
Abstract
Understanding player positional roles are important for match-play tactics, player recruitment, talent identification, and development by providing a greater understanding of what each positional role constitutes. Currently, no analysis of competition technical skill data exists by player position in the Australian Football League Women's (AFLW) competition. The primary aim of the research was to use data-driven techniques to observe what positions and roles characterise AFLW match-play using detailed technical skill action data of players. A secondary aim was to comment on the application of clustering methods to achieve more interpretable, reflective positional clustering. A two-stage, unsupervised clustering approach was applied to meet these aims. Data cleaning resulted in 165 variables across 1296 player seasons in the 2019–2022 AFLW seasons which was used for clustering. First-stage clustering found four positions following a common convention (forwards, midfielders, defenders, and rucks). Second-stage clustering found roles within positions, resulting in a further 13 clusters with three forwards, three midfielders, four defenders, and three ruck positional roles. Key variables across all positions and roles included the field location of actions, number of contested possessions, clearances, interceptions, hitouts, inside 50s, and rebound 50s. Unsupervised clustering allowed the discovery of new roles rather than being constrained to pre-defined existing classifications of previous literature. This research assists coaches and practitioners by identifying key game actions players need to perform in match-play by position, which can assist in player recruitment, player development, and identifying appropriate match-play styles and tactics, while also defining new roles and suggestions of how to best use available data.
Introduction
Australian Football (AF) can be described as a ‘dynamic invasion team sport’. 1 The national competition for women's AF, the Australian Football League Women's (AFLW) competition, was established in 2017. Research on the AFLW competition has included characterising physical2–4 and technical match-play performance.5,6 Initial research has discovered key technical performance indicators such as disposals, disposal efficiency, contested and uncontested possessions, marks, marks inside 50, contested marks, and inside 50s are linked to match-play success.5,6 The findings of these match-play studies have the potential to support coaches regarding player performance development and match-play tactics, which at the start of the AFLW had been derived from the perspective of the male equivalent Australian Football League (AFL). 7
The AFLW competition has developed greatly in the first years of its existence, with the preliminary investigation of Dwyer et al. 8 showing an increase in match-play performance metrics over subsequent seasons (2017–2019 seasons). 9 This has been suggested to be attributable to a variety of factors including the greater opportunities for talent development associated with the establishment of an elite league, new youth pathways, and increased facilities and expertise.7,8 Player positional roles are anticipated to also evolve, reflecting the development of match-play performance. Statistically significant differences in physical and technical match-play performance by player position have been reported in both the men's10,11 and women's games.3,4 However, to what extent the positional roles follow that of the men's equivalent AFL may be unclear.
Important differences exist between elite women's (AFLW) and men's AF competitions (AFL), with the AFLW having shorter quarter lengths and fewer players on the field (16 vs. 18). Fewer players on the field in the AFLW have generally meant one less player in each of the forward and defensive areas on team line-ups, but whether this is reflected in match-play has not been investigated. Departures between the competitions also exist in physiological differences of players and less established development pathways, as well as the level and length of access to high-performance facilities, all with the potential to result in different positional roles and match-play styles. 3 These potential differences in positional roles between the AFL and AFLW may be greater than in other sports because these positions are more fluid in AF compared to many other sports. 12 Research following and extending precedents of playing position and role investigation has not been conducted in the AFLW with consideration to the context surrounding the different competition and overall environment surrounding women's AF. A greater understanding of what each positional role constitutes that is reflective of the women's competition may be useful to the AFLW with respect to match-play tactics, player recruitment, talent identification, and development.
The methodology of producing these positional classifications in the AFLW is also of interest, with a look to equivalent research in men's AF as a worthwhile point of comparison. In the men's game, the position of players has been investigated in an a priori or supervised manner (i.e. using existing player position assessment to understand what variables are important).12–14 These studies in the men's AF literature have used a priori methods of dimension reduction by removing correlated variables and choosing variables that have high importance in the prediction of match results or prior knowledge of what differentiates positions.12–14 Previous literature precedents of selecting variables by importance to a priori positions or to match-play success may bias results as the variables that differentiate between positions are not necessarily identical to those that determine the match result. Previous studies have also had individual issues such as the use of aggregations of multiple variables obscuring important individual actions 12 and inability to classify position successfully either through not enough variables or different roles between junior and elite male competitions. 14 While Barake et al. 13 were successful in classifying positions and even pre-defined roles for male players at a sub-elite level, this was achieved under the assumption of the a priori positional and roles detail of the AFL being applicable to male, sub-elite competitions. Nevertheless, the results of these studies have had applications for team recruitment, benchmarking player performance, and style of play; along with how the creation of these analyses may be impacted by aspects of the data currently available, or analysis techniques used to date.
Given the mixed use and results of previous applications to determine positional classifications in the AFL, the creation of a reproducible method that can be continually updated, producing interpretable, data-driven insights for practitioners that considers the challenges that the environment specific to the AFLW and wider women's sport present, is warranted. Creating this representation of player position will produce insights into the use of current data, comment on the appropriateness of different methodologies, and suggestions surrounding data cleaning protocols used in practice by data analysts. Additionally, while initial research on women's AF has been identified, current AF literature reflects an issue in broader sports literature with a dearth of research focused on female athletes relative to the men's equivalent which this study can help to begin to alleviate.7,15
Consequently, the primary aim of this analysis was to use data-driven techniques to observe what positions and roles characterise AFLW match-play using detailed technical skill action data of players. A secondary aim was to comment on the application of clustering methods to achieve more interpretable, reflective positional results in the AFLW considering current and potential future data availability that is reproducible and comparable.
Methods
Data
Each player's seasonal average of basic performance indicators (Supplemental Material 1) captured by Champion Data match-play statistics from 2019 to the first 2022 AFLW season were used in this study. These basic performance indicators were measured using data collection procedures similar to that currently used in the AFL, which have demonstrated accuracy within the men's competition, although no reliability verification has been conducted in the AFLW. 16
Time spent in each locational zone (Figure 1) by a player throughout a match is used to determine position by Champion Data statistics service in the men's game. 13 Subsequently, locational detail was sought for this analysis due to its potential to provide greater insight into player roles. Each game-action variable had its associated field location available in data and followed five zones on the field as determined and assessed by Champion Data (attacking midfield [AM], defensive midfield [DM], true midfield [M], forward 50 [F50] and defensive 50 [D50]). These field locations can be seen in Figure 1. As such, the additional context of the field location of each statistic was available to be pivoted onto the dataset. Pivoting the locational component onto each basic variable created new versions of the variable for each zone (e.g. Kicks became Kicks_F50, Kicks_AM, Kicks_D50 and Kicks_DM, Kicks_M), resulting in a total of five variables for each basic statistic.
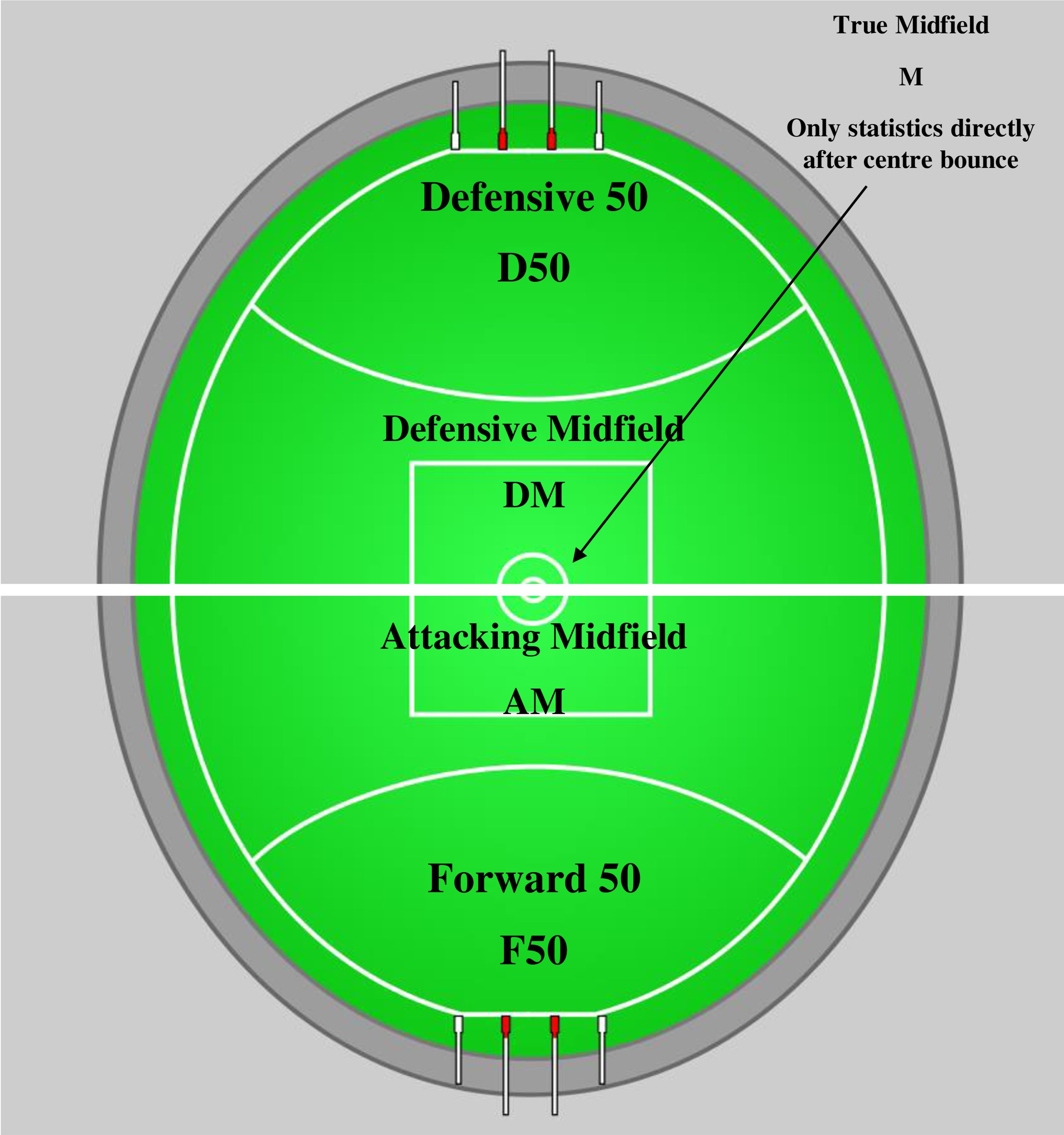
Locational information available in data. This work was built (‘remixed’) upon the previous open licence work available at: https://commons.wikimedia.org/wiki/File:AFL_stadium.svg. Attribution: Cflm001, CC BY-SA 3.0 áhttps://creativecommons.org/licenses/by-sa/3.0ñ, via Wikimedia Commons.
{kind=link}
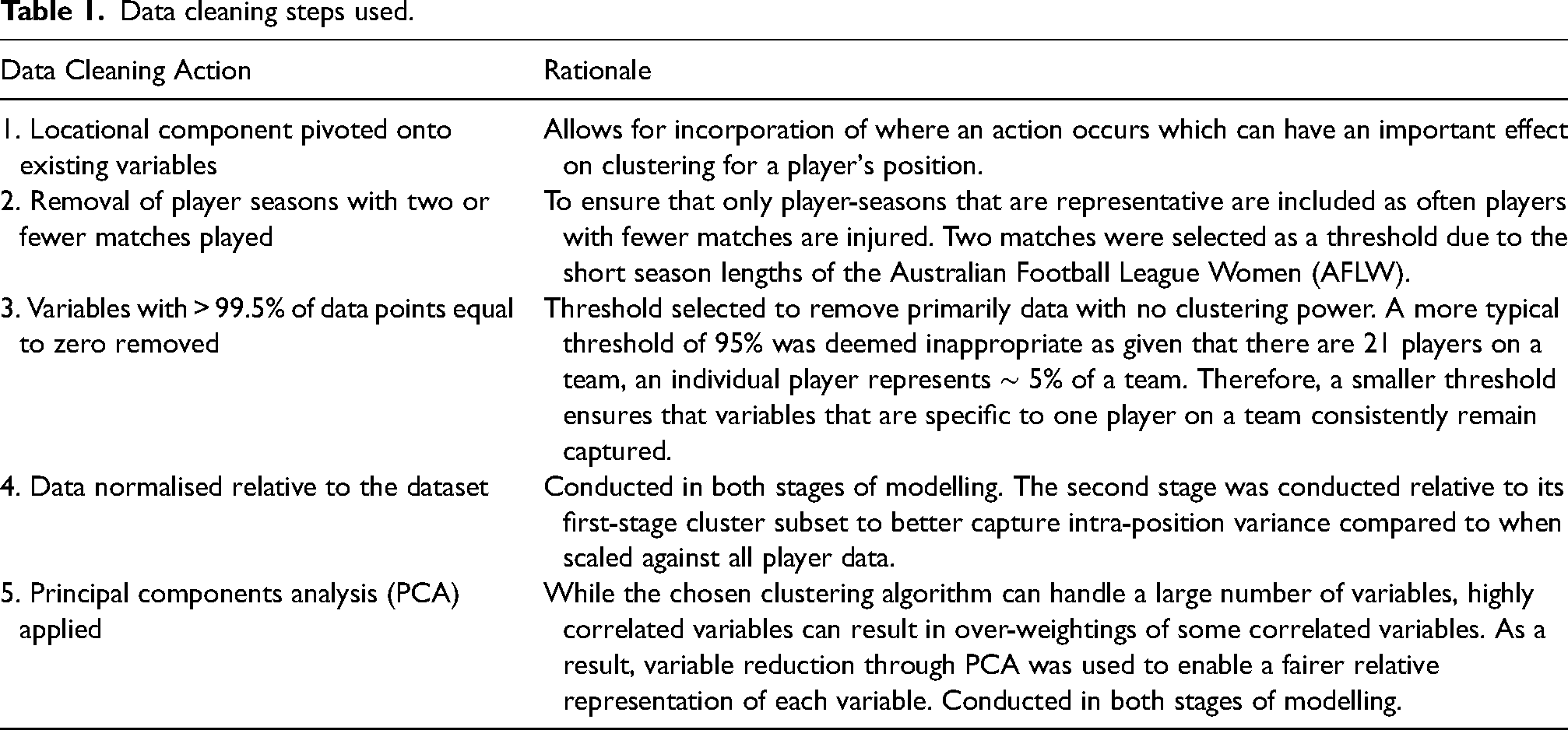
A summary of data cleaning steps and justifications can be seen in Table 1. All data and methods have received ethical approval by the Bond University Human Research Ethics Committee (BV00011).
Data cleaning steps used.
Statistical analysis
Due to the number of variables, many of which being highly correlated with one another, data was normalised, before principal components analysis (PCA) was applied, helping to enable better clustering performance. Additionally, the clustering large applications (CLARA) using the partition around medoid (PAM) technique from the cluster R package 17 was used due to the advantages surrounding sampling methods used to assist in ensuring the most relevant features are utilised. The CLARA algorithm performs iterative clustering meaning that further variable reduction does not need to be performed as variable selection is conducted through the clustering process. All stages of data cleaning and modelling were conducted in free, open-source software, R. 18
Clustering was applied in a two-step process to improve the ability to cluster on more position-specific differences in the second stage. This is similar to Barake et al., 13 who used a secondary step to split players within a position. This was performed by subsetting the data based on their first-stage cluster and then steps 3 to 5 described in Table 1 were repeated on each subset before second-stage clustering was conducted. This is important because re-normalising data relative to its own cluster allows for variations specific to the cluster that are not as obvious when comparing across all players.
The CLARA algorithm in both stages was applied with a prespecified number of clusters between two and 20. The appropriate number of clusters was then determined by firstly finding that which minimised the average cluster widths or ‘silhouette’ measure as in Wedding et al. 19 to result in the tightest, most distinct clusters through a metric that gives a relative figure of ‘tightness’ by the number of clusters that can be compared to other cluster amounts. It should be noted that this metric cannot be compared between datasets or other techniques due to differences in variation meaning its use should only be relative to other cluster amounts on the same data. Following this, individual clusters were manually checked to ensure clusters without data points were not present which would skew the silhouette metric through the creation of meaningless clusters.
As per our aim to observe what positions and roles within these positions emerge through data-driven techniques, it is not our purview to comment on the performance of players within positions. For this reason, clustering that can be seen to result in differences due to performance was to be reconsidered by merging these clusters to better distinguish between positions and roles. It was also part of our research ethical approval that we do not comment on the performance of individual players.
Variable importance interpretation
While the application of PCA multiple times provides benefits to identifying representative clusters, it does make ascertaining individual variable importance more difficult. 20 As a result, a method was used to find the underlying variables most important for distinguishing between both first- and second-stage clusters. This method of variable importance interpretation was achieved by applying random forest models using the original, non-PCA data to predict the cluster result in each stage, with results showing the most important variables to determine the cluster. Observing key variables via the mean decrease in Gini index (MDGI) provided a metric of relative variable importance, allowing for comparison between clusters using variables that best distinguish each grouping. 21 Mean decrease in accuracy attributable to each variable was also assessed as a measure of importance and was found to give very similar results. Differences in the importance of variables between clusters were best represented by descriptive tables comparing cluster characteristics.
Results
There were a total of 33 variables across 1425 player seasons across the 2019–2022 competitive AFLW seasons accessible within the Champion Data dataset. After pivoting the locational component onto variables and completing the data cleaning steps, 165 variables across 1296 player seasons were included for analysis. The full process of the application of the data cleaning, clustering, and its interpretation can be seen in Figure 2.
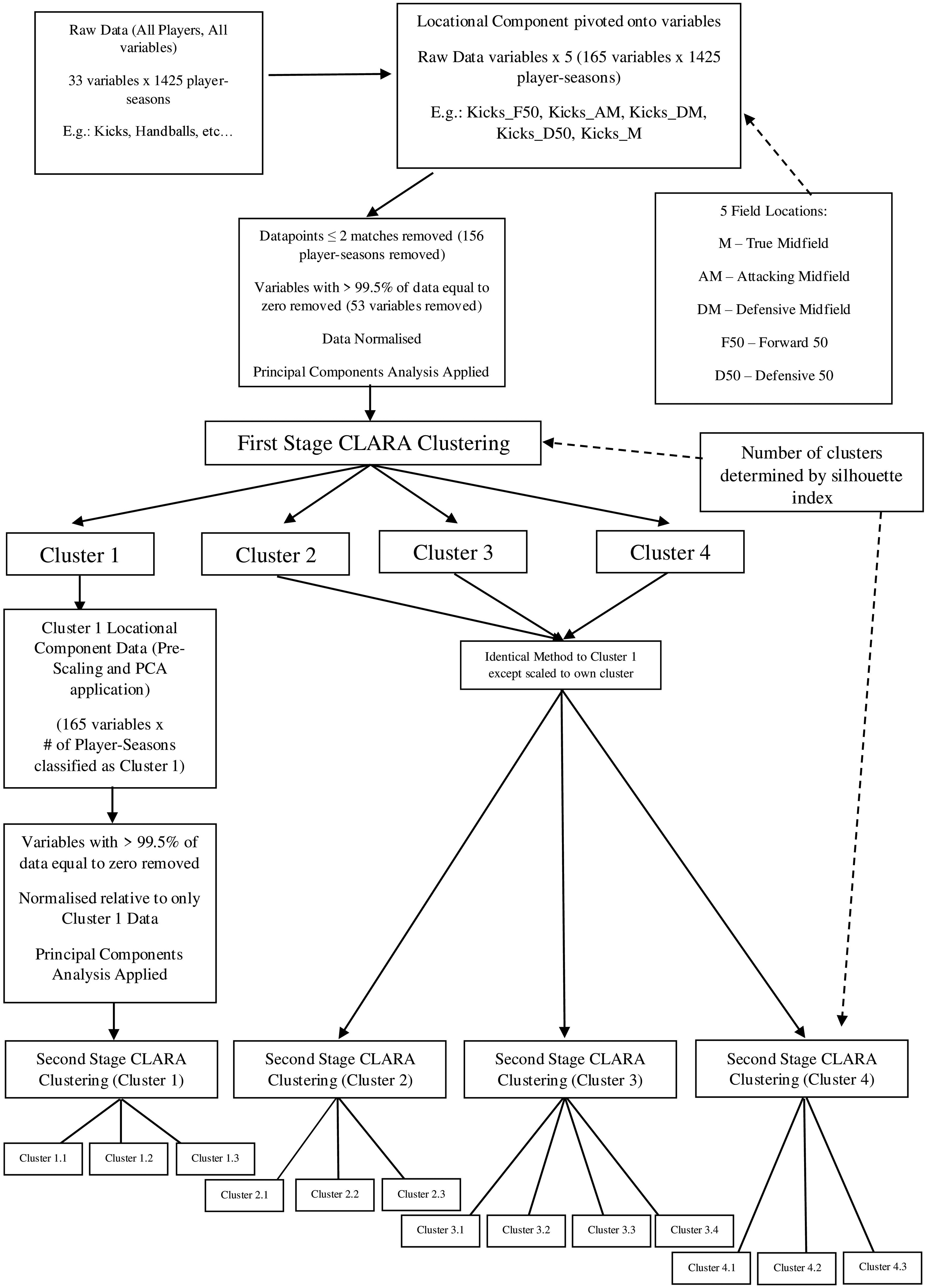
Data cleaning and clustering methods. PCA: principal components analysis.
PCA application on the first stage data of all player seasons resulted in 20 principal components that explain 71.49% of the variance in the dataset. First-stage clustering resulted in seven clusters being selected. Seven clusters resulted in a minimised silhouette metric of 0.1189. While there were lower averages in higher cluster numbers (0.102 for eight clusters), these contained empty clusters that skewed the metric.
The initial seven clusters were found to exist in pairs for each traditional position (i.e. two midfielder, forward, and defender clusters plus one ruck cluster). However, the distinguishing factor of these pairs was determined to be by player performance in all important variables of their assignment (i.e. all important variables were just higher in value relative to its pair cluster). To combat this, the seven clusters were reduced to four, following the four primary positional categories (Forward, Defender, Midfielder, and Ruck) by combining the pairs of similar clusters into a new subset. Table 2 presents descriptive statistics of the most important variables that determined cluster classification with the highest mean highlighted in each row. These variables were the highest 20 by importance (largest MDGI) in a random forest model (accuracy: 89.28%).
Stage 1 clusters descriptive table ordered by highest variable importance to clustering of AFLW positions.
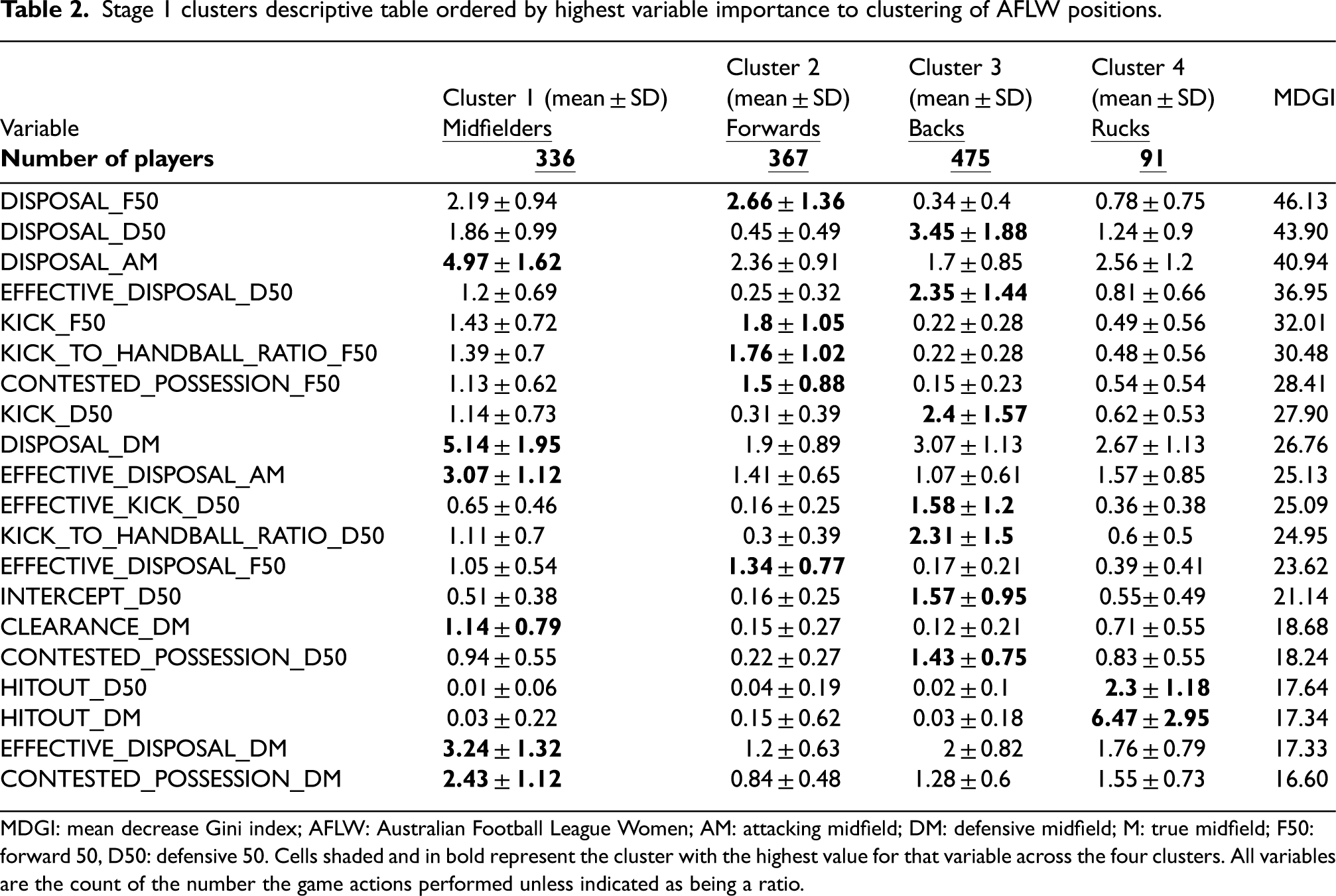
MDGI: mean decrease Gini index; AFLW: Australian Football League Women; AM: attacking midfield; DM: defensive midfield; M: true midfield; F50: forward 50, D50: defensive 50. Cells shaded and in bold represent the cluster with the highest value for that variable across the four clusters. All variables are the count of the number the game actions performed unless indicated as being a ratio.
Table 2 shows key statistics to determining first-stage clusters including the location of disposals (disposals in F50, D50, and attacking midfield). The location of other statistics like that of effective disposals, kicks, as well as contested possession are also indicators of player position. Intercepts in D50, clearances, and hitouts are other notable variables that further differentiated positions with less of a focus on location.
PCA applied to each rescaled subset in stage 2 resulted in variance in the dataset explained of: 71.5% (midfielders), 66.47% (forwards), 66.27% (defenders), and 77.36% (rucks) when using the first 20 components. Cluster silhouette metrics were 0.079 for three clusters (midfielders), 0.096 for three clusters (forwards), 0.081 for four clusters (defenders), and 0.13 for three clusters (rucks). Random forests for interpretation were fit with accuracies of 82.74% (midfielders), 82.02% (forwards), 78.95% (defenders), and 86.81% (rucks). Clusters, important variables, and descriptive statistics for each of these four, second-stage cluster subsets can be seen in Table 3.
Stage 2 clusters descriptive table ordered by highest variable importance to clustering of AFLW positional roles.
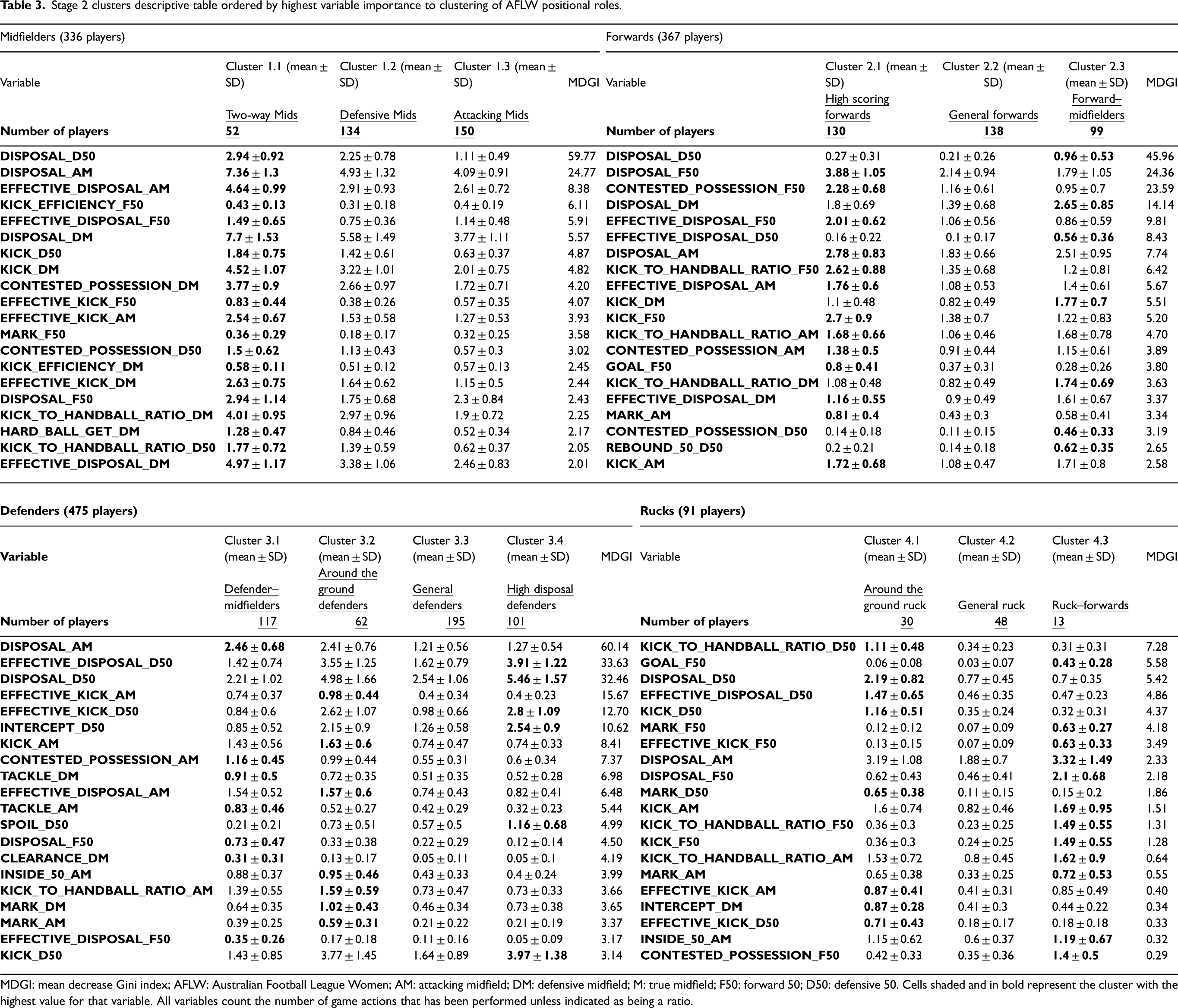
MDGI: mean decrease Gini index; AFLW: Australian Football League Women; AM: attacking midfield; DM: defensive midfield; M: true midfield; F50: forward 50; D50: defensive 50. Cells shaded and in bold represent the cluster with the highest value for that variable. All variables count the number of game actions that has been performed unless indicated as being a ratio.
Discussion
This research aimed to ascertain the positions and roles that are presented by employing data-driven techniques analysing player match-play technical skill data in the AFLW. Through the two-step cluster analysis, positional classifications were created for players across the 2019–2022 seasons of the AFLW, producing definitions of technical positions and roles for players in these positions through data-driven techniques rather than being subject to biases of current thinking within the competition. The existence of hybrid roles in the second-stage clustering has not previously been defined in academic literature. Roles identified in the second-stage may provide more targeted information for players and practitioners to better direct training and development practices. Greater guidance of recruitment for teams on an individual level, as well as when considering team tactical balance is also possible as suggested in previous literature. 13 Cluster analysis on PCA data, while initially obscuring results, has been made interpretable via random forests and descriptive tables to understand important points of difference between positional clusters.
Clustering results and practical applications
Interpreting first-stage clustering, the location of statistics, particularly disposals, was key to the differentiation of player position. Higher amounts of disposals in the D50, F50, and in midfield areas produced initial clusters of players following the sport's traditional defender, forward, and midfielder positions, respectively. 4 This shows the importance of the inclusion of locational context for positional classification research, with the critical initial distinction of position derived from these data being available. Champion Data positional classification in the men's AFL uses time in a location on the ground as the basis for the position, proving similar data to be valuable in the AFLW. 13 A fourth cluster, labelled as rucks, was typified by a high count in hitouts relative to other clusters, indicating the clear difference in their positional role. Other statistics helped further describe the differences between first-stage clusters, notably higher clearances, and statistics in all locations for midfielders, a high kick-to-handball ratio and effective disposals in F50 for forwards, and higher interceptions and kick-to-handball ratio in D50 for defenders.
The re-scaling of data to produce second-stage clusters was a key methodological decision that led to smaller, more position-specific differences being represented, showing the suggested impact that consideration of the application of normalisation and other data-cleaning procedures can have. 22 When data were scaled relative to the mean and standard deviation of the whole population dataset, differences between roles in positions (e.g. forwards) were hard to distinguish. Alternatively, when data were rescaled relative to their own positional subset, descriptive second-stage clusters were able to be created. These second-stage clusters were important as they differentiated specific positional roles within the four clusters identified in the initial analysis.
Second-stage clustering on the midfield subset produced three clusters. Once again, the location of statistics was important in classification with disposals and components of this statistic in each location key. Interpretation of these clusters suggested that players either fit into attacking midfielders that primarily had statistics in attacking locations (AM, F50), those that had more in defensive locations were named defensive midfielders (DM, D50), and those that had a high number in all zones of the ground, were referred to as two-way midfielders. Notably, the two-way midfielders cluster had the least players, suggesting this is the rarest sub-group of midfielders, possibly due to the greater running demands and physiological workloads required to substantially contribute at both ends of the ground. 2
Three clusters were identified for the forwards. Higher disposals in attacking and less in defending locations were the greatest determinant in clustering for the forward's subset with three clusters deemed appropriate. Cluster 2.3 distinguishes itself by the higher prevalence of statistics outside F50 relative to other clusters. This led to a label of those who are primarily forwards but also play in the midfield. Cluster 2.1 was those players deemed as high-scoring forwards, with these players most likely to have scoring kicks. The second cluster (Cluster 2.2) was not as large of a source of goals or a number of statistics compared to the high-scoring forwards. It is possible that further variables could help better distinguish the differences between Clusters 2.1 and 2.2, with elements like defensive pressure applied by players and gathering of ground balls being noted as defining roles in common AFL media match-play analysis, being potentially important activities for Cluster 2.2. 23
Defensive player clustering led to four role clusters, more than any other second-stage application. The highest subset of players (n = 475) was found to be defensive players in stage 1, with this either stemming from a higher number of defensive players in the competition or potentially those outliers that were harder to cluster being categorised as defenders which can occur when all datapoints need to be clustered as in this technique. 22 In Cluster 3.1, a similar phenomenon as with the forwards was seen, with those primarily considered defenders but also accumulating higher statistics in attacking zones compared to other clusters of defensive players. Cluster 3.2 also defended higher up the ground, but not in F50, suggesting that these are more of a half-back type of defenders rather than those who defend closer to the goal. Cluster 3.4 were those that had a high number of disposals in D50, indicating that they had a large role in rebounding the ball from the backline up the field as well as defending primarily in the D50. Cluster 3.3 did not have the highest average in any statistic although they had a large sample size of players. These could be defenders that are primarily focused on defensive actions that are not necessarily contained in the Champion Data statistics (perhaps as they are marking the most dangerous goalscoring forwards of the opposition team) and less focused on having many possessions or rebounding the ball out of defence.
Rucks were classified into three clusters. These were those who were more active in getting disposals around the ground (Cluster 4.1), those who were more traditional rucks with a primary focus on winning hitouts (Cluster 4.2), and those who scored more goals, which suggests they shared ruck duties with a second ruck and spent more time up forward (Cluster 4.3). Another key characteristic of Cluster 4.1 is the presence of D50 statistics including marks suggesting the importance of this type of ruckman in defending. The rucks are naturally the smallest subset, with typically only one to two ruck players on a team in a match. Despite the low sample size, clear second-stage clusters were able to be created.
When comparing the clustering of the four major positional groups, it was observed that midfielders were the smallest, non-ruck, cluster in terms of the number of players. This was an unexpected result given that AFLW team line-ups have six nominal midfielders compared to five nominal forwards and five nominal defenders, and more players with midfield roles are generally available on the interchange. A possible reason for this is the presence of part-time midfielders in defensive (117 players in Cluster 3.1) and forward (99 players in Cluster 2.3) second-stage clusters, which if they were to be considered midfielders, would make midfielders the biggest subset. This prominent presence of players who spend some time in the midfield is likely reflective of reality, given the high need for rotations in this position due to their greater running demands and physiological workloads. 24
Player position when considering the structure of a whole team is an important facet to consider, both to understand the role of positions within a team strategy and to check whether reasonable positions are being derived. Figure 3 represents two examples of team composition that can be created from the clustering results. It is an example of the team structure of two competing teams in the 2021 season using both first and second-stage clusters of players. Future research can build on this by looking into team composition and game style properties over time using these cluster definitions.

Example team structures of both first and second-stage cluster results. Defenders, midfielders, forwards, and rucks represent first-stage cluster positions for teams A and B on the far left and right, respectively. Internal labels represent the number of players clustered into each role within a position in second-stage clustering for each team in this example match (Team A on the left below each positional role box and Team B on the right). Gen: General, Def: Defender, High Disp: High Disposal, Mid: Midfield, Fwd: Forward, ATG: Around the Ground. This work was built (‘remixed’) upon the previous open licence work available at https://commons.wikimedia.org/wiki/File:AFL_stadium.svg. Attribution: Cflm001, CC BY-SA 3.0 áhttps://creativecommons.org/licenses/by-sa/3.0ñ, via Wikimedia Commons.
Previous women's AF literature has identified multiple variables as being important in match-play success. These include disposals, disposal efficiency, contested and uncontested possessions, marks, marks inside 50, contested marks, inside 50s as well as contributions from key players in a team.5,6,8 While the aim of this research differs in objective to these precedents of Black et al., 5 Cust et al., 6 and Dwyer et al., 8 overlap can be seen in important variables. The importance of variables of disposals, kicks, disposal efficiency/effective disposals, and contested possession were still evident in determining clusters through the methodology applied in this research even when accounting for the additional locational component in this analysis.
Other variables that modelling deemed important in determining either first-stage positions (forward, midfield, defender, or ruck) or second-stage roles within the position in the present study included clearances, intercepts, rebound 50s, and hitouts, which were not previously found to be important in previous research into AFLW team match-play success.5,6,8 This validates the methodological decision to not perform variable selection based on match-play success as key differentiators of positions are not necessarily the same variables. Therefore, this is a method to consider when performing more exploratory research, whereas a different dataset or treatment of the data may be needed in research to determine match outcomes. With that in mind, key variables in match-play success still being present suggest that some important actions performed by players in each position are similar to those required for team success. This indicates that our analysis shares some similarities in its results and conclusions with previous research identifying key technical variables influencing match-play success. As a result, this research assists practitioners, particularly coaches and sports scientists, by finding key game actions players need to perform in match-play by position which can assist in training practices, as well as defining new roles.
Research in men's AF at the elite AFL level, 12 the overlap of elite/sub-elite, 13 and junior levels, 14 have taken the same objective of analysis of position albeit primarily in a supervised manner with a reliable existing positional label for comparison. Variables key in distinguishing position in previous men's research include intercepts, spoils, hitouts, pre-clearance, and post-clearance disposals 12 ; uncontested and contested possession, clearances, disposals, kicks, inside 50s, contested marks, and effective disposals 14 ; and spoils and tackles in all areas of the field, along with possessions in F50/D50, intercepts in the midfield, bounces in D50, smothers in F50, total clearances, hitouts, contested marks, and shots at goal. 13
Derivatives of all of these important variables were also reflected in our research in the AFLW. Overall, there is a similarity to previous men's results in positional classification despite differences in match-play environments in terms of variables. Given the unconstrained nature of our methodology to pre-existing labels of position, this allowed for the discovery of more hybrid positions, particularly through second-stage clustering of roles. These new roles give a more specific definition of what actions a player performs in match-play, with previous general definitions of forwards, defenders, midfielders, and rucks, which may have obscured key statistics that characterise different roles in the same general classification. This comes at the cost of verification of results, as the validity of a semi-supervised approach is hard to check without a pre-defined label. 22 In the future, there is room for subjective assessment of clusters by an expert.
Clustering, data, and methodology application
Data employed for clustering were performed using the basis of the season average per player for each statistic, despite statistics representing each match and quarter being available. This was done as initial analysis using match or quarter length data demonstrated greater variance in match-play performance which made clustering harder to achieve given the need to have consistent player clusters and that the best indicator in an unsupervised clustering is tight, low-variance clusters.22,25 However, it is acknowledged that using a basis of a player's season average in each variable for clustering as in our analysis can lead to outlier results, particularly in players who have moved positions throughout a season; although this still provides greater insight than the alternative approaches. There exists the potential to revisit this clustering technique using individual matches or quarters in the future as this dataset increases in size, although management of the increased variance through a time series property or otherwise may need to be investigated to keep results consistent.
Increased sources of data including physical and anthropometric measures could also be included in the future to produce better representations of positions that may not be evident here. Rucks are generally the tallest players on the field, while midfielders typically have greater running demands and associated physiological capacities. 3 Re-investigating physical attributes exhibited by players in these new positional classifications should be considered in future research, to give a more holistic perspective of match-play demands for a player in physical, technical, and tactical capacities. Doing so could also give further clarity to current results. For example, Global Positioning System (GPS) data could be used to investigate whether players classified in hybrid roles are spending more time in specific areas of the field, or whether greater running capacity allows them to get to more areas of the field while remaining in the same overall position. Unfortunately, physical performance data is collected on an individual club basis, meaning that using this in future clustering would be difficult as it would be heavily biased toward the results of the number of clubs collected. 7
More granular data of exact locational coordinates of players or more field zones could also improve clustering. For example, some commonly acknowledged player roles, such as winger, are potentially unable to be distinguished easily without the presence of the wing location on the field in data. Further contextual information on match-play would also boost the descriptive power of clustering to better understand roles and in what phase of play players perform specific actions. This increased information in the data in the future will also cause additional difficulty in creating representative clusters due to increasing dimensionality and should consider the commentary on the methodological insights gained from this research. 22
Applying PCA on datasets was key to modelling, as the applied clustering algorithm was unable to deal with many highly correlated variables well, leading to a result not representative of match-play positional splits. The use of PCA adds difficulty to cluster interpretation, which was overcome with random forests to determine which specific variables were most important, providing an easier-to-use output that can be communicated to coaches and practitioners. Previous similar work in men‘s elite rugby league used discriminant functions 19 to distinguish cluster variable importance, although this was done on the PCA score data, giving a list of important variables rather than specific variables as presented in this analysis. Previously principal component equations were also presented as part of the analysis. Although, in this scenario, the higher number of variables made equations less interpretable, so alternatives were opted for.
It is also noted that different clustering algorithms could have been tested, with the current use of the PAM method of clustering which has Euclidean distance as the datapoint difference method potentially missing important contextual patterns that other non-linear datapoint difference methods could discover. 26 Current results were found to make sense from a statistical and match-play perspective, although re-running analysis with different algorithms could lead to alternate, insightful clustering patterns arising. The potential exists for a follow-up study repeating this methodology in the future, with the addition of an easier method of interpretation that allows the visualisation of temporal change in clusters. Use of these positional classifications in the greater analysis of team tactical phenomena can also be conducted, while the definitions provided can ensure accurate classification and understanding of the technical demands for player positions in future performance research in the AFLW competition.
Strengths and limitations
The approach used to cluster positions and roles found distinct clusters without the need for bias introduced via a priori methods given the objective to understand existing data-driven relationships which unconstrained, unsupervised learning only allows. 22 This allowed for more specific roles to be identified in second-stage clustering in addition to hybrid roles which would not be able to be produced with predetermined groupings or variable selection derived from variables previously found to be influential in match-play success. While this identification of hybrid roles is a novel contribution, it is unable to comment on a player's capability when performing other roles. The number of variables and seasons within the dataset is also a strength of this analysis, with no previous analysis of the AFLW having more than three seasons worth of data or employing data from the most recent seasons. 7 In addition, the results produced are interpretable and actionable. As the AFLW competition is still evolving, the clustering definitions may not completely hold for long as further development occurs and match-play trends change. 7 A strength of this approach is that the methodology used can be repeated into the future to ensure that results are up to date with the current trends of the AFLW.
There are some inherent limitations in the data and methodology used, much of which stems from the sample size issues derived from the relatively short seasons and history of the AFLW competition. Seasonal averages were utilised for both ethical clearance and data dimensionality reasons given limited computing power. In the future, more granular data (both temporally and additional variables) could be employed, which may provide a more robust definition. However, such an approach may also be more subject to issues surrounding increasingly sparse and noisy data in line with issues associated with the curse of dimensionality.25,27 Using only the seasonal average of players can obscure true positions in cases where players play different positions across different games in a season.
Conclusion
This study is the first to report on the technical skill positional roles within the AFLW competition using data-driven techniques, with the added benefit of a robust dataset used for classification. Two-stage clustering analysis provided a basis for classifying players into four primary position groups which followed generally accepted definitions (defender, midfielder, forward, and ruck). A further 13 groups, each representing a role within the four primary positions, were determined, which consisted of four defensive roles, and three midfielder, forward, and ruck roles. The existence of hybrid roles defining forwards and defenders that likely spend time playing as a midfielder was also revealed. Unsupervised clustering enabled a viable approach to discover these new roles rather than being constrained to pre-defined existing positional classification as has been seen in previous literature.
Variable importance that determines the classification of a player into each cluster was also presented, suggesting technical areas of focus for each specific positional group that can be applied by coaches and performance staff from developmental to elite levels of women's AF. Data analysts could also derive benefit from the application of clustering in this environment with key data and methodological considerations to make in the future while producing interpretable, reproducible, and comparable results for future research with suggestions of how to best use available data.
Supplemental Material
sj-docx-1-spo-10.1177_17479541231203895 - Supplemental material for An investigation of data-driven player positional roles within the Australian Football League Women's competition using technical skill match-play data
Supplemental material, sj-docx-1-spo-10.1177_17479541231203895 for An investigation of data-driven player positional roles within the Australian Football League Women's competition using technical skill match-play data by Braedan van der Vegt, Adrian Gepp, Justin Keogh and Jessica B. Farley in International Journal of Sports Science & Coaching
Footnotes
Declaration of conflicting interests
The author(s) declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The author(s) disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Australian Government Research Training Program Scholarship.
Supplemental material
Supplemental material for this article is available online.
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.