
Abstract
In today’s hybrid media environment, traditional news organizations extend their presence on Online Social Networks (OSNs) and compete with political and civil society organizations, public figures, and other influential digital storytelling individuals. This article examines conversations on Twitter, one of the most widely used OSNs, about Europe’s refugee crisis in 2014 and 2015. We use, in particular, topic modeling techniques to deduce the existence of a complex network of Twitter topics formed in response to coverage of and opinion formation surrounding the European refugee crisis. We collected more than 11 million tweets in six different languages. One of our most significant findings is that while most conversations happen in English, the refugee crisis has had different rhythms in other languages. Our assumption is that this could be evidence that the power of mainstream local media on Twitter to set the agenda is considerable, at least regarding refugee-related conversations in Europe.
Keywords
Introduction
This paper studies discursive dynamics on Twitter and, in particular, whether local/national contexts play a role. The paper is also a methodological one, as it aims to propose a protocol to study these discursive dynamics.
The research context is the European refugee crisis from 2012 (Syrian civil war aftermath) to 2015, which witnessed an unprecedented influx of war refugees and asylum seekers into Europe via various routes. Around 1.3 million refugees and migrants arrived on European shores in 2015, and 3550 people died along the dangerous journey. Over 75% of those who arrived in Europe did so to flee conflict and persecution in Syria, Afghanistan, or Iraq (e.g. Purcell, 2019).
We chose this particular crisis because it generates global and heated conversations. We used Twitter to collect these conversations. The refugee crisis in Europe is a natural experiment because global conversations are held in English, while other local conversations are held in the local languages.
It is an exploratory study with a multidisciplinary perspective. From Data Science, Communications to Political Science, our topic is fascinating as it allows us to try new protocols to extract as much reliable information as possible in the context of unstructured data and text-as-data.
Our proposed protocol follows: the first stage collects the data in five different languages. We collected more than 11 million tweets. The second stage is about determining the rhythms of each conversation in each language. A third stage is about identifying and analyzing topics per period and language. Due to the page limitations, we present the results for the English-based conversations in this paper. The other languages are analyzed in-depth on a companion website (see below).
This paper is primarily inspired and in the continuation of Kreis (2017), who studied the online discourse of the European refugee crisis on Twitter. Kreis (2017) focused on tweets with a specific hashtag: #refugeesnotwelcome, and explored how it was used to express negative feelings, beliefs, and ideologies toward refugees and (im)migrants in Europe. In this study, we add some new contributions, such as: collecting the whole population of tweets, analyzing the tweets across different languages, identifying critical periods and rhythms in the conversations, and comparing these periods using Structural Topic Modeling (STM) techniques.
Beyond this methodological contribution, our research question is to study discursive dynamics in English as a world language and then the role of local/national contexts in conversations about the refugee crisis.
In particular, we are interested in two dimensions: first, in knowing whether topics are different across local/national contexts, and second, in studying whether conversations on the global stage versus the national stage happened at different times.
Literature review
Information sources and the agenda-setting theory
The news media’s ability to shape a country’s political agenda and direct public attention toward a few critical public issues is well documented. People obtain factual information about public affairs from news organizations, readers, and viewers, and they also learn how much weight to give to a topic emphasized by the media. Newspapers provide numerous cues regarding the importance of daily news topics – lead story on page one, other front-page displays, large headlines, and so on. Television news also provides numerous indicators of story importance – the opening story on the newscast, the amount of time devoted to the story, and so forth. When repeated daily, these cues effectively communicate each subject’s critical nature. They established the agenda for the public’s attention on the small number of issues that shape public opinion.
Walter Lippmann sketched the broad contours of this influence in his 1922 classic, Public Opinion, which began with a chapter titled ‘The Outside World and the Images in Our Heads’. Lippmann (1922). As he noted, the news media are a primary source of images in our heads about the larger world of public affairs, a world that is ‘out of reach, out of sight, and out of mind’ for most citizens. In the last century, the media landscape has shifted dramatically. Traditional or mainstream media are also attempting to colonize what is referred to as the hybrid media system (Chadwick, 2013). They expand their social media presence and compete with millions of other digital storytellers.
Among the significant debates is that the agenda-setting theory is remarkably applicable in various areas of politics, business, and culture. It establishes a rational framework for examining the struggle of traditional (mainstream) media to expand their presence on OSNs and compete with political organizations, civil society organizations, public figures, and other influential individuals (e.g. Vestergaard, 2020).
The agenda-setting theory asserts that media outlets, governments, and influential individuals and organizations compete for agenda-setting authority. For example, Rogers and Dearing (1988) define ‘agenda setting’ as the effect of the media on determining the priorities of public opinion. The literature focuses on the impact of issues on the agendas of various actors. A sizeable portion of the literature examines how these agendas change and interact endogenously. The theory provides a convenient framework for analyzing media effects or policy processes. The pertinent literature highlights three distinct forms of agenda-setting: policy, media, and public/audience agenda setting (Chadwick, 2013). The traditional or mainstream media are the incumbents in a hybrid media system. They can amplify their social media presence by engaging in digital or fragmented storytelling. The democratized access to social media enables platforms representing various interest groups and individuals to compete for the ideological framing of issues.
Media bias
Several authors have investigated the possibility of a ‘Fox News effect’ (Della Vigna and Kaplan, 2007). The following is the link: Fox News enters cable markets and affects voter behavior. Republicans gained between 0.4 and 0.7 percentage points in vote share in the 9256 towns where Fox News was introduced between 1996 and 2000. According to the authors, Fox News persuaded voters between 3% and 28% to vote Republican. If we consider Fox News a strong conservative channel, this study demonstrates how a highly vocal national news network affects voting. This illustration establishes the concept of media bias.
Over 70% of Americans believe that news coverage is skewed by the media (PRC, 2004). Is it purely subjective, or do we have evidence of media bias? The literature has discovered biases in a variety of ways. To begin, the bias could be related to the topic selection. This was the case with the New York Times’ topic selection (Puglisi, 2011).
Additionally, some authors demonstrate that news coverage is more receptive to unexpected adverse events than to positive ones (Costa and Kahn, 2017). News media outlets can act as watchdogs or lapdogs (Puglisi, 2011). Other authors compared a news media outlet’s print and online versions to determine whether the increased engagement associated with online exposure affects people’s agendas (Althaus and Tewksbury, 2002).
It is also about the media sources, such as policy organizations and think tanks (Groseclose and Milyo, 2005). Based on the sources cited by the House of Representatives, these authors created an index of left-center-right-wing sources. They could then associate news organizations with this metric and place them on a political spectrum from left to right.
Methods
Theoretical framework
Our study’s primary objective is to examine the opinion formation process and the forces that drive influential thinking on Twitter activity related to this large-scale humanitarian crisis.
In an online world, news media outlets’ first step was creating a website and pushing their conversations on the newly appeared social media. Rapidly, social media were taken over by individuals and groups. People would decide on the story to push and build up their case using other sources (Figure 1).
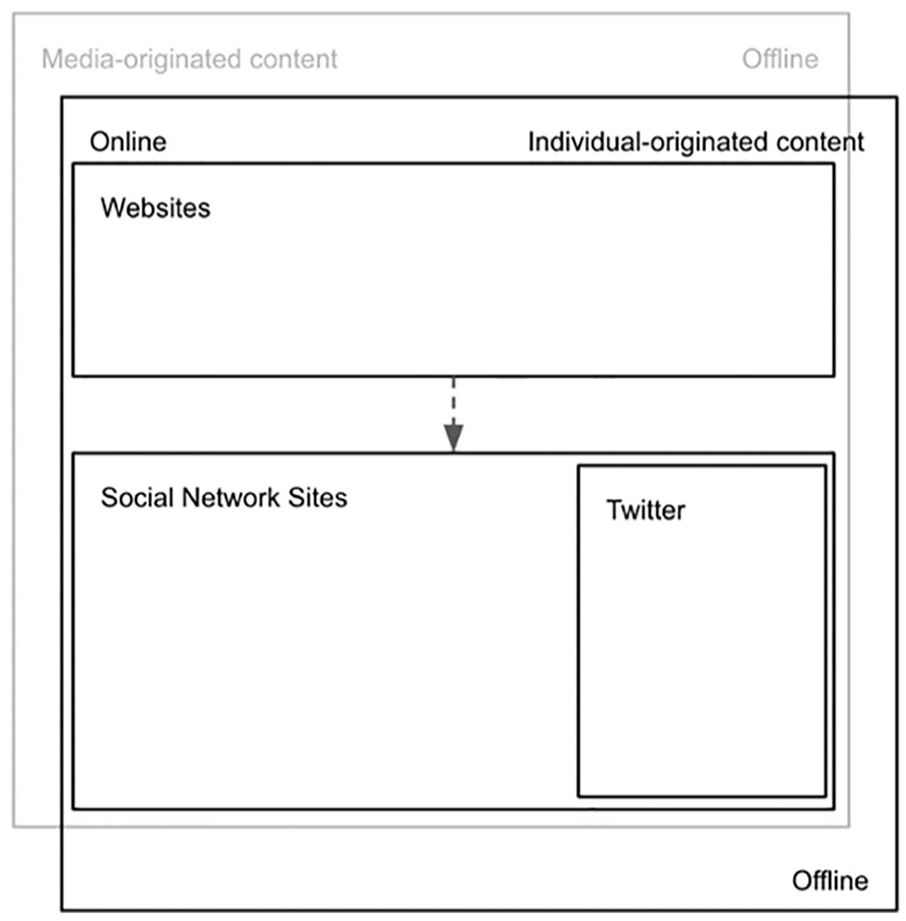
Conversation dynamics on Twitter.
Conversations can be defined as the dynamics of information sharing, editorialized or not, about a specific topic (Figure 2).
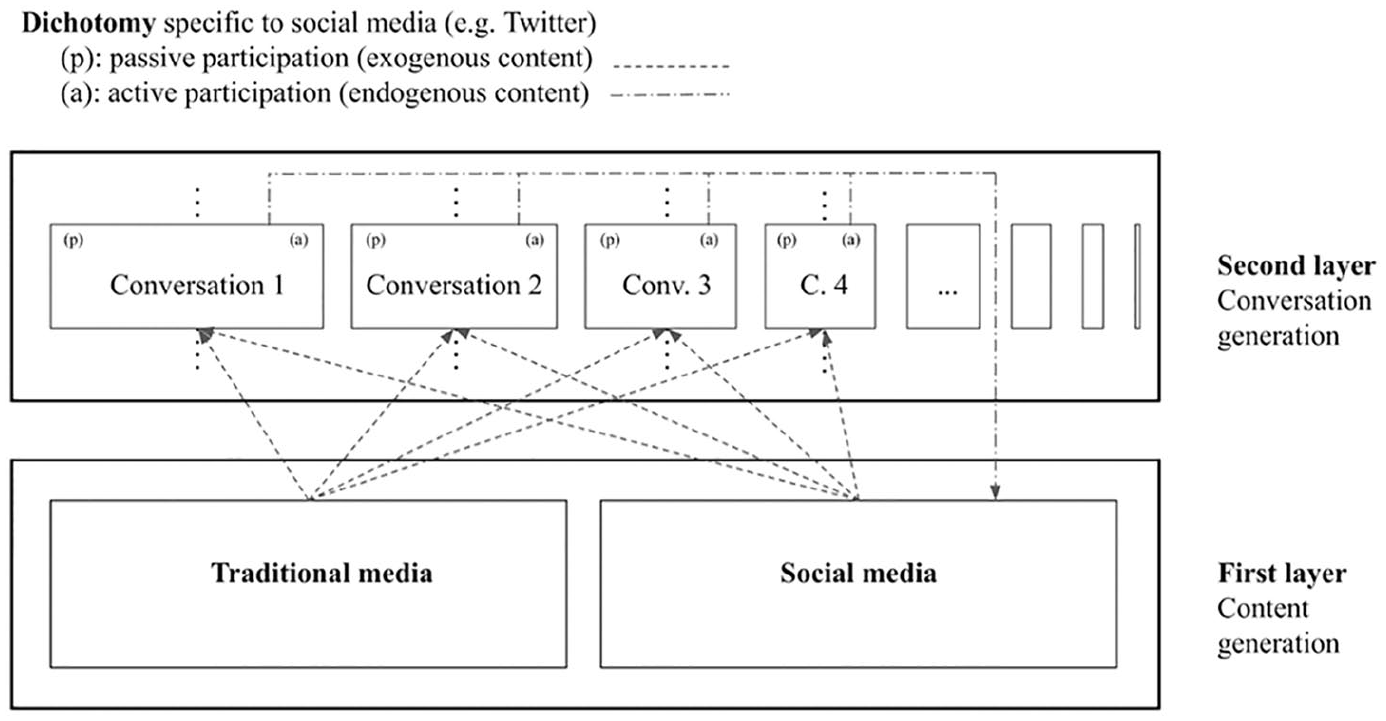
Dynamics of a social media conversation.
We find on Twitter a first layer of information materialized through ‘tweets’, and users can select a topic, read and contribute to this topic in several ways: by replying, liking and/or retweeting. The former corresponds to active participation in the conversation to the risk of oversimplifying, while the latter corresponds more to passive participation in the conversation. Conversations on Twitter are thus a blend of various sources and active or passive actions (replies, retweets, likes).
Our motivation is to analyze discursive dynamics in English as a global language, and then in different local/national contexts. We study the conversations across multiple languages. We formulate the following hypotheses:
H1. Regarding the conversations on the European refugee crisis on Twitter, English is ‘the Lingua Tweeta’ (The Language of Twitter).
H2. National/local mainstream media retain significant agenda-setting power and influence the discursive dynamics on Twitter.
Regarding H1, we assume that the English language is more frequently used to mobilize a wider audience and raise European public awareness about the implications of the refugee crisis. Some studies demonstrate that English was used to communicate greater social support during resettlement (e.g., Ahmed et al., 2020), facilitate refugee integration, and build bonding social capital (e.g. Alencar, 2018; Alford, 2014; Crepaz, 2022) or reframe the European immigration discourse (e.g. Wigger et al., 2022).
Regarding H2, with prior experience and a strong reputation, mainstream media can leverage their presence on Online Social Networks (OSNs) to gain a significant competitive edge over other users. The alternative hypothesis is that Twitter has evolved into a more competitive environment for digital storytelling, putting traditional media behind influential individual users.
We apply Structural Topic Modeling (STM) techniques to Twitter conversations on the European refugee crisis. Our primary contribution is a methodological rather than a causal relationship search. In short, we enshrine ourselves in the agenda-setting theory’s ‘media-modeling’ definition as promoted by Shaw (1977) and later redefined in the context of social media (Jungherr, 2014). We first want to map the discursive dynamics in English as a global language and then analyze the potential differences with other languages regarding topics and timing.
Twitter’s platform includes several features – such as hashtags – that enable researchers to deconstruct a sample of tweets into multiple dimensions. For example, we can determine which tweets originate from traditional media and regular users and fall into the first and second layers. Additionally, there is another dimension to consider: endogenous versus exogenous nature. The first layer of content generation (the first layer) comprises exogenous data gleaned from traditional and social media sources. The conversations are then generated by users in both an active (editorialized) and passive manner (retweets, for instance). As such, editorialized content will feed our taxonomy’s first layer, corresponding to generating new – though related – content. This pattern exemplifies Twitter’s endogenous nature.
This deconstruction technique effectively investigates the dynamics of a conversation, mainly when no other method is available. This deconstruction strategy will assist us in determining the most effective framing strategy for extracting meaningful tweets and ensuring an unbiased sample. We can generate a sample of tweets by following the steps above. This is a framing technique. The second step is to deconstruct this sample into two dimensions: tweets generated by traditional media and tweets generated by other regular users. Then, we can determine which tweets indicate active and passive participation. Thus, it is worthwhile to investigate the relationship between the dynamics of a conversation (via active and passive participation) and the information source’s nature (traditional media or regular users).
Social media is likely to play a significant role in setting the agenda. It appears as though the question of whether we can use Twitter data to deduce some fascinating statistical relationships between the number of tweets and the outcome of an election remains unanswered (Guess et al., 2019). However, Twitter exchanges can, at the very least, serve as a source of information that engages people and influences their opinions (Antonakaki et al., 2021). Indeed, because news channels and broadcasters are one method of staying informed, another is through social media, as described previously. The popularity of social media as a source of information in recent years has resulted in interesting applications and, consequently, challenges to its effective use (Agarwal et al., 2012).
Researchers are increasingly using digital trace data to analyze social phenomena. These approaches can be classified into two categories. In one, Twitter is used as a sensor to record users’ reactions to direct or mediated experiences via data traces generated by users’ interactions with the service (Jungherr et al., 2016). In the second category of studies, researchers go so far as to infer users’ attitudes, affiliations, and opinions based on their platform behavior (Barberá and Steinert-Threlkeld, 2020). Twitter messages critical of political parties lacked the temporal consistency of their television coverage or newspapers (Jungherr, 2015).
In general, these findings underscore the critical role of traditional media coverage of politics in influencing Twitter activity related to politics. This relationship, however, is not deterministic, as only a subset of mediated events generates significant volume spikes on Twitter, and the intensity of Twitter coverage of political actors varies from that of traditional media coverage. Prominent messages posted during mediated events also demonstrate how Twitter is used to contextualize and contest events presented by traditional media, potentially opening up the political communication space to new actors (Gao and Berendt, 2014; Jungherr, 2015). We identify a significant omission from the pertinent literature. Many of the existing studies are descriptive. While descriptive insights are valuable for concluding migration in public discourse, we lack an explanatory understanding of migration and its media coverage.
Twitter and influence
The conversational aspects of Twitter were examined separately by tracking usernames, hashtags, and retweets. A pioneering study by Honeycutt and Herring (2009) examined the sign ‘@’ followed by a username as a form of addressivity critical to Twitter conversations. They concluded that 90% of tweets containing (username?) were conversational.
Indeed, Small (2010) defines conversational tweets as ‘a public message sent between two individuals, distinguished from standard updates by the (username?) prefix’. Yardi and Boyd (2010) discovered that like-minded individuals tweet more frequently to one another than to others. This became apparent when examining Twitter activity related to climate change (Pearce et al., 2014).
The study of influential news sources in social media entails determining how a few sources influence other users. Generally, the blogosphere follows a power-law distribution, with a small number of influential users constituting the short head and many non-influential users constituting the long tail (Agarwal et al. 2012).
A substantial body of relevant academic literature is devoted to recognizing emotion in social media texts. Emotional ratings of words are in high demand due to their use in at least four lines of research.
The first of these lines of inquiry is into the nature of emotions: their production and perception, their internal structure, and the consequences for human behavior. For example, Verona et al. (2012) compared the responses of offenders without a personality disorder to those with antisocial personality disorder who possessed or lacked additional psychopathic traits.
The second line of research examines the effect of emotional characteristics on word processing and memory. In a lexical decision experiment, Vinson et al. (2014) discovered that participants responded more quickly to positive and negative words than to neutral words, which was later replicated in sentence reading by Scott et al. (2012). Vinson et al. (2014) assert that emotion plays a critical role in the semantic representations of abstract words. According to other research (Fraga et al., 2012), emotional words are more frequently used as attachment sites for relative clauses in sentences such as ‘Someone shot the actress’s servant. . .’
A third approach estimates the sentiments expressed by entire messages or texts using emotional ratings of words (Leveau et al., 2012).
Finally, emotional ratings of words automatically estimate the emotional values of novel words by comparing them to the emotional values of validated words. Bestgen and Vincze (2012) estimated the affective values of 17,350 words by comparing them to the rated values of semantically related words. In political science, two approaches to estimating media bias are used. First, a portion of the literature has developed similarity measures between known political actors’ ideologies and the vocabulary used in news outlets (Gentzkow and Shapiro, 2006; Groseclose and Milyo, 2005). Second, a subset of the literature examines variations in the intensity with which media outlets cover various topics (the ‘issue-volume’ aspect) (Larcinese, 2007) or in the tone with which they cover these topics (the ‘issue-framing’ aspect) (Kahn and Kenney, 2002; Lott and Hassett, 2014).
Our contribution falls closer to the former category, focusing on the issue-volume aspect of the conversation dynamics estimated through the diverse topics.
Data collection procedures
In this context, we propose the following steps to analyze the dynamics of the conversations on Twitter. We collected tweets and their metadata (date, username, retweets, hashtags, etc.) over 3 years using a framing strategy to assemble our datasets.
For our framing strategy, we used the following hashtags spanning from English words to German words: europeanmigrantcrisis, migrants, refugees, refugees welcome, refugeecrisis, réfugiés, MigrationEU, migrazione, rifugiati, migranti, fluchtlinge, asylmissbrauch, refugiados, norefugees
Thus, we build a dataset with six languages (English, French, German, Italian, Spanish, and Portuguese). Of course, English tweets dominate the conversation, for the global conversation is primarily written in English. The other languages will help us identify local/national cultural, political, or economic factors that may be promoted by traditional media channels.
Now, we recognize that languages and territories are not always equivalent. Another alternative would be to use geolocated tweets. Unfortunately, the small number of geolocated tweets prevents us from choosing that option. Another answer would be that media outlets are often more language-related than country-related.
The data is gathered using an R-based program that interrogates the streaming Application Programming Interface (API) of Twitter. The dataset contains 11,803,583 messages from August 31, 2012, to December 31, 2015. To perform the following computations, we use two dedicated servers and use parallelization techniques for our code.
Pre-processing of data is done to treat words with remarkably similar properties identically and remove unnecessary words to our interpretation and model. The literature survey indicates that 15% of tweets have 50% or more Out Of Vocabulary (OOV) words (Antonakaki et al., 2021).
This dataset contains thus a large set of tweets that emerged in the global Twittersphere regarding the refugee crisis in Europe. Since this event attracted worldwide interest, we have filtered the dataset into two high dimensions: the first dimension is linguistic, while the second dimension is temporal.
Figure 3 illustrates why we chose this timeline to build our dataset. We see the beginning of the global conversation about the refugee crisis and its end.
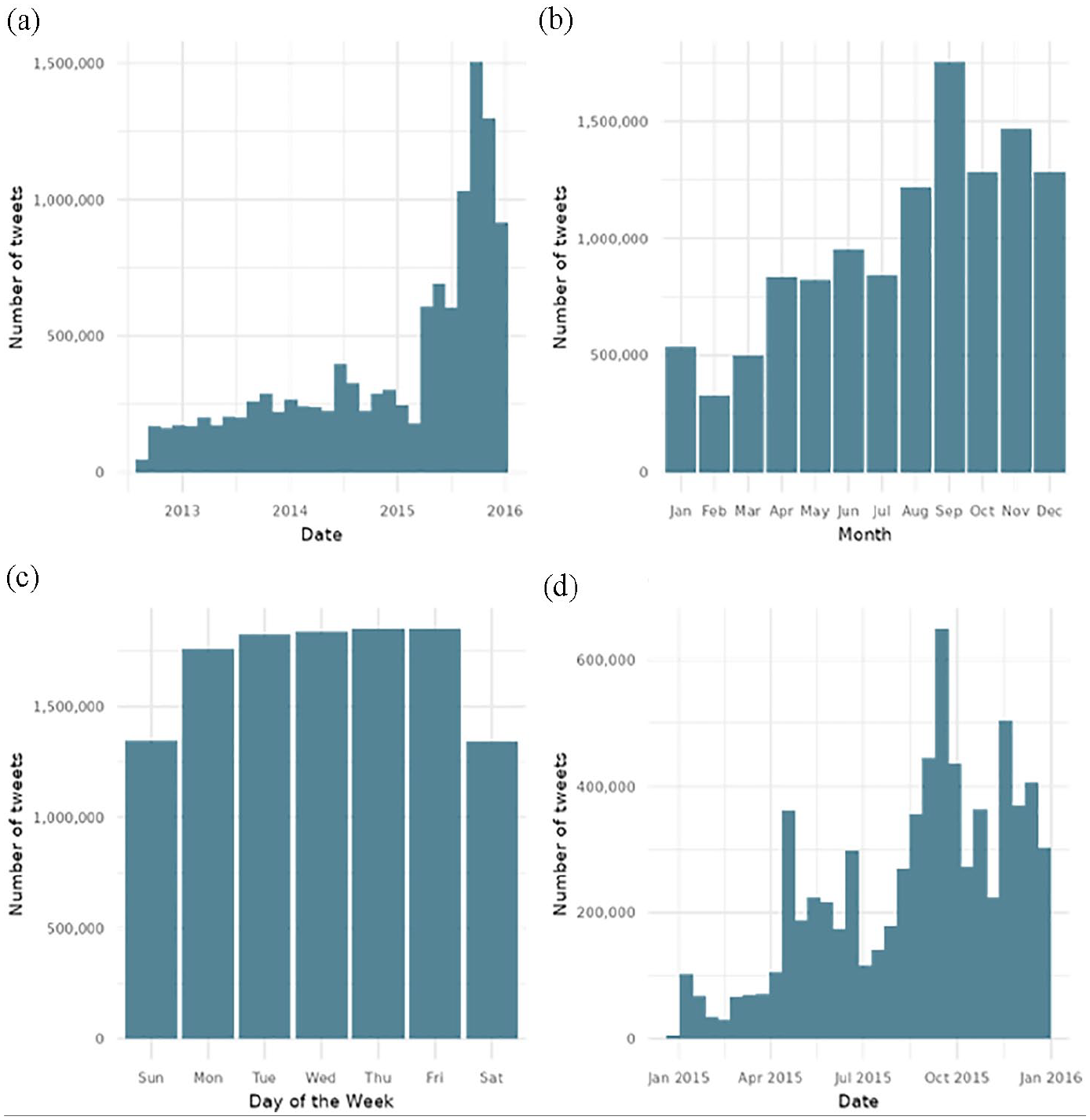
Number of tweets by years, days of the week, months, and months in 2015. (a) Count by years. (b) Count by months (2012–2015). (c) Count by days of the week. (d) Count by months in 2015.
Interestingly, we can see that 2015 saw an essential growth in the global conversation.
Also, we can see no difference between the days when people tweet. However, there is a difference in the months. It is particularly true in 2015, when the fall season was particularly active.
Another important aspect (Figure 2) is to know whether the conversations are initiated and then retweeted, replied or liked.
We see that most of the conversations are one-way conversations. Media, individuals, and groups push their content, and – across languages – only 19.2% are retweeted, 9.2% are replied to, and 15.5% are liked Table 1).
Number of retweets, replies, and likes.
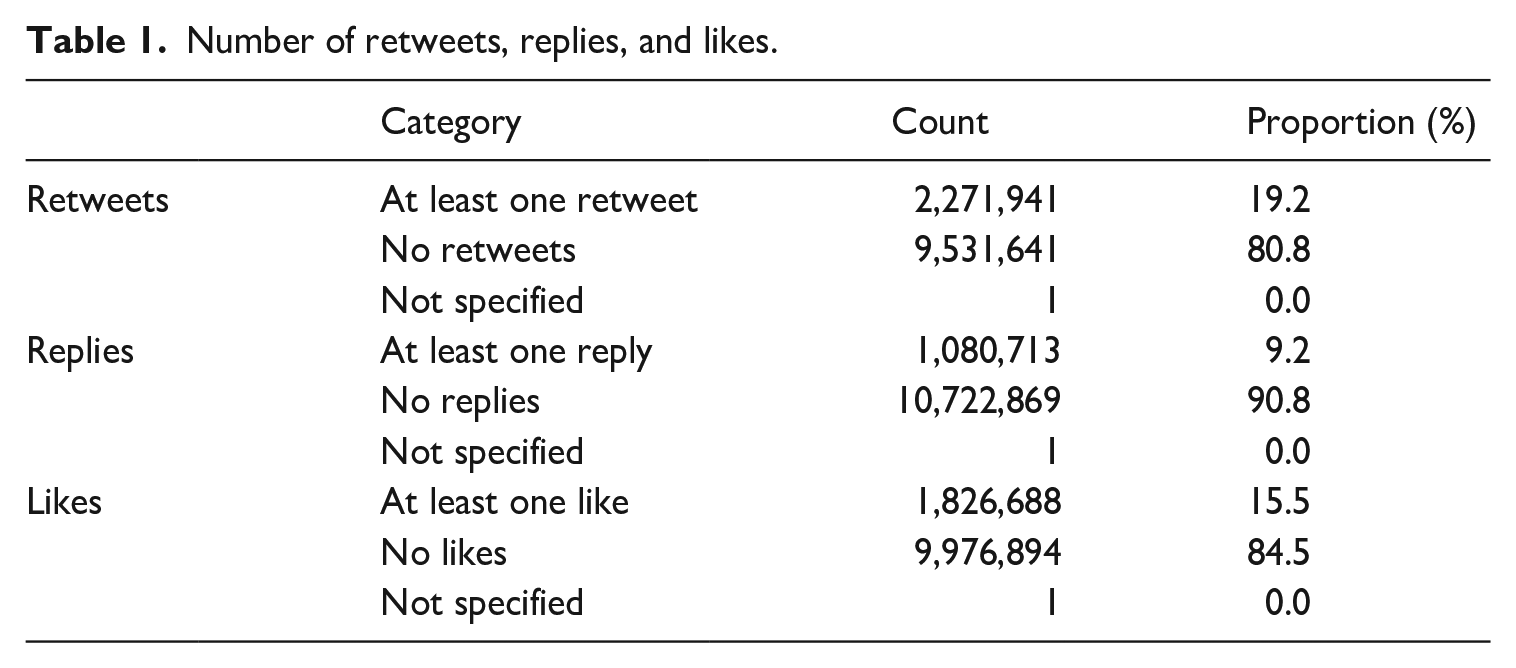
Of the 11,803,583 tweets, none are retweeted, meaning that these are only original tweets. No information is given about whether it is a replied tweet or not. However, we know that 2,271,941 tweets have at least one retweet (up to 15,437 retweets), 1,080,713 tweets have at least one reply (up to 1860 replies), and 1,826,688 tweets have at least one like (up to 14,146 likes).
Table 1 is particularly interesting to consider in the context of the languages (Table 2). We observe that 68.9% of the conversation about the refugee crisis in Europe is in English and thus likely to be a global conversation.
Number of tweets per language.
Figure 4 shows that the global conversation in English has started earlier than in any other language. Tweets in Spanish are second, followed by French, Italian, and Portuguese tweets.
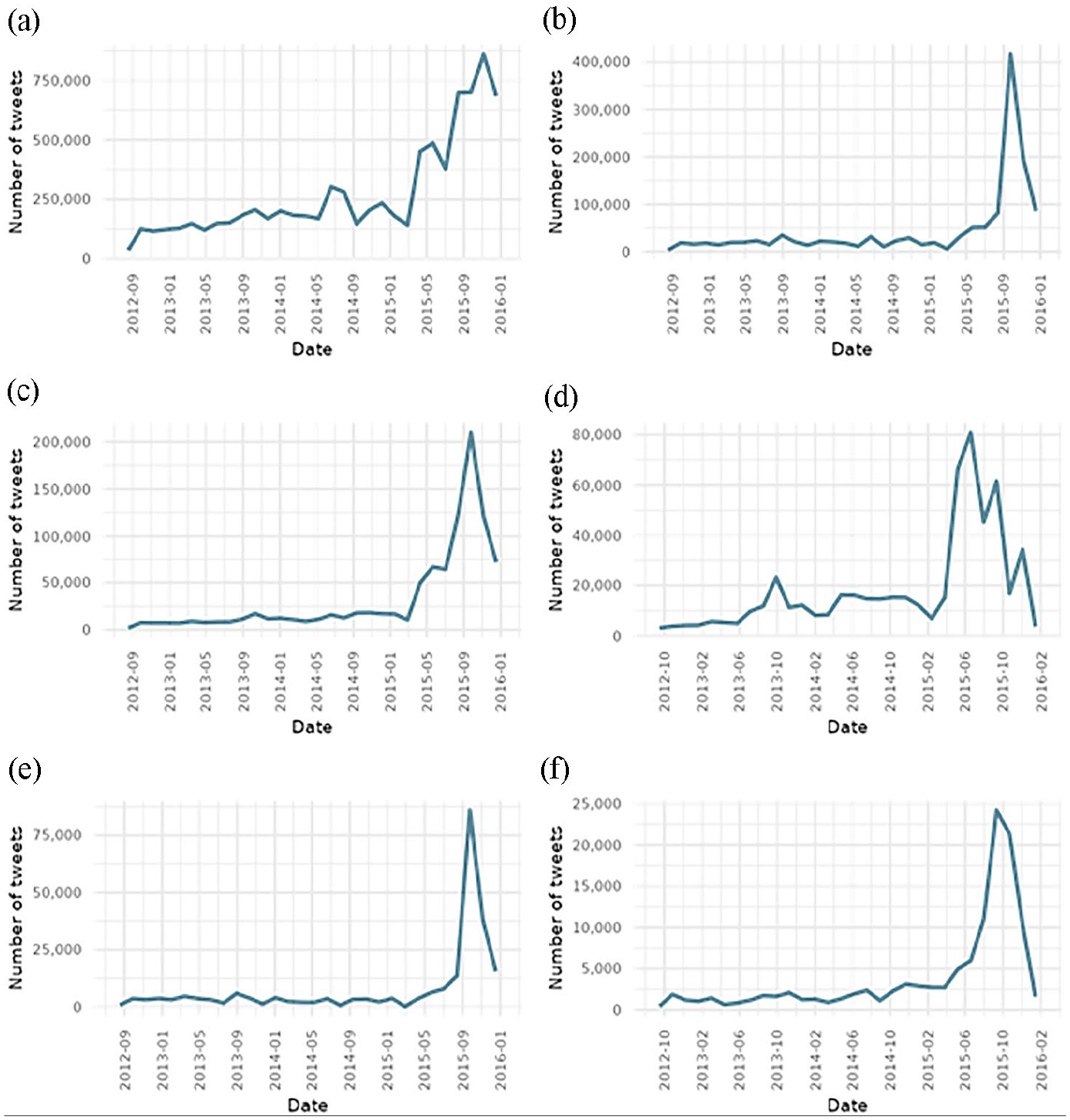
Number of tweets per language over time. (a) English. (b) Spanish. (c) French. (d) Italian. (e) Portuguese. (f) German.
In what follows, we look into the statistical difference between periods to represent when the conversation was triggered.
Protocol
Stage 1. Identifying relevant periods
Our objective in this paper is to document the dynamics of the global Twitter conversations about the refugee crisis in Europe. In terms of protocol, this means that we should ideally take into account the tweets’ geolocation, language, and time.
Geolocation is a problem, as very few tweets on Twitter are geotagged. We would be unable to conduct any topic modeling analyses due to the small sample size. Although English is frequently used even by people living in non-anglophone countries, the tweet language can be used as a proxy for geolocation. English is used as an international language to initiate or join a conversation. Though not flawless, we present language-based analyses in this section. The results for English-language tweets are presented in this paper, while those for other languages are available on a companion website (https://www.warin.ca/projects/article-refugee-crisis/index.html).
Additionally, we have mentioned the critical nature of time. To capture the evolution of the conversations, their amplitude, and their content, we must examine the entire period and its sub-periods. Our criterion for determining which periods are significant will be the number of tweets for a particular date. This date must be an ‘anomaly’ compared to the preceding days and weeks. We use the ‘anomalize’ package (https://github.com/business-science/anomalize) to accomplish this goal, inspired by time series analysis in finance. It enables us to identify days when the number of conversations increases compared to previous days. Three days before and 3 days after being used to define the period.
The package implements decomposition using median spans, the Generalized Extreme Studentized Deviation (GESD) test, and the IQR method. The two parameters, alpha, and max anoms are used to control the anomalies() function. By default, the alpha value is set to 0.05, which means that the bands cover only the extremes of the range. Reduce the alpha, and the bands expand, making it more challenging to be an outlier. When the alpha value increases, the bands narrow, making it easier to be an outlier. The max anoms parameter specifies the maximum percentage of data that can be considered an anomaly. This is advantageous when tuning alpha is too difficult, and you want to focus exclusively on the most egregious anomalies. We adjusted the alpha to 0.1 and the max_anoms to either 0.03 or 0.05, which means respectively 3% or 5% anomalies allowed (Figure 5).
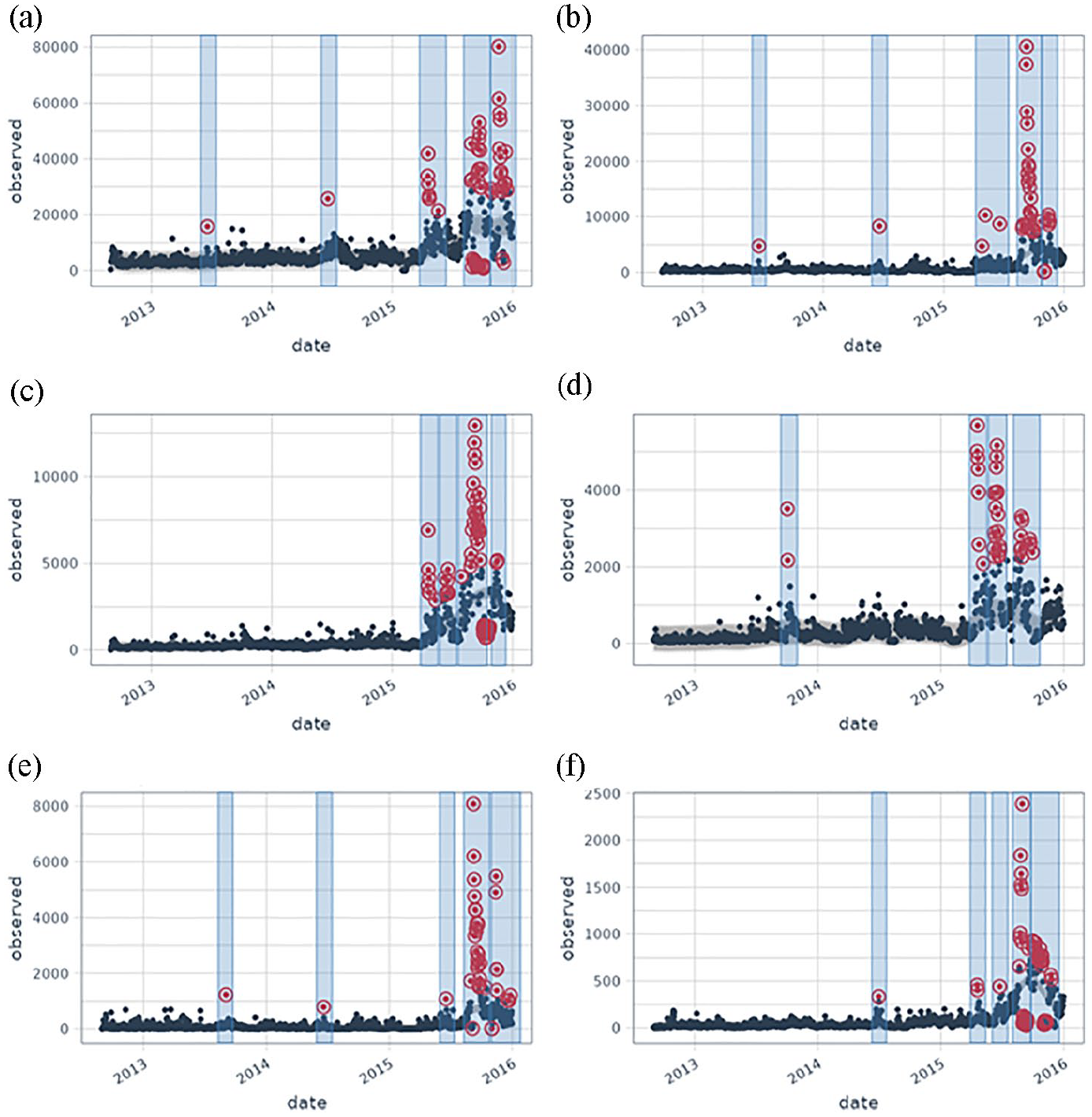
Periods per language. (a) English, 5% anomalies. (b) Spanish, 3% anomalies. (c) French, 5% anomalies. (d) Italian, 3% anomalies. (e) Portuguese, 3% anomalies. (f) German, 5% anomalies.
As a result, the conversations happened at different periods for each language, which we can identify and represent in the following table (Table 3).
Periods per language.
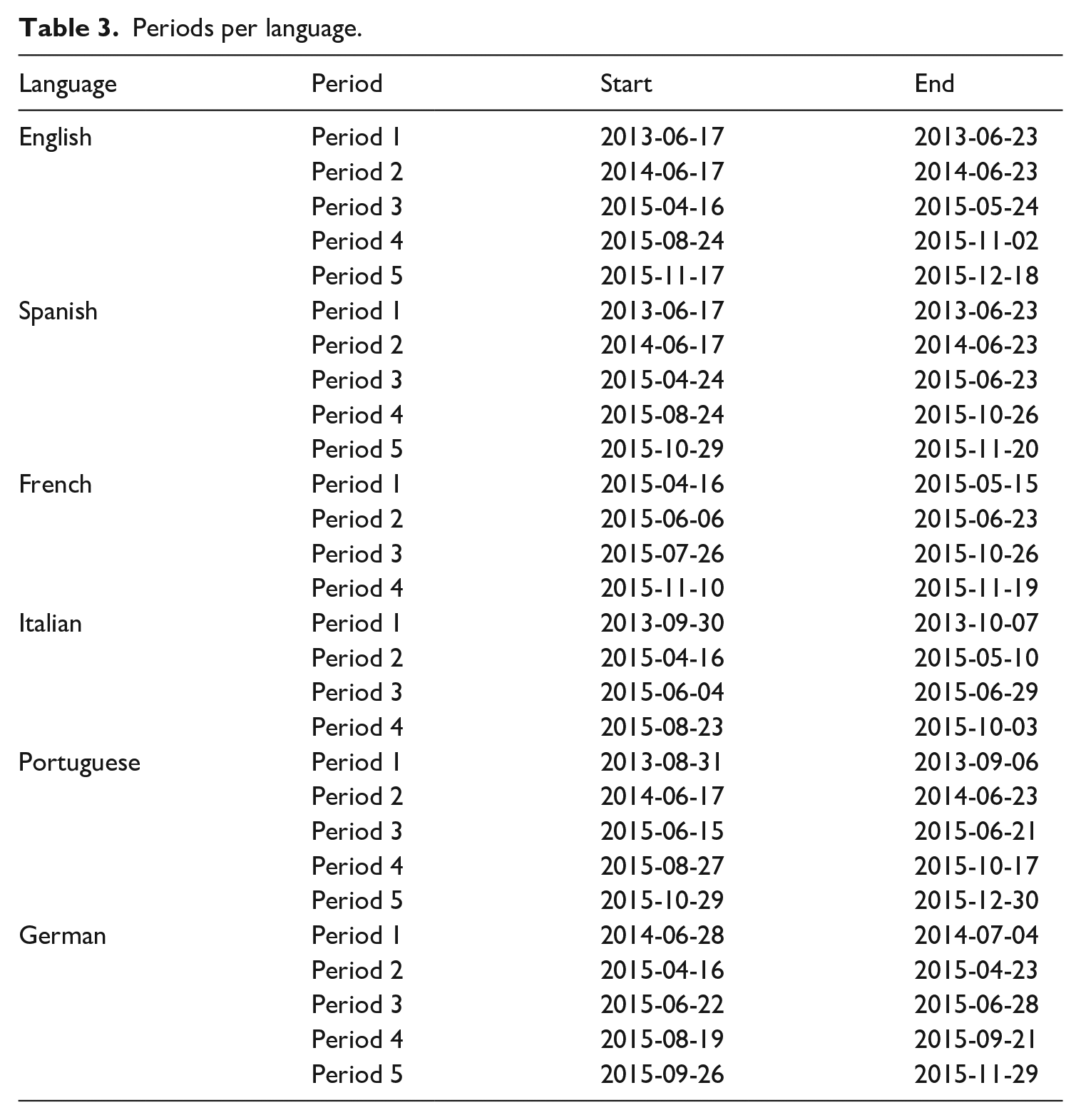
Periods are defined as time spans statistically different from the previous periods. Based on this definition, we identified five periods for English-, Spanish-, Portuguese-, and German-based conversations. French- and Italian-based conversations have four periods. So, there are five hot moments in the first series of languages and four in the second series.
It is particularly interesting to note that there exist some differences in the importance of the conversations across the different languages. Not surprisingly, English is used abundantly throughout the whole period, but apart from English, the dynamics of the conversations was high only for Portuguese until late December 2015. So Portuguese-based tweets started a little later, they also finished a little later.
By creating these statistically-based periods, another result is to see the very early stages of the conversations across languages. For instance, the conversation started in English, we see that Spanish came in second place, followed by Portuguese, Italian, and German. Although French was the third language used in this dataset, the conversation took some ground only in 2015.
Thus, conversations happen at different periods across languages (see Table 4).
Top 3 topics per language by period.1.

Stage 2. Structural Topic Modeling
The next stage is to know which topics triggered the conversations and which ones ‘entertained’ the conversations. We use the Structural Topic Modeling (STM) technique to analyze the topics. The STM technique provides tools for reading text corpora, thanks to algorithms. Based on the tradition of probabilistic topic models such as the Latent Dirichlet Allocation (LDA), the Correlated Topic Model (CTM), and other topic models that have been extended, the Structural Topic Model’s primary innovation is the ability to incorporate arbitrary metadata, defined as information about each document, into the topic model. Topic models enable the summarization of unstructured text, the discovery of clusters (hidden topics), and the assignment of a probability of belonging to a specific topic to each observation or document. STM has grown in popularity in recent years. For example, users can use the STM to simulate the framing of international newspapers, open-ended survey responses in the American National Election Study, online class forums, Twitter feeds and religious statements, as well as lobbying reports. The Structural Topic Model approach enables researchers to discover and estimate the relationships between topics and document metadata. In our empirical work, we are utilizing the STM package (http://www.structuraltopicmodel.com/).
The following illustration (Figure 6) depicts a heuristic diagram corresponding to a typical workflow. The data is initially ingested and prepared for analysis by researchers. Following that, an estimation of a structural topic model is performed. The ability to rapidly estimate an STM enables evaluation, comprehension, and visualization (Roberts et al., 2019).
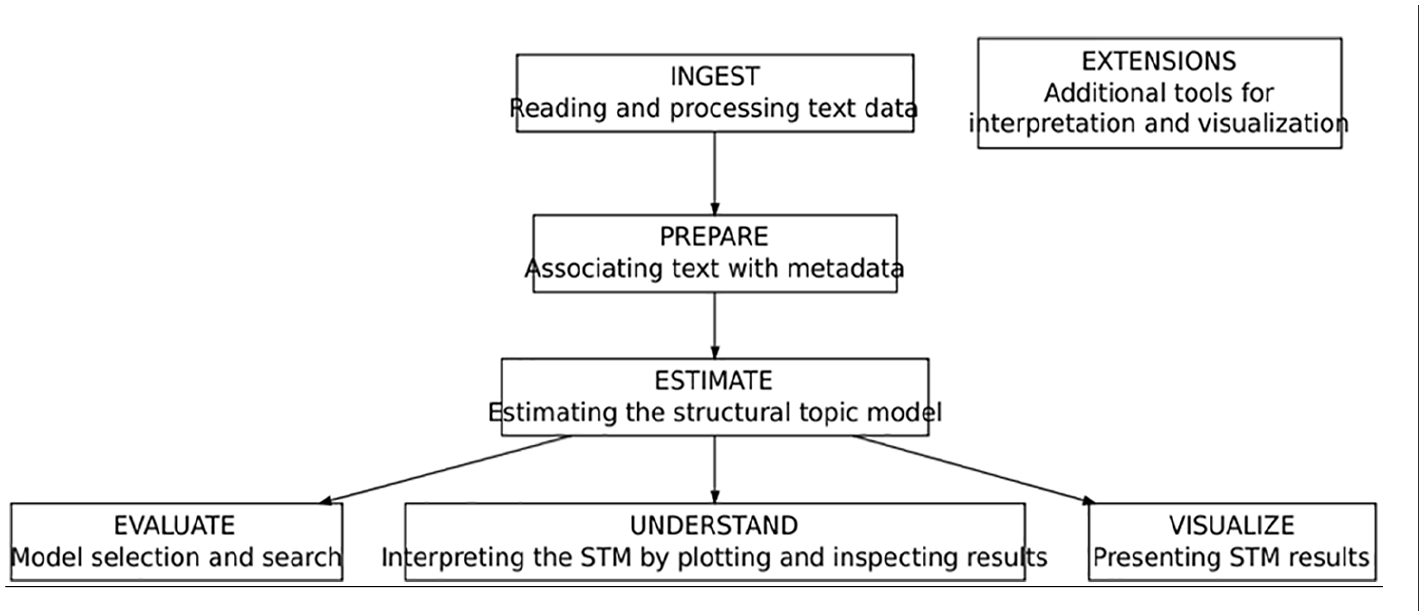
STM heuristic description.
The workflow is self-explanatory: first, our algorithms read and process the data. A second step is about joining text with metadata. The next step is about estimating the topics and evaluating its statistical significance. The last step is about producing visuals for the results in order to be interpreted.
Results
In what follows, due to page restrictions, we present the overall results for the English tweets only and some specific results for each language. On the companion website, we present the results for all the languages in our dataset. The English tweets represent 68.9% of the 11,803,583 tweets.
Overall period
The next step in our protocol is to determine which topics are trending and when. We do that for the overall period (Figure 7), and we also do it for each period of interest as determined in the previous stage (Figures 814).
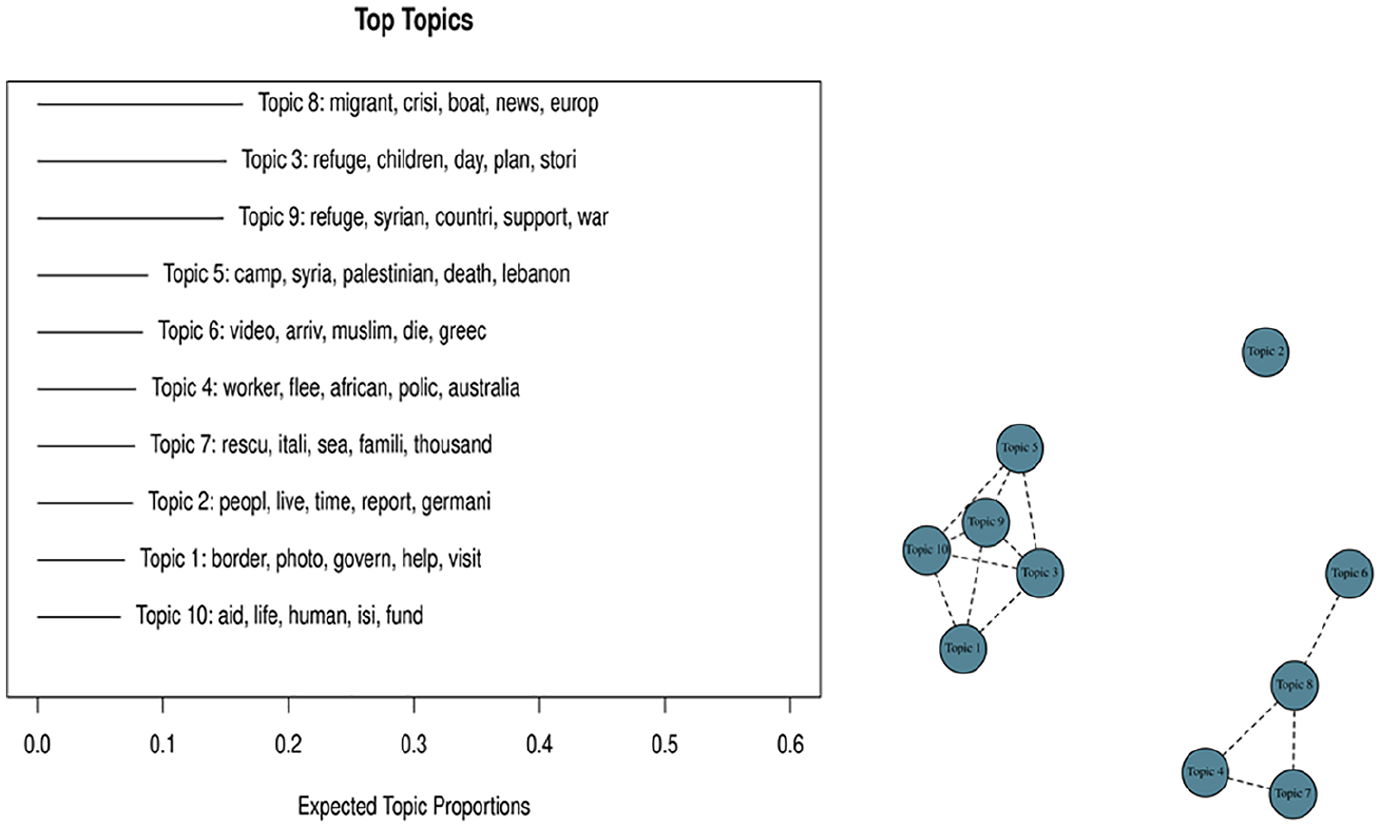
Topics for the overall period. Top 10 topics and correlations among them.
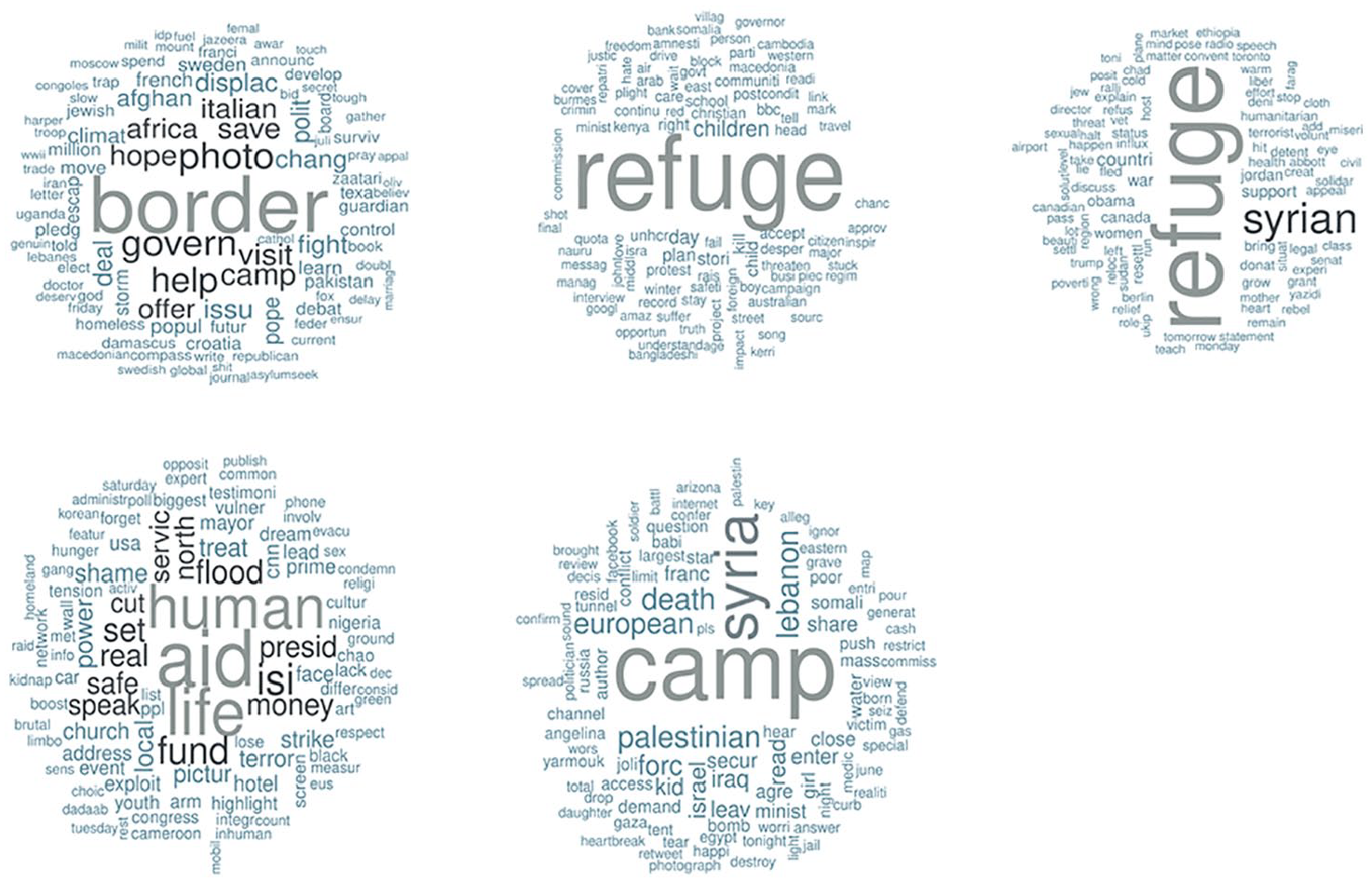
Word clouds for Group A’s top topics.

Word clouds for Group B’s top topics.
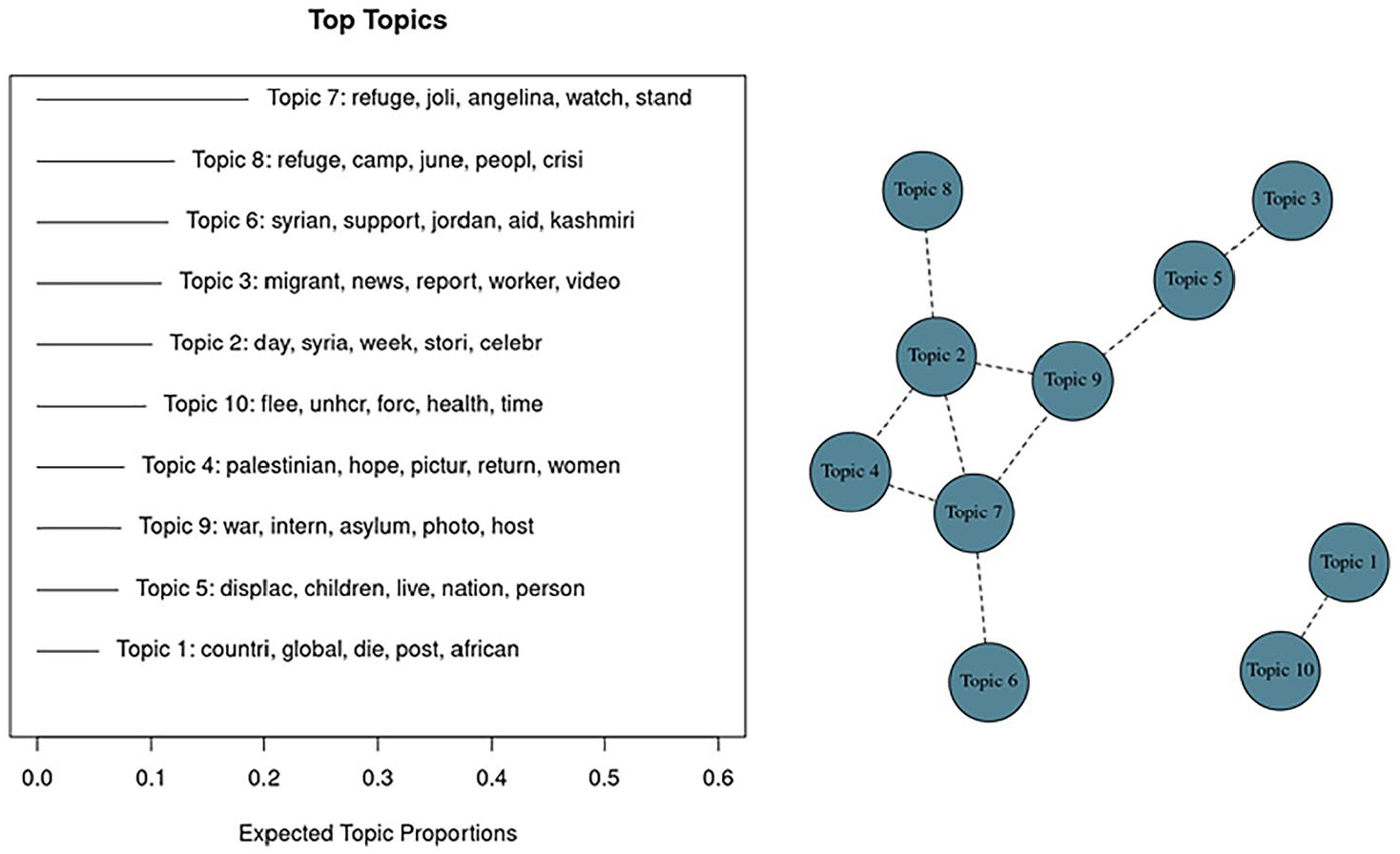
Period 1, top 10 topics and correlations among them.
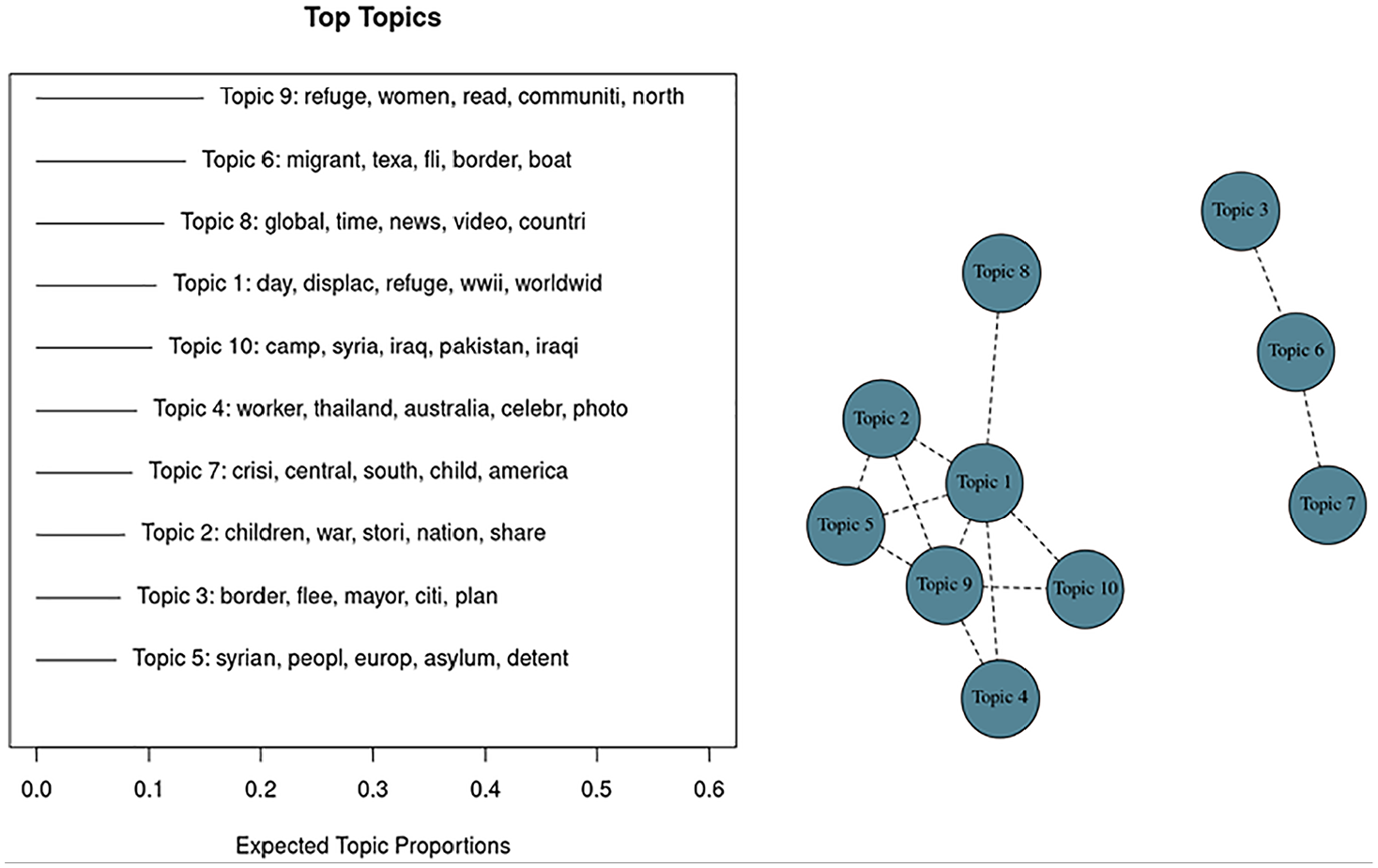
Period 2, top 10 topics and correlations among them.
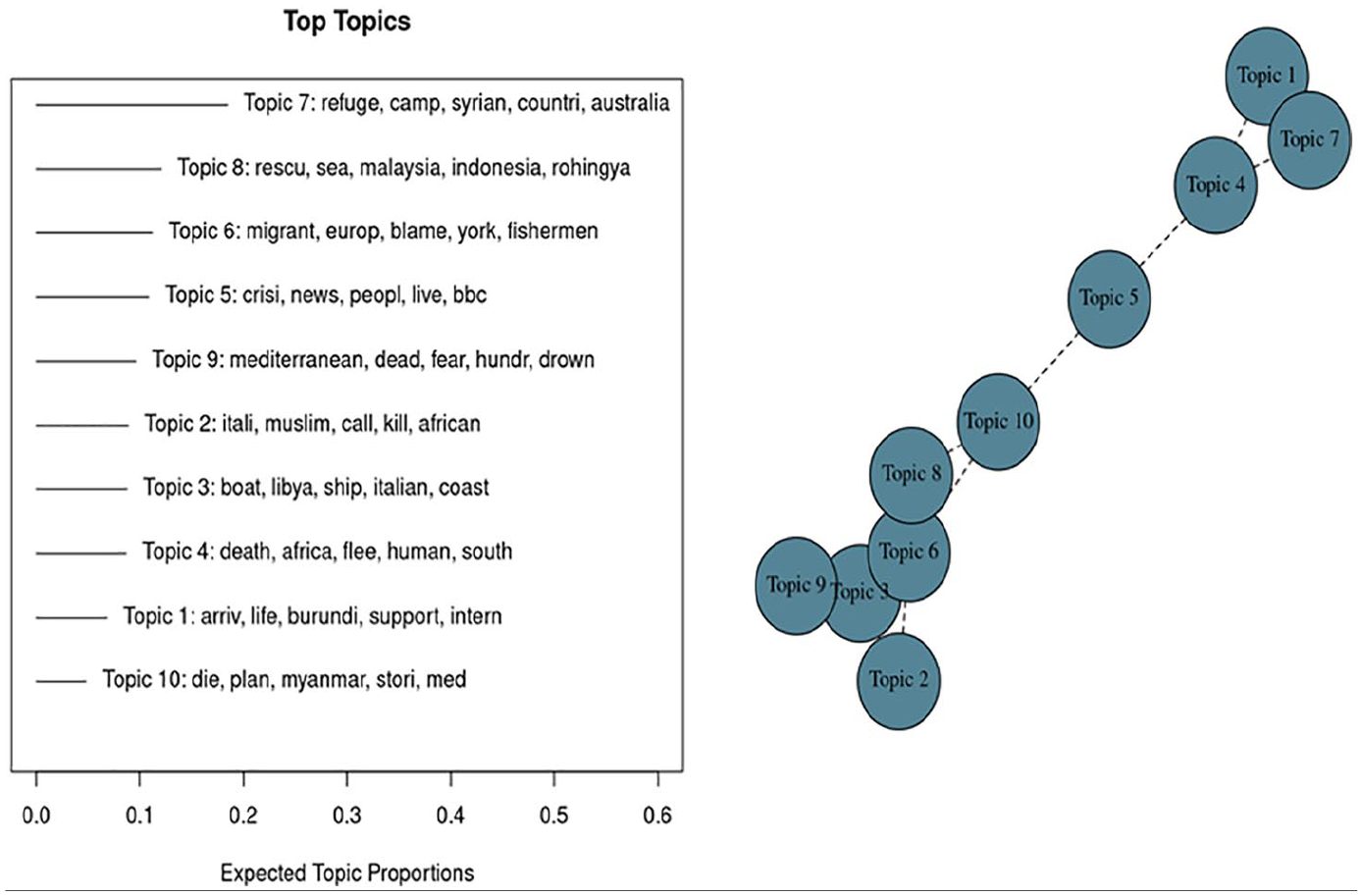
Period 3, top 10 topics and correlations among them.
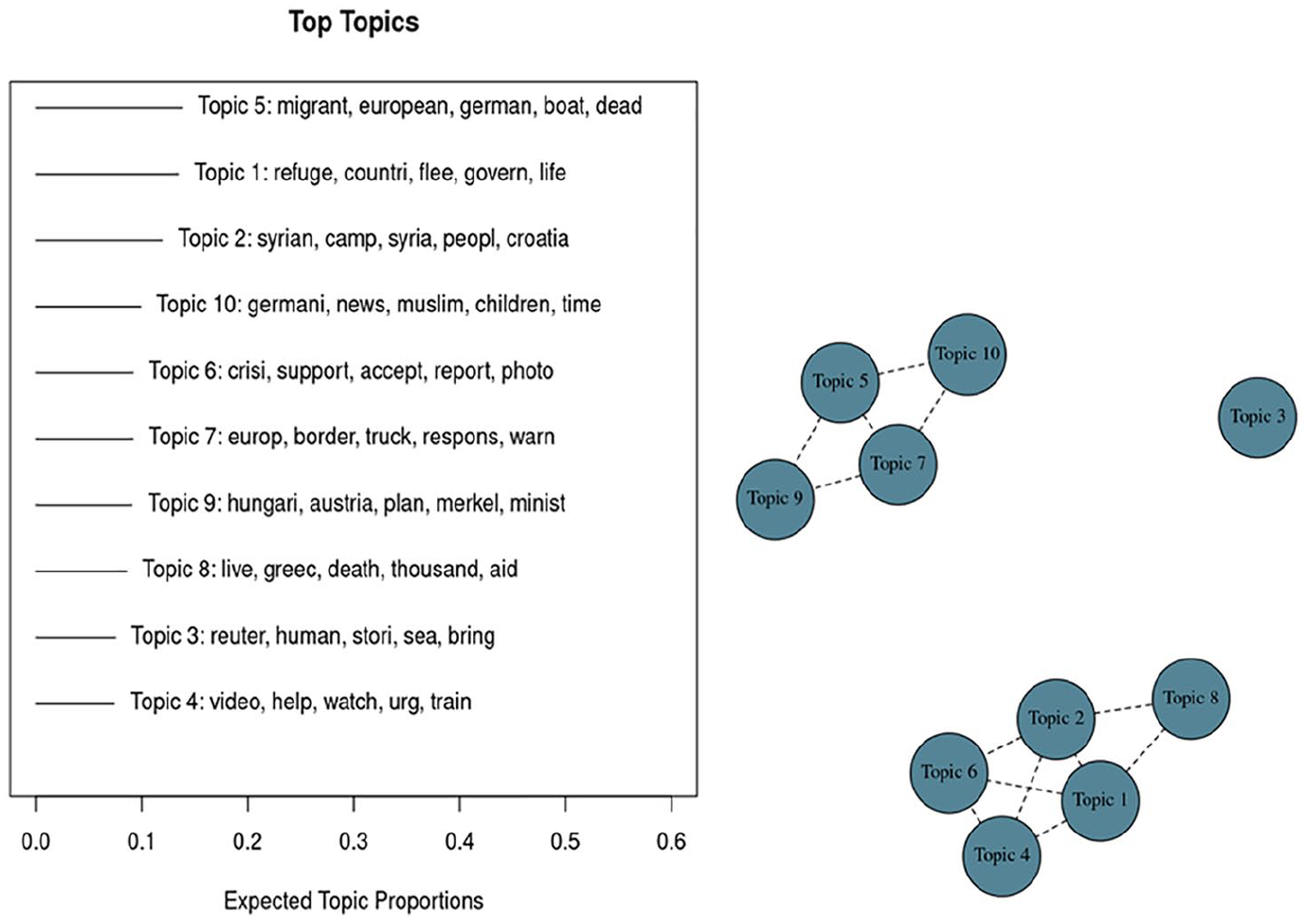
Period 4, top 10 topics and correlations among them.
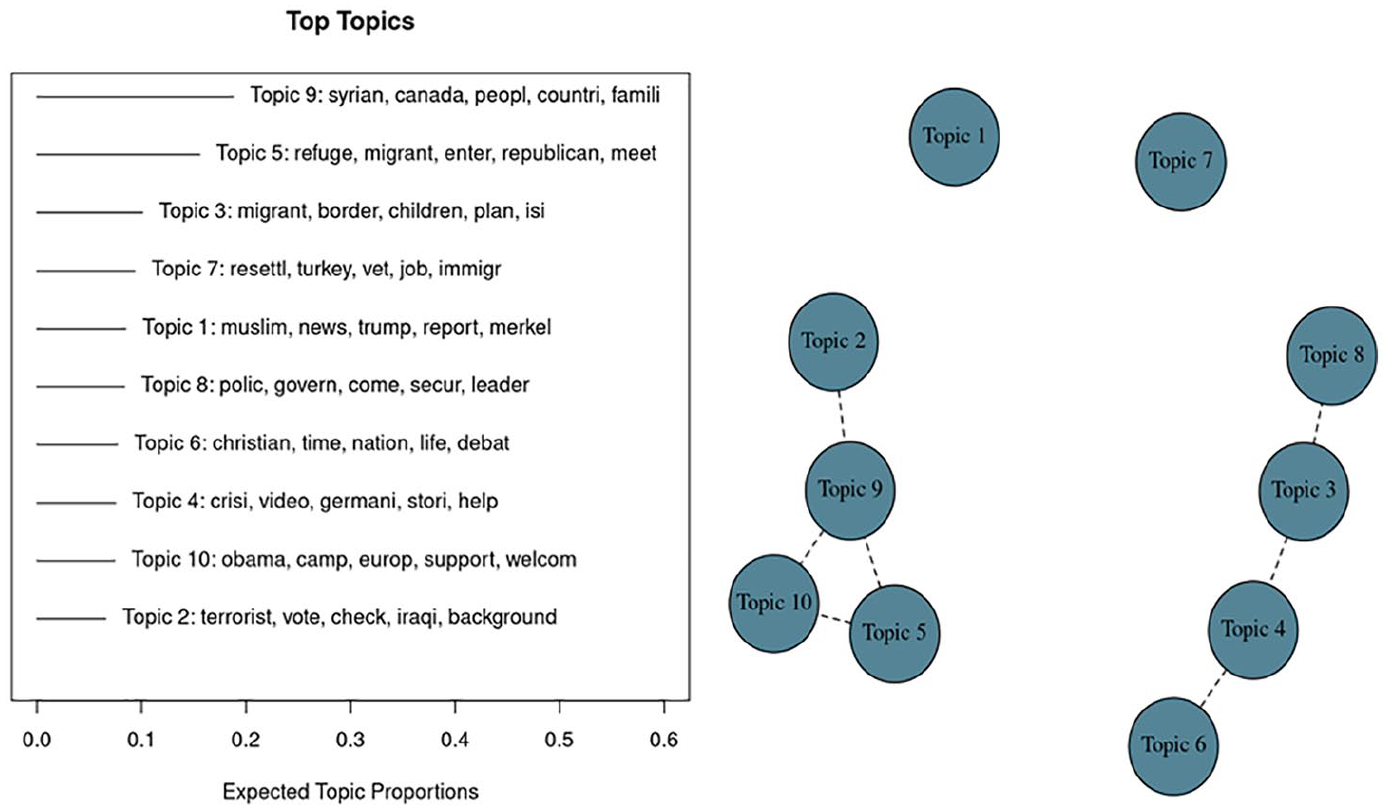
Period 5, top 10 topics and correlations among them.
In the left panel of Figure 8, we see the ranking and relative importance of each topic. In the right panel, we observe the correlations between each topic. Clearly, we have two groups of topics. Group A gathers topics 1, 3, 5, 9, and 10. Group B gathers topics 4, 6, 7, and 8.
Group A captures a general conversation about the associations between Syria, war, human lives, and aid at a macro level. Group B captures a more specific conversation about the migration process, the risk for the migrants’ lives, and the magnitude of the issue.
Thanks to the following word clouds, we can have a deeper look at the terms related to each topic. Admittedly, word frequencies might bring more information on the usage of specific words. Despite this limitation, word clouds provide prompt and useful visual summary of the most widely used terms. This allows us to bring some human context to the interpretation (Figures 8 and 9).
Group A’s context is about geography, while group B’s context is more about the magnitude and the potential solutions. Let us see how it evolves through the various periods identified.
By statistically-identified periods
The first significant period for the English-based conversation was in June 2013 (Figure 10).
Based on the right panel of Figure 10, we see a core cluster of 4 topics: 2, 4, 7, and 9. Understandably, it is still a general conversation at this stage with some political economy dimension (Palestine). Then, there is a second small cluster of two topics: 1 and 10. It is again very general but a little more specific about an international organization intervention (UNHCR).
Then, the next period of statistical interest is 1 year later in June 2014 (Figure 11).
Based on the right panel of Figure 11, we observe a large and a small cluster. The large cluster comprises topics 1, 2, 4, 5, 9, and 10 (topic 8 belongs to the cluster but is not central). One year later, the conversations in English are much more educated about the problem at stakes: which population, which region and which issues. The small cluster comprises topics 3, 6 and 7 are at a level that captures more of the inner political dynamics in the U.S.
Then, the next period of statistical interest is 1 year later in April–May 2015 (Figure 12).
Based on the right panel of Figure 12, we observe that topics are more intertwined. Nevertheless, there are two groupings on both extremities. The first cluster can be defined as the one including topics 2, 3, 6, 8, 9, and 10. So, 1 year later, the dominant conversation is still very educated and focused on what is really happening. The second cluster includes topics 1, 4, and 7. It highlights the human rights issues and the refugee camps.
Then, the next period of statistical interest is 1 year later in late August - early November 2015 (Figure 13).
Based on the right panel of Figure 13, we observe two clusters of almost equal importance. The first cluster is about topics 1, 2, 4, 6, and 8. In the fall of 2015, the conversation is now switching from what is happening in Syria to what is happening in Southern Europe. The second cluster is about topics 5, 7, 9, and 10. The conversation is about what is happening this time influenced by the political news from Germany.
Then, the next period of statistical interest is 1 year later in November-December 2015 (Figure 14).
Based on the right panel of Figure 14, we again observe two clusters of almost equal importance. The first cluster comprises topics 2, 5, 9, and 10. It is a conversation that comes back to some U.S. international dimension. The other cluster is constituted of topics 3, 4, 6, and 8 and is a more focused conversation on the inner situation in Europe.
By language and statistically identified periods
The same analysis can be done by language. Language is not a perfect proxy for a country’s conversation, but it can bring some context to the conversations. We built a companion website with the analyses for each language. In what follows (Table 4), we present the top 3 topics per language and by period (not the clusters) in order to have a contextual mapping in comparison to the English-based conversation.
As a result, although a language is not a perfect proxy for the conversations happening within the geographical borders of a country, we observe that the tweets in Italian are more about Italian issues (e.g. Lampedusa). The same holds for tweets in French (e.g. Calais).
There are numerous directions a discourse analysis could take. For instance, research on attitudes toward refugees typically fall into models of ethnic or racial group threat, labor market competition, or cosmopolitanism. We decided to briefly illustrate discourse dynamics within the cosmopolitan worldview, by analyzing pro-immigrant sentiment expressed in some of the Tweets written in English as a global language.
‘But with these migrants the victims are also amongst them. . . Usually within their family or contacts’.
https://twitter.com/Vidyut/status/285392199812775937
‘#Syria Afghanistan: Deadly Voyage Highlights Risks to Migrants and Refugees Arriving in Greece’
https://twitter.com/gcmcSyria/status/281409003639173120
‘. . . We need to raise funds now, find him a lawyer. The things migrants face when they leave home, land in Europe without papers’. . ..
https://twitter.com/tigritude/status/281141446017445891
The Twitter users underscore the extent of the humanitarian tragedy, the deadly journey, and the desperate situation of the refugees, the need for solidarity and social integration of the refugees, the inappropriate blame placement, etc.
Often influential leaders are cited or mentioned to make a stronger appeal:
‘Don’t blame migrants for problems in Britain: ex-PM Tony Blair’ - The Economic Times http://t.co/Ktai3anP
https://twitter.com/Nandavarapu/status/281412278191005697
‘The Pope with migrants at Lampeduza. . .’ http://t.co/8lS9dD76dC
https://twitter.com/Agoravox_news/status/354891292607651842
We also outline that sometimes cosmopolitanism is driven by material interests and labor market shortages to sustain economic growth.
‘South Korea needs more migrant workers to drive growth’
https://twitter.com/abs_cbn_/status/290773912399269888
It would be a promising research avenue to analyze the evolution of the conversation through the periods by language.
It is interesting to note that our hypothesis (H1) about English being less of a local/national-influenced language does not always hold. It is rejected during the early periods, when the U.S. politics clearly played a role in the conversation dynamics. The refugee crisis is thus used as a way to reflect on its own local/national context. Toward the latest periods, the conversation is a little more precise and focused on the refugee topic itself.
Another result is that our hypothesis (H2) about non-English languages being more influenced by local/national contexts holds true for some languages and some periods. Indeed, when it comes to other languages, we can observe that both the timing and the topics can be different. We can only conclude from our findings that mainstream media’s agenda-setting power on Twitter seems important, at least in terms of refugee-related conversations in Europe.
Conclusion
The European refugee crisis of 2014 and 2015 will be a focal point of European history textbooks. However, it will take time for a dominant view to emerge regarding the crisis’s origins, evolution, and implications. As the humanitarian crisis unfolded, a diverse range of actors sought to define and frame the public discourse on refugees: from the far-right (terrorists, criminals, delinquents) to the humanitarian (victims or displaced unfortunate individuals with fundamental human rights).
A sizable portion of the opinion formation process occurred on OSNs (particularly Twitter), which are an integral part of the modern hybrid media system. Mainstream media outlets, political and civil society organizations, public figures, and other influential individuals participated in the fragmented digital storytelling.
Our results show that, although about the same issue, conversations at the global stage versus the national stage happened at different times. They also show that the topics are slightly different across languages.
Our results are also interesting on the methodological front insofar as they show the extent of what researchers can do with text-as-data collected from OSNs. They also show the limitations and contribute to the methodological conversation on using unstructured data to inform new research questions.
These results open new questions about culture, political dynamics within countries, and the level of proximity with the issue at stake here, the refugee crisis. On Twitter, these different aspects are embedded within individuals, groups, and the media.
Despite the multiplicity of actors, it seems interesting to continue studying the fact that the mainstream media potentially retained significant influence in setting the agenda and tone for the European refugee crisis. While other studies have discovered that Twitter conversations represent alternative voices (e.g. Nerghes and Lee, 2019; Siapera et al., 2018), we discover a discernible local context to the conversations.
Additionally, we identify several directions for future research. A possible future research direction would be to replicate this study to other globally discussed events. It would be interesting indeed to see whether the timing of certain topics differ across languages, validating the results found in this study about the refugee crisis. It would also be interesting to see whether some topics are exclusive to some local/national contexts.
Another possible research direction is to examine whether mainstream media are powerful entities as a result of the low credibility of alternative voices expressed by other Twitter users. A portion of the literature has developed similarity measures between known political actors’ ideologies and the vocabulary used by news organizations (Gentzkow and Shapiro, 2006; Groseclose and Milyo, 2005). Another research avenue would be to develop cosine and Jaccard similarity measures based on Natural Language Processing techniques to capture this dynamic. Another significant extension would be to generate a dataset of sentiment and polarity indices and assess their exploratory power in predicting general election results in migrant-recipient countries.