
Abstract
The multi-level location routing problem (MLLRP) is an extension of the capacitated location routing problem (CLRP). MLLRPs are considered a class of combinatorial optimization problems that arise in transportation applications, such as agricultural logistic planning. Along with concerns regarding the environmental harmfulness, recent studies have considered “green” logistics. This paper addressed a low environmental impact model for MLLRP by considering characteristics, emissions, and traffic congestion that have not appeared in the recent literature. The mathematical model was formulated to deal with a reverse flow problem, which was a real case that occurs in Thailand agriculture. We developed a hybrid metaheuristic algorithm to solve the MLLRP by integrating a variable neighborhood search (VNS) with an adaptive large neighborhood search (ALNS). The experimental results shown that the hybrid algorithm had clear advantages in the time consumption and quality of the solution. The extended study indicated that the proposed algorithm obtained competitive results compared with the previously published methods. The proposed practice is useful not only for the agricultural industry but also for other industries.
Keywords
Introduction
The palm oil industry is one of the most important industries in the world. The Southeast Asia region is crucial for global palm oil production. In 2018, there were 70.6 million tons of palm oil production globally. Indonesia and Malaysia produced 39.5 and 19.7 million tons of crude palm oil, respectively, and both countries combined produced 83.8% of the global production. Thailand, the world’s third largest producer, produced approximately 2 million tons per year or 1.2% of the crude oil production in the world. 1 As the world has focused on alternative renewable energy sources, such as biodiesel production, to replace the energy from fossil fuels, oil palm plays an important role as a renewable energy plant product used in biodiesel production.
Recently, Thai oil palm fruit production has been continually increased in relation to international trends. 2 The Thai government released development plans for supporting oil palm and palm oil production during 2015–2026, with an intent to expand palm cultivation areas around 40%, improve productivity by 10%, develop oil extraction rates from 14–17% to 20% (the same rates as Malaysia), increase the domestic use of palm oil in biodiesel production and motivate domestic palm oil consumption extension by 3%. 3 Therefore, Thai oil palm fruit production has been predicted to grow according to a strategic plan and global demand.
Although oil palm production in Thailand has increased, this increase has relied on expanding the cultivation area as the productivity per area remains low as well as the production efficiency and oil extraction rates. The expansion of the plantation area affects the transshipment system in oil palm logistics. When the plantation area is larger, the location and transportation of the collector become significantly important. The number of collectors and collecting route have to be optimal so as to properly satisfy related constraints, such as the capacity of the trucks, collectors, and extraction plants.
Correspondence from Nootim et al. 4 implied that the collecting and distributing system in the Southern region, the major production region in Thailand, remained ineffective due to the number of collectors and traveling distance. This result increased the operational costs of oil palm logistics to be higher than they should be as the transportation costs are directly related to the distance. Nootim et al. 5 Illustrated the total transportation costs of Kribi, a province in Thailand, at 1,098,861,009 baht per year, in which the transportation cost from field to collector is 74.93% and the transportation cost from the collector to the extraction plant is 25.07%. As a result, this situation leads to higher costs for farmers who are the main players in oil palm production.
Transportation is one of the activities in the logistics system, which is one of the reasons for the unavoidable environmental impact. Road transportation requires fuel for combustion, in order to generate energy to drive the vehicles. Traditional fuel is a natural resource that is diminishing in the world and is difficult to replace. The carbon dioxide equivalent (CO2e) causes air pollution, which is the cause of the greenhouse effect that impacts the environment and human civilizations in the world. 6 The CO2 emissions are dependent on the amount of fuel used by a vehicle. The fuel consumption is directly proportional to the type of vehicle, load of the vehicle, vehicle speed, and traffic congestion. 7
Currently, traffic congestion in developing countries is visibly on the rise as the volume of traffic demand is larger than the road capacity. Although the capacity of the roads is increased by an average of 2–3% per year, they cannot handle the growth of the traffic demand, which increases by approximately 10% per year. 8 In 2020, the number of automobile owners in Thailand was more than 41 million, and this increases by 1 million owners annually. 9 This increasing rate is one of the primary causes of traffic congestion in Thailand, and this effects all transportation activities, including the agricultural industry. Consequently, this research considers the traffic congestion and emission costs, integrating the location and routing problem.
Locating the transshipment hubs and planning vehicle routes are commonly recognized as critical issues in the design of logistics systems. These issues consume the largest cost of the budgets. The planning and decision have to be steady with the strategy in order to reduce the costs and sustain trust in the logistics system. 10 The design of the location and routing has been raising interest over the last few decades. 11 Therefore, this research aims to study and determine the problems in the collection of oil palm fresh fruit bunches in the upstream supply chain that consist of the oil palm field, collector (depot), and extraction plant. This problem is considered a class of multi-level location routing problems (MLLRPs) as it deals with two stages of the transportation system. The research’s motivation is to reduce costs in the entire oil palm transportation chain together with environmental impact minimization. Under the new solution, the related stakeholders can reduce the transportation costs by determining the most suitable depot and economic route to convey the product. Thus, this enhances the transportation efficiency and directly increases the profitability of all stakeholders in palm oil production, particularly the farmers.
The MLLRP model in this study has the following differentiated characteristics. The proposed model is conceptually similar to the class of two-echelon location routing problem (2ELRP). As the classical 2ELRP deal with distribution problems and cost minimization (see Vidović et al. 12 and Pichka et al., 13 our MLLRP correlates not to distribution, but to collection problems that have a distinguishing system structure and desire a distinguishing problem formulation. Vidović et al. Proposed the 2ELRP model for designing hazardous waste recycling logistics networks, but they designed transportation as directed shipments at the second echelon. Our problem requires routing decisions at both levels with the total cost minimized, including the emission cost and congestion cost. Pichka et al. Studied in the two-echelon open location routing problem (2E-OLRP), the open LRP means the vehicles do not have to return to the depot or the satellites where they began. The model was formulated for the distribution problem with cost minimization that comprises the traveling costs, vehicle fixed costs, and satellite opening costs. In this paper, the MLLRP model deals with the collecting problem with the environmental conservation objective by including the emission and congestion cost. These aspects are the new features for 2ELRP research.
The contributions of this paper are the following. First, the emission cost and congestion cost are included in a multi-level LRP. To the best of our knowledge, there is no paper found in the recent literature that has taken these characteristics into account before. Second, the mathematical model of a multi-level LRP is formulated based on reverse flow logistics as this is a collecting problem with non-hazardous recyclable collection. From the review of the literature, few studies deal with the reverse flows of non-hazardous products. In addition, this paper considers the routing plan for both levels. The third contribution is to propose an efficient hybrid heuristic algorithm for solving large-size problems, particularly the case study problem that occurred in Thailand.
The remainder of this paper is constructed as follows. An overview of literature is provided in second part. The third part presents the problem description and the formulation of the MLLRP. The solution method is introduced in fourth part, and the experimental results are revealed in detail in fifth part. Finally, the sixth part gives the conclusion of this paper and suggestions for future research.
Literature review
The two-Echelon location routing problem (2ELRP) is an extension of LRP in which the problem comprises two levels. In this problem, vehicles leave the distribution center and first deliver to a main depot (satellite) where the storage operation take place. The vehicle is then moved from the depot to the customers. 14 Accordingly, routing decisions need to be solved in both echelons and cannot be considered as two problems solved sequentially. Thus, this kind of optimization problem is more complex than classical LRPs. Jacobsen and Madsen 15 introduced the multiple echelons in LRPs. They proposed the heuristics method for solving the newspaper distribution network problem. Since then, many researchers have widely studied 2ELRPs in various aspects. Lin and Lei 16 formulated a three-echelon distribution system considering the routing in two levels; the system comprised small retailers, big clients, and distribution centers (DCs). The mathematical model was proposed to minimize the total fixed cost of DCs embedded with a hybrid genetic algorithm heuristic to compare the quality of the solution with the exact solutions software. Eventually, the model was deployed to design a better distribution system in Taiwan.
Nguyen et al. 17 Solved a 2ELRP with four constructive heuristics and a hybrid metaheuristic named the greedy randomized adaptive search procedure (GRASP), which included a learning process and path relinking. The results showed that their method outperformed existing methods on LRP and 2ELRP instances. Nguyen et al. 18 Developed multi-start iterated local search (MS-ILS) embedded with greedy randomized heuristics for 2ELRP. The constructive heuristic was utilized to create an initial solution, and then ILS was applied to change the solution space. Their method improved two instance sets of 2ELRP and outperformed to GRASP algorithms.
Recently, Drexl and Schneider 19 published variants and extensions of LRPs, including multi-echelon LRP, and suggested future research directions for this area of study. Yang and Zeng 20 proposed a 2ELRP model with time constraint considerations in city logistics to minimize the total fixed costs. They also first proposed integrating metaheuristics and a comprehensive consideration of time and space accessibility as a solution approach.
Schwengerer et al. 21 proposed a variable neighborhood search (VNS) algorithm for solving 2ELRP by extending previous versions of LRP. Their VNS developed seven neighborhood structures differently with various perturbation sizes, expanded to a total of different 21 neighborhood structures. The results indicated that VNS improved several best-known solutions in term of quality and runtime. Contardo et al. 22 presented a branch-and-cut algorithm and an adaptive large neighborhood search (ALNS) to deal with the 2ELRP. Their ALNS could find a good solution quickly and outperformed existing heuristics on large-sized instances in the previous literature. VNS and ALNS were also developed for solving traditional LRP by many researchers, see refs. 23 –26
Although green logistics has received close attention from corporations and institutions, there are few papers that include environmental effects in LRPs. Recently, Toro et al. 27 formulated the Green CLRP (G-CLRP) model with a multi-objective function. The first objective was to minimize the operational cost, which consists of the facility setup cost, opening cost, vehicle used cost, and traveling cost. The second objective is to minimize the amount of fuel consumption and emissions related to fuel consumption. Toro et al. 28 presented the green open location routing problem (G-OLRP) where the vehicles are not required to return to the original depot after finishing their service. The bi-objective model was formulated with operational cost minimization and environmental impacts that consist of fuel consumption and emission amounts.
Wang and Li 29 studied an LRP with simultaneous pickup-delivery, heterogenous fleets, and time windows with the objective of total cost, including fuel consumption and carbon emission costs. They incorporated the simulated annealing (SA) concept into the VNS algorithm for solving the problem. Lately, Wang et al. 30 , Dukkanci et al. 31 and Dukkanci et al. 32 also considered the emission cost integrated in the sum of the operational costs. Few studies considered the environmental effects in 2ELRP. For instance, Govindan et al. 33 designed a supply chain network of perishable foods considering the environmental objective. The model aimed to minimize CO2 emissions throughout the network and the total operational cost as well. However, these mentioned papers formulated a model regarding the distribution problem. From a brief literature survey, there were few LRP or 2ELRP studies that addressed the collecting problem and minimized the environmental impacts simultaneously.
Overall, despite the existence of numerous publications on 2ELRP, we made the following observation: (1) Few studies dealt with the collecting problem (reverse flow logistics) together with environmental effects; it appears that the problem in this MLLRP model remains unexplored. (2) There was no 2ELRP paper that considered congestion costs in different areas in the literature. (3) Almost green concepts appeared in LRP research but were scarcely found in 2ELRP research. (4) Metaheuristic methods were achievable for solving the 2ELRP problem, in particular, the ALNS and VNS algorithm. Therefore, in this paper, we developed a hybrid algorithm based on these metaheuristics. These literature surveys motivated the initiation of the current study.
Problem description and model formulation
In this paper, the MLLRP was to determine the best subset of locations that will be opened as depots to collect oil palm. The selected locations came from all candidate oil palm fields. Then, we planned the transportation path in the first level to collect oil palm from the fields to selected depots given an oil palm quantity from each field and a vehicle capacity. After that, we determined the best location of extraction plants that will receive the oil palm from the depots. Finally, the transportation path in the second level was determined to collect the oil palm from the depots to extraction plants. Figure 1(a) illustrates the characteristic of traditional MLLRP whereas Figure 1(b) shows the problem description of this paper. If the product quantity at the field or depot is over the capacity of vehicle, that node can be visited more than once by direct shipment, and then we can provide a routing path for the remaining quantity. The different widths of the arrows indicate various routing categories that affect fuel consumption, emission and congestion cost.

The problem description (a) Traditional MLLRP and (b) MLLRP in this paper.
The objective is to minimize the total cost of both levels, including the transportation cost, depot opening cost, emission cost, and congestion cost. The emission cost is related to the CO2 emissions that arise from the fuel consumption. In this research, the fuel consumption depended on the speed of the vehicle, which differs with various road classifications. This data was taken from Akararungruangkul and Kaewman, 34 as shown in Table 1.
The fuel consumption divided by the road classifications.
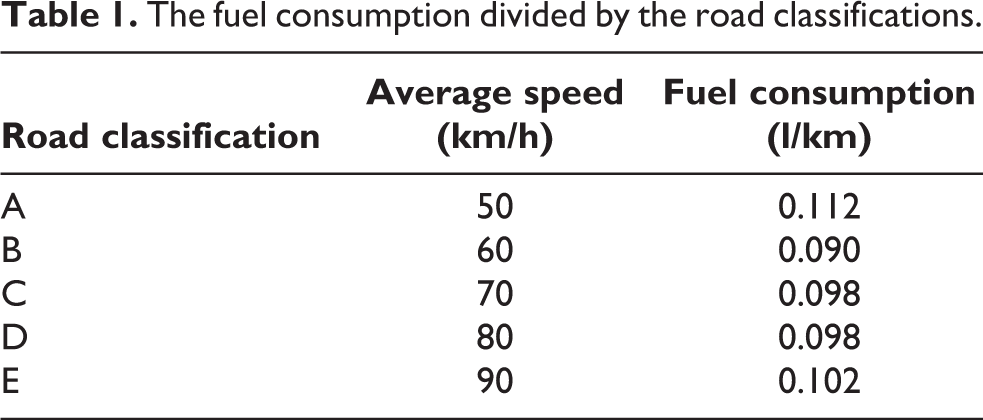
The traditional LRP focuses on transportation cost minimization that depends on distance; however, this study focuses on emission costs that vary by fuel consumption. The fuel consumption rate directly depends on the road classification. For instance, there are two routes traveling from field X to field Y, as shown in Figure 2. The traveling distances of route no. 1 and no. 2 are 24 km and 26 km, respectively. The road classifications of route no. 1 and no. 2 are A and B, respectively. The fuel consumption is calculated by the traveling distance multiplied by the fuel consumption rate, thus the fuel consumption of route no. 1 (2.688 l) is greater than for route no. 2 (2.340 l) even though it is a shorter path, as detailed in Table 2. Therefore, the model will choose route no. 2 for transportation. This illustrates the difference between this study and a traditional LRP. Finally, the emission cost is converted from the fuel used amount (liter), which differs on each route.

Illustration of traveling from field X to field Y.
The different perspectives between the classical model and proposed model.

The traffic congestion cost consists of several elements, such as the opportunity cost, delay time, vehicle operating cost, fuel cost, etc. The congestion cost depends on the traffic density of each area as well as the location of the oil palm fields in the study. According to the Victoria Transport Policy Institute, 35 the congestion cost can be estimated for different areas and vehicle types. In this report, a quantitative method is approached to estimate congestion cost for various areas using the following elements: (1) a value of travel time of passenger delay, (2) a fuel consumption cost, (3) an accident cost, (4) a reduced business accessibility, and (5) a noise pollution cost. This report also provides a comprehensive overview of external cost estimation and optimal pricing methods, to estimate congestion cost for various vehicle types. Urban areas have high density traffic, and therefore have high congestion costs as well. We adapted the congestion cost from this report, then applied it to our model, as shown in Table 3.
The estimated congestion cost divided by the routing category.
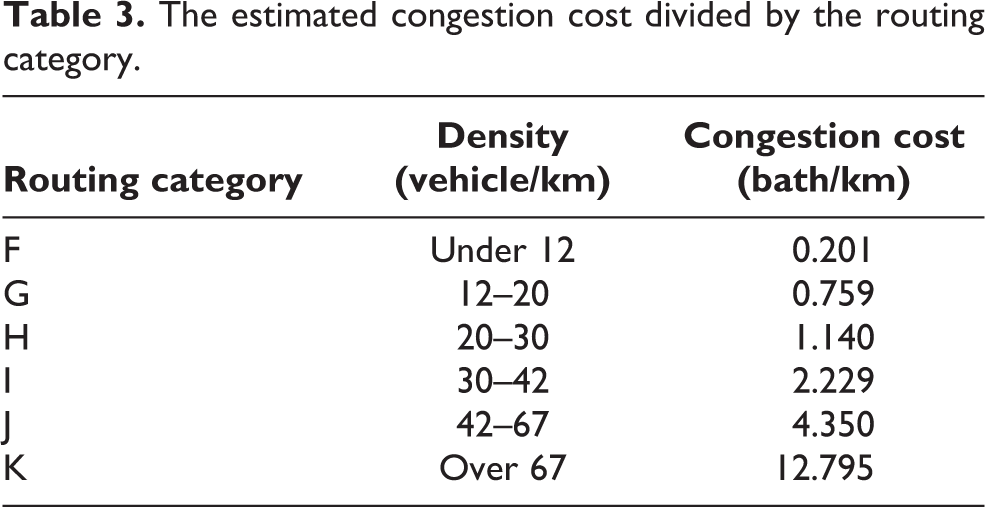
The mathematical model for MLLRP is declared as follows:
Sets
Vset of nodes, (g, h)
Iset of oil palm fields, (i, j)
Kset of extraction plants, k
Parameters
Pi Oil palm quantity of field i
Laj Land price of depot j
Buj Construction cost of depot j
Opj Other operating costs of depot j
dij Traveling length in first level from field i to field j, dij ⊂ dgh
dgh Traveling length in second level from node g to node h
djk Traveling length in second level from depotj (located at field j) to plant k djk ⊂ dgh
Rij Fuel consumption factor in first level from field i to field j, dij ⊂ dgh
Rgh Fuel consumption factor in second level from node g to node h
Rjk Fuel consumption factor in second level from depot j (located at field j) to plant k djk ⊂ dgh
Sij Congestion cost in first level from field i to field j, dij ⊂ dgh (baht/km)
Sgh Congestion cost in second level from node g to node h (baht/km)
Sjk Congestion cost in second level from depot j (located at field j) to factory k djk ⊂ dgh (baht/km)
q 1 Vehicle’s loading capacity in first level
q 2 Vehicle’s loading capacity in second level
TD j Depot’s capacity
TP k Extraction plant’s capacity
c 1Transportation cost in first level (baht/km)
c 2Transportation cost in second level (baht/km)
e 1Emission cost of fuel used in first level (baht/liter)
e 2Emission cost of fuel used in second level (baht/liter)
Decision variables
n 1 i Amount of direct shipments of field i in first level
n 2 j Amount of direct shipments of depot j in second level
z 1 ij = 1 if field i is allocated to depot j and direct shipment appears
= 0 otherwise
z 2 jk = 1 if depot j is allocated to plant k and direct shipment appears
= 0 otherwise
x 1 ij = 1 if transport from field i to field j and routing for the remaining of direct shipment appears
= 0 otherwise
x 2 gh = 1 if transport from depot j to plant k and routing occurs
= 0 otherwise
zD j = 1 if depot j is selected
= 0 otherwise
Support variables
w 1 i Remaining quantity after direct shipment at field i in first level
w 2 g Remaining quantity after direct shipment at node g in second level
u 1 i Aggregated oil palm quantity in vehicle at field i for sub-tour prevention in first level
u 2 g Aggregated oil palm quantity at node g for sub-tour prevention in second level
mD j Amount of round trip of depot j
mP k Amount of round trip of plant k
zP k = 1 if plant k is selected
= 0 otherwise
Objective function

Constraints


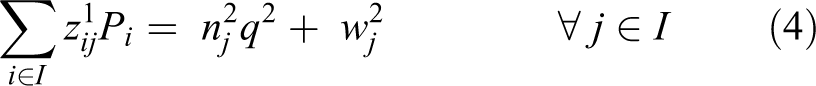

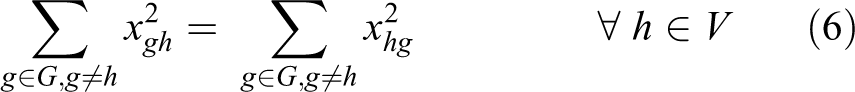





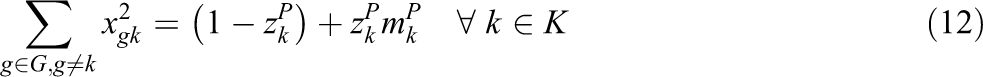


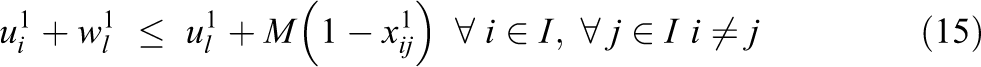

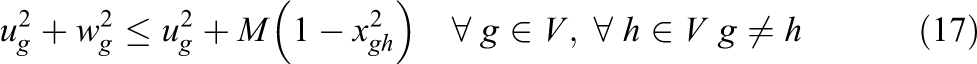
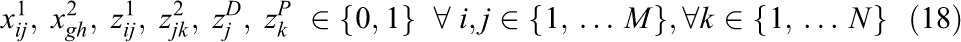
The objective function is defined by equation (1), the goal is to minimize the total cost. The first part and second part are the transportation cost for first level and second level, respectively. The third part is the opening cost of the depot. The fourth part and the fifth part are the emission cost minimization in the first level and second level, respectively. The sixth part and seventh part minimize the congestion cost in the first level and second level, respectively. Constraint (2) states that a field can be assigned to a depot only. If the product quantity is over the capacity of vehicle, Constraints (3) and (4) calculate the number of direct shipments and the remaining oil palm in the first level and second level, respectively. Constraints (5) and (6) guarantee that all routes must start and end at the same node of both field and depot, respectively. Constraints (7) and (8) ensure that the capacity of the depot and extraction plant, respectively, must never be exceeded. Constraint (9) states that a depot can be assigned to one plant only. Constraint (10) routes paths from field to field to collect oil palm. Constraint (11) routes paths to collect oil palm from the assigned field to the depot. Constraint (12) routes paths from depot to depot. Constraint (13) route paths from the assigned depot to the plant. Constraints (14) and (15) specify that the capacity of a vehicle must never be exceeded and the sub-tour prevention constraint in the first level. Constraints (16) and (17) define that the capacity of a vehicle must never be exceeded and the sub-tour prevention constraint in the second level. The binary variables are defined by constraint (18).
For solving the MLLRP problem, Lingo version 11 for Windows was used for finding the optimal solution. Lingo obtains a solution efficiently for small-size problems. As Lingo uses the exact method to find the best solution, it consumes excessive CPU time when the problem size is larger. Therefore, an effective metaheuristic was developed for solving the large-size problem within a reasonable CPU time.
Methodology
The proposed method combines the concept of two well-known metaheuristics, the variable neighborhood search (VNS) and the adaptive large neighborhood search (ALNS). The algorithm operates as follows (see Algorithm 1). It begins from an initial solution, and then a set of neighborhood structures is generated for the shaking phase. The algorithm selects a neighborhood structure randomly at each iteration to expand the searching space. In the local search phase, we applied a destroy and repair operator to improve the solution. The selection of an operator depended on a weight that reflected its performance in the past and this is automatically adjusted periodically. After a local search, if the new solution is worse than the previous one, the acceptance criterion will be applied for whether to continue with the new solution or the previous one.
Hybrid algorithm

Initial solution construction
An initial solution is created by the following constructive heuristic below:
Sum up the product quantity to obtain a number of opened depots and extraction plants. Each depot is set to store a product quantity at least 80% of the maximum capacity. The capacities of the depots and plants are predefined.
Randomly select depots to be opened one by one
Randomly select plants to be opened one by one
Assign each oil palm field to an opened depot using the nearest location, while considering the depot capacity.
Arrange a transportation route in the first level by applying the saving algorithm, 36 while considering the vehicle capacity.
Assign each depot to an opened extraction plant using the nearest location, while considering the plant capacity.
Apply step 5 to arrange a transportation route in the second level.
Figure 3 shows an example of an initial solution of the MLLRP.

Example of an initial solution.
Shaking phase
We designed difference six neighborhood structures to demonstrate the algorithm on the current solution and increase the perturbations. At each iteration, the algorithm randomly selected one of the neighborhood structures for shaking. This phase was intended to diversify into other searching spaces when trapped in a local optima. These neighborhood structures are explained below.
(N1) Exchange nodes within: Swapping two random nodes (fields or depots) within the same depot or plant. This also includes a field or depot relocation. A depot or plant is chosen with a random probability. If a depot is chosen, two assigned fields at this depot will be swapped. On the other hand, if a plant is chosen, two assigned depots at this plant will be swapped. All related fields will be re-assigned.
(N2) Exchange nodes between: Swapping two random nodes (fields or depots) between two different depots or plants at the same level. This neighborhood works as with exchange nodes within segments; however, the exchange crosses over different segments. A field or depot is selected with a random probability. If a field is selected, this field will be swapped with another field that is assigned to a different depot. If a depot is selected, this depot will be swapped with another depot that is assigned to a different plant.
(N3) Change two depots’ status: Randomly select one opened depot and one closed depot (field), then close the current depot and open a new one. As the capacity of a depot is predefined and equivalent at all depots, the number of opened depots stays the same and the solution is always feasible. After opening new depot, the reassignment of nodes and routes are executed in a cost saving manner.
(N4) Change depot status: Randomly selects a depot at random for changing its status. If its status is open, then close it or vice versa, considering the capacity. As change two depots status tries to maintain the number of opened depot and reassign fields and routes to new depot. This neighborhood allows to change the numbers of opened depots.
(N5) Change two plants’ status: Similar to changing the two depots status, this structure selects one opened plant and one closed plant then closes the current depot and opens a new one, ensuring that the plant capacity is still not exceeded. After opening a new plant, it aims to minimize the total costs by rearranging the routes to it. After that, the number of opened and closed plants remains the same. If all plants are already opened, the next neighborhood “Change plant status” will be executed instead.
(N6) Change plant status: This structure is the same concept as the change depot status, but this randomly selects a plant for changing the status. In the case of opening, existing routes in first level are reallocated to the new opened plant in a cost saving manner. Whereas, in the case of closing, the related routes are reallocated to other opened plants. The capacity constraint must also be satisfied.
Local search phase
This phase aims to reach the intensification concept. The idea of ALNS is applied to search for a solution in the different neighborhood structures. The destroy and repair methods are used as local search concepts to improve the solution. In this paper, four destroy and repair operators were developed. We let D = {di | i = 1,…, 4} be a set of destroy operators and R = {ri | i = 1,…, 4} be a set of repair operators. At each iteration, a pair of operators is selected with a probability based on the weight. The initial weight of each operator is set equally but will be adjusted at the end of iteration depending on the quality of the new solution. The highest performance operator will be rewarded with a higher score; thus, it has a high opportunity to be selected repeatedly at the next iteration. These destroy and repair operators are described below.
Destroy operator.
The destroy operator is used to ruin the solution and then turns incomplete. This method perturbed the current solution to search at a variety of areas. The destructive degree is denoted by dd = {10%, 15%, 20%, 25%, 30%}, which defines the size of destruction. For instance, if the solution contains 20 fields and dd = 20% is selected randomly, then four fields (20 × 20%) will be removed from current solution. After destruction, a repair operator will be executed to re-construct a new solution of the problem, which will be described in the next section.
1) Random removal
This operator works by randomly selecting q fields and putting them into the field pool as shown in Figure 4.

Example of random removal.
2) Connected removal
The connected removal randomly selects a field, called a seed field, and the q-1 fields that are closest to the seed field are marked. Then, all these fields are removed from the current solution and put into the field pool as shown in Figure 5.

Example of connected removal.
3) Worst removal
This operator finds the worst fields to be removed by calculating the total cost without a field in the current solution one by one. Then, this calculates the difference cost between when a field is in the solution and when it is taken off. The q fields that own the highest different cost will be removed from the current solution.
4) Fixed zone removal
Fixed zone removal was developed to destroy the solution in a specified area, called the fixed zone. The main idea is to let the solution move to a proper direction until it finds the best solution. In other words, this operator avoids the random walk search in the solution. The fixed zone removal works with the following steps: Separate the fields by four zones based on its actual location, the latitude and longitude, as shown in Figure 6. Randomly choose the fixed zone area (fa), fa = {1,2,3,4). This is the zone that will be destroyed. Randomly select a destroyed operator (random removal, worst removal, or connected removal). Execute the selected destroy operator to remove the fields within the fixed zone in step 2.

Fixed zone area.
Repair operator.
The repair operator is used to re-insert the part of the solution that is removed by the destroy operator. Each operator owns different insertion methods for improving the new solution.
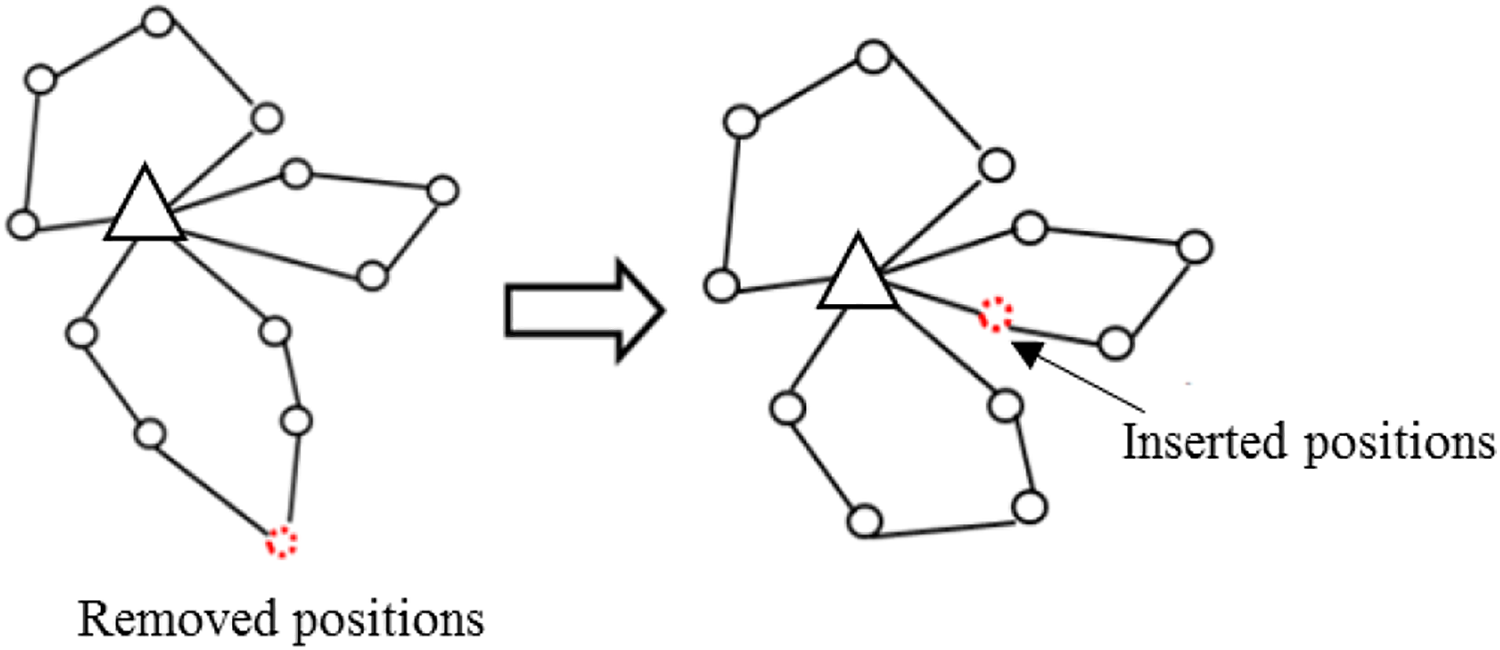
1) Random insertion
Random insertion is a simple and uncomplicated method. The operator brings the removed fields back to the solution at any position, regardless of the objective value. Figure 7 shows the characteristics of the random insertion operator.
Characteristics of random insertion operator.
2) Forbidden insertion
This operator performs same concept as the random insertion, but it is not allowed to re-insert into the same depot that it was in before the destroy operation. This forces the searching area of the new solution to be changed. This operator was developed primarily for diversification purposes.
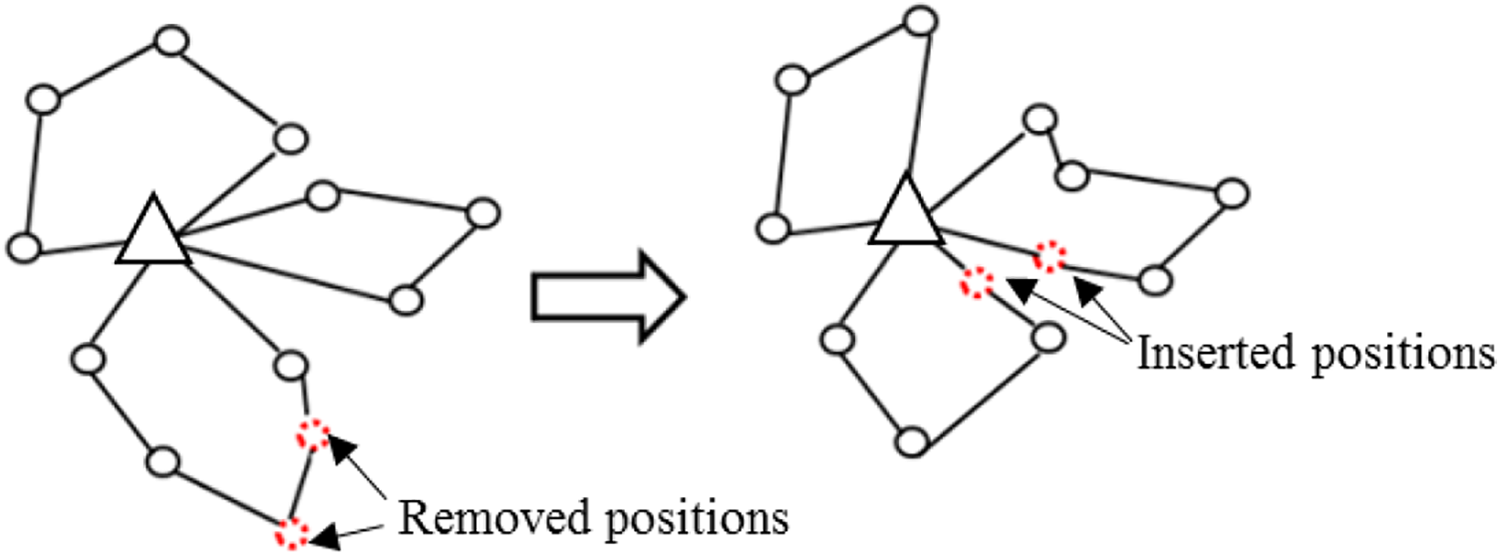
3) Best insertion
For the best insertion, the operator determines the best position that obtains the lowest cost. This inserts the fields in a random order one by one until there are no fields left in the pool. Figure 8 shows an example of best insertion operator.
Characteristics of the best insertion operator.
4) Swap
Swap is a simple and well-known local search method. This operator is used for exchanging the selected fields, which are then turned into the new solution, as shown in Figure 9. The steps of the swap method are as follows:
Select 2–3 fields randomly.
Mark the position of those fields to identify the position of the fields.
Exchange the field position as the identified point.

Characteristics of the swap operation.
Solution acceptance
Generally, the ALNS procedure contains the acceptance criterion to perform a determination for every new solution at each iteration. After the repair operation, a new solution will be obtained, if it is better than the original one, it will proceed to the next iteration. In the case of the worse solution, the solution acceptance will be conducted to provide a chance for acceptance with a small probability. In this paper, we adopted a popular criterion for ALNS, simulated annealing (SA), as the solution acceptance method. The non-improving solution was tested with probability
Experimental results
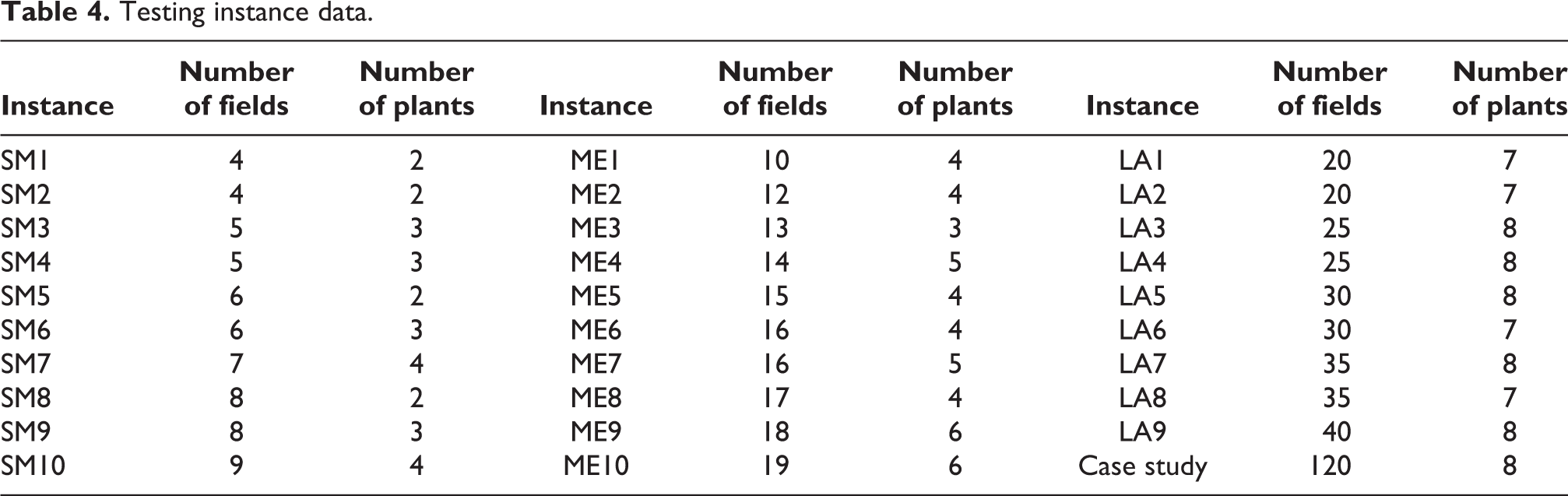
In this paper, the efficiency of the hybrid algorithm (HA) was presented for solving a multi-level location routing problem by comparing with the solution from Lingo for Windows, which is an exact methodology. The mathematical model and proposed algorithm were coded on Windows operation using a personal computer with Intel Core i5 CPU 2.7 GHz Ram DDR4 16 GB. The three groups of testing instances were randomly generated, and the details of the testing instances are shown in Table 4. The sizes of the instances were divided into small, medium, and large according to the number of fields and the number of plants. The stopping criteria of Lingo was the computational time, which was set differently depending on the instance size.
Testing instance data.
For a small-size instance, the computational time was recorded when finding an optimal solution. For medium and large-size instances, the computational time was limited to 48 h and 96 h, respectively. However, the stopping criteria of HA was the number of iterations or computational limited time, which depended on the purpose of each experiment. This will be explained next. The proposed HA was coded by Visual studio 2019 and was tested for three runs per experiment; then, the average result was reported. The statistical test was conducted via MINITAB® (Minitab Inc.) at the 95% confidence interval.
The first experimental result was a comparison of the solutions obtained by Lingo and the proposed algorithm as shown in Table 5. The stopping criteria of the proposed algorithm was set at 5000 iterations. For small-sized instances, Lingo was able to obtain the optimal solution; thus, the results of HA could be compared with the optimal solution. Both methods could find the same results within a short computational time.
The computational results of the testing instance and case study.

(a) = Optimal solution, (b) = Best solution found during limited time, (c) = Lower bound of solution, (d) = Percentage difference between result from proposed algorithm and Lingo, whereas
For medium and large-size instances, Lingo was not able to obtain the optimal solution within a reasonable time; therefore, the results of HA were compared with the BSF (best solution found during a limited time) and LB (lower bound of solution), which were obtained in 48 h and 96 h of running time, respectively. The positive sign (+) of %gap indicated that the HA result was better than the Lingo result because the BSF was not the optimal solution. On the other hand, the negative sign (−) of %gap indicated that the HA result was worse than the Lingo result because the LB was the lowest boundary of solution. From these results, the Wilcoxon’s signed rank test was conducted to verify the significant difference between the Lingo and HA result, the p-value is shown in Table 6.
Wilcoxon’s signed rank test for the results given by Table 5.

In terms of the objective value, the HA significantly improved the solution quality from the BSF obtained by Lingo in a medium-sized instance, with the average percentage differences (%gap) at −3.72%. For a large-sized instance, Lingo’s outcome was significantly better than HA but the solution’s status was only lower bound. The average %gap was not far; it was only 5.69%.
In terms of the computational time, this was not significantly different for both methods in small-sized instances. However, for medium and large-sized instances, HA used less processing time than Lingo, at 99.89% ((2880 – 3.16)/2880) and 99.83% ((5760 – 10.08)/5760), respectively.
From the %gap results, we performed ANOVA (analysis of variance) to check if the %gap was significantly different when the instance size was changed. The hypothesis test was declared as follows:
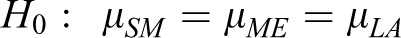
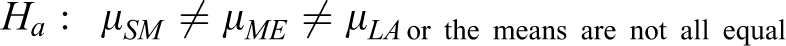
The p-value of the ANOVA test was 0.000, which indicates that the HA performed significantly differently compared to the results from Lingo when the instance size was changed. Figure 10 shows the Tukey comparison result. The interval did not contain zero; thus, the corresponding means were significantly different for all pairs.

The Tukey results from the ANOVA test.
The experimental results shown in Table 7 reveal the duration for the methods that found the best solution in small-sized instances. This experiment aimed to assess which method consumed the shortest duration to find the optimal solution. The stopping criteria of HA were the same as for the previous results; however, the time when to find the best solution was reported. The statistical test was Wilcoxon’s signed rank test method to compare the different durations. The p-value was equivalent to 0.032, which was less than the significance level. Therefore, the HA method was significantly faster than Lingo when searching the same solution quality.
The processing time when finding the best solution.

The last experiment was conducted on medium and large-sized instances to verify the solution quality when extending the duration. The computational time was set to 20 and 30 min for medium and large-sized instances as the stopping criteria. The results are shown in Table 8.
Experimental results while testing the fixed computational time.

* Bold numbers indicate that it is improved solution comparing to the results from fixed iteration experiment.
Wilcoxon’s signed rank test was conducted to check whether the proposed HA was dissimilar in performance for both sizes. The p-values are shown in Table 9.
Statistical test while using a fixed computational time.

The results demonstrated that the proposed HA generated a solution that was significantly different to the solution obtained by Lingo. However, HA gave a better solution than Lingo, which obtained only BSF. In this experiment, HA improved five solutions from 20 instances comparing to the results from the fixed iteration experiment in Table 5, with 25% improvement.
The proposed HA was deployed for solving the case study problem to decide the depot location and manage the transportation routes. For the first level, the algorithm decided to open 10 depots as the collecting points for oil palm and provided 24 different routes to transport the oil palm from field to depot, as shown in Table 10. For second level, the algorithm decided to open five extraction plants and provided 10 different routes to transport the oil palm from depot to extraction plant, as shown in Table 11. The total cost in the objective function was minimized at each route for both levels. The total cost of the case study was 865,822.52 baht, which was acquired from the summation of both levels (848,953.55 + 16,868.97).
The results of the case study at the first level.

The results of the case study at the second level.

The overall results indicate the proposed HA is efficient and suitable for solving complex problem especially the multi-level LRP, comparing to Lingo software. The HA performance is justified by small differences from Lingo’s results, but it can save huge gap of time consumption when the problem size is larger. The HA combines strength point of two well-known metaheuristics. The core concept of VNS is to randomly move the algorithm in various neighborhoods of expanding size as diversification mechanism, whereas the ALNS is aimed to find the optimal solution intently by various strategies, the most powerful strategy has a great opportunity to apply frequently. The key successes of HA are its ability to move to divers searching areas by applying different six neighborhood structures and its ability to intend to find the best solution in specified area by applying four destroy and repair methods.
Recently, Pitakaso et al. 37 introduced a new type of metaheuristic called the variable neighborhood strategy adaptive search (VaNSAS) as a solution approach for solving the green two-echelon location routing problem (G2ELRP). Table 12 shows the performance comparison between the proposed HA and VaNSAS in terms of percent difference (% gap) from Lingo’s solution. The statistical test of mean difference revealed the p-value was equal 0.166. Hence, we concluded that both methods were not significantly different regarding the percentage difference from Lingo. However, both studies contained different sizes of instances, including the product quantity, number of fields, and number of plants, as well as the limited time in the experiment. These may have impacted the comparison results.
Comparison of the results with recent research.
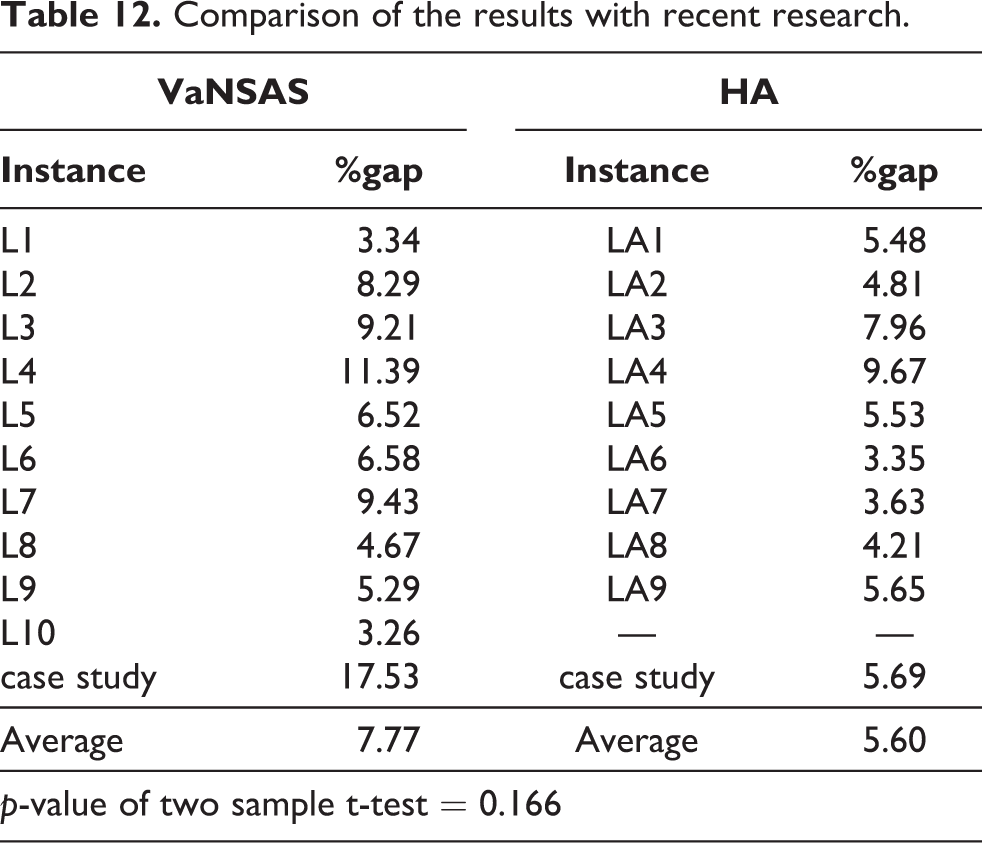
Table 13 showed the comparison results of HA and various methods in the literature that proposed for solving environmental impact characteristics. We compare HA method with VaNSAS (Pitakaso et al.) and ALNS (Demir et al.),
38
% gap is the percentage difference between results obtained by proposed methods and exact method (Lingo/CPLEX). The HA obtained the best solution
Comparison of the results with other methods for solving environmental impact.

Finally, in order to test the performance of the proposed algorithm, we performed the test on the standard instances for two-echelon LRP that was derived from Phodhon’s benchmarks. 11 We tested five runs for each instance and recorded the best total cost and CPU time. The results are presented in Table 14. The HA was compared with GRASPxLP (Nguyen et al.), 17 MS-ILS (Nguyen et al.), 18 Hybrid SA (Pichka et al.) 13 and two-phase method (TPM) (Dai et al.). 39 Column 1 and 2 define instance name and best-known solution (BKS) obtained by previous literature. In term of CPU time, TPM is the fastest in all methods as the average time of GRASPxLP, MS-ILS, Hybrid SA, TPM and HA is 22.62 s, 423.50 s, 31,260 s, 7.54 s and 8.73 s, respectively. The HA is the second best with the average difference is only 1.09 s (8.73–7.54). In term of solution’s quality, MS-ILS is the best performance in all methods since the average %gap of GRASPxLP, MS-ILS, Hybrid SA, TPM and HA is 1.16%, 0.12%, 1.04%, 2.63%, and 2.72%, respectively. HA is competitive to TPM as the average difference is only 0.09 s (2.72–2.63). Although GRASPxLP and MS-ILS and Hybrid SA are better than TPM and HA, but they consume high processing time. Thus, if the requirement of solution’s quality is not very high, HA can be acceptable. Besides fast speed of operation, HA is easy to use as it does not require tuning or setting the parameters of algorithm.
Results for two-echelon LRP testing on Prodhon’s benchmarks.

Conclusion and suggestion
This research studied a multi-level location routing problem (MLLRP) considering the environmental impact by including the emission cost and congestion cost in the objective function. The problem is considered complicated as it concerns the decision of location and routing in both levels. The depot locations must be determined from the potential fields established, and then the vehicle routes are provided for collecting the oil palm from farmers to the opened depots. After that, the extraction plants must be selected along with the vehicle routes to transport the oil palm from the opened depot to the selected plants.
The mathematical model was formulated with the purpose of total cost minimization. The model was tested using the Lingo program with three groups of testing instances, which contained different problem sizes. Although Lingo was recognized as able to find an exact solution, it was not suitable for large problems due to the unreasonable processing time. Therefore, we developed a hybrid metaheuristic for solving the MLLRP.
The proposed algorithm can solve the problem efficiently compared to Lingo’s solution. There was no gap in small-sized instances, and it outperformed Lingo’s solution in medium-sized instances. For large-sized instances, although Lingo’s solution was better than the proposed algorithm, it was lower bound in the solution. The proposed algorithm consumed approximately 99% less processing time than Lingo.
For benchmarking purposes, we compared the performance of the proposed method with another method in the related literature. The result revealed that our method was not significantly different from the method in the recent literature in terms of the solution quality. Finally, the proposed algorithm was applied to the case study problem for managing the locations of the depots, extraction plants, and transportation routes for both levels. This study will aid sustainable development in the agriculture industry by reducing the transportation costs for farmers and related collaborators and by decreasing the environmental harmfulness as well. This study can be adapted not only to the agricultural industry but also to other industries in Thailand or around the world.
For future research, the consideration of additional factors that affect the emission cost and congestion cost would be valuable. These factors will allow the model to further approach the realistic problem. Other real-world constraints, such as time windows, stochastics demands, and heterogeneous fleets of vehicles should be included into the model. Another beneficial avenue for future study is to develop other new hybrid algorithms to accelerate the computational time.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.