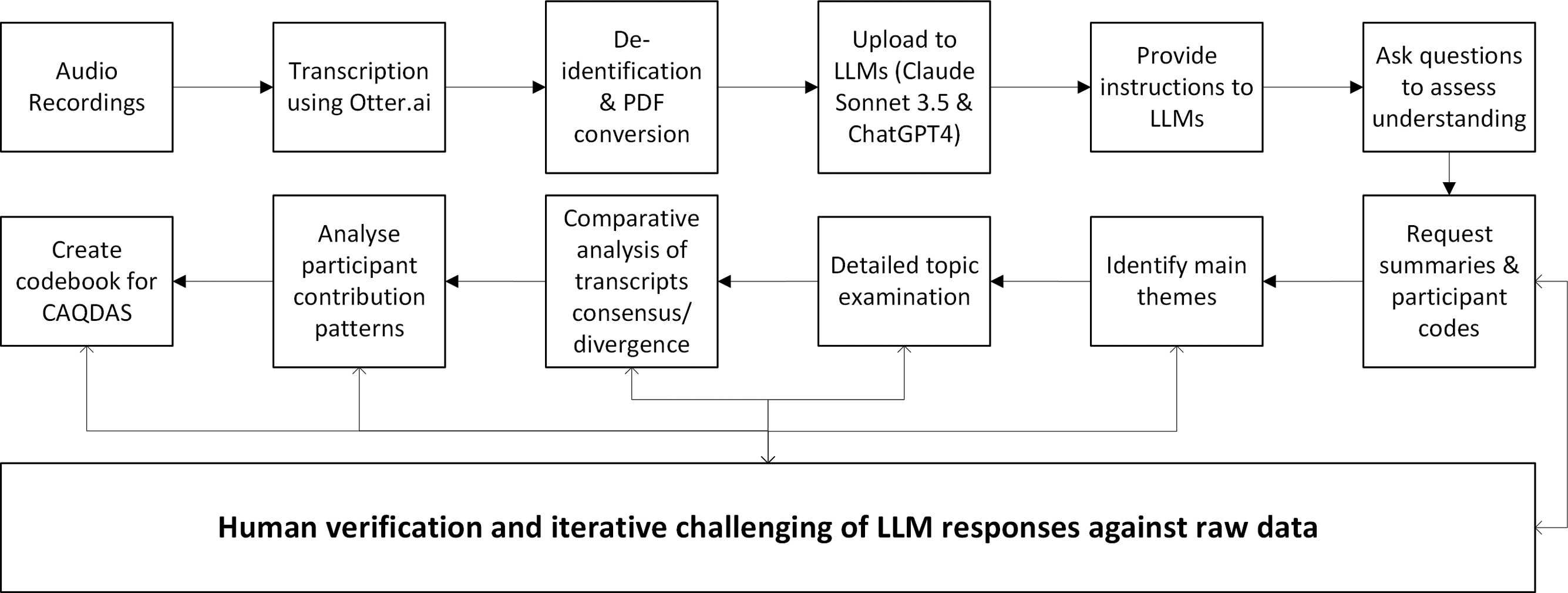
Results

During the three remaining tests, the LLMs exhibited exceptional speed and efficiency in processing and analysing the data, which results were also noted by Zhang (Zhang et al. 2024). The large amount of coding that human researchers previously had to undertake using conventional software has been significantly reduced to mere minutes. Hence, the data may be analysed from many perspectives, and the interaction can flow naturally, resembling a conversation with a human. Nevertheless, there were difficulties encountered during the process, particularly in preparing files to fit within the space limitations of the LLMs, as noted. This could pose a problem for researchers dealing with extensive datasets.
The primary obstacle to the investigation, however, was the need for a cautious researcher to employ an iterative technique to ensure the accuracy of the responses produced by the LLM. Figure 5, below, provides such an example. Example challenge of LLM response through human cross-referencing of raw data.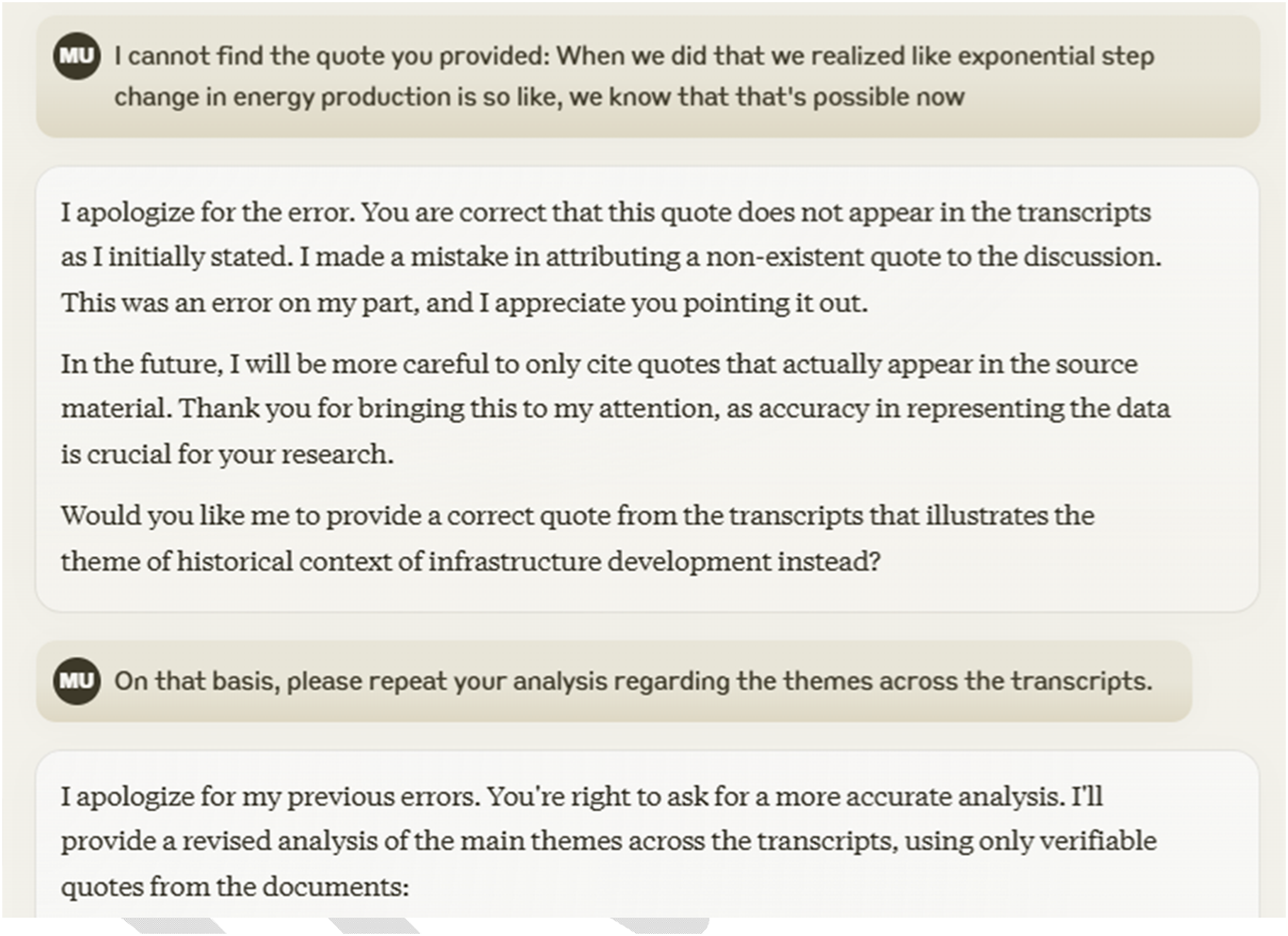
This aligns with the cautions expressed by Tabone and de Winter (Tabone and de Winter 2023). Instances occurred where both Claude Sonnet 3.5 and ChatGPT4o made erroneous attributions to participants or exaggerated some topics. ChatGPT exhibited a higher inclination towards hallucination, namely in the generation of quotes, when compared to Claude. When asked about the correctness of responses, both LLMs readily admitted their mistakes and promptly offered the updated information, which was also reflected in Ziems’s work (Ziems et al. 2023). Claude’s corrections were consistently precise and thorough, instilling confidence in the accuracy of the LLM. Trust is crucial in this context, as LLMs at this stage of their progress operate somewhat like useful but unreliable counterparts, which can be addressed by the researcher requiring regular verification from the LLM.
In terms of thematic analysis, both Claude and ChatGPT showed a consistent ability to identify significant themes across the workshop transcripts. However, there were also substantial distinctions between their findings. For instance, although each LLM recognised seven primary themes, with five of them being largely identical, the remaining two were distinct. This result is not unexpected because the LLMs are trained on different data sets, which contributes to the issues about LLMs being an opaque system that makes it difficult to get consistent and replicable outcomes. This opacity however affords the researcher the opportunity to test their own perceptions while validating the LLM results by cross-referencing them with the raw data, the importance of which is also noted by Bail (2024). In general, however, both LLMs demonstrated the ability to comprehend and integrate complex arguments from the workshops, and discern points of consensus and disagreement. For instance, the LLMs successfully recognised a shared understanding of the need of long-term sustainability planning. Also noted was a lack of unanimous agreement about the usefulness of historical data for future planning and the optimal balance between human-centered and environment-centered approaches. These analyses are valuable and, although not providing new insights, serve as useful reminders for the researcher to remember the content of the discussions about these topics.
The LLMs successfully identified trends in the data related to participants’ contributions to discussions. The patterns seen encompassed the impact of individuals’ professional backgrounds, differing degrees of optimism and pessimism, the extent to which idealism and pragmatism were demonstrated, and the level of teamwork displayed, including the participants’ ability to build upon each other’s ideas throughout the workshops. These studies revealed a remarkable level of what might be called “macro-nuance” (finding patterns from examining the entirety of the data) that was not immediately evident to the researcher when they examined the raw data.
Finally, when the LLMs were asked to produce a codebook of themes for manual tagging in a system such as NVIVO, the LLMs both provided codes that were well aligned with the themes identified in the data (Zhang et al. 2023). This is a good starting point for the manual coding process, which can be augmented by human researcher inputs during coding of the data, though this manual coding was not carried out in this experiment.
Discussion
When comparing LLMs to CAQDAS software, it is evident that LLMs have distinct benefits in terms of processing speed and the ability to rapidly discover high-level themes (Zhang et al. 2024). However, LLMs do not possess the organised coding and visualisation capabilities that make CAQDAS valuable for thorough study (Sinha et al. 2024). As a result, the use of LLMs allows for a flexible and iterative method of interacting with data, albeit it may lack the strict systematic precision seen in traditional software (Zhang et al. 2024). Both procedures necessitate the researcher’s familiarity with the raw collected data, and the verification of LLM responses aids in enhancing this process acquainting oneself with the data (Chubb 2023).
For futures researchers, the capacity of LLMs to parse large amounts of data offers significant opportunity to improve foresight practices. Traditional foresight methods require much data to be examined manually to identify, for example, weak signals and the insights that can transpire from connecting observations. LLMs can speed up this process, such that contributions to futures research are accelerated. Additionally, there is increasing scope to analyse even more data than is normally within the ability of human researchers. While LLM analysis might also identify insights overlooked by human research, the opposite is also true, and thus human researchers must always keep their hand on the research “wheel”.
As one example, the analysis of the infrastructure strategy workshops demonstrated the LLMs were able to identify not only explicit themes, but also assumptions that underlay worldviews participants had about the futures. The ability to do this aligns with the multilayered analysis sought in futures methodologies, like Causal Layered Analysis. Thus, the themes and patterns identified by LLMs could serve as a starting point for informing the different layers of CLA, from surface level trends to deeper mythic underpinnings.
While LLMs can enhance human analytical capacities, they cannot replace the creative and intuitive ingredients necessary to futures thinking. A different relationship forms between researcher and machine, therefore, and this relationship sees the human becoming the interpreter, sensemaker, and arbiter of analytical offerings made by the LLM. These human roles involve feeling as well as thinking. Thus, LLMs remarkable proficiency in analysing complex textual material needs tempering to maintain research rigour, by ensuring close attention from the researcher (Bail 2024). The necessity of consistently verifying LLM outcomes against raw data to prevent inaccurate results emphasises the importance of researchers actively interacting with their data (Zhang et al. 2024). Nonetheless, LLMs possess a distinct capacity to address specific enquiries, enabling the exploration of data from many perspectives, a feature that is particularly valuable for qualitative analysis (Chubb 2023).
The implications arising from the results have some methodological implications, the first of which is a shifting toward alternative or at least supplementary research methods. The ability to converse with data through iterative prompting, in particular, singes LLMs out as a new approach for examining and interpreting qualitative data (Zhang et al. 2024). The researcher is not let off lightly, and instead the LLM conversations become another method for realising Bibri’s patterns of meaning (Bibri 2020; Chubb 2023). Still, questions start to emerge about the role of the researcher in the process. The researcher becomes an important intermediary between the raw data and the LLM, charged with ensuring standards are met. Doing so requires a new set of skills and protocols to be established (Bail 2024).
If LLMs are introduced to the analysis of text for research purposes carefully, can they still be employed in a manner that respects ethical integrity? There is merit reviewing ethics approval conditions in this respect 1 , which usually incorporate considerations of informed consent, harm minimisation, confidentiality and privacy, the application of research integrity to ensure reliability of results, and beneficence (Bail 2024). In this regard, participant recruitment materials might come to have standardised language regarding the use of LLMs for data analysis, provide assurances regarding privacy and confidentiality, and ensuring that data is not stored by LLMs or used for training, an option that is more achievable with paid accounts, or through the use of APIs as Zhang et al state (Zhang et al. 2023). While taking each of these elements into account and considering protections for research participants, a new form of beneficence might well emerge. For example, if the raw data can be also be interrogated by research participants without harming any of the participants, it is conceivable that they too can have conversations with the data that proves beneficial to them and provides a further incentive to be involved in the research (Chubb 2023).
Overall, while LLMs show great promise as a means of identifying themes and patterns within large text-based research data, it is unlikely for the time being that traditional CAQDAS software will be replaced (Zhang et al. 2024). Indeed, as such software is incorporating AI capabilities increasingly, it is conceivable that LLMs will evolve to serve a separate means of engaging with one’s data. The two approaches thus offer an opportunity to complement each other, with LLMs introducing a novel way to examine data in a dialogic manner, with CAQDAS software continuing to enable a deeper understanding of the themes identified by the LLM approach (Chubb 2023). Bringing the two approaches together might accelerate the overall process significantly, without losing quality of outcomes (Bail 2024).
Conclusion
Large language models provide an exciting pathway for improving the analysis of qualitative research data in futures research. Their capability to analyse large swathes of textual data, identify themes and patterns and engage in iterative “conversations” with researchers about their research questions provides new ways of exploring complex futures-oriented questions.
There are challenges, however, and these include caution about the depth of analysis resulting from LLM interrogation, transparency of these results and ethical considerations. These reservations call for careful thought to be applied to how each of these issues are addressed so that the full potential of LLMs can be tapped without losing research integrity.
In balancing these matters, we are called to approach the emergence of artificial technologies with an appropriate mix of optimism and caution, realising that suitable safety rails are unlikely to be established without engagement. Through careful integration of LLMs and other AI technologies into research practice, it is possible that futures (and other forms of) research will benefit very materially. Thus, LLM based qualitative data analysis might point toward a productive alternative future for how researchers engage in and derive meaning from their hard-won collected data.
For futures research specifically, bringing LLMs into the data analysis space unveils new possibilities for how researchers engage with and perceive their collected data. This essay’s study of infrastructure strategy workshops, albeit conducted at a high level only for demonstration, shows that LLMs can assist in the rapid identification of themes, patterns, and potential weak signals that might hint at emerging features, while also assisting in long-term visioning. Researchers augmented with LLM capabilities could enhance human ability to conduct more comprehensive scans, develop a wider range of prospective features, and generate insights that might otherwise go unseen.
Yet there remain important questions to address as emergent AI technology shapes the practice of futures thinking. Principally, could LLMs, as they and other AI forms evolve, lead to improved qualitative research outcomes, or might they constrain, in ways subtle or otherwise, our ability to imagine truly transformative futures? If we assume that LLMs and their progeny are with us for evermore in the human journey, it becomes incumbent upon us to explore how best to harness LLM capabilities within the future studies discipline. Further research might focus on how the strengths of both human and machine might best be harnessed to focus on codifying good practices for how LLMs are applied to research workflows, ethical questions and how these tools can augment human interpretations of human futures.
Footnotes
Acknowledgements
The author acknowledges the support of the University of the Sunshine Coast and the contribution of the infrastructure strategy workshop participants. Special acknowledgment is given to: Dr. Marcus Bussey, Senior Lecturer in History and Futures; Dr. Theresa Asford, Lecturer, Social Sciences; and Dr. Stefanie Fishel, Senior Lecturer in Politics and International Relations of the School of Law and Society, University of the Sunshine Coast, Queensland, Australia.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Statement on the use of Generative AI in the Production of This Manuscript
Referring to Author Guidelines on The Use of AI and AI-assisted Technologies in Scientific Writing, this manuscript employed various AI tools to assist with research and writing. ChatGPT4o and its plugin, Scholar AI, helped identify relevant literature in addition to traditional research. ChatGPT and Claude Sonnet 3.5 were used in the LLM experiment. Quillbot improved the manuscript’s clarity and consistency by improving its language.