
Abstract
In safety settings, understood as situations involving the potential occurrence of unintentional events, it is common to define risk as a combination of consequences and associated probabilities or associated uncertainties. On the other hand, in security settings, understood as situations involving the potential occurrence of intentional malicious events, risk is commonly defined as the triplet asset/value, threat and vulnerability. One motivation often mentioned for the latter is that probability is considered inappropriate for intentional acts. In this article, we argue that it is unsuitable and unnecessary to define risk differently in these two settings. We show that risk, defined as the combination of future consequences and associated uncertainties, can be seen as compatible with the triplet definition of security risk. It also excludes probability from the definition of risk but explicitly includes uncertainty, which is more fundamental and present regardless of the type of events involved. The value dimension is integrated with the consequences as these are with respect to something that humans value. The purpose of the article is to contribute to a consolidation of the safety and security risk management fields at the fundamental level.
Introduction
In Norway, there has recently been a lively discussion about the risk concept in security applications. 1 The Norwegian Defence Research Establishment (FFI) has evaluated different approaches to security risk assessments for protection against intentional unwanted actions. 1 Two standards are compared: one developed for safety applications: NS 5814 2 and one for security: NS 5830.3,4 In the former standard, risk is defined as an ‘expression for the combination of likelihood and consequences of an unwanted event’ and in the latter, security risk is defined as ‘the relationship between threats towards a given asset and this asset’s vulnerability to the specified threat’.
Within the security environment, in Norway and also internationally, many analysts argue that the safety perspective, with its focus on consequences and probability, is not applicable to security.1,5,6 Probability is considered inappropriate for describing risk related to malicious intentional acts by intelligent actors. Judgements of intentions and capacities are found more suitable than probabilistic analysis. The key question is whether some parties (attackers) have the intention of and the capacity to strike at specific interests.
We also see cases where probability is used, but without a quantitative scale of [0, 1] normally used for probabilities. As a concrete example, consider the treat level by the UK Secret Services.
7
They use five categories: LOW means an attack is unlikely, MODERATE means an attack is possible, but not likely, SUBSTANTIAL means an attack is a strong possibility, SEVERE means an attack is highly likely, and CRITICAL means an attack is expected imminently. To derive at a specific treat level, many type of factors are taken into account, including the following:
7
Available intelligence. It is rare that specific threat information is available and can be relied upon. More often, judgements about the threat will be based on a wide range of information, which is often fragmentary, including the level and nature of current terrorist activity, comparison with events in other countries and previous attacks. Intelligence is only ever likely to reveal part of the picture. Terrorist capability. An examination of what is known about the capabilities of the terrorists in question and the method they may use based on previous attacks or from intelligence. This would also analyse the potential scale of the attack. Terrorist intentions. Using intelligence and publicly available information to examine the overall aims of the terrorists and the ways they may achieve them including what sort of targets they would consider attacking. Timescale. The threat level expresses the likelihood of an attack in the near term. We know from past incidents that some attacks take years to plan, while others are put together more quickly. In the absence of specific intelligence, a judgement will need to be made about how close an attack might be to fruition. Threat levels do not have any set expiry date, but are regularly subject to review in order to ensure that they remain current.
The common understanding of risk in the security community is captured by the so-called three-factor perspective, covering assets/values, threats, and vulnerabilities. Different versions of these perspectives exist, including the following:
Risk = f(asset value, threat, vulnerability), where f denotes a function. 8
Risk = asset × threat × vulnerability. 9
Risk = threat × (vulnerability and consequence). 10
Risk = threat × vulnerability × consequence (see Cox 11 ).
However, these definitions express basically the same ideas, and in the following, we refer to them as the (value, threat and vulnerability) perspective/definition of security risk.
If risk is considered the triplet, value, threat and vulnerability, we may ask where is the uncertainty component? A threat may occur or not occur, it is not deterministic. And, we cannot really multiply or introduce a function of these dimensions – it would not make sense. We may define a function of some operationalised measures of these dimensions, but these measures will to greater or lesser extent capture the concepts these are intended to measure. If, for example, we describe or measure risk, we can talk about functions of the dimensions covered, like the probability that the threat materialises and the expected consequences, given the threat (which can be seen as a measure of vulnerability). Care should, however, be shown in restricting risk to a specific function, in particular, the product, which would mean some type of expected value. It is well known from the risk literature that expected values do not in general provide an appropriate description of risk.12–14 For security applications, it is indeed problematic, as discussed by, for example, Aven and Renn. 15 Take the general event ‘terrorist attack’. It is possible to foresee many attack scenarios with severe negative consequences, ranging from a rather limited number of affected persons to situations where thousands are suffering. Grouping all such scenarios in one, and highlighting only the expected (mean) value, can obviously lead to poor descriptions of the risk.
In this article, we take a deeper look into this security perspective. We seek to clarify the basic ideas, and we question whether this perspective is really in conflict with current thinking about safety risk. If a traditional safety risk perspective is adopted, with a focus on consequences and frequentist probabilities, a rejection of the safety approach is understandable as such probabilities are difficult to justify in many security contexts, for example, related to the occurrence of terrorist attacks. A frequentist probability is a theoretical concept interpreted as the fraction of time in which the event occurs, if the situation considered can be repeated over and over again infinitely. Such a concept is obviously not appropriate in a security setting, where events will often have unique characteristics. Accordingly, current risk thinking, as, for example, reflected in the new Society for Risk Analysis (SRA) Glossary, 16 has a much broader perspective on risk and probability. The SRA Glossary covers both safety and security. See also discussions about probability in Littlewood and Strigini 17 Manunta 18 and Littlewood et al. 19
It is natural to ask whether security can be included in this broader perspective. What changes, if any, are needed in definitions and interpretations in order to make this integration work? And what are the benefits that can be gained for the risk field and security, in particular, if we are able to include security risk in this broader understanding of risk? These are the main issues discussed in this article.
To illustrate the differences in definitions of and perspectives on risk, covering both safety and security, we will present a simple example – a boulder case studied earlier by Rosa 19 in a different context. We consider a situation in which a person, call him John, is walking under a boulder that may or may not dislodge from a ledge and hit him (see Figure 1). Whether the boulder will dislodge from the ledge is subject to uncertainty, and there are uncertainties about the consequences if the boulder should in fact dislodge. The boulder represents a risk source (RS) or threat to John, who walks underneath it. The boulder may dislodge from the ledge due to natural, physical reasons or due to intentional acts. Hence, the situation covers both safety and security.

The article is organised as follows. In the coming section we present a general set-up that allows for both safety and security applications. Compared to earlier work on generic risk conceptualisation, new material is added specifically on security and on the link between safety and security. Then, in the next section we provide a discussion of this set-up, linking it to security and highlighting the implications for risk assessment and management. The final section provides some conclusions.
This work is a conceptual paper addressing how to think in relation to safety, security and risk. It is about overall generic ideas and structures, which have strong implications for the way we next assess and manage the risk, safety and security. For example, in the article, we argue that in a security context, strength of knowledge judgements should always be presented along with the likelihood judgements; this is not done following current practice. A set-up is presented for understanding risk covering both safety and security, which is new and original compared to current security thinking and practice. A recent publication 22 illustrates the differences in thinking. Here, security risk analysis is used to assist in protecting critical process infrastructure. Risk is conceptualised as the triplet, value, threat and vulnerability, but operationalised as the product, the expected value, to support the decision-making. This article provides a set-up for a proper understanding of the triplet and why it is needed to see beyond the risk characterisation used in the mentioned security risk analysis.
This article is not about detailed methods and models for analysing and modelling the concepts of risk, safety and security. There is a huge literature covering such methods and models (see the review by Kriaa et al. 23 ). We would in particular mention works on the evaluation of security risk and vulnerability for critical infrastructures24–32 which have thoroughly discussed such methods and models. These works do not, however, present a unified risk framework as this article does, capturing both safety and security, and using the recent conceptualisations of risk summarised in the SRA glossary. 16
A general framework covering both safety and security
In this section, we present a general, formal framework for conceptualising and understanding risk, in line with the ideas outlined in the previous section. The framework builds on existing theory, including the SRA Glossary 16 and Aven,33,34 but extends beyond this theory by reformulating and better adapting fundamental concepts to the security setting. Yet, the framework is applicable to all types of risk analysis applications.
Basic structure
We consider some values (V), for example, human life and health, the environment and economic assets. One or more risk sources (RS) threaten these values, for example a terrorist organisation or the boulder in the example above. An RS is an element (action, activity, component, system, event, etc.), which alone or in combination has the potential to give rise to an event (A) with a consequence (C) related to the values (V) defined. The consequences C are often seen in relation to some reference values (planned values, objectives, etc.), and the focus is normally on negative, undesirable consequences. There is always at least one potential outcome that is considered as negative or undesirable.
Think about a human being exposed to radiation from uranium in soil and rock. The uranium can be considered an RS, so can the soil and rock. This exposure may lead to cancer (A) and affect the health of the person (the value (V)). We are led to a trichotomy: the risk sources RS (uranium, soil and rock), the associated event A (cancer) and the consequences C (health effects). In the boulder example, we can analogously distinguish between the boulder (risk source RS), the boulder dislodging (event A) and the effects for John (consequences C) or, if viewed as a security case, the boulder and the attackers (risk sources RS), the boulder dislodging (event A) and the effects for John (consequences C).
Note that an RS can be an event, like failure in a system. Also, the event (A) can be considered an RS. These concepts are relative in the sense that they can be labelled both risk source (RS) or event (A), depending on the conditions we would like to highlight. In a simplified set-up, we can use only the RS.
In line with the SRA Glossary 16 we use the term threat in a broad sense, to cover both risk sources RS and events A. Observe that threat is also commonly used in relation to an attack, as a stated or inferred intention to initiate an attack with the intention to inflict harm, fear, pain or misery, 16 but we use the broad interpretation in this article. A hazard is an RS or event where the potential consequences relate to harm, that is, physical or psychological injury or damage and normally restricted to safety applications. An opportunity is an RS or event, which has the potential to give rise to some specified desirable consequences.
In most cases, we can relate the situation to a system, for example, a person, a process plant, and a country (with its entire population). The system may be exposed to the events, in the sense that the system is affected by these events – there is a physical transformation of energy. The events may be initiated externally to the system or within the system. Only in the former case it is natural to talk about the systems being exposed to the event. The systems may also be exposed to an RS, for example, the person being exposed to the radiation or John being exposed to the boulder threat.
Barriers, for example, protection measures to reduce the effects of radiation, or a warning system when the boulder is close to be dislodged, are introduced to avoid events occurring and to reduce the consequences of the events if they should in fact occur. The occurrences of the events (A) and the consequences (C) depend on the performance of these barriers.
In line with the SRA Glossary, 16 we define safe as being without unacceptable risk, and safety is interpreted in the same way (e.g. when saying that safety is achieved). We also talk about safety as the antonym of risk (the safety level is linked to the risk level, a high safety means a low risk and vice versa). Analogously, we define secure as being without unacceptable risk when restricting the concept of risk to intentional unwanted acts by intelligent actors. Security is interpreted in the same way as secure (e.g. when saying that security is achieved) and as the antonym of risk when restricting the concept of risk to intentional unwanted acts by intelligent actors (the security level is linked to the risk level, a high security level means a low risk and vice versa). By these definitions, the key concept is risk, as safe and secure are defined on the basis of this term.
To conceptualise risk, we look forward in time. We do not know what events A will actually occur and what the consequences C will be. There are uncertainties. The risk sources may also be subject to uncertainties, for example how intense the radiation will be. The Us in Figure 2 expresses that we do not know which risk sources RS will materialise and if so how these will occur, or which events A will occur and what the consequences C will be. That is, the Us refer to the state of uncertainty about RS, A and C. The real world is characterised by the risk sources RS, the events A, and the consequences C.
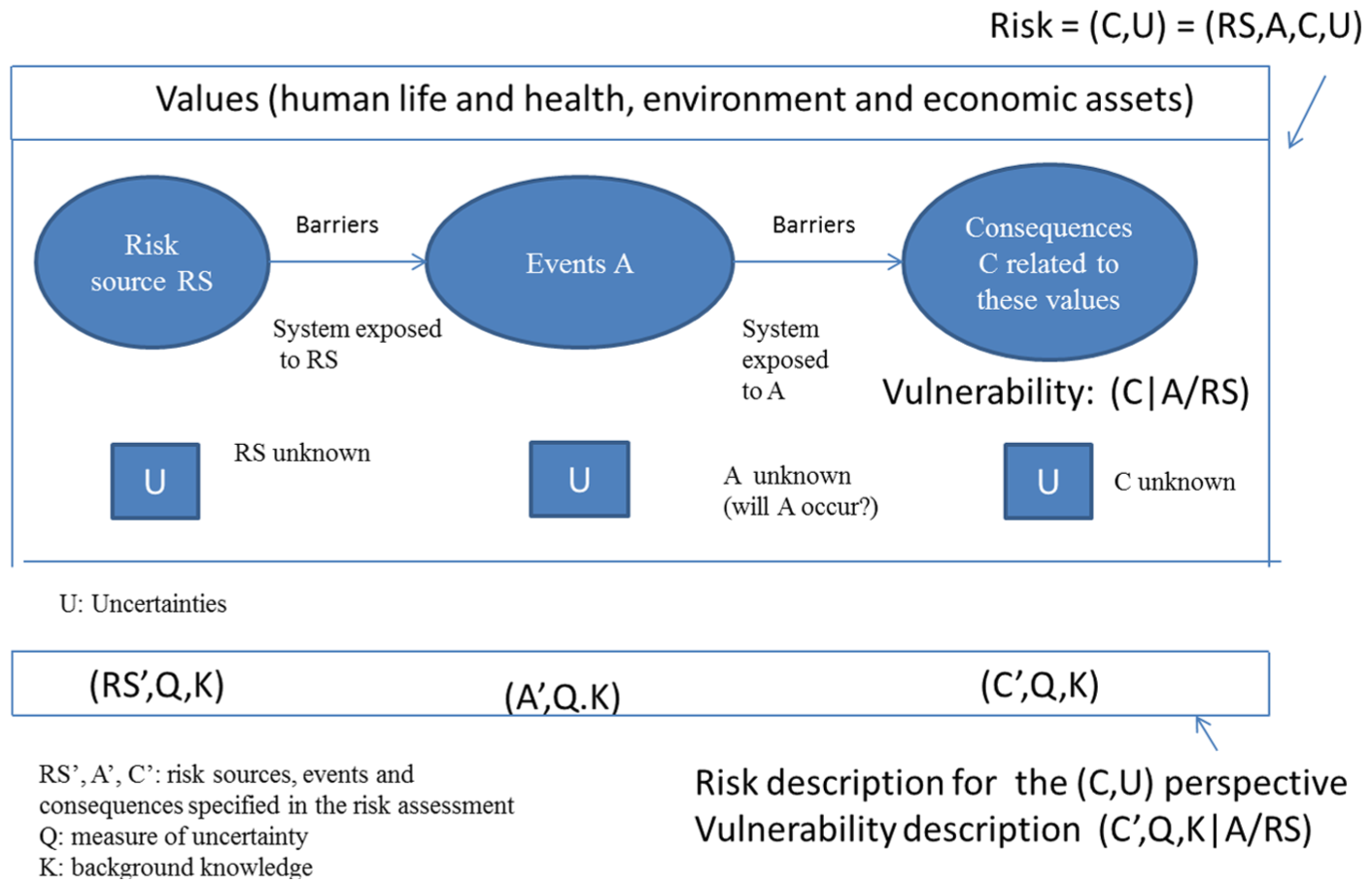
A conceptual model linking risk, risk sources, events and consequences (based on Aven 34 , “| A/RS” being read as “given the occurrence of event A or risk source RS”). Note the difference between (RS, A, C) and (RS′, A′ and C′). The former set covers the actual risk sources, events and consequences, whereas the latter set covers risk sources, events and consequences specified in the risk assessment. We may for example have an event A occurring which is not covered by A′.
In line with measurement theory and the SRA Glossary, 16 a distinction is made between the concept of risk and how to measure or describe the risk. In the risk assessment, we would like to provide a description (characterisation) of the future and we need to specify sets RS′, A′ and C′ of risk sources, events and consequences, as well as a measure Q for describing or measuring the uncertainties U related to these. Examples of RS′, A′ and C′ are radiation dose rates at some specific times and places, the event that the person gets cancer and various outcomes if cancer occurs, respectively. For the boulder example, analogous quantities are as follows: the boulder, the boulder dislodges and alternative consequence categories for John, say loss of life, serious injury, minor injury and no effect. Note that the triplet (RS′, A′, C′) specified in the risk assessment can be different than the actual risk sources, events and consequences (RS,A,C). For example, we may have an event A occurring which is not covered by A′. The distinction between the risk concept and its description is considered important as it means that there will always be a discussion of how good the tools used for describing risk are, what their limitations are and how improvements can be obtained34, p.38.
The specification of RS′, A′, and C′ and the measure Q are founded on some background knowledge (K) in the form of justified beliefs (established based on data and information, testing, argumentation, modelling, etc.). To summarise, we obtain a general risk description (RS′, A′, C′, Q, K). Note that Q and K are used as generic symbols; they need not be the same in different stages of the assessments (for example, the assessments of risk sources RS and the assessment of the consequences C). We will return to Q and K in the coming section. ‘Uncertainty assessment Q and related background knowledge K’.
The concrete format of this characterisation needs to be adapted to the specific case considered and the decision support required. Often metrics are introduced connecting consequences and probabilities, for example F-C curves showing the probability of an event with at least a loss of C, or the expected loss of C. Within this framework, traditional probabilistic approaches for quantifying uncertainties, as presented, for example, by Kaplan and Garrick, 35 constitute examples on how to describe the risk. The appropriateness of these descriptions and metrics is always an issue, in particular, when using expected values, as commented in the introduction section. In any case, according to the present framework, the knowledge dimension needs to be reflected and in particular the strength of this knowledge, as underlined above.
If we are conditioning on the actual presence or occurrence of an RS or event, we talk about vulnerability. In line with the above understanding of risk, this leads to the following definition of vulnerability: Vulnerability refers to the combination of consequences of the activity and associated uncertainties, given the occurrence of a specific risk source/event (RS/A).
Thus, returning to the radiation example, vulnerability relates to how the person is affected by the radiation when this exposure is given/known. In the boulder example, vulnerability concerns how John is affected if the boulder dislodges and may hit him or alternatively if the boulder dislodges and has hit him. Hence, we can schematically say that the vulnerability concept is risk conditional on the occurrence of a specific event (A) or a specific RS. When referring to the vulnerability term, we always need to refer to the relevant RS or A and the ‘system’ affected by RS or A.
To describe or measure the vulnerability, we follow the risk concept, and we are led to a description of the form (C′, Q, K|RS′/A′), that is, the risk described by (C′, Q, K) conditional on the occurrence of risk source RS′ or event A′. If a system is judged to have high vulnerability, we say that it is vulnerable. The term ‘robust’ is often used for the case where the vulnerability is judged as low.
Uncertainty assessment Q and related background knowledge K
The quantities of interest are RS, A and C. The challenge is how to represent or express the uncertainties about these quantities. Traditionally, probability has been used, and this measure meets some basic requirements for this type of uncertainty representation: 36
Axioms. Specifying the formal properties of the uncertainty representation.
Interpretations. Connecting the primitive terms in the axioms with observable phenomena.
Measurement procedures. Providing practical methods for interpreting the axiom system.
For the setting considered here, probability is interpreted as a subjective (judgemental, knowledge-based) probability, in the sense that a probability of say 0.10 means that the assessor has the same uncertainty or degree of belief that the event will occur as randomly drawing a specific ball out of an urn holding 10 balls.37,38
Based on an extensive literature review of security risk, as well as considerable practical experience, the authors of this article conclude that very few experts on security risk are aware of the concept of probability as described above. In our view, this situation represents a main source of the poor communication between the security risk analysts and other risk experts, as documented, for example, by FFI. 1 When security professionals talk about safety risk, they typically think about frequentist probabilities and estimates of these.
Alternatives to probability also exist (see the overview and discussion in Flage et al. 39 ) which provides some reflections on the concerns, challenges and directions of development for representing and expressing uncertainty in risk assessment. One of the issues raised relates to when subjective probability is not suitable. One line of argument often seen is that, if the background knowledge is rather weak, it will be difficult or impossible to specify a subjective probability with some level of confidence. However, a subjective probability can always be assigned. The problem is that an assigned subjective probability is considered to reflect a stronger knowledge than can be justified. Think of a situation, in which the assessor has no knowledge about a quantity x (representing, for example, the time to an attack) beyond the following: the quantity lies in the interval [0, 1] and the most likely value of x is 0.5. From this knowledge alone it is not possible to represent a specific probability distribution, and so instead we are led to the use of interval probabilities. 40 Forcing the analyst to specify one probability distribution would mean the need to add some information not available. In this way, we are led to bounds of probability distributions and interval probabilities.
To this it can be commented that, in risk assessment, the goal is not only to represent neutrally the available knowledge but also to express the beliefs of the experts, and probability is a useful tool for this purpose. It is acknowledged that these beliefs are subjective, but they nevertheless support the decision-making. Hence, probability and the alternative approaches supplement each other.
If subjective probabilities are used to express the uncertainties, we also need to reflect on the knowledge that supports these. We may have two situations, one where the strength of knowledge supporting the probability is strong, and one where the strength of knowledge is weak, but the probabilities could be the same. This motivates an uncertainty representation which in addition to the probabilities P also includes a characterisation of the strength of knowledge that supports P. Hence, we derive at the pair (P, SoK), where SoK expresses some qualitative measure of the strength of the knowledge supporting P. Examples of such measures are reported in Flage and Aven 41 and Aven, 34 with criteria related to aspects such as justification of assumptions made, amount of reliable and relevant data/information, agreement among experts and understanding of the phenomena involved. The criteria in these references are, however, rather general and primarily motivated by and developed for the safety setting. Askeland et.al. 42 develop and apply a more detailed system tailor-made for the security setting, involving, for example, assessment of aspects relating to insight into actors (RS) and their capacity and intention, as well as their knowledge and behaviour. For example, a burglary of an art museum case is presented in Askeland et al., 42 where the threat of burglary is measured by the probability of an attempted theft of (any) artwork and the conditional probability of theft of specific (high-value) artworks given an attempted theft. Consequences are measured in terms of monetary value, but an indication is given of how also qualitative characterisations of the merits of the artwork could be included. Finally, vulnerability is measured by the conditional probability of different severity levels of the consequences, that is, different ranges of monetary loss. The assigned probabilities are then supplemented by qualitative assessments of the strength of knowledge supporting these and a classification into five categories ranging from strong to weak. For example, the knowledge is considered strong if all of the following criteria are met 42 :
The phenomena involved are considered well understood: All RS (actors) are known; Both the capacity and the intention of the RS are considered well understood; Both models used to reflect and predict RS (actor) knowledge and behaviour (including knowledge of and response to measures) and models used to predict consequences are known to give predictions with the required accuracy.
Much reliable data are available: High-frequency events. Both common-cause variation and special-cause variation are well characterised; Rare events. Not relevant;
There is broad agreement among experts.
All assumptions have been identified, documented and are seen as very reasonable: All explicit assumptions are documented; A process for identifying tacit assumptions has been carried out; All explicit assumptions are seen as highly reasonable, and the effect of potential further tacit assumptions is considered negligible.
The knowledge K has been thoroughly scrutinised.
Interval probabilities (imprecise probabilities) are commonly used in risk assessments, for example, when specifying probability categories in a risk matrix. The analyst is not willing or does not make the effort to be more precise than the interval expresses. Such intervals can also be founded on possibility theory and/or evidence theory. Also, when using such intervals, it is meaningful and relevant to consider the background knowledge and the strength of this knowledge. In most cases, the background knowledge for intervals would be stronger than for precise probability assignments, but the intervals would be less informative, in the sense of communicating the judgements of the analysts and experts making the assignments.
When discussing uncertainty in risk assessment, we also need to mention uncertainty importance analysis. The challenge is to identify the most critical and essential contributors to output uncertainties and risk. Considerable work has been conducted in this area (see for example the works by Borgonovo and Plischke, 43 Baraldi et al. 44 and Aven and Nøkland 45 ).
Discussion
We return to the security risk perspective with its triplet value, threat and vulnerability. It should be clear from the previous two sections that this perspective is included in the general framework presented in this paper. The values are identified, and the consequences C of the events A and RS relate to these values. The threats T are defined as either events or RS, and the uncertainty U associated with the occurrence of the threats is addressed. Given the occurrence of a threat, we look into the consequences together with the associated uncertainties, which are referred to as the vulnerability.
These are the fundamental concepts defining risk; next, we need to describe the risk. Then we specify threats T′ (risk sources RS′, events A′) and consequences C′ and use a measure of uncertainty Q, which is based on some background knowledge K, leading to a description of risk equal to (T′, C′, Q, K). The uncertainty measure Q could be a mixture of (interval) probability, assessments of intentions and capabilities, as well as judgements of the strength of knowledge supporting the other assessments.
We see that this dichotomy between the risk concept and its measurement creates structure and a sound basis for defining and understanding key concepts. It also provides a system for continuous scrutiny, evaluation and improvement of the tools used to measure the concepts defined. A fundamental feature of scientific work is to perform assessments that are valid, in the sense that one actually measures what one aims to measure. 46 In this way, the risk field will search for new and improved methods for this task. We will argue that there is still a potential for further developments in this area. In the previous section, we outlined some directions for research works to address this issue – how to best measure the risk concept in general and in a security context in particular, but there could be other routes (see the discussion in Aven 47 ).
The security area, with its triplet value, threat and vulnerability, has, in fact, a structure that to a large extent is in line with this dichotomy, although the degree to which this dichotomy is actually implemented and communicated varies. The uncertainty measures are often rather restricted or limited, focusing on likelihood or assessments of attackers’ intentions and capacities. The framework presented in this paper extends beyond these measures by combining several approaches and in particular adding the strength of knowledge judgements, which are not normally included in security applications, at least not in the explicit form used here. Some of the criteria considered for these judgements, such as data availability, are of course covered, but a systematic approach has not been adopted.
We have highlighted the importance of including the uncertainty component of the threat dimension, and if we study the security literature, we see that there are many guidelines and studies that recommend the use of probability to represent or express the uncertainties. 23 There are, however, also many security experts who consider probability inappropriate for security applications. As discussed in the introduction section, this may partly be a result of a frequency interpretation of probability – then, this position is understandable. There are, however, some analysts, who also reject probability even in the case that the probabilities are subjectively interpreted. The main argumentation seems to be that, for security applications, the intention and capability assessments do the job and the probability judgements do not add any important insights to the decision-making process. 5 The point we are making is, however, that addressing the intention and capacity necessarily needs to cover judgements of uncertainty – relating to who are the potential attackers, what are their intentions and capacities. As stressed in the introduction section, if frequentist probability was the only tool we could use for expressing these uncertainties, we would also reject it for many security applications. There are, however, other approaches and methods for expressing uncertainties, as discussed in this article. Examples include approaches and methods based on probability intervals together with strength of knowledge judgements.
Probability as applied in the current framework is to be seen as one of several instruments to capture the knowledge available in order to support the relevant decision-making. The probabilities should not be viewed in isolation from the assessments of intentions and capabilities, nor from the judgements of the strength of knowledge supporting the probabilities and these assessments. These assessments and judgements are as important, if not more important, than the probability assignments. Current security frameworks to large extent capture these dimensions, as is demonstrated by the UK treat-level approach presented in the introduction section. However, the scale commonly used for summarising the threat level can be improved using the set-up presented in this article using well-defined probability intervals with strength of knowledge judgements. 48 Just referring to probabilities without also addressing the knowledge supporting the probabilities means that an important aspect of risk is not revealed.
The uncertainty and likelihood dimension cannot be ignored in a risk management context, if we seek to make good decisions. Think about a situation, in which the decision maker needs to consider a huge number of threats. The resources for confronting these threats are, as always, limited. Should we then not in some way address the uncertainties and likelihood related to the possible occurrences of these events? Of course, we should; the issue is not if but how we should do it. The presented framework provides a broad perspective, for how to make judgements about these uncertainties and likelihoods, that sees beyond the (interval) probabilities, adding the traditional intention and capability assessments, as well as judgements of the strength of knowledge supporting the probabilities and these assessments. Clearly, if we ignore the uncertainty/likelihood dimension, we could seriously misguide decision makers in their use of resources. Robust and resilient thinking47,49 means that we are prepared to the extent possible for foreseeable and unforeseeable events and risk sources, but we always face resource limitations and we cannot build barrier and defence systems for all possibilities. The decision makers need to be risk-informed in a broad sense, which also means covering the uncertainty/likelihood dimension.
On different organisational levels, from the international governmental level via enterprises to the level of individual human beings, there is a need to characterise risk levels, for safety and security issues and other areas. Think about the board of a company, which is informed by the administration about potential threats, vulnerabilities and risks. A common framework and terminology for all types of risk is obviously desirable, in order to be able to make sound overall judgements about the company risks and to make appropriate decisions. The current situation is rather chaotic, with different risk languages within different communities and also with a large element of mistrust. There is no need for such a condition, as we all face risk – a generic concept used to understand, assess and manage situations, in which defined values are subject to some threats and these may lead to some consequences. We hope that this work can contribute to the removal of some of the barriers to further developments in the risk field, leading towards a future state with some common risk nomenclature and principles for all types of applications.
Many variations in the security risk formulations exist, as shown in the introduction section. However, they all seem to capture the same basic ideas of values, threats, consequences and vulnerability. Some definitions are general in their form, and others more narrow and unfortunate, as discussed in the introduction section, in particular, the use of products and expected values. The NS 5830 formulation mentioned in the introduction section, defining risk as ‘the relationship between threats towards a given asset and this asset’s vulnerability to the specified threat’,3,4 is probably a misprint, as it is hardly the relationship that the definition is supposed to capture, but all these three dimensions.
Conclusion
The risk concept is generic and independent of applications. Whether we are addressing safety, security or other areas, we face some potential risk sources or events (threats) that may lead to some consequences in terms of something that humans value. Conceptualising this type of situation leads to risk sources, events, consequences and associated uncertainties. The risk assessment needs to specify potential sources, events and consequences that can be realised in the future, to the extent possible, and use some appropriate tools for representing or expressing the uncertainties. The specific application and situation will call for different tools, meeting the specific need for decision support. Probability is a key tool for this purpose, but it needs to be supplemented with others to obtain a satisfactory description of the uncertainties. Robust and resilient approaches are needed to meet potential sources or events (threats), but these approaches must always be placed in a risk management context, also giving attention to the uncertainties and the likelihood dimensions, to using the resources in the best possible way and to balancing different concerns, such as risk and costs.
Footnotes
Acknowledgements
The authors are grateful to three anonymous reviewers for their useful comments and suggestions to the original version of this paper.
Declaration of Conflicting Interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: The work was partly funded by the Norwegian Research Council as a part of the Petromaks 2 program under grant number 228335/E30.