
Abstract
The modernisation of official statistics requires facilitating new forms of data collaboration between National Statistical Offices (NSOs), researchers, government agencies, and the private sector. However, privacy concerns, legal constraints, and organisational risks associated with data access often prevent valuable initiatives from being realised. This paper argues that privacy-enhancing technologies (PETs) can fundamentally transform how sensitive data is accessed and used, enabling these barriers to be more readily overcome, and thus unlocking data collaborations that would otherwise be impossible. Drawing on examples of pilot deployments conducted through the United Nations PET Lab, we demonstrate how applying combinations of PETs can provide robust privacy guarantees and granular governance controls that enable effective use of sensitive data assets. We provide a vision for a new ecosystem for official statistics where NSOs and researchers can securely access thousands more datasets from across sectors and jurisdictions.
The demand for data access and governance for official statistics
NSOs have a unique and crucial remit: to gather, analyse, and disseminate statistical information to empower citizens, government, and society at large. This is articulated in Principle 1 of the Fundamental Principles of Official Statistics, adopted by the United Nations Statistical Commission in 1994 and endorsed by the UN General Assembly in 2014:
1
“Official statistics provide an indispensable element in the information system of a democratic society, serving the Government, the economy and the public with data about the economic, demographic, social and environmental situation. To this end, official statistics that meet the test of practical utility are to be compiled and made available on an impartial basis by official statistical agencies to honour citizens’ entitlement to public information.”
Historically, NSOs have produced official statistics using data collection methods such as censuses and surveys. However, both censuses and surveys take time to conduct, are expensive, and have experienced a decline in response rates.4,5 Moreover, the widespread digitalisation of information means that traditional sources are unlikely to fully capture new social phenomena, 6 and have created a societal expectation for rapid responses to emerging issues. This has created demand for other sources of more timely information 7 than can be provided by surveys or the typical census cycle (every 5–10 years in most countries). 8 It is prohibitively expensive and impractical to run census and other surveys more frequently, 9 and doing so would place a significant burden on respondents.
These limitations have led to an increasing demand from NSOs to access and re-use privately held third-party data to supplement their existing data collection practices,10–12 as well as for greater collaboration between NSOs to generate cross-border statistics that can inform global issues. Furthermore, government agencies, academia, and the private sector are increasingly looking to access microdata held by NSOs.13,14 In accordance with their remit, NSOs should endeavour to make such data available for public-good research whilst ensuring the privacy and security of sensitive information.
A taxonomy of information flows for official statistics
Considering these demands, it is clear that the modernisation of official statistics relies on facilitating new information flows between NSOs, researchers, governments, private sector organisations, and citizens. It is informative to take a system-level perspective and consider the question: what types of information flows are necessary to support an effective official statistics ecosystem in the twenty-first century? Informed by discussions with NSOs through the United Nations PET Lab,
15
our first contribution is to provide a high-level taxonomy of the different types of information flows that are most pertinent to answering this question:
These are summarised in Table 1. Note that this taxonomy does not intend to capture every type of potential use case, but rather serve as a useful reference for considering relevant use cases. Furthermore, certain initiatives may cross multiple categories, for example broader research infrastructures, such as ODISSEI in the Netherlands 26 and Common European Data Spaces, 27 aim to integrate and disseminate data from various public and private sources.
Taxonomy of data sharing use cases most relevant to national statistics offices.
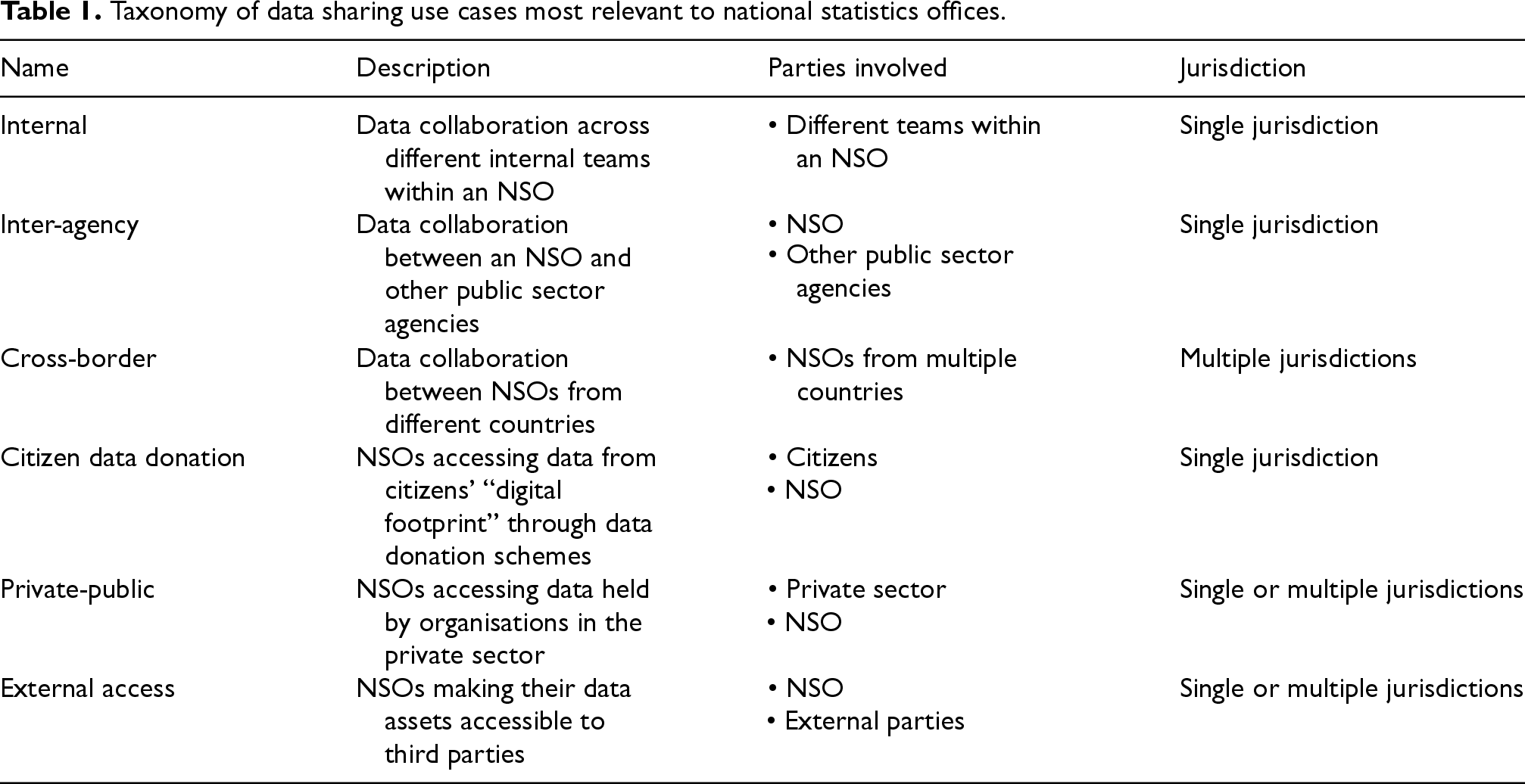
Taxonomy of data sharing use cases most relevant to national statistics offices.
Citizen data donation refers to individuals making their digital footprint data — i.e., data from their smart devices, social media, financial transactions, etc. — available for research purposes. This category does not include survey data, as data donation is presented as a potential alternative data collection method to mitigate declining survey response rates. Research has found that data donation initiatives are inhibited by concerns related to privacy (particularly for data donated with high granularity) and misuse. 28 Approaches which provide users with oversight and control over how their data is used could incentivise greater participation in data donation schemes, and PETs-based approaches are being explored in this context. 29
Enabling information flows that support each of these archetypes would provide significant benefits to NSOs and the publics they serve. However, there are acknowledgements from within the official statistics community that the current approaches to sharing and accessing sensitive data for such use cases do not suffice. 9 Current approaches may be slow or inefficient, only making data accessible at a very high-level of aggregation, or inadvertently leaking sensitive information or facilitating misuse.9,30 These issues can compound and have a chilling effect, creating a risk-averse environment in which many valuable uses of data simply do not happen, resulting in enormous inefficiencies and lost potential. 31
It is clear that we need better approaches. In this regard, the community of official statistics has recognised the application of privacy-enhancing technologies (PETs) as a promising way forward. 32 In 2019, the Task Team on PETs was established by the UN Committee of Experts on Big Data and Data Science for Official Statistics under the umbrella of the UN Statistical Commission to explore this potential. This Task Team has produced methodological guidance on PETs 26 and has collated case studies of real-world PETs deployments. 33 Furthermore, a separate but related organisation called the UN PET Lab was established to bring together technology providers and NSOs to work on practical PETs deployments. Through the PET Lab, deployments have been piloted at a number of NSOs including US Census Bureau, Statistics Canada, Italian National Institute of Statistics (ISTAT), IBGE Brazil, and UK ONS. Example projects are described in Section 4.
The statistics community is increasingly recognising the potential of PETs. Pioneering work by the United Nations, 34 Eurostat, 35 and various individual NSOs has created early PETs adopters and established a growing community of PETs practitioners across the public, private, and third sectors. By drawing on discussions with representatives of NSOs, engagement with the broader statistics community, and our own experiences working on numerous real-world PET deployments, this paper aims to help accelerate broader adoption of these technologies by providing practical insights into the technical and social challenges involved in delivering a PETs project at an NSO. We also aim to rally the statistics community behind a long-term vision for a PETs-enabled data ecosystem which maximises societal benefits of official statistics whilst protecting citizens and preventing data misuse.
Concretely, this paper will:
Outline the current challenges faced by NSOs when undertaking new data projects, providing a taxonomy of the different stakeholders involved and the different challenges they face (Section 2); Explain how effective PETs deployment can help alleviate each of these challenges, unblocking or accelerating the delivery of valuable data projects (Section 3); Describe concrete examples of PET deployments being undertaken at NSOs through the UN PET Lab, highlighting key challenges and how they can be addressed (Section 4); Provide a vision for a future PETs-enabled data ecosystem, in which NSOs — alongside other data owners, researchers, and institutions — are able to safely collaborate on larger and more diverse data, maximising public benefit, and truly fulfilling their public good remit.
We hope to show that PETs can not only enhance data privacy, but can also create scalable governance mechanisms that facilitate new collaborations and partnerships. The Royal Society in the United Kingdom has explored this framing of PETs as tools to support partnerships, 36 and Lunar Ventures has suggested the acronym be reconsidered as partnership-enhancing technologies. 37 Enabling collaborations through these technologies could be fundamental in supporting the achievement of the Sustainable Development Goals under the UN 2030 Agenda. 38
The status quo: Challenges and personas for data projects at NSOs
Getting a new data initiative off the ground can be challenging in any organisation, due to a combination of factors such as the financial cost involved, the need to ensure regulatory compliance, data privacy concerns, and the associated legal and reputational risks. These challenges can be particularly pronounced in the public sector. Research from the UK Centre for Data Ethics and Innovation highlights three categories of barriers that can inhibit data sharing:
39
To effectively address these barriers, it is crucial to understand the motivations and challenges faced by different stakeholders involved in data projects. Through our work with NSOs, we have identified four core internal stakeholder functions that typically influence decision-making (among others):
These functions are summarised in Table 2. While they may not directly correspond to specific departments or individuals within any given NSO, they represent the key types of stakeholders typically involved. These functions were identified through discussions and deliberation with statisticians at various NSOs participating in the UN PET Lab, and were validated as a useful framework for understanding the different perspectives and challenges that must be addressed when initiating new data projects.
Archetypes of internal functions responsible for approving a data sharing project at a national statistics office.

Archetypes of internal functions responsible for approving a data sharing project at a national statistics office.
We argue that privacy-enhancing technologies (PETs), when implemented effectively, can provide effective solutions to overcome the challenges outlined in the previous section, unlocking valuable data projects that would otherwise be blocked.
A brief introduction to PETs
PETs are a group of technologies which can enable access to and use of sensitive data, whilst providing certain guarantees about its privacy and security. PETs are most usefully categorised into input privacy techniques (which provide control over who can access and govern the data) and output privacy techniques (which protect sensitive information being reverse-engineered from the results of analyses). 40 Output privacy is closely related to the traditional concept of statistical disclosure control, providing methods to disseminate data whilst protecting sensitive information. There is no definitive list of which technologies should be considered as PETs, but we briefly describe several techniques that are most applicable to NSO use cases today.
Firstly, a basic input privacy technique is remote execution. This is a paradigm in which data owners permit authorised third parties to remotely query relevant datasets. This facilitates greater data privacy since the third party does not have direct read access to the data. It also offers more granular governance, as the data owner determines who is able to propose queries, and retains the authority to approve or deny those queries. This simple technique thus provides powerful safeguards against privacy and misuse risks.
Secondly, a set of more advanced input privacy techniques can be leveraged to provide mutual secrecy in cases where two or more parties have data they want to jointly run a computation on whilst keeping their data confidential from the other parties involved. Trusted execution environments (also known as secure enclaves), homomorphic encryption, and secure multi-party computation protocols achieve this by facilitating computations directly on encrypted data. The result can then only be read by pre-authorised parties. For example, such techniques can enable NSOs to perform privacy-preserving joins on their records.
Finally, differential privacy has been explored as a formal mechanism for implementing output privacy on statistical disclosures. Differential privacy is a property of an algorithm that provides an upper bound on how much information could theoretically be leaked about any individual record in the underlying dataset. Differential privacy is typically achieved by injecting a calibrated amount of noise to a statistical computation such that sensitive information cannot be inferred from the outputs of a query or algorithm run against the dataset.
It is important to acknowledge that there are practical challenges to implementing differential privacy. A fundamental challenge is calibrating the amount of noise (parameterised through the “privacy budget”, ε) to provide a level of accuracy and privacy appropriate for the given context. For smaller sample sizes, a larger value of ε is required to maintain a given level of privacy, which comes with an accuracy penalty. This can have significant implications for the accuracy of statistics derived for small sub-populations. The implementation for the 2020 Decennial Census in the United States faced such issues, which resulted in biases in redistricting data, 41 and criticism that the data releases were neither as private nor as accurate as those of previous censuses that used traditional statistical disclosure methods. 42
No single PET offers perfect data privacy, but combinations of input and output privacy techniques have the potential to provide strong end-to-end privacy guarantees and governance controls over an information flow. Combining PETs can help avoid pitfalls that might otherwise occur. For example, if only input privacy techniques are used then there may remain a risk that any party with access to the output of the computation could determine sensitive information in the underlying data through reverse-engineering. Furthermore, if only output privacy techniques are used then there can remain a risk of data misuse. For example, if a dataset that is truly anonymous is shared publicly on the internet, the data owner will be unable to oversee and govern how and for what purposes that dataset is used. By integrating both input and output privacy techniques, organizations can achieve two key objectives: they can enable privacy-preserving computations on sensitive data whilst maintaining governance over permitted computations and the dissemination of results.
For a more detailed survey of PETs and their applications in statistics, see the United Nations Guide on Privacy-Enhancing Technologies for Official Statistics. 34
How PETs can shift incentives in favour of data collaboration
To understand how PETs can fundamentally shift organisational incentives towards data collaboration, consider a common scenario: an external researcher requesting access to sensitive microdata held by an NSO. Following such a request, the internal functions at an NSO (see Table 1) are likely to have concerns:
A number of NSOs have established dedicated researcher access programmes – such as the UK ONS Secure Research Service (SRS),
24
the US Federal Statistical Research Data Centers,
43
and the New Zealand Integrated Data Infrastructure
44
– to manage these concerns by rigorously applying data governance frameworks such as the Five Safes. Data that is to be made available to researchers may first be pre-processed (for data cleaning and/or to apply “de-identification” techniques), and a copy then ingested into the research infrastructure. To access the most sensitive data, vetted researchers are typically required to physically enter a dedicated research environment. For example, accessing the highest sensitivity data through the UK ONS SRS requires using a “Safe Room” at the ONS offices, or a SafePod – a small, self-contained secure room with a single workstation. Establishing such programmes is likely to involve a significant amount of both technical (e.g., deploying dedicated physical infrastructure, implementing cybersecurity protocols) and non-technical (e.g., creating accreditation processes for potential researchers, conducting risk assessments) work, requiring significant upfront investment, in addition to ongoing operational and maintenance costs. This leads to an additional concern, particularly for NSOs that do not yet have an established researcher access programme:
In sum, each function has legitimate reasons for refusing to share the data, and in many cases this may result in the data not being shared. Moreover, even mature researcher access programmes may impose constraints on the researcher. For example, SafePods and Safe Rooms necessitate travel to a physical location and constrain what data analysis tools and packages a researcher has access to. And before being able to access such a facility, a researcher may have to go through a lengthy accreditation process.
It is our contention that PETs-based approaches to data access and governance can help to allay some of these concerns. Consider the same example, but with a basic PETs-based approach based on remote execution. First, the data owner generates a mock version of the dataset that has the same structure and schema, but with completely fictitious data entries – this mock dataset is shared directly with the researcher so they can use it to prototype their research code (and they can likely do this prior to the completion of an accreditation process). Once ready (and accredited), the researcher submits their code to the NSO, alongside relevant documentation about their research project. The data owner then reviews these materials, suggests any changes, and ultimately approves the code to be run against the real data asset in the NSO's environment. Once executed, the data owner can approve the results to be shared with the researcher, potentially in a differentially private manner if the sample size is such that there is a risk of re-identification from the output.
How might each function respond to this solution?
This example aims to illustrate how effective use of PETs has the potential to offset some of the concerns that may typically block or constrain data access at NSOs. These approaches are not without their own limitations and costs. For example, the manual approval process described is unlikely to scale to many researchers (though automatic enforcement of usage policies, 45 rate limiting and other methods can help here) and the application of differential privacy (or any other PET) may require knowledge and skills that are not currently widely available. Continued product development, foundational research, and education is required to address these challenges.
Similar considerations can be applied to the other types of use cases defined in Table 1. To avoid repetition, we do not detail each of these here, but for a detailed example of cross-border collaboration through privacy-preserving joins, see the “Private linkage of international trade microdata in a cloud-based secure enclave” paper in this edition.
Proving the concept: Establishing the united nations PET lab
The previous sections have outlined how PETs can theoretically address key barriers to data sharing and create new incentives for collaboration. However, moving from theory to practice requires demonstrating that these technologies can be successfully deployed in real-world statistical environments. Whilst there have been numerous government initiatives promoting the development and adoption of PETs,46–48 to date uptake has been slow.
Recognising this, the UN PET Lab was established in 2019 by the PETs Task Team under the auspices of the UN Statistical Commission, bringing together NSOs and PETs technologists to pilot PETs use cases in official statistics, and share learnings on challenges and opportunities for their use. Conducting concrete, real-world, deployments of PETs can establish precedent for their use, which can in turn inspire broader adoption.
This section examines such efforts by early adopters aiming to turn the potential of PETs into reality, while building evidence and best practices for broader adoption. We detail examples from the UN PET Lab and the broader statistical community. For additional examples of PETs case studies, useful resources include the UK Centre for Data Ethics and Innovation's Repository of Use Cases, 49 the United Nations’ Case Study Repository, 33 the Technical Survey and Analysis conducted for Eurostat's JOCONDE project, 50 and the OECD's report on emerging PETs. 48
Internal
As part of the national statistical system of the United States, the US Department of Education has demonstrated how PETs can be leveraged to facilitate data collaboration inside a single organisation. 51 The department needed to produce annual statistics about student financial aid, but this traditionally required sharing sensitive student data and social security numbers between two divisions (NPSAS and NSLDS). Using secure multi-party computation, they implemented an approach where each division kept their sensitive data encrypted while still performing the necessary statistical analyses. The prototype successfully produced identical results to traditional methods with reasonable computational overhead, demonstrating that privacy-preserving techniques can enable practical data collaboration while providing cryptographic guarantees that sensitive information remains protected.
Inter-agency
Two of Italy's public sector agencies — the Italian National Institute of Statistics (ISTAT) and the Italian Central Bank (Bank of Italy) — developed a privacy-preserving approach to analyse the intersection of their socio-demographic and financial datasets without directly sharing sensitive data. 52 Using a private set intersection protocol with a semi-trusted third party (who serves as a compute party and cannot learn confidential information during the protocol), they were able to perform aggregation and counting queries on the joined dataset while keeping the underlying data encrypted. The pilot was implemented with synthetic data to test the technical validity of the approach. Additional work is required to demonstrate whether this approach is feasible in a production setting..
The UK Office for National Statistics has developed a toolkit to help government departments and organisations securely match and combine their datasets without needing to share sensitive personal information such as names, dates of birth and addresses. 53 Their approach uses Bloom filters and secure enclaves to enable data to be matched with high accuracy while remaining encrypted throughout the process, addressing a key barrier to cross-organizational collaboration in the public sector. While still experimental, the open-source toolkit demonstrates how privacy technologies can enable valuable data collaborations between departments that would previously have been blocked by privacy and security concerns.
Finally, the US Department of Education (DE) and Internal Revenue Service (IRS) have joined sensitive data to create the College Scorecard platform, which enables prospective students to research evidence-based outcomes associated with different degree programmes. 54 This required joining data about degrees from DE with financial data held by the IRS, whilst protecting the privacy of the individuals to whom the information related. The two parties collaborated with Tumult Labs to develop a solution that enabled differentially private insights from the combined data to be made available to the platform. 55
Cross-border
Several NSOs including the US Census Bureau, Statistics Canada and ISTAT have collaborated through the UN PET Lab to explore the application of input privacy techniques to facilitate cross-border privacy-preserving joins 56 using the open-source PySyft software developed by the OpenMined community. In initial pilots with the primary goal of testing the technology, the US Census Bureau, ISTAT and Statistics Canada acted as data owners and provided access to artificial census data to accredited external researchers. 57 A secure cloud environment was leveraged to facilitate privacy-preserving joins between the datasets hosted by the NSOs. The US Census Bureau deployed a Syft Datasite 58 on Cloud.gov (a government-focused service based on the Cloud Foundry platform), ISTAT deployed a Datasite directly on Microsoft Azure, and Statistics Canada also deployed a Datasite to Azure through the Shared Services Canada's Science Program. 59 Successful joins were carried out between the ISTAT and Statistics Canada, and between Statistics Canada and the US Census Bureau. The resulting joined datasets were then remotely studied by external researchers. The pilot validated that an independent external researcher could successfully identify records present in the NSO datasets without the NSOs needing to share their underlying data with one another. Having demonstrated the feasibility of using PySyft for privacy-preserving computations, the Census Bureau and Statistics Canada are, alongside Mexico's National Institute of Statistics and Geography (INEGI), exploring applying the technology to facilitate collaboration on North American trade data.
Separately, Eurostat is aiming to leverage PETs to create a shared infrastructure for multi-party private computing across the European Statistical System (ESS) through the JOCONDE (Joint On-demand Computation with No Data Exchange) project. 60 The project is focused on leveraging input privacy techniques to enable multiple NSOs within the ESS to conduct joint analysis without sharing data with one another. The project is seeking to develop a prototype infrastructure with an architectural approach based on a full overlay of MPC-over-TEE . It is anticipated that outcomes from this prototyping phase will inform a potential production deployment from 2026 onwards.
Private-public
The Indonesian Ministry of Tourism used PETs to generate cross-border tourism statistics using mobile phone network data.61,62 This required comparing sensitive customer data across multiple mobile network operators without violating privacy or business confidentiality. They implemented a solution using Sharemind's secure computing platform, where data remained encrypted throughout the analysis in a secure enclave, allowing mobile operators to safely share insights without exposing their raw data. 63 The successful deployment enabled the Ministry to accurately calculate tourism statistics using mobile data for the first time, demonstrating how privacy-preserving technologies can enable valuable statistics to be derived using non-traditional data sources.
External access
The Brazilian Institute of Geography and Statistics (IBGE) collaborated with OpenMined to conduct a proof of concept with the aim of making micro-data related to Brazil's agricultural sector available to external researchers. In the first instance, the focus of the pilot has been on reproducing an existing study carried out internally by providing privacy-preserving access to the micro-data. The project leverages OpenMined's PySyft software, with IBGE deploying a Syft Datasite 58 on their IT infrastructure through which they make the microdata (and associated mock datasets) available to external researchers in a privacy-preserving way.
The Swiss Federal Statistical Office (FSO) has also developed a similar platform called Lomas, which enables external researchers to remotely run analysis against data held by the FSO and other government agencies. 64 Lomas implements differential privacy to partly automate the statistical disclosure process. For example, researchers can choose to run their analysis with a high level of perturbations to the data (i.e., low privacy budget), in which case access to the platform can be granted with minimal contractual obligations as the disclosure risk can be mathematically proved very low.
Finally UNHCR, the UN Refugee Agency, has leveraged open-source tools for differential privacy created by OpenDP to enable dissemination of refugee registration data for research purposes. 65 The approach has enabled differentially private synthetic datasets of multiple countries’ registration data to be made accessible to licensed researchers through the UNHCR Microdata Library. The data has been shown to be both more accurate and more private than what had previously been made available using traditional statistical disclosure controls.
Realising the potential: Towards a new data ecosystem for official statistics
The pilot projects described above demonstrate the feasibility of PETs-enabled data collaboration in official statistics. Building on these successes, we envision a global network for official statistics that could fundamentally transform how data is shared and accessed across organisations. In this network, data owners — including NSOs, government agencies, and private sector organisations — would securely host valuable data assets, which could then be securely accessed by approved external researchers or collaborators, using PETs. Participating NSOs would share metadata on the network to advertise what data assets they have made available and how to request access. Researchers and NSOs could then search and discover data assets across the network.
This infrastructure could build upon and extend the UN Global Platform, creating a secure network of public and non-public datasets that can be utilized for research and innovation. The network would enforce existing data release policies and implement federated data governance aligned with established frameworks such as the Five Safes. (See the subsequent “A Delphi Study on the Role of Privacy Enhancing Technologies (PETs) in Data Sharing Ecosystems” paper for further information on the role of PETs in risk assessment frameworks.)
This network has the potential to facilitate secure access to high quality datasets for tens of thousands of researchers and organisations around the world. To maximise the benefits of this network, it should be considered a public good, and be built on public, open-source infrastructure and protocols. As noted in UN Resolution 2021/30, “open-source methods, can serve as a tool for overcoming barriers to the building and dissemination of the global stock of knowledge”, and Member States should explore “ways to better leverage open-source technologies for sustainable development”. 66 It is critical that these protocols are secure, and open-sourcing can enable a broad community to inspect the source code and identify and resolve vulnerabilities rapidly. 67 Supporting the creation of a public network for non-public information built on open-source infrastructure can help realise the ambition of Res. 2021/30, and help unlock valuable data assets which can be transformational for achieving the SDGs under the UN 2030 Agenda.
The work of the UN PET Lab to date has been a critical first step toward achieving this vision. However, significant challenges remain. At present, only around a dozen of the 193 UN Member States are represented in the PET Lab, the majority from the Global North. Furthermore, participation is on a voluntary basis with no explicit funding for the group's activities, limiting the speed at which progress can be made. This means there are currently incalculable unrealized gains due to value being locked up in siloed or otherwise restricted datasets. We call on the statistical community to:
Raise awareness of the potential of PETs through education and knowledge sharing Invest in and promote open-source PETs infrastructure and pilot deployments Participate in the UN PET Lab to share experiences and best practices Develop standards and frameworks for PETs implementation in official statistics, for example by exploring the role of PETs in operationalising existing frameworks such as the Five Safes
The UN PET Lab is leading the conversation on what can be achieved through PETs-enabled data collaborations, and we invite interested NSOs, academics, and technologists from the PET and statistical communities to join us in pushing this work forward.
Conclusion
Privacy-enhancing technologies have the potential to fundamentally transform how National Statistical Offices collaborate and share data. Through strong privacy guarantees and granular governance controls, PETs can help NSOs navigate the inherent tension between maximising the public benefit of data while protecting privacy and maintaining trust. Through pilot deployments at the UN PET Lab, we have demonstrated that PETs are now sufficiently mature to enable valuable data collaborations that would otherwise be blocked by technical, legal, or organisational barriers.
However, realising the full potential of PETs requires moving beyond individual pilot projects toward a coordinated, global approach. The vision we have outlined for a PETs-enabled global network for official statistics could dramatically expand secure access to sensitive data for research and innovation. Such a network would not only modernise official statistics but could also lead to more effective evidence-based policymaking, and accelerate progress towards the Sustainable Development Goals.
Making this vision a reality requires sustained commitment from the international statistical community. NSOs must invest in building technical capacity, developing governance frameworks, and sharing learnings from PETs deployments. The UN PET Lab provides a foundation for this collaboration, but broader participation and investment are needed to scale its impact. By working together to advance the adoption of PETs, we can transform official statistics from a system constrained by privacy barriers into one where secure data collaboration enables unprecedented insights for public good — fully unlocking the value of society's data, while setting new standards for privacy protection and public trust.
Footnotes
Author note
The views expressed herein are those of the authors and do not necessarily reflect the views of the respective organizations.
Acknowledgements
The authors would like to thank all members of the UN PET Lab, UN Task Team on PETs, and the OpenMined community, whose insights and discussions have greatly informed this paper.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.