
Abstract
Moving Horizon Estimation (MHE) offers multiple advantages over Kalman Filters when it comes to the localization of drones. However, due to the high computational cost, they can not be used on Micro Air Vehicles (MAVs) with limited computational power. We have previously shown, that with a few assumptions and simplifications, MHE can be made more efficient while retaining good localization performance. In this paper, we present two additional improvements: the introduction of dynamic step sizes to the gradient descent algorithm, which leads to a significant increase in robustness, and the use of switching variables for outlier rejection, which further reduces the computational load. Both improvements are implemented and assessed in simulation and experiments. Using dynamic step sizes makes it possible to reliably use the estimator on board a real drone, and the use of Newton’s method specifically opens the option to add different types of measurements. The new outlier rejection method on the other hand is shown to reduce the computational load significantly without impacting the accuracy.
Introduction
Self-localization is an important task for autonomous drones, especially when operating in indoor environments. 1 Since navigation using Global Navigation Satellite Systems (GNSS) exhibits a significant decrease in performance when used inside buildings, other solutions are needed. Ultra-wideband (UWB) technology has been investigated as a promising alternative in scenarios where the environment can be prepared in advance.2–4 UWB localization works in a similar fashion as GNSS, but instead of ranging with respect to satellites, it uses fixed beacons at known locations in the environment. 5
The UWB range measurements can be used for triangulation, 6 but are more commonly fused with measurements from an inertial measurement unit (IMU) for more accurate results. 3 Kalman filter variants such as the Extended Kalman Filter (EKF) are often used due to their speed and efficiency. 7 However, they are not ideal when working with highly non-linear dynamics or non-Gaussian noise, both of which are present in the system in question. 8
Moving Horizon Estimators (MHEs) are better suited for state estimation in non-linear systems with non-Gaussian noise, 9 but are computationally expensive, which makes them impractical to use on small drones with limited computational power. In our previous work, we investigated several simplifications that reduce the load for localization of small drones using an MHE. 8 While the resulting estimator performed well in offline evaluations on real measurement data, its robustness was found to be lacking. Specifically in situations where the number of incoming measurements varies a lot, the tuning had to be quite conservative to avoid unstable behaviour when many measurements were coming in. Furthermore, while we were happy with the performance of Random Sample Consensus (RANSAC) for outlier rejection, its computational cost was quite high for an algorithm aimed at computationally extremely limited systems, like the micro-controllers on board of nano-drones.
In this paper, we will present the following two improvements to efficient moving horizon estimation for localization with UWB:
Using a dynamic step size in the gradient-descent step to improve robustness Outlier rejection based on switching variables to further improve the computational efficiency
Preliminaries
Computationally efficient MHE
Let us quickly review the computationally efficient MHE presented in Pfeiffer et al.
8
to highlight some of its shortfalls. We again consider the discrete-time non-linear dynamic system given by (1), expressed in terms of the system state

The full MHE problem for a horizon of length

By assuming negligible process noise (

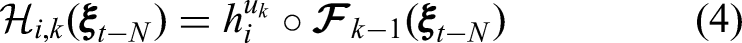

To save computation time, instead of fully solving the optimization problem at every timestep, only a single gradient descent step is performed as suggested by Alessandri and Gaggero.
10

Using the chain rule, the gradient of the cost function is easily calculated analytically. When using only a single iteration, the gradient is calculated with the prior best estimate

To save computational power, the gradient of the composite measurement equation can be simplified by iterative computation of the Jacobian of the composite prediction equation (chain rule):
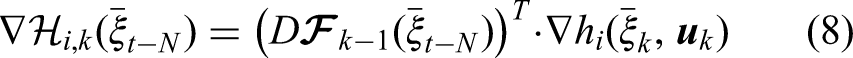
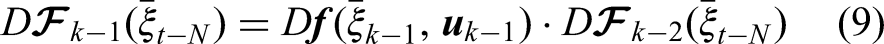
For outlier rejection, a RANSAC scheme was used, which can identify outliers very well but requires a significant amount of computational power.
Drone and measurement model
We use the drone model in Mueller et al.,
3
but represent the attitude in quaternions and simplify the drag forces. For the use in our estimator, we discretize the model using the forward Euler method.
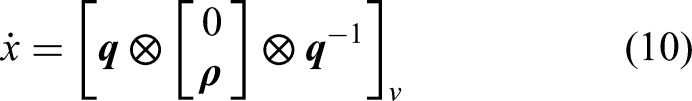

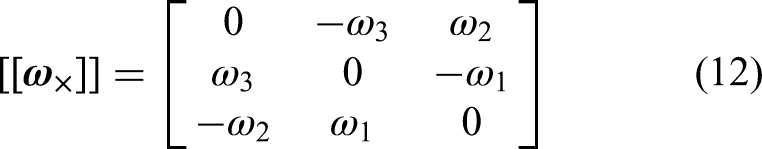
We consider two different types of UWB measurements. Two-way ranging (TWR) can be used to determine the distance between the drone and a fixed beacon located at


Dynamic step size
A serious problem with the approach in Pfeiffer et al.
8
is the fixed step size used in the gradient descent algorithm. Specifically in situations where the number of measurements
Linesearch
With the linesearch method, different values for the step size
Linesearch Method

The linesearch method is easy to implement in the existing algorithm but has the downside of scaling the step size for all state variables at once. If different types of measurements are available, this can lead to problems. As an example, if a lot of velocity estimates are available but only a few position estimates, it would be good to choose different step sizes for the different states. An approach that allows for this flexibility is the use of Newton’s method.
Newton’s method
Newton’s method is more complex to implement than linesearch, but offers two additional advantages. First, there is no need to calculate the cost of multiple estimates (which requires several predictions through the complete horizon) and second, Newton’s method allows to adjust the step size along different axes. Specifically, instead of using a scalar step size 
The Hessian matrix of the cost function can be obtained by calculating the Jacobian of the cost function gradient.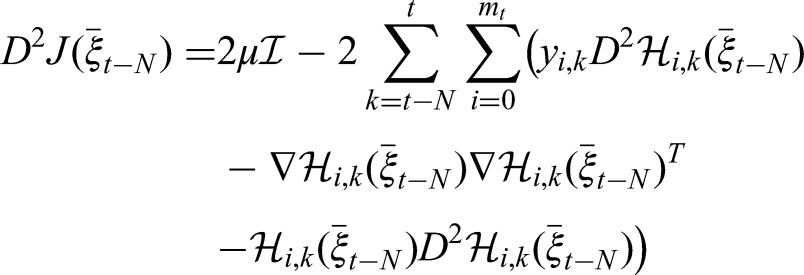
As with the gradients, the Hessian matrices of the cost and measurement functions can be calculated algebraically in an iterative manner while stepping through the horizon. Making use of the chain rule, we find the following expression:
11

Luckily, many of the terms appearing in this equation are already needed when calculating the cost function gradient. Furthermore, since the prediction model we use is linear in terms of the states, the Hessian matrix of the composite prediction equations turns out to be zero. The simplified expression for the Hessian matrix of the cost function thus only depends on the Hessian matrix of the measurement function and the Jacobian matrix of the composite prediction equation:
Switching variable outlier rejection
Since using RANSAC for outlier rejection has the disadvantage of being computationally heavy, we decided to look for a more efficient method. The need for outlier rejection in optimization problems also arises in Simultaneous Localization and Mapping (SLAM), where incorrectly identified loop-closures can cause large errors in the resulting map. A possible approach to deal with this issue is the addition of switching variables that multiply the constraints in question.
12
Applying this concept to our MHE, we introduce for each measurement
To use the switching variables as decision variables, they must be continuous. At the same time, for their function to enable and disable measurements, binary values would be more useful. Following Sünderhauf and Protzel,
12
we use a sigmoid function to convert the continuous switching variables into values between 0 and 1, which then multiply the measurement equation. A simple sigmoid function to use is the logistic function (19).
In the context of calculating gradients, it is also helpful to note the derivative of the logistic function (20).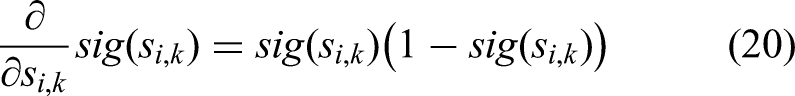
It is important to penalize the estimator for ignoring a measurement. We do this by adding a term similar to the arrival cost, that penalizes switching variables that deviate from a prior value 
When calculating the gradient of the cost function, we now also need to consider the derivative with respect to the individual switching variables. Luckily, each switching variable only appears once in each of the two sums and the corresponding derivative is easily calculated:
The changes to the derivatives with respect to 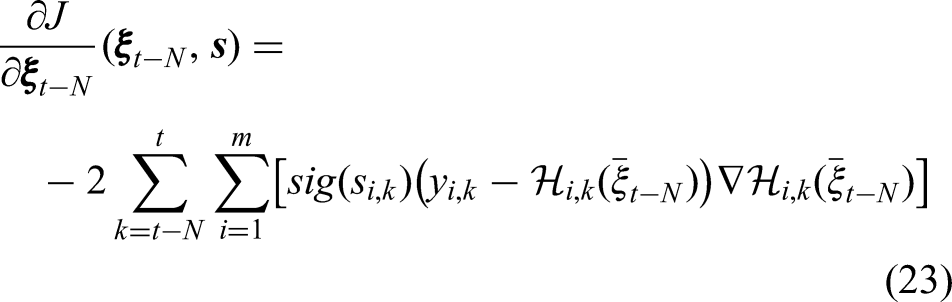
The full gradient could now be formed from the partial derivatives with respect to the state and the individual switching variables, but since the switching variables are decoupled from the rest of the system, it makes sense to update them individually using Newton’s method: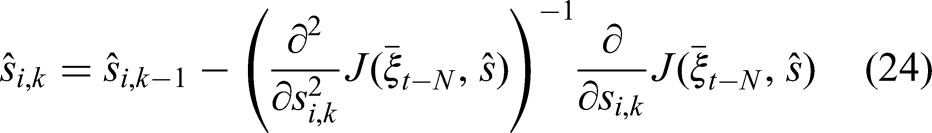
For large outliers, even with the use of a switching penalty, the switching variable can take very large negative values, resulting in a variable overflow for the intermediate result of
There is one final consideration regarding switching outlier rejection, which is the initial value of the switching variable. For simplicity, we decided to use the Mahalanobis distance based on only the measurement noise (the MHE doesn’t estimate state covariance) of the associated measurement.
Offline evaluation
The presented improvements were evaluated offline, using real UWB measurements gathered in the ”Cyberzoo” test arena at TU Delft. 13 We simulated the performance on 12 different flights for TWR and 9 different flights for TDOA. The simulations were performed 10 times with different seeds for the random number generator, for a total of 120 simulations for TWR and 90 simulations for TDOA. For every simulation, all estimators were executed in parallel and saw therefore the same noise. For comparison, we also simulated the initial version of the MHE using the simple gradient (SG) method with a fixed step size and RANSAC for outlier rejection from Pfeiffer et al., 8 as well as the EKF from Mueller et al. 3
We compared the different estimators based on three metrics, which are presented in Figure 2 for TWR and in Figure 3 for TDOA.
At first glance, we can see, that TWR yields more stable results. The success rate of all estimators is nearly identical and reaches 100% at 5 or 6 beacons. Looking at the accuracy, we can see that all MHE versions outperform the EKF slightly, but no difference can be seen between the different versions.

Moving Horizon Estimators (MHEs) usually require a lot of computational power. Improvements to our previous work on computationally efficient MHEs allow for on-board execution of the algorithm to localize a nano-copter using Ultra-Wideband measurements.

Performance of MHE configurations in simulation using TWR measurements: Simple gradient (SG), linesearch (LS) and Newton’s method to solve the minimization problem, random sample consensus (RANSAC) and switching variable outlier rejection (SVOR) for outlier rejection. Shaded regions represent the standard error of the mean.

Performance of MHE configurations in simulation using TDOA measurements: Simple gradient (SG), linesearch (LS) and Newton’s method to solve the minimization problem, random sample consensus (RANSAC) and switching variable outlier rejection (SVOR) for outlier rejection. Shaded regions represent the standard error of the mean.
The TDOA results are a bit messier. The success rate is quite different between different versions and for many estimators never reaches 100%. It is therefore more interesting to compare the quality of the estimates based on the success rate, rather than based on the accuracy of the successful runs. All MHE variants surpass the EKF in terms of success rate up to 7 beacons. The effect of a constant step size for varying numbers of measurements can be seen in the decreased performance of the simple gradient MHE when the number of beacons increases to 8. Interestingly, using switching variables for outlier rejection (SVOR) seems to be another suitable method for reducing this problem, as seen in the higher success rate. This is likely due to the fact, that SVOR can turn off measurements to keep the magnitude of the gradient closer to constant. This does however mean, that the estimator does not profit from the increased number of measurements, which becomes apparent when looking at the accuracy plots. The most successful approach for dealing with variable gradient magnitudes seems to be the linesearch (LS) approach. We suspect however, that in scenarios that incorporate other measurements (e.g. velocity from optic flow), using Newton’s method will be advantageous.
Let’s finally have a look at the computational efficiency. The EKF clearly still outperforms all versions of the MHE, but as expected, SVOR clearly reduces the computation time compared to RANSAC. Looking at the methods for choosing dynamic step sizes, Newton’s method is more efficient than Linesearch, but still adds some additional cost compared to the simple gradient method.
On-board experiments
To verify our simulation results and demonstrate that the MHE is indeed capable of running on computationally limited devices, we implemented the code on a Crazyflie 2.1. The Crazyflie 2.1. is a small (38 g), versatile platform that can be equipped with a variety of expansion boards, such as the UWB Deck for UWB ranging and the Flow Deck, for altitude and flow measurements. To make full use of the Flow Deck and challenge the versatility of our estimator, we not only used the time-of-flight measurements for altitude, but also incorporated the measurement equations for flow and adjusted the MHE formulation to enable the use of measurements with different units (the flow measurements are in pixels per second). Specifically, we use Newton’s method with SVOR and introduce the inverse covariance matrix of the prior, 
This way, the units of the measurement errors are removed and the measurements are immediately weighted according to their reliability. Each estimator was flown at least five times for a given number of beacons (4, 6 and 8) with the UWB ranging set to TWR. The results in Figure 4 show, that the MHE is indeed able to compete with the EKF in terms of performance for the given scenarios. In terms of computational requirements, we limited the number of measurements the MHE keeps in memory to 80 and used a quality measure based on the switching variable to remove bad measurements before they fall out of the window. With these changes, the MHE runs on-board, using about 25% of the available computational resources, whereas the EKF operates with only about one-fifth of this number. This actually matches quite well with the observations from the offline evaluation.

Comparison of MHE and EKF using Two-Way Ranging (5 flights per setting).
Conclusion
Moving Horizon Estimation holds a lot of potential, even for computationally limited platforms. By simplifying the problem to an output error MHE and approximating the optimization problem with a single-step gradient descent algorithm, the computational requirements of MHE can be reduced significantly, albeit at the cost of a bit of accuracy. In the end, the MHE slightly outperforms the extended Kalman Filter, which is a popular option for any non-linear state estimation problem.
The use of dynamic step sizes in a single-step gradient descent algorithm helps alleviate problems that occur when the number of incoming measurements varies greatly. Both a linesearch approach and Newton’s method are suitable, but Newton’s method offers more flexibility when dealing with different kinds of measurements.
To further reduce the computational cost, we employed outlier rejection based on switching variables, which offers advantages over RANSAC in terms of computation time.
The improved MHE shows promise in simulation and experiments, where it outperforms a classical EKF and previous iterations of our computationally efficient MHE. The main limitations of the approach are the more complex formulation and the still non-negligible increase in computational cost.
In its current formulation, the MHE only estimates position and velocity, while attitude estimates are provided by the complementary filter. This approach is suitable for pitch and roll, since the gravitational pull can be used as a reference. The yaw estimates on the other hand are subject to drift and currently require proper initialization. This problem should be addressed in future work by including yaw (error) as an additional state in the model.
Footnotes
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.