
Abstract
Over the past few years, cross-domain fault detection methods based on unsupervised domain adaptation (UDA) have gradually matured. However, existing methods usually assume that the source and target domains have the same label domain space, but ignore the problem of label expansion in the target domain. The source domain of such problems lacks transferable knowledge of newly added health categories, so the domain invariant features extracted by the UDA model only have a large correlation with the source domain health categories, but lack the key features to distinguish the newly added health categories. We found that most of the diagnostic results of this type of samples are distributed at the decision boundary of the source domain health category, and this special distribution means that the newly added health category samples have a high amount of information. Therefore, this paper considers using active learning to select samples of newly added health categories in the target domain to assist model training, and proposes an active domain adaptation intelligent fault detection framework LDE-ADA to deal with the label expansion problem. Finally, on the rotating machinery dataset, the analysis and comparison are carried out through six transfer tasks. The results show that when there is one new health category, the accuracy of LDE-ADA will increase by about 9.39% in the case of labeling three samples per round and training for 20 rounds. Experiments show that this method is an effective method to deal with the label expansion problem.
Keywords
Introduction
As the scale of mechanical equipment continues to expand and its functions become more complex, in order to avoid unnecessary economic losses, more and more attention has been paid to effectively preventing equipment failures. 1 The method of signal processing 2 requires the detection personnel to have rich knowledge and experience, and it is difficult to perform real-time monitoring. The method of machine learning (ML) 3 requires a lot of human resources for feature processing, and high-dimensional features are difficult to mine. In recent years, deep learning (DL) technology 4 has been widely studied for equipment fault detection due to its powerful feature extraction capability. However, training a high-performance DL model requires a large number of labeled samples, but the cost of collecting these labeled samples is expensive, which is the essential reason why deep models are rarely successful. Meanwhile, most of the existing deep learning methods assume the same data distribution in the source and target domains. However, in actual operation of mechanical equipment, there are reasons such as changing working conditions (such as changes in the speed and load of the equipment) and sudden changes in temperature. This assumption is unrealistic. Therefore, the performance of well-trained deep models applied to practical work will be greatly compromised.
Transfer learning (TL) can mine domain invariant fundamental features and structures in two different but related domains, which enables the information learned from the source domain to be transferred and reused between domains. 5 In recent years, transfer learning methods have been increasingly applied to the fault diagnosis of rotating machinery.6,7 Unsupervised domain adaptation (UDA) is a representative method in transfer learning. This method generally utilizes minimum domain spacing8,9 or adversarial strategies10,11 to apply the knowledge learned by the model from the source domain to the detection of the target domain, so as to solve the problem of mapping bias. In the past few years, unsupervised domain adaptation has been gradually applied and developed in the fields of image classification12,13 and mechanical fault detection.14–16
However, the detection method based on unsupervised domain adaptation still has some defects, and two problems are more prominent:
(1) Performance issues with unsupervised models. Domain adaptation enables cross-domain diagnosis by solving the problem of mapping bias between source and target domains. However, the diagnostic performance of the unsupervised domain adaptation models is far less than that of most supervised diagnostic models,17,18 and even a small number of target domain label samples can significantly improve the diagnostic performance of the model.
(2) Label domain expansion problem. Most of the current mainstream domain adaptation diagnosis methods assume that the source domain and the target domain have the same label domain space. However, when the target domain has more health categories than the source domain, it is difficult for the domain adaptation model to detect the newly added health categories.
Neglecting the above problems will cause the model to misdiagnose the health status of the equipment in practical applications, resulting in unnecessary economic losses. This problem occurs in the model due to the lack of transferable knowledge of the newly added health categories in the source domain during training, resulting in the domain invariant features extracted by the model only having strong correlation with the source domain health categories, and lack of key features that can identify the newly added health categories. We found that most of the prediction results of the model for the newly added health categories are distributed at the decision boundary of the source domain health category, so this means that the newly added health category has a higher amount of information in the mapped feature invariant space, as shown in Figure 1.
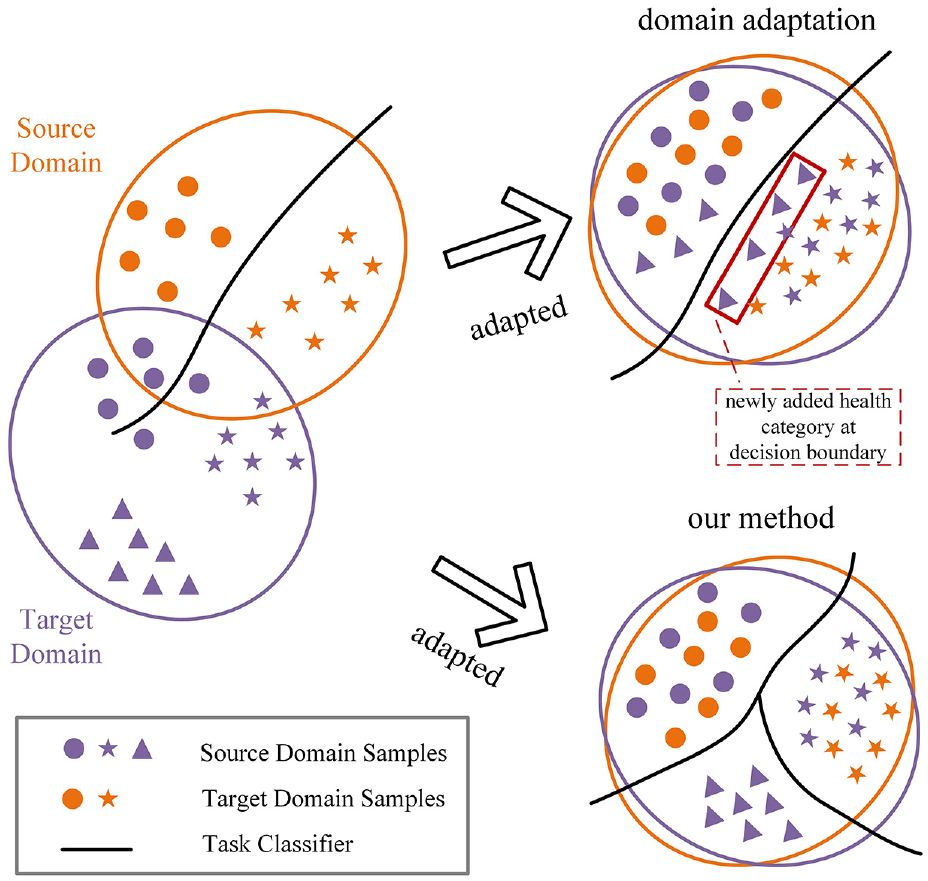
After marginal distribution alignment, the newly added health categories are mostly at the decision boundary of the source domain health categories. The UDA method without considering the label domain expansion problem is difficult to detect the newly added health categories. Our proposed method aims to correctly classify the original health categories while identifying the newly added health categories.
In recent years, some researchers have used sample selection algorithms to extract informative samples in the target domain to assist model training, which is used to improve the diagnostic performance of unsupervised models. Active learning (AL) aims to select the most valuable samples from a pool of unlabeled samples using a query strategy. Among them, the pool-based active learning (Pool-Based AL)19–21 sample selection method has been widely studied. Most previous active learning methods use a single query strategy to select samples and train models in the same domain.22,23 With the development of transfer learning techniques, active learning is applied to cross-domain sample selection, so active transfer learning24,25 has been intensively studied. Domain adaptation (DA), as a branch of transfer learning, combined with active learning is called active domain adaptation (ADA).26–28 ADA is similar to the basic AL model training steps, which are generally divided into two parts: model training and query strategy, as shown in Figure 2. Fu et al. 18 proposed a new transferable query selection (TQS) method for active domain adaptation, including transferable uncertainty, transferable domainness, and transferable committee.It is experimentally demonstrated that TQS can select the target samples with the largest amount of information under domain transfer. Su et al. 29 proposed an active learning method for transferring representations across domains. This active adversarial domain adaptation (AADA) method explores the duality between two related issues: adversarial domain alignment and importance sampling for cross-domain adaptation models. Zhou et al. 30 proposed a discriminative active learning method for domain adaptation to reduce the workload of data annotation, and demonstrated the effectiveness of this active domain adaptation algorithm. However, previous active domain adaptation do not consider the impact of label domain expansion on model diagnostic performance.
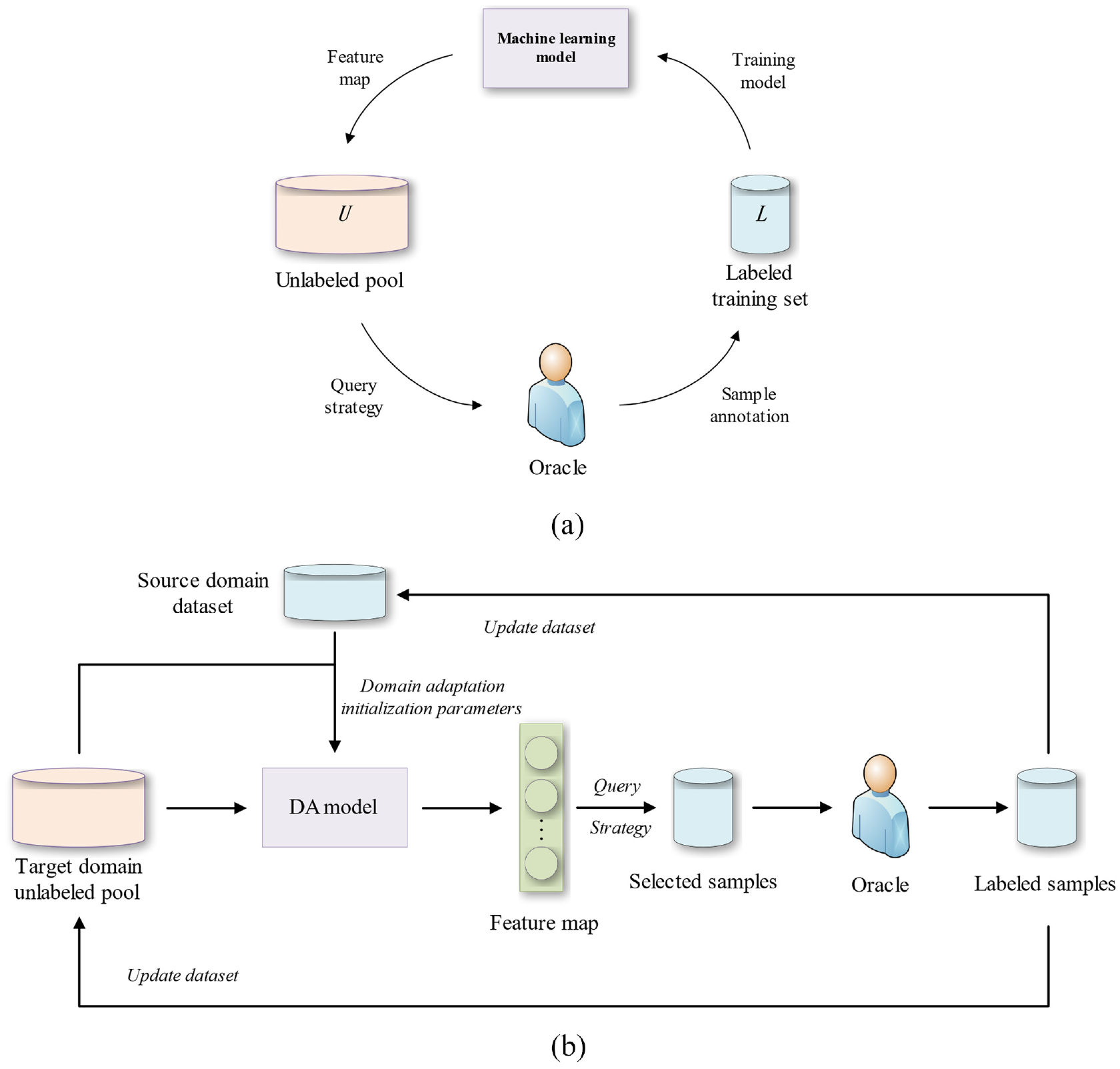
Where (a) is the pool-based active learning framework and (b) is the LDE-ADA intelligent fault detection framework proposed in this paper.
In view of the above problems, this paper considers that the newly added healthy category samples in the domain invariant space after marginal distribution alignment have a high amount of information. An active domain adaptation intelligent fault detection framework LDE-ADA is designed to deal with the label domain expansion problem, which is used to solve the label domain expansion problem in cross-domain fault diagnosis. The method firstly uses the UDA model to learn domain invariant features, which are used to solve the domain bias problem of ADA and improve the query accuracy of newly added healthy samples. Then use the improved active learning query strategy to select the most valuable samples from the target domain sample pool for labeling. Finally, use the labeled fusion sample set to train the model again, and repeat the above steps. At the same time, an improved active learning query strategy is proposed to accurately select the newly added healthy category samples in the target domain to assist model training and solve the problem of label domain expansion. The strategy first uses an uncertainty-based sampling method to select the target domain samples that are indistinguishable by the model. Then, representative samples are selected from the above samples by clustering algorithm. This method can not only select the samples with the largest amount of information, but also ensure that the selected samples are representative, so that the model can maximize the performance in each round of training. The specific query strategy and training method are introduced in Section 3.
The main points and contributions of this paper are as follows:
(1) In this paper, an active domain adaptatioin intelligent fault detection framework LDE-ADA is proposed to solvethe label domain expansion problem. This method takes into account that in the feature invariant space after marginal distribution alignment, most of the newly added health categories are distributed in the decision boundary and have a high amount of information. Therefore, the framework first performs marginal distribution alignment to improve the accuracy of active learning sample queries.
(2) An improved active learning query strategy is proposed. The query strategy can more accurately select samples of the newly added health categories in the target domain, and is suitable for solving the label domain expansion problem of UDA.
(3) The influencing factors of the diagnostic performance of the active domain adaptation framework are analyzed through experiments. These influencing factors provide ideas for the efficient application of active domain adaptation models in the field of fault detection.
The rest of this paper is organized as follows: The second part is related concepts, including domain adaptation, active learning, and active domain adaptation. In the third part, the LDE-ADA intelligent fault detection framework is introduced in detail. In the fourth part, the effectiveness and superiority of the proposed method are proved on the bearing test platform, and the factors affecting the active domain adaptation are analyzed. The fifth part summarizes this paper.
Related work
Domain adaptation
Domain adaptation (DA) is designed to solve the problem of biased feature space mappings in the source and target domains. Unsupervised domain adaptation is one such paradigms, where no labeled sample data is available in the target domain. For unsupervised domain adaptation, we generally assume that the source domain
In recent years, domain adaptation work under this assumption has achieved great success. The key idea is to fit the data distributions of the source and target domains by looking for the minimum domain spacing or using adversarial methods. However, when
Active learning
Active learning aims to select the samples that are most conducive to the improvement of model performance from unlabeled datasets, and this method can effectively solve the limitation of high sample labeling cost in some fields. The most important part of AL is the formulation of query strategy. At present, the main query strategies are committee query, uncertainty sampling query and representative query. The diagnostic effect of choosing a single query strategy is far less than the method of mixing multiple strategies.
32
For AL, we generally assume that
Only considering the query strategy of uncertainty sampling, it is unavoidable to select samples with similar amounts of information, and such samples have little improvement in model performance. On the other hand, query strategies that only consider representativeness may select samples from non-newly added health categories, resulting in increased labeling costs.
Active domain adaptation
ADA uses active learning to select a small number of target domain samples for labeling, so as to maximize the gain of the DA model. Different from the above work, our work aims to solve the label domain expansion problem in domain adaptation through active learning. Since the transferable knowledge of newly added health categories does not exist in the source domain, it is impractical to solve the label domain expansion problem only by UDA. However, AL can add the transferable knowledge of the newly added health categories to the source domain with the smallest label cost, and extract the relevant features of the newly added health categories to solve the problem of label domain expansion.
LDE-ADA intelligent fault detection framework
In this section, we introduce the detection method of LDE-ADA. Among them, Section 3.1 introduces the specific structure and loss function of the unsupervised adversarial domain adaptive networks based on minimum domain spacing (MDS-ADAN) 33 ; Section 3.2 introduces our active learning query strategy in detail; Section 3.3 summarizes the training steps of the LDE-ADA model.
Domain adaptation diagnostic model based on MDS-ADAN
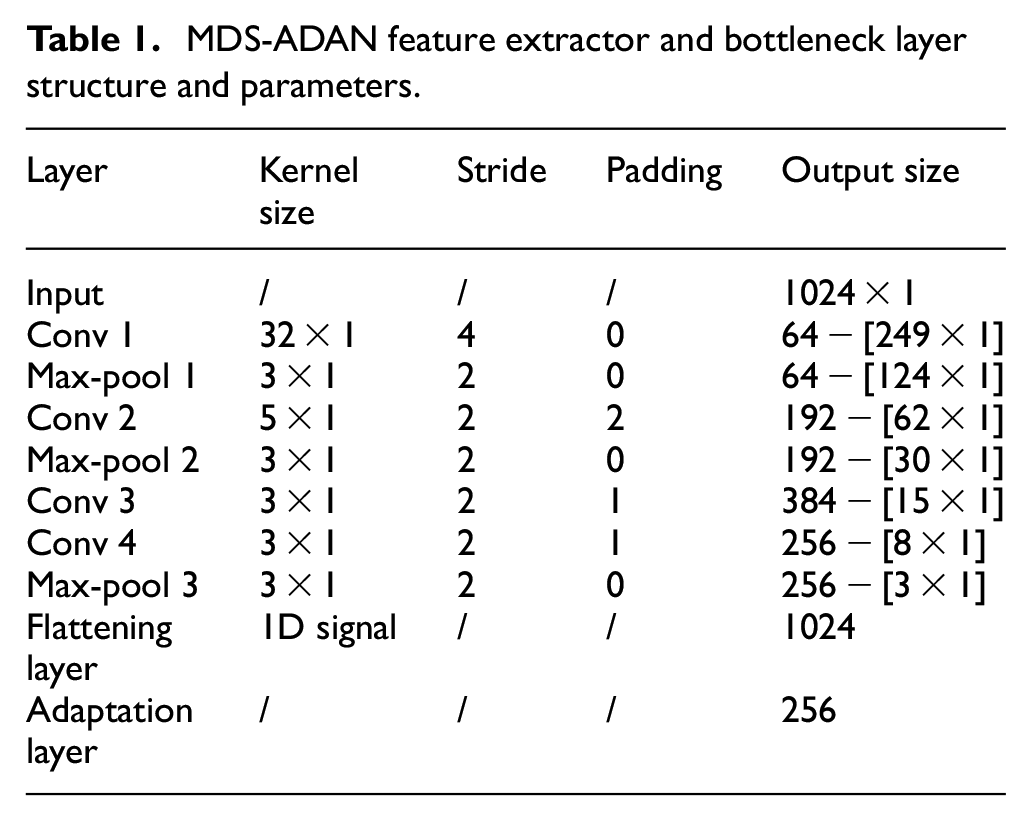
In this work, we choose the MDS-ADAN model as the basic domain adaptation diagnostic model of the LDE-ADA model, and its network structure is shown in Figure 3. The model is divided into four parts: feature extractor
MDS-ADAN feature extractor and bottleneck layer structure and parameters.
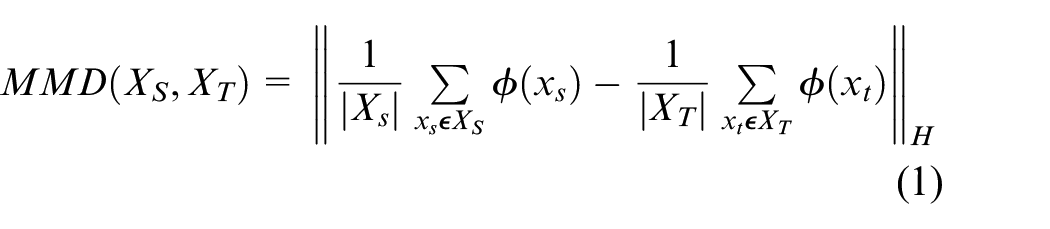
Where
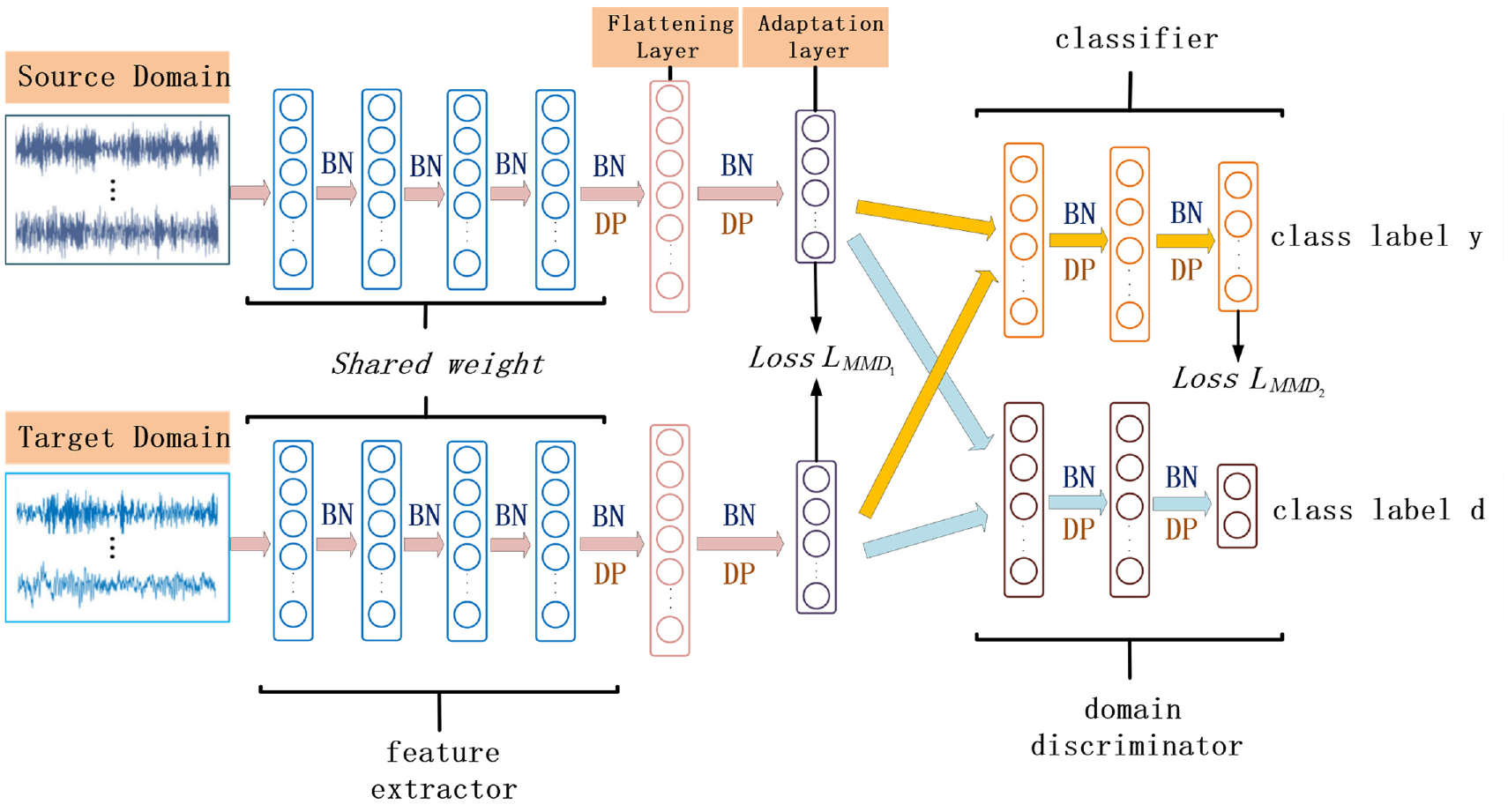
Model structure of MDS-ADAN.
Considering that the target domain labels are not available, the MDS-ADAN model draws on the idea of generative adversarial networks (GAN),
35
which adds a domain discriminator
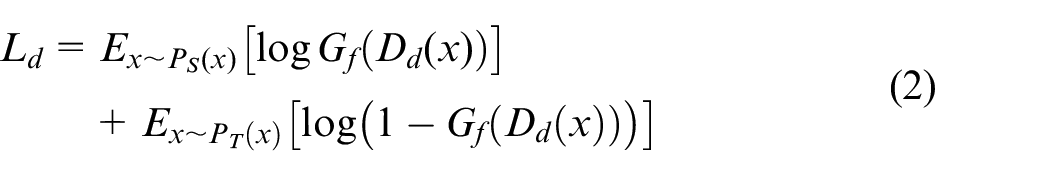
The objective function
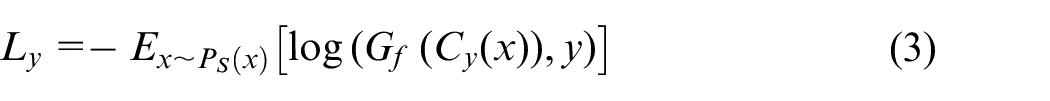
Where

Where
The MDS-ADAN model not only performs distribution calibration at the adaptation layer, but also reduces the feature distribution differences between domains at the end of the classifier. Thus the overall loss is expressed as:
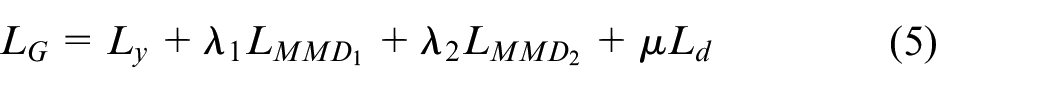
Where
The MDS-ADAN model effectively fits the data distribution of the source and target domains in the pre-training stage of LDE-ADA, learns domain-invariant features, and improves the accuracy of active learning sample queries.
Active learning query strategy
Our purpose is to select the most valuable target domain samples for labeling, that is, newly added healthy category samples in the target domain. The commonly used methods based on uncertainty sampling are margin sampling method (MS) and entropy method (ET) to measure the classifier output vector, and select the samples that are most difficult to diagnose by the model. The expression formulas of margin sampling method equation (6) and entropy method equation (7) are as follows:
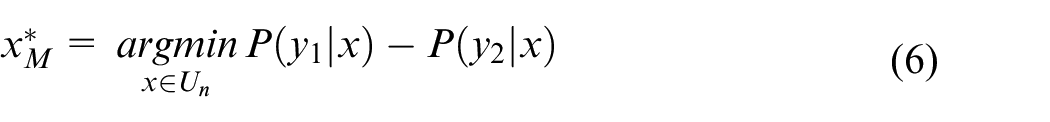
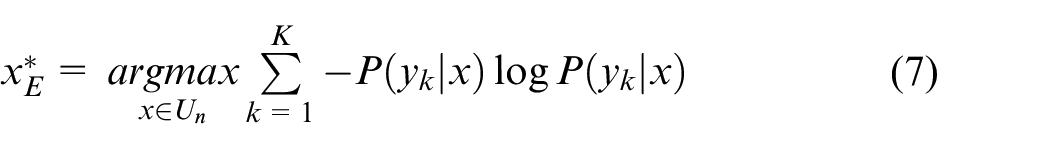
where,
In this work, we propose an uncertainty sampling method that combines the above two sampling methods, namely the entropy margin difference algorithm (EM), which performs the difference operation between the entropy method and the margin sampling method. This method uses a smaller sampling set to improve the precision of sample query. To determine the effectiveness of the method, we randomly selecte two groups of target domain data (100 samples per group) and put them into a well-trained domain adaptation model for result analysis. These three uncertainty sampling based query methods are analyzed according to the output vector, as shown in Figure 4.
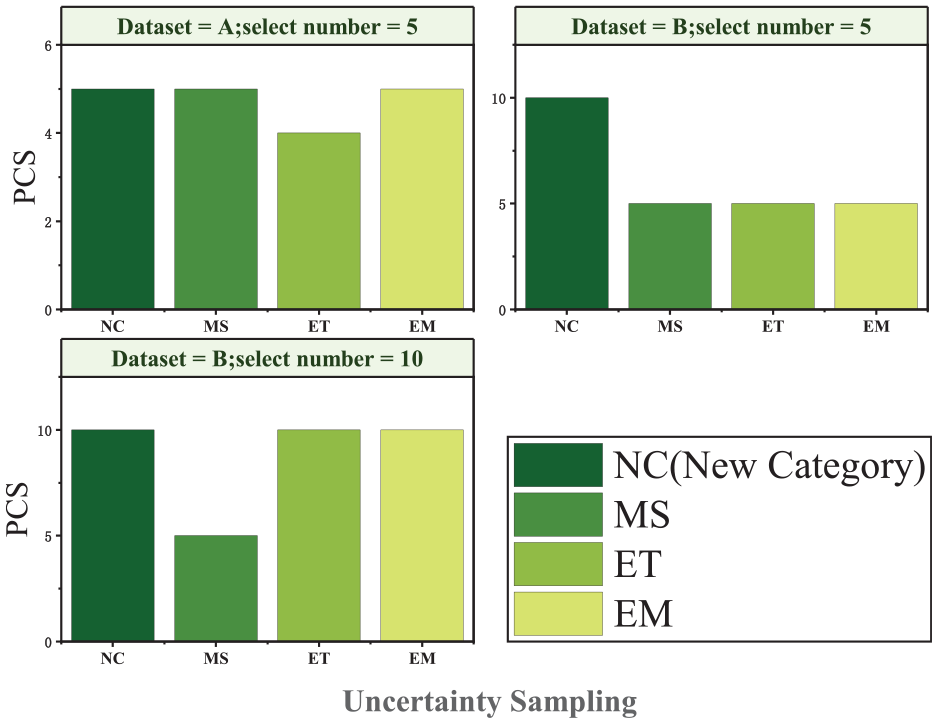
The domain adaptation model is trained by 9 types of health categories in the source domain and 10 types of health categories in the target domain, and the output vector analysis is performed by using the uncertainty sampling query strategy. EM can accurately select newly added health categories.
The two groups of data are marked as group A and group B, in which the number of newly added health category samples in group A is 5, and the number of newly added health category samples in group B is 10. In group A, we set the number of selected samples to 5. It is found that the entropy method misselected a sample that is not a newly added health category. In group B, we set the number of selected samples to be 5 and 10. It is found that when the number of selected samples is 10, the margin sampling method is not effective for the selection of newly added health categories. To sum up, it is found from the three groups of experiments that the EM method can effectively select the newly added healthy category samples of each group. Therefore, our uncertainty sampling query strategy is:

Only the sample data selected by the query method of uncertainty sampling may have great similarity in feature information. Such samples do not maximize the performance of the model in each round of training. Therefore, it is considered that in the target domain samples selected in each round, the cluster center is determined by K-means clustering, and several samples closest to the cluster center are selected for manual annotation. The mathematical formula for measuring the distance between the sample and the cluster center is:
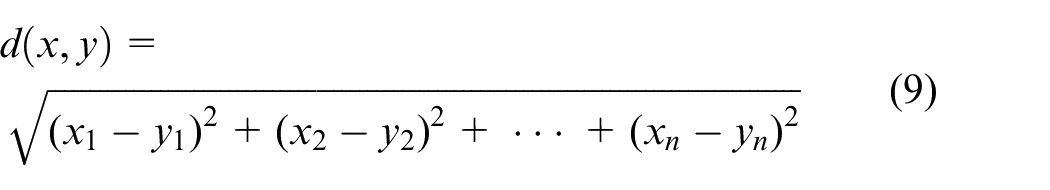
Where
Intelligent fault detection model based on LDE-ADA
Based on the analysis of the domain adaptation diagnostic model and active learning query strategy, we divide the training process of the LDE-ADA intelligent fault detection framework into three parts.
Step A: First, we pretrain a domain adaptation diagnostic model to fit the data distribution of the same health categories in the source and target domains, and learn domain-invariant features. In order to accurately select the newly added health category of the target domain, this step is crucial. Among them, the mathematical expression of the cross-entropy loss function of training the network according to the source domain samples is:
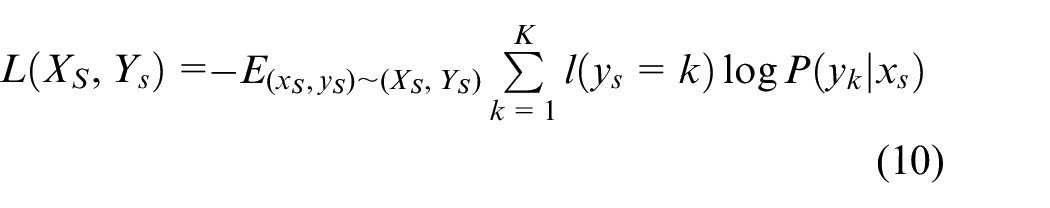

Where
Step B: In this step, on the basis of Step A, we conduct a query of newly added healthy categories in the target domain. The purpose is to use this category of samples to assist the model for retraining to solve the problem of label domain expansion. The EM method is used to measure the classifier output vector, and the samples of the target domain that are difficult to be discriminated by the model are selected, such as formula equation (8).
Then,
Step C: Finally, the selected
The training process of the LDE-ADA framework.

When dealing with unseen target domain data, the diagnostics of models often make diagnostic outputs that are overconfident and untrustworthy. 37 While minimizing the domain shift, the LDE-ADA framework uses manual intervention to correct the diagnosis of the target domain for the newly added health categories whose distribution is unknown, so as to improve the model’s ability to detect the health outside the source domain health category distribution. When the target domain distribution is unknown, the diagnosis of the LDE-ADA framework will still have high confidence.
Experimental results and analysis
Datasets and methods
Dataset
The rotating machinery dataset we use is from the public database of Case Western Reserve University, and the test object is a bearing. The test platform is shown in Figure 5. The experimental platform consists of a 2 HP motor, torque transducer/encoder, dynamometer, and control electronics. The bearings were seeded with faults using EDM, and the damage diameter is divided into 0.007, 0.014, 0.021, 0.028, and 0.04″, respectively.The bearings to be tested are divided into drive end bearings and fan end bearings. Bearing health status is divided into Normal state (NS), Inner race fault (IF), Outer race fault (OF), and Roller fault (RF). All of these are collected from the motor speed of 1797, 1772, 1750, and 1730 rpm four conditions.

Case Western Reserve University bearing experimental test bench. 38
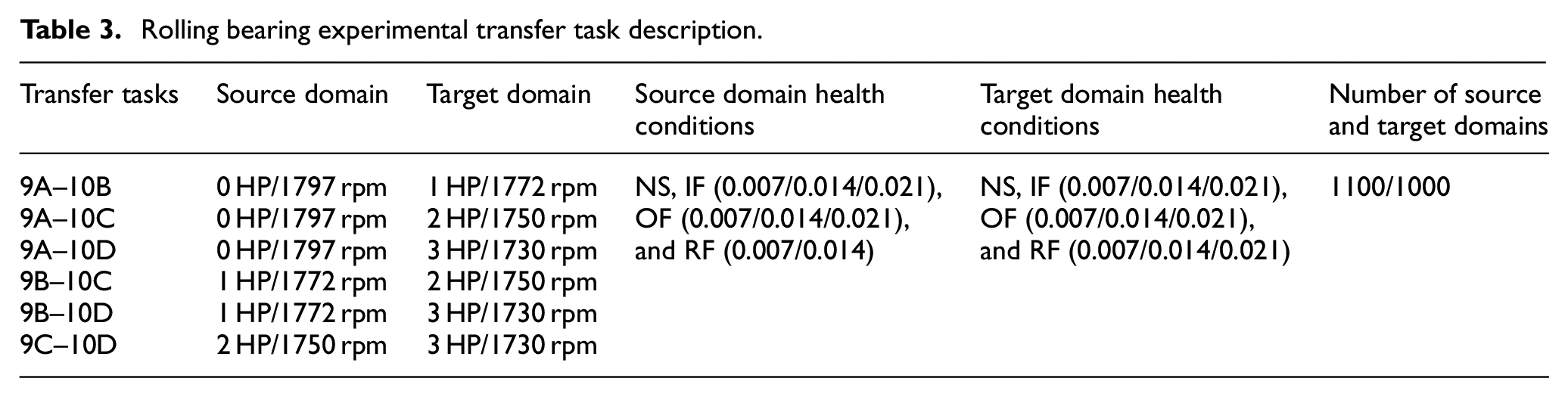
After data processing, we select the bearing dataset of the drive end for experiments. Among them, the transfer task 9A represents the nine types of health state sampling data of NS, IF, OF, and RF when the load is 0 HP. IF and OF have three damage states with diameters of 0.007, 0.014, and 0.021″. OF has two damage states with diameters of 0.007and 0.014″. Similarly, the transfer task 9B represents the sample data with a load of 1 HP, and the transfer task 9C represents the sample data with a load of 2 HP. transfer tasks 10B, 10C, and 10D represent sampled data for 10 health states at loads of 1, 2, and 3 HP. Specifically as shown in Table 3.
Rolling bearing experimental transfer task description.
Methods
In our experiments, we select two domain adaptation models, MDS-ADAN and DANN. 39 When training the domain adaptation model, set the batch size to 100 and the iteration period to 200 rounds. The AL methods involved in the comparison include LDE-ADA, Random, Uncertainty, Cluster, AC-DANN, and AADA. 29 The active learning round is set to 20 rounds, and the number of labeled samples in each round is 3.
LDE-ADA
The domain adaptation model is MDS-ADAN and the AL framework adopted is the method proposed in Section 3.3.
Random
The domain adaptation model is MDS-ADAN and the AL query strategy is to randomly select the target domain samples.
Uncertainty
The domain adaptation model is MDS-ADAN and the AL query strategy selects target domain samples for methods based on uncertainty sampling (including entropy methods and margin sampling methods).
Cluster
The domain adaptation model is MDS-ADAN and the AL query strategy is a method based on K-means clustering to select the target domain samples.
AC-DANN
The domain adaptation model is DANN and the AL framework adopted is the method proposed in Section 3.3.
AADA
The domain adaptation model is DANN and the AL query strategy is to select samples based on importance weights.
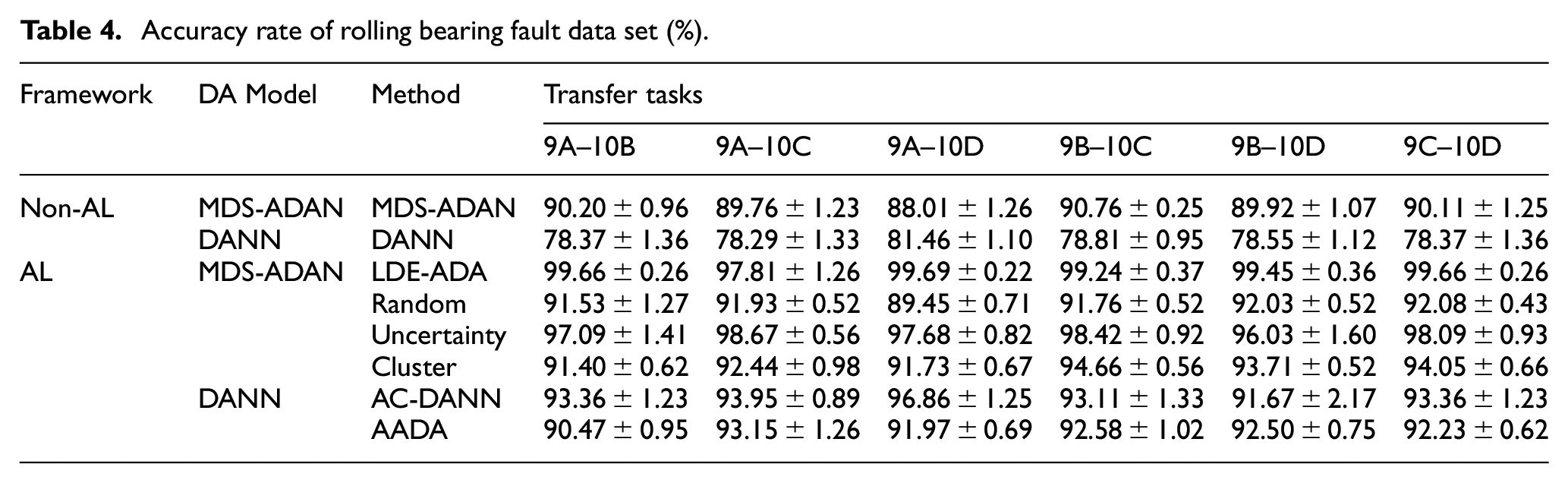
In order to ensure the accuracy of the experiment, 10 experiments are performed for each task and the average value is taken. The specific experimental results are shown in Table 4.
Accuracy rate of rolling bearing fault data set (%).
Experimental results and analysis
In order to effectively verify the detection effect of the LDE-ADA framework on the newly added health category, we show the accuracy, confusion matrix, and T-SNE visualization results for the transfer tasks 9A–10B. We illustrate the influencing factors of active domain adaptation and demonstrate the superiority of the LDE-ADA framework from the following three aspects.
Active learning: The active domain adaptation model has higher accuracy than the domain adaptation model, as shown in Table 4. Compared with the domain adaptation methods MDS-ADAN and DANN, the average accuracy of the active domain adaptation methods LDE-ADA and AC-DANN for six types of transfer tasks is improved by 9.39% and 14.56%, respectively. As can be seen from Figure 7(a) and (e), on the basis of different domain adaptation models, the active learning framework in this paper can effectively detect newly added health categories. Among them, the accuracy rate of LDE-ADA for newly added health categories is as high as more than 98%. Through the analysis of T-SNE visualization, LDE-ADA can effectively fit the feature distribution of the same category of health status, and distinguish the newly added health category as shown in Figure 8(a). This shows that the method proposed in this paper can effectively solve the problem of label domain extension.
Domain adaptation model: A good domain adaptation model is a precondition for the ADA model to be able to diagnose efficiently. A good domain adaptation model extracts more critical feature information in each round of active learning. As shown in Table 4, LDE-ADA and AC-DANN have the same query strategy, but we find that the initial accuracy of active domain adaptation is determined by the fitting effect of MDS-ADAN and DANN on the source and target domains. At the same time, the domain adaptation model is used as the training model in each round of active learning, and its ability to extract key features affects the entire training stage. If the model cannot extract the key features that fit the two domains, the results of active domain adaptation are unsatisfactory. Conversely, the stronger the fitting ability of the DA model to the two domains, the better the effect of active domain adaptation. This shows that the diagnostic capability of the active domain adaptation model is related to the domain adaptation model.
Query strategy: An excellent query strategy can select the samples that are most helpful for model performance improvement from the unlabeled target domain. As shown in Table 4, the query strategies of Random, Uncertainty, Cluster, and AADA are different. Among them, Random and Cluster have great randomness, so it is difficult to select the most valuable samples. The samples selected by these two query strategies are also difficult to improve the performance of the model, and the accuracy does not fluctuate much, as shown in Figure 6. Looking at Figure 7 at the same time, it is found that this method cannot cope with the label domain expansion problem. Although Uncertainty can pick out samples that are difficult for the model to choose, because of the existence of similar samples, the performance of the model is not as good as LDE-ADA. Compared with the latest active domain adaptation method AADA, LDE-ADA not only has advantages in the domain adaptation model, but also the query strategy can effectively select the desired samples for labeling. This shows that the diagnostic ability of the active domain adaptation model is related to the choice of query strategy.
As can be seen from Table 4, the average accuracy of the six transfer tasks is about 99.25%. From Figure 7(a), it is found that the accuracy rate of LDE-ADA for the detection of newly added health categories is more than 98%. At the same time, it is found from Figure 8(a) that LDE-ADA can effectively fit the data distribution of the source and target domains. Through the above arguments, it is proved that the method can effectively identify the newly added health categories in the target domain.
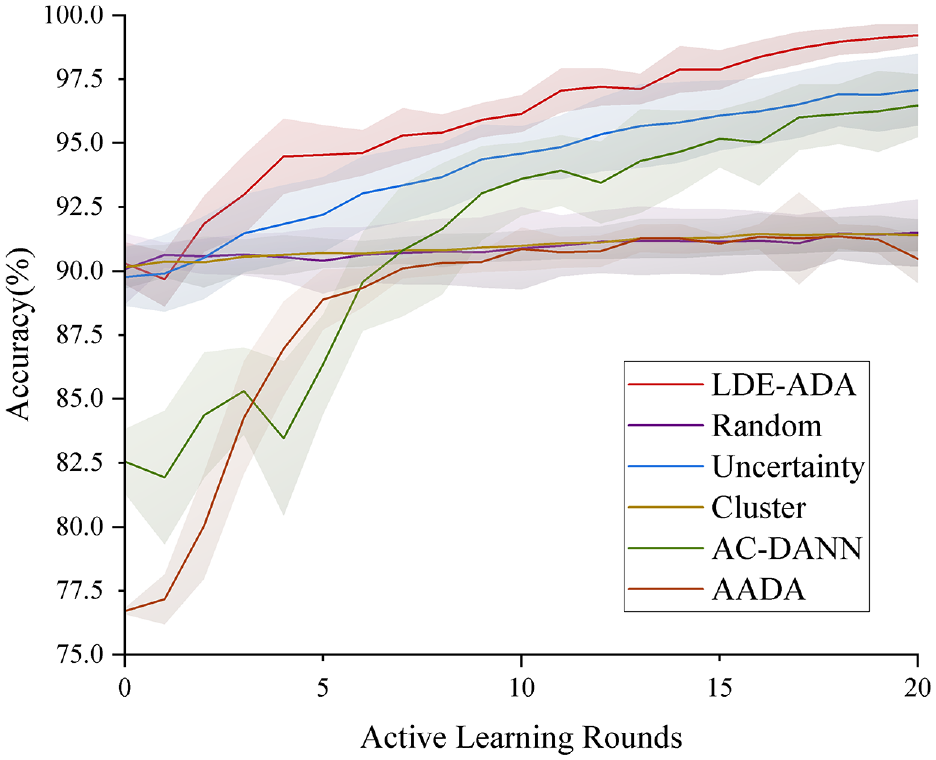
The accuracy of the transfer task 9A–10B. In order to ensure the accuracy of the results, the accuracy curve is obtained from the average value of 10 experiments.
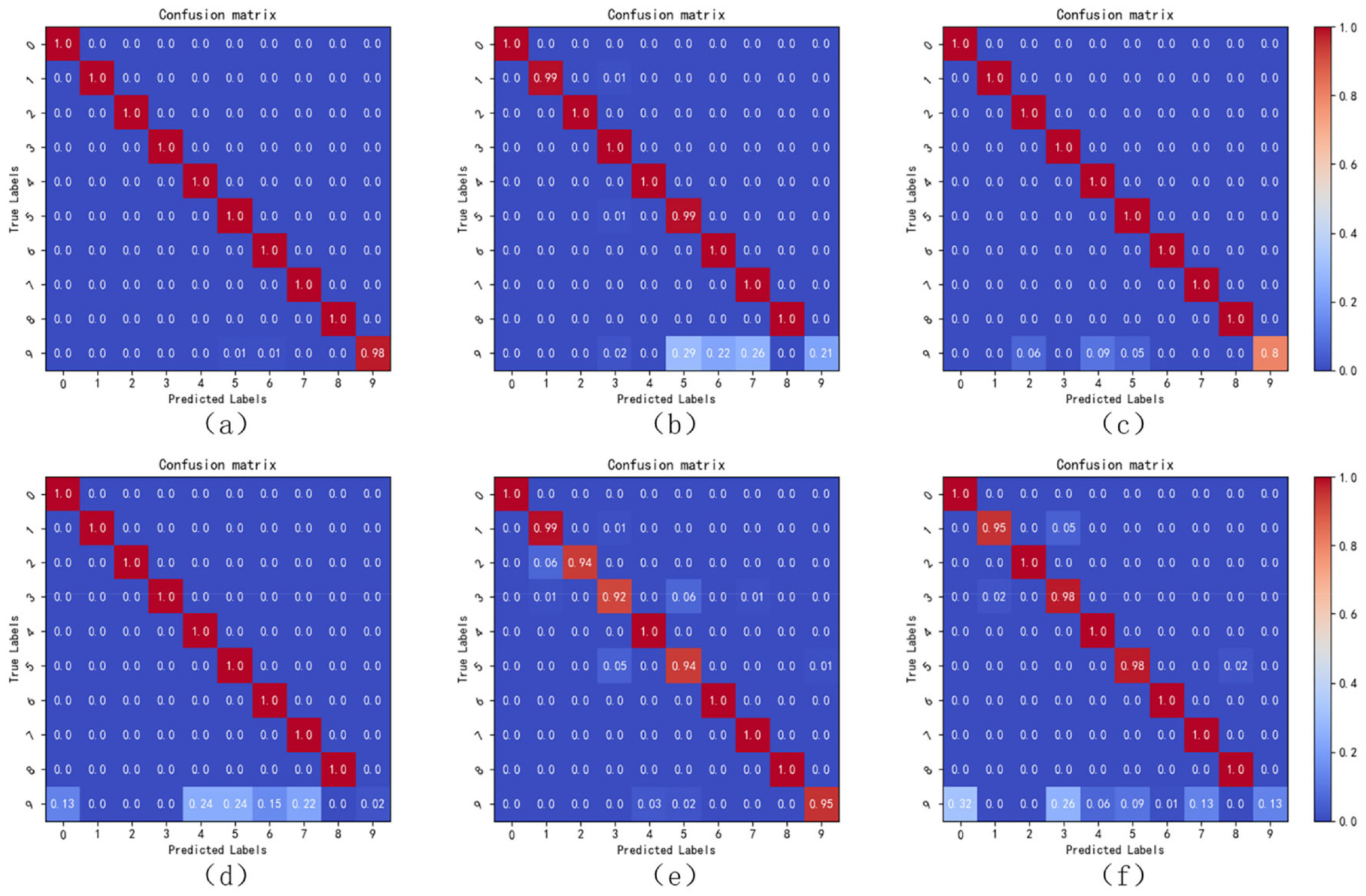
Confusion matrix of transfer tasks 9A–10B, where the horizontal axis is the predicted label, the vertical axis is the true label, and the label 9 is the newly added health category. Where (a), (b), and (c) are the confusion matrix accuracy rates for each category label of LDE-ADA, Random, and Uncertainty, respectively. (d), (e), and (f) are the confusion matrix accuracy of each category label for Cluster, AC-DANN, and AADA, respectively.
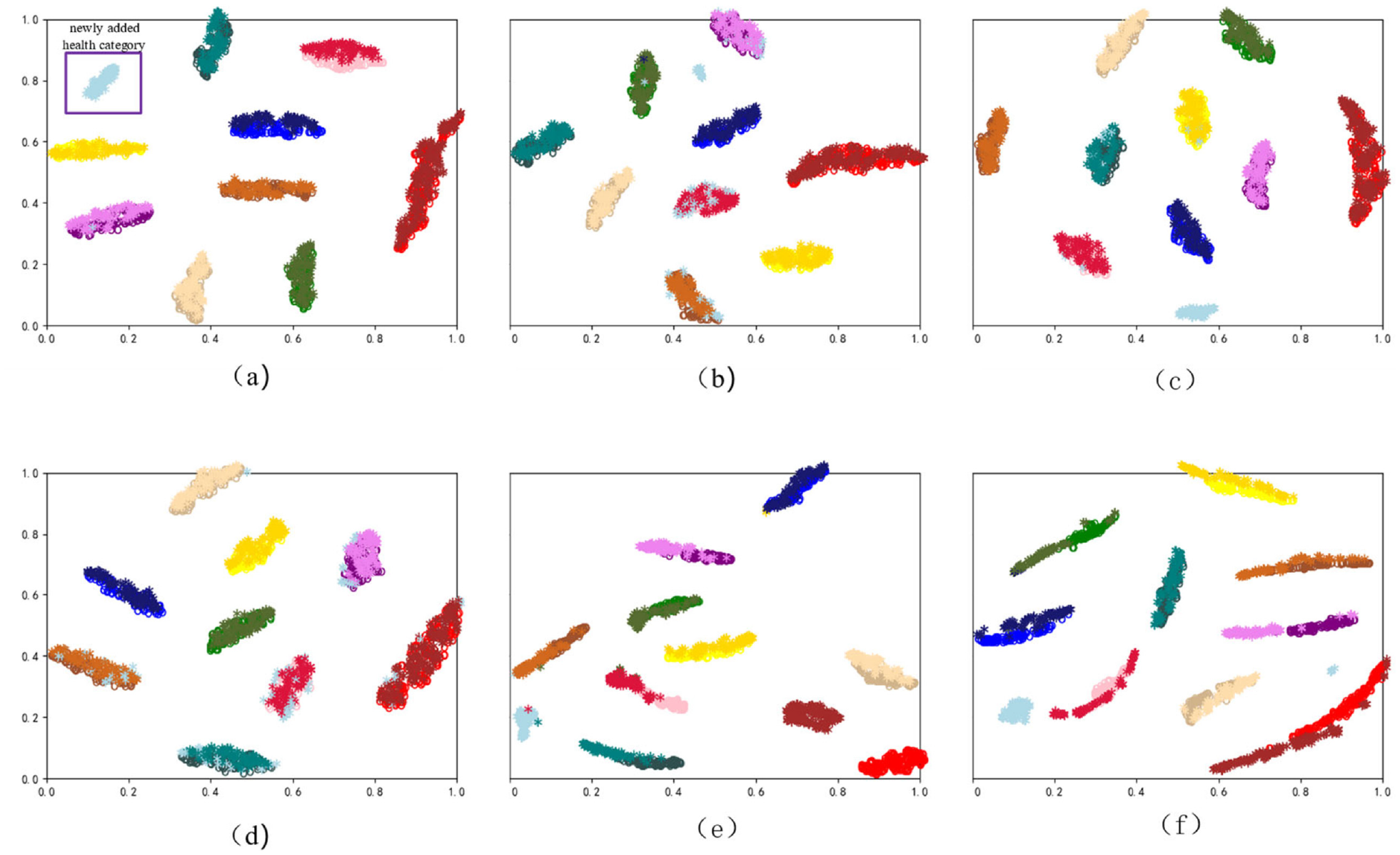
T-SNE visualization of transfer tasks 9A–10B. Where (a), (b), and (c) are the visualization results of LDE-ADA, Random, and Uncertainty, respectively. (d), (e), and (f) are the visualization results of Cluster, AC-DANN, and AADA, respectively. “o” represents 9 types of data in the source domain, and “*” represents 10 types of data in the target domain. The purple box in (a) is the newly added health category.
Research on the number of annotations
Further study the relationship between the number of newly added health categories in the target domain and the number of labeled samples per round of LDE-ADA. We compare and analyze the diagnostic effect of the model when the number of newly added health categories is 1, 2, and 3, and the number of labeled samples is 3, 5, and 10. The details are shown in Table 5, in which each experimental result is obtained by taking the average of five experiments.
Research on the relationship between the number of annotations and the number of newly added health categories.
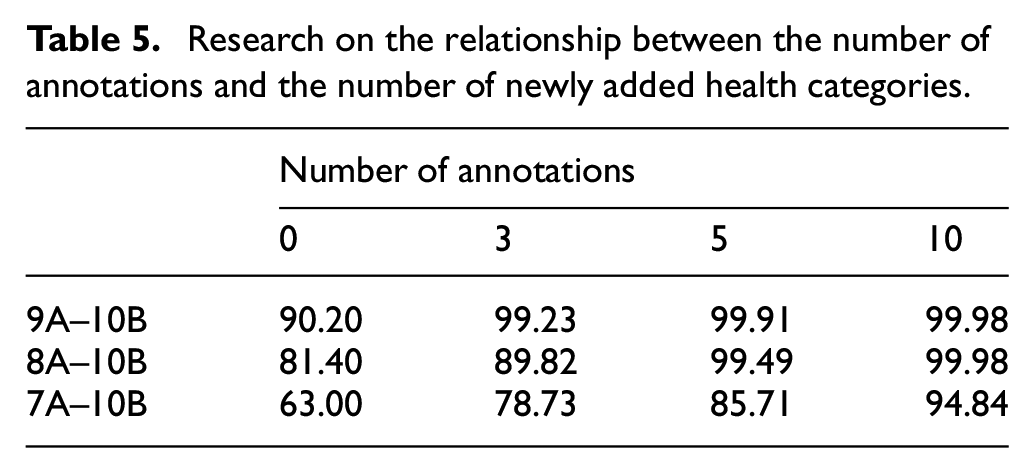
It can be found that with the increase of newly added health categories in the target domain, LDE-ADA labels three samples per round cannot meet the diagnostic conditions. One way to solve this problem is to increase the amount of annotations per round. When the number of newly added health categories reaches 3, increasing the number of labeled samples in each round to 10 can increase the accuracy rate to over 94%. Observing the experimental results of selecting 10 labeled samples in each round, it is found that the diagnostic effect of LDE-ADA is related to the number of labels. The more newly added health categories are added to the target domain, the more target domain samples need to be labeled in each round to improve the performance of the model. In Table 5, observing the experimental results of the transfer tasks 9A–10B, it is found that the more samples are labeled in each round, the greater the improvement of model performance.
Conclusion and future work
To deal with the label domain expansion problem, this paper proposes a diagnostic framework LDE-ADA based on active domain adaptation. The framework is divided into three stages: the first stage, pre-training the DA model. While correctly classifying the source domain samples, domain-invariant features are learned by optimizing the MMD loss function and adopting an adversarial strategy. In the second stage, an improved active learning query strategy is used to select the target domain samples that improve the model performance the most. In the third stage, the model is retrained using the labeled fusion sample set, and the above steps are repeated. Experiments show that the generalization ability of the framework is remarkable, and the diagnostic performance of the DA model embodied in the LDE-ADA framework has been improved. At the same time, when the target domain has more health categories than the source domain, it can effectively detect the newly added health categories.
we analyze the influencing factors of active domain adaptation and find that the diagnostic effect of active domain adaptation model is related to domain adaptation model, query strategy and the number of labeled samples per round. The domain adaptation model determines the fitting effect of the data distribution of the source and target domains. The query strategy determines the selection ability of valuable samples for each round. The number of labeled samples in each round determines the speed at which the model’s ability is improved. Next we apply this framework to more areas to explore more factors that influence active domain adaptation.
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Project of the National Natural Science Foundation of China (no. 51204185, 51974295), Jiangsu Postgraduate Research and Practice Innovation Program Project (2021ALA02016), the Graduate Innovation Program of China University of Mining and Technology (2022WLJCRCZL267), and the Postgraduate Research & Practice Innovation Program of Jiangsu Province (KYCX22_2653).