
Abstract
Importance
The performance of large language models has been compared to that of physicians.
Objective
To evaluate the performance of ChatGPT-4 in the field of otolaryngology and head and neck surgery (OTOHNS) residency training.
Design
Observational.
Setting
Virtual.
Participants
ChatGPT-4.
Interventions
All questions from the OTOHNS National In-Training Exam (NITE) for 2022 and 2023 were submitted to ChatGPT-4. Answers were graded by 2 reviewers using the official grading rubric, and the average score was used. Mean exam results from residents who have taken this exam were obtained from the lead faculty.
Main Outcome Measures
Z-tests were used to compare ChatGPT-4’s performance to that of residents. The questions were categorized by type (image or text), task, subspecialty, taxonomic level and prompt length.
Results
ChatGPT-4 scored 66% (350/529) and 65% (243/374) on the 2022 and 2023 exams, respectively. ChatGPT-4 outperformed the residents on both exams, among all training levels and within all sub-specialties except for the general/pediatrics section of the 2023 exam (Z-test −2.54). For the 2022 exam, ChatGPT-4 would rank in the 99th percentile among post-graduate year (PGY)-2 and 73rd percentile among PGY-4 classmates. For the 2023 exam, it would rank in the 99th percentile among PGY-2 and 71st percentile among PGY-4 classmates. ChatGPT-4 performed best on text-based questions (74%, P < .001) with an effect size of 1.27 (confidence interval (CI): 0.99-1.55), level 1 taxonomic questions (75%, P < .001) with an effect size of 0.084 (CI: 0.03-0.14) and guideline-based questions (70%, P = .048) with an effect size of 0.11 (CI: 0-0.23). It had no significant difference in performance based on subspecialty (P = .36) or prompt length (P = .39).
Conclusions
ChatGPT-4 not only achieved passing grades on 2 versions of the Canadian OTOHNS NITE, but it also significantly outperformed residents.
Relevance
This study underscores a critical need to redesign residency assessment methods.

Keywords
Introduction
Artificial intelligence (AI), particularly deep learning, is rapidly and profoundly impacting healthcare and becoming an integral part of clinical decision making. 1 There is growing interest in large language models (LLM), such as ChatGPT, and their potential capability to mimic physician-patient interactions and provide accurate and reliable health education. In otolaryngology, ChatGPT has been shown to offer relevant and accurate medical information, though it lacks response depth and exhibits certain knowledge restrictions.2 -6 These current limitations have hindered widespread adoption of this tool. Given that many patients rely on online resources as their primary source of health information, 7 and considering online health information can vary extensively, 8 exploring the use of LLMs as an adjunct tool in healthcare is a sensible goal.
To effectively compare chatbots to physicians, they should be subject to similar rigorous examinations. Numerous studies have demonstrated that chatbots can attain comparable performance to their human counterparts in medical examination methods.9 -13 For instance, ChatGPT successfully passed question banks designed for preparation for the United States Medical Licensing Exam, 9 a notoriously challenging multiple-choice exam. It also demonstrated similar proficiency to residents in neurology, 10 orthopedic surgery11,12 and plastic surgery 13 exams, all of which are structured as multiple-choice tests. However, less is known regarding its ability to handle short and long-answer medical examination questions, which require explicit demonstration of an examinee’s critical thinking skills. The Otolaryngology—Head and Neck Surgery National in-Training Exam (OTOHNS NITE), taken by Canadian residents, is composed primarily of such open-ended questions. Evaluating knowledge across a range of competencies, the exam aims to adequately prepare residents for their Royal College of Physicians and Surgeons of Canada (RCPSC) board exam. Given that performance on in-training examinations typically correlates with success in such board exams, 14 it is crucial to appreciate how LLMs perform on these types of assessments to begin to understand how their knowledge compares to that of physicians.
ChatGPT-4, a finely tuned supervised model trained on billions of additional parameters, is OpenAI’s most recent development, offering improved reasoning capabilities and video and image input. 15 Despite the growing use of LLMs in healthcare, their ability to perform on open-ended medical exams, and in the field of otolaryngology, has yet to be thoroughly evaluated. The goal of this paper is to understand ChatGPT-4’s performance on the OTOHNS NITE in comparison to Canadian otolaryngology residents, with a focus on how chatbots can be integrated into medical education and training.
Methods
Question Bank
OTOHNS NITE exam questions from 2022 and 2023 were collected. The question set and its answers are confidential. The lead faculty member of the OTOHNS NITE was contacted to retrieve the exams. It would therefore not be possible for the model to have access to the test materials. Follow-up questions were counted individually.
Using ChatGPT-4
The premium, paid, version of ChatGPT-4 was utilized for answering questions from April 22nd, 2024, to May 12th, 2024. The wide timeframe is due to the daily question input limit imposed by the software. A new account was created to avoid any user-dependent bias. ChatGPT-4 was accessed through OpenAI’s website.
Each question was entered using a new session. Prior to each question, the following prompt was used: “Answer the questions as though you are an otolaryngology, head and neck surgery resident taking an exam. Limit the answer to 75 words.” Prompts are essential in achieving the desired answer from chatbots. 16 This prompt was specifically designed to ensure that the model adopted the perspective of a resident, aligning with the examination scenario. The 75-word limit was established based on the expectations set for residents during these exams.
A nonresponse was defined as any reply from ChatGPT that did not adopt the resident perspective, acknowledge its identity as a chatbot, and indicate an inability to answer the question due to the limitations of its model. Nonresponses only occurred with image-based questions. In this case, the following prompt was entered: “Answer the question based on the image provided.” The second answer was used for grading. If nonresponse persisted after this prompt, it was recorded as such. Nonresponses were included in the final score, with their second answers being graded in the same manner as those from other questions.
Each question was treated independently, with the exception of follow-up questions where context from the previous response was necessary. A sample of a chatbot conversation is included in Figure 1.

Sample of the chatbot conversation.
Question Evaluation
ChatGPT-4 answers underwent independent grading by 2 reviewers. The reviewers were instructed to grade the responses using the same pre-established grading grid applied to resident responses. Inter-rater reliability was evaluated using the Intraclass Correlation Coefficient (ICC) using a 2-way random model. The average score between raters was used.
Comparison With Residents’ Performance
Anonymized mean exam results from residents who have previously taken this exam were obtained from the lead faculty of the NITE. To protect the confidentiality of the exam-takers, the available data included mean scores and standard deviations for post-graduate year (PGY)-2 to PGY-4 residents across the following categories: basic science, pediatrics/general, rhinology/laryngology, otology and head and neck oncology/facial plastics. These categories represent the official exam categorizations, which are used to inform residents about their performance after taking the exam. Per-question scores or individual resident scores were not available. PGY-1 residents are exempt from taking the exam because they undergo most of their rotations in other specialties. PGY-5 residents, having already completed the RCPSC exam, are also exempt.
Performance by Category
Questions were categorized based on subspecialty (basic science, general, pediatrics, rhinology, laryngology, otology/neurotology, head and neck oncology and facial plastics and reconstructive surgery), on type (text-based or image-based) and task (diagnosis, additional exams, treatment or guidelines). Guideline-based questions were defined as questions that directly reference published guidelines. Subspecialty categorizations were based on the classification provided by the NITE, with combined specialties (for example, pediatrics/general) categorized individually. Questions were further classified based on Bloom’s taxonomic levels 17 : level 1 (remember), level 2 (understand), level 3 (apply), level 4 (analyze), level 5 (evaluate) and level 6 (create). Taxonomic levels were determined by both reviewers. Finally, the length of the questions was recorded.
Statistical Analysis
IBM SPSS Version 29, United States, was used for statistical analysis. The performance of the chatbot was compared with national resident averages using a Z-test per training level, subspecialty and exam. A combined analysis of both exams was not possible due to the limited available data from resident scores. A statistically significant difference between the mean of the 2 groups is considered at ±1.96, with negative scores indicating better performance by residents and positive scores indicating better performance by the chatbot. Assuming normal distribution, percentile scores were calculated using a z-score table. In our study, ChatGPT is being treated as a single “test-taker,” akin to an individual resident.
For ChatGPT-4 responses, a sub-analysis was conducted for each question category to examine for variations. Given the worth of a question is variable, weighted scores were normalized to a scale of 1 to enable comparative testing. Independent t-test with Cohen’s d sample effect size for the question type was used. One-way analysis of variance (ANOVA) with eta-squared effect size for question task, subspecialty and taxonomic levels was used. If Levene’s test indicated significant results (P ≤ .05), suggesting a violation of homogeneity of variances, Welch’s ANOVA was applied. If the ANOVA test indicated significant results (P ≤ .05), post hoc Tukey’s test was used to identify specific group differences. A 2-tailed Pearson correlation test was used for prompt length. Bonferroni correction was used. Given 3 different statistical tests were used for the sub-analysis of ChatGPT’s responses, the P-value was adjusted accordingly. Results at P ≤ .0167 for a confidence interval (CI) of 95% were considered statistically significant.
Ethics
Ethics approval was not necessary for this study because it used publicly available and anonymized data.
Results
Comparison With Residents’ Performance
For the 2022 exam, there were 33 PGY-2s, 34 PGY-3s and 38 PGY-4s. For the 2023 exam, there were 28 PGY-2s, 33 PGY-3s and 38 PGY-4s. The raw scores are presented out of the total weight of the questions. The resident raw scores are presented as the average among all residents.
The ICC between the 2 raters was 99% (CI: 99.1-99.4%), with a P-value of <.001. Overall, ChatGPT-4 performed significantly better than residents at all training years (Multimedia Appendices 1 and 2), with a decreasing difference with increasing residency training. The only occurrence where residents outperformed ChatGPT-4 in a significant manner was fourth-year residents in the general/pediatrics section of the 2023 exam (Z-test −2.54).
For the 2022 exam, ChatGPT-4 would rank in the 99th percentile among PGY-2, 95th percentile among PGY-3 and 73rd percentile among PGY-4 classmates. For the 2023 exam, it would rank in the 99th percentile among PGY-2, 94th percentile among PGY-3 and 71st percentile among PGY-4 classmates.
Figure 2 visually depicts the Z-test scores, demonstrating an evidently decreasing magnitude of difference between ChatGPT-4 and resident performance with increasing training, for all sub-specialties. There was no significant difference in the distribution of image to text-based questions or low to high-order taxonomic questions per subpecialty between the 2022 and 2023 exams.
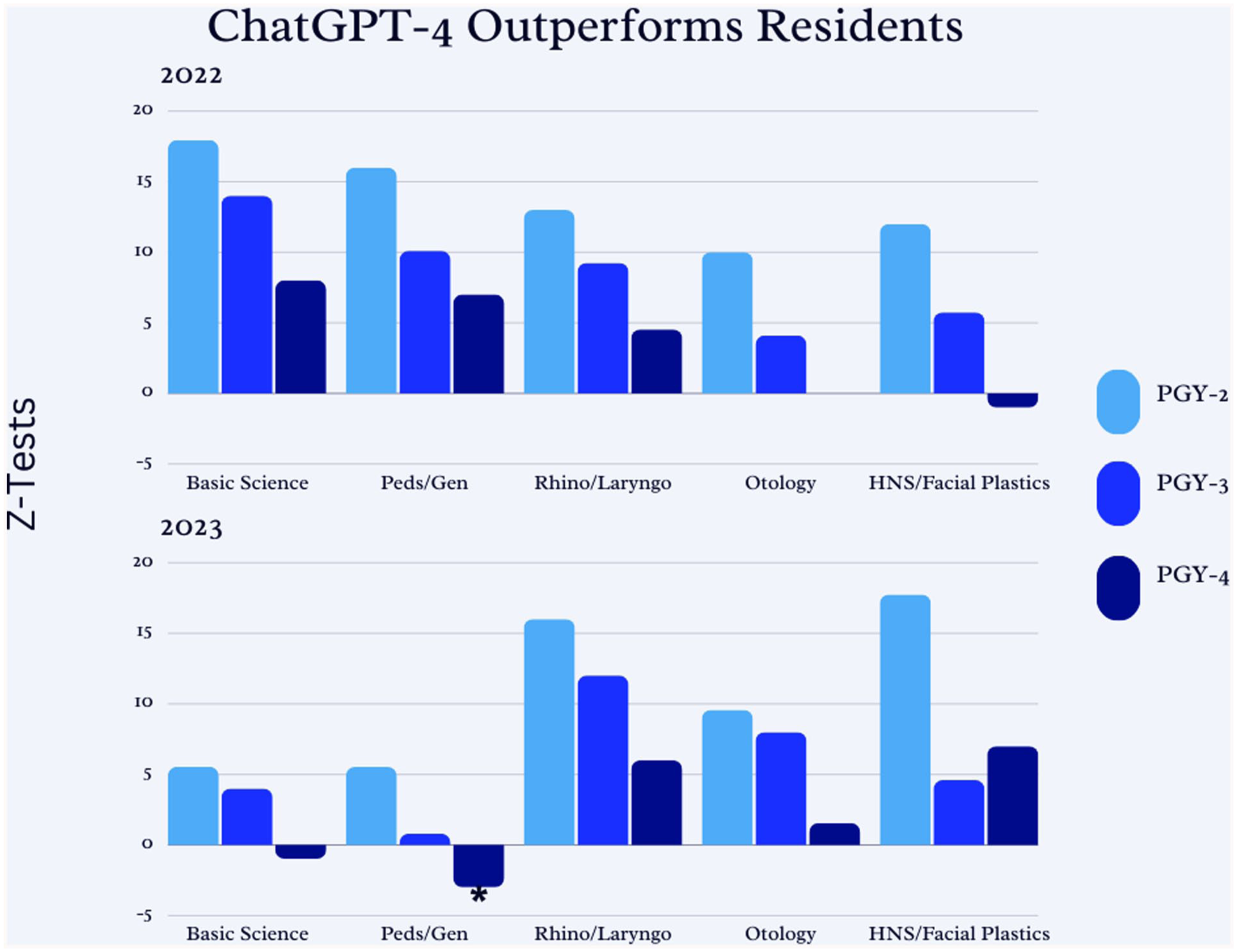
ChatGPT-4 outperforms residents.
Performance by Category
The overall breakdown of both examinations is described in Table 1, encompassing a total of 348 questions. Based on the pre-determined examination grading grid, questions were worth anywhere between 1 to 11 points, for a total of 903 points. The exam encompasses primarily short-answer questions with 9 multiple-choice questions in the 2022 exam and 2 in the 2023 exam.
ChatGPT-4 Performance Sub-Analysis.
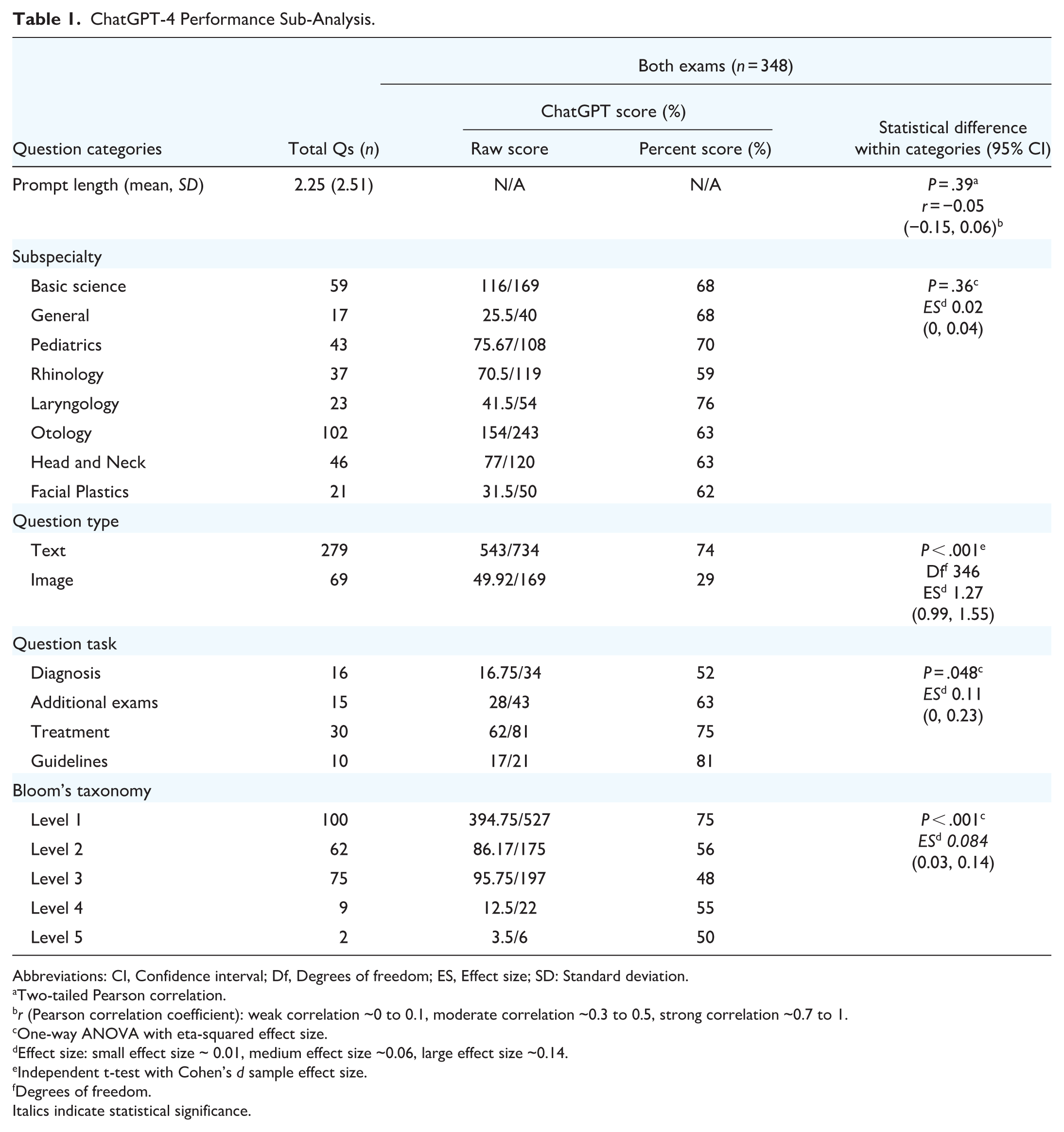
Abbreviations: CI, Confidence interval; Df, Degrees of freedom; ES, Effect size; SD: Standard deviation.
Two-tailed Pearson correlation.
r (Pearson correlation coefficient): weak correlation ~0 to 0.1, moderate correlation ~0.3 to 0.5, strong correlation ~0.7 to 1.
One-way ANOVA with eta-squared effect size.
Effect size: small effect size ~ 0.01, medium effect size ~0.06, large effect size ~0.14.
Independent t-test with Cohen’s d sample effect size.
Degrees of freedom.
Italics indicate statistical significance.
In the 2022 exam, 3 questions required at least 1 prompt, and in the 2023 exam, 6 questions required at least 1 prompt. Despite the additional prompting, ChatGPT-4 was unable to answer these questions, all of which were image-based. These were not excluded from grading and graded accordingly, with a mode of 0.
ChatGPT-4 scored 66% (350/529) and 65% (243/374) on the 2022 and 2023 exams, respectively, thereby achieving a passing score (60%). ChatGPT-4 performed significantly better on text-based questions compared to image-based questions (P < .001) with a large effect size (1.27, CI: 0.99-1.55). It also performed best on guideline-based questions (P = .048) with a large effect size (0.11, CI: 0-0.23) and on taxonomic level 1 questions (P < .001) with a moderate effect size (0.084, CI: 0.03-0.14). The lower-scoring 1- or 2-mark questions were primarily taxonomic level 1. There was no significant difference in performance based on subspecialty (P = .36) or prompt length (P = .39).
Statistically significant findings within groups include the following: for task-related questions, there was a mean difference of 0.54 (95% CI: 0.028-1.05) for guideline-related questions compared to diagnosis-related questions (2022 exam, P = .04), for taxonomic-related questions, there was a mean difference of 0.29 (95% CI: 0.025-0.56) for taxonomic level 1 questions compared to taxonomic level 2 questions (2023 exam, P = .02), a mean difference of 0.25 (95% CI: 0.022-0.486) for taxonomic level 1 questions compared to taxonomic level 3 questions (2023 exam, P = .02), a mean difference of 0.22 (95% CI: 0.069-0.38) for taxonomic level 1 questions compared to taxonomic level 2 questions (both exams, P < .001) and a mean difference of 0.26 (95% CI: 0.11-0.40) for taxonomic level 1 questions compared to taxonomic level 3 questions (both exams, P < .001).
Discussion
Principal Findings
This study represents, to our knowledge, the first investigation into a chatbot’s performance on the OTOHNS NITE, revealing ChatGPT-4’s ability to answer medically complex and open-ended questions. ChatGPT-4 outperformed residents in both exams, within all sub-specialties and at all training levels, with the exception of a marginal difference (Z −2.54) in the pediatrics/general section of the 2023 exam. It scored in the higher percentiles among national residents, demonstrating its proficiency in retrieving and applying medical knowledge.
ChatGPT-4 had a poor performance on image-based questions, frequently appearing to make educated guesses based on the available context provided without directly analyzing the images. A total of 9 image-based questions required additional prompting, reflecting the chatbot’s limitation in analyzing images. The chatbot performed best on guideline-based questions, particularly when compared to diagnosis-based questions. Given that the model directly retrieves information from the web, guideline information is easily accessible without requiring interpretation or complex application. Further, many diagnostic-based questions necessitated visual analysis to pose an accurate diagnosis, likely reflecting ChatGPT-4’s current limitations in image analysis.
Additionally, the chatbot performed best on lower taxonomy levels, which rely on information retrieval. While no statistically significant differences were identified for taxonomic levels 4 or 5 questions, this is likely due to a small question sample size. The overall high score of the chatbot aligns with the finding that the majority of the NITE exam questions assess lower cognitive levels. In addition, no significant differences were identified for prompt length or subspecialty.
Implication of Findings
OTOHNS has a match rate of 44% over the past 5 years in Canada, making it among the top 5 most competitive residency programs to match into. 18 Its training program is rigorous, requiring a thorough understanding and appraisal of medically complex material. ChatGPT-4 ranked in high percentiles among national residents across all training levels.
Since the majority of exam questions focus on direct recall, it can be expected that ChatGPT-4 obtained higher scores when compared to residents. Medical trainees must retain a large amount of information, without the use of external aids, while ChatGPT has access to extensive amounts of online data.
Unlike other studies that have excluded image-based questions,10,12,19 we have explicitly chosen to retain these questions. ChatGPT-4 claims to be able to interpret images 15 and, further, OTOHNS is a visually dependent field, relying on direct visualization of pathology via endoscopy and radiological images. Excluding image-based questions would not accurately represent the required skills to succeed in an OTOHNS knowledge assessment test. Its poor performance on image-based questions indicates an important limitation of this tool. Given this limitation, this may warrant the NITE committee and other committees alike to consider enriching the OTOHNS examination with more image-based questions. Ensuring that future examinations address skills that AI systems, such as ChatGPT, cannot yet do efficiently is an area that merits attention.
The categorization of questions into taxonomic levels highlights an unexpected finding of this study. The OTOHNS NITE relies predominantly on lower cognitive levels of assessment, a common method of educational assessment in various disciplines.20,21 As such, developing higher-order thinking testing, including image-based analysis, should be prioritized to adequately measure the required cognitive skills to become a proficient surgeon. 22
Our analysis revealed that question length did not have a significant impact on the chatbot’s performance. This finding suggests that other prompt-related factors may play a more critical role than length alone. A study published in 2024 by Patil et al demonstrated that varying the structure and vernacular of a prompt, while maintaining its context, leads to differing chatbot responses, with prompts rephrased by AI to a casual or neutral tone receiving higher grading. 23 Similarly, Meskó emphasized the importance of precise prompt engineering strategies, including being specific, describing the setting and context, identifying the prompt’s goal and assigning ChatGPT a specific role. 24 In addition, in a study published in Nature in 2024, Wang et al identified that Reflection on Search Trees prompting, a framework designed to reflect on previous tree search experiences, achieves the highest overall consistency. 25 In the context of medical exams, these findings align with the expectation that well-constructed questions, irrespective of their length, are more likely to elicit accurate responses.26,27 While our study did not identify question length to be a significant variable, future research should explore the association of other prompt factors, such as structure, tone, and context, to optimize prompt design in medical education and evaluation.
Overall, the findings of this study suggest that incorporating higher-order thinking questions and image-based questions into OTOHNS assessments may be of benefit. Shifting toward testing diagnostic reasoning, clinical judgment and image interpretation, critical skills for a proficient surgeon, for which ChatGPT demonstrated limited performance, should be strongly considered. Given ChatGPT demonstrated competency in lower cognitive level questions, it may serve as an adjunct for composing questions, aiding the Canadian otolaryngologists who compose NITE questions on a per-volunteer basis. For instance, examiners could input textbook-based information and prompt it to generate a multiple-choice question targeting simple recall. This would allow examiners to focus their time on developing more complex questions that assess higher cognitive levels. ChatGPT could also aid with the development of higher-order questions by serving as a quality check to ensure that questions are appropriately challenging. With targeted prompt engineering, it can assist in efficiently producing questions, significantly reducing the burden of exam writers. Given the anticipated growth of chatbots, their integration into OTOHNS education necessitates strong consideration. The American Medical Association 28 supports the integration of AI in medical education to enhance the learner’s experience and improve learning outcomes. AI could be integrated into exam simulations to quiz residents on basic knowledge recall, allowing residents to assess the strength of their fundamental knowledge. ChatGPT could be a helpful tool for interns to practice information recall and basic concept acquisition, an essential component for building upon more complex clinical reasoning. The chatbot could provide residents with a time-efficient and easy-to-use tool that allows them to quickly assess and reinforce their understanding of fundamental knowledge. While public concerns have been raised about the potential for AI to replace physicians and other allied health care professionals, 29 it is essential to recognize how AI can support clinical practice. While AI has demonstrated key abilities, physicians remain key contributors in defining its constraints and applications. Their input is valuable to ensure AI is trained on meaningful data and integrated safely into the field of healthcare. By partnering with software engineers, surgeons can offer the necessary clinical insights to guide the development of meaningful and patient-centered technology. 30 If effectively implemented, such integration has the potential to enhance the surgical field, 31 with the ultimate goal of improving patient outcomes.
Comparison to the Literature
When compared to similar studies as ours evaluating the ability of chatbots to undertake medical exams,9 -13 our study revealed an even better performance from ChatGPT-4. These findings suggest that ChatGPT is rapidly improving, especially in its accuracy and proficiency in answering medical questions. Notably, the increased usage of the model likely contributes to its continuous learning and enhancement, as it processes and adapts based on the vast amount of information submitted by users.
Similar challenges have been observed in other specialties. In a study on orthopedic examinations by Massey et al, 11 ChatGPT struggled with image-based questions, whereas AI performed best on text-based questions. This trend highlights the consistent limitation in current versions of this chatbot to analyze medical visual data. In addition, a study by Bhayana et al on questions modeled after the Canadian Royal College and American Board of Radiology exams 32 revealed that chatbots scored higher on lower-order thinking questions, which focus on information retrieval, while their performance weakened on higher-order thinking questions. This aligns with our study’s finding, that while ChatGPT-4 excels in direct recall, it is limited in more complex medical scenarios that require critical thinking skills and application of knowledge.
Limitations
Our study has some notable limitations. First, given that the ChatGPT model is continually evolving, there can be significant variations in responses over time, limiting the reproducibility of our results. Further, to date, there are no studies validating the NITE as an accurate method of assessment for evaluating resident competency or predicting success on surgical board examinations. The variation in performance across the 2 exams may reflect the chatbot’s inconsistency. Additionally, for anonymity, the available data on resident performance was limited, restricting our statistical analysis. Finally, the small sample size of higher-order level questions limits our ability to draw meaningful conclusions on how the chatbot performs in clinical reasoning. Evidently, surgical training goes far beyond a written exam. Surgical residents must demonstrate surgical competence, high-quality patient care, strong leadership and exceptional communication skills, 33 therefore, no conclusions can be drawn about the overall proficiency of ChatGPT compared to that of an OTOHNS resident.
Conclusions
ChatGPT-4 not only achieved passing grades on 2 versions of the Canadian OTOHNS NITE, but it also outperformed residents in a significant manner. It performed best on lower taxonomic levels, text-based and guideline-based questions. If ChatGPT-4 were seated among a class of PGY-4 residents taking the exam, it would rank in the 72nd percentile, suggesting a need to redesign residency assessment methods. Our study also highlights the importance of reevaluating expected residency training competencies as we enter this new and rapidly growing age of AI.
Footnotes
Appendix 1
Author Contributions
LN is the guarantor. EAR, KR and LN drafted the protocol. EAR provided statistical expertise. All authors read and reviewed the final manuscript.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Data Access
EAR has full access to all the data in the study and takes responsibility for the integrity of the data and the accuracy of the data analysis. Additional data may be reasonably requested.