
Abstract
Sentiment analysis (SA) has recently developed an automated approach for assessing sentiment, emotion, and these reviews or opinions to extract relevant and subjective information from text-based data. Analyzing sentiment on social networks, such as Twitter, has become a powerful means of learning about the users’ opinions and better understanding and satisfaction. However, it consumes time and energy to disperse and collect surveys from clients, often inaccurate and inconsistent, and evaluating and improving the accuracy of the methods in sentiment analysis is being hindered by the challenges encountered in Natural Language Processing (NLP). This paper uses NLP, text analysis, biometrics, and computational linguistics to detect and extract replies, moods, or emotions from Skytrax Airline Customers' Feedback SACF data. This research uses deep learning models to analyze various approaches applied to small SACF to solve sentiment analysis problems. We applied word embedding (Glove embedding models) to improve the sentiment classification performance of a series of datasets extensively utilized for feature extractions. Finally, a comparative study has been conducted on the SACF data analysis utilizing deep learning (DL)for evaluating the performance of the different models and input features, which is Recurrent Neural Networks (RNN), long short-term memory (LSTM), Gated Recurrent Unit (GRU), 1D Convolutional Neural Networks (CONV1D), and Bidirectional Encoder Representations from Transformers (BERT) for application to big datasets in 2019. This approach was assessed using each classification technique; the precision, recall, f1-score, and accuracy metrics for sentiment analysis have been identified. And The results show that LSTM outperforms in classification accuracy; the outcome was 91%.
Keywords
Introduction
The airline industry is a good case study for analyzing customer feedback because it is a highly competitive industry where customer satisfaction is critical to their strengths and weaknesses. By analyzing online passenger reviews, researchers can identify the factors that affect the perceived service quality, performance, and value of different airlines. Online reviews are a rich data source that reflects the opinions, expectations, and emotions of customers who have experienced the service firsthand.
Collecting consumer feedback through surveys and other mechanisms can assist airlines in identifying improvement opportunities. By analyzing customer comments with sentiment analysis, airlines can better understand what matters most to customers. Additionally, the Internet has increased price transparency, reducing airline profit margins and making passenger experience and satisfaction an even greater priority.1,2
Despite the importance of the SACF industry, it faces challenges and difficulties,3,4 including dealing with unorganized and heterogeneous data, as online assessments are usually unorganized and need a consistent format. They can contain various types of information, such as text, ratings, images, videos, emoji’s, etc., and vary in length, style, tone, language, and sentiment. These characteristics make it difficult to process, extract, and integrate relevant information from online reviews using traditional methods.
On the other hand, dealing with noise and bias in online reviews. Online reviews may contain noise and bias that can affect the quality and reliability of data. for example, some reviews may be fake, spam, or malicious, which are intended to manipulate the reputation or rating of a product or service. External factors, such as incentives, social pressures, or personal preferences, may influence revisions. Some reviews may need to be completed, consistent, or accurate, which may mislead the analysis.
In addition to understanding customer needs and preferences, online reviews reflect the opinions, expectations and feelings of customers who have experienced the service firsthand. However, customers may have different needs and preferences when evaluating a service. For example, some customers may care more about price, while others may focus more on quality. Some customers may be more satisfied with a service than others, even if they give the same rating. Therefore, it can be challenging to understand customers' needs and preferences from online reviews and provide them with personalized and comprehensive feedback.
NLP and emotion analysis are interrelated disciplines that can bridge the divide between humans and machines. Text SA is utilized to extract and evaluate data from personal data or internet-based product reviews and comments. Due to its commercial and academic applications and the rise of social networks, SA has become an important issue in NLP.5,6 Deep learning is learning a portion of knowledge in the form of multiple levels of representation and abstraction to form higher-level information than lower-level information (such as sound, image, etc.). 7
Several ways for assessing user sentiment in social media data have been reported in prior research 8 by Domenico et al. 9 For instance, Wang et al. 10 offer a hybrid machine learning system for categorizing negative or positive user sentiment. Bhat et al., 11 human sentiments are crucial to comprehending individual emotions. Pham and Le 12 Utilize NLP to decipher user sentiment from a set of customer evaluations. Aflakparast and others. Sezgen et al. 13 point out that sentiment analysis of airline ratings is prevalent in social media such as Twitter, 14 Skytrax, 15 and TripAdvisor; 16 therefore, the Airline Customers' Feedback industry is a relevant and interesting case study for both academic and practical purposes, has been undertaken in a few research.
There are some works from previous studies that presents an approach that relies on the human expert and the repetition of the words used, which is similar to the concept of unsupervised machine learning and is represented by demonstrating the development of an emotion-based apparel design system, with a focus on AW-to-ADP mapping, specifically from AWs to ADPs, permitting emotional design. With neural networks, both conventional and higher-order neural networks were employed, with training data acquired and evaluated using the MSE and the R test. To confirm the mapping, a case study was conducted. According to the results, the linear NN with two hidden layers mapping was superior to the quadratic NN with one hidden layer mapping. Drawing is appropriate for the affective design of apparel products. The paper differs from the Kawabata Evaluation System (KES) in two significant ways: the number of training data is restricted, and the quadratic NN model has only one hidden layer. 17
Also, previous studies analyzed flight demand forecasting for airline network planning, flight scheduling, human resource scheduling, and revenue management. It divides flight bookings into peak, average and off bookings based on season and DOW attributes. The study uses a 2D sequence prediction problem and a robust adaptive learning model for nonlinear data with large fluctuations. The SVR model improves the prediction accuracy and RMSE compared to traditional models. The test dataset includes 2 years’ worth of data from tourism, business, and public roads in China 18
The paper contributions are Using customer data from SACF, Models using word embedding (Glove embedding models) to improve the sentiment classification performance have been applied to a series of datasets, extensively utilized for feature extractions and were compassed in the training and validation phase. Finally, a comparative study has been conducted on the SACF data analysis utilizing deep learning for evaluating the performance of the different models and input features, which is RNN, LSTM, GRU, CONV1D, and BERT for application to big datasets in 2019.
The experimental results on datasets demonstrate performed airline customer sentiment analysis using deep learning algorithms RNN,86% LSTM,91% GRU, 90%CONV1D 87%and BERT transfer learning 90%. In this investigation, the study shows that deep learning is better for analyzing the sentiments within the text; LSTM was the best model, with an accuracy of 91%. Consequently, the proposed method could be a promising solution for improved classification that is scalable. The proposed method would be ideally suited for applications with large datasets, such as the sentiment analysis of product and service reviews. It can also be upgraded such that topic recognition and sentiment analysis can be used to construct the suggested model for different languages. Like Arabic reviews, we can work with different types of emoticons for different media.
Background
Numerous public evaluations, in-text remarks, postings, and status updates accompany youth participation in online activities such as Facebook, Twitter, YouTube, and e-commerce websites. NLP is fundamentally dependent upon sentiment analysis. Nonetheless, we categorize these works.
Sentiment analysis
The user’s mood can be calculated using a tweet's positive and negative terms.
20
Negative and positive sentiment scores cancel each other, resulting in a sentiment score of zero, i.e. (sentiment score = 0). Zero-emotion score produces erroneous data, so criteria must be used to distinguish between good and negative tweets. The polarity of tweets is calculated to determine if they are positive, negative, or neutral.



Deep learning
⁃ An enormous amount of labeled data is required for deep learning. For a self-driving vehicle, for example, millions of photographs and hours of video are required. ⁃ Deep learning requires a large computer capacity. The parallel architecture of high-performance GPUs is effective for deep learning.
Literature review
Sentiment analysis analyses emotions from textual data such as Internet articles, customer ratings, and Tweets. People’s perspectives on a variety of problems are often expressed in tweets. Airline travel is now one of the most popular topics. This data is beneficial when studied using deep learning algorithms since it contains factual information. The literature on sentiment analysis is so extensive and varied.
Sentiment analysis on airline industry the use of machine learning and deep learning.

Using the preceding table, we may categorize the data in various ways. Researchers, 25 [18:20], and [23:31] have used the little tweet data supplied in, 31 the majority of which was updated in 2015 and had an estimated size of 14,640 tweets. The obtained accuracy values range from 68 to 98%, with research 32 achieving the lowest accuracy and research 29 achieving the highest accuracy. Researchers 27 and 33 have utilized huge data with an estimated size of 29,530 tweets, with 27 achieving an accuracy of 91.3% using conventional approaches and just two trending methods (CNN/LSTM) and 33 achieving an accuracy of 82%. So Based on frequently used embedding models for feature extraction, this paper introduces (SACF) data analysis using deep learning algorithms RNN, LSTM, GRU, CONV1D and BERT transfer learning for application in large data. These algorithms have been updated for 2019 and are provided in 34 ; the approximate size of the tweet dataset is 65,944. The proposed study used the application in airlines on a large amount of data and the application using deep learning models to analyze customer opinions.
Methodology
Word embedding
Word Insertion Through word embedding, each word is represented numerically and in vector form. Word embedding refers to documents that contain exact representations of identically meaningful terms. Word embedding, in particular, is unsupervised learning of word representation comparable to semantic similarity. This refers to words in a coordinated scheme where terms with similar meanings are placed closer together based on a set of relationships. 35 Word2vec, Glove, and Rapid Text are the most common word embedding models. 36 This research will employ Glove embedding.
Glove: “Global Vectors” is an additional technique for word embedding proposed by Pennington et al. 37 Word2vec acquires semantic knowledge by executing a local content window over training data to predict words based on their context. Arguing that local content window models suffice for extracting semantic relationships. Glove combines local content windows and count-based matrix factorization to generate an accumulative global co-occurrence statistic of word-word.
Deep learning methods used for sentiment analysis of SACF
DL is a subfield of machine learning based on the structure and composition of ANNs; some of these algorithms have been implemented in airlines using machine learning, but on a small amount of data, and there have been high accuracy and others that are lower. In this paper, we apply some modern algorithms that have yet to be applied in airlines and deep learning in other fields, as shown in Table 1. Finally, I used a sequential search algorithm in my research because it stores data for long periods and effectively solves problems. Time series sequencing works in an iterative process. The suggested study used five deep learning models for customer review sentiment analysis: basic LSTM, RNN, GRU, covn1Dand Bert transform learning model. In this section, we examine several sentiment analysis methodologies. They are listed below:
Recurrent Neural Network (RNN) model
An RNN is an ANN where the nodes are linked in a temporally ordered directed graph. Derived from feedforward neural networks, RNNs can utilize their internal state to process input sequences of varying lengths. The model modifies the existing data using a function by including additional information. Thus, the entirety of the information is transformed, i.e., there is no distinction between 'essential' and 'less significant' information.38,39
In our experiment, we employ a straightforward 20-layer RNN. At a certain timestamp, the previous input of the previous hidden layer is retrieved and fed back to the current hidden layer’s current input. On the preceding RNN layer, a Spatial Dropout with 0.4 is inserted in. After the RNN layer, Batch Normalization, Dropout with 0.4, and GlobalMaxPool1D are successively added. Lastly, a three-connected layer with a sigmoid activation function is added to the Dense layer. 40
Long Short-Term Memory (LSTM) model
The LSTM extends the RNN. In the training of vanilla RNN, it was postulated that gradients would dissipate. It has a special memory mechanism that gives it an advantage over the standard RNN 41 and more complex functionality that regulates information flow. Memory cells, input gates, output gates, and neglect gates are components of an LSTM that determine what is to be read, written, or erased. This allocation of responsibilities enables the network model to store data for extended durations 42 ; LSTM has been recognized as an essential function because it effectively resolves time series and sequential problems 43 ; thus, the proposed method could be a promising solution for improved classification with scalability. The proposed method is ideally suited for applications with large datasets, such as detecting sentiment in product and service reviews.
Gated Recurrent Unit (GRU) Model
Gated recurrent unit is a gate mechanism for RNNs. The comparable architecture of LSTM in which GRU consists of only two gates, the update and reset gate, and has a memory of only one concealed state without a distinct cell. The update gate discovers long-term dependencies with successive inputs and determines what data the previous concealed state must transmit. Although the reset gate is supervised to learn short-term dependencies and generate the amount of information to forget, the LSTM network is the same 40 ; it is significantly simpler, quicker, and requires fewer gates to calculate. 44
1D Convolutional Neural Network (Conv1D) model
The CNN method generates a sequential model, indicating that layers are arranged sequentially. The output of one layer will be the input for the following layer. The base layer is the initial stratum. In the subsequent Conv1D layer, a 3-by-64 filter with the ReLU activation function is utilized. The succeeding layer is the Max pooling 1D layer. The dense layer receives input from the MaxPooling1D layer and generates the final output using the SoftMax activation function, 25 which makes a 1D CNN quite useful. 39 This method applies to the analysis and retrospective review of time sequences of sensor data (such as proximity or barometer data) and the study of any signal data over a predetermined time frame (such as audio signals).
Bidirectional Encoder Representations from Transformers (BERT Transformer learning) model
Transfer learning is a revolutionary paradigm in machine learning that focuses on applying the knowledge acquired for one job to other comparable tasks. Google introduced a new sort of transformer 2018, the BERT sequential language model, 2018. BERT accepts input in the sequence format X = (I0…, In) and generates contextualized vector representations H = (h0,……. hn) for the input sequence elements.
It is a highly generalizable system for language representation that performs tasks through the encoder. Encoders are derived from the transformer’s neural network design to generate encoded text representations. The BERT-Mini in question has four encoder layers.
24
Each encoder block consists of two sub-layers: multi-head attention and feed-forward Figure 1. Deep learning algorithms (RNN-LSTM-GRU_COVNID_BERT) proposed model architecture for SACF classification.
The proposed model for sentiment analysis classification SACF
Experimental and result analysis
Data description
In the Suggested technique, we will develop deep learning models on the airline sentiment dataset from numerous sources for the top 10 airlines with a total of 65,947 customer evaluations; in the underlying research effort, just one column is analyzed. The column carries a label for the sentiment. This dataset classifies labels as negative or positive, with 33,894 rows representing negative feelings and 30,546 representing good sentiments. This dataset of airline sentiment was collected and available from Kaggle in 2019. 34
Pre-processing
In this situation, we must load all necessary libraries, read the data using pandas, and then check for duplicates. If you discover duplicates, leave them there; they are useless. Instead, the data sets’ missing data will be addressed. If our dataset has any missing data, as seen in Figure 2, our model may cause an immense issue. So, the missing values within the dataset must be managed. It may be managed by replacing missing data using the mean or median and the most common term.
45
Data preprocessing works on the following data.
Text pre-processing
Pre-processing text is done using the NLP method, a problem-cracking method that helps people access and absorb vast quantities of existing text material. A token is an entity-functioning text of characters consisting of phrases, emotions, hashtags, links, or single characters. Standardization refers to grouping similarly significant terms, and a building data set with every dataset having a "feeling" for training is produced. Text may be categorized by emotional analysis into various emotions, allowing for consistency and availability of the data.
45
There are different ways of data processing
25
: - ⁃ Remove and Stop words: - In the article, ‘a' and ‘the’, prepositions ‘in’, ‘near’, ‘beside’ and in pronouns ‘he’, ‘she’, and ‘it’ stops words. ⁃ Lower Casing: - Lowercasing entails turning every uppercase letter to its lowercase counterpart. That will also be quite useful during parsing. ⁃ Tokenization: - Divining a phrase or text into tokens is known as tokenization. Tokens might be words or single characters. ⁃ Lemmatization: - This process reduces a term to its root form. The basic form of the term will make sense after Lemmatization. Many languages include a variety of word forms; hence stemming and Lemmatization varies across languages. Creating effective lemmatization algorithms is an unexplored field of study.
Data splitting
The data set is divided into training and test sets to enhance the performance of a deep-learning model. If the training accuracy of the model is not high, then the performance will decrease. To develop an effective deep-learning model, the training set and test dataset should be used. 45
Feature extraction
Data extraction is used when the original raw data is vastly dissimilar and cannot be utilized for deep-learning modeling. It converts unstructured data into the required format, and feature extraction is used when the original raw data is so different that no classification can be applied. Examples of raw data formats include Data, Pictures, Date and Time, Web Data, and Sensor Data. Text data is difficult for a computer to comprehend, so feature extraction is used to translate text data into numerical data. 25
In this study, 65,947 Internet reviews were retrieved to provide the baseline dataset for sentiment class action. The web evaluations of five major airlines were compiled: ANA All Nippon Airways, Adria Airways, Aegean Airlines Lingus, and Aeroflot Russian Airlines.
Positive and negative categories were established for Internet reviews. The sentiment distribution of Internet reviews is shown in Figure 3 and Table 2 below. Distribution of sentiment in the dataset of airline sentiment. Distribution of online review sentiment for the first dataset.

Deep learning models for sentiment classification
Recurrent Neural Network (RNN) model
To test the efficacy of various embedding, shown in Figure 4 displays the RNN model's specifics, which are detailed in further detail below. Recurrent neural networks model for sequential classification.
Long Short-Term Memory (LSTM) model
To test the efficacy of various embedding, shown in Figure 5 displays the RNN model's specifics, which are detailed in further detail below. Long short-term memory model for sequential classification.
Gated Recurrent Unit (GRU) model
The GRU model's specifics are described in the following section to evaluate the efficacy of various embedding’s, shown in Figure 6. Gated recurrent unit model for sequential classification.
1D Convolutional Neural Network (Conv1D) model
To evaluate the efficacy of various embedding’s, as shown in Figure 7, the Conv1D model’s specifics are described in the following section. Conv1D model for sequential classification.
Bidirectional Encoder Representations from Transformers (BERT Transformer Learning) model
All model checkpoint layers were employed for initializing TF Bert for Sequence Classification. The model needs to initialize many layers of TF Bert for Sequence Classification. Figure 8 depicts the “TF Bert for sequence classification” model, which should likely be TRAINED on a downstream job before use. Bidirectional encoder representations from transformers model for sequential classification.
Results analysis and discussion
Apply to evaluate user feedback for analysis. We must categorize the review as favorable or negative based on its contents: 1. We preprocessed the information using several natural language processing approaches. 2. We split the dataset into training sets comprising 80% of the total and testing sets comprising 20%. 3. We created word embedding’s, applied five distinct deep learning models, RNN, LSTM, GRU, CONV1D, and BERT, and compared the outcomes.
Python has a variety of deep learning libraries; therefore, it was used for all implementations.
Model training and testing
A labeled dataset that can train the classifier is indispensable for deep learning. The training dataset consists of samples comprising an input item and a label or class organized as a training set. An algorithm initially examines the labeled data. The system then extracts features from the input data that contain the essential information, allowing sentiment analysis to be conducted using a representation of the original data rather than the original data itself. The algorithm generates a function capable of classifying previously unknown data or evaluating the approach. The dataset is then divided into two types: the training set, which consists of 80% of the total, and the testing set, which consists of the remaining 20%. The user can evaluate and test the corresponding model by preprocessing the input data. During the preprocessing phase, the sign and number are removed. Based on the training dataset, it utilizes stored attributes for mapping.
Epochs
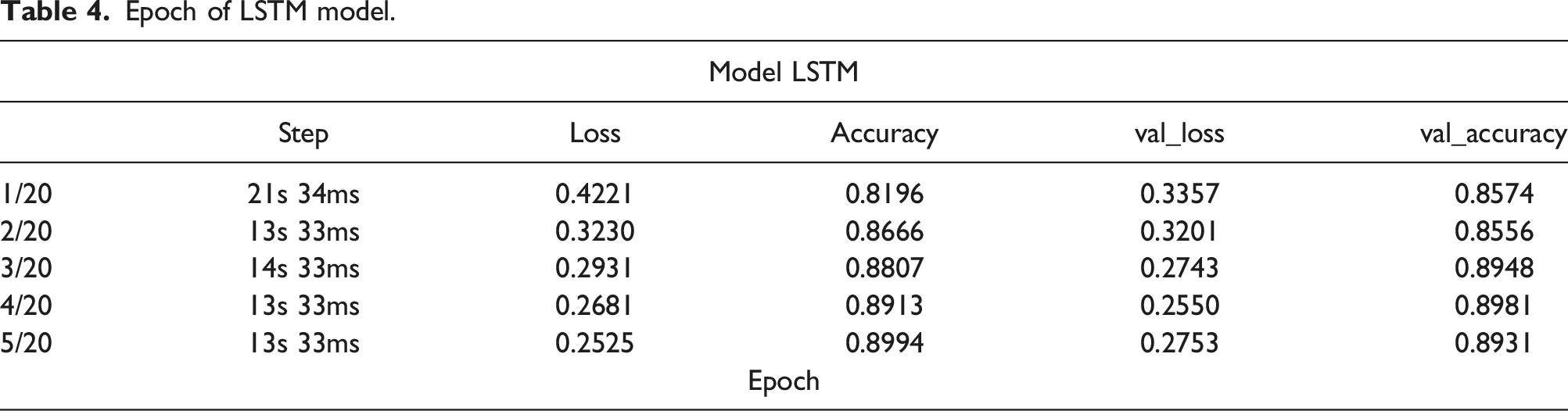
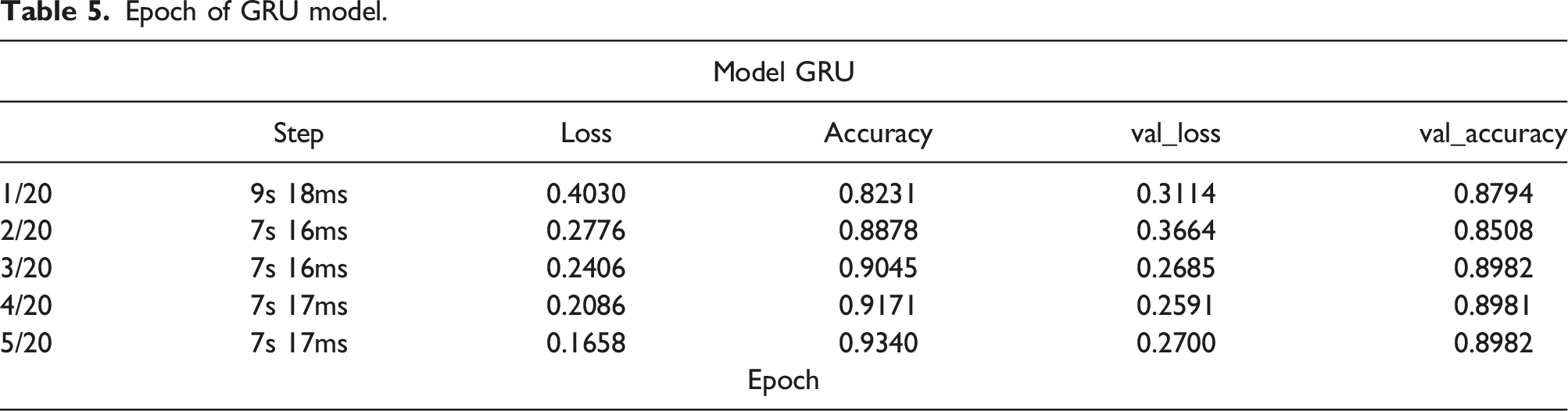
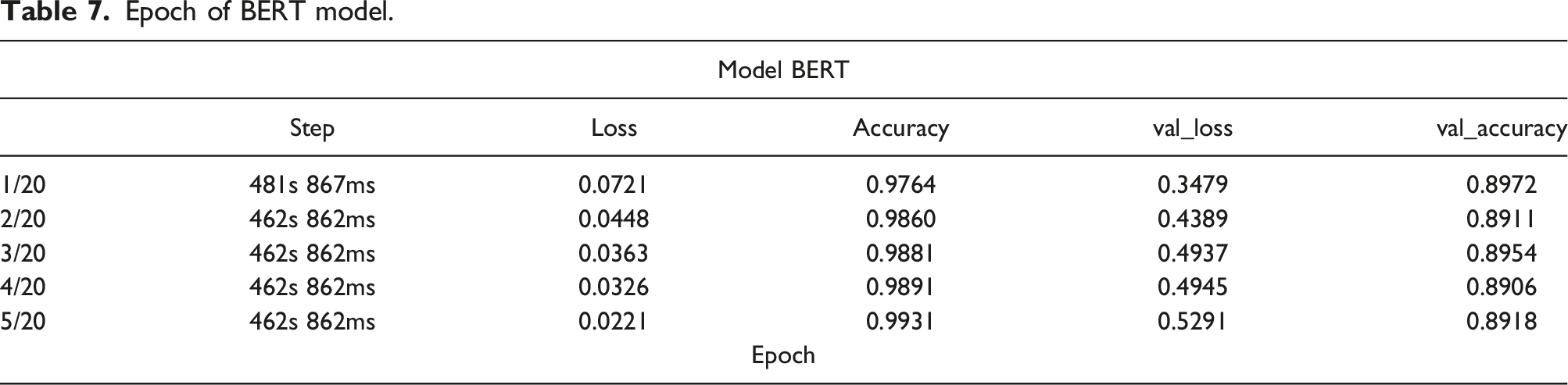
Multiple epochs have been utilized to train the full dataset; one will train the entire dataset. Since a single epoch is too large to feed the model simultaneously, it must be broken down into smaller batches. Val loss and Val accuracy reflect the inaccuracy and correctness of the validation data, respectively. Loss and accuracy indicate the error and correctness of training data.
Epoch of RNN model.

Epoch of LSTM model.
Epoch of GRU model.
Epoch OF COV1D model.

Epoch of BERT model.

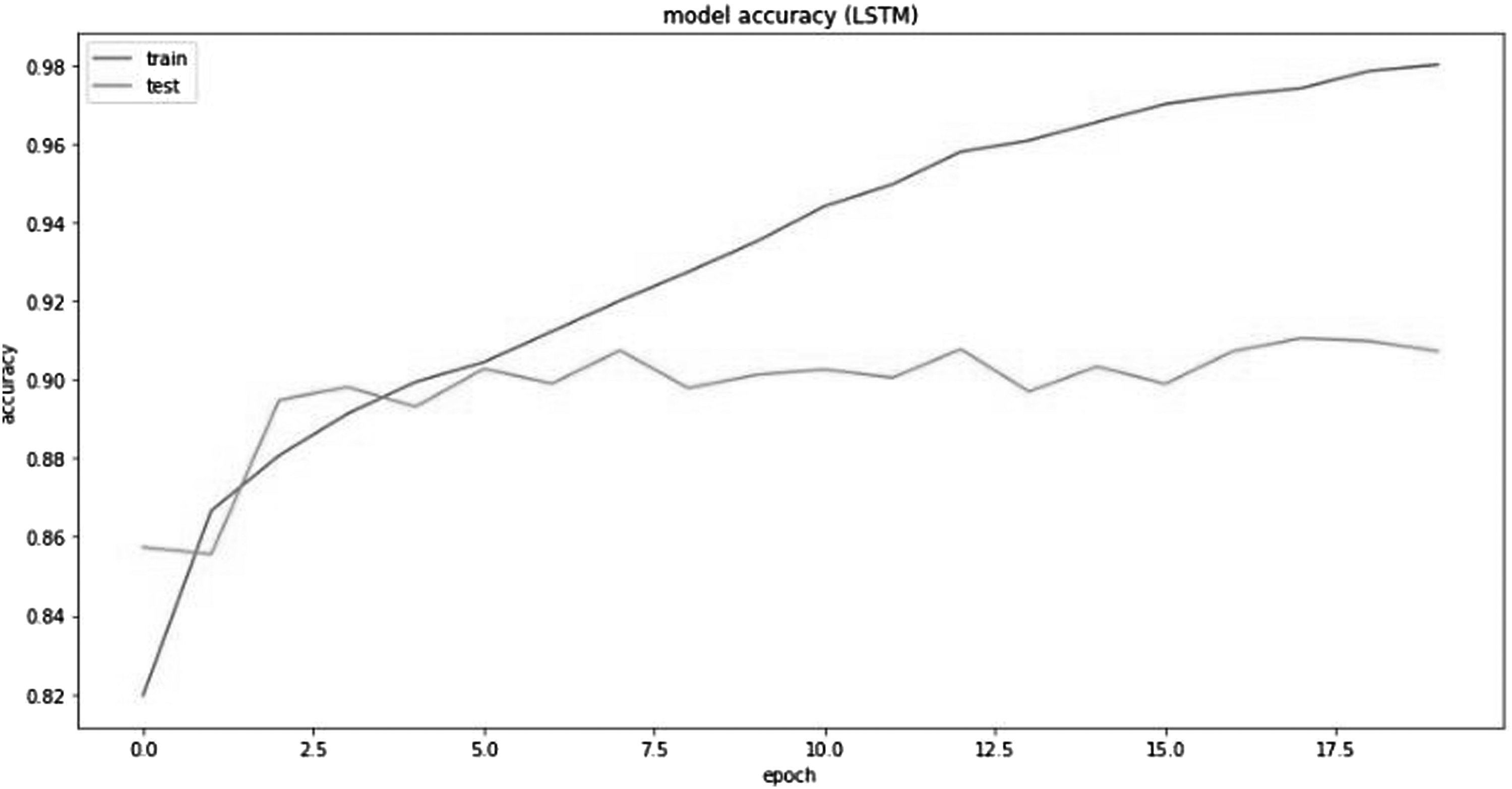
Recurrent neural networks model accuracy plot.
Long short-term memory model accuracy plot.
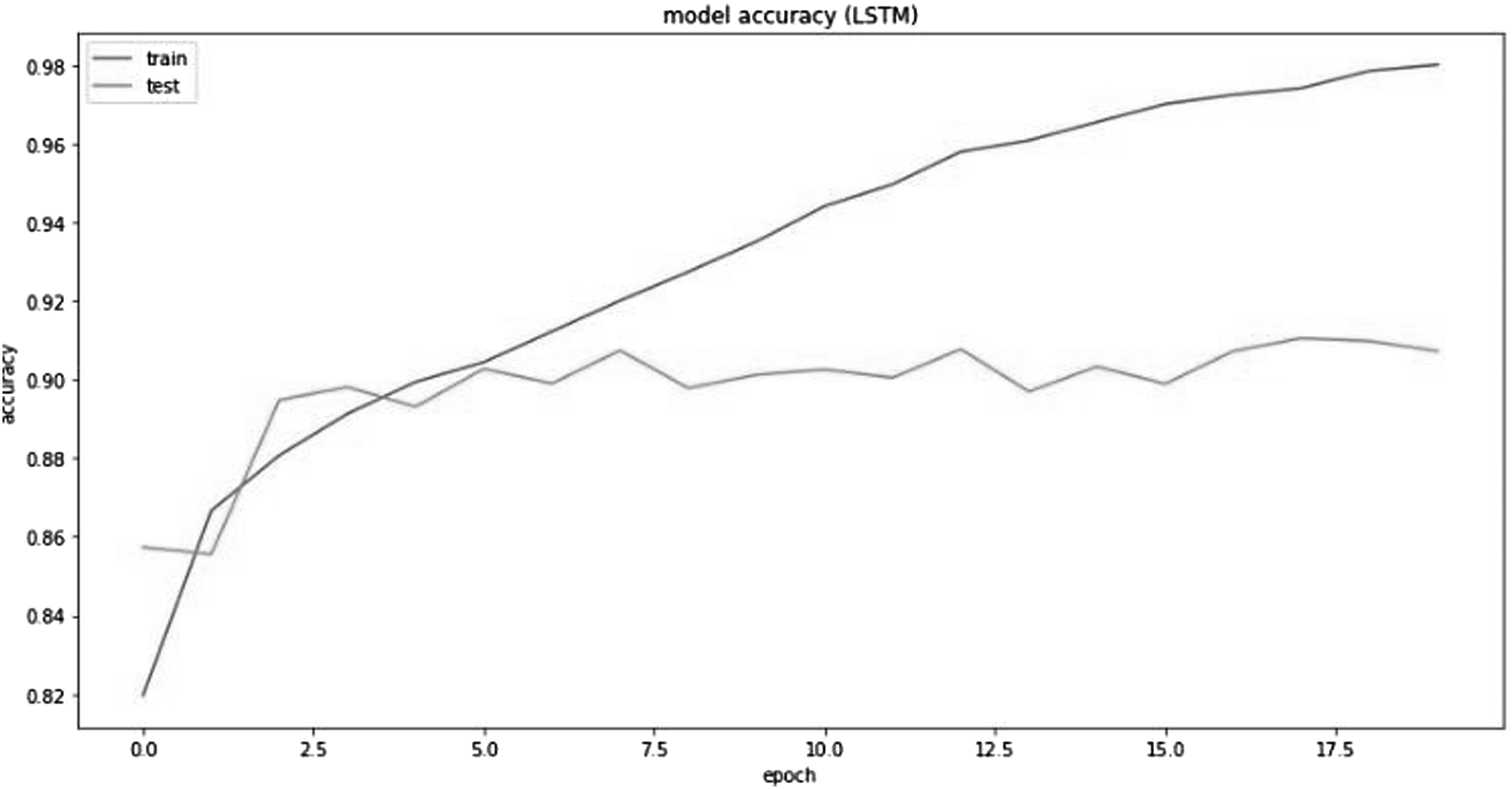
Gated recurrent unit model accuracy plot.
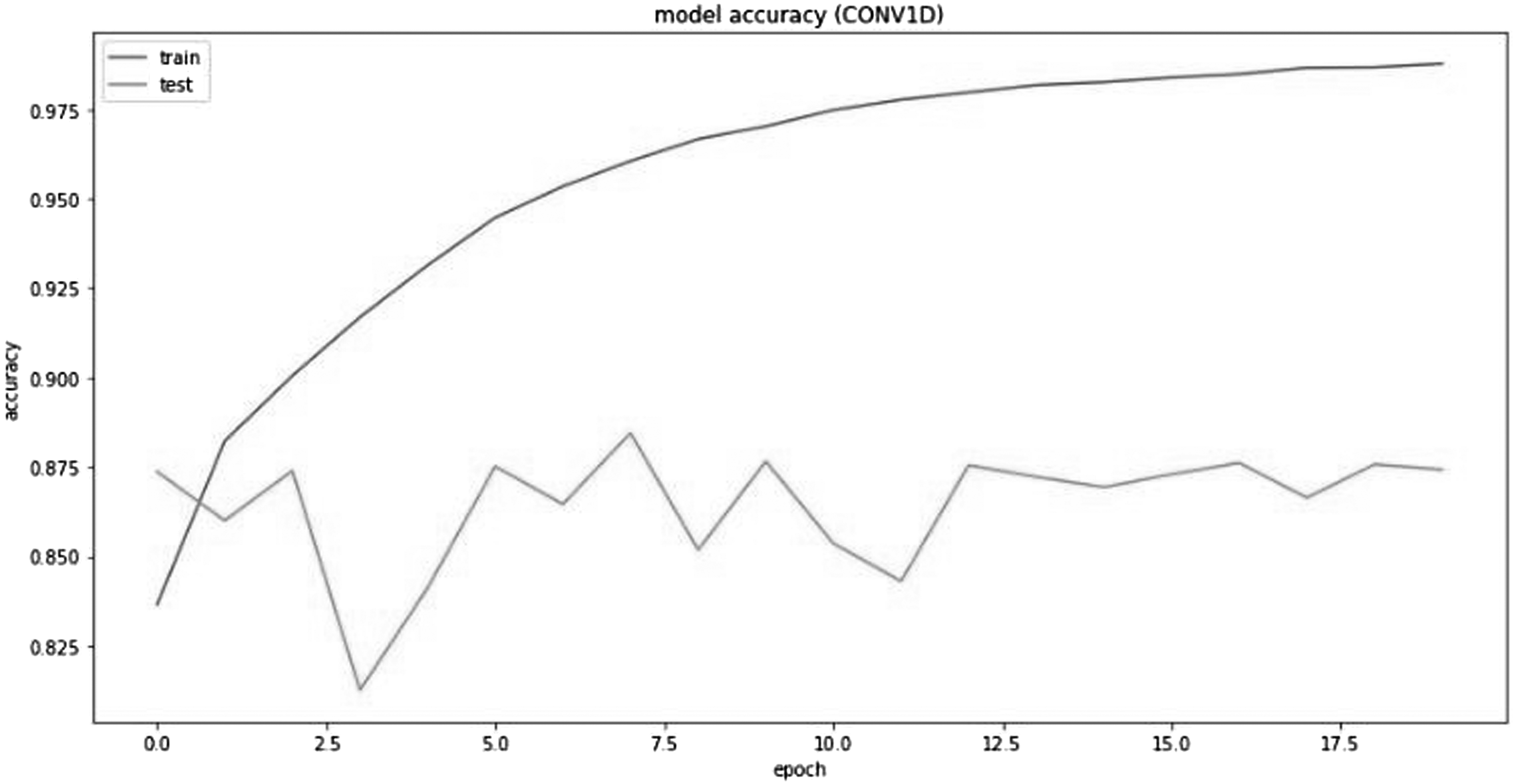
COV1D model accuracy plot.
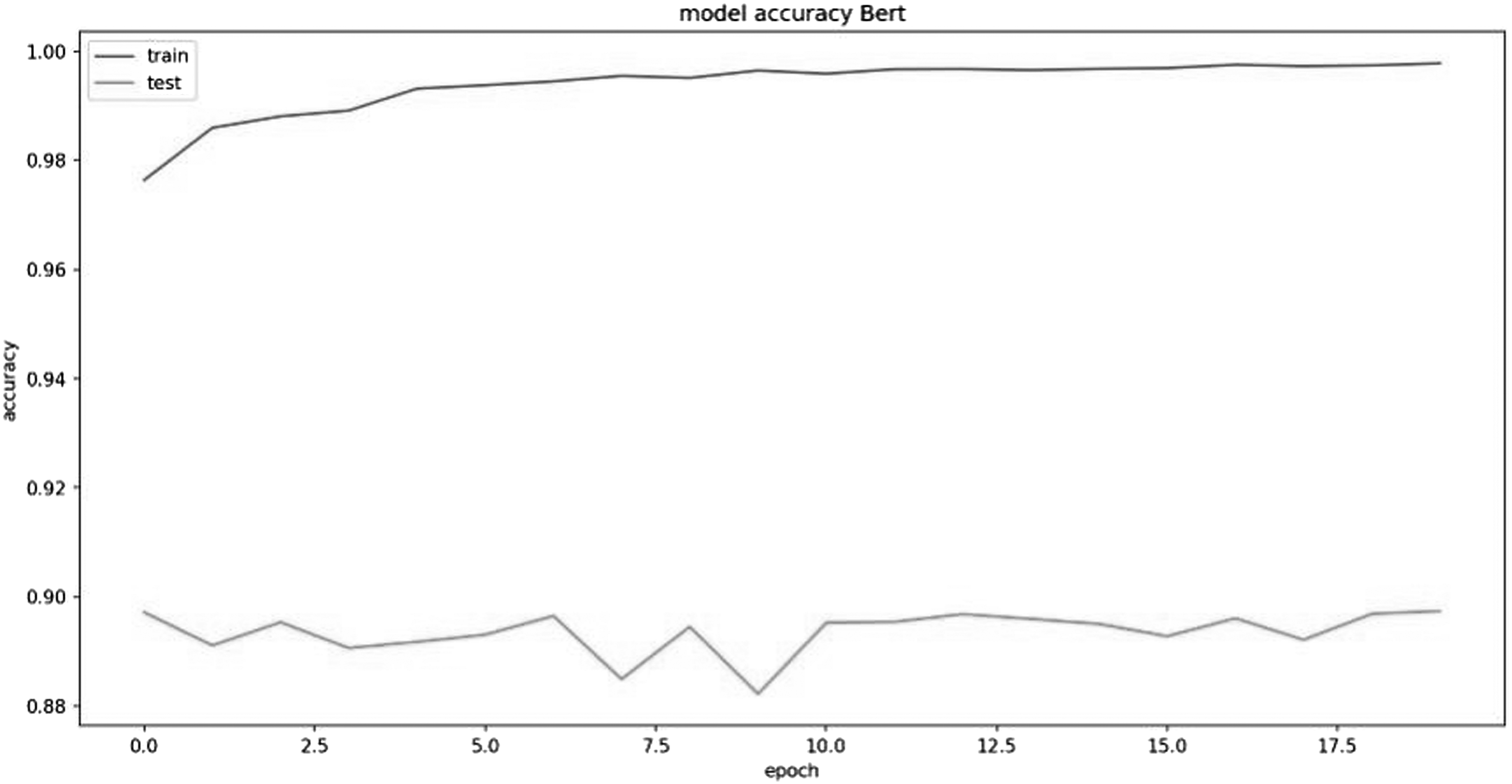
Bidirectional encoder representations from model accuracy plot.
Evaluation metrics
The accuracy metric is used as a performance matrix. Accuracy is the proportion of properly categorized data points to the total number of data points. With this precision, we can determine whether or not our model will function effectively. If we get 90% accuracy on the test in feature and feed the model any new data point, it will predict with 90% accuracy. The data is balanced after printing the accuracy plot and the confusion matrix. It will provide the number of missing categorized data points per class. The following metrics are utilized in this study 45 :
Using equation (4), accuracy may be measured.
Precision is the ratio of the number of true positives to the total number of true positive forecasts. Equation (5) is used to compute exact numbers.
The recall is the proportion of True Positives accurately identified by our model. Equation (6) determines this value.
The F1-score represents the natural logarithm of Precision and Recall. The F1 value is defined by equation (7).
Word cloud
If the item of the word calculates the frequency after the document's preprocessing, it may be used to create a variety of visualizations. This approach of visual representation is generally used and permits a more intuitive portrayal of the document’s content and qualities. The word cloud gives a more understandable representation of the features of the text by displaying the corpus in proportion to its frequency. The word cloud is a strategy for visually representing the most frequently occurring terms, and keywords that are difficult to spot quickly in a table have the benefit of being visually shown instantly in the word cloud. Figures 14 and 15 show the findings of the Word Cloud for positive and negative terms, respectively.
46
Words most often in positive comments. Words most often in positive comments.

Confusion matrix
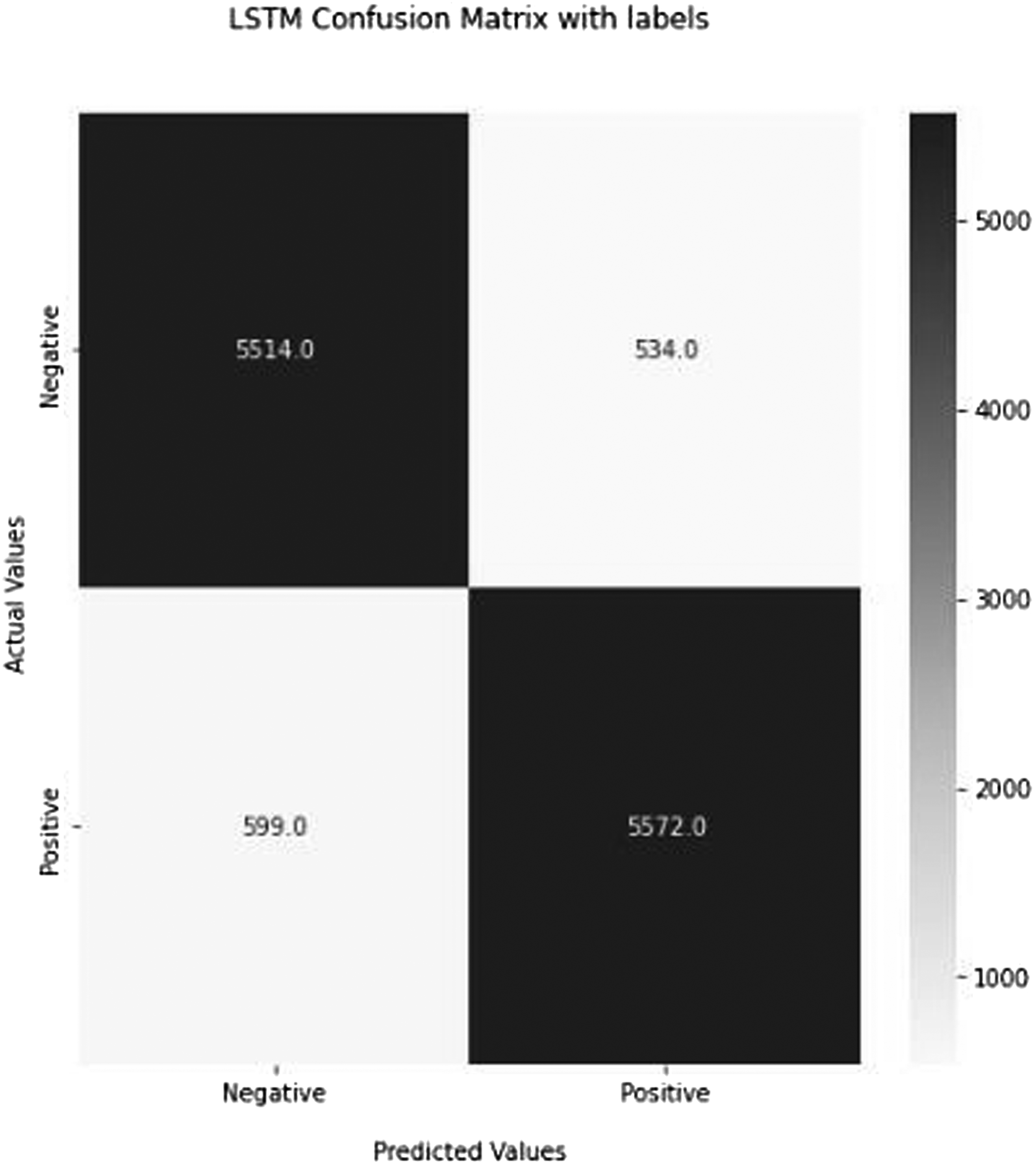
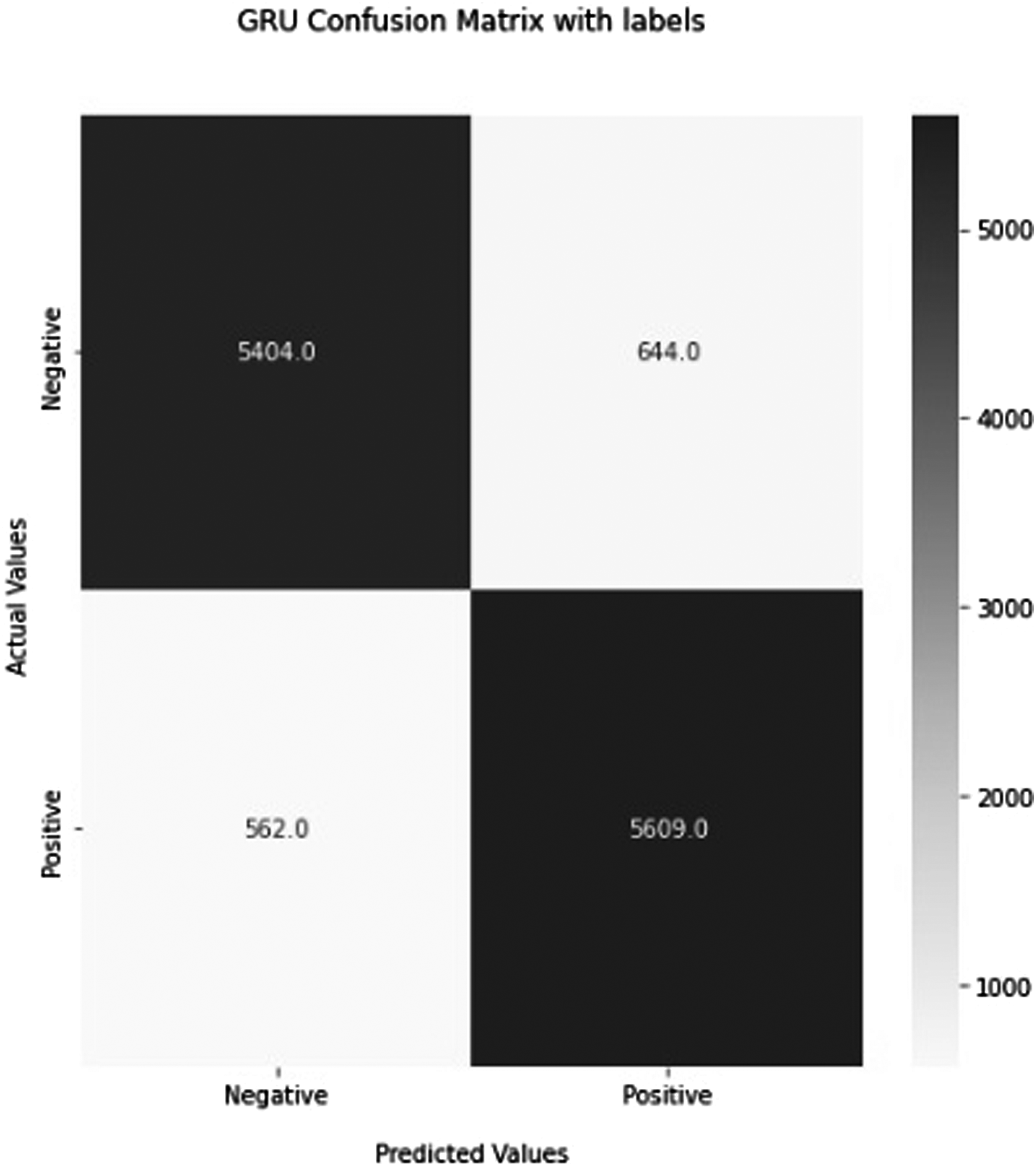
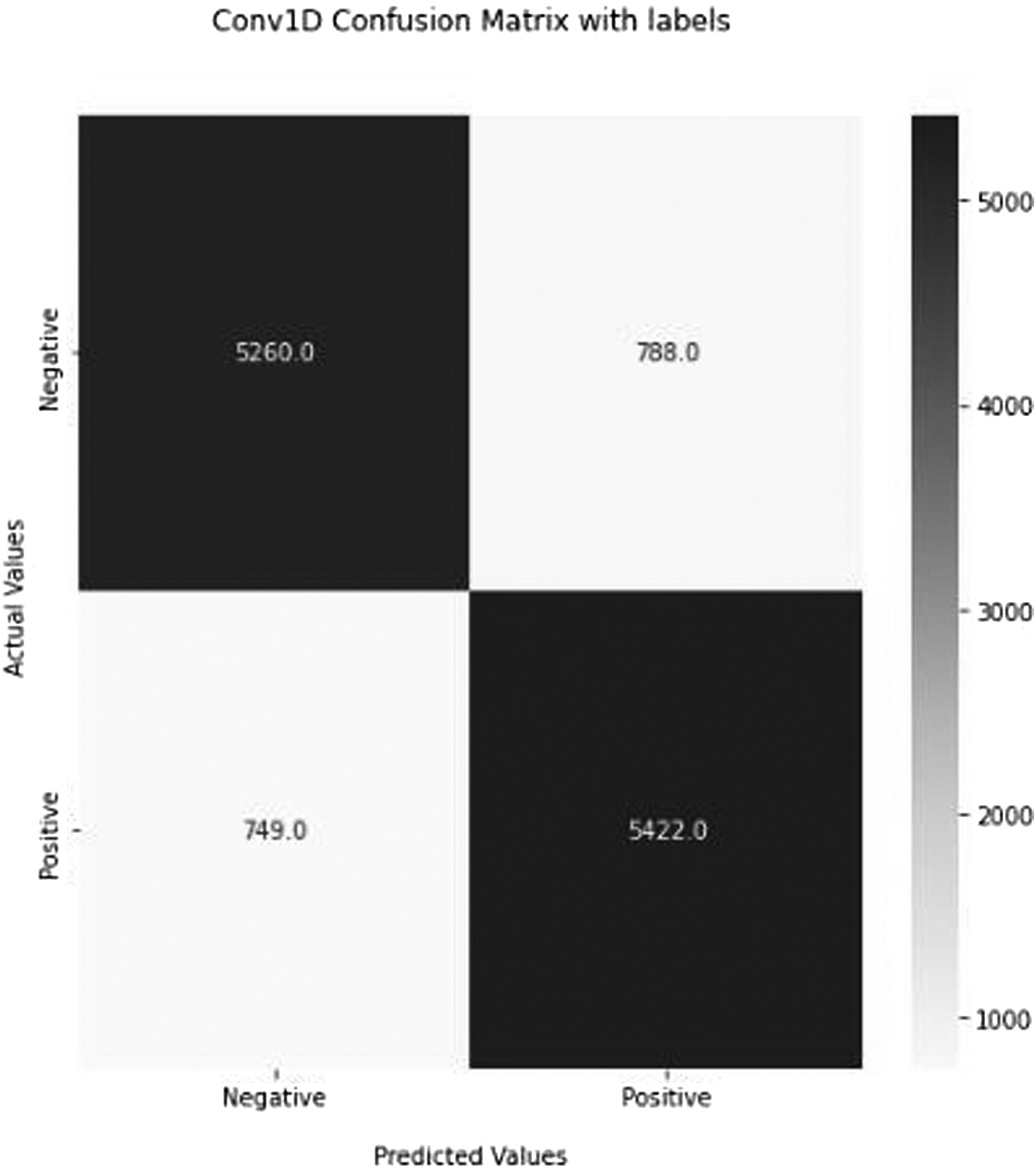
Using alternative measures aims to determine how effectively and correctly a deep learning model will function on new data. Figures 16, 17, 18, 19, and 20 depict the basic confusion matrix for a two-class classifier. Confusion matrix of the recommended RNN (deep neural network) Method. Confusion matrix of the recommended LSTM (deep neural network) Method. Confusion matrix of the recommended GRU (deep neural network) Method. Confusion matrix of the recommended CONV1D (deep neural network) Method. Confusion matrix of the recommended BERT (deep neural network) Method.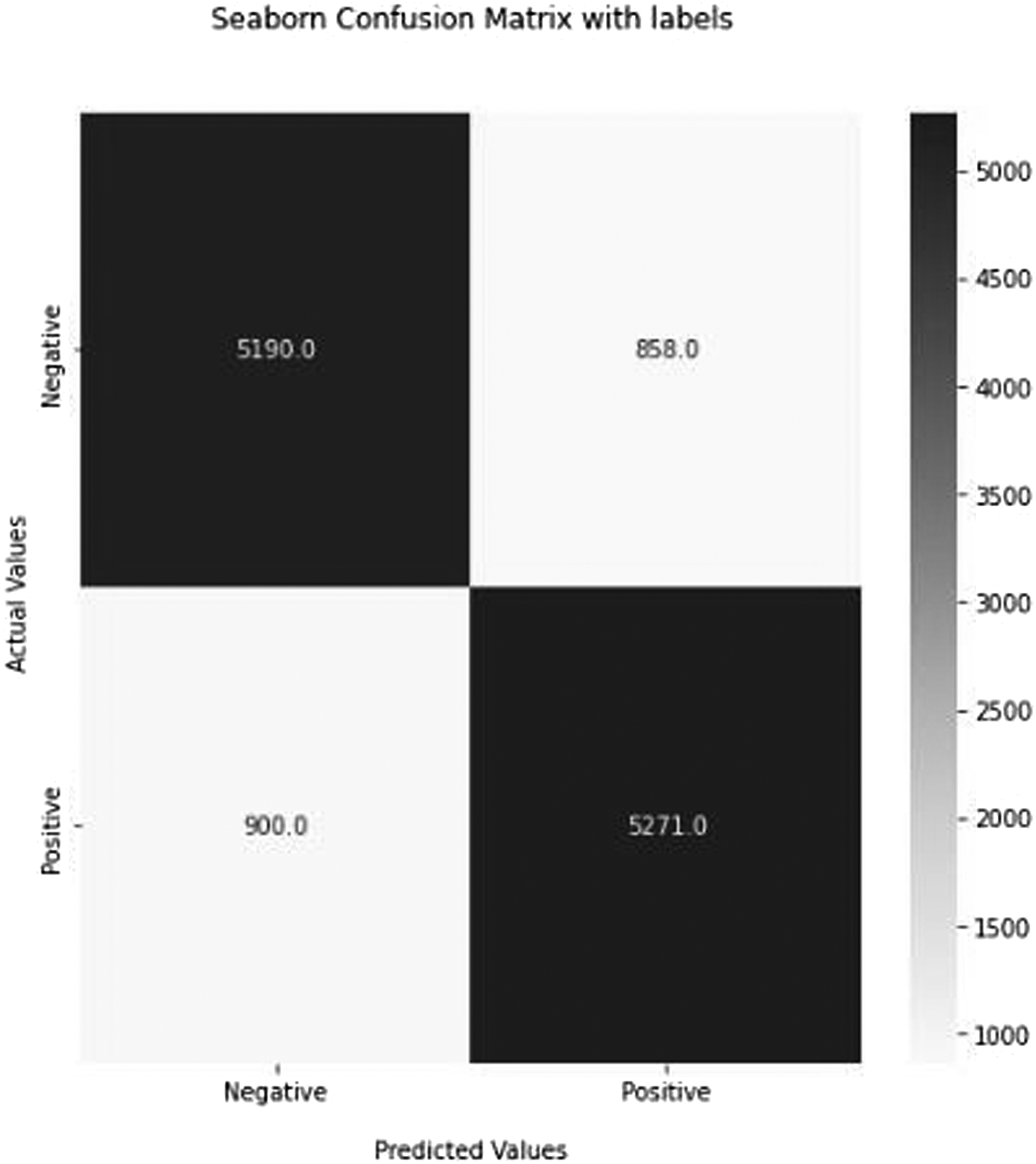

In the above equations, TP, TN, FP, and FN stand for true positive, true negative, false positive, and false negative and are defined respectively.
Deep learning classification models outcomes
classification report model.


Comparison of classifier model accuracy of 5 different classifier model using deep learning.
Shown in Figure 21 demonstrates that the F1 scores of the abovementioned approaches are generally constant throughout 10 tests. The sentiment classification effects of RNN and COVN1D are low, and their F1 score is only around 87%. The F1 score may approach 90% when sequence modelling is performed using GRU and BERT. The approach suggested in this study incorporates LSTM structure, which may capture the context’s semantic information more effectively, resulting in superior sentiment analysis. The F1 score has dramatically increased to almost 91%. Table 8 displays the average accuracy, recall, and F1 score of ten repeated trials for various sentiment analysis approaches; Table 8 and Figure 21 demonstrate that the suggested method achieves 90% precision, 91% recall, and 91% F1 score. Other techniques’ F1 scores vary from 86 to 90%, which is lower than the suggested method’s F1 score. In addition, the F1 scores of GRU and BERT are greater than those of RNN and COVN1D for sequential processing tasks.
Conclusions and future work
Due to the recent development of sentiment analysis, it takes an automated approach to assess sentiment and emotion, and these reviews or opinions extract relevant and subjective information from text-based data. Sentiment analysis on social networks like Twitter has become a powerful way to learn about and better understand users' opinions and satisfaction. The tweets are in positive and negative poles, respectively. Specifically, this study aims to provide an analysis of the content of user sentiment text tweets in airlines. However, it is time and effort-consuming to scatter and collect surveys from customers, often inaccurate and inconsistent, and assess and improve the accuracy of sentiment analysis methods hampered by challenges. NLP. Deep learning models have been a promising solution to NLP challenges in recent years. This paper analyzes different approaches applied to Skytrax Small Airline customer feedback to solve sentiment analysis problems. Previous research analyzes different approaches applied to small SACF datasets. Most of them were updated in 2015 and include approximately 14,640 tweets. They have achieved accuracy ranging from 68 to 98%. On the other hand, other algorithms have been used for the large data set of SACF, which consists of about 29,530 tweets, and the resulting accuracy values range from 82% to 91.3.
In this research, word embedding (glove embedding models) was applied to improve sentiment classification performance on a series of datasets. It was widely used for feature extraction and incorporated into the training and validation phase. A comparative study on data analysis (SACF) using deep learning was conducted to evaluate the performance of different models and input features, namely RNN, LSTM, GRU, CONV1D and BERT for application to large datasets in 2019%. The overall results on the datasets showed conducting airline customer sentiment analysis using deep learning algorithms RNN, LSTM 86%, GRU 91%, CONV1D 87%, and BERT transfer learning 90%. Finally, this approach was evaluated using measures of accuracy, recall, score f1, and accuracy for sentiment analysis that were determined for all classification techniques. The results showed that LSTM excels in classification accuracy, and the score was 91%. In future studies, the deep learning augment technique may be created to optimize the features iteratively. It can also be upgraded such that topic recognition and sentiment analysis can be used to construct the suggested model for different languages. Like Arabic reviews, we can work with different types of emoticons for different media. This study will help to develop a sentiment analysis model for airline customer feedback using deep learning techniques, especially RNN, LSTM, GRU, CONV1D, and BERT, as tools to explore sentiment quality rather than quantity. Our evaluation of the different models and also from industrial contributions in this field, including (manufacturing, hospitality, digital assistants (IoT), cars, etc.).
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.