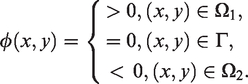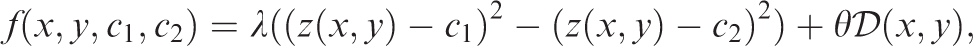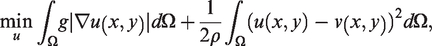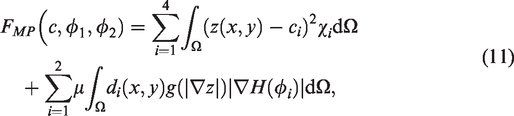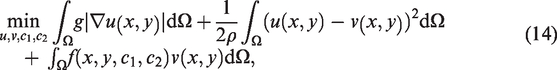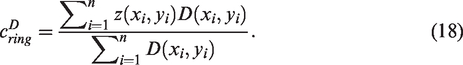It is common for a segmentation model to compute and locate edges or regions separated by edges according to a certain distribution of intensity. However such edge information is not always useful to extract an object or feature that has two distinct intensities e.g. segmentation of a building with signages in front or of an organ that has diseased regions, unless some of kind of manual editing is applied or a learning idea is used. This paper proposes an automatic and selective segmentation model that can segment a feature that has two distinct intensities by a single click. A patch like idea is employed to design our two stage model, given only one geometric marker to indicate the location of the inside region. The difficult case where the inside region is leaning towards the boundary of the interested feature is investigated with recommendations given and reliability tested. The model is mainly presented 2D but it can be easily generalised to 3D. We have implemented the model for segmenting both 2D and 3D images.
Segmentation of an image is the task of partitioning it into different segments in order to classify and identify objects. Although often the concepts of segmentation and feature extraction are synonymously used, they are not always the same thing. This paper considers a common setting where an interested object or feature has two distinct intensities e.g. segmentation of a building with signages in front or of an organ that has diseased regions. Here the segmented results by the common models show parts of an object, or not a complete object. In particular we consider this challenging setting and assume both domains have distinct intensities and are approximately homogeneous, so that a region based model is applicable.
Classic variational approaches such as the Mumford and Shah1 method aims to partition the entire image domain . Here n regions such that by finding an edge ition the entire image domain . Here the segmented results by the common models show parts of an object, or nots in an image, however it is difficult to accurately solve. Chan and Vese2 introduced a piecewise constant version of the Mumford-Shah model, overcoming the difficulty of solving Mumford-Shah model; another approach is by Ambrosio and Tortorelli,3 who proposed an approximation to Mumford-Shah using t\\Normalization\\IN\\INPROCESS\\1“ \o ”1=Ref L. Ambrosioand V.variational segmentation models for global segmentation i.e. locating all edges and different regions. Another common type are known as edge based, which aim to evolve a contour towards edges in an image by making use of an edge detector. Kass et al.4 was among the first of this type, which was further developed by the Geodesic Active Contours model by Caselles et al.5
Selective segmentation aims to identify a particular object or objects of interest, and so has very important applications in medical imaging. A set of marker points (usually 3to identify a particular object or objects of interest, and so has very important applications et al.,6 who introduced a distance constraint to the GAC model. A popular method to achieve selective segmentation is to combine elements from both region based and edge based models, as was done in Badshah and Chen7 to encourage the contour to fit to the intensity of an object. Rada and Chen8 made this more reliable by adding a constraint on the evolution of the contour by making use of the polygon formed by the marker points. More recently, Spencer and Chen9 introduced a convex model making use of the Euclidean distance from the set of marker points as a constraint. This model is able to achieve good results, however can be parameter sensitive and not as robust. It is recently improved in Roberts et al.10 by replacing the Euclidean distance with a Geodesic distance, which increases distance in an image when an edge is detected and only needs a single marker point. For selective segmentation, this is the most robust model discussed so far and is the model which we will use to obtain our segmentation results. To illustrate the differences, we refer to Figure 1 where the purpose is to segment the aorta in a real life CT image with a stent (stance in an image when an edge is detected and only needs a single marker point. For selective segmentation, this is the
Illustration of the performance of an old model Roberts et al.10 in (a)–(j): its dependence on the initial marker set l Roberts8" in microscopic images as a prelude to development of computer assisted automated di–(o), to segment the complete object in (n). (a) Marker set 1. (b) Marker set 2. (c) Marker set 3. (d) Marker set 4. (e) Marker set 5. (f) Result 1. (g) Result 2. (h) Result 3. (i) Result 4. (j) Result 5. (k) Marker set. (l) Stage 1. (m) Stage 2. (n) Final. (o) Combined.
However this paper addresses the case where the intended object has inhomogeneous intensities that may be broadly grouped into two regions of pixels each having a very different mean-intensity value. Then none of the above mentioned existing models can be used because there exist xist r this pes’ in the object that we are interested in.
To be precise, the task is to take a single input from the user to obtain segmentations of two separate, connected objects: one for the object with a marker, and the other for a larger object containing the first. In this paper we propose a nobel and yet simple method for this task. The class of the secondary objects that we can segment contains typically two phases in terms of intensities. Such an object cannot be segmented by all the known methods without manual editing. It is possible that a learning model can do the same job but such a model can deal with one type of applications per training, not for the variety of applications that we aim for.
We begin by detailing the segmentation model and then discuss some natural approaches to find a value to threshold our image in order to segment it a second time, before introducing our idea of thresholding an image in order to model the three-phase segmentation using a two-phase model. Finally, we discuss where the method might fail and then recommend a solution.
The previous segmentation works
Let z(x, y) be a given image defined on the image domain . The task of selective segmentation is to segment the object in image z that is closest to an user-provided set . However the new task that this paper tries to address is the case where the intended object has inhomogeneous intensities that may be broadly grouped into two regions of pixels each having a very different mean-intensity value. Then it is not immediately obvious which existing models can be used e.g. either Mumford-Shah type or edge type models cannot be used because there exist xist ver the new task that this paper tries to address is the case where the intende representative models that we use to build our new models.
A two-phase model
We denote as the foreground object, and the background in a two-phase model. The task here in finding is to find the boundary phase model. The task here in finding case and . Since only contains the interested object(s), not all possible objects in z, many models from the literature cannot used for the task.
We review mainly the Roberts et al.10 model, which is based on the framework of Chan and Vese2 and forms the basis of our proposed method. This model takes the following form
where c1 and c2 are the average intensities inside and respectively, and based on and gradients of z is the geodesic distance constraint which will be discussed later.
In order to solve this model, as done in Chan and Vese,2 one uses the level set idea from Osher and Sethian11 to represent our l set idea fro, i.e.
The model is reformulated to the form:
where we have set is the regularised Heaviside function, and is the edge detector to the regulariser with . The inclusion of the Heaviside function results in our current functional being non-convex. This means a minimiser found could be a local minimum, and not a global minimum. The convex relaxation idea from Chan et al.12 provides a solution to this problem. It has been shown that the Euler-Lagrange equations for the minimisation of have the same solutions to the following minimisation problem:
where and is a penalty term introduced in Chan et al.12 to ensure . The global minimizer is ensured if c1, c2 are accurate which are often assured by the marker set and its associated initial contour.
We define the geodesic distance taking the marker set from the user, by solving the Eikonal equation
where is the Euclidean distance away from . We use a fast time sweeping method Zhao13 to solve this equation, which requires setting for , and the calculation evolving from that region.
In order to perform the minimisation, we alternate between minimising c1 and c2 with u fixed, then with c1 and c2 fixed, we solve for u. Minimising with respect to c1 and c2 gives us
To minimise with respect to u with c1 and c2 fixed as above, we use the dual formulation by Chambolle,14 which was first applied to a segmentation problem in Bresson et al.,15 by introducing a second variable, v, and alternating between the minimisation of u and v. In addition, it is shown in Bresson et al.15 that the penalty term is not necessary in this framework, provided that the initialisations . Our model then becomes
where we re-define f by
and the new parameter is small. We first fix all variables except u and solve the u variational problem:
which is given via the dual variable
which is solved iteratively with and
After updating and fixing u, we solve the v variational problem
by finding its analytical solution:
A multiphase model
The traditional approach that can lead to an output approximating our desired result is to formulate the segmentation task as a multiphase problem. Then our solution will hopefully be an object that is comprised of two phases (though practically this may not be possible due to the non-convex nature of a multiphase model).
We briefly review the work of Vese and Chan,16 which explains how to extend the traditional Chan and Vese2 framework to multiple level sets, providing a method of segmenting an image into multiple phases. Their four-phase model using two level set functions, and , to segment an image is the following:
where is a constant vector and
and
We note however that this model achieves global segmentation, and therefore using this model wons. Their four-phase model using two lev Figure 1(o). To restrict the two level sets from segmenting objects outside the objects of interest, we merge ideas from Gout et al.6 and Badshah and Chen,7 by adding two distance constraints d1, d2, and edge detector g into the regularisors of the above model:
where we require two marker sets , i = 1, 2, for the computation of the two new distance constraints di, which is given by:
In Figure 2, we perform the above multiphase model to the image in Figure 1, with the aim of achieving the result in Figure 1(o). We first show the input required in Figure 2(a), and the result in (b). First, we note that the required input for the multiphase model is detailed (whereas the proposed method which we detail in the next section requires just a single click), as the multiphase method is non-convex, and therefore we need the initialisation to be close to the final solution. A single click by the user is unlikely to be enough information for a non-convex model such as this to reliably work. Despite the increased input, we can see that while the multiphase has successfully segmented the first region correctly, the second level set has failed to make its way around the lower left side of the second region.
Input and output of the multiphase model. (a) Input. Red: , Blue: . (b) Multiphase out.
In the following section we detail our proposed method, which makes use of the convex segmentation model (3) and an in-painting method to segment an object or feature of two distinct intensities.
The new model
We now present our model for the segmentation problem where an interested object or feature in the given image z has two distinct intensities. We first give a general formulation and then consider a simplified version and its special cases.
A general formulation
Consider the aorta and stent problem in top row of Figure 3 to define the notation. Given image z (as in the left plot), our task is to segment the complete organ defined by (for the aorta in the right plot). Here a marker set is placed in the domain and laced in the domain gdomain . Also we have while .
Illustration of the task of segmentation of the outer organ (aorta) distracted by the inner feature of a stent, with and also inpainted images by TV and Elastica models. (a) Given image. (b) Segmentation of domain Ω1. (c) Inpainted image by TV. (d) Inpainted image by Elastica.
The biggest challenge is that the intensities in are dominant and would prevent us from locating Γ of , our idea is to inpaint the intensities in using neighboring information to obtain an in-painted image , and segment the main feature in at the same time. Hence our segmentation takes the form
where similar to but different from (6). Here regularisation in the second term in the domain may be replaced by the whole domain Ω. Since for our type of problems, in fact, it is not difficult to see that in .
A remark is due for the second term in (12): the use of total variation for inpainting is generally a poor choice Chan and Shen17; Schönlieb18 while the elastica based model Brito and Chen19 is better. Here the assumption implies that there are no extra edges in to reconnect and hence our inpainting problem is much easier than the general case where cuts cross major features. In fact, the bottom row of Figure 3 show the results from applying the TV and the elastica models; clearly the results are good (though it takes relatively a long time to obtain such results) but not excellent due to the inpainted values of differing from neighbours.
The domain itself is usually not given but since the associated intensities are dominant, we can assume that it can be obtained.
Below we discuss how to simply (12) so that other models to inpaint can be developed.
A simplified model
Although image z has many features, our selective segmentation aims to segment one feature i.e. to find the domain by working with the new image after inpainting . As mentioned, the key to simplify the model (12) lies in two related facts: i) ; ii) there are no extra edges in to reconnect. This leads to our 2-stage model.
Stage 1 tage 1onnect. of . From (12), solution is approximated by
since u = 1 in . In the next subsection, we propose various ways of approximating .
Stage 2. Once is computed, (12) is reduced to a standard model for selective segmentation of the inpainted image , i.e.
Methods for computing
Let us assume we have obtained our first segmentation result, to represent , using the method discussed in section 2. In this modified Chan-Vese framework, the indicator function is associated with c1 (the average value of the intensity inside and c2 (the average value of the intensity outside ).
Then for Stage 1, we discuss several ways of computing in since in .
Method M1. It may be intuitive to threshold our region down to the value of c2. However, typically c2 is the average of intensities in , not exactly representative of the surrounding intensities in . We denote the method of thresholding to c2 as M1. See Figure 4.
M1 –1g.ticay Elastica Elc2. The original image is displayed on the top row, and the in-painted image is shown on the bottom.
Method M2. As demonstrated in Figure 4, c2 is perhaps not the most ideal to use for complicated images. To go beyond a constant intensity, we propose to use the variance of a region (by Jeon et al.20):
assuming mi is the mean intensity of one of region Ii (with Ni pixels) in partition of a given image I. For our case, we obtain 2 regions I1, I2 after segmenting , and compute the . Then we inpaint by a normal distribution with mean c2 and variance . Let us denote this method as M2, however this is not much of an improvement from M1 as shown in Figure 5.
M2 —2Thresholding using . Original image desiplayed on the top row, and the in-painted image is shown on the bottom.
Method M3. Since c2 is not informative due to being a large and nonhomogeneous region, we consider a local region surrounding instead. We can obtain a more accurate threshold value by making use of the segmentation result and the associated region . We extend out by pixels as shown in Figure 6(b) (we typically fix ) and obtain a fix region or, denoted as Ωring, given by , as shown in Figure 6(c).
The ring region Ωring by extending . (a) . (b) . (c) Ωring.
We simply calculate the average intensity cring of pixels contained in Ωring, and inpaint our region down to this intensity. This gives us an image in which our first region is now representative of our second target region, allowing us to perform another segmentation, as shown in Figure 7. We will denote this method as M3.
M1-3 1-3Both segmentof inpainting by a constant intensity (visually not pleasing in column 1 but leading to Stage 2he bottomottom.development of computer assisted automated disease diagnostic . (a) Thresholded image. (b) Segmentation u2. (c) Both segmentations. (d) Thresholded image. (e) Segmentation u2. (f) Both segmentations.
Method M4. The above three methods can lead to successful Stage 2 segmentation on the new inpainted image in our tests. However, the inpainted region by thresholding to a constant intensity is visually visible in the inpainted image. To improve the visual quality, we consider the idea of M2 by the Normal distribution. We threshold each pixel in individually to a number drawn from the normal distribution, with mean cring and variance in Ωring calculated as defined earlier. Denote this by M4.
Method M5. M4 may give good aesthetic results in some cases, for example in Figure 9 where we see it replicates the texture of the blood vessel very well, however for a homogeneous , the normal distribution is unlikely to perform well and the image would look out of place. In order to replicate the texture of the surrounding pixels, a simple method would be to just copy and paste values of pixels in the ring to inwards, repeating the sequence until all of has been filled in. Here, we can either fill the pixels in row by row (Figure 8(a)), by spiralling inwards towards the center of (Figure 8(b)), or completely randomly (Figure 8(c)). We recommend to fill in randomly, so that we don we dony, so that we donxels in row b occurring in the texture of the in-painted region.
In principle, the choice between M3-5 should not have too much of an effect on the second segmentation result as the average value of the region after applying a particular method should be very similar to the average value of applying another. Figure 9 shows a comparison between using each method. A second segmentation is easily achievable using either. Visually we recommend a variant of M5.
In this section we make a comparison to two traditional variational in-painting methods detailed in Schönlieb,18 firstly the Mumford-Shah method given by minimising the following energy:
where χ is an approximation of the edges in the image introduced in Ambrosio and Tortorelli.3
In addition, wee:///\\\\chenas03.cadmus.com\\smartedit\\Normalization\
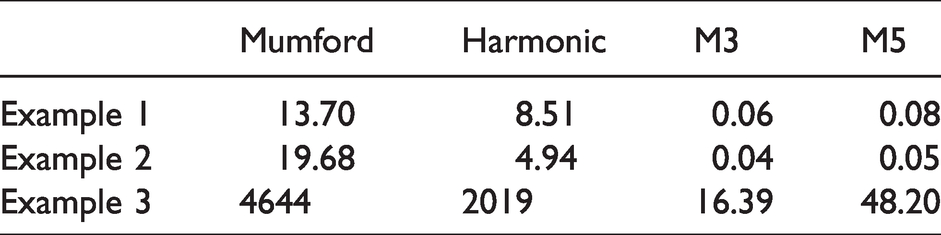
We consider three examples in total, showing the output for the first two examples in Figure 10, and the corresponding results using our methods are found in Figures 9 and 15 respectively. Example 3 is a large pathological colour image of dimension 9863 × 11,454 which we have tested for the sake of measuring the computation speed. Computation speed is given in Table 1. We see that, although the variational methods give similar results to our M3 and would therefore be suitable to use as an input for our second segmentation stage, the computation time is much larger. The in-painting step in our method is an intermediate step which allows us to obtain a second segmentation result, therefore speed is the only thing we should be concerned with.
The above recommended method M5 (and also others for this matter) would fail to yield an acceptable inpainted image if and share part of a boundary, because the threshold value out of the region surrounding will be influenced by the intensity of both the second object desired and a neighbouring objects. We now address the mathematical challenge below by modifying the band in M3-5. This scenario can occur in practical images e.g. when diseases are present near the boundary of an organ.
It is possible to accommodate this particular case if a specific application occurs in the same position all the time, for example if object one is always on the left boundary of object two, we could simply just consider the average intensity of pixels in the right hand ring. However, for a general application we need an alternative solution.
The second column of Figure 11 demonstrates the problem at the boundary using synthetic images. The more domain touches the boundary/unwanted region, the smaller(darker) the threshold value within band becomes and the less suitable the region becomes for a second segmentation result.
Column 1: Original image with user input. Column 2: Inpainted by M3. Column 3: Associated segmentation result from column two result. Column 4: Inpainted by our distance weighted method we present in section 4. Column 5: Associated segmentation result from column three result.
An easy solution would be to retrieve another marker from the user, indicating the second region, however this defeats the whole purpose of our method of segmenting two objects with one click. An alternative solution would be to ask the user to input their marker inside the first object close to the boundary between the two objects desired. Using this information, we can change our methods slightly.
M3 revisited: Instead of taking the average intensity of values near , we could apply a weight to the intensities according to a weight function. The weight is designed to have a higher value for pixels close to the marker (i.e. the intensities of object two in ). We use the Euclidean distance to weight the pixels. We consider to be the normalised Euclidean distance from the marker(s) to pixels contained in Ωring
we can define cring to threshold the region by
This makes the thresholding value to be more representative of the second object, and so the Chan-Vese fitting term is more likely to work.
For difficult images, it might be more accurate to change our weighting function to only consider the closest, say 20%, pixels in Ωring, rather the entire region. Depending on the application this amount could change. We recommend only considering the nearest 20% of all pixels regardless, as this will provide a more realistic value; there is no reason to consider the furthest pixels away contained Ωring.
We see in Figure 11 in column 4, that with this new method, the inpainted image is much more representative of the second object, and isnag influenced by the black background. In Figure 12 we see the model work on the boundary even with an awkward shape.
Using 20% as weight. (a) and marker placement . (b) Second segmentation. (c) Combined segmentation.
M5 revisited: The discussion so far shows an extension of M3 to manage in the case where is near the boundary of . In the synthetic images, performance is great, however using a single constant value to threshold leads to a visible awkward looking region as is discussed in the previous section. Instead of extending M3, we can extend M5 in a similar way to attempt to maintain some of the texture of . To do this, instead of copying and pasting the values of all the pixels in Ωring, we can set a cut off point, say, only copy 20% of the closest pixels to the marker point contained in Ωring.
Algorithmic summaries
Finally we summarise the main algorithms. All three algorithms must be used to find the two segmentations that we desire.
Algorithm 1 Segmentation algorithm
Input image z and parameters and ρ.
Calculate g and .
Initialise such that se s orithmAll throf .
fordo
Update as in (5).
Update uk and vk as in (7) and (9) respectively
end for
and set
(2) To inpaint domain , based on (other methods similar, see previous sections for details), we do the following:
Algorithm 2 Inpainting step M5
Input image z and domain to be inpainted .
Initialise inpainted image .
Obtain by extending out by pixels. Use to find .
Collect intensity values of the nearest 20% of pixels in Ωring to in a vector v.
fordo
Update .
. If , set i = 1.
End for
Output inpainted image .
(3) Finally we make use the same input and segment the inpainted image .
Algorithm 3 Proposed two stage segmentation algorithm to segment and object or feature of two distinct intensities.
Input initial image z1 and parameters and ρ1 to perform segmentation by algorithm 1, obtaining initial segmentation region as output.
Input z1 and into algorithm 2 to inpaint the image, yielding z2.
Input z2 and parameters to perform algorithm 1 again, this time using as our initialisation.
Output and , two segmented regions.
(4) If we have a case in which our desired has more than two distinct intensities contained inside it and running algorithm 3 outputs segmented regions capturing only two of the distinct regions, then we can instead in-paint the image and segment iteratively until the desired result is achieved. See Figure 15 for an example. In some cases, we could in principle use our method to hierarchically segment an entire image by iteratively segmenting and in-painting.
Numerical experiments
In this section we will demonstrate some results illustrating the principle of our method. With the geodesic distance, only a single point is required from the user inside the initial region of interest (however if the initial region is disconnected, we need one click in each disconnected region). From that we obtain segmentation of the region, a thresholded image, and another segmentation performed on the new image. In all tests we set parameters from the segmentation model ρ = 1 and , and for calculating the geodesic distance we fix and . This leaves us with only the λ and θ values in the segmentation model to vary.
Example 1: Disconnected stent
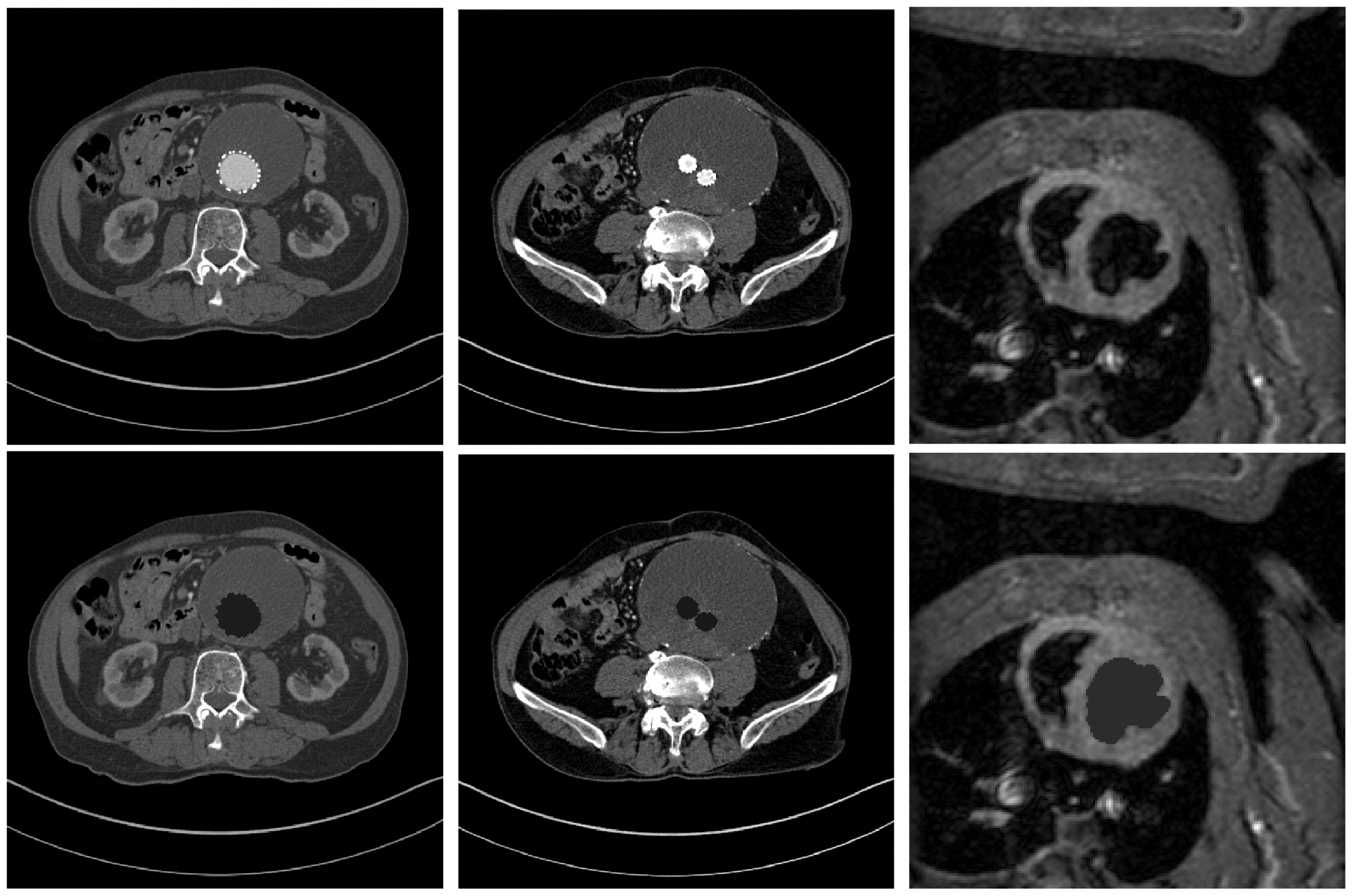
Figures 13 and 14 show a stent in an abdominal aortic aneurysm, with both images being 512 × 512. We would like to know the position of the stent relevant to the surrounding blood vessel, so this method lends itself well. Two clicks were required for the second image in Figure 13 as the stent is disconnected. From this, we obtain a realistic in-painted image with which we can perform a second segmentation and obtain very accurate results quickly.
Stent in an abdominal aortic aneurysm. (a) Original image, z1. (b) User input, . (c) . (d) Inpainted image. (e) Ω1. (f) and .
In this example we demonstrate the use of in-painting twice, requiring three segmentations due to the bright noise between the stent and the boundary of the blood vessel. (a) First segmentation, . (b) First in-painted image z2. (c) Second segmentation, . (d) Second in-painted image z3. (e) Third segmentation, . (f) and .
Example 2: Stent with noise - multiple in-paintings
Figure 14 demonstrates using the method twice to obtain segmentation of the blood vessel. In this case there is noise present produced by the metal coated stents causing the interior of the aorta to be brighter than the rest of it. This example is different to the previous one as there are three distinct intensities contained in our desired (the boundary of the blood vessel), due to noise. Therefore, we are required to segment and in-paint twice, before segmenting finally to obtain . We use and . This example requires one more in-painting step than what has been discussed
Example 3: Stent on boundary
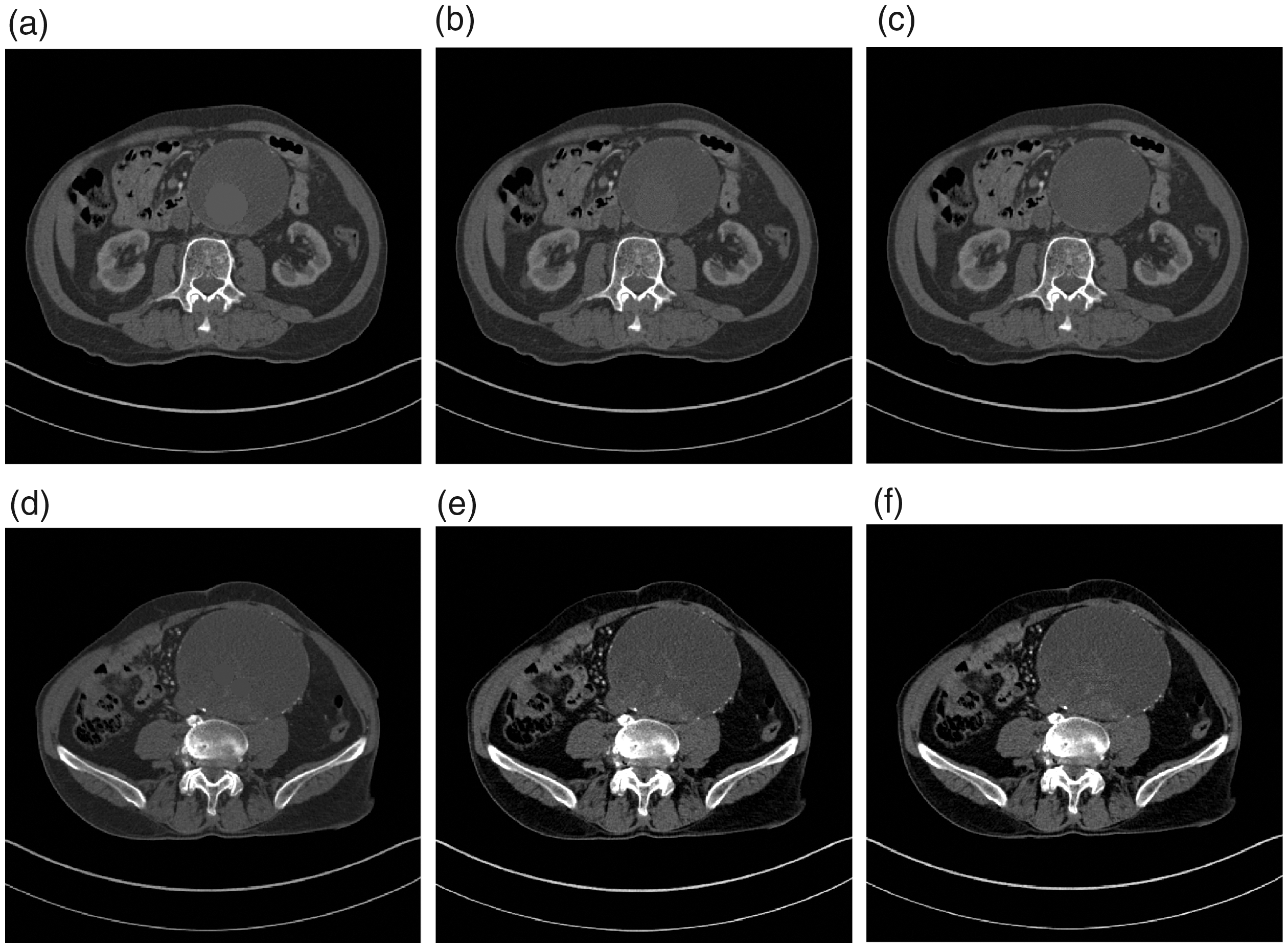
We show another stent in an abdominal aortic aneurysm in Figure 15, in which is lying on the boundary of . In this case, it is important that the methods discussed in section 4 are implemented, as otherwise our inpainted image would be not be suitable for a second segmentation. The placement of the marker is placed as close to as possible while still contained in , as shown in Figure 15(b), and when we in-paint we only consider the closest 20% of pixels contained in Ωring.
This figures shows a stent in an abdominal aortic aneurysm. In this case, is touching the boundary of . It is necessary in this case for the methods discussed in section 4 to be implemented, in order to obtain an appropriated in-painted image for an accurate to be obtained. (a) Original image, z1. (b) User input, . (c) First segmentation, . (d) In-painted image, z2. (e) Second segmentation, Ω1. (f) and .
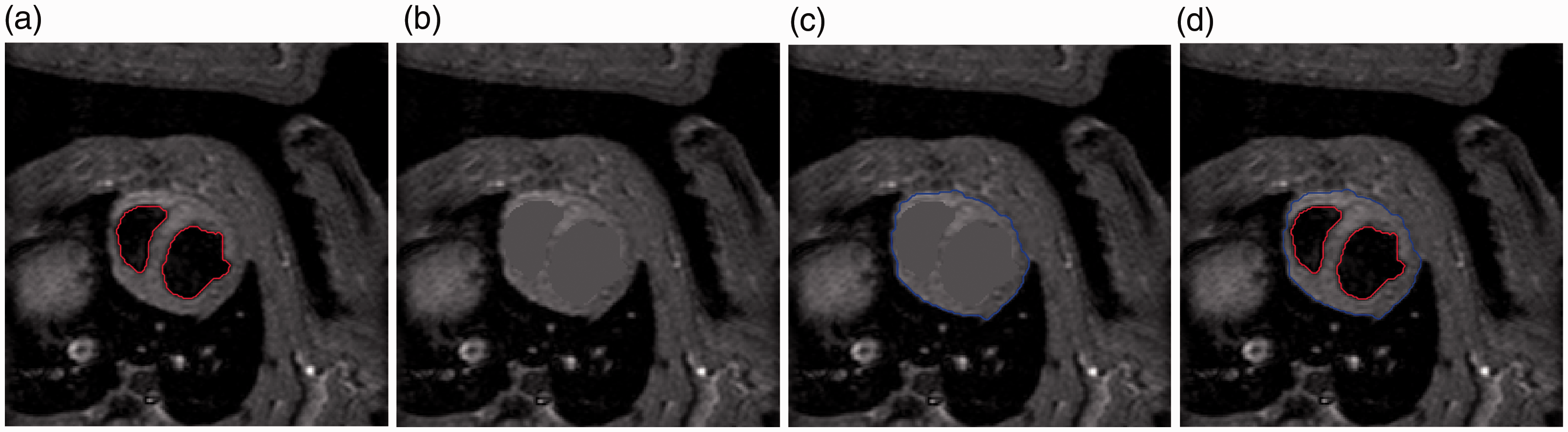
Example 4: Ventricular walls
Figure 16 show an MRI of the heart of a rat. The method required clicking once in the two chambers (the dark regions inside the red contours of Figure 16(a)), which allowed us to obtain the inside region. We then inpainted choosing simply use for this example, which allowed us to find , the outline of the ventricular walls. The image size is small at 192 osing simply use s (the dark regions inside the red cont seconds. We use parameters
Segmentation of MRI of a rat’s heart. (a) First segmentation, . (b) Inpainted image, z2. (c) Second segmentation, Ω1. (d) and .
Example 6: Extension to colour
We show a brief example of our model being applied to a colour pathological image of multiple myeloma, given by Gupta and Gupta21; Gupta et al.22,23 So far we have only presented our method working for greyscale images, however it is easy to extend the framework to RGB. First the segmentation model (3) differs as we now have a vector valued image.
Let zi be the ith channel of image z, i = 1, 2, 3 (in this example we have an RGB image), and let and be vectors corresponding to the average intensity inside and outside of Γ in each channel. We can therefore compose our fitting and distance term as and , where the calculation in (4) is calculated on zi. Our equivalent colour segmentation model is now:
The in-painting step only differs in that the values of the pixels we fill in with are vector valued, like our image, so we just fill in the corresponding each channel separately with values from the vector valued pixels from Ωring.
Figure 17 shows a cell on the boundary, in which it is necessary to have employed our distance technique, involving placing the marker point as close as possible to the second object (the light blue ellipse), but still inside the first (the purple circle).
Colour example. (a) Original image, z1. (b) User input, . (c) First segmentation, . (d) In-painted image, z2. (e) Second segmentation, Ω1. (f) and .
Example 7: Extension to 3D
Our inpainting method is easy to extend to 3D data, differing only is our image domain . Our segmentation model (3) extends easily to a third dimension, however of course our segmentation results and are now surfaces. The geodesic distance is solved using (4) with an extra dimension, and the method of solving the PDE is slightly different to the two-dimensional case, however the details are, again, contained in Zhao.13
In principle the in-painting method is the same as in two-dimensions. To achieve M5, we perform segmentation to achieve a surface , extend the surface outwards in the normal direction to obtain , and then obtain Note that despite Ωring not really being a ring in three dimensions, we keep the notation consistent to avoid confusion. We then take the intensity of voxels contained in Ωring, and use these intensities to fill in our region as before.
Figure 18 shows a selection of slices of a 3D data set of an abdominal aortic aneurysm with a stent present. This particular set was done on image data of size , with a single click required to obtain an intial segmentation of the stent, . From that we can obtain our in-painted 3D image and segment again, achieving a result for the blood vessel. In this particular example, as shown by the images, the stent begins as a single connected object at the top of the image data (top row), and in the middle bifurcates and disconnects into two seperate regions. The placement of the marker can be placed arbitrarily in any slice, regardless if on that particular slice the stent is disconnected, as in 3D the object is connected. To speed up the calculation of the geodesic distance, we place a marker on the top slice and two markers on the bottom, however in principle this result is achievable with a single click.
Nine slices from a 3D dataset.
Conclusion
In this paper, we have presented a method of obtaining a second segmentation result from a segmented region without any further user interaction. We do this using a two stage approach, by segmenting an object, intelligently inpainting our image with a similar intensity to the object surrounding the segmented object, and performing the segmentation model a second time to obtain the surrounding object. We have compared and contrasted it to alternative approaches such as multiphase segmentation methods, and classic variational in-painting methods, and saw improved performance and ease of use contrasted to the former, and drastic speed increase contrasted to the latter.
A number of quick in-painting method have been discussed, all based on the same principle of using information from surrounding region Ωring. We have discussed the potential challenges of using these methods when the initial object is on the boundary of , and have suggested a potential solution with appropriate placement of the marker point . We have then tested on many piecewise constant images, showing the effectiveness of our proposed method, as well as detailing an extension to both colour images, and 3D data.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by UK EPSRC grant EP/N014499/1.
ORCID iD
Liam Burrows
References
1.
MumfordDShahJ.Optimal approximations by piecewise smooth functions and associated variational problems. Commun Pure Appl Math1989;
42: 577–685.
2.
ChanTFVeseLA.Active contours without edges. IEEE Trans Image Process2001;
10: 266–277.
3.
AmbrosioLTortorelliVM.Approximation of functional depending on jumps by elliptic functional via t-convergence. Commun Pure Appl Math1990;
43: 999–1036.
4.
KassMWitkinATerzopoulosD.Snakes: active contour models. Int J Comput Vis1988;
1: 321–331.
5.
CasellesVKimmelRSapiroG.Geodesic active contours. Int J Comput Vis1997;
22: 61–79.
6.
GoutCLe GuyaderCVeseL.Segmentation under geometrical conditions using geodesic active contours and interpolation using level set methods. Numer Algor2005;
39: 155–173.
7.
BadshahNChenK.Image selective segmentation under geometrical constraints using an active contour approach. Commun Comput Phys2010;
7: 759–778.
8.
RadaLChenK.A new variational model with dual level set functions for selective segmentation. Commun Comput Phys2012;
12: 261–283.
9.
SpencerJChenK.A convex and selective variational model for image segmentation. Commun Math Sci2015;
13: 1453–1472.
10.
RobertsMChenKIrionK.A convex geodesic selective model for image segmentation. J Math Imaging Vis2018;
61: 482–422.
11.
OsherSSethianJA.Fronts propagating with curvature-dependent speed: algorithms based on Hamilton–Jacobi formulations. J Comput Phys1988;
79: 12–49.
12.
ChanTFEsedogluSNikolovaM.Algorithms for finding global minimizers of image segmentation and denoising models. SIAM J Appl Math2006;
66: 1632–1648.
13.
ZhaoH.A fast sweeping method for Eikonal equations. Math Comp2005;
74: 603–627.
14.
ChambolleA.An algorithm for total variation minimization and applications. J Math Imaging Vis2004;
20: 89–97.
15.
BressonXEsedoḡluSVandergheynstP, et al.
Fast global minimization of the active contour/snake model. J Math Imaging Vis2007;
28: 151–167.
16.
VeseLAChanTF.A multiphase level set framework for image segmentation using the Mumford and Shah model. Int J Comput Vis2002;
50: 271–293.
17.
ChanTFShenJ.Image Processing and Analysis: Variational, PDE, Wavelet, and Stochastic Methods. USA: SIAM Publications, 2005.
18.
SchönliebCB.Partial differential equation methods for image inpainting.
Cambridge:
Cambridge University Press, 2015.
19.
BritoCChenK.Fast numerical algorithms for Euler’s elastica inpainting model. Int J Mod Math2010;
5: 157–182.
20.
JeonMAlexanderMPedryczW, et al.
Unsupervised hierarchical image segmentation with level set and additive operator splitting. Pattern Recognit Lett2005;
26: 1461–1469.
21.
GuptaRGuptaA. Mimm sbilab dataset: microscopic images of multiple myeloma. The Cancer Imaging Archive, https://doi.org/10.7937/tcia.2019.pnn6aypl (2019, accessed 5 April 2021).
22.
GuptaAMallickPSharmaO, et al.
Pcseg: color model driven probabilistic multiphase level set based tool for plasma cell segmentation in multiple myeloma. PloS One2018;
13: e0207908.
23.
GuptaRMallickPDuggalR, et al.
Stain color normalization and segmentation of plasma cells in microscopic images as a prelude to development of computer assisted automated disease diagnostic tool in multiple myeloma. Clin Lymphoma Myeloma Leuk2017;
17: e99.