
Abstract
The proliferation of paper mills and unethical practices within the scientific community poses a significant threat to research integrity. The extent of this problem across the entire industry is recognized and yet is ambiguous, making it imperative for publishers to implement scalable solutions. Metadata, XML tagging, and industry standards offer a structured approach to scrutinizing journal articles on a large scale, empowering publishers to proactively identify potential integrity issues. This article, based upon a presentation at the 2024 NISO Plus Global conference, delves into the reasons behind the challenges and proposes ideas to make integrity checks more effective for publishing operations. It also promotes the importance of finding and remediating potential abuses early in the process to prevent further problems. Using available standards in concert with information from organizations such as ORCID, Ringgold, the Research Organization Registry (ROR), Crossref, and NISO, this article highlights powerful ways by which publishers can find and address crucial red flags before publication or peer review.
Keywords
Introduction
Research Integrity is the cornerstone of scholarly advancement and one of the hottest topics in scientific publishing today. Yet, despite its critical importance, research misconduct continues to undermine this integrity, threatening the very foundation of academia. The consequences are far-reaching, impacting researchers, publishers, institutions, and society at large.
Fortunately, the scientific community has a powerful tool for combatting research misconduct: STANDARDS. Using an unconventional analogy, this paper explores some of the common attacks on research integrity while highlighting ways to use industry standards to recognize and remediate the results of misconduct.
The chosen analogy uses the 2004 Steven Spielberg film, CATCH ME IF YOU CAN. 1 Based on the true story of Frank Abagnale Jr, the film portrays a young—and brilliant—“con artist,” a term for someone who uses deception and psychological manipulation to gain the trust of others and exploit it for personal gain. The “con” in “con artist” stands for “confidence,” as their schemes rely on instilling confidence in their victims to achieve their fraudulent goals.
Only 17 years old, Abagnale is a skilled forger who also impersonates a pilot, an FBI agent, a doctor, and a lawyer throughout the course of the film. His ability to outwit systems meant to detect fraud is not unlike the challenges posed by those in the research community committing misconduct for personal gain. Just as Abagnale thrives in a world of trust and outdated processes, research fraudsters exploit gaps in workflows, overwhelming data, and misplaced assumptions to propagate their schemes.
In this paper we explore the parallels between Abagnale’s confidence scams and research misconduct, analyze the systemic vulnerabilities that enable fraud, and propose innovative solutions to enhance research integrity. The “thrill of the chase” lies not only in catching misconduct, but also in implementing proactive measures to prevent it altogether. By leveraging standards, sharing data, and fostering collaboration across the scholarly publishing ecosystem, we can shift the narrative from detection to prevention.
The con is on: Research misconduct and its impact
The first section of this paper, “The Con is ON,” highlights what fraudsters are doing, why the publishing community is falling for it, and why it matters. Mirroring the clever deceptions seen in the film, CATCH ME IF YOU CAN, the perpetrators in our research community exploit vulnerabilities in systems designed for trust.
Research misconduct has many faces
Research misconduct manifests itself in many forms, much like Abagnale’s varied guises as a doctor, lawyer, and pilot. It encompasses plagiarism, fabrication, and falsification. As described in a 2020 article by Taraneh Mousavi and Mohammad Abdollahi,
2
it extends further into nuanced practices such as: • • • • •
As fraudsters devise more and more ingenious methods to deceive publishers, editors, and reviewers, it seems that the “con” evolves daily.
The impact of research misconduct
The repercussions of these actions ripple across the scientific community, undermining trust and wasting valuable resources. A single fabricated dataset or plagiarized manuscript can misguide future research, delay crucial advancements, and tarnish reputations. A stark case highlighted in Nature describes the alarming prevalence of fake references in the “citation black market,” underscoring the systemic vulnerability. 3
Why we miss the red flags
Many in the community wonder how this can happen. Shouldn’t there be warnings or red flags to prevent these problems? Kent Anderson explains in a recent blog post that this happens despite existing red flags and warnings:
“…this paper came in the door at (journal name omitted) adorned with red flags, flashing red lights, and warning labels, yet was accepted by a journal that really had no business getting into this topic at all.” 4
Research misconduct thrives partly because of: • • • • MEDLINE PubMed production statistics.
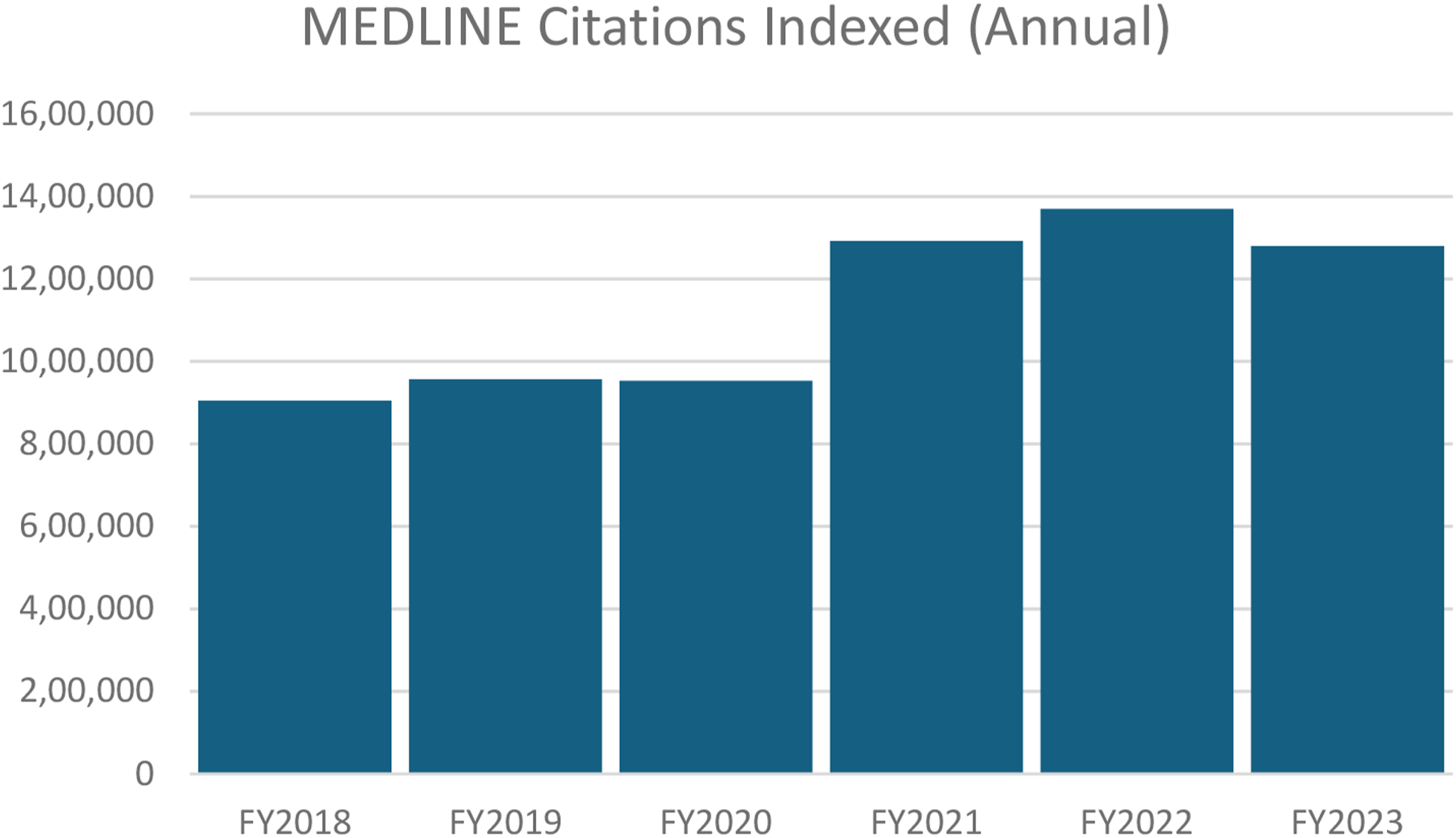
As misconduct becomes more sophisticated and pervasive, the stakes grow higher. But with heightened awareness, updated processes, and a commitment to proactive detection, the con can be curtailed. The question is not if we catch the fraudsters but when—and how much damage will have been done in the meantime.
Watching for clues: Finding the perpetrators
The next section of this paper, “Watching for Clues,” is about how publishing professionals can identify research misconduct before it escalates. Much like FBI agent Carl Hanratty’s meticulous sleuthing in CATCH ME IF YOU CAN, this requires vigilance, informed processes, and the ability to interpret early indicators.
Hanratty’s success in tracking Abagnale stems from his ability to piece together seemingly disconnected clues (Figure 2). Hanratty’s clues.
From identifying fake names like “Barry Allen” to spotting regional patterns in Abagnale’s forgeries, he continuously refines his approach. Similarly, in the realm of academic publishing, those watching for bad actors must know the Standards, the value of sharing, and the importance of starting early.
Know the standards
Understanding and implementing standards is key to identifying and addressing research misconduct. As author John MacArthur once wrote,
6
“Federal agents don’t learn to spot counterfeit money by studying the counterfeits. They study genuine bills until they master the look of the real thing. Then when they see the bogus money, they recognize it.”
In other words, knowing what the real thing is supposed to look like is critical to recognizing the fakes. We get a glimpse of this in CATCH ME IF YOU CAN when Abagnale notices a girl trying to pass a fake note at school and he explains what an authentic note is supposed to look like.
Similarly, by deeply familiarizing ourselves with standards such as XML metadata, ORCID IDs, and Crossref records, we sharpen our ability to recognize anomalies. Standards ensure uniformity and leave less room for fraudulent practices to hide. Inconsistent practices across publishers create gaps that fraudsters exploit, but shared adherence to standards such as NISO’s standard Communication of Retractions, Removals, and Expressions of Concern (CREC) 7 strengthens our ability to detect and deter misconduct. The more we know the “real thing,” the more adept we become at spotting the fakes.
The value of sharing
Beyond simply knowing the standards, additional power comes through sharing and collaboration. As highlighted in Building Our Infrastructure to Expand the Research Lifecycle, a presentation from NISO Plus 2023, “The data already exists; we just have to bring it together.”
8
When publishers, researchers, and platforms share and align data, the community becomes far more resilient against misconduct. Collaboration is not just a tool; it is a necessity… and fortunately, we have several platforms and services available to facilitate this kind of sharing such as the following:
ORCID
ORCID IDs resolve confusion between authors with similar names. You can use the name “Bill Kasdorf” within the scholarly publishing community, and everyone knows who you mean. However, if you speak of David Myers, you need clarification. For further information on ORCID’s importance for research integrity, read Summarizing ORCID Record Data to Help Maintain Integrity in Scholarly Publishing from the ORCID website. 9
Ringgold/CCC
Similar to author identifiers, Ringgold 10 (now part of the Copyright Clearance Center (CCC)) has identifiers for organizational data. Ringgold provides unique identifiers that standardize institutional affiliations, ensuring consistency and verifiability across submissions. By integrating Ringgold data into metadata workflows, publishers can prevent misrepresentation of affiliations, a common tactic in research misconduct.
Crossref
While Crossref is best known for managing DOIs, it has made several investments in research integrity. Among the most prominent is the creation of Similarity Check, a service provided by Crossref and powered by iThenticate, used by publishers worldwide to identify fraudulent papers.
Crossref recognizes that metadata—and the relationships between the various metadata—drive trust in the industry. From a 2022 blog post entitled ISR part one: What is our role in preserving the integrity of the scholarly record? The foundation of the scholarly record and Research Nexus is metadata and relationships - the richer and more comprehensive the metadata and relationships in Crossref records, the more context there is for our members and for the whole scholarly research ecosystem. This will lead to a range of benefits from better discovery and saving researchers time to the assessment of research impact
CREC
Articles retracted due to misconduct often remain cited in subsequent literature for various reasons. To combat this issue, NISO released guidelines for Communicating Retractions, Removals, and Expressions of Concern (CREC) 12 to give publishers a framework for better managing these retractions. CREC ensures that retracted articles are clearly identified and traceable across platforms, reducing the risk of misinformation and accidental citation of withdrawn work. By integrating these practices, publishers enhance transparency and safeguard the credibility of the academic record, addressing systemic gaps in how retractions are communicated.
An excellent resource on the CREC guidelines is a NISO webinar from June of 2024. 13
Looking earlier in the process
In most cases, the issue with research misconduct is not that it is not found, but that it is found too late. If we can change our processes to find it earlier, we can often prevent or at least minimize the damage of retractions, wasted time, and lost trust. A critical component of this is to create XML earlier in the publishing process.
One of the great advantages to structuring content with XML is that it creates opportunities to embed standards like ORCID IDs, funder information, and organizational data. However, because most publishers convert to XML after finalizing a manuscript, they can be delayed in their efforts to use these standards for research integrity measures.
Instead, it can be a useful thing to collaborate with a vendor or a platform provider to introduce XML up front, which enables red-flag detection before peer review. As shown in one of the presentation slides (Figure 3), this XML doesn’t have to be perfect or final, but can often be good enough to provide a start.
14
Upfront XML.
The thrill of the chase: Getting started
The next section of this paper focuses on how publishers can get started and shares exciting examples of what some are already doing in the industry. In CATCH ME IF YOU CAN, Hanratty doggedly pursues Abagnale, not just to stop his fraudulent schemes, but to restore integrity to the systems that he has undermined. Similarly, in the scholarly publishing world, the “thrill of the chase” lies in implementing innovative, effective solutions to counter research misconduct and strengthen research integrity.
The components of the chase
An effective chase has four characteristics: • Reliant on Standards • Multi-faceted to connect clues • As automated as possible • Readily adaptable
Reliant on standards
As mentioned in the previous section, knowing the standards is the foundation for ensuring research integrity. For this reason, any solution dedicated to “the chase” must rely on standards such as ORCID, ROR, Ringgold, Crossref, and CREC. Incorporating these standards and platforms into your solutions creates a stronger barrier against fraudsters exploiting inconsistencies.
Multi-faceted to connect clues
Fraud evolves quickly, so publishers want to avoid relying on a single tool or solution to combat it. Instead, they can find power by combining data and insights from various providers to ensure that there is no single point of failure. Furthermore, they need to implement checks at multiple points in the workflow.
For example, just as pre-flight checks at an airport help the airlines to identify problem passengers before they show up on a flight, publishers can create a series of pre-flight checks. As shown in Figure 4, the paper describes a workflow where a publisher might incorporate a workflow to include a series of conversions and checks prior to the peer review process to include: • XML creation • Ringgold/CCC • ORCID • ROR • Crossref iThenticate • retractions.org • other checks Example pre-flight workflow.
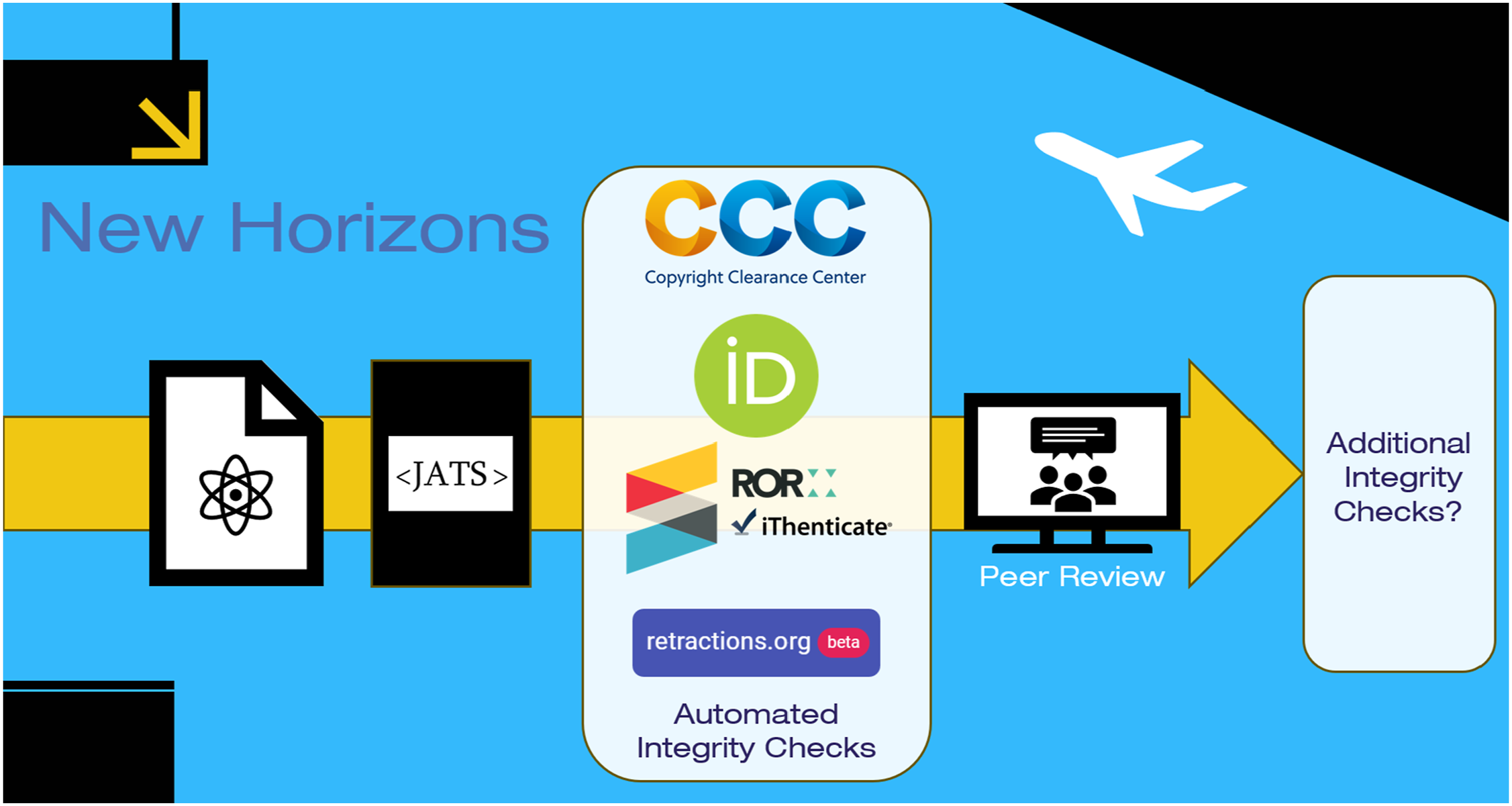
Once completed, the document may be submitted for peer review, and another set of integrity checks. After peer review, there could be other checks, followed by even more as the article is published.
As automated as possible
Another key component to a successful strategy is to make sure that the workflow is as automated as possible. Automation significantly enhances efficiency and accuracy, but the real goal is to avoid the burden it puts on your staff. Your team likely feels too busy already, so these processes must be executed with as much automation as possible. Otherwise, you risk employees pushing back, taking shortcuts, or simply not executing the tasks.
Readily adaptable
With the “face of the con” always shifting as fraudsters seek new ways to circumvent processes and safeguards, it is critical that publisher solutions are readily adaptable. Maintaining adaptability requires a modular framework that can evolve alongside changing tactics in research misconduct, as well as regular reviews and close communication with vendors.
Industry examples
This paper then provides two brief examples of ways research integrity checks that are being conducted at Data Conversion Laboratory (DCL).
Auto-classifying iThenticate reports
Many publishers use the power of Similarity Check 15 by Crossref to analyze papers and provide a report comparing articles that seem too similar. However, for some publishers, the sheer volume of papers can make it difficult for editors to sift through the large volume of corresponding Similarity Check reports.
In response, DCL worked with a large STM publisher to leverage business rules to automatically classify similarity reports. The idea is that if DCL can automatically sort or classify some of the scenarios, the editors can remain focused on the more problematic areas—streamlining the evaluation process. By creating predefined thresholds and categories, the system identifies when flagged content requires further review and when it does not. For example, • •
Flagging citation coercion
Author coercion in peer review may take forms such as “If you don’t cite me, I won’t approve you,” or “Make me an author, and I’ll ensure your paper gets approved.” These unethical practices are often difficult for organizations to detect due to their subtle and individual nature (Figures 5 and 6). Industry example: Auto-classifying similarity check reports. Industry example: Flagging citation coercion.
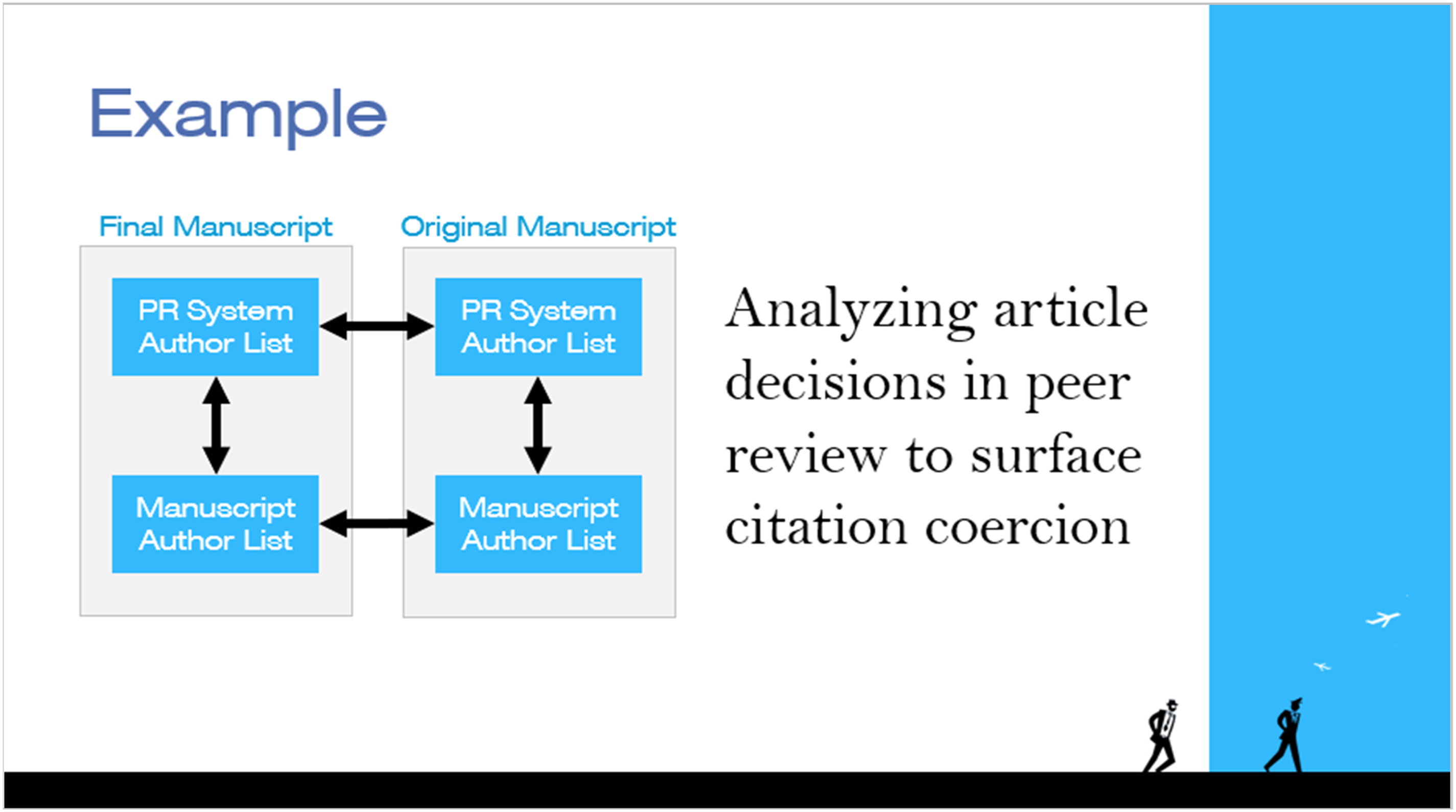
To address this, an STM publisher uses DCL automation to interact with the publisher’s peer review system in search of coercion indicators. Upon notification from the peer review system at both the start and end of the peer review process, DCL software captures the article’s author and citation data. Automated document analysis then compares these datasets, flagging any changes to authorship or citations for further scrutiny. This proactive approach surfaces potential coercion early in the process, promoting transparency and fairness in peer review workflows.
Conclusion
Research misconduct presents an ever-evolving challenge, threatening the credibility of the academic record and the trust that underpins scientific progress. The complexity of this problem mirrors the deceptive brilliance in CATCH ME IF YOU CAN, where layers of ingenuity and vulnerability combine to create opportunities for fraud. Yet, just as Frank Abagnale is [spoiler alert!] eventually caught, the scholarly publishing community has the tools and capacity to rise to the challenge.
Through the exploration of research misconduct, we have identified the various faces of the “con” and the systemic blind spots that allow it to persist. From outdated workflows and knowledge gaps to the overwhelming volume of academic content, these vulnerabilities underscore the urgent need for change. Recognizing the red flags early and implementing proactive, modular solutions rooted in standards are essential to curbing the impact of misconduct before it escalates.
The path forward lies in leveraging the power of standards, metadata, and collaboration within the academic publishing ecosystem. By adopting workflows that integrate checks at the earliest stages, fostering industry-wide partnerships, and remaining adaptable to emerging tactics, we can ensure that integrity remains at the heart of scholarly research.
This is not just about catching fraudsters—it is about preventing the harm that they cause and safeguarding the future of research and the scientific record. The chase may be ongoing, but with vigilance, innovation, and commitment, we can ensure that the house always wins when it comes to protecting the integrity of science.
Footnotes
Acknowledgements
I would like to extend my deepest gratitude to my colleagues at Data Conversion Laboratory (DCL), Marianne Calilhanna, Chris Hill, and Leigh Anne Mazure for their invaluable insights throughout the development of this presentation and manuscript. I am also thankful to the industry pioneers at NISO, Crossref, ORCID, ROR, and the Copyright Clearance Center, whose standards and practices continue to inspire transformative solutions in research integrity. This presentation would not have been possible without the many webinars, blog posts, and research provided by these entities. This work similarly would not have been possible without the mentorship I have been provided throughout the years by the great Bill Kasdorf. Finally, I would like to acknowledge the creative spark that Spielberg’s CATCH ME IF YOU CAN provided. Its themes of deception, trust, and the thrill of the chase resonated deeply and served as a fitting analogy for the challenges we face in maintaining research integrity.
Funding
The author received no financial support for the research, authorship, and/or publication of this article.
Conflicting interests
The author declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.