
Abstract
The no-wait job shop scheduling problem (NWJSP) plays a crucial role in industrial production and is an NP-hard problem. We propose a hybrid discrete artificial bee colony (HDABC) algorithm for solving the NWJSP with the total tardiness criterion. In the proposed algorithm, we first design multiple discrete operations which combine with the basic framework of the artificial bee colony algorithm. Furthermore, we propose a new selection method that allows onlooker bee to select better food sources. To determine the start times of the jobs, we introduce and adapt the left timetabling method for the tardiness objective under consideration. Experimental results show that the HDABC algorithm has better search capability than two well-performing ABC algorithms as well as an iterated greedy algorithm in solving the NWJSP with the total tardiness criterion.
Introduction
With the rapid development of manufacturing industry, the productivity and optimal utilization of resources in the job shop have attracted a lot of attention. Especially in the highly competitive market environment, the no-wait job shop scheduling problem (NWJSP) has received widespread attention. The no-wait job shop model has been used in many manufacturing industries, such as steelmaking and chemical and pharmaceutical industries. 1 These industries are characterized by the fact that products need to be processed continuously during the production process, and any waiting may lead to product quality degradation or resource waste. Therefore, research on the NWJSP is of great significance.
To solve the NWJSP, many researchers have studied and proposed various metaheuristics. Hall and Sriskandarajah 2 provided an overview of the NWJSP and raised the importance of the problem. Macchiaroli et al. 3 proposed a new decomposition method and a two-phase tabu search algorithm for solving this problem. Schuster and Framinan 4 proposed the variable neighborhood search algorithm and the hybrid algorithm combining genetic algorithm and simulated annealing (GASA) algorithm. Framinan and Schuster 5 proposed complete local search with memory (CLM) and verified the superiority of the proposed algorithm. Schuster 6 studied the NWJSP and proposed a fast tabu search algorithm. Pan and Huang 7 designed a hybrid genetic algorithm and proved that this algorithm is superior. Bozejko and Makuchowski 8 proposed a hybrid tabu search algorithm and obtained better results. Zhu et al. 9 introduced limited memory for the CLM algorithm and proposed a complete local search with limited memory (CLLM). They compared the CLLM with the CLM, VNS and GASA algorithms and proved that the CLLM is comparable. Bozejko and Makuchowski 10 proposed a genetic algorithm with automatic adjustment. Zhu and Li 11 further modified the CLLM and proposed an improved CLM (MCLM). Bürgy and Grěoflin 12 investigated the optimal job insertion problem and proposed an optimal job insertion-based heuristic for solving the NWJSP. Aitzai et al. 13 proposed an exact method and a particular swarm optimization algorithm. They demonstrated the superiority of the proposed algorithm through comparative experiments. Li et al. 14 further improved the CLM by hybridizing with variable neighborhood structure and proposed an algorithm called CLMMV. Sundar et al. 15 proposed a hybrid artificial bee colony (HABC) algorithm and proved the superiority of HABC in experiments. Bürgy and Grěoflin 16 proposed a local search method by extending the previously proposed an optimal job insertion-based heuristic 12 and proved the effectiveness of this method. Ying and Lin 17 proposed a multistart simulated annealing with bidirectional shift timetabling (MSA-BST) algorithm and analyzed the results to show that the MSA-BST outperforms the compared algorithms. Valenzuela-Alcaraz et al. 18 proposed a cooperative coevolutionary genetic algorithm integrated with a shift decoding algorithm, and proved to be competitive in solving the NWJSP. Deng et al. 19 proposed a simple migrating birds optimization algorithm to explore the original instance and the inverse instance. In addition to the above studies of the makespan criterion, there have been some research on the total flow time criterion. Deng et al. 20 developed a hybrid discrete group search optimizer to solve the problem under the total flow time criterion. Subsequently, the population-based iterated greedy (IG) algorithm was proposed for the same problem. 21 Ying and Lin 22 proposed a backtracking multistart simulated annealing (BMSA). The results show that the BMSA has certain superiority.
The above studies mainly focus on the makespan and total flow time criterions. However, studies on the total tardiness criterion already exist for other scheduling problems, such as the two-machine scheduling problem, 23 the permutation flow shop, 24 the job shop scheduling problem, 25 the flexible job shop problem (FJSP),26,27 and the parallel blocking flow shop scheduling problem. 28 The tardiness criterion reflects the degree of deviation between the completion time of the jobs and the due dates, and is closely related to production efficiency. Minimizing tardiness can effectively reduce inventory costs and improve production profits for enterprises. Therefore, this goal plays an important role in actual industrial production processes. To our knowledge, there has been little study of the NWJSP with a total tardiness criterion. For this reason, we focus on presenting an effective algorithm for minimizing total tardiness for the NWJSP in this study.
As one of the more superior algorithms nowadays, the artificial bee colony (ABC) algorithm 29 has been widely used in the field of scheduling since it was proposed. Pan et al. 30 discretized the ABC algorithm for solving the lot streaming flow shop scheduling problem. Wang et al. 31 proposed an ABC algorithm in order to solve the FJSP. Deng et al. 32 proposed a discrete ABC algorithm for the blocking flow shop scheduling problem. Zhang et al. 33 applied the ABC algorithm to the job shop problem. Gao et al. 34 adapted the ABC algorithm and proposed a two-stage ABC algorithm for solving the FJSP. Sundar et al. 35 conducted a study on the NWJSP and proposed an HABC algorithm for minimizing the makespan. Inspired by beer froth phenomenon, Sharma et al. 36 presented the beer froth ABC algorithm (BeF_ABC) and applied this algorithm to job shop problem. To the best of our knowledge, the research of the ABC algorithm is very limited on the NWJSP, especially for the problem with total tardiness criterion. The ABC algorithm adopts the evolutionary mechanisms of three roles, thus possessing good parallel evolution and global exploration capabilities. It is easy to embed local search mechanisms in the operations of the three roles, which makes it keep good local exploitation capability. Another advantage of the algorithm is that it has a relatively simple structure, making it easy to implement. Considering these advantages, we propose a hybrid discrete ABC (HDABC) algorithm for solving the NWJSP with total tardiness criterion. There are three phases in the HDABC algorithm, the employed bee, onlooker bee and scout bee phases. In the onlooker bee phase, we propose a new food source selection strategy. In addition, we combine the algorithm with several search strategies as a way to further improve the search capability. Like most researchers, we solve the NWJSP by decomposing it into two subproblems, sequencing and timetabling subproblems. The sequencing subproblem is solved by the HDABC algorithm. For the timetabling subproblem, we introduce a left timetabling method and apply it to all phases of the proposed HDABC.
We organize the remainder of the article as follows. The NWJSP with total tardiness criterion section describes and models the NWJSP with total tardiness criterion. The timetabling method section describes the timetabling method. The HDABC for the NWJSP section describes the HDABC algorithm designed to solve the sequencing subproblem. The computations and comparisons section conducts extensive experiments and analyzes the results of the experiments. Finally, the conclusions section summarizes the current study and indicates future work.
NWJSP with total tardiness criterion
Problem description
In the NWJSP, there are n jobs
Problem formulation
Assume that the processing of job


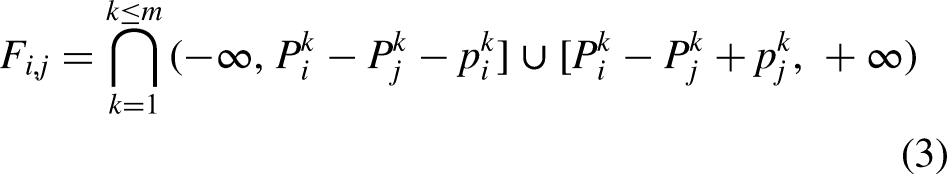


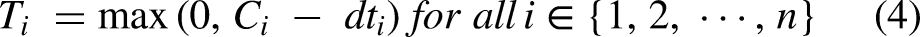






The NWJSP can be viewed as a problem consisting of sequencing and timetabling subproblems. The aim of the sequencing subproblem is to find the optimal scheduling sequence of jobs. The aim of the timetabling subproblem is to look for the set of start times that optimize the objective value of the job sequence provided by the sequence subproblem.
Timetabling method
To solve the timetabling subproblem, we introduce the left timetabling method. According to Deng et al.,
21
the left timetabling method can be implemented using the feasible time difference set
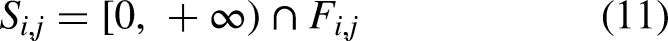


Procedure for the left method.
for (j from 2 to n)
flag = true;
flag = false;
flag = true;
break;
endif
flag = true;
break;
endif
endif
endfor
endwhile
endfor
HDABC for the NWJSP
Basic ABC algorithm
The ABC algorithm 29 is a metaheuristic algorithm to simulate honey bee foraging. The ABC algorithm classifies the colony into employed, onlooker and scout bees based on the foraging behavior, corresponding to the three phases of the algorithm. The employed bee seeks out good food sources and shares the information with the onlooker bee. The onlooker bee selects a food source based on a selection mechanism and further explores this food source. If the number of times the onlooker bee explores the neighborhood of a food source exceeds the maximum number of iterations limit and no better food source is found, it is considered that there is no need to explore the food source. At this point, the onlooker bee will turn into the scout bee and search for other food sources.
HDABC algorithm
Solution representation
Most researchers decompose the NWJSP into two subproblems: the sequence and the timetabling subproblems. Therefore, we divide the solution representation into two parts: job sequence and timetable. The job start times are determined by the timetabling method in the order of the job sequence and recorded in the timetable. In addition, the agei parameter is added to each solution Pi to record the number of iterations experienced.
Initialization
For population-based algorithms, the initialization of the population is an important part. Therefore, we introduce the NEH 37 and NEH-WPT heuristics 38 for population initialization. The procedure of the NEH is to sort the jobs nonincrementally according to their total processing time, and then insert the jobs one by one into the best position according to the order. The difference between the NEH-WPT and the NEH heuristics is that the initial sequence of the NEH-WPT is a nondescending arrangement of jobs.
In the initialization phase, two initial solutions are generated by the NEH and the NEH-WPT, and the remaining solutions are generated randomly. In addition, let each solution have agei = 0. The age of each solution will be updated at the end of each iteration. If the solution Pi is not replaced in one iteration, then agei = agei +1; otherwise, agei = 0.
Employed bee phase
In the HDABC algorithm, each employed bee searches for nectar and shares it with the onlooker bee. In this phase, we introduce the destruction and construction operator 39 to search for the nectar source. Firstly, randomly select d jobs, store them in a sequence RI, and remove from the original sequence. Then, the jobs in RI are inserted one by one into the best position in the original sequence to generate a new solution. Here, we introduce a bool variable impi. If the solution is improved impi = true; otherwise, impi = false. Finally, the employed bee will share the better of the new and old solutions with the onlooker bees. Algorithm 2 shows the procedure for the employed bee phase.
Procedure for employed bee phase.
for (i = 1 to p)
randomly select d jobs in the job sequence of individual Pi, store them in the sequence RI, and delete them from the original sequence to generate a partial solution P*;
insert the job RIj into the best of n – d + j positions of P*;
endfor
if (P* is better than Pi)
impi = true;
P* replaces Pi, and if better than Pbest, replace Pbest;
let the number of iterations agei = 0;
else
impi = false;
endif
endfor
Onlooker bee phase
During the onlooker bee phase, the onlooker bees will select the food source provided by the employed bees to explore. This selection process is usually associated with the quality of the food source. Considering that the low quality of solutions may be due to insufficient number of iterations, we propose a new selection procedure. The proposed selection process is based on whether the solution is improved or not and times the solution has been explored.
If impi = true, the solution is improved. This means that the neighborhood of the solution is valuable for further exploration, so the onlooker bee explores the solution further.
If impi = false, the solution is not improved. Here a probability of reception prob and a random number r (0 < r < 1) are introduced. If
In this phase, the search is done by the NEH heuristic. To be specific, we apply the NEH heuristic to generate a new solution P* using the sequence of Pi as the initial sequence. The solution with the better objective value among the new and old solutions is retained according to the greedy selection principle. Algorithm 3 shows the procedure for the employed bee phase.
Procedure for onlooker bee phase.
for (i = 1 to p)
if (impi == true)
the NEH heuristic generates a new solution P* using the sequence of Pi as the initial sequence;
the number of iterations agei = agei + 1;
let the number of iterations agei = 0;
P* replaces Pi, and if better than Pbest, replace Pbest;
endif
else if (r < prob)
the NEH heuristic generates a new solution P* using the sequence of Pi as the initial sequence;
the number of iterations agei = agei + 1;
let the number of iterations agei = 0;
P* replaces Pi, and if better than Pbest, replace Pbest;
endif
else
the number of iterations agei = agei + 1;
endif
endfor
Scout bee phase
In the scout bee phase, a solution Pi is considered to be fall into a local optimum if its agei exceeds the limit. For these solutions, we perturb them by performing ptb random swap operations on them. Here ptb is the extent of perturbation. Algorithm 4 shows the procedure for the scout bee phase.
Procedure for scout bee phase.
for (i = 1 to p)
generate a new solution P* by performing ptb random swap on the individual Pi;
the number of iterations agei = 0;
P* replaces Pi, and if better than Pbest, replace Pbest;
endif
endfor
Procedure of HDABC
The HDABC algorithm has the following four parameters: population size p, number of reinserted jobs d, maximum number of iterations limit and extent of perturbation ptb. Algorithm 5 shows the procedure of the HDABC algorithm.
Procedure of HDABC algorithm.
set p, d, ptb, and limit, and initialize the population;
Pbest is set to the best solution in the initial population;
while (stopping condition not met)
Algorithm 2 is performed; // employed bee phase
Algorithm 3 is performed; // onlooker bee phase
Algorithm 4 is performed; // scout bee phase
endwhile
Computations and comparisons
Experimental preparations
In this study, we implement all the algorithms in C++ and run them on a PC equipped with Intel(R) Core (TM) i5-8250U CPU 1.80 GHz processor. The benchmark instances used in the experiments of this study include the well-known instances La01-40, Abz5-9, Ft10, Ft20, Orb01-10, Yn1-4, and Swv01-20. In addition, the due date is set to
The relative percentage deviation (RPD) is used in the experiments to evaluate the performance of an algorithm. The RPD is calculated as shown in equation (14). Where the

Calibration of HDABC
Since the HDABC algorithm has a certain degree of stochasticity, the calibration of the parameters plays an important role. The HDABC algorithm is calibrated with the following parameters: population size p, number of re-inserted jobs d, maximum number of iterations limit, and extent of perturbation ptb.
A large design of experiments
40
is conducted for the remaining parameters: (1) population size

Means and 95.0% Tukey HSD intervals for all tested factors.
ANOVA results for algorithm calibration.

From the results of the ANOVA, all the parameters are statistically significant except for the limit and ptb. From Figure 1, it can be seen that 20 is significantly better than 15 and 10 for the value of parameter p. For parameter d, 6 is significantly better than 4 and 2. Furthermore, the parameter limit does not differ much for each value but 40 is slightly better than 30 and 50. The situation is similar for the parameter ptb. There are no statistical differences for the values 0.1n, 0.2n, and 0.4n. Therefore, the parameters are selected as the following combination: p = 20, limit = 40, d = 6, ptb = 0.2n.
Comparison with other metaheuristics
The discrete ABC (DABC), 30 HABC 35 and IG 39 algorithms are selected for comparison with the HDABC algorithm. To exclude the randomness of the algorithms, each algorithm is run 10 times on each instance. It is worth noting that the compared algorithms are adapted here to suit the problem of this study. In addition, the HDABC algorithm and all compared algorithms are run in the same environment. Here each algorithm is stopped by the running time, which is set to 20 mn2. This setting allows different running times for different instance sizes, so that there is not a situation where large instances do not have enough time and small instances have too much time. In calculating the RPD value, the best result of the HDABC and all the compared algorithms after 10 runs is used as the reference value. When comparing the algorithms, the instances are divided into two groups, one group with no more than 15 and the other with more than 15 jobs. Tables 2 and 3 illustrate the results, where the best solution (best), RPD of the best solution (RPD_best) and average RPD of the 10 runs (ARPD) are recorded, and Instance, n * m and ref represent the instance name, the size of the instances and the reference value, respectively. The best results of the four algorithms are shown in bold.
Results of different algorithms on the instances with no more than 15 jobs.
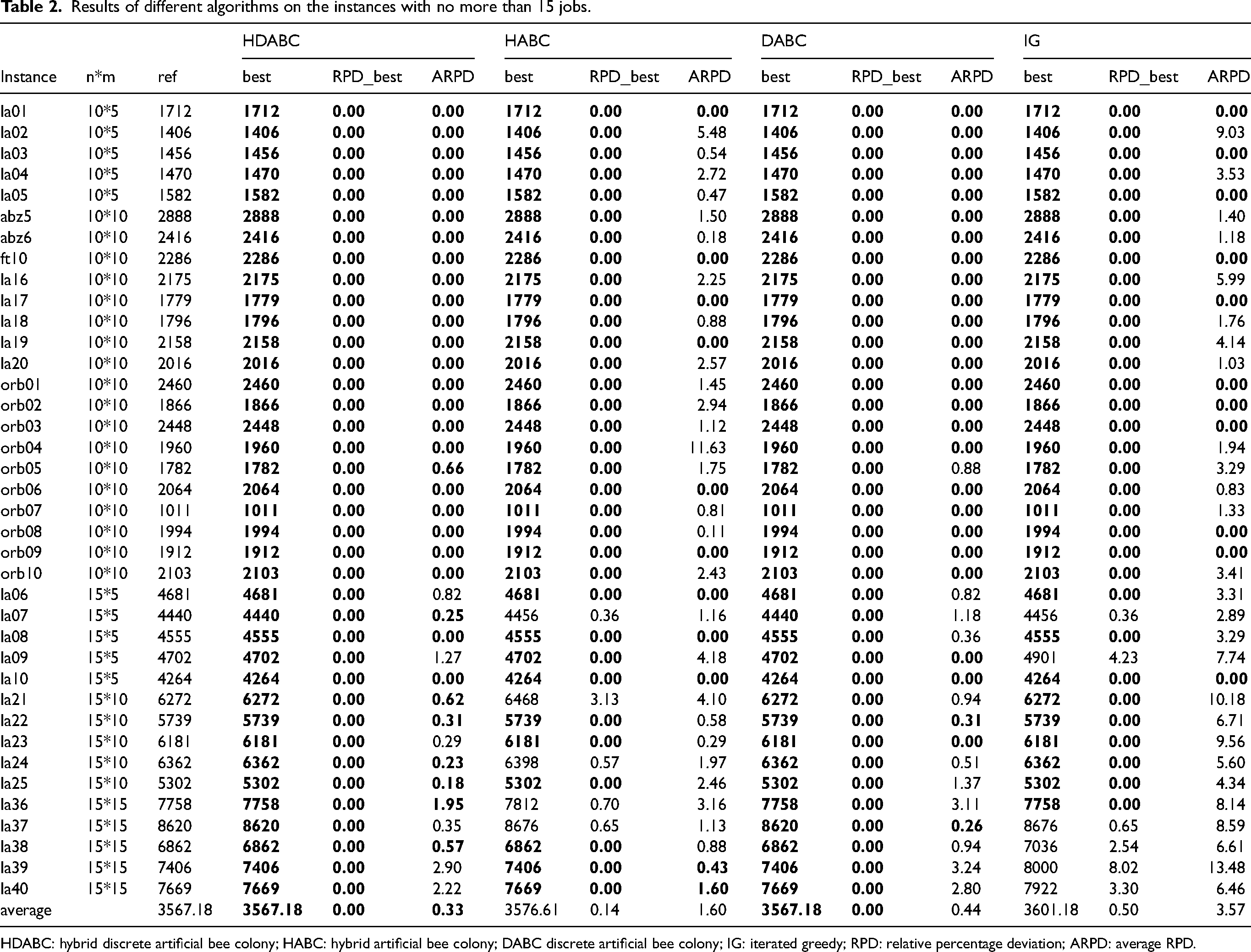
HDABC: hybrid discrete artificial bee colony; HABC: hybrid artificial bee colony; DABC discrete artificial bee colony; IG: iterated greedy; RPD: relative percentage deviation; ARPD: average RPD.
Results of different algorithms on the instances with more than 15 jobs.
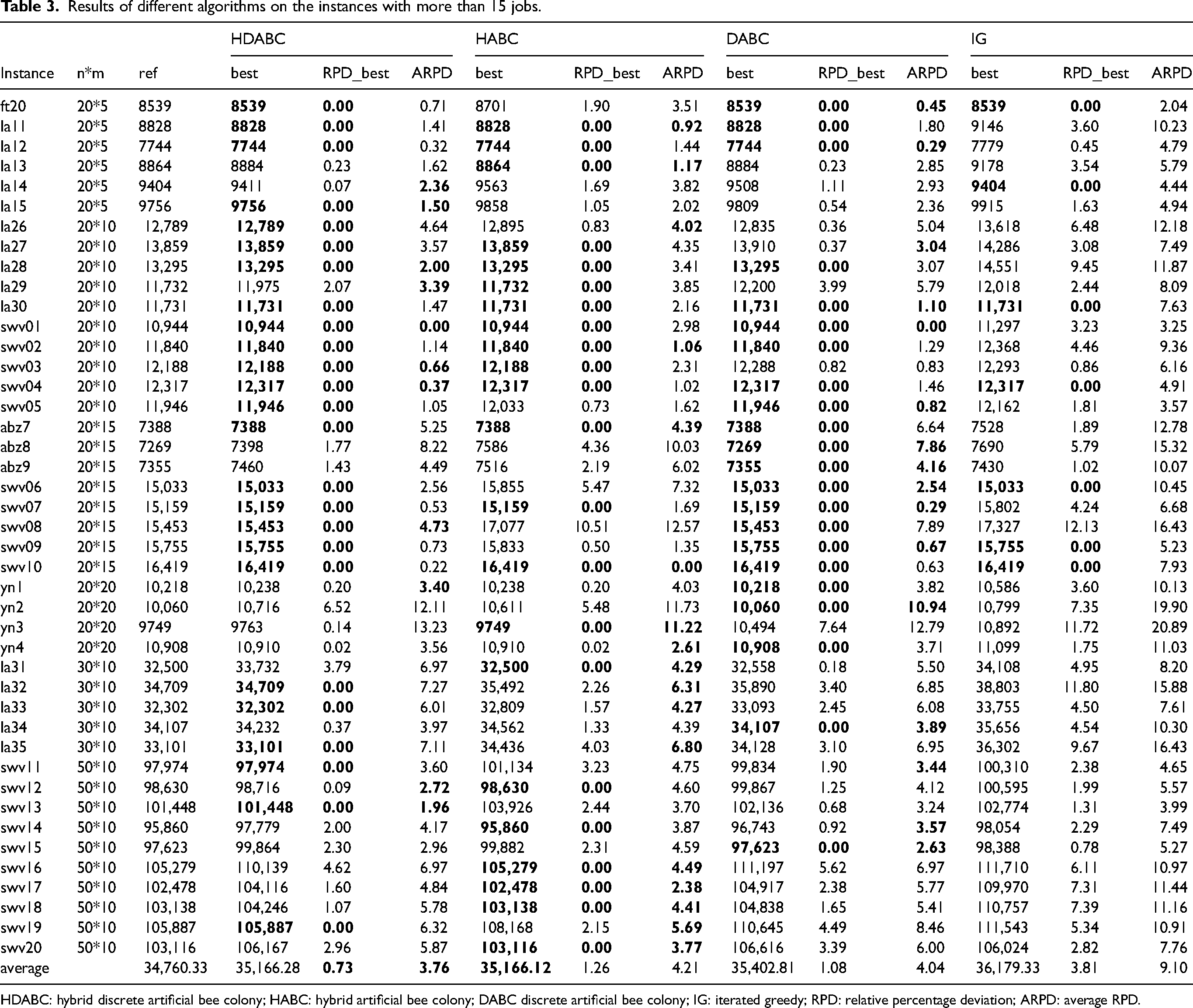
HDABC: hybrid discrete artificial bee colony; HABC: hybrid artificial bee colony; DABC discrete artificial bee colony; IG: iterated greedy; RPD: relative percentage deviation; ARPD: average RPD.
For the instances with no more than 15 jobs, the average values of the RPD_best for both the HDABC and DABC algorithms are 0, whereas those for the HABC and IG algorithms are 0.14 and 0.50, respectively. In terms of the average values of the ARPD, the HDABC, DABC, HABC and IG have 0.33, 1.60, 0.44, and 3.57, respectively. From the above results, the HDABC and DABC algorithms are better than the HABC and IG algorithms. Although the HDABC and DABC algorithms have the same average value of the RPD_best, the average ARPD of the HDABC is superior to that of the DABC.
For the instances with more than 15 jobs, the average RPD_best values of the HDABC, DABC, HABC, and IG algorithms are 0.73, 1.26, 1.08, and 3.81, respectively. The average ARPD values of the HDABC, DABC, HABC, and IG algorithms are 3.76, 4.21, 4.04, and 9.10, respectively. From the results, the conclusions are similar to those of the instances with no more than 15 jobs. In other words, the HDABC and DABC outperform the HABC and IG, while the HDABC is slightly better than the DABC.
In addition to the above comparisons, we also perform an ANOVA on the RPD values of the results of 10 runs of each algorithm. In the ANOVA, the RPD values are the dependent variables, and the algorithms and instances are the factors. The corresponding results are shown in Table 4, where the p-value for both algorithms and instances are less than .05, suggesting that both are statistically significant. The means and 95.0% Tukey HSD intervals for different algorithms are provided in Figure 2. Figure 2 shows that the HDABC and DABC are significantly better than the HABC and IG. The confidence intervals of the HDABC and DABC have some overlap, demonstrating that the difference is not significant.
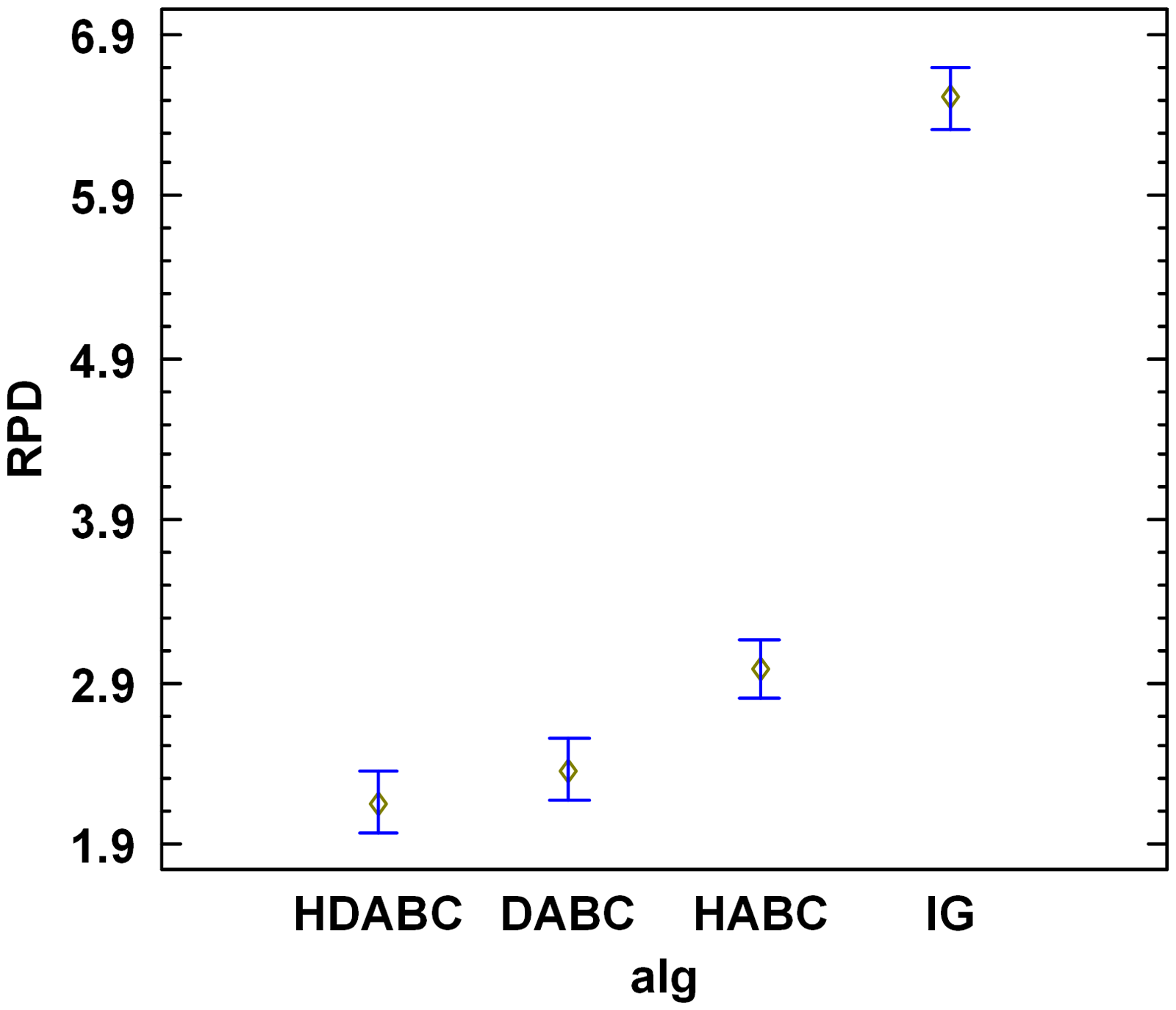
Means and 95.0% Tukey HSD intervals for different algorithms.
ANOVA results for comparing different algorithms.

ANOVA: analysis of variance.
Conclusions
This study considers NWJSP with the total tardiness criterion. For the NWJSP, we decompose it into the sequencing and timetabling subproblems, and develop an MILP model. For the timetabling subproblem, we introduce the left timetabling method for determining the start timetable of the solution. For the sequencing subproblem, we propose the HDABC algorithm for finding possible sequences of jobs. The HDABC algorithm uses the framework of the basic ABC algorithm and redefines its three phases using some discrete operations. In the onlooker bee phase, we propose a new selection mechanism with an acceptance probability. For the solutions with improvements, the search is performed directly; otherwise, the search is judged according to the acceptance probability.
In the computational experiments, we calibrate the parameters of the HDABC algorithm and compare it with the DABC, HABC, and IG algorithms. The results demonstrate that the HDABC algorithm is slightly superior to the DABC and significantly outperforms the HABC and IG algorithms.
This study aims to develop an HDABC algorithm for the NWJSP with the total tardiness criterion. It can be seen from the results of this study that the proposed algorithm has great potential for application to other complicated scheduling problems. In the future, we will consider applying the HDABC to other scheduling problems or objectives, such as distributed flow shop scheduling problem, and multiobjective scheduling problems with energy consumption related objectives.
Footnotes
Author contributions
Conceptualization: Xuemei Huang; formal analysis: Jie Yin; investigation: Guanlong Deng; methodology: Xuemei Huang; software: Jie Yin; supervision: Guanlong Deng; validation: Guanlong Deng; writing—original draft: Jie Yin.
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.