
Abstract
This paper explores the integration of confidential microdata between two National Statistics Agencies (NSOs) where a unique identifier is missing. Using mock data on international trade between these two countries, we use a cloud based secure enclave to integrate both NSOs’ trade data at the transaction level. Particular attention is given to ensuring input and output privacy, while maintaining the flexibility to produce both summary statistics on the linked data as well as econometric analyses that can lead to novel insights. As such, this study provides valuable insights into the potential of privacy enhancing techniques, in particular secure enclaves and differential privacy techniques, to improve data privacy while preserving the utility of the statistical results.
Keywords
Introduction
The digitization of data collection has significantly increased the amount of data that National Statistics Offices (NSOs) have at their disposal. A recent trend is the combination of various data sources, which further allows NSOs to monitor the various social and economic activities within its national borders. However, the combination of data sources can also pose challenges, particularly from a privacy point of view. Privacy Enhancing Techniques (henceforth PETs) hold the potential to alleviate these concerns. In this paper, we further explore the use of PETs to combine confidential data between two distinct NSOs.
The use case that we will consider involves the combination of international trade data between the Netherlands and Canada. Currently, when both countries trade with each other, each NSO holds more detailed information for imported than for exported transactions. For example, while Statistics Netherlands would know whether a Dutch importer made use of preferential tariffs under the Comprehensive and Economic Trade Agreement (CETA) between the EU and Canada, only Statistics Canada would know whether a Dutch exporter did so. However, Statistics Canada does not know anything about the Dutch exporter, other than its name. Linking this data at the transaction level would lead to much richer statistics and research on the use of international trade agreements. For example, it would allow to calculate Preference Utilization Rates (or PUR: the percentage of eligible trade that makes use of a trade agreement) by firm categories. Since PURs typically stagnate at around 60–70 percent, a better understanding of the obstacles to further use could lead to increased gains of international trade agreements. However, linking such transactions means NSOs need to share privacy sensitive information on (the activities of) individual firms, which could violate various laws and regulations such as Canada Statistics Act, 1 Statistics Netherlands Act 2 and the General Data Protection Regulation 3 in the European Union.
A potential solution is to link the data sets with a Private Set Intersection (PSI) protocol, i.e. a cryptographic protocol allowing two parties to compare their data sets and identify common elements, without revealing any information about the other elements. CBS, Statistics Canada, and Istat explored this approach for linking international trade data without unique identifiers as part of a UNECE project. 4 Their work led to a new private set intersection protocol that estimates linkage errors and a population mean, while removing any potential bias caused by the errors. In a recent study, 5 a bootstrap variance estimator is developed for the estimated mean. While the UNECE project illustrated the potential of PETs in practical applications, it also highlighted some limitations, such as the limited flexibility regarding the linkage or the supported statistical analysis, as well as the lack of statistical disclosure control.
This work focuses on overcoming these shortcomings by utilizing a cloud-based secure enclave, i.e. an isolated area of a virtual server, where sensitive data and operations are protected from unauthorized access and tampering (i.e. compromising the data or computations) by the enclave owner or any other party. Within this enclave, the records are linked with great flexibility, and the resulting links serve to compute summary statistics (e.g. on the use of preferential tariffs by Dutch exporters) and fit various statistical models (e.g. a linear or logit model). Then, the corresponding outputs are safely exported outside the enclave after they are randomly perturbed according to differential privacy methods. Furthermore, more utility is extracted from the linked data by generating some synthetic data, which is safely exported outside the enclave with all the target variables. By synthetic data, we mean a data set of fictitious transactions that are distributed like the actual transactions, according to the established links between the export and import data sets.
The paper is structured as follows. In the next section, we first explain the use case in greater detail. After that, we discuss previous and related work in Section 3. Section 4 describes the various methodological steps involved while Section 5 presents the evaluation including the tests in the enclave and simulations. Section 6 gives the conclusions and next steps.
Use case
The overarching goal of this project is to explore the use of PET to link highly detailed – and therefore typically privacy-sensitive – data from two NSOs. The case in point that we consider in this paper concerns the use of preferential trade agreements when firms trade internationally. More specifically, we assume a situation where a firm from the Netherlands exports a product to Canada which is eligible for preferential (i.e. lower) import tariffs under CETA. Only the Canadian customs authority will record (and thus Statistics Canada) whether this transaction enters Canada under preferential terms or not. On the other hand, only Statistics Netherlands holds detailed information on the Dutch exporter, e.g. whether it is a large or small firm. Both agencies could therefore benefit from linking their information at the transaction level such that both agencies could eventually gain an insight into preference utilization by firm categories.
In what follows, we will construct a mock dataset that tries to mimic the real-life data that would ultimately be used. This mock dataset will consist of several common variables, i.e. variables that both Statistics Netherlands and Statistics Canada have in their respective dataset. This includes the name of the Dutch exporter, the code of the exported product (according to the 6-digit harmonized system 6 ), as well as the date and value of the transaction. In addition, Statistics Netherlands uniquely observes some exporter characteristic for which we will assume the exporter size. Likewise Statistics Canada uniquely observes the importer size and whether this transaction entered Canada under preferential terms or not (Table 1).
Overview of the availability of different variables in each dataset.
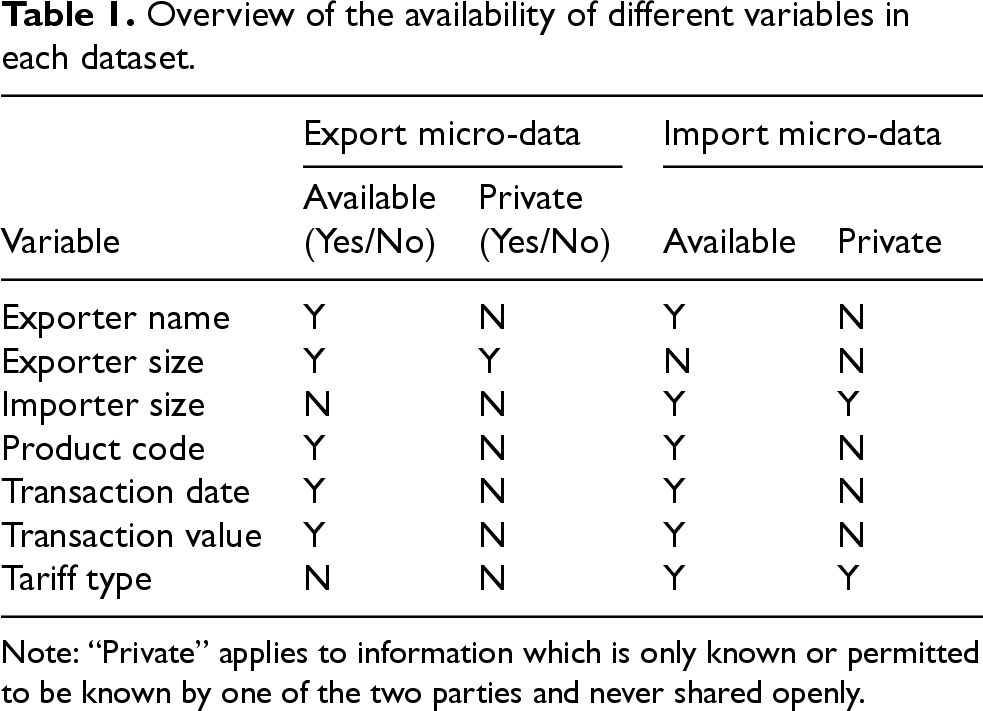
Overview of the availability of different variables in each dataset.
Note: “Private” applies to information which is only known or permitted to be known by one of the two parties and never shared openly.
In what follows, we aim to calculate descriptive statistics, perform econometric analysis and generate some synthetic data from the linked data, while ensuring that the statistical outputs are safe and keeping the inputs private. These two requirements are also called output privacy and input privacy, respectively. Output privacy corresponds to statistical disclosure control. For the use case, it means that the attributes of any given transaction cannot be inferred from the statistical outputs. In this work, output privacy is achieved through differential privacy techniques. According to the UN PET Guide 7 (p. 20), “Input privacy endeavors to allow two or more parties to submit data into a calculation without the other respective parties seeing data in clear.”. It implies that the input data remains protected when it is collected and processed. It may be based on encryption or other measures that are implemented in software or hardware. In the case of encryption, the input data is processed while it is encrypted, i.e. without prior decryption.
This work derives from a larger collaborative effort involving multiple National Statistical Organizations (NSOs). It builds upon previous projects that have laid the groundwork for the current study. These projects have explored various techniques such as private set intersection and federated learning for secure data analysis and integration, focusing on the challenges and solutions related to privacy preservation in official statistics. In addition to the foundational projects, this work also leverages extensive technological and methodological experience gained from other domains, including advancements in Secure Multi-Party Computation (SMPC) and the implementation of secure enclaves.
The main project from which this work draws inspiration is the UNECE Project on Input Privacy Preservation (IPP), 4 launched in January 2021, with the aim to explore statistical use cases that require input-side protection, assess the applicability of different privacy-preserving techniques and foster a collaborative community among statistical organizations and external partners, including academia and the private sector.
The UNECE IPP project demonstrated the feasibility of private set intersection for international trade while highlighting the need for computational efficiency and accurate linkage techniques. In that project, a protocol was developed by modifying the solution described by Bruno et al., 8 to deal with the linkage errors when the records are linked without a unique identifier. With the new protocol, a population mean is estimated while removing any potential bias that is due to the linkage errors. In recent work, a variance estimator is proposed for the estimated mean. 5 Like the solution by Bruno et al., 8 the protocol involves the two data-holding parties as well as a trusted third party called “linker”. The protocol is secure when the parties are non-colluding (i.e. not secretly cooperating or conspiring together) and honest but curious, where the latter qualifier means that the parties follow the protocol correctly but try to learn additional information from the data they observe. While this solution enables the parties to estimate a mean without sharing their clear data, it has many limitations, including no support for approximate comparisons of the linkage variables, no support for continuous target variables, a limited range for the statistical analysis, which may be performed, and no control of the statistical disclosure risk. Also, the need to have a trusted third party is restrictive.
Other solutions have been developed, which address some of these limitations. For example, Pinkas et al. 9 describe a private set intersection approach which has the advantage of not requiring a trusted third party. It is based on oblivious transfer, whereby a receiver obtains a single piece of information (to which it is entitled) from a sender that has many such pieces of information, without revealing the obtained information to the sender. This solution was used to privately link student financial aid data in the United States. 10 Zanussi, Dugdale and Santos 11 describe a similar solution. While these solutions dispense with a trusted party, they require a unique identifier and assume that there are no linkage errors.
Indeed, linkage errors are a particular concern when linking with quasi-identifiers, where a quasi-identifier is a nonunique variable that is possibly recorded with typos (e.g. the transaction date, the transaction value). To describe these errors, a record pair is called matched if its records are from the same unit. A linkage error is a false negative (i.e. not linking records from a matched pair) or a false positive (linking records from unmatched pairs). The linkage errors are usually measured by the recall and the precision, where the recall is the proportion of matched pairs that are linked, and the precision is the proportion of linked pairs that are matched. Performing approximate comparisons is an effective way to limit these errors when linking with quasi-identifiers. In a privacy-preserving context, the question is how to perform such comparisons on quasi-identifiers when they are encrypted or hashed. Encryption and hashing both aim to map a first message (called plaint text) into a second message (called cipher text) that is unreadable. While encryption is reversible, i.e. the plain text may be recovered from the plain text with a decryption key, this is not the case with hashing. One privacy-preserving linking method is to use Bloom filters that are based on hashing the quasi-identifiers. 12 While these methods can improve the linkage efficiency, they must be part of a bigger solution, which also protects the statistical summaries that are derived from the linked data. The latter is also true for all the above-described solutions.
An attractive alternative is a cloud-based secure enclave. As it has been mentioned before, it is essentially an isolated area of a virtual server, which protects sensitive data and operations from unauthorized access and tampering by the owner of the server or any other party. Enclaves provide a secure execution environment that ensures isolation, integrity, and authenticity. For our use case, this enables privacy-preserving computations with both formal security and privacy guarantees. In practice, enclaves achieve their guarantees through virtualized environments that are isolated from the host system, typically with no external network access and restricted communication through tightly controlled local channels. They also provide a cryptographic proof that their code and configuration have not been tampered with. While this solution requires trust in the cloud provider, in theory, it provides the greatest flexibility for implementing the linkage, statistical analysis and disclosure control measures, since the clear data may be processed with standard statistical packages within the enclave. This trust is necessary because the provider controls the underlying hardware and infrastructure. Nevertheless, it remains a practical and effective solution that is widely used.
Methodology
Within a secure enclave, the import and export data sets can be linked privately to fit various regression models and generate public use microdata through data synthesis, while controlling for the linkage errors, as shown in Figure 1. By design, this process preserves the privacy of the inputs, but it can also ensure that all the outputs are safe in the differential privacy (DP) framework. 13 While fitting regression models and generating synthetic data from the linked data are major improvements over the UNECE IPP project, 4 producing differentially private outputs is equally significant and requires a careful consideration of the threat model and the linkage impact on the privacy loss. Here, the term threat model loosely refers to the unit of information that is to be protected from statistical disclosure, as well as scenarios for such disclosure, which assume the curator model in this work, i.e. all the clear data is sent to a trusted third party, who performs the processing and applies the necessary disclosure control measures. Regarding the protected unit of information, a first choice is protecting each transaction, while a second choice is protecting all the transactions from a given exporter or importer. This is an important distinction when considering a regression model with fixed exporter effects. For the problem in hand, the linkage also affects the privacy loss in ways that go beyond some previous discussions of the interplay between record linkage and differential privacy. Indeed, this linkage involves data sets held by different statistical organizations, where each organization is not entitled to the private information owned by the other. However, an organization might leverage its data set to infer the private attribute, which its peer holds regarding a particular transaction, e.g. guessing the tariff type based on the variables in the export data set including the firm size. This means that each organization is a potential adversary for its peer, when it comes to protecting the private attributes.
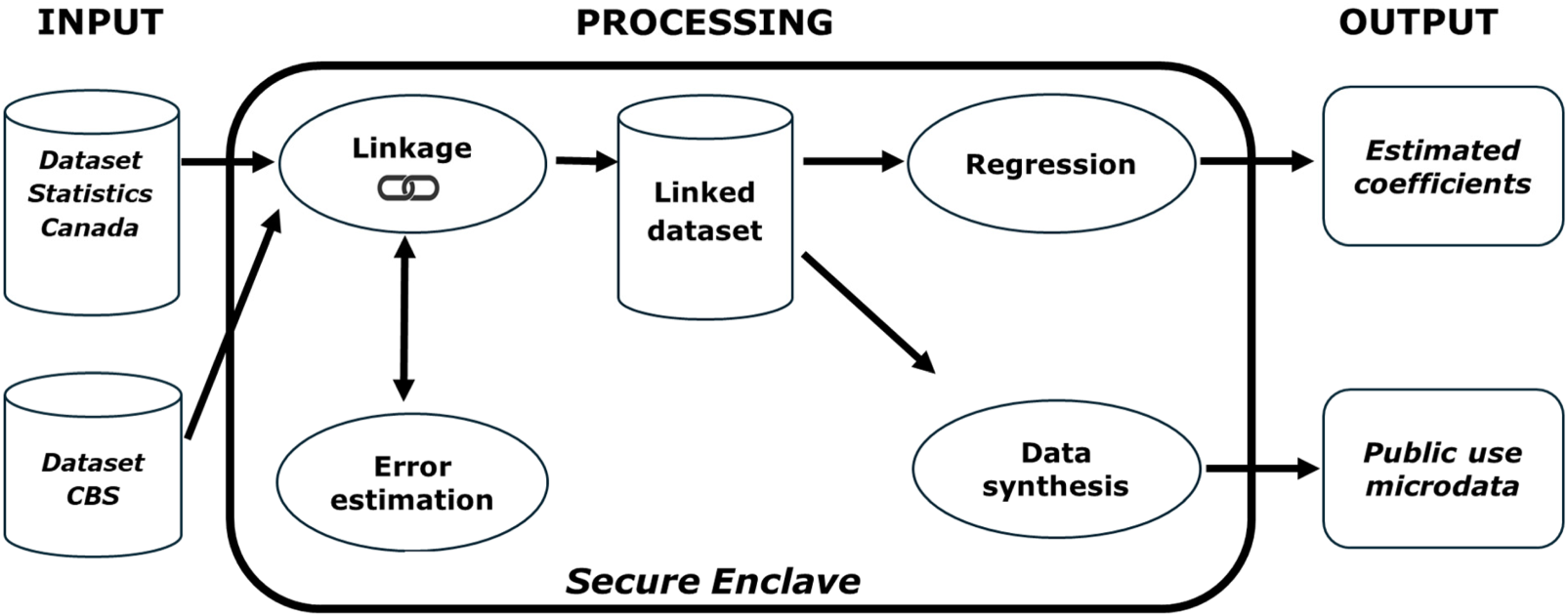
Production process.
In what follows, our goal is to produce various statistical outputs about a finite population of N international trade transactions, while respecting the above-described confidentiality constrains and leveraging the capabilities of the secure enclave. The outputs are to be based on an import data set and an export data set, which are assumed to be complete and duplicate-free censuses for simplicity. In the following paragraphs, a clear data production process is described, which operates within the boundaries of a statistical organization where there is unfettered access to all the data. Then, an overview of the DP framework is given along with a discussion of different threat models for the use case. Finally, the proposed solution is outlined based on a differentially private version of the clear data production process that runs within the secure enclave.
For ease of presentation, it is convenient to first consider the situation where an analyst at Statistics Netherlands has access to all the clear data.
Analysis
First consider a standard generalized linear model of the form
Indeed, econometricians often control for unobserved differences between observations that may lead to biased estimates by including fixed effects. In our case, there may be differences between exporters that we are unaware of, e.g. in terms of experience. To the extent that these differences are time invariant, we can control for them by using exporter fixed effects (i.e. time-invariant differences between exporters). This can be done effectively by de-meaning the data, i.e. by subtracting the average exporter response (i.e. the average response over the transactions from the same exporter) from each transaction response and subtracting the average exporter covariates from the covariates of each transaction. This only works for linear regressions such as ordinary least squares, giving it a distinct advantage over the logit model where de-meaning would not work. However, it may yield an estimate of the probability
The above estimators apply where the linkage is perfect, i.e. two records are linked if and only if they pertain to the same transaction. Such record pairs are called matched. However, linkage errors tend to occur when linking with quasi-identifiers, including false negatives and false positives, where a false negative is failing to link a matched pair, and a false positive is linking a pair that is unmatched. There are essentially two ways to mitigate the impact of these errors on an analysis including linking the records with a sufficiently high precision to suppress the false positives at the expense of more false negatives, 14 or adjusting the analysis for any potential bias,15,16 which is not discussed further. With the approach by Judson et al. 14 the linked records may be reweighted to represent the unlinked records. However, this last step is not needed if the false negatives occur at random.
Linking the records
The records may be linked with the probabilistic method,
17
which is a good choice when the linkage variables have typos. With this method, a pair may be linked only if it meets certain coarse criteria that are called blocking criteria. For such a pair that is called potential, a probabilistic linkage weight is assigned according to the observed agreements between the pair records, such that its weight increases with the similarity of the records. In the fully automated version of the method, a potential pair is automatically linked without any manual intervention if its weight exceeds a certain threshold, which is a function of the target linkage accuracy. In general, the pair weight is assigned by fitting a statistical model of the agreements in a potential pair with a numerical procedure, where the agreements are coded in a categorical vector of the form
Evaluating the linkage accuracy
While the accuracy may be evaluated according to the above-described log-linear mixture, the resulting estimates may be biased due to violations of the restrictive condition independence assumption. To avoid this problem, it is proposed to model the number of links from a record as suggested in a previous paper.
18
According to this model, the number of links 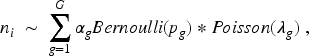
Implementing the clear data production process is straightforward with the available record linkage and statistical packages. However, there is a need to control the statistical disclosure.
Specifying the desired level of confidentiality
The protection from statistical disclosure may be provided for individual transactions or individual firms (exporters or importers). In general, the desired protection level may be concisely expressed in the language of differential privacy, a robust mathematical definition of privacy that protects against a wide range of attacks, including differencing and record linkage. 13 However, the specific constraints of the use case must be considered.
Differential privacy is a property of a statistical procedure or its output, which is hereafter called measurement. Basically, a measurement is differentially private if its distribution is essentially invariant under the modification or addition of a single record in the input dataset. The formal definition of differential privacy rests on the concept of adjacent datasets, which depends on the context. In that regard, there are two common definitions of adjacency, which both assume that each dataset comprises records from distinct individuals. According to the first definition, two datasets are called adjacent if they have the same number of records and differ in exactly one record, i.e. all the record values are identical across the two datasets except for one record. According to the second definition, two datasets are adjacent if they differ in exactly one record, and one dataset has one more record than the other. A general definition of adjacency, which includes both cases, is to call two datasets adjacent if they differ by one record (see,
13
Definition 2.3, p.17). To define exact differential privacy, consider two adjacent datasets (according to one of the two definitions given above), a measurement as well as a subset of possible measurement values, and let p and
In the use case, the computed statistics are based on the linkage of two datasets that are held by different statistical organizations. Then, the actual privacy loss may be greater than expected if the linked data is the input of a differentially private procedure, which expects the different links to represent distinct transactions. A simple fix is to set an upper limit on the number of links per record 22 and to account for this limit when setting the privacy loss parameter. Also, this parameter must account for the maximum number of transactions per exporter, where the goal is to protect individual exporters. This is detailed in the next section.
Building a differentially private process
A differentially private production process may be based on procedures, which expect that the input records represent distinct transactions. However, this is typically not true with the linked pairs as input due to the presence of false positives. While these errors may be rare at a high precision, accounting for them is crucial from a privacy standpoint, and it may be done as follows. Suppose that we wish to reuse an
With respect to privacy, there are two kinds of adversaries or attackers, where the first kind is a participating statistical organization, who tries to guess some of the private attributes that are held by its peer. This is the case if Statistics Canada is trying to infer the exporter size of a transaction, or Statistics Netherlands is trying to infer the tariff type of a transaction. This threat must be mitigated even if the produced statistical outputs are not released outside the two statistical organizations. The second kind of adversaries is someone outside the two organizations, with no access to the import and export datasets. The goal of such an adversary is to correctly guess any attribute (among those present in either dataset) of a specific transaction. This distinction is a key feature of the use case, which impacts the definition of the privacy loss.
When the attacker is one of the two statistical organizations, the differential privacy is based on the worst case where a single record is modified in the dataset held by its peer, while all the remaining records are fixed and provided to the attacker. For example, if Statistics Canada were the attacker, this would mean that all the export records are known expect the target of the inference. Of course, Statistics Canada would also benefit from knowing all the import records including the one matched with the target export record. Since the target record generates up to d linked pairs, the measurement based on the
When the attacker is outside the two statistical organizations, the privacy loss must also account for the non private attributes as defined in Section 2. These attributes include all the linkage variables, such as the exporter name, product code, etc. In this case, the worst-case means that the attacker knows all the records except those associated with the target transaction. This transaction is associated with one import record and one export record (recall that each dataset is a census), where each record has up to d links. Therefore, a transaction may generate up to
In what follows, we assume that the attacker is one of the two organizations. When the attacker is outside the two organizations, the same solutions apply after doubling the privacy budget as suggested by the above discussion. We next review the differential private procedures, which are reused, and further detail on how they are adapted.
Analysis
Many methods have been described for performing a differentially private regression including the perturbation of an objective function,23,24 which has been implemented in the enclave. Chaudhuri et al.
23
focus on high-dimensional problems, with an objective function that incorporates a penalty for regularization (i.e. penalizing the model complexity) and a perturbation of the form
Within the enclave, differentially private linear and logistic regressions are based on this package.
Data synthesis
Some synthetic data may be generated from the linked data to enable some exploratory analysis and motivate a deeper analysis. It may be generated in a differentially private manner by the Multiplicative Weights Exponential Mechanism (MWEM), 25 where the synthetic dataset is generated iteratively by minimizing the difference between the actual data and the synthetic data for a set of linear queries. Initially, the synthetic data is drawn uniformly from the universe of possible records and each synthetic record is assigned the same weight. Then, in each iteration, a query is selected and the difference between the actual data and the synthetic data is evaluated in a differentially private manner. When the answer is larger with the actual data, the weight is increased where a synthetic record makes a positive contribution to the difference, and it is decreased where the contribution is negative. When the answer is smaller with the actual data, the weight is decreased where the contribution of a synthetic record is positive, and it is increased where the contribution is negative. The resulting synthetic data is differentially private.
Within the enclave, the MWEM data synthesizer is supported by a local library of the SmartNoise package (https://docs.smartnoise.org/synth/index.html).
Linkage and error estimation
The linkage may be a source of disclosure if the probabilistic weights and estimated linkage accuracy are communicated to a participating statistical organization, e.g. to let the organization choose the probabilistic weight threshold. To limit this disclosure, the linkage parameters and estimated accuracy may be computed with differentially private procedures.
For the probabilistic linkage weights, this procedure may be based on the post-processing property as follows. First, generate a differentially private histogram of the pair distribution according to the vector of comparison outcomes. Next, use the histogram as input to the numerical optimization of the log-linear mixture likelihood. The sensitivity of the actual histogram is
The linkage accuracy may be estimated in a differentially private manner by adding an adequate amount of noise to the
To overcome this hurdle, it is possible to model the total number of links for disjoint groups of export records, i.e. to model 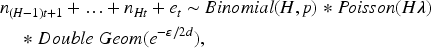
Evaluation
The methodology is evaluated with mock data and tests on the enclave. The code for these tests is publicly available on Git-Hub. 28
Generating the mock data
The mock data is based on a population of 100,000 fictitious transactions that are recorded with typos but without duplication in an export dataset and an import dataset. All the transactions are assumed to occur in the year 2021, with the exporter name, exporter size, importer size, product code, day, month, transaction value (in thousands of $), and tariff preference. These variables are distributed as follows. The exporter name is sampled with replacement from 947 firm names listed by the United States Securities and Exchange Commission (SEC). Thus, each exporter has about 100 transactions on average. The exporter size is set to ‘small’ or ‘large’ with equal probability. Likewise, the importer size is set to ‘small’ or ‘large’ with equal probability. The product code is sampled with replacement from a list of 200 six-digit product codes. The day is sampled with replacement from the set {1, …,30}, while the month is sampled with replacement from the set {1, …,12}. The transaction value is drawn uniformly between 2 and 1000. Finally, the tariff preference is set to “Preferential” with a probability that is given by a linear or logistic model. Otherwise, it is set to the regular tariff; the so called Most-Favoured Nation (MFN) tariff. The probability of a preferential tariff is a function of whether the exporter is large (
Testing the enclave
Within the enclave, the implemented production process comprises a probabilistic linkage, the model-based estimation of the linkage errors, a regression and the generation of synthetic data. At the different stages, the allocated privacy budget is determined by prior simulations outside the enclave based on the expected utility of the different estimates. The tests consist in executing the entire production process ten times (each time representing an iteration), each time with a new mock dataset that is generated as described before. For each iteration, the linkage, regression and data synthesis performance are measured. The following paragraphs provide more details, where
The linkage is probabilistic and implemented with a local version of the Record Linkage Toolkit (RLTK) using the variables exporter name, product code, transaction value, day and month. For better results, the exporter name is preprocessed including capitalization, removal of spaces and stop words such as “&”, “inc.”, “inc”, “corporation”, “corp.” and “corp”. While this preprocessing may occur within the secure enclave, it is more convenient to do so outside before uploading the datasets to the enclave. Within the enclave, blocking criteria are applied based on the following conditions.
Having the same exporter name, product code, transaction value, day and month Having the same product code, transaction value, day and month Having the same exporter name, day and month Having the same exporter name, product code, transaction value and month Having the same exporter name, product code, transaction value and day
The number of potential pairs per record is limited to
The estimated probabilistic weights are applied to the potential pairs within the enclave and the weight threshold is selected with the help of the error model to have a precision that is at least equal to 0.99. The actual procedure is iterative and visits the possible pair weights, in decreasing order, until the estimated precision falls below the target. This procedure is slightly simpler than that described in Lemma 1 in Annex 1, where some pairs are linked with a positive probability that is less than 1.0. For the estimation of the linkage accuracy, the records are partitioned into disjoint groups of 100 export records, and the group
Finally, the linked data serves to fit the relevant regression model (linear or logistic) and generate some synthetic data. In these steps, the privacy parameter is set to
The production process involves some sequential composition and some parallel composition. Some parallel composition occurs when some steps are concurrent and have the same inputs, e.g. the analysis and data synthesis that are both based on the linked pairs. There is also some sequential composition because the weight estimation procedure precedes the threshold selection procedure, and the estimated weights are utilized by the latter procedure. Besides, the outputs from both procedures serve to create the linked pairs, which are inputs for the analysis and data synthesis as mentioned above.
Allocating the privacy budget
In terms of privacy budget, we aim for an overall budget that does not exceed 5.0 for the entire production process, while having a minimum utility for the point estimates and p-values that are based on the synthetic data. For a point estimate, the utility is measured by the root mean square relative error (i.e. the square root of the mean of the square relative error between the point estimate and a reference value), to mirror the use of the coefficient of variation in assessing the reliability of published estimates at Statistics Canada.
29
Indeed, the reliability is classified as acceptable, marginal or unacceptable according to whether the coefficient of variation is less than or equal to 16.5%, greater that 16.5% and less than or equal to 33.3%, and greater than 33.3%. In what follows, these different levels are called gold, silver and bronze, respectively, and they are based on the root mean square relative error (RRMSE). For the estimated precision and recall, the reference values are the actual precision and recall based on the ground truth. For a regression coefficient, the reference value is the chosen value when generating the mock data. Our goal is producing estimates that are at least at the gold or silver reliability level, for the estimated linkage accuracy and regression coefficients (i.e.
For the error estimation step, the mock data is generated as described before, and the datasets are linked based on having the same exporter name, product code, transaction value, day and month. This has the advantage of simplicity, while resulting in a high precision like the probabilistic linkage implemented in the enclave. In the simulations, the precision is very close to 1.0 (between 0.999 and 1.0) while the recall is around 0.4. The linkage accuracy is estimated by perturbing the group
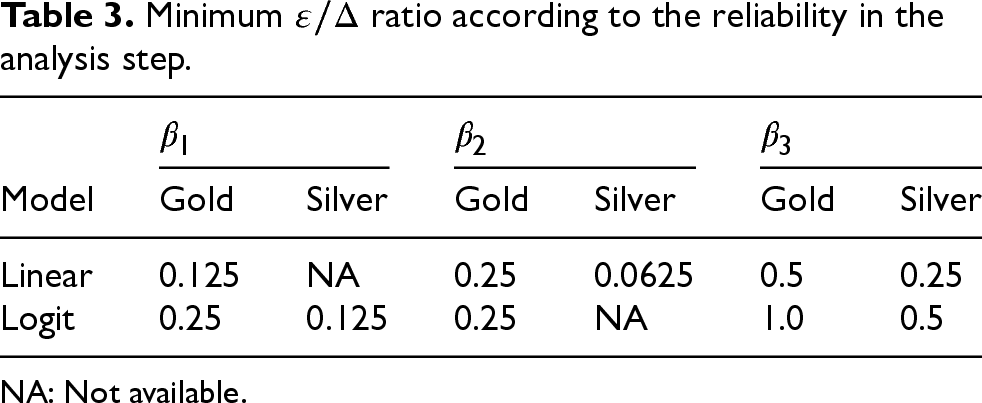
Tables 2 to 4 give the minimum
Minimum
ratio according to the reliability in the error estimation step.

Minimum
NA: Not available.
Minimum
NA: Not available.
Minimum

Table 3 gives the minimum
Finally, Table 3 shows that it is possible to test the significance of each covariate at the gold level when
Based on Tables 2 to 4, we can derive the minimum privacy loss to ensure that all the selected outputs have the desired reliability in a stage, such as the gold level, or the gold or silver level. For example, in the regression stage, having all outputs at the gold or silver level means that each regression coefficient is estimated with an RMSRE, which does not exceed 33.3%. Of course, the derived privacy budget depends on the sensitivity, which is itself of function of d (the maximum number of links per record) and T (the maximum number of transactions per exporter); the latter if protecting each exporter. We can also do this exercise in the other direction as shown in Table 5, where we derive the largest possible d (if protecting each transaction) and T (if protecting each exporter) to ensure that all selected stage outputs are at the gold level, or at the gold or silver level, for a fixed maximum privacy budget. The parameters d and T are each constrained to be at least equal to 2, otherwise the configuration is deemed infeasible. For example, if the maximum d is 2 and the maximum T is less than 2, then we can choose
Maximum d and maximum T according to the privacy budget
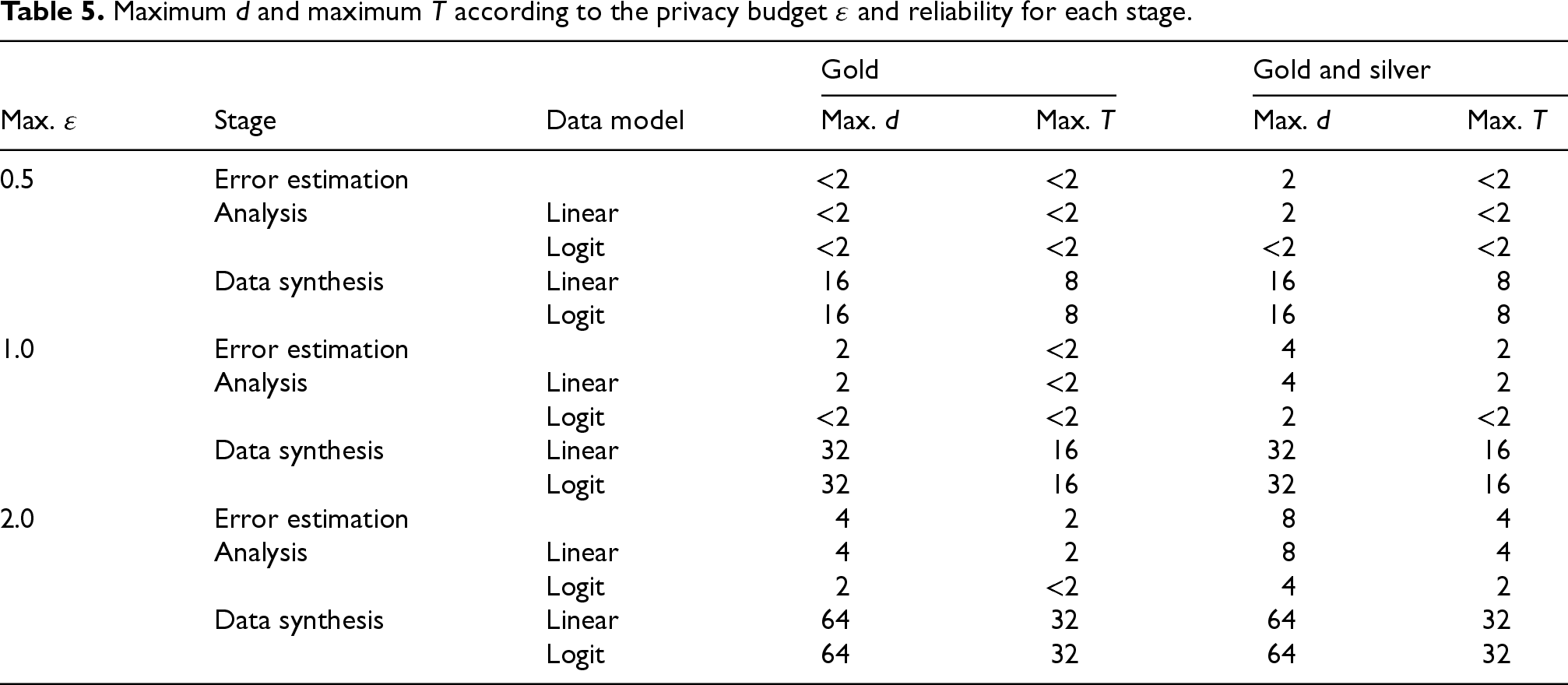
The parameters d and T are mostly constrained by the analysis stage, because the same parameter values must be used across all the stages. According to Table 5, this means that d cannot exceed 8, and T cannot exceed 4, if the privacy budget per stage does not exceed 2.0, and the outputs are to be at the gold or silver level for the analysis stage. The small value of T illustrates the difficulty of providing group privacy for all the transactions associated with each exporter. This may be facilitated by increasing the number of distinct exporters. Table 5 provides a basis for allocating the privacy budget for the test scenarios that are described in the next section.
Table 6 describes the two test scenarios, where the protection is on individual transactions and the test is repeated ten times in each scenario. A budget of 0.5 is allocated for the weight estimation procedure, including a budget of
Test scenarios.

Test scenarios.
NA: Not available.
The summary statistics for the actual and estimated linkage accuracy are shown in Tables 7 and 8, respectively. In Table 7, the mean precision is above 0.99 as expected, while the mean recall is at or above 0.795. For the estimated linkage accuracy, the absolute relative bias is below 1% while the RMSRE does not exceed 5%. Thus, the precision and recall are both estimated at the gold level.
Actual linkage accuracy.
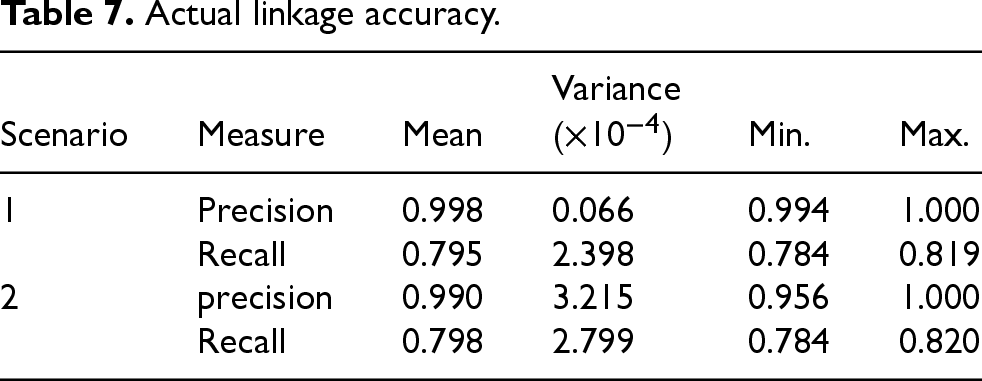
Actual linkage accuracy.
Estimated linkage accuracy.

The performance of the estimated regression parameters is shown in Table 9. The absolute relative bias does not exceed 10%, while the RMSRE does not exceed 33.3% for each coefficient, i.e. a reliability at the gold or silver level.
Estimated regression parameters.
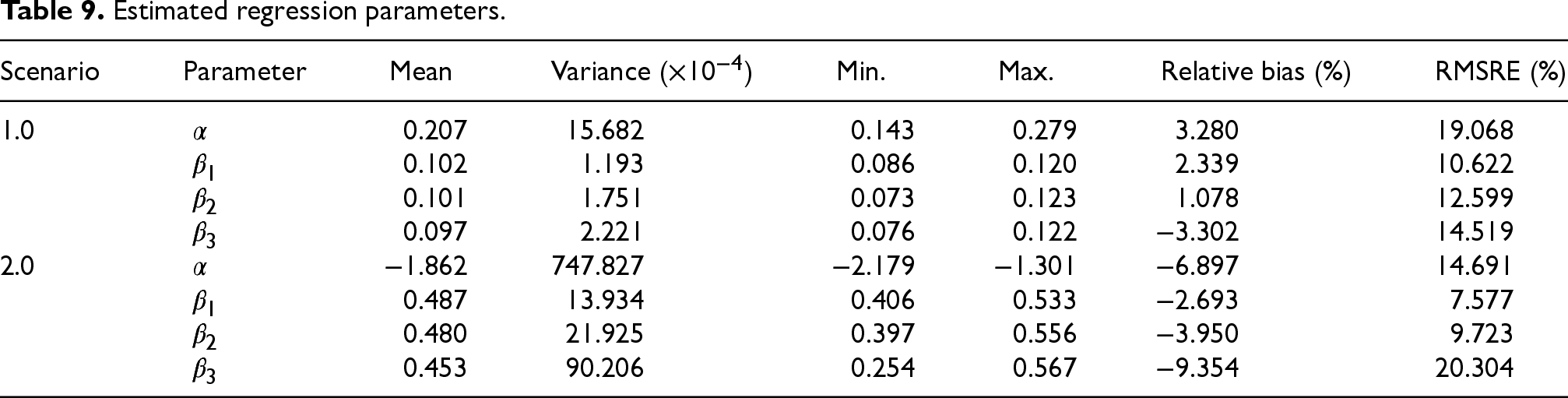
Based on the synthetic data, each regression coefficient is significant at the 0.1 level, in each scenario and iteration. Thus, the tests perform at the gold level.
The total privacy budget is shown in Table 10, It never exceeds 5.5, which is quite acceptable. Overall, the results demonstrate that it is possible to privately link the datasets while controlling the linkage accuracy and generating many useful outputs from the linked data, with a reasonable privacy budget.
Total privacy budget.

Secure enclaves have a major role to play in the private linkage of datasets across statistical organizations, regardless of the competing solutions that are based on a public key infrastructure, oblivious transfer, garbled circuits or fully homomorphy encryption. Indeed, they currently offer the greatest flexibility by far for implementing a linkage, statistical analysis or disclosure control measures, since the clear data may be processed with standard statistical packages within an enclave, at least in theory.
This study has clearly demonstrated all those benefits by implementing a differentially private production process within a cloud-based enclave for the econometric analysis of international trade micro-data, including a sophisticated probabilistic linkage with approximate comparisons to deal with typos. Additionally, the estimation of the linkage accuracy is based on the datasets that are being linked instead of relying on a prior linkage of “representative” datasets, which may be hard to find. Furthermore, the linked data not only serves to perform a differentially private linear or logistic regression, but it also serves to generate some differentially private synthetic data for data exploration outside the enclave, a very useful feature that may precede and guide the statistical analysis in practice. Overall, the production process is both input and output preserving, where the latter property is based on the application of differential privacy techniques. In tests on the enclave, the production process yields many reliable statistical outputs within a total privacy budget, which does not exceed 5.5. This process communicates with the outside world to estimate the probabilistic weights, estimate the linkage accuracy and select the weight threshold.
While these results are encouraging, some improvements are needed in many areas that may be the focus of future work, such as the computation of the probabilistic weights. Indeed, this operation may be facilitated by relaxing some of the enclave constraints, including allowing the computation of aggregate counts for observations that are cross-classified by many categorical variables, as well as enabling a much greater subset of the procedures or function calls, which are provided by the installed packages (e.g. the Record Linkage Toolkit) instead of a handful currently. Also, providing a general-purpose nonlinear optimization routine within the enclave may help implement many steps without having to communicate with the external world, which is a source of privacy loss and latency. This is true for the estimation of the linkage accuracy and the selection of the weight threshold. Another challenge is the large amount of noise required to protect each exporter, which currently limits the number of transactions per exporter. Beyond the enclave, the methodology may be improved to address some of its current limitations, regarding the lack of support for regressions with fixed effects, and the need to provide variance and confidence intervals when performing a regression. Indeed, fixed effects are an important feature of panel data, which are usually dealt with through de-meaning, in the case of a linear regression. While this de-meaning is easily done on each dataset by the corresponding organization at the source, the solution is not as simple as using the resulting linked data as input to one of the previously described procedures for a differentially private linear regression. Indeed, the actual privacy loss may exceed the expected loss, since the latter is based on the wrong assumption that each record represents the information of a single transaction in the export and import datasets. Instead, the underlying methodologies of these procedures must be examined thoroughly to update the anticipated privacy loss according to the sensitivity of the de-meaned data. Besides, the methodology must be developed further to report variances and confidence intervals, which is an active area in the research on differentially privacy. Lastly, extensions are required to deal with the situation where the datasets are not censuses. Despite these shortcomings, secure enclaves represent a viable solution.
By fostering collaboration and innovation, this work paves the way for a broader adoption of secure data integration techniques in official statistics, in compliance with international privacy regulations. It also provided the opportunity for learning many valuable lessons regarding the need to manage expectations about the reuse of existing statistical packages within an enclave, the importance of viewing differential privacy as a property of the entire production process instead of focusing on the outputs, and the usefulness of the differential privacy framework for discussing privacy risks. While, an enclave may conveniently support an existing package, it may be necessary to disable some of the package features to guarantee that all the outputs are differentially private. Also, the entire production process must be designed according to differential privacy principles, from the ground up. Finally, differential privacy concepts and definitions have helped articulate the intricate privacy risks of the use case, where each transaction has a record in each dataset and the two datasets are held by different organizations. Based on this experience, the authors are convinced that the framework of differential privacy can be the basis for the much-needed lingua franca about privacy. 30 Therefore, education about this subject is a priority for national statistical organizations.
Supplemental Material
sj-docx-1-sji-10.1177_18747655251355704 - Supplemental material for Private linkage of international trade microdata in a cloud-based secure enclave
Supplemental material, sj-docx-1-sji-10.1177_18747655251355704 for Private linkage of international trade microdata in a cloud-based secure enclave by A Dasylva, B Santos, L Franssen, M De Cubellis, F De Fausti, A Pappagallo, N Berrios and J Fitzsimons in Statistical Journal of the IAOS
Footnotes
Author note
The views expressed herein are those of the authors and do not necessarily reflect the views of the respective organizations.
Acknowledgements
The authors would like to thank the Office of National Statistics and all members of the UN PET Lab for their support and insights.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.