
Abstract
It is aimed to identify the basic success factors, which are essential for startups as they intend to develop successful and profitable business models over time. To this end, it is attempted to analyze the sentiments on user-generated content (UGC) on Twitter. First, trigram word cloud is used. Then, a sentiment analysis is done with various predictive models including random forest, support-vector machine (SVM) and multilayer perceptron (MLP) to test the labeling of unlabeled data. To divide topics into negative, positive, and neutral sentiments, latent Dirichlet allocation (LDA) has been applied. According to the results, the MLP method on the basis of accuracy criterion offers an accuracy of 0.81, which is higher than other tested methods. In this regard, random forest and SVM methods provide accuracy of 0.78 and 0.80, respectively. Voting and stacking algorithms were used to increase the accuracy of the algorithms. However, it is found that with the use of voting method, the accuracy is almost equal to the results obtained from the MLP and with stacking method the accuracy is less than all three methods. Using word cloud, it is indicated that the most negative trigram is startups innovation regarding climate change, the most positive one is product marketing management and business-related concepts are determined as neutral. It is found that startup acceleration process, pushing for quicker completion, delivering the best product at the beginning of the project, poor management practices, and focusing just on properties are grouped as negative sentiments. On the other hand, sustainable and innovative business plan, the presence of experienced entrepreneurs and investors, coronavirus (COVID-19), and innovation are recognized as positive sentiments, and no analysis is given for neutral sentiments.
Keywords
Introduction
Nowadays, around the world, changes in population, technology, inflation, unemployment, and other environmental factors have changed human society very differently from the past and have posed new challenges and opportunities. There is a lot of emphasis on entrepreneurship and attention to startups by governments, organizations and public opinion, and it is referred to as the engine of economic development. Startups are able to enhance the level of national innovation and economies. They can satisfy requirements of current and new emerging markets effectively. 1 From this perspective, entrepreneurship is a concept that has always been with human beings and as a new phenomenon has an effective role in the production and development of countries, so that in a competitive and market-based economy is a key factor.
Measuring success of a firm is recognized as a competitive advantage. In other words, the firm requires to be successful in order to experience more developments. 1 In this case, measurement of the success of startup activities is a topic that has attracted special attention in recent years. Startup refers to a new company with a new idea according to the knowledge industry. It is different from small businesses, which are categorized based on their structure’s size. It is stated that a startup is a new non-permanent company with a business model on the basis of innovation and technology. 2 There is lack of empirical studies in the area of success factors of entrepreneurs, who are involved in the creation of new ventures. 3
It should be noted that growth and development start from start-up organizations and is transferred to larger organizations and the whole country. Gaining startup expertise can help many managers succeed. If organizations can increase their effectiveness and efficiency in entering to the market, they can consolidate their market position and survive. A successful start-up usually has more growth potentials than a company with only more capitals and labors.
General objective of the study is to identify and classify key success factors for startups using text mining and sentiment analysis. In this regard, sub-objectives are (1) identifying the success factors of startups using text mining models, (2) classification of identified factors using sentiment analysis, (3) providing solutions based on the results of sentiment analysis for startups development. In other words, this study provides a methodological approach based on data text mining for identification of the success factors of startups in positive, negative, and neutral categories, so that a wide range of professionals including startup managers can be aware of these key factors and use them to improve their projects and businesses. It also provides a deep understanding of the startup ecosystem. Additionally, (4) it compares the accuracy of various predictive models including random forest, support-vector machine (SVM), and multilayer perceptron (MLP) before and after combining with voting and stacking techniques.
The following research questions are proposed for this study due to the importance of identifying the critical success factors of startups for their business models. Previous studies have shown that the most important topics for different industries can be found through the analysis of UGC.
4
This study uses the following research questions to determine whether critical success factors for startups can be found from comments on UGC on Twitter. Accordingly, the following six research questions are tried to answer in the present study. • •
Various studies have used multiple approaches with UGC content to find sentiments expressed by users in social networks such as Twitter.
4
In this study, the Twitter social network is used to analyze the positive, negative, and neutral sentiments in the area of critical success factors of startups on the UGC of Twitter users. •
Key factors are those that influence the progress of a subject.
4
For start-up businesses, key success factors can be management, business plan, or investment in innovative and sustainable development. • • •
This paper reviews existing literature, describes the research methodology, presents the analysis and results, and finally, makes conclusions and recommends some future works.
Literature review
Success factors of startups in each stage is different, for instance some factors are more important in the stage of research and planning and has less impact in the phases of execution or fund raising. The success factors include economic factors, innovation, entrepreneurship and technology variables. Abnusian et al. 5 reviewed data mining applications in e-commerce, presented its pros and cons, proposed solutions to control its challenges, and highlighted its benefits. Accordingly, data mining is able to improve e-commerce and increase the profitability and customer satisfaction. Rokhi Nasab et al. 6 addressed business intelligence as a process in which raw data is converted into business and management information using data mining. They focused on e-business and data mining, and outlined the challenges and benefits of business data mining. They also presented a classification of data mining applications used in e-business.
Nowruzi and Jafari 7 pointed out that one of the most important steps of business process management lifecycle is to monitor the proper implementation of modeled processes in the organization. Questions raised in order to monitor and decide on the improvement of business processes are sometimes complex questions about the efficiency, accuracy of implementation, the way the processes are actually implemented, and social networks formed in the organization. In addition to answering these questions, there are complex patterns and rules that need to be discovered and extracted from data to support the decision-making of a team of process excellence to improve organizational processes.
Golabi 8 declared the role of mining process in business management processes. Nowadays, due to the increasing complexity of business processes and the need for integrated information systems, new methods of data analysis has been provided. Process mining is one of the emerging methods that is used to analyze and model processes and manage organizational business. In fact, this method is applied to achieve goals such as discovering, monitoring and improving the actual processes of the organization based on the extraction of knowledge from information systems. The main purpose of process mining is to discover process models based on event shot reports in information systems. The discovered models can be used in various fields for analysis.
Ismailian and Khademi 9 introduced the text mining process and some of its most important methods and models in addition to various fields of text mining application in business. Recently, due to the huge volume of unstructured textual data produced on the Internet, text mining has gained high commercial value. Text mining is the process of extracting previously unknown, incomprehensible and potential knowledge and patterns from a set of textual data.
Azar and Mostafaei 10 after reviewing the concepts and techniques of the mining process, described α-algorithm or α-miner in the form of a numerical example. Business process is a nascent approach whose main idea is to extract the process model from the process information recorded in the event report. Event reports can be extracted from different information systems of the organization or create a report from a combination of several data files. Process mining techniques require different information depending on the goal they are pursuing. Alpha algorithm seeks for reorganizing causality of a set of sequences of events.
Minatogawa et al. 11 argued that business model innovation is the organizational key to achieve sustainability. However, there are many problems associated with business model innovation. They used a scientific design method to create an artifact to assist in business model innovation measures. The artifact uses performance metrics to measure a company’s business model, which uses big data analysis to innovate a customer-centric business model. Then, the artifact was used in a case study, whose findings show that it successfully contributes to an active and continuous effort to innovate the business model. Although the artifact is technically accessible in the context of small businesses, it helps democratize business model innovation practices and big data analytics across large organizations.
Reyes-Menendez et al.12,13 applied a latent dirichlet allocation (LDA) model to identify topics and a supervised vector machine (SVM) type analysis to classify tweets based on sentiments (positive, negative and neutral), to gain a deeper understanding of the challenges in the #MeToo movement. In this way, it has helped companies to better organize their communication and advertising actions regarding sexual harassment. Reyes-Menendez et al.12,13 based on the objective of determining the key indicators of social identity in the #MeToo movement on Twitter, using the methodological approaches of corpus linguistics (CL) and discourse analysis (DA), keywords, topics, frequency, and n-grams or combinations to understand the social identity of the #MeToo movement have been identified. Reyes-Menendez et al. 14 using sentiment analysis grouped the tweets based on the sentiments expressed. Then, textual analysis was used to group tweets based on sustainable development goals to identify key factors of environmental and public health.
Bairavel and Krishnamurthy 15 applied multilayer perceptron for sentiment classification after using oppositional grass bee optimization (OGBEE) algorithm for extracting features. Sultana et al. 16 tested on the accuracy of the training data set in order to predict the best model of sentiment analysis and found that multilayer perceptron (MLP) and SVM are the best models. Karthika et al. 17 calculated the accuracy, precision, F-measure and recall for algorithms of random forest and SVM, in which the random forest gives the best accuracy. Rahman and Islam 18 used stacking classifier, voting classifier, and bagging classifier to classify and label the tweet data. Varshney et al. 19 applied random forest and SVM with voting classification technique for sentiment analysis.
SVM is often recognized as the best classification method, followed by random forest. 20 SVM essentially determines the best possible boundaries for distinguishing between positive and negative training data and is widely used due to its exceptional performance over other methods used in most referenced machine learning models. Very quickly, in a short time, random forest became the main tool of data analysis among other standard method. MLP does not begin from any specific assumptions and does not impose any restrictions on the input data, and it can evaluate the data in spite of the existence of any noisy or distorting data. 21 Additionally, in the voting approach, overfitting is decreased and a smooth model can be produced. The advantage of stacking is that it can combine the advantages of different machine learning algorithms in a classification task and make predictions with a better performance. 22
Saura et al. 4 identified positive topics to identify key drivers of start-up business success using latent dirichlet allocation (LDA) model and a sentiment analysis was performed with a supervised vector machine (SVM) algorithm that works with machine learning in Python. Positive topics are such as startup tools, startup based on technology, the attitude of the founders, and the development of the startup methodology. Negative topics are the frameworks and programming languages, the type of job offers, and the needs of business angels. Identified neutral topics include business plan development, type of start-up project, and location of the incubator and start-up. In their study, the number of tweets in the sample and the time horizon are limited.
Sharchilev et al. 23 examined the potential of using free web-based resources to predict start-up success and modeled it using a very rich set of signals from such resources. In particular, they enriched the structured data about the startup ecosystem with information from a business and employment-oriented social networking service and the web in general. Using these signals, they trained a machine learning that includes several basic models using gradient amplification. They showed that using corporate cues on the web significantly increases performance compared to just using structured data about the startup ecosystem. It also provides a thorough analysis of the model obtained, which allows the individual to gain insight into the types of useful signals detectable on the web and the market mechanisms underlying the budget process.
Machine algorithms such as SVM, MLP, and random forest are applied in the area of sentiment analysis; therefore, this study uses these methods to test the labeling (positive, negative, and neutral) of unlabeled data. Afterwards, their accuracies are calculated and compared. Accordingly, the hypothesis is: multilayer perceptron (MLP) has the highest accuracy before and after combining with voting and stacking techniques.
Methodology
Since the subject of this research is data mining and analysis of users’ sentiments on Twitter, examining users' views and feelings plays an important role in determining the success of startups, so the present research can be considered as an applied research. In this research, the comments presented on Twitter with #Startup content have been considered as the field of research. Therefore, this study can be regarded as an exploratory-survey research. In addition, it is obvious that as a results of examining data related to a period of time, it is obtained in terms of cross-sectional time horizon and in terms of data analysis is a descriptive research with text mining approach.
Statistical population and sample
Population refers to the whole group of people, events, or things that a researcher wants to examine. By definition, a statistical population is a set of individuals or units that have at least one attribute in common. In order to determine the statistical population of this study, active users in the social network of Twitter who published content in the field of startups using the #Startup symbol were analyzed.
Data collection tools
In this research, users' opinions about the features that make startups successful are collected from Twitter using crawlers and Python libraries, and it is done in 12 steps, which include the followings: 1. Select and collect comments, 2. Data preprocessing, 3. Feature extraction - Term Frequency – Inverse Document Frequency (TF-IDF), 4. Generate word cloud, 5. Extract n-grams, 6. Principal component analysis (PCA), 7. Divide the data into train and test dataset, 8. Evaluation and modeling with random forest, SVM, and MLP 9. Combining models with voting and stacking techniques, 10. Evaluate the models made and select the best model, 11. Assign labels to test comments and separate positive, negative and neutral comments, 12. Extract the most important features related to positive, negative and neutral comments.
Figure 1 shows the proposed solution of this research. The proposed solution of the research.
Methods of data analysis
Using Text mining method, all Twitter social network posts contain the phrase #Startup are collected in the form of an Excel table including people and posts, Then, analysis is based on Python software and text mining algorithms. For Sentiment analysis, there is a need of a set of preprocessors, which have a significant impact on the model performance.
Pre-processing
The process of converting existing data into something that a computer can comprehend is called preprocessing, and one of the main activities of preprocessing is to filter out additional data before processing a natural language, which is called stop word. It refers to words that do not provide any useful information for the text classification. Because they don’t have any meaning (prepositions, conjunctions, blank spaces, emails and stickers, and URLs).
Word cloud
Word cloud is visual representation of text data, which shows a collection, or cluster of words in different sizes. Word clouds generators work fast. There are three types of word cloud algorithms for analyzing social networks: • • •
In this step, the word cloud using the trigram model, which is a three-word sequence of words is applied to positive, negative and neutral classes.
Modeling
In this step, all the results from the previous steps, which are in the classes of positive, negative and neutral are put in a data frame. It is attempted to vectorize the data based on TF-IDF vectorization, because its algorithms usually deal with numbers, and texts should be converted into numbers. Text vectorization is known as a basic process in machine learning and has different algorithms. The use of each algorithm has a great impact on the final results. In simple terms, a vector represents a word as a list of numbers that may have a set for each word, and TF_IDF is applied to determine how relevant the word is to the document. While machine learning has traditionally worked with better numbers, TF-IDF algorithms decode words by assigning numbers to vector words. And this algorithm is usually used in different ways: • •
Then PCA is applied as a dimensionality-reduction method to reduce computational complexity and make machine learning algorithms run faster. This method is an unsupervised statistical method that is used primarily to reduce the dimensions of machine learning and is one of the most widely used tools in the analysis of exploratory data for predictive models in machine learning. In this step, the data is divided into two categories of training and testing, which is 0.2 for testing and 0.8 for training.
For sentiment analysis, three algorithms of random forest, support-vector machine (SVM), and multilayer perceptron (MLP) are used.
Sentiment analysis
One of the ambiguities in the field of opinion mining is the difference between opinion and sentiment. Sentiment analysis or opinion mining from text is a field of study that tries to express and analyze the feelings, behaviors, opinions of people towards entities, which are anything like a product, brand, and service. Sentiment is a judgmental behavior that is created through the senses, but the opinion is a judgmental or analytical perspective that is constructed in the mind.
Therefore, it is important to provide methods that can prepare this knowledge in a pure and structured way. Most web data is unstructured text that makes it difficult to find information. From one point of view, exploring opinions (opinion mining) can be considered different from analyzing sentiments. Because comments are a special type of texts that are examined to evaluate the topic. But in general, in both cases, the goal is to discover the author’s point of view.
Sentiment analysis with Twitter can show aspects of business that need improvement and what makes the company stand out from its competitors. Twitter sentiment analysis causes to track and analyze all the interactions between brand and customers. This can be very useful for analyzing customers satisfaction based on the type of feedback they provide. Twitter is the main source of consumer insight. In fact, people use it to express a variety of feelings, observations, beliefs, and opinions on a variety of topics. Understanding what potential customers like, what their behaviors are, and how these changes change over time is essential if we are to launch a new product.
Many areas of research can be considered for opinion mining: • Sentiment classification: In the research method, sentiments are divided into three categories: positive, negative and neutral. • Summary of ideas: The ideas presented in various textual sources are summarized in relation to a specific topic • Topic or sentiment tracking: It is related to tracking sentiments and topics that have changed over time. • Detecting Spam Ideas: Detects false and counterfeit ideas. • Prediction: One of the new applications of opinion mining is to predict real-world events based on the ideas and feelings expressed on social media. • Satire mining: One of the very new topics that has attracted a lot of attention from researchers, which is currently only used in English and is very much related to the general culture of any society.
Random forest
Random forest algorithm is implemented on the training data. The random forest algorithm is a supervised learning algorithm that creates a forest with a set of decision trees that are usually trained by bagging. Working with this algorithm is very easy and flexible and without over-adjusting the parameters, it creates excellent results and is one of the most widely used algorithms due to its simplicity and variety.
Support vector machine
Text classification is one of the most important tasks in natural language processing. This process is the classification of text strings or documents into different categories. Depending on the content of the strings, text classification has different programs. Such as recognizing the user’s feelings from a tweet, categorizing blog posts into different categories, auto-tagging customer requests and so on. In this study, the SVM machine learning model that is able to predict the positive, negative or neutral of each of the tweets is implemented.
Multi-Layer Perceptron
One of the most basic neural models available is the Multi-Layer Perceptron (MLP), which mimics the translational function of the human brain. In this type of neural network, most of the behavior of human brain networks and signal propagation has been considered and hence, they are sometimes referred to as feedforward networks. Each neuron in the human brain receives input (from another neuron or non-neuron) and processes it, transmitting the result to another cell (neuronal or non-neuronal). This behavior continues until a definite result is reached, which is likely to eventually lead to a decision, process, thought, or move.
Voting
After implementing the above 3 algorithms on the data, it is attempted to combine the algorithms by voting method. It is trained in a set of several models and predicts a class as an output based on the highest probability of the selected class.
Stacking
After the voting stage, stacking algorithm is applied to select the best prediction combination among the above 3 methods. Stacking method is one of the machine learning algorithms that performs the best combination of prediction from several learning models with good performance. Finally, the decision tree method is used as the final estimator using the Stacking classifier command and after labeling the data, the LDA command is used to identify the topics of each sentiment (positive, negative and neutral).
Latent dirichlet allocation (LDA)
It is a model for discovering abstract topics, and is used to classify the text in a document. For example, if it is intended to classify the news on a news site every day according to their topics, it is better to use the LDA instead of reading the news every day and extracting their topics. Topics are actually hidden in texts, and the LDA’s goal is to extract these hidden topics by having texts and words. One of the advantages of the LDA technique is that one does not have to know in advance what the subjects will be.
To implement the LDA, Gensim python library is used. Gensim offers the refinement needed to implement a high quality LDA. To work on text documents, Gensim needs words to become unique identifiers. To achieve this, Gensim helps to create a dictionary object 3 that draws each word with a unique identifier. A dictionary is used to find the numerical equivalent of a word, which is used as input for the LDA in which Gensim specializes.
Validation
Cross validation is used for validation. Often in modeling, especially in the field of machine learning, it is required to estimate the model parameters. If the number of parameters is large, the complexity of the model increases and the calculations may not be easy to perform. By increasing the model parameters (increasing the independent variables), the efficiency of the model will increase, because the average squares for the collected sample will decrease as the variables increase. Therefore, the most suitable model for the sample with the maximum number of parameters is obtained. Cross validation is one of the ways that the number of model parameters (variables) can be optimally determined. The function of this algorithm is to estimate machine learning models, ie it is used to determine how the model works. The purpose of cross-validation is to test the model’s ability to predict new data that has not been used in estimation, in order to flag problems such as over-installation or selection bias and to provide insight into how to generalize the model to an independent data set.
Analysis and results
Text classification in Natural Language Processing (NLP) is the process of categorizing text strings or documents into different organized groups. Depending on the content of the text strings, text classification has different programs, including recognizing the user’s feelings from a tweet, classifying blog posts into different categories, auto-tagging customer requests and etc. In this study, machine learning algorithms that are able to predict the positive, negative or neutral of each tweet are implemented.
Data collection
Collecting the main data set for analysis is the first necessity. To collect datasets using crawlers and Python libraries, 30,000 text records have been extracted from Twitter with #startup. Twitter was founded in 2006 is the most popular microblogging service in the world and the use of tweets to evaluate research is currently a considerable topic in scientometrics and altmetric studies. 24 It is with over 100 million users posted 340 million tweets a day by 2012. 25
Data cleansing
Collected data records often suffer from what is called data contamination and therefore need to be cleared to ensure uniform formatting, duplicates are eliminated, and domain compatibility is controlled. The data collected may be incomplete or inadequate in some respects. In this case, specific data must be collected to complete the main database. 26 Errors and missing data must also be properly cleared. The process of clearing data includes handling missing values, smoothing out confusing data, identifying and fixing unwanted outliers, and checking data consistency. In addition, new variables should be formed from the initial database. 27
Delete missing values
In the primary data set, there are cases where missing values exist in the fields of a record. The data set that enters the algorithm must be complete and without missing values or damaged data. Also, cases where potentially incorrect values are assigned to the properties of a record should be corrected: otherwise, it should be removed from the data set. This problem is mostly due to the lack of integration of data sources and data collection forms.
27
Various reasons for the lack of data are mentioned, including: • Data is considered trivial in data entry. • There is a problem with the recording equipment. • There is negligence in recording data. • The data is inconsistent with other data and must be deleted.
The Pandas library was used to load the data set into the Python environment. This library provides several possibilities for processing data sets. The number of positive, negative, neutral, and the percentage of each class are specified: Positive = 678 (42.269,327%), Neutral= 463 (28.865,337%), and Negative = 463 (28.865,337%).
Text preprocessing
Data preparation is the most important step in text mining, natural language processing, and information retrieval. In text mining, data preprocessing is used to extract knowledge from unstructured textual data. Since texts often contain certain formats such as numbers, dates, and words that do not contribute to text mining and can be deleted, it is necessary to remove unnecessary formats before analyzing the data. Data preparation includes techniques such as case folding, tokenization, stop word removal, and stemming.
28
In this study, some of the processes required for text preprocessing in order to prepare for the text mining process are shown in Figure 2. Text processing.
Tokenization refers to chopping text up into pieces such as words, terms, symbols, which are called tokens. Normally, all documents are divided into smaller units, and finally the words derived from the texts are considered as separate variables. In addition, in research, words that have very few or very many letters. For example, lengths less than four letters and larger than 25 letters are not considered, because redundant and ineffective words are not considered as variables in the model. 29
Stop Words in text mining processes are words that are commonly used extensively in the language under study. In fact, stop words are words that are of little semantic importance despite the many repetitions in the text. These words do not contain information such as pronouns, prepositions and conjunctions. 30
In case folding, all the words become the same case in terms of lower or upper case letters. This step is done so that if a word is repeated several times with the same form but different in uppercase and lowercase, they are considered the same. It should be noted that this step does not apply to Persian documents and is more applicable to English texts. 29 In this research, the cleanme function is used to perform the data preprocessing process.
N-gram
N-gram in text mining processes refers to an interconnected sequence of words or phrases. For example, 3-gram (trigram) means a triple sequence of words or letters. 2-gram (a bigram) means putting two words in a sentence next to each other.
Word cloud
Word cloud is a way of visualizing data and visually shows the outline of each topic. In word cloud, words with larger fonts are more important and useful in that subject. In fact, word cloud is an image that displays words presented in a text. When it is displayed, it changes its size according to the repetition of each word. That is, the more one word is present in the text, the larger it will be in the related image. 31
As it is indicated in Figure 3, the most frequent trigram word cloud is about the discussion of innovation in startups related to climate change. The reason why it is at the top of the negative comments is negative attitude to the climate change which has nothing to do with the concepts of startups. Trigram word cloud for negative comments.
The frequent trigram for positive comments is shown in Figure 4. The concept of product marketing management is at the forefront of positive comments. Then, it is referred to different forms of management. This can be a good indication that effective and optimal management of startup activities will have a significant impact on positive comments of people. Trigram word cloud for positive comments.
Trigram word cloud for neutral comments are shown in Figure 5. As it can be seen, business-related concepts are more pronounced in neutral terms than in other concepts. Trigram word cloud for neutral comments.
Principal component analysis
In PCA, data is transferred by a linear transformation from multidimensional data to other coordinates based on maximum variance and minimum correlation. For this purpose, first the data covariance matrix is formed, then the eigenvalues and eigenvectors of the matrix are extracted and arranged. Finally, some special vectors with the highest eigenvalues are retained and the rest are removed. Data reduction simplifies the predictive model as well as data processing time. In order to establish the normality of vectors, all vectors are unit vectors and according to the orthogonality of special vectors, it can be said that there is no correlation between them. The principal component vectors are considered as inputs in the classification operation. 32
As mentioned, the PCA statistical technique selects a smaller number of factors called principal components from among the primary factors, so that some minor information is removed. In this study, the PCA method is used to reduce the number of features and the number of features has been reduced from 100 to 20. Applying this technique will simplify computational tasks. In this study, the number of components used for PCA is 20.
Modeling
There are several ways to modeling. Normally each method has power over specific issues. To use any of them, the necessary studies must be done to understand how they work. Another important point is that among these algorithms and models, there is no best and according to the data and the desired performance, the desired method must be selected.
Cross validation
In k-fold cross-validation, the data set is divided into k non-overlapping folds. Each of the k folds is used as a held-back test set, whilst all other folds, k-1 folds, collectively are used as a training dataset. This procedure is repeated until each fold has been used as a test set. The advantage of the k-fold cross validation procedure is the use of all folds for training as well as testing.
This method was used to obtain a suitable estimate, minimize the effect and dependence on specific data in the evaluation model, and construct random sections of the data set. Estimating the accuracy of algorithms in k-fold cross validation is much more reliable than conventional methods.
Thus, the process of dividing the initial data set into training and test data can be done with the help of k-fold cross validation method to reduce the complexity of the process. According to the following code, in this study, the value of k is set to 5.
Code 1: Set the value of k to 5.
cross_val_predict(text_classifier_RF, X_Total, y_Total, cv = 5)
Evaluation criteria and the confusion matrix
Various criteria including true positive, false positive, true negative, and false negative are used for evaluation. For the confusion matrix, different evaluation criteria and Roc curves will be defined. The confusion matrix shows the number of true and false predictions in a known dataset. 33
Random forest
Random forest is actually an ensemble learning method for classification, regression and other tasks. Random forests work by building a large number of decision trees during training, and their output is classification, which can mean creating classes in samples (classification) or predicting their type (regression). The random decision forest actually corrects the habit of over-fitting in decision trees. The first random decision forest algorithm was developed by Hu (1995) using his quasi-random method. In Hu formulas, a way was proposed to implement a classification system based on random discrimination. Developments of the random forest algorithm were presented, and finally the random forest algorithm was developed in its current form. 34
Random forest is created by growing a large number of classification (decision) trees. To classify a new object from an input vector, the tree classification for that object will be determined and the class to which the object belongs in terms of the tree will be recorded. The random forest algorithm runs efficiently on large databases. It can operate on thousands of input variables without the need to delete a variable. It can provide an approximate estimate of the variables, which is very important in classification. It can be an effective way to estimate lost data and maintain accuracy at times when a large part of the data is lost. It is an effective way to balance error in problems with unbalanced data sets. The generated forests can be used for future use on other data. Random forest capabilities can be used to classify unlabeled data, leading to unsupervised clustering and detecting outdated and anomalous data. 35

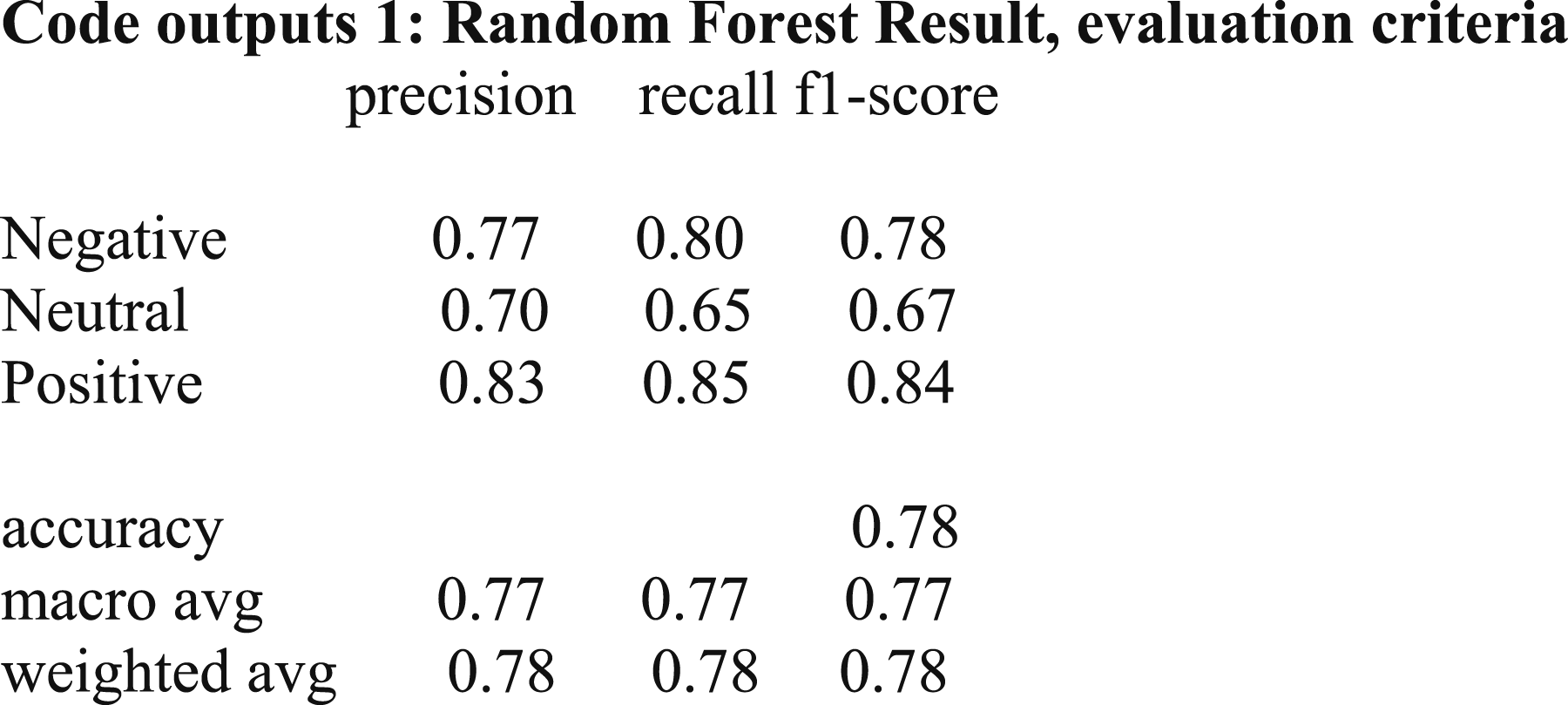

The confusion matrix for random forest.
Support vector machine (SVM)
Support vector machine is one of the supervised learning methods that is used for linear and nonlinear classification as well as multidimensional regression. The basis of the SVM classifier is linear classification of data, and in linear classification of data we choose the linear one that has a more reliable margin. Assuming the data is linearly separable, it obtains hyperplanes with maximum margins to separate categories. In cases where the data is not linearly separable, the data are mapped to a higher-dimensional space so that they can be separated linearly in this new space. 36
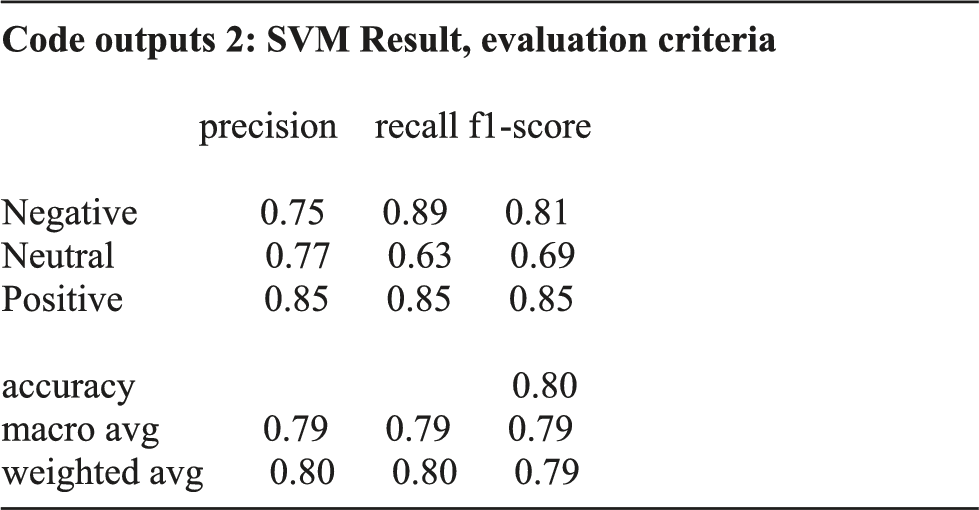


The confusion matrix for SVM.
A multilayer perceptron
A multilayer perceptron (MLP) is one of the most common types of artificial neural network (ANN), which has been used successfully in a wide range of applications, including data classification. In working with MLP, there are two problems: choosing the right architecture as well as choosing the right training algorithm. Appropriate architecture means the optimal selection of the number of layers, the number of neurons in each layer and the type of excitation function of each neuron, and the optimal architecture of NNs based on data sets and their characteristics. A variety of training algorithms are used to train NNs. The most common training algorithm of these networks is the error back propagation algorithm. In each step of the error back propagation algorithm, the newly calculated output value is compared with the actual value and the network weights are corrected according to the obtained error. So that at the end of each iteration the size of the resulting error is less than the amount obtained in the previous iteration. The basis of this minimization is the motion on the gradient vector as a function of the squares error of the network. 37
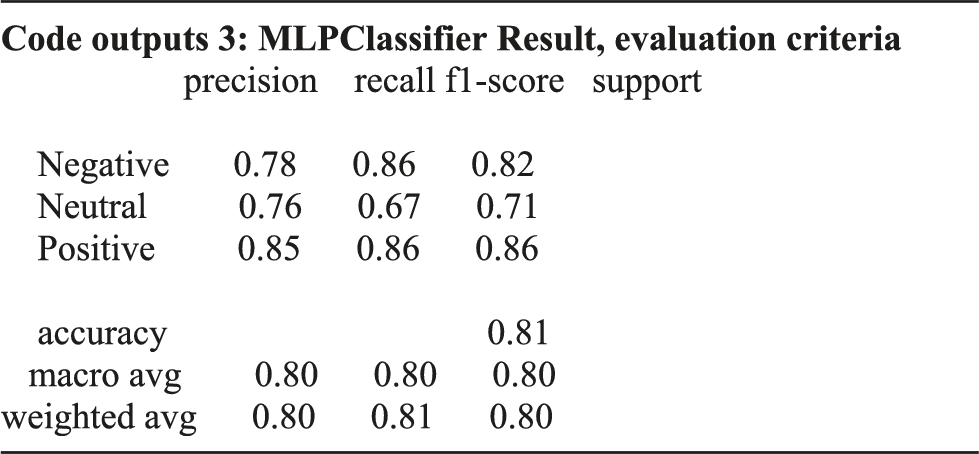
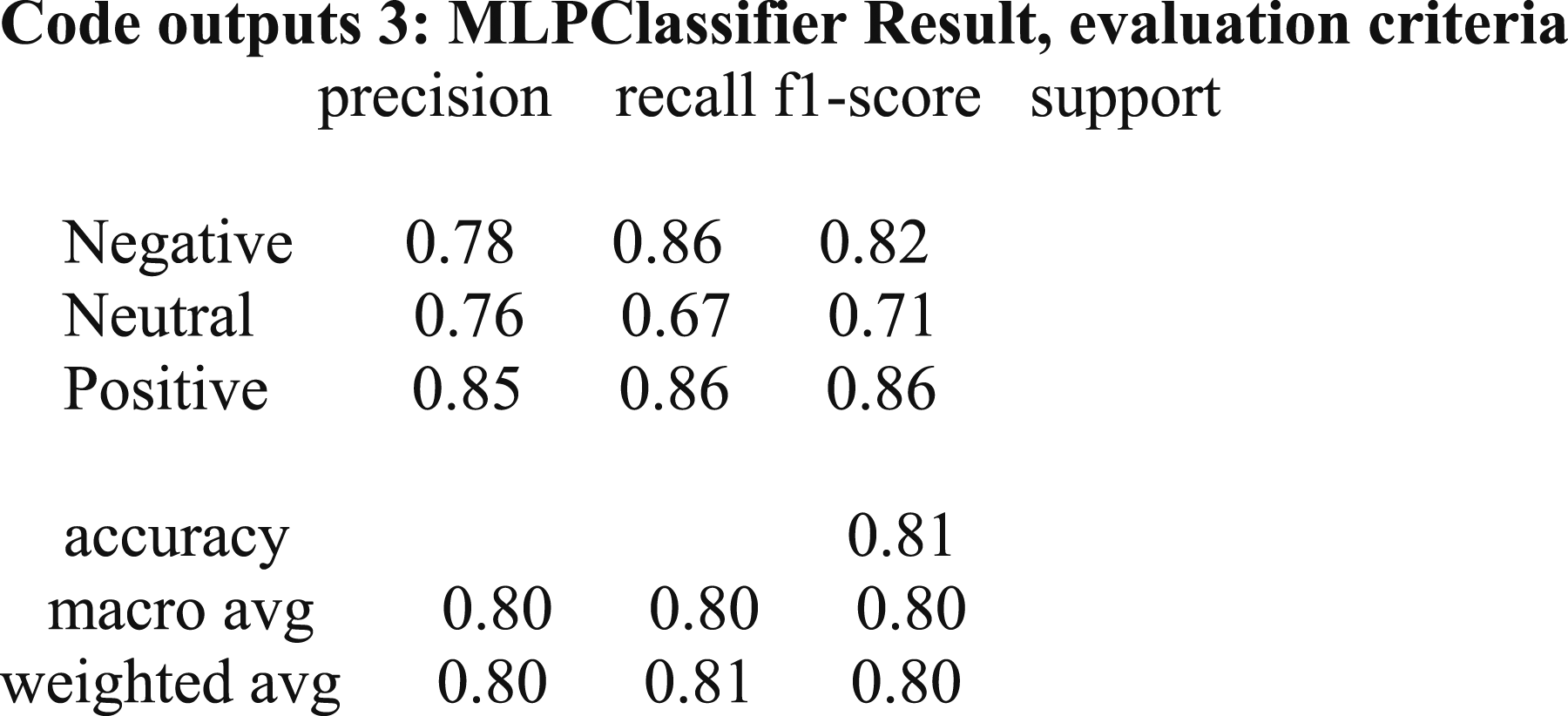

The confusion matrix for MLP.
Voting
Voting algorithms are used to enable error coverage and increase accuracy and reliability in a wide range of business and research applications. In this research, the voting majority algorithm is used. It is one of the most widely used public voting algorithms. In the majority voting algorithm, out of N outputs, the agreed outputs are selected from at least half of the voters. To implement the voting technique, random forest machine learning models, SVM and MLP are used to design a good and strong system and improve the result. Thus, the negative, positive or neutral of a comment is determined based on the majority voting between the mentioned methods. For example, if two methods vote for a comment to be negative and the third method predicts a positive opinion, the comment is ultimately considered negative.

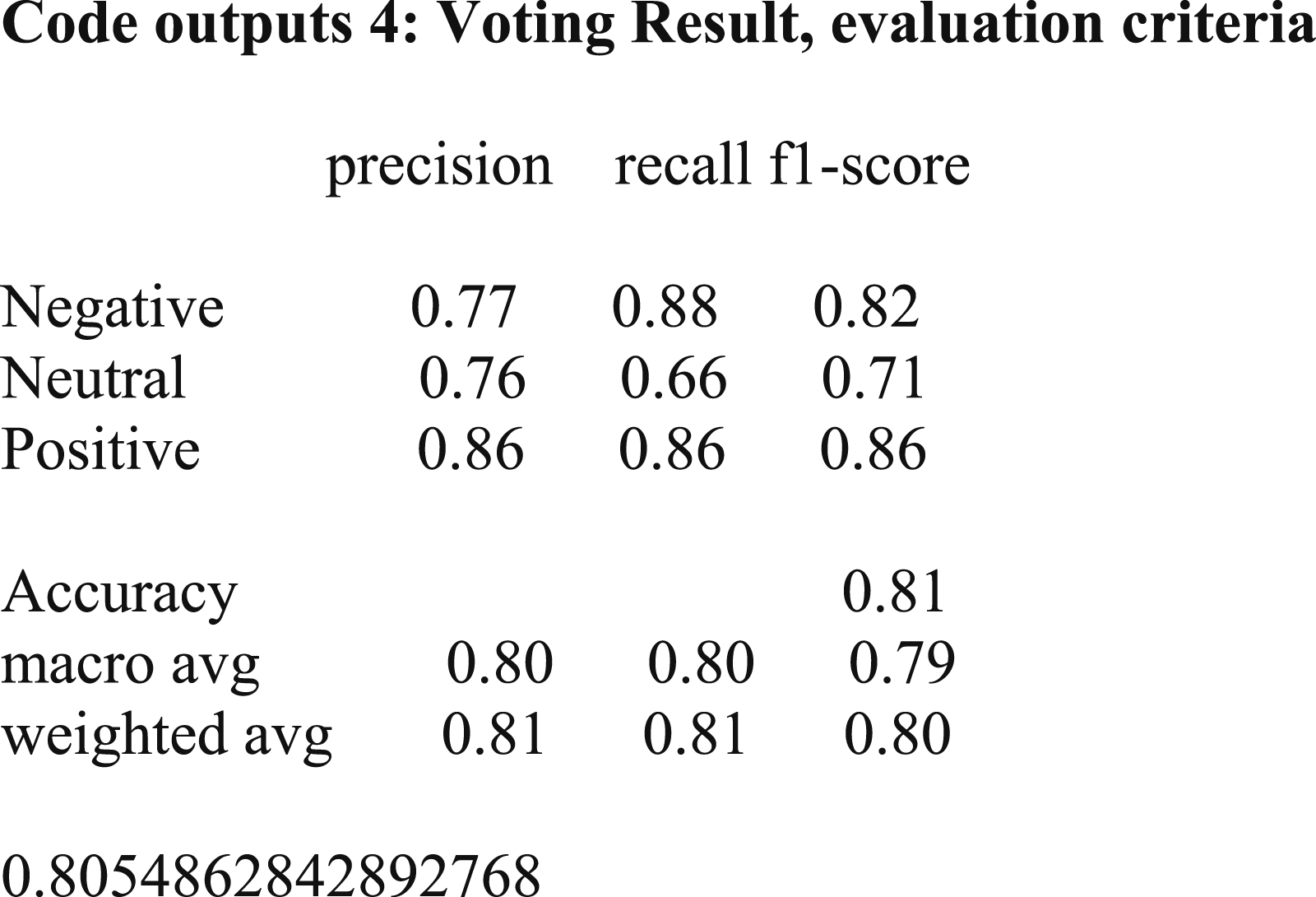
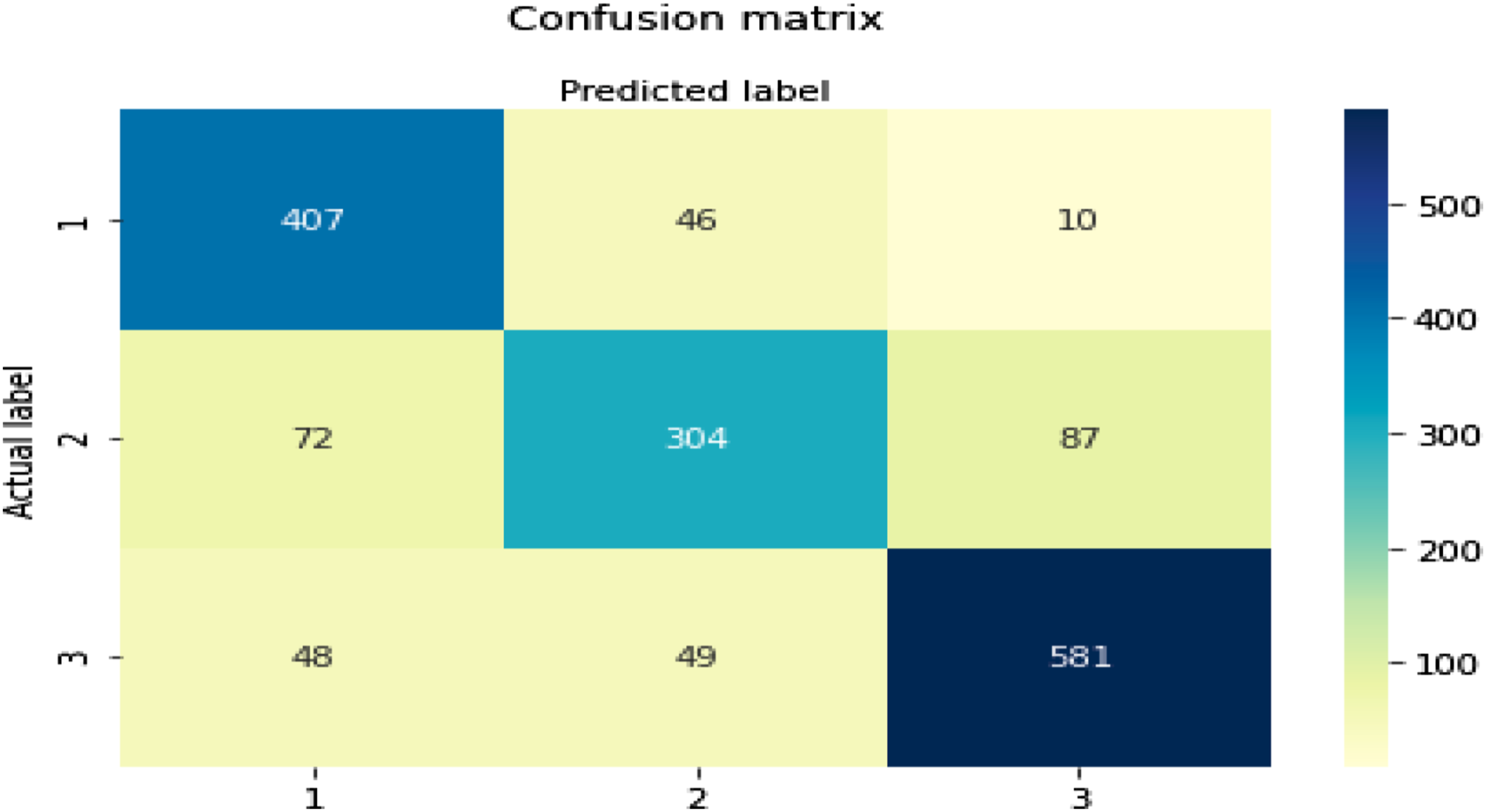
The confusion matrix for voting.
Stacking
The stacking method is a different way of combining the results of learning methods. Unlike boosting and bagging methods, the stacking method is usually used to combine different (heterogeneous) classifiers. In stacking method, several different basic models are trained independently. Finally, through the training of a metamodel, the results of the first level models are combined to make the final prediction based on the predictions made by the base models. Thus, two levels of modeling are required to implement the stacking method, several basic models for data training and a metamodel for combining results. 38
In this research, random forest, SVM and MLP methods are used as the base classifier and finally the decision tree classifier is used to combine the results. The final classifier learns from the data how to combine predictions and uses the results of different models to achieve the best classification accuracy.

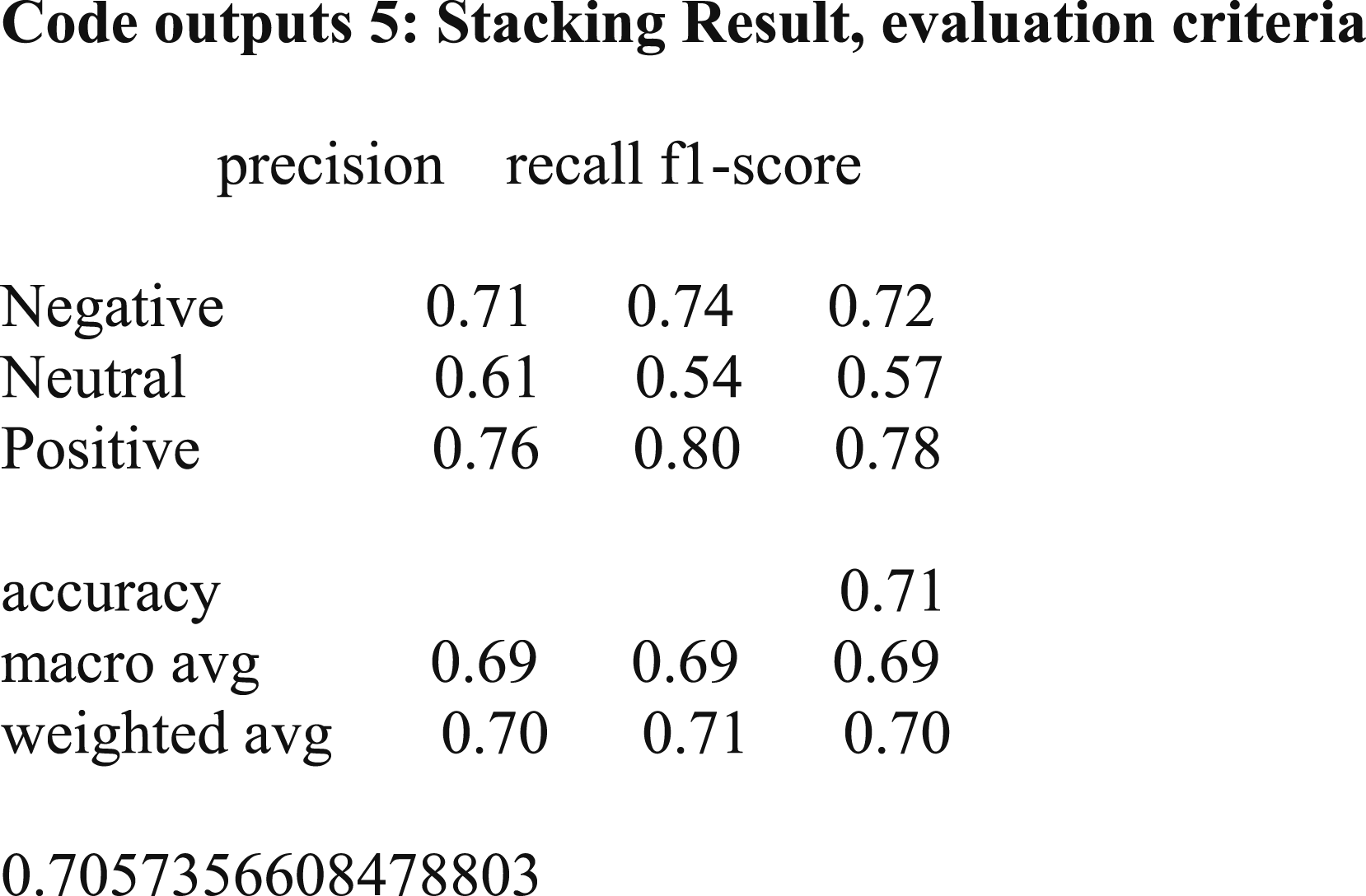

The confusion matrix for stacking.
The results have shown that the stacking method did not meet the expectation and the results obtained from the voting and MLP methods are the same. Therefore, the unlabeled comments tag is estimated using the MLP method.
Latent dirichlet allocation (LDA)
Latent Dirichlet allocation is a generative model in statistics. This model was created to model a number of hidden variables (topics) in a set of texts that contain words. In fact, in a text containing a number of words, it can be attributed to any number of topics with a certain probability, which ultimately together form a text and its topic. 39 In fact, LDA is a probabilistic language modelling (LM) which has consistent generative semantics and overcomes some of the shortcomings of Probabilistic Latent Semantic Indexing (PLSI). 40
In natural language processing, the LDA method is a statistical method that explains why parts of the data are similar. For example, in the examination of the words collected in documents, the LDA output indicates that each document is a combination of a small number of topics and that the presence of each word is related to one of the topics in the document.
LDA model assumes that documents represent multiple topics. That is, it consists of words that each belong to a topic and the proportion of topics within a text is different. According to these ratios, that text can be categorized into a specific topic. Considering a fixed set of words as a glossary, LDA method assumes that each topic is a distribution on this set of words. That is, words that are related to a topic have a high probability in that topic. It is assumed that these topics are already known. Now for each document in the existing set of documents, the words are generated in the following steps: • A possible distribution on topics is randomly selected. • For each word of the document: A topic is randomly selected using the probability distribution of the previous step. • A word is randomly selected from the glossary with the specified probability distribution.
In this algorithm β_ (k: 1) are the topics in which each β_i is a probability distribution on the word set. The ratio of topics for documents is determined by the parameter θ. This means that θ_ (k, d) represents the ratio of the topic k in the document d. The z parameter indicates the topic allocation. z_ (n, d), which refers to the topic assigned to the nth word of the document d. The variable w is the observed words, where w_ (n, d) is the nth word of the document d.
According to the above definitions, LDA algorithm can be expressed by the following formula which includes the above observable and unobservable variables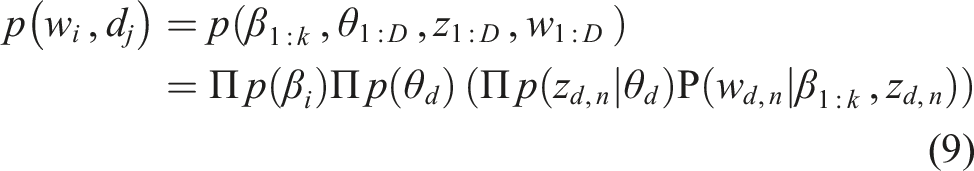
From the above formula a set of dependencies can be perceived. For example, the topic assigned to each word in a document z_ (n, d) depends on the ratio of the topics to the document θ_d, or the word observed in each document w_ n, d depends on the topic assigned to that word z_ n, d and all topics β_ (1: k). 41
LDA output analysis for negative and positive comments.

The items extracted as the output of the LDA method for neutral comments overlap with the positive and negative items, which can lead to erroneous analysis. Hence, no analysis is given for neutral cases. • On the basis of the results, innovation is considered as one of the important and positive factors for startups’ success. However, in the study of Saura et al.,
4
innovation wasn’t identified as a key success factor. • This study presented business development as one of the success factors like the results of Saura et al.
4
However, business plan development in their study was recognized as neutral comments and the present study indicates it as a positive comment. • In this study, experienced entrepreneur is identified as a positive comment which is almost aligned with the results of the study of Saura et al.,
4
in which the attitude of the founders was determined as a positive topic.
Conclusion
The growing trend of the Internet and cyberspace has provided more access to this space. This growth has led to a large volume of comments. The large volume of comments on a topic has made it very difficult and sometimes impossible to examine them. In these cases, the process of reviewing comments can be done automatically using artificial intelligence and data mining algorithms. This study has used machine learning techniques and text mining with the aim of predicting the positive, negative or neutral of each tweet. The implemented algorithms were evaluated and according to the data of this research, the best algorithms and techniques were selected.
According to the results:
• Key success factors of startups based on UGC on Twitter were identified as startups innovation, climate change, product marketing, management, business development, customer success, and software development. • Key success factors of startups were found in the UGC on Twitter using word cloud and showed that the most negative trigram word cloud is about the innovation in startups regarding climate change. The most positive concept is product marketing management and business-related concepts are considered as neutral. • Positive, negative, and neutral sentiments are expressed about the topics related to startups’ success in Twitter UGC. Startup acceleration process, pushing to complete a project in a short time, delivering the best product at the beginning of the project, poor management, paying too much attention to properties are negative comments. Creating a sustainable and innovative business plan (BP), the presence of experienced entrepreneurs, coronavirus (COVID-19), and innovation are positive comments. No neutral comments are identified. • Key success factors of startups were found through trigram word cloud as well as using LDA for grouping the most important features in Twitter UGC. • Key success factors of startups be found through LDA in Twitter UGC and positive and negative topics for the startups’ success were identified. • In this research, various predictive models including random forest, SVM and MLP were used to test the labeling of unlabeled data. According to the findings, the MLP method according to the accuracy criterion had an accuracy of 0.81, which provides a higher accuracy than other methods tested. According to Accuracy criteria, random forest and SVM methods offered accuracy of 0.78 and 0.80, respectively. The accuracy of these methods demonstrates the ability to distinguish between positive, negative, and neutral comments. Finally, in order to increase the accuracy of the algorithms, voting and stacking algorithms were used, which showed that the use of these algorithms did not have a positive effect on increasing the accuracy. The results showed that the performance of the system if using the voting method was almost equal to the results obtained from the LMP and using the stacking method the accuracy was less than all three methods of random forest, SVM and MLP. Therefore, the hypothesis is confirmed and MLP has the highest accuracy before and after combining with voting and stacking techniques.
Theoretical implications of this study are for researchers regarding the comments made on social networks, especially Twitter, for the success of start-up businesses. Text mining data allows to make sense of large amounts of data grouped by topics. Data text mining methods were applied to analyze the data in this research, and factors that were not found before were identified.
As practical implications, this research provides key success factors of startups for managers of startups and entrepreneurs for understanding the startup ecosystem, the improvement of their projects, and to ensure that the key success factors of a startup based on UGC on Twitter have been considered in the business plan. This study provides a guide for data analysis of social networks such as Twitter and in particular for the subject of startups success factors.
Suggestions for future work:
• The solution in this research is based on English language data. The study of the desired method on Persian data can be proposed. • Researchers can use other methods of text mining to classify texts and analyze the results. • Considering that data preprocessing has a great impact on the results of the next steps, researchers can focus on improving the data preprocessing. In particular, the effect of using n-grams with different sizes can be studied and their results can be compared with current research. • Considering that each of the machine learning algorithms has different parameters and proper adjustment of these parameters can improve their performance, it is suggested to optimize the parameters of each method. For this purpose, various evolutionary methods can be used, such as genetic methods, particle swarm optimization, etc. • The use of deep learning methods in recent years has been considered by researchers in various fields. Therefore, the use of deep learning strategies for the construction of classification models is proposed and the results can be compared with the current research. • The experience of the data collection method in this article showed that with the use only a special hashtag (startup #), it is not possible to collect quality data. Thus, it is recommended to not limit the data collection to just one hashtag and use words that are exclusively related to startups, such as investing in a startup and the cohesion of the startup team. • Instead of text classification method based on the LDA method, robots that have already been trained to classify text can be used. For predicting the class of extracted tweets, they can perform a higher quality classification. Because these robots are trained with a huge amount of data. • Finally, due to the remarkable performance of SVM in word separation, it is possible to combine this model with deep learning methods to create a more powerful model.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.