
Abstract
Background:
Blood transfusion is a common medical intervention. For patients with acute critical bleeding, large volume “massive” transfusion (MT) is required, and is potentially life-saving. However, the evidence-base for transfusion practice, particularly for critical bleeding/MT management, is relatively weak, and has confounded the development of clinical best practice recommendations.
Aim:
The aim was to address this evidence gap by building the Australian and New Zealand Massive Transfusion Registry (ANZ-MTR). We describe how data collection, standardisation and interoperability of data sourced from multiple electronic information systems are managed, and share the lessons learned.
Innovation:
The ANZ-MTR is a database of routine electronic hospital admission information, laboratory test results, transfusion records and outcomes of adults (18 years and older) who have received a MT for any cause of acute critical bleeding, including trauma, major surgery, obstetric or gastrointestinal haemorrhage. Source data are provided by participating hospitals and are harmonised by the registry. Since its launch in 2011, the ANZ-MTR has captured over 9200 MT episodes from 29 hospitals.
What can be learned from this case:
Effective communication with all custodians of the source data has been fundamental to the success of the registry. A preeminent outcome of this success is the current expansion of the registry to become the National Transfusion Dataset, which will capture comprehensive data for all transfusions.
Implications for health information management practice:
The ANZ-MTR illustrates that complex and varied arrays of routinely collected clinical and hospital administrative data from multiple electronic information systems can be consolidated into a resource-rich clinical database.
Keywords
Introduction
Blood transfusion is a common medical intervention used to alleviate the symptoms of a wide range of clinical conditions, including replacement of blood loss due to bleeding, anaemia or haemostatic dysfunction. The supply of blood products for patients is an essential healthcare service, but it is expensive, costing Australian governments approximately 1.7 billion Australian dollars in July 2023–June 2024 (National Blood Authority (NBA), 2024). For patients with life-threatening acute critical bleeding (CB) (Ahern et al., 2022), large volume “massive” transfusion (MT) may be required. Acute CB is often unexpected, can occur across diverse clinical settings, including trauma and non-trauma (e.g. major surgery, obstetric and gastrointestinal haemorrhage), and is associated with poorer outcomes (Green et al., 2017; Halmin et al., 2016). Although the proportion of patients who receive a MT is relatively small, they consume a disproportionately large amount of blood products. Furthermore, the emergent nature of a MT event imposes significant additional stresses and costs on health care, laboratory and transfusion services (Sanderson et al., 2021).
Efforts to improve the management and outcomes of CB/MT have been confounded by a weak and poorly documented evidence-base for transfusion practices overall (Fergusson, 2016; Spahn et al., 2013). Most of the available evidence on the management of CB/MT has come from the trauma setting, both military and civilian trauma, and has been applied to non-trauma CB/MT settings (Booth and Allard, 2018; Thomasson et al., 2019). This has occurred without robust clinical evidence for appropriateness and despite significant differences in the underlying pathophysiology of (CB) in non-trauma versus trauma patients. Moreover, there is no internationally agreed definition of MT – this is considered further in the next section. Consequently, different definitions of MT have been used in published clinical studies, making it difficult to compare findings (Lin et al., 2023; McQuilten et al., 2021).
In 2011, recognising the deficit in knowledge, and the high resource-intensity associated with managing CB/MT, Australia’s National Blood Authority published its first edition of patient blood management (PBM) guidelines for CB/MT (NBA, 2011). The guidelines, which were developed by a panel of clinical experts, constrained its recommendations to those that were sufficiently supported by available evidence. Guidance in the setting of major gaps in knowledge or weak evidence were provided as consensus-based “practice points.” Typically, evidence gaps could be addressed in well designed, sufficiently powered multicentre clinical studies. However, in the context of low-event frequency and oftentimes chaotic “life-or-death” circumstances of CB/MT, conducting prospective clinical studies is fraught with challenges and is extraordinarily expensive.
As an alternative approach to address the gaps in knowledge in the management of CB/MT, and coincident with the release of the NBA’s PBM guidelines in 2011, the Australian Government’s medical research funding body, the National Health and Medical Research Council, awarded a major partnership grant for the establishment of the Australian and New Zealand Massive Transfusion Registry (ANZ-MTR). The registry resides within the School of Public Health and Preventive Medicine (the School) at Monash University, Melbourne, Australia. The School, together with the University’s specialist computing infrastructure platform (Helix), has considerable expertise in the establishment and management of large, complex electronic clinical registries and datasets (Helix, 2025; School of Public Health and Preventive Medicine (SPHPM), 2025). Of the 131 registries listed on the Australian Register of Clinical Registries (ACSQHC, 2025), over 40 registries (>30%) – including Victorian state, Australian, bi-national and multi-national registries – are maintained under the auspices of the School, making the School the largest clinical registries manager in Australia and one of few major multi-registry managers internationally (SPHPM, 2023).
The ANZ-MTR is a database of routinely stored electronic hospital admission information, clinical laboratory test results, transfusion records and outcomes of adult patients (18 years and older) who received a MT for any cause of acute CB, including trauma and non-trauma causes. The purpose of the ANZ-MTR is to (1) improve the evidence base on MT practice; (2) monitor variations in transfusion practice and impact on clinical outcomes; (3) provide an opportunity for benchmarking, feedback to hospitals on transfusion practice and blood product use; (4) inform blood supply planning, inventory management and development of future clinical trials and (5) enhance translation of evidence into policy and PBM guidelines (Oldroyd et al., 2016). Since its launch in 2011, the ANZ-MTR has captured over 9200 MT episodes across 29 participating hospitals in Australia and New Zealand. In 2023, the National Health and Medical Research Council funding agency named the ANZ-MTR in its 13th edition of “10 of the best” showcase of research projects that have achieved exceptionally meaningful outcomes (National Health and Medical Research Council (NHMRC), 2023).
In this study, we focus on how we managed data collection, standardisation and interoperability to successfully build and expand the ANZ-MTR. We describe our data extraction processes from various health information systems, reflect on some of the challenges during data acquisition and processing, the work-around and key lessons and highlight how our experience in building the ANZ-MTR has helped in launching the National Transfusion Dataset (NTD), which will be a much larger registry of all patients who have received a transfusion at participating Australian hospitals. This current report extends our previously published article that described the establishment and early phase of the ANZ-MTR (Oldroyd et al., 2016). Other core registry operations are detailed there, including ethics, governance, data validation, privacy and security (Oldroyd et al., 2016). Notably, the ethics approval agreements held by the ANZ-MTR include a waived consent model.
The innovation
Identifying acute CB/MT patients – definition of MT
A foundational decision for the ANZ-MTR was to identify the best definition of acute CB/MT that would ensure the registry captured data on all patients across every clinical context in which CB/MT can occur, and to minimise any selection biases that may exclude certain patient cohorts.
In assessing bleeding acuity, both the volume and intensity of blood loss are fundamental considerations. However, in the clinical setting, there is no universal method that reliably measures blood loss volume (Tran et al., 2021). In the circumstance of life-threatening acute CB, a surrogate estimate of blood loss is the number of units of red blood cells (RBCs) transfused to regain haemostatic control (Mitra et al., 2011). Thus, the transfusion of a prescribed number of RBC units within a set time-period (RBC units:time, hours) can be used to define acute CB, and consequently, MT. As a reference point, the transfusion of 10 RBC units approximates the replacement of the total circulating RBCs of a 70 kg adult. Of the various MT definitions that have been used in clinical studies, the “⩾10 RBC units in 24 hours” (⩾10:24) definition is the most common (McQuilten et al., 2021). However, this definition has significant drawbacks. In particular, the ⩾10:24 MT definition excludes patients with potentially exsanguinating bleeding intensity who were transfused several units of RBCs in a relatively short time-frame, but fewer than 10 units in 24 hours because the bleeding was stemmed by effective emergency medical/surgical/radiological intervention (context bias), or the patient died (survivor bias; Green et al., 2017; Mitra et al., 2011).
To address the issue of which MT definition to use, the ANZ-MTR undertook a study that compared the inclusivity and aetiology of patients who had experienced CB defined by three different definitions of MT, ⩾10:24, ⩾6:6 and ⩾5:4 RBC units:hours (Zatta et al., 2014). The study concluded that the transfusion of ⩾5 RBC units in 4 hours was the most sensitive and inclusive of all contexts of acute CB (i.e. trauma and non-trauma), and this definition was adopted by the ANZ-MTR (Zatta et al., 2014). The National Blood Authority has espoused this definition in their recently updated guidelines for CB/MT management (NBA, 2023).
Hurdles for hospital participation in the ANZ-MTR
In order to identify MT episodes eligible for the ANZ-MTR (i.e. transfusion of ⩾5 RBC units in 4 hours), prospective participating hospitals needed to have a transfusion laboratory information system that recorded the time and date when blood components were issued to a patient. Numerous hospitals have been unable to participate in the registry because their transfusion information system did not record the time of issue. Newer generation transfusion information systems have this time-stamp capability, although it may still be an optional feature to be requested at the software system design phase.
Participation in the ANZ-MTR is voluntary. Table 1 gives an overview of the 56 hospitals (50 Australian; 6 New Zealand) that have obtained ethics/governance approval to join the registry since its commencement in 2011. We aim to have representation of all jurisdictions across Australia and New Zealand, as well as the diversity of hospitals in which MT episodes may occur, including obstetric care. Hospitals that provide specialised services, such as major surgery, trauma care and emergency medicine, have the highest rate of MT episodes. Consequently, large, public principal referral (tertiary academic) hospitals and acute care hospitals are well represented in the registry. While there is no priority process per se for hospitals joining the ANZ-MTR, consideration is given to the ease of obtaining the mandatory approvals and requested data items, together with higher likelihood of MT episodes; these considerations inevitably favour larger public hospitals. As noted in Table 1, 29 participating hospitals have provided complete packages of requested data items to the registry.
ANZ-MTR participating hospitals and imported MT episodes.
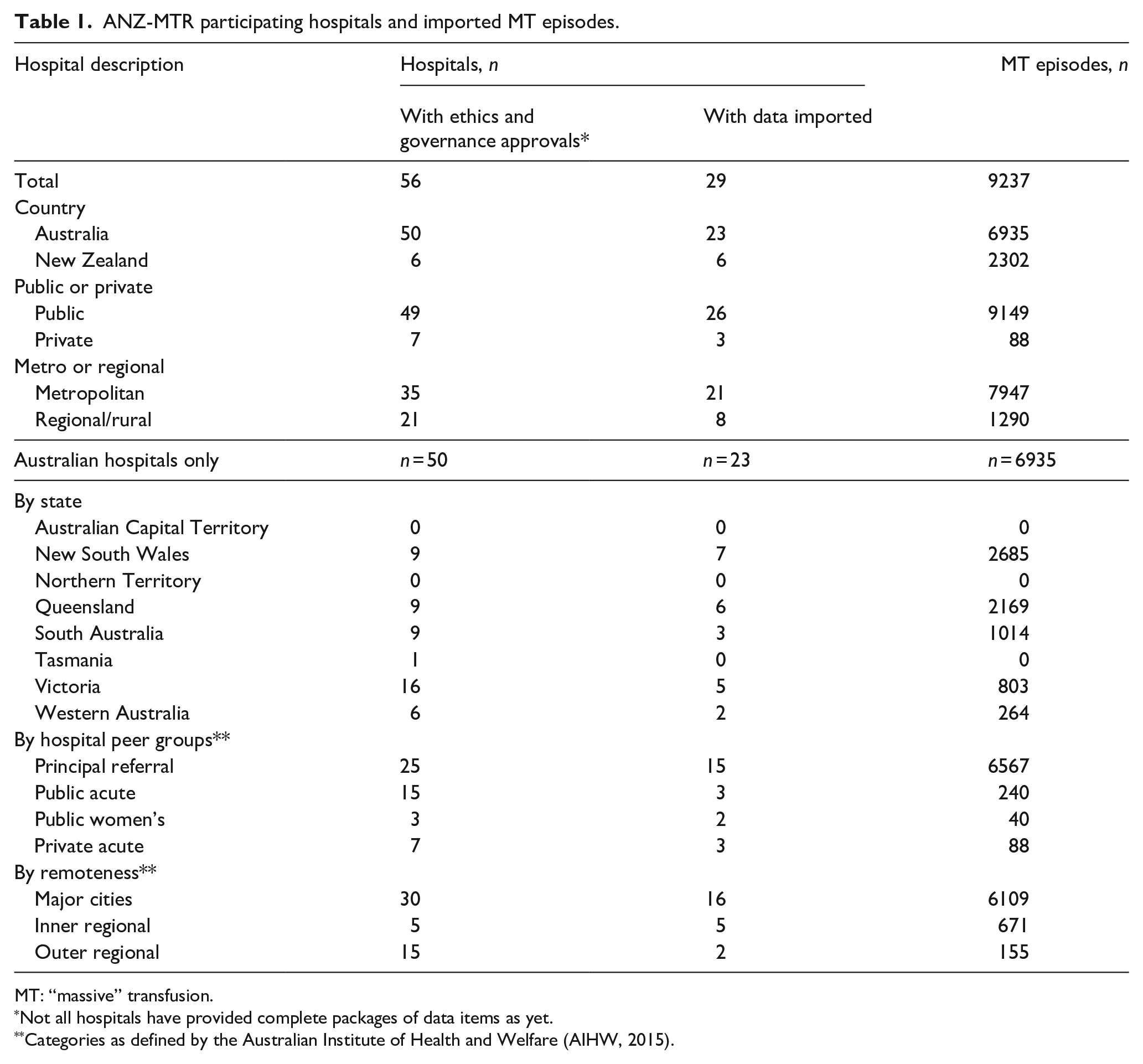
MT: “massive” transfusion.
Not all hospitals have provided complete packages of data items as yet.
Categories as defined by the Australian Institute of Health and Welfare (AIHW, 2015).
Gathering the source data
Figure 1 shows an overview of the steps in gathering the source data from individual hospitals and their pathology and transfusion laboratory providers, which in some cases were separate entities to the hospital. For hospitals that passed the hurdle for participation (see above), their first step is to query their transfusion laboratory information system to identify the patients who met the criteria of having received a MT. The records of all transfused products issued to those patients for their entire hospital admission in which the MT occurred is then extracted into a source file. The list of patients, together with the date of the MT, is shared with the nominated data analysts (custodians) of the hospital’s health information system and pathology laboratory information system; they then extract the extensive list of data items requested by the ANZ-MTR for the entire hospital admission of the patient into separate source files. The list of extracted data items has been published previously (Oldroyd et al., 2016). The source files are transferred to the ANZ-MTR via Monash University’s secure file transfer portal. Once received, the source files are initially checked for completeness and suitability before proceeding to data processing for importation into the database. Data “packets” are provided periodically from the sites – the ANZ-MTR is not a “live” database with real-time data uploads.
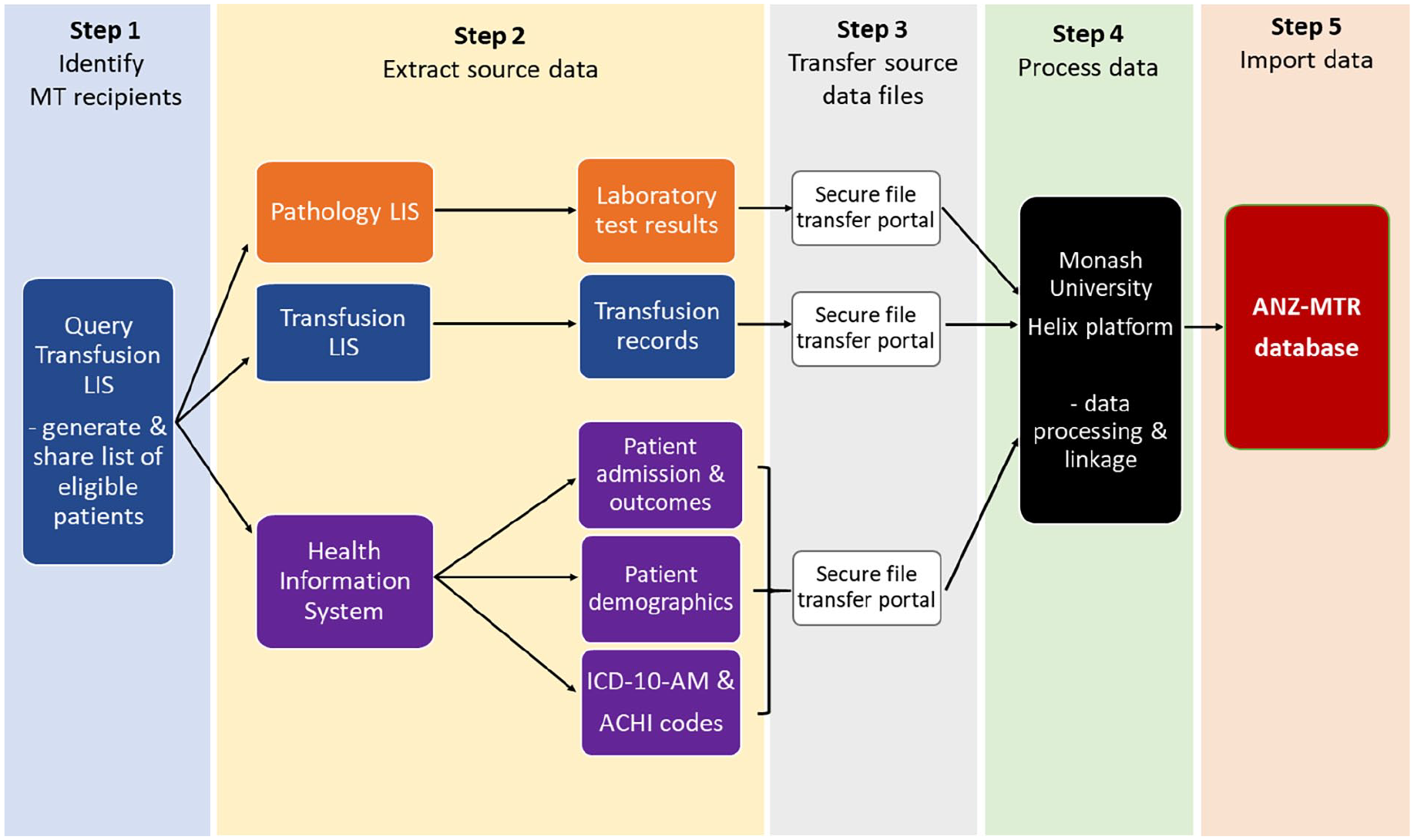
Schematic of the steps required for the collection, processing and importation of source data into the ANZ-MTR database.
In setting up a new participating site, the ANZ-MTR provide the hospital data custodians with source data extraction templates (Microsoft Excel format). However, for most hospitals various system-specific adaptions are made, and thus the format of the source data files submitted to the ANZ-MTR differ between hospitals, which is not ideal. As a work-around, data custodians are asked to use the same extraction template format that they used for their previous data extraction.
Shared, networked or centralised data information systems are helpful in reducing the variability of extraction file-formats between hospitals and/or their pathology and transfusion service providers. Centralised data systems are becoming more common-place within healthcare and hospital administrations across Australia and New Zealand. For example, obtaining source data for New Zealand patients is more straightforward for this reason. Transfusion records for all transfused patients in New Zealand are captured by the New Zealand Blood Service as an integral function of their haemovigilance program for blood donor/donation-recipient tracing. All hospital in-patient information is uploaded to the New Zealand Ministry of Health. Laboratory test results are the only data items that need to be sourced directly from each of the participating New Zealand hospitals or their pathology provider.
Data processing and importation
All source data are stored on a Microsoft SQL server hosted at Monash University. Processing of source data and importation into the ANZ-MTR database are conducted within the secure infrastructure of the University’s Helix digital technology platform (Helix, 2025).
Harmonisation of the source data is a crucial step in the overall process. A Microsoft SQL server integration services pipeline with a validation and harmonisation procedure unique to each hospital is used for this process. The harmonisation procedures require regular checking and updating to keep abreast of changes to any of the multiple information systems used to obtain the source data for each hospital. Apart from data that came from networked systems between hospitals or service providers, there was no common format for data items sourced from different information systems. For example, harmonisation of categorical variables such as blood products required a standard set of categories to be created for the registry, and each of the values supplied from the different hospitals is mapped to one of those categories. There are over 440 unique descriptors of blood products alone, which has been condensed to two sets of categories – one set of 15 categories and the other set slightly less condensed with 32 categories.
Alignment of data pertaining to the episode-of-care in which the MT occurred is central to the purpose of the ANZ-MTR. Some patients have more than one episode-of-care within a single hospital admission. However, laboratory test data or transfusion data are often not labelled at the episode level. Therefore, it is necessary to link these data to the episodes by matching dates and times. Assignment of the context of the CB underlying the MT event is fundamental to the purpose of the ANZ-MTR; however, there is no field in the source data that identifies the specific cause of the CB. This has to be inferred using a specially developed algorithm that classes the clinical diagnostic and procedure coding data into higher-level categories (e.g. trauma, cardiac surgery, obstetric haemorrhage and so forth). This hierarchical stepwise algorithm has been validated and described previously (McQuilten et al., 2017; Zatta et al., 2014). While the algorithm typically achieves a success rate of greater than 85% for the assignment of the “primary bleeding context,” the unassigned cases are reviewed by medically qualified ANZ-MTR personnel.
Database structure
Certain data items captured by the ANZ-MTR, such as transfusion and laboratory test records, have numerous and varied numbers of datapoints per patient admission. To accommodate this, the ANZ-MTR database consists of six linked data tables in which some tables have multiple-row display of data items for each admission and others have a single-row. Consequently, the structure of the ANZ-MTR database is more complex compared to many clinical registries that simply have single-row display of data items for each patient.
Figure 2 shows a simplified schematic of the ANZ-MTR database structure. The “Patients” table is the top-level table and contains a unique identifier for each patient, which is used for linkage to the “HIS admissions” table. The “HIS admissions” table contains hospital admission information, including dates/times of admission and discharge, and discharge status. Each HIS entry is given a unique identification number. Patients who have more than one hospital admission involving CB/MT will have more than one HIS identification number. The “Episodes” table is the central table of the database; it contains the details of the episode(s)-of-care within each hospital admission and is linked to the “HIS admissions” table. Each episode-of-care is given a unique identification number. The particular episode-of-care in which the CB/MT occurred is identified by aligning the start and end dates of the episode-of-care in the “Episodes” table with the dates and times of RBC transfusions in the “Transfusions” table. Records of all blood products administered to each patient during their admission is contained in the “Transfusions” table. The “Diagnosis and Procedures” table has all the clinical coding data associated with each admission; these are used to identify the primary cause of the CB/MT as well as the presence of comorbidities. The “Lab Results” table has all the results of a comprehensive panel of biochemistry and haematology tests performed during the admission. These latter three tables are linked to the “Episodes” table.
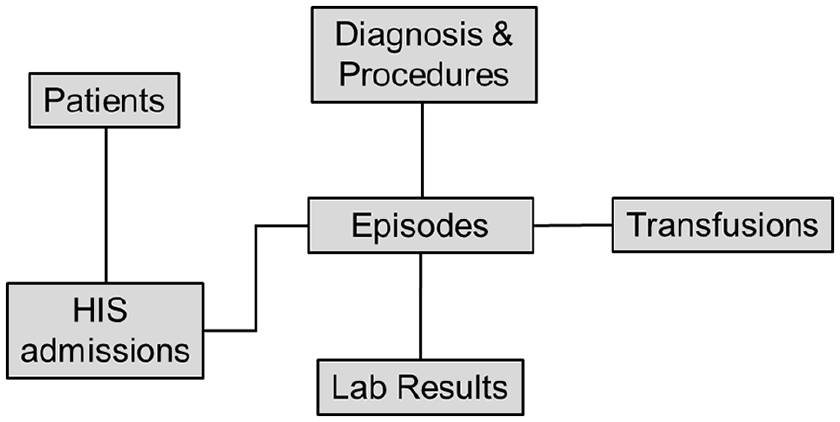
Schematic of the ANZ-MTR database structure.
The multi-table structure of the database allows analysis at the admission level, episode level, or within sub-groups, such as bleeding context level. For many analyses, tables need to be merged. Careful planning was necessary at the design stage of the database to decide which data items would sit on which tables, and which data items needed to sit on more than one table.
What was learned from this case?
The single most significant challenge of creating the ANZ-MTR database was obtaining the source data from hospitals in a timely manner. Importation of new data extractions into the ANZ-MTR database requires receipt of all three packages of source data (i.e. hospital information, transfusion records and laboratory test results). Absence of one source data file delays the entire importation process for that hospital’s data. Typically, the hospital-based champion for the ANZ-MTR is a haematologist, senior transfusion scientist or transfusion practitioner, and while being a keen advocate for the registry, they are not the authorised data custodians of the various information systems. We found the most effective strategy to overcome delays in obtaining the source data was to build good working relationships directly with the hospital data custodians-analysts tasked to perform the data extractions and the ANZ-MTR data team. Communication directly with the data custodians provides opportunities to remind them that their efforts are fundamental to the registry’s mission of advancing knowledge in transfusion medicine.
Originally, the ANZ-MTR was established as a research project and no funding was allocated in the budget to remunerate hospitals and affiliated service providers for the time invested by their staff to write and test data extraction scripts or prepare extraction files. While hospitals are keen to participate in the ANZ-MTR, research-related and non-core activities that are unfunded have low priority. This has been factored into the budget for the new NTD, which is discussed further below. In several instances, hospitals do not have in-house capability to prepare non-routine data extraction files from their various information systems due to proprietary restrictions by the software manufacturer, or constraints within service level agreements with their third-party service providers, such as private pathology companies. In some instances, third-parties have assisted to resolve the issue, while other instances could not be easily resolved. The learning from this is the importance of raising broader awareness across hospital management teams responsible for deciding the specifications of software infrastructure and third-party service level agreements to avoid these types of limitations on accessibility to their own data. As noted earlier, shared, networked or centralised health information systems across multiple hospitals at state level or nationally are beneficial in streamlining data extraction and importation processes. The efficiency and productivity gains are significant.
From the ANZ-MTR to the NTD
The ANZ-MTR was the first transfusion-focused clinical registry for Australia. The success of the ANZ-MTR has paved the way for the establishment of the NTD, which was launched in 2021. The NTD is collecting data from all adult patients (18 years and older) transfused any type of blood product (RBC, fresh frozen plasma, platelets, cryoprecipitate, fractionated blood proteins) at participating hospitals. The overall structure of the NTD database mimics that of the ANZ-MTR (i.e. as represented in Figure 2). MT cases that would otherwise be captured by the ANZ-MTR will now be identifiable by analysis of data within the NTD. Consequently, the ANZ-MTR will effectively become an entity within the NTD. By integrating datasets on blood utilisation, including pre-hospital, hospital patient admission, clinical and laboratory data, together with linkages to other registries and datasets, the NTD aims to contribute to a comprehensive haemovigilance framework, closing critical gaps in transfusion surveillance and building new knowledge to strengthen clinical best practice guidelines in transfusion medicine. The NTD will form the first integrated national database of blood use in Australia.
The development of the NTD is supported by national medical research funding focused on advancing data infrastructure and innovation that promote interoperability and accessibility. For example, the NTD will be implementing the Observational Medical Outcomes Partnership (OMOP) Common Data Model (CDM) to standardise and structure the data for better interoperability and advanced analytics. The concept behind the OMOP-CDM is the conversion of data into a common format through the harmonisation of terminologies, vocabularies and coding schemes within a unique repository (Ward et al., 2024). By adopting the OMOP-CDM, NTD will be aligned with global healthcare databases, enabling seamless integration with other clinical datasets and enabling large-scale observational research. This transformation will enhance comparative effectiveness studies, predictive modelling, and epidemiological analyses, ultimately improving transfusion practices, patient outcomes and evidence-based decision-making in transfusion medicine. Furthermore, the NTD has partnered with a major healthcare provider to pilot the CogStack platform (Cogstack, 2025) – a natural language processing and artificial intelligence technology that extracts information in any format, including structured and unstructured information within a scanned document or image (Jackson et al., 2018). The NTD CogStack will enable unlocking of unstructured data from patient records, such as medications, point-of-care testing results and transfusion-related adverse events, to supplement the routinely collected electronic patient data in the NTD (Au Yeung et al., 2024). This partnership will strengthen the data coverage and quality of the data in the NTD.
An important outcome will be the development of simple-to-use data accessibility tools for hospital quality assurance monitoring of transfusion practice. For example, a pilot interactive blood usage dashboard showcasing data from the ANZ-MTR has been developed and is now presented on the NTD (2025) website. The pilot dashboard offers a preliminary glimpse into the future capabilities of this nationally important project.
Future aspirations
We aspire for the NTD to become a comprehensive “vein-to-vein” (V2V) dataset linking blood donors/donations to recipients through linkage with the donor database of Australia’s national blood transfusion service. This will open up new opportunities to advance knowledge in transfusion medicine and transfusion science, which will benefit transfusion recipients, particularly Australian patients. New Zealand has a head start because it already has a centralised blood transfusion information system hosted by the national Blood Service, which operates across all hospitals with a transfusion laboratory linked to the Blood Service. Essentially, it is a multi-centre V2V system limited to blood donor/donation and transfusion records, but provides a good example of the benefit of national centralised health information systems.
Other large, multicentre V2V datasets exist elsewhere in the world. The Swedish-Danish Scandinavian Donation and Transfusion (SCANDAT) database utilises pre-existing Scandinavian population and health registers, and thus has almost complete life-time follow-up for both blood donors and recipients (Zhao et al., 2020). Of note, residents of Sweden are assigned national registration numbers and most regions in Sweden use the same laboratory information system, readily allowing linkages to all other health and population registers. Another V2V dataset based in the United States, Recipient Epidemiology and Donor Evaluation Study, 4th programme (REDS-IV) has linked information for blood donors/donations and the electronic medical records of patients at more than 20 participating hospitals (Birch et al., 2023). The data are collected, transformed and harmonised by a private data coordinating centre, and uses the OMOP-CDM, similar to the NTD. The SCANDAT and REDS-IV databases are used for an expansive range of epidemiological and population health knowledge-generating purposes, but clearly are most relevant for the countries and jurisdictions from which the source data originate. For the advancement of transfusion best practice in Australia, it is important that we have our own comprehensive national V2V database.
The establishment and operation of the ANZ-MTR and NTD have been instigated and driven by a non-profit research team; provision of patient source data has not been mandated. As the national blood supply is fully funded by each of the Australian and New Zealand governments, and is expensive, it is anticipated that governments will be keen to ensure best clinical practice and efficient blood usage and will support the work in the future. The NTD has the potential to become a bona fide national clinical quality and haemovigilance registry; participation of hospitals in the NTD could be made a requirement for their accreditation. Furthermore, the NTD will be a valuable resource to support innovative registry-based randomised controlled clinical trials in transfusion medicine (Brown et al., 2022; Karanatsios et al., 2024). Governments can therefore support these efforts by providing security of on-going funding for comprehensive national transfusion registries internationally, as well as promoting hospital participation in the registry, along with standardisation of healthcare information systems to streamline data importation.
Conclusion
The value of large, comprehensive datasets, such as the ANZ-MTR and NTD, that capture data on transfusion practices are increasingly being recognised as essential tools to benchmark and monitor transfusion practices, and to inform the development of improved transfusion policies and PBM guidelines. In this case study of the ANZ-MTR, we have presented our experiences in building the database of Australia’s first transfusion-focused clinical dataset capturing routinely collected hospital electronic records. This involved extensive integration and harmonisation of source data from multiple information systems within hospitals, across hospitals and in some instances, from their third-party service providers. Open communication with each custodian of the source data is fundamental to success. Standardised and centralised sources of data expedite the harmonisation and importation steps. Our experiences, together with uptake of advances in digital technologies, will hopefully allow us to spearhead the formation of a comprehensive V2V clinical dataset for Australia.
Footnotes
Acknowledgements
We thank the champions and data custodians of the ANZ-MTR participating hospitals and their affiliated service providers, the ANZ-MTR steering committee members, funders, the Monash University Helix team and past members of the ANZ-MTR team.
Accepted for publication August 19, 2025.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship and/or publication of this article: The ANZ-MTR was previously funded by the National Blood Authority of Australia, the Victorian State Government, CSL Behring, NHMRC (#APP1074654), New Zealand Blood Service and Monash University. ZKM and EMW are supported by NHMRC Investigator Grants (#1194811 and #1177784) and the NHMRC Blood Synergy program grant (#1189490 and #2036025). The National Transfusion Dataset has been funded by the Australian Research Data Commons (#DP708) and the Medical Research Future Fund (#MRFFRD000049).