
Abstract
Integrating artificial intelligence, particularly large language models, in academic writing has significantly enhanced productivity and content quality. However, effective academic writing fundamentally relies on critical thinking, which is essential for constructing persuasive arguments and identifying flaws. This study assessed the critical thinking abilities of GPT-3.5, GPT-4, LLaMA-4, and DeepSeek-R1 by using two primary tests—the multiple-choice Thinking Skills Assessment and the open-ended Ennis–Weir Critical Thinking Essay Test—and comparing their performance with 194 undergraduate students in China. The results showed that while LLaMA-4 and DeepSeek-R1 consistently outperformed students on both assessments, GPT-4 excelled only in the Thinking Skills Assessment and GPT-3.5 underperformed across both tests. These findings indicate that current large language models can excel not only in tasks targeting the specific cognitive skills of critical thinking but also in applying various skills in real-world contexts. However, detailed analysis revealed the tendency of large language models to miss key details, overlook multiple argumentative flaws, and show weakness in tasks demanding abstract reasoning, underscoring the need for human oversight and guidance when using artificial intelligence in academic writing. These results offer valuable insights for optimizing human–AI collaboration in academic writing.
Introduction
The rapid development of artificial intelligence (AI), especially large language models (LLMs), has significantly influenced the academic writing process (Golan et al., 2023; Nguyen et al., 2024; Semrl et al., 2023). Integrating LLMs into academic writing streamlines writing processes and enhances productivity and content quality (Golan et al., 2023; Nguyen et al., 2024). Students expect LLMs to fulfill various roles, including acting as a multitasking writing assistant, a virtual tutor, and a digital peer (Kim et al., 2025). However, the extent to which LLMs truly possess the necessary capabilities to fulfill these roles remains uncertain, raising questions about their effectiveness and reliability in academic contexts.
Academic writing is fundamentally a form of argumentation. It involves making claims, using evidence, and addressing counterarguments to persuade the reader to accept the author's conclusions (Bazerman, 1988; Hyland, 2004). Critical thinking is crucial for determining the quality of argumentation, as the process inherently involves constructing and evaluating arguments (Mercier & Sperber, 2011). It aids individuals in analyzing arguments, identifying flaws, and suggesting improvements, thereby enhancing the rigor and persuasiveness of the argument (Ennis, 1987; Facione, 2011). Therefore, critical thinking is the most essential skill in academic writing (Wingate, 2012). Without critical thinking, LLMs may overlook flaws in research and provide misleading recommendations. Furthermore, despite LLMs demonstrating remarkable capabilities in natural language understanding and generation, research continues to reveal fundamental deficiencies, which may undermine their performance in critical thinking tasks. For instance, studies show that LLMs struggle with processing negations in prompts (Nadeem et al., 2024), and they remain susceptible to generating “hallucinated” content—information that is fabricated or misleading (Alkaissi & McFarlane, 2023). Studies also indicate that even advanced LLMs may fail to perform reliably in straightforward tasks, producing seemingly reasonable yet incorrect responses (Zhou et al., 2024) and generating inconsistent judgments when presented with identical prompts (Zhuang et al., 2025). These findings collectively raise significant questions about the reliability of the critical thinking abilities of LLMs, highlighting the need for rigorous evaluation.
Although there have been preliminary attempts to investigate the critical thinking performance of LLMs (Betz et al., 2021; Zaphir et al., 2024), comprehensive evaluations remain lacking. Betz et al. (2021) constructed a corpus of deductive reasoning arguments for training and assessing the critical thinking of LLMs, used it for intermediate pre-training of GPT-2, and subsequently tested the model's ability to complete argument conclusions on the test set. However, this evaluation was limited to deductive reasoning, which represents only one aspect of critical thinking that encompasses a broader range of skills, and relied on a self-constructed benchmark rather than widely verified critical thinking tests. Moreover, this study did not address how model output variability or prompt design were systematically controlled—factors now considered essential in LLM evaluation practices. Zaphir et al. (2024) introduced a framework for evaluating the critical thinking abilities of LLMs, assisting educators in designing assessments which target the critical thinking abilities that LLMs cannot master or students cannot complete by simply using LLMs. However, this framework lacks empirical validation and provides no concrete evidence of the critical thinking performance of LLMs. As a result, there is a need to employ validated psychological measurement tools to systematically evaluate the critical thinking abilities of LLMs.
Critical thinking assessments typically use two formats: multiple-choice and open-ended tests. Multiple-choice tests, such as the Thinking Skills Assessment (TSA) developed by the University of Cambridge (Black et al., 2008), break down critical thinking into specific cognitive components, such as identifying assumptions and drawing conclusions. For each component, these tests provide specific prompts and options, offering the advantage of delivering detailed subscale results (Ku, 2009). In contrast, the Ennis–Weir Critical Thinking Essay Test (EWCTET; Ennis & Weir, 1985) is an example of an open-ended test, which requires the test-takers to identify argumentative flaws in a letter advocating for the citywide prohibition of nighttime roadside parking and defend their positions. Open-ended tests are considered more reflective of real-world critical thinking applications, such as academic writing, because they require the test-takers to integrate various skills in authentic contexts, identify key issues, and develop their own responses (Ku, 2009; Liu et al., 2014). Therefore, incorporating both multiple-choice and open-ended formats in critical thinking assessments provides a more comprehensive evaluation (Ku, 2009).
This study evaluates four widely used LLMs—GPT-3.5, GPT-4, LLaMA-4, and DeepSeek-R1—using the TSA and the EWCTET. These tests were administered to the LLMs and, as a baseline, a sample of 194 undergraduate students in China. The study intends to analyze the LLMs’ performance across items with different difficulties measuring various critical thinking skills and compare the LLMs’ response patterns with those of the students. The results of this study help uncover the unique characteristics of LLMs’ critical thinking, providing valuable insights for applying LLMs in practice.
Methods
This study employed the TSA and the EWCTET to measure critical thinking in both human participants and LLMs. For each test, we developed new items based on existing ones to mitigate the risk of the LLMs being previously exposed to the content during their training. In what follows, we will introduce the tests; outline the recruitment and testing procedures for the human participants; describe how the LLMs’ responses were collected; and explain the scoring process for the open-ended responses.
The Tests
The original TSA comprises seven categories of items, with each measuring a different critical thinking skill. These skills are: Identifying the Main Conclusion; Drawing a Conclusion; Identifying an Assumption; Assessing the Impact of Additional Evidence; Detecting Reasoning Errors; Matching Arguments; and Applying Principles. For each category, we selected five items from the TSA's item pool,1 resulting in 35 items. An example item is shown in Figure 1. To expand the assessment, we developed five new items for each category. These new items adhere to the original TSA format and were sourced from various contexts, including literature, news commentaries, and social media. As a result, the final TSA comprises 70 items.

An example item from the TSA and an example paragraph from the EWCTET.
The original EWCTET presents the participants with a letter advocating for a citywide ban on nighttime roadside parking, organized into eight paragraphs with each containing a built-in flaw. Figure 1 provides an example paragraph. The participants are required to evaluate each paragraph and then compose a concluding paragraph summarizing their overall judgment of the letter, which makes a total of nine items in the original EWCTET. To expand the assessment, we developed three new scenarios, each consisting of three paragraphs. Unlike the original EWCTET, some of these new paragraphs contain up to two flaws per paragraph. Each flaw is considered a separate item, resulting in 12 new items. Therefore, the final EWCTET comprises a total of 21 items.
Collecting the Responses of the Human Participants
We recruited 194 undergraduate students (83 males) from a top university in China to participate in the test online. The primary analysis of this study involves comparisons between human performance and the performance of the LLMs. Therefore, we calculated the required sample size for independent samples t-tests. Assuming a moderate effect size (Cohen's d = .5), with a two-tailed significance level of .05 and a statistical power of .80, the required sample size was estimated to be 64 participants per group. Given that our actual sample size (N = 194) exceeded this requirement, we had adequate statistical power for the planned comparisons. The students ranged in age from 17 to 20, with an average age of 18.25. The testing was conducted under selection-based conditions using a dedicated examination system to ensure high-quality responses. Given that the test results were important, the students were motivated to perform to the best of their ability. They completed the TSA and then the EWCTET, with the entire test-taking process lasting approximately 2.5 hours. After verification, all of the responses were deemed valid.
Using the student response data, we evaluated the quality of each item by calculating the correlation between each individual item score and the total test score. In both the TSA and the EWCTET, we found that a few items had item-total correlations around zero, typically due to the items being either too easy or too difficult. While these items provide limited discriminatory power for students of varying ability levels, they may still be valuable for comparing the performance of LLMs and students, as AI models and humans frequently perceive item characteristics differently (Zhuang et al., 2025). Therefore, we decided to retain these items for further analysis.
The internal consistency of the TSA, as measured by McDonald's ω (McDonald, 1999), was .66. Although this level of consistency may seem modest, it reflects the diverse nature of the test, which comprises seven distinct item categories, each targeting different critical thinking processes and skills. Similarly, the EWCTET also demonstrated an internal consistency of .66. This consistency is likely influenced by the variability in the flaws, such as faulty analogies or omissions of other influencing factors. Given the broad range of the students’ backgrounds and educational experiences, this diversity likely contributes to the relatively modest internal consistency in the EWCTET. Similarly, modest correlations between the total scores of the original and new items were observed for the two tests: .47 for the TSA and .30 for the EWCTET. Increasing the number of items could enhance the tests’ ability to capture critical thinking skills with a broader range of contexts, making the tests more robust and reliable.
Collecting the Responses of the LLMs
We utilized the public API (Application Programming Interface) to gather responses from GPT-3.5 (GPT-3.5 Turbo version), GPT-4 (GPT-4 Turbo version), Llama-4 (Maverick Instruct version), and DeepSeek-R1. For all the LLMs, we employed completely identical prompts. For the TSA, each item was introduced with the same prompt to the models: “Please read the question carefully and select the option you believe is correct.” This prompt was similar to the instructions given to the students at the beginning of the test (“Please read the following questions carefully and select the option you believe is correct.”). Each item was presented in a separate chat session to eliminate any potential influence from preceding items. For the EWCTET, which features multiple items within the same scenario, each scenario was delivered to the models in a single chat session. We used the test instructions that were given to the students as the prompts to the models, followed by the relevant items. The main content of these prompts instructed the models to evaluate the strength of argumentation in each paragraph and provide reasons for their judgements.
Temperature, which controls the randomness of LLM outputs (Wang et al., 2023), is an important parameter in LLM evaluation (Strachan et al., 2024; Webb et al., 2023). The temperature ranges from 0 to 1, with 0 resulting in minimal randomness. This study examined five temperature settings—0, 0.25, 0.5, 0.75, and 1—to ensure that the results accurately represent the LLMs’ true performance and to assess their impact on the LLMs’ critical thinking abilities. For each setting, we conducted 30 rounds of testing, totaling 150 rounds for each LLM. The number of rounds was determined to ensure robust model performance assessment while accounting for potential variations in the models’ outputs. With a human sample size of 194 and 150 responses per model, our study had adequate statistical power for the planned comparisons between human and LLM performance.
Scoring of the Responses
All the items in the TSA are multiple choice, with a single correct answer. For the EWCTET, each item has a corresponding reference answer, and the respondents answer each item with a written response. Raters were hired to evaluate each response on a scale from 0 to 3, except for Paragraph 9 in the original EWCTET, which serves as the concluding item, with a scale from 0 to 5. A score of 0 indicates that the response is completely unrelated to the reference answer, while a score of 3 (or 5 for Paragraph 9) denotes an accurate response. The rater deducts one point for each instance of an unreasonable response or argumentative error. Individuals with high levels of critical thinking are distinguished by their alignment with the reference answers, earning higher scores and incurring fewer deductions. The total test score is calculated as the sum of all the item scores.
All of the responses from the students, GPT-3.5, and GPT-4 were evaluated by three trained raters (Group 1), while the responses from LLaMA-4 and DeepSeek-R1 were evaluated by another three raters (Group 2). The intraclass correlation coefficient for inter-rater reliability was .97 for Group 1's overall test scores, with the intraclass correlation coefficients for individual items ranging from .71 to .97. For Group 2, the overall intraclass correlation coefficient was .93, with the item-level intraclass correlation coefficients ranging from .72 to .99, indicating high levels of agreement among the raters in both groups (Koo & Li, 2016). To ensure impartiality, the order of the responses was randomized and any identifying information was removed.
To ensure equivalence between the two rating groups, we randomly selected 40 students’ responses to be scored by both groups. The correlations between the two sets of ratings were high across all items (r > .82). Based on the means (μ₁, μ₂) and standard deviations (σ₁, σ₂) of the ratings given by Group 1 and Group 2 for these 40 students, we applied linear equating methods (Kolen & Brennan, 2013) to calibrate Group 2's ratings (X₂) to the scale of Group 1's using the following formula:
Adjusted X₂ = (X₂ − μ₂) × (σ₁/σ₂) + μ₁,
where this transformation maintains the relative standing of the scores while adjusting for systematic differences between the rating groups. The resulting adjusted X₂ scores were used as the final EWCTET scores for LLaMA-4 and DeepSeek-R1 in subsequent analyses.
Transparency and Openness
The materials, data, and code are available at https://anonymous.4open.science/r/Evaluating-Critical-Thinking-of-LLM-0EFF
Results
Overall Performance
We compare the total scores of the LLMs and the students on the TSA and the EWCTET. As shown in Table 1 and Figure 2, the students scored significantly higher on the TSA compared to GPT-3.5 (t(211.55) = 48.65, p < .001, d = 4.97), with a large effect size. However, the students scored significantly lower than GPT-4 (t(202) = 16.98, p < .001, d = 1.73), LLaMA-4 (t(244.8) = 15.35, p < .001, d = 1.58), and DeepSeek-R1 (t(251.72) = 13.86, p < .001, d = 1.43), all with large effect sizes. The maximum scores achieved by LLaMA-4 and DeepSeek-R1 matched the highest student scores.

Overall performance of the LLMs and the students on the TSA and the EWCTET.
Comparison of Total Scores Among Students and LLMs on the TSA and the EWCTET.

On the EWCTET, the students scored significantly higher than GPT-3.5 (t(309.19) = 23.85, p < .001, d = 2.50) and GPT-4 (t(291.74) = 8.06, p < .001, d = 0.84), with a large effect size. However, the students scored significantly lower than LLaMA-4 (t(246.46) = 11.53, p < .001, d = 1.19) and DeepSeek-R1 (t(249.55) = 7.37, p < .001, d = 0.76), with large and medium to large effect sizes. However, the maximum scores achieved by these models remained lower than the highest student scores.
A comparative analysis of the deductions on the EWCTET also revealed significant differences between the students and the LLMs. Specifically, the students incurred significantly fewer deductions compared to GPT-3.5 (t(316.63) = 17.25, p < .001, d = 1.88), GPT-4 (t(313.26) = 13.77, p < .001, d = 1.45), and DeepSeek-R1 (t(324.50) = 11.36, p < .001, d = 1.20), all with large effect sizes. In contrast, the students incurred significantly more deductions compared to LLaMA-4 (t(229.13) = 6.12, p < .001, d = 0.63), with a medium to large effect size. Notably, while some students achieved zero deductions, all of the LLMs incurred a deduction of at least one point.
Given the sample sizes and observed large effect sizes, post hoc power analyses revealed that our study achieved > 99.9% power for all these comparisons. Overall, LLaMA-4 and DeepSeek-R1, which were released in 2024 as the latest models in their respective series, demonstrate notable improvements in critical thinking compared to GPT-3.5 and GPT-4, which were released in 2022 and 2023, respectively. This suggests that the critical thinking ability of LLMs is progressively improving with technological advancements, although none of them exceed the highest student performance scores.
As shown in Figure 3, the relationship between temperature and the LLMs’ performance varied across the models and tests (as indicated by the trend lines). On the TSA, GPT-4 maintained consistent mean scores across all temperature settings, and the analysis of variance results for GPT-3.5 showed no significant differences across temperatures (F(4,145) = 0.64, p = .64). The analysis of variance results for LLaMA-4 (F(4,145) = 21.51, p < .001) showed a large effect size (η2 = 0.37). We conducted a trend analysis to explore the specific pattern of change across the ordered temperature levels. The results revealed a significant negative linear trend (t(145) = −5.83, p < .001) and quadratic trend (t(145) = −5.30, p < .001), as well as a significant cubic trend (t(145) = 1.67, p = .04). Similarly, the analysis of variance results for DeepSeek-R1 (F(4,145) = 23.33, p < .001) reached statistical significance with a large effect size (η2 = 0.39). The trend analysis revealed a significant negative linear trend (t(145) = −7.23, p < .001) and quadratic trend (t(145) = −4.70, p < .001). These results indicate that the decline in performance of LLaMA-4 and DeepSeek-R1 on the TSA becomes more pronounced at higher temperatures.

LLMs’ performance under different temperature settings.
On the EWCTET, the analysis of variance results indicated no significant differences across temperatures for GPT-3.5 (F(4,145) = 0.80, p = .53), LLaMA-4 (F(4,145) = 1.50, p = .21), and DeepSeek-R1 (F(4,145) = 0.93, p = .45). However, significant differences were found for GPT-4 (F(4,145) = 3.51, p = .01), with a small effect size (η2 = 0.09). The trend analysis revealed a significant linear trend (t(145) = 2.19, p = .03) and a significant quadratic trend (t(145) = −2.07, p = .04). These results indicate a curvilinear relationship, where the performance of GPT-4 on the EWCTET increases with higher temperatures up to a certain point, before decreasing.
The impact of temperature on the variability of the LLMs’ performance is not pronounced in the TSA but is evident in the EWCTET (as indicated by the ribbon in Figure 3). This is likely because the TSA requires determining the most appropriate option, whereas the EWCTET requires the LLMs to construct their responses, where variability directly affects the quality and scores of these responses. Overall, in the EWCTET, as the temperature increased, both the standard deviation and the range between the maximum and minimum values tended to rise, although this trend is not strictly monotonic. Therefore, for open-ended critical thinking tasks, obtaining multiple responses from LLMs and comparing them before accepting them may be a more robust strategy.
While the impact of temperature on the LLMs’ average performance can be statistically significant, the magnitude of these differences remains quite small, particularly when compared to the score distributions of the students. Consequently, in subsequent analyses, we will merge the test scores of each model across all rounds, without distinguishing between different temperatures.
Performance on Different Categories of Items in the TSA
The TSA comprises seven categories of items, with each targeting a specific cognitive component. We calculated the mean accuracy for each category for both the LLMs and the students. As shown in Figure 4, the students demonstrated the smallest variation in average accuracy across these categories, ranging from 70% to 87%. GPT-3.5 exhibited the greatest variation, with accuracies spanning from 16% to 83%. The other LLMs showed slightly more variability than the students: GPT-4 ranged from 60% to 100%, LLaMA-4 ranged from 68% to 99%, and DeepSeek-R1 ranged from 67% to 98%. These results indicate that, while an individual student may have notable strengths and weaknesses, the average performance across all students is relatively balanced across tasks. In contrast, while LLMs build on human knowledge, their learning results are less balanced. However, this imbalance seems to improve with newer versions, as GPT-4 showed more balanced performance compared to GPT-3.5.

Performance of the LLMs and the students on different categories of the TSA items.
For most skill categories, the performance accuracy generally followed this order: GPT-3.5 < students < other LLMs. However, for Matching Arguments, the students scored higher than all the LLMs except for LLaMA-4, and for Applying Principles, the students scored higher than all the LLMs except for GPT-4, the performance of which was comparable to that of the students. These two skill categories also showed the lowest accuracies among all the LLMs. Matching Arguments items require individuals to extract the reasoning structure from the passage and select the option with the same reasoning structure (Cambridge Assessment, 2021). This reasoning structure is often represented abstractly as a form of logical rule, such as: “If A is true, then B is true; given A is true, therefore B is true.” Applying Principles items require participants to identify which option follows the principle underlying the passage. A principle serves as a general guideline that can be applicable to other similar scenarios. Both categories share a common characteristic: they do not rely on the surface semantics of the specific content of the passage but rather on an underlying rule. Therefore, these items demand more abstract thinking. Examples of these two categories are shown in Figure 5.

Examples of the matching arguments and applying principles skill categories. Note. These two items were newly developed for this study.
In contrast, the other five categories of items rely heavily on the specific content of the passage provided: (1) Identifying the Main Conclusion items require the participants to select the statement that best represents the main conclusion of the argument; (2) Identifying an Assumption items ask the participants to identify which option is an essential point that, although not explicitly stated in the text, is implicitly assumed when drawing the conclusion; (3) Assessing the Impact of Additional Evidence items involve evaluating which statement among the options would most effectively weaken the argument when used as evidence; (4) Detecting Reasoning Errors items require the participants to choose the option that most accurately identifies flaws in the argument within the material; and (5) Drawing a Conclusion items prompt the participants to determine whether the information provided in the passage is sufficient to infer the statements presented in each option. These skill categories necessitate direct engagement with the content and specific inferences based on the information provided, which appears to be less challenging for LLMs as they are adept at processing and generating responses based on the context within the input (Radford et al., 2019).
Performance on Different Paragraphs in the EWCTET
Since the EWCTET features open-ended responses, analyzing the LLMs’ responses across various paragraphs can reveal their strengths, weaknesses, and linguistic features. Figure 6 illustrates that LLaMA-4 and DeepSeek-R1 caught up with or surpassed the students on many paragraphs where GPT-3.5 and GPT-4 lagged. Nevertheless, certain items still present significant challenges for the LLMs. A notable example is Scenario 1, Paragraph 2 (S1_P2), which involves the justification for a nighttime roadside parking ban based on afternoon traffic congestion, where the correct response requires noting the temporal discrepancy. While this flaw was apparent to most students, all of the LLMs tested in this study failed by incorrectly arguing that traffic congestion was a valid justification for the parking ban. This indicates that despite LLaMA-4's substantial progress in detecting reasoning flaws, it still occasionally overlooks critical details that humans identify easily.
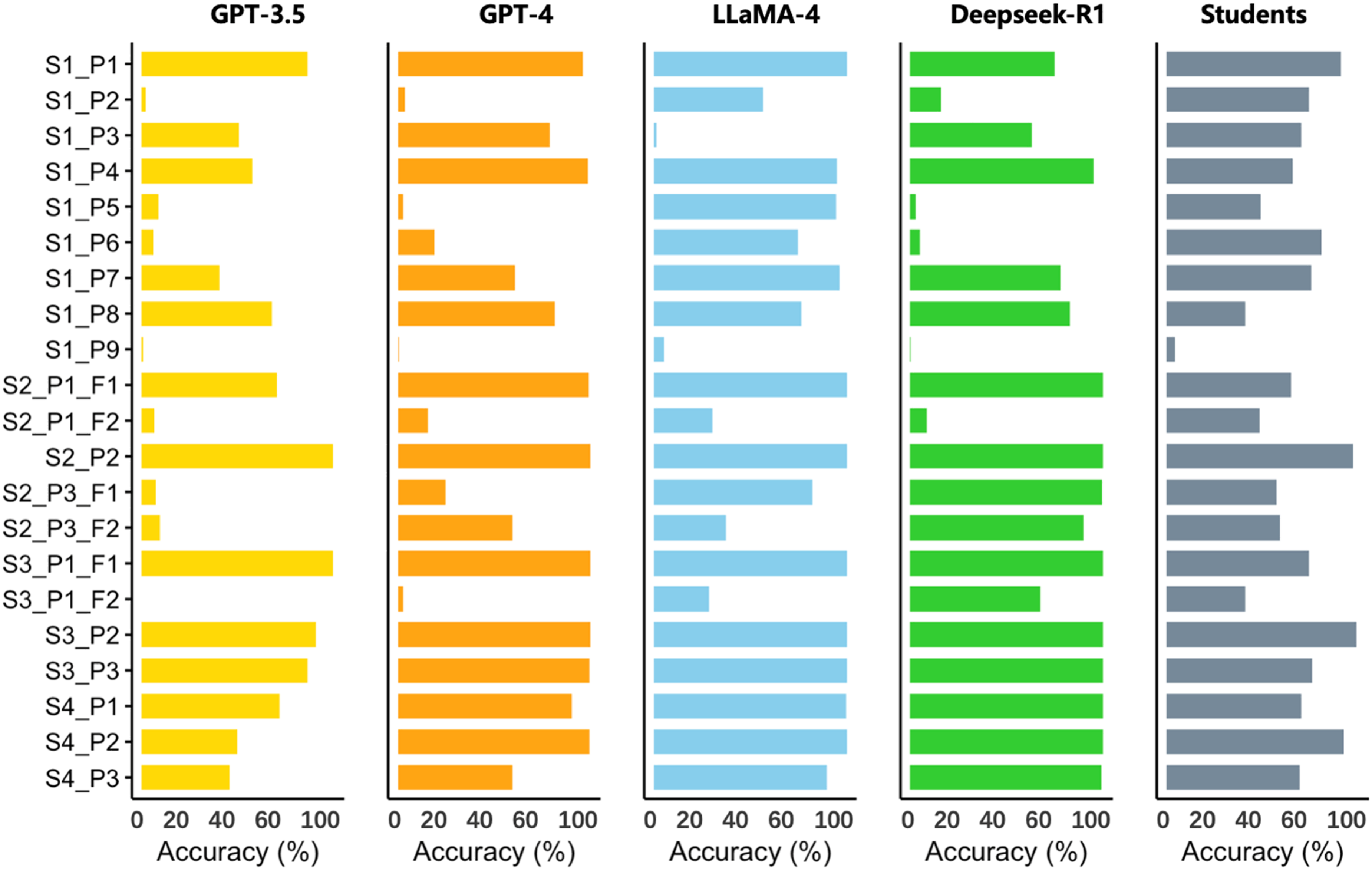
Performance of LLMs and students on different paragraphs of the EWCTET.
Some paragraphs contain two flaws—for instance, Paragraph 1 of Scenario 2 (S2_P1_F1 and S2_P1_F2). The students varied in their recognition of these flaws: some identified the first flaw, others the second, and some recognized both, resulting in relatively balanced accuracy across the two flaws. In contrast, the LLMs typically identified just one flaw. This suggests that human critical thinking may encompass a broader and more comprehensive range of perspectives, allowing for a more nuanced evaluation of multiple reasoning errors. LLMs, in generating the most probable answers based on training, might oversimplify complex scenarios with multiple embedded flaws.
Notably, LLaMA-4 unexpectedly underperformed on Paragraph 3 of Scenario 1 (S1_P3) compared to the students and other LLMs. This reflects the inherent differences between different LLM families and underscores the potential risks of overtrusting responses from a single model.
Analysis of Paragraph 7 of Scenario 1 (S1_P7) reveals notable differences in the LLMs’ linguistic features. This paragraph suggests that environments are unsafe if there is even the minimal possibility of accidents, thus recommending a ban on nighttime roadside parking to reduce potential risks. The participants need to identify that the definition of “safety” presented is overly absolute, unrealistic, or unattainable. Alternatively, they may point out that even if the parking ban were implemented, the environment would still not be “safe” by this definition, making the argument self-contradictory. In responding to this item, LLaMA-4 frequently incorporates terminology related to logical fallacies (such as the straw man fallacy, appeals to the emotions, and equivocation), which gives its responses a more professional tone. In contrast, GPT-3.5, GPT-4, and DeepSeek-R1 employ more accessible linguistic styles that rarely include such terminology. Examples of the responses of each LLM are as follows: LLaMA-4: This argument contains a logical error. It employs equivocation by redefining “safety” (as absolute zero risk) to negate the current situation. In reality, “traffic safety” is about risk probability management rather than zero risk (pedestrians crossing streets also face accident possibilities), making this argument's standard impractical for real-world application. GPT-3.5: I believe this argument is weak. While we all desire safe conditions, eliminating the possibility of accidents is impossible in reality. We should evaluate safety based on practical considerations and implement appropriate measures to reduce accident occurrence. GPT-4: I consider this a relatively weak argument. Although safety is extremely important, eliminating the possibility of accidents is unrealistic. We should seek to reduce the probability of accidents rather than attempting to eliminate risk entirely. DeepSeek-R1: The reasoning in this paragraph is weak. This definition of “safety” is excessively absolute and extreme; many real-world situations involve certain risks but are not necessarily considered unsafe.
It should be noted that LLaMA-4's use of terminology for logical fallacies is not always accurate. For example, it occasionally misidentified the fallacy in the above paragraph as a slippery slope fallacy—a logical error that claims a small first step inevitably leads to a chain of events ending in a significant negative outcome, without sufficient evidence for this inevitable progression. This warns us that LLMs’ seemingly professional expression style might lead users to place excessive trust in their responses, potentially resulting in negative consequences.
Performance Across Items of Varying Difficulty
The differences in accuracy between the LLMs and the students on the EWCTET items indicate that the same items may present different levels of difficulty for LLMs compared to humans. To investigate this, we ranked the TSA and the EWCTET items based on the students’ accuracy and, using the students’ accuracy as a measure of item difficulty, arranged the items from easiest to most difficult. The results are shown in Figure 7.

Performance of the LLMs and the students across items of varying difficulty.
In the TSA, the accuracy of GPT-4, LLaMA-4, and DeepSeek-R1 generally corresponds with the item difficulty calculated based on the student responses. For the easier items, where student accuracy exceeds 80%, these models achieve 97%–100% accuracy. However, as the items become more challenging for the students, these models begin to make errors. In contrast, GPT-3.5's performance does not align well with item difficulty; it frequently makes errors, even on easier items. For the most difficult items, where student accuracy falls below 50%, GPT-3.5 scores 0% accuracy, indicating that the items that are most challenging for humans are also extremely difficult for GPT-3.5. Notably, GPT-4's accuracy is consistently equal to or higher than that of GPT-3.5 across all items, demonstrating a clear improvement in performance with the newer model. LLaMA-4 and DeepSeek-R1 show similar accuracy trajectories across the TSA items of varying difficulty. DeepSeek-R1 is specifically optimized for complex reasoning tasks, while LLaMA-4 is a general-purpose LLM, with the version used in this study (LLaMA-4 Maverick Instruct) optimized for understanding and following instructions. The fact that they achieve such consistent accuracy patterns warrants further exploration.
On the EWCTET, all of the models show less alignment with item difficulty as determined by student performance, making errors on some easier items. However, LLaMA-4 generally aligns more closely with students’ accuracy compared to the other models.
Response Patterns of the Humans and the LLMs
Given the distinct performance patterns of the LLMs across the different tests and skill categories observed earlier, we used hierarchical clustering to explore whether the LLMs’ critical thinking performance is unique or aligns with specific subgroups of students. Hierarchical clustering is an analytical method that progressively groups data points based on similarity, starting with each point as its own cluster and merging them step by step into larger clusters to reveal natural groupings within the data (Nielsen, 2016, pp. 195–211).
Specifically, we utilized the scores from the seven skill categories in the TSA and from four different scenarios in the EWCTET, resulting in 11 variables. Initial clustering was performed on the student data. As shown in Figure 8, the clustering analysis yielded four distinct and representative clusters. Figure 9 displays the mean scores for these clusters: Clusters 1, 2, and 3 demonstrated similar performance across the TSA skill categories, with differences mainly emerging in the EWCTET scenarios. In contrast, Cluster 4 was notably different from the others, showing distinct patterns in the EWCTET scenarios and more pronounced variability across the TSA skill categories.

Hierarchical clustering results based on the students.

Performance patterns of the four clusters of students and LLMs.
Subsequently, we calculated the average performance of each LLM (GPT-3.5, GPT-4, LLaMA-4, and DeepSeek-R1) across all 11 variables to represent each model as a single entity. These averages are depicted as dashed lines in Figure 9. The clustering analysis showed that GPT-3.5 displayed similar accuracy patterns to Cluster 4, although it showed more pronounced weaknesses in Matching Arguments and Applying Principles and performed slightly worse in Scenarios 1 and 4 of the EWCTET. In contrast, GPT-4 showed similar patterns to Cluster 2, slightly outperforming the average of Cluster 2 in the first four TSA categories but underperforming in Matching Arguments. Both LLaMA-4 and DeepSeek-R1 were most similar to Cluster 3, with LLaMA-4 displaying a more balanced performance across the categories. Incorporating the LLMs as four entities into the clustering analysis further confirmed that GPT-3.5 aligns with Cluster 4, GPT-4 with Cluster 2, and both LLaMA-4 and DeepSeek-R1 with Cluster 3. Overall, the clustering analysis suggests that LLMs perform similarly to existing human groups, but different models resemble different types of human participants.
Conclusion and Discussion
Since the integration of AI into work and study environments, researchers have warned against an over-reliance on AI, emphasizing the importance of understanding the technology to fully harness its potential (Golan et al., 2023). This study evaluated the critical thinking abilities of four LLMs (GPT-3.5, GPT-4, LLaMA-4, and DeepSeek-R1) using two validated instruments (the TSA and the EWCTET), comparing their performance with undergraduate students from a top-tier Chinese university. The results suggest that advanced LLMs like LLaMA-4 and DeepSeek-R1 have not only developed a strong grasp of the cognitive skills of critical thinking, but can also effectively apply these skills to solve real-world problems.
However, while the best LLM results on the TSA matched the maximum student scores, on the EWCTET the best human results still represent an upper boundary that current LLMs have not yet reached. This performance gap indicates that tasks requiring the independent identification of key points, determination of perspectives, and integration of cognitive processes without explicit structural guidance—as exemplified by the EWCTET—pose greater challenges for current LLMs.
A closer examination reveals that advanced LLMs like LLaMA-4 still face reliability challenges due to significant performance variability. On the TSA, the LLMs demonstrated uneven performance across the different item categories, particularly struggling with more abstract tasks like Matching Arguments, where extracting reasoning structures rather than relying on content is crucial. This observation is consistent with recent findings on the limitations of LLMs in abstract reasoning (Xiong et al., 2024). Furthermore, while the LLMs performed reliably on very simple items, they became unreliable as the item difficulty increased. These findings collectively suggest that human oversight remains essential to assess task appropriateness and set realistic expectations for the performance of LLMs.
On the EWCTET, even the highest-performing model, LLaMA-4, occasionally overlooked key details and missed multiple flaws within the same material, resulting in unexpected errors on tasks that were straightforward for humans. Despite LLMs utilizing transformer architecture (Radford et al., 2019), the attention mechanism of which excels at processing contextual information by weighing the importance of different parts of the input (Vaswani et al., 2017), accurately directing attention within complex argumentative content remains challenging, particularly when multiple flaws coexist. This suggests that, in practical applications, deliberate guidance is crucial to help LLMs focus on relevant elements and comprehensively identify flaws from various perspectives. These patterns, observed across models from different series (GPT, LLaMA, and DeepSeek), appear to be general features of contemporary LLMs, reflecting the uniformity of AI systems, which stems from shared architectural principles and training methodologies (Allen-Zhu & Li, 2024).
Overall, this study underscores the advanced capabilities of LLMs in critical thinking tasks while emphasizing the irreplaceable role of human critical thinking in guiding and evaluating their outputs. Critical thinking remains essential in the era of AI as a cornerstone of 21st-century skills (Voogt & Roblin, 2012). Furthermore, as we move toward a future where humans and AI work collaboratively, understanding both the capabilities and limitations of AI's critical thinking will be crucial for effective human–AI collaboration and responsible AI deployment.
Limitations and Future Directions
This study utilized two prominent critical thinking assessments, the TSA and the EWCTET, to evaluate the performance of LLMs on critical thinking skills. However, future research should use more ecologically valid assessment methods, such as evaluating human–AI teams, to gain a more accurate reflection of AI application in task completion. Additionally, the study used prompts derived from human instructions to acquire the LLMs’ responses, which provides a baseline performance. Future research should explore alternative prompts, such as chain-of-thought techniques (Wei et al., 2022), to gain deeper insights into how different settings impact LLMs’ critical thinking abilities and their potential for optimal performance.
Furthermore, the findings of this study suggest certain potential characteristics of LLMs. Future research could benefit from experimental studies, such as designing items with superficially similar options and consistent reasoning structures for Matching Arguments items. This approach would help better understand the depth of LLMs’ critical thinking abilities.
Footnotes
Ethical Considerations
This study was conducted in accordance with ethical guidelines and approved by the Institutional Review Board of Beijing Normal University (IRB Number: BNU202409180142).
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was funded by the Beijing Natural Science Foundation (grant number L247011).
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.