
Abstract
Reliability engineering is today a well-established field, accounting for many scientific journals and conferences, educational programmes and courses, academic positions and societies. There are also many standards which guide the practice of reliability engineering, and every year a number of scientific papers are published which address reliability engineering issues. Yet the area faces many challenges, in particular when addressing systems characterised by large uncertainties, and accurate prediction models are not easily established. We see alternative analysis perspectives being advocated, with varying degrees of theoretical justification. This article argues that there is potential for improvements to be made in terms of both theoretical frameworks and the practice of reliability engineering to meet these challenges and guide reliability engineers and decision-makers. Examples relate to the understanding and treatment of uncertainties, and the use of ideas and methods from risk management. Clear recommendations are provided on how to obtain such improvements.
Introduction
There is no broadly accepted way of defining reliability engineering. However, looking at the many definitions found in the literature, it is possible to integrate most of them into the following definition: ‘reliability engineering is all activities carried out to obtain the “right” reliability of a technical system, through the various life cycle phases of the system’. We will use this in the following discussion. The term ‘right’ is important here, as it indicates that the level of reliability needs to be seen in a context where other concerns are also of importance, including risk and costs. We cannot view reliability engineering in isolation from engineering in general, risk management and economic aspects. 1
To further clarify the meaning of reliability engineering, we need to define the concept of reliability. Again many definitions exist, but they all relate to the system’s ability to function as intended. In line with measurement theory and the new Glossary from the Society for Risk Analysis, 2 a distinction is made between the concept of reliability and how to measure or describe the reliability. Formally defining system reliability ‘as the ability of the system to perform its intended function’, we may specify many ways of measuring or describing this ability. Traditional metrics used for this purpose are defined using probabilistic expressions, such as the probability that the system will fail in a specified period of time, the expected time to failure and the expected number of failures in a specific period of time.
For a historical review of the concepts of reliability and reliability engineering, see Saleh and Marais 3 and Zio. 4
Seeing reliability engineering as ‘all activities carried out to …’, we are led to the need for structuring these activities, and one way of doing this is expressed through the following two main goals:
Understand the system and its reliability, including How it works and can fail? How performance (also capturing failures and failure proneness) changes over time? How the system performance is affected by stress, shocks and so on? How the system performance is affected by maintenance, testing and so on? How early signs of failure conditions can be identified?
Use of this understanding to obtain the ‘right’ reliability for the system, by better designs, more effective maintenance policies and so on.
To meet these goals, reliability engineering has developed a number of approaches, models and methods. For example, in relation to (1a), we use standard tools such a failure mode and effect analysis (FMEA), fault tree analysis, event tree analysis and Bayesian networks. To develop, represent and express this understanding, we use models: for example, a fault tree, a stress-strength model, a model linking maintenance policies and performance and a prognostic model linking early signals with system failure. Performance and failure are associated with uncertainties, and these we represent and express using suitable measurement tools. Probability is the most common tool but there are also others, and we will come back to these later.
To obtain the ‘right’ reliability, measures and arrangements are looked into to see how we can best obtain desired objectives. The reliability engineering field has developed methods for how to support the decision-making on these issues, such as how to find the best maintenance policies.
There is a huge amount of literature on these issues and it is growing fast.4–6 In his review, Zio 4 points to the key methodological challenges that the field faces, as well as factors driving the field, such as the increased complexity of systems, larger uncertainties and security issues. As discussed by Zio, reliability engineering has from its infancy been challenged by some fundamental tasks: system representation and modelling, reliability quantification and the treatment of uncertainties. If we look at the papers of today, we see that the same issues still represent huge challenges for the field. For example, it is common practice to reject the probability-based approach to reliability analysis and use alternative approaches applying the argument that probabilities cannot be determined. However, subjective probabilities can always be assigned. Hence, the argumentation for using an alternative to probability for representing or expressing uncertainty must follow other lines, but is seldom seen. The issue is important as it affects the way in which reliability analysis is conducted and how the results are presented and communicated to decision-makers.
Another challenge relates to risk. Think about system reliability in the case of some potential surprising or unforeseen events (black swans). Should not the reliability engineering also be able to take into account such risks? Yes it should, and to some extent current practice does this by highlighting robustness and resilience. Yet common reliability engineering frameworks are often rather narrow in terms of how risk is reflected, with a focus on probability models with limited ability to capture unforeseen events. There is potential here for improvements using ideas and perspectives developed for the risk field.
This article discusses these issues, the main aim being to contribute to strengthening the foundation of reliability engineering and in this way improve its practice. There is a short way from the basic issues to the applications and practice. The idea of the article is to provide an overview of key issues and some perspectives on current thinking. It may be commented that some of the topics are already acknowledged in the reliability community, both from a scientific and a practical point of view. However, the present author will argue that this acknowledgement is weak in many respects, as demonstrated by the fact that we still struggle with establishing some fundamental pillars for the field. As a concrete example, consider the use of expected values to guide reliability decisions. Such a method is frequently adopted in practice, and the scientific journals still publish a number of papers which uncritically use such values to determine the proper reliability level, despite the strong arguments that can be raised against this approach (see section ‘Cost–benefit type of analysis’). Another example is the use of pre-defined criteria for what is the right reliability level, which are commonly used without proper considerations of uncertainties and other concerns.
The following section addresses issues related to understanding the system and its reliability, in particular the conceptualisation and treatment of uncertainty. The next main section follows this up and discusses how to determine the `right' reliability level, with a special focus on how to balance different concerns. The final section provides some conclusions and recommendations.
Understanding the system and its reliability: treatment of uncertainties
The aim of this section is contribute to improving the first category of reliability engineering activities, by
Clarifying key concepts;
Providing guidance on how to improve the treatment of uncertainty.
Concerning (a), it is essential to distinguish between variability, uncertainty and imprecision, as will be clearly explained in the coming analysis. All too often these concepts are mixed, the result being a poor basis for the analysis.
In the introduction section, we referred to an example motivating (a) and (b), which relates to the use of non-probabilistic methods to represent uncertainty. Many analysts and researchers are not familiar with or have a poor understanding of the concept of subjective (knowledge-based, judgemental) probability, the result being that this concept is not used when it could have been provided supplementing insights compared to other methods; refer discussion in section ‘Assess uncertainties’.
In practice, the understanding of the system and its reliability is closely related to the development and use of models. The modelling process typically covers the following three main steps:
Identify the relevant unknown quantities C of interest, such as Y the number of failures, or the frequentist probability Pf of Y being equal to 0, that is, Pf(Y = 0).
Develop models g of C linking these quantities with parameters on a lower system level, such as an event tree, a strength–load model or a probability model.
Assess associated uncertainties about unknown quantities.
These steps will be discussed in more detail in the following.
Quantities of interest
The analyst has to clarify whether the main quantity of interest is an observable quantity Y, like the number of failures of the system studied, or a model parameter λ, like the occurrence rate in a Poisson process representing the number of failures in the system. In this Poisson example, the occurrence rate λ represents the average number of system failures for a thought-constructed infinite population of similar systems. Hence, λ can be viewed as an approximation of the average number of failures for a huge population of similar systems.
The quantity of interest is often a frequentist probability Pf of an event A; for example, the frequentist probability that no failure occurs in a specific period of time. This probability is interpreted as the fraction of times the event A occurs if the situation considered can be repeated under similar conditions over and over again infinitely. Similarly to λ, the frequentist probability Pf can be seen as an approximation of the fraction of the systems with zero failures in a huge population of similar systems.
It is essential to be precise about terms, when they relate to observable quantities or parameters. In many cases, the key quantity of interest is an observable Y, but to assess this quantity a parametric model is introduced, as will be discussed in section ‘Assess uncertainties’.
Develop models
To be able to study the quantities of interest, models are developed and analysed. Models are tools used to both represent knowledge and generate knowledge. This is underlined in the quality discourse, which highlights that knowledge is built on theory.7,8 As argued for by Deming 9 (p. 102), rational prediction requires theory and builds knowledge through systematic revision and extension of theory based on comparison of prediction with observation. To learn, we need theory, including models.
A model is a simplified representation of the system, and in a reliability engineering context we can distinguish between two main categories of models: physical models (including logical models) and probability models.
When constructing, for example, a reliability diagram, a fault tree or an event tree, we develop a physical (i.e. logical) model of the system. We link the performance of the system Φ to the state of a set of components, as in a series system where the system state Φ(X) is the product of the states of the components, that is, Φ(X) = Π Xi, and X is the vector of the component states Xi, i = 1, 2, …, n, Another example of a physical model is the load–strength model, expressing that the system fails if the load L exceeds the strength S, that is, L − S > 0. As a third example, a physical model of the downtime of a system can be formulated as U = ∫(1 − Zs)ds, where Zs is the state process of the system which is 1 if the system is functioning and 0 otherwise, and the integral is taken over the time interval considered.
Probability models are models which include probabilities. However, for these models to be meaningfully defined, these probabilities must be understood as frequentist probabilities. Consider the above series system and assume two components only. Then simple probability calculus shows that if the two components are independent, the probability that the system is functioning is equal to the product of the probability that component 1 is functioning and the probability that component 2 is functioning, that is
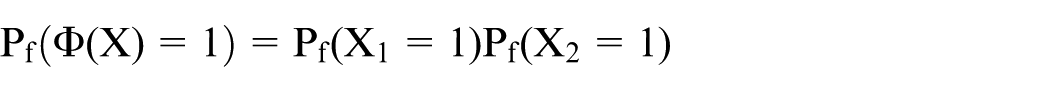
In line with common nomenclature in reliability engineering, we write the formula as
Now the system reliability h is the quantity of interest and the model g(p) = p1p2 is developed to analyse the system reliability, where p = (p1,p2).
Above, the system state Φ was the quantity of interest; now it is h. They are both considered properties of the system, they are unknown and models are developed to analyse them.
In the previous section, a frequentist probability was interpreted by reference to a huge population of similar systems. A frequentist probability is, however, also thought of as a physical characteristic of the system, in line with the so-called propensity interpretation of probability. According to this interpretation, the probability is simply the propensity of a repeatable experimental set-up which produces outcomes with limiting relative frequency Pf. 10 Suppose we have a coin; its physical characteristics (weight, centre of mass, etc.) are such that when we throw the coin over and over again, the head fraction will be p. In the same way, a system in a reliability engineering context can be seen as having a set of characteristics which define the set-up for a thought-constructed experiment producing the frequentist probability if the situation can be repeated over and over again.11,12
Again returning to the first category of activities of reliability engineering related to understanding the system and its reliability, models linking system performance and aspects like stress, shocks and maintenance strategies are developed. The majority of these models are probability models as described above, but they are often built on physical models as illustrated by the series system example. When performing reliability analysis, we do, however, often develop models like fault trees, but no modelling beyond that is actually carried out. Subjective probabilities, as discussed in the coming section, are then used to assess the uncertainties and degrees of beliefs.
Formally, we seek to obtain some insights about a probabilistic quantity r (e.g. a frequentist probability Pf), and a model g(s) of r is developed, where s are the parameters of the model reflecting the aspects of interest: for example, those related to deterioration and maintenance. Think of the basic availability model for a repairable system, which expresses that the availability of a unit is equal to MTTF/(MTTR + MTTF), where MTTF is the expected time to failure of the unit and MTTR is the expected restoration time. The set-up presumes that all probabilities are interpreted as frequentist probabilities (propensities) and the related expected values as averages in the infinite populations of similar systems.
The traditional probabilistic and statistical framework for reliability analysis, as presented in most textbooks in the field, builds on these pillars, probability models and frequentist probabilities, reflecting variation. A random variable is introduced and its probability model established. For example, let Y be a random variable representing the number of failures of a system in a specified period of time. It is assumed that Y is Poisson distributed with a parameter λ, meaning, for example, that Pf(Y = 0) = e−λ. The Poisson distribution is a model of the variation in the number of failures when considering a large number of similar systems. The parameter λ is unknown and statistical analysis is conducted to estimate λ. All probabilities used in this framework are frequentist probabilities and hence models of variation in relevant populations. This is also the case with traditional confidence intervals, which are defined such that according to the underlying frequentist probabilities of the random variables, the interval produced will in, say, 90% of the cases cover the unknown parameter if the situation considered can be repeated infinitely under similar conditions.
A model per definition simplifies the world and as such it will always have limitations. Still, it can be useful for obtaining insights as key aspects of the phenomena studied are reflected. For experimental set-ups, the models can be tested and compared with real-life observations. However, many situations in reliability engineering do not allow for such testing as the system under study is being assessed in the design phase and it is rather unique. In some cases, the models can be justified from a set of criteria, such as the binomial and Poisson’s distributions presented in basically all textbooks on probability and statistics. In other cases, the models are not easily justified by reasoning. Data analysis is then often used, but it suffers from the weakness that the data may be more or less relevant for the future situation considered. In any case, the accuracy of the model is always an issue. Any model used needs to be justified. This also applies to frequentist probabilities. Such probabilities cannot always be meaningfully defined. If meaningful repetitions cannot be constructed, in real-life or through thought-construction, such probabilities should not be used.
In a Bayesian analysis, probability models also play a key role, but in addition probabilities expressing the analyst’s uncertainties and degrees of belief are used, as will be discussed in the coming section. Selecting the proper models, verifying and validating models, cannot be seen isolated from the uncertainty assessments.
Assess uncertainties
The third step is about assessing uncertainties. We need to clarify
What are we uncertain about?
How should we represent or express this uncertainty?
Whose uncertainty are we reporting?
We may ask how large the number of failures Y will be for a specific system of the type considered. Analysts and experts are uncertain about the value of Y. In a reliability analysis, we use a measure Q to describe or characterise this uncertainty. The most common measure is probability P, expressing degrees of belief. The analyst may, for example, express a probability of 0.8 for two or more failures, and 0.2 for fewer than two failures, or a probability between 0.5 and 0.9 for the system to have two or more failures.
Such probabilities can always be assigned. They are referred to as subjective, judgemental or knowledge-based probabilities. They have an interpretation which is easy to understand but seldom referred to. If a probability of 0.10 is assigned, it means that the assigner has the same uncertainty and degree of belief in the event occurring as drawing a specific ball out of an urn comprising 10 balls under a random drawing.12,13 If a probability interval is specified, as in the case with a probability between 0.5 and 0.9, the assessor is unwilling to be more precise. We talk about imprecise or interval probabilities. The probability is not uncertain, as there is no underlying correct true value to be uncertain about, but there is imprecision in terms of assigning a specific number.
As noted in the introduction section, it is common to read in reliability analysis papers that probabilities cannot be defined and that alternative approaches need to be used. The argument for alternative approaches must be that one does not find this type of probability suitable for its purpose. This makes sense, as probability has some limitations or weaknesses. The problem is as follows.
A probability P of an event A is actually a conditional probability P(A|K), given the background knowledge K (comprising data, information, justified beliefs). The strength of this knowledge is not reflected by P alone. We may have two situations, one with strong knowledge K and one with weak knowledge K, but the Ps could be the same. Should not the strength of knowledge supporting P also be taken into account in some way when the uncertainties are reported? Yes it should.
But how should this be done? There are different approaches available, and different research directions. One approach is to replace the probability P with an interval probability, [P1, P2], in order to reflect the strength of the knowledge K (SoK). Different types of theories can be used to support these intervals, including possibility theory and evidence theory. 14
The idea is to transfer as ‘objectively’ as possible the knowledge K to the probability interval and not add anything to the interval that is not in K. For example, if it is given that a quantity y is in the interval [1,3], and 2 is the most likely value, and no more information is added, we are left with possibility theory and interval probabilities, expressing, for example, that 0 ≤ P(y ≤ 1.5) ≤ 0.5, 0 ≤ P(y ≤ 2) ≤ 1.0 and 0.5 ≤ P(y ≤ 2.5) ≤ 1.015, p.47. Here, ‘objectivity’ relates to the transformation process, not the knowledge K itself. This knowledge can be beliefs held by one expert, so clearly being subjective.
However, the issue discussed here is not only about transferring the knowledge K to a relevant uncertainty measure Q, but also about establishing the appropriate knowledge. The decision-maker could benefit from being informed by the judgements of the analyst (expert); what are the analyst’s degrees of belief concerning y? This could lead the analyst to specify a subjective probability distribution about y. The intervals derived may be considered not sufficiently informative.
However, it can be argued that this specific distribution in many cases could be rather arbitrary, at least when the knowledge basis K is weak. Some scholars see possibility theory or evidence theory as the proper framework for suitably representing and expressing the uncertainties. Others restrict their attention to probabilities, together with qualitative judgements of the SoK, with criteria related to aspects like justification of assumptions made, amount of reliable and relevant data/information, agreement among experts and understanding of the phenomena involved.16,17
The strength of knowledge judgements is also relevant when we use interval probabilities, possibility theory or evidence theory. Think about the example above with an uncertain y. The information gathered is transformed into interval probabilities, but how strong is the knowledge supporting the judgements made, such as that y is in the interval [1,3] and 2 is the most likely value? Clearly, in general a precise probability distribution assigned implies a weaker SoK than if an imprecise probability distribution is determined. In any case, probabilities, interval probabilities and SoK are judgements and aspects of importance can be lost in transforming the knowledge K to the measures used. This leads us to the conclusion that a full characterisation of uncertainty must cover all three elements P ([P1, P2]), SoK and K, that is, probability (probability interval), the strength of knowledge judgement SoK and the source knowledge K.
The uncertainty characterisations reflect the knowledge and beliefs of the assessor. Hence, we also need to reflect on potential surprises relative to this knowledge and aspects that are unforeseen. Important failure mechanisms could be overlooked because of weaknesses in the knowledge base. The assessor’s knowledge may be dependent on a critical assumption, and deviation from this assumption could lead to unanticipated results. Such aspects represent huge challenges for the analysis.17,18 The implications for reliability engineering and decision-making are discussed in section ‘Issues related to obtaining the “right” reliability’.
If a model g(X) of the quantity of interest C is developed, where X is a vector of unknown parameters, we need to perform uncertainty assessments of X and propagate these to C using the model g, as thoroughly discussed in the literature.4,15 This is commonly done in a Bayesian framework. A probability model is developed with unknown parameters, and the Bayesian machinery is used to go from the prior distribution of these parameters to the posterior distribution. Using the law of total probability, we obtain the common link between the probability model and the subjective probabilities for the observables: P(Y = y) = ∫P(Y = y|λ)dP(λ), where P(Y = y|λ) is the probability model distribution and P(λ) is the prior or posterior distribution of the parameter λ.
The Bayesian approach has a strong basis and represents a useful tool for systematising and developing knowledge. However, in view of the above discussion, care should be taken in applying this framework. Probability models require justification, and we need to consider the knowledge and strength of knowledge supporting the subjective probabilities assigned.
The difference between the model output g(X) and the quantity of interest C, that is, g(X) − C, can be referred to as the model (output) error, and uncertainty about this quantity as model uncertainty. 19 How to represent and treat this uncertainty is an important research task, and its detailed study is beyond the scope of this article. However, the above analysis provides some generic ideas which are relevant also for the uncertainty assessments of the model error g(X) − C. Characterisations of the form P ([P1, P2]), SoK and K, that is, probability (probability interval), the strength of knowledge judgement SoK and the source knowledge K, can also be used for model uncertainty. 19 See also some comments on this issue in section ‘Decision-makers’ perspective on uncertainties and risks not reflected by analysts’ related to how decision-makers need to take into account the limitations of the models.
Finally, in this section, a comment is made on the task of identifying important factors and elements contributing to the (un)reliability and the uncertainties. There is a huge literature on this topic, often referred to as sensitivity and importance measure analysis, see, for instance, Borgonovo20,21 and Borgonovo and Plischke. 22 Sensitivity analyses are essential in model corroboration by gaining insights on model behaviour, its structure and its response to changes in the model inputs. This literature is to a large extent restricted to probability and to some extent also to probability intervals. Research is needed to cover the knowledge dimensions represented by SoK judgements and K.
Remarks
Assessing unreliability and risk
To be able to understand the reliability of the system, we need to study the ability of the system to perform its intended function. This means also studying the unreliability of the system, that is, the lack of reliability. If the system is a safety valve whose main function is to close when necessary, the unreliability is related to the potential failure of this function. The unreliability may be considered an aspect of risk, as risk captures in its general form two basic features: consequences with respect to something of human value (values at stake) and uncertainties. 2 The system unreliability limits the consequence dimension to failures relative to the system functions, but otherwise from a conceptual point of view the term system unreliability can be interpreted as risk. Expressing risk in its general form means specifying the consequences C, using a description or measure of uncertainty Q, and adding the knowledge K that C′ and Q are based on. 2 For the reliability context, C′ needs then to be associated with failure of the intended function, which could be described using different quantities, such as lost capacity or production relative to a planned or maximum level. Hence, the system unreliability can be described using the same triplet as risk (C, Q, K), where Q could also cover the qualitative strength of knowledge judgements SoK. Often the assessment will be limited to inherent system failures, but if reliability is the ability of the system to perform its intended function, external threats to the system function could also be considered as is usually the case when addressing risk. 17
The comments made above are not to say that reliability assessment is the same as risk assessment. Most risk assessments address consequences with respect to loss of lives, environment and so on which are not addressed by reliability assessments. For many risk assessments, reliability assessments provide important input, for example, studies of the reliability of safety systems and barriers. The point made above in this section is that formally a reliability assessment can be viewed as a special type of risk assessment where the consequences are linked to system failures. This observation allows us to apply theory, principles and methods from the risk field, in reliability assessments. The discussion in section ‘Assess uncertainties’ about uncertainty assessment is an example of this. Ideas used in risk analysis are transferred to the reliability assessments. See also section ‘Decision-makers’ perspective on uncertainties and risks not reflected by analysts’ for some related comments concerning extreme events (black swans).
Fuzzy probabilities
In the above discussion, we were concerned about uncertainties of unknown quantities, for which some true underlying correct quantities can be defined. Uncertainty statements of vague statements like ‘few failures’, as considered in fuzzy probabilities, are controversial. Many authors such as Bedford and Cooke 23 reject them. For any concept to be used for uncertainty characterisation, it needs to be precisely defined; an interpretation is required. 24 Information that is vague and imprecise can always be included in the analysis, as shown in section ‘Assess uncertainties’, as long as the focus is on assessing uncertainties about some underlying quantities C for which some true underlying values can be meaningfully defined.
Uncertainty related to choices
It is also common to talk about uncertainty in relation to choices to be made: ‘I am uncertain what action I should take, what model I should use’ and so on. This type of uncertainty disappears when a choice has been made. If a person says that he or she is uncertain about his or her preferences, then there is an imprecision problem. There is no uncertainty as underlying correct preference values do not exist. Consider the preferences to be specified by a utility function. In the same way as for the probability P, the person specifying the utility function expressing his or her preferences may not be willing to determine just one function, the result being, for example, upper and lower bounds as for probability.
Issues related to obtaining the ‘right’ reliability
As stated in the introduction section, reliability engineering is about (1) understanding the system and its reliability and then (2) using this understanding to obtain the ‘right’ reliability for the system, by identifying better designs, more effective maintenance policies and so on. This section discusses some aspects related to category (2), obtaining the ‘right’ reliability level. The aim of the section is to contribute to improving the type (2) activities by clarifying key concepts and providing guidance on some specific management issues.
Most works on type (2) activities are carried out within the boundaries of probability models and the uncertainty framework (C, Q), where C is a specified quantity of interest, such as downtime or lost production, and Q is a quantitative measure of uncertainty. In addition, there is considerable work related to decision-making, where methods are discussed on how to go from the reliability studies to the decisions, taking into account the decision-makers’ preferences.
Decision-makers have to make decisions concerning a choice between alternatives, the need for reliability improvements, accepting arrangements and so on. The reliability analyses provide some information relevant for this decision-making, but the decision-makers also need to take into account the following:
Other aspects than reliability, including costs;
Uncertainties and risks that are not included in the information provided by the analysts.
We will discuss these two points in more detail in the following sections.
Reliability and the need to relate to other concerns such as risk and costs: the use of reliability requirements
Reliability requirements are commonly used in reliability engineering. A common requirement is that the reliability of the system should exceed a specified number, for example, 0.98, where reliability is interpreted as a frequentist probability. In this context, reliability is viewed in isolation from other aspects like risk and costs. Does this mean that there is no need to see reliability in relation to these other concerns?
A common response is that the reliability requirement developed has taken into account these other concerns. There is some type of ‘optimisation’ supporting the choice made. However, this argumentation can be challenged. Let us look at an example.
The producer of a product believes that high reliability is essential in obtaining success in a competitive market and has formulated a 0.98 reliability requirement as above in the design process. Verification (testing) processes are to be conducted to check whether the requirement is met or not. The requirement guides many choices made in the design process. It leads to the specification of requirements for the reliability of many components of the product. In this way, the reliability of the product is considered ensured during the engineering process. Cost–benefit analyses may have been conducted, showing that 0.98 provides an ‘optimal’ choice for the reliability.
However, the analysis is based on a number of assumptions as it is conducted at an early planning stage. The uncertainties are large. There is considerable risk related to deviations in these assumptions. It is impossible to know at the time of the specification of the requirement what 0.98 means relative to, say, 0.99 or 0.97, without having done the design in detail. This last is impossible at an early planning stage.
This discussion illustrates a general issue. The reliability attribute of a system is difficult to isolate from other concerns. This well-known fact has been demonstrated through many real-life examples, including works related to the design of huge offshore installations. An early example is presented by Aven and Kirkeby 25 where the project was to produce natural gas from an offshore field and bring it to shore for delivery to purchasers. A target for the reliability (availability) of the production installation was to be determined. However, the whole idea was abandoned after some time as it was concluded that it was not consistent with the primary objectives of the operator, such as profitability. If such requirements are applied, they can hinder sound innovation and judgement and result in an unnecessarily expensive design. The fundamental problem of the approach is that to be able to justify a specific number properly one needs to know the details of the design, which is impossible at an early stage of a development project. 25 The key question to be asked is what comes first, the numerical requirements or the alternative arrangements? The above analysis has argued that a requirement-driven reliability engineering approach is in general problematic. Instead, an option-driven approach is recommended, which is based on the following fundamental ideas and principles:
Reliability is not considered an objective in itself, but a benefit to be balanced against other concerns such as costs.
Qualitative policies should be defined guiding the choice of alternatives, stating, for example, that the system should show high reliability or that the reliability should be at a level comparable to that of similar systems.
Understanding and improving the processes that lead to failure, deviations and so on are highlighted.
Alternatives are generated and the ‘goodness’ of these, together with their pros and cons, is assessed to provide support for the alternative to be chosen.
When issues are raised in the development project, for example, concerns about the reliability of a specific system, an argumentative deliberative process is conducted, considering the pros and cons of the various options available. It could, for example, lead to two options: (1) improve the reliability by implementing a specific measure or (2) do nothing.
Potential vendors of reliability critical equipment and systems are approached using a similar option-directed thinking.
Further discussion on how to implement these principles is provided in the following sections.
The above reasoning is in line with fundamental ideas of quality management. This field argues strongly against the management by objectives (MBO) approach. 17 Following this approach, it is common practice to parcel out the overall organisational objectives to the various divisions or components. The common idea is that if every division or component accomplishes its shares, the whole organisation will meet the overall objectives.9, p. 30 The problem with this way of reasoning is that there are interdependences, and the efforts of the various components do not necessarily add up. Meeting one goal, reliability in our case, may lead to less flexibility and performance with respect to other dimensions, and the overall gain is lost. There is a need for an overall system thinking, not isolated optimisations.
The quality management discipline also emphasises the need for highlighting improvement processes rather than focusing on setting numerical goals. The point is that a goal alone accomplishes nothing and can easily lead to distortion and faking.9, p. 31 What is important is satisfying the goal, not the long-term losses that it could cause. The arguments are similar to those presented above. A reliability number would contribute little to the overall success of the development project of the system without going into the method of how to obtain the number. The quality field response is to focus on the understanding and improving the processes that lead to failure, deviations and so on as expressed by item (c) above and which is also in line with the reliability engineering activities of category (1) stated in the introduction section.
The above discussion also applies to the operational stage of a system. Earlier records of the system can show availability numbers in the region of, say, 0.95–0.97, and a requirement or goal of 0.98 may be considered to stimulate improvements and offer a higher level of performance. Often we also see that the management bonus system is related to meeting such goals. But again, the question is whether the use of such a number really leads to the overall best solutions, the goal being seen in isolation from other concerns. Meeting the availability number of 0.98 the next year could mean higher risk related to a major accident some years in the future or it could lead to a less profitable overall production.
Cost–benefit type of analysis
The recommended approaches 1 to 5 point to comparisons of alternatives, with assessments of their pros and cons. These pros and cons can be expressed in different ways, by means of both qualitative and quantitative formulations. As we know, there are many methods for organising the pros and cons of a decision alternative, including multi-attribute analysis, cost-effectiveness analysis, cost–benefit analysis and expected utility theory.17,26 These methods differ with respect to the extent to which one is willing to make the factors and concerns in the problem explicitly comparable.
Many of these approaches are based on the use of expected values, such as the expected cost or the expected discounted cost. The key justification for using the expected value is the law of large numbers. If we have n systems of a specific type, and the future costs associated with these systems are C1, C2, …, Cn, with a common frequentist probability distribution F, the average cost
In reliability contexts, we have cases which are well described by the above set-up and expected values provide a suitable criterion for optimisation. However, in practice, the situations considered in reliability engineering contexts are often much more challenging; the uncertainties are large and we do not have huge populations of similar systems. Then, the use of expected values to guide the decision-making cannot be justified.27,28
Consider an enterprise running some rather unique projects. To assess the future costs of the projects, subjective probabilities are used; frequentist probabilities cannot be meaningfully defined. Nonetheless, the analysts have some knowledge about the way the system works and can fail, but there are considerable uncertainties. The average cost
As another example, consider the situation where we have quite a few systems and the costs are either 0 or extremely large (corresponding to system failures with extreme impacts). In this case also, it is difficult to justify the use of expected values to guide the decision-making, even in the special situation where frequentist probabilities are available and known. The problem is that the average cost
The use of expected utility theory represents an alternative to these expected value-based approaches. The method has a strong rationale but is difficult to implement in practice. The problems relate to the difficulties in specifying both the utilities and the subjective probabilities. 29
There are many other approaches, such as the analytical hierarchy process (AHP) and fuzzy-based methods. Many of these are controversial as the rationale for specifying the numbers can be questioned. Care should be taken if it is not possible to provide meaningful interpretations of the numbers presented.
It is a research challenge to develop suitable approaches for integrating the various concerns, balancing theoretical rationale and usability. For the proper use of these methods, it is essential to acknowledge that they are to be seen merely as tools for supporting decision-making, not for prescribing what to do. All methods have limitations and weaknesses, and decision-makers need to take a broad perspective, reflecting also on the implications of these limitations and weaknesses. There is in general a gap between the analysis results and the judgements that decision-makers need to make. The reliability engineering field needs to gain substance to this gap and develop guidance for how to best deal with it, for both analysts and decision-makers.
This article provides input to this work by providing concepts and frameworks for what the gap and issues are, as well as ideas for how to deal with them. The main points addressed are the need for seeing beyond expected values, supplementing the quantitative approaches with strength of knowledge judgements, addressing potential surprises relative to the knowledge of the analysts and distinguishing between analysts’ and decision-makers’ knowledge and concerns – as will also be discussed in the coming sections of the article. The example by Bjerga and Aven 30 provides an illustration of many of these points. Analytical tools can and should be further developed, along different lines of thinking using alternative types of decision analysis frameworks, but the message here is that caution needs to be shown. Equally important as developing such tools for informing decision-makers is the acknowledgement of the need for seeing beyond them when making decisions. In cases with large uncertainties, when probability models cannot be justified, and/or the values are difficult to express (e.g., related to environmental damage), pros and cons type of judgements are recommended as discussed in section ‘Reliability and the need to relate to other concerns such as risk and costs: the use of reliability requirements’. These judgements can use the more detailed analysis tools, such as cost–benefit analysis, as input, but then giving due attention to their limitations.
Decision-makers’ perspective on uncertainties and risks not reflected by analysts
When analysts characterise the reliability and unreliability of a system, they commonly use probabilities and expected values. For example, suppose the analysts have computed the probability that the system will experience a critical failure next year and found that this probability is below a threshold value, for example, 1 × 10−4. The analysts’ message is that the analysis has demonstrated that the system is reliable.
The question now is whether the decision-maker will come to the same conclusion. The answer is, not necessarily, as the analysts’ reliability assessment is in fact a conditional judgement about the performance of the system, given their knowledge, data, information and justified beliefs (including models and the hypotheses that they are built on). This knowledge can be more or less strong and can cover beliefs and assumptions that can in fact be wrong.
An offshore oil and gas example illustrates this point. A major hydrocarbon leak occurred on an installation in May 2012 31 in relation to the testing of two emergency shutdown valves. The pipe section of interest was designed according to an older standard, where the order in which the valves are operated was critical. The operating team presumed a normal new design practice and the incident occurred. Their assessment of the system was based on an assumption that turned out to be wrong.
Many failures in systems occur as surprises relative to the knowledge of the analysts, as in this example. The relevant scenarios are not identified or else they are identified but are considered to represent a negligible risk under more or less tacit assumptions.
Decision-makers are informed by analysts, but the analyses do not report an objective ‘truth’ about reliability, only justified judgements and beliefs. The decision-makers consequently need to see beyond the analysis results and take into account the limitations and weaknesses of the analyses, as discussed above.
The decision-makers do not have the competence to evaluate all the details of the analysis. They need to focus on the big picture, including an understanding of the basic ideas of reliability and risk analyses. They need to have fundamental insights into what the analyses do and do not provide. A key point is to acknowledge that the analysts produce conditional reliability judgements given their knowledge and this knowledge also needs to be considered. In addition, concerns other than reliability need to be taken into account, as discussed in previous sections.
The decision-makers are thus faced with a situation where they are informed about the reliability of the system under consideration and also need to consider the risks and uncertainties not fully covered by the analyses. They can request more and better analyses, but the fundamental problem will not disappear. Hence, they are in need of a strategy for dealing with these risks and uncertainties.
We are led to common principles for management of risk and uncertainties, and in brief these are as follows: risk-informed principles using risk assessments, cautionary/precautionary strategies and discursive strategies.31,32 Cautionary/precautionary strategies are also referred to as strategies of robustness and resilience. They highlight features like containment, the development of substitutes, safety factors and redundancy in the design of safety devices, diversification, design of systems with flexible response options, system adaption and ability to adequately read signals and the precursors of serious events.32,33 In most cases, the appropriate strategy is a mixture of these three strategies.
How can analysts better meet decision-makers’ needs?
The above discussion has pointed to some challenges in reliability engineering. Reliability analysts can contribute to meeting these in several ways. First, they can improve the way in which they support decision-makers by developing better methods and models for understanding reliability and determining the right reliability level; refer goals (1) and (2) mentioned in the introduction section. Second, they can provide decision-makers with suitable frameworks for decisions in relation to reliability issues. We discuss these areas in more detail in the following.
In section ‘Understanding the system and its reliability: treatment of uncertainties’, we addressed some areas where there is potential for improvement in the understanding and characterisation of reliability. A key point is the way in which uncertainties are conceptualised and treated. In addition, there is potential for improvement in guiding determination of the ‘right’ reliability level, as discussed in previous sections. A key point here is the need for balancing different concerns and taking into account the limitations of the tools used to understand reliability.
Decision-makers are not professionals in the field of reliability engineering and need to be supported in terms of how they should think and make good decisions.33,34 To this end, reliability analysts and the reliability engineering field should develop suitable frameworks for decision-makers. These frameworks should cover topics as discussed in this article. The idea is not to present a lot of details on reliability analysis methods and models, but inform about the fundamental ideas and principles, for example, (1)–(5) in section ‘Reliability and the need to relate to other concerns such as risk and costs: the use of reliability requirements’. Decision-makers need to understand what analysts actually deliver and what remains for decision-maker judgements and how these can be supported.
Conclusion and recommendations
This article has shown and discussed how the foundation and practice of reliability engineering can be improved by clarifying concepts and further developing principles, methods and models for understanding reliability and determining the ‘right’ reliability level. The following list provides some key recommendations on how to obtain these improvements:
Improve the understanding of reliability Specify suitable quantities of interest, meeting the needs of the decision-making situation. Develop suitable models of system performance. Justify the models. Explain the meaning of all quantities and parameters introduced. Assess uncertainties. Be clear on what uncertainty measure is used and how this measure is to be interpreted. If a quantitative measure is used, address the SoK that the measure is based on. In assessing unreliability think risk related to not meeting the intended function. Be clear on the difference between variation, uncertainty and imprecision. Make a difference between frequentist probabilities and probabilities used to express analysts’ uncertainties or degrees of beliefs. Reject concepts which cannot be given a meaningful interpretation.
Improve the process of determining the ‘right’ reliability level Establish a clear understanding of the fundamental principles that determine the ‘right’ reliability level. Clarify the difference in perspective between analysts and decision-makers. Be clear on what the analysts produce of decision support and what the decision-makers need. Acknowledge the need for balancing different concerns when making decisions related to reliability. Acknowledge the need to take into account the full spectrum of risks and uncertainties. Develop suitable frameworks (covering ideas and principles) for decision-makers on how they should think in relation to reliability and how they can be supported to make good decisions. Use reliability requirement-driven approaches with care, considering instead option-driven approaches as described in section ‘Reliability and the need to relate to other concerns such as risk and costs: the use of reliability requirements’. Look beyond expected values when balancing different concerns, including reliability and costs.
The foundation and practice of the reliability engineering field have to a large extent already reflected and absorbed these points, but more research and developments are needed to take reliability engineering to the next phase, meeting the challenges of the coming years, as was highlighted in the introduction section and discussed in detail by Zio. 4
Footnotes
Acknowledgements
The author is grateful to two anonymous reviewers for their useful comments and suggestions to the original version of this paper.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was partly funded by the Norwegian Research Council as part of the Petromaks 2 programme (grant number no. 228335/E30). Their support is gratefully acknowledged.