
Abstract
During the recent era of big data, a huge volume of unstructured data are being produced in various forms of audio, video, images, text, and animation. Effective use of these unstructured big data is a laborious and tedious task. Information extraction (IE) systems help to extract useful information from this large variety of unstructured data. Several techniques and methods have been presented for IE from unstructured data. However, numerous studies conducted on IE from a variety of unstructured data are limited to single data types such as text, image, audio, or video. This article reviews the existing IE techniques along with its subtasks, limitations, and challenges for the variety of unstructured data highlighting the impact of unstructured big data on IE techniques. To the best of our knowledge, there is no comprehensive study conducted to investigate the limitations of existing IE techniques for the variety of unstructured big data. The objective of the structured review presented in this article is twofold. First, it presents the overview of IE techniques from a variety of unstructured data such as text, image, audio, and video at one platform. Second, it investigates the limitations of these existing IE techniques due to the heterogeneity, dimensionality, and volume of unstructured big data. The review finds that advanced techniques for IE, particularly for multifaceted unstructured big data sets, are the utmost requirement of the organizations to manage big data and derive strategic information. Further, potential solutions are also presented to improve the unstructured big data IE systems for future research. These solutions will help to increase the efficiency and effectiveness of the data analytics process in terms of context-aware analytics systems, data-driven decision-making, and knowledge management.
Introduction
Information extraction (IE) process is used to extract structured content in the form of entities, relations, facts, terms, and other types of information that helps the data analysis pipeline to prepare the data for analysis. The efficient and accurate transformation of unstructured data leads to improved performance of data analysis and IE. Various IE approaches have been proposed to extract structured and useful information from unstructured data which eventually helps to manage, process, and analyze unstructured data. IE systems are based on natural language processing (NLP), language modeling, and structure extraction technique. NLP and language modeling have a significant role in the IE process but not included in the scope of this review. This review mainly focused on the extraction techniques with respect to IE subtasks and different data types. In this regard, various statistical, rule-based, and learning-based approaches for IE have been discussed.
Big data are adding more challenges to the IE process due to huge volume and variety of data (i.e. structured, semi-structured, and unstructured data). According to IDC (International Data Corporation), by 2020, unstructured data account for 95% of global data with an estimate of the compound annual growth rate of 65%. 1 The potential opportunities and solutions for big data are obstructed by the unstructured nature of data. The main characteristics of unstructured data are: (1) unstructured data have no schema, 2,3 (2) they have multiple formats, 2 –4 (3) they come from diverse sources 2 –4 , and (4) there is no standardization 2,3 , that is, different representations. The correct transformation of unstructured data improves the performance of unstructured data analytics. The complicated heterogeneity of mixed data makes it difficult to extract useful information. Due to the quality and usability issues of unstructured big data, it is important to investigate the potential and capabilities of existing IE techniques. To the best of our knowledge, this issue has not been well explored in the literature to identify the impact of unstructured big data on existing IE techniques. In this manner, the objective of this review is twofold: first, to explore the state-of-the-art techniques in IE for variety of data and second, to identify the limitations of existing IE techniques for multifaceted unstructured big data. Further, preconditions have been proposed to overcome the limitations identified in the review. The outcome of the research contributes to the identification of future directions to improve the IE systems to tackle the unstructured big data.
The rest of the article is organized as follows. In the next section, IE approaches for unstructured data have been discussed concerning IE subtasks for each data type. Further, limitations of existing IE techniques for unstructured big data analytics have been explored followed by the proposed preconditions for efficient and effective analytics. In the end, the conclusion is presented.
Research methodology
The systematic literature review (SLR) 5 has been conducted to complete the present study. A literature review is a comprehensive investigation of existing literature on work presented on a specific topic. 6 The existing literature has been searched systematically and existing techniques and methods have been investigated thoroughly to find the limitations of the work presented on IE from unstructured data. The literature search has been made for four main data types of unstructured big data such as text, images, audio, and video. The literature has been searched based on the keywords and search strings. A SLR is the most suitable approach to identify the limitations of the existing IE systems and to meet the objectives of the study. The literature review has been completed in three phases as shown in Figure 1.

Review process.
Table 1 describes these phases with the corresponding activities performed during the literature review.
SLR process and corresponding activities.

SLR: systematic literature review.
Planning the review
Research questions
The research questions with their corresponding objectives are given in Table 2.
Research questions and objectives.

IE: information extraction.
Search string and data sources
The literature, selected for this study, has been referred from renowned databases of IEEE Xplore, Springer, ACM, ScienceDirect, Web of Science, Scopus, and Google Scholar using different search strings. The searched strings used for this review are as follows: “information extraction,” “information extraction from text,” “information extraction from images,” “information extraction from audio and video,” “multimedia information extraction,” “information extraction AND big data,” “unstructured data problems,” “challenges in big data,” “multimedia data,” “information extraction techniques,” “unstructured data types,” “challenges in information extraction,” and “issues in big data analytics.” However, the selection of the articles was based on the inclusion and exclusion criteria for this study.
Inclusion and exclusion criteria
The inclusion criteria to select research studies for this SLR are as follows: Research published between 2010 and 2018. Studies related to IE from text, images, audio, and video data. Studies discussing the IE process implemented in the domain of big data. Studies presented on IE from unstructured data.
The exclusion criteria for this review are as follows: Studies other than unstructured data. Studies related to unstructured big data but not related to IE. Duplicate studies.
Conducting the review
The most relevant studies to the research questions and objectives have been identified using the three-step process. At the first step, research studies were searched using different relevant search strings as described earlier. After searching the studies, 348 articles were selected based on their titles. Of these, 274 articles were selected based on the abstract. After scrutinizing 274 papers, only 95 relevant papers presenting the most significant and prominent work in this area were included in the review.
International journals in the areas of IE, multimedia data, data quality and extraction, biomedical, engineering data, and many other related domains have been consulted from IEEE, ACM, Springer, and other renowned databases. The journals referred in the present study include Principles of Big Data, IEEE Transactions on Multimedia, International Journal of computer and Information Engineering, Journal of Data and Information Quality, ACM Transactions on Knowledge Discovery from Data, Analysis of Images, Social Networks and Texts, Journal of Biomedical Informatics, ACM Transactions on Intelligent Systems and Technology, Journal of Visual Communication and Image Representation, Computer Speech & Language, Mining Text Data, Multisource, Multilingual Information Extraction and Summarization, ACM Queue, Procedia Computer Science, Expert Systems with Applications, International Journal of Computer Science & Engineering Technology, International Journal of Computer Applications, Technological Forecasting and Social Change, Computational Systems for Health & Sustainability, Journal of Cheminformatics, Certified International Journal of Engineering and Innovative Technology, Literature review for Language and Statistics, Semantic Technology, Advances in Computing, Database Systems for Advanced Applications, Journal of Physics, Smart Health, Computers & Electrical Engineering, Expert Systems with Applications, Towards Integrative Machine Learning and Knowledge Extraction, International Journal of Multimedia and Ubiquitous Engineering, Neurocomputing, International Journal of Computer Science & Engineering Survey, ACM Transactions on Multimedia Computing, Communications, and Applications, International Journal of Scientific & Engineering Research, International Journal of Emerging Technology and Advanced Engineering, International Journal of Electronics, Electrical and Computational System, Computer Vision and Graphics, Video Text Detection, Semantic Applications, International Journal of Simulation: Systems, Science and Technology, and PLoS Med.
The research critically reviews the limitations of methods and techniques for IE from unstructured data. The inclusion and exclusion criteria with different search strings have been strictly followed to select quality research for this literature review. The selected article has been thoroughly studied and analyzed critically to address the research objectives. The qualitative exploratory approach has been used to determine the impact of unstructured big data on IE systems. The study also explores the state-of-the-art techniques of IE from multifaceted unstructured big data. Figure 2 shows the research process flow for the SLR.
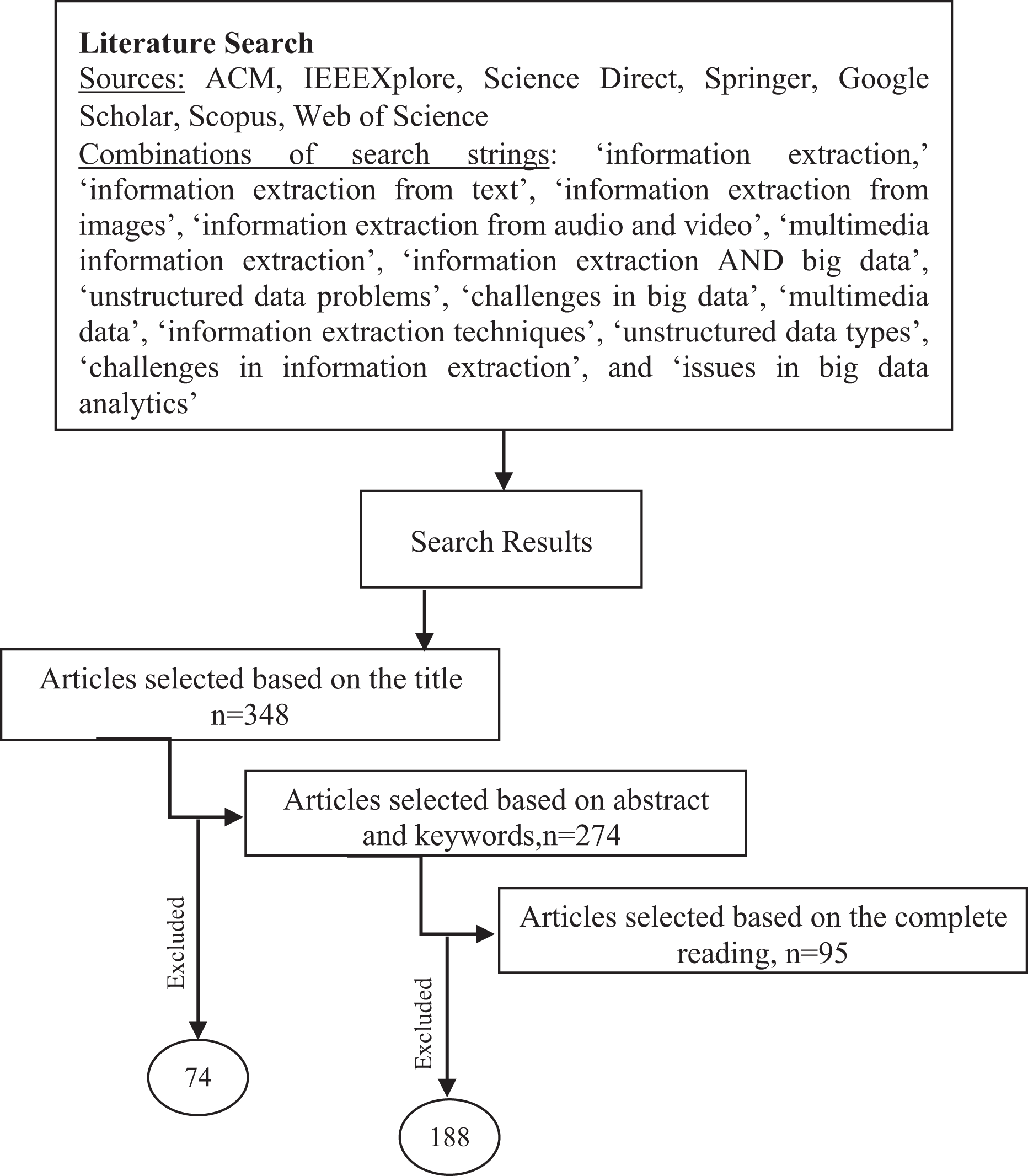
Literature selection process.
Reporting the review
After selecting the most relevant literature, research studies have been divided into four categories with respect to data types, that is, IE from text data, IE from images, IE from audio data, and IE from visual data. Table 3 presents the distribution of selected research studies for each category, and illustrated in Figure 3.
Distribution of studies for each data type.
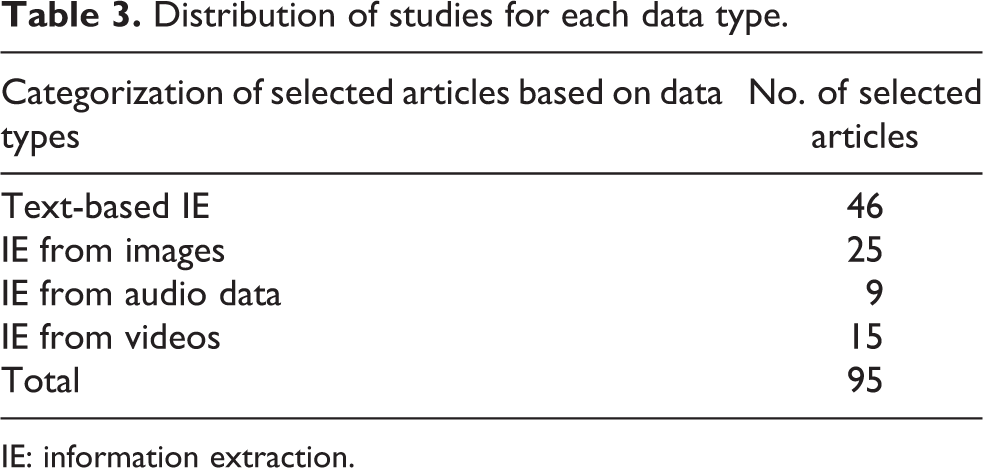
IE: information extraction.

Distribution of selected studies for each category.
The distinction of this literature review is presenting all four major unstructured data types about IE in a single review. The review identifies the limitations and shortcomings of the existing IE techniques for unstructured data which are necessary to understand to improve IE procedures. Eventually, the findings of this research would contribute onward to the usability enhancement of multifaceted unstructured big data to extract useful information from them.
IE for unstructured data analysis
People and machines are producing data at a very high rate than ever before. The volume and variety of data being produced bring more challenges in identifying useful information from them. IE is a process to extract structured information from unstructured data. As the growth rate of unstructured data is quite high as well as increasing during recent times, the significant challenges associated with IE, mining, and analytics need to comprehend. Scalability, dimensionality, and heterogeneity of unstructured data appear as the main challenges to harvest useful information. Transformation of unstructured data into a structured format for better representation are the big questions. 7 Efficient and accurate transformation of unstructured data to structured data is necessary to improve analytics. Automatic IE from unstructured data is a field to identify new methods for extracting semantics and contextual information by analyzing, managing, and querying the data. This section presents IE techniques for unstructured data, that is, text, image, audio, and video formats, respectively.
Text-based IE techniques
IE procedures emerged in the 1990s with Message Understanding Conferences where several types of IE tasks were introduced over time. 8 During the early stages of IE, the information from text has been extracted using template filling, rule-based methods, classification model-based methods, and sequential labeling. Conversion of an unstructured text document into a structured format has been divided into two subtasks such as define the high-level structure and low-level structure. The high-level structure includes major parts of a text document such as headings and title, whereas low-level structure determines the individual elements such as entities and places. 9 The discovery of the low-level structure is a more important and complex task in terms of understanding the content and context of any text document. Several dimensions for low-level structuring have been identified such as named entities, events, relations, and terms. NLP, machine learning, and computational linguistics are helping IE process to bridge the semantic gap and extracting and representing the relevant information. However, a huge volume of multifaceted unstructured data make IE process more challenging.
The IE process identifies and represents structured information from natural language text. Text strings, values, or tags extracted from the text are specified in prespecified slots of user-defined structures known as templates or objects. 10 Segmentation, classification, association, normalization, and de-duplication are five tasks for general IE and storage. 11 Similarly, another IE process was proposed for Web-originated unstructured text to present structured information in XML by following data extraction, syntactic and semantic analysis, classification, and inference rules steps. 12 Furthermore, machine translation, auto-coding, indexing, and term extraction are the main techniques to give meanings to unstructured data in IE process where auto-coding and indexing tasks help identify terms from text. 13 The sections “Named entity recognition,” “Relation extraction,” and “Event extraction” present the subtasks of IE process from text data whereas the section “Limitations of text-based IE techniques” presents all the identified limitations of the IE techniques in above sections.
Named entity recognition
Named entity recognition (NER) is used to extract descriptive information from identified entities such as person names, locations, organizations, and numerical and currency expressions. Modern solutions to NER are based on statistical sequence labeling algorithms, for example, maximum entropy. Relation extraction (RE) deals with finding the semantic relations between entities from text. Existing methods use carefully designed features and standard classification to solve this problem. 8 Entities can be generic such as a person, location, or domain-specific like proteins, chemicals, and cells. Identification of entities (named entity detection) and their classification (semantic classification) are subtasks of NER. 14 Extraction models in NER systems use three techniques: rule-based, machine learning, and hybrid approaches. 15 Rule-based methods for NER use lexico-syntactic patterns and semantic constraints to identify the occurrence of similar entities while learning-based methods use machine learning to extract named entities and their classification. Learning-based methods can be supervised, unsupervised such as clustering (hard and soft), and semi-supervised such as bootstrapping. Supervised and unsupervised approaches use a large quantity of training data to achieve high performance but semi-supervised approaches use both labeled and unlabeled corpus with a small degree of supervision. 16 Several hybrid approaches achieve better performance and accuracy than a single approach such as rule-based pattern extractor using link grammar parser and Stanford PoS (Part-of-Speech) tagger with semi-supervised approach using self-training algorithm for entity labeling, 17 maximum entropy model (MaxEnt) with language-specific rules and gazetteers for the Hindi and Bengali language text, 18 ChemSpot: a chemical hybrid system with CRF (Conditional Random Fields) and chemIDplus dictionary, 19 SVM (Support Vector Machine) with CRF for biological entities with 91% accuracy, 20 and a semantic and statistical model for medical entity recognition with semantic method MEtaMap, chunker-based noun phrase extraction, SVM, and supervised learning CRF. 21 Supervised tagger TnT and rule-based SVM for health and tourism text documents in the Malayalam language has shown 73.42% accuracy. 22 Combination of HMM (Hidden Markov Model) with hand rules for the Punjabi language has shown pretty notable results as compared to a supervised machine learning method that achieved the precision of 72.92% and 47.57% by using HMM only. 23 A semi-hybrid approach by combining HMM and some rule-based approaches for PoS tagging and entity detection from the Nepali language has been proposed to extract named entity-specific classes that include the name of the person, location, number, organization, currency, and quantifier. 24 Combination of dictionary-based, rule-based, and machine learning has been used to extract molecules and related properties from the scientific literature in biomedical domain. 25 Combined dictionary-based approach with fuzzy matching and stemmed matching is considered more helpful in finding information as it generates a new big set of annotation from the clinical text, 26 but these approaches are domain-dependent due to complex and short terms of the medical domain. A domain-independent hybrid approach has shown promising results by combining SVM and HMM with some simple linguistic pre-processing methods to identify gene and protein from the text without using external knowledge base. 27 In this regard, a hybrid named entity recognizer was applied with manual engineered rule-based predecessor combined with lexical resources and pattern bases for semantic indexing of the Turkish text. 28 Combination of HMM with gazetteer method has been outperformed with tourism text in Hindi as input. The improved accuracy of combined methods was 98.37%, whereas separately the results were 40.13% and 97.3% with a gazetteer and HMM, respectively. 29
It is found that machine learning approaches the best suit for NER techniques for various Indian regional languages such as Hindi, Marathi, Bengali, Punjabi, Malayalam, Bengali, Kannada, Telugu, Tamil, Urdu, and Oriya, while HMM and CRF give best results considering their limitations. 30 IE from human language text is different for each language. But IE is easier for rich morphological languages like Russian and English. Sazali et al. 31 proposed an IE technique to extract nouns using morphological rules from classical documents in the Malay language. Extracting nouns from Malay classical documents is a difficult task because Malay is not morphologically rich language. In their study, 31 morphological rules are used to extract nouns from the Malay language but the results still need to be evaluated by the experts because there is no complete dictionary of nouns in the Malay language.
The issues identified from literature can be categorized into entity-specific and techniques-related challenges. Traditional NER techniques are inadequate to handle the dimensionality and heterogeneity of unstructured big data. Supervised learning techniques require large annotated data for training and that is a laborious and difficult task for large-scale data sets. Weakly supervised learning is effective as compared to supervised methods due to reduced manual effort. But still, the sparsity of data make these techniques inefficient. 32 In this regard, reinforcement learning for IE can overcome the limitations of the above techniques. On the other hand, open nature of vocabulary, abbreviations, disambiguation, and different languages and domains are major entity-specific challenges. Further, noise (short and domain-specific text), 8 entity ambiguities (single entity and global entity), 33 and automatic labeling 34 are creating difficulties in identifying entities and their relations from free text big data sets. Various factors have been identified during SLR that influence the performance of NER techniques such as noise, data diversity, variation in text perspective, and data sparsity as data-related challenges that influence the performance of NER techniques. Similarly, all identified factors are categorized according to data, entities, domain, task, and language-related limitations, and have been presented in Table 4.
Limitations of NER techniques.

NER: named entity recognition.
Relation extraction
Finding the relation between entities is one of the substantial tasks in IE. The system requires to correctly annotate the data by recognizing a piece of text having the semantic property of interest. Various techniques have been applied to extract the relation between identified entities. Most commonly used techniques are knowledge-based methods, supervised methods, and semi-supervised methods. Supervised approaches use feature-based and kernel-based (bag of features kernel and tree kernel) techniques for RE and are suitable for domain-restricted RE. Semi-supervised approaches like Dual Iterative Pattern Relation Expansion, Snowball, and KnowItAll are suitable for open-domain systems. 35 These approaches are limited to sentence-level RE whereas RE in paragraphs and cross documents is a way to improve accuracy. 36 The hybrid approach provides a solution for linguistics to extract the relation between complex terms. A filtering algorithm to extract relation between complex terms of the Arabic language using deep linguistic analysis, morph syntactic and linguistic filters has been used as a hybrid method in which term extraction from the text in the Arabic language is combined with statistical approach. 37 Most relevant IE from largest biomedical database Medline has been achieved by a hybrid approach where semantic and probabilistic approaches have been used together to facilitate users in terms of searching and data representation. 38 Traditional feature-based methods combined with convolutional and recurrent neural network resulted in state-of-the-art performance for RE and classification. 39
The major focus of open IE system is to extract maximum relations from text based on the contextual decomposition of sentences. Accuracy, minimalism, and coverage are open challenges for open IE systems in RE with high precision. 40 An approach for open IE system based on lexical-syntactic patterns matching without using machine learning has also been used to extract domain-independent terms. 41 RE still needs improvement because of language ambiguity. Most of the research work, in this regard, has been conducted for the English language.
It is challenging to extract information from highly ambiguous languages, especially without diacritics. Semantic RE from the Arabic language is a complex task due to its ambiguity. A hybrid approach that combines statistical calculus with linguistic knowledge has been used as a two-stage process in which noun phrases are extracted first and then transformed into semantic relations with 60% decreased rate. 42 The performance of these approaches is evaluated using precision, recall, and f-measure. Precision and recall are the measures for completeness and correctness, respectively, 10,43 whereas F1-score (also known as f-measure or f-score) is used to measure the accuracy of a system. It is a harmonic combination of precision and recalls. 43 Extracting relations and their associative entities from radiology reports using unsupervised way as without specifying the knowledge base scored 0.94 F1-score in terms of accuracy. The proposed hybrid approach for rule-based IE systems based on distributional semantics and clustering to find similar relations outperforms other approaches 44 and is limited to one language. It has been observed that automatic annotation, 45,46 semantic RE with appropriate features 45,47 are critical factors that highly influence the results. Most of the RE techniques are extracting one to one relationship between entities whereas many to many relationships among entities can be identified also. In this regard, big data sets need high computational systems to increase performance efficiency and reduce computational delay. MapReduce was used to extract many to many relationships between entities of sized 100 GB free text and a proposed solution has outperformed as compared to existing approaches. 48 The scalability and sparsity of unstructured big data make traditional methods ineffective. 32 To overcome the limitation of existing traditional methods, distant supervised learning, CNN (Convolutional Neural Network), and transfer learning have shown pretty notable results. 49 –51
Based on the identified critical factors, limitations of RE techniques have been identified and presented in Table 5.
Limitations of RE techniques.

IE: information extraction; RE: relation extraction.
Event extraction
An event usually consists of trigger and arguments. A trigger is a verb or normalized verb that denotes the presence of an event in the text whereas arguments are usually entities which assign semantic roles to illustrate their influence toward event description. 54 There are different in-practice techniques for event extraction (EE) such as data-driven (focus on specific features such as words, n-grams, and weights), knowledge-driven (lexico-syntactic patterns and lexico-semantic patterns), and hybrid approaches. 55 Data-driven approaches require more data as input with less domain knowledge whereas knowledge-based methods require little data but high knowledge and expertise. Hybrid approaches are compromising techniques between these two approaches to minimize the effort and to improve the performance. High expertise is required to develop a hybrid approach. 55 Combining semantic knowledge and statistical learning method based on temporal and spatial elements for a semantic search engine as a hybrid approach has been used to extract event information from complex Chinese text. 56 Rule-based combined with feature-based classifiers and machine learning (SVM) approach has been used to detect event information in the three-stage model (pre-processing, trigger detection, event detection) which has shown 50.97% accuracy. Although the results were not satisfactory, however, post-processing and modified features could increase the accuracy. 57
EE from social media is more challenging than formal news article because it contains complex text in terms of informal and short words, different languages and expressions. In evaluating the combination of linguistic rules with different machine learning techniques, the comparative performance of linguistic rules (for domain-independent annotated training set and a feature set) with decision tree and SVM has shown 52% and 75.8% accuracy, respectively. Proposed hybrid techniques outperformed by 24.8% for Twitter text. 58 EE from Twitter is an arduous task because of valuable user-generated text in the form of tweets to extract general and specific event information. EE techniques for Twitter can be based on event type, tasks, detection method, and features. 59 The ambiguity of representation, noisy data, and lack of training data are open challenges to EE from tweets. Tweet replies are also helpful to identify life events. 60 EE from unstructured data across multiple sources is more complex than EE from text only. Meaningful visual patterns help to identify semantic attributes, arguments, and concepts from different data modalities. In this regard, a system that could search, identify, organize, and summarize events from unstructured Web data has been developed using online analytical processing. Adjustment of ranking and weights given to different dimensions have been used to derive meta-paths based on user browsing feedback. The identification and summarization of events for the recommendations according to the user browsing interest incorporated a medium-level human agency. 61 EE techniques help to improve the efficiency and accuracy of IE from the text, but still, the research is at the infancy stage. Unstructured big data add tremendous challenges to this research due to multimodality, heterogeneity, and complexity of data. These challenges have been presented in Table 6. Identification of events and summarization in unstructured data is a state-of-the-art challenge in IE.
Factors influencing EE techniques.
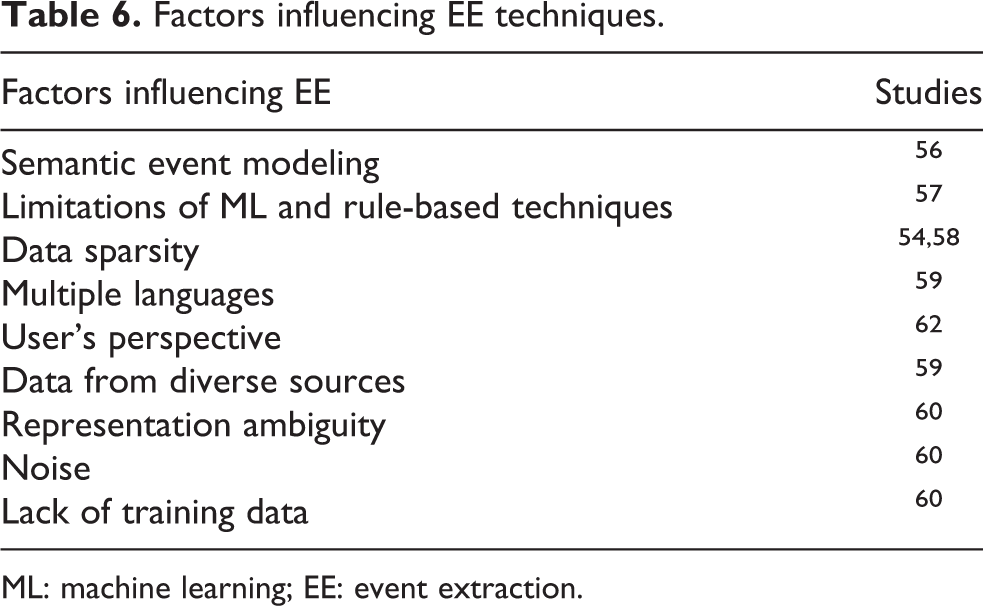
ML: machine learning; EE: event extraction.
Limitations of text-based IE techniques
More sophisticated algorithms and hybrid approaches (i.e. combining supervised and unsupervised) are required to achieve high accuracy and efficiency. 63 Self-training can reduce over-fitting issue, 64 and reinforcement learning or distant supervision can perform better with small labeled data sets. 50,65 According to the variety and volume of big data, many questions still need to be answered using deep learning such as more resources of information will increase conflicts, hence, conflict resolution became important. How to handle timeliness and data distributions, the impact of enlarged modalities on performance, 65 balance among informativeness, representativeness, and diversity, 66 modeling performance in case of heterogeneous, dimensional, sparse and imbalance data, 52 and structuring the data 67 are the challenging issues of IE from large-scale unstructured data sets.
The most critical factors as presented in Tables 4 to 6 having strong influence on the performance of NER, RE, and EE techniques, respectively, have been combined and categorized as overall limitations of text-based IE techniques in Table 7.
Limitations of text-based IE techniques.

IE: information extraction; ML: machine learning.
Image-based IE—From visual to semantic extraction
Global digitalization and social media gave exponential rise to image sharing. IE from images can be achieved by extracting elements, objects, visual concepts (low and high-level features), and shapes. Visual features are used to detect objects, entropy-based analysis of visual and geo-location data, structural decomposition of 3-D images, whereas data-driven approaches are used to extract a meaningful representation of facial expressions, classification, and segmentation. The IE from images is a field with great opportunities and challenges such as extracting linguistic descriptions, semantic, visual and tag features, improved scalability, and precision. Content and context-level IE from images could improve image analytics, mining, and processing. Visual relationship detection, text or face recognition from images provides contextual and useful information. The common applications of visual IE are content-based information retrieval, 68 visual question answering, 69 sentence to image retrieval, 70 and fine-grained recognition. 71 The sections “Feature extraction,” “Character recognition and text extraction,” “Dynamic scene understanding,” and “Semantic and geospatial information extraction” review the IE process from images based on extracted structure type and method used for IE whereas the section “Limitations of image-based IE techniques” presents the limitations of image-based IE techniques.
Feature extraction
Feature extraction and its representation is an important step to process unstructured data. Low-level and high-level visual features are used to extract semantic information from images. Visual feature extraction is used to identify the unique objects in the image. The scene in images may contain useful objects in the form of logos and signs. Such objects detection can be helpful for content-based searching, targeted advertisements, and social network applications. Feature selection and its classification are the steps to extract features from images. Automatically detecting targets in stationary images using segmentation and SIFT (scale-invariant feature transform) for feature extraction has shown average classification accuracy up to 90.99%. 72 Automatic IE from HR/VHR (high resolution) remote sensing images using classification rules and correlation using prior knowledge instead of local training data set for features extraction contributes to improving the scalability. 73 Feature extraction is important to identify any object or target which describes information about the image. Some of the important features that can be extracted from images have been discussed as follows.
Color features
Several color features have been proposed like color histogram, color moments, color coherence vector, and color correlogram. The histogram is most commonly used due to its simplicity toward computation. 74 In a multimodal learning approach for tagging and visual feature extraction based on deep learning, the popularity of image on social media is predicted by extracting tag features using sparse word count vector and visual features using real-valued dense vector. 75 Descriptive visual words extraction and Hue Saturation Value color features are combined to utilize the tags of social media images to find a correlation. The user-image-tag model has been developed with the tripartite graph according to the correlation among users, images, and top-ranking tags. 76 For HR satellite images, a data-driven algorithm has been designed to extract water information to determine the optimal threshold of water boundary using water index and color features. 77 The segmentation approach was based on the Markov random fields model.
Texture features
According to general observation, the visual system of human beings uses texture to recognize and interpret. Texture features are different from color features as it deals with the group of pixels. Spatial and spectral feature extraction are two major texture feature extraction methods used in several domains. 74 Texture information could be extracted from HR satellite images using object-oriented classification approaches based on spectral and spatial heterogeneity in segmentation. It is found that the quality of segmentation is directly affected by classification accuracy when the proved accuracy of classification is 85.16%. 78 Edge detection, only, is not sufficient to identify an object in the image, but texture information also plays an important role. Edge detection and texture IE together have been used to extract smooth regions with poison noises in image. 79
Shape features
The purpose of shape feature extraction is to identify objects using two main methods, that is, contour-based and region-based methods. Unsupervised change detection and multi-temporal Red Green Blue visualization are important tools to detect and visualize the images of different fields. Traditional extraction processes based on edge detection and template matching were not performing well when the image has noise. A combination of spectral reflectance, texture measures, and shape features could be used for object extraction based on multi-scale segmentation from geographic satellite images to improve classification accuracy, 75 but the classification accuracy is achieved only for fine images. Image segmentation algorithm to create an image object, object-based feature extraction, and classification comprises of three steps of a hybrid approach combining object-based classification technique and multi-resolution segmentation. Scales, weighted input image layers, shape ration, and compactness ratio have been used as segmentation parameters whereas classification calculation based on spectral, texture, and geometric (such as shape index and length/width) features. Classification combined with multi-resolution segmentation showed higher accuracy as compared to object-oriented classification method. 80
Character recognition and text extraction
A vast array of information is extracted from the content in images. In text extraction task, the text is segmented from the background for recognition and converted into a binary image. Text extraction from images can be divided into three subtasks: detection and localization, text enhancement and segmentation, and optical character recognition (OCR). But the noise, variation in font size, style, orientation, text alignment, illumination change, and complex background are adding complexities to this task. 81 Morphological operators, wavelet transform, artificial neural network (ANN), and histogram techniques are mostly used for text extraction, 82 whereas OCR is most commonly used for character recognition. The accuracy of character recognition using OCR for the Brahmi language was 91.57% and 89.75% for the Vattezhuthu. 83 Regions in images are recognized, classified, and converted into text with the help of classifier-based automatic IE system and ANN. ANN and a correlation algorithm were used to improve efficiency and effectiveness. 84 OCR combined with CNN improved the performance of visual IE from large data sets. 85 On the other hand, text imprints, kind of noise, make useful information unavailable. In this regard, locating the imprint location first and then applying a noise elimination technique to extract misprinted text in binary images were two main steps in IE from text imprints. Experimental results showed that Otsu’s thresholding with noise elimination performed better than the K-mean clustering method. 86 Hence, the advantages of IE from images are efficiency, less complexity, and less time-consuming but when the image is noisy, one cannot take advantage without noise removal before IE. 87 In this manner, attention mechanism is the latest solution these days which uses encoder and decoder to detect, extract, and recognize the text for images. 88 There is a big room of improvement in these attention mechanism systems for large-scale high-dimensional data sets. Text extraction from images has several difficulties and challenges in terms of detection and identification of text in images. Text in different languages makes this task more challenging. A single unified model to extract text from digital images for all applications is a robust task as there is no single unified model available. 82
Dynamic scene understanding
Contextual and semantic scene understanding are two paradigms in dynamic scene understanding. Hierarchical strategies of scene understanding are top-down, bottom-up, and combined methods, while others are nonhierarchical. 89 In terms of scene understanding, the composition of objects and their surrounding environment plays an important role to extract some useful information from the scene. Top-down and bottom-up processing approaches are used to detect objects and features from the image. Bottom-up approach extracts visual features using the deep conventional neural network. Top-down approach converts detected images into bag-of-words feature space and then combines with visual features. SVM classifiers improve the qualitative accuracy in context understanding between object and natural scene. 90 Closely relevant and important feature extraction is a challenging task in dynamic scene understanding. Type and position of images, scene motion, illumination changes, static and dynamic occlusions, type speed and pose of objects, camera synchronization and handover, event complexity, and handling dynamic scenes are adding more challenges to feature extraction. 89
Semantic and geospatial IE
Some images also contain geotags in metadata to represent a location in a pair of values for latitude and longitude. Low-level visual features and thematic classification methods are not adequate to identify and extract complex objects and their semantic and spatial relationship. Feature extraction, vector quantization, and latent Dirichlet allocation, however, are used for semantic labeling of a large collection of images in a semantic model. K-means and Gaussian mixture model (GMM) clustering have shown 73% classification accuracy for semantic labeling. 91 Structure-free document images can be represented by graphs where nodes represent dynamic semantics and edges as the attributes with spatial information. 92 GPS parameters are used to capture the objects to manage digital images and map databases for a semantic spatial IE system. 93 These parameters, however, have the limitation of nearby objects and require comparative analysis to prove the efficiency and effectiveness of the approach. Spatial features and semantic RE could also be beneficial for the content-based representation of images with the help of human–computer interaction to identify and recognize complex objects. 94
Limitations of image-based IE techniques
A vast array of information can be extracted from images because images contain visual description of entities, events, and relationships. Although images are rich container of information, certain challenges are also associated with IE from images. User-generated content on social media have variations in quality, 72,81,86,87 resolution, 81,82 and information representations. 82 Extracting useful information from these user-generated images is helpful as well as challenging. Data sparsity, 95,96 extracting relevant information from user’s perspective, 76,92,93 semantic understanding, 74,80,89 –91 language understating, object detection, and recognition are major challenges identified in this field. Furthermore, many most critical factors influencing the performance of IE process and techniques from images have been presented in Table 8.
Factors influencing the performance of IE techniques for images.
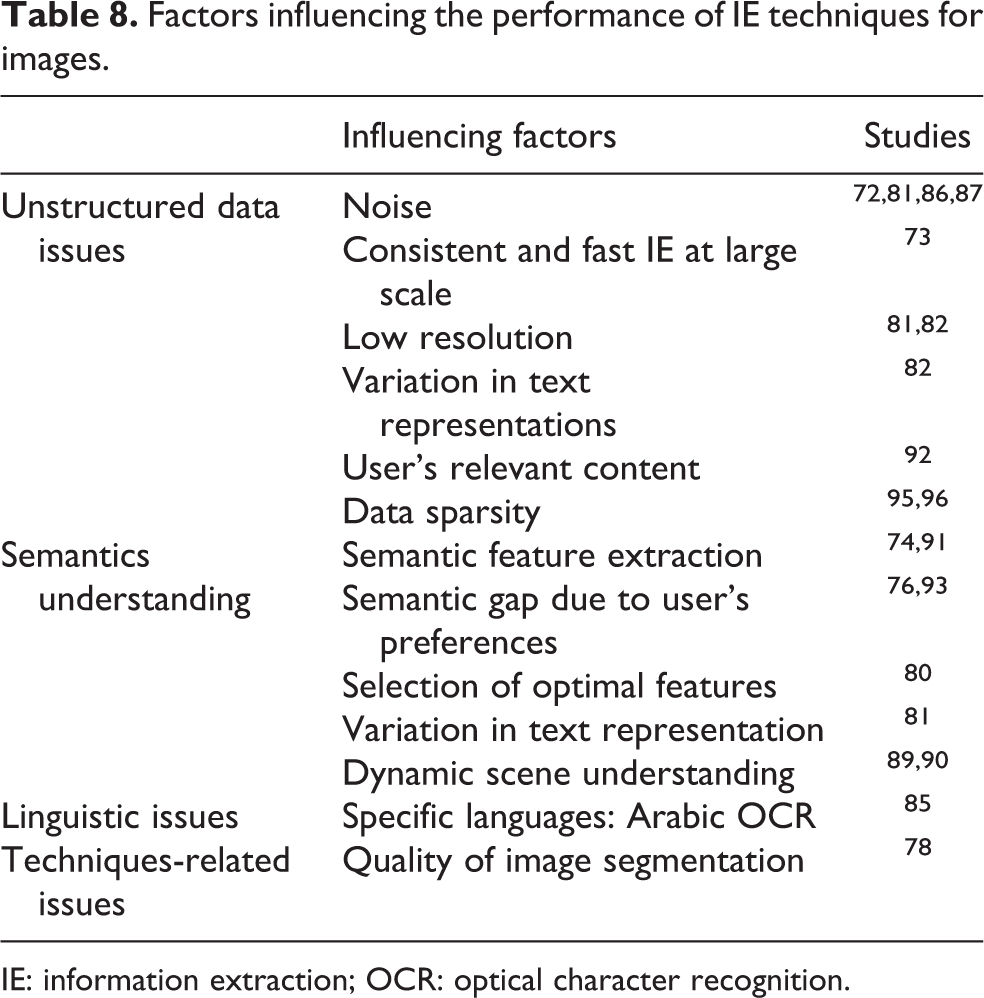
IE: information extraction; OCR: optical character recognition.
Audio content IE techniques
Companies like call centers and music industry are the major sources which generate a huge volume of audio data. Speech recognition is a process to automatically recognize spoken words. Automatic speech recognition (ASR) is mostly used to recognize speech and convert it into any other medium such as text, also known as speech to text conversion. ASR system is based on four types of speeches such as isolated, connected word, continuous, and spontaneous speech. Extraction of speech features, acoustic modeling, and recognition of words are the main steps of this process. For the first task feature extraction, acoustic feature extraction compiles a feature vector and transforms it into a compact vector. Unnecessary and redundant information is removed in this process to extract useful information. Several feature extraction techniques are linear prediction coding, mel frequency cepstral coefficient (MFCC), linear prediction cepstral coefficient, discrete wavelet transform (DWT), wavelet packet decomposition, perceptual linear prediction, and linear discriminant analysis. 97 Metrical structure extraction explicitly extracts rhythm-related information from music using mid-level features instead of using low-level or high-level features with 93% accuracy as compared to baseline methods. Several music applications are using mid-level features for IE such as automatic sequencing, database navigation, mash-up generation, and complement systems. 98
Speech recognition techniques are categorized into five main classes as the acoustic-phonetic approach, a pattern recognition approach, template-based approach, knowledge-based approach, and an artificial intelligence approach. 99 ANN-based approaches are followed in most of the research studies because these approaches can handle complex interactions and are easier to use as compared to statistical methods. A framework for event detection using SVM and neural network approaches has been proposed 100 but it shows only reasonable performance using the combination of these approaches for some events. Sound EE or acoustic EE is an emerging field which aims to process the continuous acoustic signals and convert them into the symbolic description. HMM frameworks have been utilized for ASR for more than 30 years and facilitating speech and language resources of big data. HMM performance is better in modeling the speech signals in ASR, and SVM classification accuracy was higher than others. HMM and SVM hybrid approach could combine the capabilities of both for speech recognition. MFDWC (Mel-Frequency Discrete Wavelet Coefficients) method is also a hybrid approach that combines MFCC techniques and DWT to increase the robustness. 101
Speech fusion and recognition system could be improved through transcription correction for automatic linguistic IE from the Amharic, Hindi, and Tamil sounds using the letter to sound rule. 102 Automatic integrated detection and recognition technique is required to extract information from speech, for the useful analysis of speech, speaker identification, speech, and language recognition. 103 Semantic IE from audio is capable to extract music score and text information through classification and segmentation which are helpful to update and insert music or speech occurrence and analyze arbitrary soundtracks. 104 Recently, the exponential growth of unstructured big data and computational power, ASR is moving toward more advanced and challenging applications such as mobile interaction with voice, voice control in smart systems, and communicative assistance. 105
Limitations of IE techniques for audio content
The field of acoustic IE is facing challenges such as more accurate feature selection, 97,99 classification of nonexclusive sound and content overlapping. 104 Call centers use audio data for analysis and IE in the form of conversations with clients, music, monitoring, and processing of conversations. Background noise, words overlapping, considering one single voice in crowd, and language ambiguities are open challenges in this domain. The critical factors representing limitations of audio-based IE techniques have been presented in Table 9.
Limitations of IE techniques for audio contents.
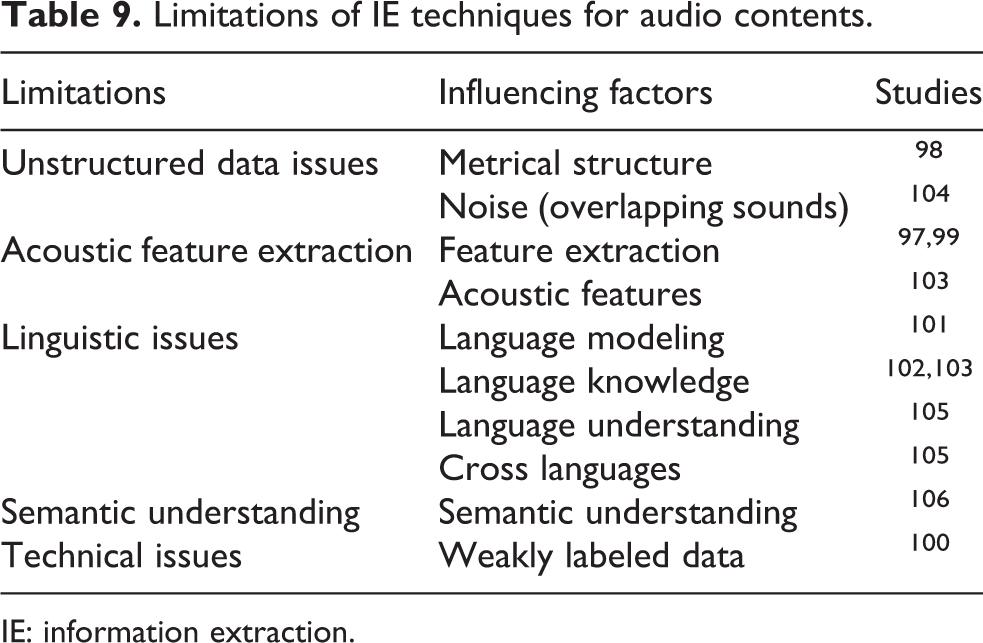
IE: information extraction.
Audiovisual IE—Exploitation of unstructured video content
The massive growth of video content on the Web and social media increases the demand to extract efficient, reliable, and valid information. Video summarization is a process that provides a condensed and concise summary of the video content to facilitate the users. Generally, video summaries are categorized into two groups which are keyframe-based video summarization (static video summarization) and video skimmed-based video summarization (dynamic video summarization). In keyframe video summarization, keyframe information is extracted from a video where frame extraction and feature extraction are the pre-steps. The video is divided into frames in the first step of keyframe extraction. The number of frames depends upon the size of the video. Normally the frame rate varies from 20 to 30 frames per second. Feature extraction is the second step where several visual and audio features are extracted. 107 Visual feature extraction through phonetic and viremic information for audiovisual speech recognition converts speech to text and vice versa. 108 Several methods are used in keyframe video summarization such as video summarization by clustering using Euclidean distance, perceived motion energy model, visual frame descriptor, motion attention model, multiple visual descriptor features, motion focusing, camera motion, and object motion. These methods are categorized based on semantic features and visual descriptors. As compared to static video summarization, skimmed-based summarization supports object recognition and its representativeness summarizes the video by replacing the original content. 109 Video skimming segments the video into smaller parts with a short duration like a movie trailer. The classification according to the static summary, dynamic summary, fixed camera, with and without knowledge about content provides information about the content. However, the selection of a method for video summarization depends on its application. 110
Generally, the content extraction is divided into perceptual and semantic content extraction. Perceptual content includes attribute like color, intensity, and so on, whereas semantic content includes visual objects, events, their relationships, and so on. 111 To overcome the semantic gap between visual appearance and semantics, spatial and temporal association between objects and events, respectively, are identified using fuzzy ontology and rule-based model. 112 The proposed system achieved high precision but relatively low recall. Similarly, EE from audiovisual content consisting of CNN-based audiovisual multimodal recognition was developed and incorporated knowledge from a website using HHMM (Hierarchical Hidden Markov Model) was used to improve the efficiency. The proposed approach outperformed in terms of accuracy and concluded that CNN provides noise and occlusion robustness. 113
IE from a video is the most complex task because it involves audio and video data and their synchronization. A video summarization system with face recognition is designed which decomposes facial areas using nonnegative matrix factorization and the coefficient for classification using SVM with the GMM-SVM approach, used for speaker identification. 114 This approach gives efficient results but performs better for one target like either face or voice. Different quality parameters have been used in temporal IE for each frame and two consecutive frames, to assess the quality of the video, 115 but it is limited to the video where scenes do not change frequently. Useful IE from dramatic video comprises of three modules such as face processing (face detection and recognition in the video), interaction score computing (based on interaction graphs and phonogram), and scenario IE (includes main character identification, video clip extraction for the selected characters, and visual graph construction). 116 Automatic subtitle generation is a process to facilitate users to understand the content of video more easily. This process includes sound extraction, ASR, and text synchronization with video. 117
Limitations of IE techniques for video content
In the age of big data, digital videos are spreading all over the Internet at very high speed. It is not only about the size but also requires high processing power to extract useful information from this huge deluge of video data. These fast processing systems are essential for applications like crime investigation. In this regard, an extensible video processing framework was designed using Apache Hadoop to distribute processing tasks in cloud environment. 118 FFmpeg was employed for video coder and OpenCV was used for image processing followed by MapReduce implementation. In result, the system had shown 75% scalability. Although, the system had not shown high scalability but the findings if the research paved the way for improvements in IE from unstructured video content in big data. Furthermore, language and accent barrier, speech to text and vice versa conversion, 108,113 automatic subtitling and labeling for different languages, 111 and noise elimination 115,119,120 are important challenges to IE from video content. The critical issues for IE from audiovisual content have been identified and presented in Table 10.
Limitations of video-based IE techniques.

IE: information extraction.
Results and discussion
The review presented in this article comprehensively investigates the IE methods for different types of unstructured data such as text, image, audio, and video. It is found that various IE methods have been used in the context of different domains and data types. Accordingly, the IE methods have been classified in the present study based on their main IE application and technique. Figure 4 shows the major classifications of IE methods used for text, images, audio, and video data. Each data type requires different methods and techniques for IE and has associated challenges and problems. The use of different techniques and methods, their varying applications in different domains and different languages have made IE procedures more complicated. It is hard to determine a standard approach for various domains and different formats of the same data type. It is evident from the study that entities, relations, and events extracted from the text use different techniques in different languages and domains. Mainly, the IE techniques on images have been applied to extract features such as color, shape and texture, scene understanding, semantic and geospatial information, character recognition, and text extraction. These techniques include several supervised, unsupervised, semi-supervised, and hybrid methods. ASR and acoustic feature extraction methods are mainly used to extract useful information from auditory data while keyframe-based and skimming-based methods are popular for video summarization for automatic video subtitling and audiovisual features. The complexities of existing IE techniques and lack of a standard technique for various formats of the same data type and domain are among the biggest challenges in IE. The unstructured data analytics and decision-making can be further improved with the help of IE.

Classification of IE techniques. IE: information extraction.
Industries and enterprises are facing challenges in finding the right information at the right time from a huge heap of data. The solution is to identify and introduce new methods to handle these challenges rather than falling back on the “drinking from a fire hose” approach, where a huge volume of unstructured data are generated every day but very less data are analyzed properly. Big data value chain illustrates the high-level activities as a series of steps required to generate value and useful information from big data where IE is concerned with the analysis. It is important to acquire raw data and transform them into useful information, but it is not well explored in literature in the context of IE. In the age of unstructured data deluge, it is necessary to make data understandable and available for analysis. IE is very helpful in this regard, but the need is to develop the advanced IE systems to facilitate analysis and mining process, and to extract useful information from different types of unstructured data. The SLR presented in this article aims to explore the limitations of existing IE techniques and identifying the improvement activities. Tables 7 to 10 present the limitations of IE techniques with respect to each data type and IE subtask, whereas Table 11 summarizes all the common and task-independent critical factors that have significant impact on the IE process due to unstructured big data.
Limitations of IE techniques for multifaceted unstructured big data.

IE: information extraction; ML: machine learning.
The following subsections present the limitations of IE techniques in detail. Furthermore, some preconditions have also been proposed by critically analyzing these limitations for multifaceted unstructured big data.
Limitations of existing IE techniques for unstructured data analytics
Unstructured big data issues
A large number of quality issues have been found in this SLR while extracting information from variety of data types. These issues are categorized as data quality, data sparsity, dimensionality, diversity, and modeling complexity. Among these issues, data sparsity, dimensionality, and diversity are more related to the data quality issues whereas the modeling complexity of unstructured big data is related to extracting and representing the structured information. The following subsections provide detailed discussion on these challenges respectively. Data quality issues: Noise in data creates problems in IE process. Noise elimination method as pre-processing step can improve IE but the selection of appropriate and efficient noise elimination technique for the specific problem is challenging. Unstructured data come with inherited problems of quality and incompleteness
123
that lead to inefficient and poor results from IE. The variety, accuracy, scalability, security, and interactivity are some of the prevalent challenges generated by unstructured data.
124
The problems of unstructured data are a huge barrier in deriving useful information because unstructured data are noisy
125
and dirty (inaccurate, improper, and incomplete).
126
(62) Unstructured data are unverified by nature and face quality issues,
127
scalability and heterogeneity,
128
which make IE more arduous. Advanced data pre-processing techniques before IE are required to handle these quality issues of unstructured data. Standardization of data and processes, efficient tools for data cleaning, and high-level data management are critical challenges that must be addressed to improve the IE systems. Data modeling complexity: Social media and smart sensors are generating a huge volume of unstructured data where streams of data are coming at a very fast rate. To analyze such fast streams of unstructured data requires very efficient IE systems to facilitate data mining and analysis techniques. The major problem for IE systems is to extract structure from unstructured data and its interpretability. High dynamicity of unstructured data as compared to structured data makes IE challenging especially for streaming data. Structural variation, different granularity levels, heterogeneity, and differences in data formats are critical challenges associated with unstructured big data.
123
The complicated heterogeneity of mixed data makes it difficult to analyze and extract useful information. Transformation of unstructured data into useful information is required to design the IE system for unstructured data. Unstructured data are growing very fast and to extract useful information requires to precisely specify the tasks of the IE process with efficient handling of interoperability and context understanding.
129
Unstructured data usability
People and machines are producing data at a very high rate than ever before. The volume and variety of data being produced bring more challenges in identifying useful information from them. 52,53,73 Variety of big data indicated the heterogeneity of data types, different representations, and complex semantic interpretation. Usability and usefulness of unstructured big data are important dimensions for extracting useful information from variety of data types. IE process is community process that highly depends on the consumer requirements. Therefore, it is necessary to understand the user’s requirements and semantics of data to extract most relevant information. Understanding the perspective is an important task where variation in user’s requirements and data representations make it more complex. Understanding and handling the user requirements in IE process would improve the effectiveness of big data analysis as it directly targets the user needs. Semantic 14,21,39,42,45,47,56,106,108,109,113 and context understanding 25,112 of content are important to extract relevant information from data. It will lead to reduce the content gap. Hence, IE systems need improvement to understand the user needs, extracting the relevant data, and interpret the results in semantically and contextually rich manner.
Domain and language issues
It has been identified that language and domain specificity are two huge barriers in extracting useful information. These require highly efficient and specific IE techniques that can handle the complexity of these barriers. The following subsections discuss these limitations in detail. Lack of multilingual systems: The complexity of natural languages is a huge barrier to IE, however, language-independent feature-based IE has been introduced to overcome it. This open multilingual IE tool and machine translation show pretty good results for the English language as compared to other languages.
130
These solutions are still facing language ambiguities issues, lexical and structural gaps, and grammatical issues. In this regard, rich morphological languages like English and Russian show more accurate results. Open nature of vocabulary, abbreviations, disambiguation, and specific dictionaries of domains are major challenges in general IE system for different language-independent features. Domain specificity: What are the steps to extract information from unstructured big data? Which techniques will play an important role in this regard? How to make data easily available for analysis? These are some questions that must be answered. These questions have different answers in different domains. The efficiency of IE techniques is highly dependent on the domain and language of unstructured text. In this regard, text in the clinical domain is different from business or other domain’s text. IE from clinical text is semantically and syntactically more challenging as compared to other fields due to highly ambiguous abbreviations and acronyms. Medical terms and entities are different from other domains that make open nature of vocabulary, abbreviations, disambiguation as serious issues that need to be considered. So, IE system for the medical domain would not provide efficient and effective results for other domains.
8
Domain-independent solution for IE systems is one of the biggest challenging tasks
Capability issues
Variety of techniques for IE subtasks of each data types have been discussed in this article. These techniques can be categorized into two major IE approaches, that is, rule-based approaches and machine learning-based approaches. Hybrid of these two have also been discussed in this review. Rule-based approaches use rule languages like UIMA Ruta and dominating in industry whereas advanced learning-based approaches like distant supervision and reinforcement learning have the capabilities to overcome the limitations of traditional learning-based approaches in terms of unstructured big data. In short, rule-based and learning-based approaches in IE have their own potentials and limitations. But unstructured big data bring more challenges to these techniques such as scalability, automatic semantic labeling, selection of appropriate techniques for the task and requirements of user, data annotation.
25,30,34,35,57,100,111
Hence, the emergence of advanced learning-based approaches with rule-based will improve the performance of IE systems for the huge volume and variety of big data. Optimal feature extraction and selection: Feature extraction and transformation from unstructured data are more critical for data analysis as compared to structured data due to the heterogeneity and multidimensionality of unstructured documents. Features like bag-of-words, orthographic features, lexical features, and gazetteer-related features can be extracted from the text for learning-based approaches
130
that improves the data analysis process. In this regard, a hybrid feature transformation technique based on iterative classification with feature weighing has been proposed for multiple domains.
131
Although feature transformation from heterogeneous unstructured data was achieved, a minimal loss of precision was observed. Feature extraction and transformation need advanced data preparation techniques. These techniques will help to improve the pre-processing and feature extraction tasks of heterogeneous, diverse, and multidimensional unstructured data. IE from unstructured clinical notes that contains inconsistent abbreviations and lack of structure can be achieved using matrix factorization, and multi-view learning technique in pre-processing and data modeling to handle the heterogeneous data.
132
While extracting features and pre-processing unstructured content, interpretability is an open quality dimension that should be considered.
133
Selecting the most relevant features from unstructured big data is a challenging task
134
that can be achieved with the help of well-defined IE systems to improve the unstructured big data analysis. Selection of technique: Many significant challenges are associated with a variety of data in terms of IE. Most importantly, data are not available in the form ready for analysis, they have to be transformed and prepared for analysis. Rather we need to identify the right IE process to pull out the required useful information from heterogeneous sources. The accuracy of the selection is a continuous challenge. Unstructured big data are not only available in the form of text, but they also include images, audio, video, animations, sequence data, and many other forms. In this scenario, IE technique selection is subjective toward its application. It is notable here that the extraction method would be different for ECG and satellite image used for forecasting. It has been observed that IE from unstructured big data faces challenges like high dimensionality, complexity in relations identification, dynamic structures, heterogeneous distribution, and scalability. Hence, advanced IE systems, to handle a variety of data types, are the ultimate need to improve the efficacy of unstructured data analysis. Volume of unstructured big data: Extracting the useful information from huge volume of data is making IE task more complex.
52,53,73
The existing techniques are inadequate to handle this huge volume of data in terms of time and cost efficiency. Parallel computing and distribution using advanced tools like Apache Hadoop and Spark have capabilities to increase the time efficiency and accuracy.
118
Therefore, more advanced techniques are required to handle the volume of unstructured big data efficiently.
Preconditions to improve unstructured big data analytics
For big data analytics, several IE approaches can be used such as statistical, machine learning, and rule-based, but interpretability, simplicity, accuracy, speed, and scalability are important characteristics that should be considered while selecting an appropriate approach for the solution. 135 Heterogeneity, scale, timeliness, complexity, and privacy are important challenges of big data analysis pipeline 128 where heterogeneity, timeliness, and complexity are more relevant to the IE from unstructured big data. Accuracy, coverage, and scalability are challenges to big data IE, whereby, accuracy and coverage are particular to IE and scalability is related to big data. 136 The following preconditions have been proposed to improve the efficiency of unstructured data analysis.
Precondition 1: Advanced data pre-processing
Advanced data pre-processing techniques before IE are required to handle the quality issues of unstructured big data like data dimensionality, diversity, sparsity, and noise. Standardization of data and processes, efficient tools for data cleaning, high-level data management, and context-aware transformation of unstructured data are important issues that must be addressed to improve the IE systems. More advanced and adaptive data pre-processing techniques are required to overcome the limitations of IE systems for unstructured big data.
Precondition 2: IE should meet pragmatics
Pragmatic IE is related to the usefulness and usability of data. This will help to identify various dimensions of unstructured data to solve the problem at hand. As most of the IE systems are task and domain-dependent but still pragmatic IE from unstructured big data is an open issue due to the volume and variety challenges of big data. In this regard, identification of pragmatic characteristics according to the type of data and problem is hard to achieve for unstructured big data. The emergence of pragmatics with semantics in IE systems will ultimately improve the efficiency of unstructured data analysis, although it is one of the critical challenges for IE from unstructured big data. Big data analysis using IE systems is based on NLP, language modeling, and structure extraction method. These systems are facing challenges that are already discussed in the previous section. Extracting the contextually relevant information will lead to improved unstructured data analysis. Although extracting contextually relevant information is not easy for unstructured big data due to quality, heterogeneity and dimensionality issues. Contextually and semantically enriched IE systems are the ultimate requirement for improved unstructured data analytics.
Precondition 3: Advance cross and multilingual systems
Advanced algorithms and solutions are required to increase the efficiency of IE systems as these systems belongs to NLP. NLP brings language complexity, ambiguities, language modeling, and understanding issues to IE systems. Meanwhile, domain-specific terms or images also require domain-specific solutions. With the limitations of language and domain specificity, new multilingual systems with reduced domain specificity can reduce the limitations of existing IE techniques.
Precondition 4: Advanced hybrid IE techniques
IE from big data is a complex process due to a large amount of variety of data. It performs an important role in the big data analysis pipeline. In this regard, a detailed discussion on IE approaches has been carried out to identify the current status and challenges. It has been concluded that hybrid approaches are performing more efficiently as these approaches can take more advantages from IE techniques by considering the cost and benefit measures. However, computational cost, accuracy, and scalability are important key factors for large-scale data IE. 137 It has been observed that deep neural networks RNN, CNN are performing better in IE field with certain limitations. However, taking advantage of both approaches (rule-based and machine learning-based) as hybrid or emerged approaches to mitigate the limitations of individuals can make IE systems more reliable and accurate. Specifically for unstructured big data, parallel and distributed computing, using Apache Hadoop and Spark, can be incorporated with these techniques that has a big room of improvement in IE from unstructured big data.
Proposed IE process improvement model for multifaceted unstructured big data
The outcome of this literature review proposed a model to overcome the limitations of existing IE techniques as depicted in Figure 5. The identified challenges of IE from unstructured big data, as presented in Table 11, and corresponding preconditions that would help to improve the IE process are followed in the proposed model to improve the IE process in big data environment.

IE process improvement model for multifaceted unstructured big data. IE: information extraction.
Conclusion
The exponential growth of multifaceted unstructured big data is creating challenges in context-aware analytics, data-driven decision-making, and data management. IE techniques are important to extract useful information from unstructured data that improve the effectiveness of data analytics. In this regard, a structured review was conducted to investigate the limitations of existing IE techniques for unstructured big data analysis. For this reason, state-of-the-art IE subtasks and their techniques from different types of data (text, images, audio, and video) have been discussed briefly. This review also investigated the effectiveness of existing IE techniques for unstructured big data. It has been observed that variety of big data is creating numerous challenges for traditional IE systems in terms of accuracy, scalability, generalizability, and usability which leads us to a new era of advanced IE approaches with new opportunities and challenges. It has also been concluded that hybrid approaches (i.e. combination of learning-based and rule-based) achieved better performance in IE whereas the quality of data has a significant impact on the effectiveness of results. However, many challenges are still associated with these hybrid approaches such as language barriers, domain issues, and appropriate method selection for the task at hand. These challenges are specific to IE process but scalability, quality, heterogeneity, and interoperability are critical factors associated with IE from unstructured big data. To overcome the limitations of existing IE techniques, more advanced and adaptive pre-processing techniques are required to remove the quality and usability issues. Further, some suggestions have also been provided in this review by critically analyzing the literature and limitations of existing solutions. Our analysis finds that there is a significant potential to improve the analysis process in terms of context-aware analytics systems. Advanced techniques and methods for IE systems, particularly for multifaceted unstructured big data sets, are the utmost requirement. Existing approaches and methods do not apply to all domains and varying types of data, even in a single data type. There is a need to develop new techniques and refine existing techniques for pre-processing stage of data that can help to significantly reduce the problems in data sets, later used for IE, knowledge discovery, and decision-making.
Limitations of the study
The SLR investigates the existing IE techniques and presents the limitations of these techniques for multifaceted unstructured big data. Various recognized data sources have been explored during the study, however, sparsity of literature on this topic and different data types, data formats, and standards made the identification and selection of articles very time-consuming and tedious. Limited but prominent literature could be selected and it restricted the investigations to the limitations of the IE techniques. It was really hard to find the right article and techniques whereby several works have presented many techniques in context of data quality, data extraction, data transformation, and information retrieval. However, it has been managed by careful and proper selection of the articles meeting the inclusion and exclusion criteria.
Future work
The existing literature presents the techniques and methods for IE from unstructured big data but does not present any model or framework to improve the IE procedures. It is also needed to present a very structured approach and devise methods for specific data types rather than presenting general techniques. Developing a theoretical model based on the comparative analysis of existing techniques (similarities and differences), defining rules for data extraction and transformation is a potential research problem to address the data quality improvement issues.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.