
Abstract
Transform learning has been successfully applied to various image processing tasks in recent years. Nevertheless, transform learning learns the representation in an unsupervised fashion. To make transform learning suitable for pattern classification, we introduce a label consistency constraint into transform learning and propose a new label consistent transform learning to enhance the classification performance of transform learning. The resulting optimization problem can be solved elegantly by employing the alternative strategy. Experimental results on publicly available databases demonstrate that label consistent transform learning outperforms several dictionary learning approaches and the recently proposed discriminative transform learning. More importantly, label consistent transform learning has the least training time which has the potential in practical applications.
Introduction
Recent years have witnessed increasing interest in the study of dictionary learning (DL) in various domains, such as face recognition, 1 image fusion, 2 and person re-identification. 3 DL can be divided into two different types, i.e. synthesis dictionary learning (SDL) and analysis dictionary learning (ADL), according to how to encode the input data. SDL aims to learn a dictionary by which the input data can be reconstructed through the linear combination of atoms in the dictionary. The most classic SDL approach is the K-SVD algorithm 4 which has been successfully applied to image compression and denoising. However, K-SVD mainly focuses on the representational ability of the dictionary without considering its capability for classification. To address this problem, Zhang and Li 5 proposed a discriminative K-SVD (D-KSVD) method by introducing the classification error into the framework of K-SVD. Jiang et al. 6 further incorporated a label consistency constraint into K-SVD and presented a label consistent K-SVD (LC-KSVD) algorithm. Yang et al. 7 developed a Fisher discrimination dictionary learning method which imposes the Fisher discrimination criterion on the coding coefficients. Wang D and Kong 8 presented an SDL approach called COPAR which explicitly learns the shared patterns and the class-specific dictionaries. Li et al. 9 proposed a locality constrained and label embedding dictionary learning algorithm to take the locality and label information of atoms into account. Many SDL employs ℓ0/ℓ1 norm to promote sparsity of the coding, which will lead to high computational complexity. To alleviate this problem, Zhao et al. 10 designed an orthogonal collaborative dictionary learning method which can derive analytical solutions for both code learning and dictionary updating.
Although SDL achieves impressive results in classification tasks, it is time-consuming to learn the dictionary. Recently ADL has attracted lots of attention due to its efficacy and efficiency. Rubinstein et al. 11 presented the analysis K-SVD which is parallel to the synthesis K-SVD. 4 Gu et al. 12 developed a projective dictionary pair learning (DPL) which simultaneously learns a synthesis dictionary and an analysis dictionary. Guo et al. 13 explored a discriminative ADL by integrating structure preserving and discriminative properties into the basic ADL model. Yang et al. 14 proposed a discriminative analysis-synthesis dictionary learning, in which a linear classifier based on the coding coefficient is jointly learned with the dictionary pair. Wang et al. 15 designed a synthesis linear classifier-based ADL (SLC-ADL) algorithm by introducing a synthesis-linear-classifier-based error term into the basic ADL framework. Similarly, Wang et al. 16 also incorporated the linear classification error term into ADL. The difference between SLC-ADL 15 and the approach proposed by Wang et al. 16 is that SLC-ADL actually uses the classification error term from the analysis viewpoint.
Transform learning (TL) is a new representation learning technique which was presented by Ravishankar et al.17,18; it utilizes a transform matrix to attain the representation of input data. In fact, TL and ADL have similar formulation. TL is mainly used in signal and image denoising. And there is few work on discriminative transform learning (DTL). Very recently, Maggu et al. 19 developed a label consistent TL for hyperspectral image classification. Although the method proposed by Maggu et al. 19 is termed as label consistent TL, they essentially introduced the linear classification error term into the framework of TL, so this method is coined as DTL in this paper. To further enhance the classification capability of TL, we introduce the label consistency term into the framework of TL and present label consistent transform learning (LCTL) for pattern classification. Compared with DTL, our proposed LCTL leverages the label information of both training data and dictionary atoms to form an ideal representation matrix. Through the ideal matrix, samples belonging to the same class are forced to have similar representation vectors while those from different classes to have distinct representation vectors. LCTL is evaluated on widely used databases and the experimental results demonstrate that LCTL is superior to DTL and other SDL approaches in terms of recognition accuracy and training time. The source code of our proposed LCTL can be downloaded from https://github.com/yinhefeng/label-consistent-transform-learning
Related work
Synthesis DL
Let
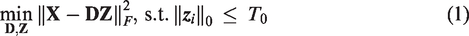
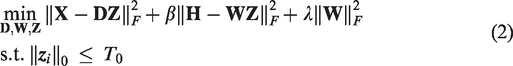
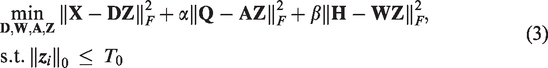
Transform learning
TL was presented by Ravishankar et al.17,18 and the objective function of TL is formulated as follows


Label consistent TL
As mentioned earlier, we want to employ the label information of both training data and dictionary atoms to boost the discriminative capability of TL, and the objective function of our proposed LCTL is formulated as
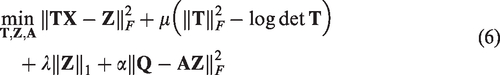

Equation (6) can be solved by alternatively updating
Update
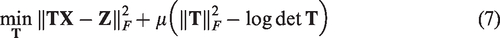

Update


Let

Update


When the training phase is completed, we can obtain the transform matrix
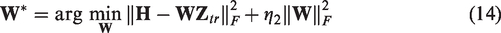

For a test sample
Experimental results and analysis
In this section, we evaluate the classification performance of our proposed LCTL on four benchmark datasets: the Yale database, the Extended Yale B database, the AR database, and the Scene 15 dataset. To illustrate the superiority of LCTL, we compare LCTL with the following approaches: SRC, 21 LLC, 22 K-SVD, 4 D-KSVD, 5 LC-KSVD, 6 and DTL. 19 Apart from the recognition accuracy, we also present the training time (in seconds) of all the competing methods. All experiments are run with MATLAB R2019a under Windows 10 on a PC equipped with Intel i9-8950HK 2.90 GHz CPU and 16 GB RAM.
Experiments on the Yale database
The Yale database consists of 165 images for 15 subjects, each individual has 11 images. These images have illumination and expression variations. Figure 1 shows some example images from this database. All the images are resized to 24 × 24, resulting in a 576-dimensional vector. Six images per subject are randomly selected for training and the remaining for testing. The learned dictionary contains 60 atoms, i.e. each class has four atoms. Experimental results are summarized in Table 1. We can see that LCTL has the highest recognition accuracy and the least training time. Specifically, the accuracy gain of LCTL over DTL is 2.6%.

Example images from the Yale database.
Recognition accuracy and training time on the Yale database.

Note: Bold values signify the best recognition accuracy and the least training time.DTL: discriminative transform learning; LCTL: label consistent transform learning.
Experiments on the Extended Yale B database
The Extended Yale B face database contains 2414 images of 38 individuals. Each individual has 59–64 images taken under different illumination conditions; example images from this dataset are shown in Figure 2. In our experiments, each 192 × 168 image is projected onto a 504-dimensional space via random projection. We randomly select half of the images per category as training and the remaining for testing. The dictionary consists of 570 items, which corresponds to an average of 15 atoms per person. Experimental results are listed in Table 2. Although the accuracy gain of LCTL over LC-KSVD is not that significant, LCTL is about 31 times faster than LC-KSVD.
Example images from the Extended Yale B database.
Recognition accuracy and training time on the Extended Yale B database.
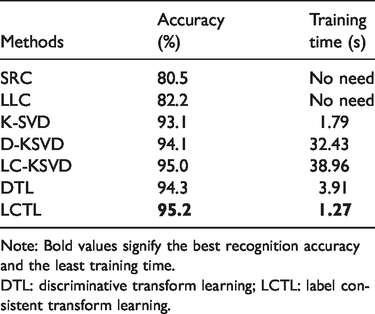
Note: Bold values signify the best recognition accuracy and the least training time.DTL: discriminative transform learning; LCTL: label consistent transform learning.
Experiments on the AR database
The AR database has more than 4000 face images of 126 subjects with variations in facial expression, illumination conditions, and occlusions. Figure 3 shows example images from the database. In our experiments, we use a subset of 2600 images of 50 male and 50 female subjects from the database. Each 165 × 120 face image is projected onto a 540-dimensional vector by random projection. For each person, 20 images are randomly selected for training and the remaining for testing. The learned dictionary has 500 dictionary items, i.e. five atoms per person. Table 3 shows the experimental results on this database. Although the AR database consists of occluded images which pose challenge to face recognition, LCTL achieves the best recognition accuracy and the highest efficiency.

Example images from the AR database.
Recognition accuracy and training time on the AR database.

Note: Bold values signify the best recognition accuracy and the least training time.DTL: discriminative transform learning; LCTL: label consistent transform learning.
Experiments on the Scene 15 dataset
Scene 15 dataset contains 15 natural scene categories introduced by Lazebnik et al., 23 which comprises a wide range of indoor and outdoor scenes, such as bedroom, office, and mountain; example images from this dataset are shown in Figure 4. For fair comparison, we employ the 3000-dimensional SIFT-based features used in LC-KSVD. 6 Following the common experimental settings, we randomly select 100 images per category as training data and use the remaining for testing. The learned dictionary has 450 atoms. Experimental results are presented in Table 4. One can see that LCTL outperforms DTL by a large margin, and it makes 7.2% and 4.7% improvement over DTL and LC-KSVD, respectively. The confusion matrix for LCTL is shown in Figure 5. As can be seen from Figure 5, LCTL obtains over 99% recognition accuracy for the categories of suburb, coast, forest, insidecity, opencountry, street, office, and kitchen.

Example images from the Scene 15 dataset.
Recognition accuracy and training time on the Scene 15 dataset.

Note: Bold values signify the best recognition accuracy and the least training time.DTL: discriminative transform learning; LCTL: label consistent transform learning.
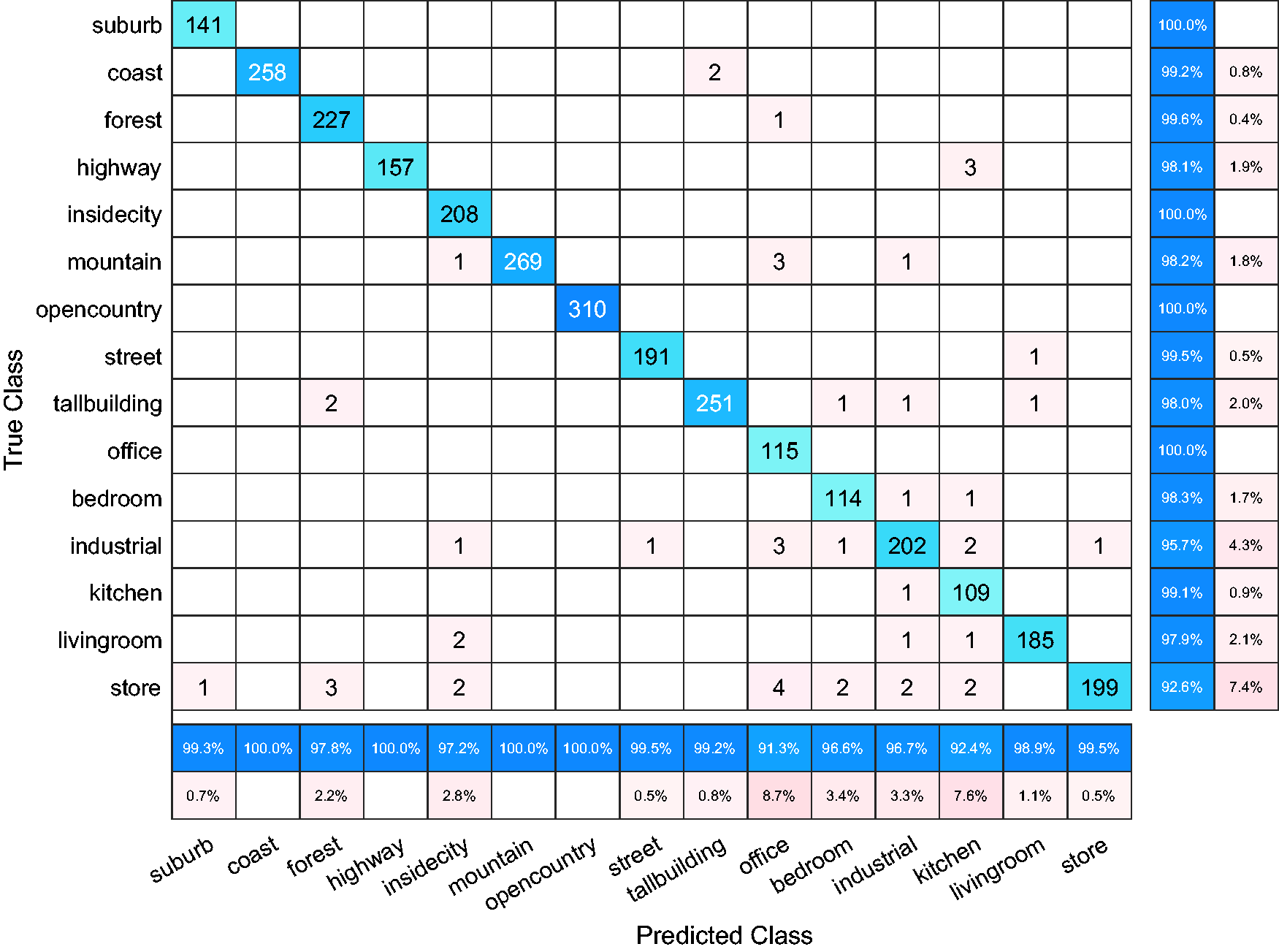
Confusion matrix on the Scene 15 dataset.
To examine how the dictionary size influences the performance of DL approaches, here we compare LCTL with DTL, LC-KSVD, D-KSVD, and K-SVD. We evaluate all the competing methods under dictionary sizes of 150, 450, 750, 1050, 1350, and 1500, which correspond to 10, 30, 50, 70, 90, and 100 atoms per category, respectively. Recognition accuracy with different dictionary sizes is plotted in Figure 6. We can observe that LCTL consistently outperforms all other approaches for all dictionary sizes.

Recognition accuracy on the Scene 15 dataset with varying dictionary size.
Conclusion
In this paper, we present an LCTL algorithm. To enhance the discriminative ability of TL and apply it to pattern classification tasks, a label consistency constraint is incorporated into the framework of TL to form a unified objective function. The variables in our optimization problem are updated alternatively and some of them have closed-form solutions. Experiments are conducted on three benchmark face databases and one scene dataset, and the results validate the effectiveness of our proposed LCTL. Moreover, LCTL shows high efficiency in terms of training time, which can be used in real-time scenarios.
Footnotes
Acknowledgements
The authors would like to thank Zhuolin Jiang for providing the source code of LC-KSVD at http://users.umiacs.umd.edu/∼zhuolin/projectlcksvd.html, and Jyoti Maggu for releasing the code of DTL at ![]() .
.
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the National Natural Science Foundation of China (Grant Nos. 61672265, U1836218), the 111 Project of Ministry of Education of China (Grant No. B12018), the Postgraduate Research & Practice Innovation Program of Jiangsu Province under Grant No. KYLX_1123, the Overseas Studies Program for Postgraduates of Jiangnan University and the China Scholarship Council (Grant No. 201706790096).