
Abstract
Research on visual word recognition has shown that letter and word processing is largely immune to variations in surface properties, such as lowercase/UPPERCASE or CaSe MiXinG presentation, which points to the existence of abstract letter representations. However, in languages with non-alphabetic scripts, a word is represented by a character or symbol, rather than a string of letters. How do biscriptal readers with a primary non-alphabetic orthography read alphabetic words? In the current study, 54 native readers of English and 48 logographic-script (Chinese and Japanese) readers performed a lexical decision task on English words and nonwords presented in upper- or lowercase. In line with previous research, case variation had only a very minor effect for the alphabetic readers, but it was much more pronounced for the logographic-script readers, and the case effect emerged both in words and nonwords. Findings are discussed in terms of abstractionist versus episodic accounts of letter processing.
Introduction
In languages with alphabetic orthographic systems, letter processing forms the basis of visual word recognition. A wide range of factors, such as size, case, font and colour, determine the appearance of words, yet these visual aspects do not substantially affect the quality of reading or comprehension. For this reason, mental letter representations are typically believed to be highly abstract: visually dissimilar instances of a given letter activate a single abstract letter code which is invariant to surface characteristics, and access to these abstract codes allows letter and word processing regardless of font and case (Bowers, 2000; Grainger et al., 2008). The assumption of abstract letter codes is so prevalent that most current models of visual word recognition do not explicitly distinguish between upper- and lowercase letters (e.g., Coltheart et al., 2001; Davis, 2010; Grainger & Jacobs, 1996; McClelland & Rumelhart, 1981; Perry et al., 2007; Seidenberg & McClelland, 1999). For instance, the Interactive Activation model of word reading (McClelland & Rumelhart, 1981) specifies orthography in terms of features and letters, with the former consisting of horizontal, vertical and diagonal lines (a coding system first used by Rumelhart & Siple, 1974) and the latter consisting of uppercase letters. The authors write that “. . .The simplicity of the present analysis [. . .] obviously skirts several fundamental issues about the lower levels of processing” (p. 383), that is, the process of normalizing the input across surface variability, and mapping upper- and lower-case letters onto a common abstract letter level. Likewise, more recent models such as Harm and Seidenberg (2004) and Zorzi et al. (1998) assume that reading involves surface invariant letter codes, and it is not central to model the process of abstraction which leads to the activation of such abstract letter representations. Dehaene et al. (2005) reviewed the evidence for visual word recognition from a neurobiological perspective and proposed a hierarchical model that brings together various stages of word processing and putative brain regions associated with invariant word recognition. In this framework, case-specific letter-shape units and abstract letter detectors are implemented by different subsets of neurons, and abstract letter representations are achieved by training the plasticity of neurons through perceptual learning. In other words, differences in neuronal plasticity and learning may affect the quality of abstract letter representations.
Nonetheless, the way in which orthographic variability affects reading has attracted researchers’ attention, with work dating back to the first half of the 20th century. For instance, Paterson and Tinker (1940) asked participants to read short paragraphs of equal difficulty in different typefaces for a fixed amount of time and then compared the average amount read by each participant. They found that on average, participants read lowercase texts about 12% faster than uppercase texts. However, in these and similar studies (e.g., Breland & Breland, 1944; Phillips, 1979; Tinker, 1963), it is less clear whether the outcomes of the research reflected the legibility of words per se, or rather more complex comprehension processes. More recently, a good deal of empirical evidence about how words and letters are mentally represented stems from studies of single-word processing. Speed and accuracy of responses in various tasks, such as lexical decision task (LDT), semantic categorisation, naming, or progressive demasking, provide important constraints on theoretical models of reading. In tasks such as these, does the presentation format of the letter string matter? For instance, does CaSe MiXinG induce slower processing time compared to the same-case strings? Mayall and Humphreys (1996; Exp. 1) suggested that in lexical decisions, case mixing had similar disruptive effects on words and on nonwords, a finding which is compatible with an early locus of the effect on letter identification. Arguing against this possibility, Perea et al. (2020) also found a case mixing effect in lexical decisions, but this effect disappeared when words were semantically classified. The authors argued that the case mixing effect in lexical decisions arose due to the lack of visual familiarity with words presented in mixed case, generating a bias to classify the words as nonwords and resulting in slower latencies and increased errors. By contrast, in semantic classifications, this bias does not arise, and mixed case presentation does not appear to disrupt letter processing.
Perhaps the most straightforward way of assessing the abstractness of letter representations is to compare performance on words (and nonwords, when using the LDT) presented in upper- vs. lowercase. Paap et al. (1984, Exp. 3) showed a small case effect in LDT which was independent of word frequency. Mayall and Humphreys’ (1996) first experiment showed that in an LDT, case only minimally affected high-frequency words (4 ms), but the effect was more pronounced for low-frequency words (38 ms) and for nonwords (26 ms). Perea and Rosa (2002) tested a group of native speakers of Spanish on an LDT with 128 five-letter Spanish words and 128 nonwords. The results showed a subtle but statistically significant lowercase advantage of case for words (16 ms) but not for nonwords. They also found a significant interaction between case and word frequency, with a lowercase advantage for low-frequency but not for high-frequency words. This finding suggests that the lowercase advantage may be specific to the processing of low-frequency words but that high-frequency word and nonword processing is not affected. Vergara-Martínez et al. (2020) assessed a group of native readers of Spanish in a LDT using 160 five- and six-letter Spanish words intermixed with 160 nonwords. They conducted the experiment alongside an event-related potential (ERP) measure to assess the time-course of brain activations during lexical decisions. In accordance with Perea and Rosa (2002), Vergara-Martínez et al. (2020) found a lowercase advantage for words (13 ms) but not for nonwords (2 ms), but in contrast to the earlier study, they found no significant interaction between case and word frequency in the response latencies, with virtually identical case effects for both word frequency groups. Similarly, regarding the ERP results, there were significant main effects of case and word frequency, in which larger negative amplitudes were recorded for lowercase than uppercase words and for low-frequency than high-frequency stimuli. However, the interactions were, again, not significant. This study provided consistent evidence for a lowercase advantage in LDT. Its ERP results also implied that the effect of the case occurred at an early stage of visual word processing and that the case effect vanished by the time the semantic processing of words began. Laham and Leth-Steensen (2022) found no case effect in the semantic judgement of single words, nor in an experiment which tested for recognition memory; however, in a sentence-judgement task (sensical vs. non-sensical), sentences presented in uppercase were judged more slowly than sentences presented in lowercase. These findings suggest that case has little impact on the speed of lexico-semantic access but may well affect the semantic processing of sentential information, perhaps via more fluent processing of lowercase sentences, or enhanced conceptual resonance. In sum, words presented in lowercase may be processed faster than words presented in uppercase, but this effect is quite subtle. As reviewed by Perea et al. (2017), evidence regarding a potential interaction between case and word frequency in LDT is inconsistent.
Despite the assumption of abstract letter (and word) representations typically taken for granted in models of visual word recognition, a theoretical alternative with a long history in cognitive research exists. The broader issue is whether cognition (language, memory, etc.) involves abstract codes, or whether empirical phenomena that suggest abstractness are better explained by an episodic account. For instance, Tenpenny (1995) reviewed findings mainly from long-term repetition priming studies and argued that the best account does not require the postulation of abstract memory codes, but rather via episodic memory. According to the latter, the mental codes used in word and object identification are the product of all previous exposures to these stimuli, with specific episodic traces of those prior exposures retained in memory. According to some views, the various episodic instances are merged across trials (e.g., connectionist frameworks such as Seidenberg & McClelland, 1989); on some other views, all instances are separately coded and retained (e.g., Goldinger, 1998). Importantly, according to these views, no abstract representations are required to explain empirical phenomena, but rather these are explained as “. . .emergent properties of a large set of highly specific traces that interact in such a way that it sometimes looks as if there are abstract codes” (Bowers, 2000, p. 84). Bowers (2000) reviewed the available evidence on short- and long-term repetition priming, and contrary to Tenpenny (1995), concluded that a “weakly abstractionist” position provided the best account, with both specific and abstract codes contributing to priming. More recently, Jamieson et al. (2022) made a convincing case that “instance theories” of cognition ought to be more seriously entertained as contenders for cohesive and integrative accounts of memory, from which phenomena in specific domains (such as language) can be accounted for: “humans store individual experiences in episodic memory and general-level and semantic knowledge such as categories, word meanings and associations emerge during retrieval” (p. 1).
Because abstractionist and episodic/instance accounts often make similar empirical predictions, it is challenging to adjudicate between them empirically. Notwithstanding, as reviewed by Jamieson et al. (2022), considerable evidence favours the latter account. For instance, despite the fact that speech is highly idiosyncratic and shows large surface variability (speaker variability, accents, etc.), the human speech recognition system typically recognises language without effort. An abstractionist view claims that a normalisation process overcomes speech variability early on; however, substantial evidence suggests that listeners’ memory retains auditory details (e.g., Goldinger & Azuma, 2004), which an episodic account (Goldinger, 1998) accounts for naturally.
Returning to reading, the finding that reading performance is largely immune to surface variability such as case (see above) could be taken to argue for abstract letter codes, but it is also compatible with the assumption of episodic accounts that alphabetic readers have comparable experience with the processing of lower- and upper-case letters. However, there are some empirical findings that are difficult to reconcile with the notion of abstract letter codes, but which are compatible with the assumptions of episodic accounts. For instance, in languages, such as German, the first letter of common nouns is capitalised (“Buch”; book), but non-nouns are not (“blau”; blue). In a semantic categorisation task, Labusch et al. (2022) found faster responses for nouns with initial capitalisation (Hund < hund) and faster responses for lowercase non-nouns (blau < Blau). They argued that initial capitalisation of German words constitutes an essential part of the words’ representations, which guides lexical access. Perea et al. (2018) explored the fact that although most words are written in lowercase, common words (e.g., street signs, billboards, etc.) are usually shown in uppercase. They showed that for the former (regular words) there was a lowercase advantage; this advantage disappeared for the words more often encountered in uppercase. When participants are asked to classify brand names, response times are faster when presented in their characteristic letter case configuration (e.g., “IKEA” is recognised faster than “ikea”; Gontijo et al., 2002; Perea et al., 2015). In a sentence reading experiment, Labusch and Perea (2025) presented participants with contained well-known brand names presented in their standard form (e.g., IKEA, Google) or altered letter cases (e.g., Ikea, GOOGLE). Results indicated a disadvantage for brands displayed in uppercase letters, regardless of their usual letter case, as seen in initial eye fixation metrics (first-fixation probability and duration). In later measures (gaze duration and total time), fixation times increased when the brand's letter case was modified, suggesting that during sentence reading, both the actual and typical letter cases of brand names interact dynamically. These and related findings challenge abstractionist models of reading and suggest a (perhaps weakly) episodic account.
Historically, research on visual word recognition has been characterised by an Anglocentric research agenda (Share, 2008). Orthographic processing in languages that do not employ an alphabetic system is bound to be fundamentally different from those that do. In logographic languages such as Japanese and Chinese (Cantonese and Mandarin), a word is visually represented not by letters or letter combinations which correspond to speech sounds, but rather by a character, sign or symbol. Hence, computational models that attempt to explain alphabetic reading make different assumptions than those that account for logographic reading (see Reichle & Yu, 2018, for an overview). For instance, as reviewed above, the Interactive Activation model of word reading (McClelland & Rumelhart, 1981) specifies orthography in terms of features and letters, whereas a subsequent extension of this model to Chinese reading (Taft et al., 1999) instead stipulates strokes, radicals, characters, and multi-character representations as orthographic building blocks. The computational model advanced by Li and Pollatsek (2020) postulates a “word processing module” which adapts many of the processing principles from the Interactive Activation Model (activation levels, excitatory and inhibitory links etc.) but discards the letter level and instead operates in terms of a “visual level,” a “character level,” and a “word level” (characters and words drive eye movement control in sentence reading, the main topic of this model). Many (perhaps most young) readers of logographic scripts are probably biscriptal in that they would have had exposure to alphabetic systems as well (for instance, Chinese readers are familiar with pinyin, a system which transcribes Chinese speech sounds into Latin letters). Nonetheless, their primary and dominant orthographic system is logographic rather than alphabetic, and this raises interesting questions about similarities and dissimilarities in the processing of alphabetically spelled languages. Specifically, how do they process letters in their non-native script/language? And for these individuals, is letter processing as insensitive to surface variability as it apparently is for native orthographic readers for whom (see summary above) variations in surface form of stimuli such as upper- versus lower-case presentation are largely irrelevant? Exploring this possibility was motivated by anecdotal reports (including from the first author) that readers of logographic scripts find processing of alphabetic words presented in uppercase considerably more difficult than in lowercase. Hence, effects of surface form variability, such as the “lowercase advantage,” might be more pronounced in logographic readers.
The current study investigated whether the assumption of abstract letter representation in most models of visual word recognition may underestimate the effect of case variations in logographic readers. We explored the “lowercase advantage” in an LDT among English readers, and the expectation from previous research (see above) was that such a case effect should be fairly limited, and perhaps entirely absent in the processing of nonwords. Additionally, a group of individuals whose primary orthography was logographic (Chinese or Japanese) carried out the same task, with the same (English) stimuli. Our primary question was whether the letter case effect might be exaggerated in these readers. If so, this would raise the possibility that in these readers, mental letter representations are less abstract than is commonly assumed for native readers of alphabetic languages. However, this hypothetical result could arise because alphabetic readers might be similarly familiar with uppercase and lowercase versions of words, whereas logographic readers, due to their overall lower English proficiency, might be particularly unfamiliar with uppercase versions of words. This possibility can be assessed by analysing performance not only on words but also on nonwords in the LDT: if an exaggerated case effect in logographic readers were to be found with nonwords as well, that would make it unlikely that visual familiarity could be a contributing factor.
Method
Participants
One hundred and thirteen students (71 females) took part in this study via volunteer and convenient sampling. Age ranged between 18 and 30 years (M = 20.8, SD = 2.6). Based on information elicited via a questionnaire, participants were assigned to one of two groups: an “alphabetic” group who had English as their first language (L1) and a “logographic” group who had Chinese (either Cantonese or Mandarin) as L1. Although some of the participants in the logographic group were recruited outside the UK, they were current students at English-taught institutions and had studied English for at least 10 years (M = 16.8, SD = 3.2), so they were quite proficient in English. Six participants were excluded from the analysis due to excessively high error rates (>25%). Following this exclusion, the final sample consisted of 54 and 53 participants in the alphabetic and logographic groups, respectively. All participants confirmed that they had normal or corrected-to-normal vision, had no history of language disorder, and gave informed consent for their participation prior to and upon completion of the experiment.
Material and Design
Each participant completed an LDT with half of the stimuli presented in uppercase and the other half in lowercase. This resulted in a 2 (alphabetic vs. logographic readers) × 2 (word vs. nonword) × 2 (upper- vs. lower-case) mixed factorial design. 120 4- to 7-letter English words were randomly selected from SUBTLEX-UK (van Heuven et al., 2014), a word frequency database for British English. All of them were singular, non-compound nouns with identical spellings in British and U.S. English, with a Zipf value between 4 and 7. The Zipf scale is a measure of word frequency developed by van Heuven et al. (2014), ranging from 1 (very low frequency) to 7 (very high frequency), with words with Zipf values of higher than 4.5 considered high-frequency stimuli. Therefore, the word stimuli used in this experiment should be generally recognisable by all participants. 120 nonwords were selected using the pseudoword generator Wuggy (Keuleers & Brysbaert, 2010). Two counterbalanced lists were produced, in which each list was comprised of 60 uppercase and 60 lowercase words, and 60 uppercase and 60 lowercase nonwords.
Procedure
The experiment was carried out online via Gorilla Experiment Builder (Anwyl-Irvine et al., 2020). The entire session lasted approximately 15 min. Participants were randomly assigned to one of the two counterbalanced lists and completed an LDT. They were instructed to categorise presented letter strings as either words or nonwords, and to carry out their decisions as fast and accurately as possible. They placed their left and right index fingers on the “f” and “J” keys of a keyboard, respectively, and responded only with these two fingers. There were 4 practice trials prior to the experimental block, and a total of 7 breaks, 1 in every 30 experimental trials, for a total of 240 critical trials.
On each trial, a black fixation cross was presented against a white background at the centre of a computer screen for 500 ms, followed by a target displayed in 32-px black Courier New. Participants judged each stimulus as a word or nonword by pressing one of the two response keys, in which the keys corresponding to word/nonword responses were counterbalanced between participants. Immediate feedback on the accuracy of the response was shown for 300 ms. Stimuli were presented in random order. Upon completion of the task, participants completed a follow-up questionnaire regarding their demographics, language background and the task stimuli.
Results
Analyses were conducted using the R Statistical language (version 4.5.0; R Core Team, 2025). Bayesian linear mixed effect models were constructed, using the packages brms (version 2.22.0; Bürkner, 2017) and bayestestR (version 0.15.2; Makowski, Ben-Shachar, & Lüdecke, et al., 2019). Follow-up tests were carried out with the package emmeans (version 1.10; Lenth, 2024). For both latencies and errors, we used the maximally possible random effect’s structure, with random slopes for case and lexicality per participant, and random slopes for case and group per stimulus. All factors were sum-coded. We followed the analytic framework described by Makowski, Ben-Shachar, Chen, et al. (2019) using the reporting guidelines at https://easystats.github.io/bayestestR/articles/guidelines.html. This framework distinguishes between indices of the existence of a given effect on the one hand, and its practical significance on the other. For the former, we report the “probability of direction” (pd), or the proportion of the posterior distribution that is of the median’s sign; for the latter, we used the portion of the full posterior distribution which is within the Region of Practical Equivalence (ROPE), or the range of parameter values that are considered practically equivalent to zero. Raw data and analysis files are available in an OSF repository at https://osf.io/gba8t/.
Response Latencies
Latencies from trials with incorrect responses (8.9%), as well as latencies less than 250 ms or greater than 1,500 ms (4.4%), were removed from the analyses. To reduce non-normality, response times were log transformed. A Bayesian model with four chains of 4,000 iterations (2,000 warmup and 2,000 sampling iterations) was run. Table 1 summarises the inferred cell means, back transformed to milliseconds. Table 2 (online Supplementary Material) shows a summary of the obtained posterior distributions for each main effect and interaction, and Figure 1 (top panel) provides a visualisation. The default ROPE, defined as ±0.1*SD(y) (Kruschke, 2014), corresponds to a range of (−21 ms, 21 ms) for our data set. Because reported case effects in the literature tend to be rather subtle, we used a somewhat narrower ROPE range of (−10 ms, 10 ms) rather than the default.
Inferred Cell Means for (in Milliseconds) and Errors (in Percent), Separately by Group (Alphabetic vs. Logographic), Lexicality (Words vs. Nonwords) and Case (Lowercase vs. Uppercase).
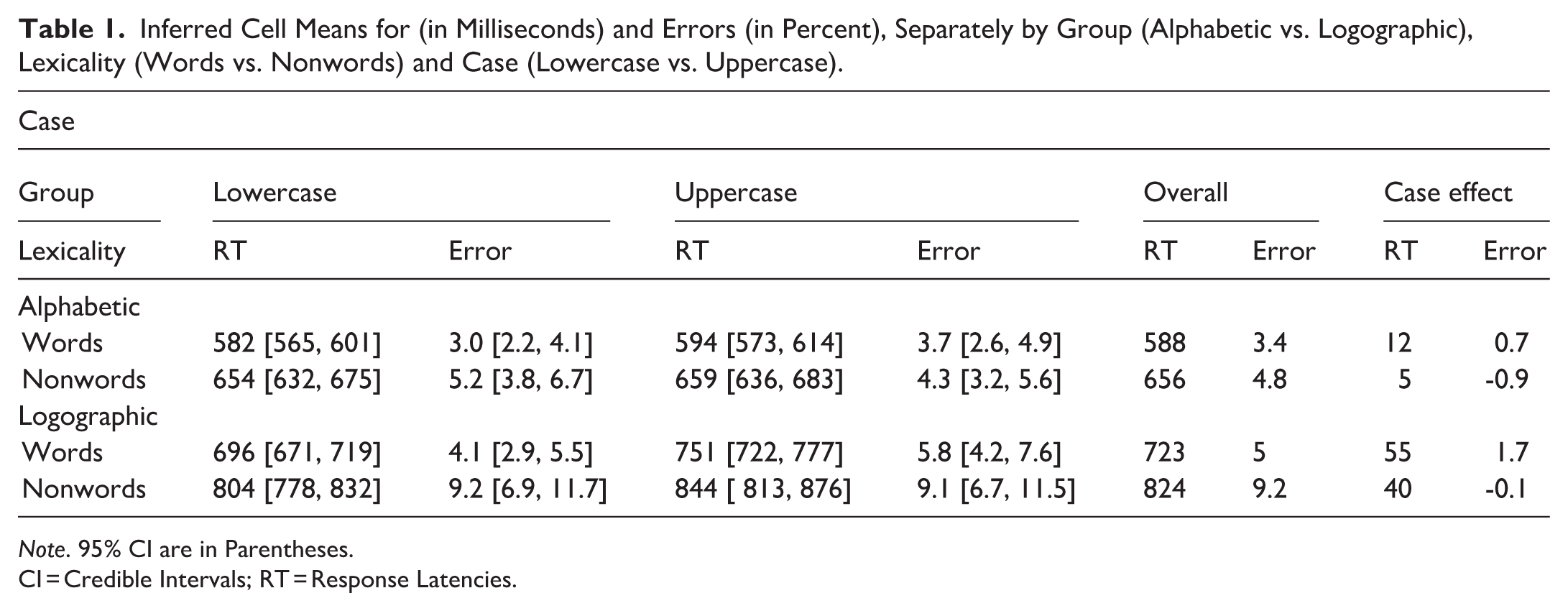
Note. 95% CI are in Parentheses.
CI = Credible Intervals; RT = Response Latencies.
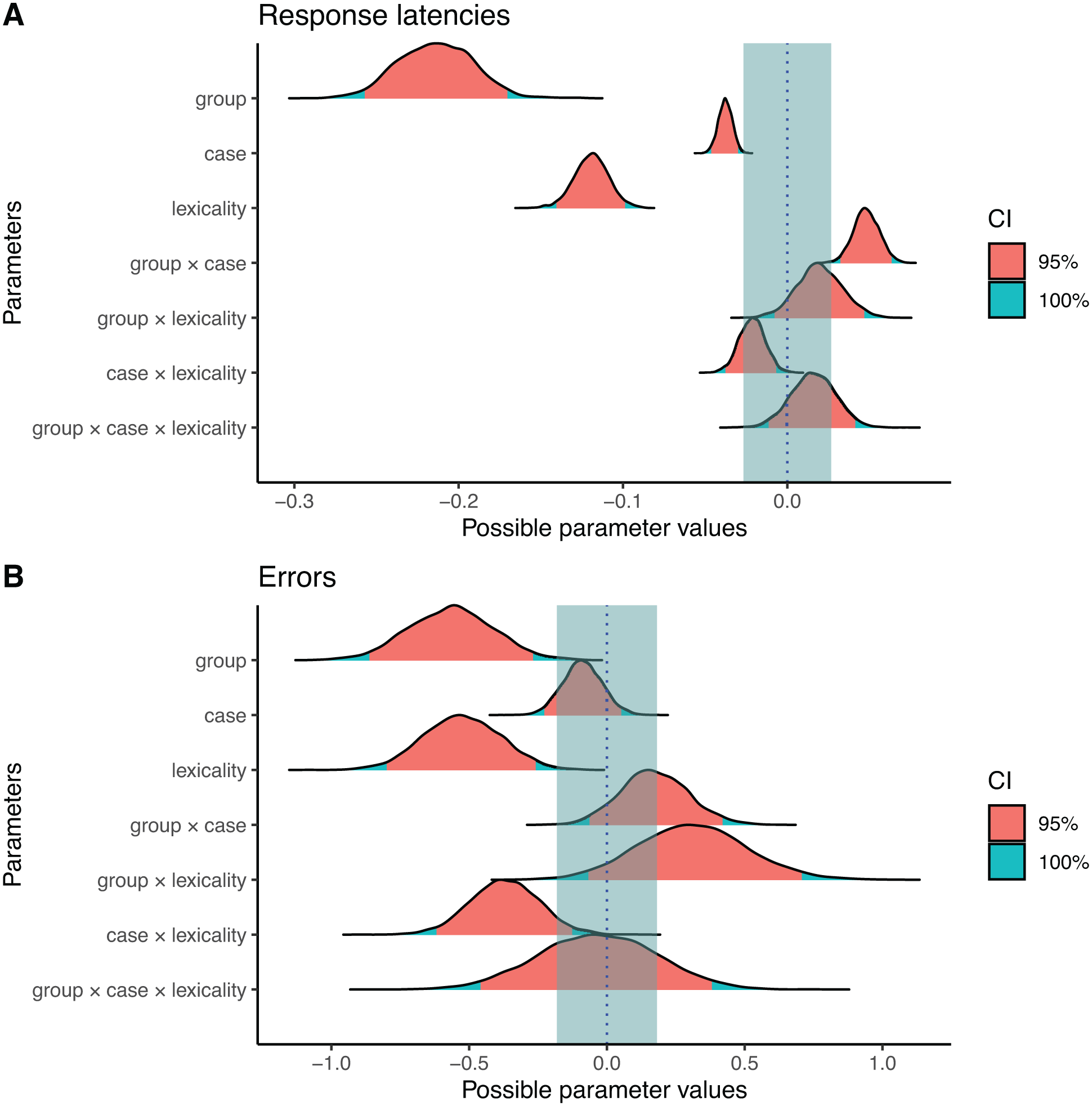
Posterior distributions of main effects and interactions, for response latencies (panel A) and errors (panel B). The shaded area around zero indicates the ROPE.
The 95% Credible Interval (CI) of the three-factor group, case, and lexicality did not include zero, with a probability of 100% of being negative and 0% of the posterior distribution included in the ROPE. Hence, all three factors “certainly exist” and are “practically significant.” Alphabetic readers responded on average 146 ms faster than logographic readers, responses to lowercase stimuli were 22 ms faster than to uppercase stimuli, and responses to words were 76 ms faster than to nonwords. Importantly, the 95% CI of the interaction between group and case did not include zero, with a probability of 100% of being positive and 0% of the posterior distribution included in the ROPE, hence this effect “certainly exists” and is “practically significant.” The case effect was 11 ms in the alphabetic group, and 40 ms in the logographic group; follow-up tests revealed that the 95% CI did not include zero for the alphabetic, nor for the logographic, group. The 95% CI of the interaction between case and lexicality did not include zero, with a probability of 99.6% of being negative but with 18.25% of the posterior distribution included in the ROPE, hence this effect “certainly exists” but is of “undecided practical significance.” The case effect was 31 ms for words, and 20 ms for nonwords; follow-up tests revealed that the 95% CI did not include zero for words nor for nonwords. The 95% CI of the interaction between group and lexicality, and the three-way interaction between group, case and lexicality all included zero.
Figure 2 presents an analysis of the response times of the logographic reader group via cumulative distribution curves (left panel) and delta plots (right panel; see Ridderinkhof et al., 2004, for an outline of this approach). Of particular interest is (a) whether or not the case effect appears consistently across the entire spectrum of response times, and (b) whether the case effect has a similar or different appearance for words and nonwords, which could be informative regarding the underlying mechanisms. Response times for each participant and condition were divided into quintiles, and the means of each quintile averaged. Figure 2 suggests that although there is some variability, the case effect appears reasonably well distributed across the spectrum of response times, and there are no systematic differences between words and nonwords. We conducted Bayesian analyses on the response times which were carried out separately for each quintile, with case and lexicality included as factors. In all five quintiles, the 95% CI of the factor case did not include zero, with a probability of ⩾99.75% of the effect being negative. Hence, a case effect emerged across the entire spectrum of response times. Of critical interest was a potential interaction between case and lexicality. For Q2 to Q4, the 95% CI of the interaction included zero. For Q1, the 95% CI just grazed zero ([−0.06, 0.00]), with a probability of 98.1% of it being negative and 20.6% of the posterior distribution included in the ROPE. Hence, for Q1 an interaction “likely exists” but is of “undecided practical significance.” For Q5, the 95% CI also just grazed zero ([−0.07, 0.00], with a probability of 95.7% of it being negative and 9.4% of the posterior distribution included in the ROPE. Hence, this interaction “possibly exists” but is of “undecided practical significance.” Overall, the case effect appears across the entire spectrum of response times, and we see no strong evidence for the possibility that it might be affected by the lexical status of the target string.
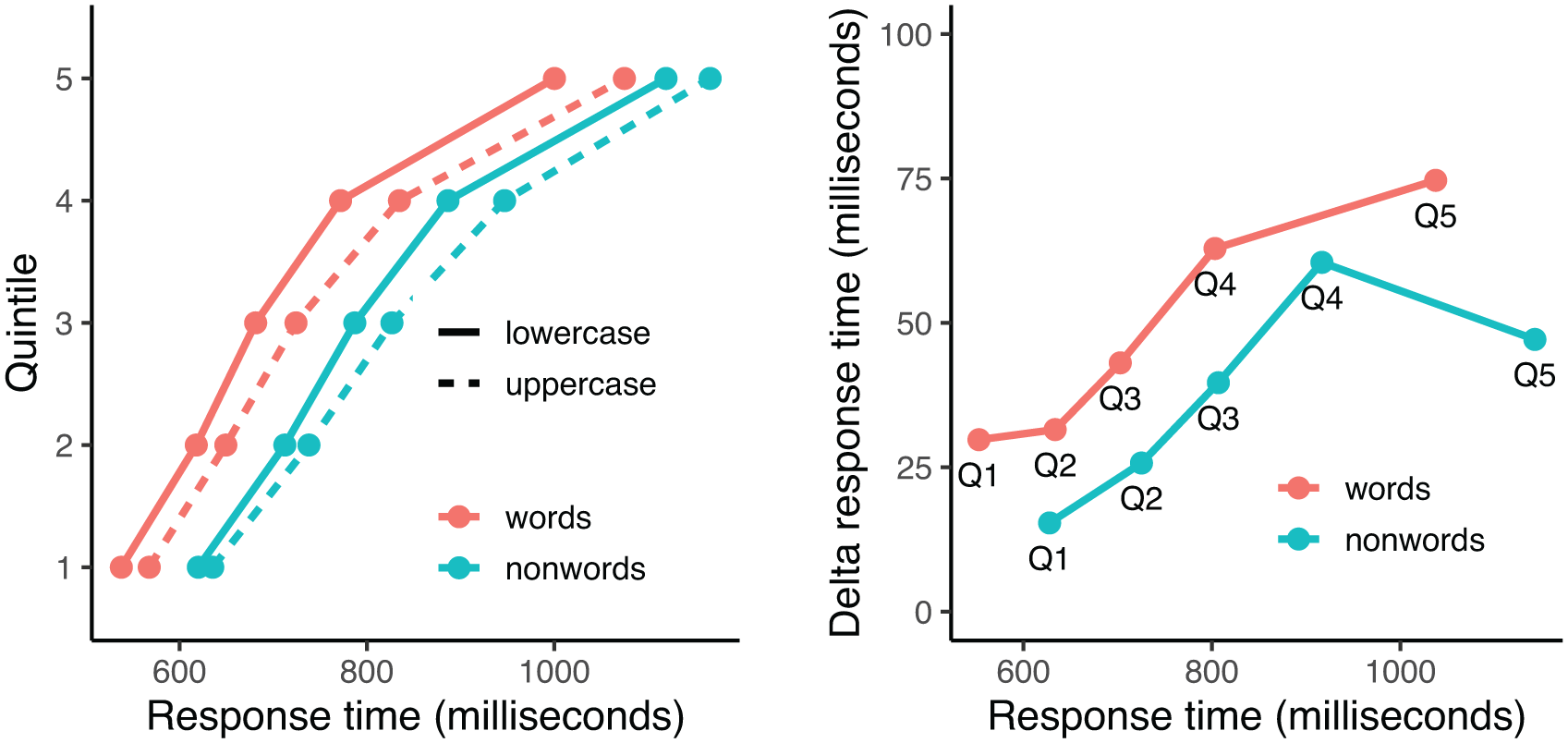
Left panel: cumulative distribution curves of response times for words and nonwords presented in lower- or uppercase. Right panel: delta plots of the case effect (uppercase minus lowercase) as a function of response time quintile (Q1–Q5), separately for words and nonwords.
Errors
A parallel Bayesian mixed linear effects model was run on the errors, but with a binomial family. Table 1 shows the inferred cell means, Table 2 (online Supplemental Material) shows a summary of the obtained posterior distributions, and Figure 1 (bottom panel) provides a visualisation. We used the default ROPE of
As outlined in the Introduction, evidence is inconsistent regarding whether a case effect is modulated by frequency (see Perea et al., 2017, for an overview). Despite the fact that in our stimuli frequency was deliberately constrained to include only medium-to-high frequency items (to ensure that all L2 readers were familiar with the words) we conducted an additional analysis on the words only for which in addition to group and case, Zipf frequency was included as a variable. The results showed that both for frequency and its interaction with group, the 95% CI did not include zero, with a probability of 100% of being negative and 0% of the posterior distribution included in the ROPE. The effect of frequency on latencies was descriptively stronger in the logographic than in the alphabetic group, but follow-up tests showed that for both groups, the 95% CI of frequency did not include zero. Critically, for the interaction between frequency and case, as well as for the three-way interaction between frequency, case, and group, the 95% CI included zero. In a parallel analysis conducted on errors, the 95% CI of frequency did not include zero. However, for all interactions that involved frequency, the 95% CI included zero. Hence, frequency clearly affected both response latencies and errors, but there is no clear evidence that frequency modulated the case effect.
Discussion
We explored the extent of a “lowercase advantage” (case) effect by comparing English words and nonwords presented in upper and lowercase in a LDT; critically, we contrasted the performance of alphabetic readers whose native language was English, with bilinguals whose native language used a non-alphabetic script. The results from the alphabetic group were in line with previous research: the case effect was 12 ms for words and 5 ms for nonwords. For comparison, Vergara-Martínez et al. (2020) reported a case effect of 12 ms for their words (high frequency condition, which aligns with the characteristics of our stimuli) and a 2 ms effect for nonwords. These results underscore the observation that for alphabetic readers, the impact of presentation format on letter/word processing is very minor. Of greater interest in our study was the contrast with readers with a native language that uses a non-alphabetic script. Our logographic group showed overall slower response latencies, but also a much more pronounced case effect for words (55 ms) and for nonwords (40 ms). Hence, for readers with a primary orthographic system that is non-alphabetic, presentation format is much more relevant than for readers of alphabetically written languages. The case effect emerged strongly not only in words but also in nonwords.
Table 1 shows that for alphabetic readers, the overall case effect in latencies (12 ms lowercase advantage for words) and in errors (0.7%) was very small. For logographic readers, the case effect in latencies was exaggerated, but as for alphabetic readers, error effects were more subtle (for both words and nonwords, the 95% CIs of error scores overlapped). It is perhaps informative to compare these findings to similar previous studies. For instance, Mayall and Humphrey (1996; Experiment 4) showed a significant case effect (upper vs. lowercase words) in latencies, but error rates of uppercase words were only somewhat higher than of lowercase words (0.9%) when collapsing across frequency and homophony status. Perea and Rosa (2002, Experiment 2) also found a case effect in latencies but not in error rates (the case effect was numerically reversed by 0.5%). Vergara-Martínez et al. (2020) found a case effect in errors, which reached significance by participants but not by items, but again the effect was numerically very subtle (0.9%). This implies that in LDT carried out by alphabetic (native) readers, uppercase presentation delays processing speed relative to lowercase presentation, but this does not impact accuracy. At the risk of simply paraphrasing these findings, the implication is that surface variability (upper vs. lowercase presentation, case mixing etc.) will influence the speed of early perceptual processing, but ultimately the correct lexical entries are accessed with high accuracy, leading to overall low error rates (in our data set, the logographic readers made on average only 1.6% more errors on word targets than the logographic readers).
The more informative finding in our study comes from the observation that the case effect was exaggerated in the logographic readers. What are the implications of our findings for current theories of visual word recognition? As highlighted in the Introduction, most current models neglect the “front end” of word recognition, and because reading is such a recent cultural invention, it must have co-opted aspects of the existing visual system in order to achieve a high degree of invariance to surface variation (Dehaene et al., 2005). According to Dehaene et al.’s (2005) model, abstract letter representation occurs after processing case-specific information on the letter shape, and neurons are trained to attune to frequently exposed letters and useful letter combinations through perceptual learning. In this model, tolerance for variation in size, location etc., is successively achieved in subsequent processing stages, with banks of “abstract letter detectors” speculated to be located bilaterally in area V8. Letter combinations such as bigrams, short words and recurring substrings are then recognised in the following stages, resulting ultimately in access to the mental lexicon. However, as summarised in the Introduction, a number of findings challenge the assumption that letter detectors are entirely abstract and suggest that an account based on episodic memory traces might fit the current array of empirical findings better.
Dehaene et al.’s (2005) as well as related models are of course models of alphabetic reading. Under an “abstractionist” viewpoint, readers of logographic scripts would presumably have attuned their visual systems to differently sized orthographic symbols (for Chinese readers: strokes, radicals, radical combinations, etc.). Because successively abstract representations are formed as the product of perceptual learning, it is plausible to assume that biscriptal readers, such as the logographic readers in our study, might have developed less tolerance to surface variation in alphabetic symbols than primarily alphabetic readers would have, despite them being successfully able to read alphabetic words. Hence, their neurons may be less well-trained for the transition from case-specific units to abstract letter detectors. Nonetheless, if letter detectors are entirely abstract (surface invariant), then models of this type would not be able to account for the exaggerated case effect in our logographic readers. The theoretical alternative consists of an “episodic” viewpoint according to which specific episodic traces of prior exposures are retained in memory and retrieved when cued. According to this viewpoint, our logographic readers would have had overall less exposure to uppercase than to lowercase letters, and therefore, retrieval of episodic traces is more effortful and slower in the former than in the latter case. By contrast, alphabetic readers presumably would have had a similarly high degree of exposure to upper- and lowercase letters, resulting in only a subtle processing advantage for the latter, as was the case in our findings.
As summarised in the Introduction, Perea et al. (2020) argued that the case effect for words in LDT may arise from a task-specific bias due to visual familiarity: uppercase (or mixed-case) words are less visually familiar than their lowercase counterparts, inducing a bias to erroneously respond negatively in a LDT, which takes a bit of time to resolve. The observation that no case effect emerged for nonwords in our alphabetic readers is in accord with this claim. Perea et al. (2020) also reported that the small mixed case effect in lexical decisions disappeared when semantic decisions were carried out on words. This makes sense given that the stipulated bias in LDT would not apply to semantic decisions. Of course, apart from such a possible bias, other task-specific demands distinguish LDT from semantic classification tasks, with the former emphasising pre-lexical processing aspects while the latter requires lexico-conceptual access. Under the assumption of a “flexible lexical processor” (Balota & Yap, 2006), it is likely that top-down influences arising from task demands modulate processing. Nonetheless, it is an interesting question whether the LDT bias advocated by Perea et al. (2020) also applies to our study: would the exaggerated case effect which we observed in logographic compared to alphabetic readers disappear if a semantic categorisation task was used instead of an LDT? If as we believe, the case effect arises due to lower letter abstractness in logographic compared to alphabetic readers, then the task should be irrelevant, we predict that even in a semantic task, case effects should still be pronounced in logographic readers. Future studies may want to explore this issue empirically.
A limitation of the current study is that the nature of the primary orthographic script (alphabetic vs. logographic) is confounded with the nativeness of language (L1 vs. L2). Logographic readers responded to stimuli in their L2, whereas alphabetic readers responded to L1, and for this reason, responses in the former group were slower than in the latter. In our view, the overall difference in response speed is unlikely to account for the differential case effects across the two groups. A common strategy in such instances (group differences in baseline processing speed) is to calculate proportional rather than absolute effects, but this is possible only with conditional means, not with the raw responses on which linear mixed effects analysis is based. Instead, we centred and scaled RTs for each participant individually, and then re-ran the Bayesian mixed linear effect model. Unsurprisingly, the main effect of group was now absent, but the 95% CI of the main effects of case and of lexicality did not include zero, and importantly, neither did the CI of the critical group × case interaction, with the latter having a probability of 100% of being positive. Hence, the larger case effect in logographic than in alphabetic readers is not due to the differential overall response speed.
Although our participants were chosen to be quite proficient in English (they had studied English for at least 10 years), we do not know the potential role of proficiency in the exaggerated case effect when reading English words. It is possible that lower-than-ceiling English proficiency drives the exaggerated case effect in these readers, although the effect also appeared in response times for nonwords (which should not be affected by proficiency). Nonetheless, inclusion of a measure of objective proficiency (such as LexTALE; Lemhöfer & Broersma, 2011) would have allowed us to use proficiency as a covariate to ascertain that the case effect is genuinely driven by orthographic script. Indeed, in the current study, script and nativeness are fundamentally confounded; future research may want to address this potential confound by including a third group, with non-native readers whose primary language uses an alphabetic script. For such a group, our prediction is that just like native readers, they will show little or no case effect.
In conclusion, native readers of alphabetic scripts show only minimal sensitivity to perceptual variations of printed words. In contrast, individuals whose primary orthographic system is non-alphabetic appear much more sensitive to such variations when processing alphabetic symbols, such as whether words are presented in lower- and in upper-case.
Supplemental Material
sj-docx-1-qjp-10.1177_17470218261427199 – Supplemental material for Exaggerated Case Effects When Logographic Readers Process Alphabetically Written Words
Supplemental material, sj-docx-1-qjp-10.1177_17470218261427199 for Exaggerated Case Effects When Logographic Readers Process Alphabetically Written Words by Sum Yin Cheung and Markus F. Damian in Quarterly Journal of Experimental Psychology
Footnotes
Ethical Considerations
This study was approved by the University of Bristol Faculty of Life Sciences Research Ethics Committee and has therefore been performed in accordance with the ethical standards laid down in the 1964 Declaration of Helsinki and its later amendments. All participants provided their informed consent.
Funding
The authors received no financial support for the research, authorship, and/or publication of this article.
Declaration of Conflicting Interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Data Availability Statement
Open Practices
For the purpose of open access, the authors have applied a Creative Commons Attribution (CC BY) licence to any Author Accepted Manuscript version arising from this submission.
Supplementary Material
The Supplementary Material is available at: qjep.sagepub.com
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.