
Abstract
In this paper, we employ the lattice Boltzmann method implemented on compute unified device architecture-enabled graphical processing unit to investigate the multiphase fluid pipe flow. The basics of lattice Boltzmann method as well as the Shan–Chen multiphase model and the fundamentals of graphical processing unit with compute unified device architecture are thoroughly introduced. The procedure of implementation of lattice Boltzmann method on graphical processing unit and the comparison of the computing performance between graphical processing unit and CPU are presented. It is demonstrated that the graphical processing unit-based lattice Boltzmann method has remarkable advantages over CPU especially with selected appropriate parameters. The results of validation cases agree well with previous numerical results or analytical solutions. The vertical and horizontal multiphase pipe flow are simulated and discussed.
Keywords
Introduction
Multiphase fluid flows involve prevalent phenomena that occur in numerous industrial and natural processes. As one of fundamental research, the multiphase pipe flows are ubiquitous in chemical and nuclear engineering, which has aroused extensive attention. 1 Due to the complexity of reactions between different phases and flow patterns, there are still plenty of remaining issues that need to be further explored in numerical simulation and experimental research.
The lattice Boltzmann method (LBM) has developed rapidly in the past years especially in the simulation of multiphase flows. As a powerful and innovative tool of computational fluid dynamics (CFD), LBM enjoys the advantage of natural parallelism, flexible geometry characteristics, simplicity of implementation and high precision. Based on the molecular kinetic theory, the LBM provides a novel approach with distinct background of physics and efficient algorithm in multi-scale analysis. In the LBM, it is not necessary to solve the Poisson equation for pressure, which saves significant calculation time compared with traditional CFD methods. In addition, with much of the computation restricted to local nodes, it is concise in programming and very suitable for implementation with parallelized algorithm and hardware. 2
The graphical processing unit (GPU) is originally designed for processing large data sets related to graphics and gradually evolved to accelerate general-purpose computations. The architecture of GPU is completely different from CPU with a larger number of parallel, multithreaded, many-core processors and higher memory bandwidth, which enables GPU to perform extremely fast when executing compute-intensive and highly parallel computation. The advent of compute unified device architecture (CUDA) has simplified the implementation of parallelization and enabled dramatic increases in computing performance by harnessing the power of the GPU. The application extends its range in scientific computation in fields with big data problem sets, including CFD, image, video and signal processing, computational biology and chemistry, etc.
The combination of LBM with GPU makes it ideal for delivering more efficient compute performance and record acceleration ratio for big data applications. In this paper, we firstly introduce the basic concept and models of the LBM. Then, we will demonstrate the details of implementation of LBM on GPU. Finally, the validation of benchmark and simulation results will be discussed.
Method
Basics of LBMs
The LBMs are based on the kinetic molecular dynamics and can be derived from the Boltzmann equation
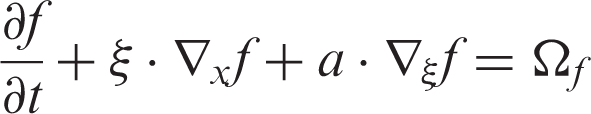
The collision operator involves nonlinear integral, which makes the computation rather complicated. With the aid of Bhatnagar–Gross–Krook (BGK) approximation, the lattice Boltzmann equation (LBE) can be significantly simplified via replacing the collision operator with linearized expression. Since the system will finally reach the equilibrium state, the distribution function f tends to approach the Maxwell distribution function
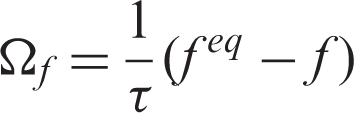
By means of discretization in the velocity, space and time, the LBE can be attained
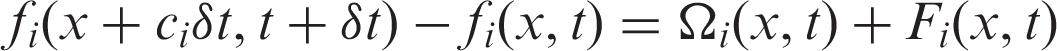
As the most popular LBE method, the lattice Boltzmann equation with BGK approximation (LBGK) has been widely applied in a variety of complex flows.
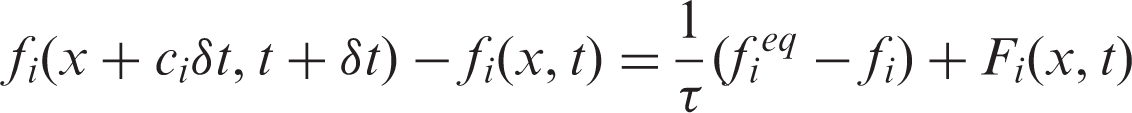
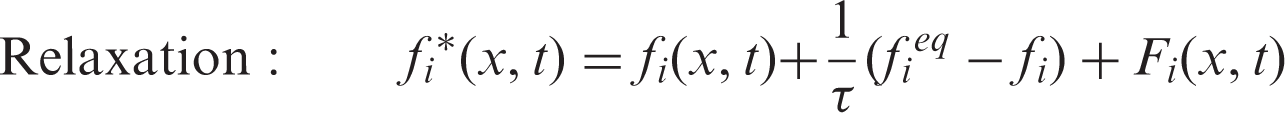
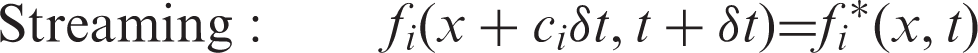
The macroscopic parameters such as density, velocity and internal energy can be calculated statistically from moments of the discrete distribution function.
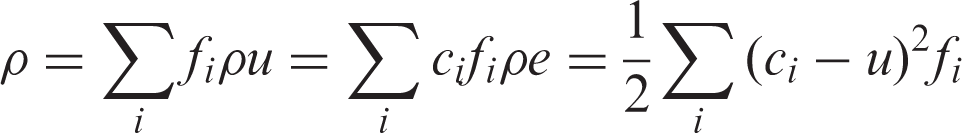
In the prevailing DdQm discretization model, where d denotes the number of dimensions and m is the number of velocity sets, the equilibrium distribution function can be described as follows
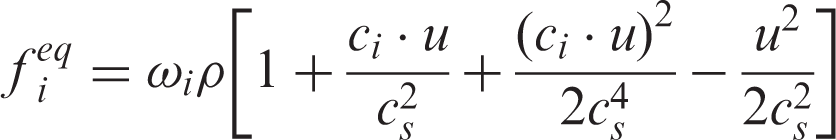
By virtue of the multi-scale analysis method called Chapman-Enskog expansion, the hydrodynamic equations corresponding to the LBGK model can be obtained
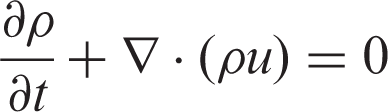
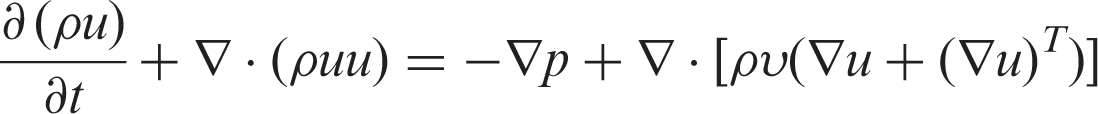
In view of multiphase fluid, there are mainly four types of LBE models, including color-gradient model, pseudo-potential model, free energy model and LBE models based on kinetic theories. Among the mentioned models, Shan–Chen model has attracted wide attention due to its simplicity and effectiveness. This model owes its name to Shan and Chen 5 who introduced a pseudo-potential and non-local force in order to depict the interaction between fluid particles.
In a multiphase fluid system constituted by n components, the LBE of Shan–Chen model can be expressed as
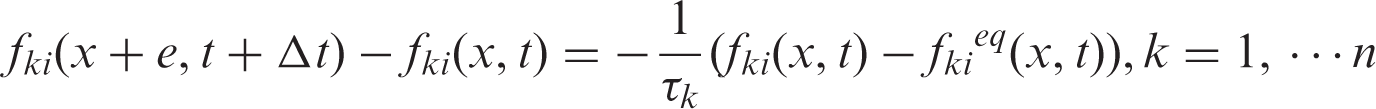
The pseudo-potential between different phases takes the following form
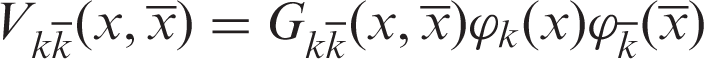
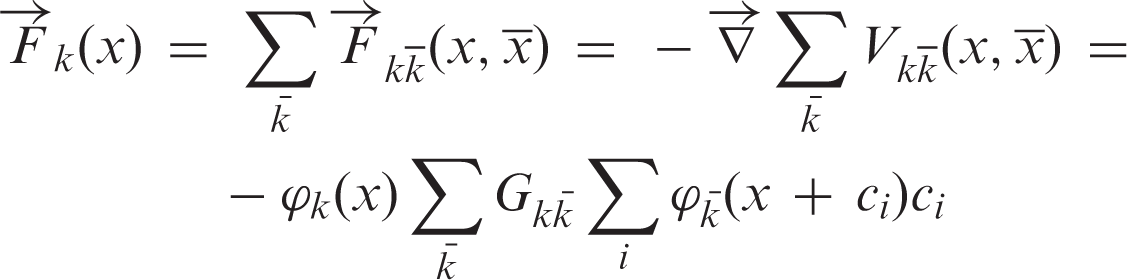
The Shan–Chen model does not need any explicit interface tracking because the macroscopic separation and interface between multiphase naturally emerges from microscopic interactions between different fluid components, which brings convenience and flexibility. Compared with other models, Shan–Chen model has satisfactory performance in both efficiency and accuracy. Thus, it is adopted in the multiphase LBM simulation.
Fundamentals of GPU and CUDA
Since the NVIDIA Corporation introduced the GPU with CUDA architecture, an increasing number of applications have witnessed desirable acceleration with the aid of parallel computation. As a parallel computing platform and programming model invented by NVIDIA, CUDA has enabled a straightforward implementation of parallel algorithms and leads to dramatic increases in computing performance. Programmers can concentrate on the task of parallelization of the algorithms rather than wasting time on the details of implementation.
In the CUDA programming model, the heterogeneous computation model is adopted. The CPU is assumed as host, and GPU is viewed as a device that is capable of executing a quantity of threads in parallel. The parallel portions of computation will be allocated to the GPU, while serial portions of applications are run on the CPU. The CPU and GPU are treated as separate devices with their own host memory and device memory. This configuration allows simultaneous computation on the CPU and GPU without conflicts on memory resources.
The CUDA-enabled GPU with multilevel memory architecture and multi-threads parallel computation method facilitates the computation with more flexibility. GPU is composed of several streaming multiprocessors (SM), each including a set of scalar processors (SP). The main storage consists of a large off-chip device memory, which is optimally divided into global, constant and texture memory. The global memory is sufficient but suffers from high latency. The constant and texture memory are especially designed for read-only data and specific data formats. Every SM also provides the SPs with local registers and on-chip shared memory that allows communication within an SP with much higher bandwidth and lower latency.
The functions in programming are called kernels which are executed N times in parallel by N different CUDA threads. Each thread has its private memory such as local register. The threads will be batched together into thread blocks in a one-dimensional, two-dimensional or three-dimensional form. All threads of a block will reside on the same processor core and share the limited memory resources, which imposes a limit on the maximum number of threads per block. Each thread block has shared memory merely visible to threads within the block. Threads in the same block can cooperate by sharing data through fast shared memory and synchronizing the execution to coordinate memory accesses. Then, blocks will be organized into a one-dimensional, two-dimensional or three-dimensional grid. This hierarchy brings about convenience when invoking computation across the elements in vector, matrix or volume. Threads indifferent thread blocks from the same grid cannot synchronize and communicate with each other. However, all threads have access to the same global, constant and texture memory. 6
The compute node is equipped with 2 CPU (Inter Xeon E5-2630v3) cores (32 hyper threaded cores) and a NVIDIA Tesla K20 GPU, which contains a total of 2496 processor cores and is equipped with 5 GB of on-board memory, with memory bandwidth up to 208 GB/s. The Tesla K20 delivers 1.17TFlops (floating point performance) peak double-precision performance and 3.52 TFlops peak single-precision performance, which can provide high throughput for the demanding high-performance computing.
Implementation of LBM on GPU
With the fundamental knowledge of architecture of GPU and CUDA, we will then focus on implementation of LBM on GPU. The methods put forward by Tölke7,8 that take advantage of shared memory to accelerate have been widely acknowledged and utilized, which is adopted in this paper.
There are mainly four kernels to achieve LBM in CUDA. The first kernel is LBCollProp, which deals with collision and propagation. The two steps are merged in one kernel to enhance the efficiency of memory access. Considering a two-dimensional grid size of NX×NY, the block is defined as (threads_num, 1, 1) and the grid is set as (NX/threads_num, NY, 1), where threads_num is the number of threads per block in X direction. Within each block, the distribution functions first execute the collision, which only contains calculation in the local node. Then, the distribution functions of
The second kernel is LBExchange, which is responsible for exchanging distribution functions across the borders of the thread blocks. Because shared memory is only accessible to threads in the same block, the distribution functions on borders of blocks will be temporarily stored at the opposite side in the first kernel. In this kernel, every row is processed in sequence along X direction to put the distribution functions on the border in the appropriate location. There are two loops that will separately move
The third kernel is LBBoundary that fulfills the boundary conditions. The configuration is the same as the second kernel. The fourth kernel is LBError, which calculates the relative error of the fluid field. Actually, it can be deemed as the procedure of reduction that adds up the error. The implementation is optimized to reduce thread divergence according to the method introduced by Kirk et al. 9
Validation
Two-dimensional lid-driven cavity flow
Since the lid-driven cavity flow presents various vortex motions, it is analyzed to validate the two-dimensional LBM and to compare the performance between implementation on CPU and GPU. In terms of the CPU code, we refer to the sample code provided by He et al.
10
in C+ + language. As for GPU code, we accomplish the program in CUDA C language. In the CPU and GPU programs, we both choose the double-precision mode to ensure the accuracy. Before the convergence, the output procedure is skipped to avoid the influence of writing data on computing time. The convergence criterion for the velocity field is according to the criterion proposed by He et al.
10
and ɛ is set at 10−6.
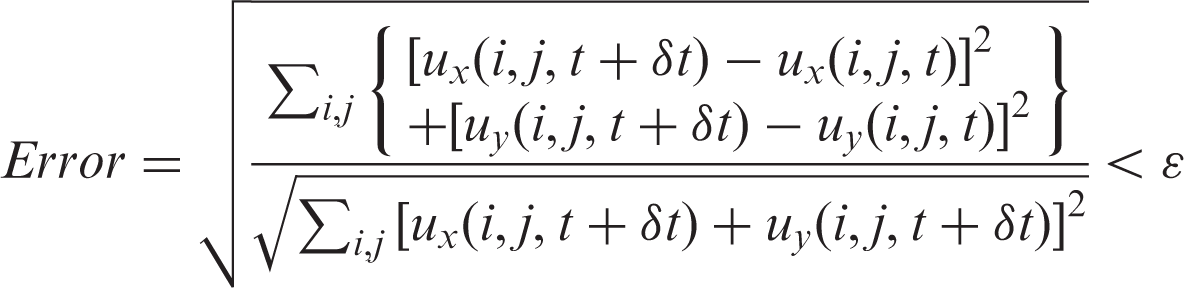
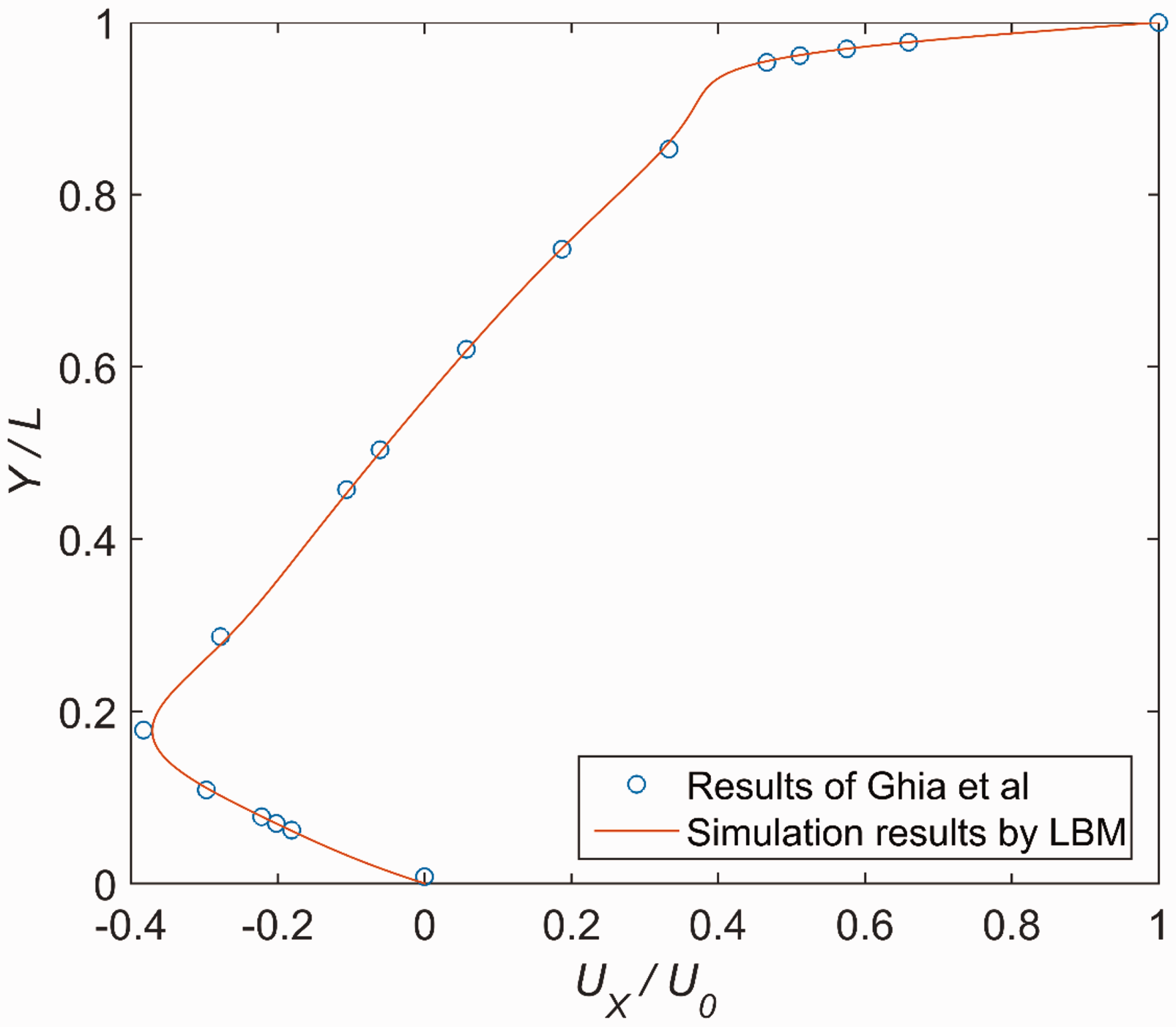
The results of velocity profile through the geometric center of the cavity using GPU are shown in Figures 1 and 2, which are in accordance with the previous benchmark data by Ghia et al.
11
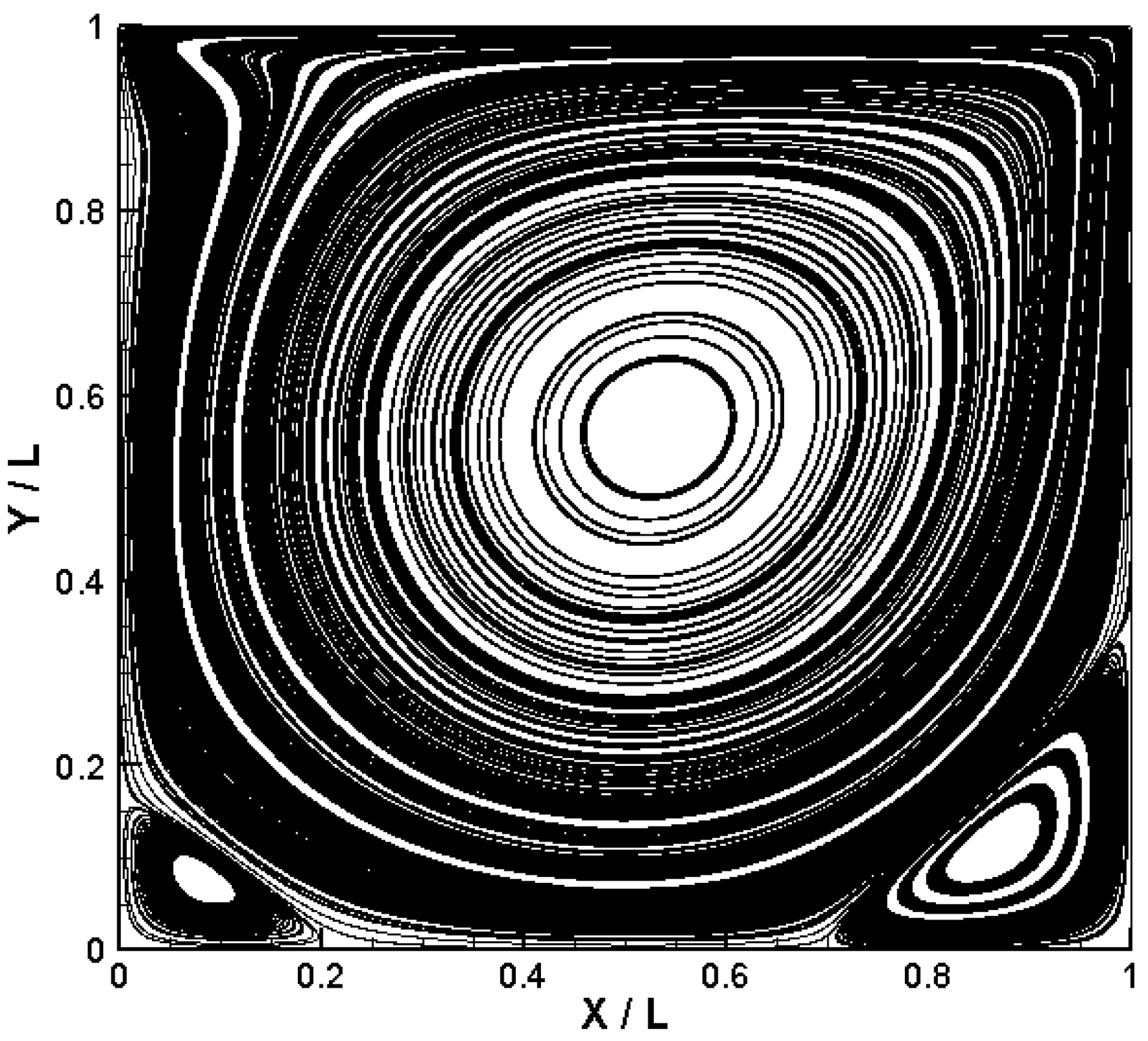
The stream function of the cavity flow with Reynolds number set at 1000 is shown in Figure 3. As is illustrated from the streamlines, a large primary vortex in the center and two secondary vortices near the two lower corners can be observed.
The velocity profiles of Vy/U0 through the geometric center of the cavity. The velocity profiles of Ux/U0 through the geometric center of the cavity. The streamline for two-dimensional lid-driven cavity flow at Re = 1000.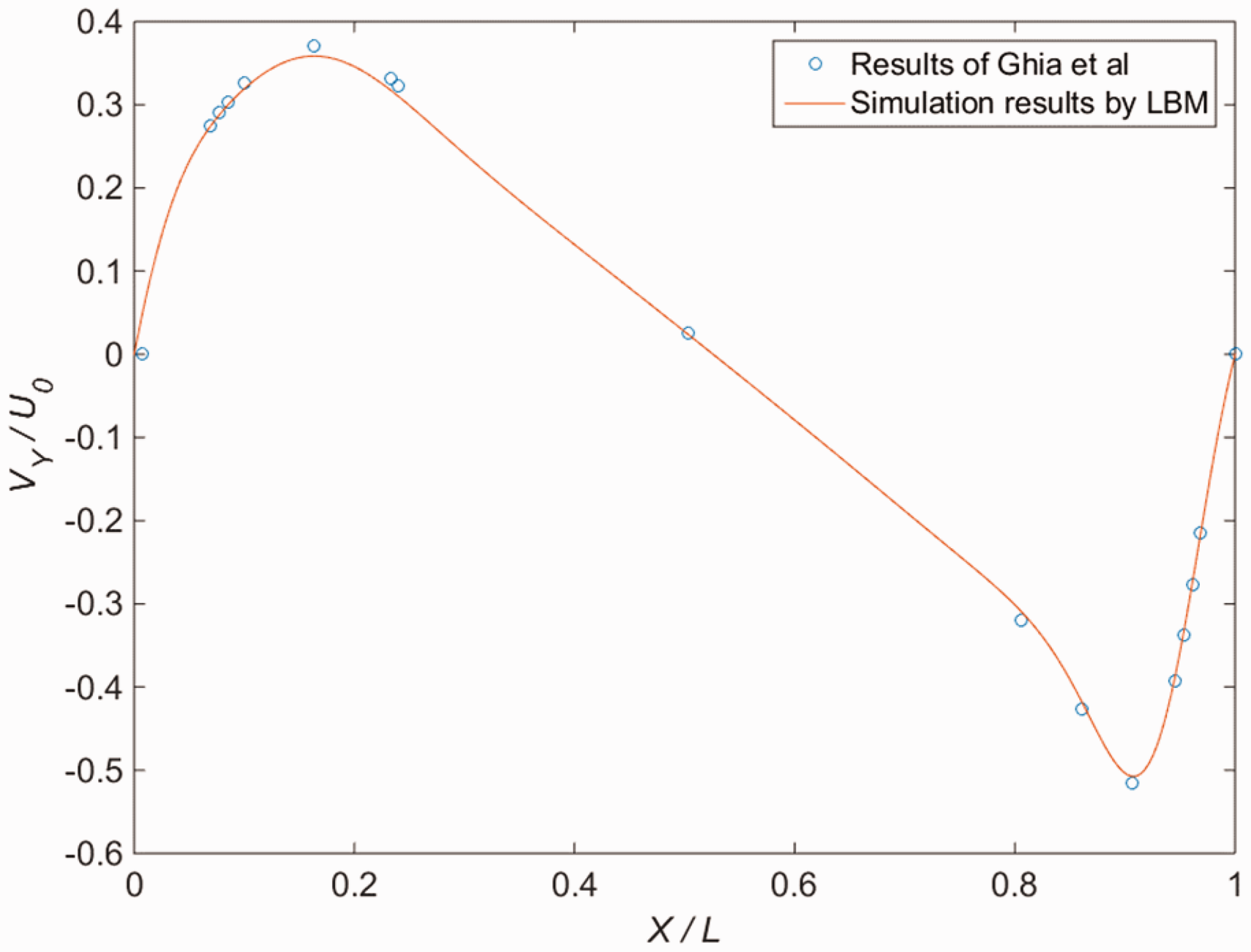
Calculation time on CPU with varying grid size of field.

Calculation time on GPU with different grid size of field and varying threads per block.
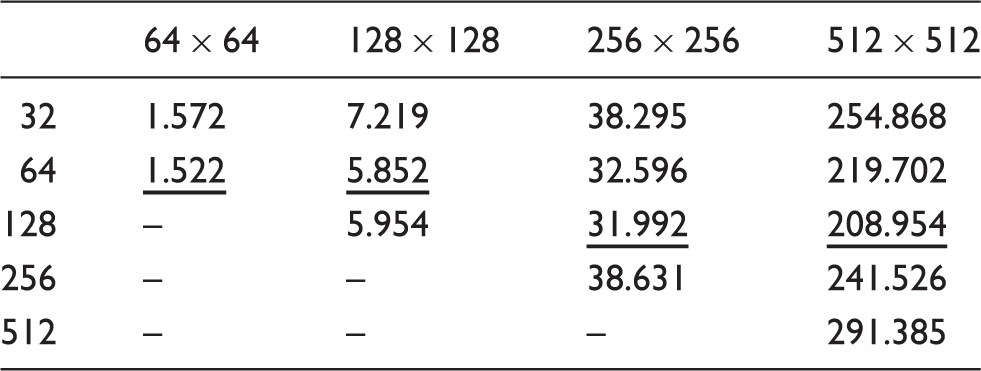
Note: The underlined ones are the minimum calculation time with a specified grid size.
Acceleration ratio with different grid size of field and varying threads per block.
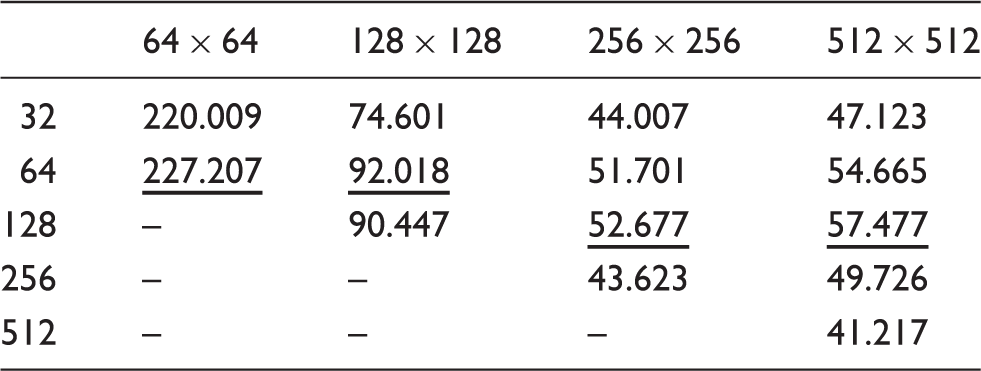
Note: The underlined ones are the maximum acceleration ratio with a specified grid size.
With a certain grid size, the minimum calculation time and the maximum acceleration ratio are underlined, which are associated with an appropriate number of threads per block. The acceleration ratio is rather desirable on the whole, which shows the distinct competitiveness of GPU over CPU in the implementation of LBM.
Two-dimensional fully developed laminar Poiseuille flow
The two-dimensional fully developed laminar Poiseuille flow can be considered as the fluid flow through two parallel infinite plates. The theoretical solution will be discussed in detail. The velocity profile can be described as the following formula
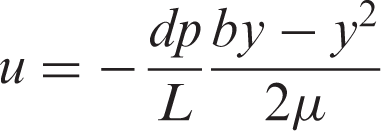
The mean velocity of the cross section is
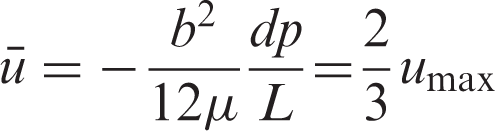
The pressure drop along the path is
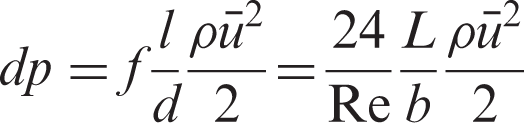
The Darcy friction factor can be derived from the above analysis
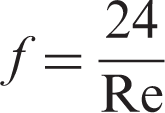
The data of pressure drop and friction factor with varying Reynolds number.
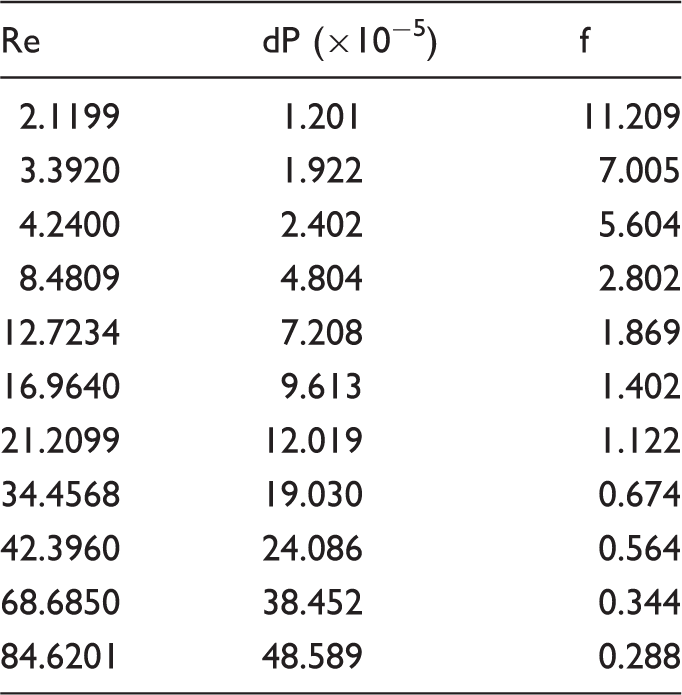
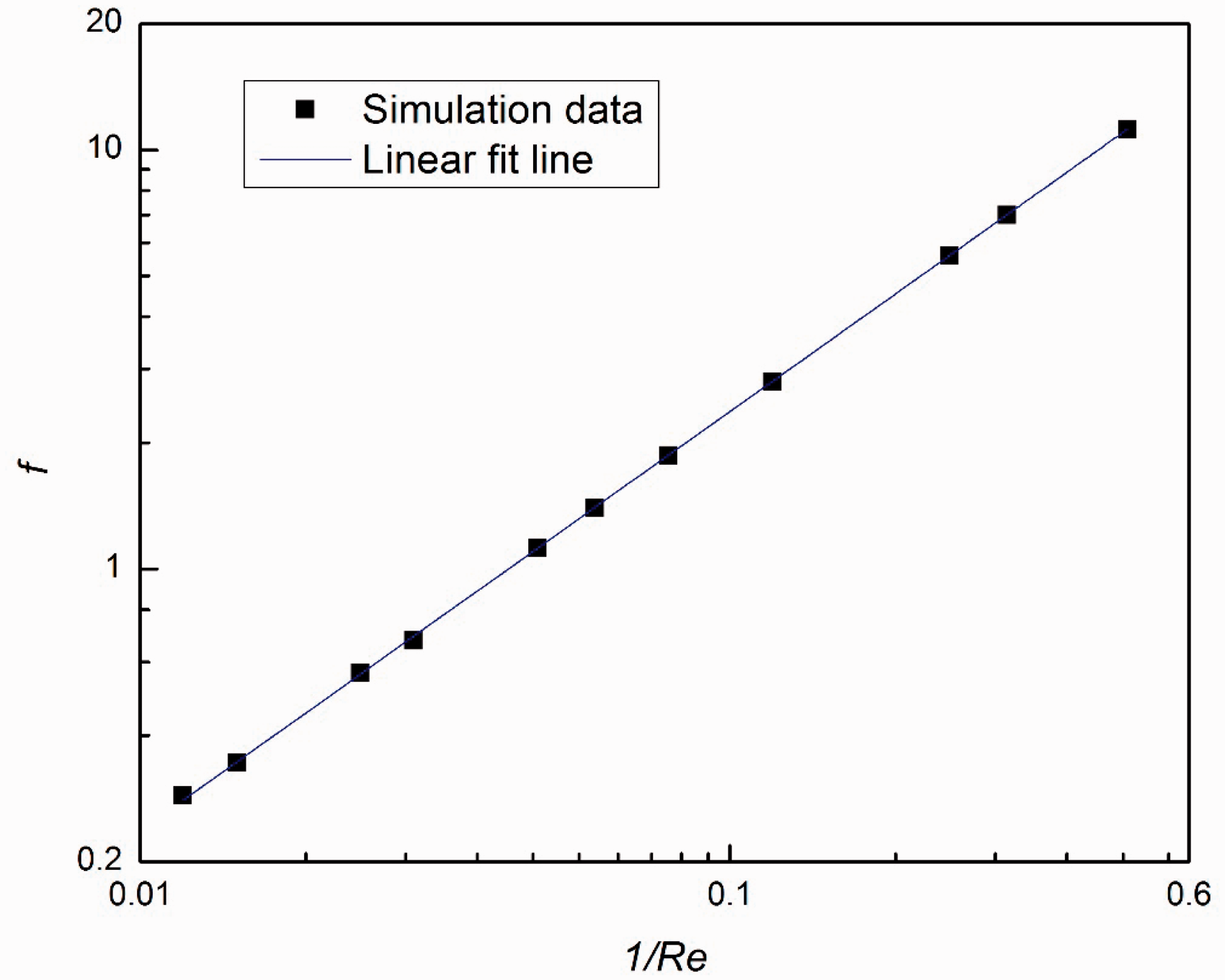
The linear fit line of Darcy friction factor with varying Reynolds number in logarithmic coordinates.
Validation of Laplace Law
In order to validate the Shan–Chen multiphase model, the Laplace Law is employed to evaluate the surface tension for droplets in equilibrium, which is defined in the following formula
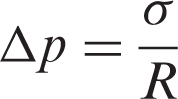
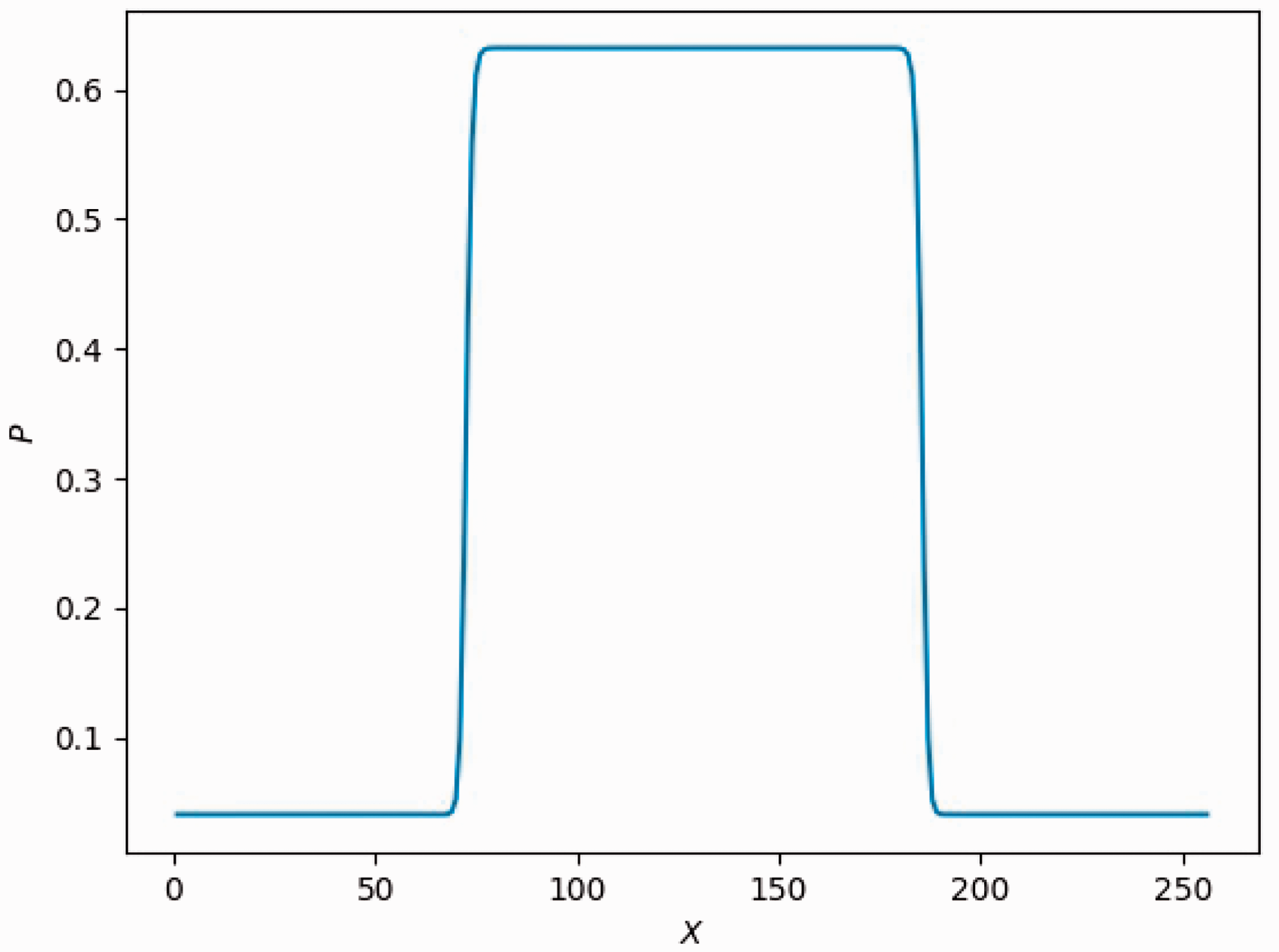
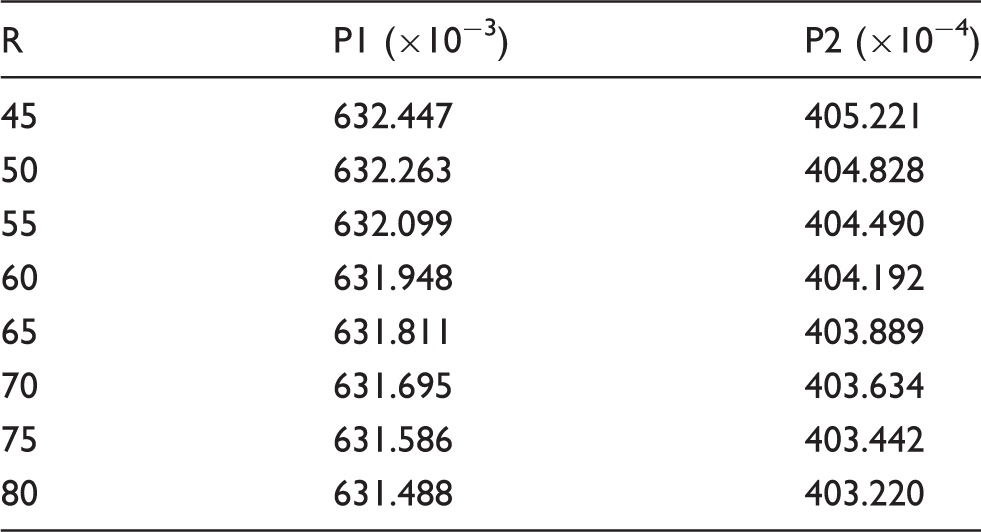
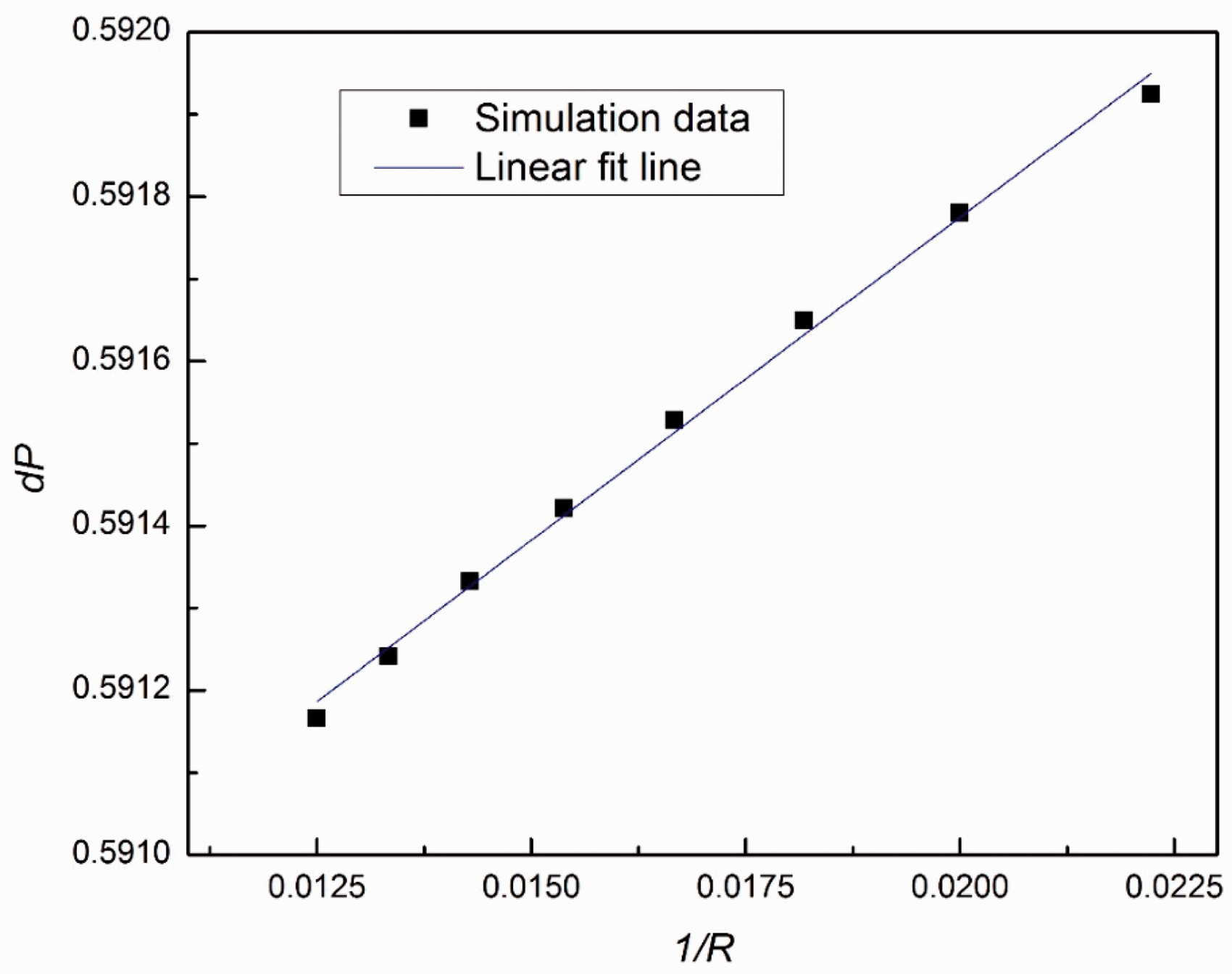
In this case, the computational domain consists of 256 × 256 lattice nodes. The boundaries are all periodic. A static droplet is initially posed in the center of the field as indicated in Figure 5. The computation is set at double-precision mode, and the pressure difference is shown in Figure 6 and Table 5. As manifested in Figure 7, the results show satisfactory linearity between the pressure difference and the reciprocal of radius with coefficient of determination above 0.99, which is in desirable agreement of the Laplace Law.
The density field of the droplet. The pressure variation along horizontal centerline. The pressure inside (P1) and outside (P2) the droplet with varying radius. The pressure difference versus reciprocal of radius.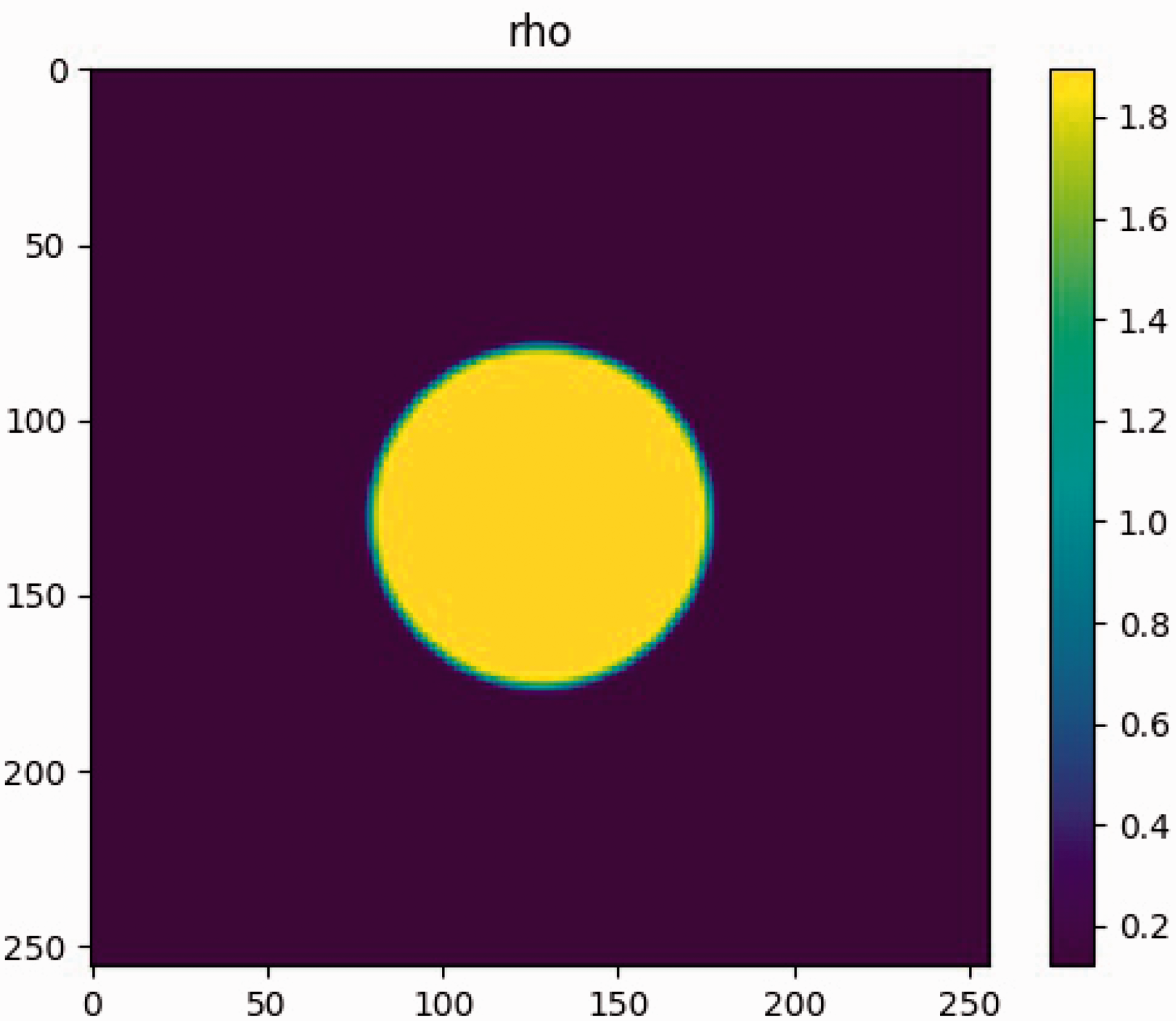
Demonstrative results and discussion
In this section, we will firstly study the two-dimensional multiphase fluid pipe flow in vertical tube under gravity with vertical periodic boundary condition. Then, we will explore the two-dimensional multiphase fluid pipe flow in horizontal tube under gravity and horizontal force with horizontal periodic boundary condition.
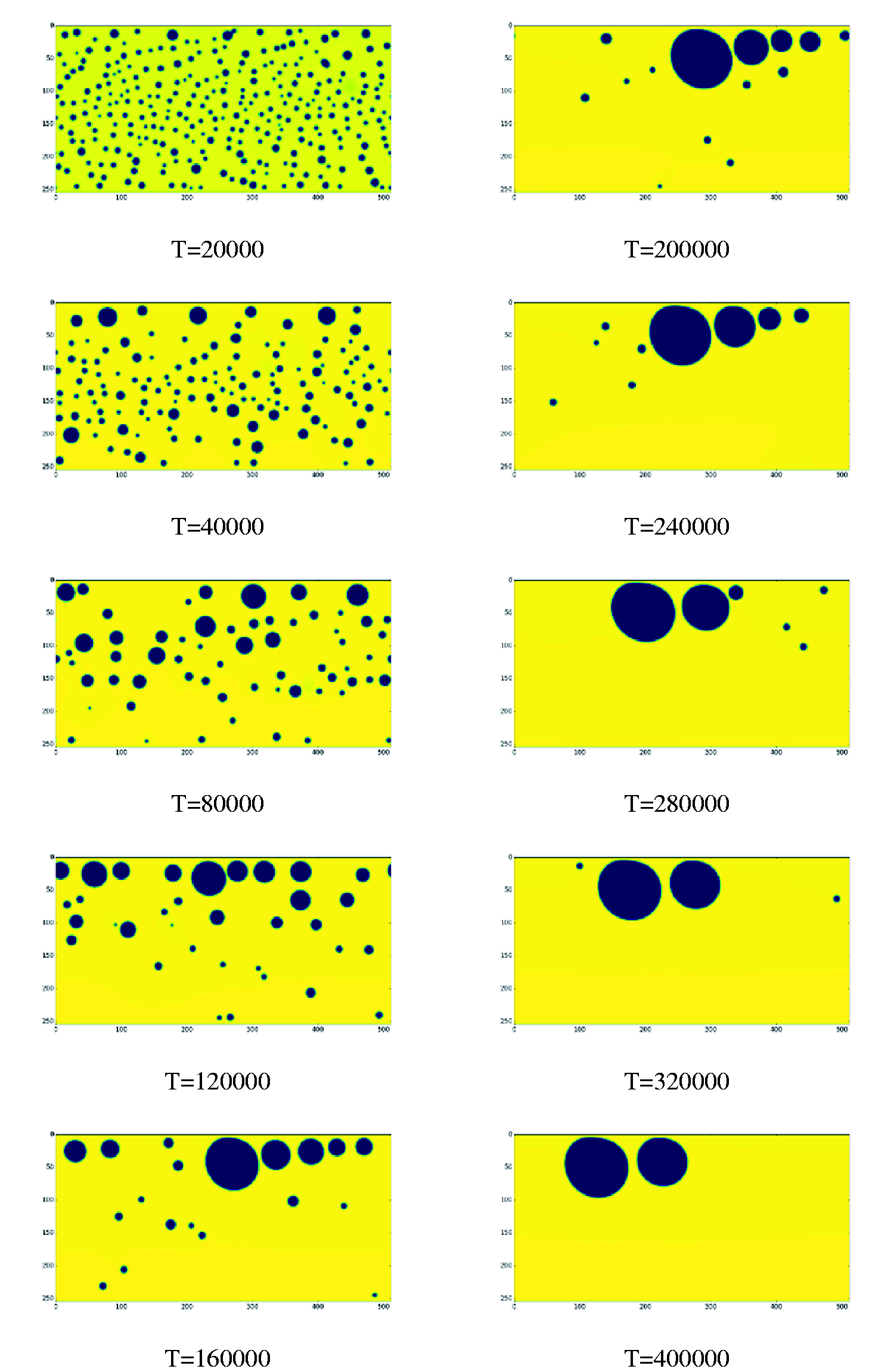
Initially, the density of the fluid field is randomly set up at higher or lower value. Under the effect of interphase force, the bubbles gradually collide and coalesce into bigger ones. At the same time, the bubbles and fluids are accelerated by the external force such as gravity or horizontal force. The gravity acceleration is set at 10−5 and the horizontal force is set at 10−6. The simulation results at different time steps are shown in Figures 8 and 9. The dark area represents the lower density bubbles, while the yellow area stands for the higher density fluid.
Density field of vertical tube at different simulation steps. Density field of horizontal tube at different simulation steps.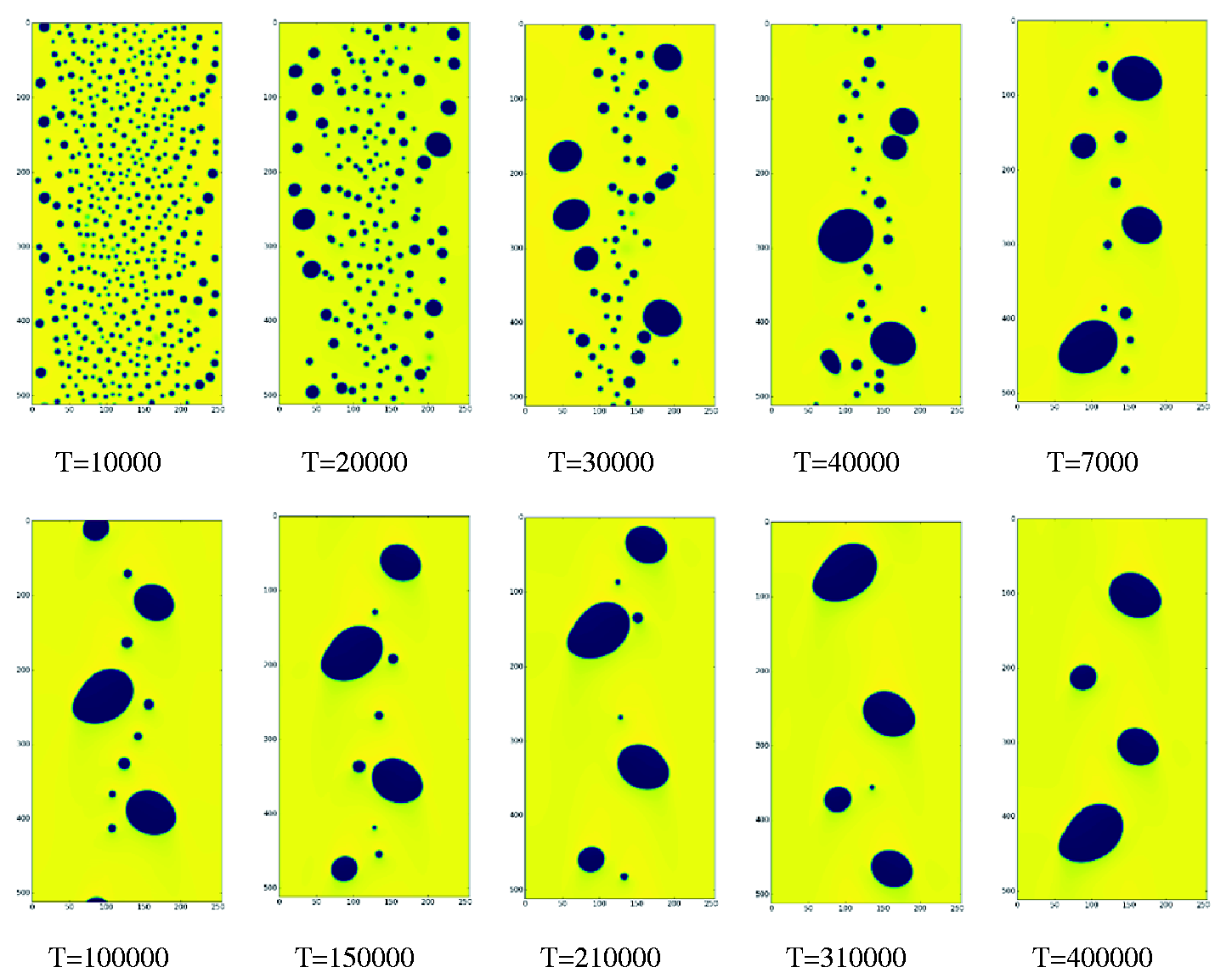
Vertical tube
In the initial stage, the bubbles distribute uniformly in the field (T = 10,000). Because the velocity near the wall is smaller than the center and wall shear stress is larger than the center, the bubbles near the wall are likely to collide with each other and gradually coalesce into bigger ones. At the same time, the bubbles in the center of tube moves faster and remain relatively small (T = 20,000). After a period of collision, the bubbles near the wall merge into medium ones and the number of bubble decreases distinctly. The distribution of bubbles appears to be smaller and more in the center, while bigger and less near the wall (T = 30,000). Because the velocity in the center of tube is higher than near the wall, the big bubbles gradually move towards the center under the impact of high-speed fluid. This process contributes to the mixture of big bubbles near the wall and small bubbles in the center (T = 40,000). Gradually, the domain of small bubbles shrinks and the number of bubble declines. With the fusion of bubbles, the size of big bubbles is on the increase. In the meanwhile, the shape of big bubbles deforms and deviates from circle, which appears a variety of shapes including, ellipse, rectangular, triangular, etc. (T = 70,000). Then, all bubbles gather in the center of tube, where the velocity is larger. By contrast, there exist barely any bubbles near the wall. The big bubbles and small bubbles appear to be intermittent and compatible in the process of simulation (T = 150,000). Finally, the small bubbles merge into the big ones and only some major elliptic bubbles exist (T = 400,000).
Horizontal tube
Similar to the vertical tube, the bubbles distribute uniformly in the field initially (T = 20,000) and gradually forms bigger bubbles near the wall, while the bubbles in the center of tube retain relatively small (T = 40,000). Later on, the bigger bubbles in the upper layer approach the wall of tube and only move in horizontal direction, while the bigger bubbles in the bottom layer rise under the effect of buoyancy force. When they go up and pass the center of tube, they encounter with the small bubbles and enhance mixture and coalescence (T = 80,000). Owing to the rising bubbles, the number of small bubbles decreases, while the number of intermediate bubbles increases. Afterwards, the bigger bubbles rise to the upper layer of tube sooner or later (T = 120,000). If they meet up with the previous big bubbles, a relatively huge bubble will be formed (T = 160,000). With the size of bubble increasing, there exists a bit of deformation of the shape of bubble and deviation from circle. At the same time, only few smaller bubbles exist in the lower domain (T = 200,000). Under the effect of horizontal force, the bubbles in the upper layer moves in horizontal direction, which promotes the medium-size bubble to collide and grow into bigger ones. An interesting phenomenon is that during the merging process, several bubbles exist very close to each other, and the size of bubbles is increasing one by one against the direction of horizontal force. The smaller bubbles move at the front while the bigger bubbles move at the end. This distribution remains stable for awhile. Even after some procedures of collision and aggregation into bigger bubbles, this distribution pattern is reproduced once again (T = 240,000). It demonstrates that this distribution is balanced under the effect of gravity and horizontal force. Then, the bubbles between the fore and tail bubbles first fuse into a big bubble (T = 280,000). Then, it incorporates the small bubble at the front (T = 320,000). Finally, the tiny bubbles join the two big bubbles and they maintain steady movement with some distance between each other (T = 400,000).
Conclusion
In summary, the LBM proves to be an innovative and promising tool for complex fluid flow compared with the traditional CFD methods. The implementation of LBM on GPU delivers satisfactory performance and manifests a notable advantage over CPU. We have accomplished the GPU code in CUDA and carried out the validation cases for the 2D lid-driven cavity flow, 2D steady Poiseuille flow, and the Laplace Law, which is in acceptable accordance with the benchmark results. We also make use of the program to conduct numerical simulations on multiphase flow in vertical and horizontal pipes. The results indicate the effectiveness and efficiency of the LBM on GPU in simulating multiphase flow.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors are grateful for the support of this research by the National Natural Science Foundations of China (Grant No. 51576211), the Science Fund for Creative Research Groups of National Natural Science Foundation of China (Grant No. 51321002), the National High Technology Research and Development Program of China (863)(2014AA052701), and the Foundation for the Author of National Excellent Doctoral Dissertation of P.R. China (FANEDD, Grant No. 201438).