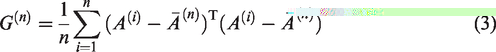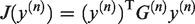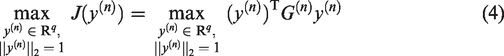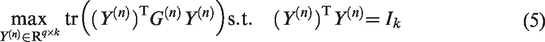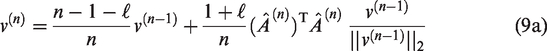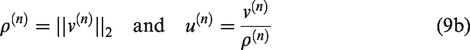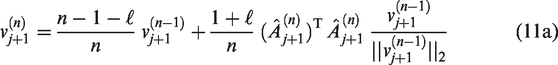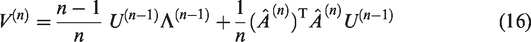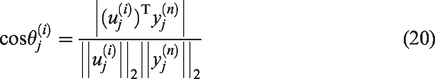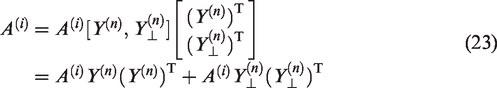Principal component analysis (PCA) has been a powerful tool for high-dimensional data analysis. It is usually redesigned to the incremental PCA algorithm for processing streaming data. In this paper, we propose a subspace type incremental two-dimensional PCA algorithm (SI2DPCA) derived from an incremental updating of the eigenspace to compute several principal eigenvectors at the same time for the online feature extraction. The algorithm overcomes the problem that the approximate eigenvectors extracted from the traditional incremental two-dimensional PCA algorithm (I2DPCA) are not mutually orthogonal, and it presents more efficiently. In numerical experiments, we compare the proposed SI2DPCA with the traditional I2DPCA in terms of the accuracy of computed approximations, orthogonality errors, and execution time based on widely used datasets, such as FERET, Yale, ORL, and so on, to confirm the superiority of SI2DPCA.
The feature extraction is one of the most popular fields in computer vision and pattern recognition over the past three decades.1–3 As an increase in the image information, a large amount of high-dimensional observation data are followed.4 If we directly deal with high-dimensional data, we will face the problem of “dimensionality disaster”.5 Thus, lots of dimensionality reduction algorithms have been proposed, such as Principal Component Analysis (PCA),6,7 Linear Discriminant Analysis (LDA),7 Neural Networks (NN),8 Canonical Correlation Analysis (CCA)9 and so on. PCA is one of the most well-known feature extraction and dimension reduction methods for high-dimensional data analysis.10,11 In the online learning system, it is usually developed into the incremental PCA algorithm to alleviate the increasing numerical difficulties in computational costs, memory demands, and numerical stability.
Denote the data set in the form of the data matrix , where d is the dimension of the data set and n is the number of data points in the data set. Without loss of generality, we assume X is centered, i.e., , where is the vector of all ones, otherwise, we can preprocess X as . To reduce the dimension of X from d to k where , PCA aims to find the first k principal eigenvectors corresponding to the first k largest eigenvalues of the covariance matrix ,12 and then projects the high-dimensional data onto the k-dimensional subspace spanned by these principal eigenvectors to achieve the purpose of dimensionality reduction.
In PCA-based feature extraction techniques, two-dimensional image training sample matrices must be previously converted into one-dimensional image vectors. This transformation leads to higher dimensional image sample vectors and a larger covariance matrix. In such a case, it is more difficult to accurately evaluate the principal eigenvectors of the larger covariance matrix. Furthermore, some structural information may be lost when sample images are transformed by the matrix-to-vector process.13,14 Hence, Yang et al.15 propose a two-dimensional PCA algorithm (2DPCA), which is based on two-dimensional matrices rather than one-dimensional vectors, to reduce time-consuming and maintain structural information.
PCA and 2DPCA algorithms mentioned above are usually performed in the batch environment. These methods are called batch methods and require that all training image sample data must be available before the principal components can be estimated. Nevertheless, batch methods are no longer satisfactory for the online learning system, which needs to update principal components for each arriving observation datum. Therefore, Oja16 proposed an incremental PCA (IPCA) iteration
to approximate the most significant principal component for observations arriving sequentially without explicitly calculating and saving the covariance matrix, where is the j-th column of X and is a stepsize, and after that the development of IPCA algorithms been active research subjects in the fields of data mining, data compression, feature extraction, and process monitoring for over three decades.17,18 For example, the incremental principal component analysis methods based on updating the eigenvalue decomposition and singular value decomposition are presented in Li19 and Zhao et al.,20 respectively. Weng et al.21 developed a candid covariance-free incremental principal component analysis (CCIPCA) algorithm for the faster convergence rate. Agraeal and Karmeshu22 proposed a new incremental online feature extraction approach which is based on the principal component analysis in conjunction with perturbation theories. Similar to IPCA algorithms, an incremental 2DPCA algorithm (I2DPCA), developed in Ge et al.,23 can directly estimate eigenvectors based on the original image sample matrix without computing the covariance matrix to overcome the loss of structural information. Some other works for the incremental PCA and 2DPCA algorithms can be found in literature.24–26 However, these algorithms can be regarded as single-vector type algorithms for the eigenvalue computation problem, i.e., the associated iteration, such as (1), only computes the eigenvector corresponding to the largest eigenvalue. To calculate the second-order eigenvector, the data should be corrected by projecting them onto the orthogonal complementary space of the subspace spanned by .21 It means that we must use the corrected data, i.e.
for the second-order eigenvector. In addition, it is well known that single-vector type methods can only find one copy of any multiple eigenvalues and may be very slow when the desired eigenvalues lie in a cluster.27 To compute all or some the copes of multiple eigenvalues and the associated eigenvectors, one prefers subspace type methods that are able to compute cluster eigenvalue problems much faster and more efficiently on modern computer architecture than single-vector methods.28,29 Moreover, the second-order eigenvector computed based on (2) is usually not orthogonal to the first eigenvector. Orthogonality is a powerful and popular criterion in pattern recognition since an orthogonal projective system is less sensitive to the influence of data distribution and noises.30–32 Motivated by these facts, in this paper, we will continue the efforts to extend increment algorithms by developing the subspaces type I2DPCA algorithm in order to extract the orthogonal eigenvectors with more efficiency and the higher accuracy of computed approximations.
The remainder of this paper is organized as follows. In Section 2, some basic concepts on the 2DPCA and I2DPCA algorithms are collected for our later developments. We describe the subspace type incremental two-dimensional principal component analysis algorithm in Section 3. In Section 4, numerical examples with face data sets (FERET, Yale, ORL) are presented to show the numerical behavior of the proposed algorithm and to support our analysis. Finally, concluding remarks are made in Section 5.
There are a few words for notations. Throughout this paper, is the set of all p × q real matrices and . Ik is the k × k identity matrix. The superscript “” takes transpose only, and and denote the -norm of a vector and Frobenius norm of a matrix, respectively. For and are the j-th column and (i, j)-th entry of X, respectively. For scalars xi for denotes the diagonal matrix
Incremental 2D principal component analysis
The 2DPCA algorithm proposed in Yang et al.15 is based on two-dimensional image training sample matrices, and evaluates the empirical covariance matrix without needing to transform image matrices into vectors.
Suppose that there are n training samples in total, the ith training image is denoted by a matrix where . The empirical covariance matrix of image training samples set can be constructed by
where is the mean of the image training samples. Let with . The generalized total scatter criterion is defined as
In fact, is the Rayleigh quotient of the covariance matrix on the projection vector .33 Then, the 2DPCA algorithm finds an optimal projection vector such that it maximizes
Usually, only one optimal projection vector is not enough. When a set of projection vectors are needed where k < q, then for can be obtained sequentially by maximizing subject to additional orthogonality constraints, i.e., required orthogonality against those vectors that are already computed. It is equivalent to solve the following optimization problem
where . In general, the solution of (5) can be obtained by computing the eigenvalue decomposition of . Denote by the eigenvalues of and order them as
Then, are the eigenvectors corresponding to , i.e.
where .
The traditional 2DPCA algorithm is an offline learning algorithm, and it is also referred to as the batch 2DPCA algorithm. The reason is that it needs to acquire all the training samples information in advance. As new image training samples are input, the batch 2DPCA algorithm (5) usually discards the training acquisition in the past, and then recomputes the covariance matrix and the wanted eigenpairs by using all currently available training samples. When the number of training samples is large, the storing and calculating of recomputing the eigenvalue decomposition for newly added data are both very expensive. To tackle the above limitations, analogously to CCIPCA,21 the I2DPCA algorithm is developed in Ge et al.23 as follows.
Let be a newly added image training sample. Then, the overall mean is calculated by
and the computed eigenvalue and the associated eigenvector are updated as
where and denotes the amnesic parameter with its range from 2 to 4. In (9 b), and are the estimations of the largest eigenvalue and the corresponding eigenvector , respectively. To compute the other eigenvectors for , the centered sample matrices must be subtracted from its projection on the estimated jth order eigenvector as (2), i.e.
where and . Then, as (9), we use
to obtain approximating to . Here, though by (10), it is clear that
is usually not equal to zero. It leads that the computed eigenvectors are not orthogonal each other, which will be detailed in our numerical examples. One can orthogonalize the approximate eigenvectors by the Gram-Schmidt orthogonalization33 as a post-processing step of (11), but it needs to add extra computational cost and the calculated result in such way is generally not the optimal approximation of (5).30
The subspace type I2DPCA algorithm
To solve the problem mentioned at the end of previous section, in this section, we present a subspace type algorithm for I2DPCA when more than one eigenvectors are required. Our motivation is from early work on the incremental principal component analysis given by Oja and Karhunen,34 where they introduced a subspace type extension of the stochastic gradient ascent algorithm (SGA) algorithm. We denote it by the SSGA algorithm which is given by
where is a normalization matrix to make have orthonormal columns. The nearly optimal convergence rate for the iteration (13) is proved in the recent paper.35 It is natural to generalize the SSGA algorithm for 2 D sample image matrices as
where , and such a is chosen as in literature.34,35
In the above process, notice that in the right-hand side of the iteration (14a) is normalized, i.e., , but the second term can take any magnitude which depends on the magnitude of the 2 D sample image matrix . In case is a very small magnitude, the second term will be too small to make any updating in the new estimation of . If has a large magnitude, the second term will dominate the right-hand side of (14a). Hence, similar to Weng et al.,21 to balance the role of the first and second terms, we derive our subspace type I2DPCA algorithm from the eigenvalue decomposition of . Using the notations of the previous section, let and write . Suppose that is equal to , i.e., . Then, according to the definition of eigenvalue decomposition, we have
As the process of iterations, it naturally hopes that the approximation is gradually close to , i.e., having a tiny magnitude. Therefore, by simply regarding as 0, we apply the iteration
to approximate .
Next, to establish the relationship between and , let the eigenvalue decomposition of be
where is a q × q orthonormal matrix. By (16), it follows that
where ). That means the approximation of can be obtained by orthogonalizing the columns of . Though several ways can be used to realize the purpose, such as , we prefer the QR factorization of . The reason is that compared to , the QR decomposition needs less computation cost and performs better numerical stability. Let the QR decomposition of be where and are the Q-factor and R-factor of , respectively. Then, will be an approximation of .
In addition, it is noted that is unknown in (16). As the definition of in (18), the matrix can be considered as the perturbation of with a multiplication structure,36 and its diagonal elements are very close to the diagonal entries of when has a tiny magnitude. Based on the QR decomposition , it is natural to use the diagonal elements of as estimations of the eigenvalues. Therefore, our incremental iteration can be written as
where and . Compared to the SSGA algorithm (14), and are the weights for the last estimate and the new data here, respectively, and is without normalization though it has orthogonal columns.
We summarize what we have done in this section in Algorithm 1, i.e., the subspace type incremental 2 D principal component analysis algorithm. We denote it by SI2DPCA for convenience. Finally, a few remarks regarding Algorithm 1 are in order:
The initial matrices and in Algorithm 1 are from the initial learning system which contains n0 samples. Let its empirical covariance matrix be . Then, is the mean of these n0 sample matrices, and we set and satisfying and where with being the first k largest eigenvalues of .
As (9a), to speed up the convergence of the estimation, the amnesic parameter is also applied at step 5 of Algorithm 1 to give a larger weight for new samples. Typically, is from 2 to 4. In our numerical example, we just simply take .
At step 6, to compute the QR decomposition of with economy-size, we use the MATLAB built-in function qr(,0) to obtain the matrices and where with and is a k × k upper triangular matrix.
Compared to the single-vector I2DPCA algorithm (11), Algorithm 1 does not need to correct the sample matrices when several eigenvectors are required, and the approximate eigenvectors extracted from the QR decomposition to make sure the orthogonality, i.e., always holds in Algorithm 1. Additionally, Algorithm 1 due to its ability in updating all approximate eigenvectors of interest at the same time is looked forward to lower time cost.
Algorithm 1. The subspace type I2DPCA algorithm (SI2DPCA).
Input: Initialization and n0, and newly added 2 D sample image matrices .
Output: The matrix composed of the first k orthogonal eigenvectors.
1: for, the following steps do
2: ,
3: ,
4: ,
5: ,
6: compute the QR factorization of to get and ,
7: let and .
8: end for
Numerical example
To demonstrate the effectiveness and efficiency of our proposed SI2DPCA algorithm, we compare it with the I2DPCA23 and SSGA (14) algorithms on some publicly available datasets. Our goal is to compute the first 8 principal component vectors, i.e., for . We select the parameters in SSGA (14) as Weng et al.21 In demonstrating the quality and orthogonality of computed approximations, we calculate the cosine of acute angles between and
and the orthogonality errors and defined by
where are computed by the batch 2DPCA algorithm with MATLAB’s function eig on , which are considered to be the “exact” eigenvalues for test purposes, and in Algorithm 1. The orthogonality errors and monitor the orthogonality between and , and the columns of , respectively. It is noted that
All the experiments in this paper are executed on a Windows 10 (64 bit) Laptop-Intel(R) Core(TM) i5-4210U CPU 1.70 GHz, 4 GB of RAM using MATLAB 2018a with machine epsilon in double-precision floating-point arithmetic. Each random experiment is repeated 10 times independently, then the average numerical results are reported.
Example 1 (Experiments on the FERET dataset). The FERET dataset (http://www.nist.gov/itl/iad/ig/colorferet.cfm) is a large face image dataset for face recognition. There are 1400 images of 200 individuals (71 females and 129 males), including frontal views of faces with different facial expressions, lighting conditions, and photographing angle. We manually crop the face portion of the image and then normalized it with the same resolution of 80 × 80 pixels. The normalized images of one individual are shown in Figure 1.
Seven images of one person from the FERET dataset.
In this example, one sample is selected randomly from the entire database as the initial learning system, and remaining samples are applied for testing incremental algorithms. We compare the accuracy of computed approximations and orthogonality errors defined in (20) and (21), respectively, the CPU time in seconds, and the image reconstruction for the SSGA, I2DPCA, and SI2DPCA algorithms in the FERET dataset. Figure 2 presents the convergence behavior of SSGA, I2DPCA and SI2DPCA for computing the first 8 eigenvectors. To the best of our knowledge, if trends to 1, it means incremental methods have good agreement with batch methods, but the corresponding cosine values of the SSGA algorithm fluctuate dramatically, and the largest one is not higher than 75%. A similar phenomenon also appears in the single-vector version of SGA.21 In addition, in Figure 2, it is not difficult to find that I2DPCA and SI2DPCA have better accuracy than SSGA. With the increasing number of samples, of the first 8 approximate eigenvectors of the I2DPCA and SI2DPCA algorithms gradually are close to or reach 1. However, the quality of the computed approximations of SI2DPCA still outperforms than I2DPCA.
Convergence behavior of SSGA, I2DPCA and SI2DPCA with the first four eigenvectors and the later four ones, respectively.
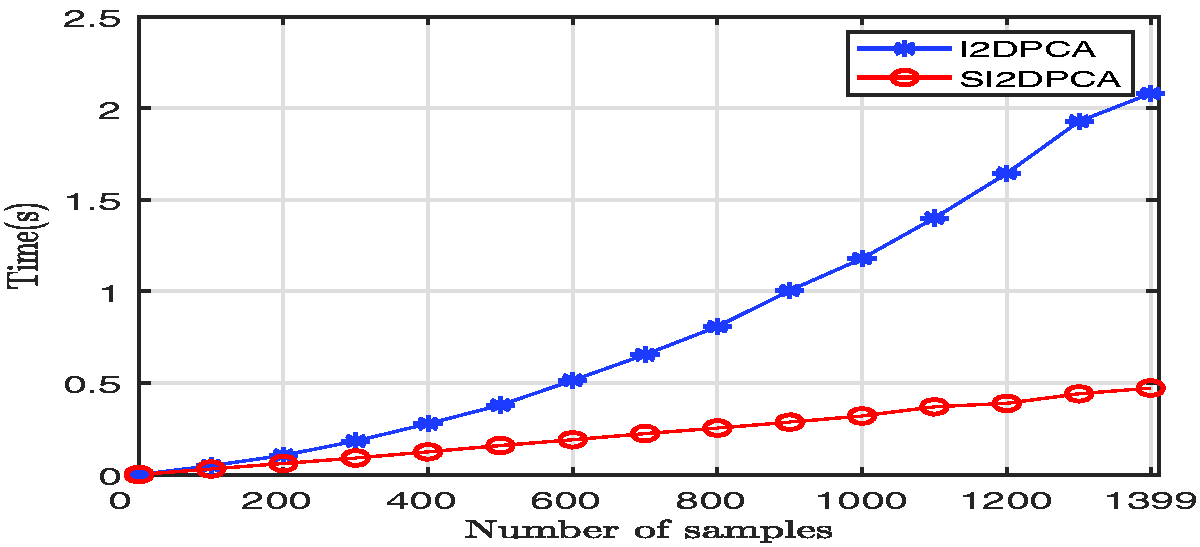
Notice that SSGA and SI2DPCA are both subspace type algorithms. It leads to that the SSGA algorithm performs almost the same numerical results in orthogonality errors and CPU time as SI2DPCA, which are not collected in our numerical examples. Therefore, in what follows, we only discuss the orthogonality errors and CPU time for SI2DPCA and I2DPCA algorithms, which are reported in Figures 3 and 4, respectively. It is demonstrated by Figure 3 that the orthogonality errors and of SI2DPCA are held around , which is near to the double-precision of floating-point arithmetic, while those of I2DPCA are close to except the first one coming from the initial system. That means the loss of orthogonality constraints on the extracted eigenvectors in the equation (5) has happened in the first iteration of I2DPCA for calculating the second-order eigenvector, but the SI2DPCA algorithm always keeps the orthogonality very well, which indicates that extracted principal component vectors are mutually uncorrelated. Computational time with respect to the number of samples is presented in Figure 4. It is observed that, compared to I2DPCA, the SI2DPCA algorithm reduces remarkably the computational time. Specifically, in Figure 4, when the number of samples is increased, SI2DPCA has a more obvious advantage in terms of the CPU time than I2DPCA. That means if the larger the sample size is referred, the difference in the CPU time will be more dramatic.
Orthogonality errors (left) and (right) of I2DPCA and SI2DPCA.
Comparison of the required CPU time in seconds for I2DPCA and SI2DPCA under the increasing of samples.
In this example, we also consider the reconstructed image of sample based on the computed eigenvectors. It is noted is orthonormal in the eigen-decomposition of (17). Thus
As stated in Yang et al.,15 is of the same size as the sample and represents the reconstructed image of . Usually, the exact is not available. It is natural that we use the computed approximations to replace with to get . Figure 5 shows the reconstructed images with k from 1 to 8. It is exhibited that the reconstructed images become clearer with the number of eigenvectors is increased. Notice that, when k = 8, the image reconstructed by our method has a change in the mouth, which is similar to the original image appearing in the last image of Figure 1, while that of I2DPCA is still the same as k = 7 in this example.
Reconstructed images based on I2DPCA (upper) and SI2DPCA (lower) with k varying from 1 to 8.
Example 2 (Experiments on the Yale Dataset). Face-image variations in the Yale dataset (https://computervisiononline.com/dataset/1105138686) include illumination (left-light, center-light, and right-light), facial expression (normal, happy, sad, sleepy, surprised, and a wink) and with or without glasses. In our experiment, 15 individuals with 165 images are selected. All images are grayscale and normalized with resolution 100 × 100 pixels. We show eleven images of one individual from the Yale dataset in Figure 6.
Eleven images of one person from the Yale dataset.
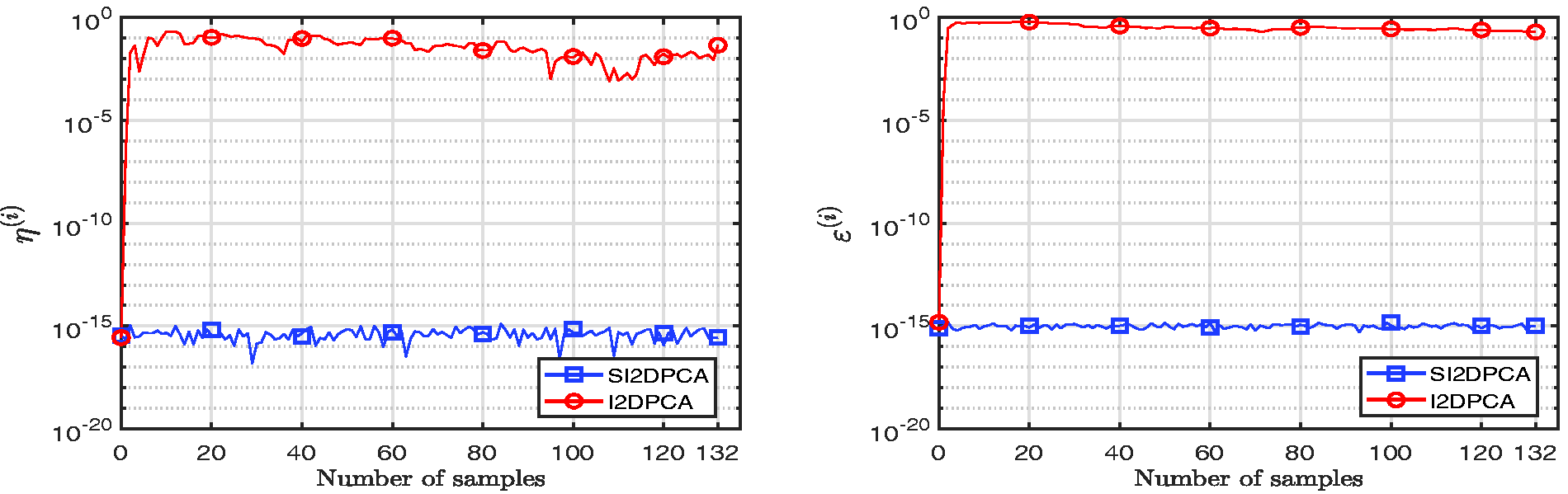
We randomly choose 20% samples for the initial system, and the rest samples are used for incremental learning, i.e., 33 and 132 image samples, respectively. The accuracy of computed approximations , and orthogonality errors and are plotted in Figures 7 and 8, respectively. They exhibit similar numerical behavior as Figures 2 and 3. In particular, in such a case, the SSGA algorithm is still not convergence by Figure 7, and all approximated eigenvectors computed by SI2DPCA are all close enough to 1, which performs superior to I2DPCA on the accuracy of computed approximations. From Figure 8, we observe that the calculated approximated eigenvectors by I2DPCA are not mutually orthogonal as well in this example, since their orthogonality errors and go from to 1, while orthogonality errors and of SI2DPCA are always between and .
Convergence behavior of SSGA, I2DPCA and SI2DPCA for computing the first 8 eigenvectors.
Orthogonality errors (left) and (right) of I2DPCA and SI2DPCA.
For the required CPU time, as shown in Figure 9(a), we consider comparing the difference between the I2DPCA and SI2DPCA algorithms with the number of wanted eigenvectors from k = 1 to k = 8. It is demonstrated that, as the number of wanted eigenvectors increased, the computational time of SI2DPCA increases significantly, but the CPU time of SI2DPCA does not change obviously, which is mainly due to subspace type methods calculating the k eigenvectors at one time when a new sample is input. Additionally, when k = 8, we repeat the I2DPCA and SI2DPCA algorithms 50, 250, 500 and 1000 times, respectively, and collect the associated average execution time in Figure 9(b) to show the efficiency of SI2DPCA.
Comparison of the required CPU time in seconds for I2DPCA and SI2DPCA with increasing the number of wanted eigenvectors (a) and the average execution time with different times of repetition (b).
Example 3 (Experiments on the ORL, AR, PIE and JAFFE Dataset). The ORL dataset (https://www.cl.cam.ac.uk/research/dtg/attarchive/facedatabase.html) contains 400 face images of 40 distinct persons. The size of ORL images is 92 × 112 pixels with 256 gray levels. The images are collected by volunteers at different times, different lighting, different facial expressions (blinking or closed eyes, smiling or no-smiling), and facial details (wearing glasses or no-glasses). Ten example images of one person from the ORL dataset are shown in Figure 10.
Ten images of one person from the ORL dataset.
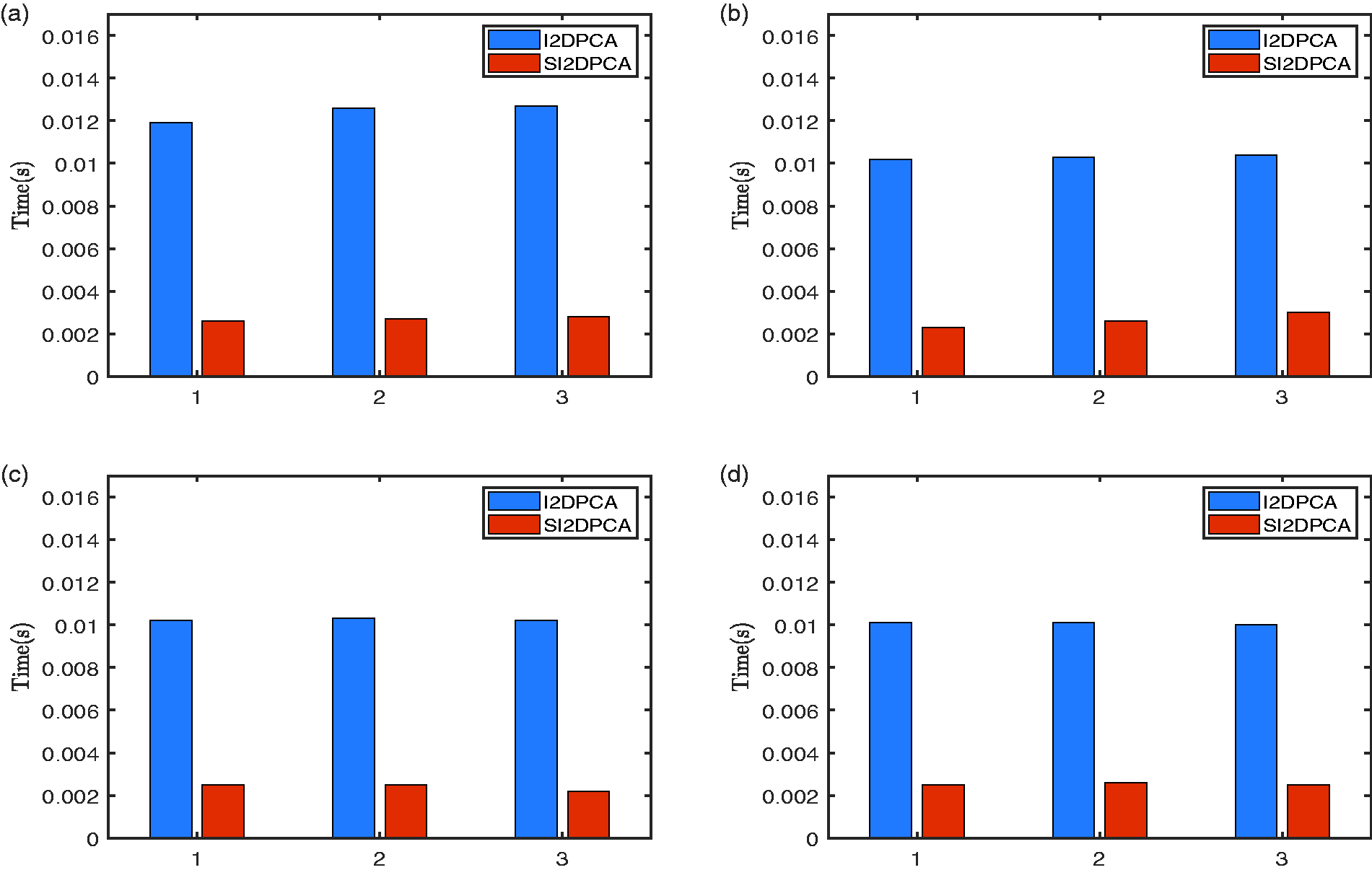
We take the five image samples selected randomly from all samples as “old” samples for exact calculations, and remaining samples are for incremental methods. Numerical results in Figures 11 and 12 clearly show that SI2DPCA outperforms significantly in the computational approximations and orthogonality in this example. As in Han et al.,37 we consider the required CPU time in seconds of newly added samples based on the initial train sample number being 285, 315, 335 and 355, respectively. The number of newly added samples is set to 15 each time, and the numerical results of new samples added 3 times are recorded in Figure 13. It is not difficult to find that the incremental learning time of I2DPCA and SI2DPCA is almost unchanged in such a case. Regardless of the size of the initial training set, the SI2DPCA algorithm always reduces remarkably the computational time.
Convergence behavior of SSGA, I2DPCA and SI2DPCA for calculating the first 8 eigenvectors.
Orthogonality errors (left) and (right) of I2DPCA and SI2DPCA.
Computational time of I2DPCA and SI2DPCA added 15 samples each time with the number of initial training sets being 285 (a), 315 (b), 335 (c) and 355 (d), respectively.
In this example, we also make a summary comparison of SSGA, I2DPCA, and SI2DPCA based on the datasets appeared in Table 1, i.e., AR (http://rvl1.ecn.purdue.edu/ aleix/aleix_face_DB.html), PIE (http://www.flintbox.com/public/project/4742/) and JAFFE,38 which also details the number of row and column of image matrices p and q, respectively, and the number of image samples n of these three datasets. The average of for where is defined in (20), together with and CPU time in seconds are collected in Table 2. Similar comments we made at Examples 1 and 2 are still valid here as well.
The detail of AR, PIE and JAFFE datasets.
Problems
AR dataset
PIE dataset
JAFFE
Size of image matrices p × q
40 × 40
64 × 64
256 × 256
Number of image samples n
2600
1632
214
Comparison of SSGA, I2DPCA and SI2DPCA based on AR, PIE and JAFFE datasets.
Experiments
CPU time (s)
AR dataset
SSGA
0.9206
0.2804
I2DPCA
0.3050
0.1182
0.0038
0.3499
SI2DPCA
0.1635
0.0927
PIE dataset
SSGA
0.9544
0.2962
I2DPCA
0.3402
0.1349
0.0660
2.2273
SI2DPCA
0.0892
0.1729
JAFFE dataset
SSGA
0.9717
0.1818
I2DPCA
0.5038
0.2170
0.0067
2.3380
SI2DPCA
0.3903
0.1708
Conclusion
Like CCIPCA,21 the essence of incremental two-dimensional PCA (I2DPCA) should be the incremental updating of one eigenvector at a time which leads to the non-orthogonality of the approximate eigenvectors. To remedy the problem, in this paper, we proposed a subspace type incremental 2DPCA algorithm (SI2DPCA), i.e., Algorithm 1, to incrementally update the eigenspace in a streaming environment. Thus, it can deal with volumes of additional data more efficiently.
To test the computational properties of SI2DPCA, we used SI2DPCA in a real-life streaming environment in which data are coming in the form of random. We conducted various tests on datasets with either the number of image samples n < 1000 (Yale, ORL and JAFFE datasets), or n > 1000 (FERET, AR and PIE dataset). We can summarize the advantages of SI2DPCA as follows: (1) SI2DPCA performs far superior to I2DPCA in terms of the accuracy of computed approximations; (2) SI2DPCA is able to effectively overcome the problem that the calculated eigenvectors are not mutually orthogonal in the existing I2DPCA algorithm; (3) SI2DPCA has very high memory and speed efficiency due to it can extract several eigenvectors in one-pass computation. These improvements will play a vital role in the processing streaming data analysis and online learning system of large datasets. Better numerical results in the computational approximations and orthogonality bring forth clearer reconstructed images, as shown in Figure 5.
From the point of view that the 2DPCA algorithm15 can be considered as a one-directional 2DPCA algorithm, the developments of Algorithm 1 can be made to work for the bidirectional 2DPCA algorithm2 without much difficulty, but we do not detail this in this paper.
Footnotes
Acknowledgements
The authors are grateful to the anonymous referees for their careful reading, useful comments, and suggestions for improving the presentation of this paper.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work is financially supported by National Natural Science Foundation of China NSFC-11601081 and the research fund for distinguished young scholars of Fujian Agriculture and Forestry University No. xjq201727.
ORCID iD
Zhongming Teng
References
1.
DaugmanJ.Face and gesture recognition: overview. IEEE Trans Pattern Anal Mach Intell1997;
19: 675–676.
2.
KimYGSongYJChangUD, et al.
Face recognition using a fusion method based on bidirectional 2DPCA. Appl Math Comput2008;
205: 601–607.
3.
TurkMPentlandA. Face recognition using eigenfaces. In Proceedings 1991 IEEE computer society conference on computer vision and pattern recognition. Piscataway, NJ: IEEE, pp. 586–591.
4.
PhillipsPJMoonHRizviSA, et al.
The FERET evaluation methodology for face-recognition algorithms. IEEE Trans Pattern Anal Mach Intell2000;
22: 1090–1104.
LiLLiuSPengY, et al.
Overview of principal component analysis algorithm. Optik2016;
127: 3935–3944.
7.
Diaz-ChitoKFerriFJHernández-SabatéA.An overview of incremental feature extraction methods based on linear subspaces. Knowl Based Syst2018;
145: 219–235.
8.
GreenwoodD.An overview of neural networks. Behav Sci1991;
36: 1–33.
9.
HotellingH.Relations between two sets of variables. Biometrika1936;
28: 321–377.
10.
TurkMPentlandA.Eigenfaces for recognition. J Cogn Neurosci1991;
3: 71–86.
11.
YangWSunCRicanekK.Sequential row-column 2DPCA for face recognition. Neural Comput Appl2012;
21: 1729–1735.
12.
SirovichLKirbyM.Low-dimensional procedure for the characterization of human faces. J Opt Soc Am A1987;
4: 519–524.
13.
HuYYangM. Face recognition algorithm based on algebraic features of SVD and KL projection. In 2016 International conference on robots and intelligent system (ICRIS). Piscataway, NJ: IEEE, pp. 193–196.
14.
KimWSuhSHwangW, et al.
SVD face: illumination-invariant face representation. IEEE Signal Process Lett2014;
21: 1336–1340.
15.
YangJZhangDFrangiA, et al.
Two-dimensional PCA: a new approach to appearance-based face representation and recognition. IEEE Trans Pattern Anal Mach Intell2004;
26: 131–137.
16.
OjaE.Simplified neuron model as a principal component analyzer. J Math Biol1982;
15: 267–273.
17.
D’EnzaAIMarkosAButtarazziD.The idm package: incremental decomposition methods in R. J Stat Softw2018;
86: 1–24.
18.
CardotHDegrasD.Online principal component analysis in high dimension: which algorithm to choose?Int Stat Rev2018;
86: 29–50.
19.
LiY.On incremental and robust subspace learning. Pattern Recognit2004;
37: 1509–1518.
20.
ZhaoHYuenPCKwokJT.A novel incremental principal component analysis and its application for face recognition. IEEE Trans Syst Man Cybern B Cybern2006;
36: 873–886.
21.
WengJZhangYHwangWS.Candid covariance-free incremental principal component analysis. IEEE Trans Pattern Anal Mach Intell2003;
25: 1034–1040.
22.
AgrawalRK.Perturbation scheme for online learning of features: incremental principal component analysis. Pattern Recognit2008;
41: 1452–1460.
23.
GeWSunMWangX.An incremental two-dimensional principal component analysis for object recognition. Math Probl Eng2018;
2018: 1–13.
24.
LiwickiSTzimiropoulosGZafeiriouS, et al.
Euler principal component analysis. Int J Comput Vis2013;
101: 498–518.
25.
HongBWeiLHuY, et al.
Online robust principal component analysis via truncated nuclear norm regularization. Neurocomputing2016;
175: 216–222.
LiRCZhangLH.Convergence of the block Lanczos method for eigenvalue clusters. Numer Math2015;
131: 83–113.
28.
TengZZhouYLiRC.A block Chebyshev-Davidson method for linear response eigenvalue problems. Adv Comput Math2016;
42: 1103–1128.
29.
TengZZhangLH.A block lanczos method for the linear response eigenvalue problem. Electron Trans Numer Anal2017;
46: 505–523.
30.
ShenXSunQ.Orthogonal multiset canonical correlation analysis based on fractional-order and its application in multiple feature extraction and recognition. Neural Process Lett2015;
42: 301–316.
31.
ZhuLZhuS.Face recognition based on orthogonal discriminant locality preserving projections. Neurocomputing2007;
70: 1543–1546.
32.
WangLZhangLHBaiZ, et al.
Orthogonal canonical correlation analysis and applications. Optim Methods Softw2020;
35: 787–807.
33.
GolubGLoanC.Matrix computations.
Baltimore:
Johns Hopkins University Press, 1996.
34.
OjaEKarhunenJ.On stochastic approximation of the eigenvectors and eigenvalues of the expectation of a random matrix. J Math Anal Appl1985;
106: 69–84.
35.
LiangXGuoZCLiRC. Nearly optimal stochastic approximation for online principal subspace estimation. Technical Report 2017-018, Department of Mathematics, University of Texas at Arlington, https://www.uta.edu/math/_docs/preprint/2017/rep2017_08.pdf (2017).
36.
LiRC.Relative perturbation theory: I. Eigenvalue and singular value variations. SIAM J Matrix Anal Appl1998;
19: 956–982.
37.
HanLWuZZengK, et al.
Online multilinear principal component analysis. Neurocomputing2018;
275: 888–896.
38.
LyonsMJAkamatsuSKamachiMG, et al. Coding facial expressions with gabor wavelets. In Proceedings of third IEEE international conference on automatic face and gesture recognition, 14–16 April 1998.