
Abstract
In the last decade, the adoption of technological tools in manufacturing industry, such as the use of the Internet of Things (IoT) and Machine Learning (ML), has led to the advent of the industry 4.0 (I4.0). In this scenario, intelligent devices can generate large volumes of data about industrial machinery and equipment that can be used to make maintenance more efficient. Prognostics and Health Management (PHM) is an emerging maintenance strategy that uses systems’ Condition Monitoring through IoT sensors installed on machinery to diagnose their faults or estimate their Remaining Useful Life (RUL). This study aims to conduct a Systematic Literature Review (SLR) on the use of ML techniques in the field of PHM of industrial mechanical systems and equipment. 50 studies resulted eligible for the above-mentioned SLR. Diagnostics and prognostics approach and the ML algorithm types used in the 50 analyzed papers have been analyzed together with the Key Performance Indicators (KPIs) used for their validation. From the analyses, it was found that Shallow Learning and Deep Learning (DL) algorithms are the most applied ones, while KPIs are used differently according to the type of task classification or regression. Moreover, results highlighted that many authors still use artificial datasets to test their algorithms, instead of datasets based on real data retrieved by their components. For the last type of datasets, this paper also introduces a schematic framework to standardize the step-by-step diagnostics and prognostics process carried out by the authors.
Keywords
Introduction
Words like “Internet of Things” (IoT), “Cyber-Physical Systems” (CPS), “Internet of Services” (IoS), “Digital Twins” (DT), and “Machine Learning” (ML) have laid the foundations for the so-called Industry 4.0 (I4.0), which has prompted many companies to completely renew the concept of maintenance, improving productivity, preventing downtimes and reducing costs.1,2
Among the different maintenance strategies, Prognostics and Health Management (PHM) represents one of the most innovative, perfectly fitting into the new I4.0 scenario; indeed it is based on systems’ Condition Monitoring (CM) through IoT sensors installed on machinery. 3 PHM absolves the two important tasks related to diagnosis and prognosis to define their health state and avoid unexpected failures by preventing damages. 4 Different parameters can be monitored in PHM according to the type of equipment, such as temperature, vibration, pressure, acoustic emission, force, tension, and others. 5 Industrial Structures, Systems, or Components (SSCs) are considered to be in a normal state if these parameters remain above a predetermined threshold. 6 Indeed, the evolution in time of these parameters can be used to monitor any deviation from normal operating conditions, which can help to determine the time the equipment is in good condition before it falls into a state of non-healthy condition. Therefore, PHM is mainly focused on both Fault Diagnosis (FD), when a failure state is present and there is the necessity to investigate the source of the anomaly, and Fault Prognosis (FP), when the necessity is to predict the future degradation until complete failure occurs; 7 in such last case, often, the Remaining Useful Life (RUL) of SSCs is estimated. RUL is defined as the time length from the current time to the end of the useful life, that is, when the system condition reaches the failure threshold. 8 The forecasting window plays a crucial role in prognosis because the objective is to provide an estimate of the future time-step when a certain event will occur. 9 In recent years, several methods to evaluate RUL or FD have been proposed, such as model-based, data-driven, or mixing both of them. Model-based approaches rely on the knowledge of the inherent system failure mechanism to build a degradation mathematical model to describe the physical nature of the fault; 10 on the other hand, data-driven techniques rely on collected data to extract knowledge about the health status of the monitored equipment. This task is particularly suitable to be performed by ML algorithms. 11 These algorithms range from conventional Shallow Learning (SL) techniques such as Artificial Neural Network (ANN), Support Vector Machine (SVM), Decision Tree (DTR), RF, to more recent techniques, such as DL algorithms. 12
Machine learning is arising as one of the major approaches for PHM and RUL estimates. Machine learning is mainly used for solving two types of tasks, namely, “Classification” and “Regression”. Classification tasks have a finite number of output classes, while, in regression tasks, an infinite number of outputs are represented as real-valued data. By its nature, the FD is a classification problem. RUL prediction, instead, is often a regression problem, even if there are rare cases in which the RUL is treated as a classification problem. 13
Regardless of the type of algorithm used or the type of task faced, an important step in using ML in PHM is being able to measure the performance of the algorithm. Therefore, it is necessary to define Key Performance Indicators (KPIs) to determine the accuracy of an algorithm and the associated methodology.
The study aims to conduct a Systematic Literature Review (SLR) on the use of ML techniques in the field of PHM of industrial mechanical systems and critical equipment. To the best of the authors’ knowledge, the problem presented in this paper has not been addressed previously. Thus, to fill this gap, the study investigates diagnostics and prognostics applied to the industrial SSCs, the kind of ML algorithms used and on the Key Performance Indicators (KPIs) for validating them.
The rest of this paper is outlined as follows: next section presents the methodology followed to conduct the research that led to the identification of the selected studies; then, the results will be analyzed and discussed by carrying out a bibliometric analysis and answering the aforementioned RQs; finally, the last section highlights the conclusions and future works.
Research methodology
To have an overview on the use of ML techniques in the field of PHM of industrial SSCs, an SLR
14
similar to the ProKnow-C methodology
15
was performed to answer the following Research Questions (RQs): - -
To answer the aforementioned questions, a literature search was performed on the Scopus database (www.scopus.com), which is often used as a unique database because it groups several types of journals covering different fields of science and, in addition, it provides exhaustive data for each document and complete information on the author(s) and their institution profiles.16–19 The research string was run on January 10, 2023. Aiming to restrain the search field to the desired themes only, several combinations of keywords have been used for including all the possible papers related to the concepts of: - PHM (i.e., “PdM” OR “predictive maintenance” OR “data-driven PdM” OR “prognostic”, OR “condition-based maintenance”); - diagnostics and prognostics (i.e., “fault” OR “RUL”); - ML (i.e., DL).
Each of these keywords was searched in the abstract, title or keywords (TITLE-ABS-KEY) of the documents, that is, at least one keyword for each of the 3 above-mentioned batches must be present either in the title, or in the abstract, or in the document keywords. This query provided a first set of 483 results; then, some Inclusion Criteria (IC) were considered: - IC 1. Only papers in the final publication stage; - IC 2. Only English language papers; - IC 3. Only recent papers that were published between 2008 and 2023.
This first filtering returned 418 papers; to further limit this number of documents, a fourth IC was added to the others: - IC 4. Only journal papers (other kinds of documents, such as books or conference papers were not considered).
Following this last IC, the database was restricted to 254 documents. The final search string is reported below:
TITLE-ABS-KEY ((Prognostic PRE/2 Management OR “PhM” OR “Data-driven PhM” OR “Predictive Maintenance” OR PdM OR “Data-driven PdM” OR “prognostic*” OR “condition-based maintenance” OR CBM) AND (“Machine Learning” OR “ML” OR “Deep Learning” OR “DL”) AND (fault OR failure OR “Remaining Useful Life” OR “RUL”)) AND PUBYEAR >2007 AND PUBYEAR <2024 AND (LIMIT-TO (PUBSTAGE, “final”)) AND (LIMIT-TO (DOCTYPE, “ar”)) AND (LIMIT-TO (LANGUAGE, “English”)).
At this point, three further steps, described below, were conducted to finally find the ultimate papers: First, 31 documents were removed by simply reading the papers and journals titles, because they were not related to the industrial mechanical systems field (i.e., medical, railway, robotics, or chemical field); Second, the remaining 223 abstracts were analyzed, discarding 148 documents because either they did not consider industrial mechanical applications, but aeronautical, aerospace, and chemical applications, or they did not consider applications to validate their ML algorithms at all; the remaining 75 documents went to the next analysis step, even if 24 of these 75 needed a more in-depth analysis because by simply reading the abstracts, it was impossible to determine neither if authors considered some kind of applications, nor if the applications were in theme with the interested industrial field; Finally, a full paper analysis was conducted, which allowed excluding 25 documents because they consider neither ML algorithms (but statistical techniques), nor industrial mechanical applications. Therefore, 50 papers out of the 254 were considered eligible for the following analysis.
An overview of the whole search process is provided in Figure 1. Overview of the literature identification process.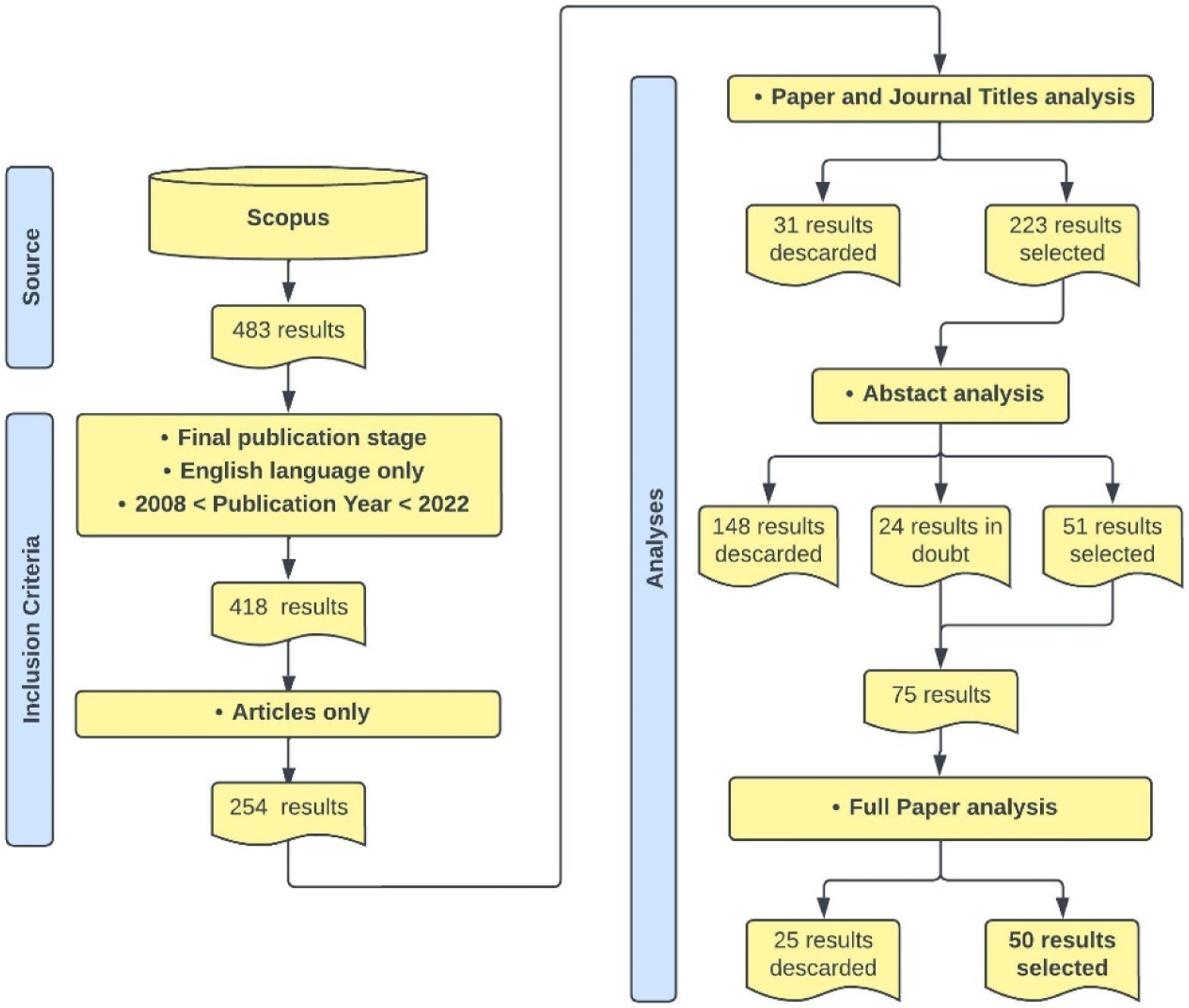
Results and discussion
In this section, the results are shown and discussed according to the previously defined RQs. First, in section 3.1, a bibliometric analysis 20 was carried out to highlight the trends of the analyzed publications over the years. Next, RQ 1 and RQ 2 were answered, respectively, in section 3.2 and section 3.3 where the ML algorithms and KPIs used in the 50 analyzed studies are examined; finally, in section 3.4, a schematic framework was developed to standardize the diagnostics and prognostics process carried out by the authors who used own unique datasets, and not the common public available datasets.
Bibliometric analysis
Figure 2 shows how the 50 selected papers are distributed over the years, including the number of citations received per year. They cover an 8-year long period, starting from 2016 until 2023, although the IC 3, defined in the previous section, considers eligible only papers starting from 2008. Only 20 papers of the first set of 483 results belong to the 2008–2015 years and none of them is about the industrial mechanical field, but medical, railway, chemical or aeronautical field. For such a reason, they were excluded from the final analysis. In Figure 2, it is possible to note that the number of papers increased in the last few years, reaching the peak of 14 publications in 2021. This increasing number of studies over the years is not surprising, considering that the word “Industry 4.0” was used for the first time in Germany in 2011, and precisely during the Hanover Fair, where the Communication Promoters Group of the Industry-Science Research Alliance (FU) announced a project for the development of the German industrial manufacturing sector, the “Zukunftsprojekt Industrie 4.0”
21
; since then, the German model, combined to the improvements of the inter-connectivity of the IoT and robotics devices brought by Artificial Intelligence (AI) technologies, has inspired numerous researchers to continue researching the ML field to improve the productivity and reduce the costs related to industrial maintenance.
22
Publication and citations trend per year.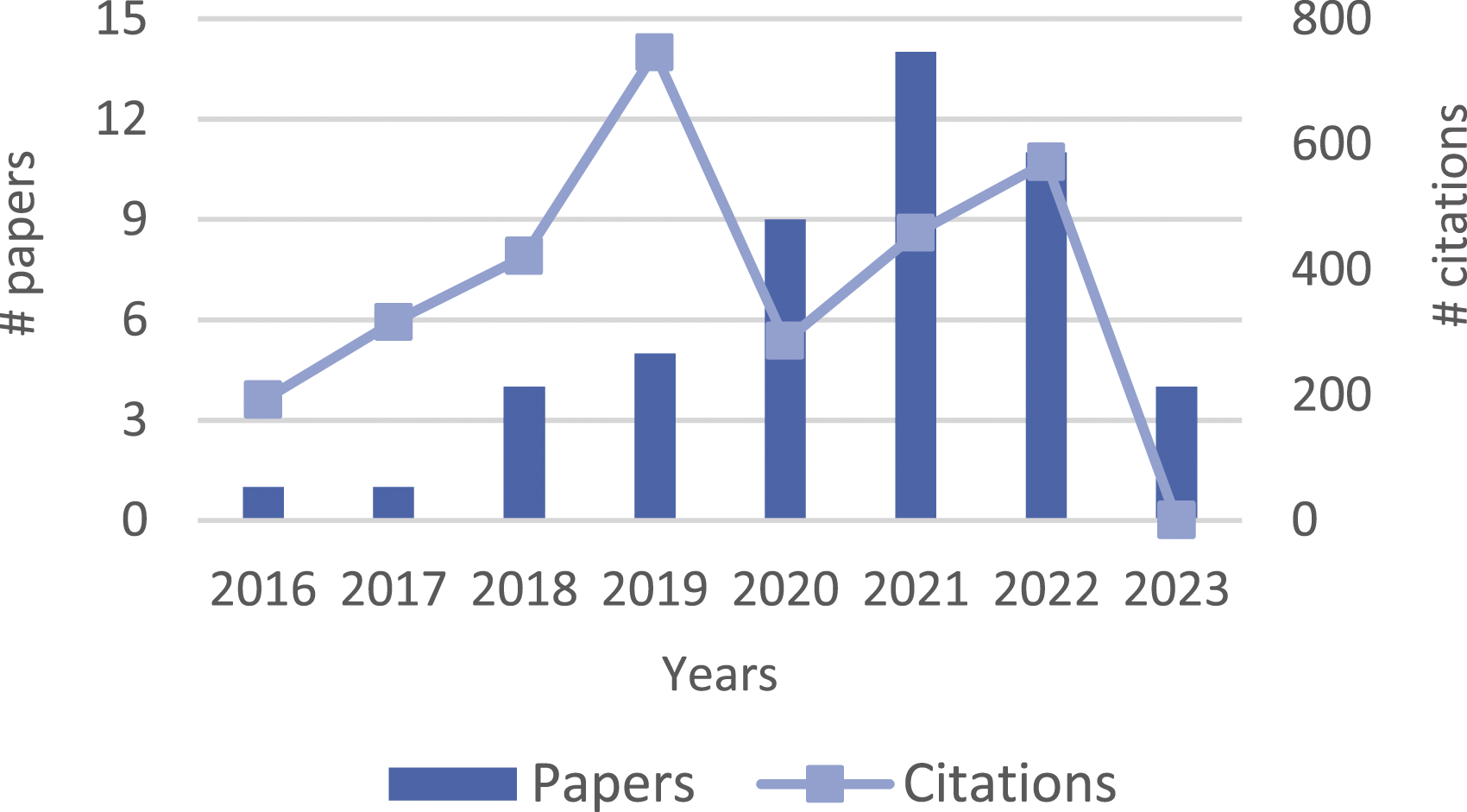
Concerning the number of citations per year, it is possible to note from Figure 2 that the trend is not stable, with a peak of 746 citations in 2019, an average of 373.8, and 0 citations in 2023, because of the narrow time window available to receive citations in this year, considering that the literature search date is on January 10th, 2023.
Number of papers related to the most relevant journals.

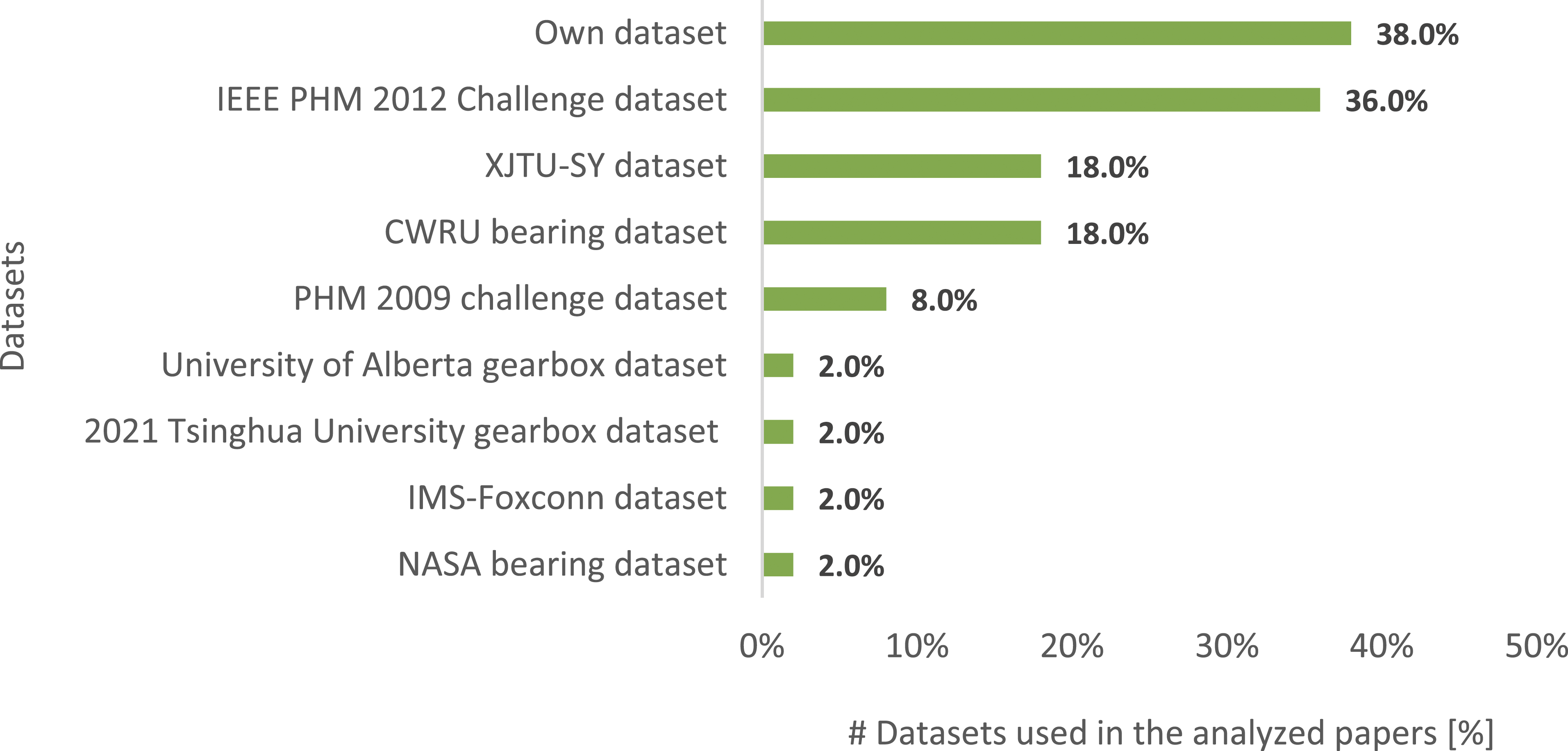
The 50 analyzed papers present 6 different types of SSCs (Figure 3) and 9 different types of datasets (Figure 4): 8 are online public datasets, and 1 is an “own-datasets” type, that is, datasets created specifically for the task addressed and the industrial application of the authors. It is possible to note that the sum of the percentage values in Figure 3 and in Figure 4 is beyond 100% because often more than one type of SSC and/or datasets was examined by the authors. About the mechanical systems and components analyzed in the papers, bearings are in 74% of the analyzed studies, followed by gears at 16%, milling machine’s cutting tools at 10%, a pump’s impeller, a ball screw and a hot strip mill’s roller at 2%. These trends can be explained by noting that the most of problems arising in rotating machinery are caused by faulty gears and bearings.
23
As components between the stationary and the rotating part of the industrial machinery, bearings represent an essential part of them; in fact, it causes more than 50% of induction motors’ failures mainly because of overheating, too high axial and radial loads, and electrical stress such as the presence of bearing currents.
24
As a consequence of the predominant presence of bearings and gears as SSCs analyzed by authors, four popular public datasets resulted to be the most used in the analyzed papers, that is, for bearings, IEEE PHM 2012 Challenge dataset (36%), XJTU-SY and CWRU bearing dataset at (18%), and, for gears, PHM 2009 challenge dataset at (8%). The remaining four datasets consist of two datasets for gearboxes (University of Alberta gearbox and 2021 Tsinghua University dataset), one dataset for milling machine’s cutting tools (IMS-Foxconn dataset), and one dataset for bearings (NASA bearing dataset). Moreover, from Figure 4, it is possible to note that 38% of the analyzed papers present datasets created for the specific problems investigated by the authors; this theme is examined in depth in section 3.4. Structures, systems, or components used in the analyzed papers. Datasets used in the analyzed papers.
Machine learning algorithms for PHM of SSCs
This section aims to respond to RQ 1, that is, What are the most used ML algorithms for PHM’s diagnostics and prognostics of industrial SSCs?
The constant increase in data availability due to intelligent sensors installed on SSCs, in addition to the technological progress in terms of computers’ hardware and software and a large number of cross-platform libraries, such as MATLAB, Python, R, and Sci-kit Learn, have led to the rapid development of multiple ML techniques to better address the issue of PHM of SSCs. These techniques range from the first classic SL techniques to the more recent DL ones. The word “shallow,” is from the single hidden layer belonging to the first simple neural networks, therefore usually nowadays “Shallow Learning” refers to all the traditional ML models, that is, those proposed before 2006; 25 among these, those used in the 50 analyzed studies are: shallow ANN, i.e., neural networks with only one hidden layer of nodes, SVM, DTR, RF, statistical models, and hybrids, that is, combinations of these algorithms; on the other hand, DL models are based on neural networks with the addition of multiple hidden layers between the network’s input and output; 7 among these, those used in the 50 analyzed studies are: Deep Neural Network (DNN), Recurrent Neural Networks (RNN), Convolutional Neural Networks (CNN), Auto-Encoders (AE), Restricted Boltzmann Machines (RBM) and hybrids, that is, combinations of these algorithms. Furthermore, the cases of SL/DL hybrid methods, that is, algorithms in which SL and DL models are combined, are not uncommon.
Machine learning algorithms used in the 50 sample papers.
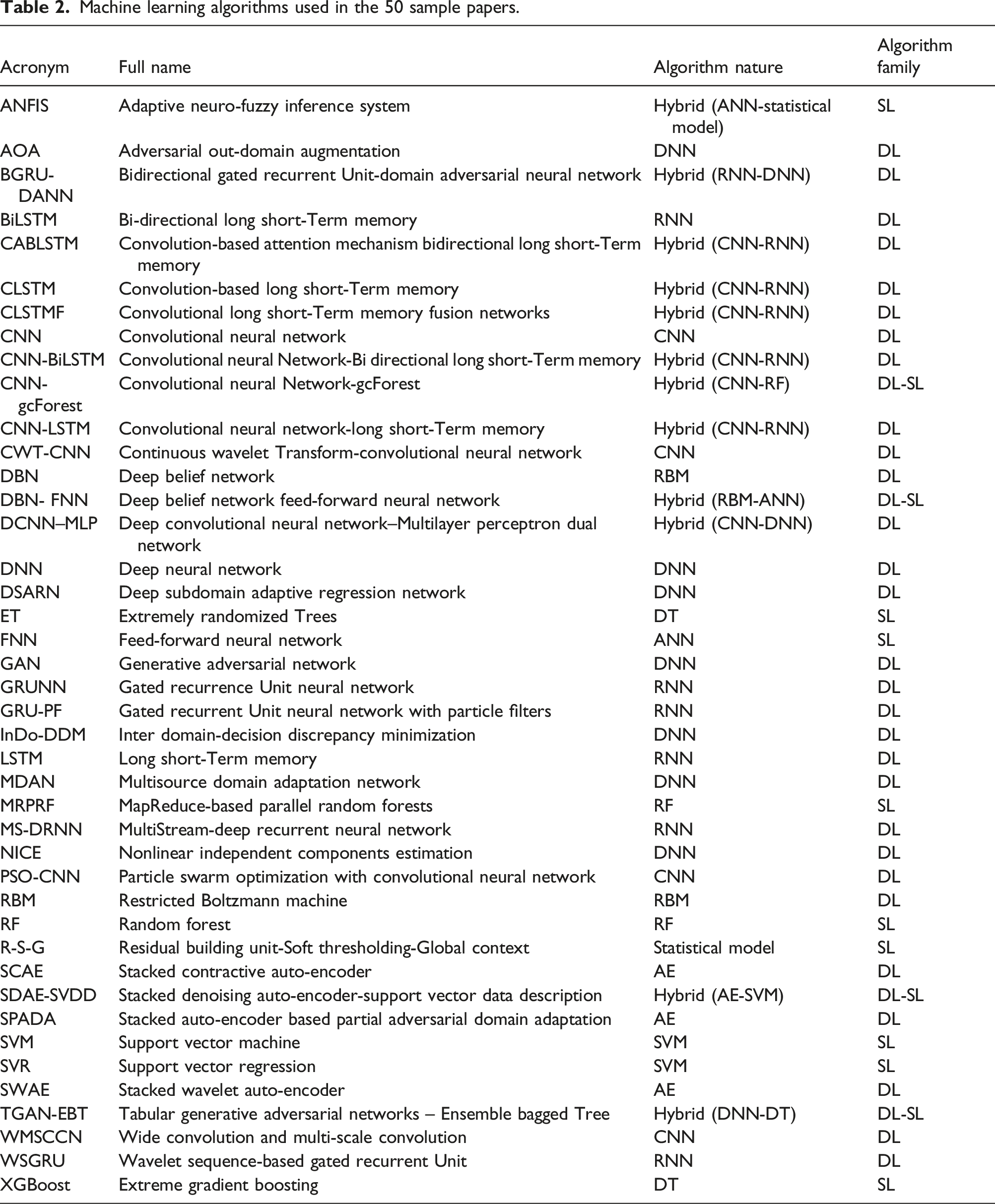
Moreover, the frequency of citations of the aforementioned ML algorithms is shown in Figure 5, where it is clear the predominance of the DL methods (82%, i.e., 41/50 sample papers) both on the SL methods (10%, i.e., 5/50 sample papers) and Hybrid SL/DL ones (8%, i.e., 4/50 sample papers). One of the reasons for the higher use of DL, supplanting the traditional SL algorithms, is the ability to skip the process of hand-extraction features from the input data before being fed into the network, thanks to a nested series of consecutive computations that result in the extraction of a set of complex and highly informative features; moreover, in these years, an increasing number of empirical results have shown that these models return better results in terms of diagnostics and prognostics performance, compared to “shallow” methods. The main problem is that, compared with SL models, DL ones require a larger amount of training data (not always available) and the models to build are more complex.
7
Frequency of the shallow learning, deep learning, and hybrid algorithms used in the 50 analyzed papers.
The pie charts in Figure 6 show how the ML techniques are distributed among the 50 sample papers, dividing them into SL algorithms (a), DP algorithms (b), and hybrid ones (c). About the SL algorithms, as aforementioned, only 5 of 50 analyzed papers use SL methods, with a prevalence of RF (30%, i.e., 3 times), followed by DT and SVM (20%, 2 times each), ANN, ANFIS (hybrid between ANN and a statistical model), and R-S-G statistical model (10%, 1 time each). RF, DT, SVM, and ANN have been used for prognostics tasks, while ANFIS and R-S-G statistical models for diagnostics tasks. About the DL algorithms used in 41 of the 50 analyzed papers, they are distributed as follows: CNN and RNN are the most used (25.6%, i.e., 11 times each), followed by DNN and Hybrid ones (16.3%, i.e., 7 times each) that are constituted by two models, that is, a mash-up between CNN and RNN (14%, i.e., 6 times) and a mash-up between RNN and DNN (2.3%, i.e., 1 time); the DL algorithms less used are RBM (9.3%, i.e., 4 times) and AE (7%, i.e., 3 times). CNN, DNN, RBM, AE, and Hybrid ones have been used both for prognostics and diagnostics tasks, while RNN has been used only for prognostics tasks. In conclusion, about the DL/SL hybrid algorithms, there are four of them: CNN-RF, RBM-ANN, DNN-DT, and AE-SVM; each of these algorithms has been used only for prognostics tasks. Types of shallow learning (a), Deep learning (b), and hybrid (c) algorithms used in the 50 analyzed papers.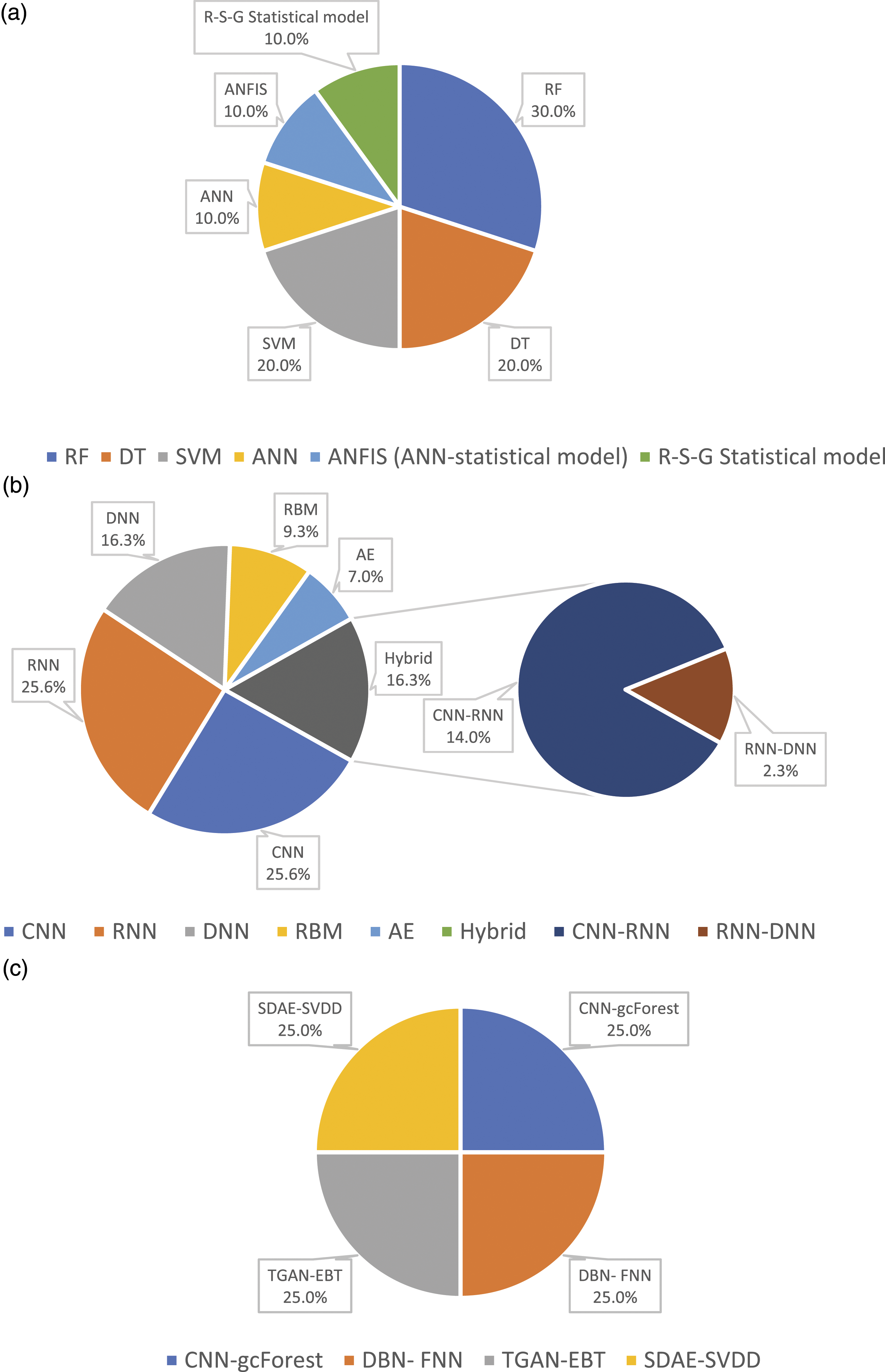
Machine learning KPIs for PHM of SSCs
KPIs for ML classification tasks.

KPIs for ML regression tasks.

Note: MSE, RMSE, MAE, and CRA are bounded to [0, +∞], while MAPE, R2, and Ai are bounded to [0, 1]; since MSE, RMSE, MAE, and MAPE are coefficients that evaluate an error, the lower the value, the greater the accuracy of the forecast. Instead, for R2, CRA, and Ai, the higher the metric, the better the prediction performance.
Moreover, the frequency of citations of the aforementioned EM is shown in the diagram in Figure 7, where the KPIs are divided into classification (a) and regression (b) tasks. Among all the 50 analyzed papers, 18 deal with the classification task, while the remaining 36 deal with the regression task. 4 papers considered both classification and regression tasks. About the classification task, Accuracy is the most used metric (58.6%, i.e., 17 times), followed by CMX (about 24.1%, i.e., 7 times), Recall (about 6.9%, i.e., 2 times), and AUROC, Precision, and F1 (about 3.4%, i.e., 1 time each). About the regression task, RMSE is the most used metric (32.4%, i.e., 22 times), followed by MAE (26.5%, i.e., 18 times), A
i
(13.2%, i.e., 9 times), MAPE (11.8%, i.e., 8 times), R
2
and MSE (7.4%, i.e., 5 times each), and CRA (1.5%, i.e., 1 time). Frequency of the key performance indicators for classification (a) and regression (b) tasks.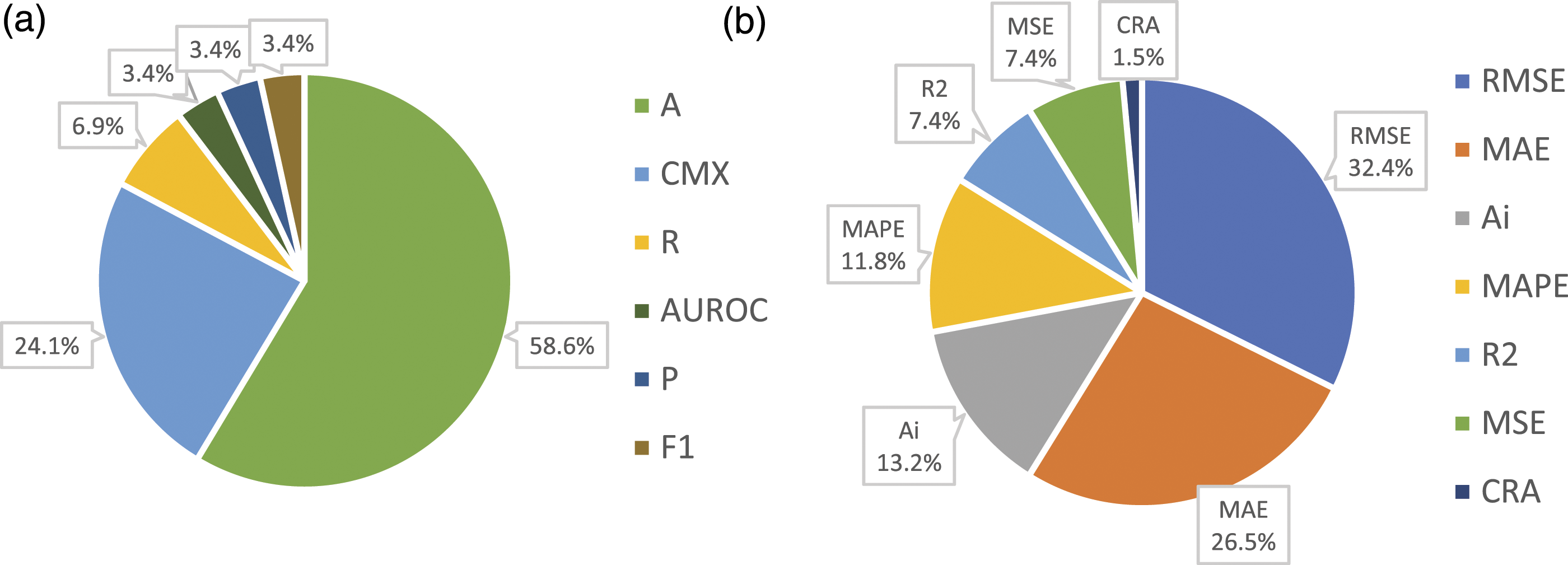
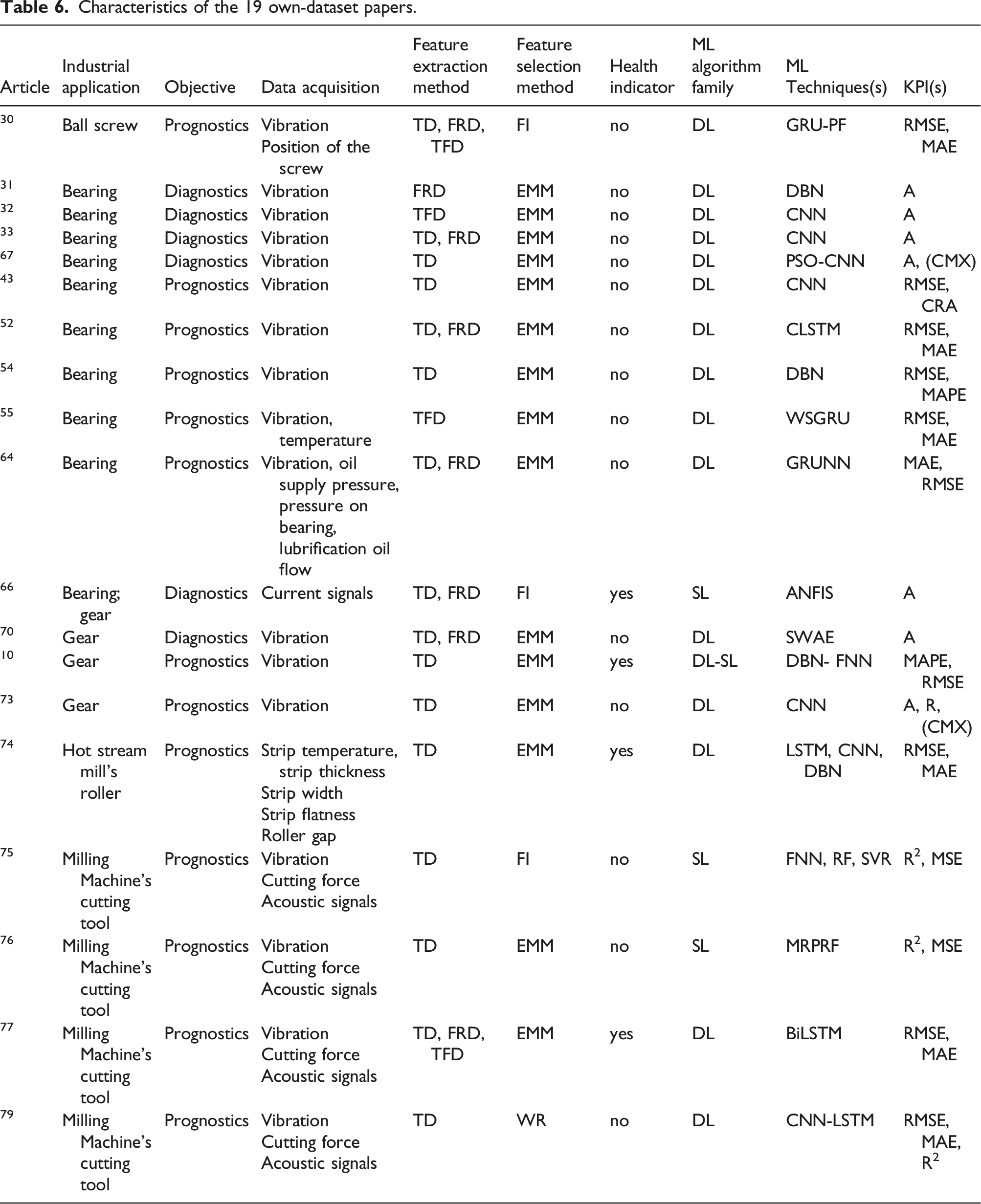
Characteristics of the selected studies.

PHM framework for the “own-dataset papers”
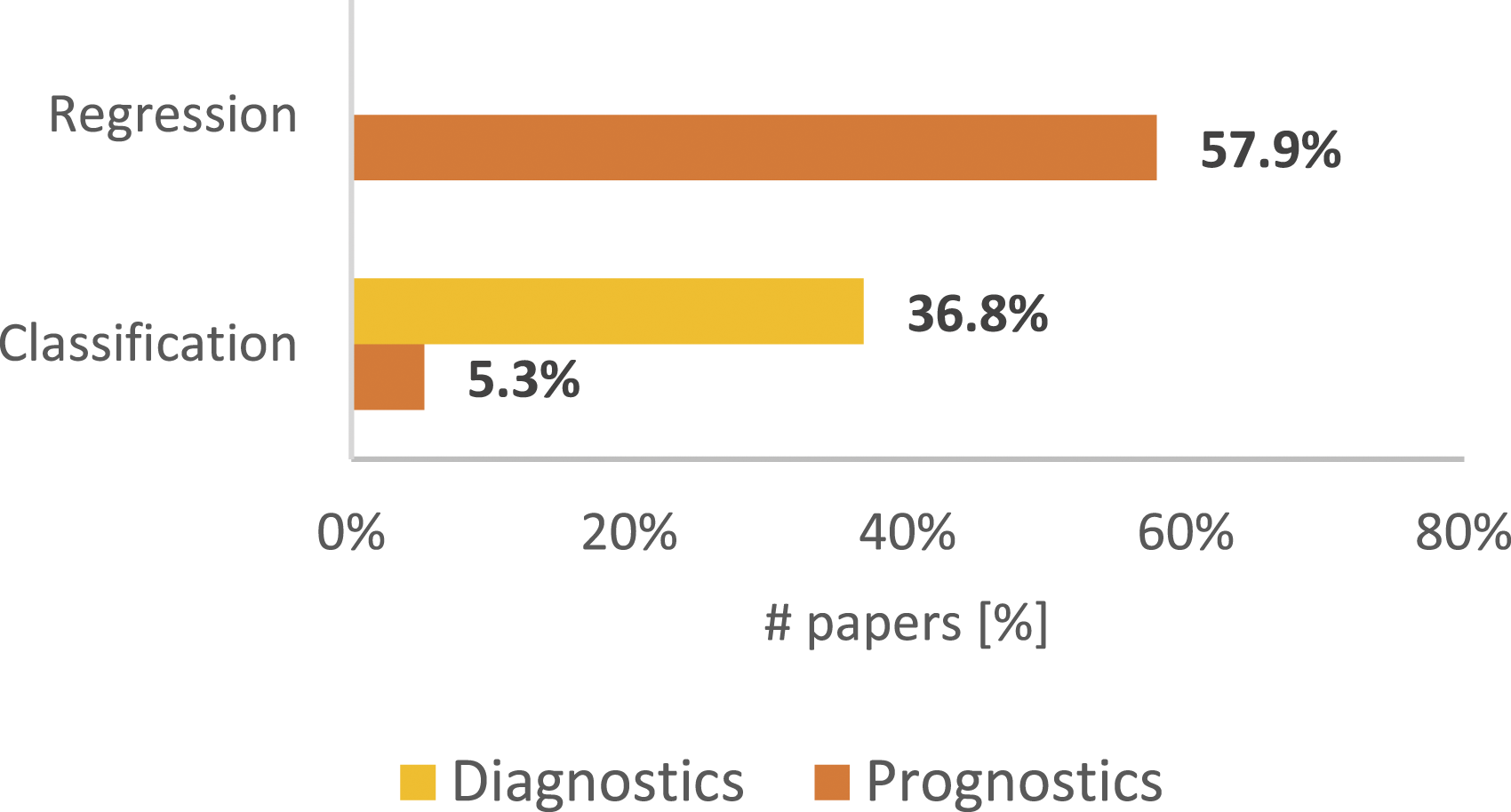
Figure 8 shows the analyzed papers’ diagnostics and prognostics distribution and how regression and classification tasks are allocated to them. It is possible to note that Prognostics overtakes its counterpart with 70% of the papers (divided by classification end regression tasks) versus 30% of the papers which face diagnostics (only through classification task). However, prognostics and diagnostics percentages, shown in Figure 8, could be misleading because they are not necessarily related to the real manufacturing industry prognostics and diagnostics data, but rather they are related to the problem of the complexity of monitoring and analyzing data through IoT devices for industries, that led to the use of pre-existing datasets just to find the best ML algorithms proposed by the 50 papers’ authors. This is the reason why the papers that present datasets created specifically for the task addressed by their authors (own-dataset papers) are further investigated in this section; from Table 5 it is possible to extrapolate that an own-dataset has been used in 19 of the 50 analyzed studies. As a first step, to better understand the real partition between prognostics and diagnostics in the industrial field, Figure 9 shows the own-dataset papers’ diagnostics and prognostics distribution related to regression and classification ML tasks. Comparing Figures 8 and 9, it emerges that both the prognostics and the diagnostics trends are confirmed, that is, a clear predominance both of Prognostics on Diagnostics and Regression on Classification. All papers’ diagnostics and prognostics distribution related to regression and classification Machine Learning (ML) tasks. Own-dataset papers’ diagnostics and prognostics distribution related to regression and classification ML tasks.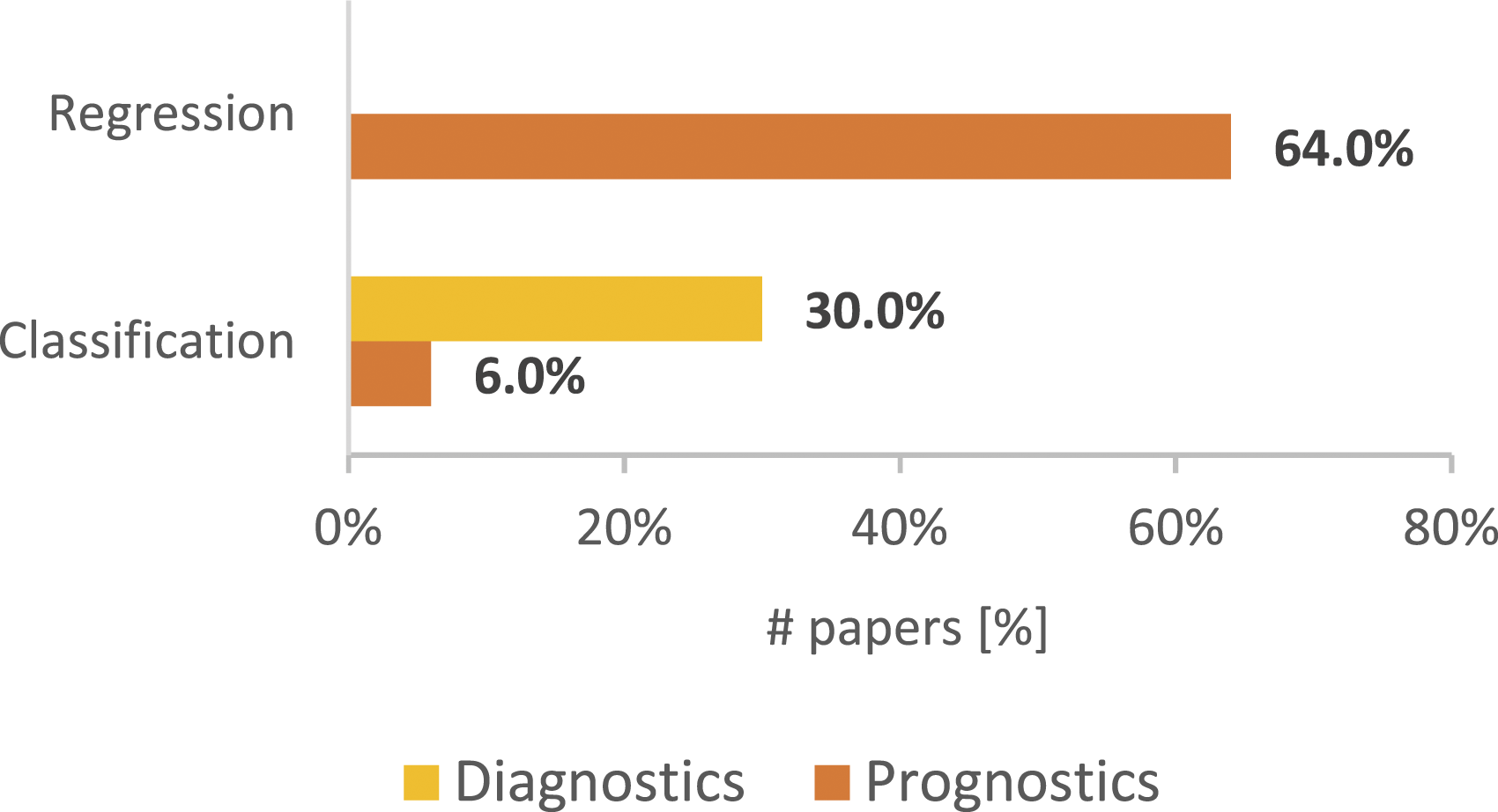
Therefore, Figure 10 below shows a single common PHM framework which describes the step-by-step diagnostics and prognostics process carried out by the authors of the 19 own-dataset papers. It is worth noting that the path is not unique since some steps could be repeated for the diagnostic and prognostic tasks, for example, although the prognostic step relies on the results of the diagnostic step, it may be necessary to perform steps from 2 to 5 again since the task purpose is changed. Moreover, step 8 could follow both steps 6 and 7. The aforementioned steps are described as follows: Diagnostics and prognostics process followed by the 19 own-dataset papers.

Time-domain is based on converting raw data into statistical features such as mean, median, standard deviation, variance, root mean square (RMS), skewness, and kurtosis. For example, Wu et al. 73 use twelve different time-domain extraction features to form a single feature vector as an input to a neural network: VPP, standard deviation, variance, mean, RMS, ARV, form factor, crest factor, kurtosis, kurtosis factor, pulse factor, and margin factor. Other papers that adopt this type of time-domain based feature extraction are Refs. [10,75,76,43,54,79]. Other time-domain feature extraction methods are Hierarchical Symbolic Analysis (HAS), 67 and a unique deep multilayer LSTM model that can fully extract the features from the monitoring raw data. 74
Frequency-domain is about extracting statistical features by applying the Fast-Fourier-Transform (FFT) to raw data; typical statistical frequency domain features are Mean Frequency (MF), Root Mean Square Fluctuations (RMSF), Frequency Modulation (FM), Root Variance Frequency (RVF), Power Spectrum Deformation (PSD), etc; for instance, Xie et al. 31 extract frequency-domain features and use them as inputs to a DBN model.
Time-frequency domain considers both time and frequency domains to capture how the frequency components of the signal vary as a function of time. It is commonly used to monitor rotating machinery state, and it is very effective for non-stationary time-series analysis. For example, the vibration signal of a bearing is non-stationary and has a weak defect signal within a strong background of noise. 80 Wavelet Transform (WT), Continuous Wavelet Transform (CWT), and Empirical Mode Decomposition (EMD) have been used to extract features from raw signals, such as in Ref. 55 where the wavelet sequences are realized using the CWT, given its capability to handle the non-stationary signals with multiscale representation, which can provide the hierarchy of structural information to show the dynamic characteristics of the vibration signals. Another example of TFD method is carried out in, Ref. 32 where 8 different TFD methods are used to extract features for bearing Fault Diagnosis.
Four further cases are about bearings’ prognostics,52,64 bearings and gears’ diagnostics, 66 and gears’ diagnostics, 70 in which both frequency and time domains are investigated separately. In particular, in Ref. 24, statistical features in time and frequency domains, such as RMS, square root value, absolute mean, kurtosis, and others, are used to describe the degradation process of bearings; in Ref. 28, a total of 16 among classic time-domain features and 3 frequency-domain features (FC, RMSF, and RVF) are extracted from five sensors as input to the proposed model; in Ref. 37, the frequency-domain analysis is used for each current signal (features are extracted from electrical signals) to extract a characteristic value corresponding to different load variation states, while, on the other hand, the time-domain analysis is applied to extract values that allow tracking the evolution of the bearing and the gear degradations; in Ref. 33, the time-domain analysis has been carried out evaluating standard deviation, kurtosis, shape factor, and impulse factor, that have been extracted from each sample of each sensor, while, the frequency-domain has been calculated from the corresponding spectrum sample of each sensor, defining 13 different statistical indexes.
Other two examples of “meshing” feature extraction domains are on Ref. 30 and Ref. 77 where all of the three different domains are examined separately (TD, FRD, and TFD) to identify the ML algorithm with the greatest number of useful features. -
FI is based on simply finding the best features’ sub-set according to the specified objective of diagnostics or prognostics through several statistical methods, such as correlation, time-series, chi-square test, and others; unlike the following two methods, FI does not use ML algorithms to perform the PHM task, therefore it allows to have a sub-set of features more versatile, to be then employed by numerous ML algorithms. For example, Saravanakumar et al. 66 use Spearman correlation to find how the extracted features are correlated with the actual RUL of bearings. Other examples of filters-based techniques are in Ref. 30 and Ref. 75.
WR is based on a specific ML algorithm that has to fit a given dataset. The evaluation criterion is simply linked to the classic ML performance metrics, including those described in sub-section 3.3. Wrappers are usually able to achieve better performances than FI-based techniques since they are optimized for a specific ML algorithm which is in turn tailored for a specific task. On the other hand, wrappers are biased toward the ML algorithm they are based on and therefore the resulting feature sub-set is not very versatile, that is, it will not be generally adequate for alternative ML techniques. 7 For example, to automatically select and classify the most informative features, Marei et al. 79 employ a CNN model, using then test accuracy to get feedback about the performance of the feature section.
EMM presents the feature extraction process into the ML algorithm, which is able to pull out the most representative features from the extracted features’ sub-set. It is possible to find examples of the embedded approach in, Ref. 31 where an adaptive DBN optimized by the Nesterov Moment (NM) is used to extract features from rotating machinery and recognize bearing fault types and degrees simultaneously, or in Ref. 43 and, Ref. 73 where the complex process of feature selection is compressed into a single deep learning algorithm (CNN) which is able to learn how to select features directly from the original vibration signals in order to predict RUL
43
or diagnose faults.
73
Other examples of the EMM are in Refs. 10,32,33,52,54,55,64,67,70–77]. - - - - - Machine Learning algorithms’ nature used in the 19 own-dataset papers.

Conclusions
A SLR about the PHM of industrial mechanical systems and equipment was carried out. The focus concerned the most used ML algorithms in diagnostics and prognostics field, and the related KPIs employed for validating them. A literature search on the Scopus database led to 50 studies eligible for the above-mentioned analyses, 31 of which present common public datasets, and the remaining 19 present own datasets, i.e., datasets created specifically for the task addressed and the industrial application used by the authors. Concerning the family of ML algorithms, DL ones result to be the most used. Moreover, among the DL techniques, CNN and RNN resulted as to be the most applied, while RF is predominant among SL techniques. Regarding the KPIs, Accuracy resulted to be largely the most used for ML classification tasks, while for ML regression tasks, the frequency of the KPIs results to be more balanced with RMSE, MAE, Ai, and MAPE. Later, a further detailed analysis has been carried out with the aim of finding a common PHM framework which describes the step-by-step Diagnostics and Prognostics process carried out by the authors of the 19 own-dataset papers. This analysis aims to provide the reader a common practice for the best choice of the ML algorithms and the related evaluation metrics for manufacturing industry.
Overall, by the analyses carried out in this paper, it resulted that research is moving towards the use of more recent DL techniques, rather than the classic SL algorithms, although DL methods are more complex to build and require the so-called “big Data,” not always available. On the other hand, the automated end-to-end feature extraction, together with an improved capacity of generalization has led to a large-scale replacement of the traditional SL architectures for DL ones.
The main limitation of this SLR is about the industrial mechanical systems and equipment’s field of application; in fact, other industrial fields, such as aeronautical, chemical, robotics, and railway fields have been excluded. Therefore, future studies may fill this gap.
Footnotes
Author contributions
Lorenzo Polverino: Study conception and design, data collection, analysis and interpretation of results, writing – original draft
Raffaele Abbate: Study conception and design, Methodology, analysis and interpretation of results, Review & editing
Pasquale Manco: Methodology, Review & editing
Donato Perfetto: Methodology, Review & editing
Francesco Caputo: Funding acquisition, Supervision, Review
Roberto Macchiaroli: Funding acquisition, Supervision, Review
Mario Caterino: Study conception and design, analysis and interpretation of results, Review & editing.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the project DESIRE (DEsign Solutions for Industry 4 Ready processes) under the PON “Ricerca e Innovazione” 2014-2020 and FSC.