
Abstract
This paper discusses the current literature surrounding the potential use of artificial intelligence and machine learning models in the diagnosis of acute obvious and occult scaphoid fractures. Current studies have notable methodological flaws and are at high risk of bias, precluding meaningful comparisons with clinician performance (the current reference standard). Specific areas should be addressed in future studies to help advance the meaningful and clinical use of artificial intelligence for radiograph interpretation.
Introduction
Research into the use of artificial intelligence (AI) fracture detection models from radiographs is well established (Kuo et al., 2022). Adequate interpretation of the clinical appropriateness of these models requires quantitative performance metrics alongside assessment of study design, bias, transparency, and applicability to the specific proposed clinical setting (Miller, Farnebo, & Horwitz, 2023). Scaphoid fracture detection has received increasing attention from researchers since 2020 (Hendrix et al., 2023; Hendrix et al., 2021; Langerhuizen et al., 2020; Li et al., 2023; Ozkaya et al., 2022; Singh A, 2023; Yang, Horng, Li, & Sun, 2022; Yoon et al., 2021; Yu-Cheng Tung, 2021), as these fractures represent a well-documented diagnostic challenge that, if missed, can result in noteworthy morbidity (Rua et al., 2020).
Current studies have notable methodological flaws and are at high risk of bias, limiting clinical usefulness. This critical review highlights the specific challenges associated with the use of diagnostic deep learning models for acute scaphoid fractures on plain radiographs and provides guidance for future model development.
Systematic review of the literature
Appropriate databases were systematically searched (Figure S1 and Table S1) and screened according to the PRISMA guidelines (Page et al., 2020). Studies were independently assessed by a clinician and a data scientist for adherence to the Checklist for Artificial Intelligence in Medical Imaging (CLAIM) (Mongan, Moy, & Kahn, 2020), and the Prediction Model Study Risk of Bias Assessment Tool checklist was used to assess studies for bias and applicability (Moons et al., 2019; Wolff et al., 2019). The full review protocol is available on PROSPERO (CRD42023416520).
Summary of the current literature
Nine studies were included for detailed analysis (Hendrix et al., 2023; Hendrix et al., 2021; Langerhuizen et al., 2020; Li et al., 2023; Ozkaya et al., 2022; Singh A, 2023; Yang et al., 2022; Yoon et al., 2021; Yu-Cheng Tung, 2021) (Figure S1). All were retrospective, and three were multicentre (Hendrix et al., 2023; Hendrix et al., 2021; Yoon et al., 2021). Four reported on an adult population only (Li et al., 2023; Ozkaya et al., 2022; Yoon et al., 2021; Yu-Cheng Tung, 2021). Two included children (Hendrix et al., 2023; Hendrix et al., 2021). Three did not specify an age range (Langerhuizen et al., 2020; Ozkaya et al., 2022; Singh A, 2023). None reported comprehensive demographic data. Three reported the sex and age of subjects (Hendrix et al., 2023; Hendrix et al., 2021; Langerhuizen et al., 2020).
Model performance
A summary of model performance metrics is provided in Table 1, with further details in the supplementary material (Table S2, and Figure S2). There was no single best model. In general, models using transfer learning achieved better Area Under Receiver Operating Curve (AUROC) and accuracy scores, despite the highest sensitivity and specificity scores being achieved by models without transfer learning (Singh A, 2023). The study that enriched model training with sex and age reported no improvement in performance metrics Langerhuizen et al., 2020).
Convolutional neural network (CNN) model performance.

Data are expressed with (95% confidence interval). CNN, Convolutional neural network; CI, confidence interval; AUC, area under the curve; NPV, negative predictive value; PPV, positive predictive value. Tung et al. not reported owing to the use of multiple CNNs with and without the use of transfer learning.
Risk of bias and quality assessment
Risk of bias and quality assessment are formally reported in Online Figures S3, S4a and S4b. These results have been used to inform the discussion below. In summary, regarding quality assessment, on a study level the percentage of reported CLAIM items overall (42 items in total) ranged from 36.8% (Yang et al., 2022) to 84.6% (Hendrix et al., 2023). Only three studies reported more than 70% of appropriate items (Hendrix et al., 2023; Hendrix et al., 2021; Yoon et al., 2021). Regarding the risk of bias, overall, it was high in all studies. A key contributing factor was the number of cases in the outcome of interest being <100, which was exacerbated when considering occult fractures.
How to make meaningful advancements
These key points should be considered when constructing or interpreting these models in a clinical context. First, inclusion and exclusion criteria must be both clearly reported and clinically relevant. Without such transparency in model design, these models will not be safe for use. Four studies reported no exclusion criteria (Ozkaya et al., 2022; Singh A, 2023; Yang et al., 2022; Yu-Cheng Tung, 2021). One only excluded incomplete or distorted images (Langerhuizen et al., 2020) and two excluded poor-quality scans (Li et al., 2023; Yoon et al., 2021). The exclusion of poor-quality scans is prone to bias and was difficult to interpret owing to inadequate reporting. In addition, which radiographic views to use poses an interesting challenge for model development and integration into clinical workflows, where views taken are not uniform or consistent. Table 2 summarizes the views used in the reviewed studies. Only one study (Hendrix et al., 2023) addressed the use of multiple views and concluded that a multi-view approach should be adopted. These pre-processing steps to identify radiographs for inclusion and exclusion would need to be either automated or performed by a human in the loop, which may limit clinical usability in live clinical workflows.
Radiograph views used for model training.
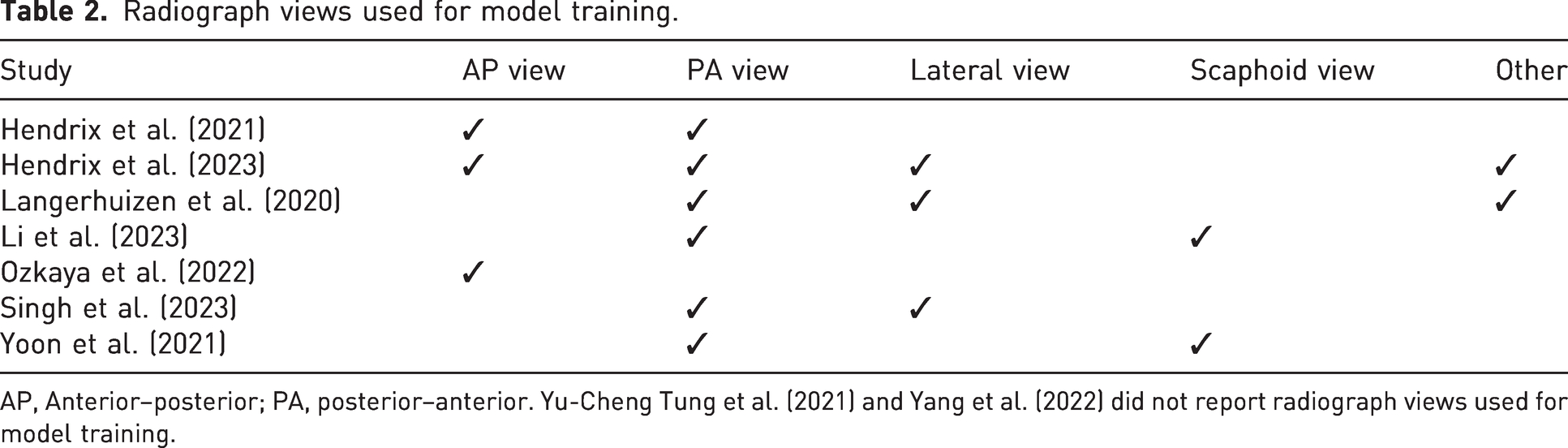
AP, Anterior–posterior; PA, posterior–anterior. Yu-Cheng Tung et al. (2021) and Yang et al. (2022) did not report radiograph views used for model training.
Second, in terms of study design, participant–radiograph disjoining (separation), is important in the context of multiple radiographic views (otherwise there can be multiple different results for the same patient, if multiple, different, radiopgraphic views are entered as different cases), which is particularly relevant for two-dimensional scanning. Most studies reported model outputs at the patient level, but this was not universal (Yoon et al., 2021). To avoid multiple results for the same patient, the output should be based on patients rather than individual scans. Another inclusion/exclusion criterion that should be reported is age limits. This has been poorly investigated and reported, although it is vitally important for clinical application as models may not perform similarly across age groups.
Third, ground truths used must be appropriate. This is of paramount importance in the context of occult fractures, where there is a risk of false negatives leading to poor-quality data. There was marked heterogeneity in the included studies, with fractures confirmed by computed tomography (CT) (Ozkaya et al., 2022), surgical exploration (Yang et al., 2022), plain radiographs only (Yu-Cheng Tung, 2021) and either CT or magnetic resonance imaging (MRI) (Langerhuizen et al., 2020). Two studies used plain radiographs for training, but they used CT (Hendrix et al., 2021) or CT with or without MRI (Hendrix et al., 2023) to confirm fractures for testing. Two used a combination of plain radiographs, further imaging and clinical notes (Li et al., 2023; Yoon et al., 2021). One used plain radiographs for obvious fractures but MRI for occult fractures (Singh A, 2023). The recommended imaging modality for the diagnosis of scaphoid fracture is MRI (Backer, Wu, & Strauch, 2020; Clementson, Bjorkman, & Thomsen, 2020; Dean, 2021) and it should therefore be considered the reference standard for determining ground truths. It should also be used to confirm fracture-negative cases (to avoid false negatives) and all occult cases used in model development. Confirmation by MRI is not required for obvious fractures on plain radiographs, and it may be acceptable to use fracture-negative plain radiographs for training data without MRI confirmation, if the scans were obtained from patients who did not present with possible scaphoid pathology. This may limit the size of the dataset but must be considered in order to facilitate high-performing, clinically meaningful models. Four studies (Hendrix et al., 2023; Li et al., 2023; Ozkaya et al., 2022; Yoon et al., 2021) distinguished between occult and non-occult fractures, while the remaining studies did not report or analyse occult fractures, which was a notable shortcoming.
Building on this, model applicability is important to consider when comparing machine learning models with clinician performance. In the papers reviewed, there was a high degree of heterogeneity between the clinicians performing the testing, which prevents meaningful comparisons and makes interpretation of pooled-clinician results difficult. Within the papers reviewed, the surgeons and radiologists used for comparison had experience ranging from 2 (Langerhuizen et al., 2020) to 30 (Hendrix et al., 2021) years, with a mix of specializations, and inexperienced clinicians may be more likely to opt for a positive diagnosis rather than miss a fracture. In addition, some papers reported average performance for groups of clinicians, and others reported individual clinician performance, making meaningful comparisons difficult. Reporting of clinician performance needs to be transparent, meaningful and consistent, and the clinicians used for comparison need to reflect the aim of the model. For example, if the model is planned to outperform expert radiologists, the clinician comparisons should be expert radiologists only. We therefore need to consider if these models are best suited to diagnose occult fractures, to automate the diagnosis of explicit fractures and possibly automate onward referral, to guide physicians or surgeons (Yoon et al., 2023), to guide expert radiologists (Hendrix et al., 2023) or to replace clinicians completely?
Fourth, training, validation and test data sets must be both clearly defined and sufficient to answer the clinical question. This is particularly important for occult fractures. The number of fracture training sets ranged from 203 (Ozkaya et al., 2022) to 8356 (Yoon et al., 2021). Test datasets ranged from 53 patients (Singh A, 2023) to 688 (Hendrix et al., 2023). Based on PROBAST, more than 100 cases should be included in test datasets (Moons et al., 2019). Two studies used an external test set (Hendrix et al., 2023; Hendrix et al., 2021); the remainder used internal test sets from the institution providing the training data, one of which had data from two different institutions (Yoon et al., 2021).
Fifth, all studies provide a binary outcome, but only one study justified the classification threshold for its model (Hendrix et al., 2023) and one study did not report a classification threshold at all (Singh A, 2023). Four studies set a classification threshold of 0.5 (Hendrix et al., 2023; Hendrix et al., 2021; Li et al., 2023; Yoon et al., 2021) without further discussion of this choice. This is a notable omission given the class imbalance between occult and non-occult fractures. To address this, at current levels of performance, it may be useful to provide clinicians with a range of probability/confidence in a fracture detection outcome, rather than a binary classification of a continuous variable. Two studies did not report how fracture outcomes were determined (Singh A, 2023; Yu-Cheng Tung, 2021). Three studies (Ozkaya et al., 2022; Singh A, 2023; Yang et al., 2022) did not report how the binary outcome was achieved.
Conclusion
The use of AI to identify acute scaphoid fractures has clinical and economic benefits. Occult fractures are a particular challenge in scaphoid injuries, and an early and accurate diagnosis is a key driver for the development of AI models in this setting. For AI to be clinically meaningful, it must either outperform clinicians or offer cost and/or process savings. Models must be transparent, have a low risk of bias (Leslie, 2019) and integrate into clinical workflows. At present, this is only an aspiration.
Performance metrics alone are insufficient to evaluate machine learning models for scaphoid fracture detection intended for clinical use, and it is not yet possible to meaningfully compare these models with clinicians (the current reference standard). Future studies should have clear and clinically meaningful inclusion/exclusion criteria, use MRI as a ground truth for occult and fracture-negative cases and provide a breakdown of model performance by subgroup to allow assessment of model bias across subgroups. Future work may seek to develop this further by enriching models with clinical data from examination findings using advances in natural language processing in electronic health records (Kraljevic et al., 2021) or using generative adversarial networks to help curate training datasets (Motamed et al., 2021).
Supplemental Material
sj-pdf-1-jhs-10.1177_17531934241312896 - Supplemental material for Artificial intelligence and machine learning capabilities in the detection of acute scaphoid fracture: a critical review
Supplemental material, sj-pdf-1-jhs-10.1177_17531934241312896 for Artificial intelligence and machine learning capabilities in the detection of acute scaphoid fracture: a critical review by Robert Miller*, Laurence Jackson, Dijana Vilic, Louis Boyce and Haris Shuaib in Journal of Hand Surgery (European Volume)
Supplemental Material
sj-pdf-2-jhs-10.1177_17531934241312896 - Supplemental material for Artificial intelligence and machine learning capabilities in the detection of acute scaphoid fracture: a critical review
Supplemental material, sj-pdf-2-jhs-10.1177_17531934241312896 for Artificial intelligence and machine learning capabilities in the detection of acute scaphoid fracture: a critical review by Robert Miller*, Laurence Jackson, Dijana Vilic, Louis Boyce and Haris Shuaib in Journal of Hand Surgery (European Volume)
Supplemental Material
sj-pdf-3-jhs-10.1177_17531934241312896 - Supplemental material for Artificial intelligence and machine learning capabilities in the detection of acute scaphoid fracture: a critical review
Supplemental material, sj-pdf-3-jhs-10.1177_17531934241312896 for Artificial intelligence and machine learning capabilities in the detection of acute scaphoid fracture: a critical review by Robert Miller*, Laurence Jackson, Dijana Vilic, Louis Boyce and Haris Shuaib in Journal of Hand Surgery (European Volume)
Supplemental Material
sj-pdf-4-jhs-10.1177_17531934241312896 - Supplemental material for Artificial intelligence and machine learning capabilities in the detection of acute scaphoid fracture: a critical review
Supplemental material, sj-pdf-4-jhs-10.1177_17531934241312896 for Artificial intelligence and machine learning capabilities in the detection of acute scaphoid fracture: a critical review by Robert Miller* , Laurence Jackson, Dijana Vilic, Louis Boyce and Haris Shuaib in Journal of Hand Surgery (European Volume)
Supplemental Material
sj-pdf-5-jhs-10.1177_17531934241312896 - Supplemental material for Artificial intelligence and machine learning capabilities in the detection of acute scaphoid fracture: a critical review
Supplemental material, sj-pdf-5-jhs-10.1177_17531934241312896 for Artificial intelligence and machine learning capabilities in the detection of acute scaphoid fracture: a critical review by Robert Miller* , Laurence Jackson, Dijana Vilic, Louis Boyce and Haris Shuaib in Journal of Hand Surgery (European Volume)
Supplemental Material
sj-pdf-6-jhs-10.1177_17531934241312896 - Supplemental material for Artificial intelligence and machine learning capabilities in the detection of acute scaphoid fracture: a critical review
Supplemental material, sj-pdf-6-jhs-10.1177_17531934241312896 for Artificial intelligence and machine learning capabilities in the detection of acute scaphoid fracture: a critical review by Robert Miller* , Laurence Jackson, Dijana Vilic, Louis Boyce and Haris Shuaib in Journal of Hand Surgery (European Volume)
Footnotes
Acknowledgements
Lisa Gardner (Imperial College Library Services, Imperial College NHS and Chelease & Westminster Hospitals NHS Trusts Libraries, London, UK) is acknowledged for supporting the systematic literature search.
Declaration of conflicting interests
The authors declare no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
Robert Miller received funding from the Health Education England Topol Digital Transformation Fellowship Programme to support his contribution to this work.
Informed consent
Not applicable.
Ethical approval
Not applicable.
Supplementary material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.