
Abstract
Artificial Intelligence (AI) has become a pivotal tool in the digital transformation of organisations across all sectors and types of organisations, including public bodies. For these, AI offers significant potential benefits such as improving the efficiency of internal operations, the effectiveness of policymaking, the responsiveness of public services, and enhancing transparency and accountability. The quality of the data used to train AI models is a key factor for the success or failure of an AI application. The main contribution of this work lies in the adoption of a data-centric approach, through which critical categories of data quality alerts are identified and related to inherent data quality characteristics for machine learning and analytics. In addition, current ISO standards and European regulations concerning AI and data quality are considered, highlighting both their technical foundations and existing limitations.
Keywords
Introduction
Artificial Intelligence plays a crucial role in the digital transformation of organisations across all sectors and types of entities. AI has become a pivotal tool for enhancing operational efficiency, enabling data-driven decision-making and driving innovation. Public bodies are aware of the multiple benefits of applying AI, both in their internal processes and in the services provided to citizens. In addition, AI has emerged as a strategic resource and general-purpose technology with the potential to transform a wide range of sectors. In the public sector, AI offers significant potential benefits such as improving the efficiency of internal operations, the effectiveness of policymaking, the responsiveness of public services, and enhancing transparency and accountability. 1
Public sector organizations occupy a significant position when it comes to data generation. In recent years, governments have increasingly pursued the publication of government data in machine-readable formats through open government data policies, associated portals for datasets and Application Programming Interfaces (API). However, public data made available to citizens must meet certain characteristics to guarantee it can be easily reused to generate new information or services and, ultimately, to increase the transparency of public bodies. In this sense, open public data aims to facilitate the reuse of public sector information through the intensive use of information and communication technologies. In short, openness of public data focuses on public bodies providing information that can be easily reused.
The benefits of open data are diverse and range from improved efficiency of public administrations, economic growth in the private sector to wider social welfare. Through open data portals, public bodies make available hundreds of thousands of datasets in automatically processable formats that facilitate redistribution, reuse and commercialisation. The opening of public data through these portals aims to access or disseminate public sector information through electronic means to give greater prominence to citizens. In fact, the opening of public data favours learning about, analysing and evaluating administrative activity. In addition, opening data also facilitates the creation of information and the offer of new value-added services based on the data disseminated by public bodies.
A key aspect of open public data is its growing importance in the field of AI. In this context, a critical issue in the successful development and deployment of AI is the quality of data: good AI depends on good data. And even going a little further AI needs data more than data needs AI. 2 AI fundamental approach should strategically link to data programmes strategies to ensure that AI systems are built on robust, accurate, and comprehensive datasets, in particular government data.
Public open data should allow AI models to become more robust and to improve their ability to generalize across different contexts. 3 The diversity and comprehensiveness of these datasets mean that AI systems are better equipped to handle new or unforeseen scenarios, reducing the risk of biased or incomplete predictions. 4
Furthermore, the relationship between AI and public open data is a mutually beneficial one. The quality and consistency of public data not only facilitate the development of more accurate AI models, but AI itself enhances the value of these datasets by uncovering complex patterns and generating actionable insights. Public data provides the essential inputs that AI algorithms need to increase their precision, while AI in turn unlocks new ways of interpreting and utilizing this data for decision-making. 4 Without access to high-quality, standardised public data, AI systems would struggle to reach their full potential in terms of performance and adaptability. Given the crucial role of public open data, many European countries have taken significant steps to consolidate and centralise access to these datasets through various national and international portals.
The European Data Portal, for example, is a central point of access to European open data from international, European Union, national, regional, local and geodata portals. It consolidates the former EU Open Data Portal (launched in 2012) and the European Data Portal (launched 2015), which were originally established to promote accessibility and reuse of public sector information. 5 The portal is intended to: (i) give access and foster the reuse of European open data among citizens, business and organisations; (ii) promote and support the release of more and better-quality metadata and data by the EU’s institutions, agencies and other bodies, and European countries, enhancing the administrative openness; and (iii) educate citizens and organisations about the opportunities that arise from the availability of open data.
Additionally to this central point of access, several European countries have developed national open data portals to facilitate access and reuse of public data to underpin the transition toward a data-driven public administration, capable of taking advantage of the potential of data using innovative technological means, enabling the design, execution and evaluation of citizen-centred public policies that promote a data-oriented, sustainable economy that generates social value. If we consider the number of datasets, as a key factor, we could highlight initiatives from Germany, 6 Spain 7 and Italy, 8 among others.
On the private sector side, but also with public sector support, there are also initiatives such as the private non-profit association GAIA-X, 9 which aims the creation of an open, federated and interoperable data infrastructure, built on the values of digital sovereignty and data availability, and the promotion of the data economy. In this way, an ecosystem will be created in which data from European entities is available and shared in a trustworthy environment managed in accordance with European principles of decentralisation, openness, transparency, sovereignty and interoperability. In addition, there is another non-profit global organization such as the International Data Spaces Association (IDSA), focusing on establishing and promoting standards for data spaces – trusted environments, where organizations can share data while retaining full control over its use. IDSA 10 promotes sovereign, interoperable, and trusted data ecosystems, enabling organizations to exchange data while maintaining control and compliance with regulatory standards.
According to all above, the importance of data will become even more relevant in the future, since data-centric AI will revolutionize machine learning (ML) in 2025. 11 In fact, the use of AI for public policy development is transforming governments’ ability to make more informed, data-driven decisions. The integration of ML algorithms enables governments to formulate more efficient and targeted policies. In addition, AI has enormous potential to further improve productivity, efficiency and the quality of public services.
Due to the rapid expansion of AI across all sectors and organisational types, numerous governments and institutions have, over the past decade, initiated efforts to promote regulations and standards targeting various aspects of AI.
Regarding regulations in European Union (EU), there are regulations intended to manage AI, such as Regulation (EU) 2024/1689. 12 There are other references from European Commission, such as the White Book on AI, 13 which searches for an approach to excellence and trust and served as a reference document for the development of Regulation (EU) 2024/1689. There are also other references and guidelines that provide a framework for developing AI systems that respect fundamental rights and are technically robust. 14
In Spain, the National Artificial Intelligence Strategy (ENIA), 15 which is articulated around the development of 20 measures structured around 6 strategic axes, together with RD 729/2023 16 establish guidelines to ensure the quality of data used in AI systems.
Regarding standardisation initiatives for AI, these address areas such as governance, management, quality and other aspects related to both AI systems and the data needed for their development and operation. Among the standardisation initiatives, the contributions made by the International Organization for Standardization (ISO) are particularly significant.
ISO/IEC JTC 1/SC 42 is the committee responsible for leading the development and publication of AI-related standards within ISO. Since its creation in 2017, the committee has published over 25 standards specifically related to AI, with more than 35 additional standards currently under development. 17 Among these standards, the following are particularly notable with regard to AI systems, their quality, and the data required for their development and operation: (i) ISO/IEC 22989:2022 and ISO/IEC 23053:2022, which provide common terminology and key concepts in the fields of AI and ML, respectively 18 , 19 ; (ii) ISO/IEC 25059:2023 and ISO/IEC TS 25058:2024, which focus on the quality of AI systems 20 , 21 ; (iii) ISO/IEC TR 24027:2021 and ISO/IEC TS 12791:2024, which address bias in AI systems 22 , 23 ; (iv) ISO/IEC 8183:2023, which outlines the data life cycle framework for AI systems 24 ; and (v) ISO/IEC 5259 series, which provide tools and methods for assessing and improving the quality of data used for ML and analytics.25–28
In particular, ISO/IEC 5259-1:2024 25 provides the means for understanding and associating the individual documents of the ISO/IEC 5259 series and is the foundation for conceptual understanding of data quality for ML and analytics. ISO/IEC 5259-2:2024 26 builds upon the ISO 8000 series, ISO/IEC 25012 and ISO/IEC 25024, describing a specific data quality model for ML and analytics through the definition of data quality characteristics and data quality measures based on ISO/IEC 25012 and ISO/IEC 25024. Regarding the data quality characteristics for ML and analytics, several categories are defined, with particular emphasis in this work on the inherent data quality characteristics: accuracy, completeness, consistency, credibility and currentness. ISO/IEC 5259-3:2024 27 specifies requirements and provides guidance for establishing, implementing, maintaining and continually improving the quality for data used in the areas of ML and analytics. ISO/IEC 5259-4:2024 28 provides general common organisational approaches, regardless of type, size or nature of the applying organization, to ensure data quality for training and evaluation in ML and analytics.
In addition to the aforementioned AI-related ISO standards, there are other standards relevant in the field of data quality, although they are not specifically addressed to AI. Considering data quality, ISO 8000 series is available as a reference for data quality, as an international standard for the quality of transaction data, product data and master data. This standard has different parts: general concepts of data quality (ISO 8000-1:2022, ISO 8000-2:2022 and ISO 8000-8-2015),29–31 data quality management (from ISO 8000-60 to ISO 8000-66 and ISO 8000-150),32–34 generalities of the exchange of master data between organizations (ISO 8000-100 to ISO 8000-140), data quality assessment (ISO/TS 8000-81 and ISO/TS 8000-82) 35 , 36 and quality of product data (ISO 8000-311). 37
ISO/IEC 25012:2008 38 defines a general model for the quality of data stored in a structured manner in information systems. It can also be considered as a reference for data quality.
To measure data quality, ISO/IEC 25024 (in development) 39 could be considered as a reference. This standard defines data quality measures for quantitatively measuring the data quality in terms of characteristics defined in ISO/IEC 25012.
Considering the current context outlined above, the main objective of this article is to explore, from multiple perspectives, the critical role of data quality in enhancing the reliability and trustworthiness of AI applications for European public bodies. To this end, the rest of the article is structured as follows: section II describes the research methodology followed in the current work; section III makes a review of EU approach to AI regulation and development; section IV highlights the significance of data quality in the current data-centric AI paradigm, exploring the crucial role of automated data cleaning and data labelling in building more reliable and unbiased AI systems; section V presents the ISO standards approach to data cleaning and data labelling; section VI presents an empirical data quality diagnosis focused on the main issues that may arise in a dataset, potentially affecting the reliability and trustworthiness of AI applications built upon such data, and relates these issues to the inherent data quality characteristics described in ISO/IEC 5259-2:2024; finally, section VII presents both the conclusions obtained with this work and the future lines of work.
Research methodology
This work adopts an exploratory research methodology to examine how data quality impacts AI applications, while considering regulatory frameworks and international standards.
The research is based on a comprehensive literature review focused on official European sources. This review encompasses academic publications, regulatory frameworks, standards, and technical references related to AI, data quality, and data processing techniques.
The methodology unfolds in several stages. First, we conduct an in-depth review of the European Union’s current regulation on AI to set the legal and strategic backdrop. Next, the study delves into the growing importance of data quality within the data-centric-AI landscape, particularly highlighting the significance of data cleaning and labelling processes. Additionally, we analyse international standards, especially those from the ISO, to grasp their perspective on data preparation for AI systems. Once these references were analysed, around 50 datasets from various European countries were downloaded from the official European data portal to continue developing this research. The goal was to analyse their data quality. Based on the results, a subset of conflicting datasets was selected to continue the research in greater detail. Lastly, the research adopts a diagnostic lens on data quality, pinpointing challenges and suggesting solutions to boost the performance and reliability of AI applications.
The integration of regulatory analysis, standards review, and data-centric technical exploration allows for a multidisciplinary understanding of how data quality influences AI system reliability and trustworthiness. The methodology also provides a foundation for the conclusions and future lines of research discussed in the final section of this work.
EU approach to AI regulation and development
European Union (EU) has established a comprehensive regulatory framework to govern the development of AI, considering clear principles of transparency and human oversight, and classifying AI systems according to their level of risk. In this way, strict requirements are defined for situations that could significantly impact fundamental rights, such as privacy, non-discrimination, and safety. This is fundamental to ensuring that the development and use of these technologies are conducted ethically and with respect for individuals’ rights. This is demonstrated by a series of strategic initiatives.
The AI Act (Regulation 2024/1689), enacted on July 12, 2024, represents the world’s first comprehensive regulatory framework for AI. The Act employs a risk-stratified approach, categorising AI systems based on their potential societal impact. It mandates stringent requirements for high-risk systems seeking EU market access, while prohibiting those deemed to pose unacceptable risks. The legislation further stipulates the necessity of fundamental rights impact assessments for novel AI systems and establishes an AI Office within the European Commission to oversee implementation and promote standardization efforts. 12
The creation of dual ecosystems is proposed in 13 according to European Commission’s strategic vision: one fostering excellence in AI development across the EU economy, and another establishing a regulatory framework to engender trust. This document outlines policy options aimed at facilitating the development of trustworthy and secure AI systems in EU, with due consideration for EU citizens’ values and rights.
On 8 April 2019, the High-Level Expert Group on AI in European Commission presented Ethics Guidelines for Trustworthy Artificial Intelligence, 14 which constitute an important contribution on the discourse on AI governance. This framework delineates a tripartite approach to AI systems development, emphasizing the critical dimension of legality, ethical adherence and technical robustness. The guidelines articulate seven fundamental principles that AI systems must embody, encompassing human agency and oversight, privacy preservation, transparency in decision-making processes, and accountability mechanisms.
Spain has developed a comprehensive national strategy and regulatory framework for AI through ENIA, 15 which represents a holistic policy framework designed to position Spain at the forefront of AI development and application. The strategy is structured around six strategic axes: (i) Advancement of scientific research, technological development, and innovation in AI; (ii) Enhancement of digital capabilities and talent development; (iii) Establishment of data platforms and technological infrastructures; (iv) Integration of AI into economic value chains; (v) Promotion of AI utilization in public administration and strategic national initiatives; and (vi) Development of an ethical and regulatory framework to safeguard individual and collective rights. ENIA encompasses 20 specific measures aimed at fostering research, innovation, and talent cultivation in AI.
The Spanish Agency for Artificial Intelligence Supervision (AESIA) is established in August 2023. 16 AESIA is instituted as an autonomous public entity under the purview of the Secretary of State for Digitalization and Artificial Intelligence. The agency’s mandate encompasses regulatory supervision, advisory services, public awareness initiatives, and training programs for both public and private sector entities. This proactive legislative measure positions Spain as the first European nation to establish a specialized AI regulatory body, anticipating the forthcoming European AI Regulation and underscoring Spain’s commitment to responsible AI development and oversight.
Data-centric AI
Data-centric AI 11 recognizes a key condition of every AI project: data quality. The importance of data quality –or lack thereof– is considered as an important factor contributing to the success or failure of an AI initiative. As a result, data serves as the fundamental fuel driving the digital transformation of the public sector.
Data quality plays a foundational role in addressing ethical and social challenges for AI, such as bias and discrimination. Poor data quality is one of the main causes of biased AI systems, so the impact of a better data quality means to prevent underperformance on minority groups, ensure model sees fair distribution of populations, to stop reinforcement of past discrimination and reduce subjective and human-induced bias.
The focus will shift from model optimisation to data quality as organizations recognize that better data –not just better algorithms– is the key to superior AI performance. This paradigm shift will drive investments in automated data cleaning and data labelling, resulting in more reliable and unbiased AI systems.
According to a survey of data scientists reported by Forbes, 40 it is estimated that data scientists spend up to 60% of their time on tasks related to data transformation, 20% on data collection and only 20% on the actual analysis.
This data transformation involves data cleaning, a key process linked to the data quality, which is performed on structured data that are used in modern data chains. Automated data cleaning is fundamental to reduce the spent time on data transformation. This involves making the appropriate modifications to the data, a process that can be sped up using rules-based AI technologies such as Robotic Process Automation (RPA).
A significant step before beginning to experiment with AI in a data project is to aggregate and analyse the data to better understand them and further prepare them for AI or ML models. This is critical, as interpreting and understanding the data at hand accounts for a substantial proportion of the time and resources involved in designing AI systems –even more than building the models and algorithms–. At this stage of the process, it is likely that some preliminary conclusions will already have been reached about the data, but work is still needed to generate working hypotheses for testing.
Data labelling can be dealt as a process that consists of the annotating and feature engineering. It is important to pay attention to the associated metadata to ensure that the data being analysed have been correctly understood. Both labelling and annotating involve looking at data and providing an additional label or annotation to ensure higher levels of usability, clarity and readability. Labelling involves identifying elements that an AI system will try to predict. Feature engineering is the process of turning a certain amount of data into a feature, or another type of data, that can be consumed by an AI project. A key action is to identify a single measure of success for the project to track over time (label) and other things that could influence it (features).
The labelling process involves adding meaningful tags, labels, or classifications to raw data so that AI systems can learn to identify patterns and make predictions. It’s a critical step in supervised and semi-supervised learning because these models rely on labelled data to train effectively.
Regarding the data labelling methods, we can classify them into manual or programmatic labelling. In the first method, humans annotate the data using tools or platforms, while in the second algorithms automatically assign labels. Manual data labelling is a time-consuming process and expensive process. If public administrations want to effectively manage data labelling, they should concentrate their efforts on auto labelling processes. Therefore, programmatic processes are faster, efficient, accurate and cost-effective.
Moreover, automated data cleaning is addressed as the process of using algorithms to automatically detect, correct, and remove errors and inconsistencies from data. This helps to ensure that data is accurate and consistent.
Latest trends about data cleaning reflect a shift towards more intelligent, real-time, and integrated processes that can adapt to the ever-growing and diverse data landscape.
We could highlight that data cleaning pull AI/ML models to automatically detect anomalies, predict missing values, and suggest corrections based on historical patterns. As well, data cleaning is moving to live data streams and is increasingly being integrated with broader data governance frameworks.
In essence, data labelling and automated data cleaning should be the bridge between public bodies raw data and intelligent AI systems, ensuring that models learn effectively and perform as expected in real-world applications. Without it, AI would be unable to achieve the precision and reliability needed for practical use.
ISO standards approach to data cleaning and data labelling
Although, as outlined in Introduction, there are several ISO standards related to AI systems, their quality, and the data required for their development and operation, only a limited number include information about data cleaning and data labelling. These key standards are subsequently described.
ISO/IEC 8183:2023
This standard, which outlines the data life cycle framework for AI systems, only defines what the operations of data cleaning and data labelling consist of, in the context of the data preparation stage. These are defined as follows:
Data cleaning: includes transforms and operations such as relevance validation, deduplication, outlier removal, bias mitigation, imputation of missing entries, correcting entries and correcting data formats. 24
Data labelling: the values of target variables should be established by a suitable manual or automatic process. For example, with supervised learning, values can be determined manually. With semi-supervised learning, values can be determined through automated techniques. An example of manual data labelling for an image recognition application is the use of humans to determine the species of animals in a set of digital images. 24
ISO/IEC 5259-3:2024
This standard, which provides requirements and guidance for establishing, implementing, maintaining and continually improving the quality of data used in the areas of ML and analytics, specifies the minimum aspects of data cleaning and data labelling operations that an organization should define although it does not delve into the underlying methods or techniques to be employed.
Concerning data cleaning, the standard stipulates that an organization should at least specify which data quality measures have been applied for detection and mitigation of missing data, detection and mitigation of data duplication, detection and mitigation of outliers and other issues, detection and mitigation of bias, drift and scaling, detection and handling of non-standard values, detection and removal of not needed data, data transformations, including data normalization, methods of verifying data cleaning results and, if applicable, data de-identification. 27
Regarding data labelling, the standard states that an organization should at least specify the following aspects: data labelling specification, required skills and resources, selection of data for labelling, monitoring and quality management of labelling processes, and potential physical and psychological impact on data labeller, including mitigation strategies. 27
ISO/IEC 5259-4: 2024
This standard, which provides general common organisational approaches to ensure data quality for training and evaluation in ML and analytics, stands out for describing in detail data labelling principles, methods and process.
Regarding data labelling methods, the most relevant aspect of the standard is its following statement: “data labelling methods depend on the data type and can include object labelling, bounding box, key-point labelling, instance segmentation, semantic segmentation and sequence labelling. Data labelling objects include the following: image labelling [..], voice labelling […] and text labelling […]”. 28
The data labelling process is described in the standard through three distinct stages: labelling preparation, labelling execution and labelling output. According to the standard, during the labelling preparation stage, the following aspects must be defined: labelling specifications, labelling participants roles and labelling tools or platforms. The labelling execution stage consists of three essential steps: labelling task establishment, labelling task assignment and labelling process control. Finally, the labelling output stage must include a labelling result quality checking and a labelling result revision. To ensure the quality of data labelling, considerations for each stage of the process are described in the standard. 28
ISO/IEC TR 24027:2021
This standard, which articulates current best practices to detect and treat bias in AI systems or in AI-aided decision-making, identifies the data labelling process as a source of cognitive or societal biases in AI systems providing some methods to prevent such biases. 22
In addition to these AI-related ISO standards, other data quality standards introduce concepts that are relevant when considering data cleaning and data labelling. These data quality standards are subsequently described.
ISO 8000
In general, the ISO 8000 standards do not provide a specific or detailed definition of data labelling. These standards primarily focus on general aspects of data quality, data quality management, master data exchange, and product data quality. However, some related concepts mentioned in the ISO 8000 standards that could be relevant to data labelling include: (i) accuracy and completeness: ISO 8000-1x0 series specifies requirements for adding information about the levels of accuracy and completeness of data in master data exchange messages; (ii) syntax and semantic encoding: ISO 8000 standard specifies requirements for declaring the syntax and semantic encoding of data, which allows for determining the limitations of data portability; and (iii) data quality: ISO 8000 standards define characteristics that determine data quality, such as accuracy, completeness, consistency, credibility, timeliness, accessibility, among others.
ISO 8000-60 introduces concepts for implementing, assessing and improving data quality management. It mentions that effective data quality management requires understanding root causes of issues to prevent future nonconformities. 32 ISO/TS 8000-81 specifies an approach to data profiling for identifying opportunities to improve data quality, which could be considered a precursor to data cleaning activities. 35 ISO/TS 8000-82 provides guidance on creating data rules although it does not specifically address data cleaning or labelling. 36 Despite ISO 8000-311 does not specifically mention data cleaning or labelling processes, it focuses on quality considerations for product shape data. 37
Visual summary
Figure 1 illustrates the relevant ISO standards related to data cleaning and data labelling previously described, additionally representing the level of detail they provide as well as the direction of their mutual references. ISO standards addressing data cleaning and data labelling.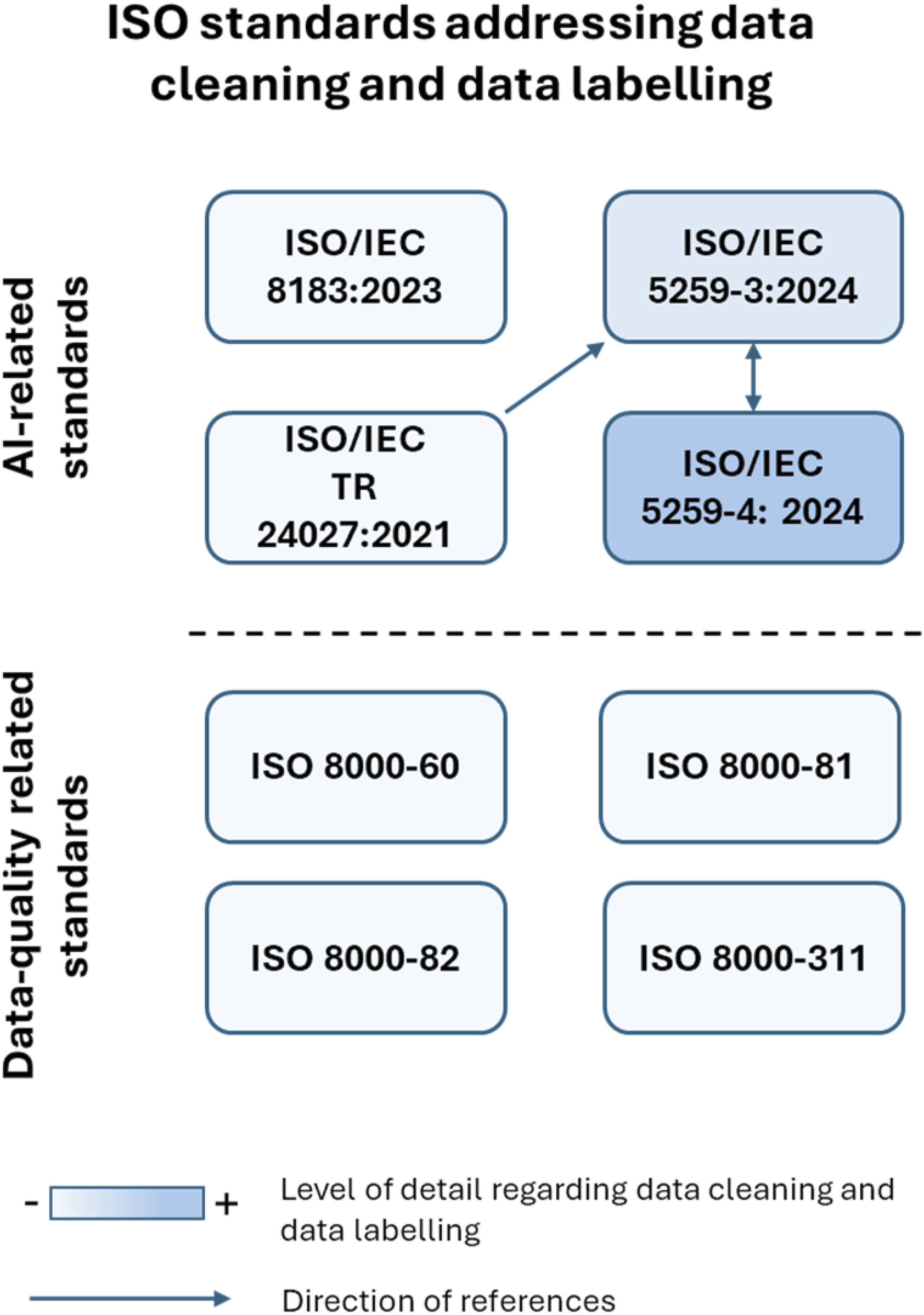
The level of detail regarding data cleaning and data labelling is visually represented using a blue colour gradient in the background of the box indicating an ISO standard. A more intense blue colour denotes a higher level of detail, whereas a lighter shade signifies less detail.
The direction of references between ISO standards is depicted with arrows. If an arrow points from ISO standard A to B, this indicates that standard A is referenced in standard B and, consequently, contributes to it.
As shown in Figure 1, among the relevant ISO standards, ISO/IEC 5259-4:2024 contains the highest level of detail. Moreover, references exist only among three standards: ISO/IEC 5259-3:2024 references ISO/IEC TR 24027:2021, while ISO/IEC 5259-3:2024 and ISO/IEC 5259-4:2024 reference each other.
Data quality diagnosis to enhance data in AI
Up to this point, we have described EU approach to AI regulation and development, the significance of data quality in the current data-centric AI paradigm; and ISO standards approach to data cleaning and data labelling. However, what are the main issues that can arise in a dataset? And what is the status of the datasets available on public bodies’ open data portals?
To address these questions, we selected approximately 50 datasets from the European Data Portal, 41 with Spain being the most represented country of origin. Of these, 20 exhibited data quality issues and were subjected to detailed analysis. This sample comprises datasets from five countries: Spain (16), Italy (1), Lithuania (1), Belgium (1) and Ireland (1).
The most frequent deficiencies involved the presence of missing values and variables with a high proportion of zeros. It is important to note that such issues tend to worsen in datasets containing a large number of variables and records, which are particularly susceptible to skewed distributions, unbalanced classes, high inter-variable correlation, or even the presence of a single unique value in each variable.
The analysis was carried out using scripts written in Python, which has been designed to systematically identify specific alerts that help detect patterns associated with data quality issues, which can compromise the reliability of statistical analysis and the performance of ML models.
Each dataset was analysed individually, and the generated alerts were collected and synthesized for a comparative analysis. We have considered the following 10 different types of alerts: (i)
Figure 2 shows the frequency of the occurrence of each type of alert across the sample. The most common issues were outliers (present in 16 datasets), followed by missing values and zero values (each present in 12 datasets). Number of datasets vs. alerts.
To support the interpretation of results, detected alerts were grouped into five main categories (grey and blue colours respectively in Figure 3), according to the type of statistical issue they represent. This classification is not intended to be exhaustive, but it provides a useful structure for understanding how different types of data quality problems may impact the robustness of analyses and the performance of ML models. Alerts grouped by category.
Categorisation vs. Potential Impact.

ISO standards referenced in section V address data quality from a conceptual standpoint but lack the operational specificity required for practical implementation. They do not provide concrete guidelines or best practices to detect and mitigate specific quality issues such as non-informative features, anomalous distributions, missing values, or redundant attributes. This lack of specificity becomes particularly evident when contrasted with empirical evidence obtained in this analysis, where multiple open datasets exhibit recurring patterns of low data quality across several categories.
Alerts vs. ISO/IEC 5259-2:2024 Inherent Data Quality Characteristics Matrix.


Conclusions and future works
The use of AI for public policy development is transforming governments’ ability to make data-driven decisions. The integration of ML algorithms enables governments to formulate more efficient and targeted policies.
AI has the potential to revolutionise public policy development, improving both the precision and effectiveness of government decision-making. Using predictive models, real-time data analysis, and policy simulations, governments can make smarter decisions, maximizing the positive impact on society. However, the key to success lies in continuously improving data quality and ensuring transparency in the decision-making process.
European open data portals facilitate access, interoperability, and reuse of information, aligning with the FAIR principles (Findable, Accessible, Interoperable, Reusable), as established in regulations such as. 5 These portals are based on the data quality guide from data.europa.eu, which provides a technical foundation to ensure data quality, focusing on aspects such as format standardisation, the removal of duplicates, and the management of null values. However, while these measures are crucial for interoperability and reuse, data quality is neither comprehensive nor complete.
A data-centric approach recognises that well-curated, consistent, and representative data is essential for building reliable and trustworthy AI systems. As data becomes increasingly relevant, it would be highly recommended that ISO standards evolve to explicitly address possible data-related alerts such as identified in this work.
These identified alerts have been organised into the following five categories to facilitate analysis and management. However, this classification is not exhaustive, and alternative groupings may also be considered: irregular or noisy data, non-informative feature descriptions, problematic distribution, incomplete or uninterpretable data, and low variability or redundancy.
The issues related to previous alerts/categories, if unaddressed, can severely compromise the integrity of AI systems outputs. Therefore, incorporating clear, actionable guidance for managing alerts within ISO standards might enhance both operational efficiency and trust in AI applications.
The following outlines a set of methods and recommendations aimed at addressing the identified alerts. These proposals could be incorporated into future updates of ISO standards, aiming to support early detection, systematic analysis, and effective correction within data environments designed for artificial intelligence applications. The proposed measures are structured according to each alert category, and include both diagnostic techniques and corrective strategies: (1) Irregular or noisy data: establish acceptable thresholds for deviation, apply smoothing techniques appropriate to the data type, and use domain-specific anomaly detection models. (2) Non-informative features description: evaluate features using mutual information scoring, apply variance analysis to detect low-relevance variables, and implement recursive feature elimination methods. (3) Problematic distribution: diagnose patterns such as skewness, outliers, or multimodality, apply suitable transformations and stratified sampling to mitigate imbalances, and integrate robust modelling techniques for non-normal distributions. (4) Incomplete or uninterpretable data: apply imputation strategies aligned with the underlying missingness mechanism, systematically document causes and patterns of missing data, and define protocols for excluding or flagging records based on their potential impact. (5) Low variability or redundancy: detect redundancy using correlation matrices, apply dimensionality reduction techniques such as Principal Component Analysis (PCA), and prioritise features using metrics like information gain.
As a complement, the following open-source Python libraries are recommended to support the practical implementation of the described measures. These tools allow diagnostic and corrective processes to be directly integrated into workflows involving artificial intelligence. (1) Pandas enables the manipulation and analysis of structured data, allowing users to detect outliers, compute statistical metrics, apply filters or moving averages, and manage missing values. It is especially useful for handling noisy or incomplete data, low variability, and manual detection of outliers. (2) NumPy provides efficient numerical operations on vectors and matrices, supporting transformations such as logarithmic scaling, custom normalisations, and tailored thresholding or smoothing. It is particularly helpful for addressing problematic distributions and applying tailored adjustments to data ranges. (3) Scikit-learn offers a comprehensive suite of tools for preprocessing, imputing missing values, selecting features, detecting outliers, reducing dimensionality, and applying robust modelling techniques. It is well-suited for dealing with non-informative features, incomplete data, low variability, anomalous distributions, and modelling under noise or imbalance. (4) specialises in anomaly detection using a wide range of unsupervised and semi-supervised algorithms, including Isolation Forest, AutoEncoders, and Local Outlier Factor (LOF). It is ideal for automated identification of noisy data, outliers, and anomalous records. (5) I provides advanced techniques to address class imbalances in classification problems, such as synthetic oversampling (SMOTE, ADASYN) and random under sampling. It is effective in correcting problematic distributions within imbalanced categorical variables, especially in training datasets. (6) Seaborn is a statistical visualisation library built on Matplotlib, enabling graphical exploration of distribution patterns, relationships between variables, outliers, bias, and redundancy. It is highly useful for visually interpreting problematic distributions, validating data transformations, and identifying non-obvious relationships or anomalies.
Building upon the insights and findings of this work, several promising research lines of future work can be identified: (1) Development of a comprehensive framework of multi-dimensional quality indicators specifically designed to assess datasets used in public sector AI applications. These indicators should address data preparation, labelling consistency, completeness, and suitability for specific AI tasks. (2) Comparative analysis of data cleaning techniques applied to public sector datasets, aiming to evaluate the effectiveness of various methodologies in improving data quality and their subsequent impact on the performance of AI models. (3) Analysis of impact of biased or erroneous data labelling on automated decision-making processes within the public sector. It focuses on how mislabelled instances and systematic biases can distort algorithmic outputs, potentially leading to inequitable or inaccurate outcomes in critical domains such as social services, employment allocation or law enforcement interventions. (4) Data governance as a strategic mechanism for institutionalizing data quality in public sector contexts. It should examine how governance frameworks can embed quality assurance practices across the entire data lifecycle, including validation, stewardship, and periodic dataset updates. (5) Analysis and impact on data quality of the relationship and traceability of ethical and social aspects considered in European regulations and legislation related to AI.
In short, future research in this area holds strong potential to complement the current analysis and to substantially advance the development of AI applications, as well as the improvement of data quality, within European public institutions.
Footnotes
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.