
Abstract
Reconstructing a 3 D object from a single image is a challenging task because determining useful geometric structure information from a single image is difficult. In this paper, we propose a novel method to extract the 3 D mesh of a flag from a single image and drive the flag model to flutter with virtual wind. A deep convolutional neural fields model is first used to generate a depth map of a single image. Based on the Alpha Shape, a coarse 2 D mesh of flag is reconstructed by sampling at different depth regions. Then, we optimize the mesh to generate a mesh with depth based on Restricted Frontal-Delaunay. We transform the Delaunay mesh with depth into a simple spring model and use a velocity-based solver to calculate the moving position of the virtual flag model. The experiments demonstrate that the proposed method can construct a realistic fluttering flag video from a single image.
Introduction
Image enhancement, which is a very important field of augmented reality, has attracted attention from both academia and industry. Increasingly more people want to obtain abundant visual information and a friendlier visual experience by processing images. Additionally, many scholars are investigating how to produce a video or animation by using a single image. For example, Carlos Castillo et al. 1 implemented the style transfer of an object in a single image with semantic segmentation. Menglei Chai et al. 2 designed the AutoHair method to model hair from a single image based on deep neural network.
Since a single image only provides color and shape information on 2 D planes, it is difficult to quickly reconstruct the 3 D structures of objects in the image. If we can reconstruct the 3 D structure of an object of interest from a single image, then a wealth of visual content can be generated. Therefore, how to generate the 3 D structure of an object from an image is one of the core problems of image enhancement.
(1) For the scene driving a flag fluttering from a single image, we should reconstruct the 3 D mesh of the flag firstly. Due to the performance of deep convolutional networks,3–6 we can estimate the depth map of the single image. If we directly segment the depth information of the flag from the depth map, it is very hard to use the depth information to generate the 3 D mesh. Because the estimated depth map is uncertain and not very accurate. And the flag material is soft, the depth map is also difficult to map the details of the flag surface such as wrinkles. Therefore, this paper will construct a 3 D mesh of the flag by combining 2 D mesh with depth map, so as to realize the 3 D detail reconstruction of the flag. On the other hand, how to drive the flag fluttering in a single image is also a very challenging problem. This is because of the lack of animation-driven information in a single image. On the basis of reconstructing the 3 D mesh of flag, we will introduce a virtual wind force as the driving force of the flag animation.
In this paper, we focus on how to drive a flag to flutter from a still image. The flag is very thin according to a large number of observations; thus, the flag can be considered as a curved mesh in the 3 D reconstruction process. The flag in the image is presented in a stereoscopic form, where the depths of field in different areas of the flag are different. Therefore, we employ the depth information to first reconstruct the 3 D mesh of the flag from the image. To improve the efficiency of mesh reconstruction, same points sampled from the single image are used in our work. Then, we use a simple linear spring model 7 to drive the reconstructed flag mesh to flutter.
The major contributions of this paper are summarized as follows:
A new animation method is proposed to generate a flag video animation form a single image. The proposed method uses a deep convolutional neural network to generate the depth map of input image. It generates a coarse 2D mesh of flag in the input image. And then, it combines the depth map of image and 2D mesh of flag to reconstruct the 3D mesh of flag. Finally, it drives the flag to Flutter by the virtual wind force. An innovative reconstruction method is designed to generate a 3D mesh of a flag in the single image. The coarse 2D mesh is generated by Alpha Shape and sampling points in the image firstly. And the Restricted Frontal-Delaunay method is used to optimize the 2D mesh. We transform the 2D mesh into 3D space based on the depth map. Finally, we use the linear subdivision method to refine the 3D mesh with high density. We propose an animation driving model to simulate the fluttering of the 3D flag mesh. The reconstructed 3D mesh is mapped into a simple linear spring model, where the vertex is transformed into a particle. We construct a joint vector model of internal and external constraints between each particle pairs. The unfired dynamics sovler is used to solver the object equation of driving flag fluttering by virtual wind force. An batch rendering technique is used to map the texture of the flag into the 3D mesh.
The remainder of this paper is organized as follows. We review the existing works related to our proposed method in the next section, such as animation based on a single Image etc. Then proposed method is thoroughly presented. We conduct some experiments and analyze the proposed method in the subsequent section. Finally, we conclude our work with conclusion section.
Related works
The method proposed in this paper is related to generating an animation from a single image, which consists of depth estimation from a single image,8,9 mesh reconstruction10,11 and generating an animation of flag fluttering. Representative works that address these four issues are briefly reviewed below.
Animation based on a single image
Driving a flag to flutter from a single image is a research work of generating an animation based on a single image. Chuang et al. 12 animated a single image using stochastic motion textures. Sun et al. 13 employed the same method to extract the parameters of wind and water animation. Xu et al. 14 constructed a video of moving animals from a single image based on the existing moving order. Jhou et al. 15 designed a cloud appearance model to simulate cloud flow. These methods did not reconstruct the 3 D shape of the object being driven from the single image, but our work constructs the 3 D geometric structure before generating the animation.
Depth estimation
Computing the depth information from a single image is another challenging work in image processing. Ashutosh Saxena et al. 3 employed supervised learning to train a Markov random field to infer the 3 D location and orientation of a single image. Hongwei Qin et al. 6 used parameter transfer from the depth maps and corresponding image database to estimate the depth of a still image with a lightweight model. Fayao Liu et al. 5 proposed a deep convolutional neural fields (DCNF) method to estimate the depth of each pixel in a single image by exploring a convolutional neural network (CNN) and continuous conditional random fields (CRF) to infer a maximum a posteriori. Evan Shelhamer et al. 4 also employed a full convolutional network to estimate the depth of a single image. Our work will use the existing method to calculate the depth of a single image.
Mesh reconstruction
Currently, 3 D mesh reconstructions based on multi-images and RGB-D images are the popular model reconstruction methods. Jakob Engel et al.
16
and Ra
Flag animation
There are many novel algorithms for fluttering a virtual flag, which is one type of cloth. For example, Robert Bridson et al. 23 described the collision, contact and friction methods for cloth animation. Rahul Narain et al. 24 proposed a cloth simulation method based on dynamically refining and coarsening meshes. Ning Jin et al. 25 introduced an inequality cloth paradigm to realize the bending and folding of virtual cloth with high expansion. Those methods consider the cloth animation in virtual 3 D space, in which the cloth or flag has a definitive 3 D mesh structure. Chen et al. 26 proposed a mesh super-resolution to enrich low reolsution cloth meshes with wrinkes based on deep learning, which uses the SRResNet to train an image synthesizer. However, our work focus on driving the virtual flag to flutter with a reconstructed approximate mesh from a single image. Additionally, we employ a simple spring model 7 to generate the video of a flag fluttering.
Proposed method
The contribution of this paper is that a fluttering flag video is generated from a single image, while the 3 D mesh is reconstructed at the same time. Figure 1 presents an overview of the proposed method. The entire process can be summarized in three steps: generate the depth map of a single image, reconstruct the 3 D mesh of the flag from the image, and drive the virtual flag to flutter in the image.

The overview of the propose method.
In the first step, we employ DCNF (F. 5) to generate the depth map of a single image. Inspired by Liu et al 5 the DCNF is trained in NYU v2 dataset. 27 The NYU v2 dataset consists of 1449 RGBD images of indoor scenes. The standard training images with the NYU v2 dataset are 795. And 654 images are used for testing.
For example, given a single image
Reconstruct the 3 D mesh of a flag from a single image
Delete
Extract the boundary
return
The shape of the flag in image
The mesh reconstruction method based on Alpha Shape and sampling points is described as Algorithm 1, which consists of three steps. A Delaunay mesh
procedure 3 D mesh:
The mesh
Subsequently, we transform the 2 D mesh
Drive the virtual flag to flutter from single image
To simulate the fluttering of the flag mesh, the reconstructed 3D mesh

The example of mesh which is transformed into linear spring model.
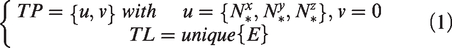
In phase space
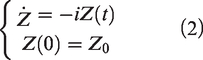
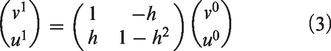
Considering the existence of internal and external constraints when driving the flag to flutter, we use a vector


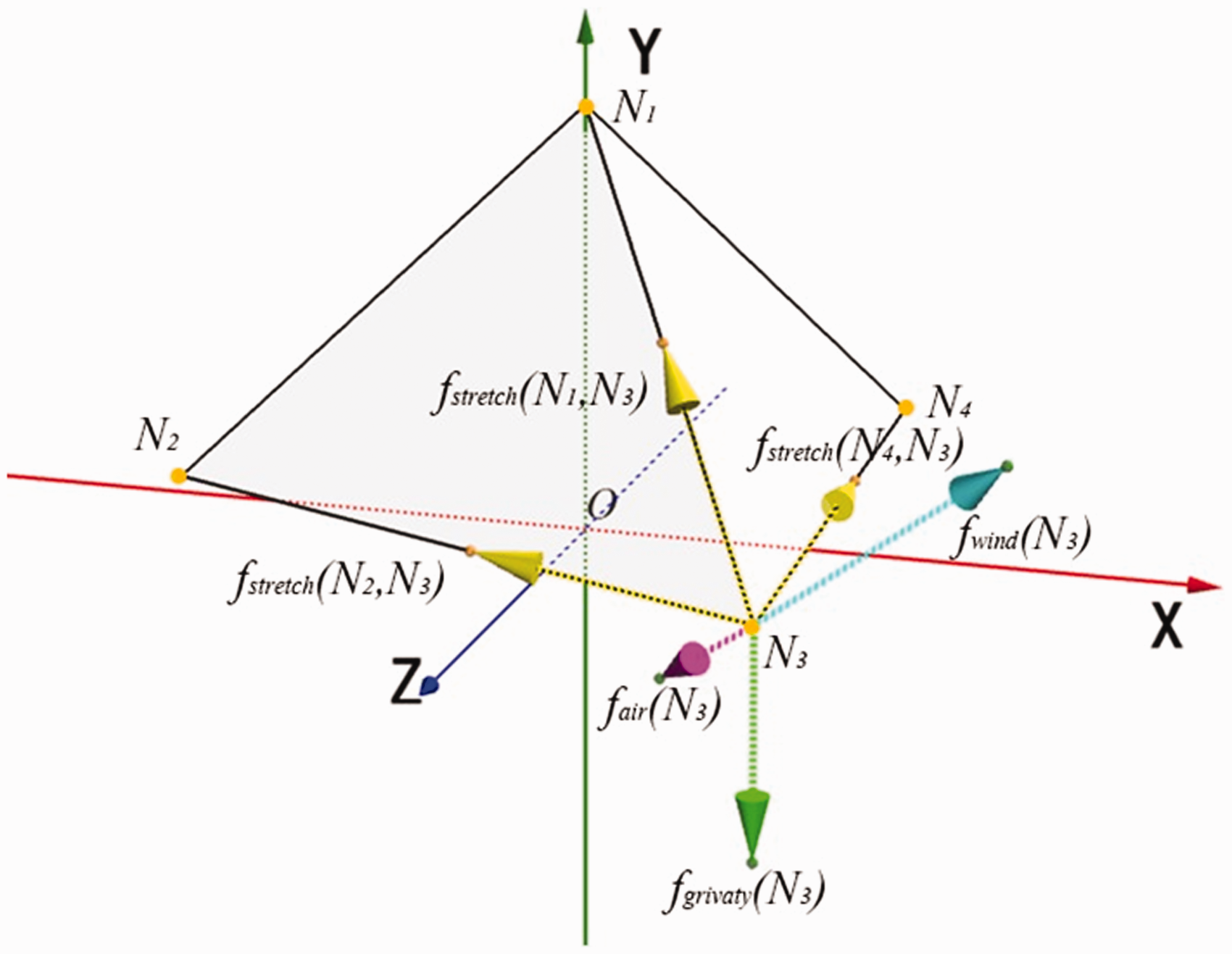
The force analysis of a vertex in reconstructed mesh.
The proposed method employs a unified dynamics solver, which was described in the article,
31
to solve the object equation (5). The unified dynamics solver uses the importance to specify the solution times of each constraint. Additionally, the order is employed to determine the solution sequence in each iteration process. Specifically, the unified dynamics solver solves the constraints vector
Based on the new position
Experiments and analysis
In this section, we describe the experiments conducted on single images that are accessed from the Internet. We analyze the advantages of the proposed method. We also present the video frames of a virtual fluttering flag created from two single images.
In this paper, we evaluate our method with some traditional mesh reconstruction methods, such as Restricted Frontal-Delaunay.
29
The baseline of our experiments is the mesh based on depth map directly. We firstly evaluate the number of vertex and face of the reconstructed mesh and optimized mesh. We also evaluate the influence of input parameter
However, there are some disadvantages when we employ the depth map of an image to generate the 3 D structure directly. The first disadvantage is that it is very difficult to generate an accurate depth map from a single image. Each pixel of the flag is regarded as a vertex in the reconstructed mesh. Thus, the virtual mesh, which is generated from the depth map, is very dense. The dense mesh will greatly increase the time cost of the solver, the instantaneous displacement and the velocity of each point in the virtual flag mesh.
Based directly on depth map

Mesh reconstruction example based on original depth map.
The vertex and face numbers of reconstructed.

From the statistical results, we can infer that our method can minimize the number of vertices on the premise of guaranteeing a grid structure because we only sample pixels at the specified areas of the flag in the image. The results also explain why we do not employ the depth of each pixel to reconstruct mesh directly. The initial input parameters of the proposed method are summarized in Table 2. We will focus on the following two parameters: the radius
The initial parameters.

Mesh reconstruction
We first sample the key points in the single image, as demonstrated in Figure 1(c). Then, Figure 5 shows the mesh reconstruction results based on the proposed method. Figure 5(a) presents the results based on Alpha Shape and sampling points, which is a 2 D constructed mesh; Figure 5(b)shows the optimization results based on Restricted Frontal-Delaunay method, and Figure 5(c) is the final linear subdivision mesh of the flag from the single image. There are clear deformations on the edge of the reconstruction results (Figure 5(b) and (c)), which are caused by the depth map. There are some significant changes in the boundary of reconstruction meshes (Figure 5(b) and (c)) over the input image (Figure 1(a)) because the distance between any two vertices in a reconstructed triangle has changed based on the different depth of each vertex. Thus, how to reconstruct a mesh without deformation is our future research work. We also use a popular tool ‘Maya’ 34 to simulate the mesh of flag in Figure 1(a), which are shown as (Figure 5(d) to (f)). The reconstruction meshes in Figure 5(d) to (f) are shown perfect boundary shapes of the virtual flag. And in especial the Figure 5(d) and (e) do not guarantee that the triangles are as average as possible. However, the shape of each triangle has high in similarity the reconstruction meshes based on the proposed method. In other words, the virtual forces can act on each vertex in Figure 5(a) to (c) to generate fluttering Flag videos as equally as possible.

Mesh reconstruction results based on the proposed method, where (a) is the mesh reconstruction result based on Alpha Shape and sampling points, (b) is the mesh reconstruction result based on Restricted Frontal-Delaunay method, (c) is the mesh. reconstruction result based on final linear subdivision, (d) is the mesh reconstruction result based on Maya, (e) is the mesh simplification result based on Maya, and (f) is mesh optimization result based on Maya.
We also count the number of vertices and faces of each reconstructed mesh in Figure 5, and the results are shown in Figure 6. The number of each vertex and face are very close between our method and Maya tool in Figure 6. This illustrates that the reconstructed meshes based on the proposed method have certain usability and can better restore the shape of the flag. And the number and distribution of final optimized triangles can guarantee that the proposed method can more evenly drive each part of the flag in the image.

The number of vertex and face of each reconstruction mesh in Figure 5.
The position of each vertex in the meshes has changed compared with Figure 5(a) and (b), as shown in Figure 7. Based on the Restricted Frontal-Delaunay method, the optimized flag mesh covers more regions in the image relative to the initial rough mesh.

The different vertex’s position of each mesh.
There is another input parameter
Figure 8 analyzes the quality of the reconstructed mesh based on the proposed method with a different value of
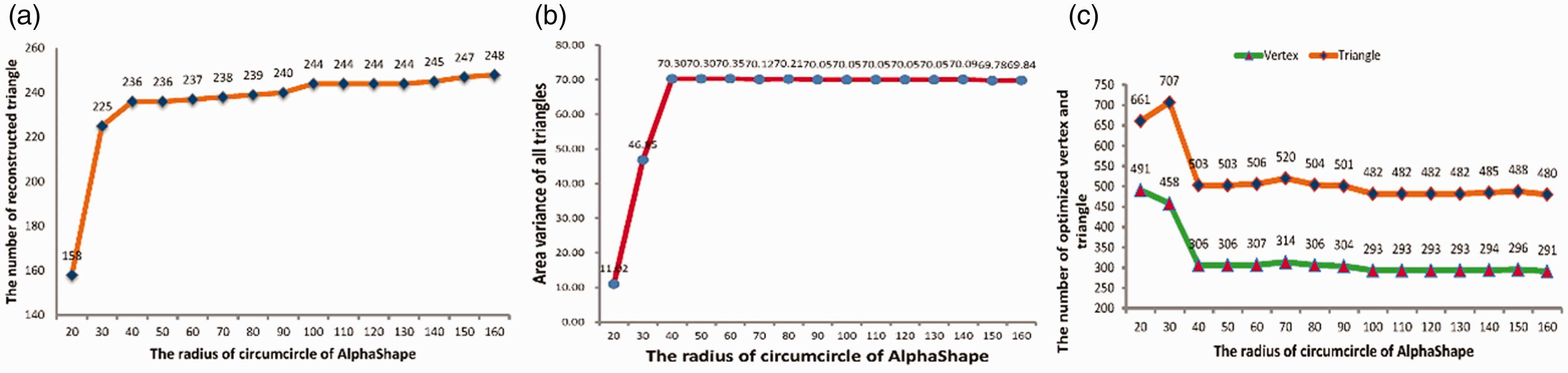
Mesh reconstruction analysis with difference R.
The final reconstructed 3 D mesh from the single image based on the proposed method is shown in Figure 9, which was rendered with texture after removing shadow and shown with different view angles. As indicated by the reconstructed 3 D mesh result, the proposed mesh reconstruction method can generate an approximate mesh from a single image. Although the reconstructed mesh does not completely reflect all the details of the flag in the image, it reconstructed the entire structure, partial shadows and folds in the same image.

The reconstruction 3 D mesh with texture in different angle views.
Fluttering flag video reconstruction
Based on the reconstructed 3 D mesh of the flag from the single image, we employ the simple spring model to drive the fluttering of flag’s mesh. We initialize the speed

The generated frames of virtual fluttering flag.
Figure 11 describes the animation results from Figure 1(a) with different wind speeds based on the proposed method. We extract three frames (

The fluttering frames of flag with different speeds of virtual wind.
To further verify the applicability of the proposed method, we generate another flag fluttering video (Figure 12) from a second single image, which is also accessed from the Internet. Thus, we can confirm that the proposed method is capable of producing a virtual flag fluttering video from a single image.

The another example of virtual flag fluttering video.
Conclusions
In this paper, a smart method for generating a flag fluttering video from a single image is proposed. The depth information of the image is calculated using the (DCNF) method, which is an inaccurate estimation value. We sample some pixels in the image to generate a rough mesh of the flag based on Alpha Shape. To generate a more uniform and reasonable mesh distribution, the Restricted Frontal-Delaunay method is employed to optimize the rough mesh. Then, the 2 D reconstructed mesh is mapped into 3 D space by the depth information of each vertex. Finally, a continuous video of the flag fluttering from the image is generated using a simple linear spring model.
Although the reconstructed 3 D mesh of the flag based on the proposed method cannot completely reflect all the details of the flag in the image, our method can generate a satisfactory flag fluttering video. The method also has the characteristics of simple processing and fast speed. In the future, we will improve the quality of the reconstructed mesh based on deep learning, and a more complex spring model will be used to process the interrelation between each vertex of the flag.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by National Natural Science Foundation of China under Grants 61562025 and 61962019, and supported by Hubei technical innovation special project (key project) of China under Grant 2018AKB035.