
Abstract
A novel dynamic cooperative random drift particle swarm optimization algorithm based on entire search history decision (CRDPSO) is reported. At each iteration, the positions and the fitness values of the evaluated solutions in the algorithm are stored by a binary space partitioning tree structure archive, which leads to a fast fitness function approximation. The mutation is adaptive and parameter-less because of the fitness function approximation enhancing the mutation strategy. The dynamic cooperation between the particles by using the context vector increases the population diversity helps to improve the search ability of the swarm and cooperatively searches for the global optimum. The performance of CRDPSO is tested on standard benchmark problems including multimodal and unimodal functions. The empirical results show that CRDPSO outperforms other well-known stochastic optimization methods.
Keywords
Introduction
With the development of science and technology, many real-world engineering optimization problems become increasingly complex. Better and more efficient optimization algorithms are urgently needed. In recent years population-based optimization techniques motivated by evolution as seen in nature such as Genetic Algorithm (GA), Evolutionary Programming (EP), Evolution Strategies (ES) and Particle Swarm Optimization (PSO) have been successfully applied to solve various fields of science and technology. Particle Swarm Optimization (PSO) is a metaheuristic optimization algorithm introduced by Kennedy and Eberhart1 to solve optimization problems inspired by the collaborative manner of social animals searching for food, such as birds flocking and fish schooling. In PSO, each volume-less individual in the swarm is called a particle, and exchange of information between particles instead of the crossover and mutation operations used in other evolutionary algorithms. PSO has been widely used to solving a number of applications owing to its simplicity and efficiency.
However, the PSO has been demonstrated that it is not a global optimization algorithm.2 Over the past decades, numerous attempts have been proposed to improve the performance of the standard PSO on both exploitative and exploratory capability. To improve the global search ability of PSO, a variant of the PSO algorithm named random drift particle swarm optimization (RDPSO) was proposed by Sun3 which is inspired by the free electron model of metal conductors in an external electric field.4 RDPSO has been successfully used to obtain effective parameter estimation for complex biochemical dynamic systems and obtained better quality solutions than most global optimization methods for solving inverse problems. RDPSO algorithm can also be used as a general tool for optimization problems that widely exist in the real world. In literature,5 RDPSO is used to obtain the expected optimal cost of the thermal power and ESS operation under different scenarios, showing its better performance than the PSO algorithm in terms of running time, the costs of each scenario and the target expected cost. Like the PSO algorithm, RDPSO also faces premature convergence and falls into local search optimization problems, which lead to huge performance loss and suboptimal solutions. An improved version of the random drift particle swarm optimization (RDPSO) algorithm was proposed for solving the economic dispatch problem.6 The algorithm integrates a self-adaption mechanism and a crossover operation as well as a greedy selection process, with the mean best position of the particles replaced by the personal best position of each particle in the velocity updating equation.
In this work, we integrate RDPSO and the search history with dynamic cooperation shown to be efficient increase the diversity of particles and further improve RDPSO’s performance on complex optimization problems. Evolutionary search history has been used in the form of memory acted as adaptive guide search strategies7–11 However, only partial search history was used in these researches. That means a portion of the information obtained from the search history is retained, and the rest is discarded. The search history includes the operations performed, the location and the fitness values of the evaluated solutions, which are extremely useful information for improving the performance of the Swarm Intelligent Algorithms (SI). Especially, it can maintain the diversity of the swarm, guide the search direction or suggest promising prospective search areas. Most importantly, when the same optimal value reappears again in the search history, it can warn that the search may fall into local optimum. Non-revisiting strategy is integrated with intelligent algorithms12–18 to avoid the re-evaluation of the evaluated solution candidates by using binary space partitioning (BSP). The non-revisiting genetic algorithm (NrGA) is proposed to prevent solution re-evaluation14,15 in the genetic algorithm by using search history and cNrGA16 is another version designed for continuous variables. In cNrGA, a parameter-less mutation operation was introduced to increase the population diversity. Therefore, cNrGA is more robust than GA and has superior performance. However, due to the limitation of sub-regions, the adaptive mutation of cNrGA cannot make the gene fully explore. The HdEA in literature17 improved the disadvantages of the sub-regions portioned by BSP so as to enhance the mutation strategy. Although HdEA is based on the entire previous search history, the global search ability is still not strong enough due to the lack of cooperative operation. Moreover, whatever cNrGA or HdEA has complex computation and slow convergence speed because of the evolutionary operations of the GA algorithm. In literature,18 the ESH-QPSO is proposed to improve the performance of QPSO by overlapped sub-region and One-Particle-Flip mutation. However, fitness values are still not utilized, and the mutation operation is lack of guidance due to randomness. Thus, an improved dynamic cooperative RDPSO algorithm is proposed, which is adaptively mutated with overlapped sub-regions based on evolutionary search history. Since all updated positions are guaranteed to be novel, faster convergence speed is expected.
The rest of the paper is organized as follows. Section 2 introduces the original PSO and RDPSO. Section 3 describes the proposed CRDPSO in detail. Section 4 elaborated the experimental environment. Section 5 presents the simulation results and analysis. Finally, conclusions are given in Section 6.
Random drift particle swarm optimization
Particle swarm optimization
The proposal of the particle swarm optimization algorithm was put forward to solve optimization problems by developing computational simulations of the movement of social animals such as flocks of birds and schools of fish. Supposed in the PSO with a swarm size m, each particle is treated as a volume-less individual in the N-dimensional search space. The position vector and velocity vector of the

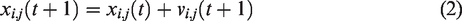


The parameters
The random drift particle swarm optimization
Trajectory analysis20 illustrated the fact the PSO algorithm's convergence may be attained supposing that each particle converges to its local attractor,


In general, the acceleration coefficients c1 and c2 are set to be the same in the PSO algorithm so that
Illuminated by the above facts, the particle in the swarm of the PSO behaving like an electron that moves in a metal conductor in an external electric field. Thus, the motion of the particles is superposed by the directional movement and the thermal movement toward

The two random scaling factors
The velocity of directional motion


As for the velocity of thermal motion



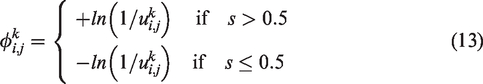
In equation (13) s and




The RDPSO algorithm is quite different from the drift particle swarm optimization algorithm (DPSO)21 because it can make a better balance between the local search and the global search of the particle population leading to better performance than DPSO. In the RDPSO algorithm, ɑ and ß are two very important user specified parameters that can be adjusted to balance the local and global search of the particles. How to choose these parameter values to prevent particle explosion is an unresolved issue. Setting a larger value for ɑ and ß means that the particle has better global search ability, and vice versa means that it has better local search ability. Thus, a good balance between the local search and the global search of the RDPSO algorithm is vital to the algorithmic performance when it is applied to solving a problem. It is recommended in literature3 that ɑ should be set to be no greater than 1.0 and ß to be no greater than 1.5. Furthermore, the performance of the population-based technique can also be affected by the maximum number of iterations (MaxIteration) and the population size. As well as other PSO variants, the swarm size of RDPSO is suggested that should be greater than 20. Configuration of the MaxIteration depends on the complexity of the problem. In general, the more complex the problem, the larger MaxIteration is required. And the velocity of a particle in RDPSO is still restricted in the interval [
Dyanmic cooperative RDPSO based on search history
Search history scheme
In the entire search history recorder scheme, the binary space (BSP) tree is used as a tree-structure archive to memorize all visited solutions and its fitness {[xi, f(xi)]}. During the iterative process, the search space is partitioned into a set of regions
The nodes in the BSP tree linearly divide adjacent sub-regions into a certain overlap with each other, that is, overlapped sub-regions. The method creates a channel in which particles could migrate from one sub-region to another with better fitness, as shown in Figure 1. The search for the overlapped sub-region d of a solution x is executed as tree nodes search. The BSP tree T is initialized to consist of the root node D only representing the entire search space. The search starts with checking the root node. Every iteration the search moves downward from the root node and d is shrunk along a specified direction until the search reaches a leaf node. The procedure to find the overlapped sub-region of a solution x is summarized in algorithm A2. Assume that there are two evaluated solutions in the two-dimensional search space indicated as m = [0.25, 0.5] and n = [0.75, 0.5]. The squares shown in Figure 1(a) and (b) represent the same sub-region of the parent node P. Since m and n have maximum distance along x axis, the partitioning cuts along x axis. The overlapped sub-regions of m and n, namely pa and pb, are defined as the gray-filled regions shown in literature 1(a) and (b) respectively. It is worth noting that the union of ra and rb creates a path where particles in ra can move to rb by mutation, and vice versa. In addition, the sub-region contraction scheme of algorithm A2 ensures that the resultant sub-region overlaps with all its adjacent sub-regions. Consequently, the opinion of overlapping sub-regions integrated with mutation allows the particles to gradually approach their optimal solution nearby. Figure 2 gives an example of the BSP tree memorized four evaluated solutions: x1, x2, x3 and x4 in two dimensional. The distribution of the evaluated solutions in search space S = [0,1]2 is shown in Figure 2(a). Figure 2(b) shows the corresponding BSP tree. The archive tree consists of seven nodes. The solutions x1 and x2 are stored in node C and D respectively whilst the solutions x3 and x4 are stored in node E and F respectively.

The example of overlapping sub-regions.

The BSP Tree of solutions.

Considering that the fitness values of the evaluated solutions are also stored in the memory archive by the BSP tree; this archive can also be regarded as the approximation
An adaptive parameter-less mutation mechanism
Each sub-region can be viewed as optimal in a certain amount neighborhood named neighborhood size that refers to the number of neighbor points (evaluated solutions) focused. The neighborhood size of a node decreases with its node depth due to the topology of the BSP tree. Thus, the neighborhood size is constituted by the tree node depth difference. If the sub-region M of node m is the neighborhood of the sub-region N of node n, the neighborhood size(denoted by L) of M related to N is defined as the depth difference of m and n. M is assigned as an optimal sub-region in case the fitness value of node n is the minimum within all evaluated solutions in N. Since L is selected to be the depth of the BSP tree, it is presumed that the approximated fitness functions consist of only one optimum. All particles are imposed to move toward the best-found optimal value. If L equals to zero, each sub-region is considered as a local optimum. Then the particles are randomly mutated within its own sub-region. To make the approximated fitness function locally guide the search with adaptive mutation, L is set to be 2 in this study because L should be slightly larger than zero but much smaller than the depth of the BSP tree.
Once the optimal sub-region of the approximate fitness function is found, the direction of the sub-region M pointing to its nearest optimal sub-region is taken as its mutation direction. Suppose H is the optimal sub-region set in search space D and the sub-regions of nodes m and n are M and N respectively. If the distance from M to N is the minimum amongst the distance from M to all optimal sub-regions, i.e.
The mutation direction of the nodes in sub-region point to its nearest optimal neighborhood sub-region. In the adaptive parameter-less mutation mechanism, a particle m moves along the direction of the local maximum increasement of approximation fitness

Dynamic cooperative evolution

Dynamic cooperative RDPSO algorithm based on search history decision

Simulation setup
Test function
A set of multimodal or unimodal benchmark functions F = {f1(x), f2(x),…, f10(x)}2425 is adopted to test for the proposed algorithm and verify its performance. The ten test functions are shown in Table 1. All the empirical studies in this paper were carried out in the MATLAB.
Test functions.

Algorithms setting
Besides RDPSO and CRDPSO, Differential Evolution (DE),26 Covariance Matrix Adaptation Evolutionary Strategies(CMA-ES),27 cNrGA and two versions of QPSO, i.e. CCQPSO23 and CLQPSO,28 were also tested on the test functions for performance comparison. The parameters of the CRDPSO and RDPSO in our experiments are set the same as those recommended in literature.3 To CLQPSO the β decreases linearly from 1 down to 0.5 and other factors are set as literature.28 To cNrGA, the cross rate is uniform crossover and sets as rx = 0.5. For all compared algorithms the population size is set to 100 and the maximum number of iterations is set to 2000. The dimension of all the test functions is set as D = 30. Each algorithm independently runs 30 times in experiments, and the mean value of optimal solutions and standard deviations are achieved after 30 independent trials.
Simulation results
For all the test functions, the statistical values from 30 search runs of 2000 iterations by each algorithm are listed in Table 2 where “Best”, “Worst” and “Ave.” stand for the best, the worst and the mean values of optimal solutions obtain in 30 independent runs, respectively. “Std.” represents the standard deviations of the achieved optimal solutions. The value of the boldface means that the corresponding algorithm gets the optimal value amongst the test algorithm for a particular benchmark function. It can clearly be seen from Table 2, the proposed CRDPSO is the most superior to other six algorithms for all the test functions. Although RDPSO and CCQPSO have both shown outstanding performance on f1, f2 and f6, CRDPSO has outperformed them on all the rest functions. It shows the standard deviation of CRDPSO is the best for almost the test functions except f9. This demonstrates that CRDPSO has the best stability for the most test functions. Moreover, the detailed simulation results (Best, Worst, Ave. and Std.) show that the best performance of CRDPSO ranks first in total of ten cases. The analysis of RDPSO29 shows that the RDPSO algorithm is more stable and better for most test environments. The algorithm can maintain the diversity of the swarm and improve the global search ability of particles by using the average position waiting mechanism. Therefore, the diversity in the algorithm declines in a smooth way in the later stage of the search process so that there is good balance between the global search and the local search of the algorithm, which results in an overall better performance than the other variants of PSO. Moreover, the simulation results of the empirical studies listed in Table 2 show that the performance of CRDPSO is better than the other compared algorithms. Using the search history mechanism, CRDPSO can ensure non-repeating access during the search process and rapid convergence to the local optimal. Meanwhile, it employs adaptive mutation to guide particles to search better neighborhoods and further improve the local search ability. In general, CRDPSO obtained the highest average accuracy and it also is the most stable.
The optimize results of the test function.

Convergence curves versus iteration for the different algorithms are shown in Figure 3. The results in Table 2 show that for f1, f2 and f6, all of RDPSO, CRDPSO, and CCQPSO finally achieve the optimal values. However, as can be seen from the convergence curves of Figure 3 (1)(2)(6) respectively, the convergence speed of CRDPSO is much better than the other two algorithms. It has converged to the global optimal value within less than 200 iterations of the search. For f3- f5 and f7- f10, the convergence speed and convergence accuracy of CRDPSO are far beyond the other six algorithms. The global optimal values of each benchmark were found within a short number of iterations. CRDPSO algorithm can search the optimal value much faster because the particles can adaptive mutate once their own nearest optimal neighborhood sub-region is found by using the entire evolutionary history information. Moreover, the coordination mechanisms can be used to keep the optimal information, so the algorithm can quickly converge to the optimal value. In Figure 3, it is shown that for f1 to f5 and f8 the CRDPSO was able to reached 0 that the Matalab can recognize and the logarithmic scale of 0 is minus infinity, so that the fitness value cannot be shown anymore in the figure. This also indicates that the simulation results for the objective function values obtained by CRDPSO for these test functions are infinitely close to the theoretical values, i.e. 0. For f7 in Figure 3(7), even though the algorithm converged, but it was able to further find a new better solution in the later stage (i.e. after 1500 iterations), implying that CRDPSO algorithm still has a better search ability in the final stage of the search process and has a large chance to escape local optimum to get a better solution. In conclusion, CRDPSO algorithm compared with other algorithms has the best convergence performance and optimization accuracy with a strong search ability.

Convergence curve of the algorithms.
In order to determine whether there was a significant difference of the performance between CRDPSO algorithm with other six algorithms in addition to the precision and convergence. Table 3 lists Wilcoxon rank sum test results for a significance level of 0.05 between different algorithms. Seen from Table 3 for f1, f2 and f6, CRDPSO, RDPSO and CCQPSO have no significant difference. Nevertheless, for the vast majority of the test functions, CRDPSO algorithm can get h = 1, shows that compared with other algorithms, the optimized performance of CRDPSO has improved significantly. It is observed that the optimal performance of CRDPSO algorithm improved prominently with better convergence and higher precision whether in the unimodal functions and multi-peak functions.
The Wilcoxon rank sum test.

Conclusion
Premature convergence and diversity are the most need to solve two problems with the RDPSO algorithm. Therefore, an improved dynamic cooperative RDPSO algorithm based on search history assisted (CRDPSO) is proposed that integrates the search history scheme and a standard random drift particle swarm optimization (RDPSO). The proposed algorithm utilizes a binary space partitioning tree (BSP) structure to store the positions and the fitness values of the evaluated solutions. The dynamic cooperation mechanism between the solutions in the swarm is introduced for better use of context information of each dimension to take advantage of any new information, which improves the capability of the variation of the particles and enhances search ability helping to prevent premature convergence. Benefiting from the spatial partitioning scheme, a fast fitness function for improving the mutation strategy in CRDPSO is obtained using the archive structure. The resultant mutation is a kind of adaptive and parameter-less. The overlap between adjacent sub-regions also provides a channel for the movement of particles in adjacent areas, making it easier for particles to move from the area to a better area. In comparison to other well-known algorithms, the experimental results on ten standard testing functions indicate that the proposed algorithm has the best global optimization ability, with enhancement in both convergence speed and precision that demonstrate the effectiveness and efficiency of the CRDPSO. The improved algorithm can be proved in theory to be superiority; however, it also needs to be further tested in practical problems. Hence the CRDPSO algorithm applied to practical engineering problems becoming the focus research in the future. The next research job is to verify the CRDPSO performance of the engineering applications such as image segmentation, data clustering and parameter identification of biological pathways.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The authors gratefully acknowledge financial support from the Qing Lan Project of Young and Middle-aged Academic Leaders in Colleges and Universities of Jiangsu Province [grant number 2019,2020]; the Qing Lan Project of Young and Middle-aged Academic Leaders of WuXi City College of Vocational Technology[grant number 2018]; and the Natural Science Foundation of the Jiangsu Higher Education Institutions of China[grant number 18KJB520046,17KJB520039].