
Abstract
Understanding how performance expression affects perceived emotion requires separating the effects of notated music from its interpretation by performers. Previous studies suggest that compositional cues (e.g., the pitches of a melody) primarily convey valence (negative–positive emotional quality), whereas performance cues (e.g., performance timing, intensity) convey arousal (low–high emotional intensity). However, these conclusions largely follow from simple single-line stimuli that lack the complexity of real-world music. To explore compositional and performance contributions to emotion in more complex works, we conducted experiments comparing participants’ (N = 120) valence and arousal ratings of 48 recorded excerpts from a Grammy-winning pianist against parallel deadpan versions lacking emotionally expressive aspects. By comparing differences in ratings of stimuli presented in expressive and deadpan conditions, we corroborate past findings highlighting performance contributions to perceived emotion, while also providing novel insight into the relative importance of analyzed cues. Our findings reveal that removing expressive aspects (i.e., the deadpan condition) significantly affects arousal ratings of 21 excerpts, but valence ratings of only 4. Additionally, we highlight how cues differ in importance between expressive and deadpan conditions through a novel analytical approach employing elastic nets. Our analyses shed new light on how performance expression affects emotions communicated across complex musical works with different levels of compositional cues.
Every piece has an essential quality which the interpretation must not betray . . . [but] we hear the style of the piece as refracted by the personality of the interpreter. (Copland, 1957, p. 161)
Introduction
Music’s capacity for emotional communication is widely regarded as one of its core functions, with emotional engagement ranking among the most salient reasons for music listening (Zentner et al., 2008). This unique power has fascinated prominent thinkers from Plato to Darwin, even inspiring Tolstoy to call music “the shorthand of emotion.” To understand the mechanisms eliciting affective responses, psychologists often manipulate specific musical properties used by composers to convey emotional messages—clarifying their effects on participants’ emotion ratings. Although such work has shed light on specific cues used in music (many of which are also used in speech), music’s emotional effects are driven not only by elements notated by composers in scores, but also by performers’ interpretations. Classical music represents a particularly interesting domain in which to study emotional communication, given that the musicians playing for audiences (i.e., performers) are often different than the ones who structured the musical sequences themselves (i.e., composers).
In order to explore the complexity of emotional messaging between composers and performers, scholars often attempt to separate their individualized contributions. For example, one study presented participants with computerized melodies crafted by composers, revealing listeners can accurately identify target emotions even when the work is not interpreted by a human performer (Thompson & Robitaille, 1992). Other studies report that performers’ interpretations of these melodies play a crucial communicative role, such as by improving participants’ decoding accuracy of emotions like anger and tenderness (Quinto et al., 2014) and enhancing the intensity of participants’ emotional responses to compositional properties (Curwen et al., 2024; Quinto et al., 2014). In communicating emotions, growing evidence suggests that compositional cues primarily differentiate the perceived valence (negative–positive quality) of musical works, whereas performance expressivity primarily affects the perceived arousal (low–high emotional intensity; Quinto & Thompson, 2013).
Performance contributions to perceived emotional meaning
Performers interpret notes with subtle deviations in dynamics and timing, shaping listeners’ perceptions of emotional meaning (Bhatara et al., 2011) and influencing mental imagery (Ayyildiz et al., 2025). To understand the perceptual consequences of performance deviations, scholars have conducted studies analyzing interpretations of musical passages and how they differ according to expertise (Kim et al., 2021; Sloboda, 1985), individual performers’ distinct approaches (Barolsky, 2007; Battcock & Schutz, 2021; Cancino-Chacón et al., 2020; Repp, 1990), or sociocultural factors such as pianists’ countries of origin (Cook, 2014). In the context of Western classical music, isolating the perceptual consequences of performance expression requires methods that can separate a performer’s intentional fluctuations from the information notated in musical scores.
To understand how a performer’s interpretation affects perceptual phenomena, previous studies have compared professional renditions of musical pieces against mechanical or deadpan performances (defined as “a literal interpretation of the score”; Canazza et al., 1996). Such methods provide a way of isolating the effect of performance expressivity—“physical phenomena, that is, deviations in timing, articulation, intonation, and so on in relation to [these] literal interpretation[s]” (Gabrielsson, 1999, p. 522). These comparisons provide valuable insight into the perceptual effects of music’s compositional cues (dictated by the performer and common across different performances of the same piece) versus performers’ interpretations (varying across different renditions of the same piece).
Quantifying performance expression
How do performers go “beyond the notes” to communicate emotions? Studies on Western classical performance suggest they apply strategies to convey composers’ emotional intentions by “identifying the structure and finding ways to bring it out” (Cook, 2014, p. 3). Pianists with greater expertise vary dynamic information to demarcate the phrase structure of musical works (Sloboda, 1983, 1985), and listeners can detect notes lengthened by as little as 20 ms (Clarke, 1989). These expressive deviations, in turn, influence how emotionally expressive a performance sounds. For example, one study exploring continuous emotion ratings of 10 pianists’ interpretations of Chopin’s E-minor prelude found higher ratings of “emotionality” in response to specific expressive devices employed by the performers (Sloboda & Lehmann, 2001).
Perceived emotionality in performances can also vary based on to the degree of expressiveness in a performance, along with the performers’ expertise in conveying it. One study presented participants with 30-s excerpts from two Chopin nocturnes, manipulating the expressivity level to range from a completely mechanical rendition (which we here call “deadpan”) to the full level of expressivity present in the original recording (Bhatara et al., 2011). Using a Yamaha Disklavier, the researchers generated five levels of expressivity from the recordings—finding that variations in timing and amplitude affect ratings of emotional expressivity. The perceived intensity of emotions can also increase with performance expertise, with professional performers eliciting emotional messages more effectively than semi-professional and amateur ones (Vigl & Zentner, 2023). However, understanding the musical cues driving those effects requires differentiating between performer-controlled and composer-influenced cues.
Prosodic and musical cues for emotion
Music is a complex multidimensional medium, making the operationalization and selection of measurable properties challenging. What specific aspects of a music performance convey emotions, and to what degree? Meta-analytic findings on 41 music emotion studies report systematic patterns in cues, including timing (tempo), intensity (sound level, intensity variability), high-frequency energy (measuring timbre), and pitch-related properties (height, contour, variability). Comparing their results to 104 speech studies, those authors concluded that the two mediums share several common “emotion-specific patterns of acoustic cues” (Juslin & Laukka, 2003, p. 797).
Music’s similarities with speech in communicating emotions have received attention in both theoretical and applied studies (Agarwal et al., 2018; Scherer, 1995). Like music, variations in acoustic cues help convey a speaker’s emotional inflections nonverbally. However, music offers one crucial advantage in explorations of nonverbal emotion—written scores provide precise indications of the pitches in a passage, and how they are differentiated in relative timing. This means we can separate the effects of expressivity (controlled by the performer) from the intended pitch–time patterns laid out by the composer. Crucially, whereas a musician’s variations of aspects like timing and loudness are critical for expressing emotional meaning, varying a melody’s pitch or rhythmic relationships during performances can be detrimental (M. R. Jones et al., 1987). Music also contains a cue not found within speech that governs the sets, combinations, and tension–resolution patterns of pitches in a piece—mode. In Western classical music, the major and minor are the two most common and are widely associated with the positive/negative quality of emotions (Dalla Bella et al., 2001; Eerola et al., 2013; Gagnon & Peretz, 2003; Hevner, 1935; Webster & Weir, 2005). Within this context, mode generally falls in the purview of the composer and is not intentionally manipulated by performers.
Quantifying performance expression
How do composer-controlled and performer-influenced cues affect perceived emotional qualities? To explore this question, researchers have adopted Russell’s (1980) circumplex model, which distinguishes emotion into dimensions of valence (negative–positive) and arousal (low–high intensity). Past emotion studies using this model suggest that mode (dictated by composers) predicts valence (Costa et al., 2004; Ilie & Thompson, 2006), whereas timing and intensity predict arousal (Carpentier & Potter, 2007; Dean et al., 2011). However, the effects of compositional versus performance properties are ultimately inseparable in those studies, and to our knowledge, only two have explored the contributions of composers and performers directly.
The first study investigating the role of expressivity in conveying circumplex dimensions used eight audio descriptors to predict continuous valence ratings of classical pieces. Comparing computational models for two pieces, the authors found compositional cues (mode, key clarity, harmonic complexity, and event density) outperformed performance-based cues (articulation, pulse clarity, and brightness; Fornari & Eerola, 2009) when tested against ground-truth data. Acknowledging the need for further exploration on the topic, they theorized that the compositional structure of a piece lays the foundation for emotional aspects brought out through performance expression (p. 131).
To assess Fornari and Eerola’s theory in an experimental setting, Quinto and Thompson (2013; abbreviated herein as Q&T) evaluated compositional and performance contributions by comparing mechanical and expressive performances of single-line melodies ranging from 5 to 9 notes. Across two experiments, different participant groups heard 52 different melodies that musicians performed while attempting to convey five target emotions (anger, fear, happiness, sadness, tenderness). The authors presented short melodies written and performed by musicians, as well as melodies written by musicians but performed mechanically by a computer. Comparing emotional effects across conditions revealed that compositional cues (pitch, pitch range, interval size) explain more variance in listeners’ valence ratings, whereas cues affected by performers’ interpretations (intensity, intensity variability, articulation, high-frequency energy) explain more variance in arousal ratings. They also found that expressive deviations in acoustic cues play a crucial role in communicating the intensity aspect of emotions.
Extant explorations of compositional versus performance contributions to valence and arousal suggest that performers and composers play distinct and complementary roles in communicating emotion: compositional properties set the emotional tone, whereas performance expression amplifies it. However, those studies’ conclusions stem from 5- to 9-note melodies (Quinto & Thompson, 2013), or a small number of ecologically valid recordings (Fornari & Eerola, 2009). Consequently, generalizing these findings to naturalistic music stimuli requires in-depth exploration of the consistency of performance effects across pieces with different levels of compositional cues.
The present study
To provide novel insight into the role of expressivity in communicating emotion dimensions, here we explore excerpts from naturalistic music performed by an internationally acclaimed pianist. Our stimuli consist of expressive and deadpan versions of 48 historically significant piano preludes by two renowned composers, performed by Vladimir Ashkenazy—a seven-time Grammy winner. Specifically, we compare Ashkenazy’s interpretations (Bach, 2006; Chopin, 1993) versus deadpan renditions of the same 48 pieces. We chose these composers’ preludes because their music has been widely performed and analyzed in past expressivity studies (Bhatara et al., 2011; Cancino-Chacón et al., 2020; Chowdhury & Widmer, 2021; Sloboda & Lehmann, 2001). These sets of 24 pieces contain one prelude in each major and minor key, avoiding imbalance in modality—a crucial cue for musical emotion. Our novel approach complements and extends previous research on compositional and performance contributions to valence and arousal while exploring a larger number of naturalistic excerpts.
Cue selection and effect measurements
To approach this topic in a theory-driven manner, building upon past work highlighting their relevance to perceived emotion, we considered all nine cues analyzed by Q&T (excluding intervals and articulation due to the substantial subjectivity they introduce in the context of polyphonic piano music). Consequently, our final selection of cues includes mode, pitch height, pitch range, timing, intensity level, intensity variability, and high-frequency energy. Most of these cues also appear in Juslin and Laukka’s (2003) highly influential meta-analysis.
Because cue relationships are inherently intercorrelated in naturalistic music, we employ a model-selection procedure using elastic net regression to measure cue effects and quantify their relative importance (Tay et al., 2023; Zou & Hastie, 2005). This procedure provides two important advantages: (a) penalizing intercorrelated relationships to reduce the risk of biased interpretations and remove null effects; and (b) rank-ordering cues based on their relative contributions. Although a related technique called ridge regression has been useful for interpreting regression coefficients while accounting for multicollinearity in music (Costa et al., 2004), to the best of our knowledge, elastic nets have not been applied in previous studies on emotional expressivity in music. However, the analytical properties of elastic nets allow us to identify which cues play a greater role in communicating valence and arousal for expressive versus deadpan conditions—building upon our team’s previous efforts to quantify the importance of features in both composers’ works (Anderson & Schutz, 2023), and applying techniques capable of accounting for intercorrelated cue effects on emotion ratings (Battcock & Schutz, 2021; Delle Grazie et al., 2025).
We present analyses of emotion ratings from four experiments where participants heard either expressive or deadpan versions of piano prelude excerpts. We matched deadpan versions of preludes in average timing and intensity with the original recordings. In total, five analyzed cues share common values between expressive and deadpan conditions (mode, timing, intensity, pitch height, pitch range), whereas two are unmatched (intensity variability and high-frequency energy). By equating timing and amplitude between conditions, our approach compares two extremes of expressivity (i.e., mechanical vs. real performance). To clarify how the deadpan manipulation affects participants’ ratings, we first assess differences in valence and arousal between conditions before evaluating how these differences relate to the analyzed musical cues.
Our approach allows us to test the generalizability of Q&T’s (2013) claim that compositional structure primarily communicates valence, whereas its interpretation in a musical performance primarily conveys arousal. We revisit this hypothesis through (a) analyses comparing differences in emotion ratings between conditions, and (b) analyses of cue effects on emotion ratings, quantifying how much variance is explained for each condition, and which cues provide the most explanatory power.
Methods
To assess the role of compositional and performance cues on perceived emotion, we varied the listening condition (deadpan vs. expressive) and composer (Bach vs. Chopin) across four experiments programmed in PsychoPy (Peirce et al., 2019), each with a different participant group. In all experiments, participants heard only one composer and one performance condition. Experiments took place between Winter 2023 and Fall 2024.
Stimulus preparation
We presented the first eight measures (short musical units) of each prelude from Book 1 of Johann Sebastien Bach’s The Well-Tempered Clavier (Bach, 1960) and Chopin’s Op. 28 Preludes (Chopin, 2007). We included anacruses (shorter lead-in measures) when present. Both sets—composed for keyboard instruments—feature 12 pieces in the major mode and 12 in the minor. This balance with respect to mode affords exploration of how performance cues affect major versus minor excerpts, as mode is strongly associated with emotions perceived in Western music (Justus et al., 2018; Yang et al., 2018). Additionally, this particular set of stimuli is useful in building upon past perceptual experiments involving prelude sets (Battcock & Schutz, 2019; Chowdhury & Widmer, 2021). For both expressive experiments, we prepared excerpts from renditions by Vladimir Ashkenazy (Bach, 2006; Chopin, 1993), an internationally acclaimed pianist who released commercial recordings of both prelude sets.
To prepare deadpan renditions, a musician with extensive experience in music engraving typeset each excerpt in Sibelius, which we then converted into Musical Instrument Digital Interface (MIDI) representations. For each of the 48 deadpan encodings, we prepared audio stimuli using the AddictiveKeys grand piano timbre (using all preset parameters) in GarageBand (Addictive Keys, 2022; Mayers & Lee, 2011), using Ashkenazy’s average attack rate to match excerpts. Finally, to equate average energy between listening conditions, we matched the average root mean squared (RMS) amplitude of the deadpan stimuli to that of Ashkenazy’s performance using the RMS Normalize plug-in for Audacity (The Audacity Team, 2007). Supplemental Figure 1 depicts examples of how the waveforms from the deadpan audio differ compared to those of the original performances. For all stimuli, we prepared 32-bit WAV files, including a 2-s fade-out at the end of each excerpt (i.e., starting at the beginning of the ninth measure).
Participants
Power analysis and exclusions
As this study is the first (to our knowledge) comparing valence and arousal ratings in recordings and computerized renditions of complex passages, we did not have a priori hypotheses regarding effect sizes. However, in previous work evaluating similar ratings in recordings of these pieces, we observed R2 statistics of at least .40 for both valence and arousal using a three-cue model comprising attack rate, pitch height, and mode (Anderson & Schutz, 2022; Battcock & Schutz, 2019). Consequently, we conducted regression power analyses to detect an effect of R2 = .40 with a statistical power of 0.90 using the pwrss R package (Bulus, 2023). Detecting this effect requires at least 26 participants per experimental group. For consistency with our past work, we analyzed data from 30 participants in each experiment. To ensure reliable data quality, we planned recruitment of up to 35 participants and included the first 30 who accurately followed instructions to use the entire range of the emotion rating scale. Following this procedure, we excluded five participants from our original sample (Bach—expressive: three exclusions; Bach—deadpan: two exclusions).
We conducted four listening experiments, analyzing data from a total of 120 nonmusicians (i.e., having less than 1 year of formal music training) recruited from McMaster University’s psychology (n = 114) and linguistics (n = 6) participant pools. All participants reported normal hearing and corrected-to-normal vision. In total, 60 of the participants (42 female, 17 male, 1 unreported; age: M = 18.13, Mdn = 18, range = 17–26, SD = 1.23) heard prelude recordings by Vladimir Ashkenazy (30 in each experiment), and 60 (46 female, 12 male, 2 unreported; age: M = 18.84, Mdn = 18, range = 17–30, SD = 1.95 [2 ages unreported]) heard deadpan versions synthesized without performance variation (30 in each experiment; participants were not aware of condition assignments). Participants received course credit for their participation. Experiments complied with the ethics policy of McMaster’s Research Ethics Board.
Procedure
We conducted all experiments in a noise-attenuating sound booth. In each experiment, participants heard excerpts (presented as 16-bit WAV files) using Sennheiser HDA-200 headphones. Prior to the experiment, we provided instructions on the task, defining the valence and arousal scales. We instructed participants to rate the emotions they perceived in the music, rather than those they felt while listening to it (see Gabrielsson, 2001, for a summary of this distinction). After completing four practice trials (comprising two randomly selected major excerpts and two randomly selected minor ones), participants rated all 24 excerpts in a randomized order using the valence (7-point) and arousal (100-point) scales (Russell, 1980). Following the ratings, participants completed the Goldsmith Musical Sophistication Index and answered additional questions about their musical background (Müllensiefen et al., 2013).
Equating cues in deadpan stimuli
We generated MIDI files from the Sibelius engravings of excerpts and matched them with Ashkenazy’s performances in average timing and intensity (described in the next subsection). In total, we analyzed seven cues examined by Q&T.
Equated cues
Mode
Mode is a structural cue widely associated with the emotional connotations of music (Justus et al., 2018). In Western classical composition, the major and minor modes are the most common. Because Bach and Chopin composed their preludes in each major and minor key, the declared major/minor mode of each piece can be identified from its title.
Attack rate
For a global summary of timing information, we counted the number of note onsets in an excerpt (with concurrent notes counting as only one onset) and divided the sum of onsets by the duration of the recorded excerpt. Attack rate (also called articulation rate or onset rate in linguistics studies; Jacewicz et al., 2009) is less dependent on rhythmic subdivisions than tempo, helping sidestep ambiguities arising when pieces with the same tempo have different underlying rhythmic structures (Schutz, 2017). As a result, this cue quantifies the performance aspect of rhythm.
Pitch height
We analyzed the average pitch height by assigning pitch numbers to each note based on the piano keyboard. To derive the pitch height, we calculated the duration-weighted sum of all pitches, following the methods outlined in the study by Poon and Schutz (2015).
Pitch range
To quantify pitch range, we calculated the difference in pitch height between the highest and lowest notes in an excerpt, extracted from MIDI files using the music21 Python library (Cuthbert & Ariza, 2010).
Intensity level
We calculated the global RMS amplitude of each excerpt in Audacity (The Audacity Team, 2007), representing the average intensity or energy.
Audio-extracted cues
Intensity variability
We calculated the standard deviation of RMS amplitude using the Librosa Python library (McFee et al., 2025), with a rolling window defined a hop length of 512 samples and a frame length of 2,048 samples. Intensity levels vary throughout musical performances, affecting perceptions of emotional arousal (Dean et al., 2011).
High-frequency energy
Following Q&T, we calculated the strength of the spectral energy above 3,000 Hz in each excerpt with the mirbrightness function in MIRToolbox (Lartillot et al., 2008). High-frequency energy influences our perception of brightness in different instruments (Saitis & Siedenburg, 2020).
Analytic strategy
To protect against experiment-wise error, we employed nonparametric tests with no assumptions regarding normality of data (Wilcoxon Signed-Rank Tests), and cross-validated regression models to predict the optimal parameters for analyzing emotion ratings with analyzed cues. For null hypothesis significance testing, we report Bonferroni-corrected p values with r effect sizes, along with 95% confidence intervals. We view analyses of how cue patterns differ between conditions as the primary goal of this study.
Transparency and openness
We comply with Level 2 compliance of the Transparency and Openness Promotion guidelines for data sharing (Nosek et al., 2015) and follow the Journal Article Reporting Standard’s guidelines for quantitative research designs (Kazak, 2018). We did not preregister the study.
Results
Comparing conditions
To explore the relationship between deadpan and expressive conditions in valence and arousal ratings, we plot circumplex visualizations of participant ratings in Figure 1, depicting the average valence and arousal ratings of each excerpt. A solid line indicates the distance between deadpan and expressive conditions along valence–arousal space. Open dots denote the average deadpan ratings, whereas closed dots denote the average expressive ratings.
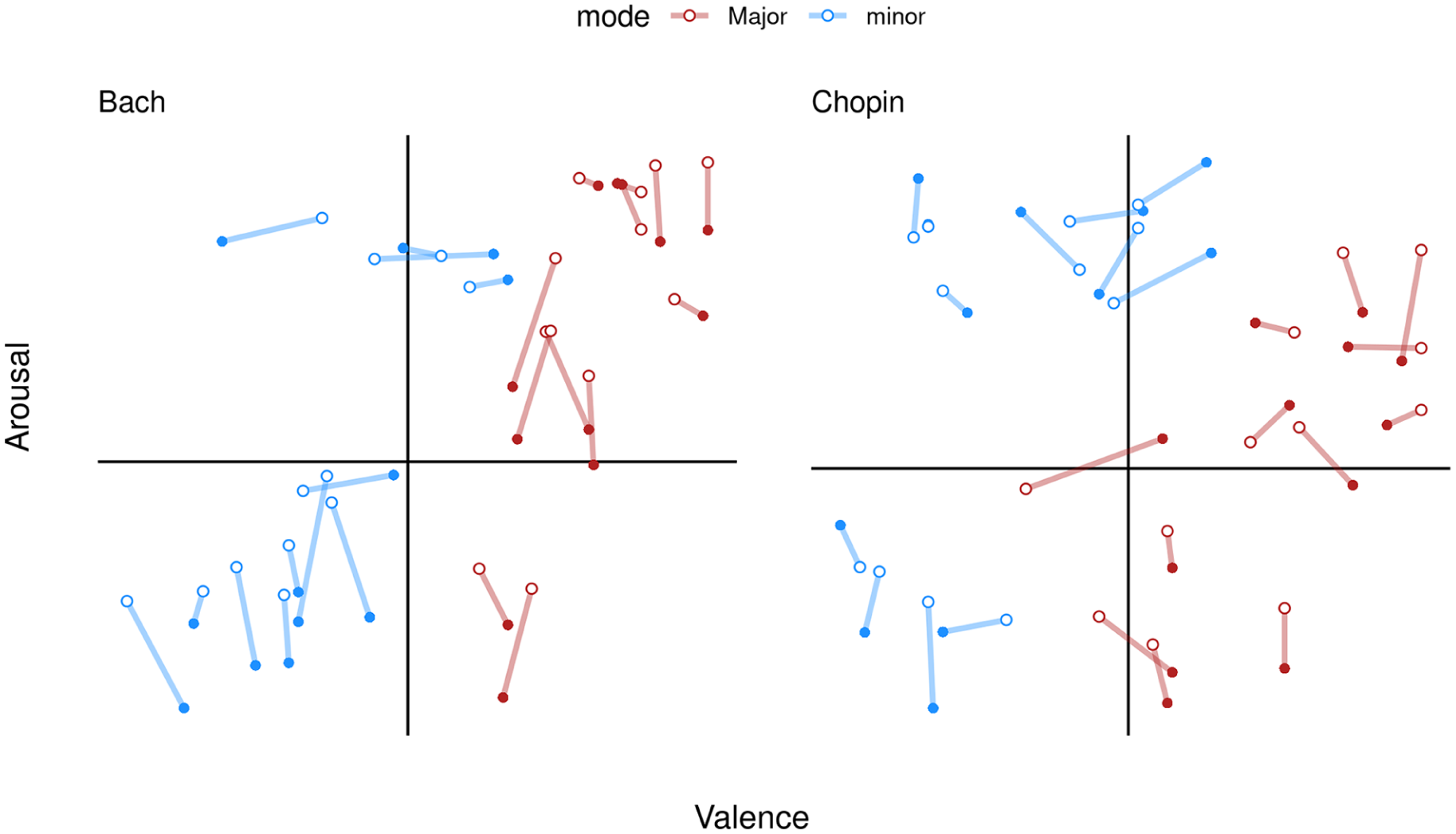
Circumplex of ratings in expressive and deadpan conditions.
Valence
On average, participants in the deadpan (M = 4.17, SD = 1.62) and expressive (M = 4.23, SD = 1.65) conditions rated valence similarly. Overall, the average valence ratings strongly correlated between expressive and deadpan conditions, r(46) = .96, 95% CI = [0.93, 0.98], p < .01. 1
Arousal
Arousal ratings for the deadpan (M = 60.14; SD = 26.56) and expressive (M = 55.67, SD = 27.68) conditions also exhibited broad similarities. As with valence, average arousal ratings strongly correlated between deadpan and expressive conditions, r(46) = .96, 95% CI = [0.93, 0.98], p < .01.
To assess whether valence and arousal ratings significantly differed between listening conditions, we conducted a series of Wilcoxon signed-rank tests assessing average ratings of each piece and calculated effect sizes using the rcompanion package for R (Mangiafico, 2024). Valence ratings did not differ significantly between deadpan and expressive conditions, V = 601, p = .35, effect size r = −.14, [−0.41, 0.16], whereas arousal ratings did, V = 234, p < .01, r = .52, [0.28, 0.72] (medium–large effect).
Bootstrap simulation
To evaluate significant differences in ratings of individual excerpts between listening conditions, we employed bootstrapping. For each excerpt, we separately resampled 30 valence and 30 arousal ratings (with replacement), averaging resampled ratings for each piece. We repeated this process 10,000 times, generating a total of 480,000 simulated ratings (48 pieces * 10,000 replications) for each condition. From these samples, we calculated the difference in valence and arousal between conditions, subtracting average deadpan ratings for each piece from the parallel expressive ratings. From the distributions of simulated differences, we used the middle 95% of differences to create percentile-based confidence intervals (CIs) for each excerpt. CIs that do not cross 0% indicate significant differences according to this method.
Figure 2 relates significant differences from the bootstrap simulations (inner panels) to the relation between deadpan and expressive ratings (outer panels).
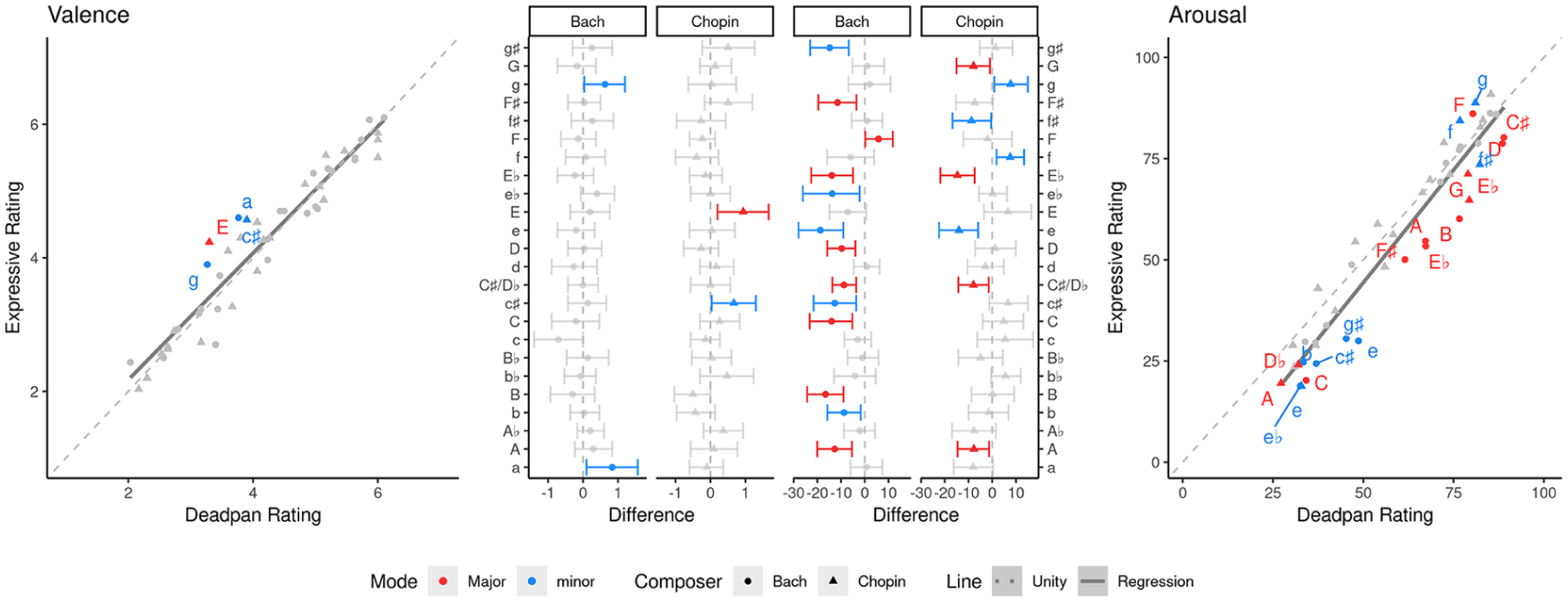
Pieces significantly differing between conditions.
Removing expression significantly affected valence ratings of four excerpts (all receiving higher ratings in the expressive condition) and affected arousal ratings of 21 excerpts (18 receiving significantly lower ratings in the expressive condition).
Coefficient of variation
To clarify how performance expressivity affects variation in valence and arousal ratings, we followed Q&T’s approach of computing Coefficients of Variation (CV) for valence and arousal ratings in each condition. Large CVs for a given emotion dimension indicate greater dispersion of ratings from the mean, suggesting performance expression aids in communicating that dimension. For valence, we observed no meaningful difference between conditions for bootstrapped CVs (M = 28.93% [95% CI: 27.65%, 30.24%] and M = 28.24% [26.87%, 29.64%] for deadpan and expressive conditions, respectively. Conversely, we found the arousal CV higher for expressive (M = 43.19% [41.79%, 44.62%]) than deadpan (M = 34.61% [32.95%, 36.25%]) ratings, consistent with Q&T.
Cue effects on emotion ratings
To understand how cues impact listeners’ ratings of valence and arousal, we modeled valence and arousal ratings using the analyzed cues by fitting elastic nets with the glmnet package in R (Tay et al., 2023; Zou & Hastie, 2005). Elastic nets overcome interpretive challenges with multiple linear regression by shrinking or removing variables disproportionately affected by multicollinearity. The behavior of the penalty parameter α is user-defined, with extremes α = 0 corresponding to ridge regression (shrinking but not removing highly correlated variables) and α = 1 corresponding to LASSO regression (discarding highly correlated variables from the model). A second parameter, λ, defines the penalty strength and is commonly selected using cross-validation. To balance the need for variable selection and penalization of multicollinearity, we chose α = .5.
We separately modeled valence and arousal ratings for each listening condition (totaling four separate models). We optimized the λ parameter of each model through 10-fold cross-validation. Iterating over several λ values, this procedure (a) splits the dataset into 10 proportional subsets (called folds), (b) trains the model using nine folds, and (c) tests the model on the tenth, repeating these steps for each fold. We selected the λ value regularizing the cross-validated error for each model. 2 As several cues affected ratings in both conditions, we henceforth differentiate them with subscript letters (expressive: λe, βe; deadpan: λd, βd).
For valence, the most regularized models for the expressive (λe = .18) and deadpan (λd = .19) conditions explained 41.33% and 46.45% of the variance in participants’ ratings, respectively. Models for both conditions included non-zero coefficients for mode (βe = .75, βd = .73), attack rate (βe = .11; βd = .14), and pitch height (βe = .05, βd = .05). Of the cues unequated between conditions, intensity variability yielded a small nonzero effect in the expressive condition (βe = .06), whereas high-frequency energy did so for the deadpan condition (βd = .07).
For arousal, the regularized model for expressive ratings (λe = 3.41) explained 68.04% of the variance, whereas the regularized deadpan model (λd = 4.92) explained 53.69%. Both models yielded nonzero coefficients for attack rate (βe = 4.61, βd = 4.14) and intensity (βe = 1.24, βd = .99), whereas the expressive condition also yielded nonzero coefficients for intensity variability (βe = 2.09), high-frequency energy (βe = 1.44), and pitch height (βe = −.03).
Because elastic nets perform regularization and shrinkage, we can estimate the relative importance of each variable by translating the absolute values of coefficients to a scale ranging from 0 to 1, where 1 represents the variable with the highest importance. Figures 3 and 4 summarize the relationship between cue values and emotion ratings. For the left panel, the x axis depicts levels of cues with coefficients greater than 0 in at least one condition, and the y axis depicts ratings along the corresponding emotion dimension. The right panel depicts relative importance estimates for expressive (green) and deadpan (purple) conditions. Importance measures indicate mode, timing, and pitch rank highest in importance to valence across both conditions, though high-frequency energy outranks pitch height in the deadpan condition. For arousal, timing and intensity rank highest across both conditions, whereas intensity variability and high-frequency energy outrank intensity for the expressive condition.
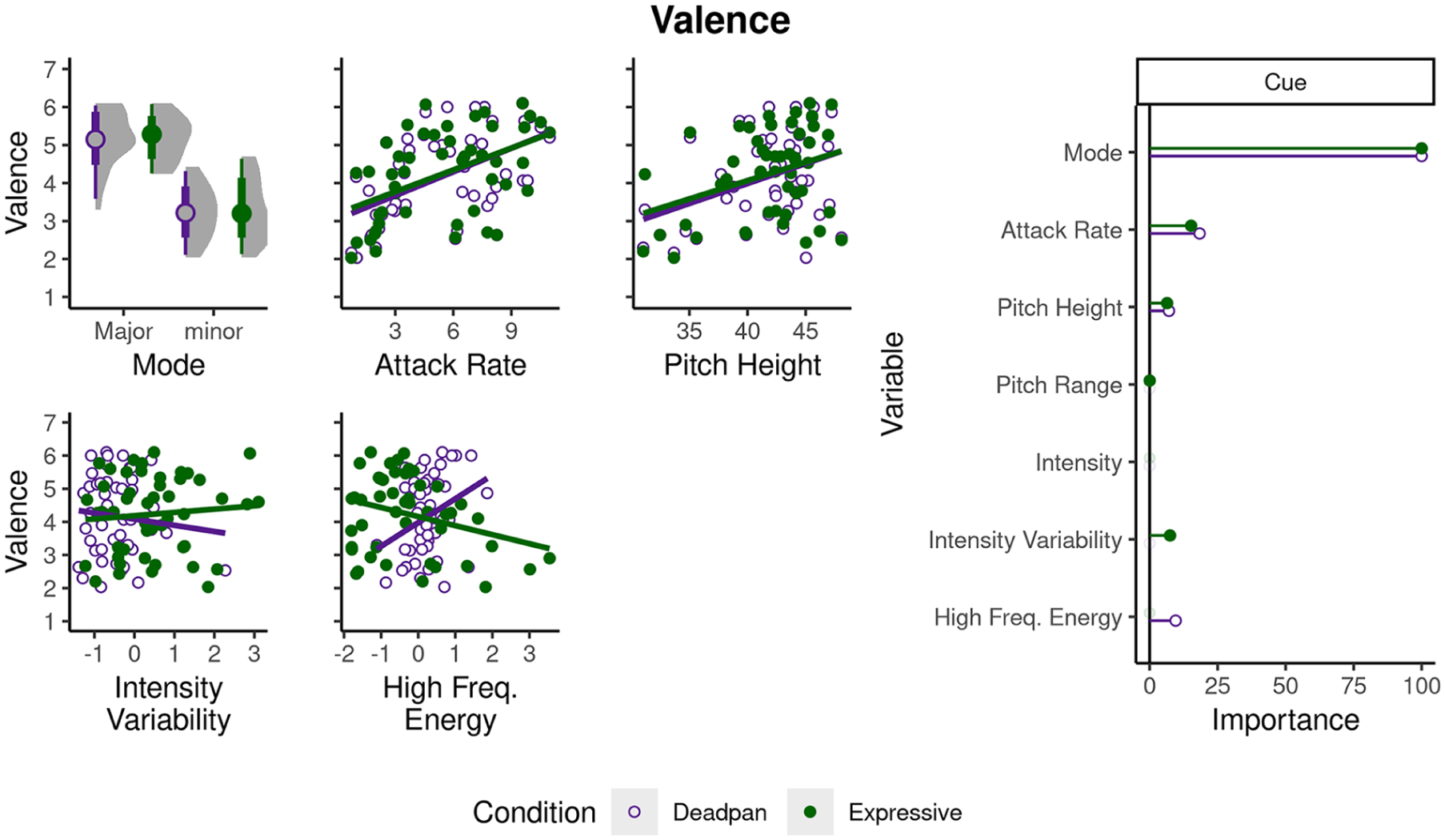
Cues affecting valence ratings.
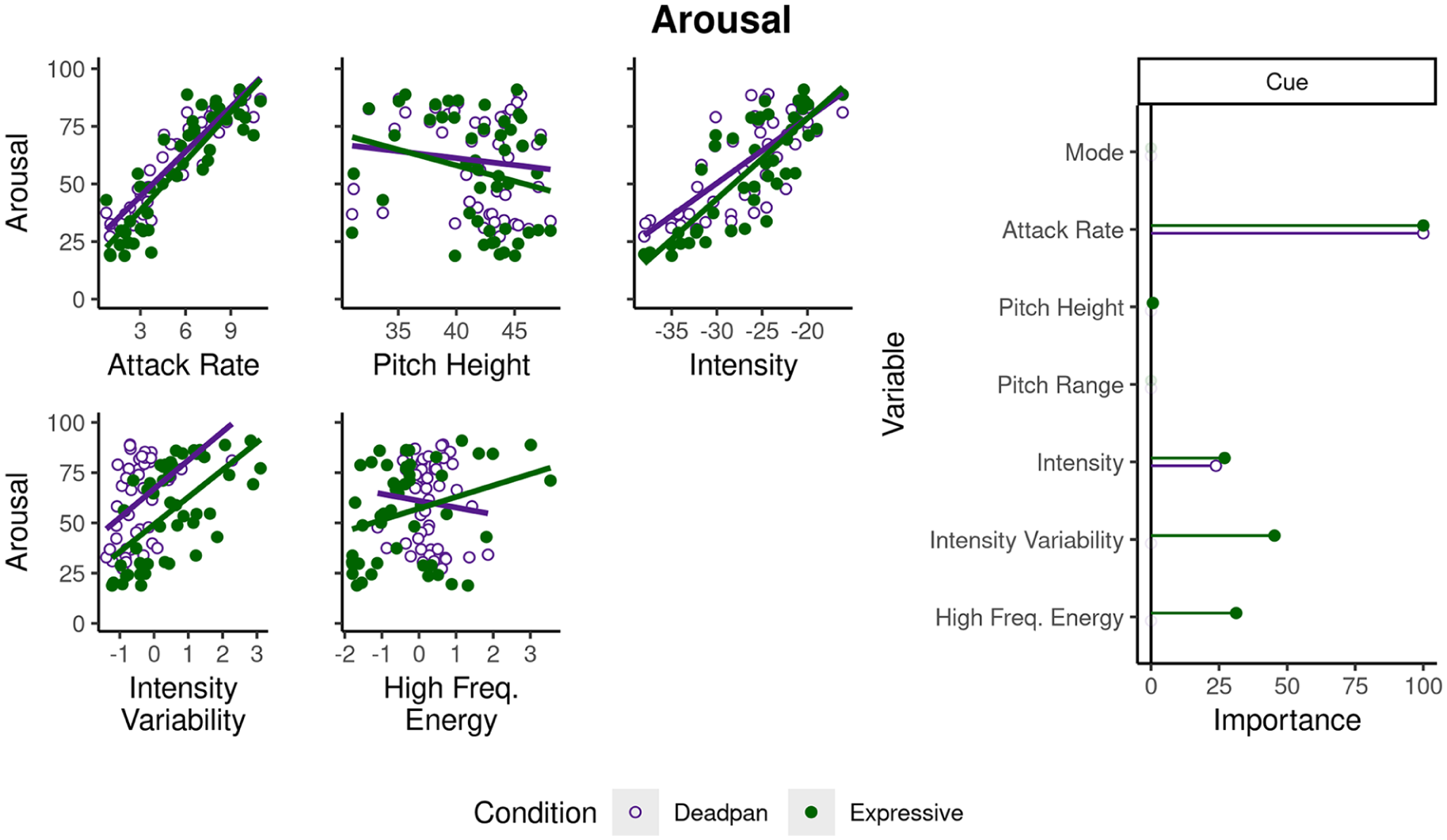
Cues affecting arousal ratings.
Discussion
We explore how score-notated and performance-analyzed cues differentially affect perceived valence and arousal by comparing a Grammy-winning pianist’s interpretations against deadpan versions lacking performance microstructure. Our approach provides insight into the degree to which conclusions largely from 5- to 9-note melodies generalize to complex piano works. Additionally, penalized regression helps clarify which cues drive emotional effects in expressive versus deadpan conditions.
We first assessed how differences between listening conditions affected valence and arousal, finding support for previous claims that compositional cues primarily affect valence, whereas performance cues affect arousal (Quinto & Thompson, 2013). We evaluated the effects of performance and compositional cues on emotion ratings (and differences between conditions) using cross-validation methods. This approach served two important goals—mitigating erroneous interpretations that might arise from confounded relationships between cues (discussed in Juslin & Lindström, 2010) and providing parsimonious explanations of which cues are most important. Our analyses show intensity variability and high-frequency energy contribute significantly to participants’ arousal ratings in the expressive condition, with the resulting model explaining an additional 14.35% of variance compared to the deadpan condition.
Comparing the effects of removing expression on valence and arousal ratings
Comparing participants’ responses between conditions revealed that excerpts’ average valence ratings strongly correlated between expressive and deadpan conditions, as did arousal ratings (all yielding r > .95). However, subsequent pairwise tests revealed significant differences in arousal between conditions. This difference suggests that listeners in both conditions perceived similar emotions but differed in how intense they perceived those emotions to be. This finding is consistent with previous evidence that computerized renditions are sufficient for conveying emotions (Thompson & Robitaille, 1992), yet performance expression influences perceived emotional intensity (Bhatara et al., 2011; Curwen et al., 2024). Listeners in the expressive condition also used a significantly wider range of the arousal rating scale than those in the deadpan condition (Figure 2, middle panels). Considering the lack of performance fluctuations in attack rate and dynamics of deadpan stimuli, this difference in scale use supports Q&T’s original claim that performance cues primarily specialize in communicating arousal.
Musical predictors for emotion
How do analyzed features account for differences in emotion ratings between listening conditions? This question is most clearly answered within the context of past work showing that mode, tempo, register, dynamics, phrasing, and timbre are crucial elements (Eerola et al., 2013; Gabrielsson & Lindström, 2010). In studies using the circumplex model, timing, amplitude, and timbre cues have helped explain variance in arousal ratings, whereas major/minor mode has explained variance in valence (Yang et al., 2018). In the context of composition versus performance, Q&T’s regression analyses show that pitch, pitch range, and interval size account for more variance in valence ratings, whereas intensity, intensity variability, articulation, and high-frequency energy account for more variance in arousal ratings. Our use of elastic nets clarifies the relative importance of these cues in explaining valence versus arousal between conditions.
Valence
Of the seven cues we drew from Q&T, three (mode, attack rate, and pitch height; all equated between conditions) account for variance in valence for both expressive and deadpan conditions (Figure 3). Similar to Q&T’s findings, mode contributes most to participants’ valence ratings, followed by timing, and pitch height. This consistency with their findings lends further support to the idea that compositional cues are primarily involved in conveying valence. Notably, attack rate (measuring average timing) reflects both compositional and performance aspects (i.e., note-level information and performance duration). Our team’s previous work suggests it also plays a supporting role in communicating valence for both composers analyzed here (Delle Grazie et al., 2025).
For cues differing between conditions, intensity variability contributes slightly in the expressive condition, whereas high-frequency energy does so for the deadpan condition (Figure 3). Although these cues differ in importance between conditions, their small contributions may actually result from a common factor—patterns in intensity across the frequency spectrum. Specifically, pianists often covary intensity and pitch to emphasize the structure of musical excerpts (G. Jones & Friberg, 2023). In doing so, they can account for the human sensitivity to low versus high-frequency energy when performing. In contrast, deadpan versions by definition cannot intelligently assign different intensities across the frequency spectrum. Because of this, participants in the deadpan condition may have rated low-energy excerpts lower in valence than those in the expressive condition due to dissonance arising from reduced intensity variation across deadpan excerpts’ frequency ranges.
Arousal
For arousal, timing and intensity (both matched between conditions) contribute to participants’ ratings in both expressive and deadpan conditions. Conversely, intensity variability and high-frequency energy (differing between conditions) play an important role in explaining expressive ratings, yet play no role in explaining deadpan ratings (Figure 4) The additional variance these cues contribute in the expressive condition is consistent with previous work highlighting their importance to the communication of arousal (Dean et al., 2011; Gingras et al., 2014; Ilie & Thompson, 2006). As the model for the expressive condition (comprising the original recordings) explains 14.35% additional variance, we interpret this to mean the presence of performance cues boosts explanatory power.
Clarifying effects of performance expression
Musicians bring individual approaches to interpreting structural information from musical scores—in part to convey emotional meaning through subtle variations in timing and intensity. Although the role of these cues in conveying emotion is widely recognized in the literature (Bhatara et al., 2011; Eerola et al., 2013; Quinto & Thompson, 2013), understanding the relative importance of performance versus compositional contributions can be challenging. This distinction is crucial, however, as differences in performance cues form the basis of musical training and performers intentionally adjust their use of these cues to communicate emotions (Van Zijl et al., 2014). The winners of major competitions play the same notes and rhythms as other competitors—it is the interpretation that sets them apart.
By comparing commercially available recordings with carefully matched deadpan versions, we complement and extend past approaches in music cognition while clarifying the relative importance of cues to expressive versus deadpan conditions. Exploring how performance expression shapes emotional meaning in naturalistic work offers an ecological compromise for studying the nonverbal aspects of emotion. It also highlights how differences in performance cues modulate the communication of emotions, such as the prominent role of intensity variability and high-frequency energy in arousal ratings for the expressive condition.
Limitations
To inform future investigations, we articulate four limitations of the present approach. First, to afford a degree of control within naturalistic stimuli, we confined our exploration to works composed with structural similarities in instrumentation, style, and tonal organization. Comparing expressive and deadpan stimuli in more diverse musical styles such as jazz (Gridley, 2010), North Indian Carnatic raag (Chordia & Rae, 2008), and music therapy improvisations (Luck et al., 2008) will provide greater generalizability of study outcomes. Additionally, exploring how different performers’ interpretations affect patterns in variable importance can provide insight into the generalizability of our findings across different interpretations of the same piece.
Second, several publications of Bach and Chopin’s preludes exist and often differ in ornamentation (optional notes added to decorate a melody) and pedaling (the use of foot-operated levers to make notes sound smoothly connected)—obfuscating whether ornamented passages reflect the composer’s intentions or an editor’s preferences. Based on the knowledge from performance practice, we omitted ornamentation from deadpan renditions of Bach but retained ornamentation and pedal markings for Chopin.
Third, we did not incorporate batteries for assessing congenital amusia, affecting roughly 1.5% of the population (Peretz & Vuvan, 2017). We suspect that this affected the current study minimally, as all participants included in our analyses used the full range of the ratings scale and most differentiated major versus minor excerpts along the valence dimension.
Finally, although our deadpan renditions lack a performer’s interpretation, the music engraving software Sibelius automatically adds very subtle computerized expressive information to audio renditions. Although our analyses suggest this did not affect participants’ ratings, explorations lacking any human- or computer-generated expressivity would capture the differential effects of performance and composition more comprehensively.
Conclusion
Here, we compared 48 performance excerpts from a Grammy-winning pianist with matching computerized versions, exploring previous claims that performance cues primarily affect arousal, whereas compositional cues primarily communicate valence. Our findings show expressive cues aid communication of arousal, allowing listeners to distribute ratings of excerpts along a wider range of the arousal scale. Clarifying expressive contributions to emotional meaning can inform the design of mood-based music recommendation algorithms (Seo & Huh, 2019) and generative models for emotional song or speech (Dhariwal et al., 2020; Triantafyllopoulos et al., 2023). Further exploration of expressive cues can shed new light on how variations in performance and compositional characteristics drive affective meaning in diverse musical works.
Supplemental Material
sj-docx-1-qjp-10.1177_17470218251372335 – Supplemental material for Beyond the notes: Clarifying the role of expressivity in conveying musical emotion
Supplemental material, sj-docx-1-qjp-10.1177_17470218251372335 for Beyond the notes: Clarifying the role of expressivity in conveying musical emotion by Cameron J Anderson, Jamie Ling and Michael Schutz in Quarterly Journal of Experimental Psychology
Footnotes
Acknowledgements
The authors thank Aditi Shukla, Benjamin Baker, Efe Momodu, Julianne Heitelmann, Madeleine Monson, Olivia McIsaac, and Sarah Abdellateef for their assistance with data collection.
Author contributions
Cameron J Anderson: Writing—original draft; writing—reviewing/editing; methodology; formal analysis; investigation. Jamie Ling: Data curation; resources; investigation. Michael Schutz: Conceptualization; writing—reviewing/editing; funding acquisition; supervision.
Data accessibility statement
Declaration of conflicting interests
The authors declared no potential conflicts of interest with respect to the research, authorship, and/or publication of this article.
Funding
The authors disclosed receipt of the following financial support for the research, authorship, and/or publication of this article: This work was supported by the Social Sciences and Humanities Research Council of Canada (grant number 435-2018-1448) and the Canada Foundation for Innovation (grant number CFI-LOF 3010). CJA is supported in part by funding from the Social Sciences and Humanities Research Council of Canada.
Ethical considerations
Experiments complied with the ethics policy of McMaster’s Research Ethics Board.
Consent to participate
Participants provided written consent to participate in this study.
Notes
References
Supplementary Material
Please find the following supplemental material available below.
For Open Access articles published under a Creative Commons License, all supplemental material carries the same license as the article it is associated with.
For non-Open Access articles published, all supplemental material carries a non-exclusive license, and permission requests for re-use of supplemental material or any part of supplemental material shall be sent directly to the copyright owner as specified in the copyright notice associated with the article.