
Abstract
Social media analytics tool aims at eliciting information and knowledge about individuals and communities, as this emerges from the dynamics of interpersonal communications in the social networks. Sentiment analysis (SA) is a core component of this process as it focuses onto the subjective levels of this knowledge, including the agreement/rejection, the perception, and the expectations by which individual users socially evolve in the network. Analyzing user sentiments thus corresponds to recognize subjective opinions and preferences in the texts they produce in social contexts, gather collective evidence across one or more communities, and trace some inferences about the underlying social phenomena. Automatic SA is a complex process, often enabled by hand-coded dictionaries, called polarity lexicons, that are intended to capture the a priori emotional aspects of words or multiword expressions. The development of such resources is an expensive, and, mainly, language and task-dependent process. Resulting polarity lexicons may be inadequate at fully covering Social Media phenomena, which are intended to capture global communities. In the area of SA over Social Media, this article presents an unsupervised and language independent method for inducing large-scale polarity lexicons from a specific but representative medium, that is, Twitter. The model is based on a novel use of Distributional Lexical Semantics methodologies as these are applied to Twitter. Given a set of heuristically annotated messages, the proposed methodology transfers the known sentiment information of subjective sentences to individual words. The resulting lexical resource is a large-scale polarity lexicon whose effectiveness is measured with respect to different SA tasks in English, Italian, and Arabic. Comparison of our method with different Distributional Lexical Semantics paradigms confirms the beneficial impact of our method in the design of very accurate SA systems in several natural languages.
Keywords
Motivations
Social and collaborative networks interest more and more the professional, social, as well as public sphere, whereas individual’s communication practices are allowed to spread across local and global communities. Notice that this is at the basis of the huge increase in the availability of large-scale Web data sets that specifically emerge and characterize, at the same time, large-scale communities on the Social Media. Although this opens the way to novel professional collaborative practices, it is also a crucial amplifying factor for the complexity of the underlying network structures, fostering new research opportunities.
One major challenge in modern social network analysis is the pervasive role played by unstructured data that characterize the nature and content of the interactions. In general, modeling precise predictions in complex networks always rely on strong abstractions about the interactions observable among individuals (i.e. nodes of the network). Binary links among nodes are a precise mathematical notion able to support dynamic models about a variety of network phenomena, such as the emergence of independent communities or the spreading of information across the networks. However, social networks, such as Web communities or Interest groups, are not artificial ones but are made of people and thus they are much more complex. The nature and depth of the interactions among members of the network live in a variety of semantic dimensions characterized by the content of the exchanged messages. Although messages are mainly textual, their content is not explicit and machine-readable in some standard formalism. If no account is provided for the content of individual messages, any analysis about their interactions and the way these influence the entire network remain too vague or even arbitrary.
For this reason, a variety of current studies concentrate on the ways linguistic content propagates across social networks and how this can be studied to capture and reuse dynamic core network properties for a variety of predictive tasks. 1 –5 These include detecting and predicting habits, trends, and expectations within the social socioeconomic systems emerging from the Web. 6 As trends, preferences, and expectations emerge from the subjective perceptions of members of a social network, the analysis of produced text for the recognition of phenomena inside this subjective sphere, including sentiments and emotions, is a strictly necessary activity.
Opinion mining (OM) 7 specifically focuses on such dimension. It aims at tracking the opinions expressed in texts with respect to specific topics, for example, products or people. In particular, sentiment analysis (SA) deals with the problem of deciding whether a portion of text, for example, a sentence or a phrase, is expressing a polarity trend toward specific feeling. It is clear that OM and SA have a huge impact over the user-generated contents that are typical in blogs and microblogs.
Opinionated lexicons and their social dynamics
In SA, polarity lexicons are special purpose dictionaries, listing positively and negatively polarized words that help in characterizing the text where they appear with respect to the attitude of the writer. They are defined to support the development of automatic systems that match terms or phrases in the incoming texts to decide the polarity of the overall text. 8,9 In these resources, entries are associated with their prior polarity, that is, whether their uses tend to evoke a positive or negative sentiment. For example, “good” can be associated with a prior positive sentiment in contrast to “sad,” considered negative in every domain. These lexicons are often hand-compiled, as by Stone et al. 10 or by Hu and Liu, 11 and they reflect the polarity of individual words outside the contexts in which they tend to occur. However, from a linguistic point of view, a priori membership of words to polarity classes can be considered too restrictive, as sentiment expressions are often context-dependent, for example, the occurrences of the word mouse are mostly neutral in the consumer electronics domain, as an example consider the review “Whether you’re blowing chunks out of opponents or demolishing those TPS reports, it’s essential that you have the right mouse under your hand,” while it can be negatively biased in a restaurant domain, as an example consider the portion of a restaurant review “Did he want extra cheese? Horrifying moment passerby snaps mouse dining on crumbs at Pizza Hut restaurant hours before it opened.” Accounting for topic-specific phenomena would require manual revisions of the lexicon. Moreover, these resources exist for English, but they are less common in other languages: compiling a lexicon for a new language represents a very expensive process.
The complexity and costs associated with the development of annotated resources are not trivial for inductive approaches to SA. In line with other natural language semantic tasks, semisupervised approaches can be applied to integrate unsupervised (such as distributional analysis of large text collections) and supervised processes (e.g. support vector machine (SVM)) in order to increase applicability and reduce costs. This integration shows performances comparable with purely supervised algorithms with much smaller training data sets. Examples are lexical generalization as promoted by the distributional models 12 (DMs) or distant supervision as applied in the study by Mintz et al. 13 for relation extraction.
In this article, we promote a semisupervised perspective to SA in Social Media, by applying an unsupervised process for the acquisition of sentiment lexicons. These can be then adopted within supervised language learning systems in order to leverage on prior polarity information of individual words.
The proposed approach is based on DMs of lexical semantics. These allow to represent both words and sentences into high-dimensional geometrical spaces where it is possible to approximate a sort of semantic equivalence between them. As an example, in the technique known as latent semantic analysis (LSA), introduced by Landauer and Dumais, 12 words and texts can be represented into the same geometrical space, the so-called dual space.
As entire sentences can be clearly related to a given polarity, a classifier can always be trained in the document/term spaces and used to transfer sentiment information from sentences to words. Specifically, a polarity classifier is trained by observing sentences and it is used to classify words to populate the polarity lexicon. Annotated messages are derived from Twitter (http://www.twitter.com) and their polarity is determined by simple heuristics. It means that words in specific domains can be related to sentiment classes by looking at their semantic closeness to emotionally biased sentences. The resulting approach is highly applicable, as the DM can be acquired without any supervision, and the provided heuristics do not have any bias with respect to languages or domains. The above methodology enables the acquisition of a polarity lexicon almost in any language and in any domain with a limited human effort.
In this work, we demonstrate the effectiveness and generality of our methodology by acquiring polarity lexicon in multiple languages, that is, English, Italian, and Arabic. Moreover, we will provide an extensive analysis aiming at verifying whether different distributional methods, such as LSA, 12 word spaces (WSs), 14 and neural word embeddings, 15 can capture different aspects of the polarity of individual words. We will provide evaluations over data sets coming from largely participated international benchmarks, such as the Association for Computational Linguistics SA in Twitter challenges. SemEval 16,17 data sets will be adopted or in English. The Evalita (http://www.evalita.it) Sentipolc 18 data will be adopted for the Italian language polarity lexicon. Finally, the Arabic language polarity lexicon will be measured against the recently released Arabic Sentiment Twitter (AST) data set. 19
In the rest of this article, related works are discussed in section “Related work.” Section “Polarity lexicon generation through distributional approaches” presents the proposed methodology, while section “Polarity lexicons acquisition” describes the experimental evaluations. Finally, conclusions and future works are discussed in section “Conclusions.”
Related work
Polarity lexicons have been seen as fundamental resources both for the manual inspection of lexical and sentiment phenomena and for the acquisition of statistical sentiment and emotional models. Their appearance can be dated back to the 60s with the work of Stone et al. 10 It is worth noting that during the decades, a plethora of techniques has been developed by the researchers to compile such lexicons. We can point out three main methodologies and areas for the acquisition of polarity lexicons, that is, manually annotated lexicons, lexicons acquired over graphs, and corpus-based lexicons. The three areas can be thought of three different basic methodologies, where, on the one hand, the aim is to automatize as much as possible the process of lexicon acquisition; on the other hand, the aim is to exploit different semantic/sentiment information between words (as for example, relationships in graphs or co-occurrences) to improve the lexicon quality. In the following, the main works in these three areas are pointed out.
Manually annotated lexicons
Earlier works are based on manual annotations of terms with respect to emotional categories. For example, in the study by Stone et al., 10 sentiment labels are manually associated with 3600 English terms. In the study by Hu and Liu, 11 a list of positive and negative words is manually extracted from customer reviews. The MPQA Subjectivity Lexicon (SBJ) 9 contains words, each with its prior polarity (positive or negative) and discrete strength (strong or weak). The National Research Council Canada Emotion Lexicon 20 is composed of frequent English nouns, verbs, adjectives, and adverbs annotated through Amazon Mechanical Turk with respect to eight emotions (e.g. joy, sadness, trust) and sentiment. However, the manual development and maintenance of lexicons may be expensive, and coverage issues can arise.
Lexicons acquired over graphs
Graph-based approaches exploit an underlying semantic structure that can be built upon words. In the study by Esuli and Sebastiani, 21 the WordNet 22 synset glosses are exploited to derive three scores describing the positivity, negativity, and neutrality of the synsets through a PageRank-style algorithm. The work of Rao and Ravichandran 23 generates a lexicon through a graph label propagation process. Each node in the graph represents a word. Each weighted edge encodes a relation between words derived from WordNet. 22 The graph is constructed starting from a set of manually defined seeds. The polarity for the other words is determined by exploiting graph-based methods.
Corpus-based lexicons
Statistics-based approaches are more general as they mainly exploit corpus processing techniques. For example, Turney and Littman 8 proposed a minimally supervised approach to associate a polarity tendency with a word by determining whether it co-occurs more with positive words than negative ones. More recently, Zhang and Singh 24 proposed a semisupervised framework for generating a domain-specific sentiment lexicon. Their system is initialized with a small set of labeled reviews, from which segments whose polarity is known are extracted. It exploits the relationships between consecutive segments to automatically generate a domain-specific sentiment lexicon. In the study by Kiritchenko et al., 25 a minimally supervised approach based on Social Media data is proposed by exploiting emotion evoking words, such as hashtags or emoticons, that are related to positivity and negativity, for example, #happy, #sad, ☺, or ☹. They compute a score, reflecting the polarity of a target word, through a point-wise mutual information-based measure between the target and the words evoking emotions. In the study by Saif et al., 26 word contexts are adopted to generate sentiment orientation for words. In particular, the sentiment of context words, available in an already built lexicon, is shown to contribute in deriving the sentiment orientation of a target word. As a result, the so-called SentiCircle is derived for each target word by considering the contexts in which they appear. Among their advantages, corpus-driven methods are appealing for the acquisition of sentiment lexicons as they can be applied to input texts even when no sense disambiguation has been (or can be) applied: in this case, polarity is an emerging property of all lexical items in a text and coverage is a major concern. The approach here presented can be seen as more general, as it does not rely on any existing lexicon, but it could be used to build a SentiCircle.
Polarity lexicon generation through distributional approaches
In order to rely on comparable representations for words and sentences to transfer sentiment information from the former to the latter, DMs of lexical semantics are exploited. DMs are intended to express semantic relationships between lexical entries, mainly by looking at the words usage. The foundation for these models is the Distributional Hypothesis, 27 that is, words that are used and occur in the same “contexts” tend to have similar meanings. A context is here a set of words that appear in the neighborhood of a target word of interest. In this sense, if two words share many contexts, then they can be considered somehow similar. Although different ways for modeling the semantics of words exist, they all derive vector representations for words from more or less complex processing stages of large-scale text collections.
This kind of approaches is effective as it enables the estimation of semantic relationships in terms of vector similarity. From a linguistic perspective, such vectors allow to geometrically model some aspects of lexical semantics and to provide a useful way to represent this information in a machine-readable format. Distributional methods can model different semantic relationships, for example, topical similarities (if vectors are built considering the occurrence of a word in documents) or paradigmatic similarities (if vectors are built considering the occurrence of a word in the context of another word 14 ). In such models, words like run and walk are close in the space, while run and read are projected in different subspaces. Here, we concentrate on DMs that are mainly adopted to model paradigmatic relationships, as we are more interested in capturing phenomena of synonymy, that is, when two words can be substituted in a sentence without significantly changing its meaning.
Word representations for lexical semantics
Two main families for the acquisition of distributional representations can be pointed out: count-based methods, where the co-occurrences between words are considered 14 and prediction-based approaches, where word representations are acquired through a supervised learning setting and correspond to distributions useful to trigger lexical prediction tasks (e.g. lexical substitution). Notice that a word here should be considered as a generic term that can potentially indicate a simple token, a stem, or a lemma. In this article, we will preprocess a text to extract morphological and grammatical information, and target words here correspond to (lemma, part of speech (pos)) pairs. In both approaches, the distributional hypothesis is exploited but with different methodologies. In this section, we briefly review the LSA 12 model and the Skip-gram model. 15 Leaving aside the computational aspects, these semantic spaces give rise to word representations that have been used traditionally in learning algorithms to reduce data sparseness and to obtain better generalization capability of the learned functions. 28 –31 An in-depth comparison of these methods is discussed in the work of Baroni et al. 32
Counting co-occurrences: The LSA approach
In a word-based count co-occurrence model, contexts correspond to all words appearing in an n-position window to the left and to the right of a target word. In the sentence,
Counting methods depend on the occurrence of words in documents
Predicting words through vector representations: The Skip-gram model
Prediction-based word vectors have been recently proposed, as an alternative to count-based methods. 32 They mostly rely on the development of more or less complex neural networks, whose aim is to learn a language model. 34 These methods have been successfully applied to different problems according to the renewed interests around the neural networks inspired by the deep learning methodology. In the study by Mikolov et al., 15 a very efficient model is proposed for deriving these representations, which are able to capture both syntactic and semantic properties. 15 Two main neural network architectures are discussed by Mikolov et al., 15 the Contextual Bag of Word (BoW) and the Skip-gram models. The former models the relationship between a context (input of the network) and its target word (output of the network): In other words, given a representation of all words in a given window around a target position (the context), the network predicts the best target word t. In this way, the vectors of words w cooperate to estimate the most likely word t.
In this article, we will adopt the Skip-gram model defined in the same work.
15
It models the inverse task, as it tries to predict the context

where c is the context size, wt+j is a word in the context of wt, and the probability in the log term is computed through a softmax function. Equation (1) is thus optimized during training through backpropagation, and an efficient formulation is obtained by applying hierarchical softmax and negative sampling. 15
Acquiring polarity lexicons in word networks within distributional spaces
Despite the specific algorithm used for the acquisition of the vectors underlying the WS, all the above approaches allow to derive a projection function Φ(⋅) for a (target) word from a dictionary into a metric space. The d-dimensional vector representation for a generic word

A word graph generated in the neighborhood of the word adequate, that is, a positive polarity word. As emerge from the network, several other words with opposite polarity (such as insufficient::j or inadequate::j) are generally near to adequate::j in the WS, according to the similarity measure, such as the cosine similarity (reported in brackets). Notice how several neutral words are also present, such as necessary::j or minimal::j. WS: word space.
However, as a large set of documents and words represented in the same space is available, we can try to detect specific subspaces where polarity is preserved. The final aim is to leverage on the DMs because of their ability to represent both sentences and words in the same space. In other words, we can hope to establish arcs between words only if these lie in subspaces where polarity is homogeneous. In the following, we discuss how observable sentence polarity is carrier of useful information about such subspaces: these can be expected to preserve word and sentence polarity as well. When transferred to single words, polarity information will help in confirming or rejecting high similarity arcs connecting opposite polarity words and adjust misleading similarities.
Lexicon generation through classification
The semantic similarity (that is the closeness between words, as established in the originating DM space) does not completely reflect emotional similarity. Sentiment or emotional differences between words must be captured into representations that are able to coherently express the underlying sentiment. In this perspective, we promote to acquire a discriminant function using DM-based representations as a source. Let us consider a space ℝ
d
where a given geometrical representation for a possibly large set of annotated examples can be derived. In general, a discriminative linear classifier can be seen as a separating hyperplane θ ∈ ℝ
d
used to classify new examples from the same space into distinct classes. Notice that the parameters of θ, in particular the individual components θi, correspond to a specific ith dimension, that is, feature, whose numerical value (the weight) depends on the annotated examples. In a classification setting, the magnitude of each θi reflects the importance of the feature i with respect to a target phenomenon, that is, the target classes to which instances in the space should be assigned. In this sense, when applied to Distributional Lexical Semantic vectors, a linear classifier is expected to learn selectively the dimensions (i.e. regions of the space ℝ
d
) useful to discriminate examples with respect to the individual target classes (in our case, the sentiment categories such as positive, negative, and neutral). Classes reflecting the sentiment expressed by words should be mapped by one such classifier into those subspaces better modeling the associations of source examples with sentiment classes. In this perspective, training examples could be gathered as any set of words
Unfortunately, a number of limitations affects this view. First, the definition and annotation of seed words could be expensive and certainly not portable across natural languages. Second, lexical items do change emotional flavor across domains, and the knowledge embodied by the seed lexicons may not generalize when different domains are faced. Notice that selecting lexical seeds is not the only possible solution for training a polarity lexicon classifier as the nature of DMs can be emphasized. The vector representations of sentences and words lie in the same distributional space, where closeness can be established between sentences, texts, as well as individual words. In this perspective, entire sentences can be seemingly adopted as source of evidences for the training of the classifier: notice how these sentences embody a specific sentiment in a more explicit (and unambiguous) manner than words. For example, sentences including strong sentiment markers can be gathered in a rather cheap manner, thus providing a large-scale seed resource. The training of the classifier over sentences and the availability of similarity metrics among sentences and words allow to transfer the polarity from a limited pool of sentences to large-scale lexicons. The training process detects the regions of the space that are strongly related to specific sentiment classes, and the resulting classifier can be used to emphasize them across the lexicon.
In more detail, we have words

It is one of the simpler, but still expressive, methods that is used to derive a representation that accounts for the underlying meaning of a sentence, as discussed by Landauer and Dumais.
12
Having projected an entire sentence in the space, we can find all the dimensions of the space that are related to a sentiment class. Sentence representations are fed to a linear learning algorithm that induces the discriminant function f expected to capture the sentiment-related subspaces by properly weighting each dimension i of the original space. The lexicon is finally generated by applying f to the entire

As a consequence, each word wk can be represented by two distinct representations. One vector expresses its distributional (semantic) properties, that is,
Regarding the second vector, such representation is different with respect to other works concerning the definition of polarity lexicons where, for example, polarity is represented with one numeric value: In the study by Kiritchenko et al., 25 the polarity of a word is represented with a real number ranging between [−1, 1]: −1 indicates strong negativity, 1 indicates strong positivity, and the values in between define the shades of the polarity (with 0 indicating neutrality). In this work, we adopted a three-dimensional representation, where each value indicates the degree with respect to a polarity dimension. We believe that such apparently redundant representation is more appropriate to express the polarity of words whose contribution depends on their context: As an example, the adjective high when modifying a noun such as cost suggests a negative polarity, while this turns to positive when modifying the noun performance. Our approach would express this case through three values, for example, 0.4 for positivity, 0.4 for negativity, and 0.2 for neutrality, meaning that this word can express both polarities. On the contrary, a singly score risks to mislead such case with a neutral word.
Generating a training data set through emoticons
An annotated data set of sentences
Polarity lexicons acquisition
In this section, details about the acquisition of polarity lexicons are provided, and different SA tasks in three different languages are evaluated with these resources to prove the effectiveness of the proposed methodology, depicted in Figure 2.
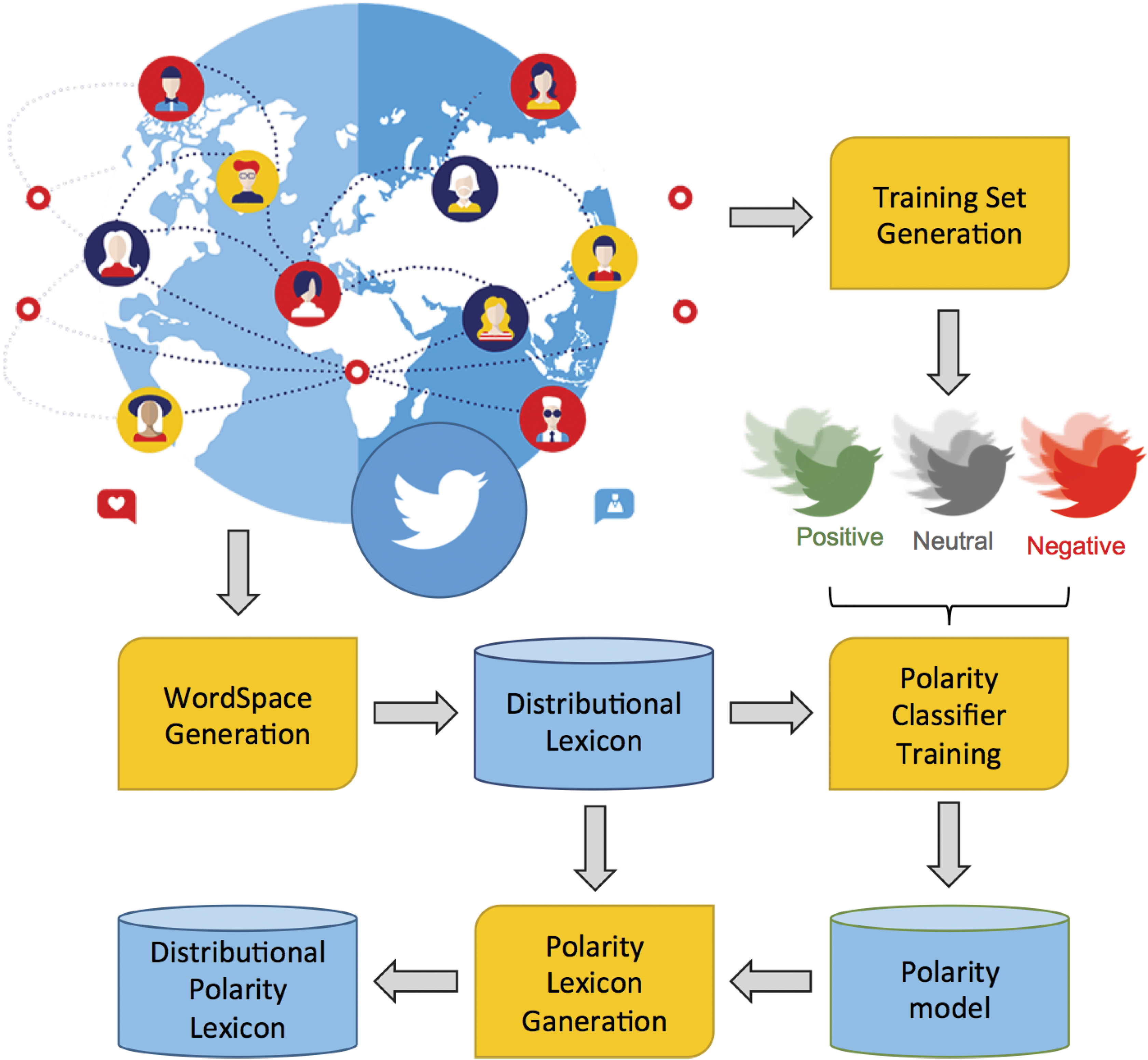
The architecture of the DPL acquisition process. DPL: Distributional Polarity Lexicon.
WS generation
As discussed in section “Lexicon generation through classification,” distributional representations for words are needed for the acquisition of a Distributional Polarity Lexicon (DPL). In the WS generation stage, a Skip-gram model 15 (described in section “Predicting words through vector representations: The Skip-gram model”) is applied to an incoming large-scale collection of unannotated tweets. The word2vec (https://code.google.com/p/word2vec/) tool is adopted to acquire the WS according to the Skip-gram model and 250-dimensional vectors are derived for the majority of words appearing in a corpus (in particular, the following settings are adopted: min-count=50, window=5, iter=10 and negative=10) in the so-called Distributional Lexicon.
Training set generation
A set of annotated tweet is derived in this stage by applying the heuristics described in section “Lexicon generation through classification” to large-scale tweet collections. In particular, we select positive, neutral, and negative messages through the use of emoticons and URLs. The original tweet collection can be the same used for the WS generation or originating from different collections.
Polarity classifier training
SVMs
37
are among the most effective classifiers applied in many different fields. In Natural Language Processing, they have been used for their capability to learn both linear and nonlinear functions (by exploiting the notion of kernel function
38
). In this stage, a linear polarity classification function (called Polarity Model) is acquired to partition streams of tweets in three sentiment classes of interest: positive, neutral, and negative tweets. We adopted the LibLinear
39
formulation of SVM that can be found in KeLP (http://www.kelp-ml.org)
40
to learn the resulting Polarity Model: it corresponds to three real-valued functions that output the independent confidence scores for the three classes. Each sentence in the training set
Polarity lexicon generation
The three acquired classifiers are then used to compile the DPL: each word from the Distributional Lexicon is classified through the Polarity Model and the resulting three polarity scores are normalized into lexical three-dimensional vectors, as described in section “Lexicon generation through classification.” A synthetic view of the process is described in Algorithm 1.
The algorithm of the Distributional Polarity Lexicon generation process.

Measuring the impact of the DPL
In recent years, the interest in mining the sentiment expressed in the Web is growing, and different Twitter-based international benchmarking campaigns have been proposed in the computational linguistics area. We want to verify whether the polarity lexicon acquisition approach proposed in the previous sections is actually beneficial to the achievable quality on a Twitter-based SA task. Moreover, we aim at showing that the approach is language independent, in the sense that the strength of its benefits does not depend on the involved natural language.
For this reason, we will evaluate automatically generated DPLs against tasks related to different benchmarking campaigns, held in three different languages. Starting from the 2013 and 2014 SemEval editions, 16,17 (for English data) we will investigate also the 2014 Evalita challenge on Twitter 18 over tweets written in Italian and finally, after generating a polarity lexicon for the Arabic language, we will also investigate the contribution against the AST data set. 19
All the above campaigns focus on the task of assigning a sentiment to a target tweet. For example, the tweet “Porto amazing as the sun sets…http://bit.ly/c28w ” should be recognized as positive, while “@knickfan82 Nooo;(they delayed the knicks game until Monday!” as negative. Notice that, as our method is based on automatically generated polarity lexicons, differences in performance obtained by classifiers that use the polarity lexicons against other uninformed classifiers (i.e. classifiers that do not use any polarity lexicon) will be assumed as quantitative indicators of the advantage produced by our DPL acquisition process.
All experiments reported in the rest of the article are performed by exploiting the kernelized formulation of the SVM algorithm 37 that can be found in the KeLP framework. 40 Kernels allow representing data at an abstract level, while their computation still refers to core informative properties. Moreover, kernel functions can be combined, for example, the contribution of kernels can be summed, in order to account at the same time for different linguistic properties. In the targeted tasks, multiple kernels are combined to verify the contribution of each representation: in particular, an independent kernel will be made dependent on one DPL to prove its effectiveness.
As presented in section ‘Polarity lexicon generation through distributional approaches’, an m = three-dimensional vector
In the remaining part of this section, we will first measure the impact of the DPL in the polarity classification task in three languages: English, Italian, and Arabic. These results will be obtained by deriving the lexicons from a distributional space generated by a neural network, that is, a prediction-based methodology. For completeness, the contribution of lexicons generated according to other count-based methodologies 41 will be then discussed in the last subsection.
Twitter SA in English
The English DPL is generated starting from a WS acquired over a corpus of more than 20 million tweets downloaded during the last months of 2014. We processed the corpus with a custom version of the Chaos parser 42 : lemmatization and pos tagging are applied to derive lemma::pos input for the word vector generation. We obtained about 190,000 words that have been classified to generate the polarity lexicon.
In Table 1, an excerpt of the English lexicon can be found, where pos, neg, and neu refer, respectively, to positivity, negativity, and neutrality scores. The approach seems to be able to transfer the polarity to words, given the sentence-based classifiers. Qualitatively, it seems that polarized words (e.g. the adjectives “good” and “bad”) tend to lie in specific independent subspaces, which are well separated by the linear classification strategy: the word good in fact receives a positive score of 0.74, while bad receives a score of 0.12; on the contrary, the former word has a negative score of 0.11, while the latter 0.80. Notice that in Table 1, words that are mostly domain independent are shown, while the lexicon generation process could be biased by the sampling process of the training messages. For example, the word Mario Monti has a different polarity signature in different domains, changing from (0.15, 0.53, 0.32) in data sampled from 2014 to (0.09, 0.13, 0.78) in data sampled from 2016.
Examples of polarity lexicon terms and relative sentiment scores (English language).a
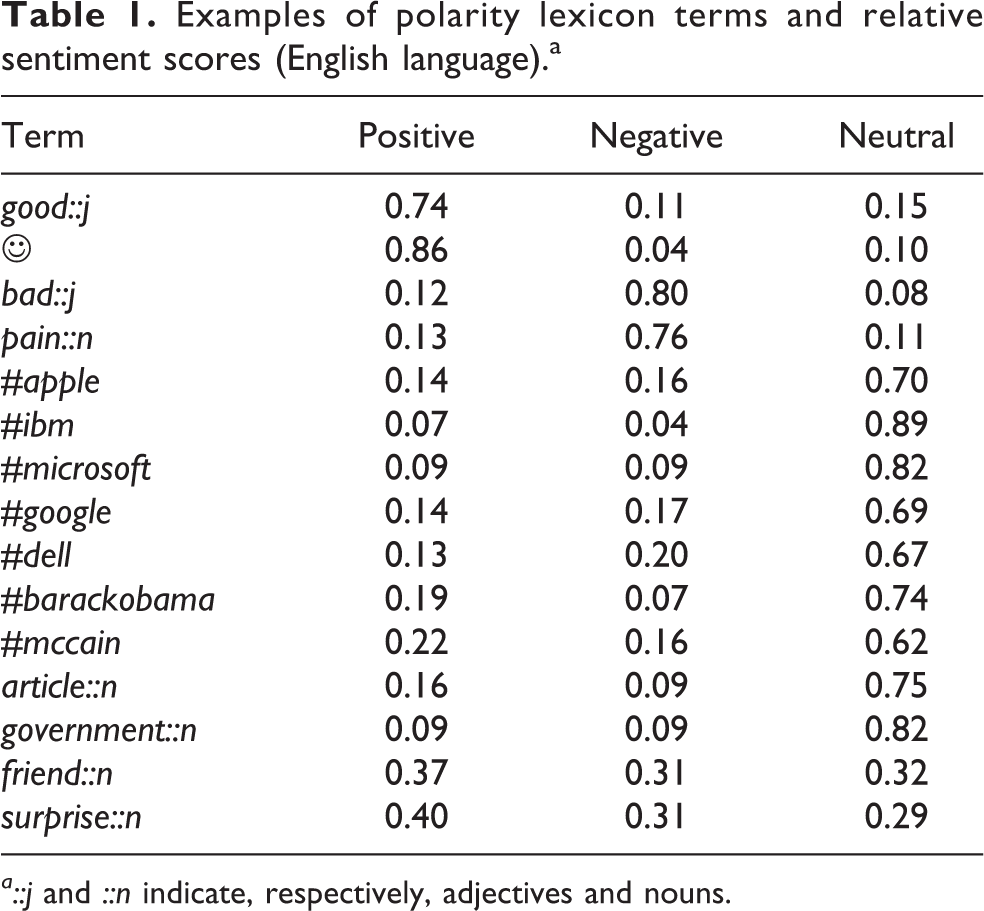
a::j and ::n indicate, respectively, adjectives and nouns.
The quantitative evaluations focus on the quality that an SVM classifier can achieve with and without the adoption of DPL. In this setting, tweets are first modeled through two basic feature representations: a BoW and a WS. The former BoW captures the lexical information directly, whereas each binary dimension of the vector represents the presence (or absence) of a particular word in a sentence. The latter WS relies on a Distributional Lexicon acquired by automatically processing a large-scale tweet collection and it is able to generalize the meaning of single words: in particular, it is used to smooth the lexical overlap measure between messages obtained from the pure occurrence model expressed by the BoW vectors. The WS representation of the sentence is obtained by summing the vectors of all its verbs, nouns, adjectives, and adverbs.
Then, lexical representation of the involved words is further augmented by the representation with the polarity scores as derived from the DPL. Again, only verbs, nouns, adjectives, and adverbs are augmented so that other categories are neglected.
The SVM learning algorithm is then applied on different representations by devoting a different kernel function to each vector. In this way, each feature vector (e.g. the three-dimensional polarity lexicon) contributes independently through its own specific kernel function: the overall kernel function is computed as the normalized sum of the kernels over the different feature vectors. For example, the BoW + WS + DPL system makes use of three kernels: the first linear kernel operates on BoW binary vectors, the second on the WS vectors, and finally the third kernel is fed with three-dimensional polarity scores of the DPL; all kernels correspond to the cosine similarity function between vector pairs.
In Tables 2 and 3, the experimental outcomes for the 2013 and 2014 SemEval data sets are reported, as well as the Best-System in the two challenges. Performance measures are the F1pn and the F1pnn. The former is the arithmetic mean between the F1 measures of the positive and negative classes, that is, the official score adopted by the SemEval challenges. The latter is the arithmetic mean between the F1 measures of the positive, negative, and neutral classes. The WS representation is based on the same WS used to generate the polarity lexicon. Here, we compare the contribution of DPL with a well-known lexicon, that is, the SBJ by Wilson et al. 9 It is composed of words manually annotated with subjective polarity information (positive, negative, neutral) and a strength (weak or strong) value. For each tweet, we generate a new feature representation SBJ where each dimension refers to a polarity value with its relative strength, as found in the message. For example, the SBJ representation of “Getting better!” is a feature vector whose only nonzero element is strong_pos. In Table 2, results are shown for the 2013 test data set, which is composed of 3814 examples. First, the baseline performance achievable with a linear kernel applied to the simple BoW (63.53% F1Pnn) representation is shown. Then, the combination of the other representations is experimented. When applying the WS, an improvement can be noticed, as demonstrated by the F1pnn score of 68.56% in the BoW + WS kernel. It means that distributional representations are useful to capture the semantic phenomena behind sentiment-related expressions, even in short texts and to alleviate data sparseness problems of the pure BoW kernel, as demonstrated by the approximately five point increment in F1Pnn in this setting. When combining also DPL, further improvements are obtained for both performance measures (66.40% F1pn and 68.68% F1pnn). It seems that DPL effectively acts as a smoothing of the contribution of the pure lexical semantics information provided by WS. It is noticeable that the BoW + WS + DPL system would have ranked in second position in the 2013 ranking, where the Best-System (the best system measured during the official competition adopted many polarity lexicons and ad hoc features.) achieved the F1pn score of 69.02%.
SA in Twitter 2013 results.a

SA: sentiment analysis; BoW: bag-of-word; DPL: Distributional Polarity Lexicon; WS: word space.
a Best-System refers to the top scoring system in SemEval 2013.
SA in Twitter 2014 results.a
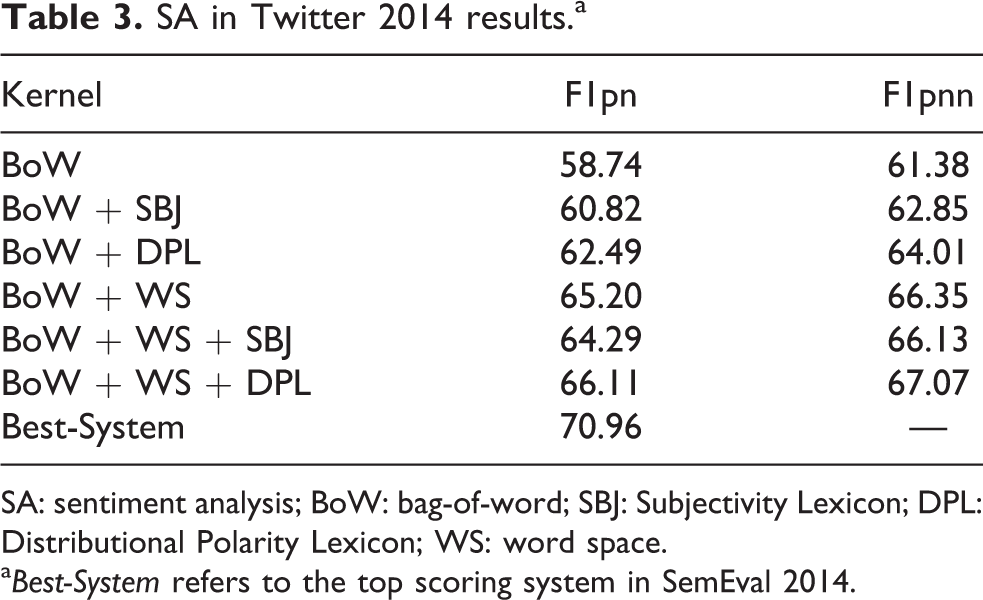
SA: sentiment analysis; BoW: bag-of-word; SBJ: Subjectivity Lexicon; DPL: Distributional Polarity Lexicon; WS: word space.
a Best-System refers to the top scoring system in SemEval 2014.
Similar trends are observable for the 2014 test set, as shown in Table 3. In this case, we were not able to rely on the complete test set, as, at the time of this experimentation, some of the messages were no longer available for download. Our evaluation is carried out on 1562 test examples, while the full test set was composed of 1853. It makes a direct comparison with the in-challenge systems impossible, but it still can give an idea of the achievable performances. Again, performances are measured with the BoW and WS representation combined with SBJ and DPL. As it can be noticed, the use of distributed word representations is also beneficial in this scenario, as demonstrated by the BoW + WS row of Table 3, where a 65.20% in F1pnn and 66.35% in F1pnn are reported. Again, when using the automatically acquired polarity lexicon, improvements in both the performance scores are noticeable, as demonstrated by 66.11% in the F1pn and 67.07% in the F1pnn of the BoW + WS + DPL setting. These results should be compared with the Best-System both in 2013 and 2014 considering that no hand-coded resource has been here adopted. Instead, the best systems measured during the official competition adopted many polarity lexicons (both automatically and manually derived) as well as different syntactic (char-ngrams and word-ngrams) and semantic features (word senses and word clusters).
Twitter SA in Italian
The Italian DPL is generated starting from a WS acquired over a corpus of more than nine million tweets. We processed, again, the corpus with a custom version of the Chaos parser 42 : lemmatization and pos tagging are applied to derive lemma::pos input for the word vector generation. We obtained about 99,000 words that have been classified to generate the polarity lexicon.
In Table 4, an excerpt of the Italian lexicon can be found. Again, pos, neg, and neu refer, respectively, to positivity, negativity, and neutrality scores: again, intrinsic positive adjectives such as “buono” (i.e. “good”) are significantly separated from intrinsically negative words, such as the noun “sofferenza” (i.e. “pain”).
Example of polarity lexicon terms and relative sentiment scores (Italian language).a

a ::j and ::n indicate, respectively, adjectives and nouns.
The impact of the Italian lexicon has been measured against the data provided by the Evalita 2014 Sentipolc 18 challenge. Here, Twitter messages are annotated with respect to subjectivity, polarity, and irony. We selected only those messages annotated with polarity and that were not expressing any ironic content in order not to have been biased by particular polarity inversion phenomena typical of ironic texts. Thus, our evaluations are pursued on 2566 and 1175 messages, used respectively for training and testing.
In Table 5, performance measures for this setting are reported. Again, the F1 mean between the positive and negative classes (F1pn), as well as the mean between all the involved classes are reported F1pnn. Notice that in the Sentipolc challenge, a slightly different evaluation has been carried out; however, in the challenge the best system obtained an F1 of 67.71% in the polarity classification subtask.
Twitter polarity classification in Italian.

BoW: bag-of-word; DPL: Distributional Polarity Lexicon; WS: word space.
We compare DPL with another Italian polarity lexicon, called SENTIX, in the study by Basile and Nissim. 43 It consists of words automatically annotated with four sentiment scores, that is, positive, negative, polarity, and intensity. In our evaluation, features correspond to the sum of the four scores across words appearing in a message (STX kernel). The benefits of using a polarity lexicon for augmenting the BoW representation are more evident, and the improvement in using the two resources is very similar. In fact, the BoW kernel alone reaches a performance of 58.58% in F1pnn, and when augmented with the STX and the DPL, the performance increases, respectively, to 59.20% and 60.75. The DPL is able to provide more information to the learning algorithm, as demonstrated by the higher performance that is measured. When adopting the WS representation, performances increase up to 63.13% in F1pnn. When using also the DPL lexicon, it seems that the interaction with the WS features is beneficial in deciding the polarity of a tweet, as demonstrated by the further improvement up to 63.35%.
We also carried out a qualitative evaluation of the lexicons in the Italian language, that is, SENTIX and DPL. In Table 6, Italian words along with their scores from the DPL and SENTIX are compared. They have been selected by looking at the accordance/discordance (given the relative scores) in the two lexicons. For example, “vantaggioso” (profitable) has been selected as it is considered positive in both lexicons, while “inestimabile” (priceless) has been selected as the two lexicons disagree about its polarity. The examples in the table have been then manually inspected and selected to point out some linguistic phenomena. For example, it is interesting to notice that for some word, the two lexicons give similar judgments for their polarity. Let us consider the words “abile” (expert) or “benefico” (beneficial). In Italian, these can be considered almost unambiguous words from a polarity point of view, and the lexicons agree as well. The role of the DPL is more evident for words that can be considered more ambiguous. For example, the word “pentimento” (regret) can be considered as a positive status that follows from a negative situation. This outcome makes explicit the strong dependence of corpus-based methods onto the nature of the used text material. In the SENTIX lexicon, it has been assigned to a negative polarity, while in the DPL, it is biased toward positivity. We thus retrieved from the tweets selected via distant supervision all messages containing “pentimento.” The following tweets confirm the positive bias assigned to this word: anche io carnivora . ma in via di pentimento . a volte ☺ (I am also a carnivore . but in repentance . sometimes ☺), é stato difficile ma alla fine con molto pentimento ce l’ho fatta !! ☺ (It was difficult but in the end with much repentance I did it !! ☺), and bene io ora ho 2 min di riflessione e pentimento sul divano ☺ (Well I have 2 min of reflection and repentance on the couch ☺).
Comparison of polarity judgment of Italian words in the SENTIX lexicon and in the DPL.a

DPL: Distributional Polarity Lexicon.
aFor the SENTIX lexicon, polarity ranges from −1 (totally negative) to 1 (totally positive) and it is a function of positive and negative scores. DPL scores are derived as described in the previous sections.
Again, the word “inestimabile” (priceless) is considered negative, while in the DPL, it is biased toward positivity. We can argue that in the modern language of Social Media, if something is “inestimabile” (priceless), that is, whose value cannot be easily measured, it is used more with a positive connotation in the data, for example, in the tweet un complimento di inestimabile valore ed importanza per me ! ☺ (a priceless and important compliment for me! ☺). When the lexicons disagree, it can be the case that the SENTIX judgment is correct or, alternatively, the DPL is correct. For example, the DPL is wrong in assigning polarity scores to “incapace” (incompetent). On the other hand, the DPL is correct with respect to SENTIX for “logica” (logic) or “imprecare” (swear), respectively, neutral and negative. DPL scores are dependent from the data used to acquire the classifiers, so it is sensible to the real usage of the words in the contexts of Social Media. A lexicon as SENTIX can be considered instead static, as it does not directly depends on real examples of the usage of words in contexts. Moreover, the DPL lexicon contains polarity judgments for some meta word, such as hashtags or users, as demonstrated in Table 4, that can be useful for analyzing how people use such kind of words. For example, a hashtag indicating an event that is biased toward positivity in the DPL can be an indicator that the event was mainly associated with positive evaluations.
Generating an Arabic lexicon
Recently, the interest in the automatic analysis of the Arabic language has seen a rapid growth. Many different systems have been released for processing the Arabic language, 44,45 but SA systems as well as SA resources are not easily available. It makes the processing of Arabic texts from a sentiment point of view not an easy process. We aim at automatically generating a sentiment lexicon for Arabic by following the same methodology adopted both for English and Italian and showing that it can be adopted in existing SA system with low effort. Again, we generated a WS through word2vec, by downloading a corpus of about two millions of Arabic tweets. A preprocessing step is adopted by applying word segmentation and pos tagging to each tweet through the Stanford Arabic Parser. 45 We adopted the same settings as for the English and Italian WSs (given the reduced size of this corpus, we reduced the except the word2vec parameter called min-count to 10). The lexicon has been generated starting from a further corpus of Arabic tweets that we heuristically classified with respect to the positive, negative, and neutral classes by adopting the same emoticons set of the English and Italian languages.
In Table 7, a portion of the lexicon is shown. Again, the lexicon is able to capture the main sentiment attitudes of the highly polar words, such as “سعيد” that is, the adjective “happy.” We conclude that the proposed methodology can be effectively considered language independent, as even in such different languages, it is able to extract meaningful polarity scores for the words.
Example of polarity lexicon terms and relative sentiment scores (Arabic language).

In order to quantitatively evaluate the lexicon, we tested its contribution against the AST data set. 19 It is a recently released data set for SA over Twitter. It contains about 10,000 Twitter messages in Arabic that have been manually annotated with respect to four classes: positive, negative, neutral, and objective. In Table 8, the number of messages in each class is reported.
AST data set statistics over the different classes.

AST: Arabic Sentiment Twitter.
An SVM classifier with multiple kernels is adopted to train a sentiment classifier over two different settings, balanced and unbalanced. In the first case, the number of examples is balanced with respect to the different classes provided by Nabil et al. 19 The unbalanced scenario instead works with training and testing data sets where the number of examples is not balanced with respect to the different polarity classes. We are going first to test the lexicon in a setting similar to the English and Italian cases, that is, a three-way classification task where we filtered out the objective class from the data set. Then, an evaluation over the four-way classification task as reported by Nabil et al. 19 is discussed.
In Table 9, the three-way task performances are reported, in terms of accuracy and F1, which are the measures used by Nabil et al. 19 We trained the SVM learning algorithm with different combination of kernel functions to test the contribution of each representation. Again, the DPL is evaluated both with a simple BoW representation and with a more complex BoW and WS representation. As it can be noticed, even in this language, the DPL lexicon is able to provide useful information to train an SA system for tweet messages, as demonstrated by the performances in the unbalanced settings (60.5% in accuracy and 57.9% in F1 with the BoW + WS + DPL kernel). In fact, the system seems to benefit more from the adoption of the lexicon when enriching the BoW + WS kernel with respect to the balanced scenario, where the performance instead decreases (56.6% and 54.9% down to 55.3% and 54.9%, respectively, in accuracy and F1). Notice that the unbalanced scenario is a more realistic setting for a final production system, as the data in real operational conditions are far from being balanced.
Evaluation of a kernel based SA system over the AST data set with the DPL: positive, negative, and neutral classes only.
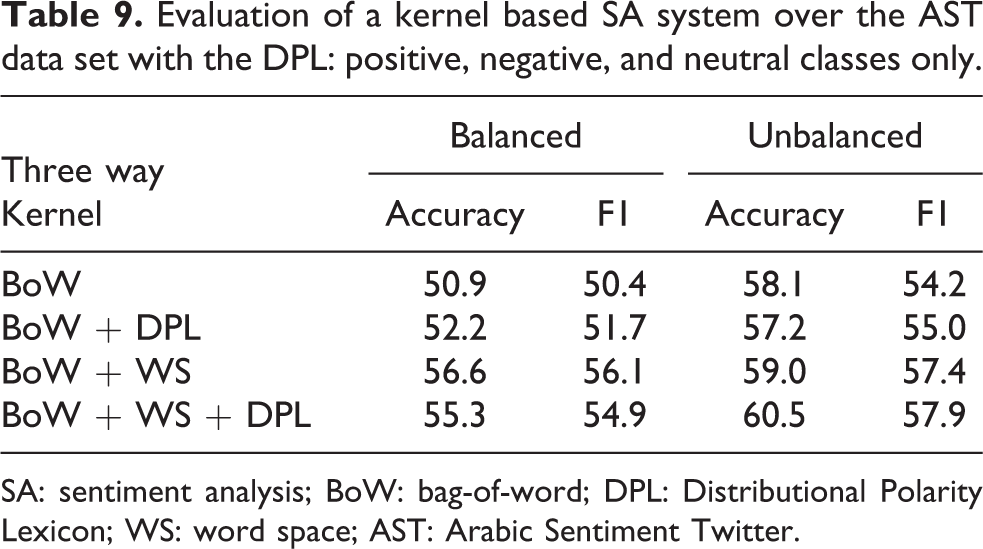
SA: sentiment analysis; BoW: bag-of-word; DPL: Distributional Polarity Lexicon; WS: word space; AST: Arabic Sentiment Twitter.
In Table 10, the four-way task results are reported with a comparison over a similar system by Nabil et al., 19 that is, an SVM-based system, and the best system reported by Nabil et al. 19 Again, the DPL features are useful in the prediction of the sentiment expressed in short messages. Notice that, except one case (the F1 measures in the unbalanced setting with a BoW + WS + DPL kernel), the lexicon always provides a beneficial impact over the performance. It is remarkable that the lexicon is able to further generalize the WS contribution, as demonstrated by the accuracy (52.5%) and F1 (52.6%) in this data set in the balanced setting. In the unbalanced case, the contribution of the lexicon is noticeable only in the accuracy measures, even if it provides a score of 63.0% in the F1. In the unbalanced four-way task, the DPL is giving too much bias to the subjective classes, resulting in worse performances in the prediction of the objective class, that is, instead, the more populated (see Table 8) in the data set. In the balanced scenario, the objective class is instead treated similarly to the others, given that all the examples are equally distributed over them.
Evaluation of a kernel-based SA system over the AST data set with the DPL: positive, negative, neutral, and objective classes.

SA: sentiment analysis; BoW: bag-of-word; DPL: Distributional Polarity Lexicon; WS: word space; AST: Arabic Sentiment Twitter; SVM: support vector machine.
Impact of the methods for acquiring WSs on the DPL generation
In all previous evaluations, we considered DPLs that have been acquired starting from WSs obtained with the so-called prediction-based methods, that is, the Skip-gram model.
15
Here, we aim at verifying whether a WS acquired through the count-based methodology can provide similar results, in terms of lexicon acquisition. We are going to acquire a WS with the LSA
12
approach described in section “Counting co-occurrences: The LSA approach.” We adopted the same set of tweet messages used to build the Skip-gram model. In order to have a comparable WS, we built the word-by-context matrix by considering a window of five words to the left and to the right of each target word, discarding the words appearing less than 50 times in English and Italian (this limit is set to 10 for Arabic) and by maintaining the most frequent contexts, that is, discarding those appearing less than 50 times in English and Italian (this limit is set to 20 for the Arabic language). We applied a point-wise mutual information weighting scheme.
14
It means that the value of a cell of the initial matrix M is computed according to the mutual information of a target word and a context in which it appears. It measures how much a target word and a context are related but penalizing most frequent words and contexts. Then, we applied the SVD algorithm, and we approximated the space with a k = 250 value, finally obtaining 250-dimensional vectors by considering the word projection
Given this space, we acquired English, Italian, and Arabic DPLs with the same settings described in the previous sections. We applied, again, the new lexicon over the SemEval Twitter SA 2013 and 2014 tasks, the Italian tweet data set and over the AST data set with the same experimental setup previously adopted as well as the same performance metrics. We applied different linear kernel combinations to verify the contribution of the newly generated sentiment representation. In the following experiments, the WS derived with the LSA method will be denoted as LSA, while the lexicon generated starting from this space will be called LSA-Based DPL.
In Table 11, the measures (F1Pnn) for all the data set in all languages are reported. First, notice that for the English data sets (En-2013 and En-2014), the LSA space is able to provide good generalization capabilities leading to performances that are comparable to the ones obtained with the prediction-based space in section “Twitter SA in English.” The outcomes when using only the two versions of DPLs with a BoW (BoW + DPL and BoW + LDPL) are quite similar in all cases, for example, 64.1% versus 64.7% in the 2013 English data set and 64.0% versus 63.6% in the 2014 English data set. It shows that the two methodologies induce very similar semantic and sentiment representations.
Twitter SA in multiple languages.a

BoW: bag-of-word; DPL: Distributional Polarity Lexicon; WS: word space; LSA: latent semantic analysis; SA: sentiment analysis; LDPL: LSA-Based DPL.
aReported measures are the F1pnn for English and Italian cases and four-way Accuracy for the Arabic language.
Moreover, we tested whether the two spaces could provide complementary information to the learning algorithm. We combined the WS and LSA kernels also with their relative lexicons DPL and LDPL. The outcome is quite interesting, as the combination BoW + WS + DPL + LSA + LDPL shows a good increment, about one point in the F1pnn for both the English Twitter data sets.
Similar trends can be observed in the Italian case (column it). The LSA lexicon (LDPL) in combination with the BoW is beneficial, as demonstrated by the 60.0% measure that is higher than 58.6% of the pure BoW kernel. The BoW + WS + LSA + DPL + LDPL kernel combination confirms its positive effects, as it seems to provide additional useful information to the learning process, as demonstrated by the score of 63.5% with this configuration.
Finally, in the Arabic language scenario (columns Arabic-balanced and Arabic-unbalanced), we measured the system with the LSA and LDPL representations against the four-way classification task. Again, we can notice a positive impact of the LSA WS and of the LSA derived sentiment lexicon, both in the balanced and unbalanced scenarios. Notice how the adoption of the BoW + WS + LSA + DPL + LDPL kernel gives an improvement in the accuracy of the unbalanced scenario reaching the score of 69.3%. The balanced setting does not benefit of the same improvement. Nevertheless, the combination of both kinds of WSs (i.e. count based and prediction based) with their DPL lexicons is beneficial. It suggests that these are capturing slightly different linguistic information, and, thus, they should be both adopted in language learning systems to capture these differences in SA tasks.
Conclusions
Subjective phenomena, such as polarity, represent crucial issues in the modeling of complex social networks that are increasingly influent on modern decision-making and business process. In this article, an unsupervised learning methodology to generate large-scale polarity lexicons (the lexicons and the emoticons used for generating them are available on: (http://sag.art.uniroma2.it/demo-software/distributional-polarity-lexicon/)) is presented to automatically acquire such precious resources for SA across social networks. The methodology is simple and allows to be easily replicated for multiple languages. We show how polarity-related aspects can be observed across streams of microblogs as they are observed in the Social Media. Through the use of simple heuristics, large data sets including annotated examples can be easily derived in terms of individual sentences that are representative of certain polarity classes. These sentences are then used to train a classifier and transfer polarity information to individual lexical items. This transfer is made possible as both sentences and words are represented in the same vector space based on DMs of lexical semantics, and therefore training the linear polarity classifier becomes straightforward. The method proved to be quite general, as it does not rely on any hand-coded resource, but mainly uses simple cues, for example, emoticons, for generating a large corpus of labeled sentences. It turns out to be largely applicable to resource poor languages, such as the Italian or Arabic languages. The generated lexicons have been in fact shown beneficial on SA tasks in three different languages. In particular, DPLs have been adopted for predictive tasks, that is, the classification of polarity in short texts. However, a DPL can be also used for different applications. For example, such a resource could be adopted to support the analysis of the words coloring in specific domains, for example, through the automatic generation of polarized tag clouds. Moreover, the generality of the lexicon generation process allows to acquire different version of the lexicons in different time periods. In fact, as we demonstrated in the study by Castellucci et al., 46 the usage of words can change over time. This is evident for such words that refer to events or people that can be used to communicate positive or negative biases. In the study by Castellucci et al., 46 we acquired different lexicons in 2014 and 2016 in Italian. For example, in these lexicons, the word referring to the former Italian prime minister Mario Monti shifted its polarity from negativity to neutrality (Mario Monti was the author of some unpopular law in 2013, resulting in one of most criticized person in Social Media.), that is, DPL vector in 2014 was (0.15, 0.53. 0.32), while in 2016, it was (0.09, 0.13, 0.78). Notice how the three-dimensional representation of the DPL allows to easily track also the neutrality of each term. In fact, differently from other lexicons, where polarity is represented only with one or two dimensions (only for positivity and negativity), we decided to track neutrality with a separated classifier. The neutral classifier is responsible to track the neutral contexts in which words appear, thus resulting in a more fine-grained representation. Moreover, this richer representation schema is flexible in combination with machine learning algorithms, such as SVMs, that can automatically select the most expressive dimension for a targeted task. In the article, we provided an analysis of the lexicon generation process by studying two different distributional methods. On the one side, we explored prediction methods, that is, method inspired by neural language models whose lexical vectors correspond to predictors of the context of individual words. On the other side, we also applied count-based methods whose vectors express for co-occurrence counts as these are found in large corpora. The two methodologies provide representations that are morphologically very similar though expressing quite different information. The acquired lexicons seem to have a comparable impact on the polarity scores generation and in sentiment classification tasks, as test over different SA data sets provides quite similar performances. Moreover, the combination of the two different representations, that is, the adoption of the resource derived by the application of both paradigms, results in further improvements. It seems that the two WSs provide slightly different contributions resulting in different and independent information about the task: it is probably due to the fact that the two WSs are built with quite diverse methods, each looking at different information of the texts. Future investigations will systematically address the problem of combining multiple lexicons when available. In fact, in English, multiple affective resources are available 25,26 : it could be an interesting direction to combine them to improve the performances of SA classifiers. Again, it could be interesting to combine the DPL representations obtained by different distributional methods. For example, all these could be adopted in combination with novel and promising convolutional neural networks used within sentence classification tasks. 47 One possibility is the investigation of the impact of these lexicons in augmenting the representation of individual words in pure neural network architectures. In this case, we expect the network should automatically learn the suitable representations for the classification of the polarity of messages, according to the different facets of the individual word semantics. A further direction is the investigation about the use of more complex grammatical features in the stage of the polarity lexicon acquisition. All the adopted classification algorithms did make no use of negation or other grammatical markers in the texts. Irony is another neglected phenomenon, so that a further extension of our method should be focusing on the management of ironic phenomena. 48,49 Distributional polarity vectors capture the main usage of words but not their ironic or metaphorical senses. It should be interesting to verify if an approach similar to the one suggested by Castellucci et al. 50 could be beneficial. In that work, deviation from standard semantic usages of words provides effective information on the irony detection task. A similar method applied on to distributional polarity vectors could provide interesting features for modeling irony in even more complex contexts.
Footnotes
Author contribution
Giuseppe Castellucci mainly contributed to this work while working at the University of Roma, Tor Vergata (Italy). Now at Almawave srl, Roma (Italy).
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
This research received no specific grant from any funding agency in the public, commercial, or not-for-profit sectors.