
Abstract
The deep convolutional neural network performs well in current computer vision tasks. However, most of these models are trained on an aforehand complete dataset. New application scenario data sets should be added to the original training data set for model retraining when application scenarios change significantly. When the scenario changes only slightly, the transfer learning can be used for network training by a small data set of new scenarios to adapt it to the new scenario. In actual application, we hope that our model has bio-like intelligence and can adaptively learn new knowledge. This paper proposes a pretrained adaptive resonance network (PAN) based on the CNN and an intra-node back propagation ART network, which can adaptively learn new knowledge using prior information. The PAN network explores the difference between the new data and the stored information and learns this difference to realize the adaptive growth of the network. The model is testified on the MNIST and Omniglot data set, which show the effectiveness of PAN in adaptive incremental learning and its competitive classification accuracy.
Introduction
In recent years, deep convolutional neural networks (DCNNs) have developed rapidly in the field of computer vision 1 and have taken a leading position in the application of image classification tasks. 2 After the proposition of the LeNet-5 network, 3 researchers have proposed many interesting improvements to DCNNs from seven directions, 4 including atial exploitation, depth increasing, width deepening, multipath, feature-map, exploitation, channel boosting, and attention, such as DeconvNet, 5 VGG, 6 GoogLeNet, 7 and ResNet. 8
However, DCNNs are usually trained on large-scale labeled data sets, and the data sets are usually required to contain all categories, which is a limitation of the supervised training of neural networks at present. In the real world, application requirements often change over time, which means that all prior knowledge cannot be provided to the network for training at the beginning. For example, in the task of remembering the name of a colleague at work, new members join every year, and the number of subtasks under the classification task of “colleagues” is also increasing in our brain. We hope that the network can be as smart as humans, and can remember a new colleague after “seeing” him a few times, or even only once. Analogously, a network that can distinguish unfamiliar information and learn from it is more in line with our needs. For such a network, we expect it to have the following capabilities:
Adaptive growth of network structure Identify unfamiliar information correctly Use a small amount of new information for effective learning Keep memory in the learning process without forgetting
Researchers have proposed various methods to improve these capabilities of neural networks. Adaptive Resonance Theory9–12 is a theory that explains how the human brain perceives environmental changes and performs continuous learning from a biological perspective, which inspired a series of ART network structures that are regulated by resonance feedback.13–17 Most of the ART network has good plasticity, which is conducive to the adaptive growth of the network structure. The basic ART model18,19 is mainly used in unsupervised learning, judges the confidence of the resonance hypothesis according to the decision-making subsystem, and determines whether the network transitions to the resonance state. If the current hypothesis is denied, the network will iterate through all the hypotheses in descending order. The network strengthens the memory when the resonance occurs according to the current input. If all assumptions are denied, the network will expand the memory.
The plasticity of the ART network allows it to flexibly switch between learning and resonance states to achieve clustering or adaptive growth, but the winner-takes-all competition rule in the category selection may lead to a surge in categories. 12 In addition, the learning process is carried out in an unsupervised way, incorrect judgments in the early stage of the network may cause clustering errors and error accumulation, which means that improving the accuracy of the initial network is particularly important to overcome this problem. Some studies use the ART network for supervised learning, such as ARTMAP, 20 FuzzyARTMAP, 15 and LAPART. 21 They usually follow the ARTMAP architecture, which consists of two basic ART units and an associated network to connect them, and the model learns through mutual verification and supplementation of the multidimensional mapping of the two networks.
Lifelong learning22,23 is a hot topic in the adaptive machine learning paradigm, which aims to distinguish “unseen” knowledge with a small amount of new knowledge. The lifelong learning-based machine learning paradigm has advantages in the full use of prior knowledge and effective learning with a small amount of information. One of the most important problems is the disaster of forgetting, that is, the learning of new knowledge makes the network lose the stored knowledge, which is also known as the stability-plasticity dilemma.22,24 To overcome this problem, researchers have conducted a lot of research from the perspective of biological systems and computational models10,11,25,26 and have proposed solutions such as regularization, joint training with the new and old information, and so on.22,27 The general idea of these studies is to balance the network's classification performance on new and old data and to learn new knowledge with minimal forgetting of stored knowledge. EWC 28 is a semisupervised learning algorithm, which allows evaluation of the importance of synapses and changes it during the learning process to reduce the loss of stored knowledge. However, the correlation of synapses is calculated online and changes dynamically along with the entire learning trajectory of the parameter space, which is not suitable for a large amount of new knowledge. The network has an increasing impact on old memories for online learning progress.
In addition, some studies find solutions from the meta-learning perspective. 29 Similar to the way of balancing the influence of new and old information, OML 30 balances the network's ability to process new and old information by constructing a global experience pool and realizes online learning through learning prediction functions. Jerfel et al. 31 make use of meta-learning and hierarchical Bayesian networks to construct a hybrid model, which improves generalization ability through the inductive transfer of meta-learning, and use Bayesian networks for online learning in the form of clustering.
Some studies are also trying to solve this problem from other perspectives, such as WANNs 32 and Tree-CNN. 33 From the perspective of network structure, the former uses structure search to adapt to new tasks quickly, while the latter uses CNN for effective feature extraction and combines with a decision tree network for adaptive growth. ConvART 17 integrates the convolutional network with the ART network, so that the new network inherits the mechanism of the ART network, and the information stored in the long-term memory (LTM) network can be used for input contrast and stored information enhancement.
This paper proposes a Pretrained Back Propagation Adaptive Resonance Theory Network (PAN) within the nodes. First, PAN realizes (1) the Adaptive growth of network structure, and (2) Identifies unfamiliar information by integrating the adaptive learning mechanism of the ART II. 19 Second, PAN uses a small amount of new information for effective learning by building a small experience pool and designing a new differentiated learning network as an adaptive learning subsystem (LS). Third, PAN maintains the memory in the learning process without forgetting by introducing “light induction” into the difference network, just like the attraction of the sun to sunflowers.
PAN consists of two parts (Figure 1): Back Propagation Adaptive Resonance Theory Network (BPART) and LS. Similar to the traditional ART network, the BPART network uses Feature Representation Field (F1) for image feature extraction and locates the memory unit where the resonance phenomenon occurs based on the short-term memory (STM). The difference is that the convolutional network is more effective for feature extraction, and the full connection layer is introduced to replace the original mechanism in the ART forward process, which is originally simple to pass the STM from bottom to top for Category Representation Field (F2). 12 This improvement enables the BPART network to update parameters in the way of back propagation and improves the positioning accuracy of the resonance unit. In addition, the fully connected layer allows the BPART network to add a pretraining process to make full use of known information.

General structure of PAN.
Whether the network enters the learning state or not is determined by the internal decision-making subsystem. To increase the accuracy of decision-making and reduce the probability of the network classifying the same category inputs into new classes, we enhance the feature information through LTM. The auxiliary criterion for obtaining the LTM area will also be mutually confirmed with the resonance information, which improves the reliability of the classification of “new colleague.” When the network enters the learning state, the LS learns the difference between the new input and the old information and then transmits the learning experience back. BPART receives the learning experience and fuses with the known knowledge to complete a round of adaptive learning. In the LS, we add the different learning mechanisms of OCSVM
34
to separate “new colleagues” (A) from “known colleagues” (B) in the way of dichotomy. Based on the above method, accurate prediction “A” can be achieved in two ways:
Increase the probability of prediction as A. Reduce the probability of predicting as B.
The former is what we want, which means that the network remembers the new object, rather than simply excluding the new object from the known object. To accurately recognize “strange objects” when they are re-input, we apply “light induction” to the learning process (Figure 2), so that the ability of the LS to classify “A” is obtained by increasing the probability of predicting the input as A.
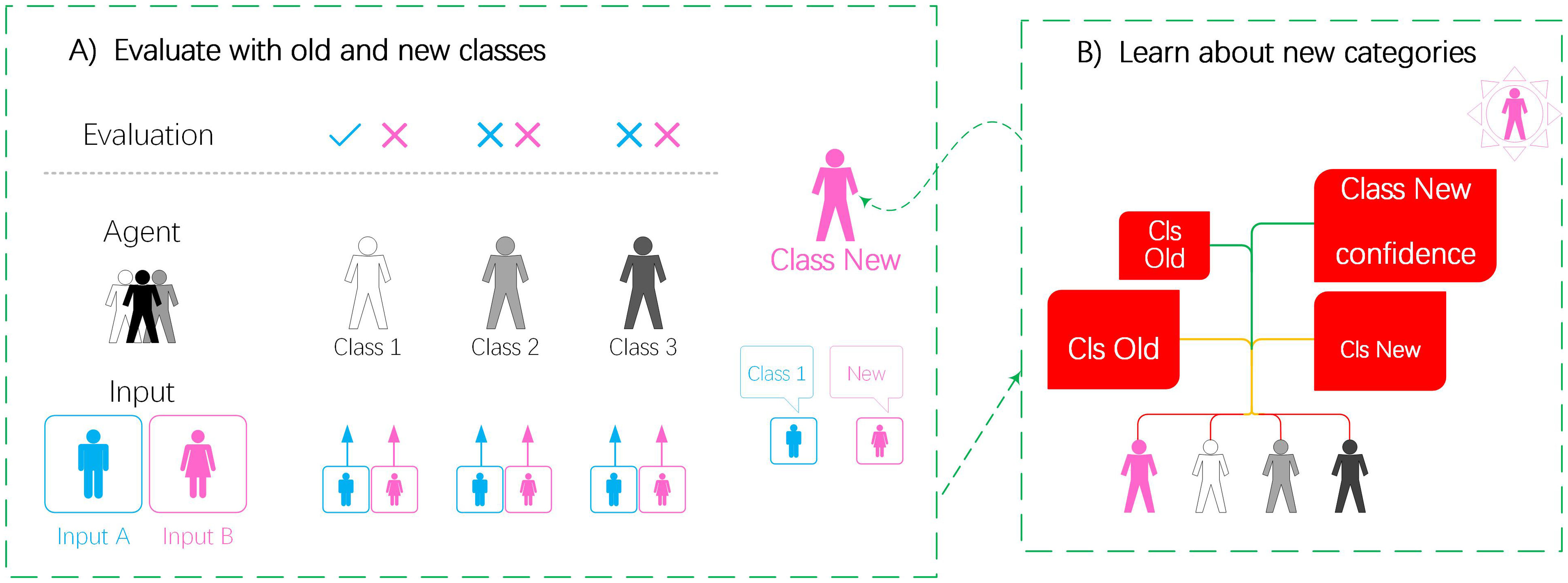
Resonance and learning. (a) Different from traditional ART networks, PAN will use prior knowledge for pretraining and build a micro-experience pool according to prior knowledge. For inputs A and B, the model predicts the known objects as “Class 1” and the unfamiliar objects as “New.” We stipulate that the network is correct if the input is correctly predicted as a known class, or judged as a new class. (b) For unfamiliar input, the network obtains a biased learning experience (Class New) through the adaptive learning subsystem to realize online learning.
The rest of the paper is organized as follows: Our approach is detailed in section “Mathematical model and learning algorithm of PAN.” In section “Experiments,” we used the training set of MNIST 3 to conduct pretraining for the network, and then tested the classification accuracy and adaptive learning ability of the network by adding an Omniglot image to the MNIST test set. Finally, section “Conclusion” is some discussion and summary.
Mathematical model and learning algorithm of PAN
The pretrained BPART (PAN) proposed in this paper combines CNN and ARTII Network and adds the back propagation mechanism and pretraining mechanism to the ART structure. These improvements enable PAN to acquire effective adaptive learning ability while maintaining strong feature extraction performance. By integrating the characteristics of other networks, PAN has achieved this and overcome the problems of ConvART, 17 such as explosive growth of pattern class and insufficient classification accuracy.
The structure of PAN
PAN is composed of BPART and a LS. Based on the traditional ART network, BPART contains Feature Representation Field (F1), Category Representation Field (F2), STM, LTM, and Decision Subsystem (DS).12,19,35 The F1 layer is a DCNN, which is trained to extract the feature of an image. The feature extracted from the F1 layer is transmitted to the STM region, a pretrained network, which is used to resonate with all memory units in the F2 layer. When the most active memory unit wins the resonance competition, its corresponding LTM is activated for feature enhancement. The enhanced feature is transmitted to the LTM region, another pretrained network, to generate auxiliary criteria. As shown in Figure 3, the DS determines whether the network enters the learning state according to the resonance intensity and auxiliary criterion.

PAN structure visualization based on a four-layer convolutional network and single-layer BP neural network. The front of the network is a shared area, while the back branch 1 (blue) represents the resonance process and branch 2 (green) represents the learning process. STM is allowed to select deep networks with different structures from LTM. The same structure is adopted in PAN, but the weights are trained separately.
When the network is in the learning state, LS uses the previous samples and current inputs to build a pool of experiences for learning. To balance the impact of the new information, the model expands the new information. In the learning process, we enable LS to focus more on the features of new information through “light induction,” that is, loss with bias. In addition, we add a “gate” at the F2 layer, which enables limited memory units with the strongest resonance to be activated during forward propagation to reduce the impact of learning new knowledge on old memories.
Back propagation adaptive resonance theory (BPART)
BPART is based on ART II using the back propagation algorithm within the node.
36


Basic structure of ART II network. The hollow circular is the data storage nodes, the solid round is the model class, and the solid line with arrows shows the data flow and data transformation.
In the formula, a and b are constant factors,

Location confidence, which is used to determine the state of the network, is calculated by weighted summation of enhanced features. In the learning state, the network is initialized according to the general rules, and the weights are updated according to the learning rules. In the resonant state, PAN completes the classification of the current input and updates the weights according to the learning rules to deepen the memory. Learning rules are:

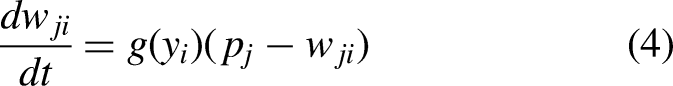


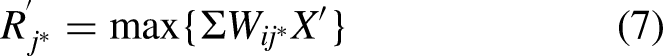

Learning subsystem
In the learning state, LS will learn through an experience pool, which contains samples collected during the previous learning. To balance the impact of old samples with new knowledge, the experience pool is expanded when new knowledge is used.
For the learning results of LS, we focus on the ability of the new learning experience to distinguish between unfamiliar and known inputs. Therefore, we put forward the expected influence factor

Experiments
In this section, we show the process and results of the experiment, including the adaptive learning ability of evaluation models (including PAN, ConvART, PConvART II, and ResART II) on MNIST and Omniglot, and feature comparison experiments based on the FLOWERS dataset.
Convolutional adaptive resonance theory neural network II (ConvART II)
ConvART 17 has been proposed by Sucholutsky et al. in a paper presented at the ICLR 2018 conference. This is an interesting idea, the main content of which was to embed convolutional neural networks into ART networks. Rotational and translational invariance are required by the ART network, which are characteristics of CNN. CNN is usually used for feature extraction and classification.2,4,37 ART network can take into account both plasticity and stability when learning new information, but the pure ART I network can only process digital quantities, which is why Sucholutsky et al. achieved image classification by embedding CNN as a feature extractor.
ART II16,19 has the ability of analog processing and can improve the confidence of network state transition through contrast with better classification ability than ART I. Therefore, this paper proposes ConvART II based on ConvART. Similar to ConvART, ConvART II uses pretrained CNN as the feature extractor. The feature sequence is transmitted to the recognition layer of the ART network and is used for similarity comparison with memory to locate resonance positions. In ART II, feature processing is a process of filtering and normalization. After the features are passed to the recognition layer, the feedback content from memory is received for contrast enhancement.12,38
We use ten types of images in the MNIST to evaluate the effect of the adaptive learning of the ConART II model and make statistics on the number of classification modes of the network and the proportion of the three most important categories. The CNN used in ConvART II is a network with a depth of four and a convolution kernel size of [5 × 5]. The network performs nonlinear operations on the output of the convolutional layer and the fully connected layer FC1. To prevent over-fitting, dropout
39
is used in the fully connected layer FC1. The learning rate of Adam optimizer
40
is set to
Figures 5 and 6 show the online learning effect of ConvART II on MNIST. During the experiment, we use 350 images of the MNIST test data set for testing and use all training sets for the training of the convolutional neural network. We use the FirstCluster and the MaxCluster as the true labels of the cluster to count the classification results. In FirstCluster, we use the label of the first image used in the training of the new cluster as the label of the cluster, while in MaxCluster, we use the label of the largest image among all the images obtained by the cluster as the label of the cluster.
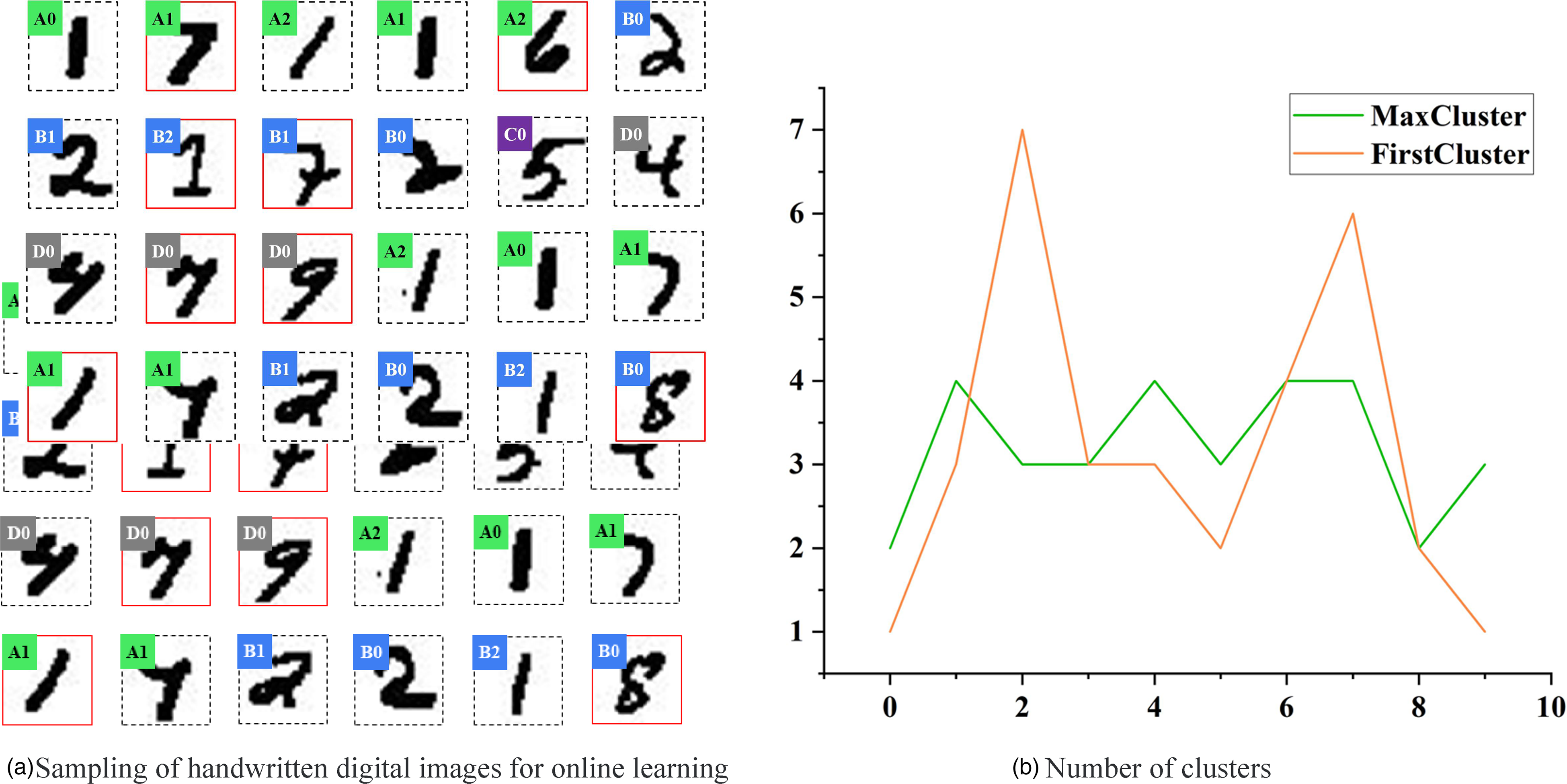
Visualization of ConvART II online learning process. (a) Sampling of handwritten digital images for online learning. The solid red box indicates that the cluster label does not match the real label, the dashed box indicates that the cluster label or image is classified correctly, the colored label letter indicates the handwritten image category, and the number indicates the cluster contained in the category. (b) Number of clusters. The number of clusters included in each category at the end of online learning. FirstCluster and MaxCluster, respectively, indicate that the parent sample of the cluster and the largest image label are used as the actual label.

Virtual matrix of categories/clusters. (a) The ordinate represents the label of the original cluster, depth of the color characterizes the image number of the cluster. (b) The ordinate represents the cluster based on the parent sample, and the color represents the scale of the corresponding category of image obtained under the cluster label. (c) The ordinate represents the clustering based on the largest scale image.
According to the statistical data of the experimental results, we construct a virtual matrix (Figure 6) to express the results more intuitively. The results show that the ConvART II network has online learning capabilities. For a completely blank initial network, ConvART II can use knowledge for online learning. With the addition of new knowledge, the model can also distinguish and learn new knowledge from old knowledge and use the learning experience in subsequent classifications.
In Table 1, we use the proportions of the scale of the largest three types of clusters as indicators for comparison with ConvART I and ART I, which is also used by Sucholutsky et al. in their paper. ConvART II has better classification performance than ConvART. In the 350 image classification experiments of MNIST, ConvART I network constructed 40 clusters, while ConvART II only constructed 33 clusters, which shows that ConvART II network learning is more effective. However, if the network produces erroneous cluster judgments at the beginning, subsequent erroneous learning will continue. Even if such errors are trivial, as long as they occur in clusters of the same category, the network will accumulate such errors in the learning process and eventually lose the classification ability of this category. To overcome the problem of network “going astray,” this paper proposes Pretrain Convolutional Adaptive Resonance Theory Neural Network.
Proportion of MNIST digits classified within their respective largest three classes.

Pretrain convolutional adaptive resonance theory neural network
The adaptive learning ability of ConvART II is better than ConvART I and ART I. However, according to the previous experiment, the network is failing on some clusters, and it became invalid after errors accumulated.
As shown in Figure 7, the cluster learns multiple classification images in the early learning stage, which generates two or more classifications at the same time. In the follow-up classification, the cluster frequently obtains more than one type of image. Due to the online learning mechanism of ConvART II, the network also deepens the memory of correct and incorrect classifications, which causes large-scale classification errors in the subsequent online learning process. To solve this problem, a pretraining mechanism is added to ConvART II.

Visualization of the accumulation process of cluster errors. The green dotted pane indicates the correct classification, the red solid line pane indicates the wrong classification, the colored background label letter indicates the classification code, and the number indicates the cluster code under the classification. (a) First-Cluster. (b) Max-Cluster.
There is some research to improve the performance of the neural network. Some improvements based on ART infrastructure are used for supervised learning, such as ARTMAP, 20 FuzzyARTMAP,15,41,42 and GART.14,43,44 These networks generally follow the basic ARTMAP architecture 12 (Figure 8), that is, two subnetworks are connected through a mapping domain to verify and supplement each other for learning.

Elementary ARTMAP model.
Different from ARTMAP, we use prior knowledge to build clusters with accurate discrimination based on traditional ART networks. Based on the above ideas, this paper proposes Pretrain Convolutional Adaptive Resonance Theory Neural Network (PConvART II) that includes a pretraining module. PConvART II can use prior knowledge to establish clusters with strong discrimination capabilities for a single category while maintaining online learning capabilities. In the initial state, PConvART II uses prior knowledge to pretrain the ART network and generate clusters with the same number of known categories. Each cluster learns all known image features under that category, thus enabling the cluster to obtain generalized memory. In the pretraining process, the known images are repeatedly learned to overcome the problem of fewer known images. By adding the pretraining subsystem, the network may obtain the following advantages: A) Reduce the same category clustering number, B) Reduce the error that learns multicategory features in the early stage of cluster construction.
As shown in Figure 9(b), through experiments on 350 MNIST images, we calculated the proportion of images of each category in the parent sample cluster label and preset label of PConvART II. It can be seen that compared to ConvART II, PConvART II has a significant advantage in the proportion of the largest cluster in most categories, and does not have serious instability like the parent sample label cluster, so it performs better in terms of global performance.

Overview of PConvART II. (a) The pretraining process of PConvART II includes two processes: CNN pretraining and ConvART pretraining. The former is performed first and generates feature vectors for the latter, but the images used for CNN pretraining are allowed to be different from the subsequent classification tasks and ConvART pretraining. (b) First-Cluster indicates the proportion of the sum of images obtained by each cluster when the cluster label inherits the parent sample label, Max-One-Cluster represents the proportion of images obtained by the largest cluster, Pre-Build-Cluster represents the proportion of images obtained by the cluster set in the pretraining session.
For the number of clusters, ConvART II generated 33 clusters on 10 types of images, while PConvART II only generated five clusters in addition to the preset 10 clusters. By comparing the classification results of First-Cluster and Pre-Build-Cluster in PConvART II, it can be seen that the number of images obtained by the preset clusters exceeds that of other clusters in the same category. The pretrained network can build clusters with strong learning ability, to obtain better results in online learning.
However, compared with the more common classification networks at present, the classification accuracy of ConvART II and PConvART II is insufficient. The global classification accuracy of the network is only 0.4–0.6, which is lower than the actual application requirements, and cannot be compared with the existing method on MNIST.45,46 There are many reasons for the poor classification accuracy of PConvART II, including:
The convolutional neural network is too simple to extract feature vectors with sufficient difference. The parameter update rules of the ART network limit its accuracy in image classification applications. The resonant intensity calculation rules of the decision-making subsystem need to be improved.
In Section “Convolutional Adaptive Resonance Theory Residual Network,” we replaced the simple CNN network with a more complex and proven DCNN and conducted experiments on the FLOWERS dataset. In Section “Pre-trained Back Propagation Adaptive Resonance Theory Network,” we improved the ART network for B) and C), proposed the PAN network, and conducted experiments.
Convolutional adaptive resonance theory residual network
In the above experiments, PConvART II and ConvART II models have the problem of unsatisfactory classification accuracy. One of the reasons is that the convolutional neural network used as the feature extractor is too simple to extract sufficient features. To verify this point of view, we used the ResNet 8 and the previous CNN to carry out a comparison of feature extraction, we also built ResConvART II to perform a classification experiment.
Due to the complex structure of ResNet, the global average pooling sequence of 2048 channels in the last convolutional layer of ResNet was taken as the feature vector in the experiment. The feature map generated in the last convolutional layer of ResNet without the back-end classifier still contains a huge number of components. For different image formats, the convolutional network with a kernel size of [1 × 1 × 3] is used to preprocess MNIST images in the experiment.
As shown in Figure 10(a), the difference between the feature vectors extracted by ResNet is higher than that of other categories. As for MNIST, the model adopts the global average pooling of the convolutional layer as the feature, and the pretreatment of MNIST can be regarded as the repeated superposition of a single channel image, so the feature is only slightly different, even worse than that of the customized convolutional network.

ResConvART II experimental results. (a) The left label indicates the network structure and the right part indicates the data set used in the experiment. The image is the distribution of the feature map, and the color label above the image is the category number of each feature map. (b) The abscissa is the experiment cycle number and global performance. The bar graphs of different colors indicate the proportion of clusters, and the values are read according to the left axis. The green broken line indicates the scale of the clusters constructed in different experimental cycles according to the right axis.
To test the online learning effect of the ART II network, the ResNet-50 removing the classifier replaces the convolutional layer of PConvART II to form the ResConvART II network and performs 10 tests on the FLOWERS dataset. Due to the huge structure of the ResNet network, only 64 images were used in each experiment. We performed a statistical of the results (Figure 10(b)). It can be seen that the global classification accuracy of 64 FLOWERS images in five categories by the ResConvART II network is not less than 0.58, which is an improvement compared to ConvART II and PConvART II. The number of clusters is not greater than 12, which means that the online learning ability of ResConvART II is more effective.
Pretrained BPART
We have improved the PConvART II network and proposed ResConvART II, whose online learning performance is better than PConvART II and ConvART II. However, the improvement is limited due to the parameter update rule of ART limiting its accuracy. In addition, there are defects in the resonance intensity calculation of the decision-making subsystem.
In the traditional ART II, the LTM and STM have the same learning rules,12,19 which can be expressed as:
In the experiment, we found that the generation of resonance intensity and positional reliability of ART follow the same rule, that is, the Euclidean norm operation on all components, which reduces the discriminative ability of the indicator to a certain extent. The reason is that the difference between different inputs is not only contained in the value of each component but also reflected in the sequence distribution (Figure 11). Performing Euclidean norm operations on the entire sequence means discarding the differences in the distribution. Since the weights of the nonimportant parts of the input sequence and the components of the input sequence are not less than zero, a large number of useless non-negative components will be generated in the feature. Norm operations of these components will also weaken the difference in resonance strength and positional reliability between different inputs, which is an important reason why ART networks cannot compete with mainstream classification networks in classification accuracy.

PConvART II network weight distribution. Digital X indicates that the weight distribution is a sampling of the clusters contained in the
To solve the problem that the learning rules of the ART network limit its accuracy in image classification, the back propagation algorithm36,47 is added to ART called the PAN network. The back propagation algorithm model gathers errors from the previous layer to update the parameters and is widely used in successful models such as CNN and RNN. 48 It does not have a non-negative limitation as ART, so it can use a large amount of data for learning to strengthen the ART network's discriminant capability, namely, resonance intensity and positional reliability, which is the basis of accurate classification and learning. The Omiglot images are added to the MNIST for verifying the performance of the model. In the experiment, the model uses a four-layer self-defined CNN for feature extraction. LTM and STM of ART are single-layer networks, which is conducive to contrast enhancement and memory fusion. In the training process, according to the complexity of the model, 60,000 preprocessed images of MNIST are used to perform different scale pretraining on CNN and ART. The pretraining of CNN is 1000 generations with 1000 images per generation. The pretraining (Figure 12) of the ART network is 100,000 generations, with 100 images in each generation, and the feature is extracted by the pretrained CNN. After the training, the node data of the ART network are saved, which is read and retrained in a small amount when used later.

(a) The pretraining process of ART. The ordinate indicates the classification accuracy of the network on the verification dataset, the red dot indicates the positioning accuracy of the resonance network, and the green cross identifier indicates the positioning accuracy of the fixed position reliability network. (b) Secondary training process of ART network. The ordinate represents the classification accuracy on the validation set. (c) The experimental process of the PAN network. The red dot indicates the resonance intensity and the green cross character indicates the positional reliability.
The test dataset used in the experiment includes 100 MNIST images and Omiglot dataset random category 1 to 6 samplesa as Table 2. The number of newly constructed pattern classes (New-CN), global average precision (GAP), average precision of Omiglot samples (Omiglot-AP), and the number of pattern classes of Omiglot samples (Omiglot-CN) are adopted as indicators to evaluate the model. For the number of final pattern classes and the global average classification accuracy (Table 3), the PAN network is significantly better than ConvART, ConvART II, PConvART II, ResART, and other models. The GAP classification accuracy of PAN is 91.3%. Most of the samples were correctly identified and classified. Therefore, the New-CN is smaller (2–6). However, for other models, such as ConvART II, the classification accuracy is only 36.1%, the model was unable to distinguish most of the samples and created new categories (11–18). According to Table 3, the lower the precision, the more types are created, because the model does not correctly summarize the same kind of samples.
Split information for MNIST and Omiglot. Each character represents a type of object under a node, and objects with the same label under different nodes have different contents.

The performance of models.

The N-Way k-Shot represents that N classes are randomly selected from the meta-dataset, and k + 1 instances of each class are randomly selected as shown in Table 4. However, the number of Omiglot sample construction pattern classes in the 6-shot classification does not meet expectations, which indicates that the newly constructed pattern class recognition in the online learning process of PAN is still insufficient to recognize new samples. In conclusion, PAN inherits the adaptive growth ability of the ART network and has a great improvement in accuracy rate, which is reasonable because PAN adopts a back propagation mechanism in the ART structure.
Online learning results (100 MNIST-images (10cls), 6 Omiglot-images (1∼6cls)).

Conclusion
In this paper, a back propagation mechanism is adopted to improve the classical adaptive resonance theory for online learning, which imitates human learning behavior. It makes full use of prior knowledge to pretrain the model, distinguishes new knowledge that never appears, learns with a small amount of sample information, and overcomes the problem of forgetting disaster. The pretrained BPART uses a convolutional Network to extract features and conducts online learning through improved Resonance and Adaptive learning rules. In the knowledge growth test of the MNIST and Omniglot combined dataset, the model can maintain the adaptive growth ability of the ART network and achieve a competitive classification accuracy compared with the network trained for fixed tasks. However, the newly constructed pattern class recognition in the online learning process of PAN is still insufficient. Therefore, our future work will be the capability strengthening of new classes increasing.
Footnotes
Acknowledgements
This research was funded by the National Key Research and Development Plan of China under Grant (2020AAA0109000), National Natural Science Foundation of China under Grants (61573213, 61803227, 61603214, 61673245), Natural Science Foundation of Shandong Province (ZR2020MD041, ZR2020MF077).
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Key Research and Development Plan of China, National Natural Science Foundation of China, Natural Science Foundation of Shandong Province, (grant number 2020AAA0108900, 61573213, 61603214, 61803227, ZR2020MD041, ZR2020MF077).