
Abstract
Network Function Virtualization addresses the defect of traditional middleboxes and enables operators to implement new services through a process named Service Function Chain mapping. Service Function Chain is composed by a sequence of Virtual Network Functions (VNFs) which is deployed in shared platforms. Service Function Chain with parallel VNFs is proposed to reduce the delivery latency. In this paper, a multiple instances mapping scheme named MIM is proposed to resolve the performance bottleneck introduced by the imbalance of parallel VNFs. A integer programing model is established to describe the multiple instances mapping problem based on queuing theory, and a double layer Genetic Algorithm is used to allocate parallel VNFs with multiple instances. Simulation results show that the multiple instances mapping scheme can improve the performance of Service Function Chain with parallel VNFs effectively.
Keywords
Introduction
Network Function Virtualization (NFV) deploys the network function on general platform through virtualization technology to address the defect of traditional dedicated middleboxes. 1 To provide complex services, the notion of Service Function Chain (SFC) is introduced, which is an ordered set of Virtual Network Functions (VNFs) connected by logical links as shown in Figure 1(a). And traffic can be steered through VNFs for processing as service provider required. Compared with traditional methods, NFV enables operators to implement new services through a process named SFC mapping, which maps the VNFs to High Volume Servers (HVSs).

Parabox and NFP introduce VNF parallelism to improve the performance of SFC. (a) Traditional sequential SFC and (b) SFC with parallel VNFs.
The benefits of NFV are multifold and range from the operational cost reductions to faster deployment of SFC. However, it also introduces significant processing latency due to extra virtualization overhead. In this context, several efforts2–6 have been proposed to address this problem. To achieve lower latency, most of the previous works choose to schedule traffic dynamically, 2 scale VNFs in a horizontal scope (i.e. VNF instances migration2,3) or a vertical scope (i.e. instantiating more VNF instances3,4). Moreover, some efforts are devoted to enhance the performance of SFC by accelerating individual VNF (e.g. ClickNP 5 and NetBricks 6 ) or packet delivery acceleration (e.g. DPDK, 7 ClickOS, 8 and NetVM 9 ). Nevertheless, sequential composition of VNFs limits the performance ceiling of these works and provides additional opportunities for performance optimization. Instead, NFP 10 and Parabox 11 break above limitation by enhancing the performance of SFC from a vertical scope. Both of them use dependency analysis module to ensure that VNFs share no dependency work in parallel. To implement the VNF parallelism, they duplicate packets and send replicas to parallel VNFs for processing, respectively. They also propose packet merger for merging replicas after processing. In this way, the processed packets of parallel VNFs are the same as the traditional sequential SFC, and VNF parallelism achieves significant latency reduction for real-world SFC.
However, since each VNF is varied from each other in the processing speed, the maximum throughput of parallel VNFs is determined by the slowest VNF, which is the bottleneck of the parallel VNF. An example of parallel VNFs is shown in Figure 1(b), assuming that the average processing time of network intrusion detection system (NIDS) is 0.2 ms, while that of the traffic shaper is 0.1 ms. In this case, when the traffic shaper completes processing tasks that target the packet replica, another packet replica is still being processed by NIDS. Thus, the total packet processing time is determined by the processing time of NIDS, i.e. 0.2 ms. Thus, the lowest efficiency VNF reduces the throughput of the parallel VNFs. To the best of our knowledge, none of existing SFC mapping algorithms has taken this issue into consideration.
To address this issue, we propose Multiple Instances Mapping scheme (MIM), which allows launching multiple instances for enhancing maximum throughput. As shown in Figure 2(a), instantiating an additional instance of NIDS is in another server for load balancing. Therefore, MIM improves the throughput of parallel VNFs. In order to minimize extra computing and network resources cost caused by launching multiple instances, we introduce queuing theory to evaluate the processing speed of multiple VNF instances, and the mapping decision is made for the best trade-off between high efficiency and resource consumption.

SFC mapping scheme. (a) Multiple instances mapping of parallel SFC and (b) normal mapping scheme.
In this paper, we have made the following contributions: first, we designed a scheme that focuses on the mapping of SFC with parallel VNFs and solved the efficiency bottleneck caused by the difference of parallel VNFs. Second, we have designed a double layer Genetic Algorithm (GA) for multiple instances mapping that can dynamically add VNF instances based on the theoretical throughput of parallel VNFs and available substrate resources.
The rest of this paper is organized as follows: “Related work” section gives an overview of previous work on SFC mapping and SFC accelerating. In “Problem formulation” section, we formulate the processing latency of multiple instances and SFC mapping problem. Section “Algorithm design” presents our heuristic algorithm of multiple instances mapping problem. We analyze the performance of our mapping algorithm in “Evaluation” section and conclude our work in “Conclusion” section.
Related work
The performance of SFC has been widely studied in the notion of NFV. Li et al. presented a scheme named Quokka that realizes lower latency for end users by placing VNFs and scheduling traffic dynamically. 2 Huang et al. maximize the network throughput by horizontal scaling and vertical scaling while meeting end-to-end transmission delay requirements. 3 Carpio et al. aim at improving load balancing of SFC and designing an algorithm for allocation and replication of VNFs. 4
There has been considerable work focusing on the issue of SFC mapping. Mehraghdam et al. describe the SFC mapping problem as a mixed integer quadratic programing model. Three objective functions are proposed in the paper to maximize the remaining bandwidth resource, minimize server utilization, and minimize latency,12 respectively. Cohen et al. describe the SFC mapping problem by integer linear programing and solve the mapping problem with the generalized assignment problem model for minimizing the resource consumption.13 Beck and Botero propose an algorithm for performing VNF forwarding graph composition and mapping simultaneously with the goal of maximizing remaining resources.14 Since SFC mapping is an NP-hard problem, there is a part of the work that applies heuristics to solve this problem. Ma et al. apply the particle swarm optimization algorithm to the mapping of SFC,15 and the experiment proves that the algorithm has achieved good results on the evaluation indexes such as acceptance rate and long-term resource utilization rate.
Although numerous studies have considered the high throughput SFC deployment, most of the existing approaches are mostly designed for sequential SFC, and rarely studies to resolve efficiency differences between VNFs through multiple instances mapping. Therefore, we propose MIM-GA algorithm to enhance the throughput of parallel VNFs while also considering resource cost of deployment.
Problem formulation
In this section, we introduce the substrate network and the SFC requests, and then formulate the relationship between VNF processing latency and number of instances by queuing theory. At last, we define SFC mapping process as Integer Programing with the objective function that enhances the throughput of parallel VNFs while minimizing the cost of SFC mapping.
VNF processing latency model
An SFC request R arrives and specifies an ordered sequence of VNFs. Suppose that there is a set of σ VNFs required in request, denoted as


Illustration of the parallel VNF queuing system.
It is reasonable to assume that the average service rate
16
of the queuing system (which is constituted by multiple instances of

The queuing theory model assumes that the input and output of the queuing system obey the “birth” and “death” process in probability theory. In this paper, “birth” means the arrival of a packet entering the

Among them, Pm,0 is the probability that there is no packet in the

Defining the expected value of the packets in the queue (excluding the packet being processed) as Lqm, which is expressed as

According to the little formula,
16
equation (6) represents average queuing latency of each packet. And the average latency of each packet replica in


SFC mapping model
The substrate network and the virtual network (i.e. SFC request) are denoted by Gs = (Ns, Ls) and Gv = (Nv, Lv), respectively. Among them, Ns is the set of substrate (i.e. HVS) nodes, and Lv/Ls represents the virtual/substrate link set. SFC mapping problem is defined by a mapping
Constraints
Multiple instances mapping relaxes the constraint of one-to-one mapping between parallel virtual nodes and substrate nodes, constraint (8) represents that the parallel VNF

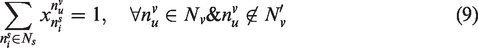
Meanwhile, there is a computing resource constraint that makes the remaining computing resources of substrate node satisfy the requirement of the virtual node, that is

Constraint (11) is proposed to ensure that the mapped substrate links of each virtual link cannot be a circle

Constraint (12) ensures that the connectivity of the physical links carrying the virtual link is consistent with

Constraint (13) ensures that the sum of the bandwidth resource occupied by the virtual link lu,
h
do not exceed the remaining bandwidth that the substrate link li,
j
can provide

Objectives
The revenue of accepting an SFC request can be formulated by equation (14)

From service provider’s opinion, an SFC mapping algorithm should maximize the revenue and increase the utilization of the substrate network in a long time run. Therefore, like previous works,
17
we defined a long-term average revenue to evaluate the benefits of accepting SFC

Service provider allocates appropriate resources for accepting an SFC request, which can be defined as the cost of a mapping

Based on equations (14) and (16), long-term revenue to cost radio is proposed to quantify the resource utilization of substrate network
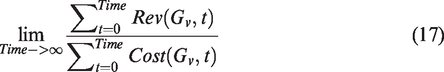
In the multi-tenant scenario, the acceptance rate is used to evaluate the proportion of requests successfully accepting

The optimization goal of this model is to minimize the maximum of parallel VNFs processing latency and minimize the substrate resources cost. The other objectives mentioned above will be used as evaluation indicators for the experiment. And the average latency Wm (m is the subscript of virtual node


Algorithm design
The SFC mapping problem is an NP-hard problem, thus we introduce GA k to solve it. GA is a random search technology that draws on evolutionary ideas and can effectively solve optimization problems under complex constraints. We designed the MIM-GA algorithm to implement multiple instances mapping for parallel chains. The MIM-GA is divided into two phases: (1) optimization of the number of
Genetic algorithm
The basic GA is based on the group search technology, and evolves according to the principle of survival of the fittest, and finally obtains the optimal solution or the quasi-optimal solution. The GA first randomly generates multiple initial solutions for the optimization problem, which is commonly referred to as population, and each chromosome (i.e. individual of population) in the population is a feasible solution to the optimization problem. GA calculates the value of each chromosome fitness function and selects good chromosomes according to the principle of survival of the fittest. The selected elite chromosomes are then encoded into binary string, and the next-generation population is generated by randomly crossing the genes of the chromosome pairs and randomly mutating the genes of certain chromosomes. In this way, the population is evolved from generation to generation until the termination condition is met. The fitness function is usually set to the objective function of the problem. 18
MIM-GA
MIM-GA is a double-layer GA.
19
The first layer GA (Algorithm 2) aims at finding out an optimal number of instances of
Population initialization
The chromosome of first-layer GA is expressed as T = (t1, t2,…, tτ), a tm ∈ T represents the number of instances of

The representation of the chromosome. (a) SFC; (b) chromosome initialization; and (c) mapping result.
Selection operator
The selection operator selects populations as parent populations by roulette algorithm according to selection probability.
Crossover operator
The crossover operator made two chromosome exchange substrings between two points which generated randomly.
Mutation operator
The mutation operator randomly selects five or fewer elements from the chromosome for mutation. In the process of mutation, a solution beyond the feasible domain may occur. For example, the element of V, which indicates the index of HVS that VNF map to, can be greater than maximum number of HVS or equal to 0. Or the element of T is greater than the instances upper limit K. For this case, the infeasible value produced by the mutation is modified to a random feasible value.
Fitness function
The objective function is used as a fitness function. After the chromosomes are crossover-operated, an infeasible solution which disobeys the constraint may occur. For example, the remaining resources of the substrate node are insufficient to instantiate the corresponding virtual node, or there is no path that satisfies the bandwidth constraint between the substrate nodes where the two VNF instances are located. When the fitness function calculates the fitness of the infeasible solution, it is uniformly taken as +∞ as a penalty function that does not satisfy the constraint. The preferred process uses the roulette wheel selection to select the descendants according to the cumulative probability of the fitness value.
1: set count = 0, V =
2:
3: calculate the candidate node set CNu for
4: sort CNu by sum of remaining CPU capacity and adjacent links’ bandwidth in descending order;
5: set NMu =
6:
7:
8: calculate the shortest path Pathu,
u
–1 between
9:
10: add
11:
12:
13:
14: mapflag = true;
15: break;
16:
17:
18:
19: mapflag = true;
20: break;
21:
22:
23: j = j +1
24:
25:
26: complement NMi by random node in CNu;
27:
28: add NMu to V
29:
1: Initialization population A to specify numbers of parallel VNFs instances under limit K
2: calculate the fitness of each chromosome of A by second layer of MIM-GA and record best result as pBest, set global best result as gBest = pBest;
3:
4: selection operator for population A to get B;
5: encoding population B to C;
6: crossover operator for population C to get D;
7: mutation operator for population D to get E;
8: decoding for population E and assigned to A;
9: calculate the fitness of population A by second layer of MIM-GA and update pBest;
10:
11: gBest = pBest;
12:
13: count++
14:
15:
16: reject the SFC request
17:
18: execute gBest’s mapping solution and update Gs(Ns, Ls)
19:
1: Initialization population F to allocate VNF in HVS by Algorithm 1
2: calculate the fitness of each chromosome of population F by equation (20) and record best result as pBest, set global best result as gBest = pBest;
3:
4: selection operator for population F to get G;
5: encoding population G to H;
6: crossover operator for population H to get I;
7: mutation operator for population I to get K;
8: decoding for population K and assigned to F;
9: calculate the fitness of each chromosome of population F second by equation (20) and update pBest;
10:
11: gBest = pBest;
12:
13: count++
14:
Evaluation
Simulation workloads
In order to verify the effectiveness of the MIM-GA algorithm, this paper evaluates the throughput of the parallel VNFs, long-term acceptance rate, and the long-term revenue to cost radio of the substrate network.
The substrate network topology is generated by GT-ITM with 100 nodes and approximately 500 links. Substrate nodes computing and network resources are subject to a uniform distribution of 50–100. It is assumed that the arrival of SFC request obeys an average arrival rate of 15 sets per unit time subjecting to poisson distribution, and an average service rate of 5 per unit time, which subject to negative exponential distribution. The number of VNFs per SFC request is subject to a uniform distribution of 2–5. The processing efficiency of the parallel nodes is randomly generated, subject to a uniform distribution of 10,000–15,000 packets per second, and the arrival rate of the packets is subject to a uniform distribution of 5000–80,000. The first layer MIM-GA has a population size of 100 and a maximum number of iterations of 500. The second layer MIM-GA sets the population size to 500 and the maximum number of iterations to 1000. The crossover probability, the selection probability, and the mutation probability are set to 0.7, 0.5, and 0.1, respectively. The simulation time is 10,000 time units, and the experimental data are recorded every 1000 time units.
Simulation results
To evaluate the effectiveness of our proposed algorithm, we compare its performance against the basic Greedy algorithm and Random Fit Algorithm (RFA) for single instance mapping of SFC with parallel VNFs.
Figure 5(a) shows the SFC requests acceptance rate with different SFC mapping strategies. We can see that MIM-GA outperforms other algorithms in acceptance ratio. It should be noted that MIM-GA maps multiple instances for each parallel VNF while other algorithms only map one. The strength of our proposed approach is that the mapping results are optimized over multiple iterations, which makes the utilization of resources more efficient, thus increasing the acceptance rate. Also, MIM-GA looks for mapping candidate nodes from the neighbors of the previous mapping substrate node in a greedy way at initialization stage, so that the fitness value of initial population has reached the level of greedy algorithm.

Comparison between mapping results of different K. (a) Acceptance rate; (b) average revenue; (c) revenue/cost; and (d) maximum throughput of parallel VNFs.
We note that the revenue curve of MIM-GA displaying in Figure 5(b) is the highest of all. Due to the more SFC requests accepted with MIM-GA, the long-term average revenue is naturally higher than the other two algorithms.
Figure 5(c) shows the long-term revenue to cost ratio (i.e. R/C ratio) of service provider. The R/C ratio of MIM-GA algorithm is about 0.1–0.15 lower than that of the greedy and RFAs. Although we have demonstrated that MIM-GA achieves higher acceptance rates and average revenue in the long-term. However, due to the extra computing resources and bandwidth resources occupied by the multiple instances, the cost of MIM-GA is higher than other single instance mapping algorithm. And this indirectly leads to a drop in the R/C ratio curve.
The maximum throughput of parallel VNFs is shown in Figure 5(d). The multiple instances mapping can effectively improve the throughput of the parallel service chain under simulation and effectively solve the bottleneck problem of the parallel VNFs. In our proposed queuing theory latency model, the MIM-GA can increase throughput by nearly 30% compared to the single instance mapping.
Conclusion
This paper focuses on the performance bottleneck of SFC with parallel VNFs, and proposes a MIM scheme for parallel VNFs. The queuing theory is introduced to describe the relationship between the amount of VNF instances and the processing latency. Based on this, minimizing the resource cost of SFC mapping and the maximum latency of parallel VNFs are taken as the objective function, and an integer programing model is established. MIM-GA algorithm is proposed to perform MIM scheme. The algorithm is implemented by a two-layer GA. The first layer of MIM-GA optimals the number of parallel VNFs, and the second layer implements the mapping operation under resource constraints. Simulation results show that sacrificing some resources for launching multiple instances of parallel VNFs can effectively break through the performance bottleneck of SFCs with parallel VNFs and reduce the latency.
Footnotes
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.