
Abstract
Background
Freezing of gait (FoG) is a complex, frequent, and disabling motor symptom of Parkinson’s disease (PD). Wearable technology has the potential to improve FoG assessment by providing objective, quantitative, and continuous monitoring.
Objective
This study aims to develop a robust FoG detection algorithm that can be embedded in a simple and unobtrusive wearable sensor system and can lead to a reliable unsupervised home assessment.
Methods
Twenty-two subjects with PD and FoG were enrolled, equipped with four inertial modules on the ankles, back, and wrist, and asked to perform different tasks. Feature-driven and data-driven machine learning approaches were implemented, optimized, and evaluated. Further testing was conducted on two external datasets including a total of 545 FoG episodes.
Results
Sixteen subjects experienced FoG, providing a total number of 101 FoG events. Results demonstrated that a single sensor on the ankle, with an adequate algorithm of data analysis based on machine learning, can provide a non-invasive approach for accurate FoG detection. The model proved robust on the independent datasets, with 88–95% FoG episodes correctly detected. Interestingly, while FoG can be easily discriminated from walking, static positions, and postural transitions, turning represents a significant challenge. The high number of false alarms still represents the main limitation of the FoG recognition algorithms.
Conclusions
The collected dataset includes data from different sensors at different body positions. This, together with detailed labeling of tasks, activities, FoG episodes and their severity, can be a significant contribution to research on automatic FoG detection and characterization.
Introduction
Parkinson’s disease (PD) is the second most common neurodegenerative disease, with over 10 million people affected in the world.1,2 One of the most disabling PD symptoms is freezing of gait (FoG), which is a relevant cause of gait impairment, instability, and falls. Management of FoG is an unmet need. It is often poorly recognized because of its episodic nature, the variability of triggering situations, and the reporting bias of patients and caregivers.3,4 Difficulties in reliable assessment and monitoring of FoG have hampered the research on the intricate pathophysiology of FoG, particularly its management. Pharmacological treatments for FoG are limited to those associated with off and wearing-off states.3,5 Administration of cues with different sensory modalities (e.g., auditory, visual, proprioceptive) can be used to prevent/reduce FoG episodes. 6 However, continuous external cueing may compromise efficacy, while personalized on-demand cueing (i.e., stimulation upon FoG detection) has proved effective in reducing FoG duration in both supervised laboratory experiments and unsupervised daily life. 7 The current standard for FoG assessment, both in clinical and research settings, is based on validated questionnaires, which are limited by recall bias and can only capture in general the severity of FoG episodes during an extended period of time.8,9 Moreover, FoG questionnaires are considered not adequate as an outcome measure for clinical trials due to their low accuracy in detecting changes in FoG frequency and severity.10,11
In this context, wearable inertial sensors have been employed in research settings to detect the presence of FoG episodes.12–14 Although wearable devices hold promise for low-cost data acquisition, the information they generate requires processing to extract clinically meaningful information. Consequently, the large volume of data can be effectively managed by applying artificial intelligence and data analysis methodologies. In particular, machine learning (ML) has emerged as a key component in the creation of remote monitoring systems based on wearable devices. ML algorithms offer the ability to examine sensor data, enabling the extraction of valuable insights or the revelation of hidden patterns in a semi-automated manner. 15 Feature-driven ML relies on the extraction and selection of relevant features from the input data. 16 These features are carefully crafted and chosen based on domain knowledge and understanding of the problem at hand. In essence, the success of feature-driven approaches heavily relies on the expertise of human practitioners in identifying the most informative aspects of the data,17,18 although many libraries exist that can automate feature extraction and selection processes on time series data (e.g., tsfresh 19 or tsflex 20 ). In contrast, data-driven deep learning (DL) harnesses the power of artificial neural networks to automatically learn hierarchical representations directly from the raw data. In this paradigm, the model autonomously discovers intricate patterns and features during the training process. 21 DL methods, such as convolutional neural networks (CNNs), recurrent (e.g., long short-term memory – LSTM, gated recurrent units –GRU) and Transformer neural networks, are particularly suitable for capturing complex relationships within large datasets. 22
Recent advances in ML and DL have provided promising results in automatic FoG recognition from wearable sensors data.22–28 Furthermore, recent studies have explored the importance of sensor placement, task-related factors, patient preferences, and user acceptance in both laboratory and unsupervised real-world applications to advance the detection and management of FoG.26–30 Despite these advances, there is a significant lack of consensus on the best procedures for FoG detection, including variations in the number and types of sensors used for data collection. 22 In addition, there is evidence of a paucity of publicly available datasets containing FoG data. At present, only five public datasets exist.26,29,31–33 Some of these datasets include only accelerometer recordings, devoid of contextual information regarding activity during FoG events. 34 However, there is evidence that artificial intelligence algorithms may fail to generalize to new tasks and activities. 27 In this context, information on contextual activities (e.g., walking, turning, stopping) can provide valuable insights into FoG detection errors and help to better design training strategies. Moreover, few studies have comprehensively evaluated the performance of FoG detection algorithms on external and independent datasets. 22 This gap is critical to realistically evaluate the performance and generalization ability of these algorithms.35,36
The present study aims to collect a dataset with accelerometers and gyroscopes strategically placed at various locations on the body. Careful identification of the beginning and end of each FoG episode is ensured, and common activities are meticulously labeled to establish a contextual background for FoG manifestations. Feature-driven and data-driven ML approaches are implemented and optimized, and the effect of sensor location, sensor type, and different activities is evaluated. The effectiveness of the algorithms on external datasets is evaluated to assess their generalization ability. Finally, a comprehensive evaluation of FoG detection is conducted, including the analysis of false positives and the calculation of prediction time and detection delay for possible closed-loop automatic application of cues to help subjects with PD to overcome FoG.
Materials and methods
Study design and participants
Twenty-two patients affected by idiopathic PD according to the international Movement Disorder Society diagnostic criteria, were enrolled in this study from two university movement disorders clinics (University Hospital Trust of Torino, Department of Neurosciences and Mental Health, Turin, Italy; University Hospital Trust of Verona, Department of Neurosciences, Biomedicine and Movement Sciences, Verona, Italy). Inclusion criteria were: (a) diagnosis of idiopathic PD,
37
(b) H&Y score between 2 and 4, (c) daily FoG episodes reported in the last month according with a score of 1 on Question 1 and score
All participants provided written informed consent prior to their inclusion. The study received approval from the institutional review boards and has been performed in accordance with the Declaration of Helsinki. The study received approval from the ethics committee for clinical trials of the provinces of Verona and Rovigo (approval no 3670CESC), Italy and Città della Salute e della Scienza di Torino (approval n
Participants were asked to perform different tasks, with a self-selected rest between them. They were instructed on how to perform the task before data collection started. Moreover, they were free to quit the experiments whenever they wanted. Table 1 reports the tasks performed in this study. Task 1 consisted of the timed-up-and-go test, which requires the user to stand up from a chair, walk back and forth for 10 meters, and sit in the same chair. In task 2, the subject was asked to keep a static upright position for one minute. Tasks 3 to 6 consist of a 10-meter walking back and forth task with or without dual-task and/or obstacles. Specifically, task 3 represents the standard walking task. Task 4 included a passage through a doorway. In task 5, a motor dual task was included, which required patients to carry a glass full of water in their hand. Task 6 included a cognitive dual-task, in which subjects were asked to count backward from 100 to 0 while walking. Finally, task 7 involved 360-degree turns in both directions.
Tasks included in the experimental protocol.

Instrumentation
Participants were equipped with four inertial measurement units (IMU). Each IMU (Nordic Thingy 52 - NRF6936, Nordic Semiconductor) is a compact device measuring 6
The recorded data from each IMU were sent to a smartphone (Realme Pro 7), which served as a gateway for data collection. An application running on the smartphone facilitated the data collection process. Furthermore, the same smartphone application was utilized for simultaneous video recording at a sampling rate of 30 frames per second (fps) (Figure 1). The smartphone was placed in a specific, predefined location to ensure consistent data collection across all participants. This location was chosen to maximize the visibility and capture of all FoG episodes. The recorded videos were visually inspected in the subsequent data annotation process, providing visual context to the sensor data. The placement of the IMUs on the body is shown in Figure 2. Two sensors were positioned on the outer part of the lower legs, just above the ankles, while another sensor was placed on the lower back at the level of L3-L5 vertebrae.
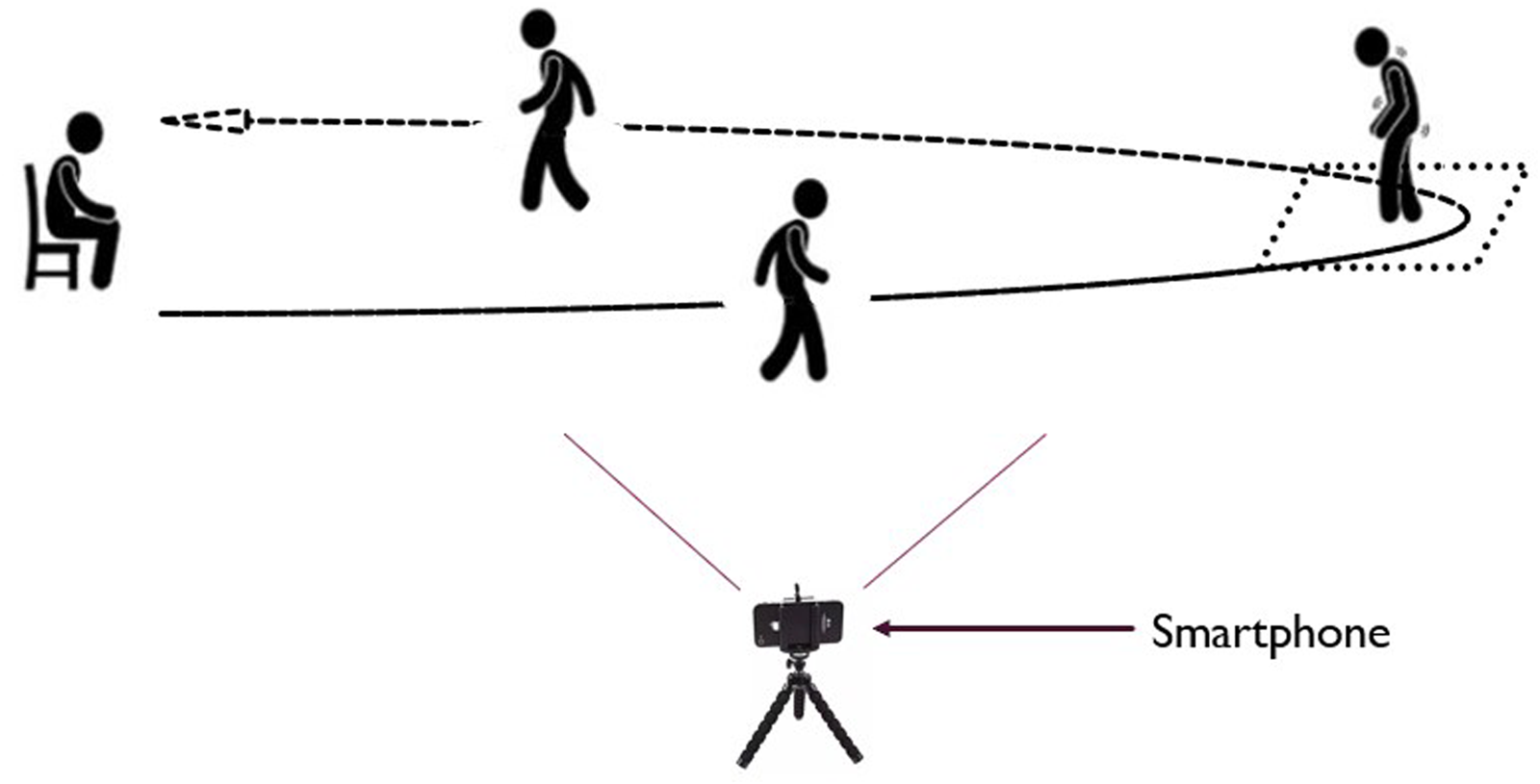
Data recording settings.
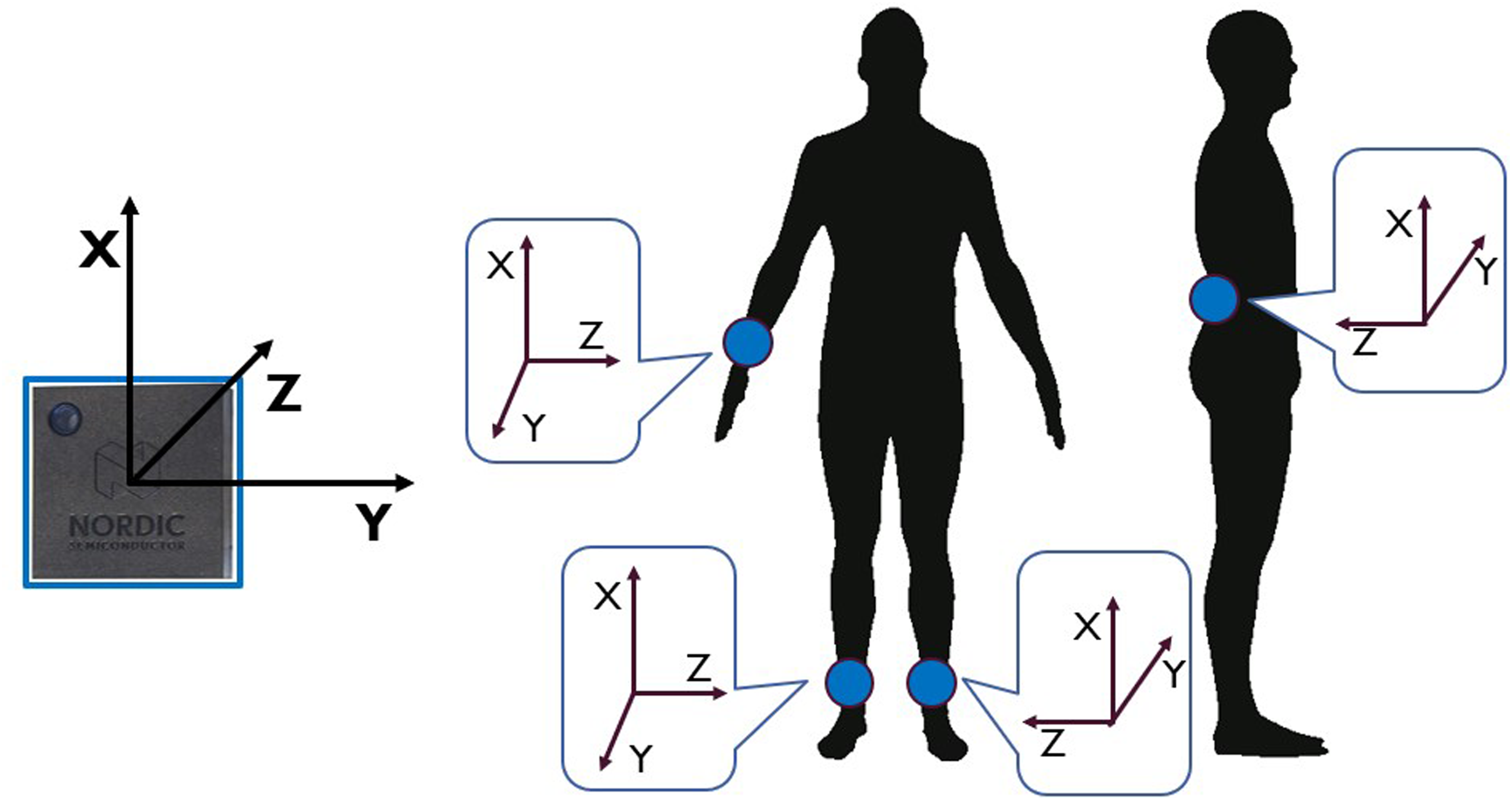
Sensor position and orientation.
The remaining sensor was positioned on the wrist of the most affected side. This sensor setup allowed for capturing detailed motion data from specific body parts and synchronize it with video footage, enhancing the accuracy and context of the collected sensor data for further analysis. To assess participants’ satisfaction with the system, the Quebec user evaluation of satisfaction with assistive technology (QUEST) questionnaire was administered to participants. 41 Specifically, a score between zero and five was assigned to each item concerning the device, namely comfort, weight, durability, adjustments, simplicity of use, dimensions, effectiveness, and safety.
Clinical rating of FoG
Two neurologists (CAA, RAB) experts in PD and movement disorders independently annotated activities and FoG episodes based on an accurate visual inspection of video recordings, according to a predefined, standardized assessment protocol. The definition of FoG (i.e., inability to produce effective steps) and types of FoG (i.e., start hesitation, turn hesitation, FoG during turning, hesitation in tight quarters, destination-hesitation or open space hesitation) were selected according to the literature.42,43 The evaluators identified the exact start of the FoG episode as the frame corresponding to the end of the last effective step preceding FoG; the end of the FoG episode was identified as the frame corresponding to the first effective step after FoG. The severity of FoG episodes was assigned with a score from 1 to 3, according to the following evaluation: 1: shuffling forward with small steps, 2: trembling in place with alternating rapid knee movements, 3: complete akinesia without limbs or trunk movement. If multiple manifestations were observed within the same FoG episode, the severity score was assigned based on the most severe manifestation. 44
Video recordings were resampled to 10 fps to ease the annotation process and save time, by using a reduced number of frames. It is worth noting that the sampling frequency was selected to ensure a time resolution of 100 ms in activity and FoG identification. The Python video–annotator software 45 was used for annotating activities, FoG episodes, and FoG severity for each episode. The resulting labeled data were exported in CSV format and subsequently analyzed. In case of discrepancies in the identification of start, end, or duration of FoG episodes, the two raters were asked to meet and solve inconsistencies, providing a final unique label for that specific episode. Specifically, the discrepancy was identified in the following cases: (a) one rater marked a FoG episode while the other did not (b) there was less than 80% overlap between the episodes identified by the two raters, or (c) a difference of more than 0.5 s in the FoG onset was identified between the two raters. In the remaining cases (i.e., episodes with high inter-rater agreement), the final FoG label in terms of FoG onset and end was calculated as the average of the indications (onset, end) of the two raters. The inter-rater agreement was calculated using the following metrics: (a) intra-class correlation coefficient (ICC) calculated on the number of episodes manifested by each subject; (b) ICC on the percent time spent with FoG (%TF) computed from each subject. In addition, agreement at recording level was detailed for each of the discrepancies.
Data processing
Two approaches were implemented for FoG detection, consisting in a feature-driven ML processing pipeline and a more advanced data-driven DL algorithm. The two methods differ for the pre-processing procedures and the classification model. In the former case, feature extraction, feature selection, and data augmentation are carried to prepare data for input to the ML model. In the latter case, the DL algorithm automatically extracts and selects the most significant features, and performs classification in an end-to-end fashion. For both approaches, data were pre-processed as in Figure 3.
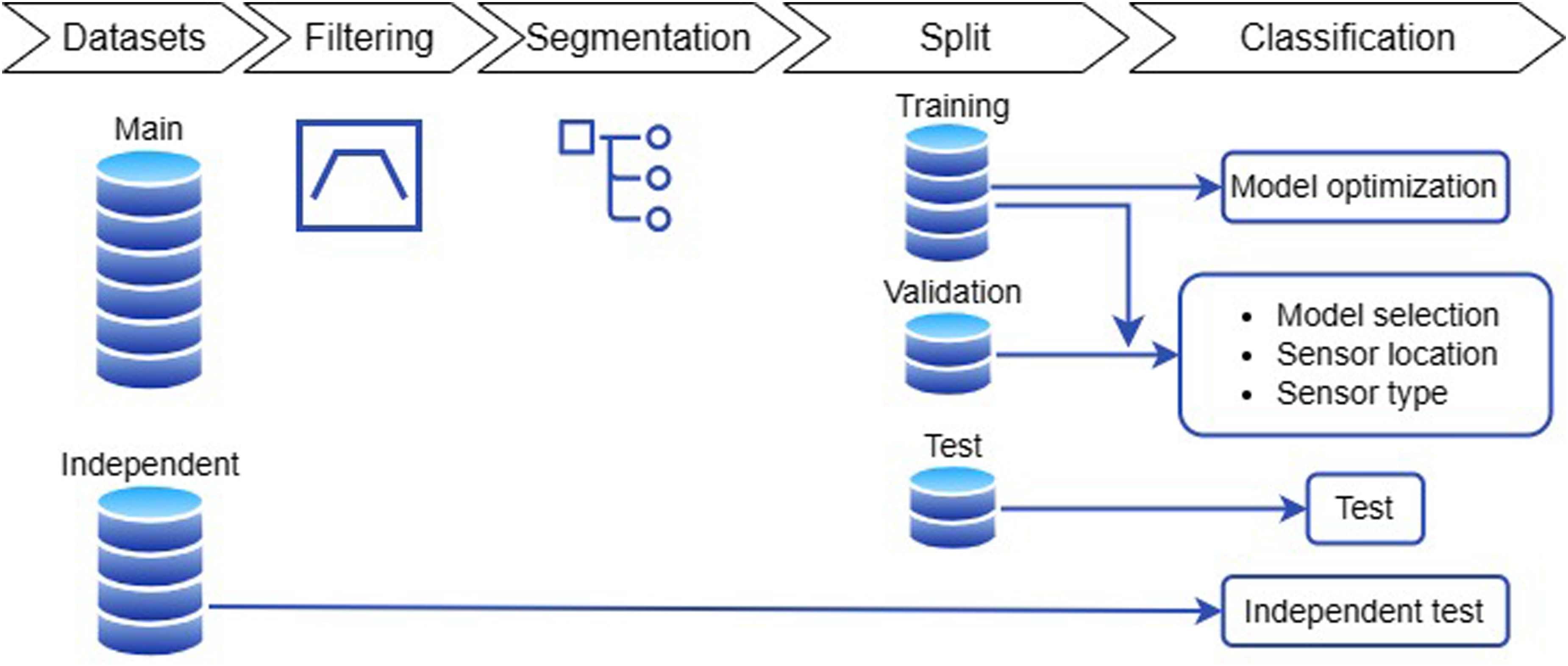
Schematic of the data processing steps.
Data were filtered using a forth-order zero-lag Butterworth band-pass filter with cut-off frequencies of 0.5 Hz and 20 Hz. This allows for removal of gravity and low-frequency trends, and discards high frequency noise. The filtered data were segmented using 2 s-long windows with 75% overlap (0.5 s slide), resulting in a total of 11,280 sliding windows (observations). The window length was selected following previous studies,35,46 while the large overlap (small slide) has the advantage of providing high temporal resolution in FoG recognition. In addition, isolated windows, i.e., windows classified as FoG/non-FoG while adjacent windows were classified as non-FoG/FoG can be safely discarded (i.e., by using moving mean or majority voting). This is better explained in Figure 4, where a FoG window completely overlaps (grey area) with two adjacent non-FoG windows. This is likely to represent a false positive.
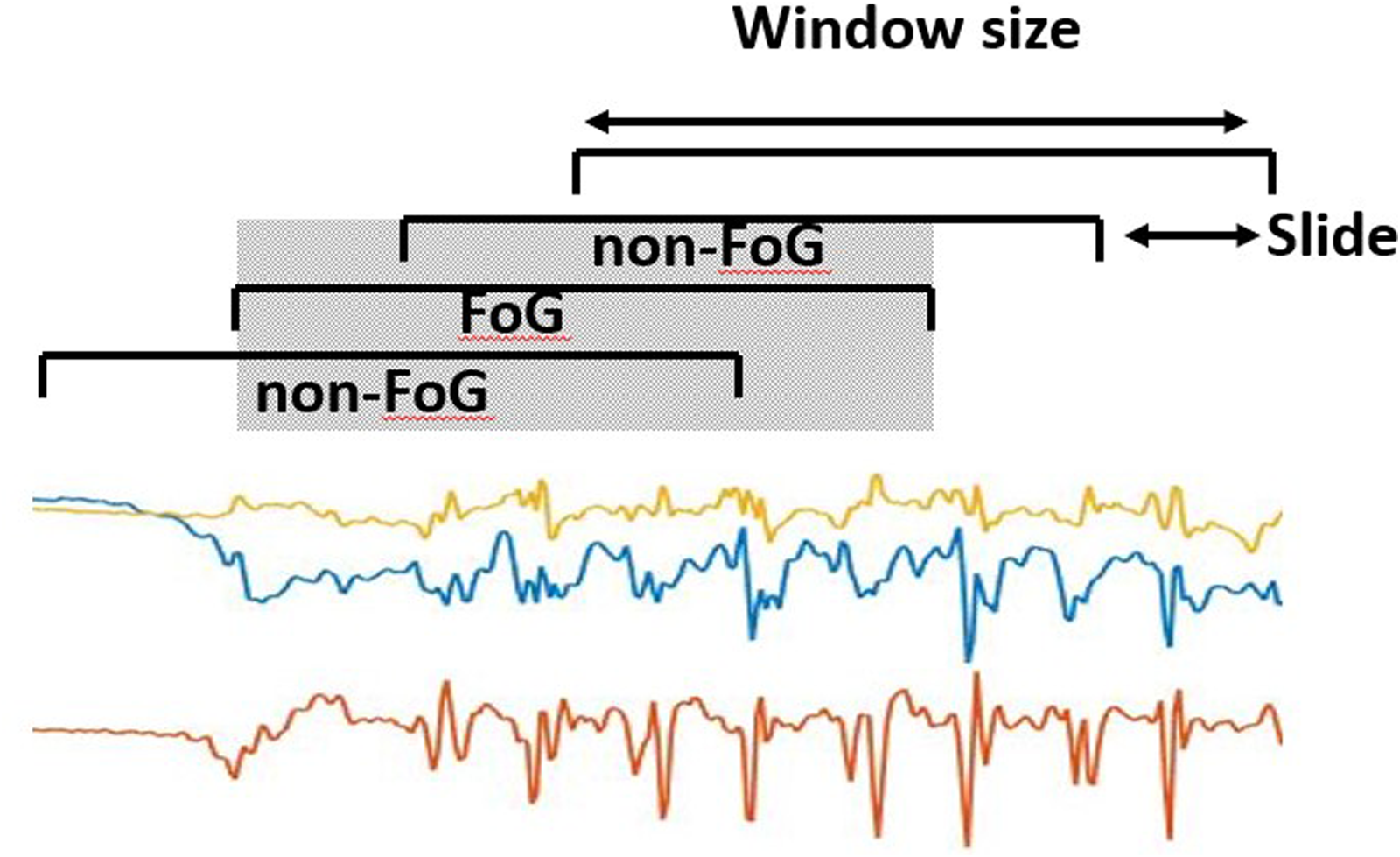
Data segmentation process, consisting in dividing the original signal into 2 s-long windows sliding with 0.5 s advance.
The mean value was removed from each component of each window separately. The generated dataset was split into a training, validation, and test sets, with a proportion of 0.5 (11 subjects), 0.25 (5 subjects) and 0.25 (6 subjects), respectively. Additionally, each subset included at least one non-freezer participant (e.g., 4 in training, 1 in validation and 1 in test). The division was performed by matching subjects in the three sets by age, H&Y, total MDS-UPDRS part-III score, and FoG Questionnaire. Models were trained and optimized on the training set, while performance was evaluated on the validation set. Specifically, the selection of the classification model and its parameters, the sensor location, and sensor type was based on the validation set (Figure 3). The best configuration (i.e., that providing the best performance) was saved and used for testing on the test set, which included new subjects who were not previously assessed. Finally, the model was further tested on two external datasets that included data collected from different subjects in different conditions. This allows us to assess possible over-fitting and obtain a real estimate of the model performance and generalization capability.
Feature-driven approach
Figure 5 schematically reports the feature-driven processing pipeline. A set of features was extracted from the segmented data.
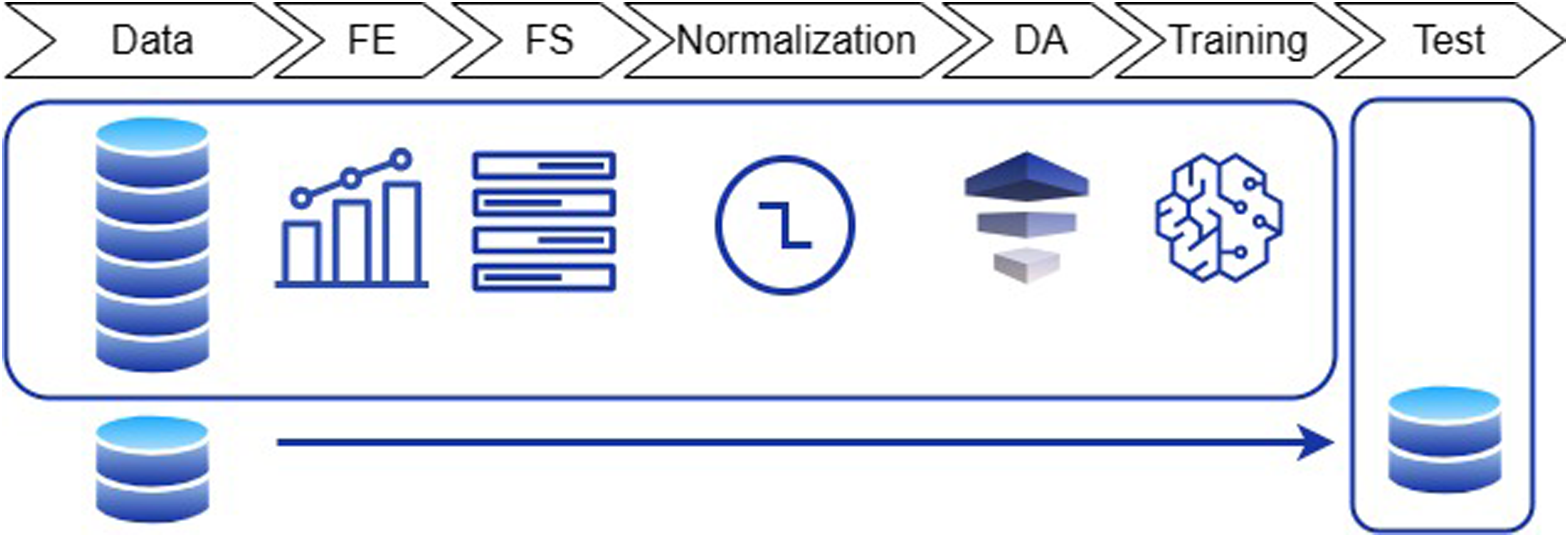
Overview of the feature-driven processing pipeline. FE: feature extraction; FS: feature selection; DA: data augmentation.
All the pre-processing steps described below were based on the training set and applied to the other sets, thus ensuring independent sets. This is particularly important, as the feature selection, normalization, and data augmentation can generate biased results if carried on the entire dataset prior to the training-test split. Each individual processing step is described in the following.
List of extracted features. Features were extracted from each component (x,y,z) of each sensor (accelerometer, gyroscope) at each body position (ankles, back, wrist).
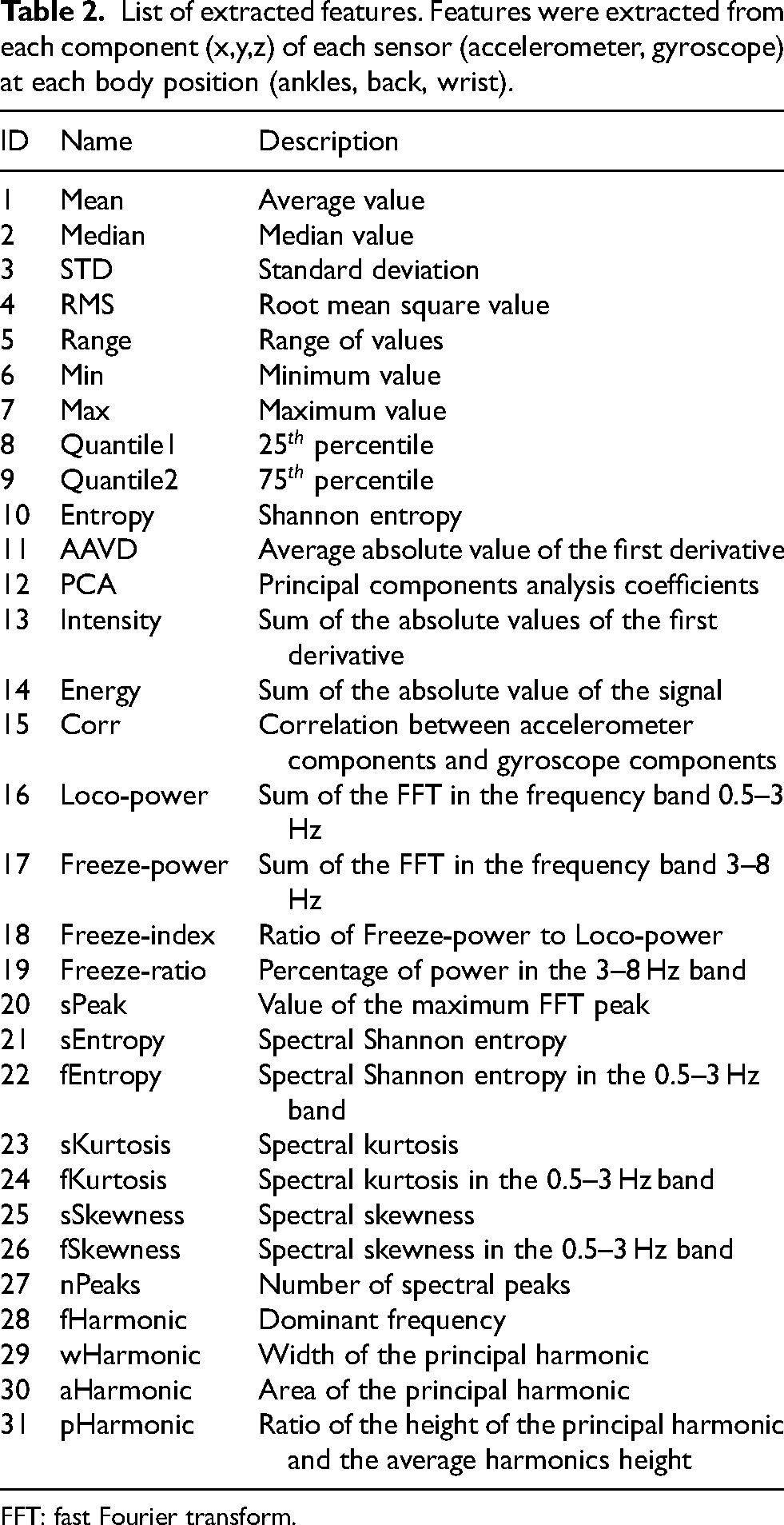
FFT: fast Fourier transform.
For each sensor, a total number of 15 time-domain features were extracted from the preprocessed signals and 16 frequency-domain features were calculated from the fast Fourier transform (FFT). Features were extracted from each signal component (

Data-driven approach
The segmented data were input to a CNN. This was selected as data-driven model due to its capability of learning high-level features from large data sets while simplifying the training process and speeding up the computation during inference.22,49
The implemented model architecture is schematically represented in Figure 6. The CNN has two consecutive convolutional layers followed by a max-pooling layer. A third convolutional block is followed by a max-pooling layer, while the last convolutional layer is connected to a global average pooling layer. The latter is fully-connected to a dense layer, followed by the single output neuron.
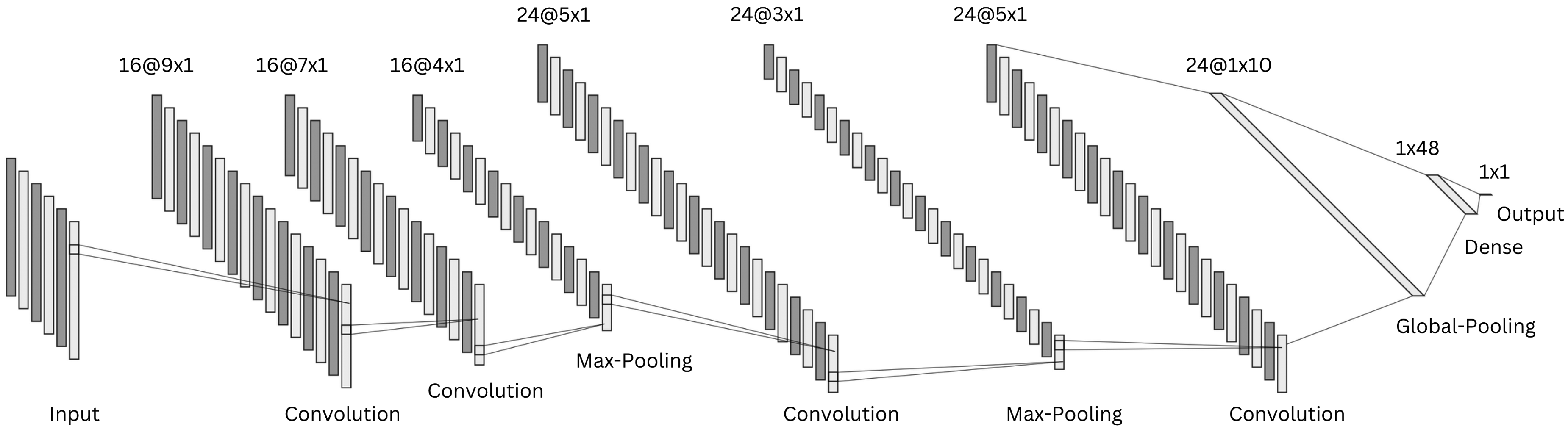
Schematic representation of the implemented one-dimensional convolutional neural network architecture.
Rectified linear unit activation function was used in all layers except for the output, where a sigmoid activation function determines the class probability. Dropout rate of 0.4 and L2 regularization of 0.001 were used in all layers to prevent over-fitting.
The model was trained using a batch size of 64, maximum number of iterations of 120, binary cross-entropy loss-function, and area under the receiver operating characteristic (AUROC) curve metric. Model weights were optimized with the adaptive moment estimation with weight decay algorithm, with an initial learning rate of 8
External datasets
Two publicly available datasets29,31 were selected due to the common sensor locations employed in the present study. In O’Day et al.,
29
seven subjects with PD (four men and three women) were enrolled, with an average age of 58.4
In Guo et al.,
31
twelve subjects with PD (six men and six women) were enrolled, with an average age of 69.1
Data from the two external datasets were uniformed to that of the present study. Specifically, data were resampled to 60 Hz, and axes orientation and unit of measurement were adjusted to match the system configuration of this study. Data underwent the same pre-processing (i.e., filtering and segmentation) of the main dataset. The datasets were employed as independent test sets, meaning that their data were not included in the training or validation procedure. This allows one to get a real estimate of model performance when tested on data from new unseen subjects, collected using a different wearable sensor and under different experimental procedures.
Performance evaluation
The performance of ML and DL methods was evaluated and compared. Moreover, the effect of the sensor location, sensor type, tasks, and activities was evaluated. Sensitivity (equation (2)), specificity (equation (3)), precision (equation (4)), accuracy (equation (5)), and F–score (equation (6)) were computed as follows: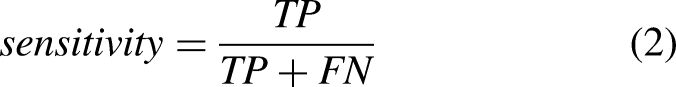
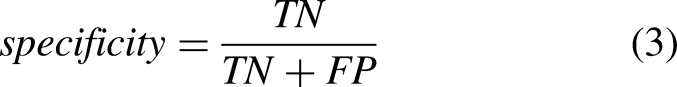
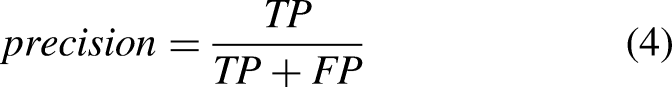
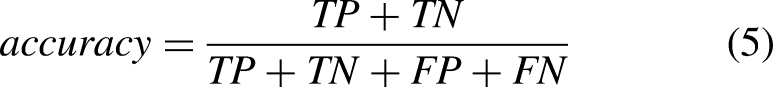
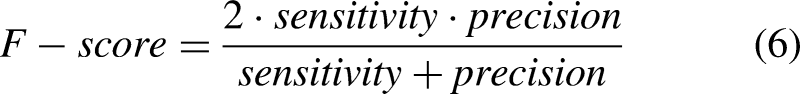
Statistical tests were conducted to identify significant differences in the performance of different models (e.g., models trained with data from different sensors or combinations of sensors). To this end, ROC metrics (true positive rate and false positive rate) were calculated for each model using fixed threshold values (i.e., from 0 to 1 with 0.01 increments). The Mann-Whitney U-test was used to compare any differences in performance, with a statistical significance level of 0.05.
In addition to the window-level performance evaluation described above, episode-based performance was computed as follows. Starting from the model outputs, consecutive windows classified as FoG were aggregated to form a FoG episode. The overlap between real and detected FoG episodes was used to compute the following metrics. Real FoG episodes in which no windows were classified as FoG were considered missed/false negatives (Figure 7). On the other hand, FoG episodes detected by the model but not corresponding to real FoG were considered false episodes/false positives (Figure 8). The number of detected episodes (Figure 9) was computed. In this case, the detection delay was computed as the temporal difference (A) between the FoG onset and the beginning of the detected FoG ( i.e., end of the first window classified as FoG). The proportion of FoG episodes correponds to the proportion of detected/real FoG episodes (C/B). Finally, predicted FoG episodes (Figure 10) were identified as real episodes that were predicted before their actual occurrence. In this case, the prediction horizon was computed as the temporal distance (A) between the beginning of the detected FoG (corresponding to the end of the first window predicted as FoG) and the beginning of the real FoG episode (as identified by the clinical raters). Again, the proportion of FoG episodes detected can be calculated as C/B.
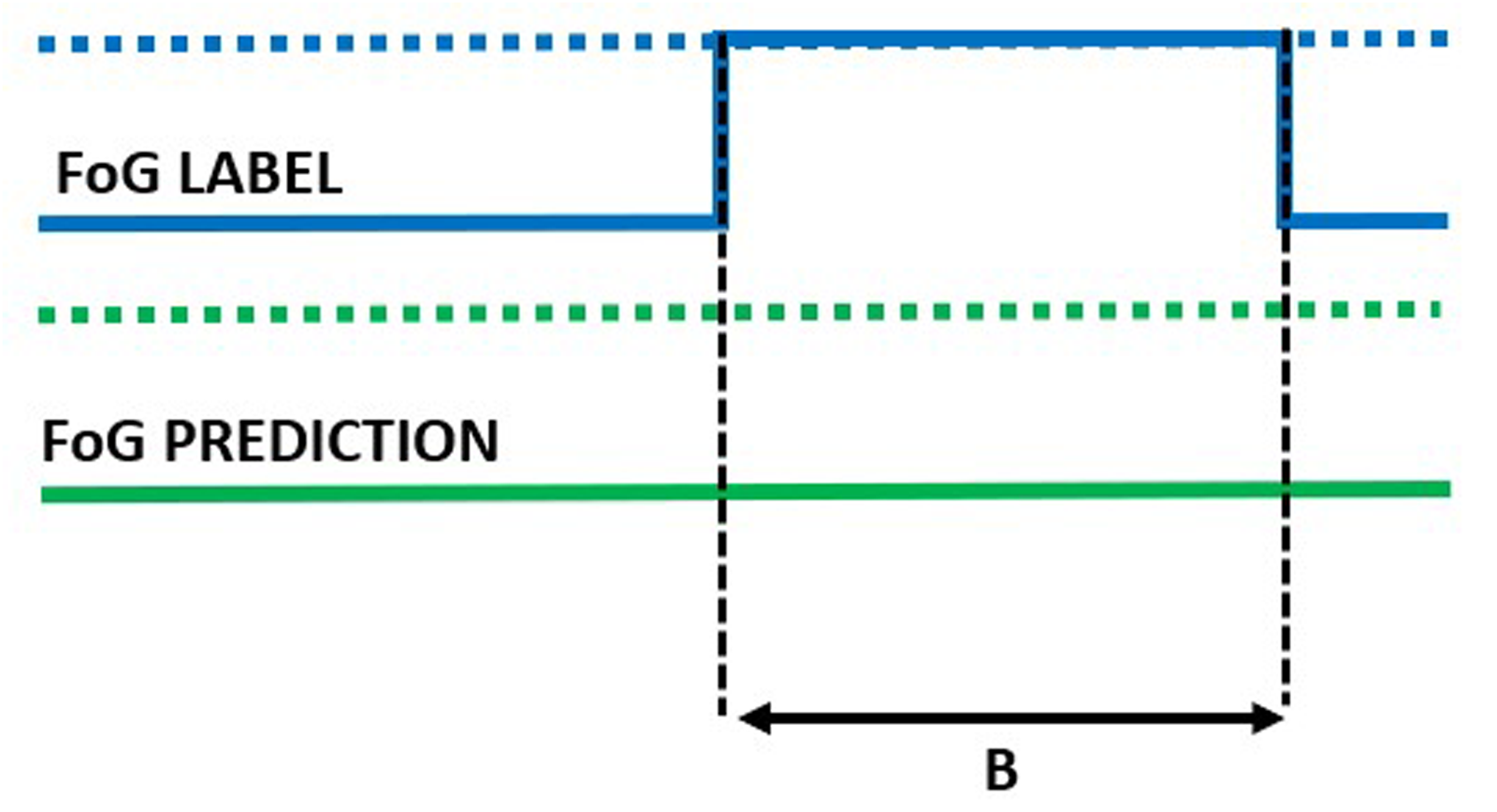
Missed episode of duration B.
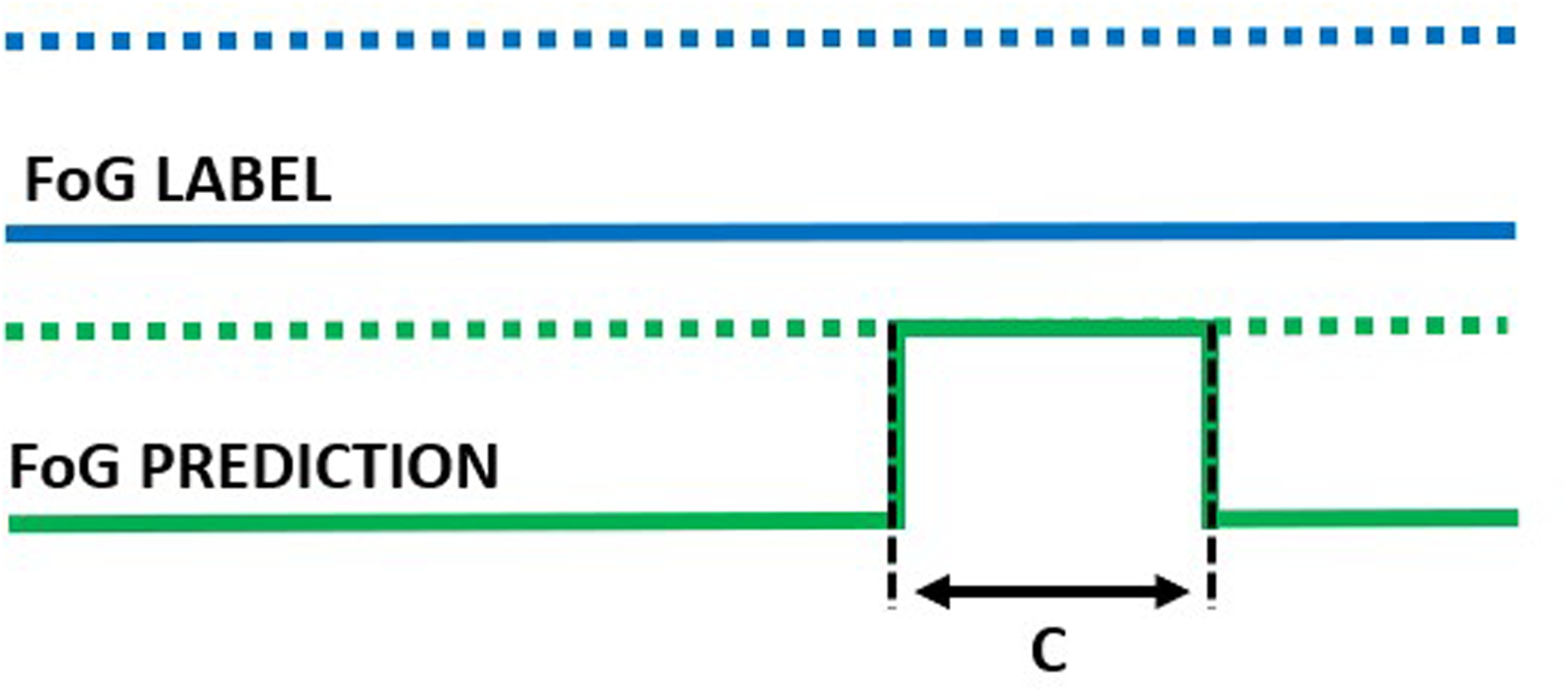
False episode of duration C.
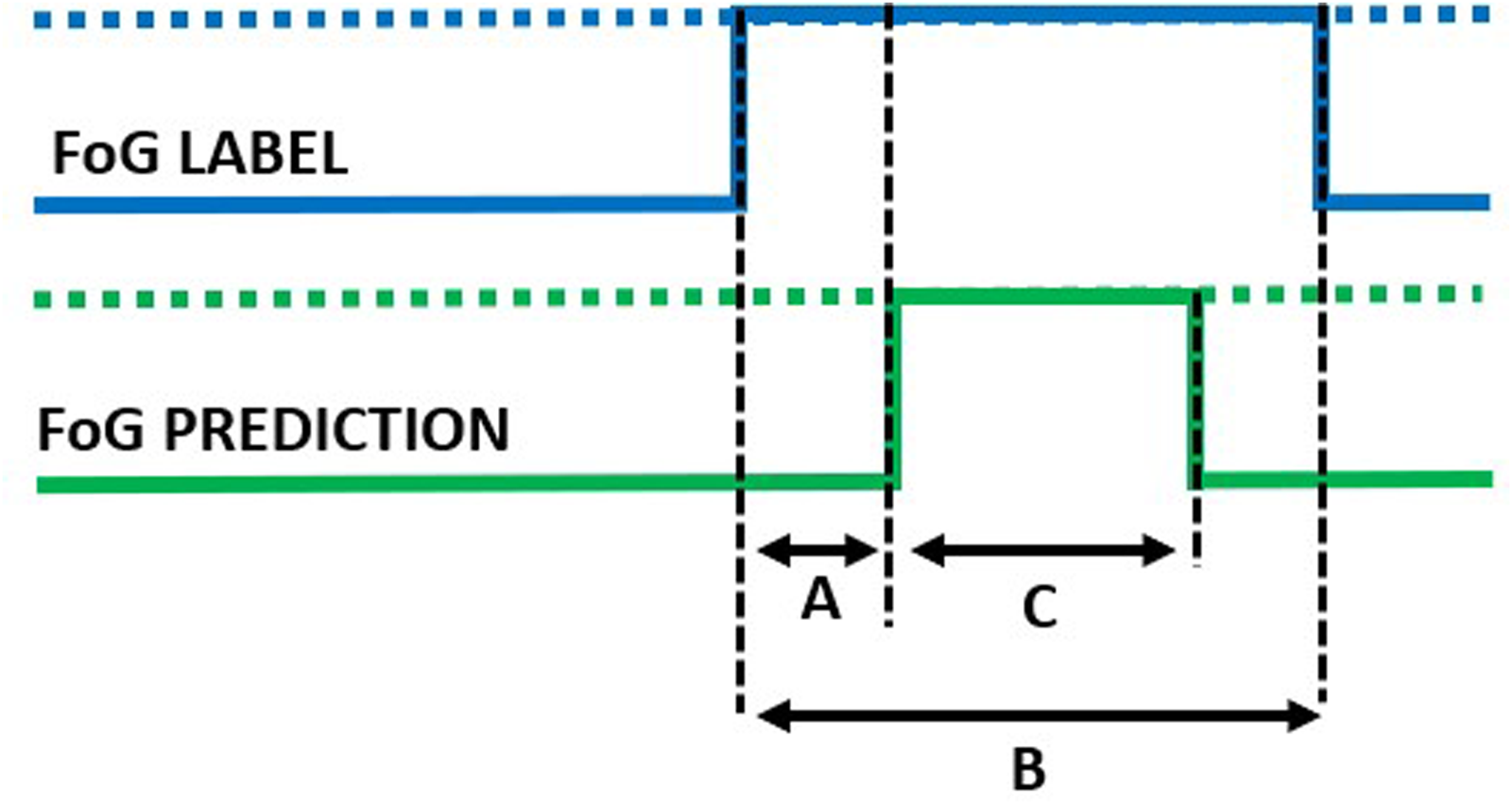
Detected episode. A: detection delay; B: true episode duration; C: detected episode duration.
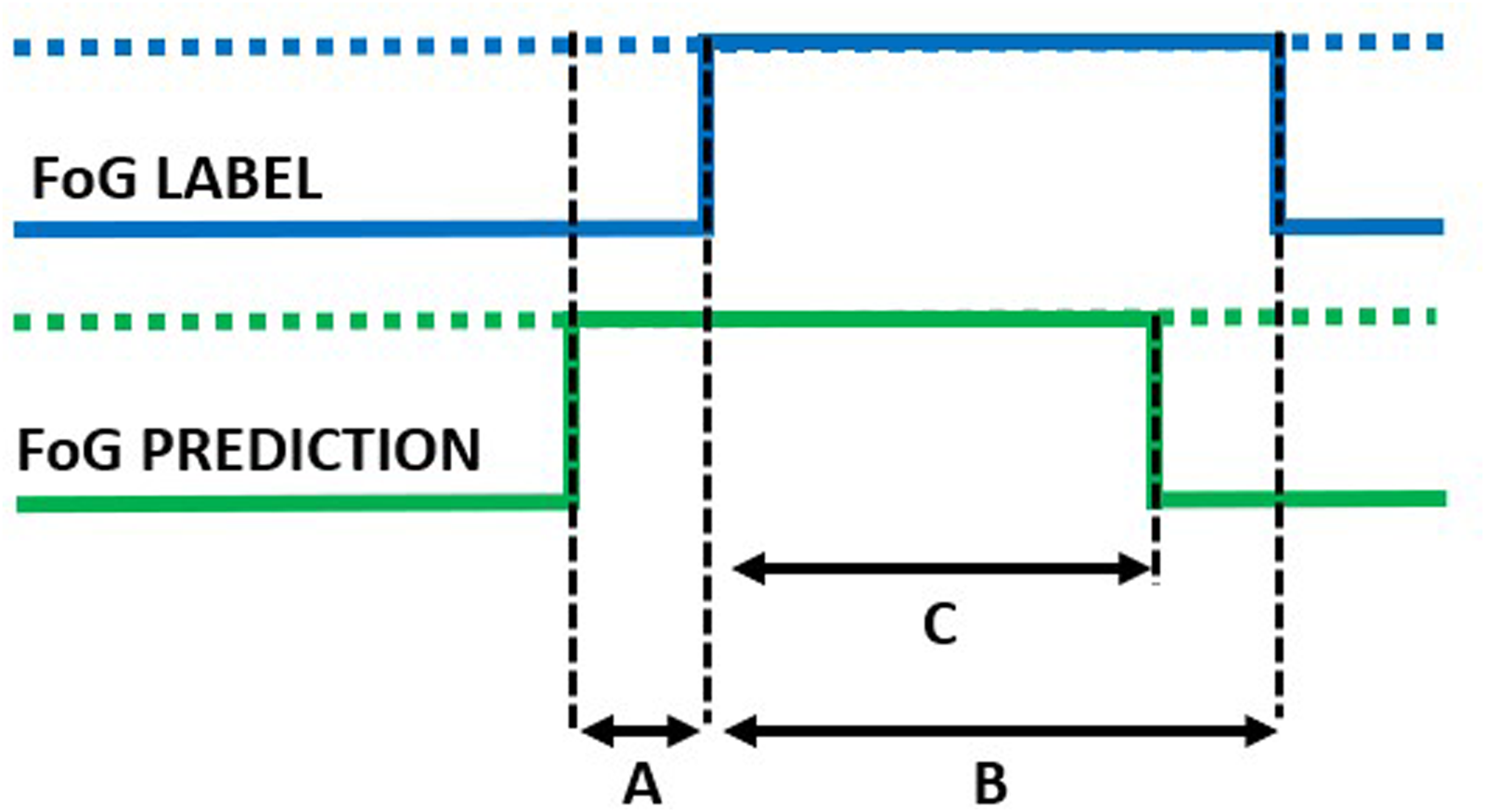
Predicted episode. A: prediction horizon; B: true episode duration; C: detected episode duration.
The experiments were performed on a computer with a 2.3 GHz processor, 16 GB RAM and 4 GB GPU. Pre- and post-processing were performed in Matlab (version R2023a), while ML and DL model training and optimization were carried out in Python (version 3.11.6), using keras (version 2.12.0) with tensorflow backend (2.12.0) and scikit-learn (version 1.2.2) packages.
Results
Demographic and clinical characteristics of the sample
Table 3 reports the demographic and clinical information of the subjects enrolled in this study.
Demographic and clinical information of patients enrolled.
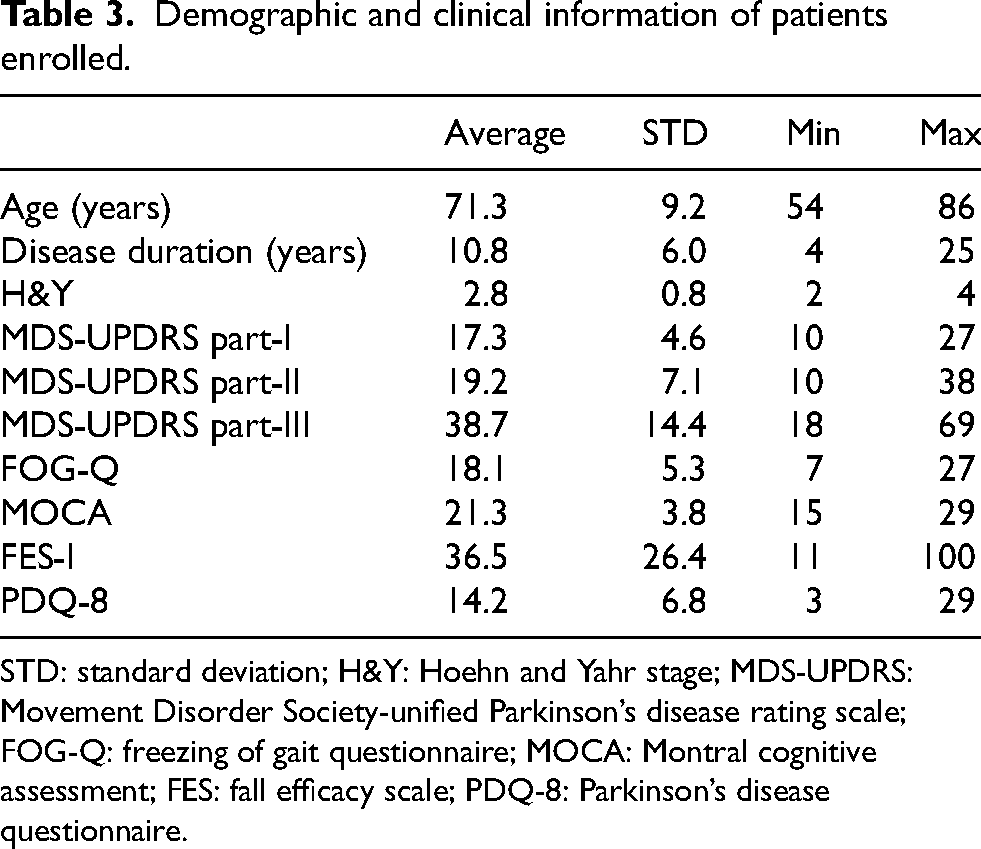
STD: standard deviation; H&Y: Hoehn and Yahr stage; MDS-UPDRS: Movement Disorder Society-unified Parkinson’s disease rating scale; FOG-Q: freezing of gait questionnaire; MOCA: Montral cognitive assessment; FES: fall efficacy scale; PDQ-8: Parkinson’s disease questionnaire.
Twenty-two participants (12 males and 10 females) were included in this study, with a mean age of 71.3
Data
Four wearable IMUs recorded three-axis acceleration and angular velocity signals from both ankles, lower back, and wrist, providing a total of 91.4 minutes of data. Figure 11 shows the total duration of each activity included in the experimental protocol. More than an hour of gait was recorded, comprising a similar duration of walking and turning. Static positions account for 18 minutes, where subjects were sit (5 minutes) or in an upright position (13 minutes). A total of 5 minutes of postural transitions (i.e., stand-to-sit and sit-to-stand) and 18 minutes of FoG were recorded.
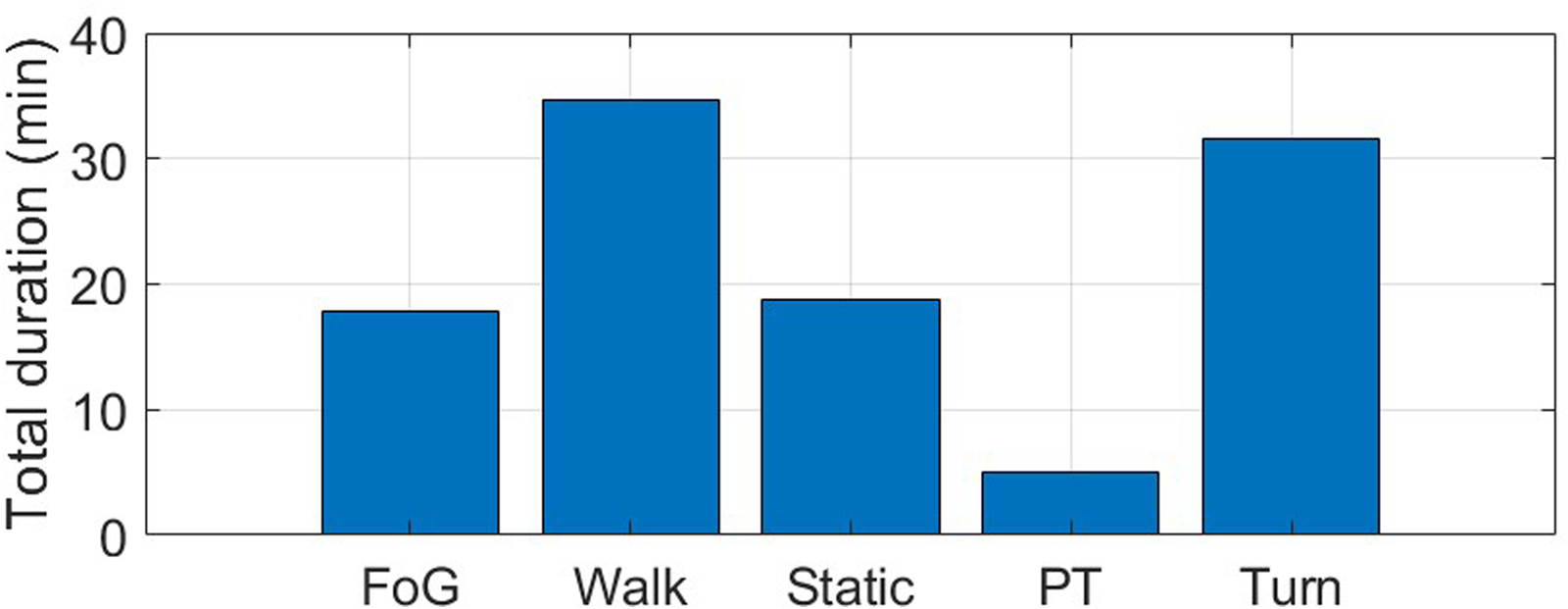
Total duration (min) of the different activities included in the experimental protocol. FoG: freezing of gait; Static: static postures, including stance and sit; PT: postural transitions, including sit-to-stand and stand-to-sit.
From the total sample of twenty-two subjects, sixteen (73%) experienced FoG during the experiments while six (27%) did not. Figure 12 reports the histogram of FoG episodes duration. A total of 101 episodes were recorded, with a mean duration of 9.2 s (median: 5.3 s, standard deviation: 16.9 s, interquartile range: 2.6 s–11.6 s, range: 0.6 s–108 s). Two episodes lasted more than 100 s, and manifested during 360-degree turn in two patients with an Hoehn & Yahr of 4. FoG severity was balanced across classes, with approximately 30% of mild FoG, and around 35% of moderate and severe FoG (Figure 13). More than 80% of FoG episodes manifested during turning, with only 10% of start hesitations and 10% of FoG during straight-line walking.
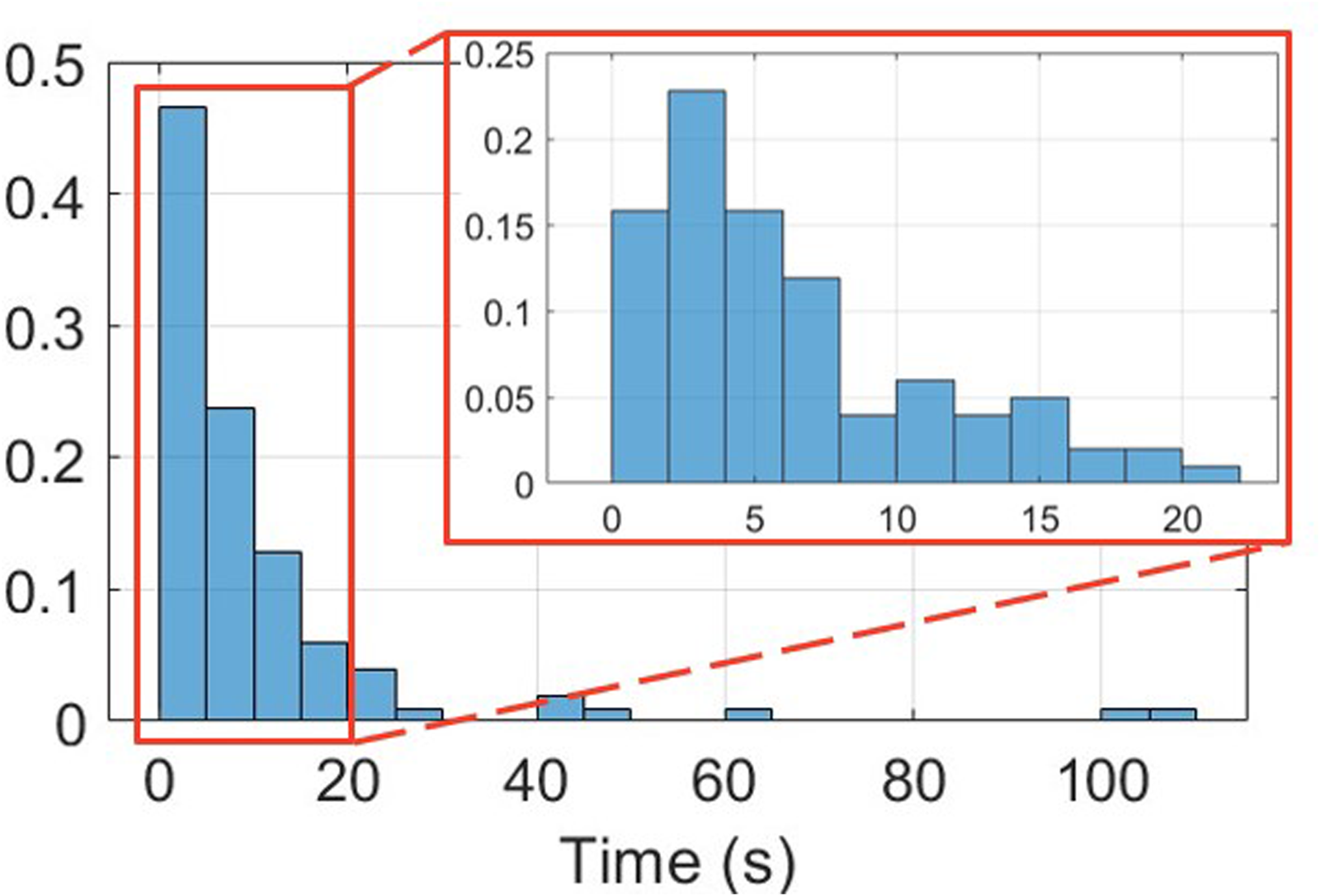
Normalized histogram of FoG episodes duration.
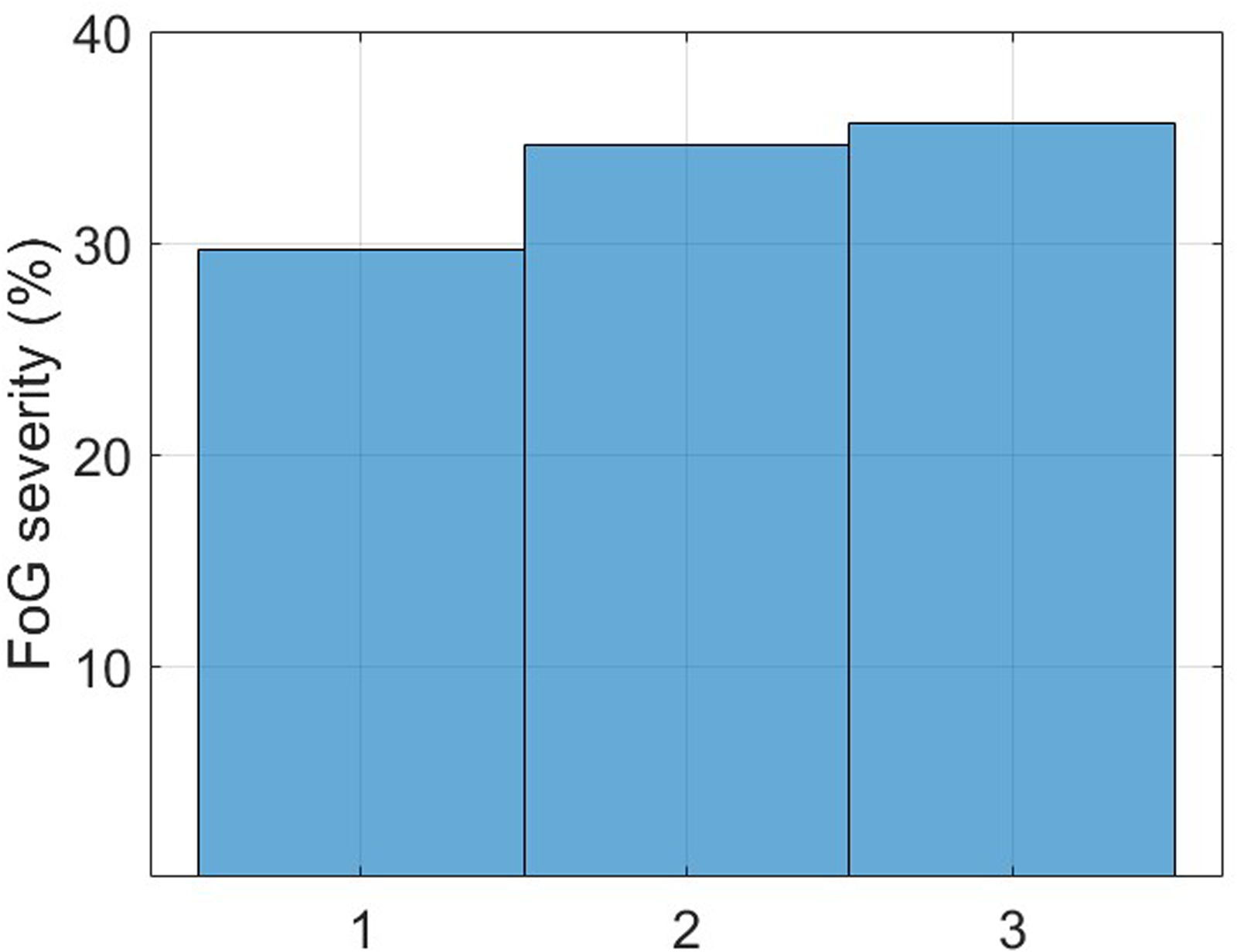
FoG episodes severity (1: shuffling forward with small steps, 2: trembling in place with alternating rapid knee movements, 3: complete akinesia without limbs or trunk movement).
Rater agreement
Raters 1 and 2 identified 125 and 99 episodes of FoG, respectively. After resolving the inconsistencies, they finally agreed in identifying 101 episodes. The ICC between the two raters was 0.80 for the number of FoG episodes and 0.88 for %TF, which show good-to-strong agreement between raters.50,51 Interestingly, rater agreement varied across tasks, with strong agreement on the %TF during gait tasks (ICC = 0.80–0.92) and significantly lower agreement in the 360-degree task (ICC = 0.49). From the total number of video-recordings (
It is worth noting that in some cases, especially during turning, two different episodes of FoG occurred with a very short free interval and without a clear resume of the standard velocity and stride amplitude of patient’s gait. After having verified these particular conditions, clinical raters agreed to consider these episodes as a unique episode of FoG as this was considered the best choice from the clinical and algorithm training standpoints.
FoG detection performance
From the total number of participants, eleven were used for training and optimizing the ML models, five for validation, and six for test. This approach ensured subject independence across sets, providing more realistic estimates of model performance on unseen data. The training and validation sets did not significantly differ for age (70.8
Table 4 reports the classification results of the feature-driven (i.e., extracted features input to a random forest algorithm) and data-driven (raw data input to a CNN) approaches on the validation set. The results are expressed in terms of mean and standard deviation over five iterations, to account for the effects of random weight and bias initialization across network layers. It is noteworthy that the metrics (e.g., mean and standard deviation) were calculated using the same data distribution for training, validation, and test. Data from all sensors were used at this stage. The data-driven DL model outperformed the feature-driven ML algorithm in all classification metrics. Overall, the DL approach provided an increase of 25.3% in F-score and 29.9% in AUROC. This demonstrates the superior performance of the data-driven approach, which automatically extracts and selects salient features capable of accurately detect FoG. It is worth noting that, despite very good performance in terms of sensitivity, specificity and AUROC, the low F-score indicates the difficulty in discarding false positives.
Classification results on the validation set.
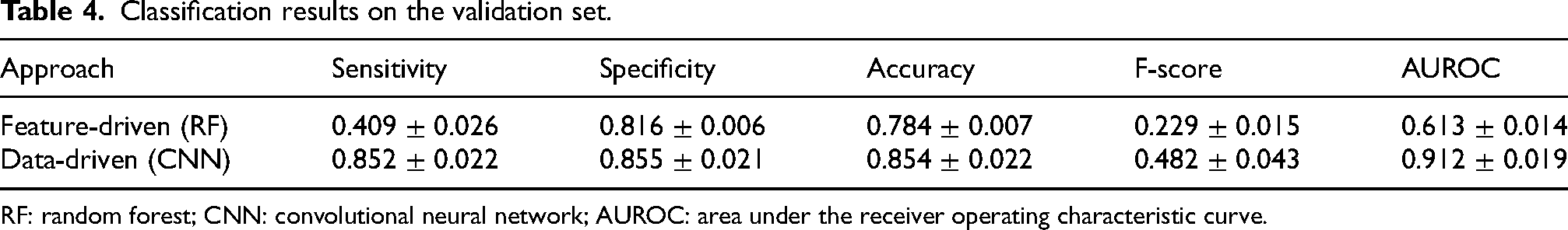
RF: random forest; CNN: convolutional neural network; AUROC: area under the receiver operating characteristic curve.
The effect of sensor location
Table 5 reports the classification performance of the data-driven algorithm for different sensor locations. At this stage, both acceleration and angular velocity signals were used for the analysis. Individually, sensors on the ankles were the best-performing, followed by the sensors on the lower back and the wrist. Further combining the sensors on both ankles, ankle and lower back, or ankle and wrist did not provide incremental performance, compared to the left-ankle only. The combination of all sensors provided the best results, with a slight improvement over the left-ankle sensor only. However, this performance improvement was not statistically significant (
Classification results on the validation set based on sensor location.
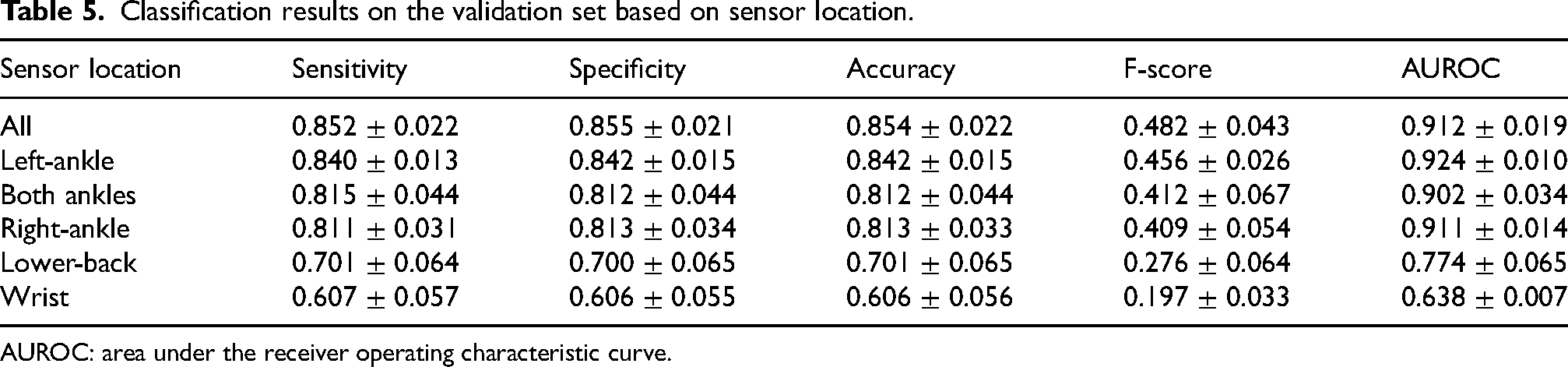
AUROC: area under the receiver operating characteristic curve.
The effect of sensor type
Table 6 reports the classification performance of the DL model based on different sensor types. The results refer to the sensor on the left ankle. The gyroscope sensor provided significantly better results (
Classification results on the validation set based on sensor type.

AUROC: area under the receiver operating characteristic curve.
Distinguishing FoG from various activities
Table 7 reports the classification performance in discriminating FoG from different activities. FoG can be easily distinguished from walking (AUROC 0.97), postural transitions (AUROC 0.95) and static positions (AUROC 0.93). On the other hand, discriminating FoG from turning represents a more complex task, proved by a net decrease in F-score and AUROC. The higher F-score observed when discriminating between FoG and postural transitions may be due to the fact that transitions are less represented than walk and static postures (see Figure 11). The proportion of negative instances and thus of possible false positives is reduced in this case.
Classification results on the validation set based on different activities.

Transition: sit-to-stand, stand-to-sit; Static: stand, sit; AUROC: area under the receiver operating characteristic curve.
Classification results on the test set
Validation and test sets did not significantly differ for age (68.2
Classification results on the validation and test sets. Results refer to the gyroscope sensor positioned on the left ankle.

AUROC: area under the receiver operating characteristic curve.
Overall, 25% of episodes were predicted on average 2 s in advance from FoG onset, 25% were detected at onset, 37.5% were recognized with an average delay of 1 s, and 12.5% were not detected.
As far as concerns false FoG episodes, 65.3% of the recognized episodes were false positives. However, 23.4% of them represented isolated single-window episodes with adjacent non-FoG windows. The remaining false FoG episodes had a mean duration of 2.7 s, which is far lower than the mean duration of real FoG episodes (9.2 s). False FoG episodes mostly manifested during stance (46%) and turning (36%), while a small percentage occurred during straight walking (4%) and postural transitions (4%). This confirm the results reported in the previous section, i.e., very good capability in discriminating FoG from walk and postural transitions, and more difficulty in distinguishing FoG from turns and static upright positions. Specifically, false FoG episodes that manifested during static positions were shorter (2 s on average) than those occurring during turning (5.8 s on average). These results demonstrate the challenging gait pattern during turning, that can be confused with FoG.
Classification results on the independent datasets
Table 9 compares the FoG detection performance on the test set and the two external datasets. Results refer to the gyroscope sensor on the left ankle. It is worth noting that all the sets include new subjects, who were never assessed before by the model. Thus, all of them contribute to real performance estimates in unseen data.
Classification results on the test set and independent datasets. Results refer to the gyroscope sensor positioned on the left ankle. The results refer to the performance on the entire dataset.

The sets differ for the subjects characteristics and the experimental procedures, together with a different amount of data. Specifically, the test set includes 6 subjects, with a total of 14 min of data (18% of FoG); the O’Day dataset 29 comprises 7 subjects, with a total of 89 min of data (24% FoG); the Multi-modal dataset 31 includes 12 subjects with 222 min of data (40% FoG). Moreover, the set of performed activities is different, with additional ellipses and figures of eight tasks in O’Day et al., 29 and walking through randomly placed obstacles in Guo et al. 31 Indeed, the larger proportion of turning may have affected the performance, as previously discussed. Overall, AUROC decreases by 9.9–10.7% in the external datasets. However, the F-score is consistent, with 0.7% decrease in the O’Day dataset 29 and 10.7% increase in the Multi-modal dataset. 31
In the O’Day dataset, 9.2% episodes were detected at onset, 26.2% were predicted on average 2.4 s before FoG onset, 56% were recognized with an average delay of 1.3 s, and 5% were not detected. As far as concerns false FoG episodes, 65.1% of the recognized episodes were false positives. However, 61.4% of them represented single-window episodes, which can be easily discarded. The remaining false FoG episodes had a mean duration of 1.8 s, which is far lower than the mean duration of real FoG episodes (7.8 s).
In the Multi-modal dataset, 11.6% episodes were detected at onset, 35.9% were predicted on average 2.1 s before FoG onset, 30.6% were recognized with an average delay of 2.1 s, and 12% were not detected. As far as concerns false FoG episodes, 39.6% of the recognized episodes were false positives. However, 44.8% of them represented single-window episodes, which can be easily discarded. The remaining false FoG episodes had a mean duration of 3 s, which is far lower than the mean duration of real FoG episodes (8.2 s).
It is worth noting that the F-score is generally low in all datasets, indicating a low precision value. To further investigate the relationship between sensitivity and precision, the area under the precision-recall curve was calculated, resulting in 0.669, 0.593 and 0.748 in the test set, O’Day and Multi-modal dataset, respectively. This confirms the difficulty of combining adequate sensitivity with good precision.
Figures 14 and 15 provide a visual representation of some predicted and timely detected FoG episodes, along with false positives. Data refer to the O’Day dataset. In Figure 14, two correctly detected FoG episodes are shown, along with three false positives.
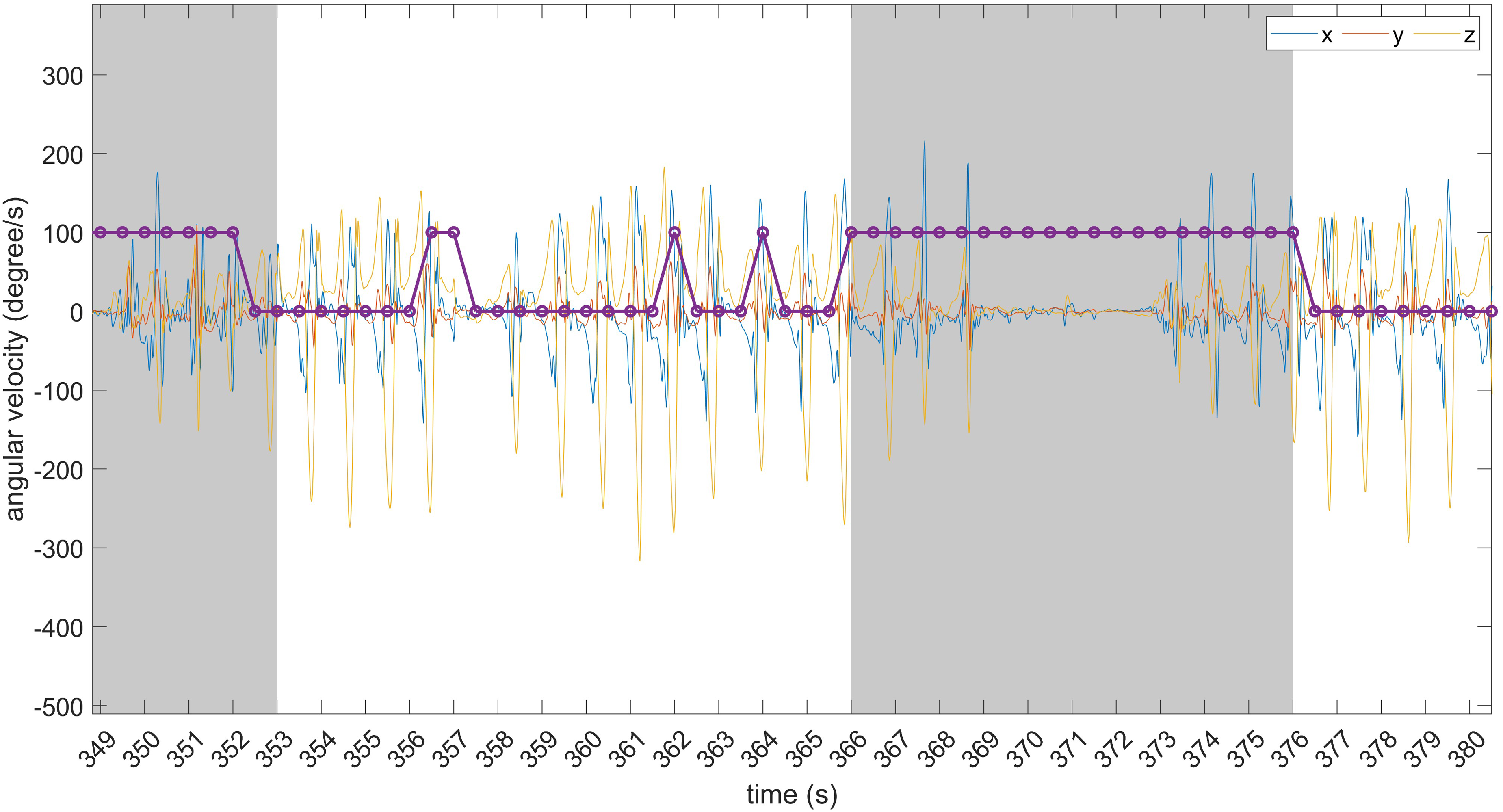
Examples of timely detected FoG episodes and false positives. The grey area identifies FoG events. From left to right: correctly detected FoG episode; false positive consisting of two consecutive windows; two isolated (single-window) false positives; timely detected FoG episode.
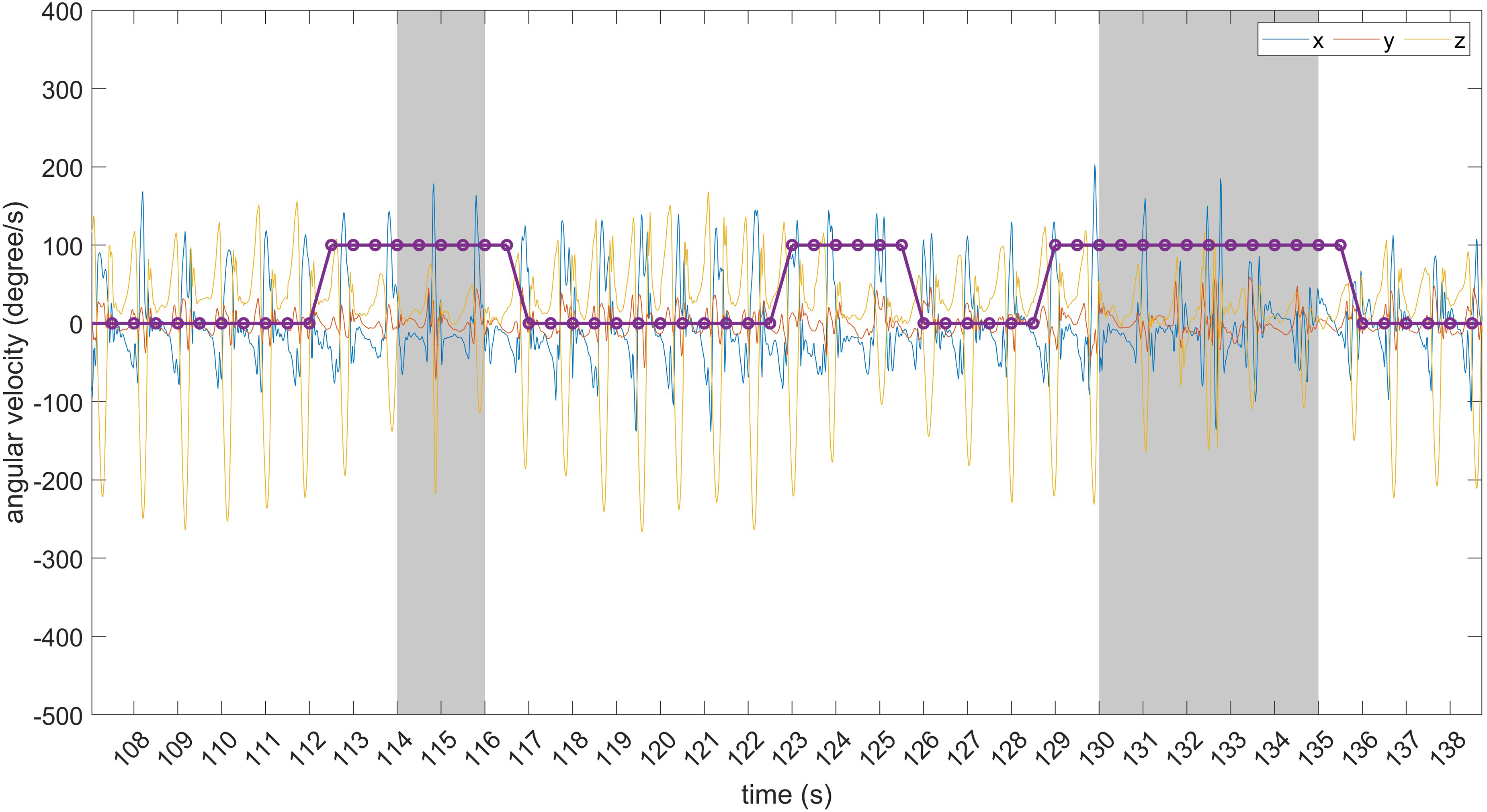
Examples of predicted FoG episodes and false positives. The grey area identifies FoG events. From left to right: predicted FoG episode; false positive consisting of six consecutive windows; predicted FoG episode.
Of these, one is made of two consecutive windows while the others are isolated (single-window) predictions. The latter can be discarded using some post-processing (e.g., majority voting over consecutive overlapped windows). Figure 15 shows two predicted FoG episodes, with different prediction horizons. As evident, FoG prediction starts before the real FoG occurrence and lasts for the entire FoG duration. On the other hand, the false positive is made of six consecutive windows and can not be discarded using post-processing techniques.
The results of the present study are in line with those of the original authors of the O’Day dataset. 29 When using a single sensor for FoG recognition, the ankle-mounted sensor performed best, with an AUROC between 0.60 and 0.80. This is in line with the AUROC of 0.81 obtained in this study. It is worth considering that O’Day et al. 29 trained and tested the model in a leave-one-subject-out validation, whereas in this work the entire dataset was used as an independent test. Regarding the Multi-modal dataset, 31 the authors reported 0.756 sensitivity and 0.741 F-score when they used three accelerometers placed on both shins and lower back. This is in line with the 0.765 sensitivity and 0.739 F-score obtained in this study. However, while Guo et al. 31 trained and tested the model in a leave-one-subject-out validation and used three sensors, in this work the entire dataset was used as an independent test and a single sensor was employed on the ankle.
Table 10 reports the classification performance on the independent datasets, calculated at subject-level and expressed in terms of mean and standard deviation across subjects. The comparison of Tables 9 and 10 highlights no evident difference in performance, in terms of sensitivity, specificity, accuracy, and AUROC. On the other hand, the F score is influenced by the different evaluation procedures. In particular, subject-level performance leads to an increase of the F-score in the test set and a decrease of the F-score in the O’Day dataset, while it shows similar values for the Multi-modal dataset.
Classification results on the test set and independent datasets. Results refer to the gyroscope sensor positioned on the left ankle. The results are expressed as the average (and standard deviation) of performance at subject-level.

Discussion
Two independent raters meticulously annotated the beginning and end of FoG episodes, reconciling any disparities in counts, durations, and onset of FoG. Additionally, the raters classified participants’ activities, encompassing static postures, postural transitions, walking, and turning. Overall, this annotation approach not only holds significance for prospective applications in automatic activity segmentation but can also contributes substantially to the understanding of FoG characteristics. To ensure a comprehensive data collection process, a multi-sensor system was deployed, comprising four IMUs equipped with 3-axis accelerometers and 3-axis gyroscopes strategically placed on the ankles, lower back, and wrist. This systematic configuration enables the examination of each sensor’s contribution, the identification of optimal sensor locations, and the formulation of sensor combinations that optimally capture FoG characteristics. Finally, participants underwent various gait tasks under triggering conditions, including motor and cognitive dual-tasks, negotiation of obstacles, and execution of 360-degree turns. The complete dataset, including the sensor data and both the final and intermediate annotations from the raters, will be made open-source in a dedicated publication, where the dataset will serve as the primary outcome and enable future research.
The data-driven DL algorithm outperformed the feature-driven ML algorithm. It is worth noting that the latter (random forest) is a well-known algorithm, which has proven robust in a large variety of tasks, including FoG detection.12,52,53 Moreover, the features extracted in this study were selected from similar works.23,54–56 Finally, the processing pipeline comprised feature selection and data augmentation, which demonstrated to improve performance.57,58 The superior performance of the DL model confirms the findings of similar recent studies, where a consistent performance improvement was registered using DL algorithms.26,27,36,59,60 Indeed, data-driven neural networks can find salient hidden patterns, and extract and select the most significant features for the specific classification task.
The combination of sensors on different positions proved to be beneficial to the final performance. However, the use of a single sensor on the ankle provides similar performance to the combination of all inertial modules, while reducing the complexity of the sensor setup. Thus, this can represent a minimally invasive solution for accurate FoG monitoring. When using a single sensor, the present results are in line with those of related studies,29,59,61 suggesting that the ankle is the best position for FoG detection. However, when using multiple body-worn sensors, O’Day et al. 29 found that the combination of sensors on the ankle and lower back provides better performance than the ankle sensor only. In Li et al., 59 the ankle-mounted sensor provided similar performance than the combination of ankle, thigh, and back. In Mesin et al. 62 the sensor on the ankle provided similar results than the combination of sensors on the ankle and back. The heterogeneity of sample, experimental procedures, and findings does not allow to identify the best single-sensor or sensor-combination setting. Furthermore, the results need to be contextualized, as classification performance depends on several factors, including the size of the dataset, the number of FoG events and the total duration of the FoG, the number and heterogeneity of subjects, the heterogeneity of the activities included, the pre-processing steps and the model selection. Interestingly, the results of the present study suggest that the performance achieved by a single sensor mounted on the ankle is dependent on the direction of turning. From the perspective of a general FoG detection system, sensors on both ankles may provide a more robust solution that is less sensitive to turning direction.
At present, only few studies have evaluated the performance of unsupervised FoG detection methods in daily life. In Mancini et al., 28 three sensors were positioned on both ankles and the lower back, continuously recording data for a week. In Salomon et al., 26 data were collected over 7 days using a single device mounted on the lower back. Finally, in Zoetewei et al., 7 two sensors placed on the shoes monitored FoG and provided on-demand feedback. Again, lower limbs and the lower back seem to be the preferred choice for continuous FoG monitoring in unsupervised settings.
The type of sensor affected the final performance. Specifically, the gyroscope performed better than the accelerometer. This is an interesting result, since some large and commonly used datasets23,32,55 do not include gyroscope recordings. It is worth noting that the results refer to the sensor on the ankle, where wide rotational movements are recorded during walking. Using a single sensor on the lower back may provide different results, as high angular velocity values can be observed only during turning.
Few studies have compared the ability to distinguish FoG from different activities, confirming that FoG can be differentiated across different medication states and FoG-provoking tasks.23,26,27,63 Consistent with these findings, our results demonstrated that walking, static postures, and postural transitions do not represent a major challenge. On the other hand, the gait patterns generated during turning impaired classification algorithms performance, in line with recent research. 27 This is an important finding and the topic for future studies, as most FoG episodes manifest during turning. 43 However, most studies grouped all activities different from FoG to form the “non-FoG” class, and few considered walking and turning activities as part of the “gait” class. This study suggests that activities should be better characterized. In particular, turning should be better represented in the experimental protocols and carefully labelled, 26 as it may significantly affect detection performance.
The results on the test set showed good generalization ability, with similar performance to the validation set. Moreover, the results at the episode level complemented those at the single-window level. In fact, a sensitivity of 82% was obtained at the window level, but 94% of episodes were recognized correctly. This shows that window-level performance does not provide a complete picture of FoG detection performance.
False positives still represent a major challenge in the development of FoG recognition algorithms. In the present study, a generally low F-score between 0.525 and 0.728 was found in the different datasets, together with an area under the precision-recall curve between 0.593 and 0.748. This demonstrates the difficulty of achieving high sensitivity and good precision. As the sensitivity increases, so does the false alarm rate, to the point where precision can be significantly impaired, compromising the ability to use the algorithm in real-world contexts. Indeed, it is necessary to reduce the number of false alarms, which can be annoying for patients when applying on-demand cueing strategies in daily life. Overall, it is clear that an acceptable compromise between sensitivity and false-positive rate must be carefully chosen. Furthermore, as the results suggest, post-processing methods can be used to discard isolated false positives. This can be done by applying majority voting on multiple overlapping windows, thus detecting FoG only when a certain number of consecutive windows are classified as FoG. On the one hand, this will improve the precision of the model. On the other hand, the sensitivity will decrease slightly, the prediction horizon will be reduced and the detection delay will increase. These considerations highlight the need for a careful evaluation of classification performance at both the window and episode level in order to provide a robust detection system that is ready to operate under real-world conditions.
For the first time, we performed a comprehensive cross-dataset test aimed at real performance estimation of the FoG recognition model. Testing the model on two external datasets resulted in generally lower performance in terms of AUROC. However, the rate of FoG episodes detected and false positives were consistent with those obtained on the main dataset. It is worth noting that the datasets differ in terms of sample, sensor setting, experimental procedures, and environment. Furthermore, the precise methods for clinical labelling of FoG episodes may differ in different datasets. Although it is not possible to control for this difference, 64 the results obtained, in line with those of the original authors, suggest a good ability to generalize to external datasets.
In view of an online, closed-loop wearable cueing system, real-time applications of the algorithm should be explored. Recent studies have shown potential for reducing FoG episodes, however, fast and lightweight algorithms are still needed for real-time implementation on resource-constrained devices such as wearables.7,65 In this context, the DL model is light (35 KB memory, 8.3 K parameters) and very fast (60 ms for classification of a single window), and little pre-processing is needed (i.e., mean-removal). Moreover, the small slide of 0.5 s ensures timely data analysis and increases the possibility for timely intervention. The results of the test set demonstrated that more than half of FoG episodes were detected at onset and even predicted few seconds before the actual occurrence. The remaining episodes were detected on average after 1 s from FoG onset, and only 12% were missed. These results put the basis for future on-device implementation of the DL model, which can timely trigger some sort of somatosensory stimuli (auditory, visual, tactile).6,66
Although this study has provided valuable insights, there are some limitations to acknowledge. Despite the number of participants included in this study is higher than most FoG datasets,29,31,32,55,67 the number of recorded FoG episodes (101 FoG episodes) is reduced compared to 211 episodes, 29 334 episodes, 31 180 episodes, 67 237 episodes, 32 and more than 1000 episodes23,26,55 registered in previous studies. This is due to the designed experimental procedures, producing a total recording time of few minutes per subject. Furthermore, of the twenty-two subjects enrolled in this study, only sixteen manifested FoG. As FoG varies widely between individuals, the design of a general detection system is challenging and limits the ability to draw definitive results and make accurate comparisons. The use of a more comprehensive dataset, such as DeFOG or transcranial direct current stimulation (tDCS), 26 could improve results by enabling the application of techniques such as transfer learning. Finally, the resampling of videos at 10 fps, while improving the clinical rating in terms of agreement and time, could have slightly affected the precision of the exact moment of start and end of FoG episodes, if compared to a video sampled at 30 or even 60 fps. In line with related works,29,31,32 subjects were assessed in the OFF condition, to increase the probability of FoG manifestation. This does not allow to assess the effect of medication on the algorithm performance. Interestingly, a recent study 27 found that models trained on a specific medication state can generalize to unseen states. This study simulated free-living situations by asking patients to perform different tasks and activities. However, free-living movements (e.g., daily activities) are much more heterogeneous than those detected during standardized tasks. Moreover, the severity of FoG during laboratory assessment does not necessarily represent that of daily life. 26 Finally, data from QUEST to evaluate patients satisfaction with the devices is of limited generalizability due to the laboratory setting and the presence of investigators who helped patients putting sensors on and off. Therefore, future work should establish the reliability of the proposed approach to data measured in free-living situations or during the execution of complex real-world activities, as demonstrated in May et al. 68
Footnotes
Acknowledgements
This work was partially supported by the European Union under the Italian National Recovery and Resilience Plan (NRRP) of NextGenerationEU, with particular reference to the partnership on “Telecommunications of the Future” (PE00000001 - program “RESTART”) and the PRIN 2022 project “WE.SMOOTH.PD” (Grant 2022EJM345); the Brain Research Foundation Verona Onlus; FSE Projects under Grant 1695-0013-1463-2019.
ORCID iDs
Funding
The author(s) received no financial support for the research, authorship and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.