
Abstract
We examine whether it is worthwhile eliciting subjective judgements to account for dependency in a multivariate Poisson-Gamma probability model. The challenge of estimating reliability during product design motivated the choice of model class. For the multivariate Poisson-Gamma model we adopt an empirical Bayes methodology to present an estimator with improved accuracy. A simulation study investigates the estimation error of this estimator for different degrees of dependency and examines the impact of dependency being mis-specified when assessed by subjective judgement. Our theoretical and simulation findings give analysts insights about the value of eliciting dependency.
Keywords
Introduction
Probability modelling is an established means of representing and analysing uncertainties associated with risk and reliability problems. Dependencies between uncertain variables expressed probabilistically require appropriate modelling to provide meaningful results. Consider a problem that can be characterised by multiple uncertain variables, then dependency will arise if information for one variable provides information about other variables. That is, the conditional expectation of a variable differs from its unconditional expectation. Some modelling classes explicitly capture dependency within the probabilistic structure. For example, Bayesian belief networks (BBN) reported in a range of contexts1–3 as well as multivariate distributions for risk and reliability problems.4–7
Quantifying probability models with dependent variables means that the joint, or conditional, probability distributions need to be expressed in addition to the marginal probability distribution. Data might not be available to support such quantification for various reasons. For example, if the purpose of the model is to support analysis of the reliability of new designs or during product development, or if the model is to analyse risk in a context with rare events, then in such contexts observed events might be unavailable in whole or part given the nature of the data generating processes. We could also encounter situations, say for operational systems, where data might be too expensive to collect. An alternative to data can involve assessing dependency by eliciting subjective probabilities.
Many methods and processes for the structured elicitation of subjective probabilities exist.8–10 Specifically, there has been consideration of the particular challenges of assessing dependency using subjective judgement.11–13 A comprehensive literature review of issues associated with assessing dependency via elicitation is given in Werner et al. 14 This review emphasises the need for a structured approach to support the assessment of informed subjective judgements and to explore particular issues, such as cognitive fallacies, that might affect the accuracy of the assessments made. Methods for elicitation of probabilistic dependency are summarised and classed as direct models (this includes many approaches used in risk and reliability such as BBN, multivariate distributions) and indirect models where auxiliary methods are used (such as regression models). While the majority of methods considered by Werner et al. 14 express judgements as probabilities, they also consider methods that express dependencies using moments, referencing 15 who evaluated this approach for modelling the reliability of new system designs to inform assurance decisions. Building on their review in Werner et al. 14 an elicitation process for dependent events is proposed in Werner et al. 16 This process is designed to mitigate the particular cognitive challenges associated with eliciting dependency.
We argue that representing dependencies appropriately is important if we are to build good models for risk and reliability problems. However drawing on the literature 14 and references therein, as well as, for example,2,8,17,18 we also recognise that eliciting dependency for real model building is challenging and resource intensive. This leads us to ask whether eliciting dependency is worth the effort?
We do not seek to provide a universal answer to this question. Rather, we investigate this issue for a particular multivariate probability model, a Poisson-Gamma model. This model has underpinned analysis for real industry problems. For example, recent modelling (involving two of the authors) to support decisions about the reliability of a one-shot system during new product development. This was a new generation of a product design family for which data from earlier design generations was deemed relevant for some elements of the new system together with test data generated for the new design throughout its development project. A correlation parameter represents the dependency in the multivariate Poisson-Gamma probability model used for this reliability estimation problem for the new design. The dependencies were elicited from suitably qualified engineers using a structured process based on the method described in Quigley and Walls. 19 This elicitation methodology maps the model parameters to the engineering expertise then uses relevant data (say from related past design elements and/or test) to quantify the dependency in view of the elicited judgements. The elicitation approach, grounded in a specifically designed defensible protocol, was resource intensive. It was also cognitively demanding for those expressing their subjective assessments despite having adopted an approach which asked engineers to express their engineering, rather than probabilistic, expertise.
This research aims to investigate, in the context of the multivariate Poisson-Gamma probability model, whether accounting for correlation in the analysis is worth the effort. To address this aim we state two objectives which examine the statistical value of modelling dependency, thereby enabling an analyst to trade-off the wider benefits and the costs of elicitation. Our first objective is to examine the benefits towards error reduction, and hence estimation accuracy, when we explicitly account for the correlation in the model. Our second objective is to explore the consequences of the correlation being mis-specified when assessed via subjective judgement elicitation. Our findings contribute new insights for this particular probability model by providing a formula to express the mis-specification error in the dependency parameter. Although our results are limited by both the chosen probability model and its parameter sets examined, we provide analysts with an approach to considering modelling choices applicable to a wider classes of probability models with dependency.
The paper is structured as follows. First we present an estimator for the multivariate Poisson-Gamma model that pools data from correlated processes and should result in reduced model estimation error. We develop this estimator through a comparative argument based on alternative inference approaches. We describe a simulation study to investigate the accuracy of the proposed inference approach given the degree of dependency (controlled through the correlation parameter) and the amount of data (controlled by the number of processes in the pool). This study is extended to further examine the impact of subjective mis-specification of the correlation parameter. We conclude by reflecting on the limitations of our study, the implications of our findings and provide suggestions for further work.
Model and inference framework
Our first objective is to develop an understanding of how pooling data from similar processes can reduce estimation error. Specifically, we consider Homogeneous Poisson Processes (HPP) and we adopt an empirical Bayes framework to support the inference under the assumption of Gamma marginal prior distributions. These are conjugate to the Poisson and so are mathematically convenient as well as flexible. To motivate the value of the proposed inferential framework for our multivariate Poisson-Gamma model, we develop our reasoning through comparisons with standard methodological approaches. After describing a classical inference approach, which provides a benchmark for later assessing estimation error, we present the Bayesian approach and show the theoretical error reduction resulting by incorporating prior information. Since expressing subjective judgement in the form of a prior distribution can be challenging and resource intensive to elicit, 20 we are motivated to present an empirical Bayes approach where the Bayes mechanism is used but the prior distribution is estimated by pooling data on similar processes. Finally in this section we consider the pooling of data from multiple processes which are measurably correlated in their underlying mean rates, such that data from other processes can be explicitly incorporated into the inferential updating to reduce estimation error.
Classical inference
Under classical inference we assume a probability model that measures the variation in the data as a function of a parameter. We consider a Poisson distribution with parameter
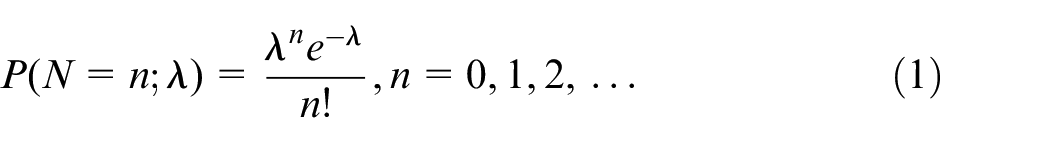
A typical classical approach to estimation would be either to estimate

To assess the accuracy of such an estimator we treat the data as random variables from the probability distribution and evaluate the Mean Square Error (MSE) which is given by:
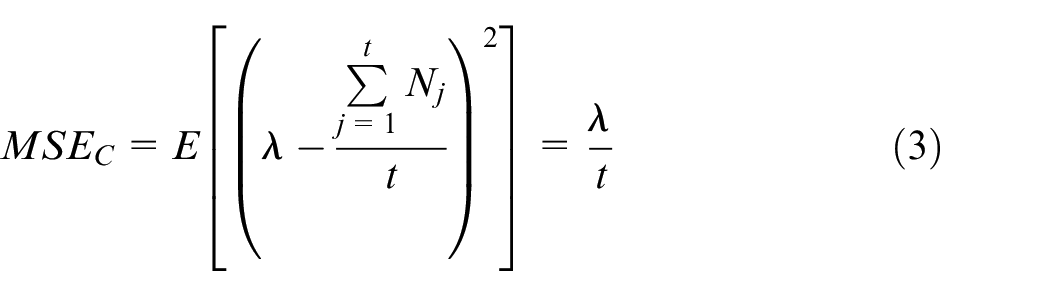
The
Bayesian inference
Under Bayesian inference we again assume the Poisson distribution but now consider it as a conditional probability distribution assuming the true mean, denoted by
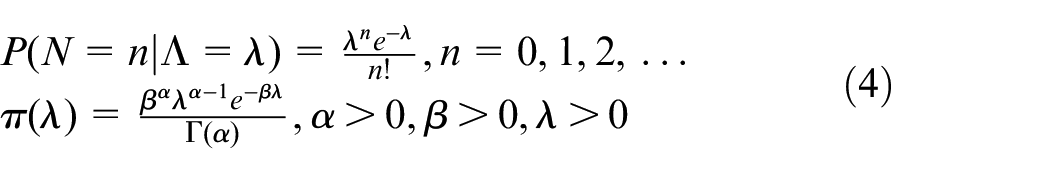
Combining the Poisson and Gamma models, we obtain the predictive distribution which is essentially a weighted average of Poisson distributions where the weights are provided by the prior distribution. For this combination of Poisson and Gamma, the predictive distribution is in the form of a Negative Binomial distribution:
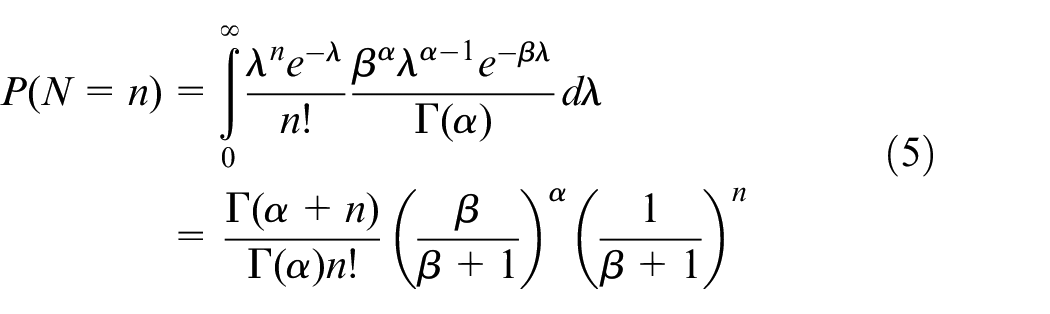
Since Bayesian inference incorporates prior information on the process then the mean prior, denoted by

Once data have been observed on the process (such as the aforementioned
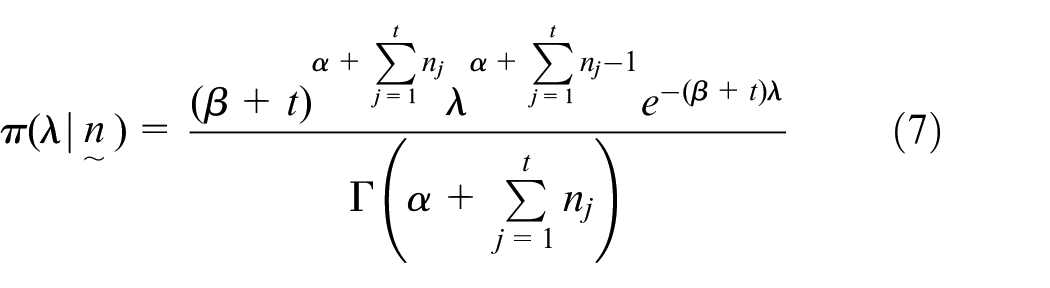
The associated posterior mean is:

To facilitate comparison with the classical inference for the same model, we calculate the MSE assuming a Bayesian framework by first averaging over the mean and subsequently over the data that will be realised to obtain:
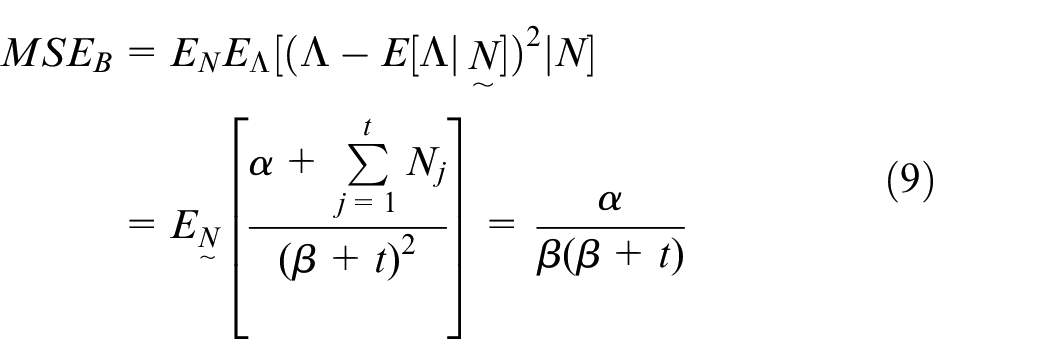
The
Empirical Bayes inference
An empirical Bayes inference approach presumes we have a pool of Poisson processes, each with their own
The empirical Bayes estimator for the Poisson-Gamma model is given by:

where the estimators of the prior distribution are denoted by
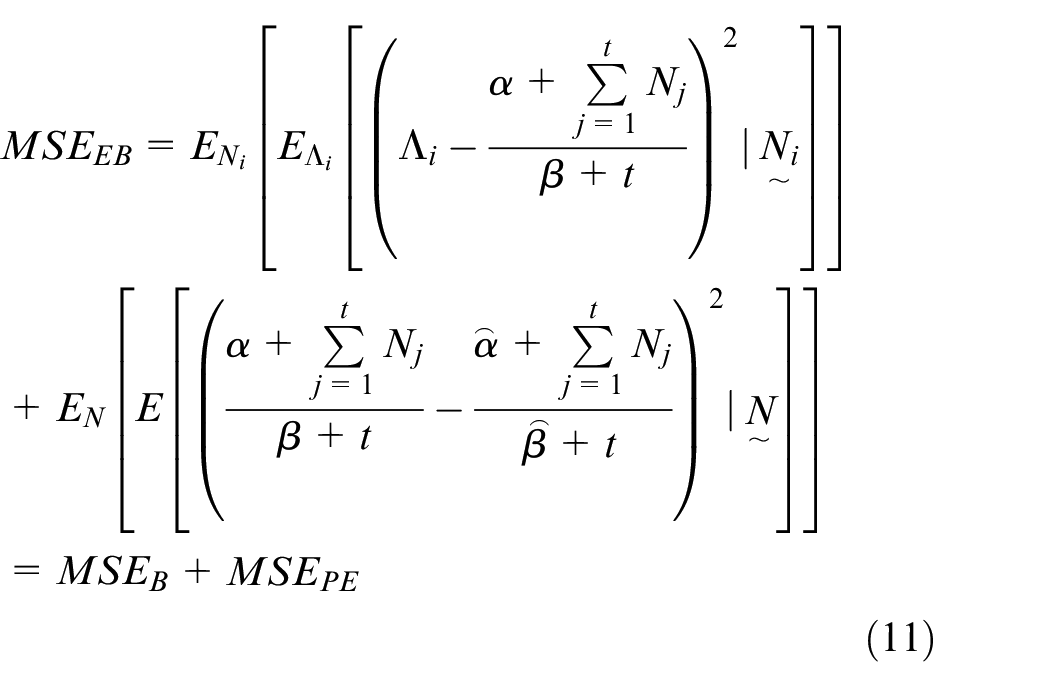
The
Dependency between processes
We now consider the situation of primary interest where we wish to include data that is correlated with a process of interest with the aim of reducing
As a motivating example, we could consider estimating the rate of occurrence of major accidents at a specified location. By pooling data on major accidents across multiple locations then an empirical Bayes estimator could be derived to improve the accuracy of the estimators. However, we can also include data on minor accidents at each location where the rates are likely to be correlated with each other but not necessarily perfectly. As such, the data from the minor accidents for the same location can have a direct impact on reducing the
Here we propose a framework that could be operationalised with a Bayesian or an empirical Bayes approach to inference depending upon how the prior parameters have been obtained. Let

For
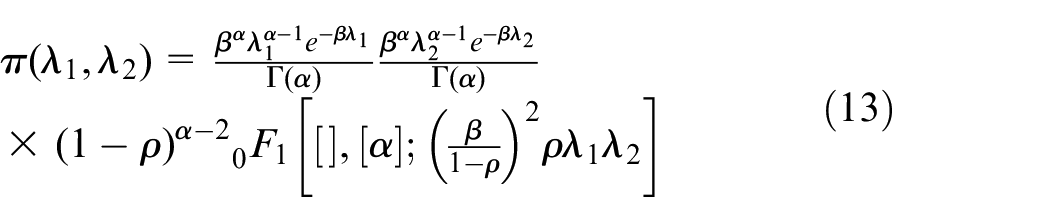
where
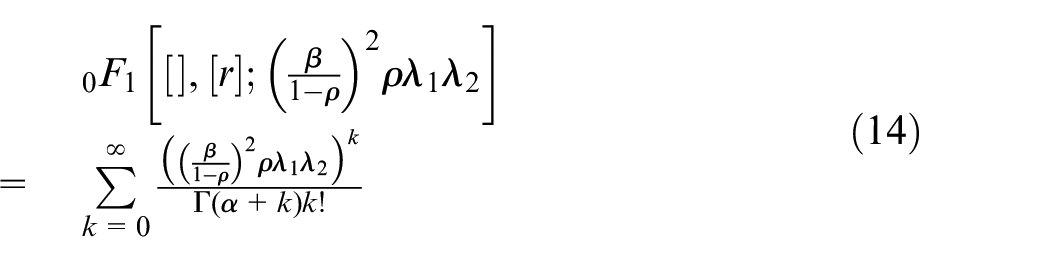
For
The bivariate Gamma distribution in equation (13) was first proposed as a multivariate prior for an HPP by Quigley et al. 4 where many of the results we require are derived. Here we state only those results which are key for our research. The posterior mean for this model which is given by:
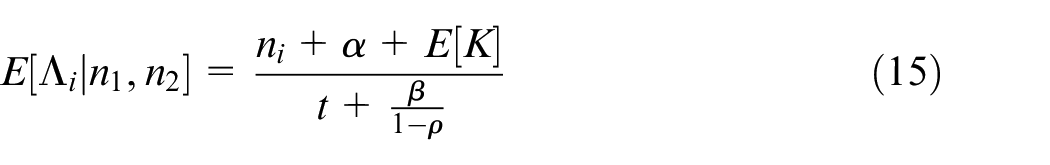
where
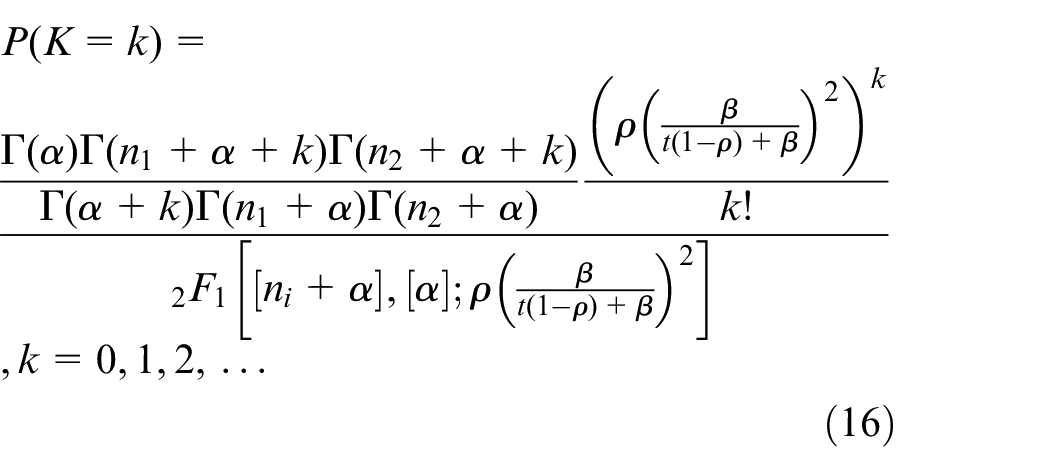
Further Quigley et al. 4 show that:

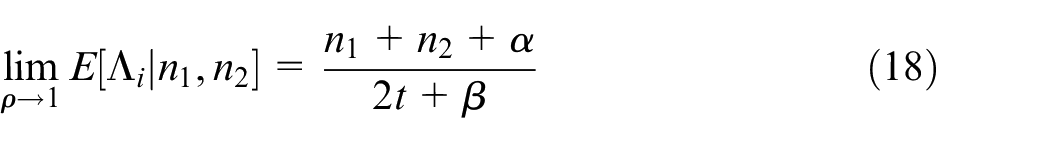
These results indicate that as the correlation approaches 0, we obtain the Bayes estimate for the multivariate Poisson-Gamma model. Also, as correlation approaches 1, we obtain the same estimate as we would derive if all
Hence now that we have presented an estimator that, by pooling data from correlated processes, should reduce estimation error, we investigate the accuracy of this method for changes in the degree of correlation and the size of the pool of processes.
Simulation study for estimation error
We conduct a simulation study to investigate the MSE of the estimator obtained from pool dependent data, where the parameters of the marginal distribution are estimated from observations using an empirical Bayes approach but the correlation parameter is specified through subjective judgement. This reflects the general modelling situation where engineering experts identify relevant data sets and provide a measure of their similarity between these data sets. Specifically this is the case for our motivating industry problem when we estimated the reliability of a new variant engineering system design.
After describing the simulation study design, we discuss the conditions that lead to under dispersed data being generated in our simulations under dispersion occurs when the variance of the Negative Binomial distribution used to model the distribution of the data in the pool is less that the corresponding mean. Then we present the results from the simulation study and provide an expression that relates the MSE to correlation and pool size.
Study design
We assume the correlation between two processes has been specified by subjective judgement but that the marginal Gamma distributions have been estimated with observed data, hence an empirical Bayes inference approach is adopted (e.g. following Quigley and Walls
19
). We assume a pool of HPPs each with a pair of correlated observations. The purpose of the study is to assess the impact of the correlation (


where
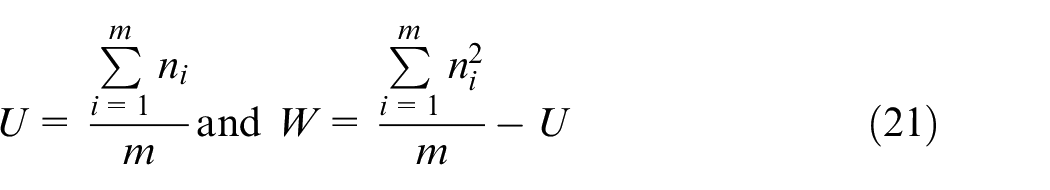
A range of values are specified for the three parameters we wish to control in the simulation study correlation, pool size, shape parameter of the marginal distribution as shown in Table 1.
Parameter values controlled in the simulation study.
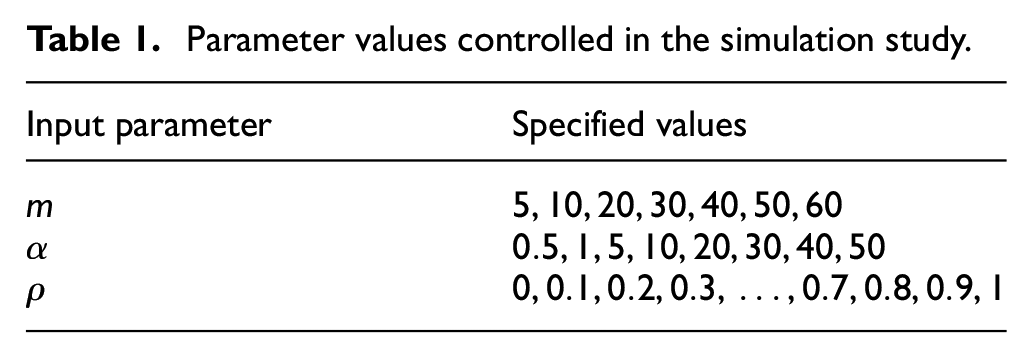
Parameter values controlled in the simulation study.

The algorithm for the study is as follows.
Treatment of underdispersion
Since we use a Negative Binomial distribution for the data in the pool when sampling from Poisson-Gamma model we risk encountering the problem of underdispersed data, as discussed in Kokonendji et al. 24 Underdispersion occurs if the variance of the Negative Binomial distribution is smaller than its mean due to sampling and compromises the moment estimator proposed by Quigley et al. 23
Figure 1 shows the probability of underdispersion given the choice of pool size and shape parameter across all simulation combinations in our study. The plot shows that the highest chance of underdispersion ocurring is for our smallest combination of shape parameter and pool size (
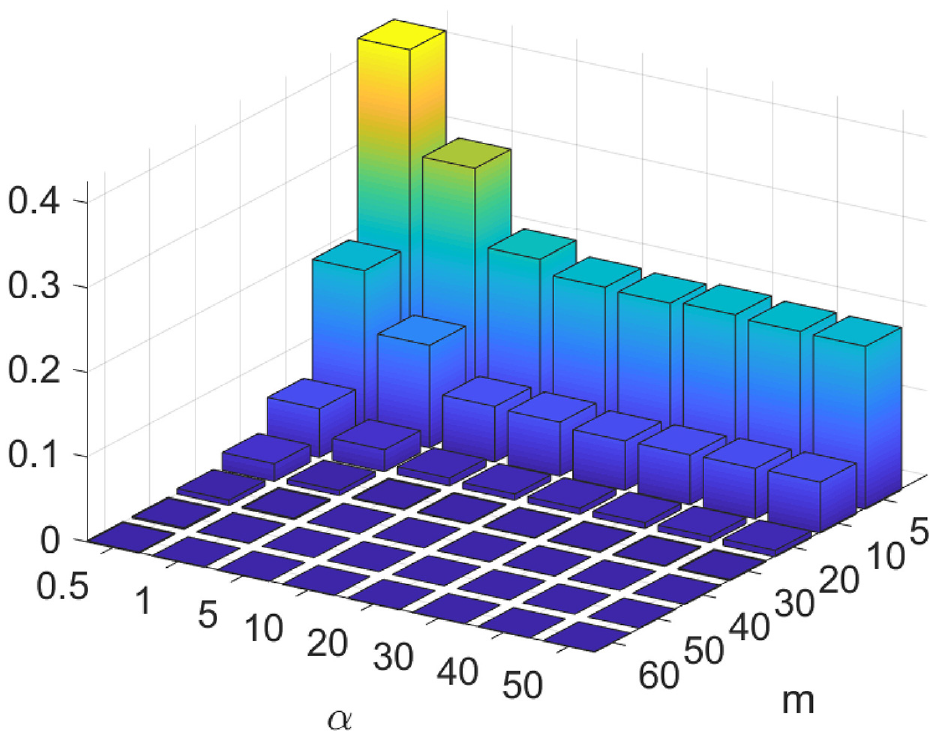
Probability of underdispersion for simulation combinations of shape parameter and pool size.
MSE results
We now consider the findings of the simulation study to examine the impact of the shape parameter (
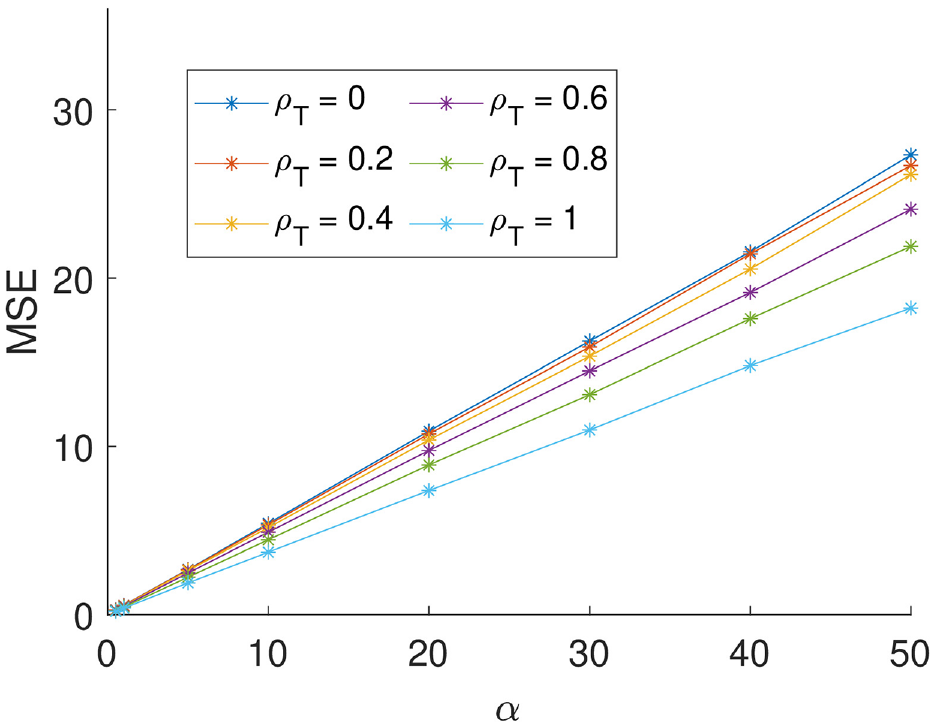
Relationship between MSE and the prior shape parameter for pool size = 20 and selected values of the true correlation.
Next we examine the relationship between the ratio of
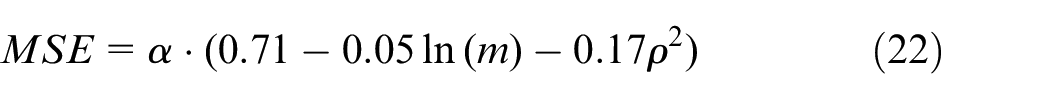
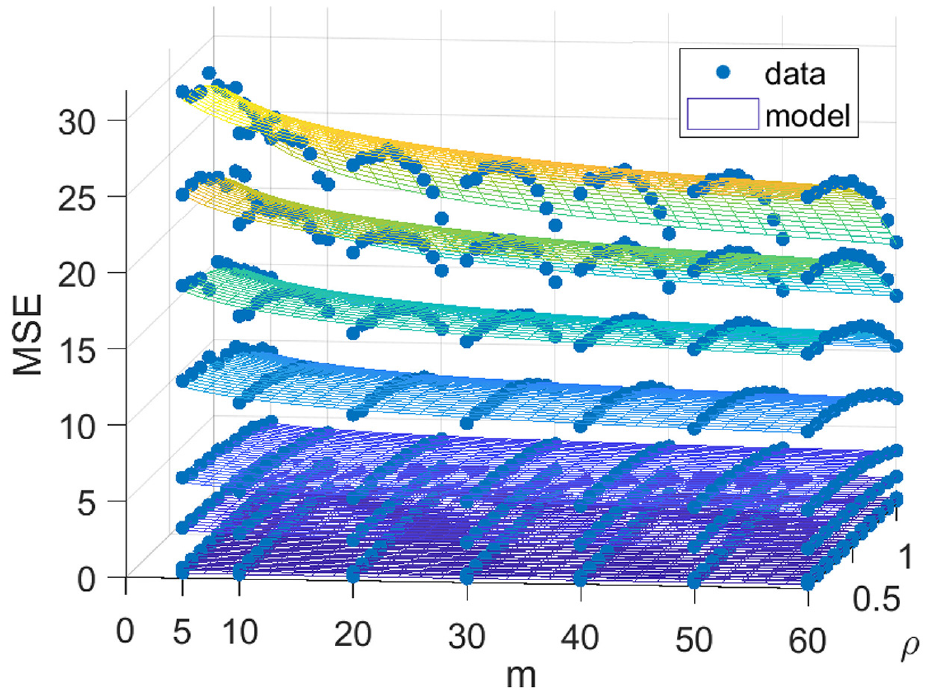
MSE at different values of shape parameter α for settings of pool size and true correlation parameter with fitted model of the form
Interestingly we find that the interaction terms between
While this regression model is defensible only for the range of parameter values used in the simulation study, we can build upon our earlier consideration of the inference approaches to develop analytical results to provide the limit of the MSE as


The difference between these two limits,


Therefore, extrapolating our regression model would underestimate the MSE when processes are independent and overestimate the MSE when processes are perfectly dependent.
Dependency mis-specification
Let us now investigate the implications of mis-specifying the correlation parameter. We extend the simulation study to explore situations where we assume a correlation
Figure 4 shows the relationship between the MSE and
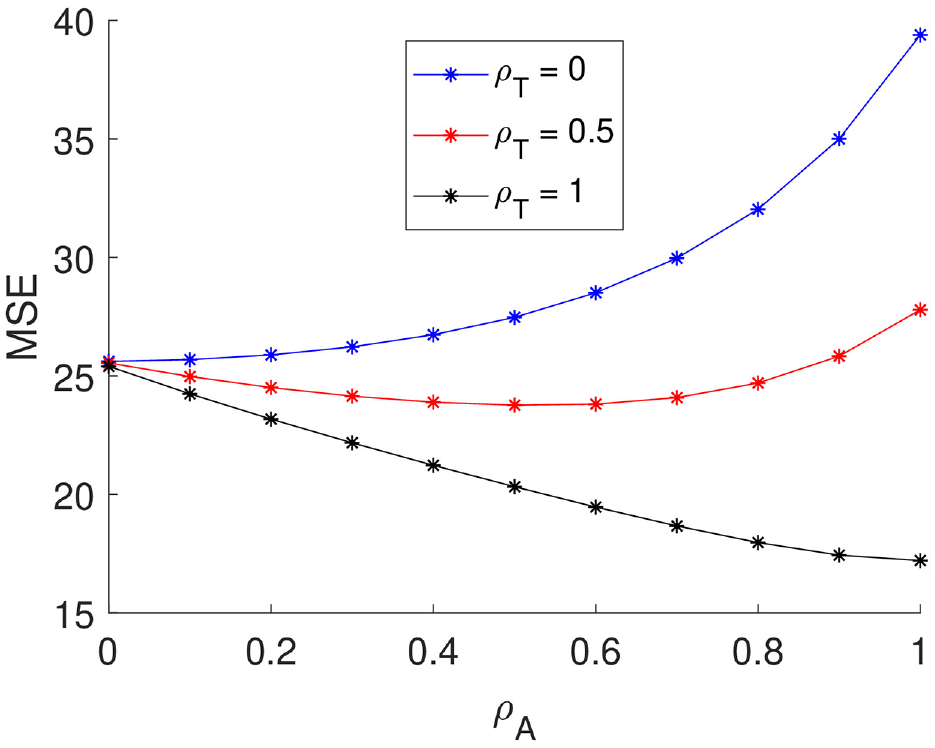
MSE when correlation is mis-specified, where
By assuming a true

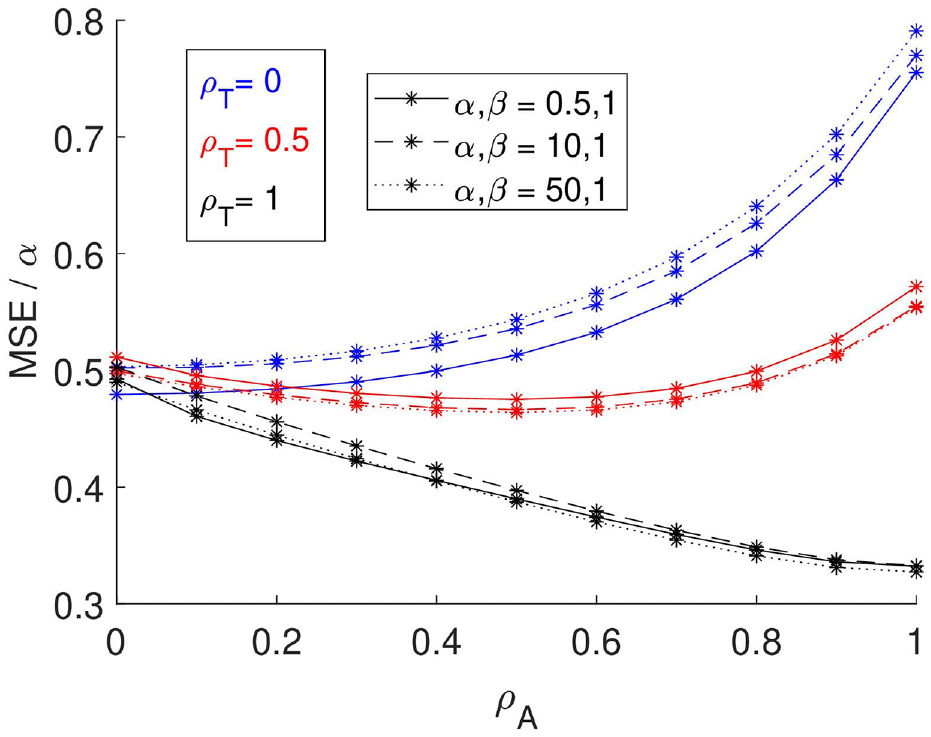
Therefore, incorporating data under the assumption it is realised from the same HPP (i.e.
Conclusion and further work
Our study has investigated the effect of incorporating data that is correlated with the event process of interest to reduce estimation error. This requires the correlation between processes to be assessed by subjective judgement, which under many circumstances can require a resource intensive elicitation exercise. Through our study we have explicated the relationship between correlation, pool size and MSE within the context of a particular probability model to provide insight as to whether gains from MSE reduction are worth the cost of elicitation.
Empirical Bayes is a rich methodology offering the opportunity to gain the benefits of error reduction enjoyed by the Bayesian methodology but without the same elicitation burden for subjective assessment with its recognised associated biases. Empirical Bayes relies on pooling relevant data together. It is well known that the more homogeneous this data pool, then the stronger the inference in the sense that the estimation error will be smaller. One way of homogenising the pool is to assess correlations between processes and so discriminate between degrees of similarity for the events of interest. For example, in our motivating industry case, the events related to failures, the candidate pools were formed by data on events experienced by earlier design generations or on test for the new system design, and the correlation was assessed by engineering experts via a structured elicitation. However, regardless of how well this elicitation was constructed and managed there still lurks the possibility that the dependency is mis-specified. This will be the case more generally too when we develop risk and reliability models with probabilistic dependencies.
Our study has explored the impact of corrupting the inference through mis-specifying the correlation. We have derived a formula to explicate the MSE in relation to the parameters of the marginal distribution under cases of assumed assessed and true correlations. A more general derivation is shown in the Appendix. Such formulae can inform analytical choices about the incorporation of data from perceived correlated processes by aiding assessment of the consequences. These findings can guide practical choices about the elicitation method selected to support inference about the reliability of a new system design or other applications where a multivariate Poisson-Gamma model is appropriate. Further, the methodological approach we have adopted to assess an understanding of mis-specification could be applicable to examine the implications for estimation errors for a wider class of probability models.
Is elicitation worth the effort? Rather anti-climatically, our answer is it depends. It depends on how accurate the results need to be so that the value of elicitation can be assessed in relation to a fuller consideration of the costs and benefits. Costs include not only the time and effort to plan and conduct an elicitation but also the cognitive burden to those providing subjective assessments. For the particular context of our study, the value depends on the potential of the candidate correlated processes. This potential is determined by both the correlation as well as the characteristics of the marginal distribution, since the benefits of eliciting the dependency are found to be proportional to the shape parameter in our study for a multivariate Poisson-Gamma model.
There are a number of limitations of our study even within the context of HPPs. First, we had a specific form to our multivariate prior distribution. It would be interesting to investigate the sensitivity to the form of this distribution to both the dependency structure and the marginal distributions. Second, it would be interesting to explore the impact of using data to assess the correlation between processes to allow a full empirical Bayes solution to be found. Thirdly, it would be of value to develop a value of information framework to coherently assess the decision as to whether more precise assessments of correlation is worth learning. This latter point opens up questions in relation to probability models with dependencies more generally and need not be constrained to the particular model considered here.
Footnotes
Appendix
The general derivation of the Mean Squared Error (MSE) is as follows:
The moments under different assumptions are given by:
Substituting the moments into the expression for the MSE results in the following:
This form is as we would expect because we are ignoring the information from
Assuming dependence when the rates are independent results in the following:
Assuming dependence when the rates are dependent results in the following:
Again this is as we would expect because we are correctly using a Bayesian approach with two observations.
Setting
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) received no financial support for the research, authorship, and/or publication of this article.